
Real-Time Detection of Insulator Defects with Channel Pruning and Channel Distillation


Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. YOLOV7-Tiny Algorithm
3.2. The Improved YOLOv7-Tiny Network Model
- FasterNet Backbone
- 2.
- New Feature Fusion Network: OD-Slimneck
- 3.
- Decoupled Head
- 4.
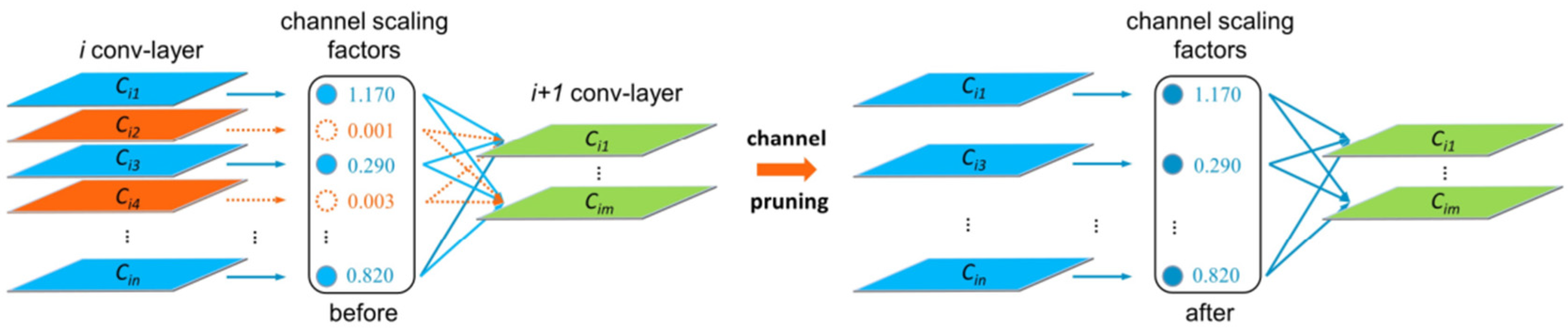
- Channel pruning of the improved YOLOv7-tiny network
- 5.
- Channel Distillation
4. Experiment and Results
4.1. The Experimental Environment and Dataset
4.2. Pefermence Matric
4.3. Experiment
- Ablation experiment
- 2.
- Channel pruning
- 3.
- Channel distillation
- 4.
- Comparative experiment
- 5.
- Generalization Ability Verification
4.4. Experiment Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, K.; Li, B.; Qin, L.; Li, Q.; Zhao, F.; Wang, Q.; Xu, Z.; Yu, J. A review on the application of deep learning target detection algorithm in overhead transmission line insulator defect detection. High Volt. Technol. 2022, 49, 3584–3595. [Google Scholar]
- Tian, Y. Artificial intelligence image recognition method based on convolutional neural network algorithm. IEEE Access 2020, 8, 125731–125744. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Q.; Liu, Y.; Wang, C. Insulator defect detection based on improved YOLOv5 algorithm. In Proceedings of the 2023 IEEE 12th Data Driven Control and Learning Systems Conference (DDCLS), Xiangtan, China, 12–14 May 2023; pp. 770–775. [Google Scholar]
- Zeng, Y.; Zhang, R.; Lim, T.J. Wireless communications with unmanned aerial vehicles: Opportunities and challenges. IEEE Commun. Mag. 2016, 54, 36–42. [Google Scholar] [CrossRef]
- Xu, L.; Xu, X.; Xia, Q.; Yao, Y.; Jiang, Z. A light-weight defect detection model for capacitor appearance based on the Yolov5. Measurement 2024, 232, 114717. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–27 June 2023; pp. 7464–7475. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 1–July 2016; pp. 779–788. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Ye, J.; Lu, X.; Lin, Z.; Wang, J.Z. Rethinking the smaller-norm-less-informative assumption in channel pruning of convolution layers. arXiv 2018, arXiv:1802.00124. [Google Scholar]
- Huang, Z.; Wang, N. Data-driven sparse structure selection for deep neural networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 304–320. [Google Scholar]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Hua, B.-S.; Tran, M.-K.; Yeung, S.-K. Pointwise convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 984–993. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Zhuang, J.; Qin, Z.; Yu, H.; Chen, X. Task-specific context decoupling for object detection. arXiv 2023, arXiv:2303.01047. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Yang, Y.; Qiu, J.; Song, M.; Tao, D.; Wang, X. Distilling knowledge from graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7074–7083. [Google Scholar]
- Zhou, Z.; Zhuge, C.; Guan, X.; Liu, W. Channel distillation: Channel-wise attention for knowledge distillation. arXiv 2020, arXiv:2006.01683. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Simon, M.; Rodner, E. Neural activation constellations: Unsupervised part model discovery with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1143–1151. [Google Scholar]
- Adriana, R.; Nicolas, B.; Ebrahimi, K.S.; Antoine, C.; Carlo, G.; Yoshua, B. Fitnets: Hints for thin deep nets. Proc. ICLR 2015, 2, 1. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part V 13. pp. 198–213. [Google Scholar]
- Srinivas, S.; Subramanya, A.; Venkatesh Babu, R. Training sparse neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 138–145. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Tang, S.; He, F.; Huang, X.; Yang, J. Online PCB defect detector on a new PCB defect dataset. arXiv 2019, arXiv:1902.06197. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | P | R | mAP@0.5 | mAP@0.5:0.95 | Parameter Size (M) | GFLOPs | Inference Time (Batch Size 32) | |
|---|---|---|---|---|---|---|---|---|
| A | YOLOV7-tiny | 71.6% | 56.0% | 62.4% | 28.1% | 6.1 | 13.0 | 1.25 ms |
| B | A+FasterNet | 71.1% | 60.5% | 63.4% | 28.4% | 4.1 | 8.5 | 1.16 ms |
| C | B+OD-Slimneck | 74.5% | 63.1% | 68.2% | 30.3% | 3.9 | 7.7 | 1.14 ms |
| D | C+Decoupled_detect | 78.4% | 65.4% | 71.2% | 32.8% | 5.5 | 10.7 | 1.31 ms |
| Speed_up Ratio | Sparsity Learning Epoch | Fine-Tune Training Epoch | Sparsity Ratio | P | mAP@0.5 | Inference Time (Batch Size 32) |
|---|---|---|---|---|---|---|
| 2.0 | 300 | 300 | 32.7% | 73.3% | 64.6% | 0.78 ms |
| 3.0 | 300 | 300 | 46.5% | 50.6% | 39.2% | 0.61 ms |
| P | R | mAP@0.5 | mAP@0.5:0.95 | Parameter Size (M) | GFLOPs | Inference Time (Batch Size 32) | |
|---|---|---|---|---|---|---|---|
| Before pruning | 78.4% | 65.4% | 71.2% | 32.8% | 5.5 | 10.7 | 1.31 ms |
| After channel pruning | 73.3% | 58.5% | 64.6% | 28.0% | 2.8 | 5.3 | 0.78 ms |
| After Random pruning | 70.9% | 58.6% | 61.7% | 26.3% | 2.8 | 5.3 | 0.81 ms |
| mAP@0.5 | mAP@0.5:0.95 | Parameter Size (M) | GFLOPs | |
|---|---|---|---|---|
| OD-YOLOV7-tiny | 66.3% | 28.4% | 2.8 | 5.3 |
| SSD-lite | 47.4% | 12.0% | 3.0 | 3.8 |
| YOlOx-tiny | 68.9% | 26.7% | 5.0 | 7.6 |
| YOLOV5s | 68.4% | 27.5% | 4.9 | 12.4 |
| YOLOV8n | 69.2% | 28.1% | 3.2 | 8.7 |
| Network | P | R | mAP@0.5 | mAP@0.5:0.95 | Parameter Size (M) | GFLOPs | Inference Time (Batch Size 32) |
|---|---|---|---|---|---|---|---|
| YOLOV7-tiny | 71.6% | 56.0% | 62.4% | 28.1% | 6.1 | 13.0 | 1.25 ms |
| Improved model | 78.4% | 65.4% | 71.2% | 32.8% | 5.5 | 10.7 | 1.31 ms |
| Pruned model | 73.3% | 58.5% | 64.6% | 28.0% | 2.8 | 5.3 | 0.78 ms |
| Distilled model | 75.5% | 61.3% | 66.3% | 28.4% | 2.8 | 5.3 | 0.78 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, D.; Xu, X.; Jiang, Z.; Xu, L. Real-Time Detection of Insulator Defects with Channel Pruning and Channel Distillation. Appl. Sci. 2024, 14, 8587. https://doi.org/10.3390/app14198587
Meng D, Xu X, Jiang Z, Xu L. Real-Time Detection of Insulator Defects with Channel Pruning and Channel Distillation. Applied Sciences. 2024; 14(19):8587. https://doi.org/10.3390/app14198587
Chicago/Turabian StyleMeng, Dewei, Xuemei Xu, Zhaohui Jiang, and Lei Xu. 2024. "Real-Time Detection of Insulator Defects with Channel Pruning and Channel Distillation" Applied Sciences 14, no. 19: 8587. https://doi.org/10.3390/app14198587
APA StyleMeng, D., Xu, X., Jiang, Z., & Xu, L. (2024). Real-Time Detection of Insulator Defects with Channel Pruning and Channel Distillation. Applied Sciences, 14(19), 8587. https://doi.org/10.3390/app14198587