Abstract
In abstract argumentation frameworks, the computation of stable extensions is an important semantic task for evaluating the acceptability of arguments. The current approaches for the computation of stable extensions are typically conducted through methodologies that are either label-based or extension-based. Label-based algorithms operate by assigning labels to each argument, thus reducing the attack relations between arguments to constraint relations among the labels. This paper analyzes the existing two-label and three-label enumeration algorithms for stable extensions through case studies. It is found that both the two-label and three-label algorithms are not precise enough in defining types of arguments. To address these issues, this paper proposes a four-label enumeration algorithm for stable extensions. This method introduces a label to pre-mark certain -type arguments, thereby achieving a finer classification of -type arguments. This enhances the labelings’ propagation ability and reduces the algorithm’s search space. Our proposed four-label algorithm was tested on authoritative benchmark sets of abstract argumentation framework problems: ICCMA 2019, ICCMA 2021, and ICCMA 2023. Experimental results show that the four-label algorithm significantly improves solving efficiency compared to existing two-label and three-label algorithms. Additionally, ablation experiments confirm that both the four-label transition strategy and preprocessing strategy enhance the algorithm’s performance.
1. Introduction
Computational argumentation is an essential component of artificial intelligence [1,2,3], aiming to analyze the acceptability of arguments and ultimately achieve consensus. The abstract argumentation framework (abbreviated AAF or AF), first proposed by Dung [4], consists of a set of arguments and a set of attack relations. By determining the acceptability of arguments, AF derives relevant semantic extensions. This framework abstracts complex problems into simple argumentation models, making it a fundamental model for argumentation across various domains. Moreover, AF serves as a reasoning model and a research cornerstone in fields such as decision support systems [5], non-monotonic reasoning [6], machine learning [7], medical decision-making [8,9], explainable artificial intelligence, and intelligent interactions in multi-agent systems [10].
Enumerating stable extensions is a fundamental problem in abstract argumentation frameworks. Previous algorithms for enumerating stable extensions include dynamic programming algorithms [11], reduction algorithms [12], and depth-first search (DFS) algorithms [13], among which DFS algorithms commonly use labeling models. Typical label-based methods for enumerating stable extensions include two-label and three-label algorithms. The two-label algorithm for stable extensions is an intuitive method based on the definition of stable extensions. This labeling method is relatively simple and direct in algorithm design but suffers from numerous ineffective searches. Additionally, Nofal et al. proposed a three-label algorithm for stable extensions [14], introducing a new labeling to the two-label algorithm to differentiate argument types and reduce the search space. Although the three-label algorithm partially optimizes the issues present in the two-label algorithm, it still has problems with redundant searches. To our knowledge, there is currently no comprehensive, efficient, and direct DFS within backtracking algorithms for enumerating stable extensions. Therefore, this paper introduces a four-label enumeration algorithm for stable extensions by adding the label.
The main contributions of this paper can be summarized in two aspects. First, this paper conducts a comprehensive analysis of the existing two-label and three-label enumeration stable extension methods, illustrating their limitations through sample analyses. Second, by introducing the label, a four-label algorithm is proposed. In the four-label algorithm, we first propose a preprocessing strategy that can preemptively label and address arguments concerning confirmed labeling types, thereby achieving the target state (i.e., stable extensions) earlier. Additionally, a four-label transition strategy is introduced to enhance collaboration between labels, thereby accelerating labeling propagation and reducing the search space of the algorithm.
The paper is organized as follows. Section 2 gives an introduction to the semantic extension model of the abstract argumentation framework and the related algorithms for solving stable extensions. Section 3 presents the definitions of the argumentation framework, labeling model, and stable extensions, as well as their interrelationships. Section 4 gives a comparative analysis of the existing two-label and three-label algorithms for solving stable extensions and highlights their limitations. Section 5 elaborates on the concepts and details of the four-label algorithm. Section 6 demonstrates the experimental results of the four-label algorithm and other label algorithms on the ICCMA benchmark sets and analyzes the impact of the preprocessing strategy and labeling transition strategy on the algorithm’s efficiency through ablation experiments. Section 7 contains the remarks and future work.
2. Related Work on Reduction-Based Methods and Direct Solving for AF
In early abstract argumentation frameworks, the concepts of admissible set, complete extension, grounded extension, preferred extension, and stable extensions were generally represented through extension models [15]. Furthermore, these concepts can also be expressed through labeling models [16,17]. In the current research on abstract argumentation frameworks, the design of algorithms for solving stable extensions primarily revolves around these two models. These algorithms can generally be divided into reduction-based algorithms (or methods) and direct solving algorithms [12].
Reduction-based methods transform the problem of solving abstract argumentation frameworks (such as stable extensions) into another classical NP problem, by using existing mature algorithms to solve this NP problem. These reduction-based methods can be further subdivided into reduction methods based on extension models and those based on labeling models. The reduction methods based on extension models leverage the properties of extension models to transform the abstract argumentation framework problem into a classical NP problem. For example, ASPARTIX-V [18,19] encodes the problem of finding stable extensions in an argumentation framework into an answer set problem (ASP). Since there is a direct correspondence between answer sets and stable models, this method can use a standard ASP solver to directly model and solve the semantics of the abstract argumentation framework. The solutions to the ASP problem can then be decoded to obtain solutions to the original problem. Similarly, -toksia [20] encodes the problem of solving semantic extensions into a SAT problem, then uses the SAT solver CryptoMinSat [21] as the underlying solver. The reduction methods based on labelings combine the definition of the semantics with their corresponding labelings to reduce the problem to a classic NP problem. For instance, ArgSemSAT uses the Glucose [22] SAT solver, while Fudge uses the CaDiCaL [23,24] SAT solver. Essentially, mature and general solvers like ASP solvers and SAT solvers employ complex and efficient algorithmic strategies, such as conflict-driven clause learning [25,26].
Direct methods for solving semantic problems in abstract argumentation frameworks can be divided into incomplete search algorithms [27] and complete search algorithms. A representative example of incomplete algorithms is the local search algorithm. This kind of algorithm first initializes a set of labels for the arguments, then continually selects and flips the labels of some conflicting arguments using heuristic strategies until a legal solution is found [28]. Complete algorithms, on the other hand, are based on a depth-first search framework and traverse the entire solution space to find the solution. To enhance the efficiency of complete algorithms, effective branching strategies, labeling propagation methods, and pruning strategies are commonly employed. Notable solvers of this type include ArgTools [29] and DREDD [30]. The four-label algorithm presented in this paper is also a direct solving algorithm. By introducing a new label, our proposed algorithm optimizes the labeling transition strategy, thereby accelerating labeling propagation and reducing the search space.
3. Background
3.1. Abstract Argumentation Framework and Stable Extensions
An abstract argumentation framework consists of a set of arguments and binary attack relations between them. In other words, each AF corresponds to a directed graph where each argument in the framework represents a vertex, and each attack relation represents an edge.
Definition 1.
(Abstract Argumentation Framework): Given an abstract argumentation framework AF, it is a tuple , where A is a set of arguments, and is a binary relation representing the attack relations on the set A.
In an abstract argumentation framework , if , it means that argument a attacks argument b (or b is attacked by a), and this can also be denoted as . Let denote the subset of arguments attacked by a and denote the subset of arguments that attack a. Given a set of arguments :
Definition 2.
(Conflict-Free Set): Given an abstract argumentation framework , a subset is a conflict-free set iff , , , meaning there is no direct attack relationship between a and b. The set of conflict-free sets is denoted by .
Definition 3.
(Acceptability of Arguments): Given an abstract argumentation framework , where , an argument is acceptable with respect to X iff and, ∀ (), if , then must hold.
Definition 4.
(Admissible Set): Given an abstract argumentation framework , a subset is an admissible set iff , and each argument in X is acceptable with respect to X. The set of admissible sets is denoted by .
Definition 5.
(Complete Extension): Given an abstract argumentation framework , a set of arguments X is a complete extension iff , and every argument acceptable with respect to X belongs to X. The set of complete extensions is denoted by .
A complete extension includes all arguments that are acceptable with respect to itself and does not allow for the addition of any new acceptable arguments through extension.
Definition 6.
(Stable Extension): Given an argumentation framework , a set of arguments is a stable extension iff and, for every argument such that , it holds that . In other words, a stable extension attacks every argument that does not belong to that extension. The set of stable extensions is denoted by .
Stable extensions can be obtained using a characteristic function derived from complete extensions. Each complete extension corresponds to a stable extension. However, different complete extensions may yield the same stable extension through further extension, hence .
3.2. The Relationship between Arguments and Labelings
There is a one-to-one correspondence [17] between labelings and arguments. In an abstract argumentation framework , each extension E implicitly defines a three-valued labeling of arguments: if an argument a belongs to E, then a is labeled as ; if a is labeled as , it indicates that there exists an argument in E attacking a; if neither condition applies, a is labeled as . Here, the label signifies explicit support for the argument, the label denotes explicit opposition to the argument, and the label indicates that the status of the argument remains undecided.
Definition 7.
(Labeling Model): Given an argumentation framework and argument , let be a mapping from arguments of the argumentation framework Γ to labels.
Definition 8.
(Legal Label): Given an argumentation framework and arguments , let represent a mapping from arguments of the argumentation framework Γ to labels. It is known that , for any , so it holds that , and, for any , it holds that .
Definition 9.
(Legal Label): Given an argumentation framework and arguments , let represent a mapping from arguments of the argumentation framework Γ to labels. If , then there exists such that .
Definition 10.
(Legal Label): Given an argument framework and arguments , let denote the mapping from arguments of the argumentation framework Γ to labels. If , then there exists such that .
In the mapping of arguments to labels within an abstract argumentation framework, a set of labels is considered a complete labeling when all three types of label are legal. This complete labeling serves as the foundation for defining other semantic labeling. Consequently, when the set of labels in a set of complete labeling is empty, this complete labeling is also a stable labeling. In the subsequent discussion of stable extension algorithms, it is assumed that the label set is empty; hence, the label will not be included in the labeling propagation process of the stable extension algorithms.
4. Comparison of Two-Label and Three-Label Enumeration Algorithms for Stable Extensions
4.1. Labeling Model for Stable Extensions
In current research, algorithms that solve stable extensions based on depth-first search include two-label algorithms and three-label algorithms. The two-label algorithm is an intuitive labeling algorithm designed based on the properties of stable extensions. The three-label algorithm is a labeling algorithm designed on the basis of the two-label algorithm by introducing the label.
In the two-label algorithm, since arguments within a stable extension attack all arguments not included in the extension, there are only two types of legal labels in the stable extension: the label and the label. The label is used to label arguments that can be included in the stable extension sets, while the label is used to label arguments that are attacked by arguments and thus cannot be included in the stable extension sets. Therefore, the two-label algorithm employs two types of label transitions: transition and transition.
Definition 11.
(Two-Label Stable Extension): Given an argumentation framework and arguments , let be a mapping from arguments of the argumentation framework Γ to labels. A stable extension satisfies the following conditions:
In the three-label algorithm, the label is introduced to label arguments that attack the arguments labeled as , thereby distinguishing between different types of arguments. Consequently, three labeling types participate in labeling propagation within the algorithm. However, the algorithm defines only two types of labeling transition rules: transition and transition. The reasons for using and for the labeling transition in this algorithm are as follows. Firstly, a binary branching structure is more suitable for solving stable extension problems compared to other multi-branch structures. Secondly, conflicting arguments are generally labeled as . The legality check of the argument labels only needs to focus on the set of arguments labeled as . Using the label as a type of labeling transition can eliminate conflicting arguments more quickly, enabling the algorithm to enumerate stable extensions faster.
Definition 12.
( Label): Given an argumentation framework and arguments , let be a mapping from arguments of the argumentation framework Γ to labels. If b satisfies and , then .
Definition 13.
(Three-Label Stable Extension): Given an argumentation framework and arguments , let be the mapping from arguments of the argumentation framework Γ to labels. The three-label stable extension satisfies the following conditions:
4.2. Comparison of Two-Label and Three-Label Algorithms
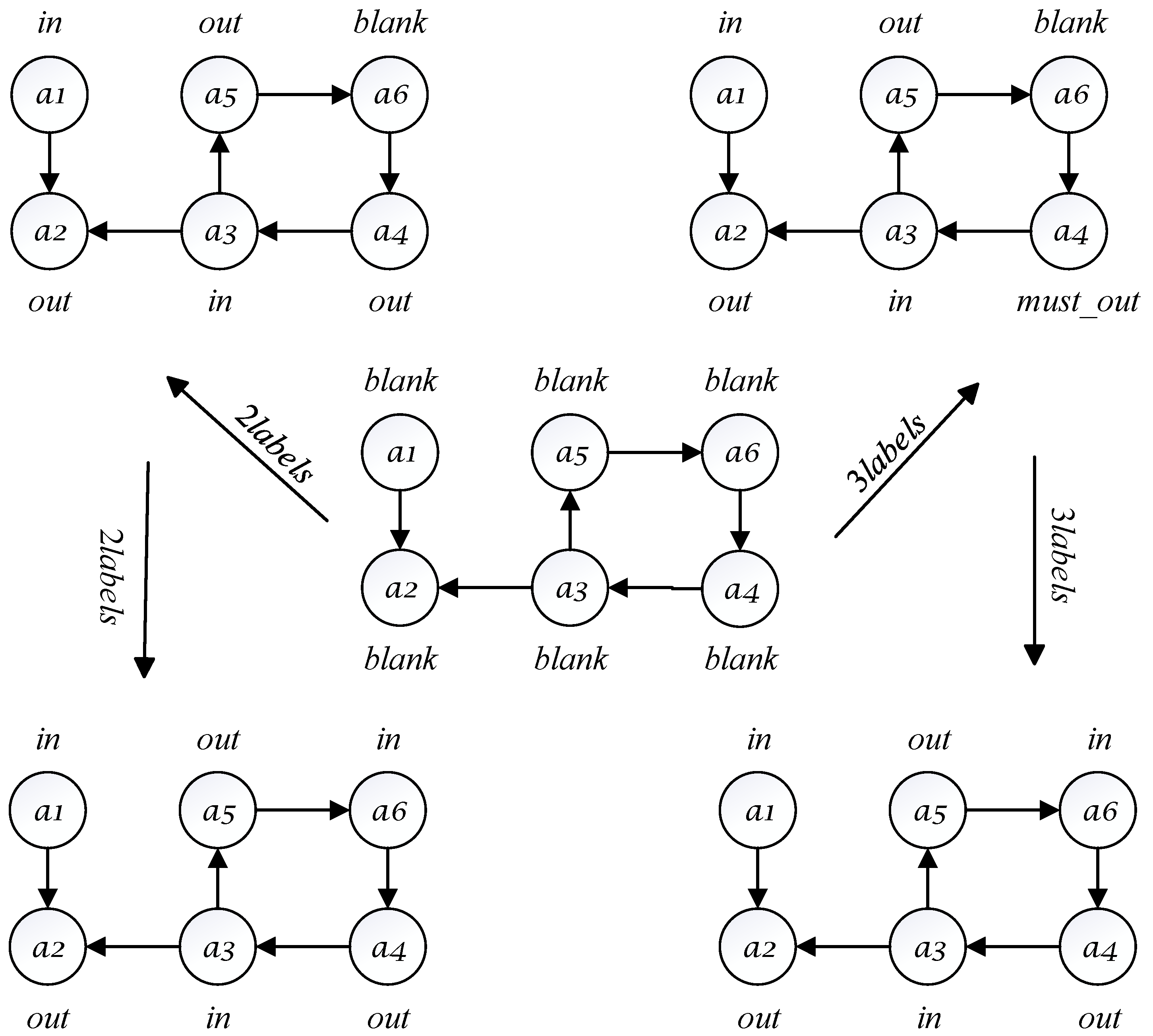
Figure 1 illustrates specific instances of the two-label (left) and three-label (right) solving algorithms, using the label to represent arguments that have not been labeled. In the instance of the two-label algorithm (left), the algorithm performs three argument selections in the order of , , and . After each labeling propagation, the algorithm checks for label legality. The two-label algorithm primarily involves the following three steps:
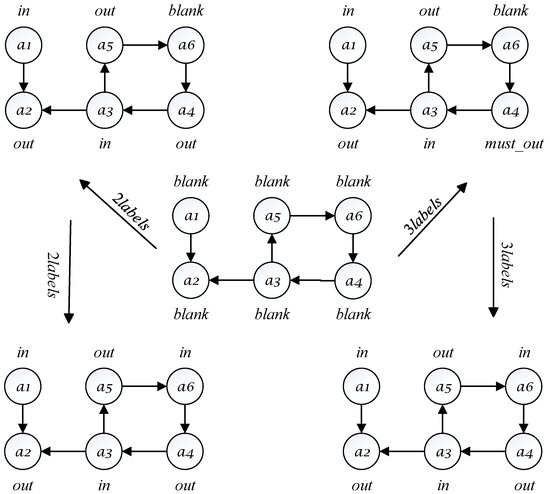
Figure 1.
How the two-label (left) and three-label (right) algorithms work on an AF instance.
- Step 1: Argument is labeled as and propagates the label to argument , with all propagated labels being legal.
- Step 2: Argument is labeled as and propagates the label to arguments and . The arguments , , and , labeled as , are all legal.
- Step 3: Argument is labeled as without propagating any other argument labels, so no labeling legality check is needed. At this point, all arguments have been legally labeled, so the set of arguments labeled as forms a stable extension.
In the instance of the three-label algorithm (right), there are also three argument selections, following the same order as above. However, the label legality check in this algorithm only applies to arguments labeled as . The three-label algorithm primarily involves the following three steps:
- Step 1: Argument is labeled as and propagates the label to argument . No labeling legality check is needed in this round.
- Step 2: Argument is labeled as and propagates the labels and to arguments and , respectively. A legality check is performed for argument , which is labeled as .
- Step 3: Argument does not propagate any other argument labels, so no legality check is needed.
From Figure 1, it is evident that the two-label algorithm is indeed quite simple and intuitive. However, it also shows that, during the label legality check, it often encounters unnecessary checks. For instance, after the labeling propagation in Step 2 of Figure 1, only argument actually requires a label legality check, but the two-label algorithm performs redundant checks on arguments and . This greatly affects the algorithm’s efficiency. Therefore, to reduce the frequency of redundant searches, the label legality check process needs to be optimized. In the three-label algorithm, the introduction of the label distinguishes between arguments that may result in illegal labeling propagation and those that definitely will not. Consequently, during each label legality check, only arguments labeled as need to be checked. The three-label algorithm significantly reduces the number of redundant searches during the labeling propagation process.
Although the three-label algorithm appears to have optimized the issue of redundant searches present in the two-label algorithm, it still has some shortcomings. The three-label algorithm only distinguishes the nature of arguments labeled as and does not perform a comprehensive and systematic analysis of the nature of all arguments. In fact, the nature of arguments labeled as in the labeling propagation process of the three-label algorithm also exhibits diversity. In the next section, this paper introduces a four-label enumeration stable extension algorithm by incorporating the label, along with an illustrative example and detailed description of the algorithm.
5. The Labeling Algorithm for Four-Label Enumeration Stable Extension
5.1. The Concept of the Four-Label Enumeration Stable Extension Algorithm
In this section, a four-label solving algorithm is proposed, aiming to more quickly address the enumeration problem of stable extensions in abstract argumentation frameworks. This new algorithm builds upon the existing two-label and three-label algorithms by introducing the label to differentiate between type arguments with varying properties. This allows for the early labeling of some arguments, thereby accelerating labeling propagation and reducing the algorithm’s search space. The following provides the algorithm concept and an illustrative example.
In the four-label algorithm, the abstract argumentation framework is first preprocessed, categorizing the arguments into three types: initial argument set (labeled as ), self-attacking argument set (labeled as ), and ordinary argument set (others). Arguments in the set are prioritized for labeling transition in this round. Next, the algorithm selects an argument from the ordinary argument set for the transition. After this labeling transition, a label legality check is performed (only for arguments). If all propagated labels are legal, the algorithm continues to select ordinary arguments for the labeling transition; if it is illegal, the chosen ordinary argument is set to , and a label legality check is conducted again. The algorithm then checks the legality of the results. When all argument labels are legally and , the set of arguments labeled as is considered a stable extension. Finally, this process is repeated until all stable extensions are enumerated.
Definition 14.
( Label): Given an argumentation framework and arguments , let represent the mapping from arguments of the argumentation framework Γ to labels. If an argument a satisfies or , , then .
Definition 15.
(Four-Label Stable Extension): Given an argumentation framework and arguments , let represent the mapping from arguments of the argumentation framework Γ to labels. The four-label stable extension satisfies the following conditions:
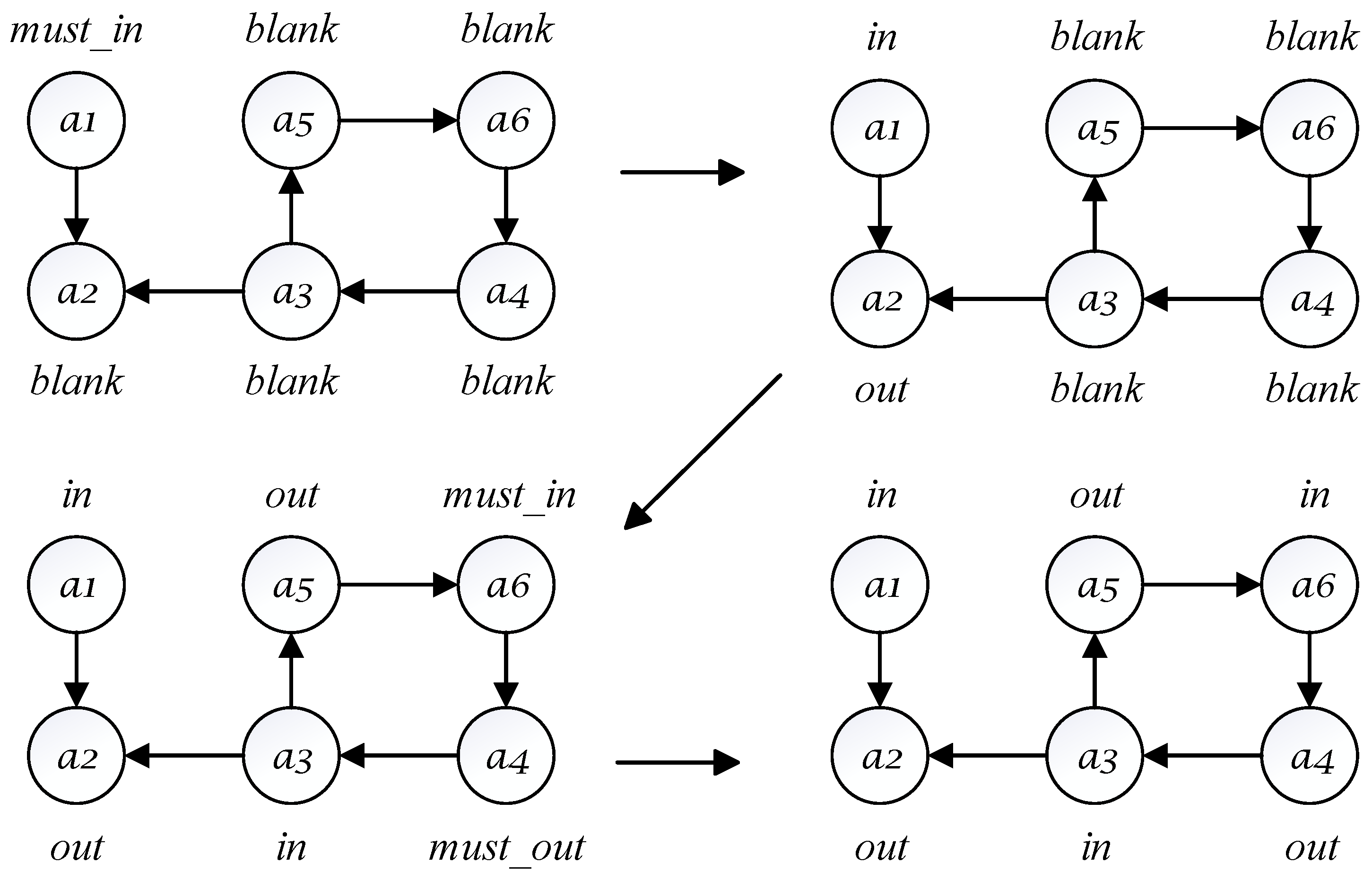
Figure 2 illustrates a specific instance of the four-label stable extension solving algorithm, with the label representing arguments that have not been labeled. This instance can be divided into the following two steps:
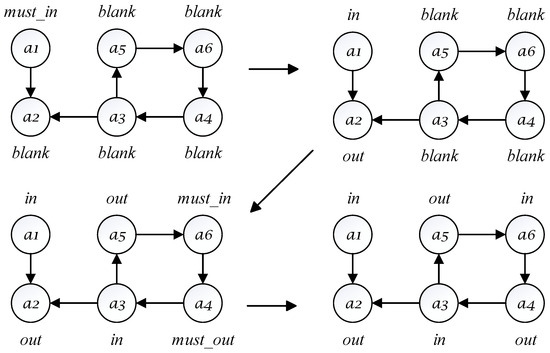
Figure 2.
How the four-label algorithm (Algorithm 1) works on an AF.
- Step 1: During preprocessing, the initial argument is labeled as , and other ordinary arguments are labeled as . The arguments in the label set are then prioritized for the transition. Consequently, argument is labeled as and propagates the label to argument .
- Step 2: The argument is selected from the ordinary argument set. Then argument is labeled as and propagates labels and to arguments and , respectively. The labeling legality of argument , which is labeled as , is then checked and found to be legal. Next, the algorithm attempts to further propagate labels based on the propagated arguments and . Argument propagates the label to argument , which is then labeled as . At this point, a stable extension is obtained.
| Algorithm 1: Four-Label Enumerate All Stable Extensions of . |
 |
5.2. Four-Label Algorithm Description
In the four-label enumeration stable extension algorithm, the algorithm first classifies the arguments in the input abstract argumentation framework based on their different properties, aiming to differentiate the arguments by priority. Then, it performs a labeling transition on the arguments according to their priority order. Finally, the algorithm collects the legal labeling sets, where the set of arguments constitutes the stable extension. The algorithm framework is outlined below.
The framework of the four-label algorithm is illustrated in Algorithm 1. Here, represents the input abstract argumentation framework, denotes the mapping from arguments of the argumentation framework to labels, E is the stable extension set, and the label represents arguments that have not been labeled. In Algorithm 1, the algorithm first preprocesses the input abstract argumentation framework (line 7); then, it selects unlabeled arguments (i.e., ordinary arguments) for labeling transition, prioritizing the transition. If this fails, it attempts the transition. The process is repeated until all arguments are fully labeled, provided that the labeled arguments are legal (lines 8–14); finally, the legality of the labeling results is checked (lines 2–6).
The framework of the four-label algorithm can be divided into two functional modules: the preprocessing strategy and the four-label transition strategy. The preprocessing strategy primarily performs two operations: identifying high-priority arguments and labeling them as and further processing the arguments. In the four-label transition strategy, the focus is on performing the transition and the transition and then checking the legality of the labels. The following sections will detail each of these modules.
Preprocessing Strategy. The preprocessing strategy is used to differentiate the order of argument labeling, with the main objectives of accelerating labeling propagation and reducing the number of algorithmic backtracks. In the abstract argumentation framework, since initial arguments are included in all extensions and since self-attacking arguments are not included in any extension, the algorithm can distinguish these special arguments during preprocessing based on their properties. Once these special arguments are labeled, initial arguments can be directly subjected to the labeling transition. Additionally, during the labeling transition process, the labels of some arguments can be inferred based on existing labels, and the handling of these arguments can be analogized to the initial arguments.
- Q1:
- Why not directly label initial arguments with the label but rather with the label?
- Q2:
- Why not directly label the self-attacking arguments with the label but rather with the label?
We address these questions directly in the following paragraphs:
- A1:
- The advantage of using the label is as follows. Since initial arguments are included in all semantic extensions, labeling these arguments with allows the algorithm to focus on arguments that can be further processed, thus avoiding unnecessary argument search issues. Similarly, in the subsequent labeling transition strategy, labels can also be used to label arguments whose label types are determined through inference. Thus, during argument label branching decisions, the algorithm only needs to consider those arguments whose label types are not yet determined and whose label is being attempted to be set as , thereby reducing the number of algorithmic backtracks.
- A2:
- Since self-attacking arguments do not belong to any semantic extension, their final label type is generally . However, in practice, self-attacking arguments may also contain contradictory arguments (e.g., self-attacking arguments that are not attacked by any other arguments) that cannot be legally labeled as . Therefore, self-attacking arguments should be labeled as first to facilitate legality checks. Similarly, contradictory arguments will also arise in the labeling transition strategy, requiring special marking with labels for legality checks, thereby improving the algorithm’s efficiency.
Algorithm 2 illustrates the preprocessing procedure; here, x refers to an argument selected from the set A, with the label representing arguments that have not been labeled. It defines three useful mappings, and the subsequent operations of the algorithm are based on them. The labels in the mapping functions are , , and . Specifically, self-attacking arguments are labeled with , initial arguments that are not attacked by any other arguments are labeled with , and all other arguments are labeled as (lines 2–10). Next, the algorithm stores the resulting arguments in set S, and then it prioritizes checking whether set S is empty. If S is not empty, the arguments in S are subjected to the transition (lines 11–12). Otherwise, the algorithm moves to the stage of selecting arguments. This preprocessing strategy is similar to methods used for solving grounded extensions.
| Algorithm 2: Preprocessing Labels |
 |
Labeling Transition Strategy. After the preprocessing is finished, the algorithm proceeds with a labeling transition and a legality check. First, the algorithm selects arguments that have not been labeled for the labeling transition, following the transition rules for and labels. The labeling transition process is a binary tree searching framework, which tends to perform better than other multi-branch structures in algorithms. When all arguments have been labeled, the algorithm performs a legality check on the labeled argumentation framework for stable extensions. The criterion for this check is that the set contains only two types of labels: legal labels and legal labels.
During the labeling transition, the algorithm first performs the transition operation. As shown in Algorithm 3, it selects an argument x from the arguments that have not been labeled and labels the chosen argument x as . The arguments attacking x are labeled as (lines 10–11), and the arguments attacked by x are labeled as (lines 3–5). After marking the arguments that have a direct attack relationship with x, the algorithm checks the legality of the generated labels. If they are legal, the algorithm uses the arguments labeled as and as two label inference directions. First, it judges whether more labels can be propagated in the direction (lines 12–16). For instance, in Figure 2, argument propagates to argument . Then, it judges whether more labels can be propagated in the direction (lines 6–9). If the labels are not legal, the label of the argument causing the conflicting argument is set to , and the algorithm continues to repeat the labeling transition operation until all arguments are legally labeled. The specific transition details are shown in Algorithm 4.
Definition 16.
(Contradictory Argument): Given an argumentation framework and argument , let represent a mapping from arguments of the argumentation framework Γ to labels. If and or , , then argument a is called a contradictory argument.
Definition 17.
(-): Given an argumentation framework and arguments , let represent a mapping from arguments of the argumentation framework Γ to labels. The label represents an unmarked argument. The specific transition rules are shown in Algorithm 3.
Definition 18.
(--): Given an argumentation framework and arguments , let represent a mapping from arguments of the argumentation framework Γ to labels. The label represents an unlabeled argument. The specific propagation rules are shown in Algorithm 4.
| Algorithm 3: 4lab-in-transitions |
 |
| Algorithm 4: 4lab-must_out-transitions |
 |
In the evaluation of the result, first, it is checked whether all arguments have been labeled, and then it is checked whether any contradictory arguments exist. If neither condition is present, then the set of arguments labeled as forms a stable extension. The final stable extension set E may be empty, may contain a single subset, or may contain multiple subsets.
In summary, the algorithm introduces the label, providing more variety in argument labeling. This increases the length of the labeling propagation chain and reduces the search space. Therefore, the four-label algorithm proposed in this paper is more suitable for solving the stable extension problem compared to the two-label and three-label algorithms.
6. Experiment Analysis
6.1. Experiment Setup
To accurately evaluate the performance of the proposed method, both the four-label method that we propose in this paper and the two-label method used for comparison were implemented on the ArgTools solver (which uses the three-label method). All experiments run on Ubuntu 22.04 LTS (64 bit) with Intel Core i7-11700 @ 2.50 GHz CPU and 32 GB of RAM. The three methods above were tested on the ICCMA 2019, ICCMA 2021, and ICCMA 2023 datasets from the International Competition on Computational Models of Argument (ICCMA) (https://argumentationcompetition.org/2023/tracks.html, accessed on 3 August 2024). To be consistent with the testing standards of ICCMA 2023, we set the time limit as 1200 s for stable extensions of every AF instance. The result of each instance was presented as success (if the problem was solved) or failure (including crashes or timeouts). The source code has been made available (https://github.com/bear-eng/label-algorithm.git, accessed on 3 August 2024).
In the analysis of the experiment results, this paper primarily considers two metrics: the number of solved instances and PAR-2. PAR-2 represents an absolute performance measure, where the run time for problems that could not be solved within the allotted time is set to twice the cutoff time, while the run time for other instances is the actual run time.
6.2. Experiment Results and Analysis
Table 1 presents a comparative analysis of the performance of the two-label algorithm (ArgTools_2lab), the three-label algorithm (ArgTools_3lab), and the four-label algorithm (ArgTools_4lab) on the benchmarks of the main track of ICCMA 2019, ICCMA 2021, and ICCMA 2023. From Table 1, it can be concluded that the four-label algorithm outperforms the other two algorithms across all three benchmarks. In other words, this method improves algorithm efficiency by introducing new labels to differentiate between the types of arguments and by refining the labeling rules based on the relationships among arguments. Next, we conducts three sets of ablation experiments to analyze the reasons for the efficiency improvements and demonstrates that the method is also effective in other solvers. Overall, the four-label algorithm has improved efficiency by 17.4% compared to the two-label algorithm and by 13.5% compared to the three-label algorithm.

Table 1.
Experiment results on instances of the main track of ICCMA 2023 and ICCMA 2019.
In the ablation experiments of the preprocessing strategy and the four-label transition strategy, we configured these two strategies separately in the ArgTools solver and then ran the configured solvers on the main track of the ICCMA 2023 benchmark. Additionally, to better illustrate the algorithm’s performance on each instance and on each instance family, we have created cactus plots for individual instances and scatter plots for instance families. Note that instance family refers to a set of instances with similar names. Based on the solution results in Table 2, there are three main families with difficult-to-solve problems: SccGenerator (25) (https://argumentationcompetition.org/2017/benchmark_selection_iccma2017.pdf, accessed on 3 August 2024), StableGenerator (25) (https://argumentationcompetition.org/2017/benchmark_selection_iccma2017.pdf, accessed on 3 August 2024), and Crusti_g2io (32) (https://helda.helsinki.fi/items/7c4a0bad-0604-44c5-b5cb-1a6a487fa8af, accessed on 3 August 2024). These three types of instances share two common characteristics that may have led to suboptimal solving performance, namely, the issues of randomness and community structure. Our algorithm leverages label characteristics to directly perform tree search on the problem, while SAT-based reduction methods encode the original problem into a SAT problem and then call a SAT solver. SAT-based methods may obscure some of the original problem’s information, so directly incorporating SAT techniques into the tree search for the original problem could be a key direction for future improvements.
Table 2.
Experiment results on the ICCMA 2023 benchmark of different instance families.
- ArgTools_3lab: The basic Argtools solver which uses three labels.
- ArgTools_3lab+: Argtools solver with the preprocessing strategy applied.
- ArgTools_3lab++(ArgTools_4lab): Argtools solver with the proposed four-label method applied.
- ArgSemSAT: Stable extension solving algorithm based on the reduction model.
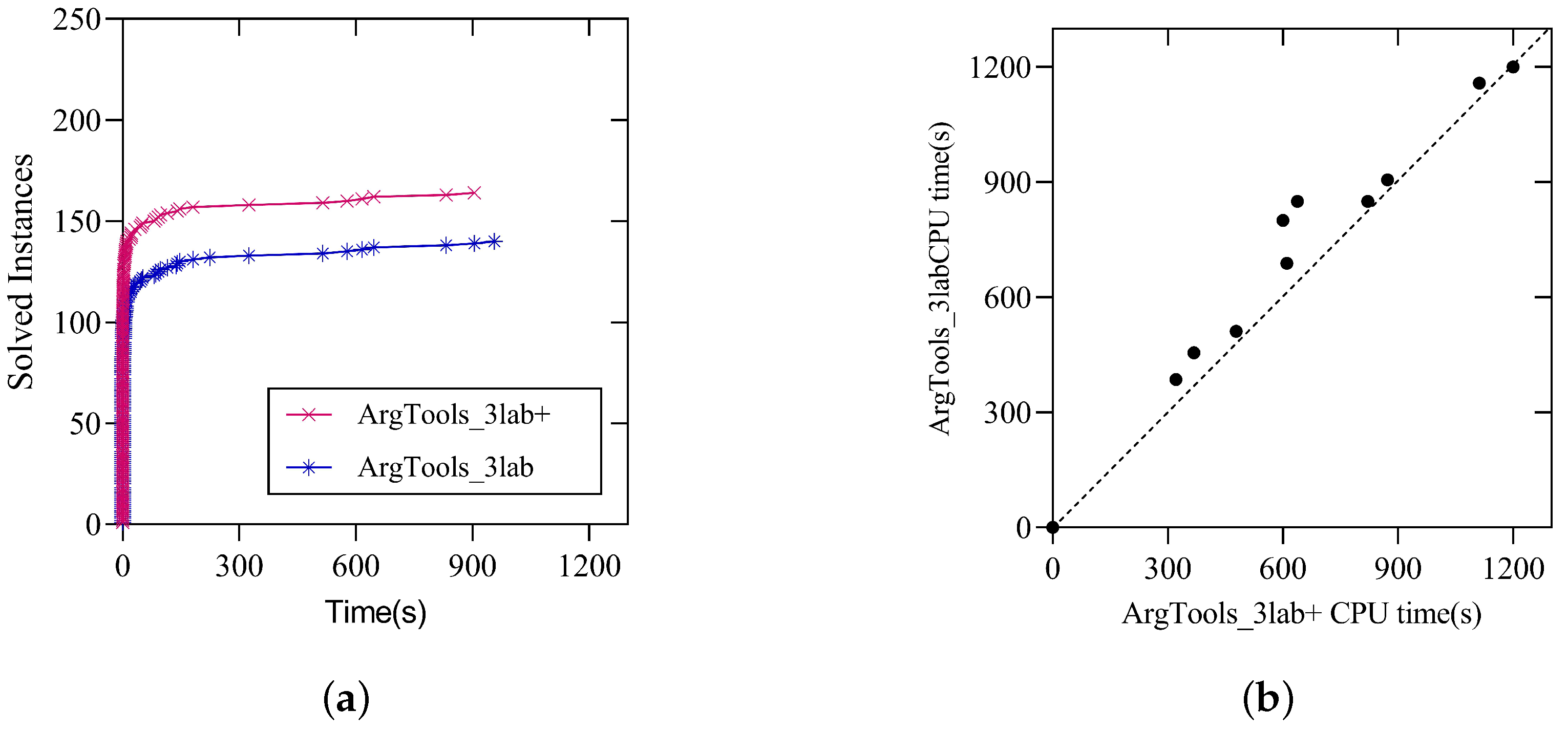
Figure 3 shows the results of the ArgTools_3lab+ and ArgTools_3lab solvers on the instances of the main track of ICCMA 2023, which include a total of 330 instances. Figure 3a displays the cactus plot for these two solvers on the above instances. Each point in the figure corresponds to the solving time for a specific instance, where the x-axis represents the runtime, and the y-axis represents the number of instances solved. From this, it can be concluded that preprocessing operations for solving instances, such as prioritizing initial and self-attacking arguments, can speed up labeling propagation efficiency.
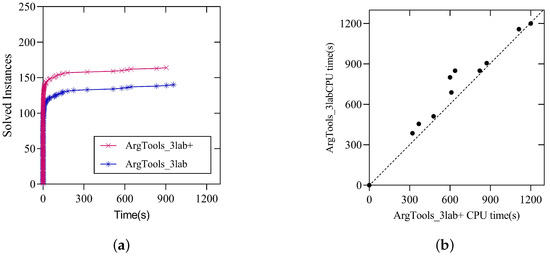
Figure 3.
(a) Cactus plots comparing the number of solved instances by ArgTools_3lab+ and ArgTools_3lab on the benchmark of the main track of ICCMA 2023. (b) Scatter plots comparing the runtime of ArgTools_3lab+ (x-axis) and ArgTools_3lab (y-axis) on 17 benchmark families of the main track of ICCMA 2023. If the point is on the dashed line, then the solving effects of both solvers are the same; If the point is above the dashed line, then the solver ArgTools_3lab+ performs better; conversely, if it is below the line, the performance is the opposite.
Figure 3b shows the scatter plot for the instance families in the main track of ICCMA 2023. These instances are grouped into 17 families, with each family consisting of instances with similar names. A point in the figure represents an instance family, where x (y) denotes the average solving time of ArgTools_3lab+ (ArgTools_3lab) for each instance in the respective family. From Figure 3b, we can see that the preprocessing strategy of the four-label algorithm is effective across all instance families.
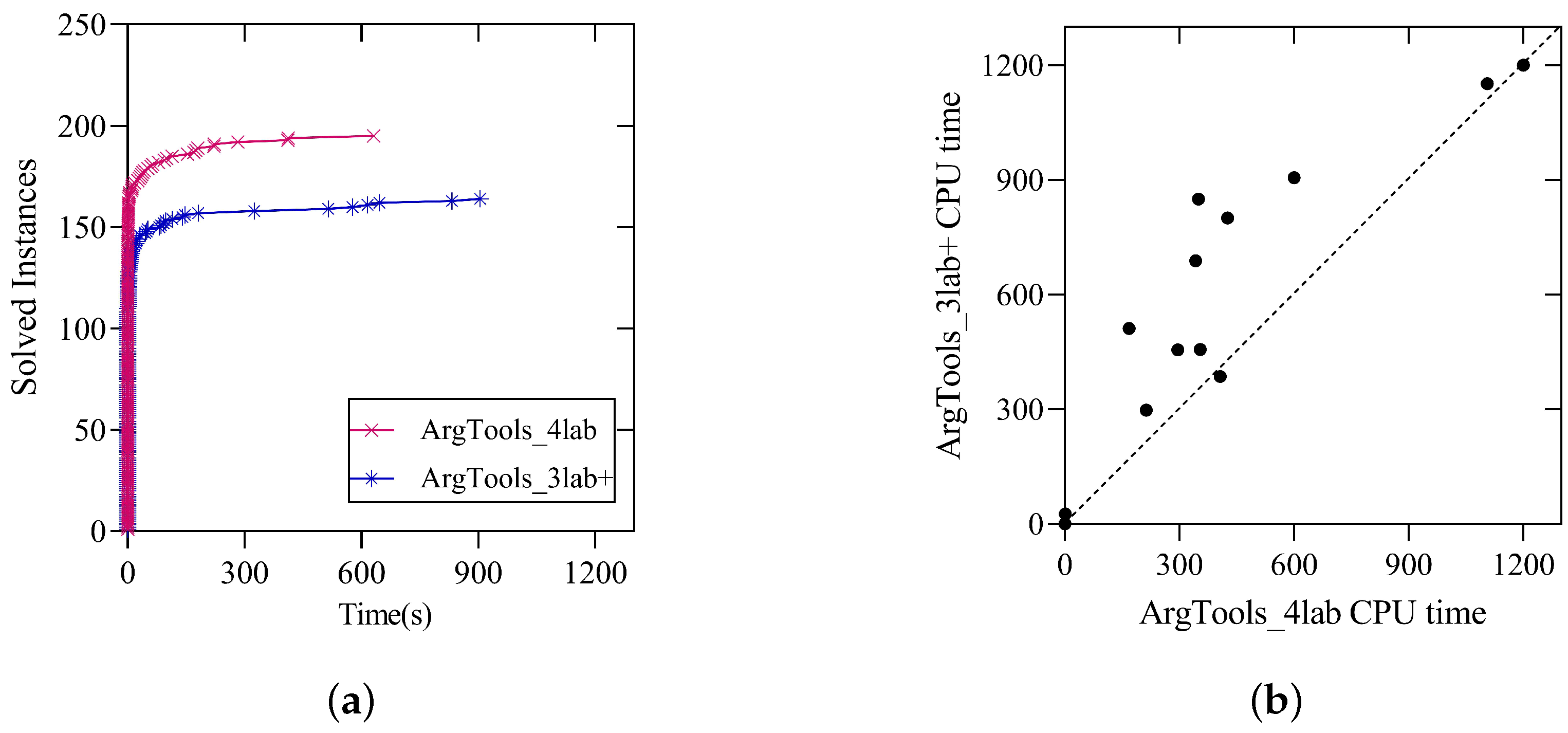
Similar to Figure 3, Figure 4 presents a comparison of the solving performance between the ArgTools_4lab and ArgTools_3lab+ solvers on the instances of the main track of ICCMA 2023. From the figure, it is evident that the four-label method is more effective in propagating argument labelings compared to the two-label and three-label methods. Additionally, the four-label labeling rules are generally effective across all instance families.
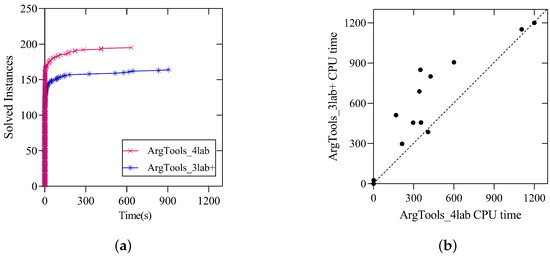
Figure 4.
(a) Cactus plots comparing the number of solved instances by ArgTools_4lab and ArgTools_3lab+ on the benchmark of the main track of ICCMA 2023. (b) Scatter plots comparing the runtime of ArgTools_4lab (x-axis) and ArgTools_3lab+ (y-axis) on 17 benchmark families of the main track of ICCMA 2023. If the point is on the dashed line, then the solving effects of both solvers are the same; If the point is above the dashed line, then the solver ArgTools_4lab performs better; conversely, if it is below the line, the performance is the opposite.
To further demonstrate that the four-label method proposed in this paper is not only applicable to the ArgTools solver mentioned in the article but also performs well in other labeling algorithms, we selected the DREDD solver by Matthias Thimm et al. (http://taas.tweetyproject.org, accessed on 3 August 2024), which participated in ICCMA 2019 and is also based on depth-first search for stable extensions. We then integrated the four-label method into the DREDD solver and tested the configured algorithm (DREDD_4lab) and the original DREDD algorithm on instances of the main track of ICCMA 2019 and ICCMA 2023. The comparison results are shown in Table 3.
Table 3.
Experiment results on the instances of the main track of ICCMA 2023 and the instances of ICCMA 2019.
- DREDD: The basic DREDD solver using three labels.
- DREDD_4lab: DREDD solver with the proposed four-label method applied.
In Table 3, we observe that DREDD_4lab shows a significant improvement in efficiency compared to the original DREDD algorithm. This indicates that, by introducing labels to differentiate between the nature of arguments in the DREDD_4lab algorithm, the cooperation among labels is enhanced, leading to faster labeling propagation and reduced search space. Therefore, we can conclude that the proposed four-label method is also applicable in other labeling-based solvers.
7. Conclusions and Future Work
This paper compares and analyzes two-label and three-label algorithms for solving stable extensions and proposes a four-label algorithm to address their limitations, aiming to enumerate all stable extensions of a given abstract argumentation framework more quickly. Meanwhile, the four-label algorithm has been experimentally validated and analyzed using benchmarks from ICCMA 2019, ICCMA 2021, and ICCMA 2023. The results demonstrate that this additional labeling approach significantly improves algorithm efficiency. Additionally, the four-label method was configured in some state-of-the-art solvers, proving its effectiveness in those contexts as well.
In future work, the new labeling strategy and preprocessing strategy proposed in this algorithm could still be applied to solving other semantic extension problems. Although the four-label algorithm significantly outperforms the previous two-label and three-label algorithms, there is still a gap compared to popular reduction-based methods. Therefore, in future work, these strategies can be encoded as SAT problems and combined with popular solvers to solve semantic extension problems more quickly. Additionally, when solving extensions, we can consider integrating conflict-driven clause learning mechanisms directly into the tree search framework, thereby designing a new solver specifically for abstract argumentation framework problems.
Author Contributions
Conceptualization, M.L.; Investigation, N.H.; Methodology, X.W.; Project administration, C.X.; Software, N.H. and W.X.; Writing—original draft, N.H.; Writing—review and editing, N.H. and M.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (grant No. 62402164) and the Doctoral Research Launch Fund Project of Hubei University of Technology (2022-4301/00655).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The code used in this paper can be found at (https://github.com/bear-eng/label-algorithm.git, accessed on 3 August 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bench-Capon, T.J.; Dunne, P.E. Argumentation in artificial intelligence. Artif. Intell. 2007, 171, 619–641. [Google Scholar] [CrossRef]
- Rahwan, I.; Simari, G.R. Argumentation in Artificial Intelligence; Springer: Cham, Switzerland, 2009; Volume 47. [Google Scholar]
- Atkinson, K.; Baroni, P.; Giacomin, M.; Hunter, A.; Prakken, H.; Reed, C.; Simari, G.; Thimm, M.; Villata, S. Towards artificial argumentation. AI Mag. 2017, 38, 25–36. [Google Scholar] [CrossRef]
- Dung, P.M. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games. Artif. Intell. 1995, 77, 321–357. [Google Scholar] [CrossRef]
- Amgoud, L.; Prade, H. Using arguments for making and explaining decisions. Artif. Intell. 2009, 173, 413–436. [Google Scholar] [CrossRef]
- Caminada, M. Rationality postulates: Applying argumentation theory for non-monotonic reasoning. J. Appl. Logics 2017, 4, 2707–2734. [Google Scholar]
- Možina, M.; Žabkar, J.; Bratko, I. Argument based machine learning. Artif. Intell. 2007, 171, 922–937. [Google Scholar] [CrossRef]
- Kökciyan, N.; Sassoon, I.; Sklar, E.; Modgil, S.; Parsons, S. Applying metalevel argumentation frameworks to support medical decision making. IEEE Intell. Syst. 2021, 36, 64–71. [Google Scholar] [CrossRef]
- Walton, D.; Oliveira, T.; Satoh, K.; Mebane, W. Argumentation analytics for treatment deliberations in multimorbidity cases: An introduction to two artificial intelligence approaches. Topoi 2021, 40, 373–386. [Google Scholar] [CrossRef]
- Caminada, M.W.; Gabbay, D.M. A logical account of formal argumentation. Stud. Log. 2009, 93, 109–145. [Google Scholar] [CrossRef]
- Dvořák, W.; Morak, M.; Nopp, C.; Woltran, S. dynPARTIX-A dynamic programming reasoner for abstract argumentation. In Proceedings of the International Conference on Applications of Declarative Programming and Knowledge Management, Vienna, Austria, 28–30 September 2011; pp. 259–268. [Google Scholar]
- Charwat, G.; Dvořák, W.; Gaggl, S.A.; Wallner, J.P.; Woltran, S. Methods for solving reasoning problems in abstract argumentation—A survey. Artif. Intell. 2015, 220, 28–63. [Google Scholar] [CrossRef] [PubMed]
- Cerutti, F.; Gaggl, S.A.; Thimm, M.; Wallner, J. Foundations of implementations for formal argumentation. IfCoLog J. Logics Their Appl. 2017, 4, 2623–2705. [Google Scholar]
- Nofal, S.; Atkinson, K.; Dunne, P.E. Algorithms for decision problems in argument systems under preferred semantics. Artif. Intell. 2014, 207, 23–51. [Google Scholar] [CrossRef]
- Baroni, P.; Caminada, M.; Giacomin, M. An introduction to argumentation semantics. Knowl. Eng. Rev. 2011, 26, 365–410. [Google Scholar] [CrossRef]
- Caminada, M. An algorithm for computing semi-stable semantics. In Proceedings of the European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty, Hammamet, Tunisia, 31 October–2 November 2007; pp. 222–234. [Google Scholar]
- Prakken, H.; Vreeswijk, G. Logics for defeasible argumentation. In Handbook of Philosophical Logic; Springer: Cham, Switzerland, 2002; pp. 219–318. [Google Scholar]
- Dvořák, W.; König, M.; Rapberger, A.; Wallner, J.P.; Woltran, S. ASPARTIX-V-A Solver for Argumentation Tasks Using ASP. In Proceedings of the 14th Workshop on Answer Set Programming and Other Computing Paradigms, Virtual, 20–27 September 2021; pp. 1–12. [Google Scholar]
- Dvorák, W.; König, M.; Wallner, J.P.; Woltran, S. ASPARTIX-v21. arXiv 2021, arXiv:2109.03166. [Google Scholar]
- Niskanen, A.; Järvisalo, M. μ-TOKSIA in ICCMA 2023. In Proceedings of the ICCMA 2023, Helsinki, Finland, 1–3 November 2023; p. 31. [Google Scholar]
- Kamal, A.A.; Youssef, A.M. Applications of SAT solvers to AES key recovery from decayed key schedule images. In Proceedings of the 2010 Fourth International Conference on Emerging Security Information, Systems and Technologies, Venice, Italy, 18–25 July 2010; pp. 216–220. [Google Scholar]
- Audemard, G.; Simon, L. Predicting learnt clauses quality in modern SAT solvers. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009. [Google Scholar]
- Fleury, A.; Heisinger, M. Cadical, kissat, paracooba, plingeling and treengeling entering the sat competition 2020. SAT Compet. 2020, 2020, 50. [Google Scholar]
- Queue, S.D. CaDiCaL at the SAT Race 2019. SAT Race 2019, 2019, 8. [Google Scholar]
- Gebser, M.; Kaminski, R.; Kaufmann, B.; Schaub, T. Answer Set Solving in Practice; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Biere, A.; Heule, M.; van Maaren, H. Handbook of Satisfiability; IOS Press: Amsterdam, The Netherlands, 2009; Volume 185. [Google Scholar]
- Niu, D.; Liu, L.; Lü, S. New stochastic local search approaches for computing preferred extensions of abstract argumentation. AI Commun. 2018, 31, 369–382. [Google Scholar] [CrossRef]
- Thimm, M. Stochastic Local Search Algorithms for Abstract Argumentation Under Stable Semantics. In Proceedings of the COMMA, Warsaw, Poland, 12–14 September 2018; pp. 169–180. [Google Scholar]
- Nofal, S.; Atkinson, K.; Dunne, P.E. Looking-ahead in backtracking algorithms for abstract argumentation. Int. J. Approx. Reason. 2016, 78, 265–282. [Google Scholar] [CrossRef]
- Geilen, N.; Thimm, M. Heureka: A General Heuristic Backtracking Solver for Abstract Argumentation. In Proceedings of the Theory and Applications of Formal Argumentation, Melbourne, VIC, Australia, 19–20 August 2018; pp. 143–149. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).