
Authenticated Multicast in Tiny Networks via an Extremely Low-Bandwidth Medium


Abstract
:Featured Application
Abstract
1. Introduction
1.1. Problematic Communication Channels
1.2. Tradeoff between Channel Security and Payload Capacity
1.3. Communication versus Computational Complexity
1.4. Network Scale
1.5. Multicasting and the Problem of Shared Symmetric Keys
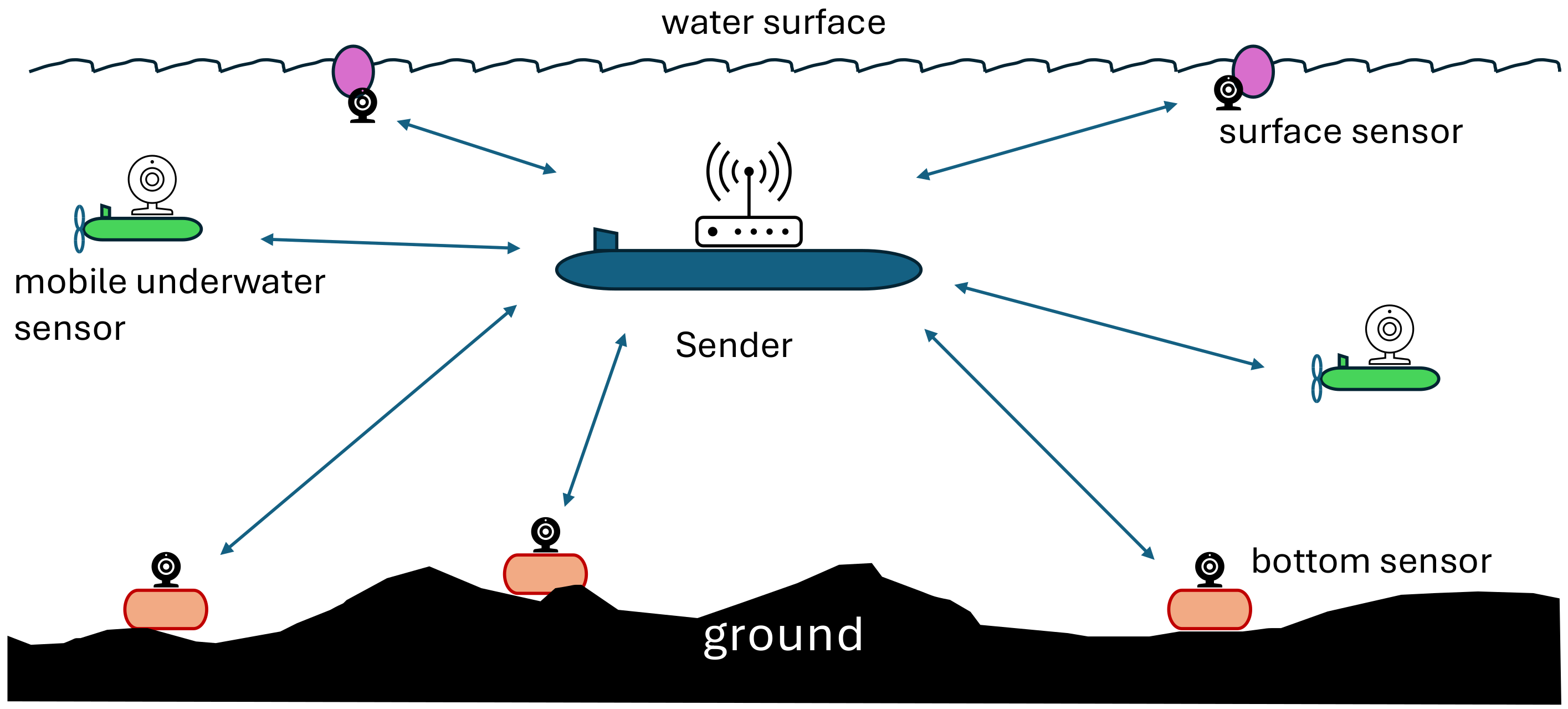
1.6. Further Operating Environment Details
1.7. Network Setup: Multicast Groups
1.8. Node Subversion Threat: Impact on Multicast Groups
2. Problem Statement
- 1.
- How can the shared keys between the sender and multicast group members be derived without resorting to asymmetric methods such as Diffie–Hellman key exchange, where the messages are relatively long bit strings?
- 2.
- In reference to the message authentication mechanism for a multicast group, how can the asymmetry in key knowledge between the sender and the receivers be preserved, as is the case of digital signatures, while keeping the total overhead as small as possible?
Our Contribution and Paper Organization
- We provide an optimized scheme for multicast group establishment based on summing smaller receiver sets into larger ones.
- We connect the summing strategy for group establishment to a combinatorics problem of covering designs and conclude that improvements to the above scheme are unlikely.
- We introduce a novel scheme for multicast group establishment based on onion encryption that minimizes the communication overhead.
- We introduce a framework of separating families for studying sender authentication schemes in tiny networks under the assumption of a highly constrained communication channel.
- We provide an efficient sender authentication scheme that fits the above framework to enable tweaking the security level and making different trade-offs based on assumptions about the adversary’s behavior.
- We extend the separating families framework to the setting of two corrupt parties, showing that the problem of sender authentication becomes significantly more difficult.
- We propose security policies that complement the proposed sender authentication scheme, increasing the overall security of the system.
3. Establishing Group Keys
3.1. Summing Strategies
- 1.
- Chooses a group key K at random;
- 2.
- Selects a set of w indices I such that ;
- 3.
- Broadcasts w messages, with the ith message being a ciphertext of K obtained with the key , i.e., .
3.1.1. Decimating the Power Set
- 1.
- Chooses a key K at random;
- 2.
- Finds the intersection for each ;
- 3.
- Broadcasts k messages, with the i-th message being a ciphertext of K obtained with the key , i.e., ;
- 4.
- For such that , the ciphertext of K is send to the only member via one-to-one channel (unicast transmission).
3.1.2. Optimizing the Summing Strategy
3.2. Intersection Strategy with Onion Encryption
- 1.
- Chooses a group master key K at random;
- 2.
- Broadcasts the onion ciphertexttogether with an identifier of the set .
4. Sender Authentication
4.1. TESLA Protocol
4.2. Inadequacy of TESLA for Low-Bandwidth High-Latency Communication Media
- 1.
- If messages are asynchronous and not sent at a steady rate (e.g., they are triggered by external events), then certain epochs may pass without any workload messages. However, TESLA requires some technical messages in each epoch to operate properly.
- 2.
- Alternatively, if the epochs are driven not by the clock but by the number of messages sent (e.g., the epoch changes every v messages), then some messages can be left unauthenticated for a long time. On the other hand, when a burst of multicast messages occurs in a short time, the epochs will change quickly. This creates a security risk, discussed in Section 4.2.1.
- 3.
- The length of the clock-driven epoch should be adjusted to variable message delivery delays for different network nodes. Thus, the choice implies either long waits for authentication data or the security risk discussed in Section 4.2.1.
- 4.
- If messages are not known in advance, the immediate packet authentication mentioned above cannot be used. It seems that in the case of a network constrained in terms of communication, the opportunities for the messages to be known d epochs ahead of time will be rare; thus, in most cases the mechanism will not be applicable.
4.2.1. Wormhole Attacks against TESLA
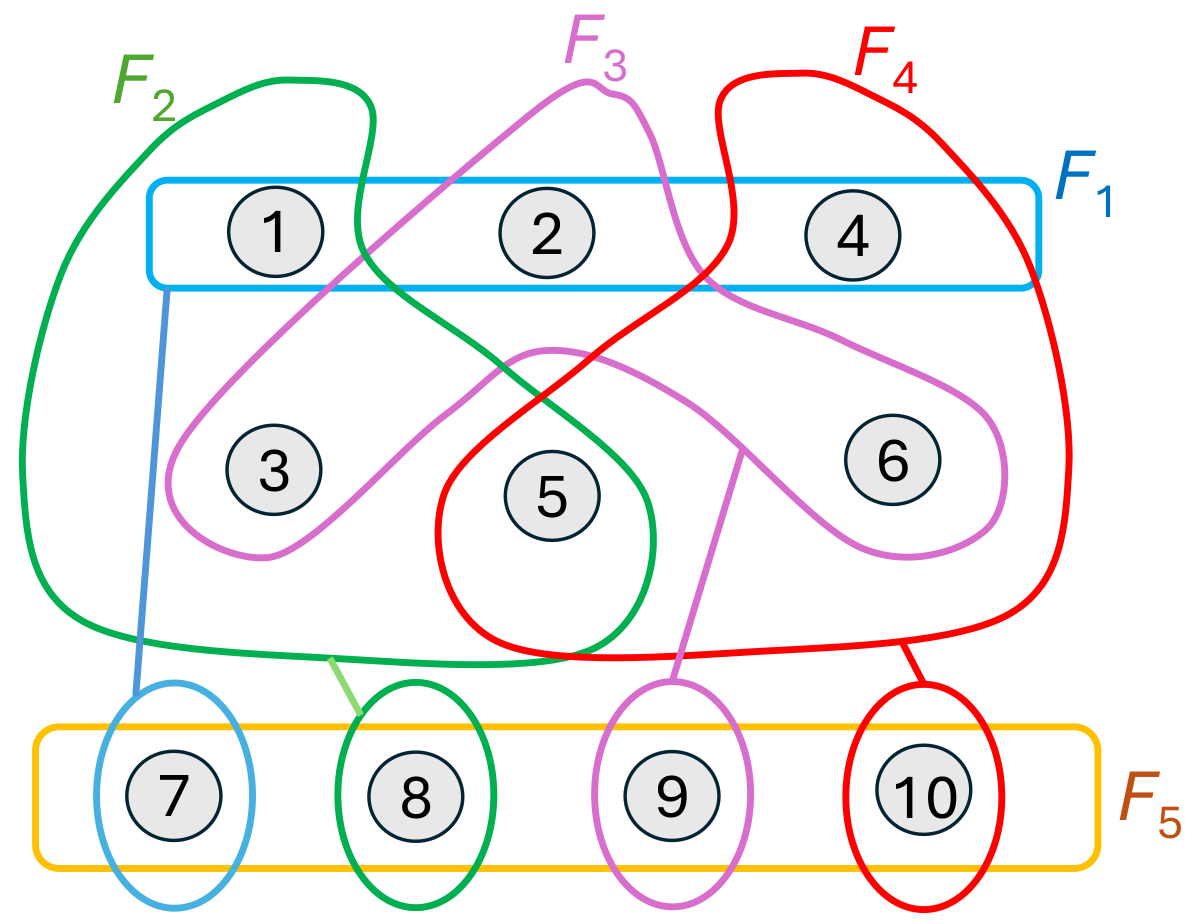
4.3. Separating Families
- The ith tag is created with a separate symmetric key shared by the sender and a set of receivers ;
- A receiver j may verify the i-th tag if and only if it knows , i.e., .
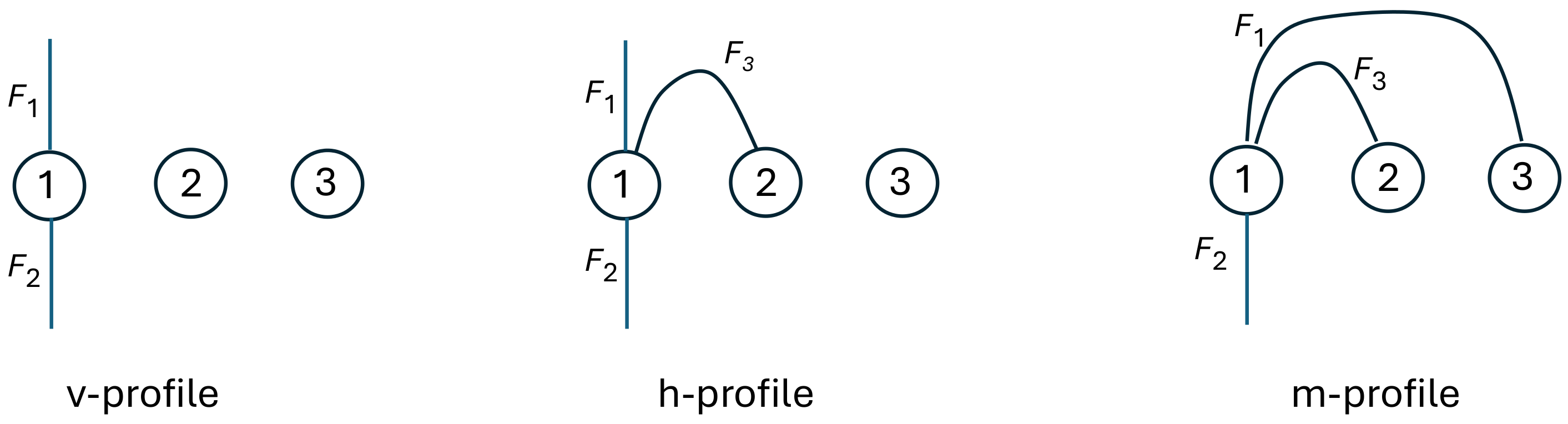
4.3.1. Basic Examples
4.3.2. Minimal Separating Families
4.4. Dual Graph Construction
- 1.
- Create a graph G with k vertices labeled by and with no edges;
- 2.
- For :
- (a)
- find two vertices not yet connected in G,
- (b)
- connect by an edge labeled by i.
- 3.
- For :
- —
- define set as the set of all labels of the edges incident to the vertex labeled by .
4.5. Optimal Values for Small Number of Nodes
4.5.1. Preliminary Facts
4.5.2. Exact Values of for Small r
- :
- Obviously, as 1 must be separated from 2 by a different set than 2 from 1.
- :
- We have ; thus, we assume that , and is the corresponding minimal separating family. Each must belong to some set from ; thus, by the pigeonhole principle, there is that contains two elements, say, a and b. We need two sets that separate a and b, say , and , . Thus, , are different from F, and we have at least three sets in , which is a contradiction.
- :
- Similar to above, we have . By way of contradiction, suppose that ; then, by the pigeonhole principle, there exists a set in that contains at least two elements. Without loss of generality, we may assume that there is no four-element set in , as it would not contribute to the separation of any elements. Supposing first that there exists an set that contains 3 elements, say, , then the elements 1, 2, and 3 must be separated; however, F does not contribute to this separation. Thus, there must be elements in other than F that separate these elements. Therefore, has at least four elements, which is a contradiction.Suppose now that there is no three-element set in . Because there must be at least one two-element set, let it be . Similarly as in the case of , the elements 1 and 2 must be separated; thus, there exist such that , , and , . Therefore, consists of at least the three sets: , , and . Because 3 and 4 must belong to some set of , and no set has three elements, we have (up to exchanging the elements 3 and 4) , . However, in this case, elements 1 and 3 are not separated, which is a contradiction.
- :
- Because , and (as we later show) , we obtain as well. However, for later use we need to show that (up to a permutation on ) the only solution with four sets is the family . Let be a separating family consisting of four sets. The first observation is that does not contain any set F of cardinality 4. Indeed, the elements of F must be separated from each other, and we need sets for this purpose. As F does not separate any pair of its elements, would contain at least 5 elements, which is a contradiction. Similar reasoning shows that does not contain any one-element set.Now, cannot contain only sets of cardinality 2, otherwise the sets from would contain eight elements altogether (with repetitions), meaning that some element i would appear in only one set. As this set would contain another element j, it would be impossible to separate i from j.As must contain a set of cardinality 3, we assume without loss of generality that . In order to separate , each must be included in a set such that and none of the remaining elements from belongs to . Thus, consists of the following sets (where the dots ‘…’ stand for yet unknown element or elements):Element 4 must belong to at least two sets; otherwise, if 4 belonged only to , it could not be separated from other elements from F. It cannot belong to all of them, as then it would be impossible to separate 5 from 4. Thus, up to renaming the nodes, consists of the following sets:Now, element 5 must go in the last set (as there is no set in with only a single element), and the other 5 to either or , providing the solutions and (see Figure 6). In fact, these solutions are the same, only the nodes are renamed.
- :
- We have a separating family consisting of four sets: , , , . As , we can conclude that .For later use, we show that this is the only solution up to a permutation of nodes. Let be a separating family containing four sets.First, we observe that there is no set with one or two elements. By way of contradiction, we can assume that F is such a set. Then, contains at least four elements. To separate them, we need at least four elements in , as . None of these sets is F, because F does not separate any pair of elements from U. Thus, together, we would have at least five sets in , which is a contradiction. If F contains four or more elements, a similar argument applies. To separate the elements of F, we need at least sets, where none of them is F. Thus, we can conclude that contains only sets of cardinality 3.The next observation is that if , then a must appear in at least one other set to separate it from . As four sets with three elements each have twelve elements altogether (with repetitions), each element must appear in exactly two sets from .Now, let us construct an optimal solution (up to renaming the nodes). Without loss of generality, assume that . Thus, consists of the sets having the following form (the asterisk * stands for an unknown element):Element 4 belongs to two sets; because of symmetry (permuting ), we may assume that consists of the following sets:We need to put the remaining elements 5 and 6 in place of the asterisks. One of them falls into , say, element 5; consequently, it cannot appear in , as then we could not separate 4 and 5. This means that 5 is placed in , and 6 must then be placed in the remaining two places, providing the following solution (see Figure 7):
- :
- First, we note that by Lemma 2. We also know that .Assuming towards contradiction that , let be a separating family with four sets; we first consider the case in which no set in contains more than two elements. Each element of must belong to some set in , meaning that at least three out of four sets in must be disjoint (say, , , are in ). However, the elements must be separated, and none of the sets above separates them; thus, we need two additional sets and must contain at least five sets altogether, which is a contradiction.Suppose now that there exists a set with three elements in . Without loss of generality, let these elements be and consider the remaining elements 4, 5, 6, and 7. As , we need four sets to separate these remnants. As does not separate any pair of elements from , consists of at least sets in total, which again is a contradiction.Finally, suppose there is a set consisting of at least four elements. To separate these elements, we need at least four additional sets. Again, would have at least five elements, which is a contradiction.
- for :
- It suffices to present a separating family for ; however, we will show slightly more. Specifically, we shall identify all separating families for with five elements. Similar to the case with , we show that there is only one solution up to some trivial transformations.Let us start with a simple observation:
- Let be a separating family for .
- Observe that no contains 7 or more elements. Indeed, suppose that , where . Consider , …, . Then, must separate every . However, it is impossible to find a separating family with 4 sets for an ℓ-element set (), as .
- Let us now assume that and, without loss of generality, let . Consider for , as before. Clearly, is a separating family for . Therefore, without loss of generality (see the case with above), we may assume that , , , . The sets can be obtained by adding some number of elements 7, 8, 9, 10 to .
- First, observe that no can belong to only one set ; indeed, in this case a would not be separated from other elements of . Thus, we assume that a belongs to two sets, say, . However, . If , then we would be unable to separate a from b. Of course, a cannot belong to all , as we would be unable to separate elements in from a. Thus, we may conclude that a belongs to three of the sets . In order to guarantee that are separated from each other, each must be missing in a separate set. Thus, up to a permutation on , the sets are equal toNow, assume that one of the sets in the separating family contains five elements, say , and that no set has more than five elements. Consider for and for . These are separating families for and , respectively. Thus, without loss of generality, we may assume that these families (after permuting the elements and order of the sets) are as follows:andrespectively. We have to find a matching between these two lists and sum up each pair to obtain the sets . Note that we always have to match a set of cardinality 2 with a set of cardinality 3 in order to satisfy the assumption that no contains more than five elements. Now, consider element 7. The set is matched with some two-element set , while the set is matched with a three-element set . However, note that in this case we have (cf. (6)). If , then we cannot separate 7 from b, which is a contradiction. It can be seen that there is no separating family consisting of five sets where at least one of the sets contains exactly five elements.
- We are left with the case that every set in a separating family has at most four elements. Per Lemma 4, any such separating family corresponds to a separating family in which every set contains at least elements. All such families have been identified above. Thus, up to a permutation, by applying Lemma 4 we obtain the following family (see Figure 8):
- :
- Per Lemma 2, ; thus, it suffices to show that . We know by monotonicity of that . We assume towards a contradiction that a separating family for contains five sets.Consider an arbitrary and . If either F or U has cardinality at least 7, then we need sets to separate elements in this set by a similar argument as in the case. None of them is F, meaning that we have at least six elements in , which is a contradiction. We can conclude that each set contains either five or six elements.First, assume that F contains five elements. Without loss of generality, let . Let , , , be the remaining four sets of family . Note that must be a separating family for the set . According to what we have learned for the case with , without loss of generality, we may assume that we obtain , , , . Analogously, again without loss of generality, when we intersect with U, we obtain the following sets: , , , Thus far, we do not know how to link these sets to , , , (i.e., the intersections of the with F), to recover the full sets . However, we may assume that , as we can always rename the elements. Then, of course, cannot be used to separate 6 from 1, 2, and 3, while remains as a candidate for a set that separates 6 from 1, 2, and 3. It can be matched with any of the remaining intersections, namely, , , or . Unfortunately, none of these works:
- If , then 6 cannot be separated from 1;
- If , then 6 cannot be separated from 2;
- If , then 6 cannot be separated from 3;
which results in a contradiction.Now, let us assume that F contains six elements, say, 6, 7, 8, 9, 10, and 11, and let U be the complement of F, namely, . Let , , , and be the remaining sets of . As before, without loss of generality, we may assume that , , , and . Intersecting the with U results in , , , (not necessarily in this order, and up to a permutation of ). Again, the question is whether the elements of U can be separated from the elements of F. As the elements of U have changed, this is a different question than before. Again, without loss of generality, we may assume that . Then, cannot be used to separate 1 from 6, 7, or 8. The only other set that contains 1 and can be used to separate it from 6, 7, and 8 is . One is a sum of with one of the sets , , or . Again, no matter what we choose, the resulting set will contain some and 1 will not be separated from j. - :
- Let us take the separating family for presented above, which consists of the sets , , , , . We can create a family for that consists of the following sets:, , , , , and . Let us first check whether is a separating family. If , then the separation property follows from the properties of . For , it follows from the fact that each appears in a separate set in the list . If and , then i is separated from j by . The only unclear case is that of and . However, each appears in one of the sets , while i occurs in two such sets; thus, there is always a set such that and .
- :
- First, recall from Definition 5 that . Thus, it suffices to show that . Conversely, we can assume that is a separating family for .First, we assume that some set, say, contains at least eleven elements. Then, for is a separating family for U. This is impossible, as . If contains at most nine elements, then for is a separating family for . This is a contradiction, as this set contains at least eleven elements. Thus, we conclude that each is a ten-element set.Without loss of generality, we assume that . Consider for and for . These families are separating families for and , respectively. Luckily, we already know what they may look like, as are all either six-element sets or four-element sets. The same holds for the family . As , one family consists of six-element sets and the other of four-element sets. Without loss of generality, we assume that are six-element sets and that they are equal toWe rename elements to and assume that the family isAs before, the sets are obtained by finding a matching between the sets in (9) and (8). We have to do this in such a way that each element can be separated from each element (note that is useless for this purpose). Consider and assume, without loss of generality, that it is matched with to obtain . Note that in this way cannot be used to separate from . The only that can be used for this purpose must be created by joining with one of the remaining sets on the list (8). This set must not contain any of the elements in order to be able to separate from them. Unfortunately, every two sets on the list (8) have a non-empty intersection with , resulting in a contradiction.
4.6. Use of Separating Families for Construction of Authentication Tags
4.6.1. Construction of the Tags
4.7. Attack Attempts
4.7.1. External Adversary
4.7.2. Internal Adversary
4.7.3. Example
4.8. Two Malicious Receiver Nodes
- 1.
- may contain more than four elements; let V be its four-element subset. Without loss of generality, we assume that .
- 2.
- We consider on V and show how many different sets from are needed to guarantee the 2-separation property for the elements of V. It turns out that at least six or seven sets are needed, depending on the case.
- 3.
- We consider how the 2-separating property can be fulfilled when we add the remaining elements:
- If seven subsets are already in to separate on V, there are eight sets with altogether. Thus, the minimal r to consider is 9. Note that the elements must be added somehow to already identified elements of in such a way that the 2-separation property is fulfilled. We aim to show that this is impossible.
- If there are six elements in to separate within V, then the proof is similar, but we must take into account an additional element of not identified so far if . For , all sets are already named.
- case
- : Each trace has cardinality 1; per Claim 6, there are eight traces (two per element), meaning that together with V there are at least nine sets in . Consequently, .
- case
- : Two nodes belong to traces of cardinality 1, meaning that they correspond to four different sets.The remaining two nodes, say, , belong to one or more sets with trace . As in the proof of Claim 6, we can conclude that, apart from these sets, 1 belongs to at least two more sets from . Indeed, if there is only one such set F, we take , . Then, 1 cannot be separated from i and 2. If no such F exists, then the argument is even easier: we cannot separate 1 from 2. The same holds for 2. Thus, the number of sets with nonempty traces in V is at least . With V, we have identified ten different sets in . Consequently, .
- case
- : If, say, belong to traces of cardinality 2 while 4 does not, then per Claim 6 there are two sets with the trace . Per Claim 6, each element belongs to three different sets (apart from V). Thus, when counting with repetitions, there are nine sets. As traces are of cardinality at most 2, there are at most three two-element traces: , , . If they occur once, they cover six out of nine sets with repetitions counted above. Then, the number of sets in is at least , and consequently . However, if a trace appears twice, then we need an additional set at 1 (and at 2 as well). Thus far, there is no set in that would separate 1 from 2 and 3. We are again left with three sets (with repetitions) and a newly identified set in . Continuing in this way, it can be seen that we shall always conclude that .
- case
- : For each i, there are at least three different sets in . Counting with repetitions, there are in total sets. Each set with a two-element trace is counted twice, and there are no traces with more than two elements that would be counted more than twice. Thus, there are at least six sets in .Note that there are different pairs of elements in V; hence, the number of two-element traces is at most 6.
- ; indeed, is incident , meaning that they would not belong to . Only and are left, but they are incident, and only one of them can belong to . Thus, we would end up with two sets in , which is contrary to Claim 11.
- In the same way, we argue that .
- ; indeed, if , then , as they are incident to . Thus, we are left with only. However, they are incident, and would contain only two sets, contradicting Claim 11.
- In the same way, we argue that .
- : i belongs to exactly two sets . Then, .
- : i belongs to exactly three sets , where and .
- : i belongs to exactly three sets , where and .
- : any of the above, but a trace may correspond to more sets.
- If , then ;
- If , then .
- , if i has ;
- , if i has ;
- , if i has ;
- , if i has .
4.9. Strengthening Authentication Scheme
4.9.1. Obligation to Raise an Alarm
- The messages in question;
- The identifier of the group together with the index of the wrong ;
- The observed values of the chunks ;
- The correct values of the chunks .
- They can also complain to S about the wrong in order to not be blamed for being the author of the messages ; however, the adversary then informs the sender about their own malicious activity. Moreover, the adversary should provide to S with the correct values of the chunks . If the guesses are wrong, then the adversary automatically points to themselves as the author of the suspicious messages.
- They can refrain from complaining to S about the wrong ; however, the alleged sender will gradually obtain information from other nodes, narrowing the set of suspected nodes. In this case, the adversary not sending a complaint will confirm the suspicions.
4.9.2. Two-Factor Authentication
4.9.3. Response to the Incident
5. Related Work
6. Conclusions and Final Remarks
- 1.
- How to establish a shared key for a multicast group;
- 2.
- How to authenticate the source of multicast messages so as to prevent senders being impersonated by internal adversaries.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Set of potential receivers | |
| n | Cardinality of |
| Set of receivers in a multicast transmission | |
| r | Cardinality of |
| Separating family of subsets of ; see Definition 3 on page 13 | |
| Size of minimal separating family for ; see Problem 2 on page 14 | |
| Trace of ; see Definition 7 on page 26 | |
| BER | Bit Error Rate |
| DPSK | Differential Phase Shift Keying |
| DRNG | Deterministic Random Number Generator |
| ECDSA | Elliptic Curve Digital Signature Algorithm |
| LoRaWAN | Long-Range Wide-Area Network |
| MAC | Message Authentication Code |
| TESLA | Timed Efficient Stream Loss-tolerant Authentication |
| UUV | Unmanned Underwater Vehicle |
References
- Zieliński, A. Communications underwater. Hydroacoustics 2004, 7, 235–252. [Google Scholar]
- Alraie, H.; Alahmad, R.; Ishii, K. Double the data rate in underwater acoustic communication using OFDM based on subcarrier power modulation. J. Mar. Sci. Technol. 2024, 29, 457–470. [Google Scholar] [CrossRef]
- Kochańska, I.; Schmidt, J.H.; Marszal, J. Shallow Water Experiment of OFDM Underwater Acoustic Communications. Arch. Acoust. 2020, 45, 11–18. [Google Scholar]
- Winderickx, J.; Braeken, A.; Singelée, D.; Mentens, N. In-depth energy analysis of security algorithms and protocols for the Internet of Things. J. Cryptogr. Eng. 2022, 12, 137–149. [Google Scholar] [CrossRef]
- Silva, B.L.M.T.; Sousa, F.S.; Santos, G.G.; Santos, D.F.S.; Morais, M.R.A.; Perkusich, A. A Low-Power Cryptographic Coprocessor Design for the Internet of Things. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 January 2022; pp. 1–2. [Google Scholar]
- El-Hadedy, M.; Guo, X.; Yoshii, K.; Cai, Y.; Herndon, R.; Banta, B.; Hwu, W.M. RECO-ASCON: Reconfigurable ASCON hash functions for IoT applications. Integr. VLSI J. 2023, 93. [Google Scholar] [CrossRef]
- Pearson, B.; Zou, C.C.; Zhang, Y.; Ling, Z.; Fu, X. SIC2: Securing Microcontroller Based IoT Devices with Low-cost Crypto Coprocessors. In Proceedings of the 26th IEEE International Conference on Parallel and Distributed Systems, ICPADS 2020, Hong Kong, 2–4 December 2020; pp. 372–381. [Google Scholar] [CrossRef]
- Xing, G.; Chen, Y.; He, L.; Su, W.; Hou, R.; Li, W.; Zhang, C.; Chen, X. Energy Consumption in Relay Underwater Acoustic Sensor Networks for NDN. IEEE Access 2019, 7, 42694–42702. [Google Scholar] [CrossRef]
- Sehgal, A.; David, C.; Schönwälder, J. Energy consumption analysis of underwater acoustic sensor networks. In Proceedings of the OCEANS’11 MTS/IEEE KONA, Waikoloa, HI, USA, 19–22 September 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Dobraunig, C.; Eichlseder, M.; Mendel, F.; Schläffer, M. Ascon v1.2: Lightweight Authenticated Encryption and Hashing. J. Cryptol. 2021, 34, 33. [Google Scholar] [CrossRef]
- Dargahi, T.; Javadi, H.H.S.; Shafiei, H. Securing Underwater Sensor Networks Against Routing Attacks. Wirel. Pers. Commun. 2017, 96, 2585–2602. [Google Scholar] [CrossRef]
- Perrig, A.; Canetti, R.; Song, D.X.; Tygar, J.D. Efficient and Secure Source Authentication for Multicast. In Proceedings of the Network and Distributed System Security Symposium, NDSS 2001, San Diego, CA, USA, 8–9 February 2001; The Internet Society: Reston, VA, USA, 2001. [Google Scholar]
- Steiner, J. Combinatorische Aufgabe. J. Reine Angew. Math. 1853, 45, 273–280. [Google Scholar]
- Schönheim, J. On coverings. Pac. J. Math. 1964, 14, 1405–1411. [Google Scholar] [CrossRef]
- Perrig, A.; Canetti, R.; Tygar, J.; Song, D. The TESLA Broadcast Authentication Protocol. RSA CryptoBytes 2002, 5, 2–13. Available online: https://www.cryptrec.go.jp/cryptrec_03_spec_cypherlist_files/PDF/cryptobytes_v5n2.pdf (accessed on 1 September 2024).
- Baugher, M.; Carrara, E. The Use of Timed Efficient Stream Loss-Tolerant Authentication (TESLA) in the Secure Real-Time Transport Protocol (SRTP); RFC 4383; Internet Engineering Task Force (IETF): Fremont, CA, USA, 2006. [Google Scholar]
- Lamport, L. Password Authentification with Insecure Communication. Commun. ACM 1981, 24, 770–772. [Google Scholar] [CrossRef]
- Diamant, R.; Casari, P.; Tomasin, S. Cooperative Authentication in Underwater Acoustic Sensor Networks. IEEE Trans. Wirel. Commun. 2019, 18, 954–968. [Google Scholar] [CrossRef]
- NATO Standardization Office (NSO). NATO Standard, ANEP-87; Digital Underwater Signalling Standard for Network Node Discovery & Interoperability; NATO: Brussels, Belgium, 2024; Edition A, Version 2. [Google Scholar]
- Téglásy, B.Z.; Wengle, E.; Potter, J.R.; Katsikas, S.K. Authentication of underwater assets. Comput. Netw. 2024, 241, 110191. [Google Scholar] [CrossRef]
- Ateniese, G.; Capossele, A.; Gjanci, P.; Petrioli, C.; Spaccini, D. SecFUN: Security framework for underwater acoustic sensor networks. In Proceedings of the OCEANS 2015, Genova, Italy, 18–21 May 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Souza, E.; Wong, H.C.; Cunha, Í.; Loureiro, A.A.F.; Vieira, L.F.M.; Oliveira, L.B. End-to-end authentication in Under-Water Sensor Networks. In Proceedings of the 2013 IEEE Symposium on Computers and Communications, ISCC 2013, Split, Croatia, 7–10 July 2013; IEEE Computer Society: Washington, DC, USA, 2013; pp. 299–304. [Google Scholar] [CrossRef]
- Banerjee, U.; Chandrakasan, A.P. A Low-Power BLS12-381 Pairing Crypto-Processor for Internet-of-Things Security Applications. arXiv 2022, arXiv:2201.07496. [Google Scholar]
- Barbulescu, R.; Gaudry, P.; Kleinjung, T. The Tower Number Field Sieve. In Proceedings of the Advances in Cryptology—ASIACRYPT 2015—21st International Conference on the Theory and Application of Cryptology and Information Security, Auckland, New Zealand, 29 November–3 December 2015; Proceedings, Part II. Iwata, T., Cheon, J.H., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9453, pp. 31–55. [Google Scholar] [CrossRef]
- Kumar, M.; Chand, S. Pairing-Friendly Elliptic Curves: Revisited Taxonomy, Attacks and Security Concern. arXiv 2022, arXiv:2212.01855. [Google Scholar]
- Casari, P.; Diamant, R.; Tomasin, S.; Neasham, J.; Lampe, L. Practical Security for Underwater Acoustic Networks: Published Results from the SAFE-UComm Project. Forum Acusticum. 2023. Available online: https://dael.euracoustics.org/confs/fa2023/data/articles/000615.pdf (accessed on 1 September 2024).
- Casari, P.; Ardizzon, F.; Tomasin, S. Physical Layer Authentication in Underwater Acoustic Networks with Mobile Devices. In Proceedings of the 16th International Conference on Underwater Networks & Systems, WUWNet ’22, Boston, MA, USA, 14–16 November 2022. [Google Scholar] [CrossRef]
- Canetti, R.; Garay, J.A.; Itkis, G.; Micciancio, D.; Naor, M.; Pinkas, B. Multicast Security: A Taxonomy and Some Efficient Constructions. In Proceedings of the IEEE INFOCOM ’99, The Conference on Computer Communications, Eighteenth Annual Joint Conference of the IEEE Computer and Communications Societies, the Future Is Now, New York, NY, USA, 21–25 March 1999; IEEE Computer Society: Washington, DC, USA, 1999; pp. 708–716. [Google Scholar] [CrossRef]
- Challal, Y.; Bettahar, H.; Bouabdallah, A. A taxonomy of multicast data origin authentication: Issues and solutions. IEEE Commun. Surv. Tutorials 2004, 6, 34–57. [Google Scholar] [CrossRef]
- El Chall, R.; Lahoud, S.; El Helou, M. LoRaWAN Network: Radio Propagation Models and Performance Evaluation in Various Environments in Lebanon. IEEE Internet Things J. 2019, 6, 2366–2378. [Google Scholar] [CrossRef]
- Falanji, R.; Heusse, M.; Duda, A. Range and Capacity of LoRa 2.4 GHz. In Mobile and Ubiquitous Systems: Computing, Networking and Services 19th EAI International Conference, MobiQuitous 2022, Pittsburgh, PA, USA, 14–17 November 2022; Proceedings; Longfei, S., Bodhi, P., Eds.; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2022; Volume 492, pp. 403–421. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Rate (bps) | Bandwidth/ Carrier (kHz) | Bandwidth Efficiency (bps/Hz) | Range (km) | Shallow/Deep |
|---|---|---|---|---|
| 1600 | 10/50 | 0.16 | 0.1 | shallow |
| 16,000 | 8/20 | 2.0 | 6.5 | deep |
| 20,000 | 10/50 | 2.0 | 1.0 | deep |
| Method of Message Authentication | Size of the Authentication Component (in bits) |
|---|---|
| ECDSA signature on a 256-bit curve | 512 |
| FALCON 512 post-quantum signature (with parameters for NIST security level 1) | >5000 |
| n authentication tags, each 20-bits long (a separate tag generated for each receiver, probability of a forgery of a single tag: ) |
| Number of Receiver Nodes | k | # Group Keys per Receiver | # Keys Stored by the Sender |
|---|---|---|---|
| 8 | 2 | 7 | 22 |
| 8 | 4 | 1 | 4 |
| 16 | 2 | 127 | 494 |
| 16 | 4 | 7 | 44 |
| r: | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| number of sets in a separating family | ||||||||||||||||||
| Definition 4 | 6 | 6 | 6 | 6 | 6 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 10 | 10 | 10 | 10 | 10 |
| Definition 5 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 5 | 6 | 6 | 6 | 6 | 6 | 7 | 7 | 7 | 7 | 7 |
| r | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 6 | 6 | 6 | 6 | 6 | 7 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | x | x | x | x | |||||||||||
| x | x | x | x | x | |||||||||||
| x | x | x | x | x | |||||||||||
| x | x | x | x | x | |||||||||||
| x | x | x | x | x | |||||||||||
| x | x | x | x | x |
| Algorithm | Security Level | Number of Nodes in the Network | |||
|---|---|---|---|---|---|
| 3 | 6 | 9 | 15 | ||
| Basic by Canetti et al. [28] | Number of MAC keys = 41 Communication overhead = 451 bits | ||||
| Number of MAC keys = 79 Communication overhead = 1659 bits | |||||
| Low overhead by Canetti et al. [28] | Number of MAC keys = 148 Communication overhead = 148 bits | ||||
| Number of MAC keys = 300 Communication overhead = 300 bits | |||||
| Our construction (tag ) | , 3 MAC keys 30 bits | , 4 MAC keys 40 bits | , 5 MAC keys 50 bits | , 6 MAC keys 60 bits | |
| , 3 MAC keys 60 bits | , 4 MAC keys 80 bits | , 5 MAC keys 100 bits | , 6 MAC keys 120 bits | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kutyłowski, M.; Cinal, A.; Kubiak, P.; Korniienko, D. Authenticated Multicast in Tiny Networks via an Extremely Low-Bandwidth Medium. Appl. Sci. 2024, 14, 7962. https://doi.org/10.3390/app14177962
Kutyłowski M, Cinal A, Kubiak P, Korniienko D. Authenticated Multicast in Tiny Networks via an Extremely Low-Bandwidth Medium. Applied Sciences. 2024; 14(17):7962. https://doi.org/10.3390/app14177962
Chicago/Turabian StyleKutyłowski, Mirosław, Adrian Cinal, Przemysław Kubiak, and Denys Korniienko. 2024. "Authenticated Multicast in Tiny Networks via an Extremely Low-Bandwidth Medium" Applied Sciences 14, no. 17: 7962. https://doi.org/10.3390/app14177962