Abstract
Currently, a large number of pornographic images on the Internet severely affect the growth of adolescents. In order to create a healthy and benign online environment, it is necessary to recognize and detect these sensitive images. Current techniques for detecting pornographic content are still in an immature stage, with the key issue being low detection accuracy. To address this problem, this paper proposes a method for detecting pornographic content based on an improved YOLOv8 model. Firstly, InceptionNeXt is introduced into the backbone network to enhance the model’s adaptability to images of different scales and complexities by optimizing feature extraction through parallel branches and deep convolution. Simultaneously, the SPPF module is simplified into the SimCSPSPPF module, which further enhances the effectiveness and diversity of features through improved spatial pyramid pooling and cross-layer feature fusion. Secondly, switchable dilated convolutions are incorporated to improve the adaptability of the C2f enhancement model and enhance the model’s detection capability. Finally, SEAattention is introduced to enhance the model’s ability to capture spatial details. The experiments demonstrate that the model achieves an mAP@0.5 of 79.7% on our self-made sensitive image dataset, which is a significant improvement of 5.9% compared to the previous YOLOv8n network. The proposed method excels in handling complex backgrounds, targets of varying scales, and resource-constrained scenarios, while simultaneously improving the model’s computational efficiency without compromising detection accuracy, making it more advantageous for practical applications.
1. Introduction
The Internet has deeply penetrated people’s lives and continues to progress and expand. With the continuous growth of Internet users, the data on the Internet are also showing explosive growth. However, the Internet also contains a large amount of undesirable information, such as pornography, violence, and politically sensitive content, which violates laws and regulations and affects social order and morality. In order to build a healthy and harmonious cyberspace, it is necessary to detect and block such undesirable information.
Many experts and scholars have conducted in-depth research on sensitive image recognition, proposing various methods and techniques. These methods and techniques primarily focus on detection and recognition based on image classification, which involves performing multi-layer convolution operations on images to extract features, and then using classifiers to classify images and determine whether they belong to sensitive categories. However, these methods also have some problems and deficiencies, mainly manifested in the following aspects: First, insufficient sensitivity to the size and position of sensitive information in the image. That is, when sensitive information occupies only a small part of the image or is located at the edge or corner of the image, it is difficult to detect. Second, inadequate adaptability to the complexity and diversity of sensitive information in the image. That is, when sensitive information is mixed or obscured with the background or other objects in the image, it is difficult to recognize. These problems and deficiencies result in reduced accuracy and efficiency of image classification methods for sensitive image recognition, which is very detrimental to the inspection and management of images.
In early research, researchers utilized global features of images and classified them using classifiers such as nearest neighbors and support vector machines. By the year 2000, the research focus shifted from global features of images to local features, leading to the emergence of various techniques for local feature extraction. The two main algorithms for feature extraction were the Bag of Visual Words (BOVW) algorithm proposed by J. Sivic and A. Zisserman in 2003 [1], and the Scale-Invariant Feature Transform (SIFT) algorithm proposed by D. G. Lowe in 2004 [2]. Combining local feature extraction algorithms with support vector machine classifiers became the standard approach during this period. Wang et al. [3] proposed a nude image recognition algorithm based on navel and body features, targeting the recognition of nudity composed of the torso, limbs, and face. The algorithm constructs structured feature vectors and then employs a neural network for recognition. Deselaers et al. [4] utilized a bag-of-visual-words model to create a visual word dictionary, extracting image feature information, and subsequently used an SVM model for the detection of pornographic images. The detection of exposed skin areas is the most primitive method, based on the idea that pornographic images typically contain more exposed skin areas compared to ordinary images. JORGE et al. proposed a method for detecting pornographic images based on the YCbCr color model [5], while H. Yin et al. introduced geometric filters based on fractal dimension and rough text filters to detect skin in images [6]. The AlexNet model was proposed in 2012 and achieved good results on ImageNet in the same year [7]. Since then, most methods proposed have been based on deep convolutional neural networks. In 2015, Mohamed N. Moustafa fine-tuned AlexNet and GoogleNet pretrained on the ImageNet dataset to recognize sensitive images, obtaining a model with recognition accuracy surpassing any other model at that time [8]. With the introduction of two-stage object detection models, such as the RCNN series algorithms [9] and one-stage object detection models like YOLO [10] and SSD [11], many researchers began to incorporate object detection algorithms into their studies. Y. Chen et al. proposed an improved YOLOv4 model, which can accurately achieve rapid detection and statistics of the quantity of bayberry trees in large orchards [12]. L. Sumi et al. utilized the YOLOv5 model to detect weapons such as knives and guns [13]. C. Chen et al. applied the Faster RCNN convolutional neural network to weld defect detection [14]. C. Liang et al. used YOLOv7 for human action recognition [15]. Meanwhile, the introduction of object detection methods gradually became the mainstream research approach in sensitive information recognition fields. Mao et al. proposed a lightweight sensitive information detection method based on YOLOv5 [16].
Therefore, this paper proposes an improved model for detecting pornographic sensitive image information based on YOLOv8 to enhance detection accuracy. The specific improvements are as follows: First, introducing InceptionNeXt in the backbone network to enhance the model’s adaptability to images of different scales and complexities through parallel branches and optimized feature extraction with deep convolution, enabling the model to more accurately locate and recognize objects. Second, replacing the SPPF module with the SimCSPSPPF module, which enhances the handling of features at different scales through more efficient feature fusion and spatial pyramid pooling strategies, thereby improving the detection capability of objects of various sizes in complex scenes. Third, incorporating switchable dilated convolution SAConv to significantly improve the model’s detection capability for objects at different scales. Fourth, introducing SEAattention to enhance the model’s ability to capture spatial details through axial attention mechanisms and feature compression. Experimental results show that the improved model performs exceptionally well on the custom sensitive image dataset, achieving an mAP@0.5 of 79.7%, significantly surpassing the original YOLOv8 network. The improved model is particularly outstanding in recognizing challenging sensitive categories, such as exposed genitalia. In terms of accuracy, precision, and recall, the improved model outperforms other classical algorithms, while maintaining a good balance between detection speed and computational resource consumption, making it suitable for devices or scenarios with limited computational power. This research optimizes the model structure to enhance detection accuracy and efficiency in handling complex backgrounds and multi-scale targets. This is especially important for real-time detection applications, such as content moderation, social media monitoring, and ad content filtering, enabling faster processing of large volumes of image data, reducing the workload of manual review, and improving operational efficiency.
2. YOLOv8 Detection Algorithm
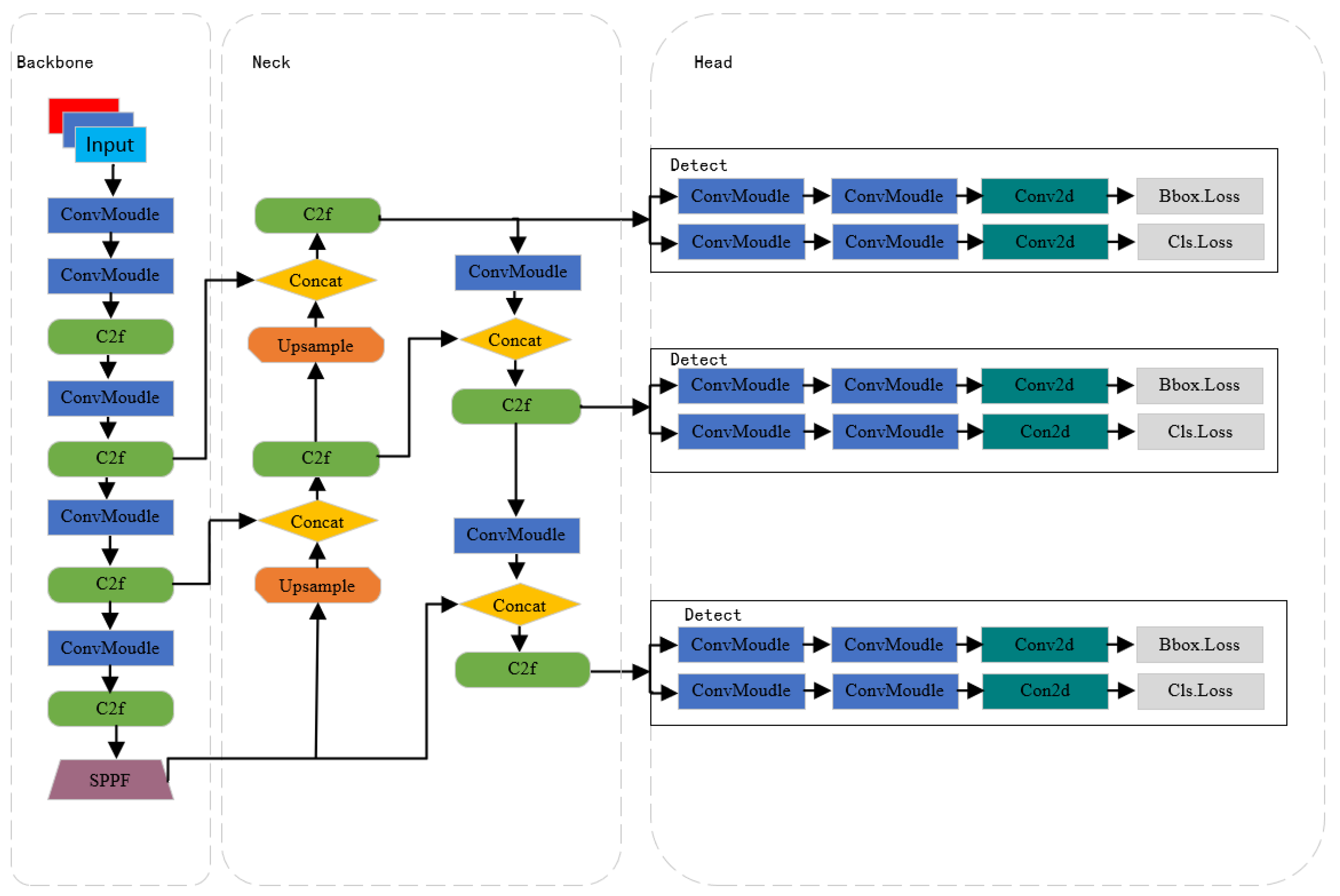
Since its introduction, the YOLO model has made significant achievements in the field of computer vision, particularly excelling in object detection tasks. As a key player in this field, Ultralytics released YOLOv8 on 10 January 2023, following the successes of YOLOv5 and YOLOv7. Building upon the strengths of its predecessors, YOLOv8 further enhances detection accuracy and processing speed, making it even more outstanding in real-time object detection tasks. Compared to previous versions, YOLOv8 may have undergone significant adjustments and optimizations in its algorithm structure, such as introducing more efficient network architectures, more precise object detection algorithms, and more advanced learning techniques. These improvements aim to enhance the model’s ability to recognize objects of different types and sizes while maintaining or improving processing speed, thereby achieving higher practicality and accuracy in various application scenarios. Figure 1 depicts the network structure of YOLOv8. The core architecture of YOLOv8 consists of a backbone network and a neck module. In this structure, the backbone network is responsible for the initial processing of input images, extracting basic visual features through multiple convolutional layers (Conv). These convolutional layers not only capture image information at different levels but also optimize the balance between performance and efficiency through adjustments in their depth and width. The C2f module, an evolution of the C3 module, plays a crucial role in residual learning. It integrates the advantages of the ELAN structure in YOLOv7, enhancing gradient branching by reducing the number of standard convolutional layers and effectively utilizing bottleneck modules. This design maintains the lightweight nature of the model while improving the capability to capture fine details in gradient flow. After feature extraction, the SPPF module further processes the feature maps. By applying pooling kernels of different sizes, the SPPF module can aggregate features of different scales, thereby enhancing the network’s adaptability to changes in target size. This makes the model more robust in detecting objects of different sizes. The neck layer of YOLOv8 adopts an FPN+PAN structure, effectively integrating features from different levels. The FPN structure enhances the model’s semantic understanding of targets by combining high-level semantic information with low-level detail information. The PAN structure, on the other hand, promotes information flow between different feature layers through upsampling and downsampling techniques, further enhancing the fusion effect of features. This mechanism enables the network to perform exceptionally well in processing and fusing target features. The head utilizes features extracted from the preceding two stages to extract category and positional information of detected targets for recognition. It has been replaced by the currently popular decoupled head structure, separating the classification and detection heads. This addresses the differing focus between classification and localization. Additionally, an anchor-free object detection method is employed to improve detection speed. In terms of loss computation, a dynamic allocation strategy for positive and negative samples is utilized, with VFL Loss as the classification loss and DFL Loss+CIOU Loss as the regression loss.
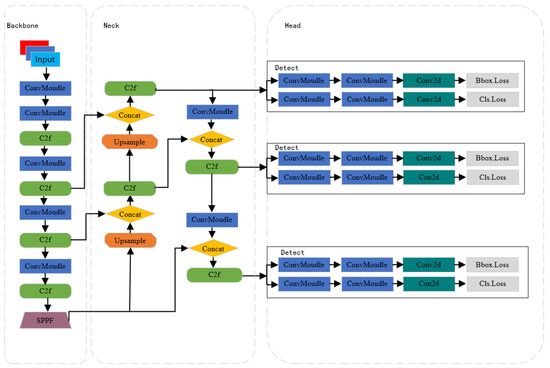
Figure 1.
Network structure of YOLOv8.
3. Improved YOLOv8 Model
3.1. Improved YOLOv8 Algorithm Architecture
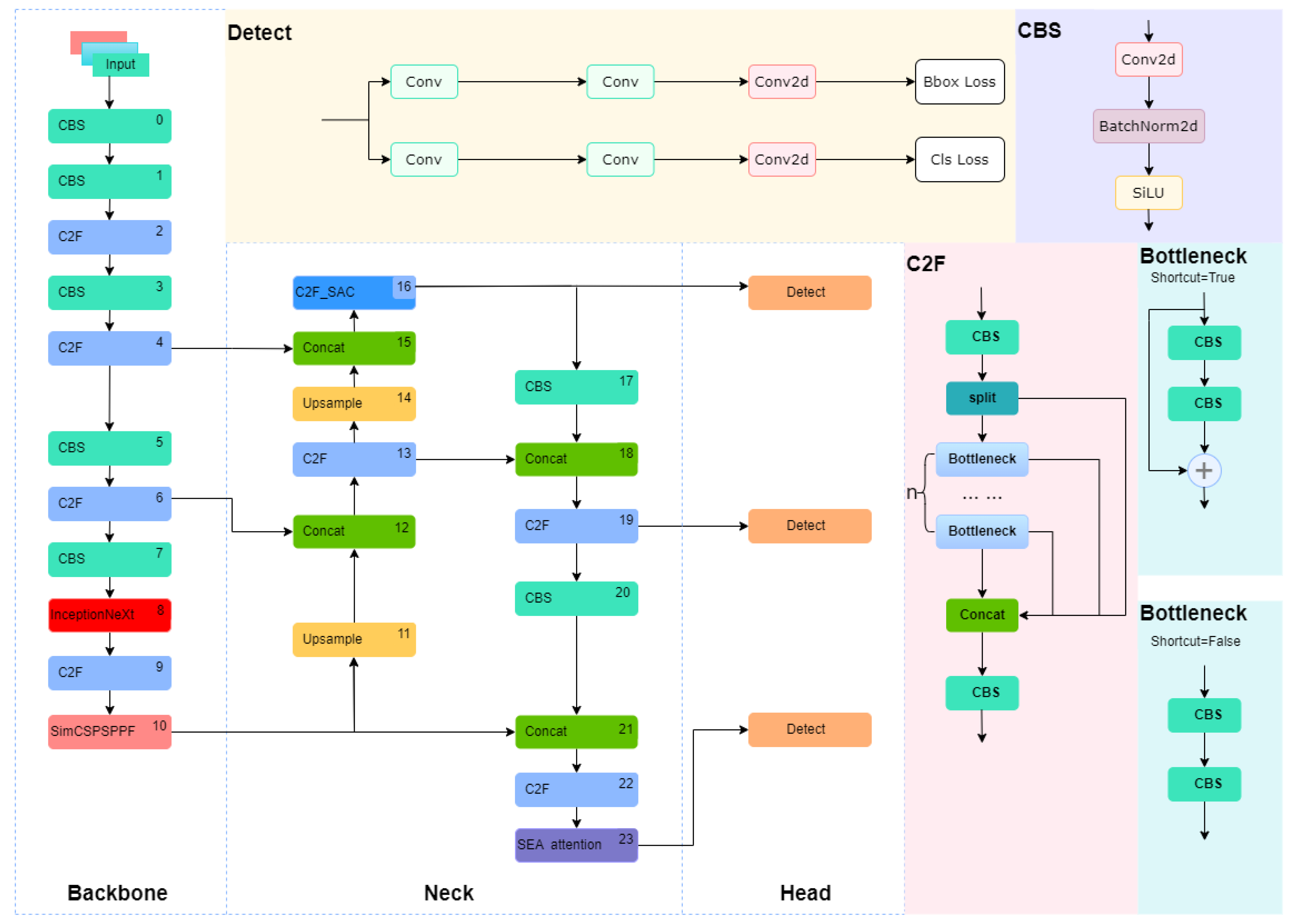
To address the issue of low accuracy in detecting pornographic sensitive image information, this paper proposes a model for detecting pornographic sensitive image information based on improved YOLOv8. In the backbone network, InceptionNeXt is introduced to enhance the model’s adaptability to images of different scales and complexities through parallel branches and deep convolution optimized feature extraction. The SPPF module is simplified to an SimCSPSPPF module, which further improves the effectiveness and diversity of features through improved spatial pyramid pooling and cross-level feature fusion. Switchable dilated convolution is incorporated to improve the adaptability of C2f and enhance the model’s detection performance. SEAattention is introduced to enhance the model’s capture capability of spatial details. The structural diagram of the improved YOLOv8 algorithm is shown in Figure 2.
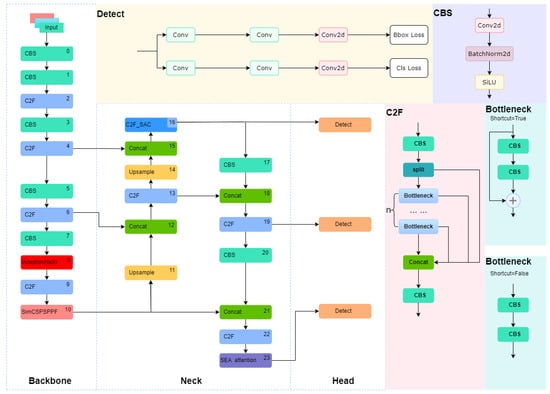
Figure 2.
Improved YOLOv8 network structure.
3.2. Optimizing Feature Extraction Capability
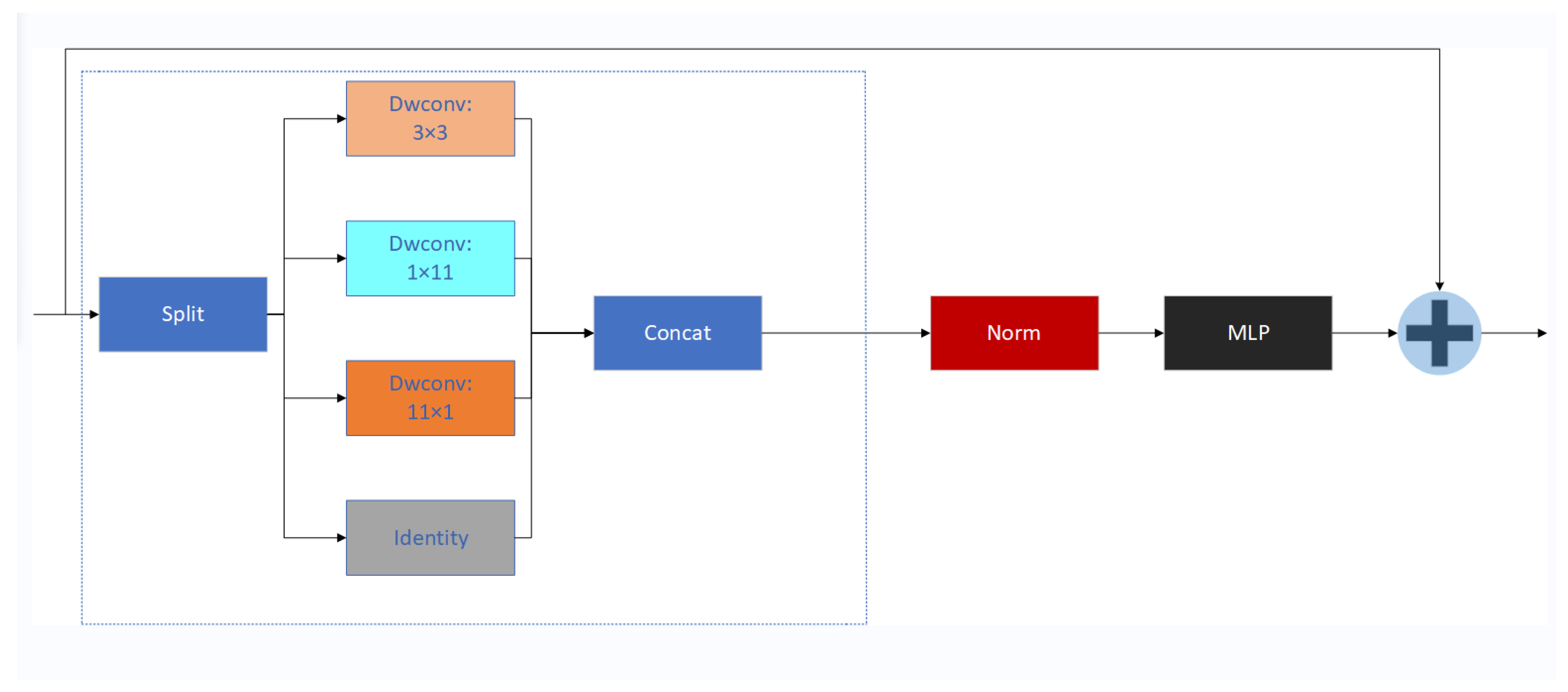
In complex backgrounds or when parts of the target are occluded, the YOLOv8 model struggles to accurately extract target features, resulting in a decrease in detection performance. To improve the model’s adaptability to images of different scales and complexities and enhance the model’s receptive field, we introduce the InceptionNeXt structure as part of the YOLOv8 backbone network. InceptionNeXt is a deep learning module that effectively captures multi-scale information in images through parallel branches and deep convolution optimized feature extraction [17]. One of the key innovations of InceptionNeXt is the Inception Depthwise Separable Convolution (Inception DWConv), which decomposes traditional large kernel convolutions into three branches of small kernel convolutions and one identity mapping branch. Specifically, for the input feature map X, we divide it into four groups along the channel dimension:
The segmented input is fed into four different parallel branches:
- Small square kernels (3 × 3):where C represents the number of channels, is the processed number of channels, and denotes depthwise separable convolution.
- Horizontal stripe-shaped kernel (1 × 11):
- Vertical stripe-shaped kernel (11 × 1):
- The identity mapping branch remains unchanged:
Finally, the outputs of these four branches are merged:
The structure of InceptionNeXt is shown in Figure 3.
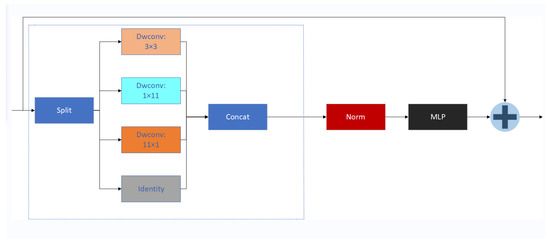
Figure 3.
Diagram of InceptionNeXt network structure.
3.3. Optimizing Spatial Pyramid Pooling
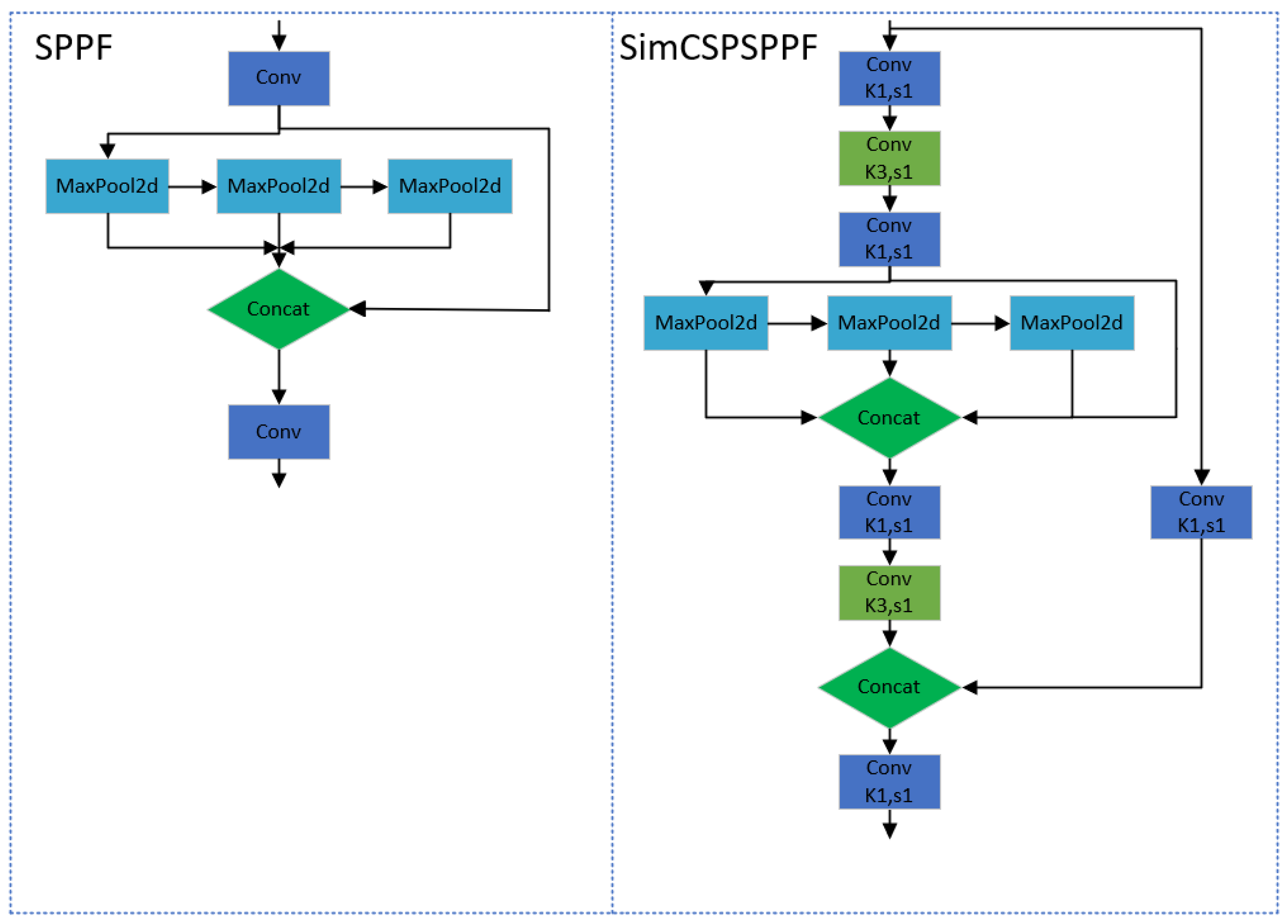
To further enhance the model’s ability to recognize objects of different scales, this paper replaces the original SPPF (Spatial Pyramid Pooling Fusion) module in the YOLOv8 model with the SimCSPSPPF (Simultaneous Cross-Stage Partial Spatial Pyramid Pooling in Feature Fusion) module. The SimCSPSPPF structure was initially introduced in YOLOv6 v3.0 [18], which modifies the SimSPPCSPC module in YOLOv7 [19] by reducing the hidden layer channels and modifying the spatial pyramid pool. According to the YOLOv6 v3.0 paper, the SimCSPSPPF module significantly improves the model’s mAP (mean average precision) metric while maintaining similar inference speed. Particularly, the SimCSPSPPF module demonstrates stronger performance in handling small-sized objects. Compared to the SPPF module, the SimCSPSPPF module adopts an improved pooling strategy to better capture multi-scale features in the image, which helps the model accurately recognize and locate objects of different sizes. The structural diagrams of SPPF and SimCSPSPPF are shown in Figure 4.
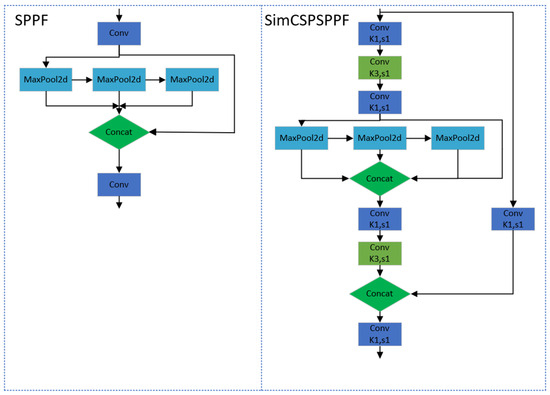
Figure 4.
Network structure diagram of SPPF and SimCSPSPPF.
3.4. Improving Model Detection Performance
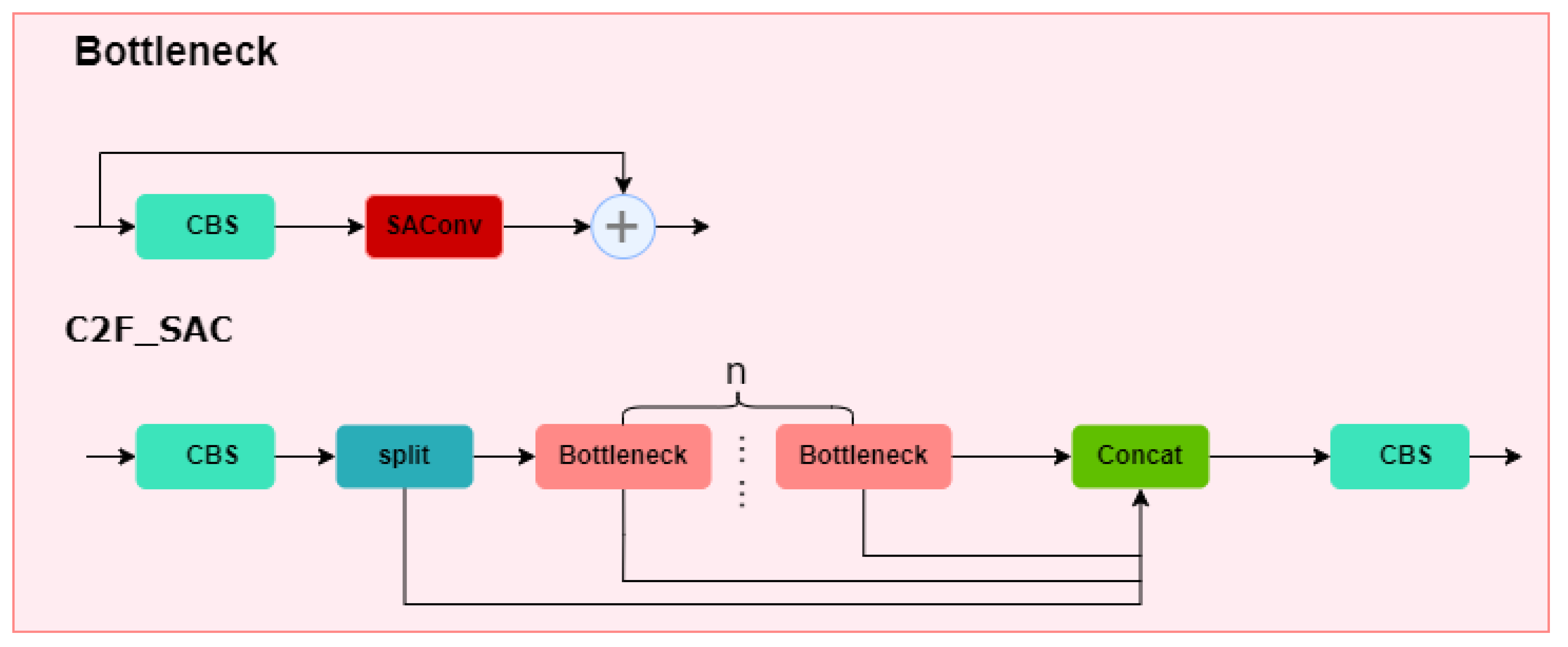
In pornographic sensitive images, targets such as body parts may vary greatly in size and shape, making it challenging for traditional convolutional networks to effectively capture both these details and large-scale features simultaneously, resulting in lower detection accuracy. To address this issue, we attempt to improve the original YOLOv8 convolutional network. Inspired by the DetectoRS architecture proposed by Qiao et al. for object detection [20], we incorporate the SAConv from the DetectoRS architecture into the C2F module. By integrating SAConv into the Bottleneck structure of the C2f module, we can adaptively make it more effective in handling objects of different sizes. Specifically, this improvement primarily involves replacing the Conv in the Bottleneck of the C2F module with SAConv, which we refer to as C2F_SAC. Its structural diagram is shown in Figure 5.
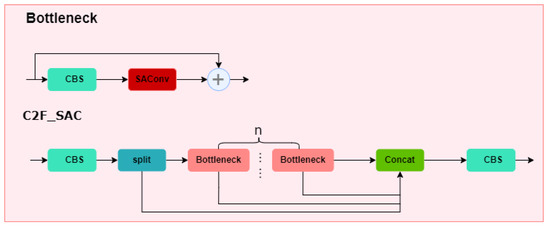
Figure 5.
Network structure diagram of C2F_SAC.
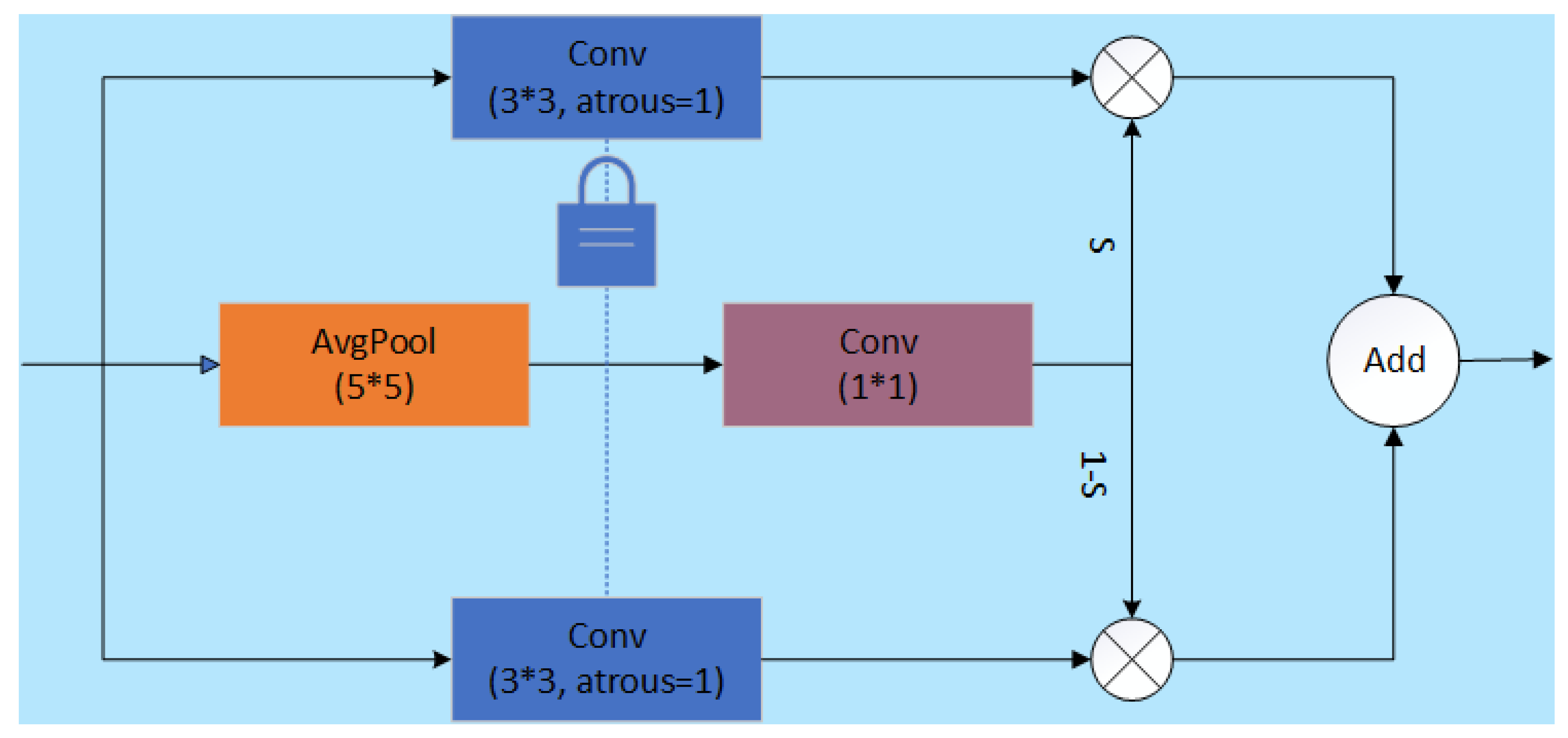
SAConv utilizes different dilation rates to perform multi-scale convolution processing on input features, dynamically selecting the most suitable convolution output for each position on the feature map through a switch function. This mechanism enables SAConv to adaptively adjust the receptive field size of its convolution kernel based on changes in the size of the target object, effectively capturing feature information ranging from details to large scales. Additionally, SAConv adopts a weight sharing strategy, where convolutions with different dilation rates share base weights and are supplemented with a learnable difference. This aims to maintain the compactness of model parameters while ensuring efficiency and flexibility during the transition from pretrained models. This design, which combines multi-scale perception capabilities and parameter efficiency, significantly enhances the model’s recognition performance for objects of various scales. The structure of SAConv is illustrated in Figure 6, where a switch function S is computed by using an average pooling layer and a 1 × 1 convolution layer before the convolutional layer. Then, S and 1-S are multiplied with the results of convolutions with different dilation rates, respectively, and finally, the results of these two parts are added together to obtain the final output.
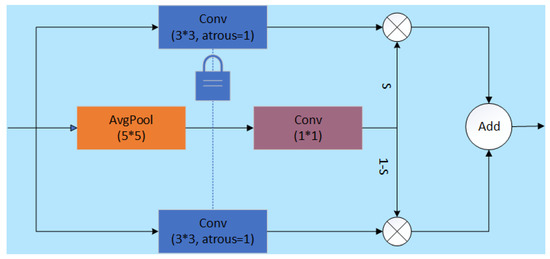
Figure 6.
Network structure diagram of SAConv.
3.5. Enhancing the Model’s Capture Capability
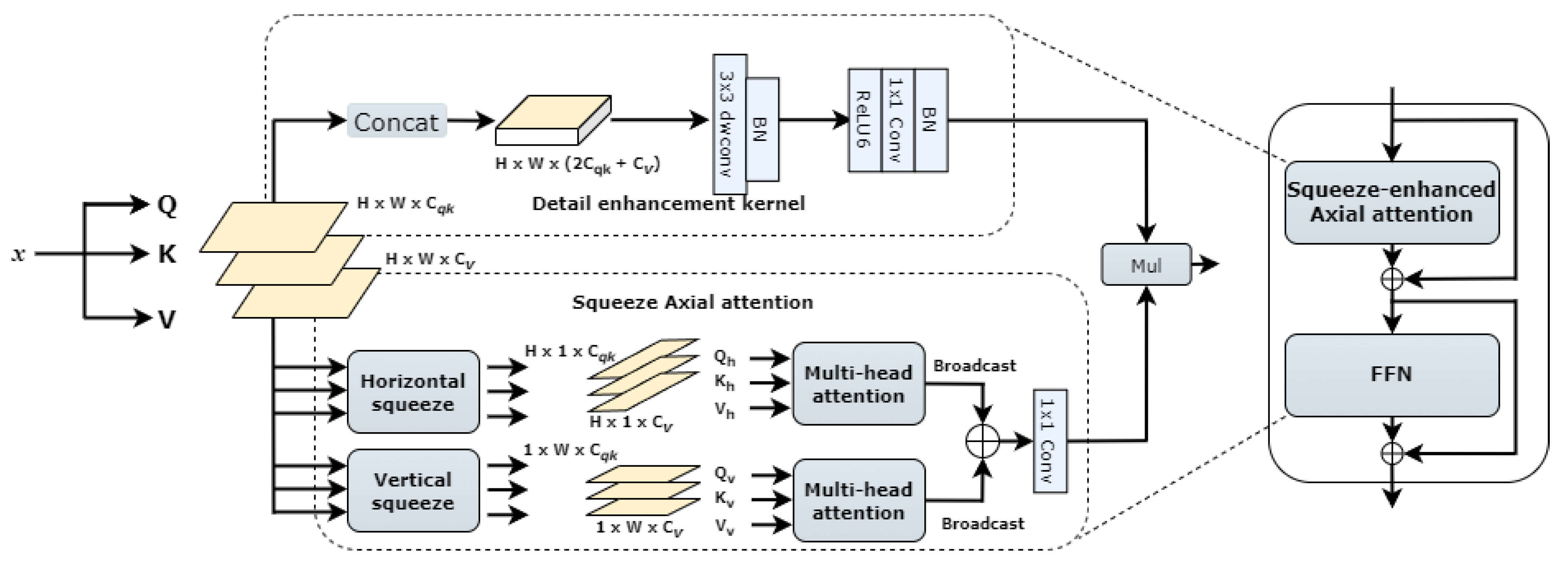
Recognition of sensitive content relies not only on local image features, such as skin regions, but also on how these features are presented and combined in the global context. Therefore, accurately identifying pornographic sensitive content is particularly crucial. SeaFormer [21] was originally proposed for mobile semantic segmentation, introducing a compressed–enhanced axial attention mechanism that effectively captures global and local contextual information while reducing computational costs. Inspired by this, we introduce it into the neck of the YOLOv8 model. The design of SeaAttention preserves global information through compression operations while emphasizing local details through a detail enhancement kernel. This enhances the model’s ability to capture sensitive content features without sacrificing global understanding. Compared to traditional global attention mechanisms, SeaAttention reduces computational complexity through compression and axial operations, enabling efficient operation even on mobile or resource-constrained devices. The structure of SeaAttention is illustrated in Figure 7.
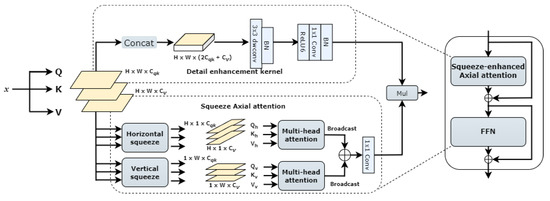
Figure 7.
Network structure diagram of SeaAttention.
4. Experiments
4.1. Experimental Dataset
Due to the uniqueness and high sensitivity to privacy of pornographic sensitive image detection, there is currently no publicly available unified dataset for training. Therefore, the dataset used in this study was collected from the Internet. In the collected image data, we first conducted preliminary screening to remove images that did not meet the research requirements, ensuring the quality and relevance of the final annotated dataset. Then, the data were preprocessed by converting compatible images to jpg format and manually labeling each image using the LabelImg annotation tool (v.1.8.6). The dataset consists of 9900 images, divided into a training set (7920 images), validation set (495 images), and test set (1485 images). To more accurately identify pornographic sensitive information in the images, this paper specifically categorizes pornographic sensitive information, including non-pornographic parts (Calisan), exposed abdomen (EXPOSED_BELLY), exposed female breasts (EXPOSED_BREAST_F), exposed male breasts (EXPOSE_BREAST_M), exposed buttocks (EXPOSED_BUTTOCKS), female genitalia (EXPOSED_GENITALIA_F), and male genitalia (EXPOSED_GENITALIA_M).
To verify the robustness of the proposed model, we conducted comparative experiments on the Pascal VOC public dataset. The PASCAL VOC dataset provides a thorough and standardized benchmark for image recognition and classification. It served as the foundation for an annual image recognition competition from 2005 to 2012. The core datasets, VOC 2007 and VOC 2012, are divided into four main categories and twenty subcategories, making them crucial benchmarks for assessing object detection algorithms. The VOC 2007 dataset contains a total of 9963 annotated images, including 5011 images in the validation set and 4952 images in the test set. The VOC 2012 dataset includes 11,540 annotated images used for training. In this study, we used the VOC 2007 validation set and the VOC 2012 training set for training and evaluated the performance on the VOC 2007 test set.
4.2. Experimental Environment and Parameter Settings
The experiment utilized the NVIDIA A30 GPU, with the software environment comprising the Centos operating system, Python 3.8 programming language, PyTorch 1.10 deep learning framework, and CUDA 11.3. Parameters set during training included a maximum of 300 iterations, batch size of 8, learning rate of 0.01, optimizer SGD, momentum 0.9, and input image size of 640 × 640 (images are resized to the specified size before detection, with the dimensions set to 640 × 640 in this paper).
4.3. Experimental Evaluation Indicators
To comprehensively evaluate the detection performance of our proposed improved model, we utilize metrics including mAP@0.5, number of model parameters, model computational complexity, precision, recall, and detection speed as evaluation indicators.
The Mean Average Precision (mAP@0.5) is the average detection accuracy across all classes at an IoU threshold of 0.5. In object detection, a higher mAP value indicates better detection performance. The calculation formula is shown as Formula (7):
where represents the average precision for the i-th category, and N denotes the number of categories.
Params refers to the number of parameters in the model, expressed in millions (M) in this paper. The fewer parameters a model has, the smaller the resources required for storage and computation during execution. When the number of model parameters is large, it implies better feature capture but also consumes more storage space and computational resources.
FLOPS (Floating Point Operations Per Second) is a metric used to measure the computational efficiency of a model, expressed in billions (G) in this paper. A lower FLOPS value implies a smaller demand for computational resources and higher operational efficiency of the model.
Precision refers to the ratio of the number of true positives to the total number of detected targets among all detected targets. Its calculation formula is shown as Formula (8):
where TP represents true positives, which are the number of correctly detected targets in the detection results; FP represents false positives, which are the number of targets incorrectly detected in the detection results.
Recall refers to the proportion of positive samples correctly detected by the model among all true positive samples. Its calculation formula is shown as Formula (9):
where FN represents false negatives, which are the number of targets in the ground truth that were not detected by the model.
Detection speed refers to the time it takes for the model to process a single image, expressed in milliseconds (ms) in this paper. The lower the processing time, the fewer computational resources the model requires during execution.
4.4. Experimental Results and Analysis
4.4.1. Comparison of Different Spatial Pyramid Pool Layers
A comparison of detection accuracy among different spatial pyramid pooling layers, namely, SPP, SPPF, SimSPPF [22], SimSPPCSPC, and SimCSPSPPF, is shown in Table 1. From the experimental data in the table, it can be observed that the average detection accuracy of SimCSPSPPF is the highest. Although the parameter and computational requirements of the SPPF and SimSPPF models are the lowest, their detection accuracy is 4.1% and 3.1% lower than SimCSPSPPF, respectively. Compared to SimSPPCSPC, SimCSPSPPF improves model detection accuracy and speed without increasing the parameter or computational requirements.

Table 1.
Comparison of experimental data for different spatial pyramid pool layers.
4.4.2. Comparison of Different Attention Mechanism Effects
To investigate the impact of different attention mechanisms on the neck network, this paper conducts comparative experiments on the improved YOLOv8n model with various attention mechanisms integrated into the neck. The improved YOLOv8n model referred to here is one that incorporates the InceptionNeXt structure, SimCSPSPPF module, and improved C2F module, abbreviated as IS-YOLOV8n. The experimental results are shown in Table 2. From the experimental data in the table, it can be observed that introducing the Sea Attention into the neck network yields the best detection performance.
Table 2.
Comparative experiments with different attentional mechanisms.
4.4.3. Ablation Experiment
According to the experimental data in Table 3, each improvement has enhanced the detection performance of the network to varying degrees. Introducing InceptionNext as part of the backbone network resulted in a 2.2% increase in mAP@0.5, indicating that InceptionNext enhances the network’s feature extraction capability. Introducing the SimCSPSPPF module to optimize spatial pyramid pooling resulted in a 2.5% increase in mAP@0.5. After improving the second layer C2F module in the neck, not only did it increase the network’s average detection accuracy, but it also reduced the computational load, thereby improving detection speed. Finally, introducing Sea Attention led to a 0.5% increase in mAP@0.5, indicating that Sea Attention enhances the network’s ability to capture sensitive content features. The experimental results demonstrate that the improved YOLOv8 network achieved a 5.9% increase in mAP@0.5, a 5.1% increase in Precision, and a 6.4% increase in Recall.
Table 3.
Ablation experiments with the modules. (The ✓ represents substitutions or embeddings of our improvement modules on the YOLOv8n model.)
4.4.4. Comparative Experiment
To validate the detection effectiveness of the model proposed in this paper, under the same configuration conditions, we trained different object detection models using the same test set. As shown in Table 4, compared to other classical algorithms, such as YOLOv3-tiny [29] and RT-DETR [30], our model demonstrates higher accuracy in detecting sensitive content, particularly pornography. Although the parameter and computational requirements of YOLOv5n and the Gold-YOLO [31] algorithm are lower than our model’s, their detection accuracy is significantly lower than that of our model. Furthermore, while the computational requirements of YOLOv9-c [32] and the RT-DETR algorithm are much higher than ours, their detection accuracy is still inferior to ours. In summary, the algorithm proposed in this paper outperforms other algorithms, such as YOLOv3-tiny and RT-DETR, exhibiting better performance in terms of detection accuracy and speed, making it more suitable for practical deployment.
Table 4.
Performance comparison of different models in detection.
4.4.5. Generalization Comparative Experiment
To demonstrate the generalizability of the proposed method, we conducted comparative experiments on the public Pascal VOC dataset. The experimental results, shown in Table 5, indicate that our model outperforms the baseline model with a 2.7 percentage point increase in mAP@0.5%, a 2.1 percentage point increase in precision, and a 2.1 percentage point increase in recall. The results confirm that the improved method is effective not only on our custom dataset but also on other public datasets.
Table 5.
Performance comparison of different models in detection on the Pascal VOC dataset.
4.4.6. Visualization Analysis
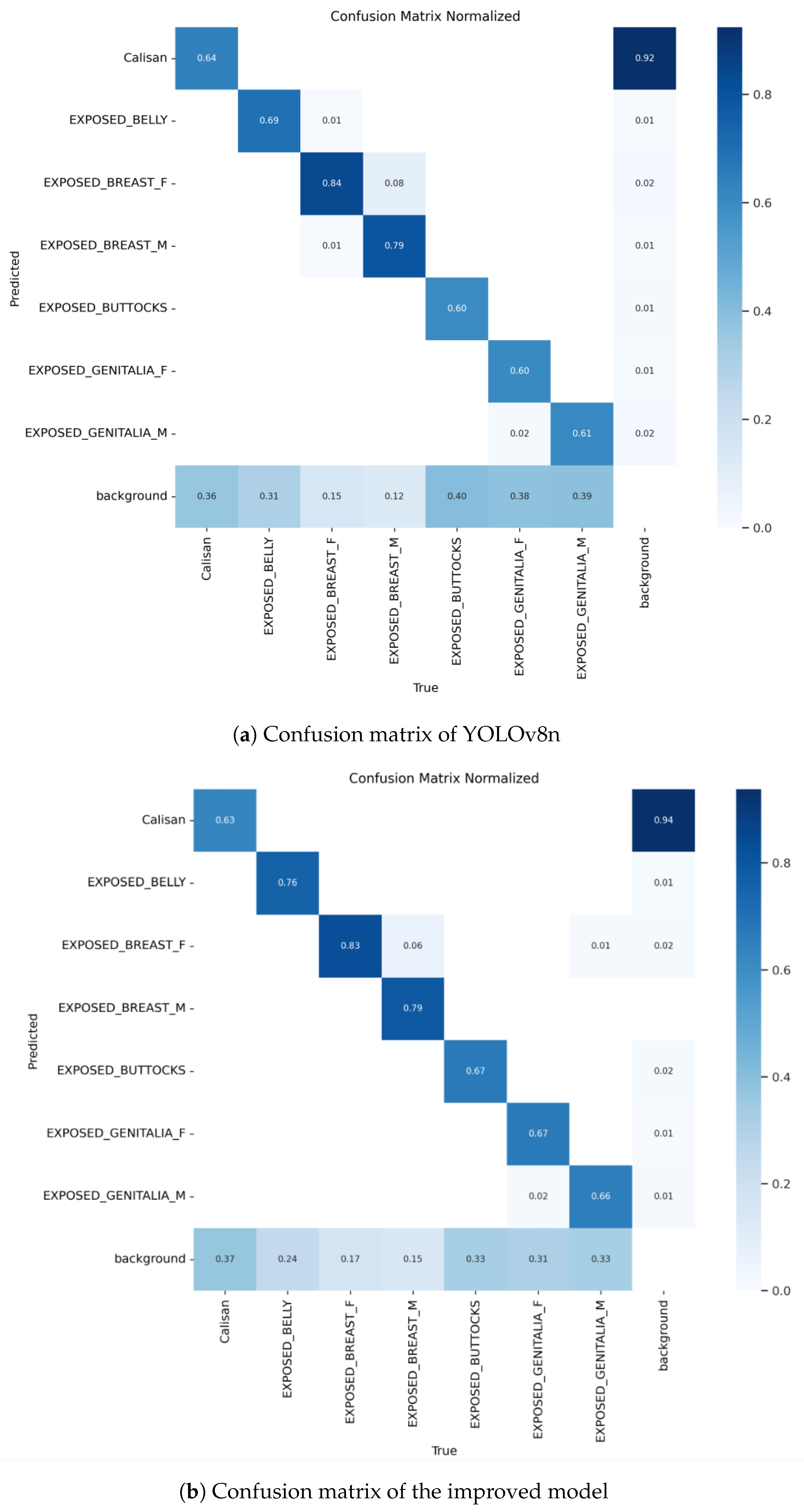
To visually demonstrate the predictive capabilities of our model for sensitive content, we plotted the confusion matrices of the improved model and YOLOv8n, as shown in Figure 8. The horizontal axis of the confusion matrix represents the true classes, while the vertical axis represents the predicted classes by the model. The diagonal values indicate the proportion of correct predictions for each class, while the off-diagonal values represent the proportion of misclassifications. From Figure 8, it can be observed that compared to the confusion matrix of YOLOv8n, most of the values on the diagonal of the confusion matrix of the improved model have increased. This indicates that the improved model has significantly improved performance across multiple categories, especially in recognizing some challenging sensitive categories. For example, in the ‘EXPOSED_GENITALIA_F’ category, the accuracy has increased from 0.60 to 0.67. As adjustments were made to the feature extraction mechanism during model improvement to better capture features related to ‘EXPOSED_GENITALIA_F’ and ‘EXPOSED_GENITALIA_M’, this resulted in a slight decrease in accuracy for the ‘EXPOSED_BREAST_F’ category. We will continue to adjust the model to balance the performance of all categories in subsequent iterations.
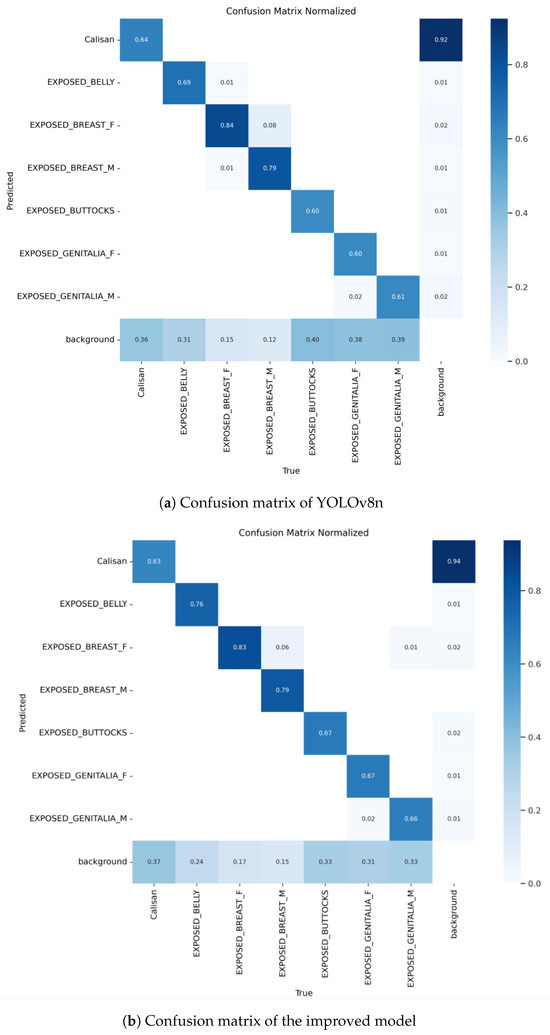
Figure 8.
Confusion matrix comparative effectiveness diagram.
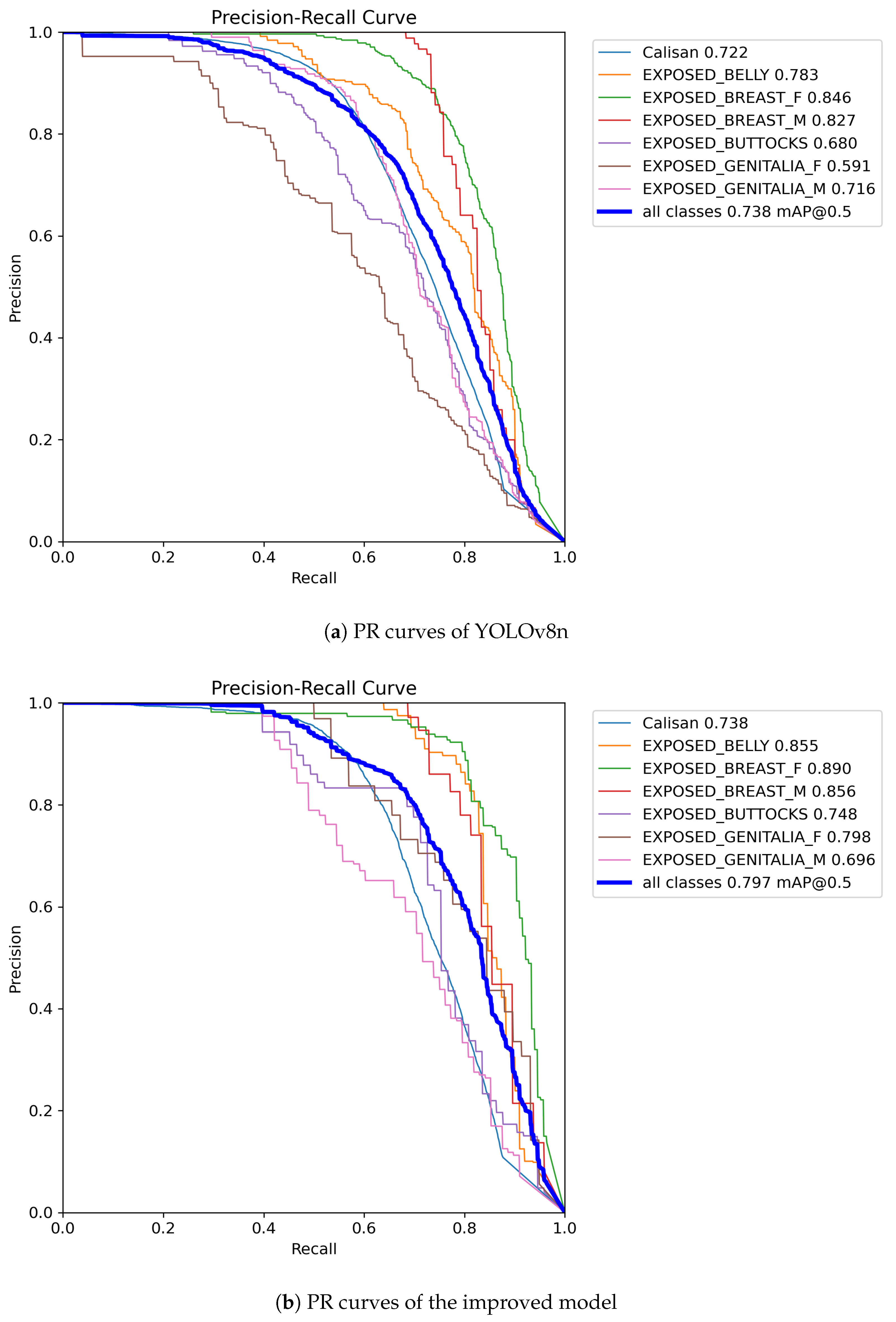
To showcase the precision of model predictions for positive classes at various recall levels, we generated PR (Precision-Recall) curves for both the improved model and YOLOv8n, as depicted in Figure 9. Upon comparison, it is evident that the improved model exhibits significantly enhanced accuracy across most categories, particularly notable in the ‘EXPOSED_GENITALIA_F’ category where accuracy has surged from 0.591 to 0.798. Moreover, the average precision (mAP@0.5) for all categories in the improved model has escalated from 0.738 to 0.797, further confirming the superior overall performance of our model over YOLOv8n. Despite these advancements, we acknowledge there is still room for improvement in the ‘EXPOSED_GENITALIA_M’ category.
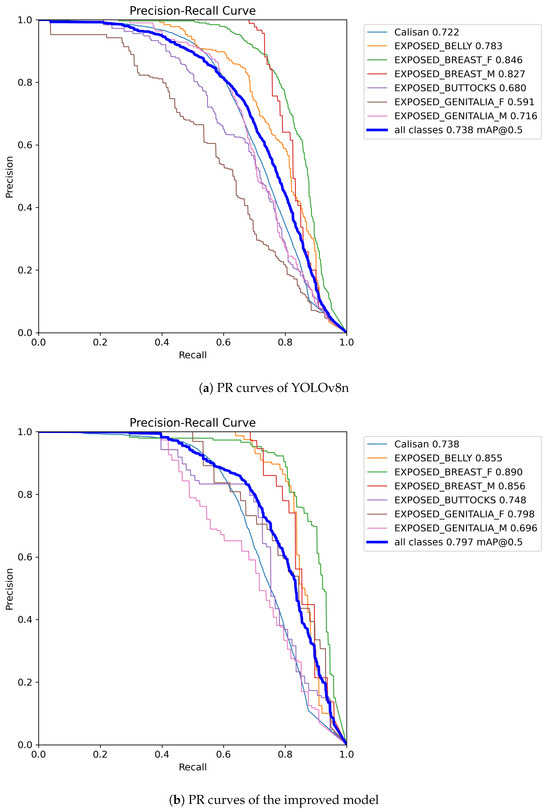
Figure 9.
Comparison effect diagram of PR curves.
5. Conclusions
This paper proposes a method for detecting pornographic and sensitive images based on an improved YOLOv8 algorithm. The aim is to effectively identify and filter such harmful content, helping to maintain a healthy and harmonious online environment and ensuring the safety of users, especially minors. By introducing the InceptionNeXt structure into the backbone network of YOLOv8, the feature extraction capability is optimized, enhancing the model’s adaptability to images of different scales and complexities. Additionally, the SPPF module is simplified into the SimCSPSPPF module, which improves the effectiveness and diversity of features through enhanced spatial pyramid pooling and cross-layer feature fusion. Furthermore, the model incorporates switchable dilated convolutions to improve adaptability and detection performance, while the SEA attention mechanism enhances the model’s ability to capture spatial details. The experimental results demonstrate that the proposed model performs excellently on a self-made sensitive image dataset, achieving an mAP@0.5 of 79.7%, which represents a significant improvement compared to the original YOLOv8 network. This indicates the effectiveness and superiority of the model in detecting sensitive content. The improved model outperforms other classical algorithms in terms of accuracy, precision, and recall, while also maintaining a good balance between detection speed and computational resource consumption, demonstrating high practicality and effectiveness. Looking ahead, we plan to continuously expand the scale and diversity of the dataset, incorporating a wider range of sensitive content categories and images under various backgrounds and lighting conditions, thereby comprehensively enhancing the model’s generalization ability and robustness. We will continue to conduct in-depth research to explore more efficient network architectures, aiming to further reduce the consumption of computational resources without sacrificing model accuracy, and strive to develop models that are both lightweight and efficient.
Author Contributions
Conceptualization, R.Z., D.Z. and C.H.W.; methodology, R.Z. and D.Z.; software, R.Z.; validation, R.Z.; formal analysis, R.Z. and C.H.W.; investigation, R.Z., C.W. and J.X.; resources, R.Z. and D.Z.; data curation, R.Z. and J.X.; writing—original draft preparation, R.Z.; writing—review and editing, D.Z.; visualization, R.Z.; supervision D.Z.; project administration, R.Z. and D.Z., funding acquisition, D.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are not publicly available due to privacy and ethical restrictions. The dataset contains sensitive images related to pornography detection, and sharing these images publicly could compromise privacy. Therefore, the dataset cannot be made available.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; IEEE: Piscatway, NJ, USA, 2003; Volume 2, pp. 1470–1477. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Wang, X.; Hu, C.; Yao, S. An adult image recognizing algorithm based on naked body detection. In Proceedings of the 2009 ISECS International Colloquium on Computing, Communication, Control, and Management, Sanya, China, 8–9 August 2009; Volume 4, pp. 197–200. [Google Scholar]
- Deselaers, T.; Pimenidis, L.; Ney, H. Bag-of-visual-words models for adult image classification and filtering. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Basilio, J.; Torres, G.; Sanchez-Perez, G.; Toscano, K.; Perez-Meana, H. Explicit Image Detection Using YCbCr Space Color Model as Skin Detection. Appl. Math. Comput. Eng. 2011, 123–128. [Google Scholar]
- Yin, H.; Xu, X.; Ye, L. Big Skin Regions Detection for Adult Image Identification. In Proceedings of the 2011 Workshop on Digital Media and Digital Content Management, Hangzhou, China, 15–16 May 2011; pp. 242–247. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Moustafa, M. Applying Deep Learning to Classify Pornographic Images and Videos. arXiv 2015, arXiv:1511.08899. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscatway, NJ, USA, 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE: Piscatway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Chen, Y.; Xu, H.; Zhang, X.; Gao, P.; Xu, Z.; Huang, X. An object detection method for bayberry trees based on an improved YOLO algorithm. Int. J. Digit. Earth 2023, 16, 781–805. [Google Scholar] [CrossRef]
- Sumi, L.; Dey, S. YOLOv5-based weapon detection systems with data augmentation. Int. J. Comput. Appl. 2023, 45, 288–296. [Google Scholar] [CrossRef]
- Chen, C.; Wang, S.; Huang, S. An improved faster RCNN-based weld ultrasonic atlas defect detection method. Meas. Control. 2023, 56, 832–843. [Google Scholar] [CrossRef]
- Liang, C.; Yan, W.Q. Human Action Recognition Based on YOLOv7. In Deep Learning, Reinforcement Learning, and the Rise of Intelligent Systems; Uddin, M., Mashwani, W., Eds.; IGI Global: Hershey, PA, USA, 2024; pp. 126–145. [Google Scholar]
- Mao, Y.; Song, B.; Zhang, Z.; Yang, W.; Lan, Y. A lightweight image sensitive information detection model based on yolov5s. Acad. J. Comput. Inf. Sci. 2023, 6, 20–27. [Google Scholar]
- Yu, W.; Zhou, P.; Yan, S.; Wang, X. InceptionNeXt: When Inception Meets ConvNeXt. arXiv 2023, arXiv:abs/2303.16900. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A Full-Scale Reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE/CVF: Piscatway, NJ, USA, 2023; pp. 7464–7475. [Google Scholar]
- Qiao, S.; Chen, L.-C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE/CVF: Piscatway, NJ, USA, 2021; pp. 10208–10219. [Google Scholar]
- Wan, Q.; Huang, Z.; Lu, J.; Yu, G.; Zhang, L. SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation. arXiv 2023, arXiv:2301.13156. [CrossRef]. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE/CVF: Piscatway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE/CVF: Piscatway, NJ, USA, 2021; pp. 13708–13717. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscatway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Yu, Y.; Zhang, Y.; Cheng, Z.; Song, Z.; Tang, C. MCA: Multidimensional collaborative attention in deep convolutional neural networks for image recognition. Eng. Appl. Artif. Intell. 2023, 126, 107079. [Google Scholar] [CrossRef]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:abs/2112.05561. [Google Scholar]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Object Detection and Recognition using one stage improved model. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Piscatway, NJ, USA, 2020; pp. 687–694. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2023, arXiv:abs/2304.08069. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Han, K.; Wang, Y. Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism. arXiv 2023, arXiv:abs/2309.11331. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:abs/2402.13616. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).