
Knowledge Graph and Personalized Answer Sequences for Programming Knowledge Tracing



Abstract
1. Introduction
- (1)
- Exercises are not independent—clear predecessor and successor relationships between KCs exist. For example, after the exercise was answered incorrectly, continued to be attempted by student . Due to insufficient mastery of the predecessor of , the exercise resulted in a timeout. However, after exercises related to the previous KCs, and , were completed, was answered correctly by student .
- (2)
- Multiple attempts reflect individualized knowledge mastery. For example, two failed attempts were made by student even after exercise was answered correctly, which may have been submitted for testing reasons and should not be interpreted as a lack of mastery over the KCs involved. Another example is when exercise was faced; students and answered correctly on the first attempt, while three attempts were required by student to get it right. Therefore, the mastery of the knowledge concept “Struct” is clearly different for and compared to .
- We construct a knowledge graph in the programming field to constrain the embedding of knowledge concepts by perceiving their types. The resulting embedding vectors can effectively connect the KCs in the exercises.
- In response to the phenomenon of students answering consecutive programming exercises, we explore students’ learning behavior and learning ability, and a gating mechanism is introduced to balance their historical and current knowledge states. This approach better reflects the personalized knowledge mastery of students.
- We conduct extensive experiments on two real-world programming datasets, which shows that GPPKT outperforms state-of-the-art models, with an average AUC improvement of 9.0%. Ablation experiments are also performed to ensure the reliability and effectiveness of each component in the study.
2. Related Work
3. Method
3.1. Presentation of the Problem
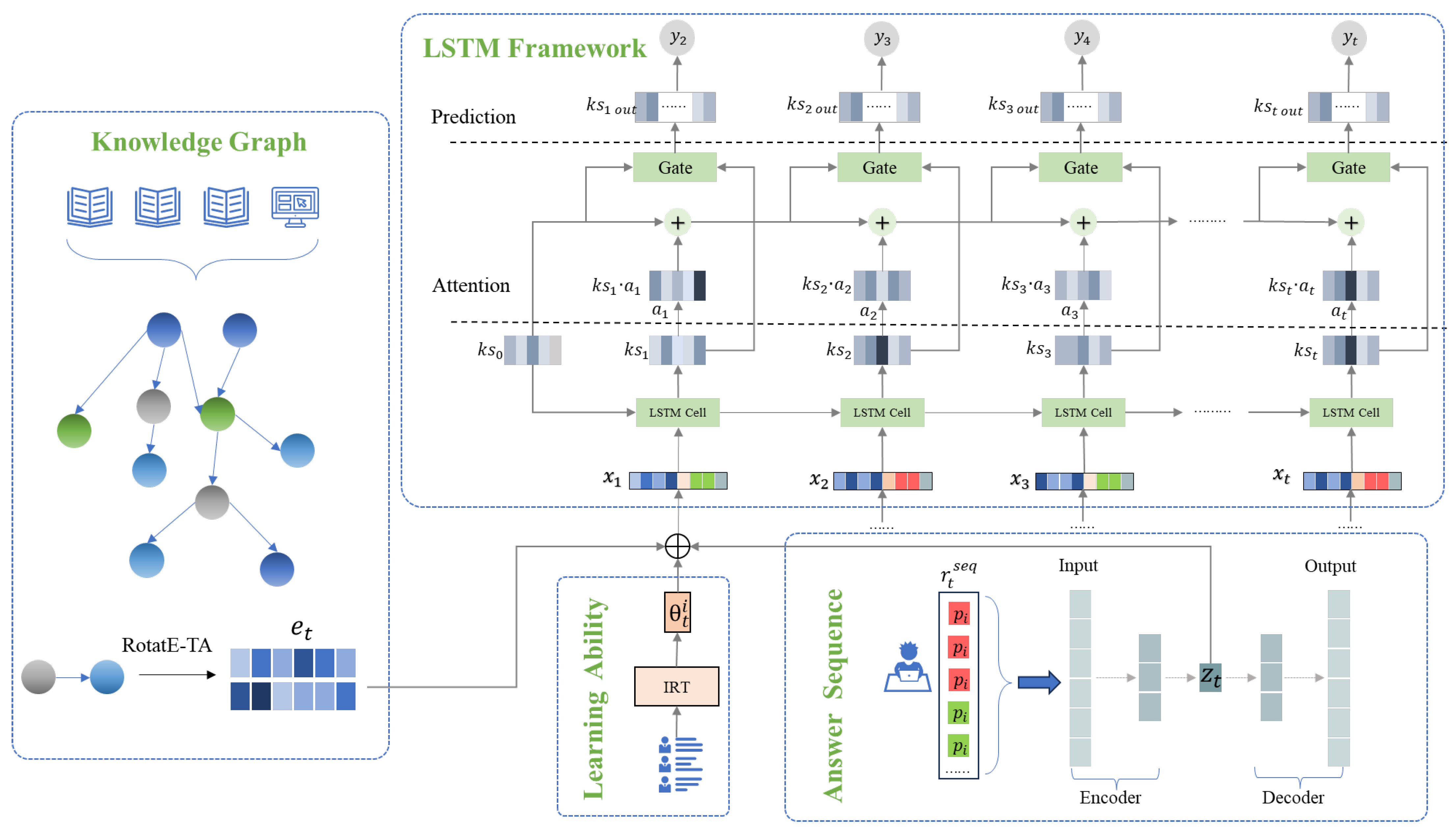
3.2. Overall Architecture
3.3. Knowledge Graph to Represent Exercise Vectors
3.3.1. Constructing Knowledge Graph
- Knowledge concept acquisition: We gather information about KCs from the OI-Wiki website. Specifically, hierarchical and relational information about programming concepts, such as “Dynamic Programming” and its associated subtopics, like “Depth First Search” and “Recurrence”, is extracted. To ensure the completeness and correctness of these concepts, the obtained KCs are categorized and organized with the help of information from CSDN and Wikipedia. Additionally, three authoritative textbooks, Data Structure Programming Practice, Introduction to Competitive Programming (2nd Edition), and Introduction to Algorithms, are used for validation. This process results in a knowledge graph with 11 topics and 204 KCs.
- Knowledge graph design: Introductory KCs in the field of programming are first identified based on various knowledge sources. For instance, under the “Fundamentals” category, concepts such as “Divide and Conquer” and “Function” are categorized as basic KCs. Next, predecessor–successor relationships are established, linking more advanced KCs like “Dynamic Programming” to foundational concepts. These relationships are labeled with references to content from Data Structure Programming Practice and OI-Wiki. Further validation of the initial knowledge graph is carried out using Introduction to Competitive Programming (2nd Edition) and Introduction to Algorithms to minimize potential subjective biases. The graph is then optimized by retrieving additional hierarchical relationships for KCs from Wikipedia, ensuring a more comprehensive coverage.
- Knowledge storage: After KC acquisition and knowledge graph design, we obtain the nodes and relationships required for the knowledge graph and finally use Neo4j for knowledge storage.
3.3.2. Knowledge Graph Embedding Model: RotatE-TA
- Entity and Relation Definition: We define predecessor KC as head entities and successor KC as tail entities , with the relation denoted as r. These two KCs, along with the relation, are represented as a triple .
- Scoring Function: We define a scoring function for the triple as , which evaluates the importance of a candidate triple.
- Type Comparison: The knowledge topics for all KCs in the knowledge graph are defined as , where each KC is associated with a knowledge topic , and each KC belongs to only one knowledge topic. The comparison of the two knowledge topic types is calculated as follows:
- Distance Scoring with Type-Awareness: Based on the type comparison function, we introduce type-aware weights into the distance scoring function as follows:In Equation (2), ∘ represents the Hadamard product, and represent the modular lengths of the head entity and tail entity, respectively. is a hyperparameter representing the magnitude of type-aware weights.
3.4. Modeling Answer Sequences with VAE
3.4.1. Input Representation
3.4.2. Model Architecture
3.4.3. Objective Function
- Reconstruction Loss: This loss measures the difference between the original input and the output of the decoder y. It is defined as:where N represents the dimensions of the student’s answer sequence, and represent the i-th element of the input sample and the decoder output y, respectively.
- KL Divergence Loss: This loss encourages the learned latent variable distribution to be close to a standard normal distribution. It is defined as:where D represents the dimensions of the latent variable , and and represent the mean and standard deviation of the j-th dimension of the latent variable , respectively.
3.5. Students’ Personalized Learning Abilities
3.5.1. First-Order IRT for Ability Assessment
3.5.2. Inverting Ability Parameters
3.6. LSTM Framework
3.6.1. Modeling Knowledge States with LSTM
3.6.2. Attention Mechanism
3.6.3. Gating Mechanism
3.7. Prediction
4. Experiments
4.1. Dataset
4.1.1. Data Source
4.1.2. Data Preprocess
- Filtering Invalid Submissions: We filtered out invalid submission records, such as those labeled “Time limit exceeded”, “Runtime error”, or “Unanswered”, to retain only valid and meaningful submission data. These invalid records were considered noise and could skew the analysis if included.
- Removing Irrelevant Users: We excluded users with an insufficient number of answer sequences, as these would not provide enough data to model effectively. Additionally, non-student users, including administrators and virtual users, were removed to ensure that the dataset reflected genuine student learning behavior.
- Normalizing Sequence Lengths: Since the number of exercises answered by each student varied significantly, directly modeling answer sequences of different lengths would be challenging. To address this, we standardized the sequence length to a fixed value, ensuring that all input sequences were of uniform length for the model. This involved truncating longer sequences and padding shorter ones to the specified length.
4.2. Environment
4.3. Evaluation Metrics and Baseline Methods
4.3.1. Evaluation Metrics
4.3.2. Baseline Methods
- DKT [1]: A pioneering knowledge tracing method using recurrent neural networks.
- DKT+ [2]: An improved DKT model addressing input reconstruction and state fluctuations.
- DKVMN [3]: A memory network-based model with interpretable knowledge and student state representation.
- Deep-IRT [13]: Combines IRT with DKVMN for an interpretable deep knowledge tracing model.
- AKT [6]: Introduces the Rasch model and self-attention for better exercise and interaction modeling.
- ATKT [15]: Adds adversarial perturbations to LSTM-based sequences to reduce overfitting.
- IEKT [5]: Combines individual cognition and learning processes for accurate knowledge state tracing.
- SAKT [4]: Uses self-attention mechanisms in Transformer to handle sparse data in knowledge tracing.
- SAINT [35]: Extends SAKT with additional attention modules for deeper exercise–answer relationship modeling.
4.4. Model Training and Parameter Selection
4.5. Experiment Results
4.5.1. Comparative Experiment Analysis
4.5.2. Ablation Experiment Analysis
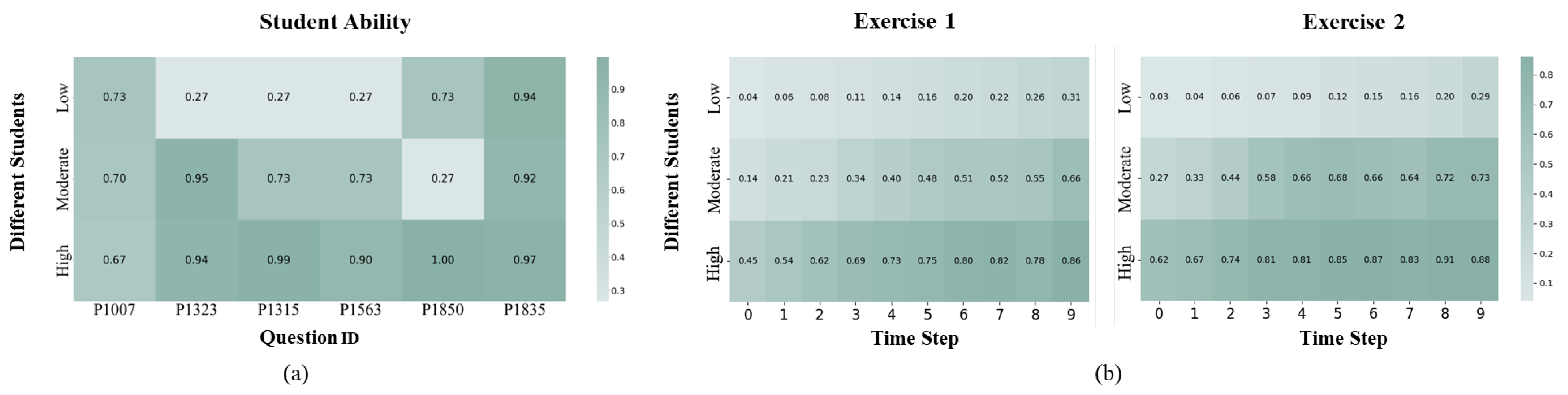
4.6. Visualization
4.6.1. Knowledge Graph Visualization
4.6.2. Student Learning Abilities Visualization
4.6.3. Personalized Answer Sequence Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep knowledge tracing. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Yeung, C.K.; Yeung, D.Y. Addressing two problems in deep knowledge tracing via prediction-consistent regularization. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale, London, UK, 26–28 June 2018; pp. 1–10. [Google Scholar]
- Zhang, J.; Shi, X.; King, I.; Yeung, D.Y. Dynamic key-value memory networks for knowledge tracing. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 765–774. [Google Scholar]
- Pandey, S.; Karypis, G. A self-attentive model for knowledge tracing. arXiv 2019, arXiv:1907.06837. [Google Scholar]
- Long, T.; Liu, Y.; Shen, J.; Zhang, W.; Yu, Y. Tracing knowledge state with individual cognition and acquisition estimation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 173–182. [Google Scholar]
- Ghosh, A.; Heffernan, N.; Lan, A.S. Context-aware attentive knowledge tracing. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 23–27 August 2020; pp. 2330–2339. [Google Scholar]
- Nakagawa, H.; Iwasawa, Y.; Matsuo, Y. Graph-based knowledge tracing: Modeling student proficiency using graph neural network. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; pp. 156–163. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Su, Y.; Liu, Q.; Liu, Q.; Huang, Z.; Yin, Y.; Chen, E.; Ding, C.; Wei, S.; Hu, G. Exercise-enhanced sequential modeling for student performance prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Minn, S.; Yu, Y.; Desmarais, M.C.; Zhu, F.; Vie, J.J. Deep knowledge tracing and dynamic student classification for knowledge tracing. In Proceedings of the 2018 IEEE International conference on data mining (ICDM), Singapore, 17–20 November 2018; pp. 1182–1187. [Google Scholar]
- Lee, J.; Yeung, D.Y. Knowledge query network for knowledge tracing: How knowledge interacts with skills. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019; pp. 491–500. [Google Scholar]
- Yeung, C.K. Deep-IRT: Make deep learning based knowledge tracing explainable using item response theory. arXiv 2019, arXiv:1904.11738. [Google Scholar]
- Abdelrahman, G.; Wang, Q. Knowledge tracing with sequential key-value memory networks. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 175–184. [Google Scholar]
- Guo, X.; Huang, Z.; Gao, J.; Shang, M.; Shu, M.; Sun, J. Enhancing knowledge tracing via adversarial training. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 367–375. [Google Scholar]
- Pandey, S.; Srivastava, J. RKT: Relation-aware self-attention for knowledge tracing. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1205–1214. [Google Scholar]
- Shen, S.; Liu, Q.; Chen, E.; Wu, H.; Huang, Z.; Zhao, W.; Su, Y.; Ma, H.; Wang, S. Convolutional knowledge tracing: Modeling individualization in student learning process. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 1857–1860. [Google Scholar]
- Wang, W.; Liu, T.; Chang, L.; Gu, T.; Zhao, X. Convolutional recurrent neural networks for knowledge tracing. In Proceedings of the 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Chongqing, China, 29–30 October 2020; pp. 287–290. [Google Scholar]
- Liu, Q.; Huang, Z.; Yin, Y.; Chen, E.; Xiong, H.; Su, Y.; Hu, G. Ekt: Exercise-aware knowledge tracing for student performance prediction. IEEE Trans. Knowl. Data Eng. 2019, 33, 100–115. [Google Scholar] [CrossRef]
- Ebbinghaus, H. Memory: A contribution to experimental psychology. Ann. Neurosci. 2013, 20, 155–156. [Google Scholar] [CrossRef] [PubMed]
- Nagatani, K.; Zhang, Q.; Sato, M.; Chen, Y.Y.; Chen, F.; Ohkuma, T. Augmenting knowledge tracing by considering forgetting behavior. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3101–3107. [Google Scholar]
- Yang, Y.; Shen, J.; Qu, Y.; Liu, Y.; Wang, K.; Zhu, Y.; Zhang, W.; Yu, Y. GIKT: A graph-based interaction model for knowledge tracing. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2020, Ghent, Belgium, 14–18 September 2020; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2021; pp. 299–315. [Google Scholar]
- Song, Q.; Luo, W. SFBKT: A Synthetically Forgetting Behavior Method for Knowledge Tracing. Appl. Sci. 2023, 13, 7704. [Google Scholar] [CrossRef]
- Kasurinen, J.; Nikula, U. Estimating programming knowledge with Bayesian knowledge tracing. ACM SIGCSE Bull. 2009, 41, 313–317. [Google Scholar] [CrossRef]
- Wang, L.; Sy, A.; Liu, L.; Piech, C. Learning to Represent Student Knowledge on Programming Exercises Using Deep Learning. In Proceedings of the International Educational Data Mining Society, Paper Presented at the International Conference on Educational Data Mining (EDM), Wuhan, China, 25–28 June 2017. [Google Scholar]
- Piech, C.; Huang, J.; Nguyen, A.; Phulsuksombati, M.; Sahami, M.; Guibas, L. Learning program embeddings to propagate feedback on student code. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1093–1102. [Google Scholar]
- Swamy, V.; Guo, A.; Lau, S.; Wu, W.; Wu, M.; Pardos, Z.; Culler, D. Deep knowledge tracing for free-form student code progression. In Proceedings of the Artificial Intelligence in Education: 19th International Conference, AIED 2018, London, UK, 27–30 June 2018; Proceedings, Part II 19. Springer: Berlin/Heidelberg, Germany, 2018; pp. 348–352. [Google Scholar]
- Shi, Y.; Chi, M.; Barnes, T.; Price, T. Code-dkt: A code-based knowledge tracing model for programming tasks. arXiv 2022, arXiv:2206.03545. [Google Scholar]
- Jiang, B.; Wu, S.; Yin, C.; Zhang, H. Knowledge tracing within single programming practice using problem-solving process data. IEEE Trans. Learn. Technol. 2020, 13, 822–832. [Google Scholar] [CrossRef]
- Liang, Y.; Peng, T.; Pu, Y.; Wu, W. HELP-DKT: An interpretable cognitive model of how students learn programming based on deep knowledge tracing. Sci. Rep. 2022, 12, 4012. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Le Cun, Y.; Fogelman-Soulié, F. Modèles connexionnistes de l’apprentissage. Intellectica 1987, 2, 114–143. [Google Scholar] [CrossRef]
- Koedinger, K.R.; Baker, R.S.; Cunningham, K.; Skogsholm, A.; Leber, B.; Stamper, J. A data repository for the EDM community: The PSLC DataShop. Handb. Educ. Data Min. 2010, 43, 43–56. [Google Scholar]
- Feng, M.; Heffernan, N.; Koedinger, K. Addressing the assessment challenge with an online system that tutors as it assesses. User Model. User-Adapt. Interact. 2009, 19, 243–266. [Google Scholar] [CrossRef]
- Choi, Y.; Lee, Y.; Cho, J.; Baek, J.; Kim, B.; Cha, Y.; Shin, D.; Bae, C.; Heo, J. Towards an appropriate query, key, and value computation for knowledge tracing. In Proceedings of the Seventh ACM Conference on Learning@ Scale, Virtual, 12–14 August 2020; pp. 341–344. [Google Scholar]
- Liu, Z.; Liu, Q.; Chen, J.; Huang, S.; Tang, J.; Luo, W. pyKT: A python library to benchmark deep learning based knowledge tracing models. Adv. Neural Inf. Process. Syst. 2022, 35, 18542–18555. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Sources | Students | Exercises | Interactions | Knowledge Concepts |
|---|---|---|---|---|
| Luogu | 2081 | 3329 | 299,168 | 190 |
| Codeforces | 1685 | 8237 | 630,724 | 204 |
| Configuration Environment | Configuration Parameters |
|---|---|
| Operating System | Windows 10 64-bit |
| GPU | RTX 3070ti |
| CPU | i7-13700H |
| Memory | 16 GB |
| Programming language | Python 3.7 |
| Deep learning framework | tensorflow 2.1.0 |
| Python library | Scikit-learn, Numpy, Pandas |
| Methods | Luogu | Codeforces | ||
|---|---|---|---|---|
| AUC | ACC | AUC | ACC | |
| DKT | 0.8114 | 0.8397 | 0.6804 | 0.8574 |
| DKT+ | 0.8104 | 0.8388 | 0.7037 | 0.8589 |
| Deep-IRT | 0.8020 | 0.8271 | 0.6702 | 0.8526 |
| DKVMN | 0.8058 | 0.8300 | 0.6828 | 0.8573 |
| IEKT | 0.8230 | 0.8309 | 0.7308 | 0.8567 |
| SAKT | 0.8301 | 0.8307 | 0.6708 | 0.8550 |
| SAINT | 0.8263 | 0.8254 | 0.6763 | 0.8577 |
| AKT | 0.8313 | 0.8394 | 0.7491 | 0.8595 |
| ATKT | 0.8380 | 0.8418 | 0.7543 | 0.8614 |
| GPPKT (our) | 0.8840 | 0.8472 | 0.7770 | 0.8799 |
| Methods | AUC | ACC |
|---|---|---|
| (1) LSTM | 0.8097 | 0.7954 |
| (2) LSTM + VAE | 0.8576 | 0.8343 |
| (3) LSTM + KG | 0.8654 | 0.8361 |
| (4) LSTM + ABI | 0.8679 | 0.8380 |
| (5) LSTM + VAE + ABI | 0.8762 | 0.8425 |
| (6) LSTM + VAE + KG | 0.8749 | 0.8392 |
| (7) LSTM + KG + ABI | 0.8703 | 0.8411 |
| (8) LSTM + VAE + KG + ABI | 0.8840 | 0.8472 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, J.; Dong, Z.; Yan, L.; Cai, X. Knowledge Graph and Personalized Answer Sequences for Programming Knowledge Tracing. Appl. Sci. 2024, 14, 7952. https://doi.org/10.3390/app14177952
Pan J, Dong Z, Yan L, Cai X. Knowledge Graph and Personalized Answer Sequences for Programming Knowledge Tracing. Applied Sciences. 2024; 14(17):7952. https://doi.org/10.3390/app14177952
Chicago/Turabian StylePan, Jianguo, Zhengyang Dong, Lijun Yan, and Xia Cai. 2024. "Knowledge Graph and Personalized Answer Sequences for Programming Knowledge Tracing" Applied Sciences 14, no. 17: 7952. https://doi.org/10.3390/app14177952
APA StylePan, J., Dong, Z., Yan, L., & Cai, X. (2024). Knowledge Graph and Personalized Answer Sequences for Programming Knowledge Tracing. Applied Sciences, 14(17), 7952. https://doi.org/10.3390/app14177952