
Toward Smart SCADA Systems in the Hydropower Plants through Integrating Data Mining-Based Knowledge Discovery Modules




Abstract
:1. Introduction
- Remote monitoring and control: The SCADA systems can help reduce the need for travel to physical places of the electrical/mechanical aggregates from the hydropower plant due to the remote terminal units (RTUs), thereby decreasing carbon emissions associated with transportation. The systems allow the remote monitoring and control of aggregates/equipment from the control room using RTUs. Because the dispatcher can monitor and control the systems using RTUs, this flexibility reduces the need to move the service team in all important points, contributing thus to sustainability by lowering carbon emissions.
- Energy efficiency: A smart SCADA system can help the use of a smaller water amount from the dam by monitoring and storing historical data in real time. This enables them to identify the improper working and leaks in the aggregates and installations, which can result in timely repairs and lower energy consumption.
- Compliance with environmental regulations: A smart SCADA system can generate reports and track key environmental metrics, allowing hydropower companies to reduce their ecological footprint by monitoring the working hours of their generators and turbines. This enables them to plan their maintenance operations more precisely, which helps them save on resources and minimizes downtime.
- Predictive maintenance: Predictive maintenance is ensured by a smart SCADA system, which keeps track of the hydro aggregate’s performance and running hours. This helps in identifying potential issues and planning preventive maintenance activities, which extends the lifespan of the equipment and reduces waste and the impact of manufacturing new machinery and parts. These systems can also provide notifications in real time in the event of malfunctions.
- Rapid response to issues: Integrating with the Internet of Things can help a SCADA system provide rapid response capabilities. This allows it to monitor and respond to environmental incidents and operational issues in real time. It can also prevent more significant issues, such as failure or water leaks.
- How can a deeper analysis of the data from various processes and equipment within the hydropower plant be performed?
- Which is the best approach to perform the analysis?
- The vast majority of applications aim for a single task implemented at the level of data analysis regarding the energy production relationship between upstream and downstream hydro plants, energy production forecasting, identifying the operating regimes, improving the data quality, outliers’ detection, identifying faults, or determining the typical operating profiles.
- The analysis time horizon corresponds with a day, season, or year.
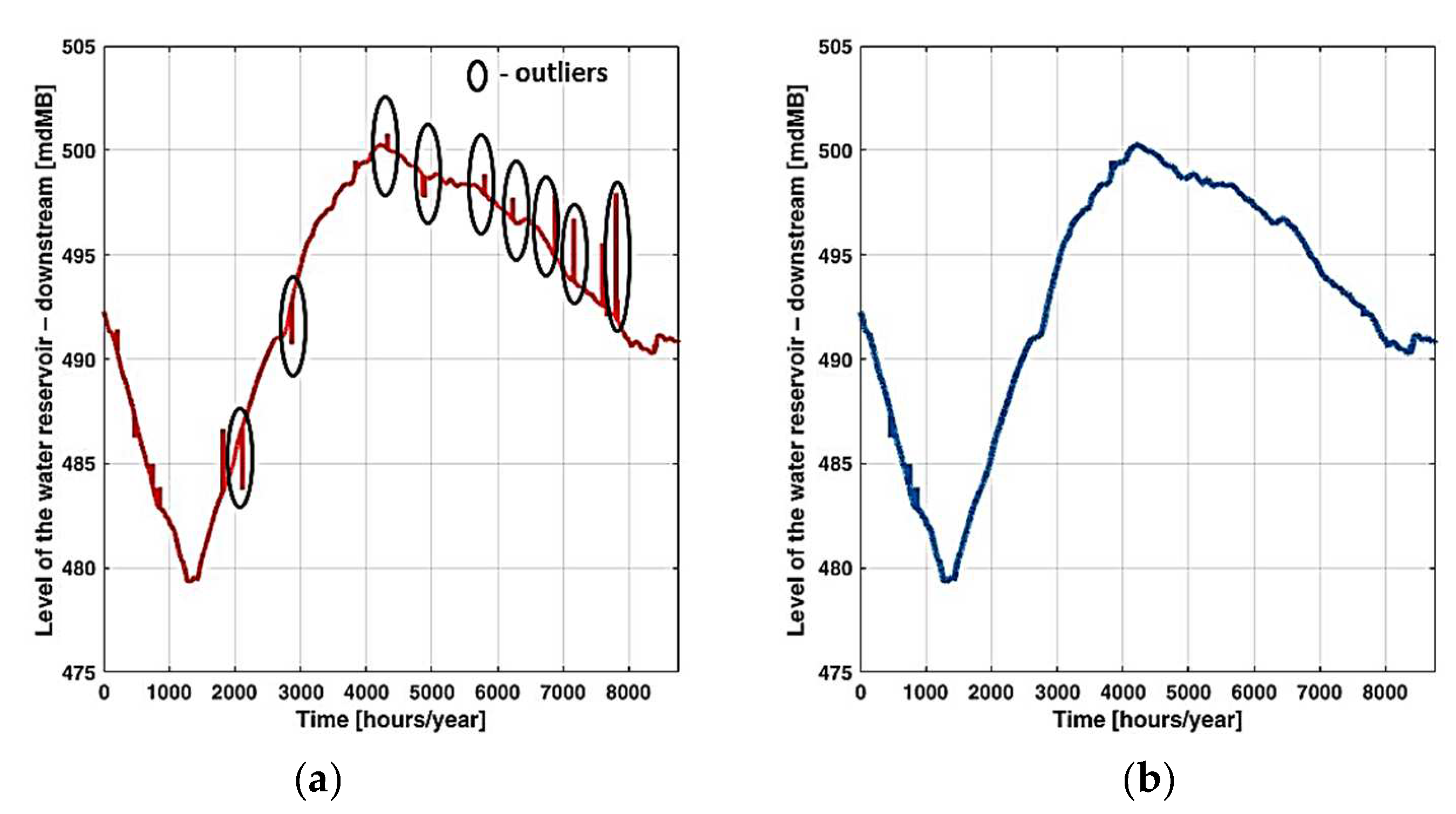
- Performing an advanced statistical analysis and outliers’ detection,
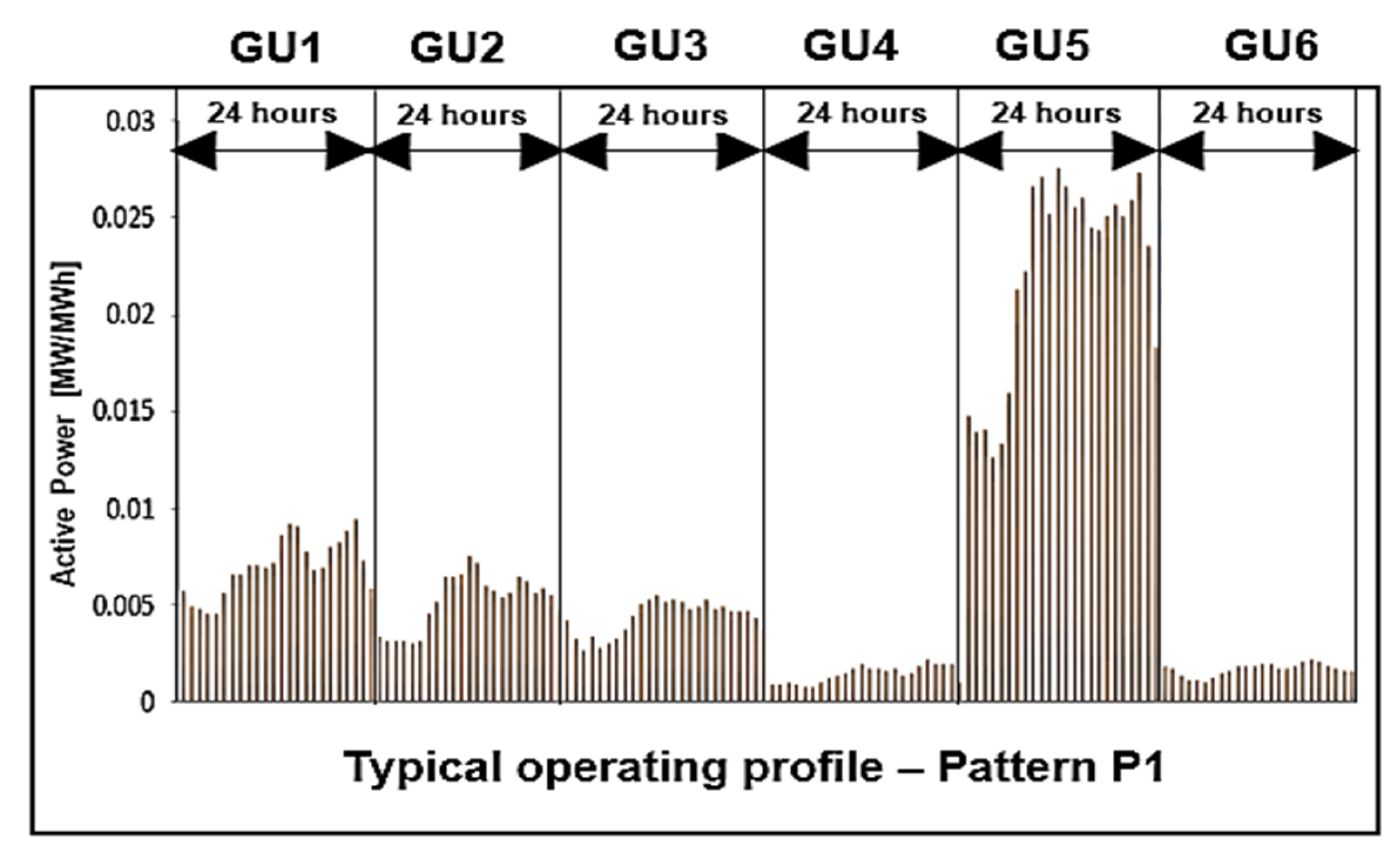
- Identifying the operating regimes and hourly typical operating profiles,
- Developing the strategies for loading the generation units that consider the number of hours of operation and the minimization of the amount of water used to satisfy the power required by the system.
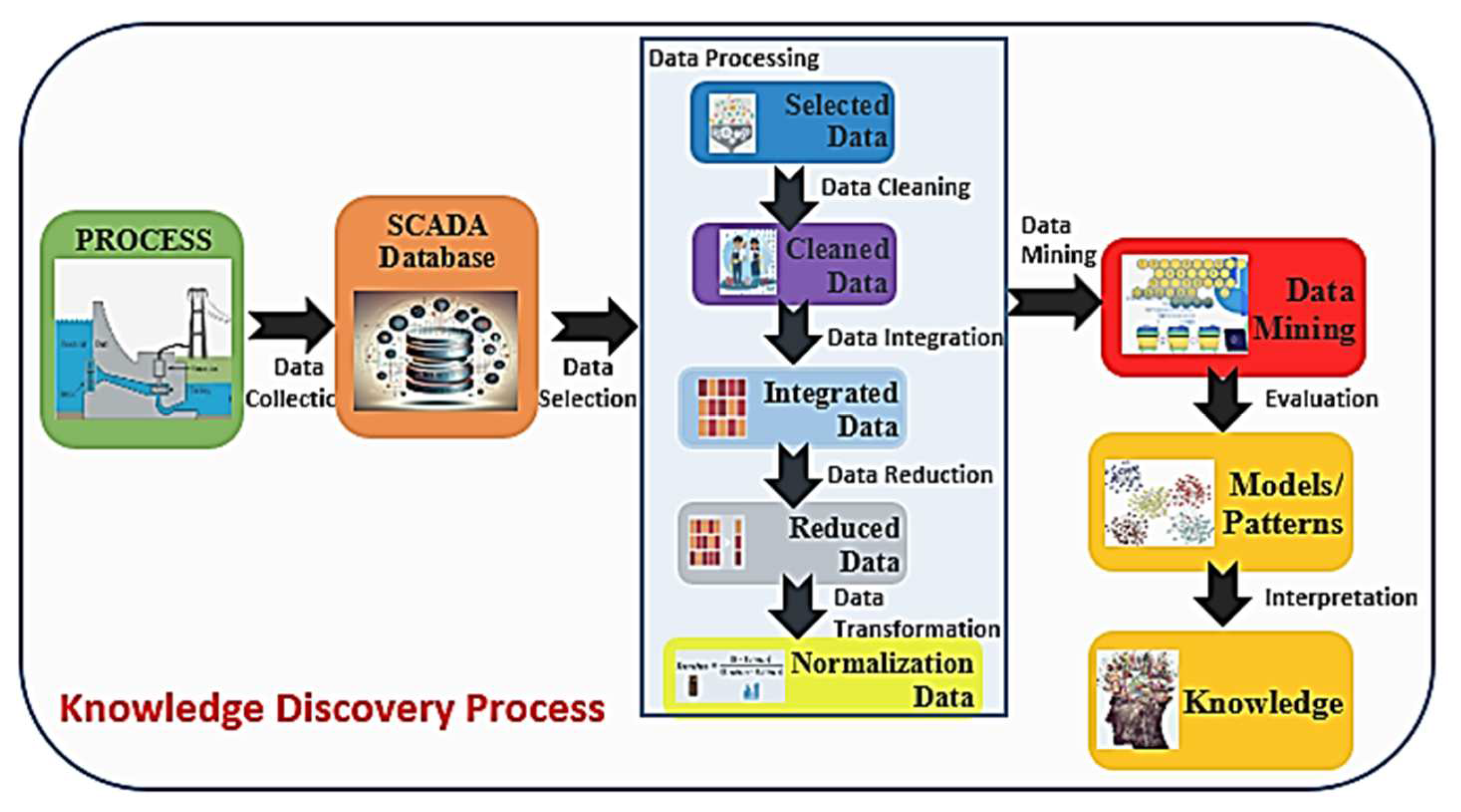
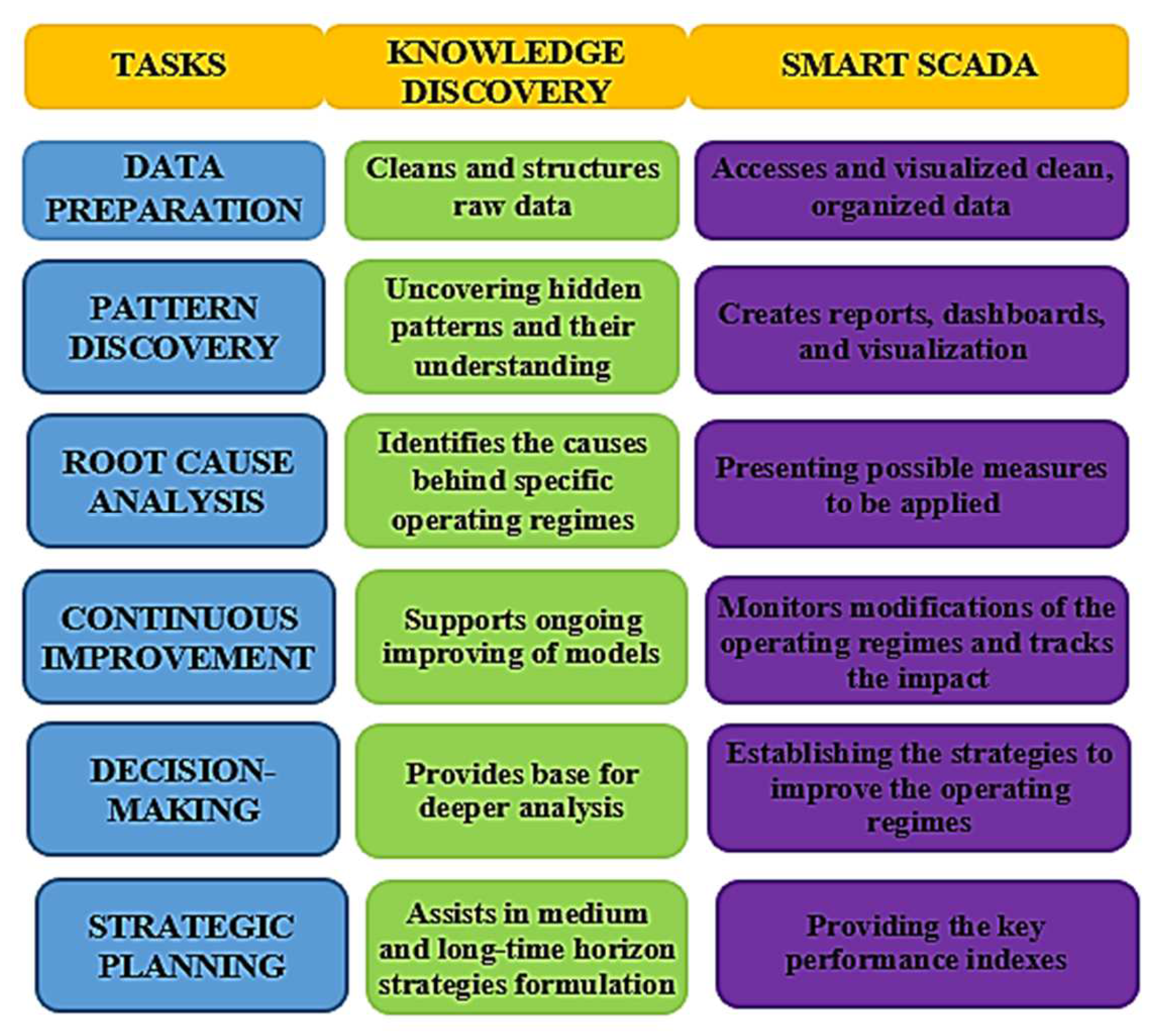
2. Knowledge Discovery and Data Mining in Smart SCADA
2.1. Knowledge Discovery vs. Data Mining
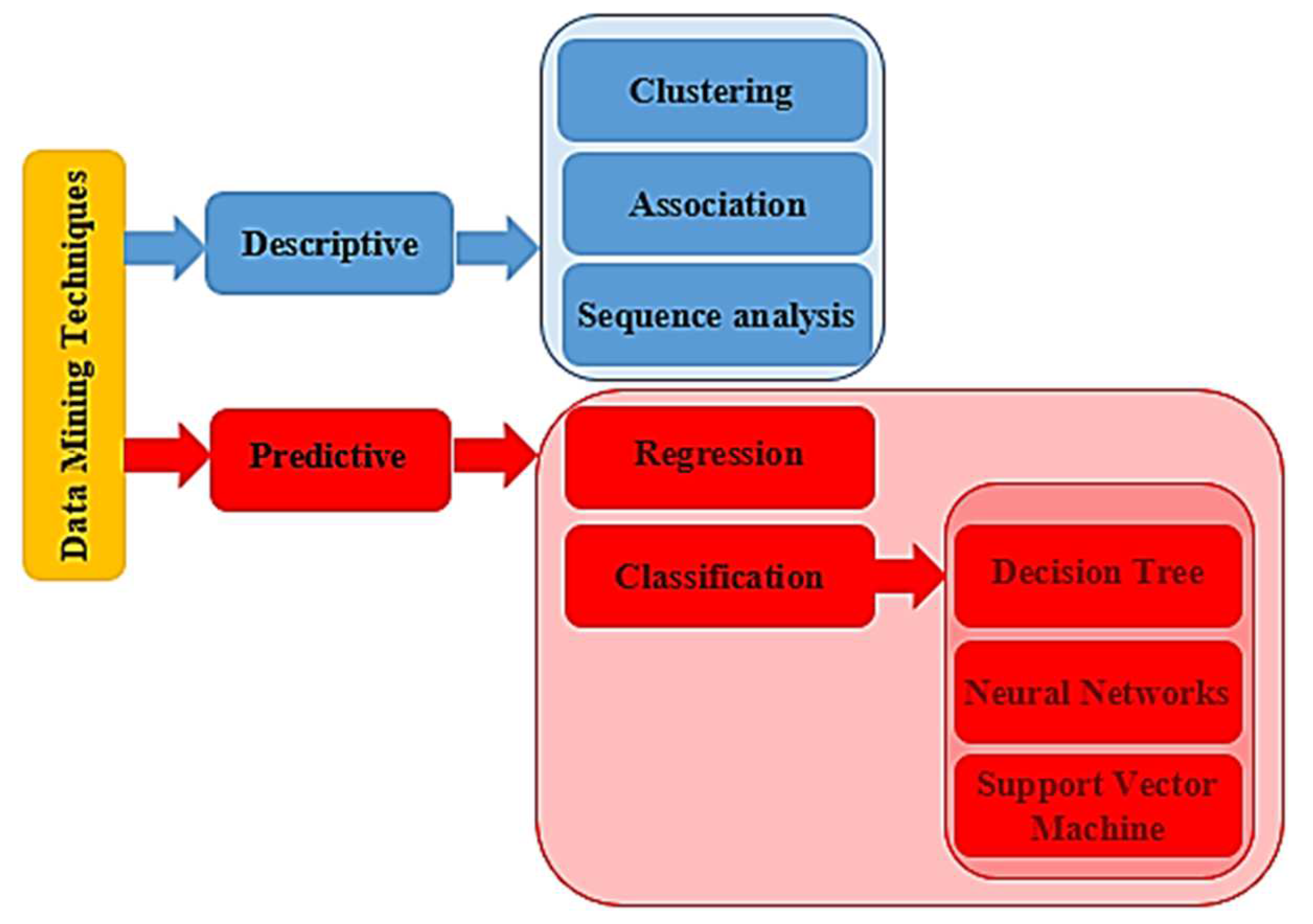
2.2. Data Mining Techniques
- Support Vector Machine. This algorithm creates a boundary between the different classes/patterns. It identifies the features that are most important to the classification process.
- Decision Tree. The classification process is carried out using a tree-based structure. This algorithm uses a set of conditions to categorize the data. The root nodes of the structure are set for the test conditions, while the leaf nodes are for the outcome.
- Neural Network. A neural network model is a computational resource that can recognize the relationships between various data sets. These units, which act like neurons, are formed by connecting the inputs and outputs. The model considers the connection strength and outputs the information in a hidden layer. The neural network is similar to the human brain in that it requires training to be effective. Although it can be hard to interpret, the models are reliable and can even classify past training procedures.
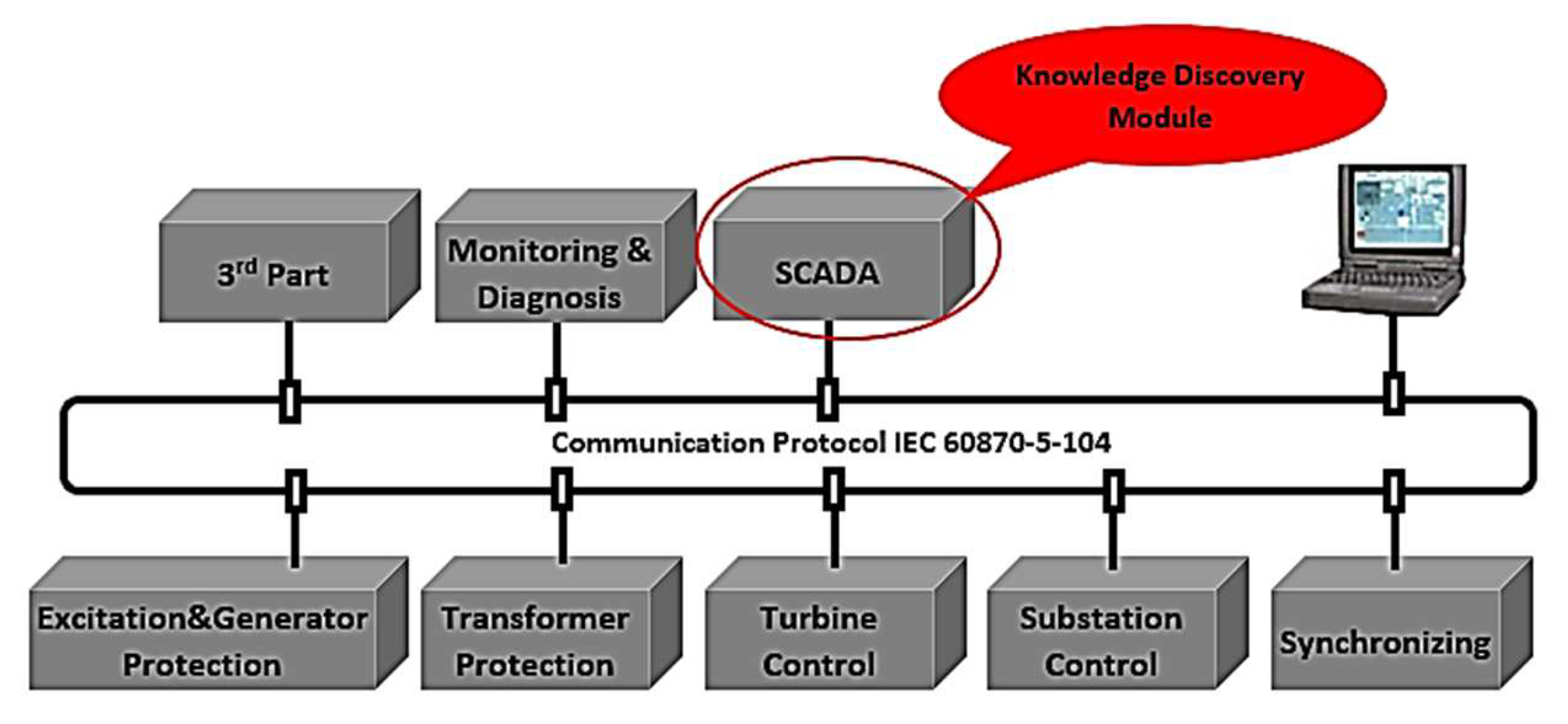
3. Multi-Task Framework Integrated into the Knowledge Discovery Module
- The knowledge base is composed of two main elements: the rules base (which contains the knowledge required to solve problems) and the facts base (the patterns obtained in the clustering-based data mining are recorded in this base).
- The inference engine can determine the mode in which knowledge derived from the rules base is utilized to interpret the data from the information base. It can perform various tasks, such as confirming or rejecting a hypothesis or the solution of a problem.
- The editor of the knowledge base provides the DEMA with the ability to update and inspect the information base’s content, particularly its rules base’s content.
- The explanation system can provide explanations for the stages in the Expert System’s reasoning.
4. Case Study
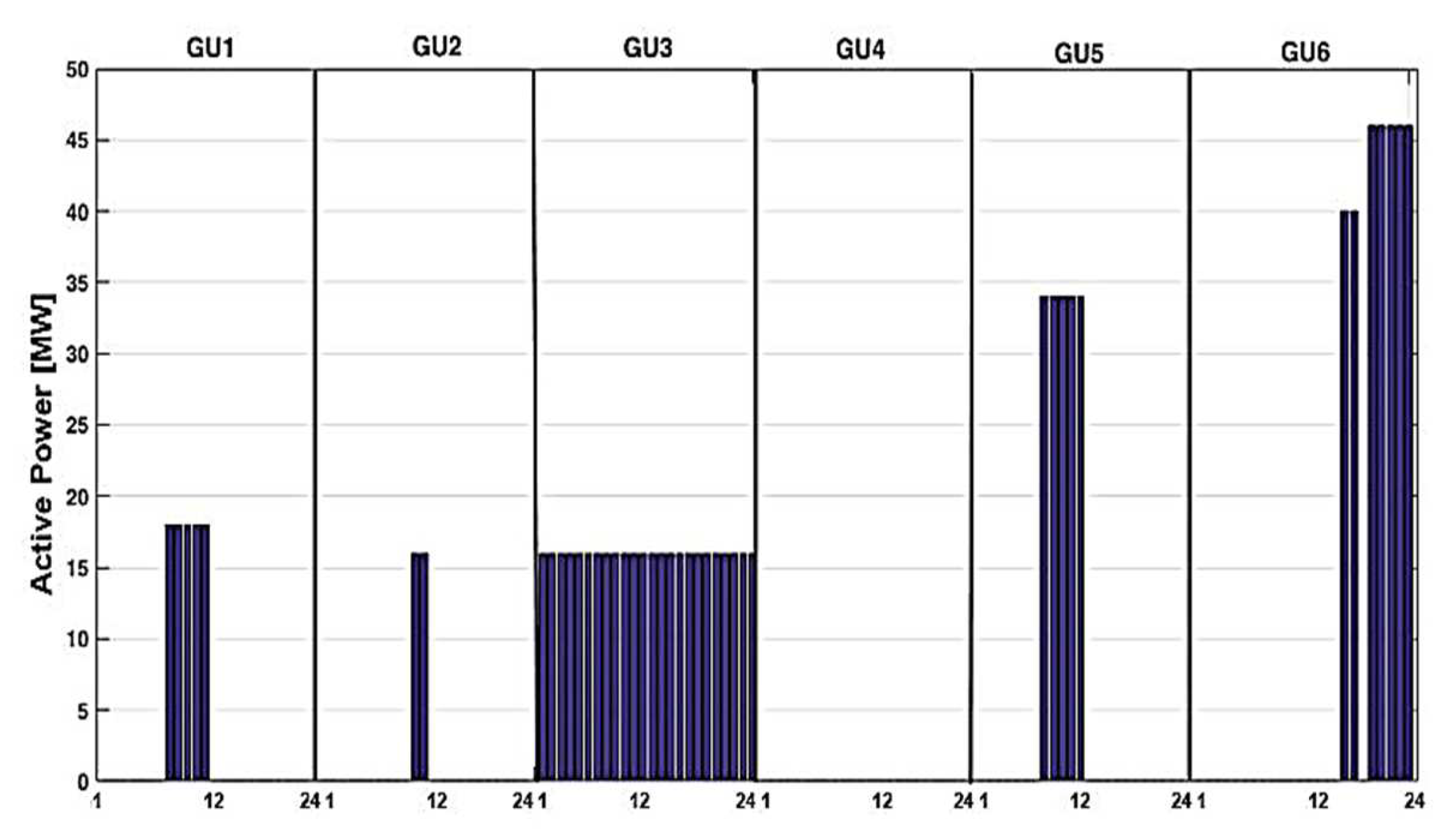
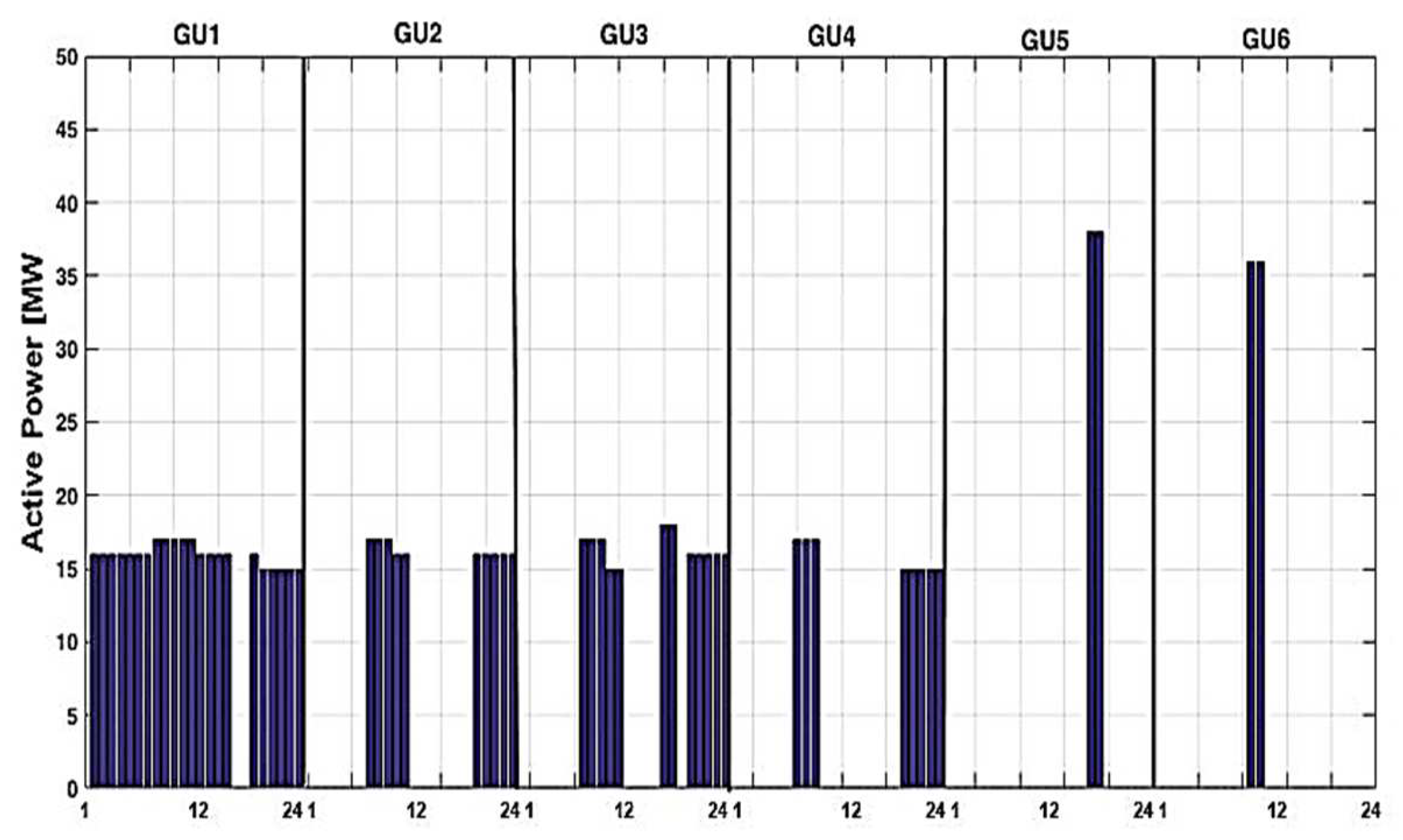
- Red color is associated with the generation units that have been loaded in the experience-based strategy but not considered in the case of the expert system-based strategy (the sign is “-“).
- Blue color is associated with the generation units that have been loaded in the expert-based strategy but not considered in the case of the experience-based strategy (only with the sign “+“).
- Green color is associated with the generation units loaded in the expert-based strategy, having the same (value “0”) or having another loading in the expert-based strategy (with signs “+“ or “−“).
- Yellow color is associated with the generation units that have not been loaded in either strategy.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| DEMA | Decision-Makers |
| DM | Data Mining |
| GU | Generation Unit |
| HPP | Hydropower Plant |
| KD | Knowledge Discovery |
| O&M | Operations and Maintenance |
| SCADA | Supervisory Control and Data Acquisition |
| RTU | Remote Terminal Units |
| WF_Pipe_n | Water flows in the pipe n from the hydropower plant HPP, in [m3/s] |
| Iex_GUn | Excitation current of the generation unit GUn from the hydropower plant HPP, in [V] |
| Is_GUn | Stator current of the generation unit GUn from the hydropower plant HPP, in [A] |
| Hyear | the number of hours when at least one GU works, in [hours] |
| m | mean of the data set |
| NHPPGU | the number of generation units from the hydropower plant |
| P_GU_Pipe_n | Active power produced by the generation units, GU, which are supplied through the pipe n from the hydropower plant HPP, in [MW] |
| P_GUn | Active power produced by the generation unit GUn from the hydropower plant HPP, in [MW] |
| P_req | Requested active power of the system to the hydropower plant HPP, in [MW] |
| Q0 | zeroth quartile (minimum value of the data set) |
| Q1 | first quartile (25%) |
| Q2 | second quartile (50%) |
| Q3 | third quartile (75%) |
| Q_GU_Pipe_n | Reactive power produced by the generation units, GU, which are supplied through the pipe n from the hydropower plant HPP, in [MVAr] |
| Q_GUn | Reactive power produced by the generation unit GUn from the hydropower plant HPP, in [MVAr] |
| Q_req | Requested active power of the system to the hydropower plant HPP, in [MVAr] |
| Vex_GUn | Excitation voltage of the generation unit GUn from the hydropower plant HPP, in [V] |
| Vs_GUn | Stator voltage of the generation unit GUn from the hydropower plant HPP, in [kV] |
| WLr_d | Water levels of the reservoir downstream, in [mdMB] |
| WLr_u | Water levels of the reservoir upstream, in [mdMB] |
| σ | standard deviation of the dataset |
Appendix A

| Hour | GU1 | GU2 | GU3 | |||||||||||||||
| Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | |
| 1 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 2 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 3 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 4 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 5 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 6 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 7 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 8 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 10.5 | 1.10 | 20 | 1 | 100 | 290 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 9 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 10.5 | 1.10 | 20 | 1 | 100 | 290 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 10 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 11 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 12 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 13 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 14 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 15 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 16 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 10.5 | 1.10 | 20 | 5 | 110 | 300 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 17 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 18 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 18 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 20 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 21 | 10.5 | 1.10 | 20 | 5 | 110 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 5 | 105 | 300 |
| 22 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 23 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| 24 | 10.5 | 1.10 | 20 | 1 | 90 | 290 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.00 | 19 | 1 | 95 | 290 |
| Hour | GU4 | GU5 | GU6 | |||||||||||||||
| Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | Vs [kV] | Is [A] | P [MW] | Q [MVAr] | Vex [V] | Iex [A] | |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 11 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.70 | 30 | 1 | 90 | 300 |
| 12 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 1.70 | 30 | 1 | 90 | 300 |
| 13 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 10.6 | 1.70 | 32 | 1 | 95 | 300 |
| 14 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | 10.5 | 1.00 | 18 | 5 | 100 | 310 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 17 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 5 | 120 | 360 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 5 | 120 | 360 | 0 | 0 | 0 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 5 | 120 | 360 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 5 | 120 | 360 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 5 | 120 | 360 | 0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 0 | 0 | 0 | 10.5 | 2.20 | 40 | 1 | 110 | 340 | 0 | 0 | 0 | 0 | 0 | 0 |
| Hour | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 |
|---|---|---|---|---|---|---|
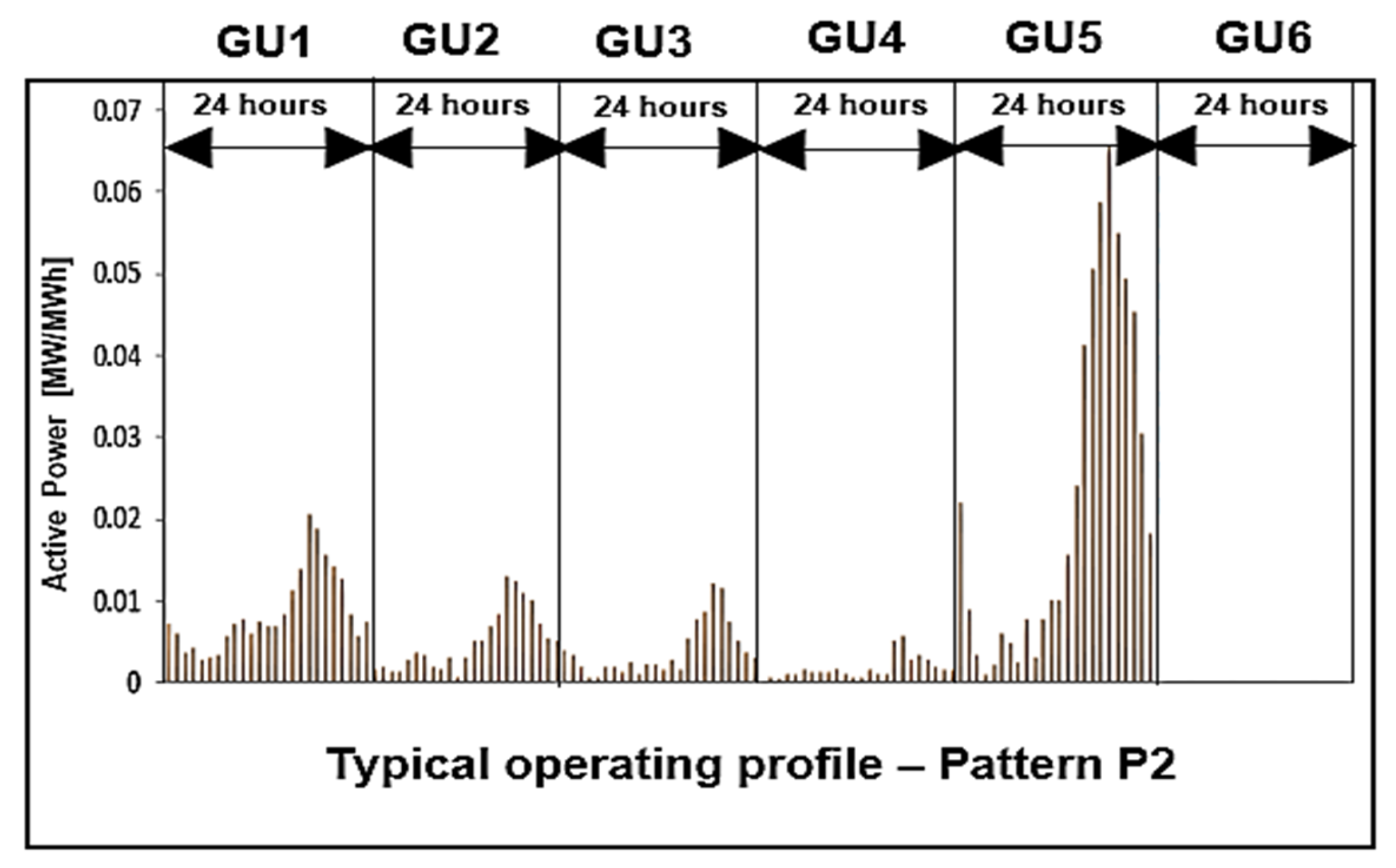
| 1 | 0.00575 | 0.00334 | 0.00319 | 0.00091 | 0.01470 | 0.00181 |
| 2 | 0.00494 | 0.00315 | 0.00259 | 0.00092 | 0.01385 | 0.00169 |
| 3 | 0.00479 | 0.00311 | 0.00332 | 0.00093 | 0.01399 | 0.00134 |
| 4 | 0.00458 | 0.00310 | 0.00282 | 0.00091 | 0.01260 | 0.00108 |
| 5 | 0.00451 | 0.00294 | 0.00295 | 0.00073 | 0.01334 | 0.00107 |
| 6 | 0.00562 | 0.00317 | 0.00323 | 0.00071 | 0.01596 | 0.00104 |
| 7 | 0.00656 | 0.00455 | 0.00367 | 0.00097 | 0.02124 | 0.00122 |
| 8 | 0.00651 | 0.00510 | 0.00448 | 0.00119 | 0.02218 | 0.00145 |
| 9 | 0.00698 | 0.00638 | 0.00507 | 0.00131 | 0.02658 | 0.00157 |
| 10 | 0.00697 | 0.00640 | 0.00523 | 0.00142 | 0.02702 | 0.00176 |
| 11 | 0.00690 | 0.00660 | 0.00548 | 0.00169 | 0.02510 | 0.00176 |
| 12 | 0.00719 | 0.00751 | 0.00519 | 0.00188 | 0.02749 | 0.00177 |
| 13 | 0.00854 | 0.00720 | 0.00524 | 0.00174 | 0.02658 | 0.00194 |
| 14 | 0.00910 | 0.00592 | 0.00516 | 0.00166 | 0.02548 | 0.00192 |
| 15 | 0.00909 | 0.00573 | 0.00482 | 0.00163 | 0.02595 | 0.00168 |
| 16 | 0.00778 | 0.00536 | 0.00486 | 0.00171 | 0.02440 | 0.00169 |
| 17 | 0.00683 | 0.00566 | 0.00527 | 0.00138 | 0.02433 | 0.00182 |
| 18 | 0.00693 | 0.00648 | 0.00480 | 0.00151 | 0.02508 | 0.00202 |
| 19 | 0.00792 | 0.00619 | 0.00485 | 0.00186 | 0.02556 | 0.00212 |
| 20 | 0.00825 | 0.00558 | 0.00470 | 0.00215 | 0.02507 | 0.00200 |
| 21 | 0.00879 | 0.00586 | 0.00469 | 0.00192 | 0.02590 | 0.00185 |
| 22 | 0.00936 | 0.00549 | 0.00470 | 0.00193 | 0.02723 | 0.00174 |
| 23 | 0.00729 | 0.00483 | 0.00428 | 0.00190 | 0.02345 | 0.00160 |
| 24 | 0.00580 | 0.00418 | 0.00366 | 0.00102 | 0.01833 | 0.00161 |
| Hour | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 |
|---|---|---|---|---|---|---|
| 1 | 0.00714 | 0.00723 | 0.00385 | 0.00000 | 0.02189 | 0.00000 |
| 2 | 0.00595 | 0.00156 | 0.00325 | 0.00058 | 0.00867 | 0.00000 |
| 3 | 0.00353 | 0.00180 | 0.00179 | 0.00051 | 0.00342 | 0.00000 |
| 4 | 0.00401 | 0.00123 | 0.00056 | 0.00099 | 0.00091 | 0.00000 |
| 5 | 0.00263 | 0.00123 | 0.00056 | 0.00091 | 0.00202 | 0.00000 |
| 6 | 0.00287 | 0.00274 | 0.00177 | 0.00148 | 0.00597 | 0.00000 |
| 7 | 0.00334 | 0.00352 | 0.00177 | 0.00119 | 0.00477 | 0.00000 |
| 8 | 0.00547 | 0.00317 | 0.00116 | 0.00115 | 0.00240 | 0.00000 |
| 9 | 0.00720 | 0.00184 | 0.00243 | 0.00115 | 0.00764 | 0.00000 |
| 10 | 0.00775 | 0.00155 | 0.00109 | 0.00167 | 0.00311 | 0.00000 |
| 11 | 0.00583 | 0.00298 | 0.00225 | 0.00109 | 0.00772 | 0.00000 |
| 12 | 0.00741 | 0.00053 | 0.00211 | 0.00058 | 0.00998 | 0.00000 |
| 13 | 0.00683 | 0.00294 | 0.00141 | 0.00058 | 0.01011 | 0.00000 |
| 14 | 0.00674 | 0.00498 | 0.00262 | 0.00148 | 0.01545 | 0.00000 |
| 15 | 0.00816 | 0.00514 | 0.00148 | 0.00106 | 0.02402 | 0.00000 |
| 16 | 0.01109 | 0.00683 | 0.00524 | 0.00102 | 0.04126 | 0.00000 |
| 17 | 0.01380 | 0.00830 | 0.00751 | 0.00510 | 0.05050 | 0.00000 |
| 18 | 0.02052 | 0.01275 | 0.00860 | 0.00575 | 0.05867 | 0.00000 |
| 19 | 0.01872 | 0.01230 | 0.01201 | 0.00280 | 0.06564 | 0.00000 |
| 20 | 0.01555 | 0.01080 | 0.01157 | 0.00328 | 0.05483 | 0.00000 |
| 21 | 0.01391 | 0.00992 | 0.00739 | 0.00281 | 0.04916 | 0.00000 |
| 22 | 0.01258 | 0.00719 | 0.00516 | 0.00181 | 0.04508 | 0.00000 |
| 23 | 0.00832 | 0.00541 | 0.00366 | 0.00146 | 0.03031 | 0.00000 |
| 24 | 0.00575 | 0.00512 | 0.00299 | 0.00146 | 0.01821 | 0.00000 |
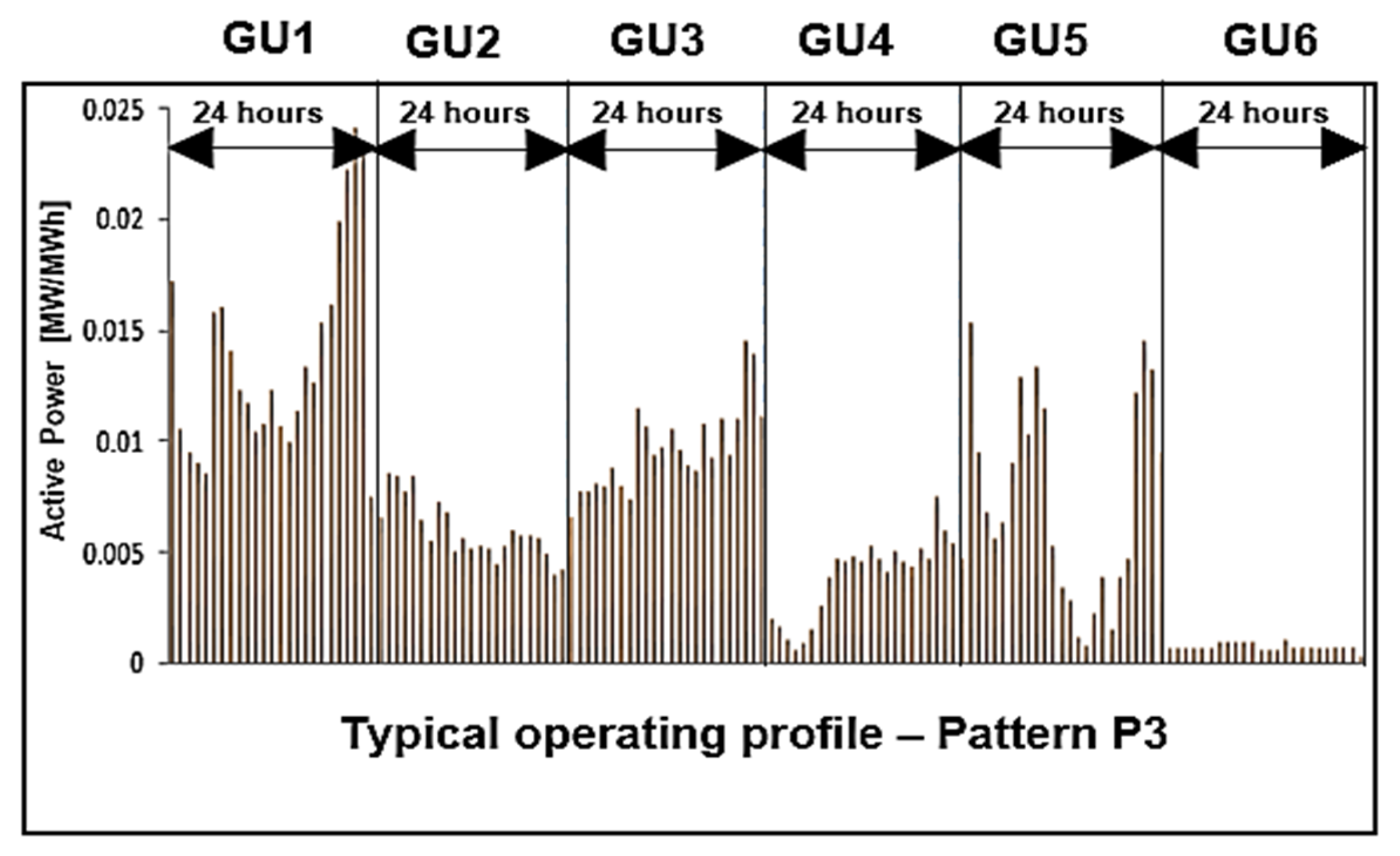
| Hour | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 |
|---|---|---|---|---|---|---|
| 1 | 0.01713 | 0.00741 | 0.00655 | 0.00192 | 0.01527 | 0.00062 |
| 2 | 0.01045 | 0.00646 | 0.00763 | 0.00154 | 0.00945 | 0.00062 |
| 3 | 0.00950 | 0.00852 | 0.00764 | 0.00099 | 0.00676 | 0.00062 |
| 4 | 0.00903 | 0.00841 | 0.00805 | 0.00058 | 0.00552 | 0.00062 |
| 5 | 0.00850 | 0.00765 | 0.00798 | 0.00084 | 0.00623 | 0.00062 |
| 6 | 0.01580 | 0.00840 | 0.00871 | 0.00144 | 0.00901 | 0.00062 |
| 7 | 0.01595 | 0.00643 | 0.00792 | 0.00255 | 0.01280 | 0.00095 |
| 8 | 0.01405 | 0.00548 | 0.00728 | 0.00382 | 0.01031 | 0.00095 |
| 9 | 0.01227 | 0.00727 | 0.01146 | 0.00465 | 0.01336 | 0.00095 |
| 10 | 0.01166 | 0.00675 | 0.01059 | 0.00456 | 0.01138 | 0.00095 |
| 11 | 0.01041 | 0.00494 | 0.00936 | 0.00475 | 0.00521 | 0.00095 |
| 12 | 0.01072 | 0.00556 | 0.00967 | 0.00458 | 0.00330 | 0.00057 |
| 13 | 0.01224 | 0.00515 | 0.01046 | 0.00525 | 0.00272 | 0.00058 |
| 14 | 0.01063 | 0.00528 | 0.00961 | 0.00463 | 0.00108 | 0.00058 |
| 15 | 0.00989 | 0.00507 | 0.00890 | 0.00402 | 0.00073 | 0.00096 |
| 16 | 0.01135 | 0.00445 | 0.00857 | 0.00504 | 0.00217 | 0.00066 |
| 17 | 0.01331 | 0.00520 | 0.01076 | 0.00451 | 0.00385 | 0.00066 |
| 18 | 0.01266 | 0.00598 | 0.00919 | 0.00431 | 0.00145 | 0.00066 |
| 19 | 0.01525 | 0.00567 | 0.01098 | 0.00511 | 0.00382 | 0.00064 |
| 20 | 0.01608 | 0.00567 | 0.00932 | 0.00467 | 0.00467 | 0.00064 |
| 21 | 0.01984 | 0.00560 | 0.01101 | 0.00747 | 0.01211 | 0.00068 |
| 22 | 0.02218 | 0.00490 | 0.01453 | 0.00588 | 0.01447 | 0.00068 |
| 23 | 0.02410 | 0.00390 | 0.01394 | 0.00540 | 0.01314 | 0.00068 |
| 24 | 0.02336 | 0.00414 | 0.01110 | 0.00468 | 0.00939 | 0.00033 |
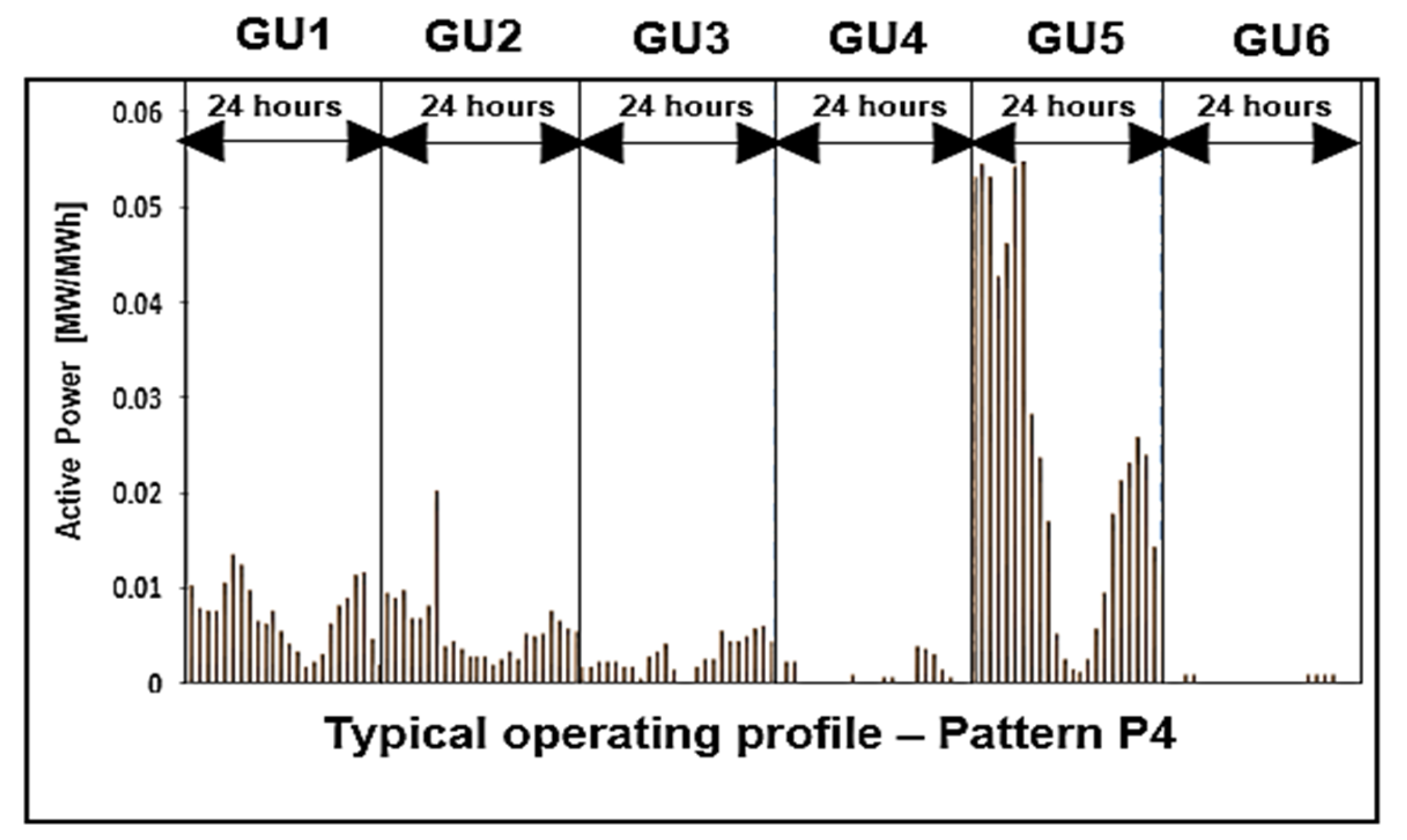
| Hour | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 |
|---|---|---|---|---|---|---|
| 1 | 0.01024 | 0.00938 | 0.00177 | 0.00000 | 0.05302 | 0.00000 |
| 2 | 0.00779 | 0.00898 | 0.00170 | 0.00226 | 0.05455 | 0.00000 |
| 3 | 0.00762 | 0.00958 | 0.00215 | 0.00226 | 0.05302 | 0.00083 |
| 4 | 0.00750 | 0.00668 | 0.00215 | 0.00000 | 0.04260 | 0.00083 |
| 5 | 0.01061 | 0.00667 | 0.00215 | 0.00000 | 0.04609 | 0.00000 |
| 6 | 0.01355 | 0.00796 | 0.00170 | 0.00000 | 0.05410 | 0.00000 |
| 7 | 0.01236 | 0.02001 | 0.00177 | 0.00000 | 0.06093 | 0.00000 |
| 8 | 0.00967 | 0.00388 | 0.00045 | 0.00000 | 0.02815 | 0.00000 |
| 9 | 0.00640 | 0.00420 | 0.00263 | 0.00000 | 0.02356 | 0.00000 |
| 10 | 0.00629 | 0.00347 | 0.00319 | 0.00080 | 0.01695 | 0.00000 |
| 11 | 0.00747 | 0.00262 | 0.00416 | 0.00000 | 0.00504 | 0.00000 |
| 12 | 0.00540 | 0.00275 | 0.00133 | 0.00000 | 0.00239 | 0.00000 |
| 13 | 0.00413 | 0.00272 | 0.00000 | 0.00000 | 0.00143 | 0.00000 |
| 14 | 0.00335 | 0.00181 | 0.00000 | 0.00063 | 0.00120 | 0.00000 |
| 15 | 0.00171 | 0.00235 | 0.00167 | 0.00063 | 0.00251 | 0.00000 |
| 16 | 0.00221 | 0.00313 | 0.00250 | 0.00000 | 0.00566 | 0.00000 |
| 17 | 0.00300 | 0.00236 | 0.00246 | 0.00000 | 0.00937 | 0.00000 |
| 18 | 0.00631 | 0.00512 | 0.00550 | 0.00372 | 0.01772 | 0.00083 |
| 19 | 0.00807 | 0.00492 | 0.00445 | 0.00362 | 0.02117 | 0.00083 |
| 20 | 0.00883 | 0.00515 | 0.00445 | 0.00301 | 0.02311 | 0.00083 |
| 21 | 0.01128 | 0.00748 | 0.00488 | 0.00131 | 0.02587 | 0.00083 |
| 22 | 0.01156 | 0.00647 | 0.00575 | 0.00060 | 0.02382 | 0.00000 |
| 23 | 0.00453 | 0.00568 | 0.00595 | 0.00000 | 0.01412 | 0.00000 |
| 24 | 0.00193 | 0.00529 | 0.00431 | 0.00000 | 0.01227 | 0.00000 |
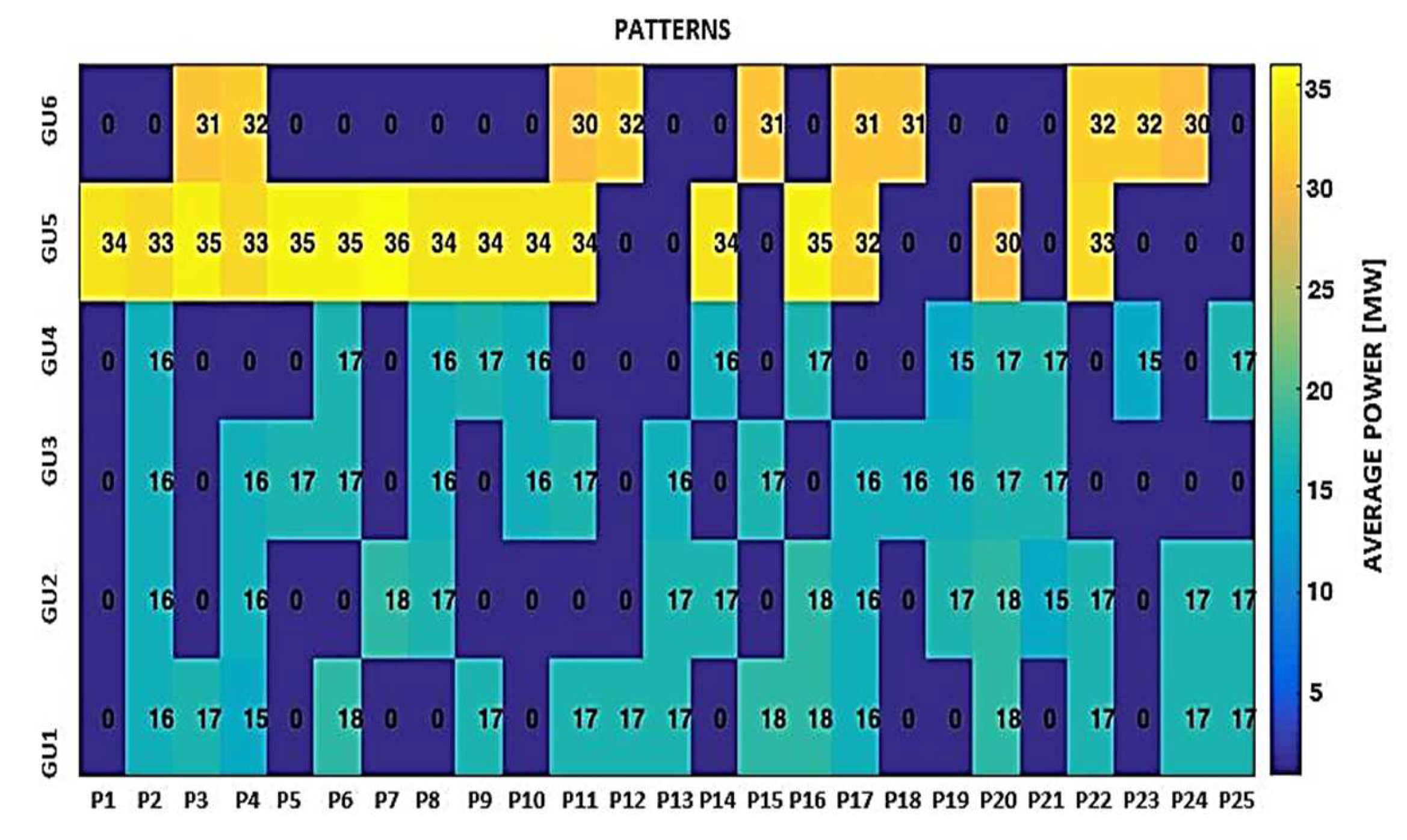
| Pattern | 2017 | 2018 | 2019 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GU1 | GU2 | GU3 | GU4 | GU5 | GU6 | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 | |
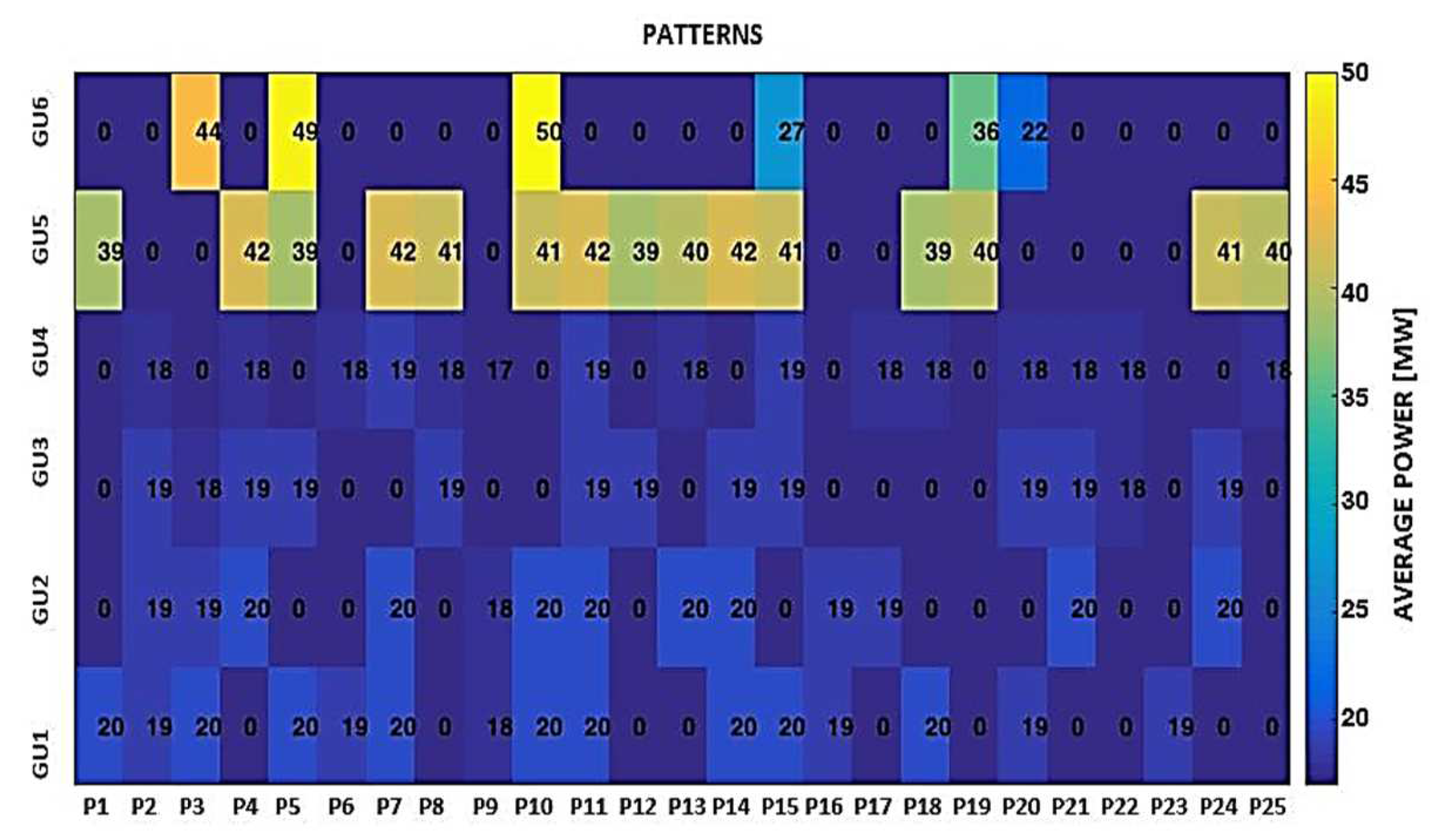
| P1 | 0 | 0 | 0 | 0 | 34 | 0 | 0 | 21 | 20 | 20 | 40 | 0 | 20 | 0 | 0 | 0 | 39 | 0 |
| P2 | 16 | 16 | 16 | 16 | 33 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 19 | 19 | 19 | 18 | 0 | 0 |
| P3 | 17 | 0 | 0 | 0 | 35 | 31 | 20 | 20 | 20 | 18 | 0 | 0 | 20 | 19 | 18 | 0 | 0 | 44 |
| P4 | 15 | 16 | 16 | 0 | 33 | 32 | 20 | 20 | 20 | 20 | 39 | 0 | 0 | 20 | 19 | 18 | 42 | 0 |
| P5 | 0 | 0 | 17 | 0 | 35 | 0 | 19 | 19 | 0 | 18 | 38 | 0 | 20 | 0 | 19 | 0 | 39 | 49 |
| P6 | 18 | 0 | 17 | 17 | 35 | 0 | 19 | 0 | 19 | 18 | 38 | 0 | 19 | 0 | 0 | 18 | 0 | 0 |
| P7 | 0 | 18 | 0 | 0 | 36 | 0 | 0 | 20 | 20 | 18 | 0 | 0 | 20 | 20 | 0 | 19 | 42 | 0 |
| P8 | 0 | 17 | 16 | 16 | 34 | 0 | 0 | 20 | 19 | 0 | 40 | 0 | 0 | 0 | 19 | 18 | 41 | 0 |
| P9 | 17 | 0 | 0 | 17 | 34 | 0 | 19 | 0 | 18 | 18 | 0 | 0 | 18 | 18 | 0 | 17 | 0 | 0 |
| P10 | 0 | 0 | 16 | 16 | 34 | 0 | 19 | 0 | 18 | 0 | 38 | 0 | 20 | 20 | 0 | 0 | 41 | 50 |
| P11 | 17 | 0 | 17 | 0 | 34 | 30 | 0 | 0 | 0 | 0 | 36 | 0 | 20 | 20 | 19 | 19 | 42 | 0 |
| P12 | 17 | 0 | 0 | 0 | 0 | 32 | 19 | 0 | 0 | 0 | 38 | 0 | 0 | 0 | 19 | 0 | 39 | 0 |
| P13 | 17 | 17 | 16 | 0 | 0 | 0 | 0 | 17 | 16 | 17 | 0 | 0 | 0 | 20 | 0 | 18 | 40 | 0 |
| P14 | 0 | 17 | 0 | 16 | 34 | 0 | 0 | 0 | 18 | 17 | 0 | 0 | 20 | 20 | 19 | 0 | 42 | 0 |
| P15 | 18 | 0 | 17 | 0 | 0 | 31 | 0 | 18 | 0 | 0 | 36 | 0 | 20 | 0 | 19 | 19 | 41 | 27 |
| P16 | 18 | 18 | 0 | 17 | 35 | 0 | 19 | 20 | 19 | 0 | 39 | 0 | 19 | 19 | 0 | 0 | 0 | 0 |
| P17 | 16 | 16 | 16 | 0 | 32 | 31 | 19 | 0 | 17 | 17 | 37 | 0 | 0 | 19 | 0 | 18 | 0 | 0 |
| P18 | 0 | 0 | 16 | 0 | 0 | 31 | 19 | 19 | 0 | 18 | 0 | 0 | 20 | 0 | 0 | 18 | 39 | 0 |
| P19 | 0 | 17 | 16 | 15 | 0 | 0 | 0 | 20 | 10 | 18 | 39 | 0 | 0 | 0 | 0 | 0 | 40 | 36 |
| P20 | 18 | 18 | 17 | 17 | 0 | 0 | 0 | 0 | 18 | 0 | 38 | 0 | 19 | 0 | 19 | 18 | 0 | 22 |
| P21 | 0 | 15 | 17 | 17 | 0 | 0 | 0 | 0 | 17 | 17 | 35 | 0 | 0 | 20 | 19 | 18 | 0 | 0 |
| P22 | 17 | 17 | 0 | 0 | 33 | 32 | 0 | 0 | 0 | 17 | 35 | 0 | 0 | 0 | 18 | 18 | 0 | 0 |
| P23 | 0 | 0 | 0 | 15 | 0 | 32 | 19 | 0 | 0 | 18 | 0 | 0 | 19 | 0 | 0 | 0 | 0 | 0 |
| P24 | 17 | 17 | 0 | 0 | 0 | 30 | 19 | 19 | 19 | 0 | 0 | 0 | 0 | 20 | 19 | 0 | 41 | 0 |
| P25 | 17 | 17 | 0 | 17 | 0 | 0 | 17 | 18 | 0 | 0 | 36 | 0 | 0 | 0 | 0 | 18 | 40 | 0 |
| Patterns | Operating Time | Powers Required by the System [MW] | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hours | Days | Hours/Day | Minimum Value | Average Value | Maximum Value | |||||||||||||
| 2017 | 2018 | 2019 | 2017 | 2018 | 2019 | 2017 | 2018 | 2019 | 2017 | 2018 | 2019 | 2017 | 2018 | 2019 | 2017 | 2018 | 2019 | |
| P1 | 432 | 471 | 323 | 128 | 35 | 49 | 3 | 13 | 7 | 30 | 75 | 42 | 34 | 102 | 63 | 40 | 107 | 59 |
| P2 | 360 | 235 | 539 | 54 | 81 | 55 | 7 | 3 | 10 | 71 | 15 | 60 | 82 | 18 | 79 | 110 | 22 | 76 |
| P3 | 810 | 908 | 276 | 152 | 66 | 42 | 5 | 14 | 7 | 44 | 64 | 47 | 53 | 78 | 108 | 88 | 85 | 58 |
| P4 | 165 | 424 | 467 | 23 | 36 | 45 | 7 | 12 | 10 | 60 | 90 | 89 | 86 | 119 | 100 | 108 | 129 | 99 |
| P5 | 267 | 166 | 276 | 60 | 27 | 29 | 4 | 6 | 10 | 45 | 75 | 67 | 52 | 94 | 129 | 60 | 105 | 79 |
| P6 | 116 | 288 | 47 | 30 | 40 | 16 | 4 | 7 | 3 | 42 | 75 | 34 | 65 | 95 | 40 | 101 | 107 | 37 |
| P7 | 488 | 137 | 372 | 99 | 11 | 34 | 5 | 12 | 11 | 43 | 45 | 88 | 54 | 58 | 103 | 60 | 64 | 101 |
| P8 | 235 | 313 | 429 | 52 | 40 | 52 | 5 | 8 | 8 | 57 | 60 | 63 | 69 | 78 | 80 | 100 | 84 | 78 |
| P9 | 115 | 165 | 209 | 29 | 45 | 27 | 4 | 4 | 8 | 60 | 30 | 48 | 67 | 46 | 59 | 81 | 64 | 54 |
| P10 | 95 | 397 | 129 | 16 | 59 | 30 | 6 | 7 | 4 | 60 | 60 | 73 | 66 | 75 | 132 | 73 | 84 | 82 |
| P11 | 452 | 425 | 516 | 101 | 112 | 38 | 4 | 4 | 14 | 58 | 30 | 103 | 69 | 36 | 122 | 100 | 44 | 120 |
| P12 | 287 | 806 | 101 | 103 | 118 | 16 | 3 | 7 | 6 | 13 | 45 | 47 | 18 | 57 | 62 | 51 | 64 | 58 |
| P13 | 151 | 119 | 131 | 30 | 46 | 19 | 5 | 3 | 7 | 35 | 0 | 55 | 49 | 19 | 81 | 59 | 39 | 71 |
| P14 | 156 | 91 | 149 | 25 | 33 | 21 | 6 | 3 | 7 | 45 | 15 | 92 | 56 | 23 | 102 | 76 | 42 | 100 |
| P15 | 183 | 418 | 243 | 49 | 67 | 22 | 4 | 6 | 11 | 26 | 45 | 86 | 36 | 55 | 128 | 68 | 64 | 99 |
| P16 | 485 | 159 | 186 | 91 | 34 | 42 | 5 | 5 | 4 | 58 | 78 | 28 | 72 | 96 | 42 | 97 | 106 | 38 |
| P17 | 92 | 216 | 131 | 15 | 39 | 42 | 6 | 6 | 3 | 62 | 60 | 15 | 89 | 73 | 40 | 126 | 84 | 23 |
| P18 | 71 | 198 | 355 | 30 | 48 | 40 | 2 | 4 | 9 | 14 | 30 | 58 | 19 | 45 | 82 | 50 | 61 | 77 |
| P19 | 102 | 71 | 280 | 44 | 17 | 64 | 2 | 4 | 4 | 15 | 60 | 30 | 18 | 76 | 90 | 34 | 90 | 40 |
| P20 | 119 | 201 | 191 | 15 | 41 | 32 | 8 | 5 | 6 | 50 | 45 | 33 | 68 | 56 | 93 | 94 | 63 | 49 |
| P21 | 23 | 88 | 117 | 11 | 16 | 20 | 2 | 6 | 6 | 28 | 60 | 35 | 35 | 69 | 58 | 47 | 84 | 56 |
| P22 | 161 | 101 | 58 | 20 | 31 | 21 | 8 | 3 | 3 | 46 | 45 | 15 | 82 | 53 | 38 | 106 | 63 | 27 |
| P23 | 55 | 52 | 121 | 25 | 16 | 48 | 2 | 3 | 3 | 0 | 30 | 15 | 10 | 37 | 21 | 33 | 41 | 19 |
| P24 | 92 | 172 | 34 | 40 | 33 | 8 | 2 | 5 | 4 | 30 | 39 | 75 | 36 | 55 | 82 | 62 | 65 | 80 |
| P25 | 76 | 293 | 179 | 22 | 58 | 44 | 3 | 5 | 4 | 30 | 60 | 46 | 40 | 71 | 61 | 58 | 85 | 58 |
References
- International Hydropower Association. World Hydropower Outlook. Opportunities to Advance Net Zero. 2024. Available online: https://www.hydropower.org/publications/2024-world-hydropower-outlook (accessed on 5 September 2024).
- Parvez, I.; Shen, J.; Hassan, I.; Zhang, N. Generation of Hydro Energy by Using Data Mining Algorithm for Cascaded Hy-dropower Plant. Energies 2021, 14, 298. [Google Scholar] [CrossRef]
- International Energy Agency. Hydropower Special Market Report Analysis and Forecast to 2030. 2021. Available online: https://iea.blob.core.windows.net/assets/83ff8935-62dd-4150-80a8-c5001b740e21/HydropowerSpecialMarketReport.pdf (accessed on 5 September 2024).
- Essenfelder, A.H.; Larosa, F.; Broccoli, D.; Mazzoli, P.; Bagli, S.; Luzzi, V.; Mysiak, J.; dalla Vallw, F. Smart Climate Hydro-power Tool: A Machine-Learning Seasonal Forecasting Climate Service to Support Cost–Benefit Analysis of Reservoir Management. Atmosphere 2020, 11, 1305. [Google Scholar] [CrossRef]
- Garbea, R.; Scarlatache, F.; Grigoras, G.; Neagu, B.C. Extracting the Operating Characteristics of Hydropower Plants Using a Clustering-based Efficient Methodology. In Proceedings of the IEEE 9th International Conference on Modern Power Systems (MPS), Cluj-Napoca, Romania, 16–17 June 2021. [Google Scholar]
- International Finance Corporation. Hydroelectric Power. A Guide for Developers and Investors. 2024. Available online: https://documents1.worldbank.org/curated/en/917841468188335073/pdf/99392-WP-Box393199B-PUBLIC-Hydropower-Report.pdf (accessed on 5 September 2024).
- International Renewable Energy Agency. Renewable Energy Technologies: Cost Analysis Series. Hydropower. 2012. Available online: https://www.irena.org/-/media/Files/IRENA/Agency/Publication/2012/RE_Technologies_Cost_Analysis-HYDROPOWER.pdf (accessed on 5 September 2024).
- Eker, O.F. Data Science for Industry: Hydropower Condition Monitoring and Predictive Maintenance. 2022. Available online: https://medium.com/@omerfarukeker/data-science-for-industry-hydropower-condition-monitoring-and-predictive-maintenance-49952215fdd7 (accessed on 31 July 2024).
- Quaranta, E.; Aggidis, G.; Boes, R.; Comoglio, C.; De Michele, C.; Ritesh Patro, E.; Georgievskaia, E.; Harby, A.; Kougias, I.; Muntean, S.; et al. Assessing the energy potential of modernizing the European hydropower fleet. Energy Convers. Manag. 2021, 246, 114655. [Google Scholar] [CrossRef]
- Betti, A.; Crisostomi, E.; Paolinelli, G.; Piazzi, A.; Ruffini, F.; Tucci, F. Condition Monitoring and Predictive Maintenance Methodologies for Hydropower Plants Equipment. Renew. Energy 2021, 171, 246–253. [Google Scholar] [CrossRef]
- European Commission. 2050 Long-Term Strategy. Striving to Become the World’s First Climate-Neutral Continent by 2050. Available online: https://climate.ec.europa.eu/eu-action/climate-strategies-targets/2050-long-term-strategy_en (accessed on 5 September 2024).
- Ovarro. Five Ways SCADA Systems Can Benefit Sustainability: Although Hidden in the Background, SCADA Systems Are Crucial to Energy Savings. 2024. Available online: https://www.linkedin.com/pulse/five-ways-scada-systems-can-benefit-sustainability-although-hidden-sbdae/ (accessed on 31 July 2024).
- Yang, S.; Stempfle, T.; Thiede, S.; Lanza, G. Approach for the Development of a Sustainability-oriented Implementation Strategy of Smart Automation Technologies. Procedia CIRP 2024, 122, 849–854. [Google Scholar] [CrossRef]
- Vagnoni, E.; Gezer, D.; Anagnostopoulos, I.; Cavazzini, G.; Doujak, E.; Hočevar, M.; Rudolf, P. The New Role of Sustainable Hydropower in Flexible Energy Systems and its Technical Evolution Through Innovation And Digitalization. Renew. Energy 2024, 230, 120832. [Google Scholar] [CrossRef]
- Feng, Z.K.; Niu, W.J.; Zhang, R.; Wang, S.; Cheng, C.-T. Operation Rule Derivation of Hydropower Reservoir by K-Means Clustering Method and Extreme Learning Machine Based on Particle Swarm Optimization. J. Hydrol. 2019, 576, 229–238. [Google Scholar] [CrossRef]
- Zhang, F.; Guo, J.; Yuan, F.; Qiu, Y.; Wang, P.; Cheng, F.; Gu, Y. Enhancement Methods of Hydropower Unit Monitoring Data Quality Based on the Hierarchical Density-Based Spatial Clustering of Applications with a Noise–Wasserstein Slim Generative Adversarial Imputation Network with a Gradient Penalty. Sensors 2024, 24, 118. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Xu, J.; Zhou, Z. Mobile Information Systems, Retracted: Design of Data Classification and Classification Management System for Big Data of Hydropower Enterprises Based on Data Standards, Mobile Information Systems. 2022. Available online: https://onlinelibrary.wiley.com/doi/10.1155/2022/8103897 (accessed on 31 July 2024).
- Ahmed, I.; Dagnino, A.; Bongiovi, A.; Ding, Y. Outlier Detection for Hydropower Generation Plant. In Proceedings of the IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018. [Google Scholar]
- Valencia, A.M.; Caratar, J.; Caicedo, G.; Chamorro, C. Proposal for a KDD-Based Procedure to Obtain a Set of Intelligent Systems Training Applied to the Identification of Failures in Hydroelectric Power Plants. J. Appl. Res. Technol. 2021, 18, 376–389. [Google Scholar] [CrossRef]
- Zhang, W.; Ge, Y.; Liu, G.; Qi, W.; Xu, S.; Peng, Z.; Li, Y. Clustering and Decision Tree Based Analysis of Typical Operation Modes of Power Systems. Energy Rep. 2023, 9, 60–69. [Google Scholar] [CrossRef]
- Garbea, R.; Scarlatache, F.; Grigoras, G.; Neagu, B.C. Integration of Data Mining Techniques in SCADA System for Optimal Operation of Hydropower Plants. In Proceedings of the IEEE 13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 1–3 July 2021. [Google Scholar]
- Sahin, M.E.; Ozbay Karakus, M. Smart Hydropower Management: Utilizing Machine Learning and Deep Learning Method to Enhance Dam’s Energy Generation Efficiency. Neural Comput. Appl. 2024, 36, 11195–11211. [Google Scholar] [CrossRef]
- Shu, X.; Ye, Y. Knowledge Discovery: Methods from Data Mining and Machine Learning. Soc. Sci. Res. 2023, 110, 102817. [Google Scholar] [CrossRef] [PubMed]
- Monika; Shauib, M. Implementation Platforms and Strategy for the Knowledge Discovery from the Data. In Proceedings of the International Conference on Computational Modelling, Simulation and Optimization (ICCMSO), Pathum Thani, Thailand, 23–25 December 2022. [Google Scholar]
- Ghongade, T.G.; Khobragade, R.N. Evaluation on Utilization and Emaciation of Data Mining Techniques in Information System. In Proceedings of the OPJU International Technology Conference on Emerging Technologies for Sustainable Development (OTCON), Raigarh, Chhattisgarh, India, 8–10 February 2023. [Google Scholar]
- Järvinen, P.; Siltanen, P.; Kirschenbaum, A. Data Analytics and Machine Learning. In Big Data in Bioeconomy; Södergård, C., Mildorf, T., Habyarimana, E., Berre, A.J., Fernandes, J.A., Zinke-Wehlmann, C., Eds.; Springer Nature: Cham, Switzerland, 2021; pp. 129–146. [Google Scholar]
- Garbea, R.; Grigoras, G. Clustering-Using Data Mining-based Application to Identify the Hourly Loading Patterns of the Generation Units from the Hydropower Plants. In Proceedings of the IEEE International Conference and Exposition on Electrical and Power Engineering (EPE), Iasi, Romania, 20–22 October 2022. [Google Scholar]
- Odrynska, A. What is Data Mining: Definition, Process, Techniques and Role in Business Intelligence. 2023. Available online: https://www.alphaservesp.com/blog/what-is-data-mining-definition-process-techniques-and-business-intelligence (accessed on 31 July 2024).
- Onlogic. Setting Up Smart SCADA for Digital Transformation. 2024. Available online: https://www.onlogic.com/blog/smart-scada-digital-transformation (accessed on 5 September 2024).
- Kaur, S.; Kathpal, N.; Munjal, N. Role of SCADA in Hydro Power Plant Automation. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2015, 4, 8085–8090. [Google Scholar]
- Mirzargar, M.; Whitaker, R.T.; Kirby, R.M. Curve Boxplot: Generalization of Boxplot for Ensembles of Curves. IEEE Trans. Vis. Comput. Gr. 2023, 20, 2654–2663. [Google Scholar] [CrossRef] [PubMed]
- Chelaru, E.; Grigoras, G. Decision Support System to Determine the Replacement Ranking of the Aged Transformers in Electric Distribution Networks. In Proceedings of the IEEE 12th International Conference on Electronics, Computers and Artificial Intelligence (ECAI) Proceedings, Bucharest, Romania, 25–27 June 2020. [Google Scholar]
- Neagu, B.C.; Grigoras, G.; Scarlatache, F. Outliers Discovery from Smart Meters Data Using a Statistical Based Data Mining Approach, In Proceedings of the IEEE 10th International Symposium on Advanced Topics in Electrical Engineering (ATEE), Bucharest, Romania, 23–25 April 2017.
- Wang, Z.; Wang, S.; Zhang, S.; Zhan, J. An Expert System Based on Data Mining for a Trend Diagnosis of Process Parameters. Processes 2023, 11, 3311. [Google Scholar] [CrossRef]
- Dandea, V.; Grigoras, G. Expert System Integrating Rule-Based Reasoning to Voltage Control in Photovoltaic-Systems-Rich Low Voltage Electric Distribution Networks: A Review and Results of a Case Study. Appl. Sci. 2023, 13, 6158. [Google Scholar] [CrossRef]
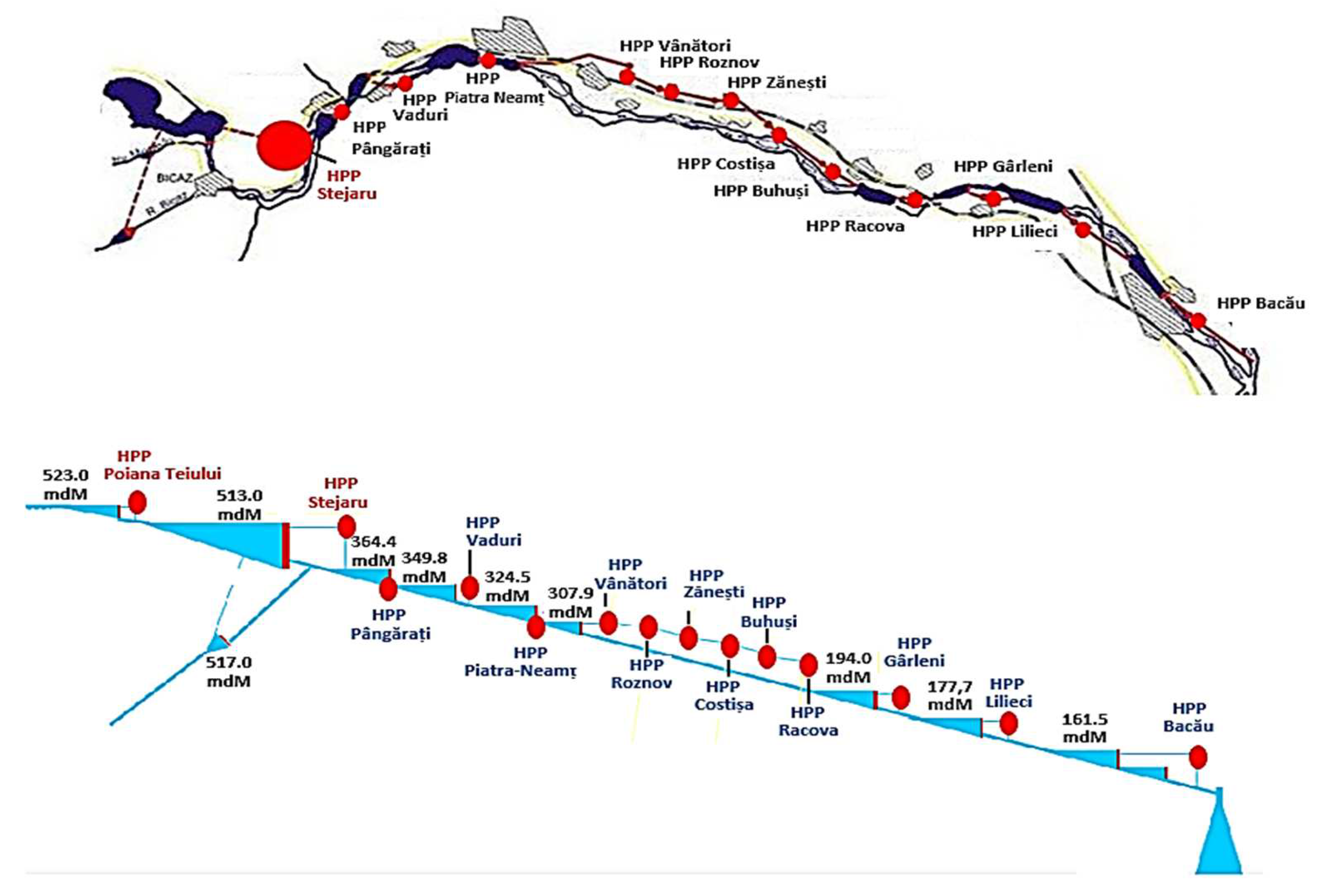
- Dunca, G.; Ghergu, C.M.; Rosioru, O.; Bucur, M.D. Analysis of the Areas with Optimal Working of Aggregates in CHE Stejaru, Symposium on Informatics, Automation and Telecommunications in Energy, Sinaia, Romania. 2010. Available online: https://www.researchgate.net/publication/281646497_Analiza_zonelor_cu_functionare_optima_ale_agregatelor_din_CHE_Stejaru (accessed on 31 July 2024). (In Romanian).
- Cojoc, G.M. Analysis of The Hydrological Regime of the Bistrita River in the Context of Hydrotechnical Developments; Terra Nostra Publishing House: Iasi, Romania, 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
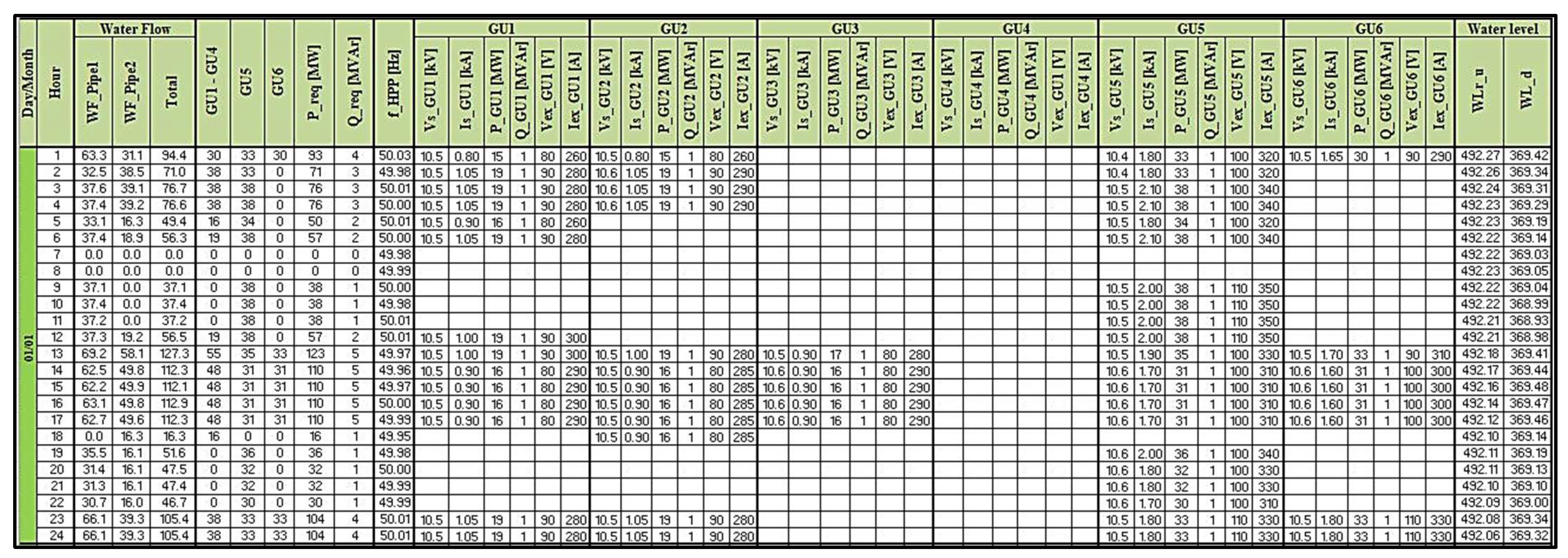




| Statistical Parameters | m | σ | Q0 | Q1 | Q2 | Q3 | Q4 | |
|---|---|---|---|---|---|---|---|---|
| Water flow | WF_Pipe1 [m3/s] | 36.42 | 9.75 | 18.70 | 31.50 | 34.50 | 36.30 | 74.40 |
| WF_Pipe2 [m3/s] | 29.92 | 14.02 | 13.40 | 17.30 | 30.80 | 36.60 | 78.20 | |
| Total [m3/s] | 56.14 | 21.35 | 10.50 | 44.50 | 54.10 | 70.80 | 133.20 | |
| Active and reactive powers | GU1-GU4 [MW] | 29.60 | 13.54 | 0.90 | 18.00 | 30.00 | 37.00 | 78.00 |
| GU5 [MW] | 34.33 | 3.09 | 29.00 | 31.00 | 35.00 | 37.00 | 40.00 | |
| GU6 [MW] | 31.51 | 2.01 | 1.00 | 30.00 | 31.00 | 33.00 | 40.00 | |
| Total [MW] | 56.34 | 20.39 | 13.00 | 45.00 | 56.00 | 72.00 | 126.00 | |
| Total [MVAr] | 6.39 | 5.90 | 1.00 | 2.00 | 3.00 | 10.00 | 30.00 | |
| Frequency | [Hz] | 49.99 | 0.02 | 49.10 | 49.98 | 50.00 | 50.01 | 50.40 |
| GU 1 | Vs [kV] | 10.43 | 0.71 | 1.40 | 10.40 | 10.40 | 10.50 | 50.00 |
| Is [kA] | 0.96 | 0.11 | 0.08 | 0.90 | 0.95 | 1.00 | 1.90 | |
| P [MW] | 17.20 | 1.89 | 0.90 | 15.00 | 17.00 | 18.00 | 22.00 | |
| Q [Mvar] | 2.60 | 1.99 | 1.00 | 1.00 | 1.00 | 5.00 | 11.00 | |
| Vex [V] | 88.28 | 8.80 | 8.00 | 80.00 | 90.00 | 95.00 | 110.00 | |
| I ex [A] | 287.91 | 17.29 | 100.00 | 280.00 | 290.00 | 300.00 | 360.00 | |
| GU 2 | Vs [kV] | 10.48 | 0.38 | 1.10 | 10.50 | 10.50 | 10.50 | 10.70 |
| Is [kA] | 0.96 | 0.10 | 0.70 | 0.90 | 0.95 | 1.05 | 1.20 | |
| P [MW] | 17.35 | 1.86 | 14.00 | 16.00 | 17.00 | 19.00 | 21.00 | |
| Q [Mvar] | 2.58 | 1.99 | 1.00 | 1.00 | 1.00 | 5.00 | 21.00 | |
| Vex [V] | 89.84 | 7.80 | 70.00 | 85.00 | 90.00 | 95.00 | 110.00 | |
| I ex [A] | 289.65 | 15.01 | 245.00 | 280.00 | 290.00 | 300.00 | 320.00 | |
| GU 3 | Vs [kV] | 10.41 | 0.42 | 1.60 | 10.40 | 10.50 | 10.50 | 10.70 |
| Is [kA] | 0.91 | 0.08 | 0.70 | 0.85 | 0.90 | 0.95 | 1.15 | |
| P [MW] | 16.48 | 1.41 | 13.00 | 15.00 | 16.00 | 17.00 | 20.00 | |
| Q [Mvar] | 2.76 | 2.00 | 0.50 | 1.00 | 1.00 | 5.00 | 10.00 | |
| Vex [V] | 89.60 | 40.80 | 65.00 | 80.00 | 90.00 | 95.00 | 870.00 | |
| I ex [A] | 289.21 | 58.37 | 115.00 | 280.00 | 290.00 | 300.00 | 2980.00 | |
| GU 4 | Vs [kV] | 10.45 | 0.09 | 10.10 | 10.40 | 10.50 | 10.50 | 10.60 |
| Is [kA] | 0.92 | 0.08 | 0.75 | 0.85 | 0.90 | 1.00 | 1.10 | |
| P [MW] | 16.59 | 1.36 | 14.00 | 15.00 | 17.00 | 18.00 | 20.00 | |
| Q [Mvar] | 2.78 | 1.99 | 1.00 | 1.00 | 1.00 | 5.00 | 5.00 | |
| Vex [V] | 87.38 | 8.87 | 60.00 | 80.00 | 90.00 | 95.00 | 105.00 | |
| I ex [A] | 290.13 | 15.75 | 260.00 | 280.00 | 290.00 | 300.00 | 330.00 | |
| GU 5 | Vs [kV] | 10.41 | 0.52 | 1.40 | 10.40 | 10.50 | 10.50 | 10.70 |
| Is [kA] | 1.89 | 0.17 | 0.85 | 1.70 | 1.90 | 2.05 | 2.70 | |
| P [MW] | 34.33 | 3.09 | 29.00 | 31.00 | 35.00 | 37.00 | 40.00 | |
| Q [Mvar] | 2.56 | 1.96 | 1.00 | 1.00 | 1.00 | 5.00 | 10.00 | |
| Vex [V] | 104.78 | 17.89 | 10.00 | 100.00 | 100.00 | 110.00 | 1110.00 | |
| Iex [A] | 332.53 | 108.88 | 235.00 | 315.00 | 330.00 | 340.00 | 3210.00 | |
| GU 6 | Vs [kV] | 10.49 | 0.07 | 10.30 | 10.50 | 10.50 | 10.50 | 10.60 |
| Is [kA] | 1.70 | 0.07 | 1.50 | 1.65 | 1.70 | 1.75 | 1.85 | |
| P [MW] | 31.52 | 1.33 | 29.00 | 30.00 | 31.00 | 33.00 | 33.00 | |
| Q [Mvar] | 2.07 | 1.77 | 1.00 | 1.00 | 1.00 | 5.00 | 5.00 | |
| Vex [V] | 94.47 | 6.15 | 80.00 | 90.00 | 95.00 | 100.00 | 110.00 | |
| I ex [A] | 303.34 | 10.77 | 280.00 | 300.00 | 300.00 | 310.00 | 340.00 | |
| Water level | WLr_u [mdMB] | 492.66 | 5.86 | 479.28 | 489.80 | 493.40 | 497.99 | 500.80 |
| WLr_d [mdMB] | 368.21 | 5.90 | 356.43 | 368.90 | 369.06 | 369.20 | 497.48 | |
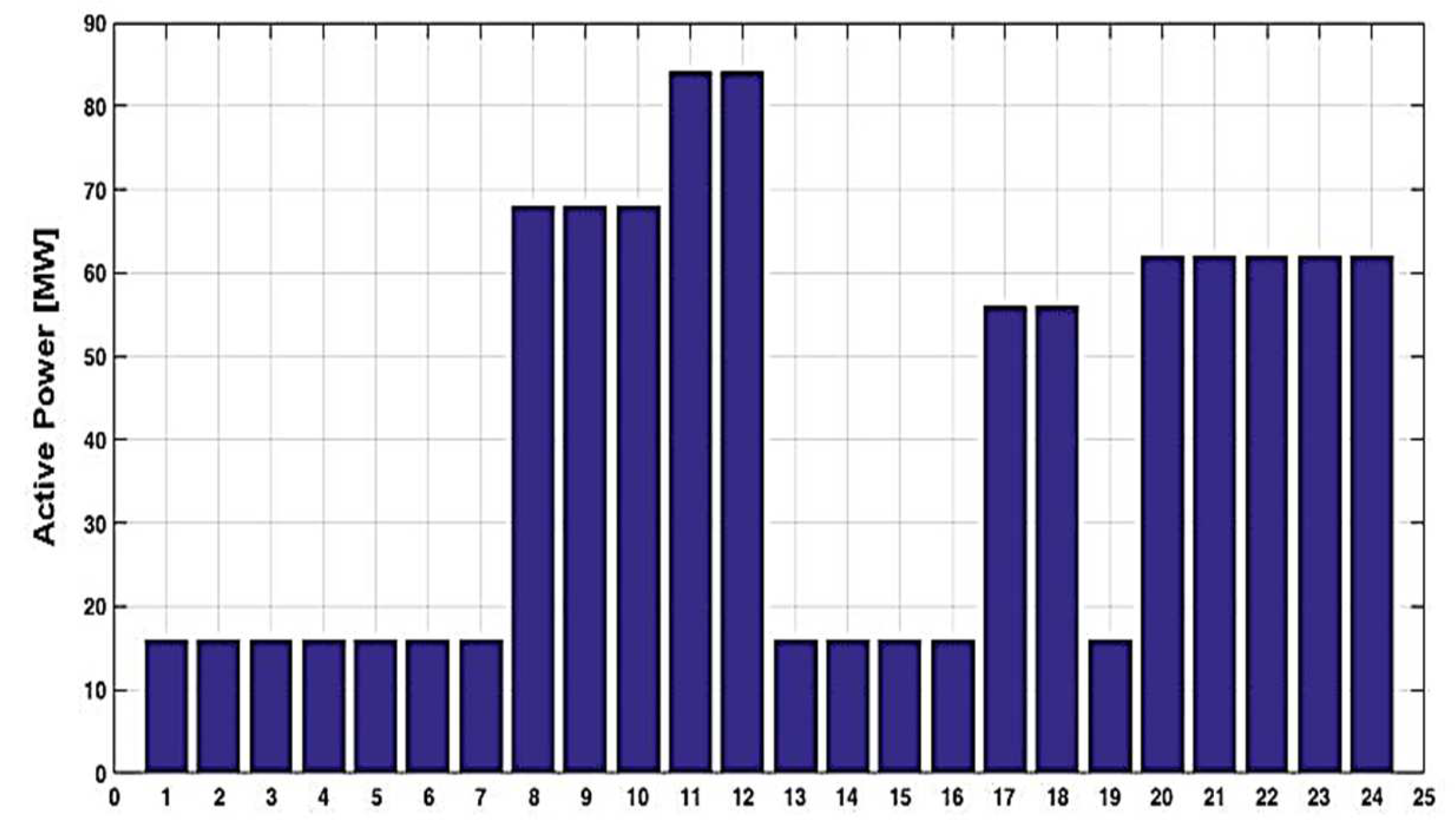
| Hour | P_GU1 [MW] | P_GU2 [MW] | P_GU3 [MW] | P_GU4 [MW] | P_GU5 [MW] | P_GU6 [MW] |
|---|---|---|---|---|---|---|
| 1 | +16 | 0 | −16 | 0 | 0 | 0 |
| 2 | +16 | 0 | −16 | 0 | 0 | 0 |
| 3 | +16 | 0 | −16 | 0 | 0 | 0 |
| 4 | +16 | 0 | −16 | 0 | 0 | 0 |
| 5 | +16 | 0 | −16 | 0 | 0 | 0 |
| 6 | +16 | 0 | −16 | 0 | 0 | 0 |
| 7 | +16 | 0 | −16 | 0 | 0 | 0 |
| 8 | −1 | +17 | +1 | +17 | −34 | 0 |
| 9 | −1 | +17 | +1 | +17 | −34 | 0 |
| 10 | −1 | +17 | +1 | +17 | −34 | 0 |
| 11 | −1 | 0 | −1 | 0 | −34 | +36 |
| 12 | −1 | 0 | −1 | 0 | −34 | +36 |
| 13 | +16 | 0 | −16 | 0 | 0 | 0 |
| 14 | +16 | 0 | −16 | 0 | 0 | 0 |
| 15 | +16 | 0 | −16 | 0 | 0 | 0 |
| 16 | 16 | 0 | −16 | 0 | 0 | 0 |
| 17 | 0 | 0 | +2 | 0 | +38 | −40 |
| 18 | 0 | 0 | +2 | 0 | +38 | −40 |
| 19 | +16 | 0 | −16 | 0 | 0 | 0 |
| 20 | +15 | +16 | 0 | +15 | 0 | −46 |
| 21 | +15 | +16 | 0 | +15 | 0 | −46 |
| 22 | +15 | +16 | 0 | +15 | 0 | −46 |
| 23 | +15 | +16 | 0 | +15 | 0 | −46 |
| 24 | +15 | +16 | 0 | +15 | 0 | −46 |
| Generation Unit | GU1 | GU2 | GU3 | GU4 | GU5 | GU6 | HPP |
|---|---|---|---|---|---|---|---|
| Operating time [hours] | 3460 | 1970 | 1520 | 1484 | 1271 | 3255 | 12960 |
| Energy production [TWh] | 72.33 | 40.60 | 29.3 | 28.26 | 46.37 | 161.85 | 378.71 |
| Average loading [MW] | 21 | 21 | 19 | 19 | 36 | 50 | 166 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grigoras, G.; Gârbea, R.; Neagu, B.-C. Toward Smart SCADA Systems in the Hydropower Plants through Integrating Data Mining-Based Knowledge Discovery Modules. Appl. Sci. 2024, 14, 8228. https://doi.org/10.3390/app14188228
Grigoras G, Gârbea R, Neagu B-C. Toward Smart SCADA Systems in the Hydropower Plants through Integrating Data Mining-Based Knowledge Discovery Modules. Applied Sciences. 2024; 14(18):8228. https://doi.org/10.3390/app14188228
Chicago/Turabian StyleGrigoras, Gheorghe, Răzvan Gârbea, and Bogdan-Constantin Neagu. 2024. "Toward Smart SCADA Systems in the Hydropower Plants through Integrating Data Mining-Based Knowledge Discovery Modules" Applied Sciences 14, no. 18: 8228. https://doi.org/10.3390/app14188228
APA StyleGrigoras, G., Gârbea, R., & Neagu, B.-C. (2024). Toward Smart SCADA Systems in the Hydropower Plants through Integrating Data Mining-Based Knowledge Discovery Modules. Applied Sciences, 14(18), 8228. https://doi.org/10.3390/app14188228