
Imbalanced Diagnosis Scheme for Incipient Rotor Faults in Inverter-Fed Induction Motors





Abstract
1. Introduction
2. Background
2.1. Diagnosis Signals
2.2. Time-Domain Fault Signatures
2.3. Fault Signatures from Spectra
2.4. Feature Selection through ReliefF Algorithm
| Algorithm 1 ReliefF [18] |
| Input: Training observations with their respective vector of features Output: The vector W with the quality estimation of the features
|
3. Problem Statement for a Class-Imbalanced Scenario
3.1. SMOTE and Following Extensions for Balancing Datasets
3.2. Safe Level-SMOTE
3.3. Relocating Safe Level SMOTE
3.4. Density-Based SMOTE
3.5. Majority Weighted Minority Oversampling Technique
4. Test Bench and Signal Acquisition
5. Experimental Results
5.1. Feature Selection
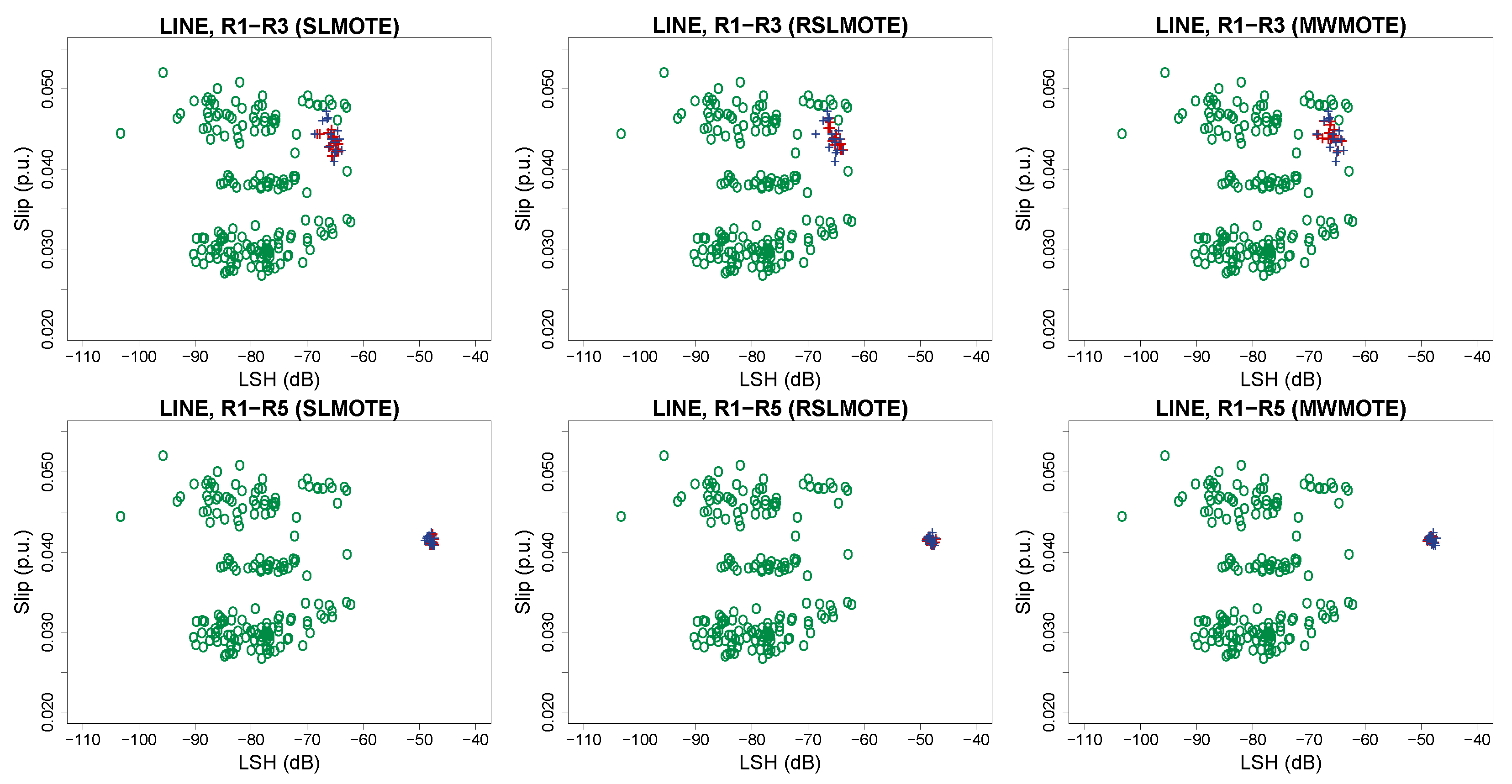
5.2. Effect on the Feature Subspace
5.3. Classification Stage
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUC | Area Under the ROC Curve |
| BRB | Broken Rotor Bar |
| DBSMOTE | Density-Based Synthetic Minority Oversampling Technique |
| FD | Fault Data |
| HT | Holm Test |
| k-NN | k-Nearest Neighbors |
| MCSA | Motor Current Signature Analysis |
| MWMOTE | Majority weighted minority oversampling technique |
| RSLS | Relocating Safe-Level SMOTE |
| SLSMOTE | Safe-Level SMOTE |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVM | Support Vector Machine |
Appendix A. Equipment Specifications
References
- Park, Y.; Jeong, M.; Bin Lee, S.; Teska, M.; Antonino-Daviu, J.A. Influence of Blade Pass Frequency Vibrations on MCSA-Based Rotor Fault Detection of Induction Motors. IEEE Trans. Ind. Appl. 2017, 53, 2049–2058. [Google Scholar] [CrossRef]
- Zhou, Z.J.; Hu, C.H.; Wang, W.B.; Zhang, B.C.; Xu, D.L.; Zheng, J.F. Condition-based maintenance of dynamic systems using online failure prognosis and belief rule base. Expert Syst. Appl. 2012, 39, 6140–6149. [Google Scholar] [CrossRef]
- Pons-Llinares, J.; Antonino-Daviu, J.; Roger-Folch, J.; Morinigo-Sotelo, D.; Duque-Perez, O. Mixed eccentricity diagnosis in Inverter-Fed Induction Motors via the Adaptive Slope Transform of transient stator currents. Mech. Syst. Signal Process. 2014, 48, 423–435. [Google Scholar] [CrossRef]
- Benbouzid, M.E.H. A review of induction motors signature analysis as a medium for faults detection. IEEE Trans. Ind. Electron. 2000, 47, 984–993. [Google Scholar] [CrossRef]
- Cunha Palacios, R.; Da Silva, I.; Goedtel, A.; Godoy, W. A comprehensive evaluation of intelligent classifiers for fault identification in three-phase induction motors. Electr. Power Syst. Res. 2015, 127, 249–258. [Google Scholar] [CrossRef]
- Prieto, M.D.; Cirrincione, G.; Espinosa, A.G.; Ortega, J.A.; Henao, H. Bearing fault detection by a novel condition-monitoring scheme based on statistical-time features and neural networks. IEEE Trans. Ind. Electron. 2013, 60, 3398–3407. [Google Scholar] [CrossRef]
- Ghate, V.N.; Dudul, S.V. Cascade neural-network-based fault classifier for three-phase induction motor. IEEE Trans. Ind. Electron. 2011, 58, 1555–1563. [Google Scholar] [CrossRef]
- Gonzalez-Jimenez, D.; del Olmo, J.; Poza, J.; Garramiola, F.; Madina, P. Data-Driven Fault Diagnosis for Electric Drives: A Review. Sensors 2021, 21, 4024. [Google Scholar] [CrossRef]
- Gonzalez-Jimenez, D.; Del-Olmo, J.; Poza, J.; Garramiola, F.; Madina, P. Data-Driven Low-Frequency Oscillation Event Detection Strategy for Railway Electrification Networks. Sensors 2023, 23, 254. [Google Scholar] [CrossRef]
- Gonzalez-Jimenez, D.; del Olmo, J.; Poza, J.; Garramiola, F.; Sarasola, I. Machine Learning-Based Fault Detection and Diagnosis of Faulty Power Connections of Induction Machines. Energies 2021, 14, 4886. [Google Scholar] [CrossRef]
- Martin-Diaz, I.; Morinigo-Sotelo, D.; Duque-Perez, O.; Romero-Troncoso, R.J. Early fault detection in induction motors using AdaBoost with imbalanced small data and optimized sampling. IEEE Trans. Ind. Appl. 2016, 53, 3066–3075. [Google Scholar] [CrossRef]
- Niu, G.; Dong, X.; Chen, Y. Motor Fault Diagnostics Based on Current Signatures: A Review. IEEE Trans. Instrum. Meas. 2023, 72, 1–19. [Google Scholar] [CrossRef]
- Rivera, W.A. Noise Reduction A Priori Synthetic Over-Sampling for class imbalanced data sets. Inform. Sci. 2017, 408, 146–161. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar] [CrossRef] [PubMed]
- Kliman, G.; Stein, J. Methods of motor current signature analysis. Electr. Mach. Power Syst. 1992, 20, 463–474. [Google Scholar] [CrossRef]
- Martin-Diaz, I.; Morinigo-Sotelo, D.; Duque-Perez, O.; Delgado-Arredondo, P.; Camarena-Martinez, D.; Romero-Troncoso, R. Analysis of various inverters feeding induction motors with incipient rotor fault using high-resolution spectral analysis. Electr. Power Syst. Res. 2017, 152, 18–26. [Google Scholar] [CrossRef]
- Bruzzese, C. Analysis and Application of Particular Current Signatures (Symptoms) for Cage Monitoring in Nonsinusoidally Fed Motors With High Rejection to Drive Load, Inertia, and Frequency Variations. IEEE Trans. Ind. Electron. 2008, 55, 4137–4155. [Google Scholar] [CrossRef]
- Robnik-Sikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Kononenko, I.; Robnik-Sikonja, M.; Pompe, U. ReliefF for Estimation and Discretization of Attributes in Classification, Regression, and ILP Problems; IOS Press: Amsterdam, The Netherlands, 1996; Volume 35. [Google Scholar]
- Murcia-Sepúlveda, N.; Cruz-Duarte, J.M.; Martin-Diaz, I.; Garcia-Perez, A.; Rosales-García, J.J.; Avina-Cervantes, J.G.; Correa-Cely, C.R. Fractional Calculus-Based Processing for Feature Extraction in Harmonic-Polluted Fault Monitoring Systems. Energies 2019, 12, 3736. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-Level-SMOTE: Safe-Level-Synthetic Minority Over-Sampling TEchnique for Handling the Class Imbalanced Problem. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Bangkok, Thailand, 27–30 April 2009; Theeramunkong, T., Kijsirikul, B., Cercone, N., Ho, T.B., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 475–482. [Google Scholar]
- Siriseriwan, W.; Sinapiromsaran, K.; Tipawanna, M.; Bunkhumpornpat, C.; Keatruangkamala, K. The effective redistribution for imbalance dataset: Relocating Safe-level SMOTE with minority outcast handling. Chiang Mai J. Sci. 2016, 43, 1288–1300. [Google Scholar]
- Barua, S.; Islam, M.M.; Yao, X.; Murase, K. MWMOTE—Majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 405–425. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables in Time-Domain | ||
|---|---|---|
| Variable | Notation | Formula |
| 1st. Moment | ||
| 2nd. Moment | ||
| 3rd. Moment | ||
| 4th. Moment | ||
| 2nd. Cumulant | ||
| 3rd. Cumulant | ||
| 4th. Cumulant | ||
| Skewness | ||
| Kurtosis | ||
| Absolute mean (ABM) | ||
| Peak value | PV | |
| Squared root value | SRV | |
| RMS value | RMS | |
| Crest factor | CF | |
| Shape factor | SF | |
| Supply | Severities | Imbalance Ratio (IR) | #Samples (Healthy–Faulty) | % (Healthy–Faulty) | Case Number |
|---|---|---|---|---|---|
| Line-fed | R1–R3 | 12 | 195–15 | 92.85–07.15 | 1 |
| R1–R3 | 7 | 105–15 | 87.50–15.50 | 2 | |
| R1–R3 | 3 | 45–15 | 75.00–25.00 | 3 | |
| Line-fed | R1–R5 | 12 | 195–15 | 92.85–07.15 | 4 |
| R1–R5 | 7 | 105–15 | 87.50–15.50 | 5 | |
| R1–R5 | 3 | 45–15 | 75.00–25.00 | 6 | |
| Inverter-fed | R1–R3 | 12 | 195–15 | 92.85–07.15 | 7 |
| R1–R3 | 7 | 105–15 | 87.50–15.50 | 8 | |
| R1–R3 | 3 | 45–15 | 75.00–25.00 | 9 | |
| Inverter-fed | R1–R5 | 12 | 195–15 | 92.85–07.15 | 10 |
| R1–R5 | 7 | 105–15 | 87.50–15.50 | 11 | |
| R1–R5 | 3 | 45–15 | 75.00–25.00 | 12 |
| Classifier | Supply | Case Number | Severity | Imbalance Ratio (IR) | AUC (%) | p-Value | Gmean1 (%) |
|---|---|---|---|---|---|---|---|
| SVM | Line-fed | 1 | R3 | 12 | |||
| Line-fed | 2 | R3 | 7 | ||||
| Line-fed | 3 | R3 | 3 | ||||
| Line-fed | 4 | R5 | 12 | ||||
| Line-fed | 5 | R5 | 7 | ||||
| Line-fed | 6 | R5 | 3 | ||||
| Inverter | 7 | R3 | 12 | ||||
| Inverter | 8 | R3 | 7 | <0.01 | |||
| Inverter | 9 | R3 | 3 | <0.01 | |||
| Inverter | 10 | R5 | 12 | ||||
| Inverter | 11 | R5 | 7 | ||||
| Inverter | 12 | R5 | 3 | ||||
| AdaBoost | Line-fed | 1 | R3 | 12 | |||
| Line-fed | 2 | R3 | 7 | ||||
| Line-fed | 3 | R3 | 3 | ||||
| Line-fed | 4 | R5 | 12 | ||||
| Line-fed | 5 | R5 | 7 | ||||
| Line-fed | 6 | R5 | 3 | ||||
| Inverter | 7 | R3 | 12 | ||||
| Inverter | 8 | R3 | 7 | <0.01 * | |||
| Inverter | 9 | R3 | 3 | <0.01 * | |||
| Inverter | 10 | R5 | 12 | ||||
| Inverter | 11 | R5 | 7 | ||||
| Inverter | 12 | R5 | 3 | ||||
| k-NN | Line-fed | 1 | R3 | 12 | |||
| Line-fed | 2 | R3 | 7 | ||||
| Line-fed | 3 | R3 | 3 | ||||
| Line-fed | 4 | R5 | 12 | ||||
| Line-fed | 5 | R5 | 7 | ||||
| Line-fed | 6 | R5 | 3 | ||||
| Inverter | 7 | R3 | 12 | ||||
| Inverter | 8 | R3 | 7 | <0.01 * | |||
| Inverter | 9 | R3 | 3 | <0.01 | |||
| Inverter | 10 | R5 | 12 | ||||
| Inverter | 11 | R5 | 7 | ||||
| Inverter | 12 | R5 | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin-Diaz, I.; Garcia-Calva, T.; Duque-Perez, Ó.; Morinigo-Sotelo, D. Imbalanced Diagnosis Scheme for Incipient Rotor Faults in Inverter-Fed Induction Motors. Appl. Sci. 2024, 14, 7237. https://doi.org/10.3390/app14167237
Martin-Diaz I, Garcia-Calva T, Duque-Perez Ó, Morinigo-Sotelo D. Imbalanced Diagnosis Scheme for Incipient Rotor Faults in Inverter-Fed Induction Motors. Applied Sciences. 2024; 14(16):7237. https://doi.org/10.3390/app14167237
Chicago/Turabian StyleMartin-Diaz, Ignacio, Tomas Garcia-Calva, Óscar Duque-Perez, and Daniel Morinigo-Sotelo. 2024. "Imbalanced Diagnosis Scheme for Incipient Rotor Faults in Inverter-Fed Induction Motors" Applied Sciences 14, no. 16: 7237. https://doi.org/10.3390/app14167237
APA StyleMartin-Diaz, I., Garcia-Calva, T., Duque-Perez, Ó., & Morinigo-Sotelo, D. (2024). Imbalanced Diagnosis Scheme for Incipient Rotor Faults in Inverter-Fed Induction Motors. Applied Sciences, 14(16), 7237. https://doi.org/10.3390/app14167237