
YOLOv8n–CBAM–EfficientNetV2 Model for Aircraft Wake Recognition


Abstract
:1. Introduction
2. LiDAR RHI Scanning Detection
3. The Proposed Method
3.1. YOLOv8n–CBAM–EfficientNetV2 Modules
3.1.1. EfficientNetV2 Submodule
3.1.2. CBAM
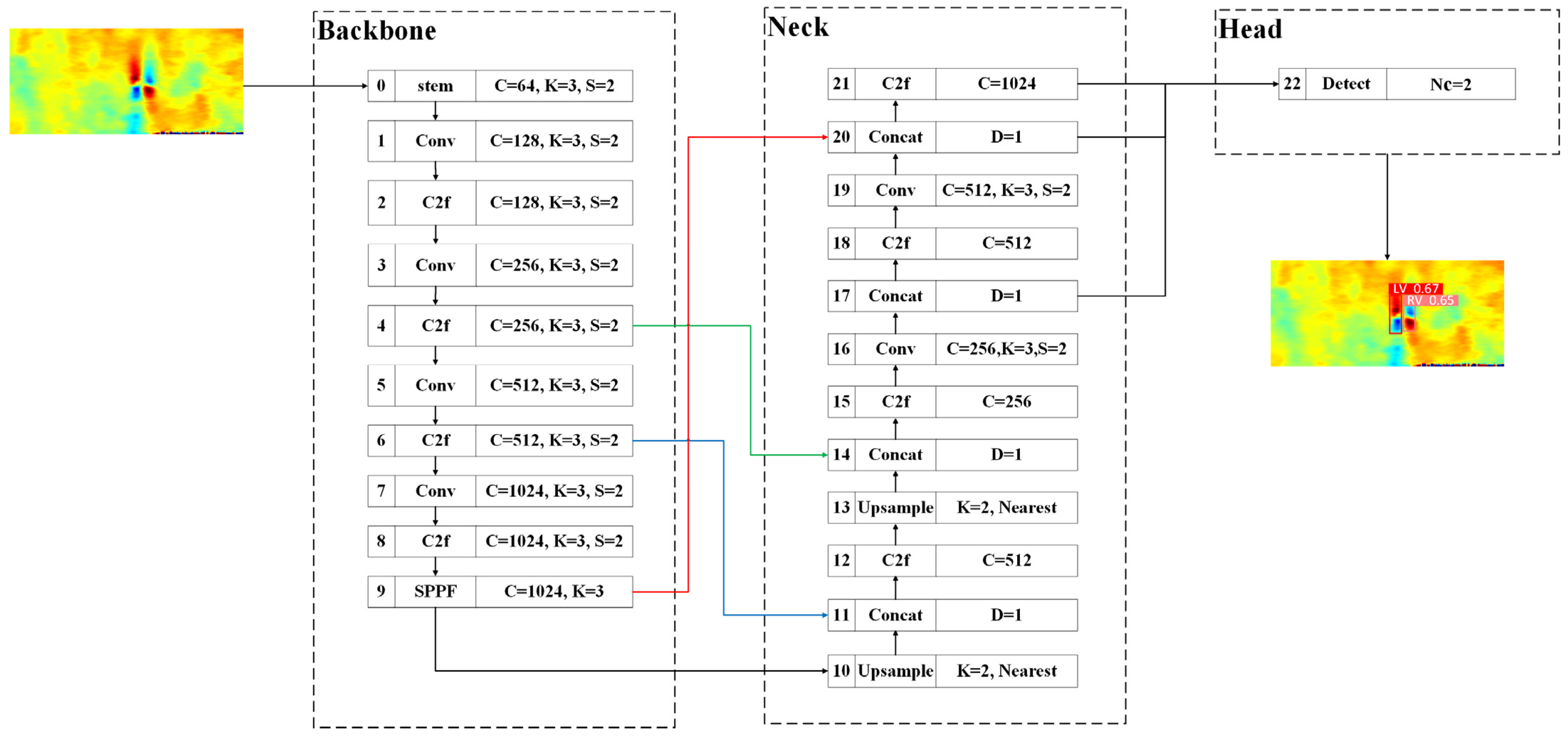
3.2. YOLOv8n–CBAM–EfficientNetV2 Network Design
3.2.1. Backbone Network
3.2.2. Neck Network and Head Network
4. Aircraft Wake Recognition
4.1. Aircraft Wake Image Dataset
4.2. Experimental Environment
4.3. Loss Function
4.4. Metrics of Proposed Method for Wake Recognition
4.5. Ablation Experiment
4.6. Wake Recognition Results
4.7. Performance of Different Recognition Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hallock, J.N.; Holzäpfel, F. A review of recent wake vortex research for increasing airport capacity. Prog. Aerosp. Sci. 2018, 98, 27–36. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Wang, T.; Wang, X. A survey of the scattering characteristics and detection of aircraft wake vortices. J. Radars 2017, 6, 653–672. [Google Scholar]
- Kaden, A.; Luckner, R. Impact of wake vortex deformation on aircraft encounter hazard. J. Aircr. 2019, 56, 800–811. [Google Scholar] [CrossRef]
- Dolfi-Bouteyre, A.; Canat, G.; Valla, M.; Augere, B.; Besson, C.; Goular, D.; Lombard, L.; Cariou, J.P.; Durecu, A.; Fleury, D.; et al. Pulsed 1.5-µm LIDAR for axial aircraft wake vortex detection based on high-brightness large-core fiber amplifier. IEEE J. Sel. Top. Quantum Electron. 2009, 15, 441–450. [Google Scholar] [CrossRef]
- Shen, C.; Gao, H.; Wang, X.; Li, J. Aircraft wake vortex parameter-retrieval system based on LiDAR. J. Radars 2020, 9, 1032–1044. [Google Scholar]
- Smalikho, I.N.; Banakh, V.A.; Holzäpfel, F.; Rahm, S. Method of radial velocities for the estimation of aircraft wake vortex parameters from data measured by coherent Doppler LiDAR. Opt. Express 2015, 23, A1194–A1207. [Google Scholar] [CrossRef] [PubMed]
- Eiichi, Y.; Naoki, M. Aircraft Wake Vortex Retrieval Method on LiDAR Lateral Range–Height Indicator Observation. AIAA J. 2017, 55, 2269–2278. [Google Scholar]
- Xu, S.; Hu, Y.; Wu, Y. Identification of aircraft wake vortex based on Doppler spectrum features. J. Optoelectron. Laser 2011, 22, 1826–1830. [Google Scholar]
- Li, J.; Shen, C.; Gao, H.; Chan, P.W.; Hon, K.K.; Wang, X. Path integration (PI) method for the parameter-retrieval of aircraft wake vortex by LiDAR. Opt. Express 2020, 28, 4286–4306. [Google Scholar] [CrossRef]
- Wang, X.; Wu, S.; Liu, X.; Yin, J.; Pan, W.; Wang, X. Observation of aircraft wake vortex based on coherent Doppler LiDAR. Acta Opt. Sin. 2021, 41, 9–26. [Google Scholar]
- Pan, W.; Wu, Z.; Zhang, X. Identification of aircraft wake vortex based on k-nearest neighbor. Laser Technol. 2020, 44, 471–477. [Google Scholar]
- Wang, X.; Pan, W.; Han, S.; Wu, Z. Identification of aircraft wake vortex using LiDAR based on SVM. J. Ordnance Equip. Eng. 2021, 42, 150–155. [Google Scholar]
- Pan, W.; Duan, Y.; Zhang, Q.; Wu, Z.; Liu, H. Research on aircraft wake vortex recognition using AlexNet. Opto-Electron. Eng. 2019, 46, 121–128. [Google Scholar]
- Pan, W.; Leng, Y.; Wu, T.; Wang, X. Rapid identification of aircraft wake based on improved GoogLeNet. J. Ordnance Equip. Eng. 2022, 43, 38–44. [Google Scholar]
- Ma, Y.; Zhao, J.; Han, H.; Chan, P.W.; Xiong, X. Aircraft Wake Recognition Based on Improved ParNet Convolutional Neural Network. Appl. Sci. 2023, 13, 3560. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 12–14 December 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wei, Z.; Qu, Q.; Li, W.; Xu, X. Review on the artificial calculating methods for aircraft wake vortex flow field parameters. Acta Aerodyn. Sin. 2019, 37, 33–42. [Google Scholar]
- Fu, J.; Li, J.; Wu, Q. Application and prospect of Dopplar LiDAR in the wind field observation. Acta Aerodyn. Sin. 2021, 39, 172–179. [Google Scholar]
- Bretschneider, L.; Hankers, R.; Schönhals, S.; Heimann, J.M.; Lampert, A. Wind Shear of Low-Level Jets and Their Influence on Manned and Unmanned Fixed-Wing Aircraft during Landing Approach. Atmosphere 2021, 13, 35. [Google Scholar] [CrossRef]
- Jiang, L.; Tian, B.; Xiong, X.; Zhuang, Z.; Yao, B. Numerical simulations of low attitude wind shear based on Doppler LiDAR. Infrared Laser Eng. 2012, 41, 1761–1766. [Google Scholar]
- Goyal, A.; Bochkovskiy, A.; Deng, J.; Koltun, V. Non-deep networks. arXiv 2021, arXiv:2110.07641. [Google Scholar]
- Hon, K.K.; Chan, P.W.; Chim, K.C.Y.; Visscher, I.D.; Thobois, L.; Troiville, A.; Rooseleer, F. Wake vortex measurements at the Hong Kong International Airport. In Proceedings of the 2022 AIAA Science and Technology Forum and Exposition, San Diego, CA, USA, 3–7 January 2022. [Google Scholar]
- Cheng, Y.; Li, G.; Chen, H.B.; Tan, S.X.; Yu, H. DEEPEYE: A Compact and Accurate Video Comprehension at Terminal Devices Compressed with Quantization and Tensorization. arXiv 2018, arXiv:1805.07935. [Google Scholar]
- Wang, H.; Zhou, L.; Zhang, J. Region-based bicubic image interpolation algorithm. Comput. Eng. 2010, 36, 216–218. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Radar wavelength | 1.54 μm |
| Pulse width | 200 ns |
| Pulse repetition rate | 20 kHz |
| Detection range | 1000 m–1785 m |
| Range gate width | 5 m |
| Angular resolution | 0.5° |
| Elevation | −0.125°–5° |
| Azimuth | 340° |
| Hyperparameter | Epoch | Batch Size | Optimiser | Initial Learning Rate |
|---|---|---|---|---|
| Value | 200 | 16 | AdamW optimisation algorithm | 0.001 |
| Model | Precision | Recall | F1-Score | FPS | GFLOPs | Number of Parameters |
|---|---|---|---|---|---|---|
| YOLOv8n | 93.87% | 93.71% | 93.79% | 161 | 8.195 | 3,006,038 |
| YOLOv8n-CBAM | 94.52% | 93.32% | 93.91% | 175 | 8.209 | 3,014,601 |
| YOLOv8n–EfficientNetV2 | 95.39% | 92.22% | 93.78% | 238 | 2.569 | 2,126,686 |
| YOLOv8n–CBAM–EfficientNetV2 | 96.59% | 93.58% | 95.06% | 250 | 2.573 | 2,135,249 |
| Model | Precision | Recall | F1-Score | FPS | GFLOPs | Number of Parameters |
|---|---|---|---|---|---|---|
| KNN | 92.31% | 89.55% | 86.15% | - | - | - |
| SVM | 88.41% | 93.85% | 91.04% | - | - | - |
| ParNet | 92.64% | 96.92% | 94.73% | 67 | 12.386 | 7,721,645 |
| SSD | 88.14% | 89.27% | 88.70% | 41 | 60.807 | 23,612,246 |
| YOLOv5-lite | 93.70% | 94.26% | 93.98% | 208 | 7.178 | 2,508,854 |
| YOLOv8n | 93.87% | 93.71% | 93.79% | 161 | 8.195 | 3,006,038 |
| YOLOv8n–CBAM–EfficientNetV2 | 96.59% | 93.58% | 95.06% | 250 | 2.573 | 2,135,249 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Tang, X.; Shi, Y.; Chan, P.-W. YOLOv8n–CBAM–EfficientNetV2 Model for Aircraft Wake Recognition. Appl. Sci. 2024, 14, 7754. https://doi.org/10.3390/app14177754
Ma Y, Tang X, Shi Y, Chan P-W. YOLOv8n–CBAM–EfficientNetV2 Model for Aircraft Wake Recognition. Applied Sciences. 2024; 14(17):7754. https://doi.org/10.3390/app14177754
Chicago/Turabian StyleMa, Yuzhao, Xu Tang, Yaxin Shi, and Pak-Wai Chan. 2024. "YOLOv8n–CBAM–EfficientNetV2 Model for Aircraft Wake Recognition" Applied Sciences 14, no. 17: 7754. https://doi.org/10.3390/app14177754