
Attention-Based Light Weight Deep Learning Models for Early Potato Disease Detection
Abstract
:1. Introduction
1.1. Literature Review
1.2. Motivation
- In CNN-based image classification tasks, feature extraction is achieved using filters or kernels which extract edges, shapes, and textures. These are used to produce more prominent features that aid in classifying different images. Since an image may contain multiple features, not all of which are relevant to classification tasks, a mechanism is needed to focus only on the relevant features. This is where the attention mechanism comes in; it prioritizes specific parts of an image that are crucial for distinguishing between classes while downplaying irrelevant areas. By assigning greater weight to distinguishing features, the attention mechanism enhances the model’s ability to classify images accurately.
- In order to capture minute features in the image, a series of convolution layers are used because initial layers only capture prominent features and as we go deeper into the layers, the model is able to capture very specific features as well. A dense network has large number of trainable parameters, which increases the training time. Additionally, the size of the model increases, making it unsuitable for integration in devices with less computation power and memory.
- In a multi-layer CNN model, the large number of trainable parameters makes the model highly complex. This complexity increases the risk of overfitting, making the model difficult to train. Additionally, training a complex model is time consuming due to the need to compute optimal values for numerous parameters.
1.3. Contribution
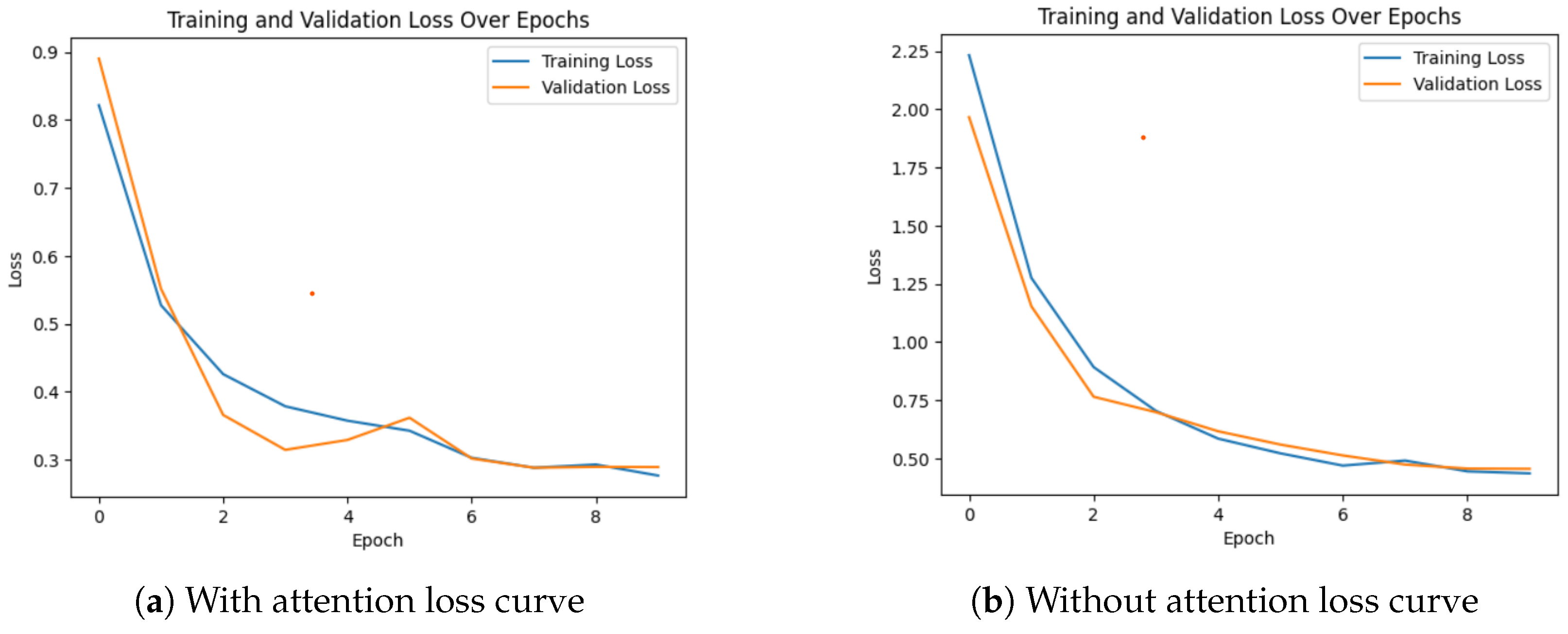
- We propose an attention-based CNN model that selectively focuses on specific parts of an image to differentiate between healthy and infected. The model utilizes the Convolutional Block Attention Module (CBAM) developed by Sanghyun et al. [23].
- The proposed model emphasizes distinguishing features while minimizing the importance of other features. This helps the model to achieve comparable results without relying on complex architectures, resulting in a simpler model with fewer parameters and lighter weights.
- By focusing on the most informative features of an image, the model significantly reduces the number of parameters. This results in fewer trainable parameters which avoids model overfitting and significantly reduces the training time. Additionally, the simplified model lowers computational costs and eliminates the need for high-end GPUs.
2. Convolutional Block Attention Module-Based Technique
- Channel attention focuses on highlighting relevant and important features across channels. It processes an image or a feature map, which consists of multiple channels, each representing a different pattern or aspect detected by a filter. The feature map is passed through a global average pooling layer, generating an average value for each channel to capture the general importance of each channel across the feature map. Simultaneously, the feature map is passed through a global max pooling layer to identify the max value in each channel. The purpose of the global max pooling layer is to highlight the most prominent features in each channel. The outputs from the global average and global max layers are then fed into dense layers, with the final dense layers containing a number of neurons equal to the number of channels in the feature map. These dense layers assign weights to each channel based on importance, which helps in generating the final attention map. After processing through the dense layers, the outputs are combined using element-wise addition to produce a single feature map with multiple channels, each channel containing a single number representing its importance. The feature map is then passed through a sigmoid activation function to normalize its values. Finally, the normalized feature map is combined with the original feature map through element-wise multiplication, resulting in a feature map that retains the original feature map with prominent channels having highlighted features. Figure 2 shows the flow of the channel attention mechanism.
- Spatial attention focuses on finding the most dominant regions in an image by identifying the most significant group of pixels. It processes an image or a feature map composed of multiple channels, each channel representing a grid. The feature map is passed through two layers: a global average pooling layer and global max pooling layer. Unlike channel attention, where the average value within each channel is obtained, here the average pooling is performed across the channel axis calculating the average value across all channels for each pixel. Similarly, average max pooling is performed across the channel axis to obtain the maximum value across all channels for each pixel. This results in two feature maps, each highlighting the brightest spots across all channels. These feature maps are then combined to form a two-channel feature map which is then passed through one or more convolutional layers, resulting in a single-channel feature map. This is the attention map highlighting the location of the most important features. This attention feature map is then combined with the original feature map through the element-wise multiplication operation. Shape matching of both feature maps is handled by the broadcasting feature of the Numpy library. Figure 3 illustrates the flow of the channel attention mechanism.Both the channel attention module and spatial attention module can be implemented either in a parallel or sequential fashion. In our proposed technique, we used a sequential arrangement where channel attention is performed first and its output is then fed into the spatial attention module. In simple terms, the channel attention focuses on finding “what” are the important features in an image and the spatial attention focuses on finding “where” those important features are located within the image.
3. Experimental Results and Analysis
3.1. Dataset Used
3.2. DenseNet169
3.3. MobileNet
3.4. XceptionNet
3.5. VGG16
3.6. Comparison of the Inference Time
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McNicoll, G. The United Nations’ Long-Range Population Projections. Popul. Dev. Rev. 1992, 18, 333. [Google Scholar] [CrossRef]
- Hughes, D.; Salathé, M. An open access repository of images on plant health to enable the development of mobile disease diagnostics. arXiv 2015, arXiv:1511.08060. [Google Scholar]
- Baker, N.; Capel, P. Environmental Factors that Influence the Location of Crop Agriculture in the Conterminous United States; US Department of the Interior, US Geological Survey: Reston, VA, USA, 2011.
- Khan, A.; Vibhute, A.D.; Mali, S.; Patil, C.H. A systematic review on hyperspectral imaging technology with a machine and deep learning methodology for agricultural applications. Ecol. Inform. 2022, 69, 101678. [Google Scholar] [CrossRef]
- Dubey, S.; Jalal, A. Adapted Approach for Fruit Disease Identification Using Images. In Image Processing: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2013; pp. 1395–1409. [Google Scholar]
- Li, G.; Ma, Z.; Wang, H. Image Recognition of Grape Downy Mildew and Grape. In Proceedings of the International Conference on Computer and Computing Technologies in Agriculture, Beijing, China, 29–31 October 2011; pp. 151–162. [Google Scholar]
- Rauf, H.; Saleem, B.; Lali, M.; Khan, M.; Sharif, M.; Bukhari, S. A citrus fruits and leaves dataset for detection and classification of citrus diseases through machine learning. Data Brief 2019, 26, 104340. [Google Scholar] [CrossRef] [PubMed]
- Sujatha, R.; Chatterjee, J.; Jhanjhi, N.; Brohi, S. Performance of deep learning vs. machine learning in plant leaf disease detection. Microprocess. Microsyst. 2021, 80, 103615. [Google Scholar] [CrossRef]
- Geetharamani, G.; Pandian, A. Identification of plant leaf diseases using a nine-layer deep convolutional neural network. Comput. Electr. Eng. 2019, 76, 323–338. [Google Scholar]
- Khamparia, A.; Saini, G.; Gupta, D.; Khanna, A.; Tiwari, S.; de Albuquerque, V. Seasonal Crops Disease Prediction and Classification Using Deep Convolutional Encoder Network. Circuits Syst. Signal Process. 2019, 39, 818–836. [Google Scholar] [CrossRef]
- Liang, Q.; Xiang, S.; Hu, Y.; Coppola, G.; Zhang, D.; Sun, W. PD2SE-Net: Computer-assisted plant disease diagnosis and severity estimation network. Comput. Electron. Agric. 2019, 157, 518–529. [Google Scholar] [CrossRef]
- Khalifa, N.; Taha, M.; Abou El-Maged, L.; Hassanien, A. Artificial Intelligence in Potato Leaf Disease Classification: A Deep Learning Approach. In Machine Learning and Big Data Analytics Paradigms: Analysis, Applications and Challenges; Springer: Berlin/Heidelberg, Germany, 2021; pp. 63–79. [Google Scholar]
- Rozaqi, A.; Sunyoto, A. Identification of Disease in Potato Leaves Using Convolutional Neural Network (CNN) Algorithm. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 72–76. [Google Scholar]
- Iqbal, M.; Talukder, K. Detection of potato disease using image segmentation and machine learning. In Proceedings of the 2020 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 4–6 August 2020; pp. 43–47. [Google Scholar]
- Singh, A.; Kaur, H. Potato plant leaves disease detection and classification using machine learning methodologies. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1022, 012121. [Google Scholar] [CrossRef]
- Chakraborty, K.; Mukherjee, R.; Chakroborty, C.; Bora, K. Automated recognition of optical image based potato leaf blight diseases using deep learning. Physiol. Mol. Plant Pathol. 2022, 117, 101781. [Google Scholar] [CrossRef]
- Mahum, R.; Munir, H.; Mughal, Z.; Awais, M.; Sher Khan, F.; Saqlain, M.; Mahamad, S.; Tlili, I. A novel framework for potato leaf disease detection using an efficient deep learning model. Hum. Ecol. Risk Assess. Int. J. 2023, 29, 303–326. [Google Scholar] [CrossRef]
- Bajpai, A.; Tyagi, M.; Khare, M.; Singh, A. A Robust and Accurate Potato Leaf Disease Detection System Using Modified AlexNet Model. In Proceedings of the 2023 9th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 15–16 August 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Olawuyi, O.; Viriri, S. Plant Diseases Detection and Classification Using Deep Transfer Learning. In Proceedings of the Pan-African Artificial Intelligence and Smart Systems Conference, Dakar, Senegal, 2–4 November 2022; pp. 270–288. [Google Scholar]
- Acharjee, T.; Das, S.; Majumder, S. Potato Leaf Diseases Detection Using Deep Learning. Int. J. Digit. Technol. 2023, 11, 3. [Google Scholar]
- Kumar, A.; Patel, V. Classification and identification of disease in potato leaf using hierarchical based deep learning convolutional neural network. Multimed. Tools Appl. 2023, 82, 31101–31127. [Google Scholar] [CrossRef]
- Rashid, J.; Khan, I.; Ali, G.; Almotiri, S.H.; AlGhamdi, M.A.; Masood, K. Multi-Level Deep Learning Model for Potato Leaf Disease Recognition. Electronics 2021, 10, 2064. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Batch Size | 32 |
| Input Shape | (256, 256) |
| Optimizer | Adam |
| Loss Function | Categorical Cross Entropy |
| Epochs | 10 |
| Class Labels | Samples |
|---|---|
| Early Blight | 1000 |
| Late Blight | 1000 |
| Healthy | 152 |
| Total Samples | 2152 |
| Class Labels | Samples |
|---|---|
| Early Blight | 1628 |
| Late Blight | 1414 |
| Healthy | 1020 |
| Total Samples | 4062 |
| Class Labels | Samples |
|---|---|
| Early Blight | 2628 |
| Late Blight | 2414 |
| Healthy | 2059 |
| Total Samples | 7101 |
| With Attention | Without Attention | |||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| Accuracy | 97.47 | 96.83 | 96.12 | 97.17 | 97.78 | 97.58 |
| With Attention | Without Attention | |||
|---|---|---|---|---|
| Training | Validation | Training | Validation | |
| Loss | 0.1329 | 0.1551 | 0.3273 | 0.3078 |
| With Attention | Without Attention | |
|---|---|---|
| Precision | 95.24 | 96.44 |
| Recall | 95.93 | 96.55 |
| F1 Score | 95.56 | 96.49 |
| With Attention | Without Attention | |||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| Accuracy | 96.09 | 95.25 | 97.25 | 95.96 | 94.14 | 94.67 |
| With Attention | Without Attention | |||
|---|---|---|---|---|
| Training | Validation | Training | Validation | |
| Loss | 0.2526 | 0.2549 | 0.4147 | 0.4429 |
| With Attention | Without Attention | |
|---|---|---|
| Precision | 96.84 | 94.82 |
| Recall | 97.15 | 92.90 |
| Score | 96.99 | 93.70 |
| With Attention | Without Attention | |||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| Accuracy | 92.70 | 93.19 | 93.70 | 93.62 | 92.87 | 93.70 |
| With Attention | Without Attention | |||
|---|---|---|---|---|
| Training | Validation | Training | Validation | |
| Loss | 0.3267 | 0.3310 | 0.2852 | 0.3116 |
| With Attention | Without Attention | |
|---|---|---|
| Precision | 92.92 | 92.88 |
| Recall | 93.54 | 93.07 |
| F1 Score | 93.21 | 92.96 |
| With Attention | Without Attention | |||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| Accuracy | 89.22 | 88.91 | 90.32 | 90.46 | 89.86 | 90.48 |
| With Attention | Without Attention | |||
|---|---|---|---|---|
| Training | Validation | Training | Validation | |
| Loss | 0.2813 | 0.2872 | 0.4361 | 0.4556 |
| With Attention | Without Attention | |
|---|---|---|
| Precision | 89.62 | 90.03 |
| Recall | 89.36 | 89.68 |
| F1 Score | 89.42 | 89.71 |
| With Attention | Without Attention | |
|---|---|---|
| DenseNet169 | 42 ms | 32 ms |
| MobileNet | 34 ms | 22 ms |
| XceptionNet | 32 ms | 21 ms |
| VGG16 | 23 ms | 18 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasana, S.S.; Rathore, A.S. Attention-Based Light Weight Deep Learning Models for Early Potato Disease Detection. Appl. Sci. 2024, 14, 8038. https://doi.org/10.3390/app14178038
Kasana SS, Rathore AS. Attention-Based Light Weight Deep Learning Models for Early Potato Disease Detection. Applied Sciences. 2024; 14(17):8038. https://doi.org/10.3390/app14178038
Chicago/Turabian StyleKasana, Singara Singh, and Ajayraj Singh Rathore. 2024. "Attention-Based Light Weight Deep Learning Models for Early Potato Disease Detection" Applied Sciences 14, no. 17: 8038. https://doi.org/10.3390/app14178038