
Research on Surgical Gesture Recognition in Open Surgery Based on Fusion of R3D and Multi-Head Attention Mechanism

 ,
,
Abstract
:1. Introduction
- We constructed a simulated open surgery dataset and, with the assistance of professional surgeons, defined a surgical gesture vocabulary suitable for suture-based open surgeries, completing all annotations for the dataset.
- We proposed an open surgery gesture recognition method combining R3D and multi-head attention mechanisms. The applicability of this method for recognizing open surgery gestures was validated through offline and online recognition tasks.
- In addition to evaluating and analyzing the method on the open surgery dataset, we also tested the proposed model on the public JIGSAWS dataset for online recognition tasks and compared it with other online recognition models used for robotic gestures. This experiment demonstrated the potential application of our model in the field of surgical gesture recognition.
2. Materials and Methods
2.1. Dataset Overview
2.2. Surgical Gesture Description
2.3. Data Processing
2.4. R3D-MHA Network Architecture
2.5. Overall Technical Framework
2.6. Implementation Details
2.7. Evaluation Metrics
3. Results
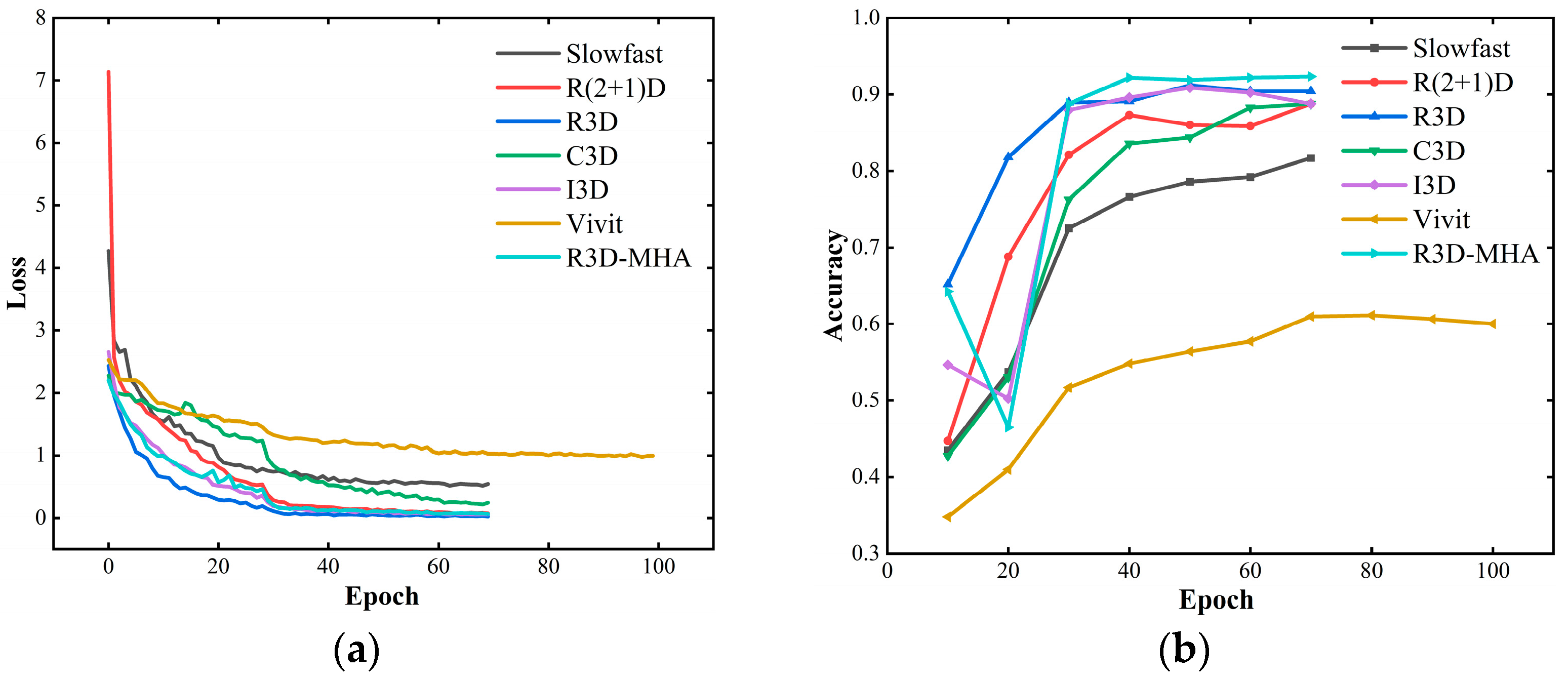
3.1. Offline Recognition
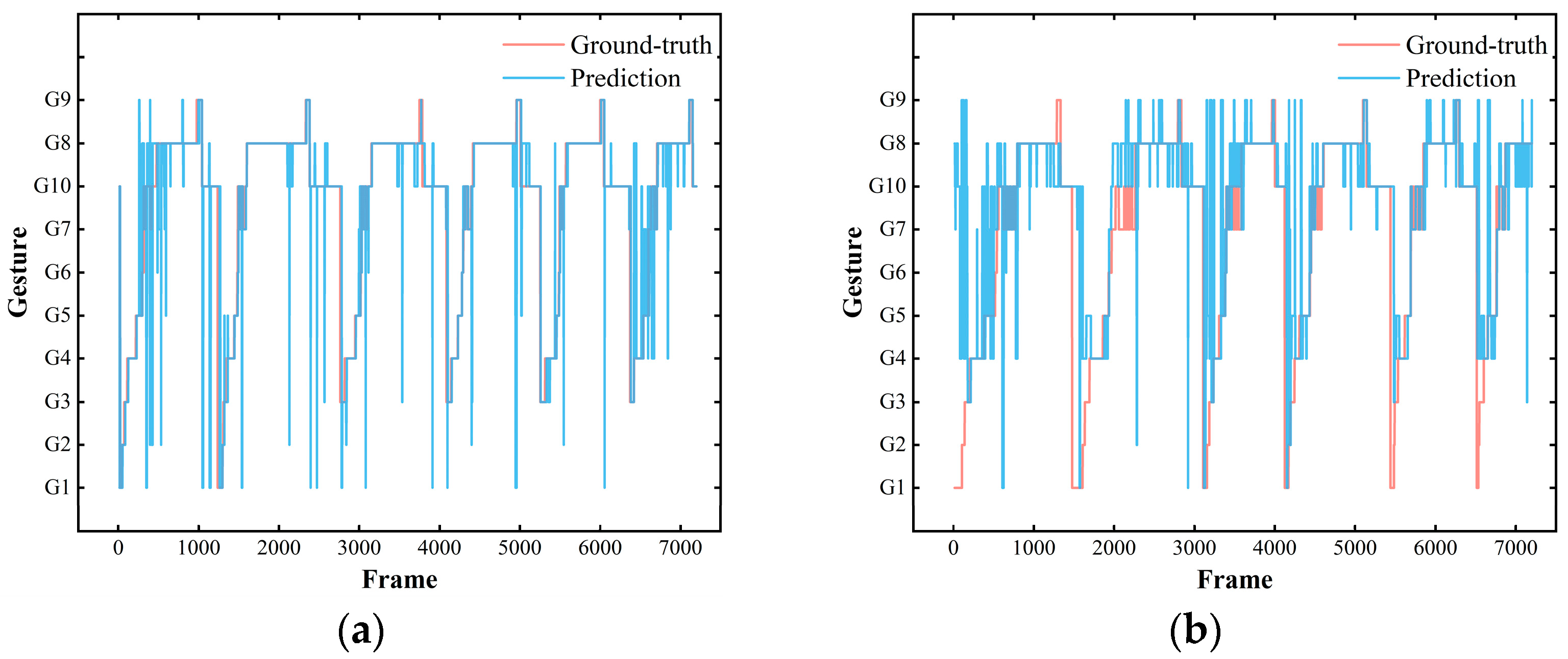
3.2. Online Recognition
3.3. Evaluation of the JIGSAWS Dataset
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Béjar, B.; Yuh, D.D.; et al. JHU-ISI gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling. In Proceedings of the Modeling and Monitoring of Computer Assisted Interventions (M2CAI)—MICCAI Workshop, Boston, MA, USA, 25 September 2014; Volume 1, pp. 1–10. [Google Scholar]
- Yasar, M.S.; Alemzadeh, H. Real-time context-aware detection of unsafe events in robot-assisted surgery. In Proceedings of the 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), IEEE, Valencia, Spain, 29 June–2 July 2020. [Google Scholar]
- Maier-Hein, L.; Vedula, S.S.; Speidel, S.; Navab, N.; Kikinis, R.; Park, A.; Eisenmann, M.; Feussner, H.; Forestier, G.; Giannarou, S.; et al. Surgical data science for next-generation interventions. Nat. Biomed. Eng. 2017, 1, 691–696. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Gu, J. Open surgery in the era of minimally invasive surgery. Chin. J. Cancer Res. 2022, 34, 63–65. [Google Scholar] [CrossRef] [PubMed]
- Funke, I.; Bodenstedt, S.; Oehme, F.; von Bechtolsheim, F.; Weitz, J. Using 3D convolutional neural networks to learn spatiotemporal features for automatic surgical gesture recognition in video. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]
- Tao, L.; Zappella, L.; Hager, G.D.; Vidal, R. Surgical gesture segmentation and recognition. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2013, Proceedings of the 16th International Conference, Nagoya, Japan, 22–26 September 2013; Part III; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Lea, C.; Hager, G.D.; Vidal, R. An improved model for segmentation and recognition of fine-grained activities with application to surgical training tasks. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision, IEEE, Waikoloa, HI, USA, 5–9 January 2015. [Google Scholar]
- Mavroudi, E.; Bhaskara, D.; Sefati, S.; Ali, H.; Vidal, R. End-to-end fine-grained action segmentation and recognition using conditional random field models and discriminative sparse coding. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Zhang, J.; Nie, Y.; Lyu, Y.; Yang, X.; Chang, J.; Zhang, J.J. SD-Net: Joint surgical gesture recognition and skill assessment. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 1675–1682. [Google Scholar] [CrossRef] [PubMed]
- DiPietro, R.; Lea, C.; Malpani, A.; Ahmidi, N.; Vedula, S.S.; Lee, G.I.; Lee, M.R. Recognizing surgical activities with recurrent neural networks. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2016, Proceedings of the 19th International Conference, Athens, Greece, 17–21 October 2016; Part I; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. PMLR 2013, 28, 1310–1318. [Google Scholar]
- Lea, C.; Vidal, R.; Reiter, A. Temporal convolutional networks: A unified approach to action segmentation. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Part III. Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhang, J.; Nie, Y.; Lyu, Y.; Li, H.; Chang, J.; Yang, X. Symmetric dilated convolution for surgical gesture recognition. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020, Proceedings of the 23rd International Conference, Lima, Peru, 4–8 October 2020; Part III; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Gazis, A.; Karaiskos, P.; Loukas, C. Surgical gesture recognition in laparoscopic tasks based on the transformer network and self-supervised learning. Bioengineering 2022, 9, 737. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; Lecun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Lin, H.C. Structure in Surgical Motion. Ph.D. Thesis, Johns Hopkins University, Baltimore, MD, USA, 2010. [Google Scholar]
- Ahmidi, N.; Tao, L.; Sefati, S.; Gao, Y.; Lea, C.; Haro, B.B.; Zappella, L.; Khudanpur, S.; Vidal, R.; Hager, G.D. A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Trans. Biomed. Eng. 2017, 64, 2025–2041. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Rupprecht, C.; Lea, C.; Tombari, F.; Navab, N.; Hager, G.D. Sensor substitution for video-based action recognition. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Daejeon, Republic of Korea, 9–14 October 2016. [Google Scholar]
- DiPietro, R.; Ahmidi, N.; Malpani, A.; Waldram, M.; Lee, G.I.; Lee, M.R.; Vedula, S.S.; Hager, G.D. Segmenting and classifying activities in robot-assisted surgery with recurrent neural networks. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 2005–2020. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Wang, Y.; Li, M. Towards accurate and interpretable surgical skill assessment: A video-based method incorporating recognized surgical gestures and skill levels. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020; Volume 1, pp. 668–678. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Name | Device Model | Data Format | Resolution | Frame Rate |
|---|---|---|---|---|
| Surgical lamp coaxial camera (Shanghai Pinxing Medical Equipment Co., LTD., Shanghai, China) | WYD2015-LC | Structured light video data *.mkv | 1920 × 1080 | 30.0 |
| Kinect depth camera (Microsoft, Redmond, WA, USA) | Kinect v2.0 | Deep grayscale video data *.avi | 512 × 424 | 25.0 |
| Head-mounted video camera (GoPro, Inc., San Mateo, CA, USA) | HERO4 Black | Structured light video data *.MP4 | 1920 × 1080 | 25.0 |
| Gestures | Gesture Description | Boundary Frame |
|---|---|---|
| G1 | Clamping the needle | Forceps just touching the tissue |
| G2 | Forceps pick up the tissue | The holder has just started to move |
| G3 | Positioning needle | The needle has just made contact with the tissue |
| G4 | Pushing the needle through tissue | The needle tip has penetrated the tissue |
| G5 | Clamping the needle through tissue | The needle has just departed from the tissue |
| G6 | Pulling suture with holder | The holder loosens the needle or moves out of view |
| G7 | Hand pulling suture | The needle holder approaches the vicinity of the suture line |
| G8 | Knotting the suture | The scissors are not visible in the field of view |
| G9 | Cutting the suture | The scissors are removed from the field of view |
| G10 | Other | The holder regrasps the needle, Actions other than the nine surgical gestures (G1–G9), Other scenarios |
| Gesture | G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 | G9 | G10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Instances | 168 | 163 | 220 | 218 | 219 | 203 | 326 | 218 | 217 | 665 |
| Overlapping segments | 1495 | 1347 | 2376 | 4144 | 3086 | 1490 | 2493 | 17,173 | 2857 | 13,846 |
| Mean frame count | 33 | 28 | 45 | 108 | 75 | 18 | 23 | 432 | 59 | 110 |
| Min frame count | 3 | 5 | 6 | 21 | 11 | 2 | 3 | 99 | 26 | 3 |
| Max frame count | 314 | 97 | 170 | 356 | 297 | 73 | 135 | 1435 | 216 | 593 |
| Model | Accuracy (%) | Precision (%) | Recall (%) |
|---|---|---|---|
| R(2+1)D | 88.7 | 89.0 | 87.8 |
| C3D | 88.6 | 88.0 | 87.2 |
| Slowfast | 81.7 | 79.7 | 78.3 |
| Vivit | 60.0 | 56.3 | 55.6 |
| I3D | 88.8 | 88.6 | 88.1 |
| R3D | 90.4 | 90.5 | 90.0 |
| R3D-MHA | 92.3 | 92.5 | 92.0 |
| Model | G1 | G2 | G3 | G4 | G5 | G6 | G7 | G8 | G9 | G10 |
|---|---|---|---|---|---|---|---|---|---|---|
| R(2+1)D | 0.85 | 0.74 | 0.81 | 0.92 | 0.94 | 0.94 | 0.78 | 0.90 | 0.94 | 0.94 |
| C3D | 0.59 | 0.67 | 0.91 | 0.93 | 0.95 | 0.73 | 0.76 | 0.86 | 0.91 | 0.92 |
| Slowfast | 0.73 | 0.72 | 0.53 | 0.81 | 0.89 | 0.83 | 0.77 | 0.60 | 0.90 | 0.93 |
| Vivit | 0.73 | 0.44 | 0.60 | 0.48 | 0.32 | 0.45 | 0.70 | 0.44 | 0.62 | 0.79 |
| I3D | 0.85 | 0.80 | 0.94 | 0.92 | 0.90 | 0.87 | 0.81 | 0.85 | 0.94 | 0.92 |
| R3D | 0.88 | 0.79 | 0.92 | 0.96 | 0.96 | 0.89 | 0.76 | 0.92 | 0.98 | 0.93 |
| R3D-MHA | 0.90 | 0.82 | 0.96 | 0.94 | 0.94 | 0.94 | 0.85 | 0.92 | 0.98 | 0.94 |
| Model | Video00 | Video01 | Video02 | Average (%) |
|---|---|---|---|---|
| R3D | 61.3 | 75.7 | 82.1 | 73.0 |
| R3D-MHA | 62.6 | 75.7 | 81.8 | 73.4 |
| Fold | SU-001 | SU-002 | SU-003 | SU-004 | SU-005 | Average (%) |
|---|---|---|---|---|---|---|
| 1 | 77.9 | 83.7 | 74.4 | 69.3 | 67.1 | 74.5 |
| 2 | 66.6 | 80.6 | 79.5 | 79.9 | 82.9 | 77.9 |
| 3 | 67.2 | X | 80.7 | 76.3 | 81.7 | 76.5 |
| All | 76.3 |
| Model | Acc (%) | Trained on Additional Dataset | Applicable Online |
|---|---|---|---|
| CRF (dense) [6] | 68.8 | - | √ |
| MsM-CRF (STIP–STIP) [6] | 66.3 | - | √ |
| MsM-CRF (dense–dense) [6] | 71.8 | - | √ |
| CNN+LC-SC-CRF [23] | 76.6 | √ (Sensor Values) | √ |
| ST-GCN [24] | 67.9 | - | √ |
| MTL-VF [25] | 82.1 | √ (Sports-1M and ImageNet) | √ |
| 3D-CNN [5] | 84.0 | √ (Kinetics) | √ |
| C3Dtrans [14] | 75.8 | - | √ |
| R3D-MHA | 76.3 | - | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Men, Y.; Luo, J.; Zhao, Z.; Wu, H.; Zhang, G.; Luo, F.; Yu, M. Research on Surgical Gesture Recognition in Open Surgery Based on Fusion of R3D and Multi-Head Attention Mechanism. Appl. Sci. 2024, 14, 8021. https://doi.org/10.3390/app14178021
Men Y, Luo J, Zhao Z, Wu H, Zhang G, Luo F, Yu M. Research on Surgical Gesture Recognition in Open Surgery Based on Fusion of R3D and Multi-Head Attention Mechanism. Applied Sciences. 2024; 14(17):8021. https://doi.org/10.3390/app14178021
Chicago/Turabian StyleMen, Yutao, Jian Luo, Zixian Zhao, Hang Wu, Guang Zhang, Feng Luo, and Ming Yu. 2024. "Research on Surgical Gesture Recognition in Open Surgery Based on Fusion of R3D and Multi-Head Attention Mechanism" Applied Sciences 14, no. 17: 8021. https://doi.org/10.3390/app14178021