
Prediction of Total Soluble Solids Content Using Tomato Characteristics: Comparison Artificial Neural Network vs. Multiple Linear Regression




Abstract
1. Introduction
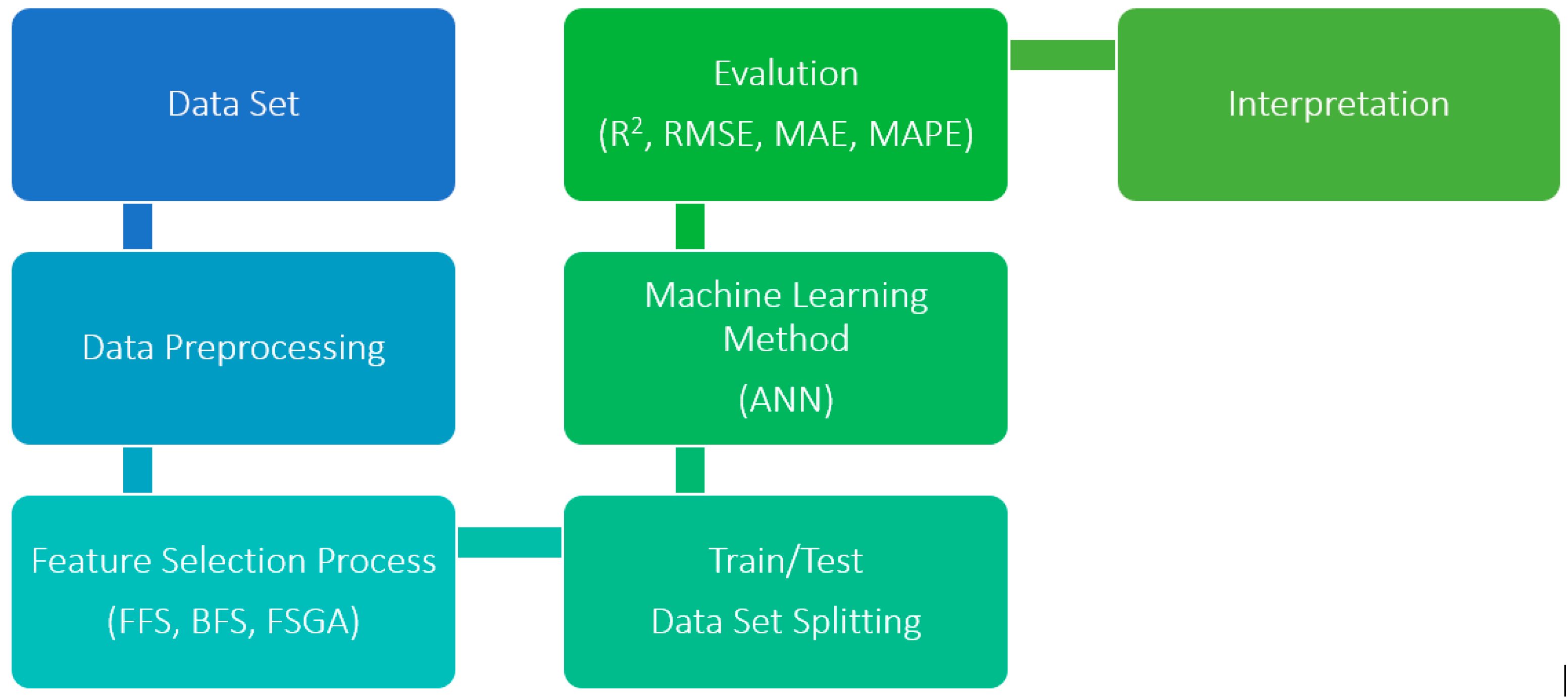
2. Materials and Methods
2.1. Tomato Characteristics Testing
2.2. Linear Regression
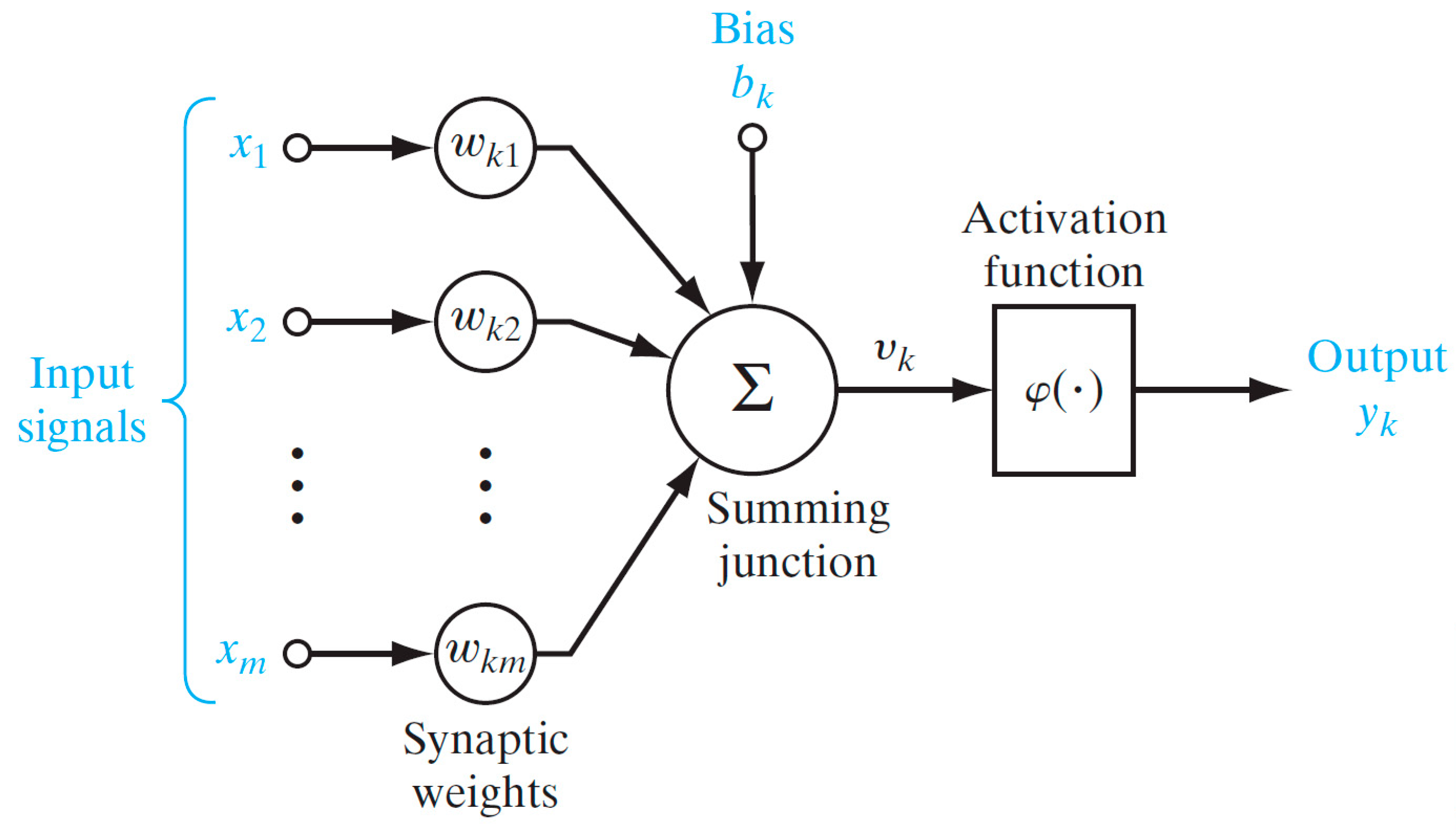
2.3. Artificial Neural Networks
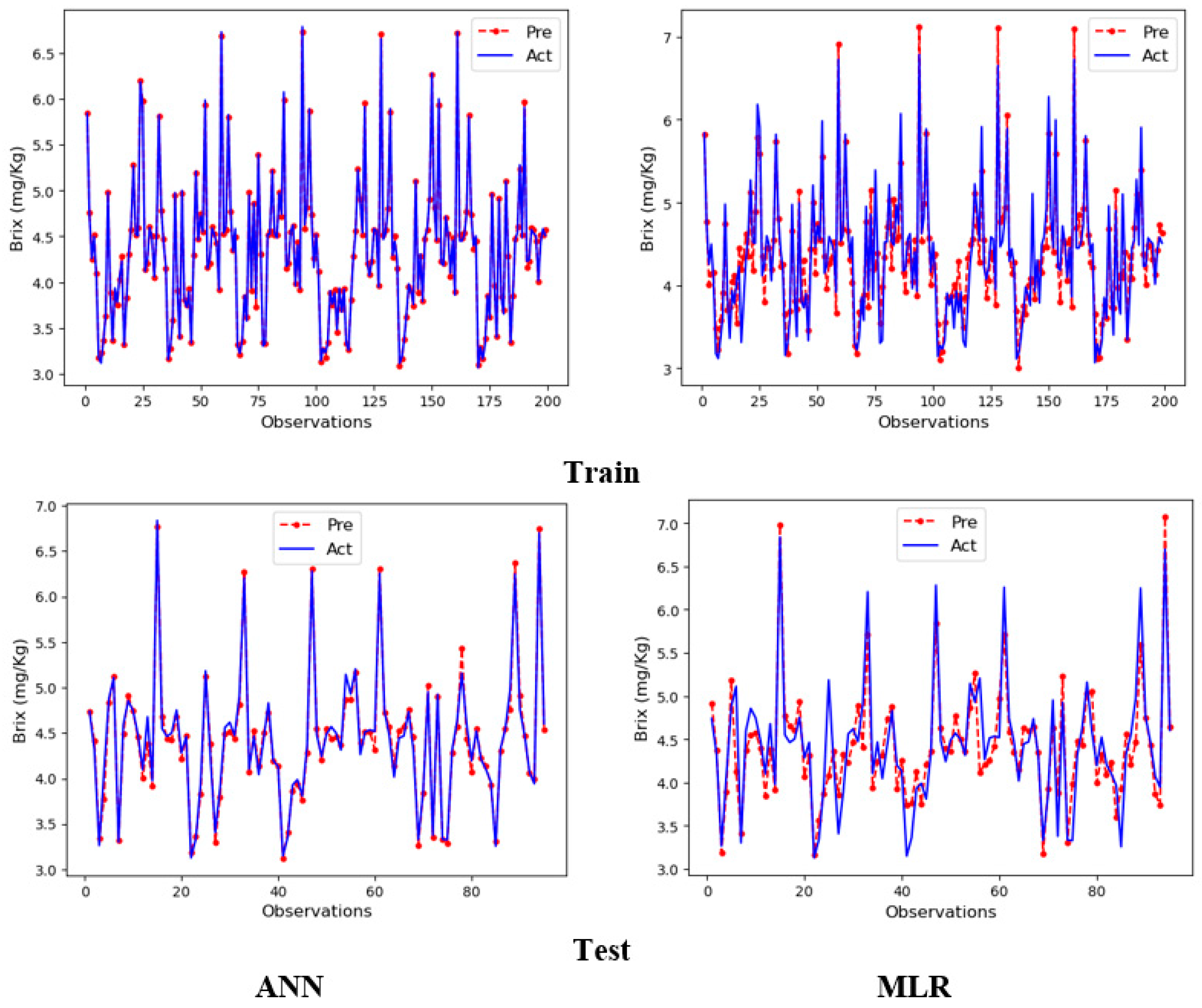
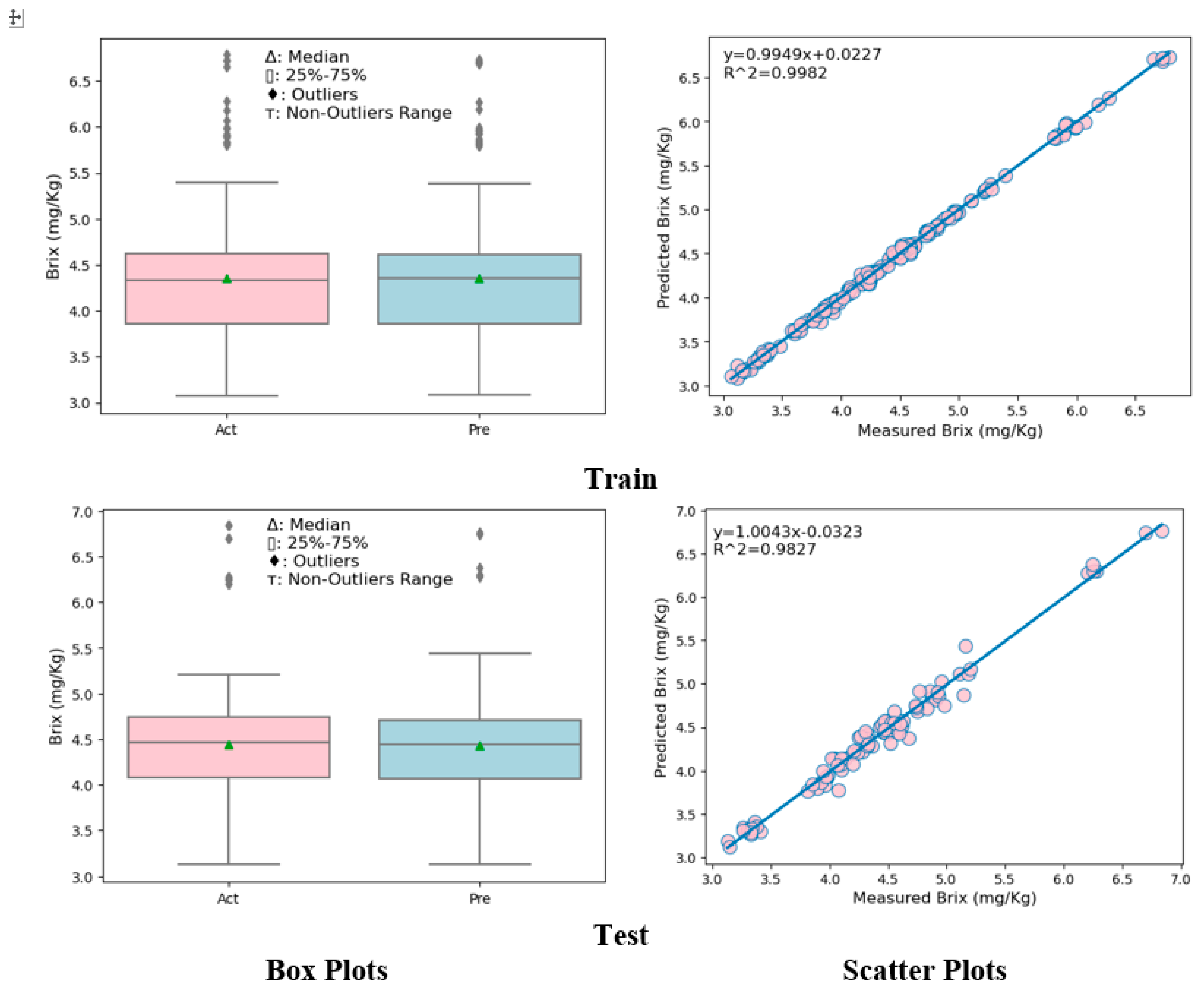
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- FAO FAOSTAT. Available online: https://www.fao.org/faostat/en/#data/QCL (accessed on 28 January 2024).
- Abdel-Sattar, M.; Al-Saif, A.M.; Aboukarima, A.M.; Eshra, D.H.; Sas-Paszt, L. Quality Attributes Prediction of Flame Seedless Grape Clusters Based on Nutritional Status Employing Multiple Linear Regression Technique. Agriculture 2022, 12, 1303. [Google Scholar] [CrossRef]
- Olaniyi, J.O.; Akanbi, W.B.; Adejumo, T.A.; Akande, O.G. Growth, Fruit Yield and Nutritional Quality of Tomato Varieties. African J. Food Sci. 2010, 4, 398–402. [Google Scholar]
- Quinet, M.; Angosto, T.; Yuste-Lisbona, F.J.; Blanchard-Gros, R.; Bigot, S.; Martinez, J.P.; Lutts, S. Tomato Fruit Development and Metabolism. Front. Plant Sci. 2019, 10, 475784. [Google Scholar] [CrossRef]
- Tieman, D.M.; Zeigler, M.; Schmelz, E.A.; Taylor, M.G.; Bliss, P.; Kirst, M.; Klee, H.J. Identification of Loci Affecting Flavour Volatile Emissions in Tomato Fruits. J. Exp. Bot. 2006, 57, 887–896. [Google Scholar] [CrossRef] [PubMed]
- Beckles, D.M.; Hong, N.; Stamova, L.; Luengwilai, K. Biochemical Factors Contributing to Tomato Fruit Sugar Content: A Review. Fruits 2012, 67, 49–64. [Google Scholar] [CrossRef]
- Li, N.; Wang, J.; Wang, B.; Huang, S.; Hu, J.; Yang, T.; Asmutola, P.; Lan, H.; Qinghui, Y. Identification of the Carbohydrate and Organic Acid Metabolism Genes Responsible for Brix in Tomato Fruit by Transcriptome and Metabolome Analysis. Front. Genet. 2021, 12, 714942. [Google Scholar] [CrossRef] [PubMed]
- Bergougnoux, V. The History of Tomato: From Domestication to Biopharming. Biotechnol. Adv. 2014, 32, 170–189. [Google Scholar] [CrossRef]
- Georgelis, N. High Fruit Sugar Characterization, Inheritance and Linkage of Molecular Markers in Tomato; University of Florida: Gainesville, FL, USA, 2002. [Google Scholar]
- Tieman, D.; Zhu, G.; Resende, M.F.R.; Lin, T.; Nguyen, C.; Bies, D.; Rambla, J.L.; Beltran, K.S.O.; Taylor, M.; Zhang, B.; et al. A Chemical Genetic Roadmap to Improved Tomato Flavor. Science 2017, 355, 391–394. [Google Scholar] [CrossRef]
- Ikeda, H.; Hiraga, M.; Shirasawa, K.; Nishiyama, M.; Kanahama, K.; Kanayama, Y. Analysis of a Tomato Introgression Line, IL8-3, with Increased Brix Content. Sci. Hortic. 2013, 153, 103–108. [Google Scholar] [CrossRef]
- Amr, A.; Raie, W.Y. Tomato Components and Quality Parameters. A Review. Jordan J. Agric. Sci. 2022, 18, 199–220. [Google Scholar] [CrossRef]
- de Brito, A.A.; Campos, F.; dos Nascimento, A.R.; de Carvalho Corrêa, G.; de Silva, F.A.; de Almeida Teixeira, G.; Júnior, L.C.C. Determination of Soluble Solid Content in Market Tomatoes Using Near-Infrared Spectroscopy. Food Control 2021, 126, 108068. [Google Scholar] [CrossRef]
- Kabas, O.; Kayakus, M.; Ünal, İ.; Moiceanu, G. Deformation Energy Estimation of Cherry Tomato Based on Some Engineering Parameters Using Machine-Learning Algorithms. Appl. Sci. 2023, 13, 8906. [Google Scholar] [CrossRef]
- Maulud, D.H.; Mohsin Abdulazeez, A. A Review on Linear Regression Comprehensive in Machine Learning. J. Appl. Sci. Technol. Trends 2020, 1, 140–147. [Google Scholar] [CrossRef]
- Belouz, K.; Nourani, A.; Zereg, S.; Bencheikh, A. Prediction of Greenhouse Tomato Yield Using Artificial Neural Networks Combined with Sensitivity Analysis. Sci. Hortic. 2022, 293, 110666. [Google Scholar] [CrossRef]
- Tripathi, P.; Kumar, N.; Rai, M.; Shukla, P.K.; Verma, K.N. Applications of Machine Learning in Agriculture. In Smart Village Infrastructure and Sustainable Rural Communities; Khan, M., Gupta, B., Verma, A., Praveen, P., Peoples, C., Eds.; IGI Global: Hershey, PA, USA, 2023; pp. 99–118. [Google Scholar]
- Attri, I.; Awasthi, L.K.; Sharma, T.P. Machine Learning in Agriculture: A Review of Crop Management Applications. Multimed. Tools Appl. 2024, 83, 12875–12915. [Google Scholar] [CrossRef]
- Araújo, S.O.; Peres, R.S.; Ramalho, J.C.; Lidon, F.; Barata, J. Machine Learning Applications in Agriculture: Current Trends, Challenges, and Future Perspectives. Agronomy 2023, 13, 2976. [Google Scholar] [CrossRef]
- Yang, B.; Gao, Y.; Yan, Q.; Qi, L.; Zhu, Y.; Wang, B. Estimation Method of Soluble Solid Content in Peach Based on Deep Features of Hyperspectral Imagery. Sensors 2020, 20, 5021. [Google Scholar] [CrossRef]
- Akbarzadeh, S.; Paap, A.; Ahderom, S.; Apopei, B.; Alameh, K. Plant Discrimination by Support Vector Machine Classifier Based on Spectral Reflectance. Comput. Electron. Agric. 2018, 148, 250–258. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Guo, H.Y.; Cheng, Y.S.; Chen, S.L.; Lin, H.S.; Chen, S.H. Machine Learning Approaches for Rice Crop Yield Predictions Using Time-Series Satellite Data in Taiwan. Int. J. Remote Sens. 2020, 41, 7868–7888. [Google Scholar] [CrossRef]
- Shah, S.S.A.; Zeb, A.; Qureshi, W.S.; Malik, A.U.; Tiwana, M.; Walsh, K.; Amin, M.; Alasmary, W.; Alanazi, E. Mango Maturity Classification Instead of Maturity Index Estimation: A New Approach towards Handheld NIR Spectroscopy. Infrared Phys. Technol. 2021, 115, 103639. [Google Scholar] [CrossRef]
- Zhao, C.; Lee, W.S.; He, D. Immature Green Citrus Detection Based on Colour Feature and Sum of Absolute Transformed Difference (SATD) Using Colour Images in the Citrus Grove. Comput. Electron. Agric. 2016, 124, 243–253. [Google Scholar] [CrossRef]
- Ozaktan, H.; Çetin, N.; Uzun, S.; Uzun, O.; Ciftci, C.Y. Prediction of Mass and Discrimination of Common Bean by Machine Learning Approaches. Environ. Dev. Sustain. 2024, 26, 18139–18160. [Google Scholar] [CrossRef]
- Kour, V.P.; Arora, S. Fruit Disease Detection Using Rule-Based Classification. Adv. Intell. Syst. Comput. 2019, 851, 295–312. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Y.; He, D.J.; Li, Y. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2017, 10, 11. [Google Scholar] [CrossRef]
- Castro, W.; Oblitas, J.; De-La-Torre, M.; Cotrina, C.; Bazan, K.; Avila-George, H. Classification of Cape Gooseberry Fruit According to Its Level of Ripeness Using Machine Learning Techniques and Different Color Spaces. IEEE Access 2019, 7, 27389–27400. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Parsaeian, M.; Baradaran, M. Seed Yield Prediction of Sesame Using Artificial Neural Network. Eur. J. Agron. 2015, 68, 89–96. [Google Scholar] [CrossRef]
- Tang, C.; He, H.; Li, E.; Li, H. Multispectral Imaging for Predicting Sugar Content of ‘Fuji’ Apples. Opt. Laser Technol. 2018, 106, 280–285. [Google Scholar] [CrossRef]
- Huang, X.; Wang, H.; Luo, W.; Xue, S.; Hayat, F.; Gao, Z. Prediction of Loquat Soluble Solids and Titratable Acid Content Using Fruit Mineral Elements by Artificial Neural Network and Multiple Linear Regression. Sci. Hortic. 2021, 278, 109873. [Google Scholar] [CrossRef]
- Özreçberoğlu, N.; Kahramanoğlu, İ. Mathematical Models for the Estimation of Leaf Chlorophyll Content Based on RGB Colours of Contact Imaging with Smartphones: A Pomegranate Example. Folia Hortic. 2020, 32, 57–67. [Google Scholar] [CrossRef]
- Abdipour, M.; Ramazani, S.H.R.; Younessi-Hmazekhanlu, M.; Niazian, M. Modeling Oil Content of Sesame (Sesamum Indicum L.) Using Artificial Neural Network and Multiple Linear Regression Approaches. J. Am. Oil Chem. Soc. 2018, 95, 283–297. [Google Scholar] [CrossRef]
- Torkashvand, A.M.; Ahmadi, A.; Nikravesh, N.L. Prediction of Kiwifruit Firmness Using Fruit Mineral Nutrient Concentration by Artificial Neural Network (ANN) and Multiple Linear Regressions (MLR). J. Integr. Agric. 2017, 16, 1634–1644. [Google Scholar] [CrossRef]
- Pflanz, M.; Zude, M. Spectrophotometric Analyses of Chlorophyll and Single Carotenoids during Fruit Development of Tomato (Solanum Lycopersicum L.) by Means of Iterative Multiple Linear Regression Analysis. Appl. Opt. 2008, 47, 5961–5970. [Google Scholar] [CrossRef] [PubMed]
- Vursavuş, K.; Kesilmiş, Z.; Benal, Y.; Ondokuz, Y.; Üniversitesi, M.; Vursavus, K.K.; Kesilmis, Z.; Oztekin, Y.B. Nondestructive Dropped Fruit Impact Test for Assessing Tomato Firmness. Chem. Eng. Trans. 2017, 58, 1–6. [Google Scholar] [CrossRef]
- Takahashi, N.; Yokoyama, N.; Takayama, K.; Nishina, H. Estimation of Tomato Fruit Lycopene Content after Storage at Different Storage Temperatures and Durations. Environ. Control Biol. 2018, 56, 157–160. [Google Scholar] [CrossRef]
- Garcia, M.B.; Ambat, S.; Adao, R.T. Tomayto, Tomahto: A Machine Learning Approach for Tomato Ripening Stage Identification Using Pixel-Based Color Image Classification. In Proceedings of the 2019 IEEE 1th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management, HNICEM, Laoang, Philippines, 29 November–1 December 2019. [Google Scholar] [CrossRef]
- Berrueta, C.; Heuvelink, E.; Giménez, G.; Dogliotti, S. Estimation of Tomato Yield Gaps for Greenhouse in Uruguay. Sci. Hortic. 2020, 265, 109250. [Google Scholar] [CrossRef]
- Nyalala, I.; Okinda, C.; Chao, Q.; Mecha, P.; Korohou, T.; Yi, Z.; Nyalala, S.; Jiayu, Z.; Chao, L.; Kunjie, C. Weight and Volume Estimation of Single and Occluded Tomatoes Using Machine Vision. Int. J. Food Prop. 2021, 24, 818–832. [Google Scholar] [CrossRef]
- Pathare, P.B.; Al-Dairi, M. Bruise Damage and Quality Changes in Impact-Bruised, Stored Tomatoes. Horticulturae 2021, 7, 113. [Google Scholar] [CrossRef]
- Égei, M.; Takács, S.; Palotás, G.; Palotás, G.; Szuvandzsiev, P.; Daood, H.G.; Helyes, L.; Pék, Z. Prediction of Soluble Solids and Lycopene Content of Processing Tomato Cultivars by Vis-NIR Spectroscopy. Front. Nutr. 2022, 9, 845317. [Google Scholar] [CrossRef]
- Dhakshina Kumar, S.; Esakkirajan, S.; Vimalraj, C.; Keerthi Veena, B. Design of Disease Prediction Method Based on Whale Optimization Employed Artificial Neural Network in Tomato Fruits. Mater. Today Proc. 2020, 33, 4907–4918. [Google Scholar] [CrossRef]
- USDA. U.S. Standards for Grades of Fresh Tomatoes; USDA: Washington, DC, USA, 1991.
- Javanmardi, J.; Kubota, C. Variation of Lycopene, Antioxidant Activity, Total Soluble Solids and Weight Loss of Tomato during Postharvest Storage. Postharvest Biol. Technol. 2006, 41, 151–155. [Google Scholar] [CrossRef]
- Cemeroğlu, B. Meyve ve Sebze İşleme Endüstrisinde Temel Analiz Metotları; Biltav Yayınları: Ankara, Turkey, 1992. [Google Scholar]
- Gıda İşleri Genel Müdürlüğü. Gıda Maddeleri Muayene ve Analiz Yöntemleri; T.C. Tarım Orman ve Köy İşleri Bakanlığı Gıda İşleri Genel Müdürlüğü: Ankara, Turkey, 1983.
- Uluisik, S.; Oney-Birol, S. Uncovering Candidate Genes Involved in Postharvest Ripening of Tomato Using the Solanum Pennellii Introgression Line Population by Integrating Phenotypic Data, RNA-Seq, and SNP Analyses. Sci. Hortic. 2021, 288, 110321. [Google Scholar] [CrossRef]
- Topuz, A. Determination of Some Physical, Chemical Properties of Loquat Cultivars (Eriobotrya Japonica L.) and Possibilities of Their Being Processed into Marmalade, Nectar and Canned Fruit. Master’s Thesis, Akdeniz University, Antalya, Turkey, 1998. [Google Scholar]
- Fish, W.W.; Perkins-Veazie, P.; Collins, J.K. A Quantitative Assay for Lycopene That Utilizes Reduced Volumes of Organic Solvents. J. Food Compos. Anal. 2002, 15, 309–317. [Google Scholar] [CrossRef]
- Karhan, M.; Aksu, M.; Tetik, N.; Turhan, I. Kinetic Modeling of Anaerobic Thermal Degradation of Ascorbic Acid In Rose Hip (Rosa Canina L.) Pulp. J. Food Qual. 2004, 27, 311–319. [Google Scholar] [CrossRef]
- Kacar, B.; İnal, A. Bitki Analizleri; Nobel Yayın: Ankara, Turkey, 2010; ISBN 978-605-395-036-3. [Google Scholar]
- Kaymak, H.Ç.; Rastilantie, M.; Caglar Kaymak, H.; Ozturk, I.; Kalkan, F.; Kara, M.; Ercisli, S. Color and Physical Properties of Two Common Tomato (Lycopersicon Esculentum Mill.) Cultivars. Agric. Environ. 2010, 8, 44–46. [Google Scholar]
- Mert, M. SPSS/STATA Yatay Kesit Veri Analizi Bilgisayar Uygulamaları; Detay Yayıncılık: Ankara, Turkey, 2016. [Google Scholar]
- Su, X.; Yan, X.; Tsai, C.L. Linear Regression. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 275–294. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Larose, D.T. Discovering Knowledge in Data: An Introduction to Data Mining; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Kantardzic, M. Data Mining: Concepts, Models, Methods, and Algorithms, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019. [Google Scholar]
- Skias, S.T. Background of the Verification and Validation of Neural Networks. In Methods and Procedures for the Verification and Validation of Artificial Neural Networks; Taylor, B.J., Ed.; Springer: NewYork, NY, USA, 2006; pp. 1–12. ISBN 0387282882. [Google Scholar]
- Srinivasulu, S.; Jain, A. A Comparative Analysis of Training Methods for Artificial Neural Network Rainfall–Runoff Models. Appl. Soft Comput. 2006, 6, 295–306. [Google Scholar] [CrossRef]
- Tino, P.; Benuskova, L.; Sperduti, A. Artificial Neural Network Models. In Springer Handbook of Computational Intelligence; Springer: New York, NY, USA, 2015; pp. 455–471. [Google Scholar] [CrossRef]
- Benardos, P.G.; Vosniakos, G.C. Optimizing Feedforward Artificial Neural Network Architecture. Eng. Appl. Artif. Intell. 2007, 20, 365–382. [Google Scholar] [CrossRef]
- Hossain, M.S.; Mahmood, H. Short-Term Photovoltaic Power Forecasting Using an LSTM Neural Network and Synthetic Weather Forecast. IEEE Access 2020, 8, 172524–172533. [Google Scholar] [CrossRef]
- Song, X.H.; Hopke, P.K. Kohonen Neural Network as a Pattern Recognition Method Based on the Weight Interpretation. Anal. Chim. Acta 1996, 334, 57–66. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A Survey on Electric Power Demand Forecasting: Future Trends in Smart Grids, Microgrids and Smart Buildings. IEEE Commun. Surv. Tutor. 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- García, C.; Gómez, R.S.; García, C.B. Choice of the Ridge Factor from the Correlation Matrix Determinant. J. Stat. Comput. Simul. 2019, 89, 211–231. [Google Scholar] [CrossRef]
- Eldomiaty, T.; Eid, N.; Taman, F.; Rashwan, M. An Assessment of the Benefits of Optimizing Working Capital and Profitability: Perspectives from DJIA30 and NASDAQ100. J. Risk Financ. Manag. 2023, 16, 274. [Google Scholar] [CrossRef]
- Aksoy, E.; Kocer, A.; Yilmaz, İ.; Akçal, A.N.; Akpinar, K. Assessing Fire Risk in Wildland–Urban Interface Regions Using a Machine Learning Method and GIS Data: The Example of Istanbul’s European Side. Fire 2023, 6, 408. [Google Scholar] [CrossRef]
- Ercan, U.; Kocer, A. Prediction of Solar Irradiance with Machine Learning Methods Using Satellite Data. Int. J. Green Energy 2024, 21, 1174–1183. [Google Scholar] [CrossRef]
- Duman, S.; Elewi, A.; Yetgin, Z. Distance Estimation from a Monocular Camera Using Face and Body Features. Arab. J. Sci. Eng. 2022, 47, 1547–1557. [Google Scholar] [CrossRef]
- Hodson, T.O. Root-Mean-Square Error (RMSE) or Mean Absolute Error (MAE): When to Use Them or Not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Kocer, A. Numerical Investigation of Heat Transfer and Thermo-Hydraulic Performance of Solar Air Heater with Different Ribs and Their Machine Learning-Based Prediction. J. Brazilian Soc. Mech. Sci. Eng. 2024, 46, 73. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Coefficient of Determination R-Squared Is More Informative than SMAPE, MAE, MAPE, MSE and RMSE in Regression Analysis Evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Jierula, A.; Wang, S.; Oh, T.M.; Wang, P. Study on Accuracy Metrics for Evaluating the Predictions of Damage Locations in Deep Piles Using Artificial Neural Networks with Acoustic Emission Data. Appl. Sci. 2021, 11, 2314. [Google Scholar] [CrossRef]
- Cortina, P.R.; Santiago, A.N.; Sance, M.M.; Peralta, I.E.; Carrari, F.; Asis, R. Neuronal Network Analyses Reveal Novel Associations between Volatile Organic Compounds and Sensory Properties of Tomato Fruits. Metabolomics 2018, 14, 1–15. [Google Scholar] [CrossRef]
- Lan, H.; Wang, Z.; Niu, H.; Zhang, H.; Zhang, Y.; Tang, Y.; Liu, Y. A Nondestructive Testing Method for Soluble Solid Content in Korla Fragrant Pears Based on Electrical Properties and Artificial Neural Network. Food Sci. Nutr. 2020, 8, 5172–5181. [Google Scholar] [CrossRef]
- Guo, W.; Shang, L.; Zhu, X.; Nelson, S.O. Nondestructive Detection of Soluble Solids Content of Apples from Dielectric Spectra with ANN and Chemometric Methods. Food Bioprocess Technol. 2015, 8, 1126–1138. [Google Scholar] [CrossRef]
- Kadam, A.K.; Wagh, V.M.; Muley, A.A.; Umrikar, B.N.; Sankhua, R.N. Prediction of Water Quality Index Using Artificial Neural Network and Multiple Linear Regression Modelling Approach in Shivganga River Basin, India. Model. Earth Syst. Environ. 2019, 5, 951–962. [Google Scholar] [CrossRef]
- Ziari, H.; Amini, A.; Goli, A.; Mirzaiyan, D. Predicting Rutting Performance of Carbon Nano Tube (CNT) Asphalt Binders Using Regression Models and Neural Networks. Constr. Build. Mater. 2018, 160, 415–426. [Google Scholar] [CrossRef]
- Niazian, M.; Sadat-Noori, S.A.; Abdipour, M. Modeling The Seed Yield of Ajowan (Trachyspermum ammi L.) Using Artificial Neural Network and Multiple Linear Regression Models. Ind. Crop. Prod. 2018, 117, 224–234. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Mean | Min | Max | Std,Dev | Variables | Mean | Min | Max | Std,Dev |
|---|---|---|---|---|---|---|---|---|---|
| Brix * | 4.32 | 2.90 | 6.82 | 0.76 | a | 24.78 | 16.99 | 31.78 | 3.07 |
| TKM | 5.72 | 4.14 | 9.15 | 0.84 | b | 23.30 | 18.55 | 31.97 | 3.01 |
| Ash | 0.50 | 0.30 | 0.75 | 0.09 | C | 34.06 | 25.27 | 45.02 | 3.92 |
| pH | 4.25 | 4.03 | 4.46 | 0.10 | h | 43.48 | 35.43 | 49.97 | 3.11 |
| Acidity | 0.38 | 0.27 | 0.54 | 0.06 | Manganese | 1.13 | 0.69 | 1.76 | 0.22 |
| Hardness | 1.07 | 0.55 | 1.70 | 0.26 | Sodium | 32.35 | 22.68 | 42.85 | 4.95 |
| Fructose | 1.24 | 0.51 | 2.18 | 0.29 | Calcium | 360.62 | 206.56 | 583.91 | 87.62 |
| Glucose | 1.10 | 0.48 | 2.05 | 0.31 | Potassium | 2305.29 | 1305.35 | 2936.53 | 365.29 |
| Lycopene | 51.32 | 20.08 | 105.23 | 15.72 | Magnesium | 115.41 | 78.32 | 171.63 | 23.58 |
| Vitamin C | 20.45 | 12.98 | 29.54 | 3.69 | Phosphor | 169.65 | 99.39 | 325.63 | 38.16 |
| L | 40.07 | 35.70 | 46.16 | 2.10 |
| Variables | Std. | Beta | Std. | p Value |
|---|---|---|---|---|
| TKM | 0.588 | 0.047 | 11.356 | 0.000 |
| Acidity | 0.267 | 0.592 | 6.238 | 0.000 |
| Vitamin C | 0.061 | 0.008 | −1.72 | 0.087 |
| L | 0.213 | 0.017 | −4.637 | 0.000 |
| a | 1.557 | 0.153 | 2.665 | 0.008 |
| b | 2.814 | 0.152 | 4.986 | 0.000 |
| C | 3.828 | 0.188 | −4.239 | 0.000 |
| h | 0.585 | 0.062 | −2.386 | 0.018 |
| Potassium (K) | 0.216 | 0.000 | −3.934 | 0.000 |
| Magnesium (Mg) | 0.116 | 0.002 | 2.084 | 0.038 |
| Sodium (Na) | 0.199 | 0.007 | −4.55 | 0.000 |
| Phosphor (P) | 0.217 | 0.001 | 3.552 | 0.000 |
| Constant | 2.816 | 9.79 | 3.476 | 0.001 |
| Technique | Evaluation Metrics | Training Partition | Testing Partition |
|---|---|---|---|
| MLR | MAE | 0.2349 | 0.2573 |
| RMSE | 0.3048 | 0.3343 | |
| R2 | 0.8441 | 0.7843 | |
| MAPE | 5.5368 | 5.8199 | |
| ANN | MAE | 0.0250 | 0.0720 |
| RMSE | 0.0331 | 0.0964 | |
| R2 | 0.9982 | 0.9827 | |
| MAPE | 0.5814 | 1.6240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kabaş, A.; Ercan, U.; Kabas, O.; Moiceanu, G. Prediction of Total Soluble Solids Content Using Tomato Characteristics: Comparison Artificial Neural Network vs. Multiple Linear Regression. Appl. Sci. 2024, 14, 7741. https://doi.org/10.3390/app14177741
Kabaş A, Ercan U, Kabas O, Moiceanu G. Prediction of Total Soluble Solids Content Using Tomato Characteristics: Comparison Artificial Neural Network vs. Multiple Linear Regression. Applied Sciences. 2024; 14(17):7741. https://doi.org/10.3390/app14177741
Chicago/Turabian StyleKabaş, Aylin, Uğur Ercan, Onder Kabas, and Georgiana Moiceanu. 2024. "Prediction of Total Soluble Solids Content Using Tomato Characteristics: Comparison Artificial Neural Network vs. Multiple Linear Regression" Applied Sciences 14, no. 17: 7741. https://doi.org/10.3390/app14177741
APA StyleKabaş, A., Ercan, U., Kabas, O., & Moiceanu, G. (2024). Prediction of Total Soluble Solids Content Using Tomato Characteristics: Comparison Artificial Neural Network vs. Multiple Linear Regression. Applied Sciences, 14(17), 7741. https://doi.org/10.3390/app14177741