
Containment Control-Guided Boundary Information for Semantic Segmentation


Abstract
1. Introduction
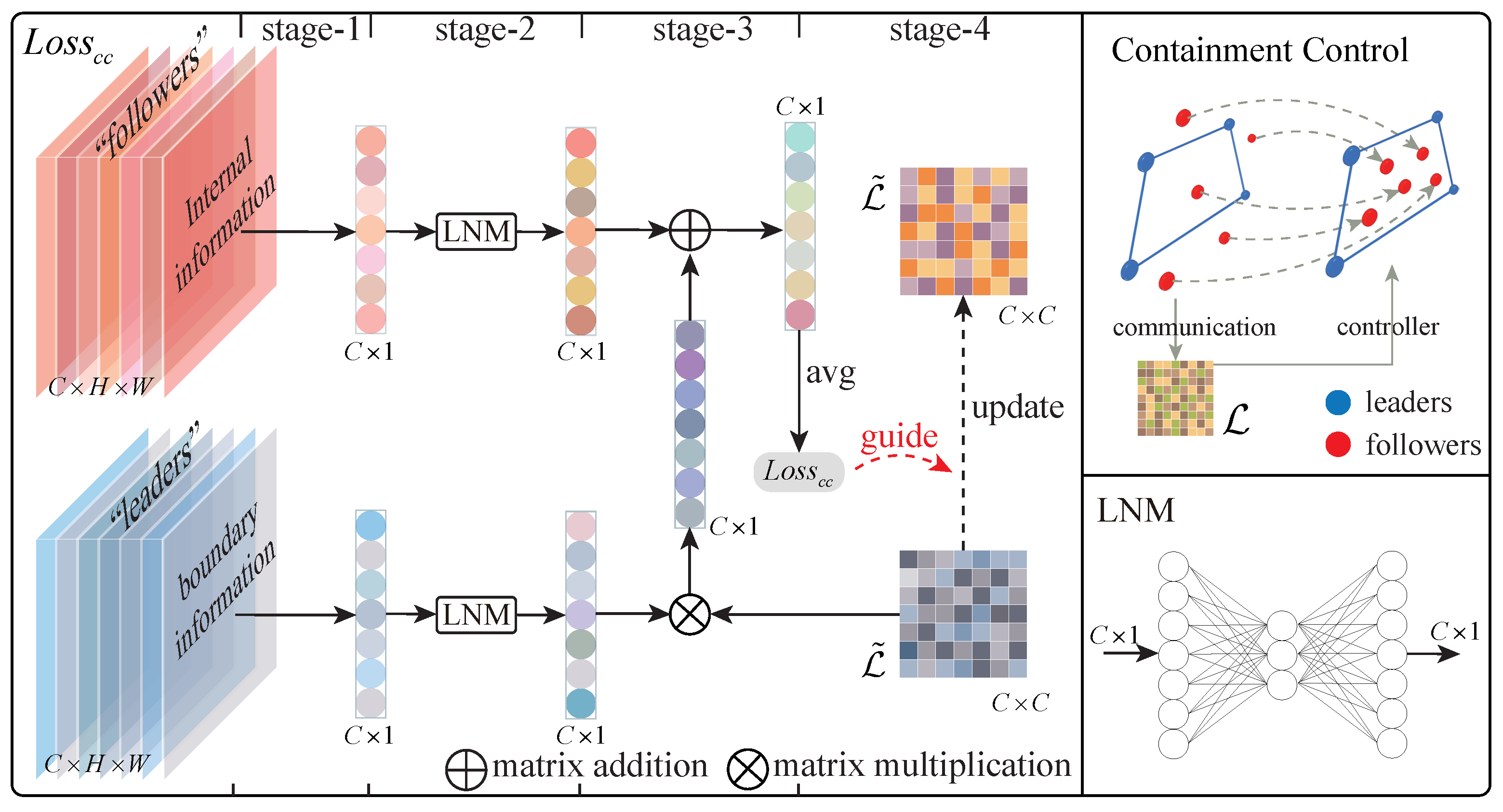
- Boundary Feature Integration: We recognize the importance of boundary feature information in semantic segmentation tasks and dig deep into the way it is used. The dynamic fusion process of boundary features and internal representations is quantified by building a features fusion matrix based on the Laplacian matrix, which effectively improves the model’s ability to capture and utilize boundary information.
- Containment Control-Guided Segmentation: We utilize the containment control criterion to construct a dedicated loss function for updating the features fusion matrix, which achieves finer control over the information fusion between boundary features and internal representations. Through the gradient descent algorithm, on the one hand, the internal representations and the external features are made to present a contained spatial relationship, and on the other hand, a suitable features fusion matrix can be established to guide the feature fusion.
- Multi-scale Feature Enhancement: To improve the quality of features, we have designed and introduced the Feature Enhancement Unit. This innovative module is specifically crafted to tackle the challenge of maximizing the utility of multi-scale features essential for semantic segmentation tasks through the meticulous reconstruction of these features.
- Performance Evaluation: Conduct extensive experiments and performance evaluations to validate the effectiveness of our proposed approach. Compare the results with traditional segmentation methods to showcase the superiority of our model in handling complex scene structures.
2. Related Works
2.1. Semantic Segmentation with Multi-Scale Features
2.2. Semantic Segmentation of Geometric Relations
3. Method
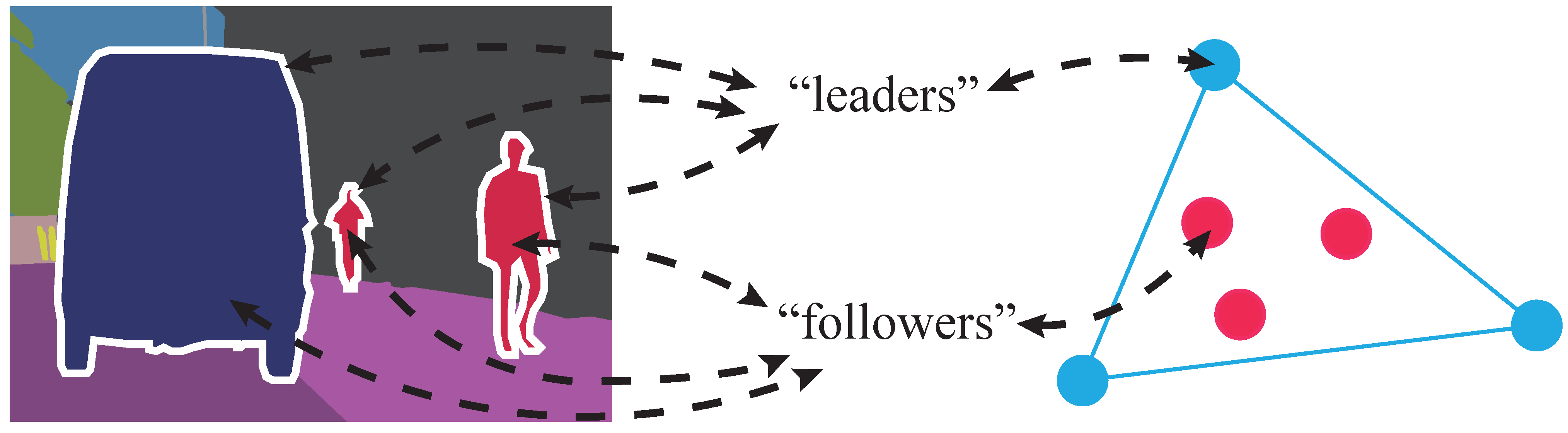
3.1. How Containment Control Guides Semantic Segmentation
3.2. CcNet
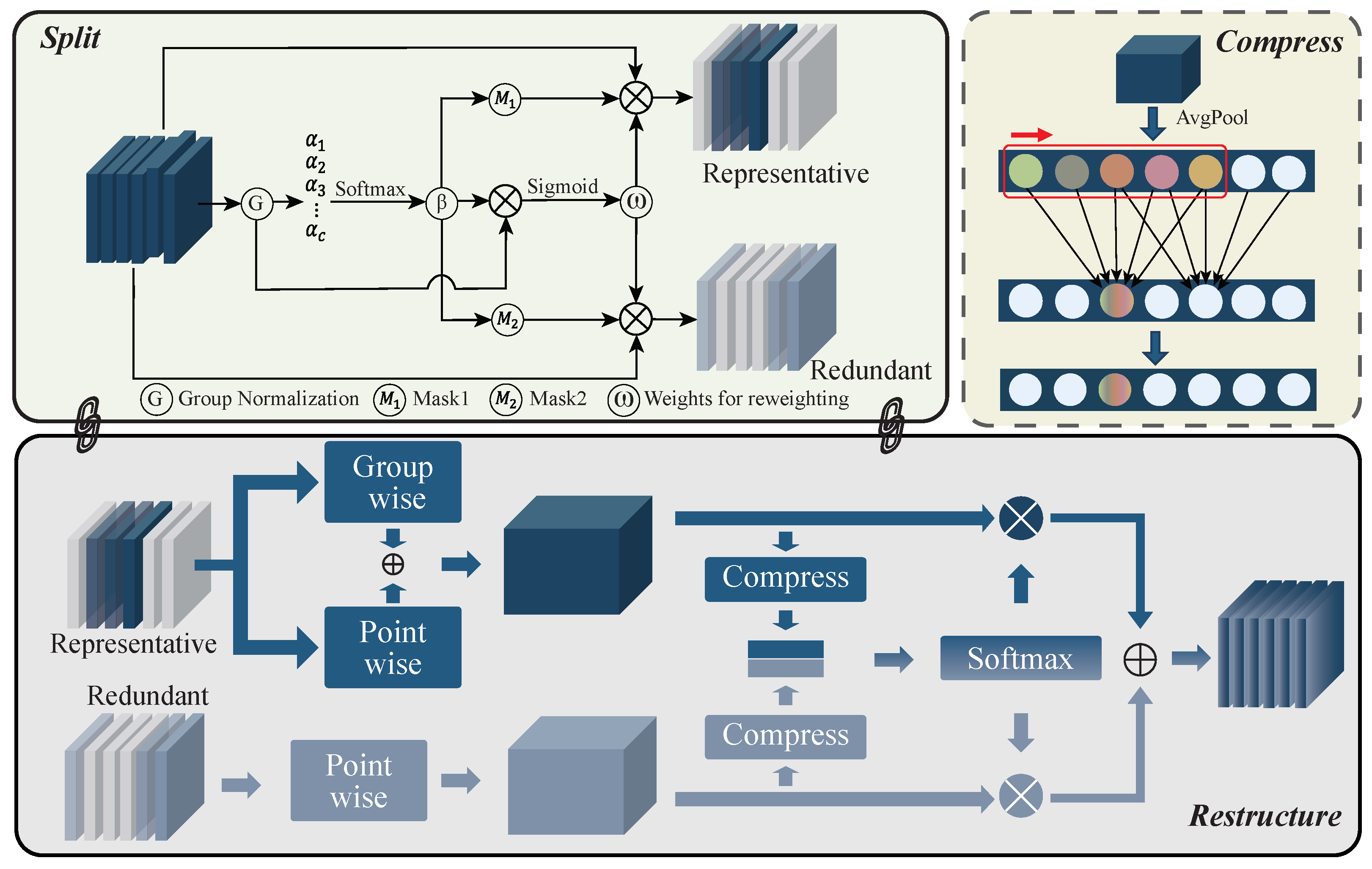
3.3. Feature Enhancement Unit
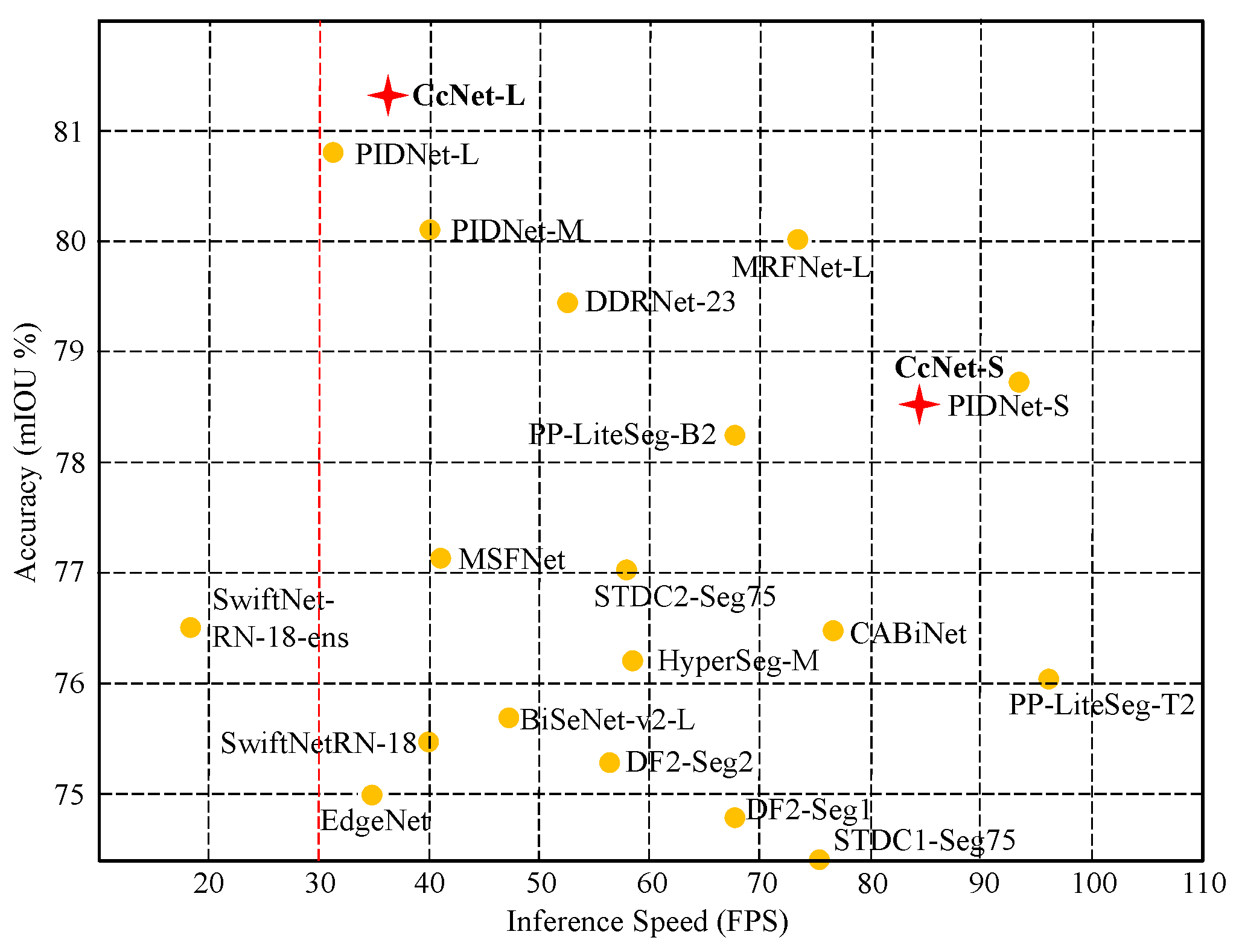
4. Experiment
4.1. Dataset
4.2. Quantitative Analysis
4.3. Qualitative Analysis
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bertasius, G.; Shi, J.; Torresani, L. Semantic Segmentation with Boundary Neural Fields. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation; Springer: New York, NY, USA, 2021. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J.; Wei, X. Rethinking BiSeNet For Real-time Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9711–9720. [Google Scholar] [CrossRef]
- Li, Z.; Ren, W.; Liu, X.; Fu, M. Distributed containment control of multi-agent systems with general linear dynamics in the presence of multiple leaders. Int. J. Robust Nonlinear Control 2013, 23, 534–547. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, F.; Feng, T.; Deng, T.; Zhao, Y. Fastest containment control of discrete-time multi-agent systems using static linear feedback protocol. Inf. Sci. 2022, 614, 362–373. [Google Scholar] [CrossRef]
- Wang, X.; Xu, R.; Huang, T.; Kurths, J. Event-Triggered Adaptive Containment Control for Heterogeneous Stochastic Nonlinear Multiagent Systems. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 8524–8534. [Google Scholar] [CrossRef] [PubMed]
- Zuo, R.; Li, Y.; Lv, M.; Park, J.H.; Long, J. Event-triggered distributed containment control for networked hypersonic flight vehicles. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5271–5280. [Google Scholar] [CrossRef]
- Yan, J.; Peng, S.; Yang, X.; Luo, X.; Guan, X. Containment Control of Autonomous Underwater Vehicles With Stochastic Environment Disturbances. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 5809–5820. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Peng, J.; Liu, Y.; Tang, S.; Hao, Y.; Chu, L.; Chen, G.; Wu, Z.; Chen, Z.; Yu, Z.; Du, Y.; et al. Pp-liteseg: A superior real-time semantic segmentation model. arXiv 2022, arXiv:2204.02681. [Google Scholar]
- Pan, H.; Hong, Y.; Sun, W.; Jia, Y. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Traffic Scenes. IEEE Trans. Intell. Transp. Syst. 2023, 24, 3448–3460. [Google Scholar] [CrossRef]
- Li, T.; Cui, Z.; Han, Y.; Li, G.; Li, M.; Wei, D. Enhanced multi-scale networks for semantic segmentation. Complex Intell. Syst. 2024, 10, 2557–2568. [Google Scholar] [CrossRef]
- Yan, H.; Wu, M.; Zhang, C. Multi-Scale Representations by Varying Window Attention for Semantic Segmentation. arXiv 2024, arXiv:2404.16573. [Google Scholar]
- Wu, Z.; Gan, Y.; Xu, T.; Wang, F. Graph-Segmenter: Graph transformer with boundary-aware attention for semantic segmentation. Front. Comput. Sci. 2024, 18, 185327. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, G.; Sun, X.; Hu, P.; Liu, Y. Attention-Based Multi-Kernelized and Boundary-Aware Network for lmage semantic segmentation. Neurocomputing 2024, 597, 127988. [Google Scholar] [CrossRef]
- Wu, D.; Guo, Z.; Li, A.; Yu, C.; Gao, C.; Sang, N. Conditional Boundary Loss for Semantic Segmentation. IEEE Trans. Image Process. 2023, 32, 3717–3731. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Qiang, Y.; Mo, Y.; Wu, X.; Latecki, L.J. BANet: Boundary-Assistant Encoder-Decoder Network for Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25259–25270. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, Y.; Fan, Y.; Wu, X.; Zhang, S.; Kang, B.; Latecki, L.J. AGLNet: Towards real-time semantic segmentation of self-driving images via attention-guided lightweight network. Appl. Soft Comput. 2020, 96, 106682. [Google Scholar] [CrossRef]
- Han, H.Y.; Chen, Y.C.; Hsiao, P.Y.; Fu, L.C. Using Channel-Wise Attention for Deep CNN Based Real-Time Semantic Segmentation with Class-Aware Edge Information. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1041–1051. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A Real-Time Semantic Segmentation Network Inspired by PID Controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]
- Meng, Z.; Ren, W.; Zheng, Y. Distributed finite-time attitude containment control for multiple rigid bodies. Automatica 2010, 46, 2092–2099. [Google Scholar] [CrossRef]
- Zhang, Q.; Jiang, Z.; Lu, Q.; Han, J.; Zeng, Z.; Gao, S.; Men, A. Split to be slim: An overlooked redundancy in vanilla convolution. arXiv 2020, arXiv:2006.12085. [Google Scholar]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Kumaar, S.; Lyu, Y.; Nex, F.; Yang, M.Y. CABiNet: Efficient Context Aggregation Network for Low-Latency Semantic Segmentation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13517–13524. [Google Scholar] [CrossRef]
- Nirkin, Y.; Wolf, L.; Hassner, T. HyperSeg: Patch-Wise Hypernetwork for Real-Time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4061–4070. [Google Scholar]
- Zhou, Y.; Zheng, X.; Yang, Y.; Li, J.; Mu, J.; Irampaye, R. Multi-directional feature refinement network for real-time semantic segmentation in urban street scenes. IET Comput. Vis. 2023, 17, 431–444. [Google Scholar] [CrossRef]
- Si, H.; Zhang, Z.; Lv, F.; Yu, G.; Lu, F. Real-Time Semantic Segmentation via Multiply Spatial Fusion Network. arXiv 2019, arXiv:1911.07217. [Google Scholar]
- Hu, P.; Caba, F.; Wang, O.; Lin, Z.; Sclaroff, S.; Perazzi, F. Temporally Distributed Networks for Fast Video Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, L.; Jiang, F.; Yang, J.; Kong, B.; Hussain, A. A real-time lane detection network using two-directional separation attention. Comput. Aided Civ. Infrastruct. Eng. 2024, 39, 86–101. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | GPU | Resolution | mIOU (%) | #FPS | GFLOPs | Params (M) |
|---|---|---|---|---|---|---|
| CABiNet [30] | GTX 2080Ti | 2048 × 1024 | 76.6 | 76.5 | 12.0 | 2.64 |
| AMKBANet-T [19] | A100 | 2048 × 1024 | 81.1 | - | 884 | 64 |
| BiSeNetV2 [5] | GTX 1080Ti | 1536 × 768 | 74.8 | 65.5 | 55.3 | 49 |
| BiSeNetV2-L [5] | GTX 1080Ti | 1024 × 512 | 75.8 | 47.3 | 118.5 | - |
| STDC1-Seg75 [6] | RTX 3090 | 1536 × 768 | 74.5 | 74.8 | - | - |
| STDC2-Seg75 [6] | RTX 3090 | 1536 × 768 | 77.0 | 58.2 | - | - |
| PP-LiteSeg-T2 [14] | RTX 3090 | 1536 × 768 | 76.0 | 96.0 | - | - |
| PP-LiteSeg-B2 [14] | RTX 3090 | 1536 × 768 | 78.2 | 68.2 | - | - |
| HyperSeg-M [31] | RTX 3090 | 1024 × 512 | 76.2 | 59.1 | 7.5 | 10.1 |
| HyperSeg-S [31] | RTX 3090 | 1536 × 768 | 78.2 | 45.7 | 17.0 | 10.2 |
| DDRNet-23-S [15] | RTX 3090 | 2048 × 1024 | 77.8 | 108.1 | 36.3 | 5.7 |
| DDRNet-23 [15] | RTX 3090 | 2048 × 1024 | 79.5 | 51.4 | 143.1 | 20.1 |
| MRFNet-S [32] | GTX 1080Ti | 512 × 1024 | 79.3 | 144.5 | - | - |
| MRFNet-L [32] | GTX 1080Ti | 1024 × 1024 | 79.9 | 73.63 | - | - |
| PIDNet-S-Simple [24] | RTX 3090 | 2048 × 1024 | 78.8 | 100.8 | 46.3 | 7.6 |
| PIDNet-S [24] | RTX 4090 | 2048 × 1024 | 78.8 | 93.2 | 47.6 | 7.6 |
| PIDNet-M [24] | RTX 3090 | 2048 × 1024 | 80.1 | 39.8 | 197.4 | 34.4 |
| PIDNet-L [24] | RTX 4090 | 2048 × 1024 | 80.9 | 31.1 | 275.8 | 36.9 |
| CcNet-S | RTX 4090 | 2048 × 1024 | 78.5 | 83.4 | 55.0 | 7.85 |
| CcNet-L | RTX 4090 | 2048 × 1024 | 81.2 | 30.2 | 290.2 | 37.4 |
| Model | mIOU | #FPS | GPU |
|---|---|---|---|
| MSFNet [33] | 75.4 | 91.0 | GTX 2080Ti |
| PP-LiteSeg-T [14] | 75.0 | 154.8 | GTX 1080Ti |
| TD2-PSP50 [34] | 76.0 | 11.0 | TITAN X |
| BiSeNetV2 [5] | 76.7 | 124.0 | GTX 1080Ti |
| BiSeNetV2-L [5] | 78.5 | 33.0 | GTX 1080Ti |
| HyperSeg-S [31] | 78.4 | 38.0 | GTX 1080Ti |
| HyperSeg-L [31] | 79.1 | 16.6 | GTX 1080Ti |
| TSA-LNet [35] | 79.7 | 143.0 | GTX 2080Ti |
| DDRNet-23-S [15] | 78.6 | 182.4 | RTX 3090 |
| DDRNet-23 [15] | 80.6 | 116.8 | RTX 3090 |
| PIDNet-S [24] | 80.1 | 153.7 | RTX 3090 |
| PIDNet-S-Wider [24] | 82.0 | 85.6 | RTX 3090 |
| CcNet-s | 80.6 | 182.0 | RTX 4090 |
| Model | FWF | mIOU | ||
|---|---|---|---|---|
| D Branch | C Branch | Head | ||
| CcNet-S | ✔ | ✔ | 78.12 | |
| ✔ | ✔ | 78.16 | ||
| ✔ | ✔ | 78.48 | ||
| CcNet-L | ✔ | ✔ | 79.85 | |
| ✔ | ✔ | 80.55 | ||
| ✔ | ✔ | 81.15 | ||
| Model | FEU | mIOU | |
|---|---|---|---|
| C Branch | Head | ||
| CcNet-S | 77.78 | ||
| ✔ | 78.04 | ||
| ✔ | 78.48 | ||
| CcNet-L | 80.73 | ||
| ✔ | 81.15 | ||
| ✔ | 80.00 | ||
| Weights of | mIOU | |
|---|---|---|
| Random Search | D + C | |
| ✔ | 65.62 | |
| ✔ | 70.52 | |
| ✔ | 69.17 | |
| ✔ | 81.15 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Zhang, J.; Zhao, C.; Huang, Y.; Deng, T.; Yan, F. Containment Control-Guided Boundary Information for Semantic Segmentation. Appl. Sci. 2024, 14, 7291. https://doi.org/10.3390/app14167291
Liu W, Zhang J, Zhao C, Huang Y, Deng T, Yan F. Containment Control-Guided Boundary Information for Semantic Segmentation. Applied Sciences. 2024; 14(16):7291. https://doi.org/10.3390/app14167291
Chicago/Turabian StyleLiu, Wenbo, Junfeng Zhang, Chunyu Zhao, Yi Huang, Tao Deng, and Fei Yan. 2024. "Containment Control-Guided Boundary Information for Semantic Segmentation" Applied Sciences 14, no. 16: 7291. https://doi.org/10.3390/app14167291
APA StyleLiu, W., Zhang, J., Zhao, C., Huang, Y., Deng, T., & Yan, F. (2024). Containment Control-Guided Boundary Information for Semantic Segmentation. Applied Sciences, 14(16), 7291. https://doi.org/10.3390/app14167291