


A Machine Learning Predictive Model for Ship Fuel Consumption
 , ,
, , 
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Acquisition
2.2. Database
2.3. Data Processing
2.3.1. Filling in Missing Data
2.3.2. Transformation of Categorical Variables
2.3.3. Removing the Outliers
2.3.4. Standardization
2.4. Feature Selection
- The strength of the relationship between the variables could admit any value between −1 and +1, and the closer to one of the extremes, the stronger the correlation would be; it is further assumed that for a perfect linear relationship to occur, the correlation shown should be equal to −1 or +1;
- When equal to zero, there is no linear relationship between the two variables under analysis;
- A positive value of the correlation coefficient would determine the existence of a directly proportional relationship between two variables; that is, as one of them grows, the behavior of the curve of the other variable will also increase; on the other hand, for a negative coefficient, the attributes would be considered inversely proportional, which, in other words, means that as one attribute increases, the other decreases).
2.5. Model Building and Training
2.5.1. Decision Tree
2.5.2. Assembly Method
Random Forest
Extra Trees
Gradient Boosting (GB)
Extreme Gradient Boosting (XGBoost)
CatBoost
2.6. Hyperparameters Tuning
2.7. Model Performance Evaluation
2.7.1. Mean Absolute Error (MAE)
2.7.2. Mean Squared Error (MSE)
2.7.3. Root Mean Square Error (RMSE)
2.7.4. Coefficient of Determination (R2)
2.8. Model Validation
3. Analysis of Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kee, K.-K.; Simon, B.-Y.L.; Renco, K.-H.Y. Prediction of Ship Fuel Consumption and Speed Curve by Using Statistical Method. J. Comput. Sci. Comput. Math 2018, 8, 19–24. [Google Scholar] [CrossRef]
- Wu, Z.; Xia, X. Tariff-Driven Demand Side Management of Green Ship. Sol. Energy 2018, 170, 991–1000. [Google Scholar] [CrossRef]
- IMO. Third IMO GHG Study; International Maritime Organization: London, UK, 2014. [Google Scholar]
- Figueiredo, N.; Moraes, H.; Loureiro, E.; Lameira, P. Caracterização Da Oferta e Da Demanda Do Transporte Fluvial de Passageiros e Cargas Na Região Amazônica; Agência Nacional de Transportes Aquaviários(ANTAQ); Universidade Federal do Pará—UFPA: Belém, Brazil, 2018. [Google Scholar]
- da Costa, D.S.; de Assis, M.V.G.S.; de Figueiredo, N.M.; de Moraes, H.B.; Ferreira, R.C.B. The Efficiency of Container Terminals in the Northern Region of Brazil. Util. Policy 2021, 72, 101278. [Google Scholar] [CrossRef]
- De Figueiredo, N.M.; Blanco, C.J.C. Water Level Forecasting and Navigability Conditions of the Tapajós River-Amazon-Brazil. La Houille Blanche 2016, 102, 53–64. [Google Scholar] [CrossRef]
- Da Silva Holanda, P.; Blanco, C.J.C.; Mesquita, A.L.A.; Junior, A.C.P.B.; de Figueiredo, N.M.; Macêdo, E.N.; Secretan, Y. Assessment of Hydrokinetic Energy Resources Downstream of Hydropower Plants. Renew. Energy 2017, 101, 1203–1214. [Google Scholar] [CrossRef]
- Benjamin, C.; Figueiredo, N. The Ship Recycling Market in Brazil-The Amazon Potential. J. Environ. Manag. 2020, 253, 109540. [Google Scholar] [CrossRef]
- Beşikçi, E.B.; Arslan, O.; Turan, O.; Ölçer, A.I. An Artificial Neural Network Based Decision Support System for Energy Efficient Ship Operations. Comput. Oper. Res. 2016, 66, 393–401. [Google Scholar] [CrossRef]
- Stopford, M. Maritime Economics 3e; Routledge: New York, NY, USA, 2009. [Google Scholar]
- Buhaug, Ø.; Corbett, J.; Endresen, Ø.; Eyring, V.; Faber, J.; Hanayama, S.; Lee, D.S.; Lee, D.; Lindstad, H.; Markowska, A.; et al. Second IMO GHG Study 2009; International Maritime Organization: London, UK, 2009. [Google Scholar]
- Eide, M.S.; Longva, T.; Hoffmann, P.; Endresen, Ø.; Dalsøren, S.B. Future Cost Scenarios for Reduction of Ship CO2 Emissions. Marit. Policy Manag. 2011, 38, 11–37. [Google Scholar] [CrossRef]
- Hochkirch, K.; Heimann, J.; Bertram, V. Hull Optimization for Operational Profile–the next Game Level. In Proceedings of the MARINE V: Proceedings of the V International Conference on Computational Methods in Marine Engineering, Hamburg, Germany, 29–31 May 2013; CIMNE: Barcelona, Spain, 2013; pp. 81–88. [Google Scholar]
- Adland, R.; Cariou, P.; Jia, H.; Wolff, F.-C. The Energy Efficiency Effects of Periodic Ship Hull Cleaning. J. Clean. Prod. 2018, 178, 1–13. [Google Scholar] [CrossRef]
- Islam, H.; Soares, C.G. Effect of Trim on Container Ship Resistance at Different Ship Speeds and Drafts. Ocean Eng. 2019, 183, 106–115. [Google Scholar] [CrossRef]
- Ionescu, R.D.; Szava, I.; Vlase, S.; Ivanoiu, M.; Munteanu, R. Innovative Solutions for Portable Wind Turbines, Used on Ships. Procedia Technol. 2015, 19, 722–729. [Google Scholar] [CrossRef]
- Wang, H.; Oguz, E.; Jeong, B.; Zhou, P. Life Cycle and Economic Assessment of a Solar Panel Array Applied to a Short Route Ferry. J. Clean. Prod. 2019, 219, 471–484. [Google Scholar] [CrossRef]
- Yu, W.; Zhou, P.; Wang, H. Evaluation on the Energy Efficiency and Emissions Reduction of a Short-Route Hybrid Sightseeing Ship. Ocean Eng. 2018, 162, 34–42. [Google Scholar] [CrossRef]
- Alujević, N.; Ćatipović, I.; Malenica, Š.; Senjanović, I.; Vladimir, N. Ship Roll Control and Energy Harvesting Using a U-Tube Anti-Roll Tank. In Proceedings of the International Conference on Noise and Vibration Engineering (ISMA2018), Leuven, Belgium, 17–19 September 2018; pp. 1621–1634. [Google Scholar]
- Shih, N.-C.; Weng, B.-J.; Lee, J.-Y.; Hsiao, Y.-C. Development of a 20 kW Generic Hybrid Fuel Cell Power System for Small Ships and Underwater Vehicles. Int. J. Hydrogen Energy 2014, 39, 13894–13901. [Google Scholar] [CrossRef]
- Schiller, R.A. Análise da Eficiência Energética em Navios Mercantes e Estudo de Caso do Consumo de Combustível em Navio Aliviador do Tipo Suezmax. Ph.D. Thesis, Universidade de São Paulo, São Paulo, Brazil, 2016. Available online: https://www.teses.usp.br/teses/disponiveis/3/3135/tde-03032017-135911/publico/RodrigoAchillesSchillerOrig16 (accessed on 15 February 2021).
- Gainza, J.A.N.; Brinati, H.L. Análise da Operação de Navios Porta Contêineres em Velocidade Reduzida. Inst. Pan-Am. Eng. Nav. 2010, 1–15. [Google Scholar]
- Barua, L.; Zou, B.; Zhou, Y. Machine Learning for International Freight Transportation Management: A Comprehensive Review. Res. Transp. Bus. Manag. 2020, 34, 100453. [Google Scholar] [CrossRef]
- Cipollini, F.; Oneto, L.; Coraddu, A.; Murphy, A.J.; Anguita, D. Condition-Based Maintenance of Naval Propulsion Systems: Data Analysis with Minimal Feedback. Reliab. Eng. Syst. Saf. 2018, 177, 12–23. [Google Scholar] [CrossRef]
- Abebe, M.; Shin, Y.; Noh, Y.; Lee, S.; Lee, I. Machine Learning Approaches for Ship Speed Prediction towards Energy Efficient Shipping. Appl. Sci. 2020, 10, 2325. [Google Scholar] [CrossRef]
- Hu, Z.; Zhou, T.; Osman, M.T.; Li, X.; Jin, Y.; Zhen, R. A Novel Hybrid Fuel Consumption Prediction Model for Ocean-Going Container Ships Based on Sensor Data. J. Mar. Sci. Eng. 2021, 9, 449. [Google Scholar] [CrossRef]
- Zhang, C.; Zou, X.; Lin, C. Fusing XGBoost and SHAP Models for Maritime Accident Prediction and Causality Interpretability Analysis. J. Mar. Sci. Eng. 2022, 10, 1154. [Google Scholar] [CrossRef]
- Coraddu, A.; Oneto, L.; Baldi, F.; Anguita, D. Vessels Fuel Consumption Forecast and Trim Optimisation: A Data Analytics Perspective. Ocean Eng. 2017, 130, 351–370. [Google Scholar] [CrossRef]
- Jeon, M.; Noh, Y.; Shin, Y.; Lim, O.; Lee, I.; Cho, D. Prediction of Ship Fuel Consumption by Using an Artificial Neural Network. J. Mech. Sci. Technol. 2018, 32, 5785–5796. [Google Scholar] [CrossRef]
- Wickramanayake, S.; Bandara, H.D. Fuel Consumption Prediction of Fleet Vehicles Using Machine Learning: A Comparative Study. In Proceedings of the 2016 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 5–6 April 2016; pp. 90–95. [Google Scholar]
- Theodoropoulos, P.; Spandonidis, C.C.; Themelis, N.; Giordamlis, C.; Fassois, S. Evaluation of Different Deep-Learning Models for the Prediction of a Ship’s Propulsion Power. J. Mar. Sci. Eng. 2021, 9, 116. [Google Scholar] [CrossRef]
- Gkerekos, C.; Lazakis, I.; Theotokatos, G. Machine Learning Models for Predicting Ship Main Engine Fuel Oil Consumption: A Comparative Study. Ocean Eng. 2019, 188, 106282. [Google Scholar] [CrossRef]
- Uyanık, T.; Karatuğ, Ç.; Arslanoğlu, Y. Machine Learning Approach to Ship Fuel Consumption: A Case of Container Vessel. Transp. Res. Part D Transp. Environ. 2020, 84, 102389. [Google Scholar] [CrossRef]
- Štepec, D.; Martinčič, T.; Klein, F.; Vladušič, D.; Costa, J.P. Machine Learning Based System for Vessel Turnaround Time Prediction. In Proceedings of the 2020 21st IEEE International Conference on Mobile Data Management (MDM), Versailles, France, 30 June–3 July 2020; pp. 258–263. [Google Scholar]
- Okumuş, F.; Ekmekçioğlu, A.; Kara, S.S. Modelling Ships Main and Auxiliary Engine Powers with Regression-Based Machine Learning Algorithms. Pol. Marit. Res. 2021, 28, 83–96. [Google Scholar] [CrossRef]
- Dietterich, T.G. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed]
- Batista, G.E.d.A.P.A. Pré-Processamento de Dados Em Aprendizado de Máquina Supervisionado. Ph.D. Thesis, Universidade de São Paulo, São Paulo, Brazil, 2003. [Google Scholar]
- Baranauskas, J.A.; Monard, M.C. Metodologias Para a Seleção de Atributos Relevantes. XIII Simpósio Bras. De Inteligência Artif. 1998, 1–6. Available online: https://www.researchgate.net/profile/Maria-Carolina-Monard/publication/267780870 (accessed on 15 February 2022).
- Petersen, J.P.; Winther, O.; Jacobsen, D.J. A Machine-Learning Approach to Predict Main Energy Consumption under Realistic Operational Conditions. Ship Technol. Res. 2012, 59, 64–72. [Google Scholar] [CrossRef]
- Liang, Y.; Wu, J.; Wang, W.; Cao, Y.; Zhong, B.; Chen, Z.; Li, Z. Product Marketing Prediction Based on XGboost and LightGBM Algorithm. In Proceedings of the 2nd International Conference on Artificial Intelligence and Pattern Recognition, London, UK, 16–18 August 2019; pp. 150–153. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Kwak, S.K.; Kim, J.H. Statistical Data Preparation: Management of Missing Values and Outliers. Korean J. Anesthesiol. 2017, 70, 407–411. [Google Scholar] [CrossRef]
- Jian, S.; Cao, L.; Pang, G.; Lu, K.; Gao, H. Embedding-Based Representation of Categorical Data by Hierarchical Value Coupling Learning. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2017. [Google Scholar]
- Tan, P.-N.; Steinbach, M.; Kumar, V. Data Mining Cluster Analysis: Basic Concepts and Algorithms. Introd. Data Min. 2013, 487, 533. [Google Scholar]
- Potdar, K.; Pardawala, T.S.; Pai, C.D. A Comparative Study of Categorical Variable Encoding Techniques for Neural Network Classifiers. Int. J. Comput. Appl. 2017, 175, 7–9. [Google Scholar] [CrossRef]
- Yin, W. Machine Learning for Adaptive Cruise Control Target Selection. 2019. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1375828&dswid=120 (accessed on 15 February 2021).
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis Distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Leys, C.; Klein, O.; Dominicy, Y.; Ley, C. Detecting Multivariate Outliers: Use a Robust Variant of the Mahalanobis Distance. J. Exp. Soc. Psychol. 2018, 74, 150–156. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis; Pearson: London, UK, 1977. [Google Scholar]
- Singh, D.; Singh, B. Investigating the Impact of Data Normalization on Classification Performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Tong, H. Data Mining: Concepts and Techniques; Morgan kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Pandey, A.; Jain, A. Comparative Analysis of KNN Algorithm Using Various Normalization Techniques. Int. J. Comput. Netw. Inf. Secur. 2017, 9, 36. [Google Scholar] [CrossRef]
- Manju, N.; Harish, B.; Prajwal, V. Ensemble Feature Selection and Classification of Internet Traffic Using XGBoost Classifier. Int. J. Comput. Netw. Inf. Secur. 2019, 10, 37. [Google Scholar] [CrossRef]
- Pani, C. Managing Vessel Arrival Uncertainty in Container Terminals: A Machine Learning Approach. 2014. Available online: https://hdl.handle.net/11584/266426 (accessed on 15 February 2021).
- Brillante, L.; Gaiotti, F.; Lovat, L.; Vincenzi, S.; Giacosa, S.; Torchio, F.; Segade, S.R.; Rolle, L.; Tomasi, D. Investigating the Use of Gradient Boosting Machine, Random Forest and Their Ensemble to Predict Skin Flavonoid Content from Berry Physical–Mechanical Characteristics in Wine Grapes. Comput. Electron. Agric. 2015, 117, 186–193. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients: Appropriate Use and Interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Singh, K.K.; Kumar, S.; Dixit, P.; Bajpai, M.K. Kalman Filter Based Short Term Prediction Model for COVID-19 Spread. Appl. Intell. 2021, 51, 2714–2726. [Google Scholar] [CrossRef]
- Xu, H.; Deng, Y. Dependent Evidence Combination Based on Shearman Coefficient and Pearson Coefficient. IEEE Access 2017, 6, 11634–11640. [Google Scholar] [CrossRef]
- Izbicki, R.; dos Santos, T.M. Machine Learning Sob a Ótica Estatística: Uma Abordagem Preditivista Para Estatística com Exemplos em R; Ufscar/Insper: São Paulo, Brazil, 2018; Available online: https://www.est.ufmg.br/~marcosop/est171-ML/MachineLearning_Izbicki (accessed on 15 February 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost Method for Prediction of Reference Evapotranspiration in Humid Regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for Big Data: An Interdisciplinary Review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased Boosting with Categorical Features. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; pp. 6638–6648. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Probst, P.; Wright, M.N.; Boulesteix, A.-L. Hyperparameters and Tuning Strategies for Random Forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Kitsikoudis, V.; Sidiropoulos, E.; Hrissanthou, V. Machine Learning Utilization for Bed Load Transport in Gravel-Bed Rivers. Water Resour. Manag. 2014, 28, 3727–3743. [Google Scholar] [CrossRef]
- Toqué, F.; Khouadjia, M.; Come, E.; Trepanier, M.; Oukhellou, L. Short & Long Term Forecasting of Multimodal Transport Passenger Flows with Machine Learning Methods. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 560–566. [Google Scholar]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for Predicting Daily Global Solar Radiation Using Temperature and Precipitation in Humid Subtropical Climates: A Case Study in China. Energy Convers. Manag. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Dawood, E.G. Geo-Locating UEs Using Multi-Output Decision Tree Regressor. Ph.D. Thesis, Florida Institute of Technology, Melbourne, FL, USA, 2019. [Google Scholar]
- Alawadi, S.; Mera, D.; Fernández-Delgado, M.; Alkhabbas, F.; Olsson, C.M.; Davidsson, P. A Comparison of Machine Learning Algorithms for Forecasting Indoor Temperature in Smart Buildings. Energy Syst. 2020, 13, 689–705. [Google Scholar] [CrossRef]
- Yuan, Z.; Liu, J.; Liu, Y.; Yuan, Y.; Zhang, Q.; Li, Z. Fitting Analysis of Inland Ship Fuel Consumption Considering Navigation Status and Environmental Factors. IEEE Access 2020, 8, 187441–187454. [Google Scholar] [CrossRef]
- Panapakidis, I.; Sourtzi, V.-M.; Dagoumas, A. Forecasting the Fuel Consumption of Passenger Ships with a Combination of Shallow and Deep Learning. Electronics 2020, 9, 776. [Google Scholar] [CrossRef]
- Mohr, F.; Wever, M.; Hüllermeier, E. ML-Plan: Automated Machine Learning via Hierarchical Planning. Mach. Learn. 2018, 107, 1495–1515. [Google Scholar] [CrossRef]
- Yadav, S.; Shukla, S. Analysis of K-Fold Cross-Validation over Hold-out Validation on Colossal Datasets for Quality Classification. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016; pp. 78–83. [Google Scholar]
- Zeng, X.; Luo, G. Progressive Sampling-Based Bayesian Optimization for Efficient and Automatic Machine Learning Model Selection. Health Inf. Sci. Syst. 2017, 5, 2. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Liao, S.; Jiang, S.; Ding, L.; Lin, H.; Wang, W. Fast Cross-Validation for Kernel-Based Algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1083–1096. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, A.; Ostrowski, K.A.; Maślak, M.; Farooq, F.; Mehmood, I.; Nafees, A. Comparative Study of Supervised Machine Learning Algorithms for Predicting the Compressive Strength of Concrete at High Temperature. Materials 2021, 14, 4222. [Google Scholar] [CrossRef]
- Afrifa-Yamoah, E.; Mueller, U.A.; Taylor, S.; Fisher, A. Missing Data Imputation of High-Resolution Temporal Climate Time Series Data. Meteorol. Appl. 2020, 27, e1873. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-Squared Is More Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]



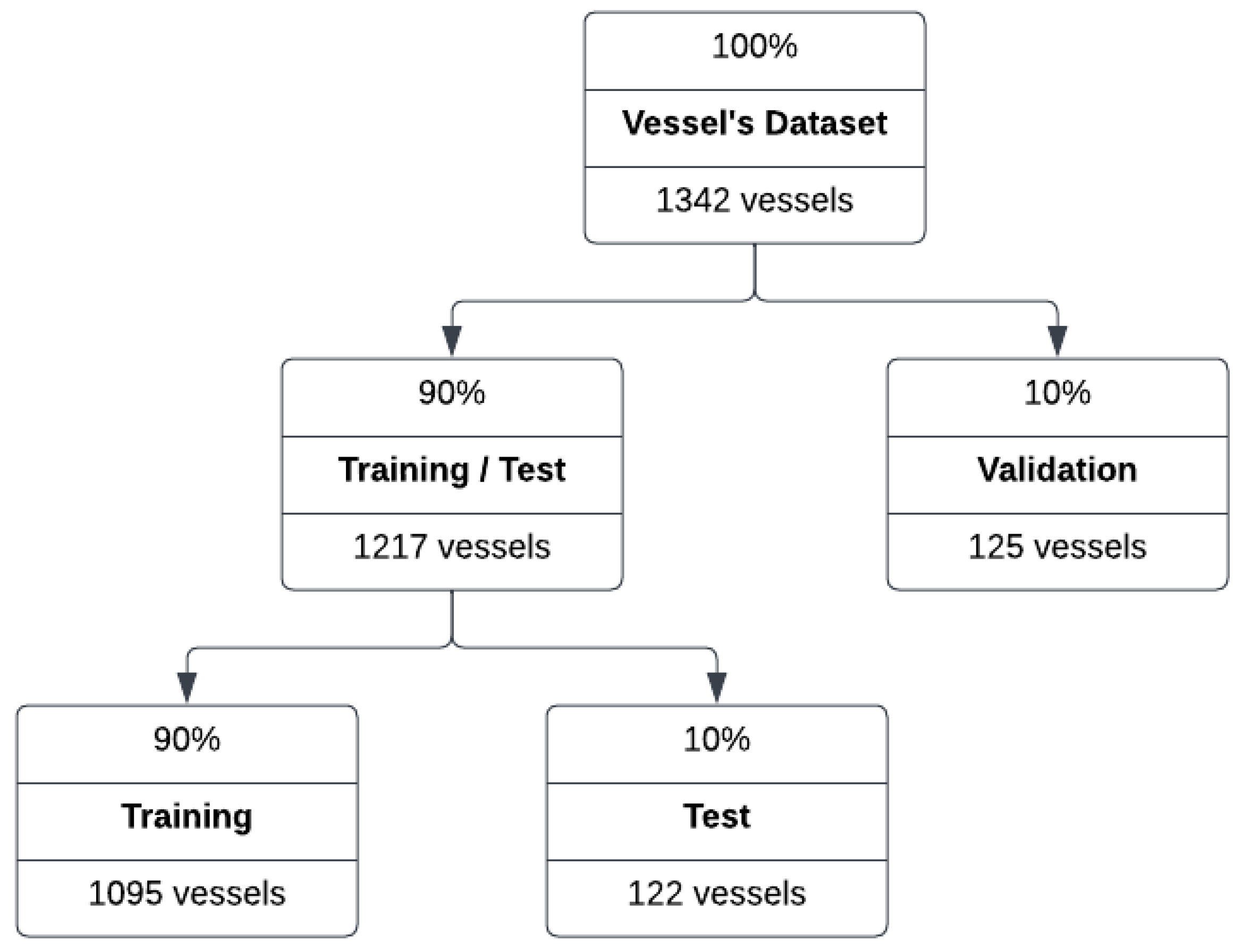

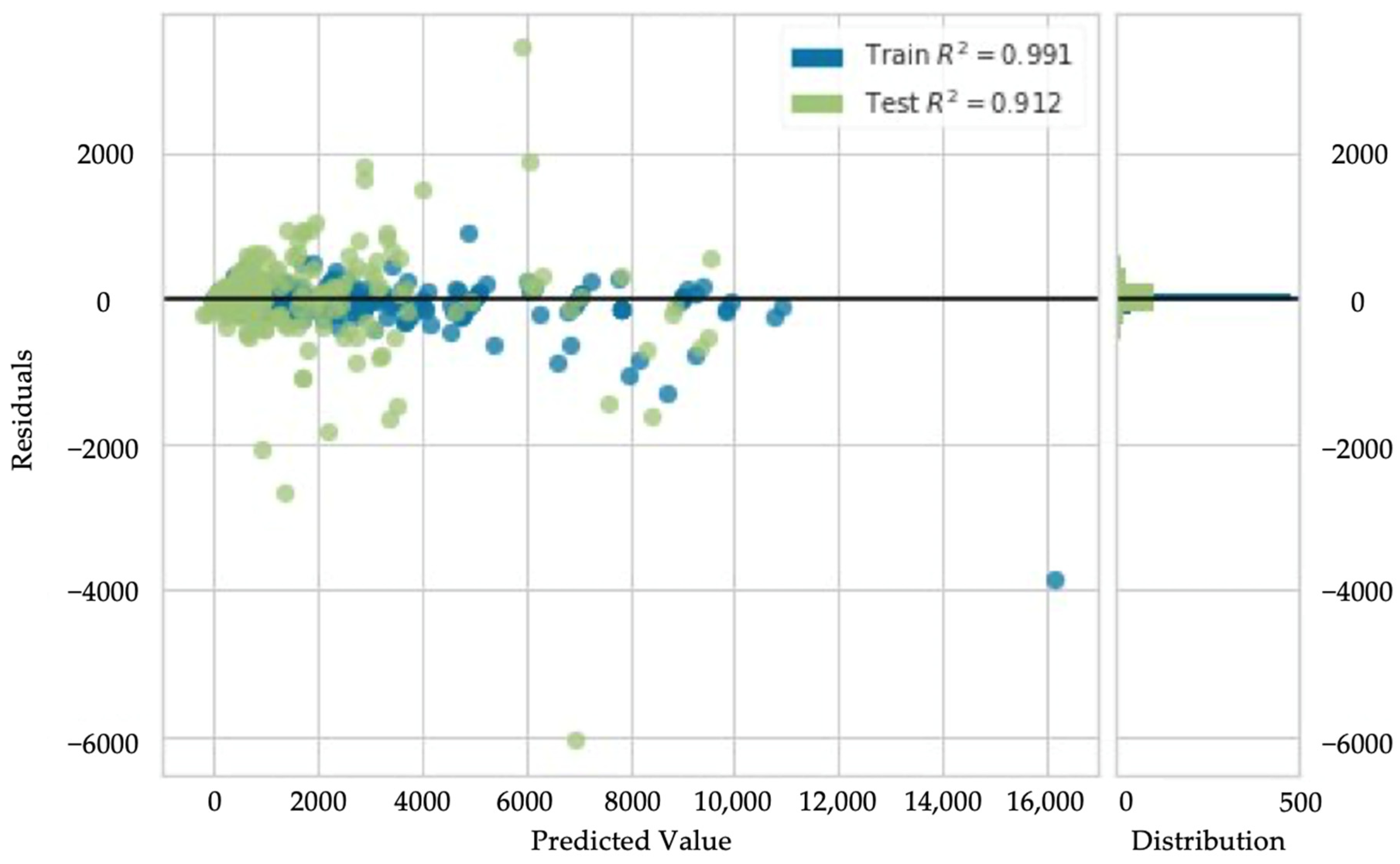


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Input Variable | Unit |
|---|---|---|
| VT | Vessel Type | Passenger, Cargo, Mixed |
| HM | Hull Material | Wood, Marine Steel, Fiber, Aluminum |
| LEN | Length | Meters |
| BRH | Breadth | Meters |
| DFT | Draft | Meters |
| DPH | Depth | Meters |
| NT | Number of Thrusters | Units |
| NG | Number of Generators | Units |
| MP | Motor Power | Horse Power |
| TV | Travel Time | Days |
| LD | Light Displacement | Cubic Meters |
| CS | Cruising Speed | Knots |
| TGS | Gross Tonnage Shipping | Tons |
| PC | Passenger Capacity | Passengers |
| CC | Cargo Capacity | Tons |
| NCM | Number of Crew Members | Crew members |
| FOC | Fuel Consumption | Liters |
| VT 1 | HM | LEN | BRH | DFT | DPH | NT | NG | MP | TV | LD | CS | TGS | PC | CC | NCM | FOC 2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Speedboat | Aluminum | 17 | 3.45 | 1.2 | 1.9 | 215 | 22 | 1 | 35 | 7 | 0 | 100 | 0 | 3 | 0.45 | 70 |
| 2 | Ferry Boat | Marine steel | 32 | 8 | 5 | 6 | 450 | 19 | 1 | 528 | 98 | 2 | 99 | 670 | 8 | 36 | 3000 |
| 3 | Speedboat | Marine steel | 25.6 | 6.3 | 1.8 | 2.2 | 315 | 18 | 1 | 21 | 6 | 2 | 90 | 0 | 2 | 24 | 2500 |
| 4 | Speedboat | Marine steel | 24.89 | 6.3 | 1.4 | 2.3 | 550 | 18 | 1 | 21 | 6 | 2 | 90 | 0 | 2 | 24 | 2500 |
| 5 | Passenger/ General Cargo | Wood | 19 | 5.3 | 1.8 | 2.8 | 200 | 10 | 2 | 109 | 21 | 2 | 65 | 25 | 3 | 7 | 300 |
| 6 | Passenger/ General Cargo | Wood | 24 | 6 | 2.15 | 2.8 | 315 | 15 | 3 | 109 | 21 | 2 | 88 | 34 | 3 | 8 | 400 |
| 7 | Passenger/ General Cargo | Wood | 32 | 8 | 2.4 | 3 | 400 | 20 | 3 | 109 | 21 | 1 | 126 | 288 | 7 | 40 | 2300 |
| 8 | Passenger/ General Cargo | Wood | 28 | 7.4 | 1.5 | 1.75 | 367 | 14 | 2 | 109 | 21 | 2 | 130 | 90 | 5 | 144 | 5000 |
| 9 | Passenger/ General Cargo | Wood | 17.6 | 4.2 | 1.8 | 1.8 | 612 | 15 | 1 | 109 | 21 | 1 | 60 | 19 | 2 | 6 | 180 |
| 10 | Speedboat | Aluminum | 12 | 2.4 | 1 | 1.8 | 481 | 20 | 1 | 35 | 7 | 0 | 35 | 0 | 1 | 2 | 87 |
| Vessel 1 | Wood | Marine Steel | Aluminum | Fiber |
|---|---|---|---|---|
| Vessel A | 1 | 0 | 0 | 0 |
| Vessel B | 0 | 0 | 1 | 0 |
| Features 1 | M | MD | MN | 25% | 50% | 75% | MX |
|---|---|---|---|---|---|---|---|
| Length | 26.0 | 10.9 | 6.0 | 19.0 | 23.3 | 31.3 | 76.0 |
| Breadth | 5.9 | 2.6 | 1.5 | 4.0 | 5.7 | 7.4 | 21.4 |
| Draft | 1.5 | 0.58 | 0.3 | 1.1 | 1.5 | 1.8 | 5.0 |
| Depth | 2.1 | 0.79 | 0.6 | 1.6 | 2.0 | 2.5 | 14.0 |
| Motor Power | 393.1 | 281.1 | 80.0 | 200 | 350.0 | 480.0 | 2750.0 |
| Cruising Speed | 16.2 | 6.34 | 8.0 | 12.0 | 15.0 | 19.7 | 40.0 |
| Number of Thrusters | 1.3 | 0.59 | 1.0 | 1.0 | 1.0 | 2.0 | 5.0 |
| TGS | 150.6 | 187.3 | 5.0 | 35.0 | 109.0 | 141.5 | 1600.0 |
| Light Displacement | 29.0 | 35.5 | 2.0 | 7.0 | 21.0 | 28.0 | 297.0 |
| Number of Generators | 1.2 | 0.7 | 0.0 | 1.0 | 1.0 | 2.0 | 5.0 |
| Passenger Capacity | 140.0 | 159.3 | 10.0 | 52.0 | 88.0 | 145.0 | 1400.0 |
| Cargo Capacity | 113.3 | 182.1 | 0.0 | 5.0 | 46.0 | 130.0 | 1600.0 |
| Crew | 4.4 | 2.42 | 1.0 | 3.0 | 4.0 | 6.0 | 22.0 |
| Travel Duration | 20.4 | 37.5 | 0.2 | 3.0 | 9.0 | 21.7 | 768.0 |
| Fuel Consumption | 1270.8 | 2136.6 | 5.0 | 150.0 | 400.0 | 1300.0 | 20,000.0 |
| Model | MAE | MSE | RMSE | CPT | R2 | |
|---|---|---|---|---|---|---|
| 1 | CatBoost | 348.48 | 728,175 | 779.98 | 3.802 | 0.852 |
| 2 | Extreme Gradient Boosting | 409.23 | 979,122 | 899.79 | 1.499 | 0.797 |
| 3 | Random Forest | 387.08 | 1,006,461 | 909.40 | 0.647 | 0.790 |
| 4 | Gradient Boosting | 406.33 | 1,018,512 | 916.01 | 0.240 | 0.787 |
| 5 | Extra Tree | 352.67 | 1,054,447 | 912.19 | 0.526 | 0.751 |
| 6 | Decision Tree | 433.02 | 1,581,347 | 1144.34 | 0.015 | 0.669 |
| Hyperparameters | Values |
|---|---|
| base_estimator_iterations | 1000 |
| base_estimator_learning_rate | 0.2 |
| base_estimator_depth | 5.0 |
| base_estimator_l2_leaf_reg | 10.0 |
| base_estimator_loss_function | RMSE |
| base_estimator_border_count | 32.0 |
| base_estimator_random_state | 955.0 |
| base_estimator | CatBoost Regressor |
| n_estimators | 10.0 |
| Fold | MAE | MSE | RMSE | R2 |
|---|---|---|---|---|
| 1 | 294.056 | 261,096 | 510.976 | 0.931 |
| 2 | 325.923 | 381,541 | 617.690 | 0.908 |
| 3 | 569.990 | 2,726,221 | 1651.127 | 0.693 |
| 4 | 237.294 | 465,902 | 682.570 | 0.877 |
| 5 | 382.079 | 1,078,487 | 1038.502 | 0.788 |
| 6 | 429.818 | 796,458 | 892.445 | 0.791 |
| 7 | 271.196 | 219,112 | 468.094 | 0.919 |
| 8 | 297.043 | 378,350 | 615.102 | 0.932 |
| 9 | 209.607 | 124,925 | 353.447 | 0.937 |
| 10 | 261.891 | 339,094 | 582.318 | 0.870 |
| Mean | 327.890 | 677,119 | 741.227 | 0.865 |
| VT 1 | HM | LEN | BRH | DFT | DPH | NT | NG | MP | TV | LD | CS | TGS | PC | CC | NCM | FOC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Speedboat | Aluminum | 17 | 3.4 | 1.2 | 1.9 | 215 | 22 | 1 | 35 | 7 | 0 | 100 | 0 | 3 | 0.45 | 70 |
| 2 | Ferry Boat | Marine steel | 32 | 8 | 5 | 6 | 450 | 19 | 1 | 528 | 98 | 2 | 99 | 670 | 8 | 36 | 3000 |
| 3 | Speedboat | Marine steel | 25.6 | 6.3 | 1.8 | 2.2 | 315 | 18 | 1 | 21 | 6 | 2 | 90 | 0 | 2 | 24 | 2500 |
| 4 | Speedboat | Marine steel | 24.8 | 6.3 | 1.4 | 2.3 | 550 | 18 | 1 | 21 | 6 | 2 | 90 | 0 | 2 | 24 | 2500 |
| 5 | Passenger/ General Cargo | Wood | 19 | 5.3 | 1.8 | 2.8 | 200 | 10 | 2 | 109 | 21 | 2 | 65 | 25 | 3 | 7 | 300 |
| Model | MAE | MSE | RMSE | R2 |
|---|---|---|---|---|
| CatBoost | 274.5 | 346,143 | 588.34 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melo, R.F.; Figueiredo, N.M.d.; Tobias, M.S.G.; Afonso, P. A Machine Learning Predictive Model for Ship Fuel Consumption. Appl. Sci. 2024, 14, 7534. https://doi.org/10.3390/app14177534
Melo RF, Figueiredo NMd, Tobias MSG, Afonso P. A Machine Learning Predictive Model for Ship Fuel Consumption. Applied Sciences. 2024; 14(17):7534. https://doi.org/10.3390/app14177534
Chicago/Turabian StyleMelo, Rhuan Fracalossi, Nelio Moura de Figueiredo, Maisa Sales Gama Tobias, and Paulo Afonso. 2024. "A Machine Learning Predictive Model for Ship Fuel Consumption" Applied Sciences 14, no. 17: 7534. https://doi.org/10.3390/app14177534