

Advancing in RGB-D Salient Object Detection: A Survey

Abstract
1. Introduction
2. Classification and Comparison of Cross-Modal Fusion Strategies
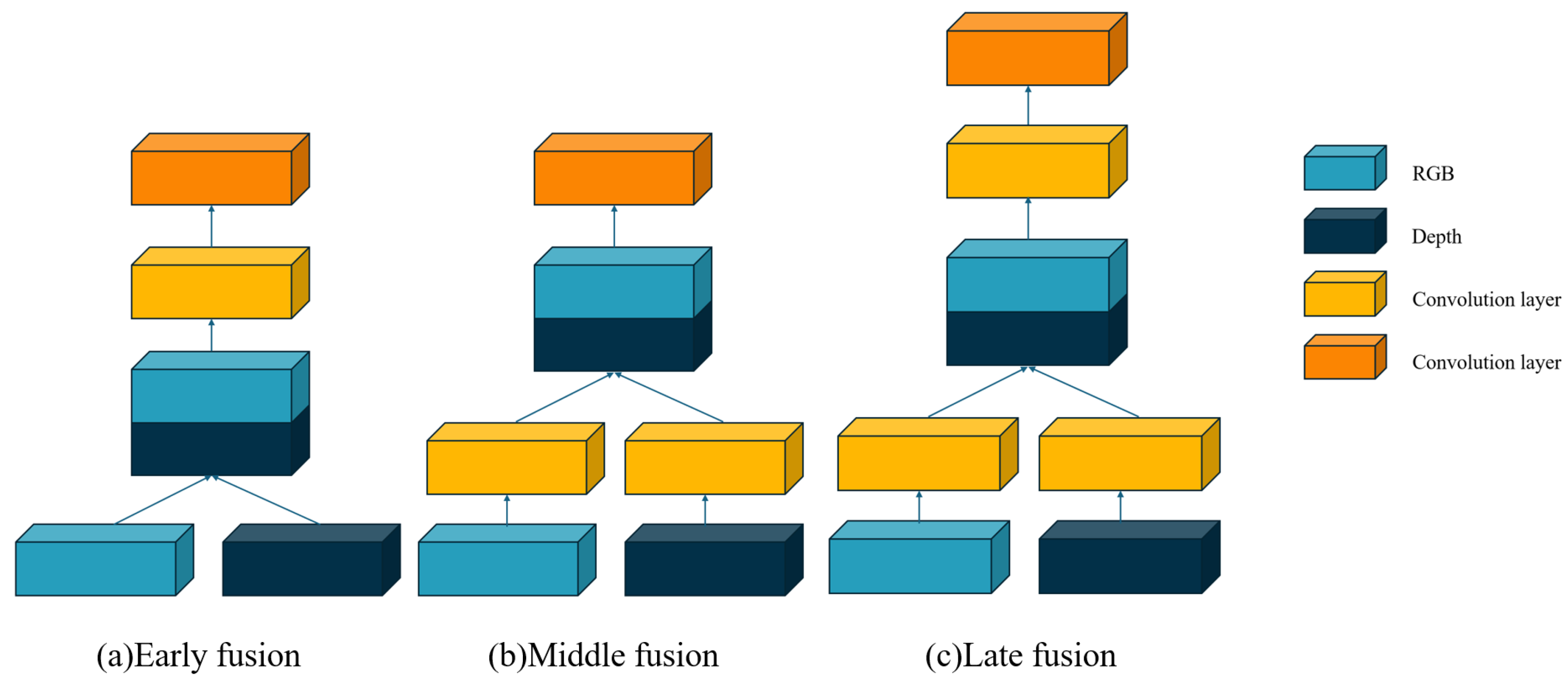
2.1. Classification of Fusion Strategies
2.2. Comparison of Fusion Strategies
3. Attention Mechanisms in RGB-D SOD
3.1. Classification of Attention Mechanisms
3.2. Attention Models in SOD
4. Performance Evaluation and Comparison
4.1. RGB-D Dataset
4.2. Evaluation Criteria
4.3. Model Comparison
4.4. Comparing with Prior Art
5. Challenges and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Gonzalez-Garcia, A.; Weijer, J.V.D.; Danelljan, M.; Khan, F.S. Learning the model update for siamese trackers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 4010–4019. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Lang, C.; Nguyen, T.V.; Katti, H.; Yadati, K.; Kankanhalli, M.; Yan, S. Depth Matters: Influence of Depth Cues on Visual Saliency. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012, Proceedings, Part II 12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 101–115. [Google Scholar]
- Liu, Z.; Tan, Y.; He, Q.; Xiao, Y. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4486–4497. [Google Scholar] [CrossRef]
- Li, N.; Ye, J.; Ji, Y.; Ling, H.; Yu, J. Saliency detection on light field. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2806–2813. [Google Scholar]
- Li, G.; Bai, Z.; Liu, Z.; Zhang, X.; Ling, H. Salient object detection in optical remote sensing images driven by transformer. IEEE Trans. Image Process. 2023, 32, 5257–5269. [Google Scholar] [CrossRef]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Peng, Y.; Zhai, Z.; Feng, M. RGB-D Salient Object Detection Based on Cross-Modal and Cross-Level Feature Fusion. IEEE Access 2024, 12, 45134–45146. [Google Scholar] [CrossRef]
- Zhang, J.; Fan, D.P.; Dai, Y.; Yu, X.; Zhong, Y.; Barnes, N.; Shao, L. RGB-D saliency detection via cascaded mutual information minimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 4338–4347. [Google Scholar]
- Huang, N.; Yang, Y.; Zhang, D.; Zhang, Q.; Han, J. Employing bilinear fusion and saliency prior information for RGB-D salient object detection. IEEE Trans. Multimed. 2021, 24, 1651–1664. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y. Progressively complementarity-aware fusion network for RGB-D salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3051–3060. [Google Scholar]
- Xiao, F.; Pu, Z.; Chen, J.; Gao, X. DGFNet: Depth-guided cross-modality fusion network for RGB-D salient object detection. IEEE Trans. Multimed. 2023, 26, 2648–2658. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Han, J. Learning selective self-mutual attention for RGB-D saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 13756–13765. [Google Scholar]
- Liu, N.; Han, J. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 678–686. [Google Scholar]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Ren, J.; Gong, X.; Yu, L.; Zhou, W.; Ying Yang, M. Exploiting global priors for RGB-D saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 25–32. [Google Scholar]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD Salient Object Detection: A Benchmark and Algorithms. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014, Proceedings, Part III 13; Springer: Berlin/Heidelberg, Germany, 2014; pp. 92–109. [Google Scholar]
- Zhang, Q.; Qin, Q.; Yang, Y.; Jiao, Q.; Han, J. Feature calibrating and fusing network for RGB-D salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1493–1507. [Google Scholar] [CrossRef]
- Desingh, K.; Krishna, K.M.; Rajan, D.; Jawahar, C. Depth really Matters: Improving Visual Salient Region Detection with Depth. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013; pp. 1–11. [Google Scholar]
- Hu, X.; Sun, F.; Sun, J.; Wang, F.; Li, H. Cross-modal fusion and progressive decoding network for RGB-D salient object detection. Int. J. Comput. Vis. 2024, 132, 3067–3085. [Google Scholar] [CrossRef]
- Sun, F.; Ren, P.; Yin, B.; Wang, F.; Li, H. CATNet: A cascaded and aggregated transformer network for RGB-D salient object detection. IEEE Trans. Multimed. 2023, 26, 2249–2262. [Google Scholar] [CrossRef]
- Li, H.; Han, Y.; Li, P.; Li, X.; Shi, L. Hybrid Attention Mechanism And Forward Feedback Unit for RGB-D Salient Object Detection. IEEE Access 2023, 26, 2249–2262. [Google Scholar] [CrossRef]
- Luo, Y.; Shao, F.; Xie, Z.; Wang, H.; Chen, H.; Mu, B.; Jiang, Q. HFMDNet: Hierarchical Fusion and Multi-Level Decoder Network for RGB-D Salient Object Detection. IEEE Trans. Instrum. Meas. 2024, 73, 5012115. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from Rgbd Images. In Proceedings of the Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012, Proceedings, Part V 12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1265–1274. [Google Scholar]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Ha, H.; Im, S.; Park, J.; Jeon, H.G.; Kweon, I.S. High-quality depth from uncalibrated small motion clip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5413–5421. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Zhang, X.; Xu, Y.; Wang, T.; Liao, T. Multi-prior driven network for RGB-D salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2023. early access. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30; NIPS: La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Zhang, Z.; Lin, Z.; Xu, J.; Jin, W.D.; Lu, S.P.; Fan, D.P. Bilateral attention network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 1949–1961. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, W.; Wang, H.; Li, S.; Li, X. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1407–1417. [Google Scholar]
- Lv, P.; Yu, X.; Wang, J.; Wu, C. HierNet: Hierarchical Transformer U-Shape Network for RGB-D Salient Object Detection. In Proceedings of the 2023 35th Chinese Control and Decision Conference (CCDC), Yichang, China, 20–22 May 2023; pp. 1807–1811. [Google Scholar]
- Gao, X.; Cui, J.; Meng, J.; Shi, H.; Duan, S.; Xia, C. JALNet: Joint attention learning network for RGB-D salient object detection. Int. J. Comput. Sci. Eng. 2024, 27, 36–47. [Google Scholar] [CrossRef]
- Jiang, B.; Zhou, Z.; Wang, X.; Tang, J.; Luo, B. CmSalGAN: RGB-D salient object detection with cross-view generative adversarial networks. IEEE Trans. Multimed. 2020, 23, 1343–1353. [Google Scholar] [CrossRef]
- Wu, Z.; Allibert, G.; Meriaudeau, F.; Ma, C.; Demonceaux, C. Hidanet: Rgb-d salient object detection via hierarchical depth awareness. IEEE Trans. Image Process. 2023, 32, 2160–2173. [Google Scholar] [CrossRef]
- Wang, N.; Gong, X. Adaptive fusion for RGB-D salient object detection. IEEE Access 2019, 7, 55277–55284. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, W. Hybrid-attention network for RGB-D salient object detection. Appl. Sci. 2020, 10, 5806. [Google Scholar] [CrossRef]
- Yuan, Y.; Liu, W.; Gao, P.; Dai, Q.; Qin, J. Unified Unsupervised Salient Object Detection via Knowledge Transfer. arXiv 2024, arXiv:2404.14759. [Google Scholar]
- Wang, F.; Su, Y.; Wang, R.; Sun, J.; Sun, F.; Li, H. Cross-modal and cross-level attention interaction network for salient object detection. IEEE Trans. Artif. Intell. 2023, 5, 2907–2920. [Google Scholar] [CrossRef]
- Chen, H.; Shen, F.; Ding, D.; Deng, Y.; Li, C. Disentangled cross-modal transformer for RGB-d salient object detection and beyond. IEEE Trans. Image Process. 2024, 33, 1699–1709. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, W.; Li, S.; Guo, Y.; Song, C.; Li, X. Learnable depth-sensitive attention for deep rgb-d saliency detection with multi-modal fusion architecture search. Int. J. Comput. Vis. 2022, 130, 2822–2841. [Google Scholar] [CrossRef]
- Niu, Y.; Geng, Y.; Li, X.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 454–461. [Google Scholar]
- Ju, R.; Ge, L.; Geng, W.; Ren, T.; Wu, G. Depth saliency based on anisotropic center-surround difference. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1115–1119. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef]
- Piao, Y.; Ji, W.; Li, J.; Zhang, M.; Lu, H. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7254–7263. [Google Scholar]
- Ciptadi, A.; Hermans, T.; Rehg, J.M. An In Depth View of Saliency. In Proceedings of the BMVC, Bristol, UK, 9–13 September 2013; pp. 1–11. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply supervised salient object detection with short connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3212. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Fan, D.P.; Ji, G.P.; Qin, X.; Cheng, M.M. Cognitive vision inspired object segmentation metric and loss function. Sci. Sin. Informationis 2021, 6, 5. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Cmputer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognitio, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Huang, P.; Shen, C.H.; Hsiao, H.F. RGBD salient object detection using spatially coherent deep learning framework. In Proceedings of the 2018 IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 19–21 November 2018; pp. 1–5. [Google Scholar]
- Liu, Z.; Shi, S.; Duan, Q.; Zhang, W.; Zhao, P. Salient object detection for RGB-D image by single stream recurrent convolution neural network. Neurocomputing 2019, 363, 46–57. [Google Scholar] [CrossRef]
- Zhu, C.; Cai, X.; Huang, K.; Li, T.H.; Li, G. PDNet: Prior-model guided depth-enhanced network for salient object detection. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 199–204. [Google Scholar]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Zhao, J.X.; Cao, Y.; Fan, D.P.; Cheng, M.M.; Li, X.Y.; Zhang, L. Contrast prior and fluid pyramid integration for RGBD salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3927–3936. [Google Scholar]
- Chen, H.; Li, Y. Three-stream attention-aware network for RGB-D salient object detection. IEEE Trans. Image Process. 2019, 28, 2825–2835. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, L.; Pang, Y.; Lu, H.; Zhang, L. A single stream network for robust and real-time RGB-D salient object detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 646–662. [Google Scholar]
- Zhao, Y.; Zhao, J.; Li, J.; Chen, X. RGB-D salient object detection with ubiquitous target awareness. IEEE Trans. Image Process. 2021, 30, 7717–7731. [Google Scholar] [CrossRef] [PubMed]
- Ji, W.; Li, J.; Zhang, M.; Piao, Y.; Lu, H. Accurate RGB-D salient object detection via collaborative learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XVIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 52–69. [Google Scholar]
- Li, G.; Liu, Z.; Ye, L.; Wang, Y.; Ling, H. Cross-modal weighting network for RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 665–681. [Google Scholar]
- Li, G.; Liu, Z.; Ling, H. ICNet: Information conversion network for RGB-D based salient object detection. IEEE Trans. Image Process. 2020, 29, 4873–4884. [Google Scholar] [CrossRef]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and attentive depth distiller for efficient RGB-D salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9060–9069. [Google Scholar]
- Chen, S.; Fu, Y. Progressively guided alternate refinement network for RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 520–538. [Google Scholar]
- Pang, Y.; Zhang, L.; Zhao, X.; Lu, H. Hierarchical dynamic filtering network for RGB-D salient object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXV 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 235–252. [Google Scholar]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q.; Shen, J.; Zhu, C. Siamese network for RGB-D salient object detection and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5541–5559. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Zhang, Y.; Piao, Y.; Hu, B.; Lu, H. Feature reintegration over differential treatment: A top-down and adaptive fusion network for RGB-D salient object detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4107–4115. [Google Scholar]
- Zhang, M.; Fei, S.X.; Liu, J.; Xu, S.; Piao, Y.; Lu, H. Asymmetric two-stream architecture for accurate RGB-D saliency detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXVIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 374–390. [Google Scholar]
- Li, C.; Cong, R.; Piao, Y.; Xu, Q.; Loy, C.C. RGB-D salient object detection with cross-modality modulation and selection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part VIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 225–241. [Google Scholar]
- Li, C.; Cong, R.; Kwong, S.; Hou, J.; Fu, H.; Zhu, G.; Zhang, D.; Huang, Q. ASIF-Net: Attention steered interweave fusion network for RGB-D salient object detection. IEEE Trans. Cybern. 2020, 51, 88–100. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Li, S.; Chen, C.; Fang, Y.; Hao, A.; Qin, H. Data-level recombination and lightweight fusion scheme for RGB-D salient object detection. IEEE Trans. Image Process. 2020, 30, 458–471. [Google Scholar] [CrossRef]
- Chen, Q.; Liu, Z.; Zhang, Y.; Fu, K.; Zhao, Q.; Du, H. RGB-D salient object detection via 3D convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 1063–1071. [Google Scholar]
- Huang, Z.; Chen, H.X.; Zhou, T.; Yang, Y.Z.; Liu, B.Y. Multi-level cross-modal interaction network for RGB-D salient object detection. Neurocomputing 2021, 452, 200–211. [Google Scholar] [CrossRef]
- Zhang, W.; Jiang, Y.; Fu, K.; Zhao, Q. BTS-Net: Bi-directional transfer-and-selection network for RGB-D salient object detection. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Wen, H.; Yan, C.; Zhou, X.; Cong, R.; Sun, Y.; Zheng, B.; Zhang, J.; Bao, Y.; Ding, G. Dynamic selective network for RGB-D salient object detection. IEEE Trans. Image Process. 2021, 30, 9179–9192. [Google Scholar] [CrossRef]
- Zhou, T.; Fu, H.; Chen, G.; Zhou, Y.; Fan, D.P.; Shao, L. Specificity-preserving RGB-D saliency detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4681–4691. [Google Scholar]
- Zhang, C.; Cong, R.; Lin, Q.; Ma, L.; Li, F.; Zhao, Y.; Kwong, S. Cross-modality discrepant interaction network for RGB-D salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 2094–2102. [Google Scholar]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and cross-scale adaptive fusion network for detecting salient objects in RGB-D images. IEEE Trans. Multimed. 2021, 24, 2192–2204. [Google Scholar] [CrossRef]
- Zhang, M.; Yao, S.; Hu, B.; Piao, Y.; Ji, W. C2 DFNet: Criss-cross dynamic filter network for RGB-D salient object detection. IEEE Trans. Multimed. 2022, 25, 5142–5154. [Google Scholar] [CrossRef]
- Wang, F.; Pan, J.; Xu, S.; Tang, J. Learning discriminative cross-modality features for RGB-D saliency detection. IEEE Trans. Image Process. 2022, 31, 1285–1297. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Wang, L.; Lu, H.; Huang, K.; Shi, X.; Liu, B. Mvsalnet: Multi-view augmentation for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 270–287. [Google Scholar]
- Lee, M.; Park, C.; Cho, S.; Lee, S. Spsn: Superpixel prototype sampling network for rgb-d salient object detection. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 630–647. [Google Scholar]
- Xia, W.; Zhou, D.; Cao, J.; Liu, Y.; Hou, R. CIRNet: An improved RGBT tracking via cross-modality interaction and re-identification. Neurocomputing 2022, 493, 327–339. [Google Scholar] [CrossRef]
- Yang, Y.; Qin, Q.; Luo, Y.; Liu, Y.; Zhang, Q.; Han, J. Bi-directional progressive guidance network for RGB-D salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5346–5360. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Xiang, T.Z.; Zhang, L.; Lu, H. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2160–2170. [Google Scholar]
- Liang, Y.; Qin, G.; Sun, M.; Qin, J.; Yan, J.; Zhang, Z. Multi-modal interactive attention and dual progressive decoding network for RGB-D/T salient object detection. Neurocomputing 2022, 490, 132–145. [Google Scholar] [CrossRef]
- Bi, H.; Wu, R.; Liu, Z.; Zhu, H.; Zhang, C.; Xiang, T.Z. Cross-modal hierarchical interaction network for RGB-D salient object detection. Pattern Recognit. 2023, 136, 109194. [Google Scholar] [CrossRef]
- Wei, L.; Zong, G. EGA-Net: Edge feature enhancement and global information attention network for RGB-D salient object detection. Inf. Sci. 2023, 626, 223–248. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. CAVER: Cross-modal view-mixed transformer for bi-modal salient object detection. IEEE Trans. Image Process. 2023, 32, 892–904. [Google Scholar] [CrossRef]
- Zhuge, M.; Fan, D.P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient object detection via integrity learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3738–3752. [Google Scholar] [CrossRef]
- Wang, H.; Wan, L.; Tang, H. Leno: Adversarial robust salient object detection networks with learnable noise. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2537–2545. [Google Scholar]
- Wang, F.; Wang, R.; Sun, F. DCMNet: Discriminant and cross-modality network for RGB-D salient object detection. Expert Syst. Appl. 2023, 214, 119047. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, J.; Zhou, Z.; An, Z.; Jiang, Q.; Demonceaux, C.; Sun, G.; Timofte, R. Object segmentation by mining cross-modal semantics. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 3455–3464. [Google Scholar]
- Huo, F.; Liu, Z.; Guo, J.; Xu, W.; Guo, S. UTDNet: A unified triplet decoder network for multimodal salient object detection. Neural Netw. 2024, 170, 521–534. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Wang, Q.; Dong, B.; Ma, R.; Liu, N.; Fu, H.; Xia, Y. EM-Trans: Edge-Aware Multimodal Transformer for RGB-D Salient Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2024. early access. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Wang, W.; Li, W.; Li, G.; Li, M.; Zhou, M. MFUR-Net: Multimodal feature fusion and unimodal feature refinement for RGB-D salient object detection. Knowl.-Based Syst. 2024, 299, 112022. [Google Scholar] [CrossRef]
- Fang, X.; Jiang, M.; Zhu, J.; Shao, X.; Wang, H. GroupTransNet: Group transformer network for RGB-D salient object detection. Neurocomputing 2024, 594, 127865. [Google Scholar] [CrossRef]
- Gao, H.; Su, Y.; Wang, F.; Li, H. Heterogeneous Fusion and Integrity Learning Network for RGB-D Salient Object Detection. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–24. [Google Scholar] [CrossRef]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Yu, M.; Liu, J.; Liu, Y.; Yan, G. Feature interaction and two-stage cross-modal fusion for RGB-D salient object detection. J. Intell. Fuzzy Syst. 2024, 46, 4543–4556. [Google Scholar] [CrossRef]
- Sun, H.; Wang, Y.; Ma, X. An adaptive guidance fusion network for RGB-D salient object detection. Signal Image Video Process. 2024, 18, 1683–1693. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Fusion Strategy | Advantages | Disadvantages |
|---|---|---|
| Early Fusion | Maximizes data interaction | Less flexible |
| Middle Fusion | Balances independent processing | Designing and training multiple feature extractors and the fusion of features at intermediate layers increase model complexity and training difficulty |
| Late Fusion | Ensures robustness to modality-specific noise | Limited in capturing beneficial cross-modal interactions at early stages |
| Hybrid Fusion | Integrates advantages of all stages | Complex in implementation and optimization |
| Time | Name | Backbone | Attention Mechanism | Multi-Model Fusion | MAE | |||
|---|---|---|---|---|---|---|---|---|
| 2018 | PCF [57] | VGG-16 | ✗ | ✗ | 0.872 | 0.877 | 0.924 | 0.059 |
| 2019 | SSRCNN [58] | VGG-16 | ✗ | ✓ | 0.876 | 0.890 | 0.912 | 0.047 |
| PDNet [59] | VGG-16, VGG-19 | ✗ | ✗ | 0.823 | 0.877 | 0.899 | 0.071 | |
| MMCI [60] | - | ✗ | ✓ | 0.868 | 0.859 | 0.882 | 0.079 | |
| CPFP [61] | VGG-16 | ✗ | ✓ | 0.890 | 0.878 | 0.900 | 0.053 | |
| TANet [62] | VGG-16 | ✓ | ✓ | 0.888 | 0.878 | 0.909 | 0.061 | |
| DMRA [50] | VGG-19 | ✓ | ✓ | 0.896 | 0.885 | 0.920 | 0.051 | |
| 2020 | DANet [63] | VGG-16, VGG-19 | ✓ | ✓ | 0.905 | 0.897 | 0.926 | 0.046 |
| DASNet [64] | ResNet-50 | ✗ | ✓ | 0.911 | 0.902 | 0.927 | 0.042 | |
| CoNet [65] | ResNet | ✗ | ✗ | 0.872 | 0.894 | 0.912 | 0.047 | |
| CMWNet [66] | VGG-16 | ✗ | ✓ | 0.902 | 0.903 | 0.936 | 0.046 | |
| ICNet [67] | VGG-16 | ✗ | ✓ | 0.891 | 0.894 | 0.926 | 0.052 | |
| S2MA [16] | VGG-16 | ✓ | ✓ | 0.889 | 0.894 | 0.930 | 0.053 | |
| A2dele [68] | VGG-16 | ✓ | ✗ | 0.873 | 0.869 | 0.916 | 0.051 | |
| PGAR [69] | VGG-16 | ✗ | ✓ | 0.893 | 0.909 | 0.916 | 0.042 | |
| HDFNet [70] | VGG-16, VGG-19 | ✗ | ✓ | 0.922 | 0.908 | 0.932 | 0.038 | |
| JL-DCF [71] | VGG-16, ResNet-101 | ✗ | ✓ | 0.903 | 0.903 | 0.944 | 0.043 | |
| FRDT [72] | VGG-19 | ✗ | ✓ | 0.879 | 0.898 | 0.917 | 0.048 | |
| CmSalGAN [39] | VGG-16 | ✓ | ✓ | 0.897 | 0.903 | 0.94 | 0.046 | |
| ATSA [73] | VGG-19 | ✓ | ✓ | 0.893 | 0.901 | 0.921 | 0.040 | |
| cmMS [74] | VGG-16 | ✗ | ✓ | 0.897 | 0.900 | 0.936 | 0.044 | |
| D3Net [49] | VGG-16 | ✗ | ✓ | 0.887 | 0.893 | 0.930 | 0.051 | |
| ASIFNet [75] | VGG-16 | ✓ | ✓ | 0.901 | 0.889 | - | 0.047 | |
| DRLF [76] | VGG-16 | ✗ | ✓ | 0.883 | 0.886 | 0.926 | 0.550 | |
| 2021 | RD3D [77] | ResNet-50 | ✗ | ✓ | 0.914 | 0.916 | 0.947 | 0.036 |
| MCINet [78] | ResNet-50 | ✗ | ✓ | 0.902 | 0.906 | 0.939 | 0.039 | |
| SwinNet [7] | ResNet-50, ResNet-101 | ✓ | ✓ | 0.922 | 0.935 | 0.934 | 0.027 | |
| BiANet [35] | VGG-16 | ✓ | ✓ | 0.920 | 0.915 | 0.948 | 0.039 | |
| BTSNet [79] | ResNet-50 | ✗ | ✓ | 0.924 | 0.921 | 0.954 | 0.036 | |
| DSNet [80] | ResNet-50 | ✗ | ✓ | 0.895 | 0.921 | 0.945 | 0.034 | |
| SPNet [81] | Res2Net-50 | ✗ | ✓ | 0.935 | 0.925 | 0.954 | 0.028 | |
| EBFNet [13] | VGG-16 | ✗ | ✓ | 0.895 | 0.907 | 0.936 | 0.038 | |
| CMINet [12] | ResNet-50 | ✗ | ✓ | 0.925 | 0.939 | 0.956 | 0.032 | |
| CDINet [82] | VGG-16 | ✗ | ✓ | 0.922 | 0.919 | - | 0.036 | |
| CCAFNet [83] | - | ✗ | ✓ | 0.911 | 0.910 | 0.920 | 0.037 | |
| DSA2F [36] | VGG-19 | ✓ | ✓ | 0.892 | 0.918 | 0.950 | 0.024 | |
| 2022 | C2DFNet [84] | ResNet-50 | ✗ | ✓ | 0.937 | 0.922 | 0.948 | 0.020 |
| DCMF [85] | VGG-16, ResNet-50 | ✗ | ✓ | 0.913 | 0.922 | 0.940 | 0.029 | |
| MVSalNet [86] | ResNet-50 | ✗ | ✓ | 0.942 | 0.937 | 0.973 | 0.019 | |
| SPSN [87] | ResNet-50 | ✗ | ✗ | 0.942 | 0.937 | 0.973 | 0.017 | |
| CIRNet [88] | RepVGG | ✗ | ✓ | 0.927 | 0.925 | 0.925 | 0.035 | |
| BPGNet [89] | VGG-16 | ✗ | ✓ | 0.926 | 0.923 | 0.953 | 0.034 | |
| ZoomNet [90] | ResNet-50 | ✗ | ✓ | 0.926 | 0.914 | 0.940 | 0.037 | |
| MIADPD [91] | ResNet-50 | ✓ | ✓ | 0.916 | 0.914 | 0.951 | 0.036 | |
| 2023 | HINet [92] | ResNet-50 | ✗ | ✓ | 0.914 | 0.915 | 0.945 | 0.039 |
| HiDAnet [40] | VGG-16, ResNet-50 | ✓ | ✓ | 0.927 | 0.928 | 0.962 | 0.021 | |
| CATNet [24] | Swin-B | ✓ | ✓ | 0.929 | 0.937 | 0.933 | 0.025 | |
| EGANet [93] | - | ✗ | ✓ | 0.883 | - | 0.922 | 0.033 | |
| CAVER [94] | ResNet-50, ResNet-101 | ✗ | ✓ | 0.928 | 0.926 | 0.958 | 0.030 | |
| ICON [95] | VGG, PVT, ResNet | ✗ | ✓ | 0.891 | 0.893 | 0.937 | 0.051 | |
| LENO [96] | ResNet-50 | ✓ | ✗ | 0.824 | 0.838 | 0.888 | 0.073 | |
| DCMNet [97] | Res2Net | ✓ | ✓ | 0.899 | - | 0.920 | 0.036 | |
| MPDNet [33] | ResNet-50 | ✓ | ✗ | 0.912 | 0.912 | 0.937 | 0.041 | |
| XMSNet [98] | PVT | ✓ | ✓ | 0.942 | 0.931 | 0.960 | 0.025 | |
| 2024 | UTDNet [99] | VGG-16, ResNet-50 | ✗ | ✓ | 0.925 | 0.923 | 0.948 | 0.036 |
| DCMTrans [45] | T2T-14 | ✓ | ✓ | 0.934 | 0.932 | 0.959 | 0.031 | |
| EMTrans [100] | PVTv2-B2 | ✓ | ✓ | 0.920 | 0.903 | 0.944 | 0.039 | |
| MFURNet [101] | ResNet-50 | ✗ | ✓ | 0.937 | 0.923 | - | 0.035 | |
| Group TransNet [102] | ResNet-50 | ✗ | ✓ | 0.923 | 0.924 | 0.928 | 0.027 | |
| CPNet [23] | Swin-B | ✓ | ✓ | 0.933 | 0.935 | 0.935 | 0.025 | |
| HFILNet [103] | Swin-Trans | ✓ | ✓ | 0.931 | 0.936 | 0.939 | 0.025 | |
| HFMDNet [26] | VGG-16, ResNet-50, Swim-Trans | ✗ | ✓ | 0.944 | 0.937 | 0.966 | 0.023 |
| Technique | Performance Metric | Scenario | Key Strengths | Key Limitations |
|---|---|---|---|---|
| Attention Mechanisms | Accuracy (e.g., F-measure) | Complex scenes with clutter | Enhances feature focus, improves object localization | High computational cost, may overfit in complex scenarios |
| Cross-Modal Fusion | Precision, Recall | Low-light environments, occlusions | Combines complementary data, robust to sensor noise | Requires high-quality depth data, integration complexity |
| Attention + Cross-Modal Fusion | Accuracy, Precision, Recall | Complex and diverse scenarios, real-time | Maximizes feature extraction and data integration, improves robustness and accuracy | Higher computational demand, requires sophisticated model design |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, A.; Li, X.; He, T.; Zhou, J.; Chen, D. Advancing in RGB-D Salient Object Detection: A Survey. Appl. Sci. 2024, 14, 8078. https://doi.org/10.3390/app14178078
Chen A, Li X, He T, Zhou J, Chen D. Advancing in RGB-D Salient Object Detection: A Survey. Applied Sciences. 2024; 14(17):8078. https://doi.org/10.3390/app14178078
Chicago/Turabian StyleChen, Ai, Xin Li, Tianxiang He, Junlin Zhou, and Duanbing Chen. 2024. "Advancing in RGB-D Salient Object Detection: A Survey" Applied Sciences 14, no. 17: 8078. https://doi.org/10.3390/app14178078
APA StyleChen, A., Li, X., He, T., Zhou, J., & Chen, D. (2024). Advancing in RGB-D Salient Object Detection: A Survey. Applied Sciences, 14(17), 8078. https://doi.org/10.3390/app14178078