
A Robust and Efficient Method for Effective Facial Keypoint Detection
Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Basic Concepts
3.2. Keypoint Detection
3.3. Regression
3.4. Heatmap
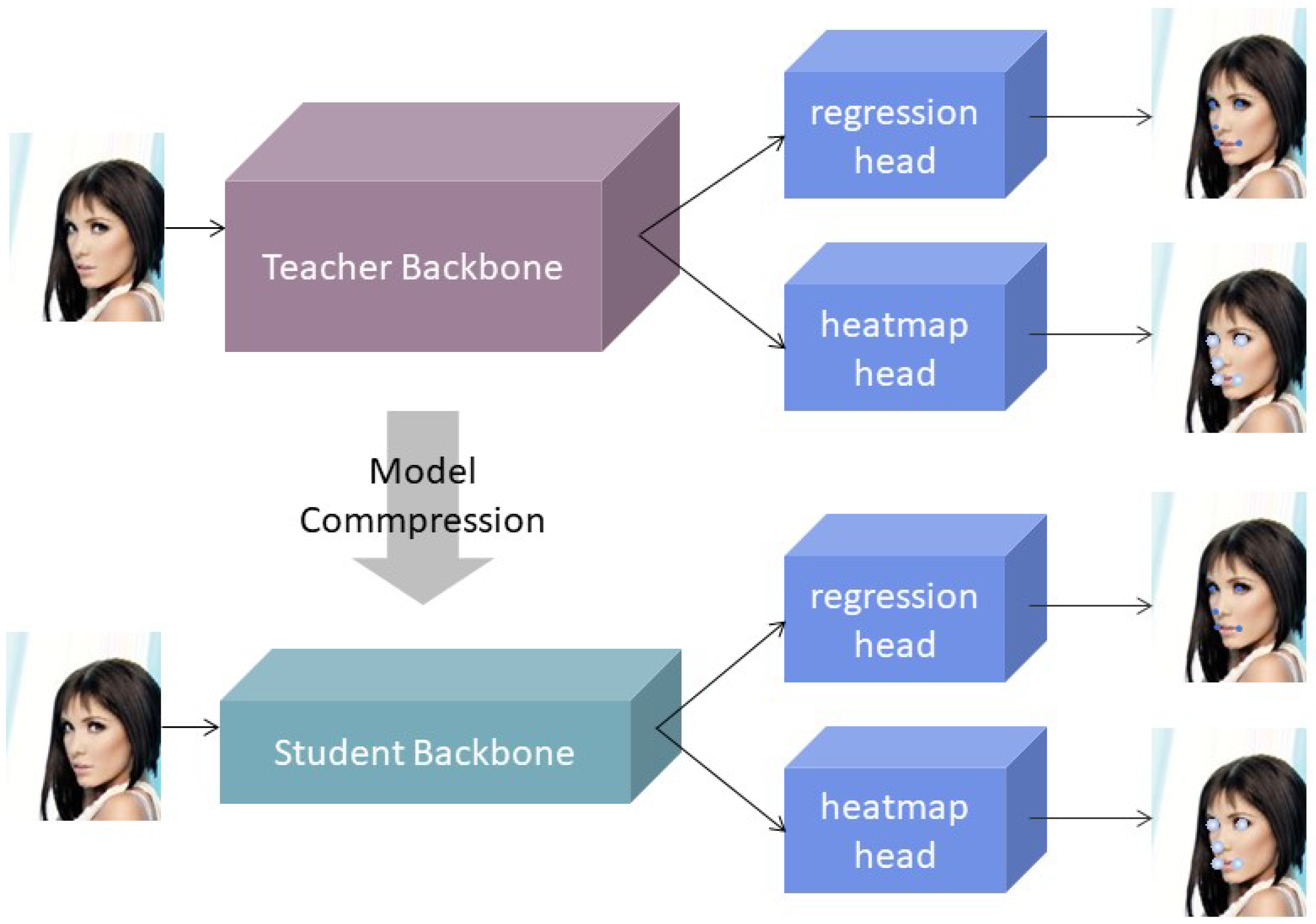
3.5. Model Compression
3.5.1. Knowledge Transfer
3.5.2. Model Cutting
4. Experimental Results
4.1. Detailed Setup
4.2. Main Results
4.2.1. Comparison with Existing Methods
4.2.2. Regression Combined with Heatmap Results
4.2.3. Distillation Combined with Pruning Results
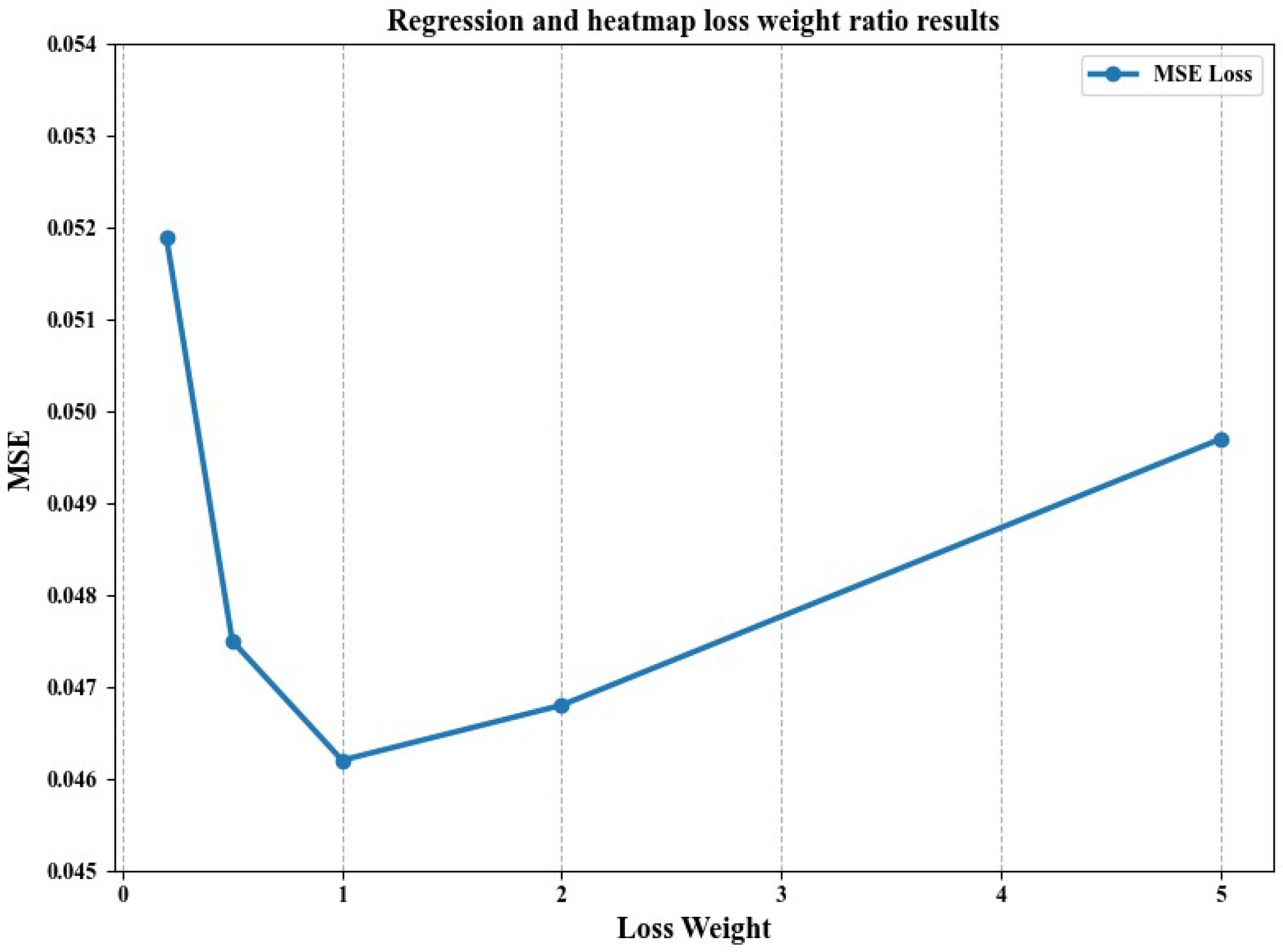
4.2.4. Regression and Heatmap Loss Weight Ratio Results
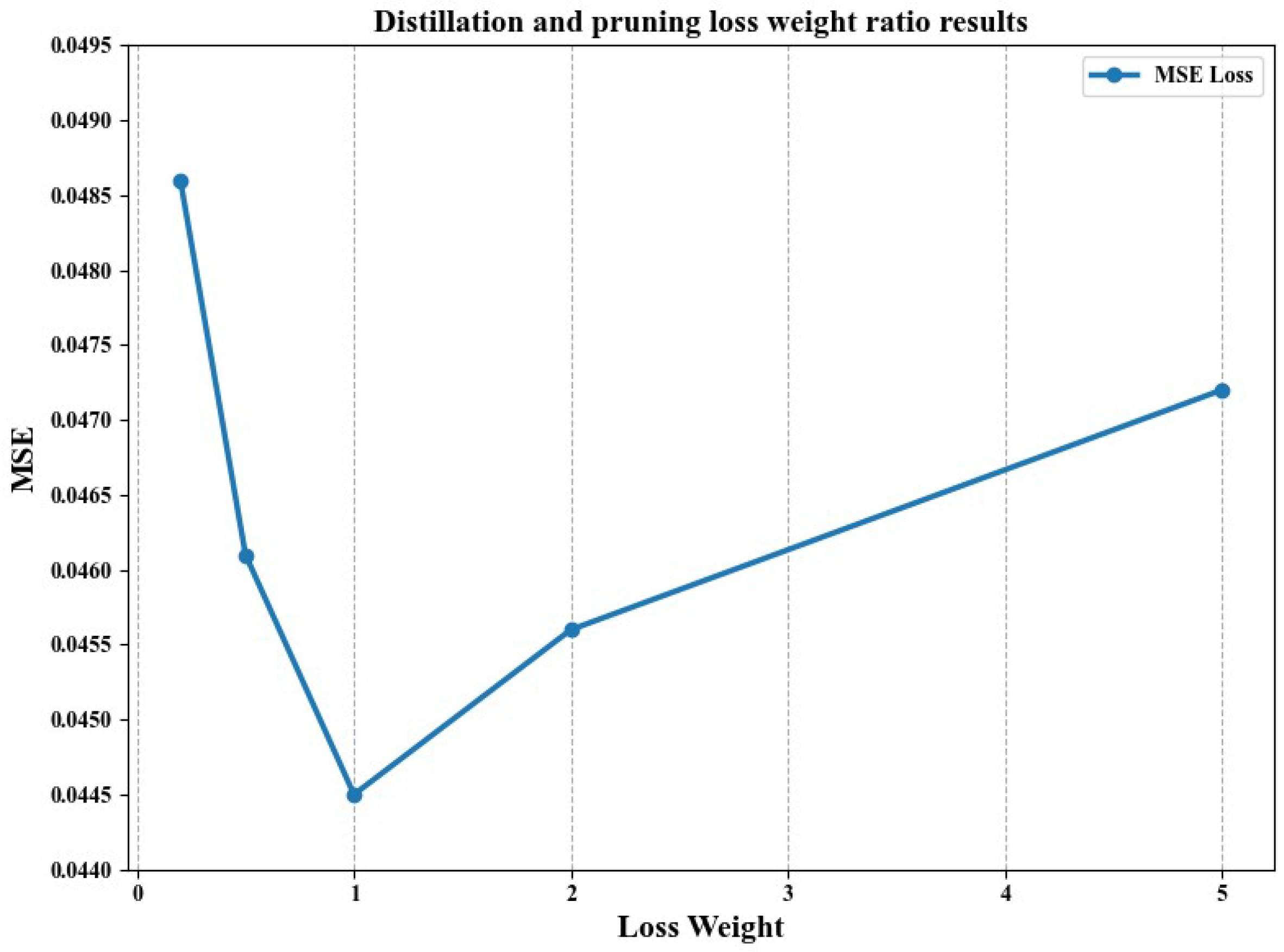
4.2.5. The Result of Distillation and Pruning Loss Weight Ratio
4.2.6. Experimental Results of Different Pruning Rates
4.2.7. Performance Analysis of Model Size, Computational Speed, and Running on Mobile Devices
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, X.; Li, S.; Yu, J.; Zhang, J.; Ma, J.; Ma, L.; Liu, W.; Ling, H. PFLD: A practical facial landmark detector. arXiv 2019, arXiv:1902.10859. [Google Scholar]
- Wang, X.; Bo, L.; Fuxin, L. Adaptive wing loss for robust face alignment via heatmap regression. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6971–6981. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Yan, W.; Yang, G.; Luo, J.; Li, T.; He, J. CenterFace: Joint face detection and alignment using face as point. Sci. Program. 2020, 2020, 7845384. [Google Scholar] [CrossRef]
- Browatzki, B.; Wallraven, C. 3FabRec: Fast few-shot face alignment by reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6110–6120. [Google Scholar]
- Liu, Z.; Lin, W.; Li, X.; Rao, Q.; Jiang, T.; Han, M.; Fan, H.; Sun, J.; Liu, S. ADNet: Attention-guided deformable convolutional network for high dynamic range imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 463–470. [Google Scholar]
- Li, Y.; Yang, S.; Liu, P.; Zhang, S.; Wang, Y.; Wang, Z.; Yang, W.; Xia, S.T. Simcc: A simple coordinate classification perspective for human pose estimation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 89–106. [Google Scholar]
- Bai, Y.; Wang, A.; Kortylewski, A.; Yuille, A. Coke: Contrastive learning for robust keypoint detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 65–74. [Google Scholar]
- Wan, J.; Liu, J.; Zhou, J.; Lai, Z.; Shen, L.; Sun, H.; Xiong, P.; Min, W. Precise facial landmark detection by reference heatmap transformer. IEEE Trans. Image Process. 2023, 32, 1966–1977. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. Yolo-facev2: A scale and occlusion aware face detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Rangayya; Virupakshappa; Patil, N. Improved face recognition method using SVM-MRF with KTBD based KCM segmentation approach. Int. J. Syst. Assur. Eng. Manag. 2024, 15, 1–12. [Google Scholar] [CrossRef]
- Khan, S.S.; Sengupta, D.; Ghosh, A.; Chaudhuri, A. MTCNN++: A CNN-based face detection algorithm inspired by MTCNN. Vis. Comput. 2024, 40, 899–917. [Google Scholar] [CrossRef]
- Blalock, D.; Gonzalez Ortiz, J.J.; Frankle, J.; Guttag, J. What is the state of neural network pruning? Proc. Mach. Learn. Syst. 2020, 2, 129–146. [Google Scholar]
- Vadera, S.; Ameen, S. Methods for pruning deep neural networks. IEEE Access 2022, 10, 63280–63300. [Google Scholar] [CrossRef]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]
- Sun, M.; Liu, Z.; Bair, A.; Kolter, J.Z. A simple and effective pruning approach for large language models. arXiv 2023, arXiv:2306.11695. [Google Scholar]
- Ji, M.; Heo, B.; Park, S. Show, attend and distill: Knowledge distillation via attention-based feature matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Volume 35, pp. 7945–7952. [Google Scholar]
- Yao, Y.; Huang, S.; Wang, W.; Dong, L.; Wei, F. Adapt-and-distill: Developing small, fast and effective pretrained language models for domains. arXiv 2021, arXiv:2106.13474. [Google Scholar]
- Beyer, L.; Zhai, X.; Royer, A.; Markeeva, L.; Anil, R.; Kolesnikov, A. Knowledge distillation: A good teacher is patient and consistent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10925–10934. [Google Scholar]
- Park, J.; No, A. Prune your model before distill it. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–27 October 2022; pp. 120–136. [Google Scholar]
- Waheed, A.; Kadaoui, K.; Abdul-Mageed, M. To Distill or Not to Distill? On the Robustness of Robust Knowledge Distillation. arXiv 2024, arXiv:2406.04512. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Sagonas, C.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: The first facial landmark localization challenge. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 1–8 December 2013; pp. 397–403. [Google Scholar]
- Koestinger, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2144–2151. [Google Scholar]
- Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Style aggregated network for facial landmark detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 379–388. [Google Scholar]
- Wu, W.; Qian, C.; Yang, S.; Wang, Q.; Cai, Y.; Zhou, Q. Look at boundary: A boundary-aware face alignment algorithm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2129–2138. [Google Scholar]
- Kumar, A.; Chellappa, R. Disentangling 3D pose in a dendritic CNN for unconstrained 2D face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 430–439. [Google Scholar]
- Burgos-Artizzu, X.P.; Perona, P.; Dollár, P. Robust face landmark estimation under occlusion. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1513–1520. [Google Scholar]
- Zhang, J.; Shan, S.; Kan, M.; Chen, X. Coarse-to-fine auto-encoder networks (cfan) for real-time face alignment. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 1–16. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Xiong, X.; De la Torre, F. Supervised descent method and its applications to face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 532–539. [Google Scholar]
- Ren, S.; Cao, X.; Wei, Y.; Sun, J. Face alignment at 3000 fps via regressing local binary features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Ohio, USA, 23–28 June 2014; pp. 1685–1692. [Google Scholar]
- Zhu, S.; Li, C.; Change Loy, C.; Tang, X. Face alignment by coarse-to-fine shape searching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4998–5006. [Google Scholar]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3D solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 146–155. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial landmark detection by deep multi-task learning. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 94–108. [Google Scholar]
- Trigeorgis, G.; Snape, P.; Nicolaou, M.A.; Antonakos, E.; Zafeiriou, S. Mnemonic descent method: A recurrent process applied for end-to-end face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4177–4187. [Google Scholar]
- Honari, S.; Molchanov, P.; Tyree, S.; Vincent, P.; Pal, C.; Kautz, J. Improving landmark localization with semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1546–1555. [Google Scholar]
- Xiao, S.; Feng, J.; Xing, J.; Lai, H.; Yan, S.; Kassim, A. Robust facial landmark detection via recurrent attentive-refinement networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 57–72. [Google Scholar]
- Wu, W.; Yang, S. Leveraging intra and inter-dataset variations for robust face alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 150–159. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Valle, R.; Buenaposada, J.M.; Valdes, A.; Baumela, L. A deeply-initialized coarse-to-fine ensemble of regression trees for face alignment. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 585–601. [Google Scholar]
- Lv, J.; Shao, X.; Xing, J.; Cheng, C.; Zhou, X. A deep regression architecture with two-stage re-initialization for high performance facial landmark detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3317–3326. [Google Scholar]
- Jourabloo, A.; Ye, M.; Liu, X.; Ren, L. Pose-invariant face alignment with a single CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3200–3209. [Google Scholar]
- Xiao, S.; Feng, J.; Liu, L.; Nie, X.; Wang, W.; Yan, S.; Kassim, A. Recurrent 3D-2D dual learning for large-pose facial landmark detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1633–1642. [Google Scholar]
- Yu, X.; Huang, J.; Zhang, S.; Yan, W.; Metaxas, D.N. Pose-free facial landmark fitting via optimized part mixtures and cascaded deformable shape model. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1944–1951. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Zhu, S.; Li, C.; Loy, C.C.; Tang, X. Unconstrained face alignment via cascaded compositional learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3409–3417. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3706–3714. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Common | Challenging | Fullset |
|---|---|---|---|
| Inter-pupil Normalization (IPN) | |||
| RCPR [33] | 6.18 | 17.26 | 8.35 |
| CFAN [34] | 5.50 | 16.78 | 7.69 |
| ESR [35] | 5.28 | 17.00 | 7.58 |
| SDM [36] | 5.57 | 15.40 | 7.50 |
| LBF [37] | 4.95 | 11.98 | 6.32 |
| CFSS [38] | 4.73 | 9.98 | 5.76 |
| 3DDFA [39] | 6.15 | 10.59 | 7.01 |
| TCDCN [40] | 4.80 | 8.60 | 5.54 |
| MDM [41] | 4.83 | 10.14 | 5.88 |
| SeqMT [42] | 4.84 | 9.93 | 5.74 |
| RAR [43] | 4.12 | 8.35 | 4.94 |
| DVLN [44] | 3.94 | 7.62 | 4.66 |
| CPM [45] | 3.39 | 8.14 | 4.36 |
| DCFE [46] | 3.83 | 7.54 | 4.55 |
| TSR [47] | 4.36 | 7.56 | 4.99 |
| LAB [31] | 3.42 | 6.98 | 4.12 |
| PFLD 0.25X [1] | 3.38 | 6.83 | 4.02 |
| PFLD 1X [1] | 3.32 | 6.56 | 3.95 |
| Mobile–distill–prune-0.25X (vs. PFLD 0.25X [1]) | 3.36 (+0.59%) | 6.78 (+0.73%) | 3.98 (+0.99%) |
| Mobile–distill–prune-1X (vs. PFLD 1X [1]) | 3.24 (+2.4%) | 6.54 (+0.3%) | 3.89 (+1.5%) |
| ResNet-50 | 3.20 | 6.48 | 3.87 |
| Inter-ocular Normalization (ION) | |||
| PIFA-CNN [48] | 5.43 | 9.88 | 6.30 |
| RDR [49] | 5.03 | 8.95 | 5.80 |
| PCD-CNN [32] | 3.67 | 7.62 | 4.44 |
| SAN [30] | 3.34 | 6.60 | 3.98 |
| PFLD 0.25X [1] | 3.03 | 5.15 | 3.45 |
| PFLD 1X [1] | 3.01 | 5.08 | 3.40 |
| Mobile–distill–prune-0.25X (vs. PFLD 0.25X [1]) | 3.02 (+0.3%) | 5.14 (+0.19%) | 3.44 (+0.28%) |
| Mobile–distill–prune-1X (vs. PFLD 1X [1]) | 2.98 (+0.99%) | 5.04 (+0.78%) | 3.38 (+0.58%) |
| ResNet-50 | 2.96 | 4.96 | 3.34 |
| Method | RCPR [33] | CDM [50] | SDM [36] | ERT [51] | LBF [37] | CFSS [38] | CCL [52] | Binary-CNN [53] | PCD-CNN [32] |
|---|---|---|---|---|---|---|---|---|---|
| AFLW | 5.43 | 3.73 | 4.05 | 4.35 | 4.25 | 3.92 | 2.72 | 2.85 | 2.40 |
| Method | TSR [47] | CPM [45] | SAN [30] | PFLD 0.25X [1] | PFLD 1X [1] | mobile–distill–prune-0.25X | mobile–distill–prune-1X | ResNet-50 | |
| AFLW | 2.17 | 2.33 | 1.91 | 2.07 | 1.88 | 2.06 | 1.86 | 1.84 |
| Backbone | Algorithm | MSE | t-Test/p-Value | Levene-Test/ p-Value |
|---|---|---|---|---|
| MobileNet | regression | 0.0556 | T: 0.52, 0.97, 0.44 | L: 0.73, 1.23, 0.06 |
| P: 0.59, 0.32, 0.65 | P: 0.39, 0.26, 0.80 | |||
| MobileNet | regression + heatmap | 0.0462 | T: 0.64, 0.93, 0.29 | L: 0.03, 1.87, 1.28 |
| P: 0.52, 0.34, 0.76 | P: 0.84, 0.34, 0.25 |
| Backbone | Algorithm | MSE | t-Test/p-Value | Levene-Test/p-Value |
|---|---|---|---|---|
| ResNet-50 | regression + heatmap | 0.0457 | T: 0.13, 0.48, 0.35 | L: 1.21, 1.55, 0.02 |
| P: 0.89, 0.62, 0.72 | P: 0.26, 0.21, 0.88 | |||
| MobileNet | regression + heatmap | 0.0462 | T: 0.64, 0.93, 0.29 | L: 0.03, 1.87, 1.28 |
| P: 0.52, 0.34, 0.76 | P: 0.84, 0.34, 0.25 | |||
| MobileNet | regression + heatmap + distillation | 0.0434 | T: 0.49, 0.54, 0.05 | L: 0.15, 0.02, 0.29 |
| P: 0.61, 0.58, 0.95 | P: 0.69, 0.88, 0.58 | |||
| MobileNet | regression + heatmap + distillation + pruning (50%) | 0.0445 | T: 0.18, 0.63, 0.45 | L: 0.98, 0.42, 0.09 |
| P: 0.85, 0.52, 0.65 | P: 0.34, 0.51, 0.76 |
| Model | SDM [36] | SAN [30] | LAB [31] | PFLD 0.25X [1] | PFLD 1X [1] | mobile– distill– prune-0.25x | mobile– distill– prune-1x |
|---|---|---|---|---|---|---|---|
| Size (Mb) | 10.1 | 270.5 + 528 | 50.7 | 2.1 | 12.5 | 2.5 | 7.8 |
| Speed | 16 ms (C) | 343 ms (G) | 2.6 s (C) 60 ms (G*) | 1.2 ms (C) 1.2 ms (G) 7 ms (A) | 6.1 ms (C) 3.5 ms (G) 26.4 ms (A) | 2 ms (C) 1.9 ms (G) 12 ms (A) | 4.5 ms (C) 3.6 ms (G) 18.7 ms (A) |
| Mobile | HUAWEI Mate9 Pro | Xiaomi MI 9 | HUAWEI P30 Pro |
|---|---|---|---|
| CPU | Kirin960 | Snapdragon855 | Kirin980 |
| Frequency | GHz + GHz | GHz + GHz + GHz | GHz + GHz + GHz |
| RAM | 4 GB | 8 GB | 8 GB |
| ResNet50 | 87 ms | 63 ms | 49 ms |
| Mobile–distill–prune-1x | 31 ms | 18 ms | 14 ms |
| Mobile–distill–prune-0.25x | 19 ms | 13 ms | 11 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Chen, Y.; Wang, J.; Zhou, P.; Lai, J.; Wang, Q. A Robust and Efficient Method for Effective Facial Keypoint Detection. Appl. Sci. 2024, 14, 7153. https://doi.org/10.3390/app14167153
Huang Y, Chen Y, Wang J, Zhou P, Lai J, Wang Q. A Robust and Efficient Method for Effective Facial Keypoint Detection. Applied Sciences. 2024; 14(16):7153. https://doi.org/10.3390/app14167153
Chicago/Turabian StyleHuang, Yonghui, Yu Chen, Junhao Wang, Pengcheng Zhou, Jiaming Lai, and Quanhai Wang. 2024. "A Robust and Efficient Method for Effective Facial Keypoint Detection" Applied Sciences 14, no. 16: 7153. https://doi.org/10.3390/app14167153