1. Introduction
Building construction, road construction, and other types of construction are high-risk operations. During construction activities, improper operations and construction personnel failing to follow prescribed measures can cause damage to their life and health. Among these risks, improper wearing of protective devices is a major cause of serious consequences. According to statistics, there were 689 municipal engineering production safety accidents in China in 2020, including 83 incidents of physical strikes. These statistics indicate that it is essential to take safety protection measures at construction sites.
Head injuries during construction are extremely dangerous. Helmets can absorb external impact forces and prevent object penetration, making them essential tools for reducing the incidence of such injuries. However, according to a survey by the Bureau of Labor Statistics, 84 percent of workers who suffered head injuries were not wearing helmets [
1]. Therefore, monitoring the use of helmets by construction workers is crucial.
Manual monitoring is costly, time-consuming, and inefficient. In contrast, automatic detection and supervision, facilitated by computer vision, the Internet, and other technologies, have emerged as new developmental trends. This approach offers both cost savings and significantly increased security. Research into construction site security protection, closely integrated with deep learning technology, is gradually becoming a hotspot among scholars. This research provides a new model for production safety management and can offer technical support and references for future smart construction sites, intelligent manufacturing, and other fields.
In previous studies, safety helmet detection primarily involved traditional methods and deep learning-based approaches. Initially, Kelm et al. [
2] proposed the employment of RFID (Radio Frequency Identification) to check workers’ compliance with safety wear. However, RFID is limited in scope, as it can only confirm the helmet’s proximity to the worker, not whether it is being worn correctly. Santiago et al. [
3] put forward a cyber-physical system (CPS) to detect workers wearing PPE (personal protective equipment) in real-time, but this system could not determine whether workers were wearing helmets correctly. Dong et al. [
4] utilized a positioning system for virtual building technology where a pressure sensor in the helmet recorded relevant information and relayed it via Bluetooth. However, this method was ineffective over long distances. Sun X et al. [
5] employed a visual background difference algorithm for worker identification and used principal component analysis for feature dimensionality reduction. They ultimately used the Bayesian optimization SVM (Support Vector Machine) model to identify hard hats, but the accuracy was not high. Traditional methods for safety helmet detection have low accuracy, poor generalization, and low efficiency. Consequently, deep learning-based object detection techniques are now the preferred approach.
Qi Fang et al. [
6] implemented helmet detection using Faster R-CNN for targets in the far field and scenes with various construction site backgrounds, achieving excellent detection results on the collected dataset. Although the Faster R-CNN model has higher detection accuracy, it is poor in real-time and has a large model size. Zhao et al. [
7] addressed the problem of low helmet detection accuracy; they improved YOLOv5 by increasing the detection head, feature fusion, and attention mechanism, which enhanced the model’s detection accuracy in complex backgrounds, and the average accuracy was improved by 2.6%. However, the inference time of the model is not satisfactory enough, and there is a large room for improvement. Hayat et al. [
8] conducted extensive experimental research on helmet detection systems and found that YOLOv5X performs excellently in low-light conditions with high precision. However, the YOLOv5X model is large, and its inference time requires further investigation. Z. Li et al. [
9] proposed a safe helmet detection algorithm based on YOLOv5s. The approach employed a hierarchical sample selection mechanism and a density-based post-processing algorithm, significantly enhancing detection accuracy. Their method improved F1 scores by 12.47% at a threshold of 0.1. However, the speed of model detection was largely overlooked. Li et al. [
10] introduced a model based on Faster R-CNN-LSTM to address the accuracy issues due to an insufficient spatial and temporal feature mining in the detection process. The improved model fuses temporal and spatial features, greatly enhancing accuracy. However, the model has a large number of parameters, and the inference time needs further improvement. Fu et al. [
11] proposed the YOLOv8n-FADS helmet detection algorithm, which improves the detection head, enhancing the model’s ability to perceive complex patterns and handle occlusions effectively. Although the parameters and accuracy of the model have been improved, the overall accuracy is not high, and the inference time needs further improvement. Barlybayev et al. [
12] used YOLOv8 to detect PPE. It was concluded that YOLOv8x and YOLOv8l performed well on PPE detection. However, the detection accuracy in complex backgrounds needs to be further improved, and the number of parameters and inference time of the models also need to be improved. He et al. [
13] proposed a lightweight helmet detection algorithm called YOLO-M3C, which uses MobileNetV3 instead of the YOLOv5s backbone network and introduces the CA attention mechanism and knowledge distillation. The model size and detection speed are effectively improved. However, the accuracy of the method only reaches 82.2%, which is not very reliable. Xu et al. [
14] proposed MCX-YOLOv5 to address the problem of low detection accuracy caused by the small size of the helmet. Several methods, including a coordinate space attention module, a multi-scale asymmetric convolutional downsampling module, and a lightweight decoupling head, were used. Through several experiments, the accuracy of the method is improved by 2.7% compared to YOLOv5. However, the inference time of the algorithm still has a large room for improvement.
In the aforementioned studies, most of them focus on how to improve the detection accuracy of safety helmets, ignoring the attention to the inference time or the number of parameters. Enhancing inference time and reducing parameters will help the models to be more practical. Therefore, it is necessary to increase inference speed and decrease parameters while maintaining accuracy. Based on this, we propose EGS-YOLO. EGS represents EIOU, GhostModule, SE, respectively. The real-time performance is enhanced while maintaining high detection accuracy and achieving a certain degree of being lightweight. The method is validated by using the SHEL5K [
15] dataset. In our study, in order to speed up the inference of the model and enable the model to fully process useful information in complex contexts with low-cost operations, we improved YOLOv7 using three approaches: GhostModule, SE (Squeeze and Excitation), and EIOU (Efficient Intersection over Union). This paper completes the following:
Based on YOLOv7 [
16], to increase the model’s inference speed and decrease parameters, part of the CBS modules are replaced with GhostModule to compose efficient structures. After comparing it with several other lightweight modules, GhostModule was selected. Reducing computing costs.
To enhance the feature extraction performance of the model in complex contexts, the SE attention mechanism is adopted into the model. This allows the model to focus on worthwhile information in the image without compromising inference speed. After comparing it with several other attention mechanisms, SE was selected.
To accelerate the model’s convergence, the EIOU loss function is introduced. This helps the model focus on the difference between the width and height of the object in the image rather than the aspect ratio.
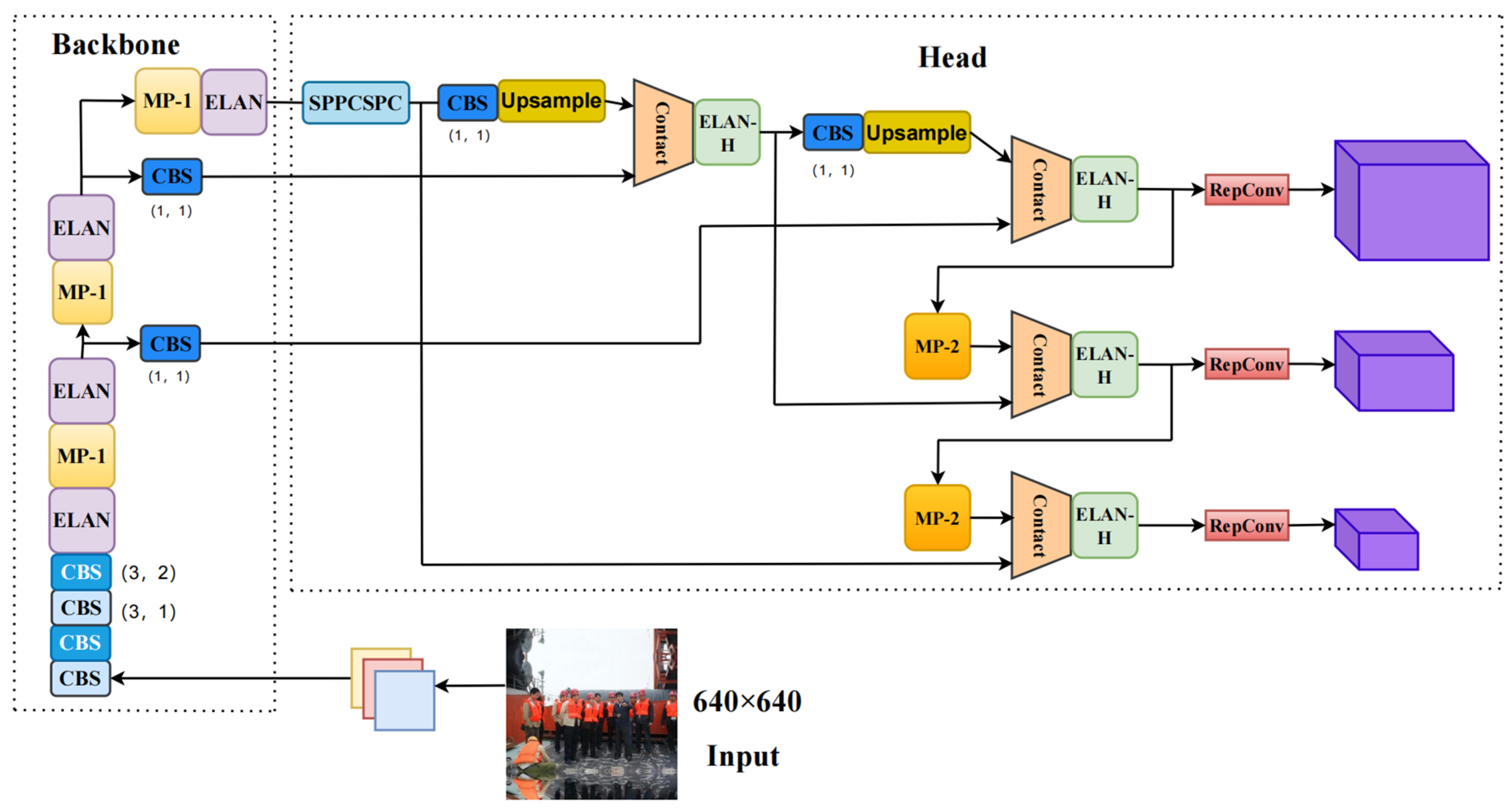
3. Proposed Method EGS-YOLO
To construct a helmet-wearing detection model with superior comprehensive performance, we integrate GhostModule, SE, and EIOU into the network structure of YOLOv7 to achieve high real-time performance while maintaining high accuracy.
3.1. GhostModule
To achieve high real-time performance in helmet wear detection, a preferable approach involves lightening the model. A better real-time and lighter-weight model will facilitate deployment into embedded devices. As convolutional neural networks continue to progress, lightweight convolutional neural networks are becoming highly favored, and this trend will likely continue in the future.
A main approach to creating lightweight neural networks is designing compact models, and many such models have emerged in recent years. The idea behind MobileNetv1 [
22] is depthwise separable convolutions, a lightweight architecture. MobileNetv2 [
23] introduces linear bottlenecks and inverse residuals based on the previous generation, enhancing the network’s representation ability. MobileNetv3 [
24] incorporates the SE module, updates the activation function, and achieves better performance. MBConv [
25] is an inverse residual structure that combines depthwise separable convolutions and attention mechanisms, characterized by inverted linearity. DSConv (depthwise separable convolution) [
26] is a flexible, lightweight convolution operator that replaces single-precision operations with low-cost integer operations while maintaining performance. PConv (Partial Convolution) [
27] can reduce redundant calculations and storage access, making the model more effective at extracting spatial features and maintaining performance while remaining lightweight. However, none of the above methods makes adequate use of feature mapping, and they do not handle redundant feature maps very well. GhostModule is an effective way to address these issues at a lower operational cost and is especially suitable for scenes with complex image backgrounds.
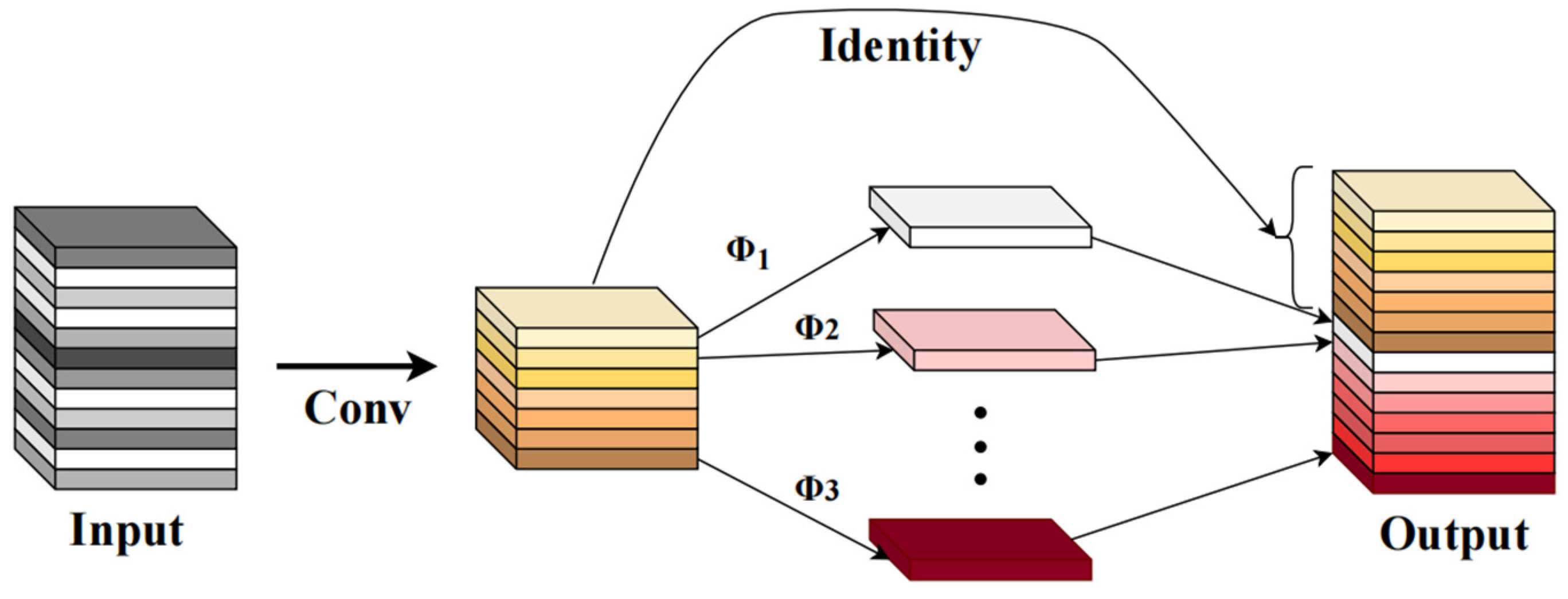
Han Kai et al. proposed GhostModule, a module capable of generating more feature maps from low-cost operations. Based on a set of inherent feature maps, a series of low-cost linear transformations are used to generate many feature maps that can reveal inherent feature information [
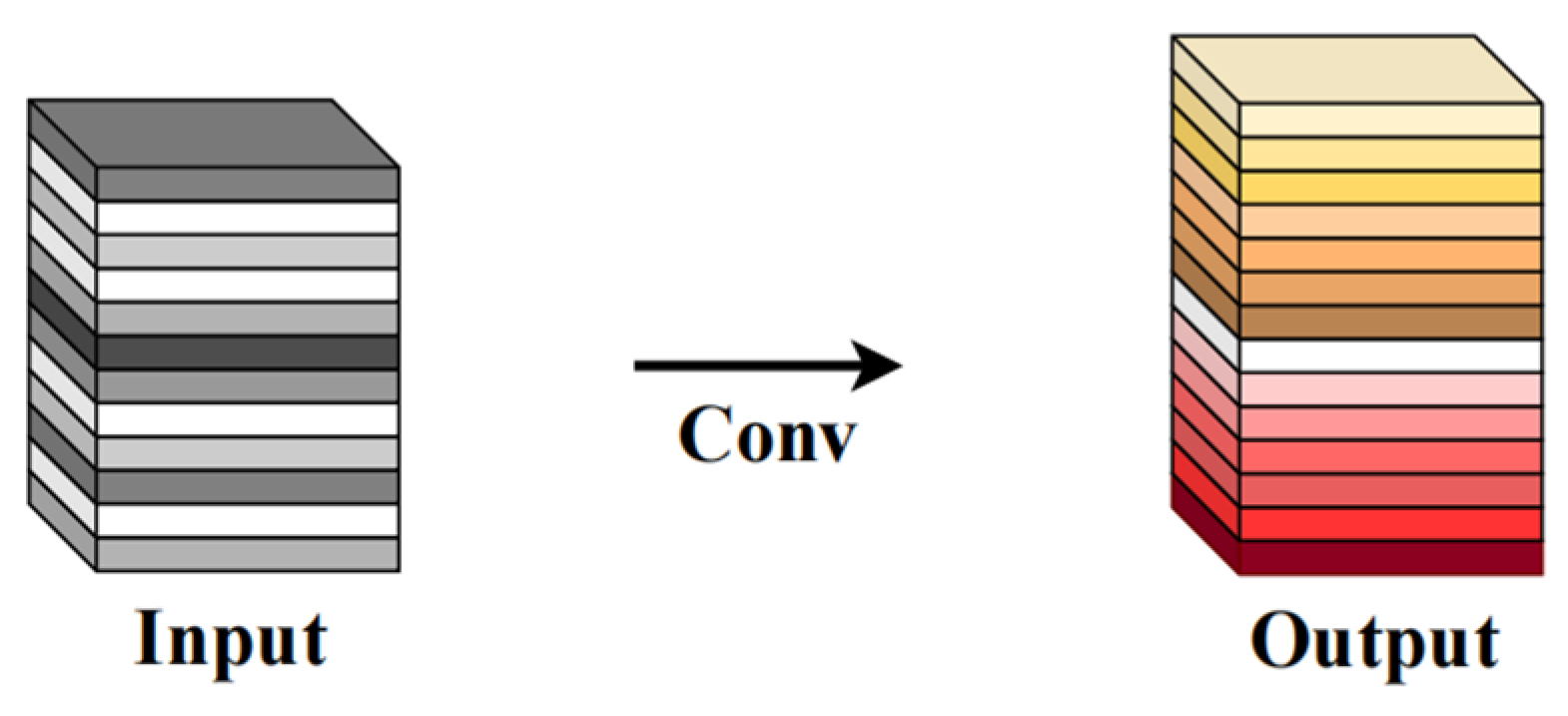
28]. Compared with normal convolution, GhostModule requires less computational complexity and fewer parameters while maintaining similar performance. After some experimentation, GhostModule was the most suitable choice in this study. GhostModule can effectively deal with the redundancy of feature maps. Ordinary convolution and GhostModule are shown in
Figure 7 and
Figure 8, respectively. In
Figure 8, the GhostModule is divided into three parts. The first part is a normal convolution operation, the second part is a grouped convolution operation, and the third part is Identity, which is the sum of the number of channels in the first and second parts.
GhostModule can be divided into two steps: The first part performs ordinary convolution and limits the quantity of convolution; the second part consists of some low-cost linear transformations that use the inherent feature mappings to yield more feature mappings. The feature maps generated from the two sections are then stitched together to produce a new output. This procedure enhances real-time performance and decreases the model’s parameters and computational complexity with minimal loss of precision. The ratio of computational and parametric quantities for ordinary convolution is shown in Equation (3).
In Equation (3), is the channel of the input, is the number of channels, and are, respectively, the width and height of the output data, is the kernel size of the convolution filter, represents the kernel size of each linear operation. The ratio of the amount of calculation and the number of parameters of GhostModule is shown in Equation (4).
In Equation (4), directly impacts the ratio of computational and parametric quantities. The more feature maps produced in that output, the better the acceleration. Introducing GhostModule into the model allows the model to utilize the correlation and redundancy between feature mappings in a better way, generating many more feature maps, decreasing the parameters and calculations in the model, and enhancing speed.
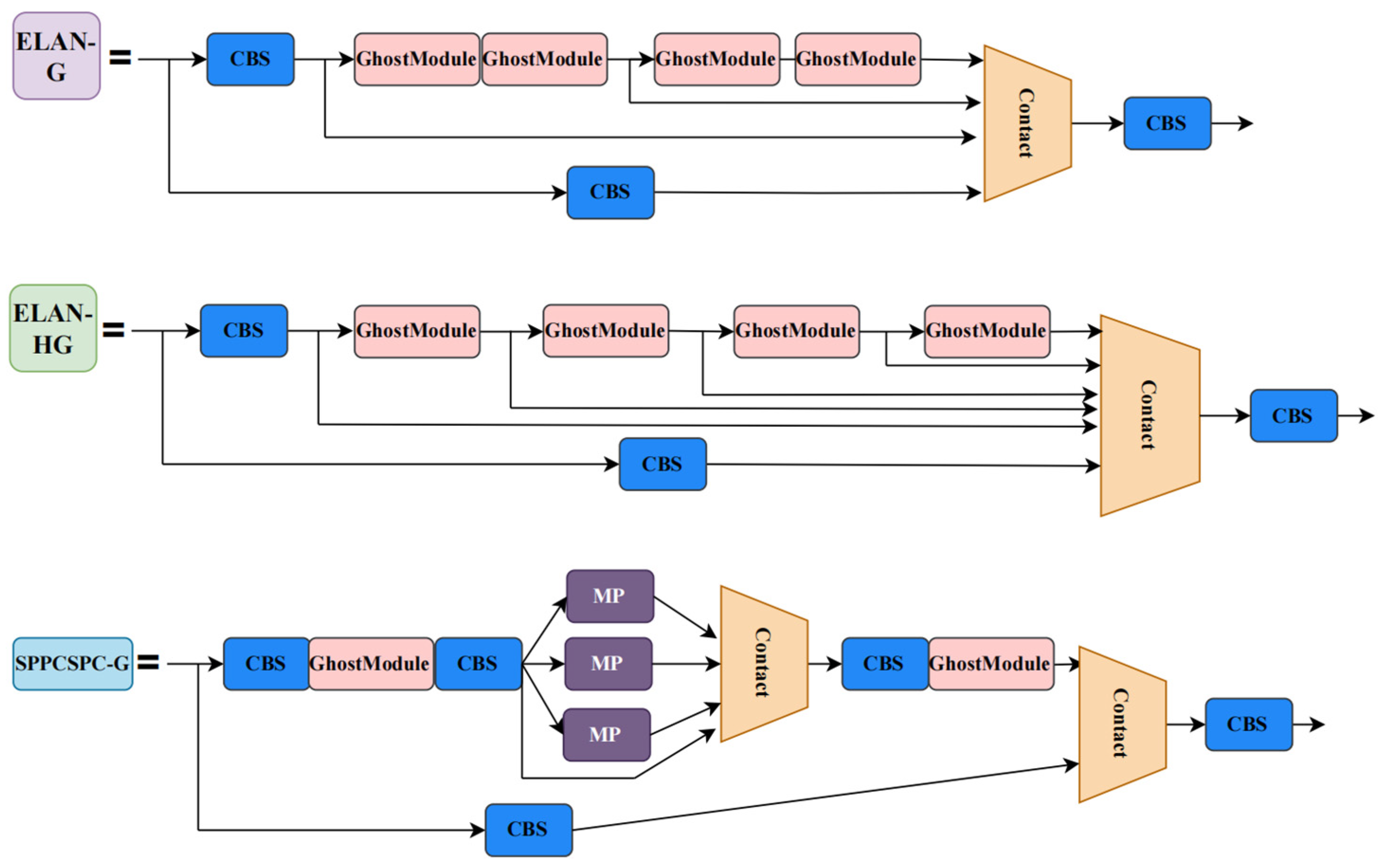
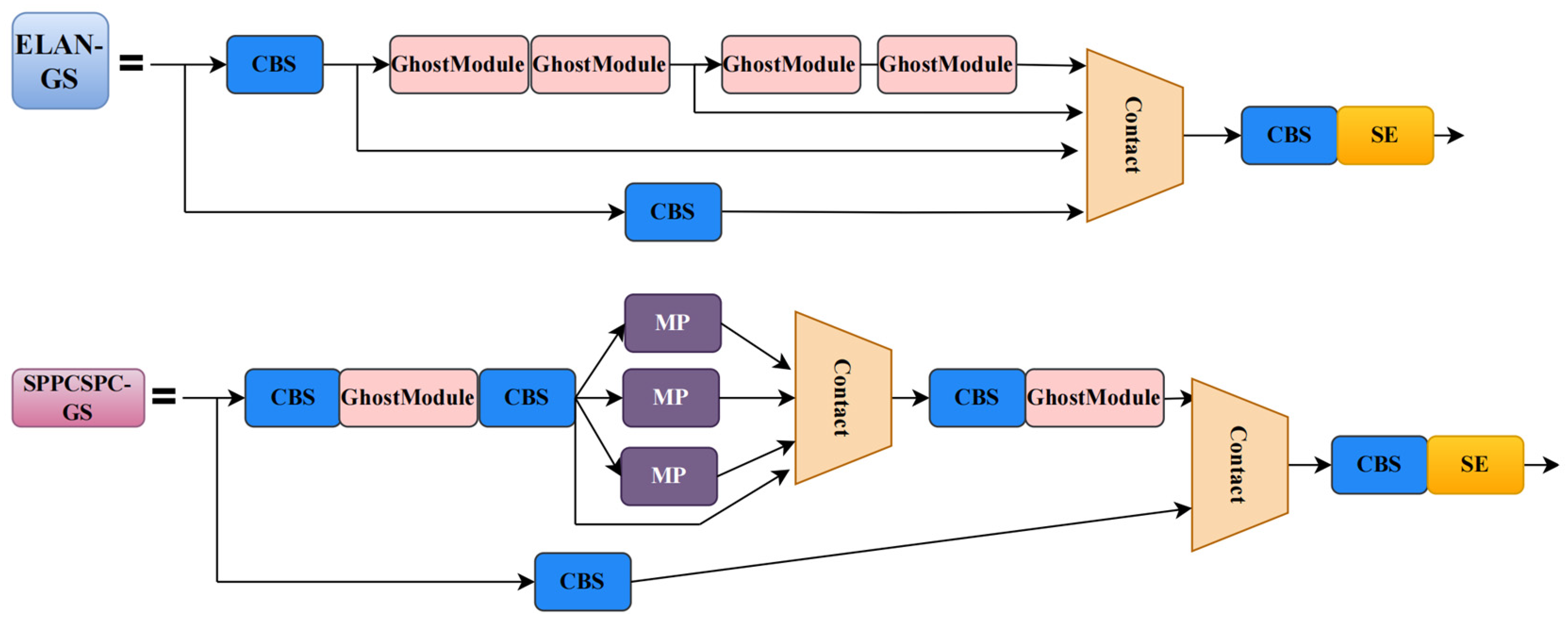
In YOLOv7, the major function of a 3 × 3 convolution with a step size of 1 is to perform feature extraction; these convolutions are computationally intensive. We use the low-computation GhostModule instead of these convolutions. In this part, the CBS modules that conduct feature extraction operations in ELAN, ELAN-H, and SPPCSPC are replaced by GhostModule, that is, replacing the CBS module with a 3 × 3 kernel and a stride of 1 in these structures with the GhostModule. The new structures ELAN-G, ELAN-HG, and SPPCPSC-G are, respectively, presented in
Figure 9. The enhanced structures can generate feature maps that reveal intrinsic feature information through a series of cost-effective operations. However, it also affects the model’s feature extraction capability and convergence speed, resulting in a loss of accuracy. Measures will be taken next to resolve this issue.
3.2. SE (Squeeze and Excitation Block)
As for limited computational power, the attention mechanism can distribute computational power to the more important parts of the task. Attention mechanisms are widely used in deep learning to enhance the performance of models [
29]. Currently, attention mechanisms are categorized into three types. The squeeze excitation network (SENet) [
30] is a typical representative of channel attention. The second type is the spatial attention mechanism, with SAM [
31] as a typical example. The third type is the mixed frequency domain mechanism, with CBAM [
32] as its representative. SE is able to reduce the problem of vanishing gradients by re-weighting the channel features. To speed up the model’s inference time and lighten the model, we introduced GhostModule. However, this weakened the model’s feature extraction capability, leading to a loss in accuracy. To address this, we incorporated attention mechanisms.
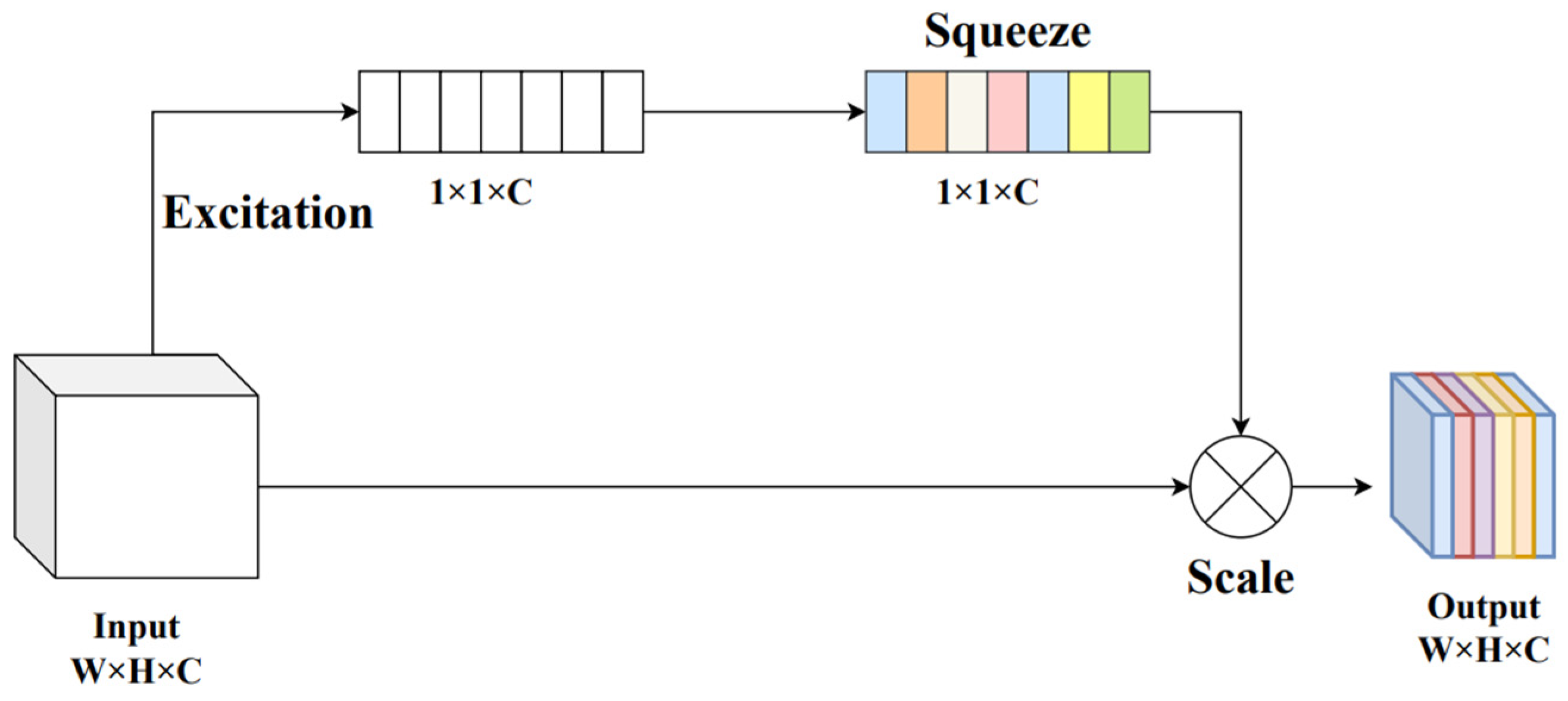
The SE (Squeeze-and-Excitation) module can mitigate the problem of accuracy loss due to the different significance attributed to various channels. This unit adaptively recalibrates the channel feature response by explicitly modeling the interdependencies between channels. The goal is to improve the quality of the representations produced by the network by highlighting valuable parts and suppressing less meaningful information. SE allows networks to use overall information to selectively emphasize significant features. The context of construction sites is usually complex and diverse, causing many interferences and difficulties in helmet detection. SE suppresses insignificant information in the image, making it effective for tasks like helmet detection with mixed backgrounds. And we have experimented with a variety of attention mechanisms to conclude that SE is the most appropriate choice. SE is more lightweight and has almost no effect on the parameters. The structure of SE is visible in
Figure 10; the image input is first subjected to a Squeeze-and-Excitation operation, followed by a scale operation to generate the final feature map.
An SE block is equivalent to a calculation unit. The feature map
is generated by passing the input
through the transformation operation, as shown in Equation (5). The output is expressed as
.
indicates the 2D spatial kernel of a single channel, which acts on the correspondent channel of . There are two key steps in the SE block: the compression operation and the excitation operation.
The compression procedure is essentially a process of global average pooling. It compresses the global spatial information into the channel descriptor. The channel statistics are generated by using global average pooling, resulting in a feature map as a 1*1*C vector, where a numerical value represents each channel. This operation is shown in Equation (6).
Here, and are, respectively, the height and width of the feature map.
The second step is the excitation operation, which obtains channel-related reliance relationships using the information aggregated during the compression operation. This is done through two fully connected layers, as shown in Equation (7).
is the weight, through which the required weight information is generated, and the value of is produced by learning. is the ReLU function.
The final output of the block is to weight the generated weight
to the feature map
, as shown in Equation (8).
,
represents the channal-by-channel multiplication between the scalar
and the feature map
. The key information in the image is amplified once again after the squeeze and excitation operations, effectively reducing the interference from complex backgrounds in helmet wear detection. Building on the introduction of the GhostModule in the previous section, we have embedded SE into the structure ELAN-G and SPPCSPC-G. The SE together with the GhostModule compose the new efficient structures ELAN-GS and SPPCSPC-GS, as presented in
Figure 11. We have embedded a total of four SE blocks into the model, specifically positioned as shown in
Figure 12, labeled ELAN-GS and SPPCSPC-GS.
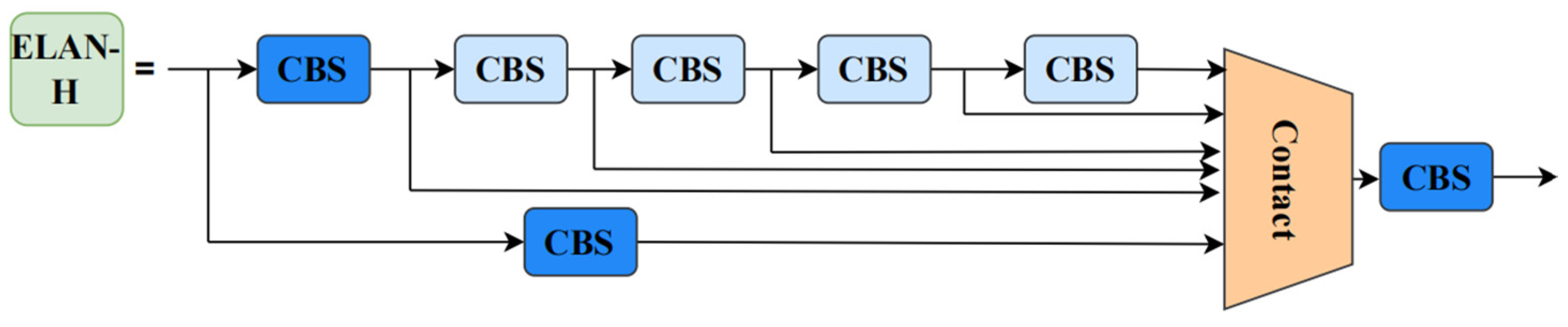
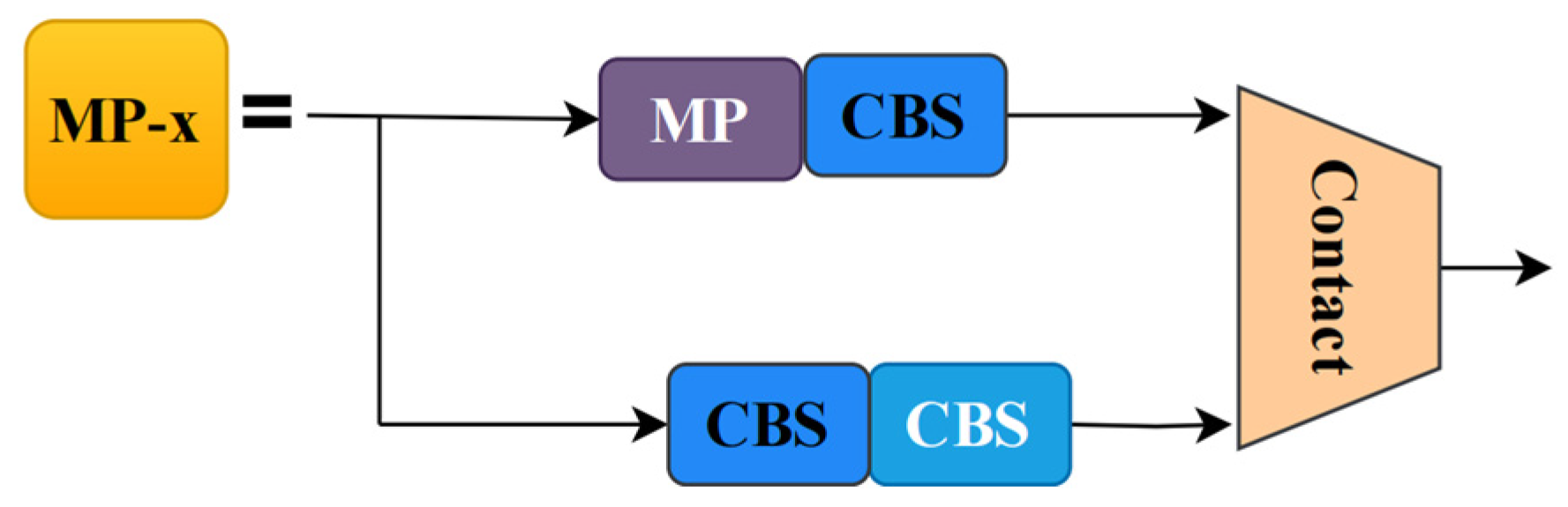
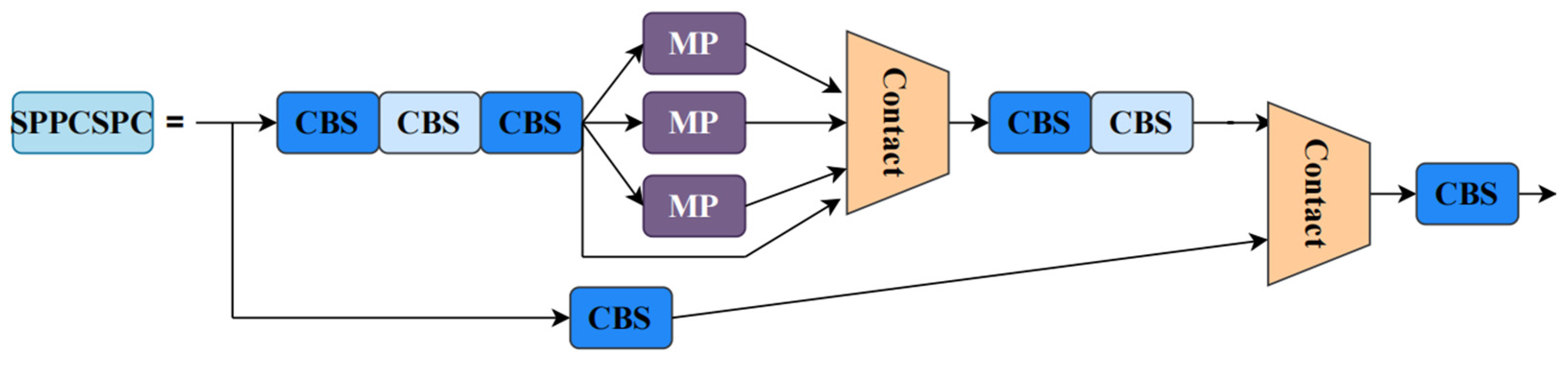
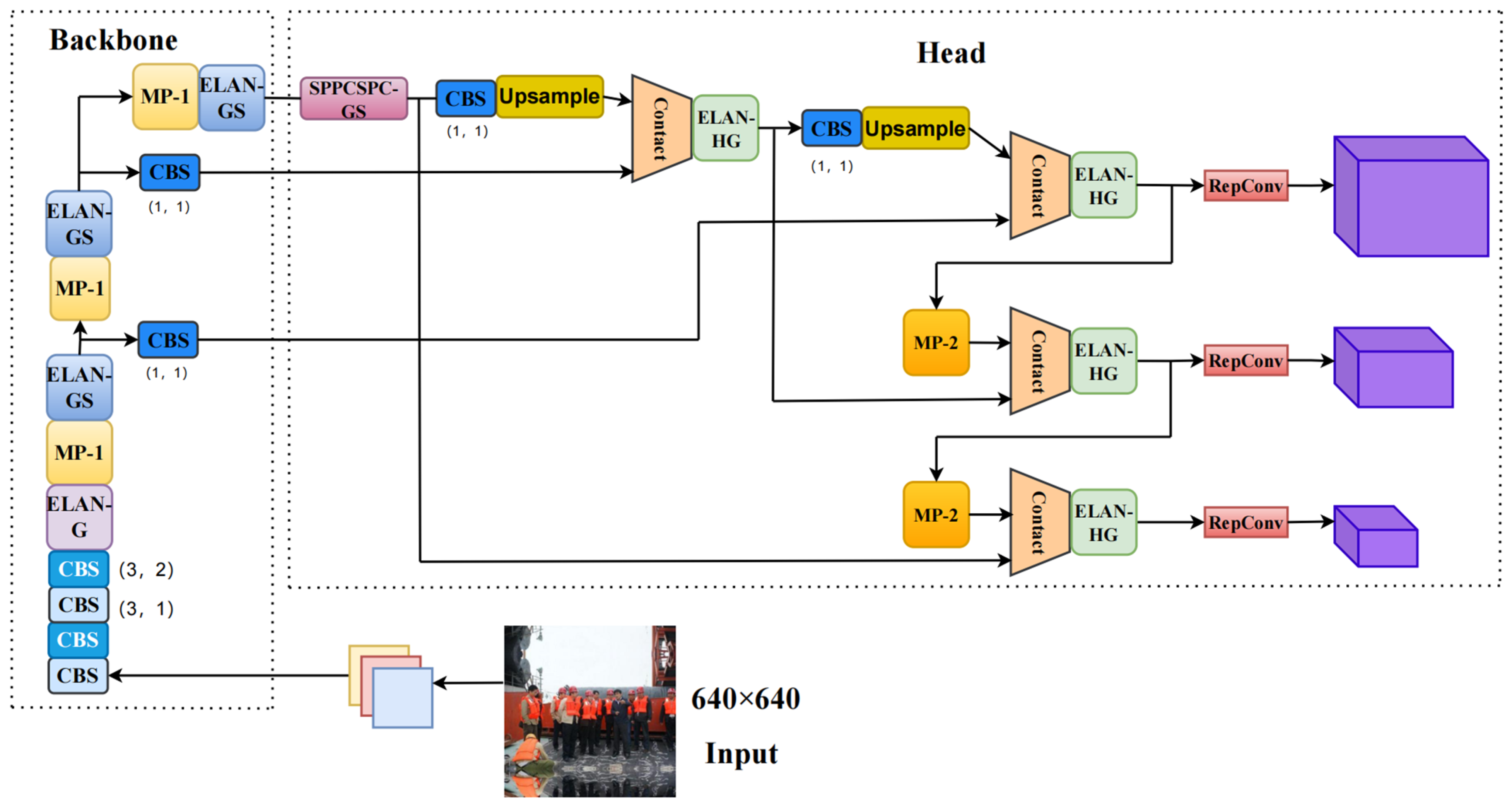
Figure 12 shows the model structure of EGS-YOLO, we improve on the structures ELAN, ELAN-H, and SPPCSPC in YOLOv7 by constructing ELAN-G, ELAN-HG, ELAN-GS, and SPPCSPC-GS.
3.3. EIOU Loss
The loss function is crucial in judging the difference between the forecast and the true value. The Intersection over Union (IOU) ratio is a widely used index to indicate the precision of prediction boxes in object detection tasks. Many loss functions based on IOU have been proposed to optimize detection.
DIOU [
33] loss makes it more robust by considering the distance and area of overlap between the target and the forecast. CIOU (Complete Intersection over Union) adds two new losses, a detection box scale, and an aspect to make the target box regression more stable. The idea of EIOU [
34] is to separate the impact factors of the aspect ratio of the predicted box and the real box and to calculate the length and width of the predicted box and the real box separately.
The original loss function of YOLOv7 is CIOU, which adequately takes into account the overlap area, center-of-mass distance, and aspect ratio between the predicted and real boxes. The CIOU contains three main components: loss of target box and prediction box position, classification loss, and loss of target confidence. The CIOU is presented in Equation (9).
The ratio of the intersection and concatenation between two bounding boxes is defined as IOU. The centroids of the prediction and real frames are represented by and , respectively. The Euclidean distance between the center of mass in the prediction box and the center of mass in the real box is designated by .
In Equation (10), the weighting factor is indicated by
. In Equation (11), the similarity of the aspect ratios is characterized by
. The width and height of the real box are, respectively, represented by
and
; the width, and height of the prediction box are, respectively, indicated by
and
. The bounding box regression problem in object detection is represented in
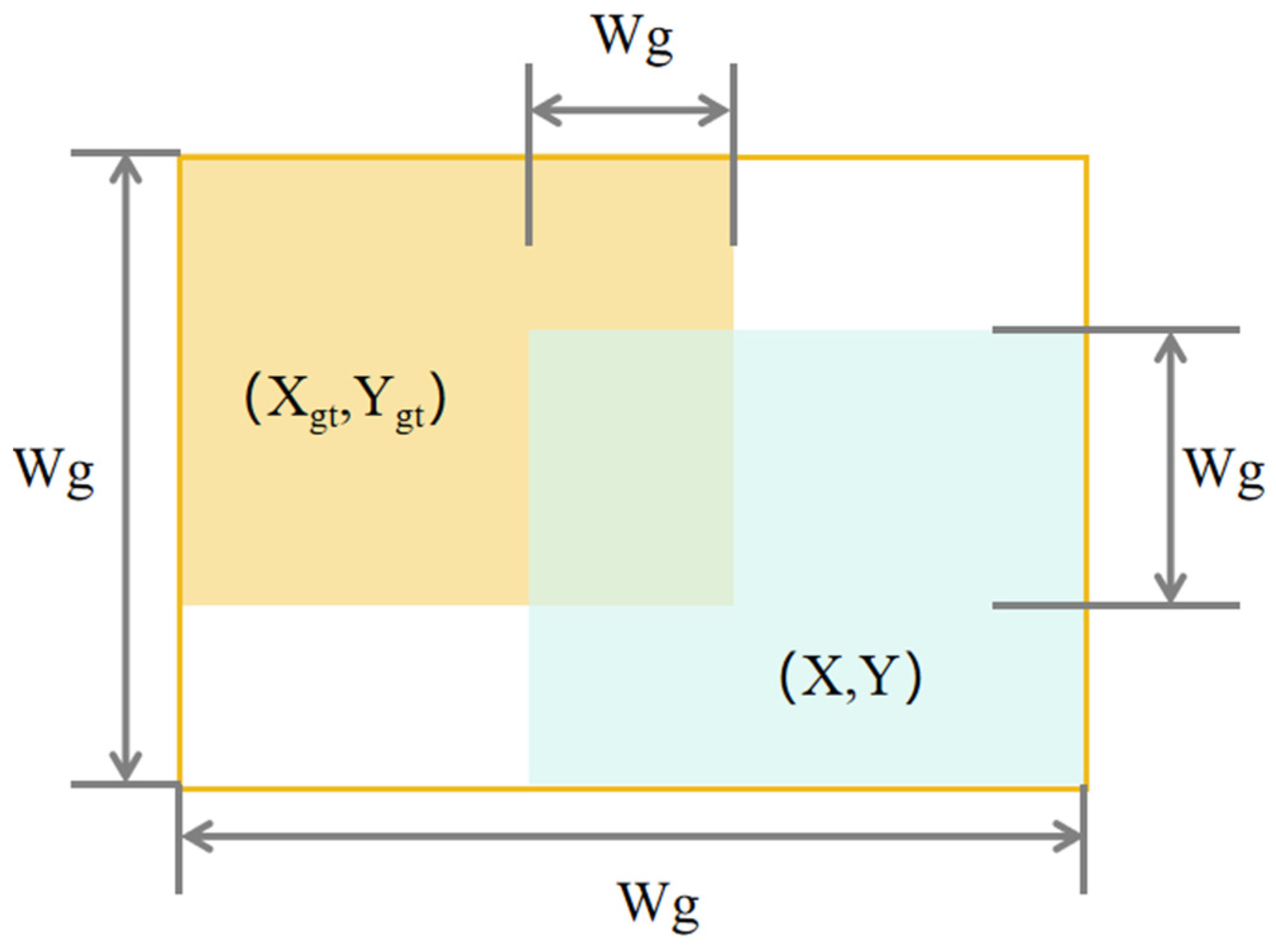
Figure 13. The orange section is the true box, and the light blue section is the predicted box. The overlap of the yellow and blue boxes is used to assess how well the predicted and true boxes match.
Although CIOU effectively solves the problem that IOU cannot handle non-overlapping bounding boxes, there are inevitably low-quality samples in the training set. Additionally, there exists some ambiguity in the aspect ratio in CIOU, and
has a flaw that ignores the true relationship between width and height, affecting the speed of model convergence. The EIOU loss function is proposed to solve this problem effectively. Therefore, the EIOU loss function is adopted in our study. The EIOU is presented in Equation (12).
is the overlap loss, is the center distance loss, is the loss of width and height, is the minimum rectangle width that can surround the two bounding boxes, is the minimum rectangle height that can surround two bounding boxes.
The EIOU loss function carries over the advantages of CIOU, such as distance loss. Additionally, EIOU minimizes the gap between the width and height of the predicted and real boxes, which accelerates model convergence, making it better overall. EIOU introduces more geometric information, effectively reducing the accumulation of errors in multiple dimensions of the prediction frame. This helps the model adjust the size and position of the prediction box more accurately during training. EIOU can be adapted to multi-scale objects, making it suitable for the helmet detection scenario. Introducing GhostModule enhances the efficiency of the network structure but adversely affects its convergence speed, leading to a loss of accuracy. Therefore, we opt for the EIOU loss function to address this issue.
5. Conclusions
In this study, we improved YOLOv7 and successfully constructed EGS-YOLO. Compared to YOLOv7, the model boasts improved real-time performance while maintaining high precision, and it also has reduced parameters and computational complexity. Compared with the existing research, it has taken into account a variety of metrics and has excellent performance with high accuracy and high real-time performance. The GhostModule is adopted to enhance real-time performance and to lighten the model to some extent. The SE block is introduced to strengthen the model’s ability to extract valuable features and mitigate the impact of complex factors. The EIOU loss function is utilized to achieve faster convergence and more accurate localization. We successfully constructed new efficient structures such as ELAN-G, ELAN-HG, ELAN-GS, and SPPCSPC-GS. EGS-YOLO is capable of adapting to diverse and complex scenarios in helmet wear detection, achieving both high real-time and high-accuracy performance. The detection
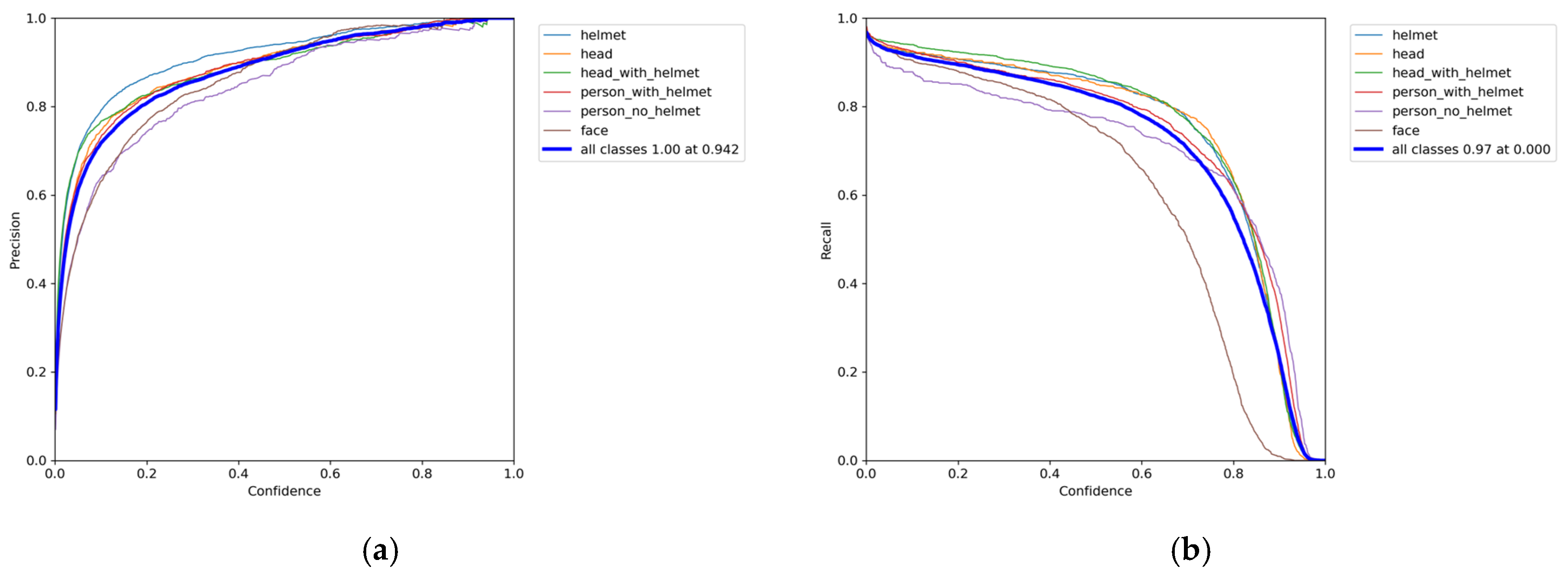
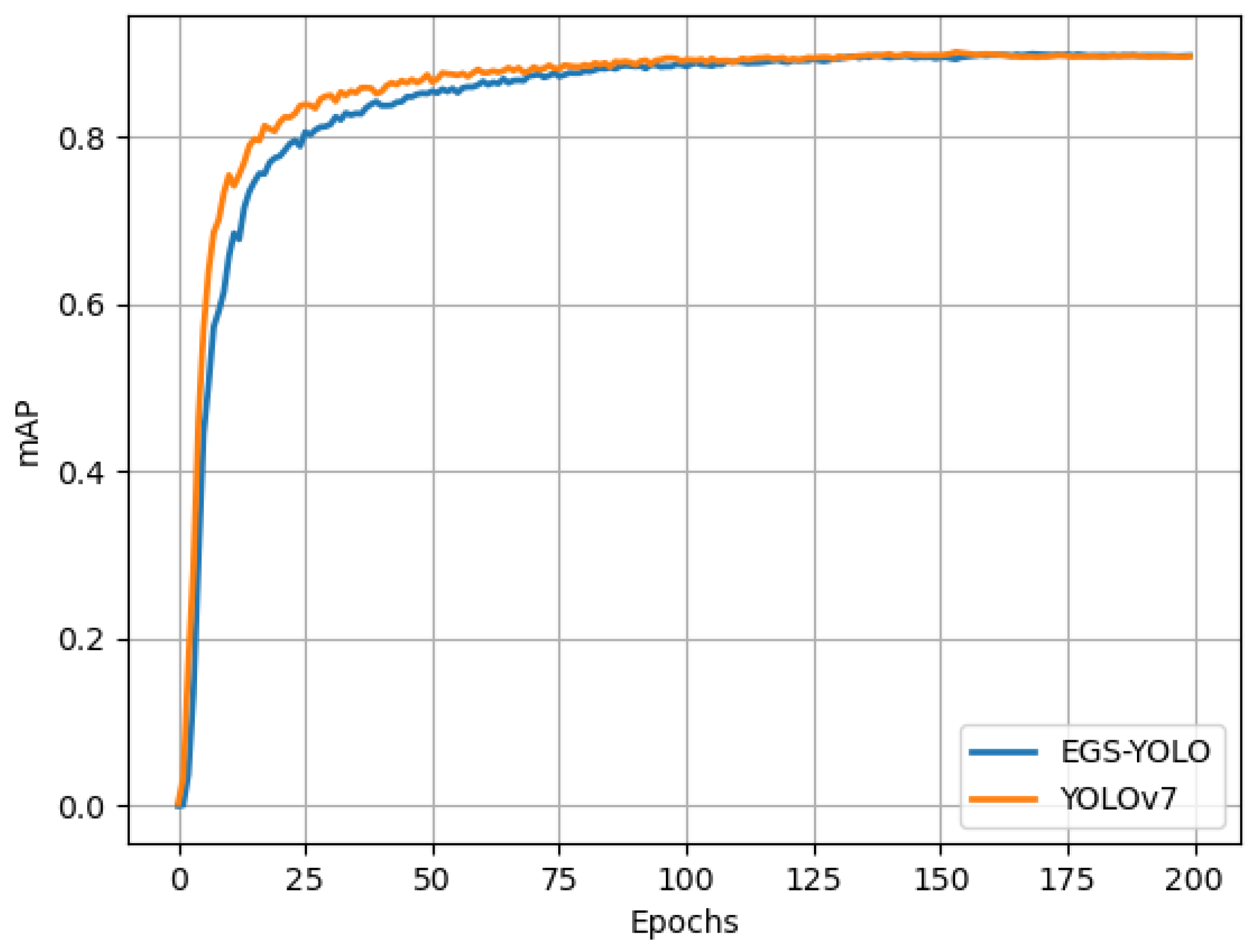
[email protected] of EGS-YOLO is 91.1%, with Precision and Recall rates of 89.9% and 84.7%, respectively. Notably, compared to YOLOv7, EGS-YOLO has a 0.2% higher
[email protected], a 37.3% reduction in parameters, a 33.8% decrease in computational complexity, and an inference time of 3.9 ms, a 13.3% reduction. The EGS-YOLO proposed in this study meets the requirements for high-accuracy and high real-time detection of safety helmets on construction sites.
In future research, we will focus on optimizing the model to investigate ways to further enhance accuracy. This will be achieved by incorporating dynamic convolution, deformable convolution, and feature fusion. Additionally, we will research further lightweight models, making them lighter through model pruning and other techniques.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}