
FrameSum: Leveraging Framing Theory and Deep Learning for Enhanced News Text Summarization

Abstract
1. Introduction
- We innovatively introduce news framing theory into the text summarization task. This paper combines framing theory from the field of news communication with the text summarization task in natural language processing, constructing a novel frame-aware text summarization model that enriches the theoretical foundation and technical approach of text summarization.
- We propose a deep learning-based news frame identification model. This paper designs a deep learning model that can automatically identify core frame elements (e.g., factual frames, responsibility frames, conflict frames) from news texts, laying the foundation for frame-aware summarization.
- We construct an encoder–decoder summary generation model that integrates frame information. This model incorporates frame identification results into text representation and attention mechanisms, generating summaries that closely adhere to the core of the news frame and have high information coverage and readability.
- We conducted a systematic empirical evaluation of our proposed model on the standard CNN/Daily Mail dataset. Through quantitative and qualitative analysis, we assessed the model’s performance across multiple dimensions, including information completeness, news frame relevance, and reading experience readability. Experimental results show that our model outperforms several existing summarization baseline models on the standard dataset, validating the guiding value and innovative significance of introducing framing theory into the news text summarization task.
2. Literature Review
2.1. Text Summarization
2.1.1. Extractive Summarization
2.1.2. Abstractive Summarization
2.1.3. Text Summarization for News Domain
2.2. Framing Theory
2.2.1. Defining the Concept of Framing
2.2.2. News Framing Research
2.2.3. News Framing Analysis Methods
2.2.4. Algorithm-Based News Frame Analysis
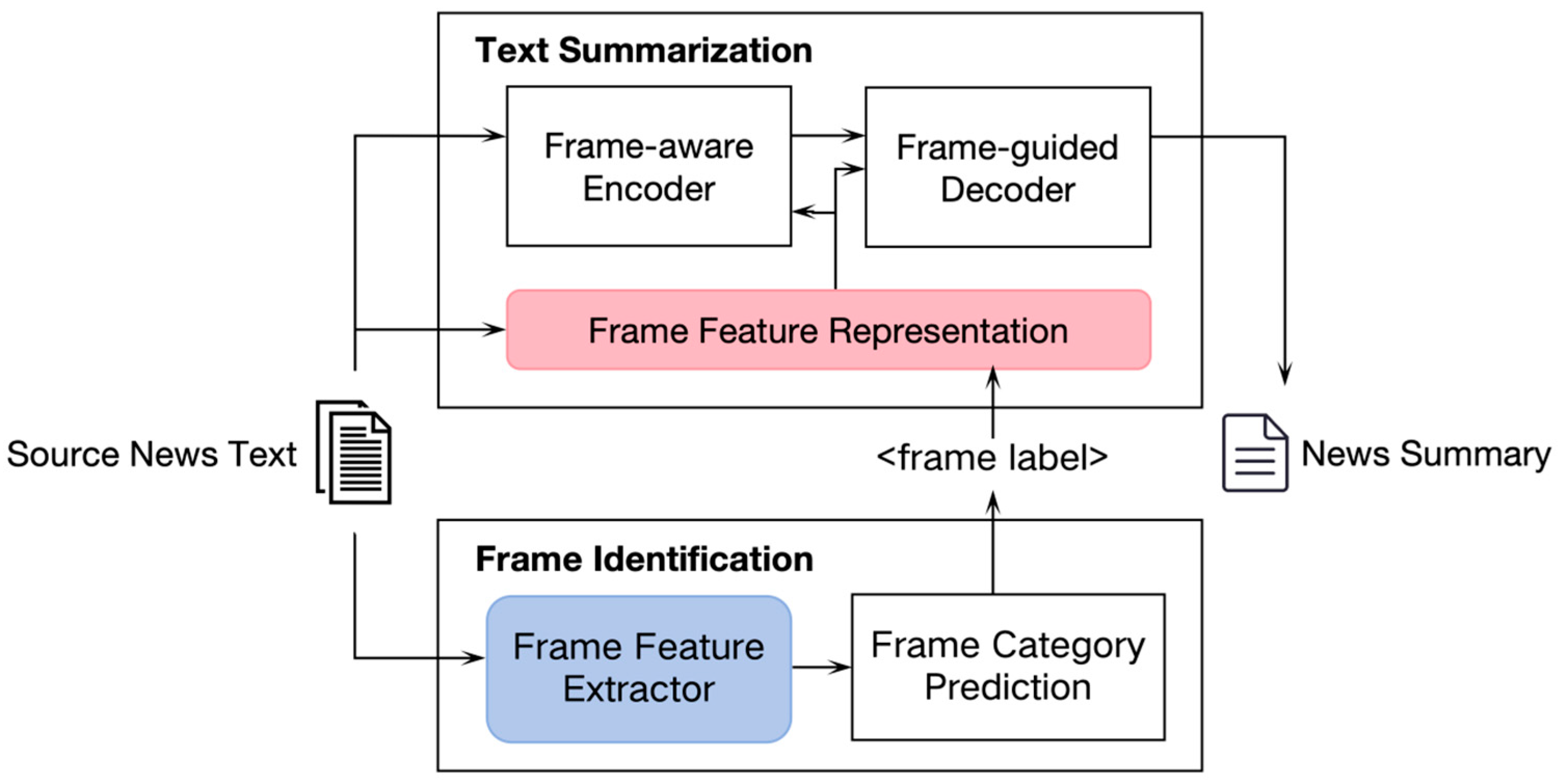
3. News Text Summarization Model Based on Framing Theory
3.1. Overview
3.2. News Framing Recognition Module (NFRM) Based on Deep Learning
3.2.1. Constructing Frame Categories
- Fact frame: Objectively describes the basic aspects of an event, including the cause, process, involved personnel, time, location, and other fundamental factual elements, aiming to answer the core question of “what happened”.
- Responsibility frame: Attributes and assigns the cause or responsible party for the event’s occurrence, or comments on and questions the actions of the responsible party, exploring the deep-rooted causes of the issue.
- Conflict frame: Emphasizes the conflicts of interest, divergent opinions, or contradictions among the involved parties in the event, highlighting the complexity and controversy of the event.
- Human interest frame: Evokes the audience’s empathy and resonance by vividly depicting individuals’ personal experiences and emotional journeys in the event, enhancing the infectiousness of the report.
- Economic consequences frame: Focuses on and evaluates the actual or potential impact of news events on the economy, including economic indicators, trade, gains, and losses.
- Morality frame: Examines news events from a moral and ethical perspective, discussing the moral concepts of fairness, justice, integrity, obligation, and rights behind the event, judging the moral responsibility and social norms of the parties involved, and prompting the public to reflect on and discuss moral values.
- Leadership frame: Focuses on reporting the role and performance of leaders and decision-makers in the event, assessing their decision-making abilities, crisis response strategies, and leadership roles for the public and team, and exploring how leaders’ words and actions influence the event’s process and outcome.
3.2.2. Constructing a Frame Annotation Corpus
3.2.3. Design of NFRM
- 1.
- Text Preprocessing
- 2.
- Text Semantic Representation
- 3.
- Frame Element Feature Extraction
- 4.
- News Frame Classification and Prediction
- 5.
- Loss Function and Optimization Strategy
3.3. A Summarization Model Incorporating Framework Information (FrameSum)
3.3.1. Encoder Design Incorporating Framework Information
- Frame Feature Representation
- 2.
- Framework-Aware Attention Mechanism
- 3.
- Text Representation Incorporating Framework Information
3.3.2. Decoder with Framework Information
- Framework-Guided Decoding Strategy
- 2.
- Coverage Loss
- 3.
- Framework Relevance Loss
- 4.
- Cross-Entropy Loss
4. Experiments
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
4.1.2. Evaluation Metrics
- (1)
- A senior editor with over 15 years of experience in a major news organization
- (2)
- A professor of computational linguistics with a focus on text summarization
- (3)
- A researcher specializing in news framing analysis with 10+ years of experience
4.2. News Framing Identification Experiments
4.2.1. Experimental Setup
4.2.2. Baseline Models
- (1)
- NBM (naive Bayes multi-nomial): A probabilistic graphical model based on Bayes’ theorem that estimates the conditional probabilities of each category through word frequency statistics and performs classification based on the maximum a posteriori probability criterion.
- (2)
- SVM (support vector machine) [12]: A classic discriminative model that seeks the maximum-margin hyperplane to separate samples of different classes in a high-dimensional space. We used a linear kernel function in our experiments.
- (3)
- TF-IDF+LR: Converts text into a TF-IDF-weighted bag-of-words representation and uses L2-regularized logistic regression for classification.
- (4)
- RNN: Employs a bidirectional LSTM network for sequence modeling of text and maps the hidden state of the last time step to class labels through a fully connected layer.
- (5)
- Transformer: A text encoding model based on self-attention mechanisms that captures global semantic information of text through positional encoding and multi-head attention. We used a 6-layer transformer encoder in our experiments.
- (6)
- BERT: Directly performs classification using the pre-trained BERT model, where the output vector corresponding to the [CLS] token is used as the classification feature.
4.2.3. Experimental Results and Analysis
4.3. News Text Summarization Generation Experiments
4.3.1. Experimental Setup
4.3.2. Baseline Models
- (1)
- Lead [56]: A simple text summarization method based on fixed rules. It directly extracts the first few sentences of the original document as the summary, without any semantic understanding or generation process.
- (2)
- LexRank [57]: A graph-based keyword extraction algorithm that considers sentences as nodes and selects the most relevant sentences as the summary based on node scores.
- (3)
- TextRank [15]: A graph-based ranking algorithm used for keyword extraction and document summarization in natural language processing.
- (4)
- T5 [58]: An advanced natural language processing model based on the transformer architecture, designed to convert all NLP problems into a text-to-text format. We fine-tuned T5 on the summarization dataset.
- (5)
- Flat transformer (FT) [59]: A transformer model that handles flat text sequences after merging multiple documents. It concatenates all documents into a single input sequence and utilizes the standard self-attention mechanism to capture and integrate information for generating summaries.
- (6)
- Pointer-generator (PG) [60]: A pointer-generator network that mitigates the OOV (out-of-vocabulary) problem through a copying mechanism and introduces a coverage loss to avoid repetition.
- (7)
- GPT-2 [61]: A self-regressive language model developed by OpenAI that considers all previously generated content when generating text.
- (8)
- Llama3 [62]: A large pre-trained language model developed by OpenAI that demonstrates excellent performance on various language tasks and possesses the ability to generate high-quality text.
- (9)
- Qwen [63]: An AI-based writing assistant that utilizes advanced natural language processing techniques to provide users with services such as grammar correction, style improvement, and content generation.
4.3.3. Experimental Results and Analysis
- Automatic Evaluation Results
- 2.
- Manual Evaluation Results
- 3.
- Case Analysis
- 4.
- Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frame Name | Annotation Description | Label |
|---|---|---|
| Fact Frame | [Definition] Objectively presents the basic facts of the event, including the cause, process, involved parties, time, location, and other elements, answering “what happened”. [Identification Points] Describes facts in an objective and neutral language; explains the background information such as time, place, and characters (5W1H) of the event; includes key aspects such as the cause, process, and result of the event; usually used at the beginning of news reports to provide context. [Example] On November 2nd, a terrorist attack occurred in the city center, causing at least ten civilian casualties. | |
| Responsibility Frame | [Definition] Explores the causes attributed to the occurrence of the event, identifies the responsible parties, and comments on or questions the dereliction of duty by the responsible parties. [Identification Points] Analyzes the causes of the event; identifies the responsible parties; criticizes or holds the responsible parties accountable for their dereliction of duty; discusses how to prevent similar events from happening again. [Example] The government was accused of failing to effectively prevent the terrorist attack, sparking questions and blame regarding the government’s security policies. | |
| Conflict Frame | [Definition] Highlights the evident divergence, opposition, and conflicts between the parties involved in the event. [Identification Points] Identifies the different interest groups involved in the event; describes the opposing views or interest demands between different interest groups; emphasizes the complexity and controversial nature of the event; commonly seen in event reports involving public policies or the interests of different groups. [Example] The terrorist attack triggered tensions between the government and counter-terrorism departments, with the government demanding stricter security measures while the opposition accused the government of neglecting counter-terrorism efforts. | |
| Human Interest Frame | [Definition] Presents vivid details and reveals individual fates by describing individuals involved in the event, evoking emotional resonance with the audience. [Identification Points] Selects individuals from the event for a special feature; vividly describes the experiences, psychological states, and emotional changes of individuals; rich in details and dramatic tension; evokes sympathy and empathy from the audience. [Example] A survivor recounted his fear and despair during the terrorist attack, as well as the painful experience of losing loved ones. | |
| Economic Consequence Frame | [Definition] Focuses on the impact of the event on the economic domain, including aspects such as costs, benefits, and budgets. [Identification Points] Analyzes the economic impact of the event on related industries, businesses, or individuals; involves economic indicators such as data and amounts; discusses economic issues such as cost control, benefit improvement, and budget balancing; commonly seen in reports involving public policies and business operations. [Example] The terrorist attack not only led to a sharp decline in business activities in the city center but also caused economic losses and a decrease in investor confidence. | |
| Morality Frame | [Definition] Evaluates the event and related behaviors from the perspective of moral ethics, involving values, social norms, etc. [Identification Points] Judges the behaviors of the parties involved from a moral perspective; discusses the value conflicts or moral dilemmas reflected by the event; provokes societal reflection and discussion on moral choices and ethical principles; commonly seen in hot social events and criminal cases. [Example] Various sectors of society called on the government to strengthen counter-terrorism measures and condemned terrorist acts as a serious challenge to human values and moral norms. | |
| Leadership Frame | [Definition] Focuses on the performance of leaders or managers in responding to the event, evaluating their leadership, decision-making, and control abilities. [Identification Points] Reports on the words and actions of managers and decision-makers in the event; analyzes the response strategies and solutions of leaders; evaluates the abilities and determination demonstrated by leaders in the event; reflects the public’s expectations of leaders. [Example] Government leaders issued statements condemning the terrorist attack, pledging to take all necessary measures to ensure public safety, demonstrating the leaders’ firm resolve and leadership capabilities. |
Appendix B
- 1.
- Fact Frame Feature Extraction
- (1)
- Keyword extraction: Define part-of-speech patterns for factual keywords, such as = “who/WP”, = “what/WP”, etc. Match the tokenized and part-of-speech tagged results. Extract the words corresponding to the matched pattern positions as the set of factual keywords . The keyword feature vector is represented as .
- (2)
- Named entity recognition: Perform named entity recognition to obtain the set of named entities . For each named entity type , calculate its occurrence frequency in the set , then , where is the number of named entity types. The named entity feature vector can be represented as .
- (3)
- Numerical information statistics: Use regular expressions to match numerical information in the news text, obtaining the set of numerical information . For each type of numerical information, calculate its occurrence frequency in the set , then , where is the number of numerical information types. The numerical information feature vector can be represented as .
- (4)
- Factual statement extraction: Extract the subject–verb–object structure of each sentence in the text and determine whether it is a factual statement. Extract the set of factual statements and calculate the proportion of factual statements where is the total number of sentences in the text. The factual statement feature vector can be represented as .
- 2.
- Responsibility Frame Feature Extraction
- (1)
- Causal relation extraction: Perform dependency parsing on the text to obtain dependency structure triples in the form. Based on dependency relation patterns = , such as = (“nsubj”, “dobj”, “cause”), = (“nsubj”, “prep”, “pobj”), match the “cause-effect” semantic relation pairs and determine the causal relation type they belong to. Calculate the frequency of each causal relation type , then .
- (2)
- Sentiment analysis: Using the sentiment analysis module provided by spaCy, we perform sentiment analysis on the events and , obtaining scores and . The spaCy sentiment analyzer classifies text into positive, negative, or neutral categories, providing a comprehensive understanding of the emotional tone associated with each event. The sentiment feature of the causal relation pair is = + . Calculate the average sentiment score of all relation pairs as the overall sentiment orientation feature, then .
- (3)
- Responsibility keyword statistics: Construct a responsibility keyword dictionary , including words such as “responsibility”, “accountability”, “investigate”, etc. Calculate the occurrence frequency of each keyword in each event (denoted as , where represents the -th keyword in the dictionary ). For each causal relation pair , calculate the sum of keyword frequencies = + . The keyword feature vector is represented as .
- (4)
- Context information encoding: Extract the contextual information such as time and location of each event occurrence, then . Convert each piece of contextual information into a feature vector , then the contextual information feature matrix is represented as .
- 3.
- Conflict Frame Feature Extraction
- (1)
- Sentiment lexicon extraction: We use the sentiment analysis module from spaCy to identify words expressing negative emotions such as anger, frustration, and disagreement in the text. While “conflict” and “confrontation” are not emotions per se, they often indicate underlying emotional states commonly associated with conflict situations. We calculate the sentiment intensity si of each identified word based on the context. Calculate the total number of negative sentiment words and the sum of their sentiment intensities .
- (2)
- Opposing entities identification: Through named entity recognition, obtain the opposing entities and For each entity , extract its occurrence frequency in the text and its key descriptive words . The opposing entities feature vector is represented as .
- (3)
- Argumentation pattern matching: Predefine argumentation pattern templates , such as “A argued that..”., “A and B debated..”., etc. Calculate the number of matches for each pattern template in the text. The argumentation pattern feature vector is represented as .
- (4)
- Rhetorical device analysis: Define a set of rhetorical devices that express conflict, such as = “metaphor”, = “hyperbole”, etc. Design corresponding recognition rules for each rhetorical device. For example, metaphor can be recognized through “is like”, “is a”, while hyperbole can be recognized through “most”, “always”, etc. Calculate the occurrence frequency of each rhetorical device in the news text. The rhetorical device feature vector is represented as .
- 4.
- Human Interest Frame Feature Extraction
- (1)
- Character sketch identification: For each paragraph in the text, extract person names, pronouns, and other character references , and calculate the density of character references in each paragraph, where is the number of character references in . Set a character sketch density threshold θ, and select paragraphs with density higher than the threshold as character sketch paragraphs. The character sketch feature vector is represented as .
- (2)
- Sentiment lexicon extraction: Perform sentiment analysis on each paragraph and extract sentiment words to form the sentiment lexicon set . Calculate the sentiment lexicon density of each paragraph . The sentiment lexicon feature vector is represented as .
- (3)
- Character perspective analysis: Extract the subject of each paragraph and determine whether each subject is a character reference. Calculate the proportion of character subjects . Set a character perspective proportion threshold , and select paragraphs with proportion higher than the threshold as character perspective paragraphs. The character perspective feature vector is represented as .
- (4)
- Rhetorical device detection: Define a set of rhetorical devices and design corresponding recognition rules for each rhetorical device , then . Use the rule set to detect whether each paragraph contains rhetorical devices , and obtain the occurrence count of rhetorical devices. The rhetorical device feature vector is represented as .
- 5.
- Economic Consequence Frame Feature Extraction
- (1)
- Economic lexicon extraction: Construct an economic domain vocabulary dictionary , including economic terms, financial terms, etc. Calculate the TF-IDF weight of each word in the text within the dictionary , and use it as the economic relevance of that word. Select the top words with the highest economic relevance as the economic lexicon features .
- (2)
- Economic data statistics: Define a set of economic data types , such as GDP, CPI, unemployment rate, etc. Design corresponding regular expression templates for each data type , and extract economic data values from the news text based on the templates to form the economic data features .
- (3)
- Economic impact analysis: Extract event entities from the news text, such as “new policy introduced”, “company bankruptcy”, etc. Determine whether there is a causal relationship between each event entity and economic entities , and obtain the causal relationship set , where represents the causal relationship type, such as “promote”, “inhibit”, etc. For each event entity , calculate the number of causal relationships between it and economic entities . The economic impact feature vector is represented as .
- (4)
- Industry association assessment: Define a set of industry domains related to the economy, and construct a corresponding set of keywords for each industry domain . Calculate the co-occurrence frequency of each event entity with the keywords of each industry in the text, . The industry association feature vector is represented as , that is the association degree between each event entity and each industry.
- 6.
- Morality Frame Feature Extraction
- (1)
- Moral lexicon extraction: Construct a moral domain vocabulary dictionary , including words related to morality, ethics, justice, etc. Calculate the occurrence frequency of each word in the text within the dictionary , and use it as the moral relevance of that word. Select the top words with the highest moral relevance as the moral lexicon features .
- (2)
- Moral pattern matching: Define a set of moral judgment sentence patterns , such as “is a virtue”. For each sentence in the text, match the sentence patterns and obtain , where indicates a successful match and indicates a failure. The moral pattern feature vector is represented as , where is the total number of sentences in the text.
- (3)
- Rhetorical device analysis: Define a set of rhetorical devices related to moral appeals, and design corresponding recognition rules for each rhetorical device . For each sentence in the text, use the recognition rules to determine whether it contains rhetorical devices , then , where indicates occurrence and indicates non-occurrence. The rhetorical device feature vector is represented as .
- (4)
- Semantic reasoning: Construct a knowledge base containing moral common sense, values, etc., represented as a set of triples , where and are entities or concepts, and is the relationship between them. Extract entities, concepts, and their relationships from the text to obtain the semantic representation . Use a knowledge reasoning algorithm to determine whether each triple in can be inferred from the moral knowledge base , and obtain the reasoning results , where indicates that it can be inferred and indicates that it cannot be inferred. The semantic reasoning feature vector is represented as .
- 7.
- Leadership Frame Feature Extraction
- (1)
- Leader identification: Obtain the set of person names in the text through named entity recognition. Construct a leadership position dictionary , including leadership position names such as president, prime minister, CEO, etc. Match the leadership position dictionary in the context of each person name . If a match exists, mark it as a leader. The leader feature vector is represented as , where indicates that the person is a leader, and indicates that the person is not a leader.
- (2)
- Leadership behavior extraction: Construct a leadership behavior verb dictionary , including words such as decide, instruct, encourage, etc. Perform dependency parsing on the text, extract verbs and their subjects, and determine whether they are in the dictionary and whether their subjects are leaders. Calculate the frequency of leadership behavior verbs corresponding to each leader , then , where represents the co-occurrence frequency of the leader and the leadership behavior verb .
- (3)
- Leadership ability evaluation: Construct a leadership ability evaluation dictionary , including adjectives such as strong, excellent, incompetent, etc. Use an opinion mining model to identify evaluative sentences in the text, and extract the evaluation object, evaluation word, and sentiment polarity. For each leader , calculate the frequency of positive and negative leadership ability evaluation words related to them, then , where and represent the frequency of positive and negative leadership ability evaluation words for the leader , respectively.
- (4)
- Rhetorical device analysis: Define a set of rhetorical devices used to describe leaders, and design corresponding recognition rules for each rhetorical device to determine whether a sentence contains that rhetorical device. For each sentence in the text, use the recognition rules to determine whether it contains rhetorical devices , then , where indicates occurrence, and indicates non-occurrence. The rhetorical device feature vector is represented as .
References
- IDC. Expect 175 Zettabytes of Data Worldwide by 2025. Networkworld. 2018. Available online: https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html (accessed on 25 July 2024).
- Mohsin, M.; Latif, S.; Haneef, M.; Tariq, U.; Khan, M.A.; Kadry, S.; Choi, J.I. Improved Text Summarization of News Articles Using GA-HC and PSO-HC. Appl. Sci. 2021, 11, 10511. [Google Scholar] [CrossRef]
- Singh, R.K.; Khetarpaul, S.; Gorantla, R.; Allada, S.G. SHEG: Summarization and headline generation of news articles using deep learning. Neural Comput. Appl. 2021, 33, 3251–3265. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, C.; Zeng, M. End-to-end segmentation-based news summarization. arXiv 2021, arXiv:2110.07850. [Google Scholar]
- Ma, C.; Zhang, W.E.; Wang, H.; Gupta, S.; Guo, M. Dependency Structure for News Document Summarization. arXiv 2021, arXiv:2109.11199. [Google Scholar]
- Huang, Y.H.; Lan, H.Y.; Chen, Y.S. Unsupervised Text Summarization of Long Documents using Dependency-based Noun Phrases and Contextual Order Arrangement. In Proceedings of the 34th Conference on Computational Linguistics and Speech Processing (ROCLING 2022), Taipei, Taiwan, 18–19 November 2022; pp. 15–24. [Google Scholar]
- Bateson, G. A theory of play and fantasy. Psychiatr. Res. Rep. 1955, 2, 39–51. [Google Scholar]
- Goffman, E. Frame Analysis: An Essay on the Organization of Experience; Harvard University Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Heidenreich, T.; Lind, F.; Eberl, J.; Boomgaarden, H.G. Media Framing Dynamics of the ‘European Refugee Crisis’: A Comparative Topic Modelling Approach. J. Refug. Stud. 2019, 32, i172–i182. [Google Scholar] [CrossRef]
- Nassar, R. Framing refugees: The impact of religious frames on U.S. partisans and consumers of cable news media. Polit. Commun. 2020, 37, 593–611. [Google Scholar] [CrossRef]
- Calabrese, C.; Anderton, B.N.; Barnett, G.A. Online representations of “Genome Editing” uncover opportunities for encouraging engagement: A semantic network analysis. Sci. Commun. 2019, 41, 222–242. [Google Scholar]
- Burscher, B.; Odijk, D.; Vliegenthart, R.; de Rijke, M.; de Vreese, C.H. Teaching the computer to code frames in news: Comparing two supervised machine learning approaches to frame analysis. Commun. Methods Meas. 2014, 8, 190–206. [Google Scholar] [CrossRef]
- Eisele, O.; Heidenreich, T.; Litvyak, O.; Boomgaarden, H.G. Capturing a News Frame–Comparing Machine-Learning Approaches to Frame Analysis with Different Degrees of Supervision. Commun. Methods Meas. 2023, 17, 205–226. [Google Scholar]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Barzilay, R.; Elhadad, M. Using Lexical Chains for Text Summarization. In Advances in Automatic Text Summarization; MIT Press: Cambridge, MA, USA, 1997; pp. 111–121. [Google Scholar]
- Nallapati, R.; Zhou, B.; Ma, M. Classify or select: Neural architectures for extractive document summarization. arXiv 2016, arXiv:1611.04244. [Google Scholar]
- Yasunaga, M.; Zhang, R.; Meelu, K.; Pareek, A.; Srinivasan, K.; Radev, D. Graph-based neural multi-document summarization. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 452–462. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A.M. Abstractive sentence summarization with attentive recurrent neural networks. In Proceedings of the 2016 Conference of the North American Chapter of the ACL: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 93–98. [Google Scholar]
- Nallapati, R.; Zhou, B.; Santos, C.N.; Gulcehre, C.; Xiang, B. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Antropic. The Claude 3 Model Family: Opus, Sonnet, Haiku. Available online: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf (accessed on 25 July 2024).
- Google. Gemini: A Family of Highly Capable Multimodal Models. Available online: https://assets.bwbx.io/documents/users/iqjWHBFdfxIU/r7G7RrtT6rnM/v0 (accessed on 25 July 2024).
- OPENAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- OPENAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 25 July 2024).
- Baidu. The Report of Ernie Bot. Available online: https://aistudio.baidu.com/aistudio/projectdetail/5748979 (accessed on 25 July 2024).
- Peng, W.; Yang, A.; Rui, M.; Wang, Y.; Guo, C.; Ren, B.; Lin, Y.; Zhou, P.; Huang, L.; Peng, N.; et al. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Maynez, J.; Narayan, S.; Bohnet, B.; Karamanolakis, G. On Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1906–1919. [Google Scholar]
- Sotudeh, S.; Gharebagh, S.S.; Goharian, N. TLDR: Extreme Summarization of Scientific Documents. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 4766–4777. [Google Scholar]
- Dou, Z.Y.; Liu, P.; Hayashi, H.; Jiang, Z.; Neubig, G. GSum: A General Framework for Guided Neural Abstractive Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4830–4842. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Gitlin, T. The Whole World Is Watching: Mass Media in the Making and Unmaking of the New Left; University of California Press: Berkeley, CA, USA, 1980; pp. 6–7. [Google Scholar]
- Gamson, W.A.; Modigliani, A. Media discourse and public opinion on nuclear power: A constructionist approach. Am. J. Sociol. 1989, 95, 1–37. [Google Scholar] [CrossRef]
- Entman, R.M. Framing: Toward clarification of a fractured paradigm. J. Commun. 1993, 43, 51–58. [Google Scholar] [CrossRef]
- Tuchman, G. Making News: A Study in the Construction of Reality; Free Press: New York, NY, USA, 1978. [Google Scholar]
- Zang, G.R. News Media and News Sources: A Discourse on Media Framing and Reality Construction; San Min Book Co., Ltd.: Taipei, Taiwan, 1999. [Google Scholar]
- Huang, D. The Image of the Messenger: The Construction and Deconstruction of Journalistic Professionalism; Fudan University Press: Shanghai, China, 2005. [Google Scholar]
- Cacciatore, M.A.; Scheufele, D.A.; Iyengar, S. The End of Framing as we Know it … and the Future of Media Effects. Mass Commun. Soc. 2016, 19, 7–23. [Google Scholar] [CrossRef]
- Pan, Z.D. Frame Analysis: A Field in Urgent Need of Theoretical Clarification. Commun. Soc. 2006, 1, 17–46. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Fairclough, N. Analysing Discourse: Textual Analysis for Social Research; Psychology Press: London, UK, 2003. [Google Scholar]
- Ryan, M.L. Narrative as Virtual Reality; Johns Hopkins University Press: Baltimore, MD, USA, 2001; pp. 357–359. [Google Scholar]
- Semetko, H.A.; Valkenburg, P.M. Framing European politics: A content analysis of press and television news. J. Commun. 2000, 50, 93–109. [Google Scholar] [CrossRef]
- Zhang, P.W. Research on News Framing of Public Health Emergencies. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2022. [Google Scholar]
- Iyengar, S. Is Anyone Responsible?: How Television Frames Political Issues; University of Chicago Press: Chicago, IL, USA, 1994. [Google Scholar]
- De Vreese, C.H. Framing Europe: Television News and European Integration; Aksant: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Lawlor, A.; Tolley, E. Deciding who’s legitimate: News media framing of immigrants and refugees. Int. J. Commun. 2017, 11, 25. [Google Scholar]
- Walter, D.; Ophir, Y. News frame analysis: An inductive mixed-method computational approach. Commun. Methods Meas. 2019, 13, 248–266. [Google Scholar] [CrossRef]
- Valkenburg, P.M.; Semetko, H.A.; De Vreese, C.H. The effects of news frames on readers’ thoughts and recall. Commun. Res. 1999, 26, 550–569. [Google Scholar] [CrossRef]
- Tong, J. Environmental risks in newspaper coverage: A framing analysis of investigative reports on environmental problems in 10 Chinese newspapers. Environ. Commun. 2014, 8, 345–367. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I. spaCy: Industrial-Strength Natural Language Processing in Python. Available online: https://spacy.io (accessed on 21 August 2024).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the ACL-04 Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Wasson, M. Using leading text for news summaries: Evaluation results and implications for commercial summarization applications. In Proceedings of the 17th International Conference on Computational Linguistics, Montreal, QC, Canada, 10–14 August 1998; pp. 1364–1368. [Google Scholar]
- Erkan, G.; Radev, D.R. LexRank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Xiao, T.; Xu, C.; Wu, H.; Ji, Z.; Wang, C.; Zhou, H.Y. Flat Transformer for Long Document Summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 11545–11552. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- MetaAI. Llama3-Model Card. 2024. Available online: https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3 (accessed on 25 July 2024).
- Qwen Team, Alibaba Group. Qwen Technical Report. Available online: https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf (accessed on 25 July 2024).
- Yan, M.; Xiong, R.; Wang, Y.; Li, C. Edge Computing Task Offloading Optimization for a UAV-assisted Internet of Vehicles via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2024, 73, 5647–5658. [Google Scholar] [CrossRef]
- Yan, M.; Luo, M.; Chan, C.A.; Gygax, A.F.; Li, C.; Chih-Lin, I. Energy-Efficient Content Fetching Strategies in Cache-Enabled D2D Networks via an Actor-Critic Reinforcement Learning Structure. IEEE Trans. Veh. Technol. 2024; early access. [Google Scholar] [CrossRef]
- Yan, M.; Chan, C.A.; Gygax, A.F.; Li, C.; Nirmalathas, A.; Chih-Lin, I. Efficient Generation of Optimal UAV Trajectories with Uncertain Obstacle Avoidance in MEC Networks. IEEE Internet Things J. 2024; early access. [Google Scholar] [CrossRef]





| Dataset | Size |
|---|---|
| Training set (CNN/Daily Mail) | 2400 |
| Validation set (CNN/Daily Mail) | 300 |
| Test set (CNN/Daily Mail) | 300 |
| Test set (BBCnews) | 450 |
| Test set (XSum) | 450 |
| Train | Test | Validation | |
|---|---|---|---|
| Avg#tokens | 807 | 827 | 814 |
| Max#entities | 199 | 148 | 234 |
| Avg#entities | 44 | 44 | 44 |
| Vocabsize | 48,020 | 22,311 | 22,433 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| NBM | 0.44 | 0.33 | 0.45 | 0.31 |
| SVM | 0.61 | 0.62 | 0.61 | 0.58 |
| TF-IDF | 0.62 | 0.69 | 0.61 | 0.56 |
| RNN | 0.47 | 0.37 | 0.49 | 0.34 |
| Transformer | 0.71 | 0.69 | 0.70 | 0.65 |
| BERT | 0.79 | 0.75 | 0.79 | 0.72 |
| Our Model (NFRM) | 0.92 | 0.87 | 0.89 | 0.90 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead | 34.17 | 12.44 | 31.17 |
| LexRank | 36.75 | 13.54 | 29.89 |
| TextRank | 37.17 | 13.62 | 32.82 |
| PG | 39.53 | 17.28 | 36.38 |
| T5 | 43.21 | 17.82 | 38.96 |
| FT | 40.46 | 25.26 | 34.65 |
| GPT-2 | 43.21 | 17.82 | 38.96 |
| Llama3 | 44.18 | 26.43 | 37.91 |
| Qwen | 43.74 | 24.68 | 37.62 |
| Our model (FrameSum) | 44.82 | 26.84 | 39.56 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead | 56.65 | 44.83 | 55.84 |
| LexRank | 55.75 | 44.83 | 55.00 |
| TextRank | 52.64 | 41.33 | 51.51 |
| T5 | 54.28 | 41.79 | 55.01 |
| FT | 55.61 | 44.21 | 55.92 |
| Llama3 | 56.73 | 47.18 | 56.84 |
| Our model (FrameSum) | 57.14 | 47.49 | 56.91 |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead | 34.91 | 12.03 | 27.07 |
| LexRank | 32.83 | 10.93 | 25.44 |
| TextRank | 35.01 | 11.51 | 31.42 |
| T5 | 38.98 | 13.07 | 29.34 |
| FT | 40.52 | 14.16 | 29.92 |
| Llama3 | 42.13 | 14.51 | 28.41 |
| Our model (FrameSum) | 43.48 | 19.29 | 30.85 |
| Model | Summary Content |
|---|---|
| Original News | (PEOPLE.com)—Reese Witherspoon wants to move on after her accident. The actress is not pressing charges against the 84-year-old driver who struck her as she was jogging Wednesday in Santa Monica, Calif., her rep tells PEOPLE. The actress, 35, suffered minor injuries and went home to recover, her rep said at the time. The driver, meanwhile, was cited for failing to yield to a pedestrian in a crosswalk. |
| Lead | (PEOPLE.com)—Reese Witherspoon wants to move on after her accident. The actress is not pressing charges against the 84-year-old driver who struck her as she was jogging Wednesday in Santa Monica, Calif., her rep tells PEOPLE. The actress, 35, suffered minor injuries and went home to recover, her rep said at the time. |
| LexRank | Reese Witherspoon was struck by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian. |
| TextRank | Reese Witherspoon was hit by a driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian. |
| PG | Reese Witherspoon, 35, was struck by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian in a crosswalk. |
| T5 | Reese Witherspoon was hit by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian. |
| FT | Actress Reese Witherspoon, 35, was struck by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian in a crosswalk. |
| GPT-2 | Reese Witherspoon, 35, was struck by an 84-year-old driver while jogging in Santa Monica on Wednesday. She suffered minor injuries and went home to recover. The actress is not pressing charges, but the driver was cited for failing to yield to a pedestrian in a crosswalk. |
| Llama3 | Reese Witherspoon, 35, was hit by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries but is not pressing charges. The driver was cited for failing to yield to a pedestrian in a crosswalk. |
| Qwen | Actress Reese Witherspoon, 35, was struck by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries and is not pressing charges. The driver was cited for failing to yield to a pedestrian in a crosswalk. Witherspoon wants to move on from the incident. |
| FrameSum | Reese Witherspoon, 35, was hit by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries but is not pressing charges. The driver was cited for failing to yield to a pedestrian. Witherspoon wants to move on from the accident. |
| Reference Summary | Actress Reese Witherspoon, 35, was struck by an 84-year-old driver while jogging in Santa Monica. She suffered minor injuries but is not pressing charges. The driver was cited for failing to yield to a pedestrian in a crosswalk. Witherspoon wants to move on from the incident. |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| FrameSum | 44.82 | 19.24. | 39.56 |
| -w/o frame emb. | 44.23 | 18.79 | 38.91 |
| -w/o frame feat. | 43.11 | 18.07 | 38.85 |
| -w/o cov. loss | 41.57 | 17.62 | 37.40 |
| -w/o frame rel. loss | 41.96 | 18.23 | 39.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wei, Q.; Zheng, B.; Liu, J.; Zhang, P. FrameSum: Leveraging Framing Theory and Deep Learning for Enhanced News Text Summarization. Appl. Sci. 2024, 14, 7548. https://doi.org/10.3390/app14177548
Zhang X, Wei Q, Zheng B, Liu J, Zhang P. FrameSum: Leveraging Framing Theory and Deep Learning for Enhanced News Text Summarization. Applied Sciences. 2024; 14(17):7548. https://doi.org/10.3390/app14177548
Chicago/Turabian StyleZhang, Xin, Qiyi Wei, Bin Zheng, Jiefeng Liu, and Pengzhou Zhang. 2024. "FrameSum: Leveraging Framing Theory and Deep Learning for Enhanced News Text Summarization" Applied Sciences 14, no. 17: 7548. https://doi.org/10.3390/app14177548
APA StyleZhang, X., Wei, Q., Zheng, B., Liu, J., & Zhang, P. (2024). FrameSum: Leveraging Framing Theory and Deep Learning for Enhanced News Text Summarization. Applied Sciences, 14(17), 7548. https://doi.org/10.3390/app14177548