
Enhancing Diabetes Prediction and Prevention through Mahalanobis Distance and Machine Learning Integration


Abstract
:1. Introduction
2. Related Works
3. Methodology
3.1. Preparing Experimental Dataset
3.2. Feature Selection Based on MC Analysis
3.3. Feature Selection Based on Reliability Analysis
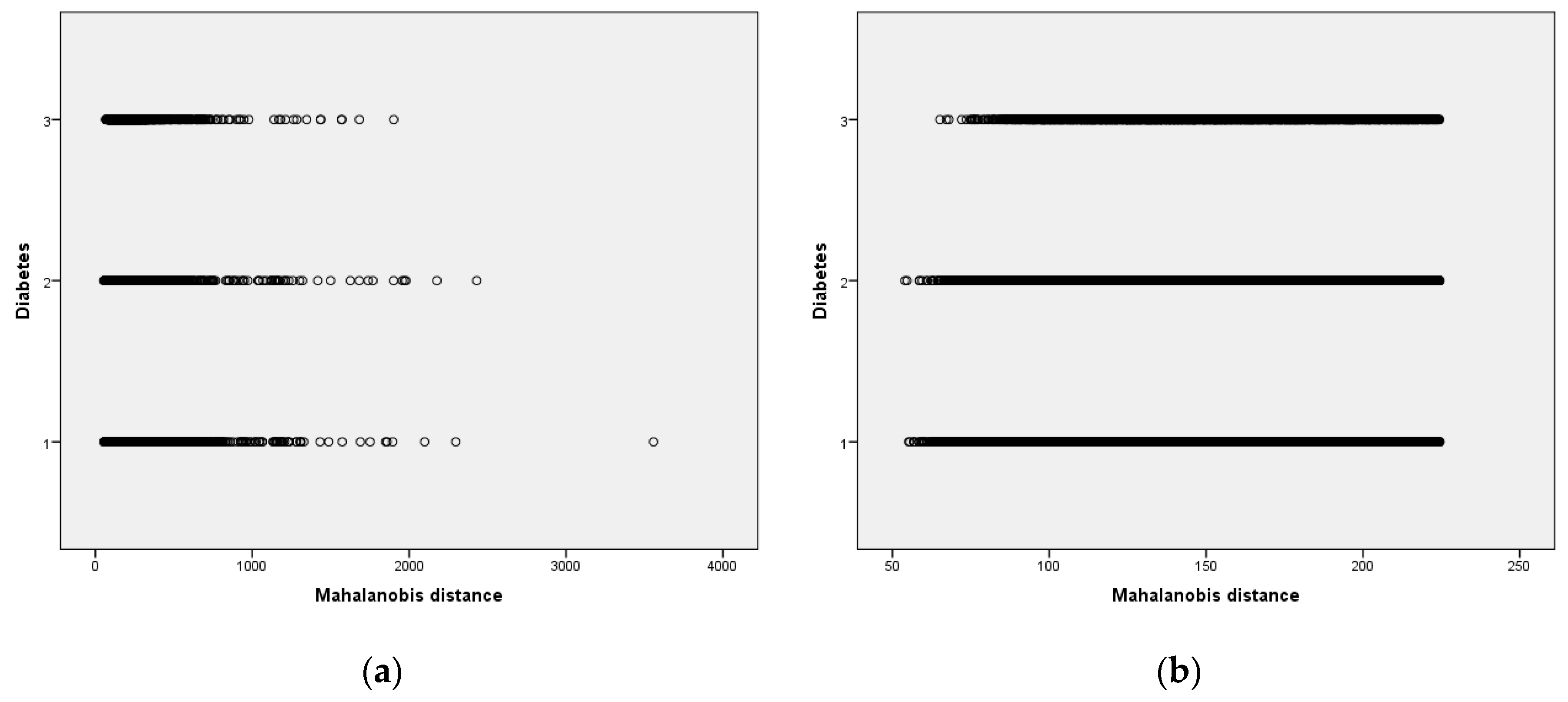
3.4. Outlier Detection Based on MAH
3.5. Classifiers
3.6. Evaluation Metrics
4. Experimental Study
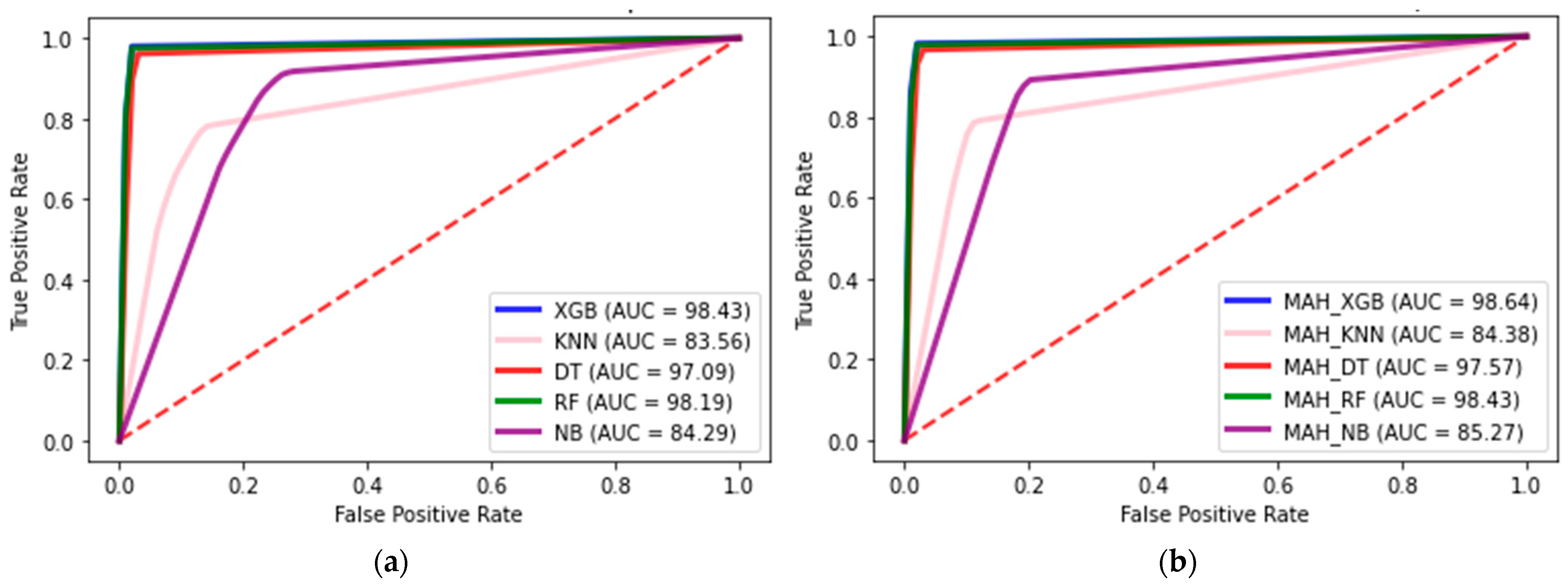
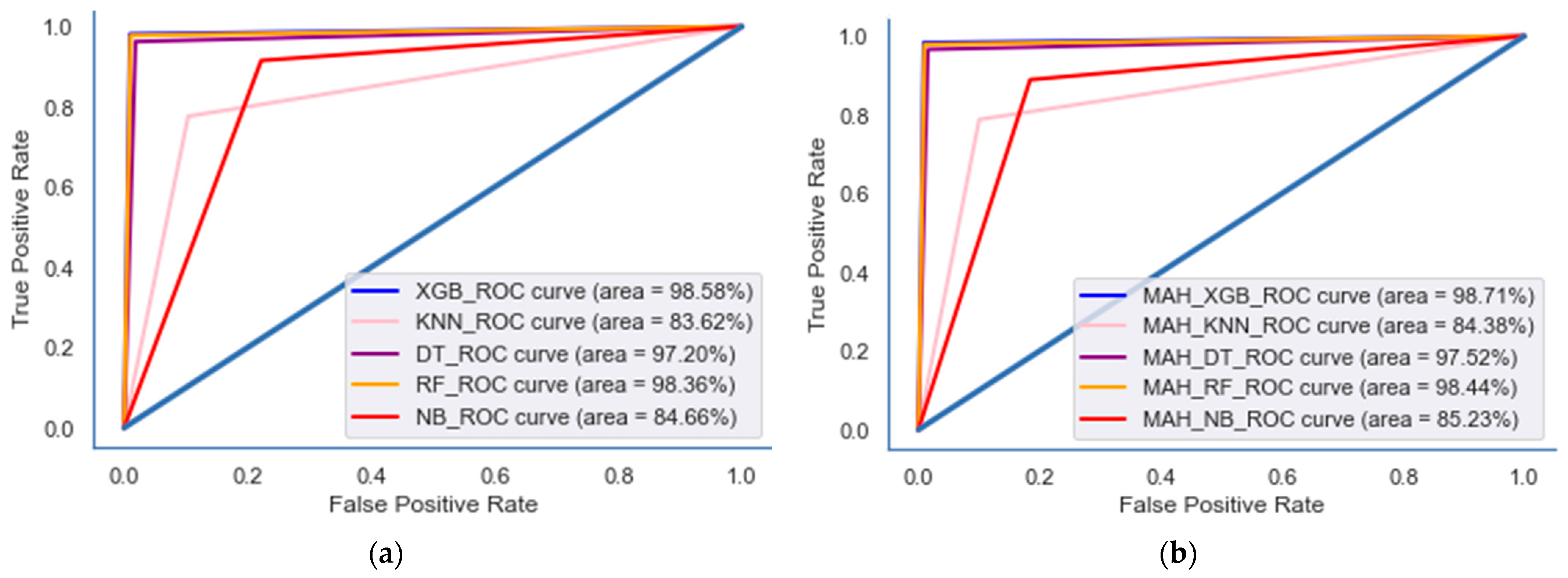
4.1. Classifier Results
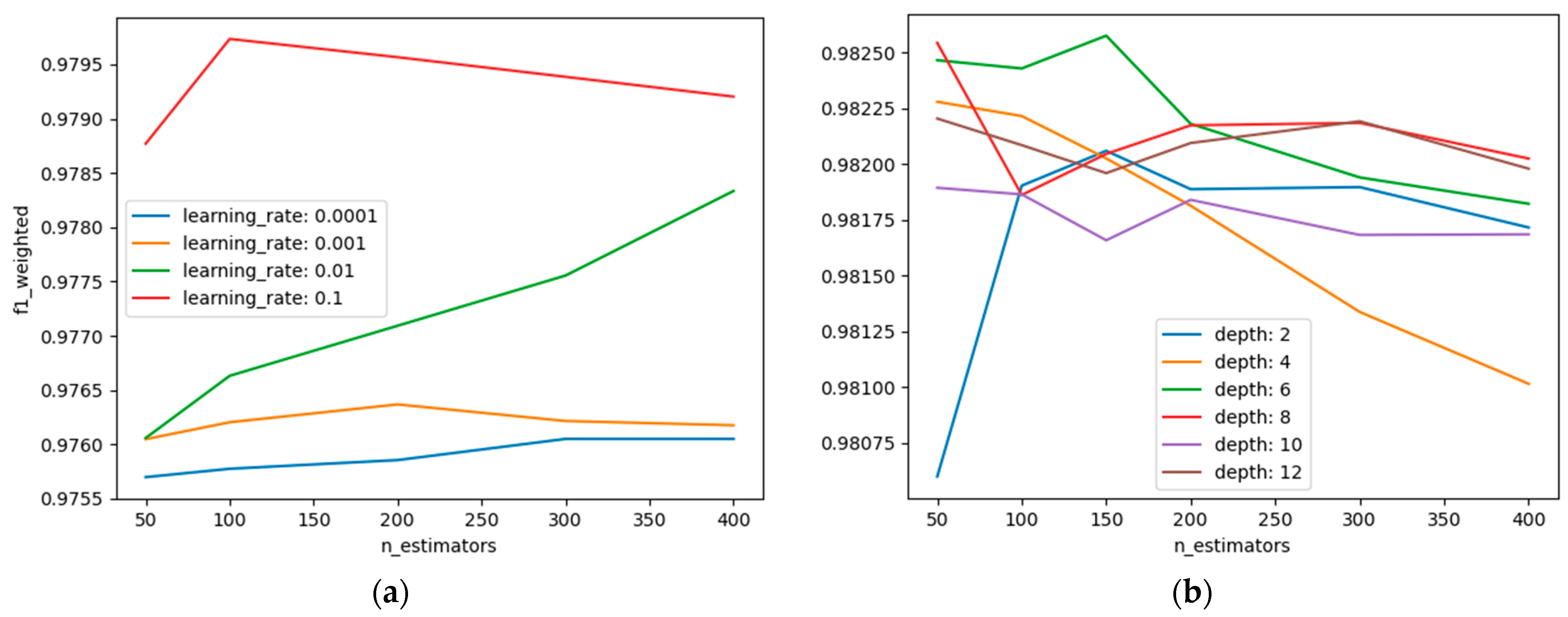
4.2. Hyperparameter Results
5. Discussions
Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Diabetes | Total | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Before COVID-19 Pandemic | During COVID-19 Pandemic | ||||||||
| 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | |||
| Residential area | |||||||||
| Rural | 76 (0.7) | 164 (1.4) | 185 (1.6) | 57 (0.5) | 247 (2.2) | 244 (2.1) | 244 (2.1) | 1217 (10.7) | |
| Urban | 158 (1.4) | 144 (1.3) | 154 (1.4) | 51 (0.4) | 171 (1.5) | 181 (1.6) | 180 (1.6) | 1039 (9.1) | |
| Sex | |||||||||
| Male | 123 (1.3) | 159 (1.7) | 184 (2.0) | 0 (0) | 222 (2.4) | 218 (2.4) | 216 (2.3) | 1122 (12.2) | |
| Female | 111 (0.8) | 149 (1.1) | 155 (1.1) | 108 (0.8) | 196 (1.4) | 207 (1.5) | 208 (1.5) | 1134 (8.4) | |
| Age | |||||||||
| 19–29 years old | 0 (0.0) | 1 (0.0) | 0 (0.0) | 0 (0.0) | 0 (0.0) | 2 (0.1) | 1 (0.0) | 4 (0.2) | |
| 30–39 years old | 2 (0.1) | 6 (0.2) | 7 (0.2) | 3 (0.1) | 11 (0.3) | 10 (0.3) | 3 (0.1) | 42 (10.3) | |
| 40–49 years old | 19 (0.4) | 20 (0.5) | 28 (0.7) | 8 (0.2) | 37 (0.9) | 34 (0.8) | 30 (0.7) | 176 (40.1) | |
| 50–59 years old | 43 (0.9) | 60 (10.3) | 79 (10.7) | 24 (0.5) | 71 (10.5) | 107 (20.3) | 63 (10.4) | 447 (90.7) | |
| 60–69 years old | 96 (20.2) | 10 (20.3) | 106 (20.4) | 32 (0.7) | 127 (20.9) | 137 (30.2) | 154 (30.6) | 752 (170.4) | |
| 70–79 years old | 67 (20.3) | 109 (30.8) | 97 (30.4) | 33 (10.2) | 142 (50.0) | 107 (30.7) | 138 (40.8) | 693 (240.2) | |
| Over 80 years old | 7 (10.0) | 12 (10.7) | 22 (30.0) | 8 (10.1) | 30 (40.1) | 28 (30.9) | 35 (40.8) | 142 (190.5) | |
| Hypertension | |||||||||
| Normal | 49 (0.5) | 45 (0.4) | 60 (0.6) | 17 (0.2) | 64 (0.6) | 85 (0.8) | 77 (0.7) | 397 (3.8) | |
| Pre-hypertension | 49 (0.9) | 69 (1.2) | 57 (1.0) | 15 (0.3) | 91 (1.6) | 85 (1.5) | 79 (1.4) | 445 (7.9) | |
| Hypertension | 136 (2.0) | 194 (2.9) | 222 (3.3) | 76 (1.1) | 263 (3.9) | 255 (3.8) | 268 (3.9) | 1414 (20.8) | |
| Obesity | |||||||||
| Underweight | 1 (0.1) | 2 (0.2) | 4 (0.4) | 0 (0.0) | 3 (0.3) | 2 (0.2) | 7 (0.8) | 19 (2.1) | |
| Normal | 127 (1.2) | 152 (1.5) | 88 (0.8) | 32 (0.3) | 92 (0.9) | 87 (0.8) | 112 (1.1) | 690 (6.6) | |
| Pre-obesity stage | 106 (1.8) | 154 (2.6) | 80 (1.4) | 30 (0.5) | 102 (1.7) | 111 (1.9) | 93 (1.6) | 676 (11.4) | |
| 1st stage obesity | - | - | 144 (3.1) | 38 (0.8) | 182 (3.9) | 171 (3.6) | 181 (3.8) | 716 (15.2) | |
| 2nd stage obesity | - | - | 22 (3.2) | 7 (1.0) | 35 (5.1) | 52 (7.6) | 21 (3.1) | 137 (20.0) | |
| 3rd stage obesity | - | - | 1 (1.1) | 1 (1.1) | 4 (4.3) | 2 (2.2) | 10 (10.8) | 18 (19.4) | |
References
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef]
- Zheng, Y.; Ley, S.H.; Hu, F.B. Global aetiology and epidemiology of type 2 diabetes mellitus and its complications. Nat. Rev. Endocrinol. 2018, 14, 88–98. [Google Scholar] [CrossRef] [PubMed]
- Sonia, J.J.; Jayachandran, P.; Md, A.Q.; Mohan, S.; Sivaraman, A.K.; Tee, K.F. Machine-learning-based diabetes mellitus risk prediction using multilayer neural network no-prop algorithm. Diagnostics 2023, 13, 723. [Google Scholar] [PubMed]
- Care, D. Classification and diagnosis of diabetes. Diabetes Care 2017, 40, S11–S24. [Google Scholar]
- Kopitar, L.; Kocbek, P.; Cilar, L.; Sheikh, A.; Stiglic, G. Early detection of type 2 diabetes mellitus using machine learning-based prediction models. Sci. Rep. 2020, 10, 11981. [Google Scholar] [CrossRef]
- Adua, E.; Kolog, E.A.; Afrifa-Yamoah, E.; Amankwah, B.; Obirikorang, C.; Anto, E.O.; Acheampong, E.; Wang, W.; Tetteh, A.Y. Predictive model and feature importance for early detection of type II diabetes mellitus. Transl. Med. Commun. 2021, 6, 17. [Google Scholar]
- Sadeghi, S.; Khalili, D.; Ramezankhani, A.; Mansournia, M.A.; Parsaeian, M. Diabetes mellitus risk prediction in the presence of class imbalance using flexible machine learning methods. BMC Med. Inform. Decis. Mak. 2022, 22, 36. [Google Scholar] [CrossRef]
- Dritsas, E.; Trigka, M. Data-driven machine-learning methods for diabetes risk prediction. Sensors 2022, 22, 5304. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Kumar, Y.; Singh, P.K. Hybrid diabetes disease prediction framework based on data imputation and outlier detection techniques. Expert Syst. 2022, 39, e12785. [Google Scholar] [CrossRef]
- Nnamoko, N.; Korkontzelos, I. Efficient treatment of outliers and class imbalance for diabetes prediction. Artif. Intell. Med. 2020, 104, 101815. [Google Scholar]
- Dashdondov, K.; Kim, M.H. Mahalanobis distance based multivariate outlier detection to improve performance of hypertension prediction. Neural Process. Lett. 2023, 55, 265–277. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar]
- Flores-Guerrero, J.L.; Grzegorczyk, M.A.; Connelly, M.A.; Garcia, E.; Navis, G.; Dullaart, R.P.; Bakker, S.J. Mahalanobis distance, a novel statistical proxy of homeostasis loss is longitudinally associated with risk of type 2 diabetes. eBioMedicine 2021, 71, 103550. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Lai, Z.; Tang, N.; Tang, F.; Huang, G.; Lu, P.; Jiang, L.; Lei, D.; Xu, F. Diabetic retinopathy related homeostatic dysregulation and its association with mortality among diabetes patients: A cohort study from NHANES. Diabetes Res. Clin. Pract. 2024, 207, 111081. [Google Scholar] [CrossRef] [PubMed]
- Korea Centers for Disease Control & Prevention. Available online: http://knhanes.cdc.go.kr (accessed on 4 February 2014).
- Kwan, B.S.; Cho, I.A.; Park, J.E. Effect of breastfeeding and its duration on impaired fasting glucose and diabetes in perimenopausal and postmenopausal women: Korea National Health and Nutrition Examination Survey (KNHANES) 2010–2019. Medicines 2021, 8, 71. [Google Scholar] [CrossRef]
- Bae, J.H.; Han, K.D.; Ko, S.H.; Yang, Y.S.; Choi, J.H.; Choi, K.M.; Kwon, H.-S.; Won, K.C.; on Behalf of the Committee of Media-Public Relation of the Korean Diabetes Association. Diabetes fact sheet in Korea 2021. Diabetes Metab. J. 2022, 46, 417–426. [Google Scholar] [CrossRef]
- Dashdondov, K.; Kim, M.H.; Song, M.H. Deep autoencoders and multivariate analysis for enhanced hypertension detection during the COVID-19 era. Electron. Res. Arch. 2024, 32, 3202–3229. [Google Scholar] [CrossRef]
- Montesinos, L.; Osval, A.; Crossa, J. Multivariate Statistical Machine Learning Methods for Genomic Prediction; Springer Nature: Cham, Switzerland, 2022. [Google Scholar]
- Taber, K.S. The use of Cronbach’s alpha when developing and reporting research instruments in science education. Res. Sci. Educ. 2018, 48, 1273–1296. [Google Scholar] [CrossRef]
- Khongorzul, D.; Mi-Hye, K.; Kyuri, J. NDAMA: A Novel Deep Autoencoder and Multivariate Analysis Approach for IoT-Based Methane Gas Leakage Detection. IEEE Access 2023, 11, 140740–140751. [Google Scholar]
- Anthony, H.; Kamnitsas, K. On the use of Mahalanobis distance for out-of-distribution detection with neural networks for medical imaging. In Proceedings of the International Workshop on Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, Vancover, BC, Canada, 12 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 136–146. [Google Scholar]
- Zhang, M.; Zhang, Y.; Shen, G. PPDDS: A privacy-preserving disease diagnosis scheme based on the secure Mahalanobis distance evaluation model. IEEE Syst. J. 2021, 16, 4552–4562. [Google Scholar] [CrossRef]
- Sun, S. Segmentation-based adaptive feature extraction combined with mahalanobis distance classification criterion for heart sound diagnostic system. IEEE Sens. J. 2021, 21, 11009–11022. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, H.; Yang, C.; An, T.; Kuang, Z.; Shi, L. Attention-Oriented CNN Method for Type 2 Diabetes Prediction. Appl. Sci. 2024, 14, 3989. [Google Scholar] [CrossRef]
- Belsti, Y.; Moran, L.; Du, L.; Mousa, A.; De Silva, K.; Enticott, J.; Teede, H. Comparison of machine learning and conventional logistic regression-based prediction models for gestational diabetes in an ethnically diverse population the Monash GDM Machine learning model. Int. J. Med. Inform. 2023, 179, 105228. [Google Scholar] [CrossRef]
- Gupta, N.; Kaushik, B.; Imam Rahmani, M.K.; Lashari, S.A. Performance Evaluation of Deep Dense Layer Neural Network for Diabetes Prediction. Comput. Mater. Contin. 2023, 76, 347–366. [Google Scholar] [CrossRef]
- Al Sadi, K.; Balachandran, W. Prediction model of Type 2 diabetes mellitus for omanpre-diabetess patients using artificial neural network and six machine learning classifiers. Appl. Sci. 2023, 13, 2344. [Google Scholar] [CrossRef]
- Hasan, M.K.; Alam, M.A.; Das, D.; Hossain, E.; Hasan, M. Diabetes prediction using ensembling of different machine learning classifiers. IEEE Access 2020, 8, 76516–76531. [Google Scholar] [CrossRef]
- Ali, M.S.; Islam, M.K.; Das, A.A.; Duranta, D.U.; Haque, M.F.; Rahman, M.H. A novel approach for best parameters selection and feature engineering to analyze and detect diabetes: Machine learning insights. BioMed Res. Int. 2023, 1, 8583210. [Google Scholar]
- Sharma, S.K.; Zamani, A.T.; Abdelsalam, A.; Muduli, D.; Alabrah, A.A.; Parveen, N.; Alanazi, S.M. A Diabetes Monitoring System and Health-Medical Service Composition Model in Cloud Environment. IEEE Access 2023, 11, 32804–32819. [Google Scholar] [CrossRef]
- Aminizadeh, S.; Heidari, A.; Toumaj, S.; Darbandi, M.; Navimipour, N.J.; Rezaei, M.; Talebi, S.; Azad, P.; Unal, M. The applications of machine learning techniques in medical data processing based on distributed computing and the Internet of Things. Comput. Methods Programs Biomed. 2023, 241, 107745. [Google Scholar] [CrossRef]
- Xu, J.; Chen, T.; Fang, X.; Xia, L.; Pan, X. Prediction model of pressure injury occurrence in diabetic patients during ICU hospitalization—XGBoost machine learning model can be interpreted based on SHAP. Intensiv. Crit. Care Nurs. 2024, 83, 103715. [Google Scholar] [CrossRef]
- Uddin, M.J.; Ahamad, M.M.; Hoque, M.N.; Walid, M.A.; Aktar, S.; Alotaibi, N.; Alyami, S.A.; Kabir, M.A.; Moni, M.A. A comparison of machine learning techniques for the detection of type-2 diabetes mellitus: Experiences from Bangladesh. Information 2023, 14, 376. [Google Scholar] [CrossRef]
- Pina, A.F.; Meneses, M.J.; Sousa-Lima, I.; Henriques, R.; Raposo, J.F.; Macedo, M.P. Big data and machine learning to tackle diabetes management. Eur. J. Clin. Investig. 2023, 53, e13890. [Google Scholar] [CrossRef] [PubMed]
- Wee, B.F.; Sivakumar, S.; Lim, K.H.; Wong, W.K.; Juwono, F.H. Diabetes detection based on machine learning and deep learning approaches. Multimed. Tools Appl. 2024, 83, 24153–24185. [Google Scholar] [CrossRef]
- Dashdondov, K.; Song, M.H. Factorial Analysis for Gas Leakage Risk Predictions from a Vehicle-Based Methane Survey. Appl. Sci. 2021, 12, 115. [Google Scholar] [CrossRef]
- Brownlee, J.; Machine Learning Algorithms from Scratch with Python. Machine Learning Mastery. 2016. Available online: https://machinelearningmastery.com/machine-learning-algorithms-from-scratch/ (accessed on 1 August 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- WHO. Diabetes. Available online: https://www.who.int/news-room/fact-sheets/detail/diabetes (accessed on 1 August 2024).


| Authors | Years | Algorithms | Comments |
|---|---|---|---|
| [25] | 2024 | SECNN | The SECNN model has an accuracy of 94.12% in NHANES dataset and an accuracy of 89.47% on the PIMA Indian dataset. |
| [26] | 2023 | CBC | CatBoost classifier best performance, with an accuracy of 85% and an AUC of 93%. |
| [27] | 2023 | DDLNN | The model is best, with an accuracy of 84.42%. |
| [31] | 2023 | PCA + ELM | PCA has the best performance with an accuracy of 90.57%. |
| [29] | 2020 | AB + XB | The best model reaches an AUC of 95%. |
| [30] | 2023 | RFWBP | The best performance, with an accuracy of 95.83%. |
| Feature | Descriptions | Mean | Std. Dev | p-Value | Tolerance | VIF 1 |
|---|---|---|---|---|---|---|
| BP6_31 | Attempted suicide for 1 year | 2 | 0.04 | 0.189 | 0.193 | 5.171 |
| BP7 | Counseling for mental issues for 1 year | 1.98 | 0.143 | 0.149 | 0.235 | 4.261 |
| HE_HbA1c | Glycated hemoglobin | 5.69 | 0.623 | <0.001 | 0.282 | 3.546 |
| HE_glu | Fasting blood sugar | 99.12 | 16.855 | <0.001 | 0.315 | 3.173 |
| HE_sbp | End systolic blood pressure | 118.67 | 16.223 | 0.290 | 0.350 | 2.857 |
| HE_alt | Serum glutamic pyruvic transaminase | 21.18 | 13.468 | <0.001 | 0.380 | 2.632 |
| HE_HP | Hypertension | 1.86 | 0.859 | <0.001 | 0.392 | 2.554 |
| HE_ast | Serum glutamic oxaloacetic transaminase | 22.8 | 8.248 | 0.670 | 0.428 | 2.335 |
| Age | Age | 4.73 | 1.686 | <0.001 | 0.441 | 2.270 |
| Sex | Sex | 1.6 | 0.489 | <0.001 | 0.442 | 2.260 |
| HE_obe | Obesity (over 19 years old) | 2.75 | 0.964 | <0.001 | 0.464 | 2.155 |
| HE_dbp | End diastolic blood pressure | 75.03 | 9.623 | <0.001 | 0.484 | 2.065 |
| BO1 | Subjective body shape recognition | 3.37 | 0.906 | <0.001 | 0.487 | 2.053 |
| HE_HCT | Hematocrit | 42.33 | 4.201 | <0.001 | 0.520 | 1.924 |
| BS13 | Exposure to secondhand smoke indoors in public | 1.85 | 0.36 | 0.101 | 0.526 | 1.900 |
| HE_crea | Blood creatinine | 0.8 | 0.183 | 0.686 | 0.592 | 1.688 |
| HE_BUN | Blood urea nitrogen | 14.6 | 4.285 | <0.001 | 0.640 | 1.563 |
| BS9_2 | Exposure to secondhand smoke indoors at home | 2.8 | 0.498 | 0.294 | 0.712 | 1.405 |
| BP6_2 | Planned suicide for a year | 1.99 | 0.101 | <0.004 | 0.759 | 1.317 |
| BP1 | Perceived level of stress on a daily basis | 2.88 | 0.72 | 0.227 | 0.789 | 1.268 |
| BO2_1 | Weight control for 1 year | 2.28 | 1.3 | 0.213 | 0.805 | 1.242 |
| Year | Survey year | 2018.12 | 2.032 | <0.001 | 0.827 | 1.209 |
| HE_HCHOL | Hypercholesterolemia | 0.24 | 0.428 | <0.001 | 0.851 | 1.175 |
| HE_WBC | Leukocyte | 6.09 | 1.628 | <0.001 | 0.857 | 1.166 |
| HE_HTG | Hypertriglyceridemia | 0.12 | 0.328 | <0.005 | 0.888 | 1.126 |
| Graduate | Education level—graduation status | 1.56 | 1.363 | 0.319 | 0.896 | 1.116 |
| DJ8_pt | Allergic rhinitis treatment | 6.91 | 2.699 | 0.362 | 0.907 | 1.102 |
| DJ6_pt | Sinusitis treatment | 7.54 | 1.847 | 0.261 | 0.948 | 1.055 |
| BD1_11 | Frequency of drinking per year | 3.69 | 2.122 | <0.019 | 0.951 | 1.051 |
| DL1_pt | Atopic dermatitis treatment | 7.88 | 0.968 | 0.176 | 0.958 | 1.044 |
| HE_fh | Family history of chronic dis. diagnosed | 0.67 | 0.793 | 0.060 | 0.972 | 1.028 |
| DH4_pt | Otitis media treatment | 7.63 | 1.676 | 0.245 | 0.975 | 1.026 |
| Region | Region | 7.39 | 4.918 | 0.520 | 0.976 | 1.024 |
| HE_hepaB | Hepatitis B surface antigen positive | 0.02 | 0.129 | <0.043 | 0.991 | 1.009 |
| Class | Dataset with FS | Dataset with FS and MAH | ||||
|---|---|---|---|---|---|---|
| Total | Train 70% | Test 30% | Total | Train 70% | Test 30% | |
| Normal | 14,648 | 10,186 | 4442 | 13,318 | 9324 | 3994 |
| Pre-diabetes | 8876 | 6238 | 2638 | 7775 | 5426 | 2349 |
| Diabetes | 3778 | 2673 | 1105 | 2518 | 1777 | 741 |
| Total | 27,282 | 19,097 | 8185 | 23,611 | 16,527 | 7084 |
| Total Case | Cronbach’s Alpha | Features Number | |
|---|---|---|---|
| Dataset without MAH * | 27,282 | 0.599 | 24 |
| Dataset with MAH ** | 23,611 | 0.641 | 24 |
| Algorithms (Selected Features) | Accuracy (%) | AUC (%) | F1-Score (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base (165) | MC (24) | XGB (66) | RF (22) | Base (165) | MC (24) | XGB (66) | RF (22) | Base (165) | MC (24) | XGB (66) | RF (22) | ||
| Baseline model * | XGB | 96.78 | 97.75 | 97.72 | 97.74 | 97.83 | 98.48 | 98.47 | 98.46 | 97.24 | 97.95 | 97.96 | 97.97 |
| KNN | 40.09 | 77.47 | 66.13 | 66.38 | 58.50 | 83.56 | 75.74 | 75.92 | 44.44 | 79.71 | 70.68 | 70.83 | |
| DT | 93.81 | 94.07 | 93.96 | 93.93 | 96.92 | 97.05 | 97.04 | 96.94 | 95.87 | 96.17 | 95.92 | 96.05 | |
| NB | 48.21 | 53.33 | 48.21 | 53.14 | 78.23 | 84.29 | 79.37 | 83.43 | 63.75 | 70.40 | 64.29 | 69.26 | |
| RF | 95.42 | 97.26 | 96.91 | 97.25 | 97.29 | 97.26 | 98.04 | 98.21 | 97.49 | 97.74 | 97.68 | 97.91 | |
| Proposed model ** | MAH_XGB | 97.79 | 97.98 | 97.92 | 97.76 | 98.52 | 98.64 | 98.61 | 98.47 | 97.99 | 98.21 | 98.17 | 97.94 |
| MAH_KNN | 41.93 | 78.71 | 67.69 | 67.48 | 59.53 | 84.39 | 76.76 | 76.59 | 44.12 | 79.71 | 70.81 | 70.98 | |
| MAH_DT | 94.51 | 95.31 | 95.05 | 94.13 | 97.17 | 97.58 | 97.46 | 97.03 | 96.34 | 96.86 | 96.63 | 96.04 | |
| MAH_NB | 54.94 | 60.92 | 55.71 | 64.60 | 79.45 | 85.27 | 80.47 | 83.81 | 66.12 | 71.96 | 67.68 | 72.65 | |
| MAH_RF | 96.67 | 97.62 | 97.29 | 97.25 | 97.96 | 98.43 | 98.28 | 98.22 | 97.51 | 97.93 | 97.94 | 97.74 | |
| Algorithms (Selected Features) | Accuracy (%) | AUC (%) | F1-Score (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base (165) | MC (24) | XGB (66) | RF (22) | Base (165) | MC (24) | XGB (66) | RF (22) | Base (165) | MC (24) | XGB (66) | RF (22) | ||
| Baseline model * | XGB | 97.02 | 97.96 | 97.83 | 97.77 | 97.51 | 98.58 | 98.55 | 98.5 | 97.04 | 98.08 | 98.03 | 97.96 |
| KNN | 33.68 | 77.6 | 65.66 | 66.01 | 54.00 | 83.62 | 75.35 | 75.64 | 33.93 | 77.93 | 66.76 | 67.12 | |
| DT | 94.501 | 94.44 | 94.39 | 94.63 | 97.5 | 97.2 | 97.15 | 97.3 | 96.69 | 96.30 | 96.24 | 96.41 | |
| NB | 42.08 | 54.00 | 48.56 | 53.9 | 77.77 | 84.66 | 79.8 | 83.78 | 69.65 | 78.54 | 72.73 | 77.35 | |
| RF | 96.08 | 97.55 | 97.178 | 97.47 | 96.68 | 98.36 | 98.21 | 98.35 | 96.72 | 97.80 | 97.63 | 97.80 | |
| Proposed model ** | MAH_XGB | 97.22 | 98.04 | 97.96 | 97.69 | 97.44 | 98.71 | 98.72 | 98.39 | 97.22 | 98.24 | 98.27 | 97.81 |
| MAH_KNN | 48.52 | 78.80 | 67.36 | 67.4 | 64.69 | 84.38 | 76.46 | 76.47 | 52.67 | 78.79 | 68.02 | 67.97 | |
| MAH_DT | 94.14 | 94.97 | 94.94 | 94.16 | 95.07 | 97.47 | 97.49 | 97.08 | 94.75 | 94.68 | 96.61 | 96.16 | |
| MAH_NB | 53.60 | 61.01 | 57.03 | 65.61 | 82.81 | 85.23 | 81.51 | 84.44 | 77.4 | 79.16 | 74.94 | 78.44 | |
| MAH_RF | 96.85 | 97.71 | 97.28 | 97.17 | 96.73 | 98.44 | 98.34 | 98.16 | 96.74 | 97.89 | 97.82 | 97.52 | |
| Algorithms | Accuracy (%) | p-Value | 95% CI |
|---|---|---|---|
| MAH_XGB | 98.04 | 3.52 × 10−15 | 97.89~98.59 |
| MAH_KNN | 78.80 | 3.89 × 10−15 | 77.66~79.89 |
| MAH_DT | 94.97 | 3.33 × 10−15 | 93.56~97.52 |
| MAH_RF | 97.71 | 3.98 × 10−15 | 97.62~98.08 |
| MAH_NB | 61.01 | 3.93 × 10−15 | 79.88~81.96 |
| Algorithms | Accuracy (%) | AUC (%) |
|---|---|---|
| CatBoost CBC [26] | 85.0 | 93.0 |
| DDLNN [27] | 84.42 | - |
| AB + XB [29] | - | 95.0 |
| RFWBP [30] | 83.0 | 86.0 |
| PCA + ELM [31] | 90.57 | - |
| Proposed method_MAH_XGB | 98.04 | 98.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dashdondov, K.; Lee, S.; Erdenebat, M.-U. Enhancing Diabetes Prediction and Prevention through Mahalanobis Distance and Machine Learning Integration. Appl. Sci. 2024, 14, 7480. https://doi.org/10.3390/app14177480
Dashdondov K, Lee S, Erdenebat M-U. Enhancing Diabetes Prediction and Prevention through Mahalanobis Distance and Machine Learning Integration. Applied Sciences. 2024; 14(17):7480. https://doi.org/10.3390/app14177480
Chicago/Turabian StyleDashdondov, Khongorzul, Suehyun Lee, and Munkh-Uchral Erdenebat. 2024. "Enhancing Diabetes Prediction and Prevention through Mahalanobis Distance and Machine Learning Integration" Applied Sciences 14, no. 17: 7480. https://doi.org/10.3390/app14177480