
A Bearing Fault Diagnosis Method in Scenarios of Imbalanced Samples and Insufficient Labeled Samples


Abstract
1. Introduction
2. Sample Expansion Methodology Based on CVAE-SKEGAN
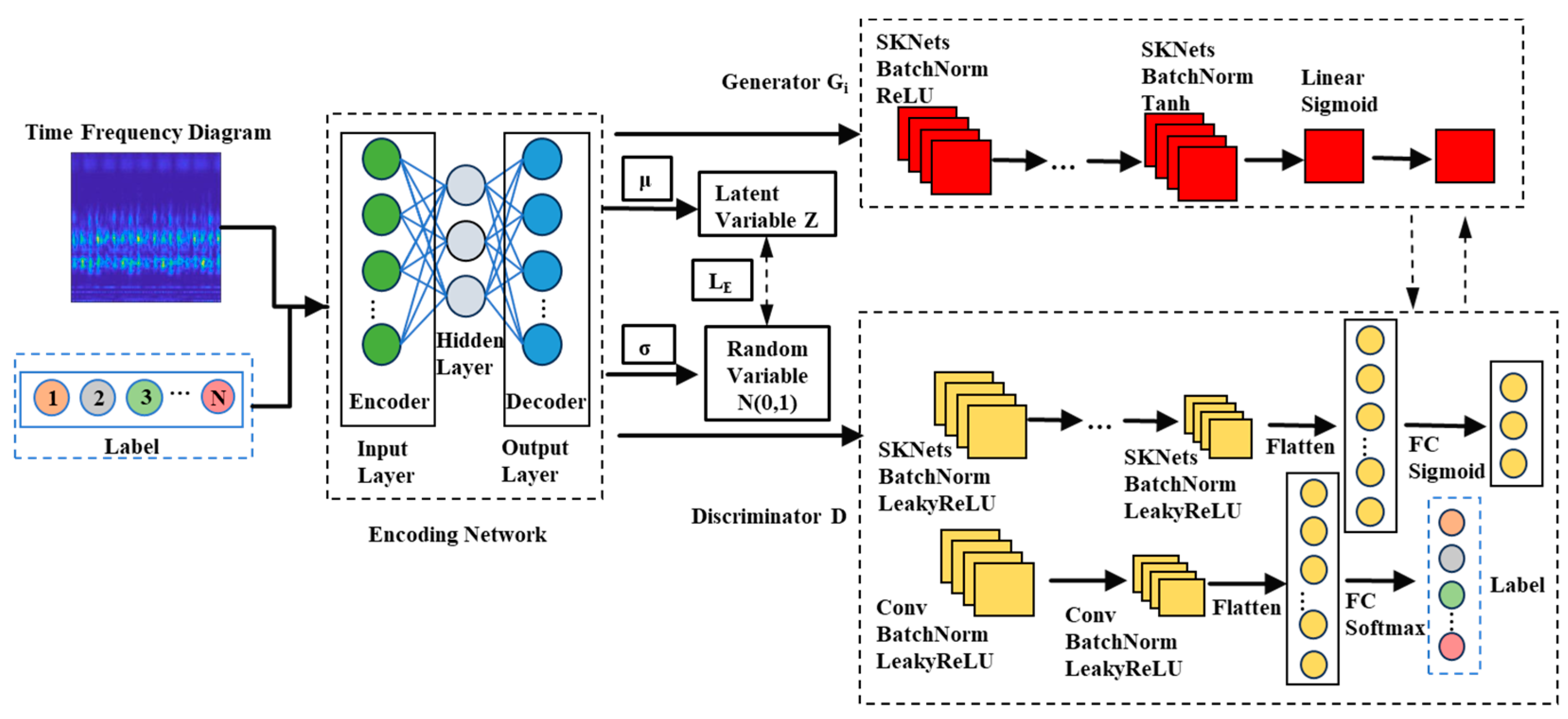
2.1. Architecture of CVAE-SKEGAN Network
- (1)
- Encoding network
- (2)
- Generator
- (3)
- Discriminator
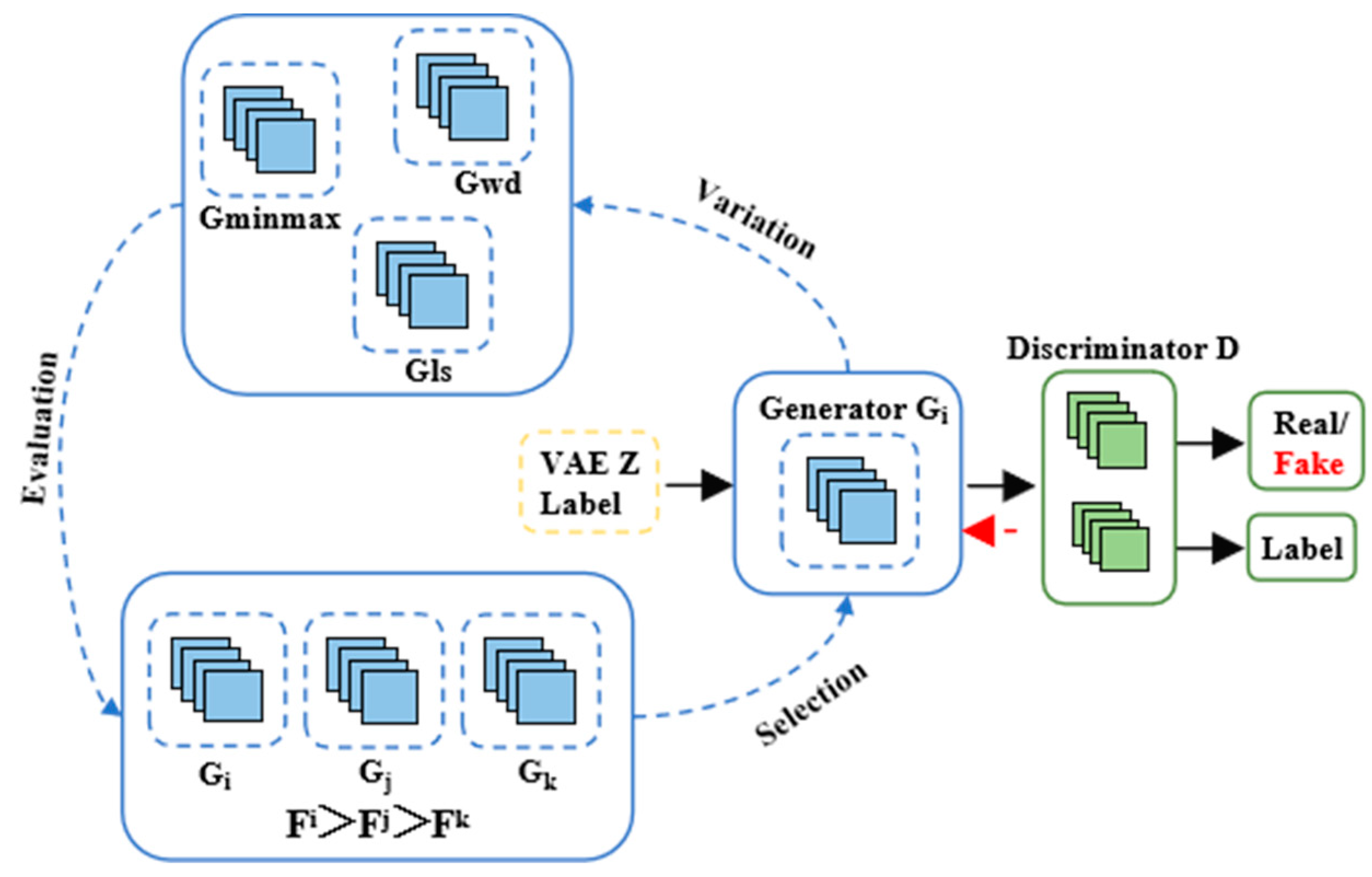
2.2. Assessment of Sample Generation Capability
- (1)
- MMD
- (2)
- K-L divergence
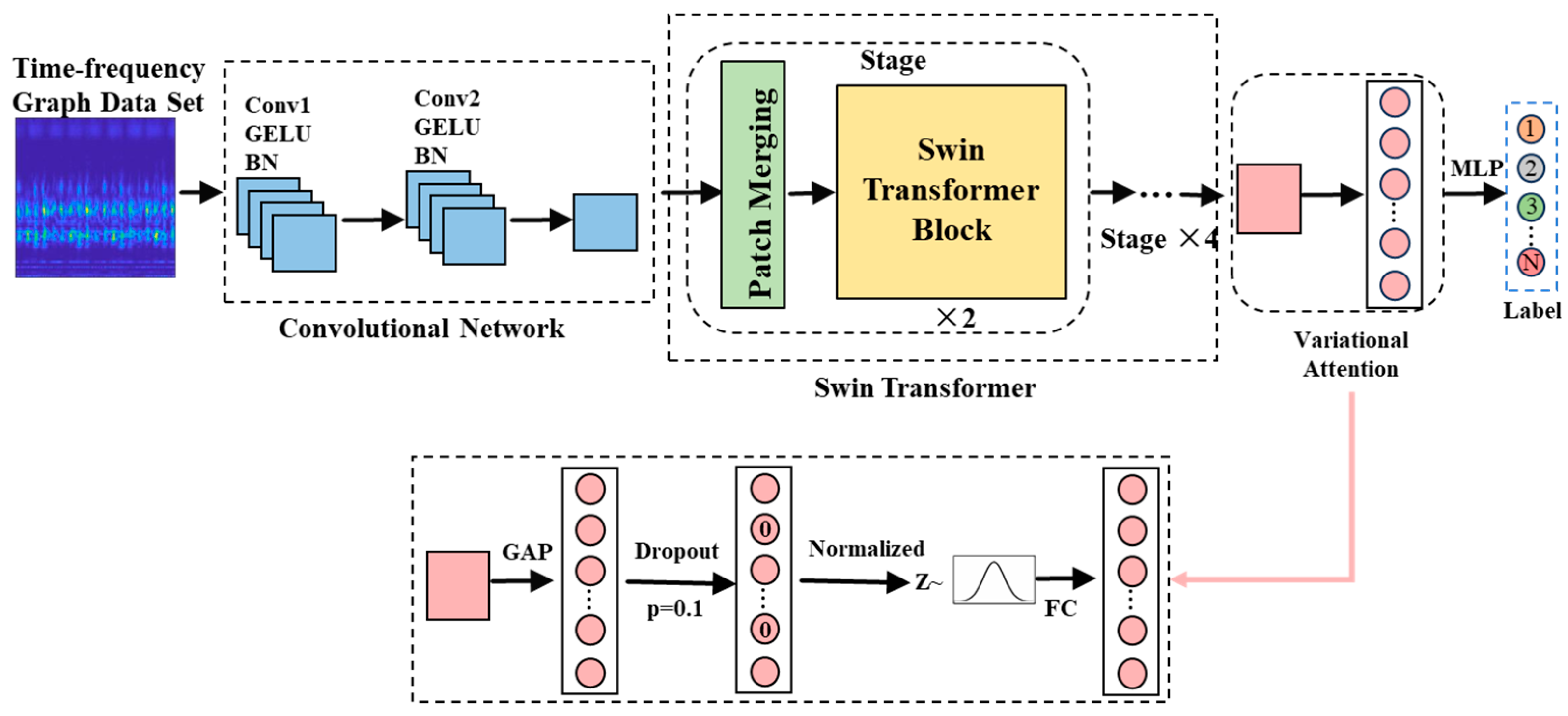
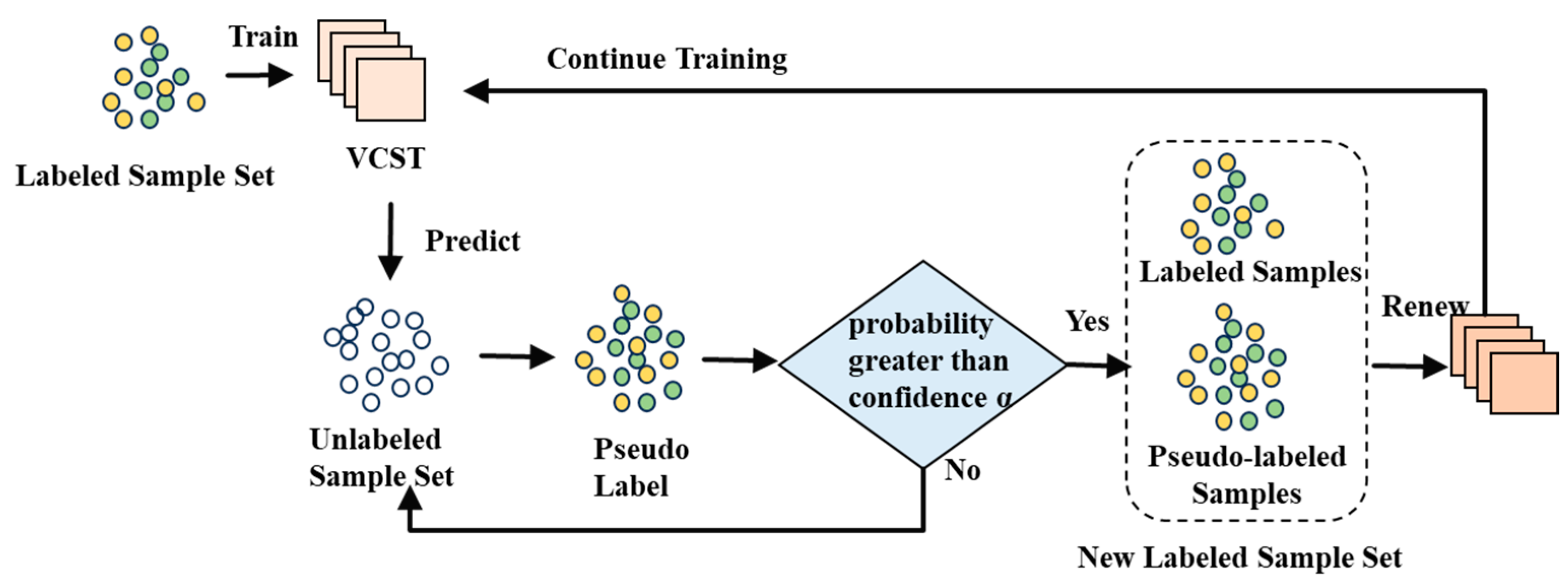
3. Bearing Fault Recognition Based on SSL-VCST Method
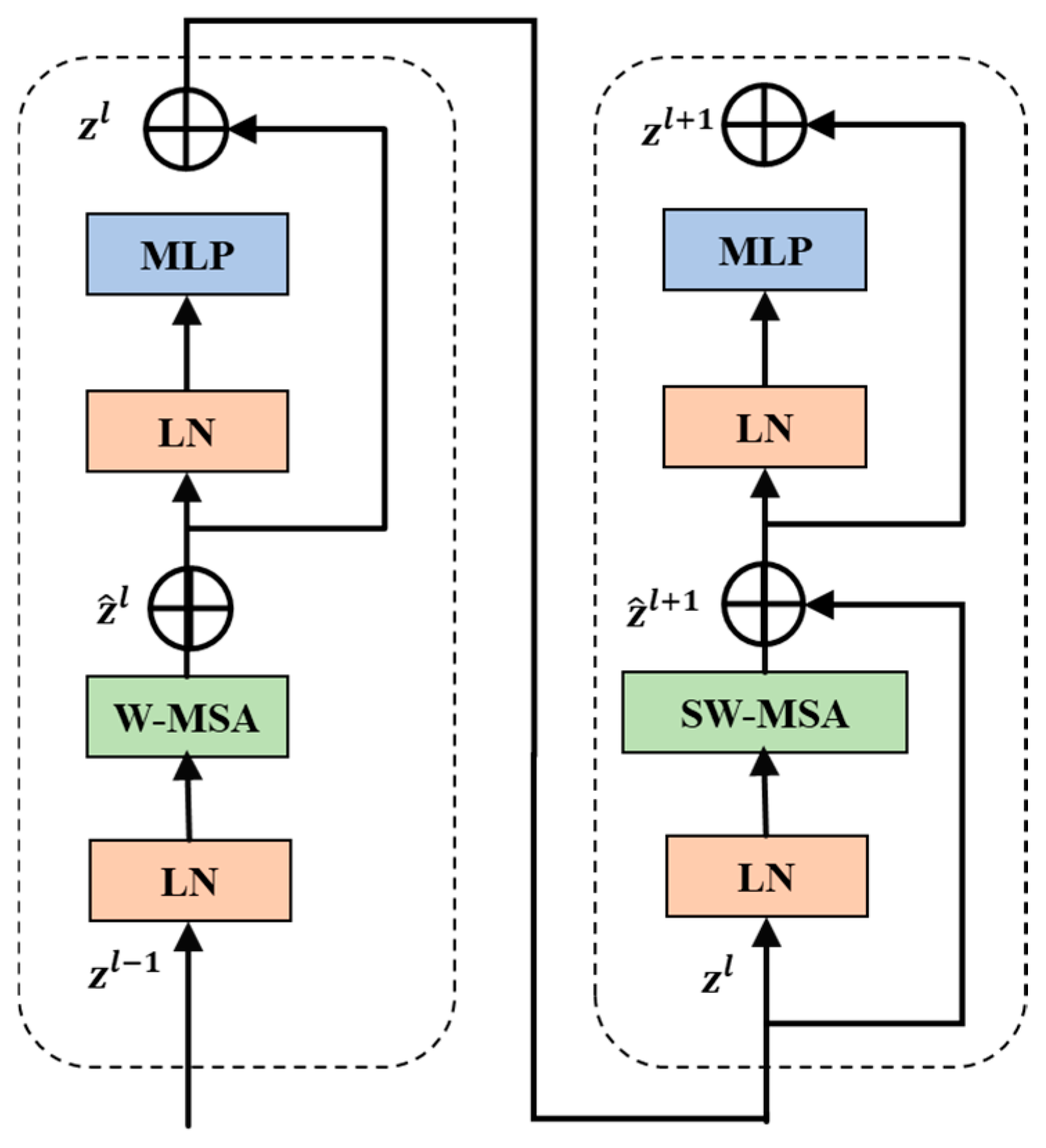
3.1. Architecture of VCST Network
3.2. Principle of SSL-VCST Algorithm
3.3. Assessment of Classification Ability with Insufficient Labeled Samples
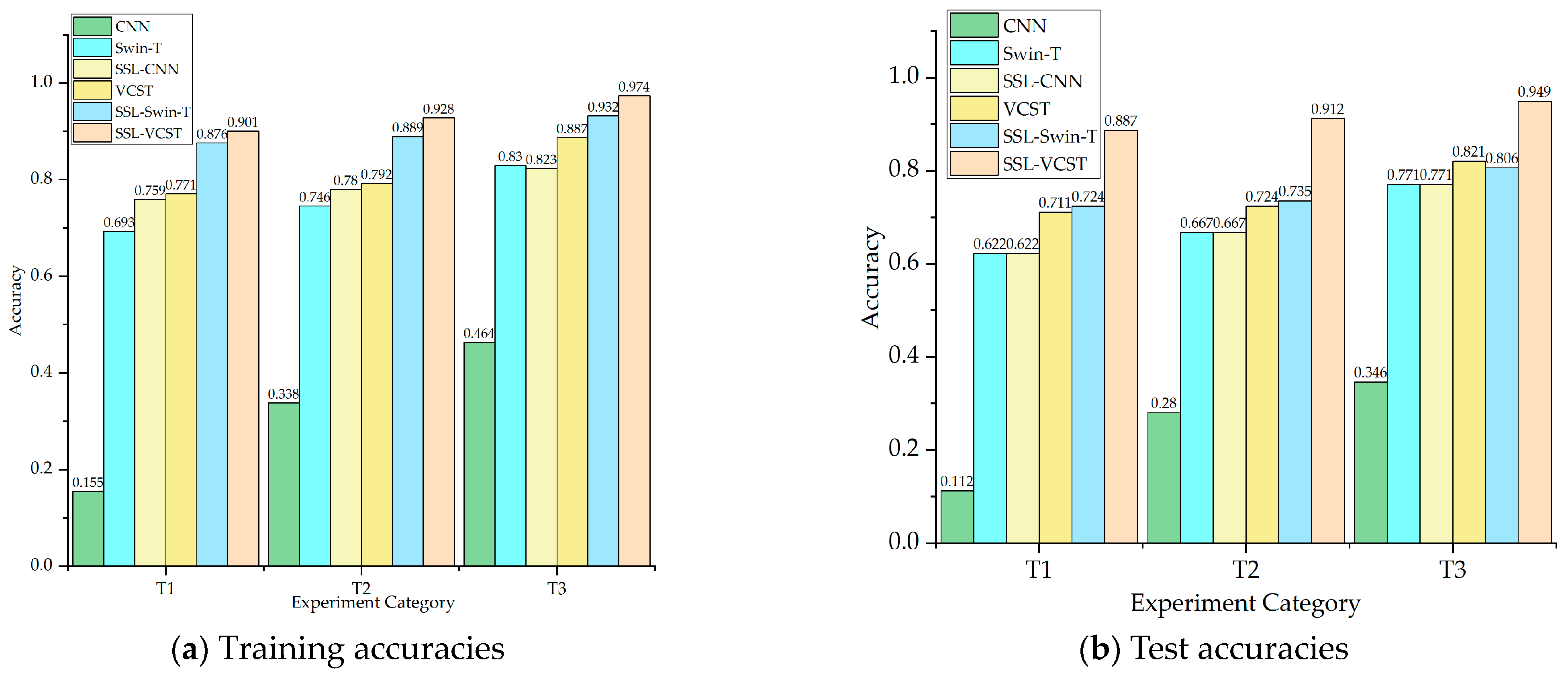
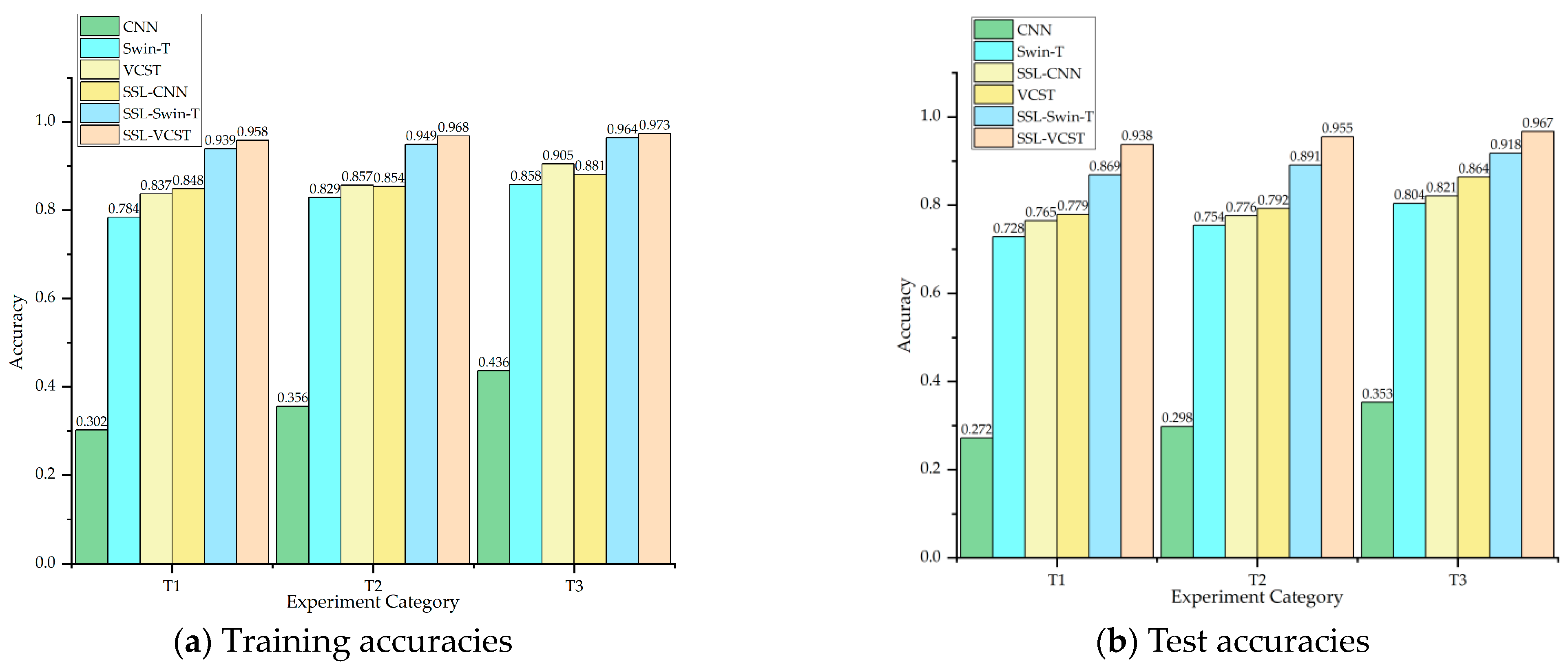
4. Applicability Experiments on Imbalanced SAMPLES and Insufficient Labeled Samples under Multiple Operating Conditions
4.1. Experiment 1: Constant Speed Conditions of Rotating Machinery
4.2. Experiment 2: Variable Speed Conditions of Rotating Machinery
4.3. Experiment 3: Constant Speed Condition of Vibrating Machinery
4.4. Experimental Analysis
5. Conclusions
- (1)
- To address the imbalance problem between normal and fault samples of bearings, a CVAE-SKEGAN network is proposed for the expansion of time–frequency image datasets. SKNets and genetic algorithms are introduced in CVAE-SKEGAN, which can adaptively select the convolutional kernel and the loss function to improve the model’s feature-learning ability and alleviate the problem of gradient vanishing. The experimental results show that the generated data distribution from CVAE-SKEGAN is closer to the real data distribution, and the information loss of the generated images is less.
- (2)
- Aiming at the challenge of inadequate labeled samples, an SSL-VCST network is proposed for bearing fault identification. In SSL-VCST, a variational attention mechanism is introduced to reduce the risk of overfitting and improve the adaptability of the model. The introduction of SSL fully utilizes unlabeled samples to supplement training, avoiding the waste of unlabeled data. The experimental results show that SSL-VCST can adapt to different sample imbalance levels and achieve a more stable accuracy. So, SSL-VCST has better generalization ability and stability.
- (3)
- The verification results under three typical operating conditions show that after the powerful balancing effect of the CVAE-SKEGAN, the SSL-VCST network is fully utilized to explore the value of unlabeled data, and the fault diagnosis accuracy achieved is significantly improved compared to other methods. The entire diagnostic scheme described here has strong applicability to multiple operating conditions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Mao, W.; Yang, B.; Meng, Z.; Tong, K.; Yu, S. RUL prediction of rolling bearings across working conditions based on multi-scale convolutional parallel memory domain adaptation network. Reliab. Eng. Syst. Safe. 2024, 243, 109854. [Google Scholar] [CrossRef]
- Xu, F.; Ding, N.; Li, N.; Liu, L.; Hou, N.; Xu, N.; Guo, W.; Tian, L.; Xu, H.; Wu, C.L.; et al. A review of bearing failure Modes, mechanisms and causes. Eng. Fail. Anal. 2023, 152, 107518. [Google Scholar] [CrossRef]
- Henriquez, P.; Alonso, J.B.; Ferrer, M.A.; Travieso, C.M. Review of automatic fault diagnosis systems using audio and vibration signals. IEEE Trans. Syst. Man Cybern. Syst. 2013, 44, 642–652. [Google Scholar] [CrossRef]
- Zhu, Z.; Lei, Y.; Qi, G.; Chai, Y.; Mazur, N.; An, Y.; Huang, X. A review of the application of deep learning in intelligent fault diagnosis of rotating machinery. Measurement 2023, 206, 112346. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Wang, B.; Habetler, T.G. Deep learning algorithms for bearing fault diagnostics—A comprehensive review. IEEE Access 2020, 8, 29857–29881. [Google Scholar] [CrossRef]
- An, F.; Wang, J. Rolling bearing fault diagnosis algorithm using overlapping group sparse-deep complex convolutional neural network. Nonlinear Dynam. 2022, 108, 2353–2368. [Google Scholar] [CrossRef]
- Pham, M.T.; Kim, J.; Kim, C.H. Deep learning-based bearing fault diagnosis method for embedded systems. Sensors 2020, 20, 6886. [Google Scholar] [CrossRef]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, C.; Lam, K.M.; Kong, J. Decouple and Resolve: Transformer-Based Models for Online Anomaly Detection From Weakly Labeled Videos. IEEE Trans. Inf. Forensics Secur. 2023, 18, 15–28. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Huo, J.Y.; Li, C.J.; Yu, C.X. Multi-label industrial fault diagnosis method based on the Transformer network model. J. Vib. Shock 2023, 42, 189. [Google Scholar] [CrossRef]
- Yang, Z.; Cen, J.; Liu, X. Research on bearing fault diagnosis method based on transformer neural network. Meas. Sci. Technol. 2022, 33, 085111. [Google Scholar] [CrossRef]
- Jaber, M.M.; Ali, M.H.; Abd, S.K.; Jassim, M.M.; Alkhayyat, A.; Majid, M.S.; Alkhuwaylidee, A.R.; Alyousif, S. Resnet-based deep learning multilayer fault detection model-based fault diagnosis. Multimed. Tools Appl. 2024, 83, 19277–19300. [Google Scholar] [CrossRef]
- Qian, G.; Liu, J. A comparative study of deep learning-based fault diagnosis methods for rotating machines in nuclear power plants. Ann. Nucl. Energy 2022, 178, 109334. [Google Scholar] [CrossRef]
- Xu, K.; Kong, X.; Wang, Q.; Han, B.; Sun, L. Intelligent fault diagnosis of bearings under small samples: A mechanism-data fusion approach. Eng. Appl. Artif. Intel. 2023, 126, 107063. [Google Scholar] [CrossRef]
- He, Q.; Tang, X.H.; Li, C.J.; Lu, J.G.; Chen, J.D. Bearing fault diagnosis method based on small sample data under unbalanced loads. China Mech. Eng. 2021, 32, 1164–1171,1180. [Google Scholar] [CrossRef]
- Ma, R.; Han, T.; Lei, W. Cross-domain meta learning fault diagnosis based on multi-scale dilated convolution and adaptive relation module. Knowl.-Based Syst. 2023, 261, 110175. [Google Scholar] [CrossRef]
- Han, X.; Wang, Y.; Feng, J. A survey of transformer-based multimodal pre-trained modals. Neurocomputing 2023, 515, 89–106. [Google Scholar] [CrossRef]
- Jin, Y.; Hou, L.; Chen, Y. A Time Series Transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Wang, G.; Liu, D.; Cui, L. Auto-embedding transformer for interpretable few-shot fault diagnosis of rolling bearings. IEEE Trans. Reliab. 2023, 73, 1270–1279. [Google Scholar] [CrossRef]
- Liu, S.; Chen, J.; He, S. Few-shot learning under domain shift: Attentional contrastive calibrated transformer of time series for fault diagnosis under sharp speed variation. Mech. Syst. Signal Proc. 2023, 189, 110071. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2672–2680. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhang, Y.H.; Zhang, Z.Y.; Zhao, X.P.; Wang, L.H.; Shao, F.; Lu, K.Y. Bearing fault diagnosis method based on VAE-GAN and FLCNN unbalanced samples. J. Vib. Shock 2022, 41, 199–209. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5769–5779. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.; Wang, Z.; Smolley, S.P. On the effectiveness of least squares generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2947–2960. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.; Deng, C.; Wu, J.; Yang, Z.; Zhu, J.; Zhang, Z. Single and simultaneous fault diagnosis of gearbox via a semi-supervised and high-accuracy adversarial learning framework. Knowl.-Based Syst. 2020, 198, 105895. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C.; Jiang, X. Imbalanced fault diagnosis of rolling bearing using improved MsR-GAN and feature enhancement-driven CapsNet. Mech. Syst. Signal Process. 2022, 168, 108664. [Google Scholar] [CrossRef]
- Dixit, S.; Verma, N.K.; Ghosh, A.K. Intelligent fault diagnosis of rotary machines: Conditional auxiliary classifier GAN coupled with meta learning using limited data. IEEE Trans. Instrum. Meas. 2021, 70, 3517811. [Google Scholar] [CrossRef]
- Raouf, I.; Lee, H.; Kim, H.S. Mechanical fault detection based on machine learning for robotic RV reducer using electrical current signature analysis: A data-driven approach. J. Comput. Des. Eng. 2022, 9, 417–433. [Google Scholar] [CrossRef]
- Raouf, I.; Lee, H.; Noh, Y.R.; Youn, B.D.; Kim, H.S. Prognostic health management of the robotic strain wave gear reducer based on variable speed of operation: A data-driven via deep learning approach. J. Comput. Des. Eng. 2022, 9, 1775–1788. [Google Scholar] [CrossRef]
- Raouf, I.; Kumar, P.; Lee, H.; Kim, H.S. Transfer Learning-Based Intelligent Fault Detection Approach for the Industrial Robotic System. Mathematics 2023, 11, 945. [Google Scholar] [CrossRef]
- Raouf, I.; Kumar, P.; Cheon, Y.; Tanveer, M.; Jo, S.H. Advances in Prognostics and Health Management for Aircraft Landing Gear—Progress, Challenges, and Future Possibilities. Int. J. Precis. Eng. Manuf.-Green Tech. 2024. [Google Scholar] [CrossRef]
- Kumar, P.; Raouf, I.; Kim, H.S. Transfer learning for servomotor bearing fault detection in the industrial robot. Adv. Eng. Softw. 2024, 194, 103672. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Wang, C.; Xu, C.; Yao, X.; Tao, D. Evolutionary generative adversarial networks. IEEE Trans. Evol. Comput. 2019, 23, 921–934. [Google Scholar] [CrossRef]
- Shahshahani, B.M.; Landgrebe, D.A. The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon. IEEE Trans. Geosci. Remote Sens. 1994, 32, 1087–1095. [Google Scholar] [CrossRef]
- Bently, D. Predictive maintenance through the monitoring and diagnostics of rolling element bearings. Bently Nev. Co. Appl. Note 1989, 44, 2–8. [Google Scholar]
- Liu, S.; Chen, J.; He, S.; Shi, Z.; Zhou, Z. Subspace network with shared representation learning for intelligent fault diagnosis of machine under speed transient conditions with few samples. ISA Trans. 2022, 128, 531–544. [Google Scholar] [CrossRef]
- Xu, Y.B.; Cai, Z.Y.; Hu, Y.B.; Ding, K. A frequency-weighted energy operator and variational mode decomposition for bearing fault detection. J. Vib. Eng. 2018, 31, 513–522. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Category | WGAN-GP | CVAE-GAN | CVAE-SKEGAN |
|---|---|---|---|
| 0 | 1.342 | 2.562 | 0.431 |
| 1 | 1.277 | 2.353 | 0.277 |
| 2 | 1.407 | 2.570 | 0.407 |
| 3 | 1.291 | 2.191 | 0.291 |
| 4 | 1.358 | 2.506 | 0.358 |
| 5 | 1.395 | 2.379 | 0.395 |
| 6 | 1.403 | 2.334 | 0.403 |
| 7 | 1.271 | 2.251 | 0.271 |
| 8 | 1.444 | 2.504 | 0.444 |
| 9 | 1.315 | 2.451 | 0.315 |
| Average | 1.347 | 2.410 | 0.359 |
| Fault Category | WGAN-GP | CVAE-GAN | CVAE-SKEGAN |
|---|---|---|---|
| 0 | 2.517 | 2.231 | 0.322 |
| 1 | 2.692 | 2.039 | 0.411 |
| 2 | 2.643 | 2.188 | 0.618 |
| 3 | 2.354 | 2.001 | 0.621 |
| 4 | 2.614 | 2.173 | 0.343 |
| 5 | 2.379 | 2.182 | 0.379 |
| 6 | 2.453 | 2.204 | 0.418 |
| 7 | 2.367 | 2.067 | 0.218 |
| 8 | 2.621 | 2.115 | 0.591 |
| 9 | 2.507 | 2.196 | 0.312 |
| Average | 2.515 | 2.140 | 0.423 |
| Sample Size | T1 | T2 | T3 | T4 |
|---|---|---|---|---|
| Labeled samples | 100 | 200 | 500 | 1000 |
| Unlabeled samples | 1000 | 1000 | 1000 | 1000 |
| Test set | 500 | 500 | 500 | 500 |
| Task | Sample Type | Normal | Inner Race Fault | Outer Race Fault | Ball Fault |
|---|---|---|---|---|---|
| T1 | Training sets: Labeled samples | 100 | 27 | 27 | 6 |
| T2 | 100 | 45 | 45 | 10 | |
| T3 | 100 | 90 | 90 | 20 | |
| T1-T3 | Training sets: Unlabeled samples | 100 | 100 | 100 | 100 |
| T1-T3 | Testing sets | 50 | 50 | 50 | 50 |
| Task | Sample Type | Normal | Inner Race Fault | Outer Race Fault |
|---|---|---|---|---|
| T1 | Training sets: Labeled samples | 100 | 12 | 12 |
| T2 | 100 | 27 | 27 | |
| T3 | 100 | 45 | 45 | |
| T1-T3 | Training sets: Unlabeled samples | 100 | 100 | 100 |
| T1-T3 | Testing sets | 50 | 50 | 50 |
| Task | Sample Type | Normal | Inner Race Fault | Outer Race Fault |
|---|---|---|---|---|
| T1 | Training sets: Labeled samples | 100 | 12 | 12 |
| T2 | 100 | 27 | 27 | |
| T3 | 100 | 45 | 45 | |
| T1-T3 | Training sets: Unlabeled samples | 100 | 100 | 100 |
| T1-T3 | Testing sets | 50 | 50 | 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Lu, Y.; Liang, Z.; Zhao, L.; Gong, Y.; Wang, M. A Bearing Fault Diagnosis Method in Scenarios of Imbalanced Samples and Insufficient Labeled Samples. Appl. Sci. 2024, 14, 8582. https://doi.org/10.3390/app14198582
Cheng X, Lu Y, Liang Z, Zhao L, Gong Y, Wang M. A Bearing Fault Diagnosis Method in Scenarios of Imbalanced Samples and Insufficient Labeled Samples. Applied Sciences. 2024; 14(19):8582. https://doi.org/10.3390/app14198582
Chicago/Turabian StyleCheng, Xiaohan, Yuxin Lu, Zhihao Liang, Lei Zhao, Yuandong Gong, and Meng Wang. 2024. "A Bearing Fault Diagnosis Method in Scenarios of Imbalanced Samples and Insufficient Labeled Samples" Applied Sciences 14, no. 19: 8582. https://doi.org/10.3390/app14198582
APA StyleCheng, X., Lu, Y., Liang, Z., Zhao, L., Gong, Y., & Wang, M. (2024). A Bearing Fault Diagnosis Method in Scenarios of Imbalanced Samples and Insufficient Labeled Samples. Applied Sciences, 14(19), 8582. https://doi.org/10.3390/app14198582