Abstract
Text augmentation plays an important role in enhancing the generalizability of language models. However, traditional methods often overlook the unique roles that individual words play in conveying meaning in text and imbalance class distribution, thereby risking suboptimal performance and compromising the model’s generalizability. This limitation motivated us to develop a novel technique called Text Augmentation with Word Contributions (TAWC). Our approach tackles this problem in two core steps: Firstly, it employs analytical correlation and semantic similarity metrics to discern the relationships between words and their associated aspect polarities. Secondly, it tailors distinct augmentation strategies to individual words based on their identified functional contributions in the text. Extensive experiments on two aspect-based sentiment analysis datasets demonstrate that the proposed TAWC model significantly improves the classification performances of popular language models, achieving gains of up to 4% compared with the case of data without augmentation, thereby setting a new standard in the field of text augmentation.
1. Introduction
Sentiment analysis is a fundamental task in natural language processing (NLP). The primary goal of the proposed model is to predict the sentiment polarity of sentences. In addition to sentiment analysis at the sentence level, different aspects of a sentence may express different sentiment polarities [1]. Aspect-based sentiment analysis (ABSA) determines fine-grained opinion polarity toward a given term. Compared to traditional text sentiment analysis, ABSA can extract more fine-grained emotional expressions, analyze users’ specific emotional views of various objectives, and gain a more granular understanding of products, providing more accurate decision support to decision-makers [2].
Many algorithms, especially deep learning models, have gained popularity in ABSA due to their high learning capacity in capturing the semantics of sentences, such as recurrent neural networks (RNNs) [3], convolutional neural networks (CNNs) [4], and transformer models [5]. ABSA deep learning requires labeled datasets for training, and model performance is related to training data size; the larger the training data, the better. Adding more examples reduced the margin error and increases the model’s generalizability.
However, large, labeled corpora are limited because people often develop them manually, which is a time-consuming and inefficient procedure. The lack of labeled data in a low-resource corpus introduces obstacles such as model overfitting or underfitting and tends to cause the problem of class imbalance [6]. In addition, imbalance class distribution in the training data affects text classification outcomes [7]. Therefore, text data augmentation techniques are used to balance classes in terms of sample size and to improve the total sample size of small datasets. These improvements boost classification accuracy and minimize the need for manual intervention.
Diverse text augmentation approaches have been proposed to expand training data, including replacing words in sentences [8], back-translation [9], and language model-based methods [10]. However, previous methods primarily augment the text randomly without considering the different contributions and roles of words to the context. Although the proposed method incurs a minimal time cost, it may lose the semantic structure and order of the original training data, resulting in changes to the enhanced semantic labels. Hence, the informed replacement of a specific word is expected to yield different results compared to the random replacement of words. Furthermore, ABSA augmentation strategies should ensure that aspect words are not substituted during augmentation because they influence the sentiment classification effect [11].
Based on our previous study using an integrated gradient attribution score [12], we found that each token in the text sequence has different contributions to the generation of the label. The text label is a word that highly generalizes the text content. However, the drawback of the proposed method is that the integrated gradient only captures positive and negative labels, whereas a sentence with neutral polarity as the minority class provides a zero score.
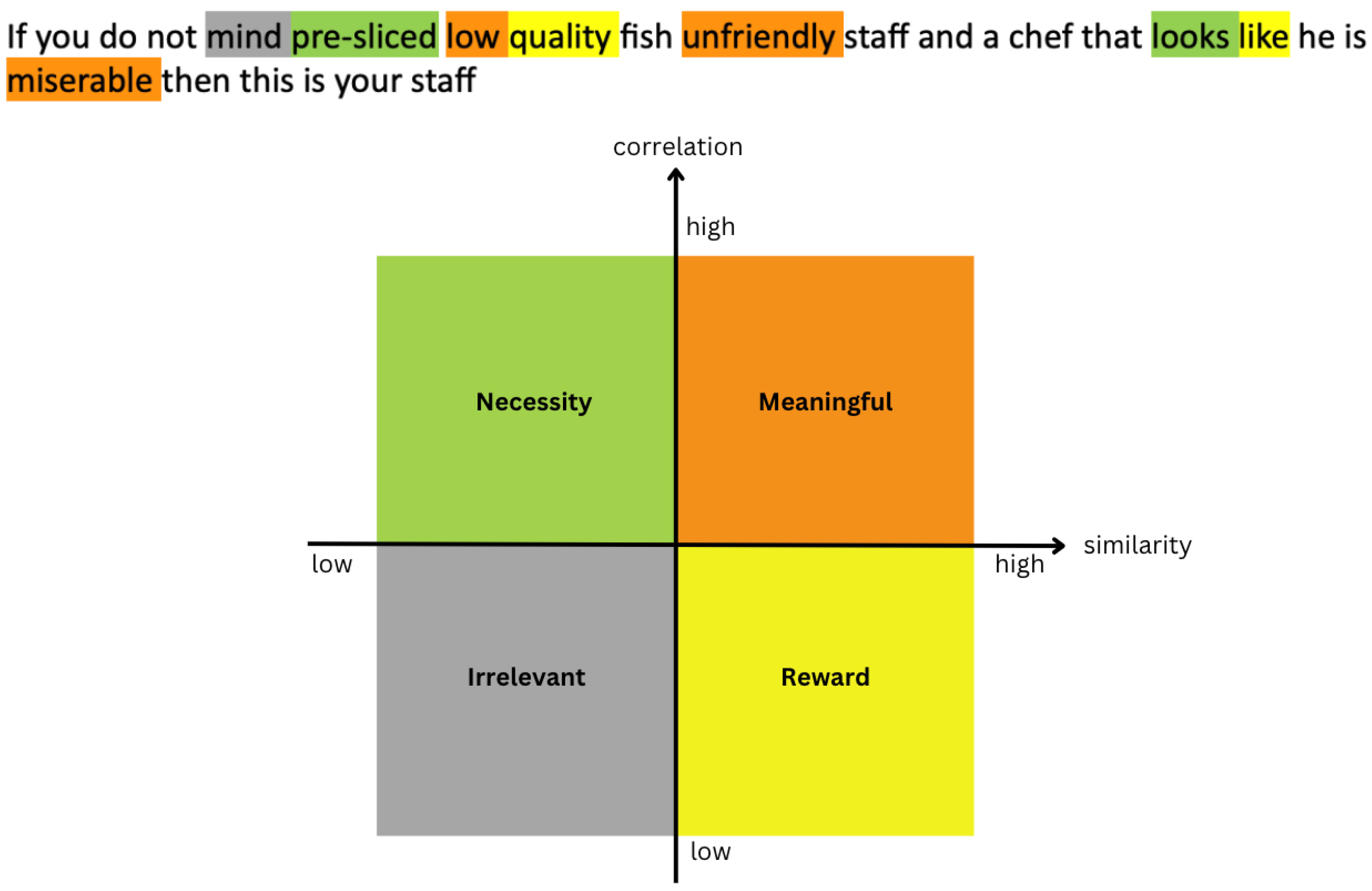
Motivated by the above considerations, we propose a lightweight and effective augmentation method named text augmentation with word contributions (TAWC) for aspect-based sentiment tasks. The proposed method can generate diverse and clean text samples while maintaining the original meaning. It focuses on text editing techniques to improve training data, using simple modifications to the text without relying on large, pre-trained language models. The proposed method emphasizes efficiency and simplicity and provides better training samples via basic text editing operations. In particular, we first introduce word contribution identification using analytical correlation, which examines how frequently a word co-occurs with a particular label while occurring less often with other labels, and semantic similarity, which measures the semantics between a word and its polarity. Words with varying degrees of correlation and semantic similarity should contribute differently to the sentiment classification task. The sentence’s words can be categorized into four groups according to the two perspectives (high and low degrees, as illustrated in Figure 1. Take the following example of a sentence with negative sentiment: If you do not mind pre-sliced low quality fish unfriendly staff and a chef that looks like he is miserable then this is your staff. The words low, unfriendly, and miserable are identified as words with high correlation and high similarity to the negative label. In contrast, mind is categorized in the irrelevant group with low correlation and similarity. Furthermore, pre-sliced and looks are included in the necessity words category, while the low correlation and high similarity categories consist of the words quality and like.
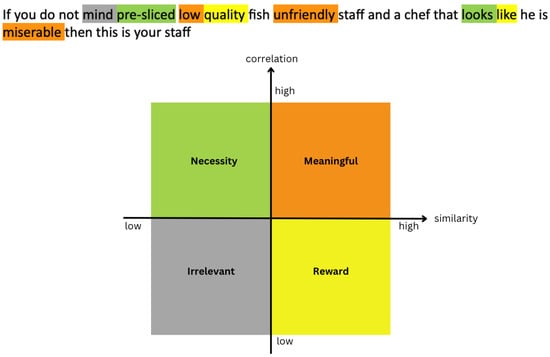
Figure 1.
A group ofword contribution illustrations based on high and low degrees of two perspectives: correlation and semantic similarity.
Subsequently, we selectively replace words in the sentence according to their groups during augmentation. We used word embedding models rather than WordNet to identify the most similar words for synonym replacement. Word embedding is one of the most popular representations of document vocabulary, and it can capture the context of a word in a document, its semantic and syntactic similarity, and its relationships with other words [13].
We design appropriate methods to handle the challenges of low-resource aspect-based fine-grained sentiment classifications. The proposed strategies balance the training data by oversampling minority classes and increasing the data size to improve the learning efficiency and accuracy of the aspect-based text sentiment classifier. Moreover, they enhance the portability and interpretability of the classification model on the benchmark ABSA datasets, namely SemEval 2015 and SemEval 2016, for the restaurant domain. We consider three representative pre-trained language models: the BERT [5], DistilBERT [14], and RoBERTa [15] classification models. The experimental results demonstrate that the proposed selective word augmentation outperforms the baseline methods. The contributions are summarized as follows:
- We introduce an effective method to determine individual word contributions in a sentence. Word contributions represent the relationship between words and sentiment polarity considering both analytical and semantic perspectives, which guarantee the recognition accuracy of the word contributions.
- We propose a selective augmentation method based on word contributions that uses synonyms by measuring the similarity between word embeddings. The proposed method generates a relatively clean sample and is simple to implement.
- We conduct extensive comparative experiments to verify the effectiveness of the proposed augmentation approaches.
- We present a lightweight word extraction strategy that can motivate research in other disciplines such as information retrieval and document representation.
The remainder of this paper is organized as follows: Section 2 introduces related works on data augmentation methods. Section 3 presents the proposed method. Section 4 describes the experimental setup. Section 5 demonstrates the comparative experiment and discussion. Section 6 concludes the paper and discusses future work.
2. Related Work
Data augmentation has proven to be an effective method for increasing the number and quality of training data; it is critical for successfully implementing deep learning models for data-driven initiatives. Data augmentation techniques for natural language processing (NLP) can be categorized as supervised or unsupervised methods.
2.1. Supervised Methods
Most supervised approaches acquire synthetic words and sentences for augmentation by training or fine-tuning a neural language model. Contextual augmentation [10] uses other words predicted by the language model to generate new samples. Similar to contextual augmentation, CBERT replaced the bidirectional language model with BERT and fine-tuned BERT, introducing the label information of the original text to ensure that the labels of the augmented samples were the same as those of the original training dataset [16].
Liu et al. [17] introduced data augmentation using a heuristic mask language model to obtain high-quality data. For class balance, ref. [18] trains a variational autoencoder (VAE) or generative adversarial networks (GANs) for each class to control the number of synthetic sentences. Productive approaches can synthesize diverse phrases, such as [19,20]. However, supervised-based augmentation methods are generally difficult to apply due to their complexity or cost, particularly for non-experts in NLP.
2.2. Unsupervised Methods
Among the various unsupervised methods, synonym replacement is the simplest [21]. It creates new sentences by replacing some words in the source sentence with synonyms from WordNet. For effectiveness, Ref. [8] develops an easy data augmentation (EDA) technique with four simple operations: synonym replacement, random insertion, random deletion, and random swap. Despite these successes, EDA still has a few limitations. For example, word substitution without consideration may give rise to the loss of the semantic structure of the augmented data. Several strategies are introduced to expand words selectively. The term frequency-inverse document frequency (TF-IDF) score replaces uninformative words and keeps words with high TF-IDF values to enhance the classification performance [22]. In addition, Ahmed et al. [23] proposed a clonal selection algorithm to select representative words in text classification tasks. The adversarial word dilution approach was introduced by [24], which learns the dilution weights through a constrained min–max optimization process guided by the labels. Moreover, reference [25] proposed tailored text augmentation by combining probabilistic synonym replacement and irrelevant zero masking. This method improves the generalizability of the model and enhances its accuracy.
In aspect-based sentiment tasks, each word contributes a degree of contribution to discriminate aspect polarity prediction differently. In addition, the aspect term should not be replaced, as introduced by [11,26]. Therefore, reference [12] applied an integrated gradient to identify the attribute score of each word in an aspect-based sentence; however, the integrated gradient was unable to measure the attribute score in neutral polarity.
In this paper, we propose word selection for augmentation based on word contributions, which considers the correlation and semantic similarity between a word and a label. We study how to generate a better-augmented sentence for aspect-based sentiment classification.
3. Word Selection for Augmentation
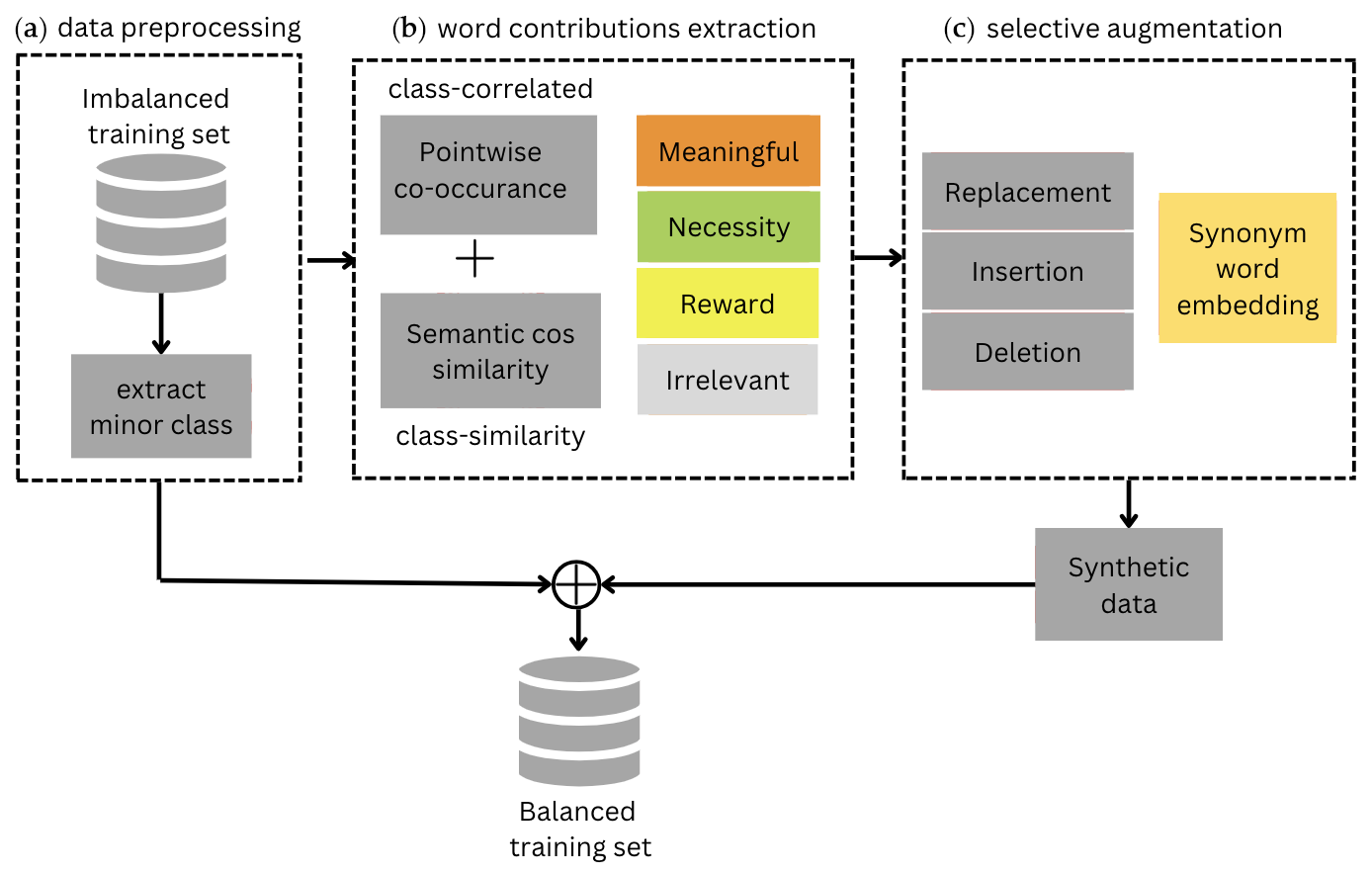
In this section, we present the word selection method proposed in this paper. The primary idea of the proposed strategies is to modify a word based on its contribution to sentiment polarity during augmentation. The proposed framework comprises three parts, (a) data preprocessing, (b) word contribution extraction, and (c) selective augmentation, as illustrated in Figure 2. Each part is described in the following subsections.
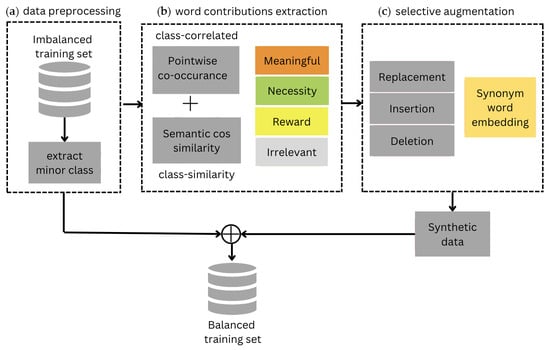
Figure 2.
The workflow of our proposed word selection for augmentation method consists of three parts: (a) data preprocessing to provide the minor class of the cleaned dataset, (b) extracting word contributions into four categories, and (c) applying selective augmentation procedures to generate synthetic data.
3.1. Data Preprocessing
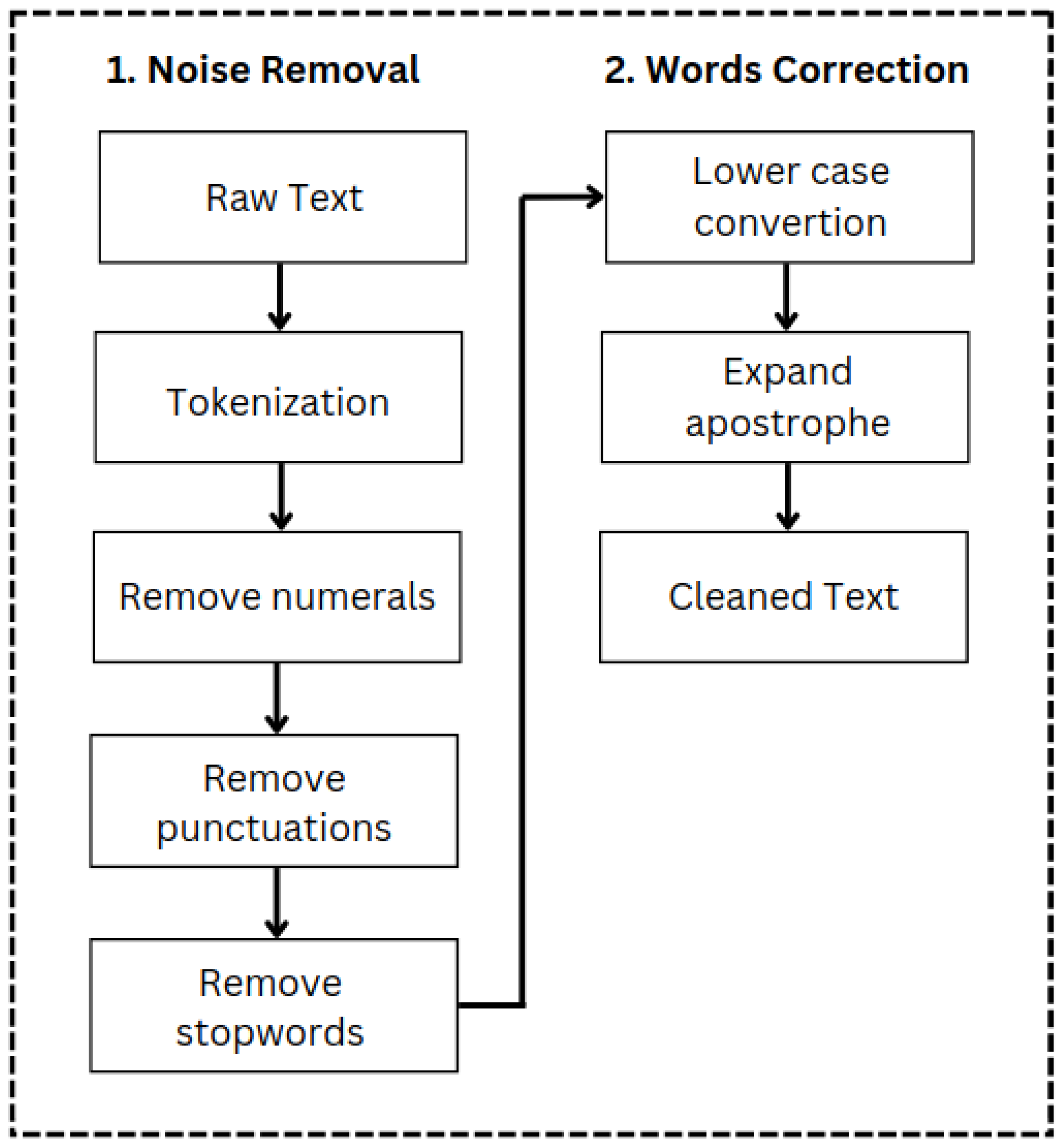
One critical step in text classification is data preprocessing [27]. The text is preprocessed prior to implementing the categorization algorithm. A common practice in natural language processing (NLP) is to clean sentences from noise by performing stop-word removal, stemming, and pegmatization [28]. In this study, we applied noise removal and word correction to clean the text, as presented in Figure 3.
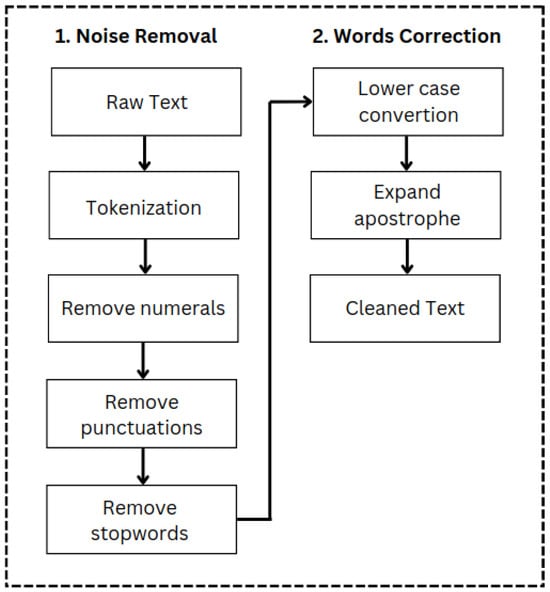
Figure 3.
Data preprocessing steps: (1) noise removal and (2) word correction to clean text.
In summary, we wanted to remove lexical noise from the sentence and correct words so that the text can be analyzed. Refining the text sentence was critical because it provided a solid basis for the next procedure (i.e., word extraction). We eliminated syntactical noise comprising numbers, punctuation, and stop words during noise removal. Then, we converted words to lowercase letters and expanded apostrophe words, such as the word doesn’t, which expanded to does not. Furthermore, using the cleaned dataset, we extracted the minority classes to be augmented using the proposed method.
3.2. Word Contributions Extraction
In a sentiment classification task, the model is trained to assign one label from to a sentence. Here, the training set is D, and its lexicon is L. For words and a class , we can determine their relationship from two perspectives:
- Analytical Correlation. This metric assesses how frequently word co-occurs with class but not other words in the training dataset;
- Semantic Similarity. This measures a word’s semantic similarity with class .
Thus, each metric’s impact on word selection for augmentation can be determined. Analytical correlation can guide the preservation of important relationships in data. If two words are highly correlated, we want to ensure that substitutions do not break the relationship. In addition, semantic similarity ensures that word replacements are meaningful and retain the original intent of the given text. When both analytical correlation and semantic similarity are used together, the augmentation process becomes more refined. For example, when augmenting sentiment analysis data, we used correlation to ensure that key sentiment-bearing words like unfriendly and bad are kept in sync. Furthermore, we used semantic similarity to replace appetizer with pasta (semantically similar) rather than an unrelated word like table.
According to the two measurements, all words in the training dataset can be categorized into four groups:
- Meaningful words: Words in this group are useful class-indicating words with high correlation and high semantic similarity with the corresponding label.
- Necessity words. Words usually co-occur frequently with classes but have low semantic similarity. These words can provide extra information about the class. However, their low semantic similarity may cause noise.
- Reward words: These words have low correlation but high semantic similarity, which is useful for model generalization.
- Irrelevant words: Words with less contribution to sentiment classification because they have low correlation and low semantic similarity.
We had to use appropriate metrics to recognize the contribution of words in the sentiment classification task. To measure analytical correlation with the label, we applied pointwise mutual information (PMI) to extract label-correlated words from the sentence. PMI in sentiment analysis helps to identify words that are strongly correlated with specific sentiment labels by calculating how much more likely they are to appear in relation to certain sentiments than by random chance. It efficiently extracts sentiment-related features from text data. This was inspired by [29], which applied PMI to build a system to automatically create a sentiment lexicon. Padmakumar and He [30] used PMI to define an essential sentence based on the semantic similarity between a sentence and a document for the summarization task. The PMI score is computed as follows:
where w is a word, c is a class or label of a sentence, is the probability of a word and class co-occurring in the corpus, is the probability of a word occurring in the corpus, and is the probability of a class occurring in the corpus. We use the frequency of a word occurring in a certain class to estimate the probability of a word. Take the following example of a sentence with negative sentiment: The product quality was disappointing and the customer service was horrible. Words like disappointing and horrible are often associated with negative sentiment in a larger dataset. The PMI computes how frequently each word, such as disappointing or horrible, co-occurs with negative sentiment compared to how often they appear independently. For example, if horrible is commonly used in negative reviews, the PMI score between horrible and the negative class would be high. High PMI scores indicate words strongly associated with the label.
We utilized the word embedding Word2vec based on the skip-gram model [31] to measure the semantic similarity between a word and the meaning of the label polarity. Due to the high inference costs of transformer-based models, such as BERT, we did not use them for similarity measurements. Some studies have also demonstrated that static word embeddings can outperform BERT-like models in context-free similarity measurement tasks, particularly at the word level [32]. We computed the cosine similarity to determine the semantic distance between a word and a class. The cosine similarity evaluates the semantic similarity between words and sentiment labels by calculating the angle between their vector representations. It is particularly useful in sentiment analysis when using word embeddings because it captures the strength of the association between words and different sentiment categories. A high cosine similarity indicates that the word is closely aligned with a particular sentiment, which makes it a useful measure for identifying sentiment words. Given two vectors of attributes, w and c, the cosine similarity is represented by the dot product and magnitude as
Taking the illustration into account, we calculated the cosine similarity between a word horrible and the negative sentiment. Here, we identified the vectors of horrible = [0.9, 0.8, 0.7] and negative sentiment = [1.0, 0.9, 0.8] from Word2vec embedding. Calculating the dot product = (0.9 × 1.0) + (0.8 × 0.9) + (0.7 × 0.8) = 0.9 + 0.72 + 0.56 = 2.18, the score magnitudes of horrible and negative classes were 1.39 and 1.57, respectively. The score of cosine similarity was calculated using Equation (2) to reach 1.0, indicating perfect alignment (strong association with negative sentiment).
We computed each word’s correlation and similarity scores and defined a threshold to divide high and low degrees. Let words with high (low) correlation scores be and words with low (high) similarity scores be . We chose the first (third) quartile as the low (high) degree threshold, as it provided better results than the median. In our initial experiment, we used the second quartile (median) as the threshold. However, we observed that the word extraction results did not adequately represent their role in the sentence in relation to the label. Upon further experimentation, we discovered that the first (or third) quartile yielded better performance during our second attempt, and we opted not to fine-tune the thresholds further. Nevertheless, adjusting these hyperparameters may still lead to additional improvements in the proposed method. In order to reduce the variance, we transformed the correlation and similarity scores using the min–max normalization technique, as shown in Equation (3) and Equation (4), respectively. In addition, we extracted the words into four categories according to the rules presented in Table 1.

Table 1.
The rules for each word category.
The pseudocode for word contribution extraction is given in Algorithm 1. We implemented the word contribution procedure in the SemEval 2016 dataset of negative and neutral labels, and some examples are presented in Table 2.
| Algorithm 1 Word Contributions Extraction |
| Require: sentences, labels, and word embeddings Ensure: set of word contributions
|
Table 2.
Examples of word contributions in minority classes.
3.3. Selective Augmentation Operations
According to the identified word contributions, we proposed a text augmentation method for ABSA that selects words for each sentence consisting of three operations. In our previous work [12], we applied unimportant words to synonym replacements and important words to synonym insertions, which outperformed the baselines. Motivated by this result, we applied the text editing operation based on the following considerations:
- Selective Replacement (SR): Select n words, except Meaningful words from the given sentence and replace them with synonyms. The only thing to keep in mind is that the replacement should not fall within the aspect term. This is ensured by replacing the aspect term with a fixed expression ($t$) before the replacement.
- Selective Insertion (SI): Select n words, except Necessity, and Irrelevant words from the sentence and then insert their synonyms. We must ensure that the aspect words remain unchanged. Replacing the aspect with a single expression ($t$) resolves this problem.
- Selective Deletion (SD): Choose n words, except aspect term and Meaningful words from the sentences, and then delete them. We must apply a procedure similar to that described above and replace the aspect word with a fixed expression ($t$) to ensure that this expression cannot be selected for deletion.
Each augmentation operation was performed to generate different types of augmented text to balance the training sets. Regarding synonym replacement and insertion operations, we implemented an alternative resource using a word embedding model to provide high-quality synonyms. The n was determined by hyperparameter , representing the augmentation strength. The pseudocode for selective replacement is presented in Algorithm 2.
| Algorithm 2 Selective replacement |
| Require: training dataset , aspect term, , fixed expression $t$, Necessity words ; reward words ; irrelevant words ; and Word2Vec Ensure: augmented dataset
|
4. Experiments
In this section, we describe our experiments. We conducted a comprehensive investigation of two benchmark datasets to evaluate the performance of the proposed text augmentation with the word selection algorithm. Section 4.1 introduces the datasets used to test the efficiency of the proposed method, Section 4.2 describes the baselines to be compared, and finally, Section 4.3 explaines our parameter settings.
4.1. Datasets
We used the Semantic Evaluation (SemEval) datasets for 2015 and 2016 as the benchmark for the ABSA task. The SemEval datasets perform different tasks depending on the goal of the study. We selected task 12 subtask 1 from SemEval 2015 [33] and task 5 subtask 2 from SemEval 2016 [34]. These tasks predict the aspect polarity of each sentence, which agrees with our study.
The datasets comprise training and testing sets for evaluating the model. The polarity frequencies in the training and testing datasets are shown in Table 3. The number of positive-sentiment words was much greater than the neutral sentiment in each dataset. Therefore, we considered balancing the class using a text augmentation method. We trained the full datasets for the main results. In addition, we also randomly sampled examples from the training sets to evaluate the effectiveness of the proposed method in low-resource scenarios.
Table 3.
The statistics of the datasets.
4.2. Baselines
In this study, we evaluate the performance of the proposed selective word augmentation method using the following baselines:
- No-DA trains the three classifiers without data augmentation operations.
- EDA [8] is a random word replacement method based on WordNet.
- EDA-w2v [35] is an alternative version of the original EDA that implements the word2vec model [31] to find similar words.
- IG [12] selects the word in the text to be replaced based on the integrated gradient attribute score and uses WordNet to identify synonyms.
- IG-w2v is the extended version of the original IG. We applied the word2vec model to obtain similar words.
4.3. Parameter Settings
We used three types of transformer models for sentiment classifiers: (1) BERT is pre-trained on a massive amount of text and reads text from both left-to-right and right-to-left, giving it a better understanding of word meaning in context. (2) DistilBERT is a smaller, faster, and lighter version of BERT, with approximately 40% fewer parameters but retaining 97% of BERT language understanding capabilities. (3) RoBERTa is an improvement over BERT, where the training procedure is optimized, including larger batches, more data, and dynamic masking. The models provided better representations and improved performances compared to BERT on many benchmarks. These models offered excellent performances on a large variety of classifiers in NLP tasks, including sentiment analysis, and often surpass traditional models due to their powerful representation learning ability to capture the semantic and syntactic features of text. The learning rate of the AdamW optimizer [36] was 5e-5, and the cross-entropy loss function was implemented. We trained 64 samples in each batch, and the maximum input sequence length of the text was 512. The number of iterative rounds (epochs) was 50. The augmentation strength was set to 0.2, which affected the number of augmented words. We ran the training set three times for each augmentation method, and the average accuracy was reported as the final performance for fair comparison. The selected values of the hyperparameters were based on the setting from the references [12,35].
We set the number of augmentations to six for the neutral class, which was determined according to the imbalance ratio of the training dataset. For example, the frequency of neutral sentiment in the SemEval 2015 dataset prior to augmentation was 36 sentences, and after generating new sentences, it expanded to sentences.
5. Results and Discussion
In this section, we present the results of our study consisting of four main parts: First, we compare performances with baselines using full-set training as the main results. Second, we analyze the performances of the strategies in low-data scenarios. In addition, we explore the effectiveness of the proposed method in each augmentation operation. Lastly, we conduct an ablation study to investigate the urgency impact of two metrics, correlation and similarity, in our proposed method.
5.1. Comparison of Performances with Baselines
Table 4 compares the performances, including the average, standard deviation, and best accuracy, of the training set without data augmentation (No-DA) and the data augmentation methods for the three classifiers. The results demonstrate that text augmentation methods are valuable for sentiment classification as they improve the accuracy of the two benchmark datasets. Text augmentation methods not only expand the number of features for training models but also consider balancing the class. Consequently, the model tends to fit and increase the performance compared to the No-DA case. Among the baselines, EDA-w2v and IG-w2v are quite competitive in terms of performance. Both methods provide better results than the original method for all classifiers. In addition, IG-w2v achieves outstanding average accuracy for the DistilBERT model on the SemEval 2015 dataset. In other words, the word2vec model is an appropriate alternative synonym resource for word replacement augmentation.
Table 4.
Average accuracies across both datasets.
Table 4 also shows that the proposed TAWC method can elevate robust transformer classifiers that achieve outstanding performance in terms of best and average accuracy in most cases. These results demonstrate that the proposed word selection for augmentation is suitable for different versions of the BERT-series model classification. Compared to the No-DA case, the proposed TAWC significantly outperforms the RoBERTa method by over 2% and 4% on the SemEval 2015 and SemEval 2016 datasets, respectively. Furthermore, compared to IG for selective augmentation, the proposed TAWC demonstrates improvement for the two datasets with all classifiers in terms of best and average accuracy. We also averaged the value of each method over the classifier according to the standard deviation. The results imply that our proposed method has better generalization than IG-w2v.
On the SemEval 2015 dataset, using the DistilBERT model, the proposed selective augmentation strategy outperformed EDA as a non-selective method by over 2%. Although the average accuracy of TAWC was less than that of IG-w2v, it obtained the highest score in terms of best accuracy. On the SemEval 2016 dataset, among the three word2vec-based augmentation approaches, TAWC outperformed the other methods by nearly 3% when applying DistilBERT and nearly 2% when using RoBERTa. For the best accuracy, the TAWC method increased the BERT and RoBERTa models to a superior score by over 90%. Generally, text augmentation based on word contributions enhances the accuracy of the sentiment classification model.
We believe that the performance improvement of word contribution-based augmentation is due to its advantage of selecting augmented words considering the roles and contributions of sentiment prediction. Furthermore, the robustness of the word2vec model ensures that relevant synonyms are used to replace augmented sentences. In addition, the model tends to generalize well due to the synthetic samples managing the balance class of the training set.
5.2. Evaluation of Data Augmentation Methods for Low-Resource Scenarios
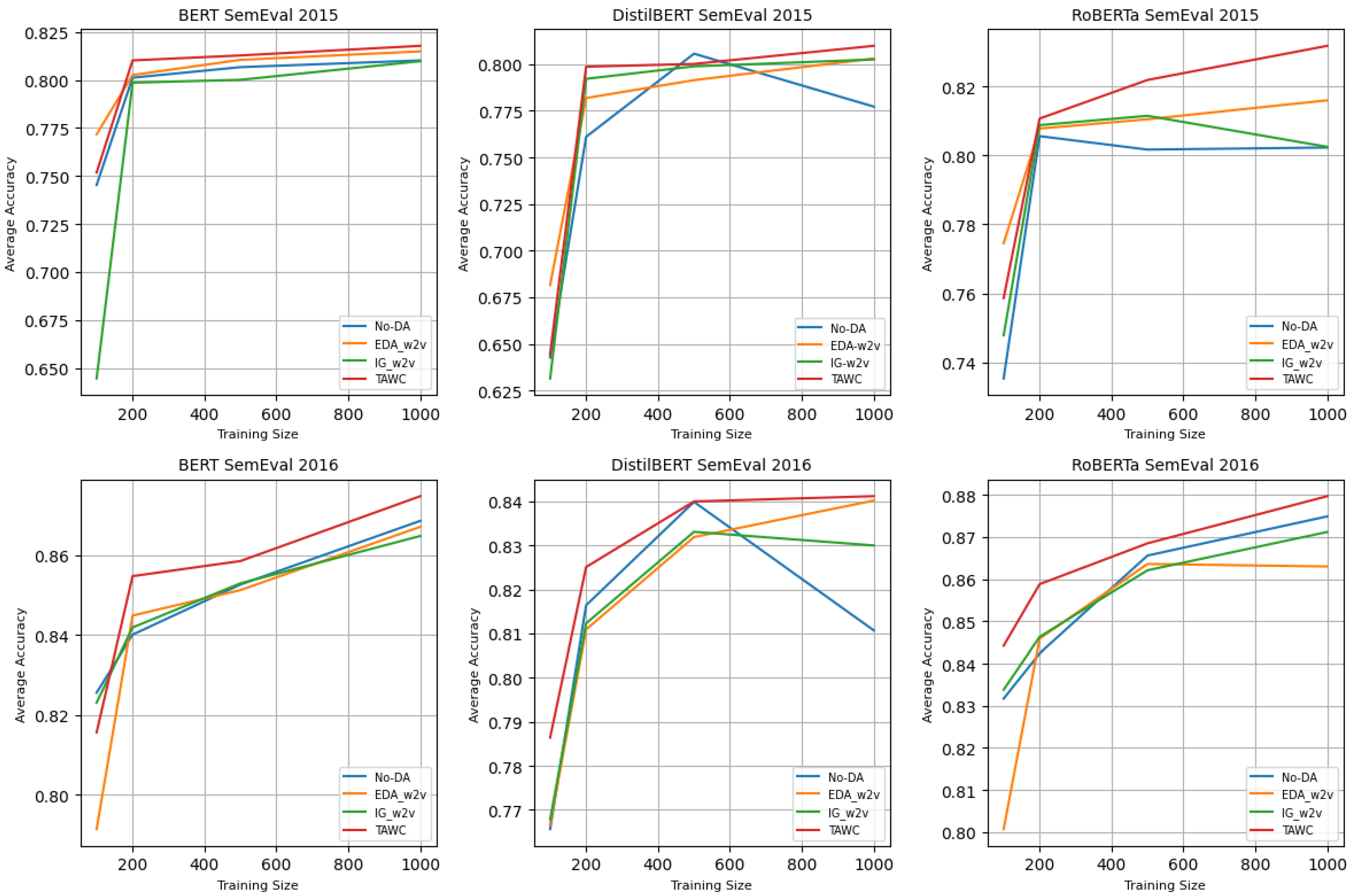
The above experiment demonstrates that the proposed TAWC strategy outperforms the baseline methods on the two benchmark datasets. To evaluate TAWC more comprehensively, we ran the experiment on low-resource scenarios where the training data size was set to 100, 200, 500, and 1000, respectively. We compared the performance of EDA-w2v and IG-w2v as competitive baselines. The experimental results are shown in Figure 4.
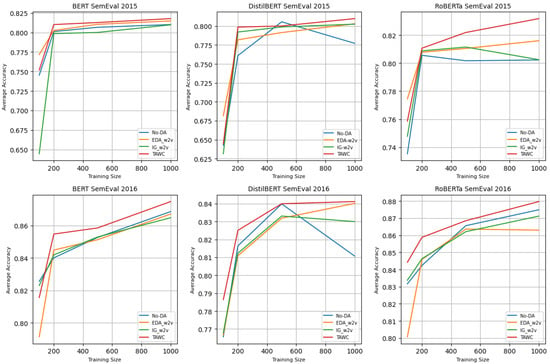
Figure 4.
Result of performance: average accuracy of data augmentation methods for small training size (n = 100, 200, 500, and 1000) for SemEval 2015 and SemEval 2016 datasets.
It was observed that TAWC consistently improved the low-data schemes, suggesting its robustness. The most distinct improvement occurred with the SemEval 2015 dataset under the scenario of 200 samples, where the DistilBERT average accuracy increased by nearly 4% compared with No-DA case. In contrast, for a training size of 100, EDA-w2v achieved excellent performance for all classifiers. Instinctively, most sentences in the training samples were short. Therefore, as a random-based replacement, EDA-w2v outperformed TAWC. Using the SemEval 2016 dataset, TAWC exceeded the average accuracy of the baselines in all scenarios. However, IG-w2v was slightly superior by less than 1% when applying BERT classification on 100 training sets. The highest TAWC attainment occurred within the scenarios of 200, 500, and 1000 training sizes for the two datasets with the three classification models. We, thus, found that TAWC can be applied to a small training size without compromising performance.
5.3. Effectiveness of Each Augmentation Operation
In the previous Section 3.3, we showed that TAWC comprises three operations: selective replacement, selective insertion, and selective deletion. The previous evaluation only implemented selective replacement compared with the baseline values. Therefore, we conducted experiments on a full-set training size for the three classification models to evaluate the effectiveness of each operation. The results are presented in Table 5.
Table 5.
Results of performance for each selective augmentation procedure.
The results indicate that the three operations are competitive for expanding the training set. The results demonstrate the improvement in the average accuracy of the sentiment classifiers compared to the No-DA case. On the SemEval 2015 dataset, SI outperforms the other methods in terms of average accuracy for the DistilBERT and RoBERTa models. However, selective replacement improves the performance of the BERT model. Furthermore, the SD procedure obtains the highest average accuracy on the SemEval 2016 dataset under the BERT model, and the remaining classifiers are uplifted by SI augmentation. This implies that SI is more reliable than SR and SD. Generally, our results are consistent with our previous study [12], which found that inserting words performs better than replacing words. We consider that inserting Meaningful and Reward words into the generated sentence helps to minimize noise for a certain dataset. Therefore, the model tends to generalize well. Furthermore, these outcomes have inspired us to investigate more deeply what conditions are suitable for applying each augmentation operation. Choosing words carefully for augmentation according to their attention to sentiment labels improves the sentiment classifiers.
5.4. Ablation Study
We designed the TAWC technique for selective augmentation, which is determined by using two metrics, (1) analytical correlation and (2) semantic similarity, to measure the relationship between a word and a sentiment polarity. In the ablation study, correlation and similarity measurements were applied separately to small training data to investigate which approach greatly influenced keyword extraction. We designed two types of TAWCs:
- TAWC-C: We only applied correlation to extract words in the sentence into two groups: high and low correlation.
- TAWC-S: We only used semantic similarity to separate words in the text into two types: high and low similarity.
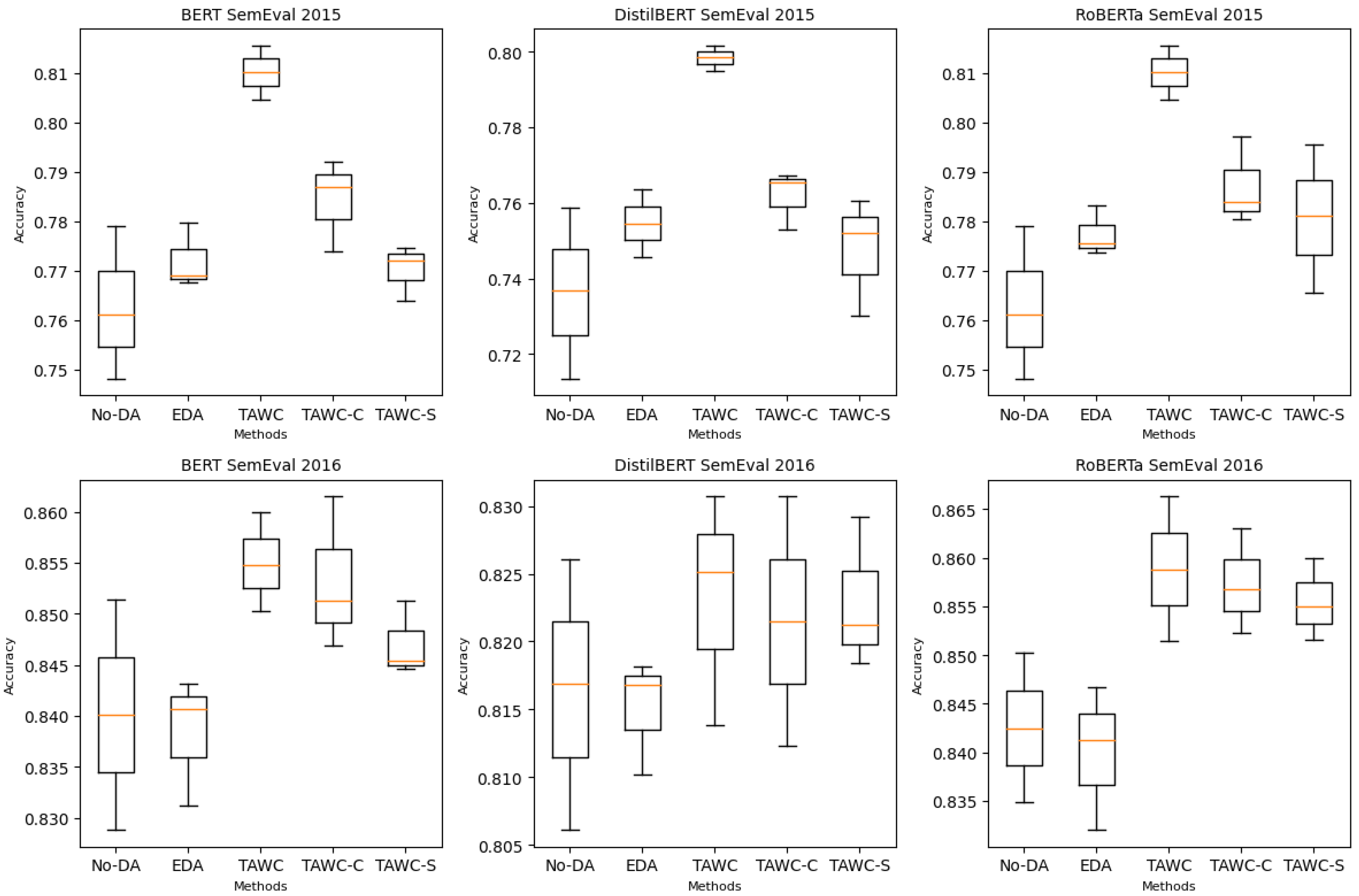
We ran experiments on 200 training sets with the balance class, while the test data remained unchanged. The experimental results are illustrated in Figure 5. Both TAWC-C and TAWC-S outperformed the training data without augmentation and EDA over the three classifiers on the two datasets, indicating selective words by correlation and semantic similarity function. In addition, each approach led to improvement, and the integration of the two approaches showed the best performance; thus, they were complementary.
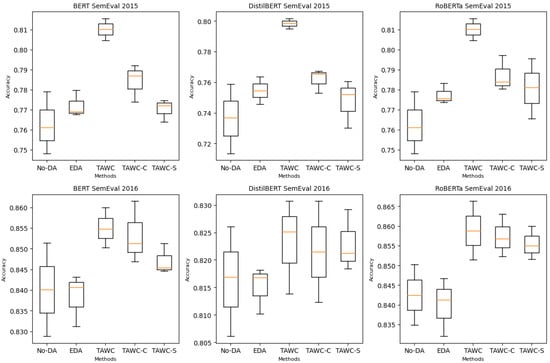
Figure 5.
Boxplot for evaluation of correlation and similarity metrics for TAWC compared to No-DA and EDA under 200 training sets from SemEval 2015 and SemEval 2016.
However, according to the boxplots, removing the analytical correlation or semantic similarity led to decreased accuracy. The TAWC-S score was worse than the TAWC-C score, suggesting that the statistical correlation factor is more crucial than semantic similarity for the TAWC procedure. This finding has inspired us to explore similarity measurements further in future works. However, compared to the original TAWC, the results obtained by TAWC-C and TAWC-S demonstrate that word selection is a promising method for text augmentation.
6. Conclusions
In this paper, we introduce a lightweight yet effective text augmentation using word contributions (TAWC) strategy for aspect-based sentiment classification tasks. The proposed method uses correlation and semantic similarity measurements to extract keywords that make high (low) contributions to sentiment polarity. We then selectively augment the sentence according to the word weights. In addition, we apply word2vec embedding as a synonym resource to capture rich semantic word representations. The proposed method balances classes and maintains semantics while introducing diversity to the training set. Comprehensive experiments on the two benchmark ABSA datasets demonstrate that the proposed TAWC obtains the generalization capability of the trained model. The results also verify the effectiveness of TAWC as a selective word augmentation method for small training sizes. In addition, selective insertion augmentation could provide better performance than selective replacement.
In addition, we use the same parameters and domain throughout the experiment. Thus, in future, we plan to consider fine-tuning the hyperparameters for different augmentation strategies and more domain variants. Moreover, to improve the clarity of our study, future research can assess the effectiveness of our proposed method by incorporating an attention module into the architecture of a classifier alongside BERT-based models. We are also interested in exploring another measurement to determine the word similarity of model embedding. In addition, motivated by [37,38], we will expand our experiment to investigate the performance of word contribution-based text augmentation in ABSA tasks in the context of different sentence lengths.
Author Contributions
Conceptualization, N.S.; methodology, N.S., and I.M.; software, N.S.; validation, N.S., I.M., and M.A.; formal analysis, M.A.; investigation, M.A.; resources, N.S.; data curation, N.S.; writing—original draft preparation, N.S.; writing—review and editing, N.S., I.M., and M.A.; visualization, N.S.; supervision, I.M., and M.A. All authors have read and agreed to the publication of the finale version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
In this study, we used two public datasets. SemEval 2015 was released by the published paper https://doi.org/10.18653/v1/S15-2082 at http://alt.qcri.org/semeval2015/task12/ [33], accessed on 20 August 2022. SemEval 2016 was released by the published paper https://doi.org/10.18653/v1/S16-1002 and is available at http://alt.qcri.org/semeval2016/task5/ [34], accessed on 20 August 2022.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, X.; Rao, Y.; Xie, H.; Wang, F.L.; Zhao, Y.; Yin, J. Sentiment Classification Using Negative and Intensive Sentiment Supplement Information. Data Sci. Eng. 2019, 4, 109–118. [Google Scholar] [CrossRef]
- Xu, L.; Wang, W. Improving aspect-based sentiment analysis with contrastive learning. Nat. Lang. Process. J. 2023, 3, 100009. [Google Scholar] [CrossRef]
- Wang, W.; Gan, Z.; Wang, W.; Shen, D.; Huang, J.; Ping, W.; Satheesh, S.; Carin, L. Topic Compositional Neural Language Model. arXiv 2017. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Xu, P.; Ji, X.; Li, M.; Lu, W. Small data machine learning in materials science. NPJ Comput. Mater. 2023, 9, 42. [Google Scholar] [CrossRef]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6382–6388. [Google Scholar] [CrossRef]
- Sugiyama, A.; Yoshinaga, N. Data augmentation using back-translation for context-aware neural machine translation. In Proceedings of the Fourth Workshop on Discourse in Machine Translation (DiscoMT 2019), Stroudsburg, PA, USA, 3 November 2019; pp. 35–44. [Google Scholar] [CrossRef]
- Kobayashi, S. Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 452–457. [Google Scholar] [CrossRef]
- Li, G.; Wang, H.; Ding, Y.; Zhou, K.; Yan, X. Data augmentation for aspect-based sentiment analysis. Int. J. Mach. Learn. Cyber. 2023, 14, 125–133. [Google Scholar] [CrossRef]
- Santoso, N.; Mendonça, I.; Aritsugi, M. Text Augmentation Based on Integrated Gradients Attribute Score for Aspect-based Sentiment Analysis. In Proceedings of the 2023 IEEE International Conference on Big Data and Smart Computing (BigComp), Kota Kinabalu, Malaysia, 13–16 February 2023; pp. 227–234. [Google Scholar] [CrossRef]
- Şenel, L.K.; Utlu, İ.; Yücesoy, V.; Koç, A.; Çukur, T. Semantic Structure and Interpretability of Word Embeddings. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1769–1779. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019. [Google Scholar] [CrossRef]
- Wu, X.; Lv, S.; Zang, L.; Han, J.; Hu, S. Conditional BERT Contextual Augmentation. In Proceedings of the Computational Science—ICCS 2019, Faro, Portugal, 12–14 June 2019; Rodrigues, J.M.F., Cardoso, P.J.S., Monteiro, J., Lam, R., Krzhizhanovskaya, V.V., Lees, M.H., Dongarra, J.J., Sloot, P.M., Eds.; Springer: Cham, Switezerland; pp. 84–95. [Google Scholar] [CrossRef]
- Liu, X.; Zhong, Y.; Wang, J.; Li, P. Data augmentation using Heuristic Masked Language Modeling. Int. J. Mach. Learn. Cybern. 2023, 14, 2591–2605. [Google Scholar] [CrossRef]
- Moreno-Barea, F.J.; Jerez, J.M.; Franco, L. Improving classification accuracy using data augmentation on small data sets. Expert Syst. Appl. 2020, 161, 113696. [Google Scholar] [CrossRef]
- Anaby-Tavor, A.; Carmeli, B.; Goldbraich, E.; Kantor, A.; Kour, G.; Shlomov, S.; Tepper, N.; Zwerdling, N. Not Enough Data? Deep Learning to the Rescue! arXiv 2019. [Google Scholar] [CrossRef]
- Kumar, V.; Choudhary, A.; Cho, E. Data Augmentation using Pre-trained Transformer Models. arXiv 2020. [Google Scholar] [CrossRef]
- Wang, W.Y.; Yang, D. That’s So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using petpeeve Tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 17–21 September 2015; pp. 2557–2563. [Google Scholar] [CrossRef]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, M.T.; Le, Q.V. Unsupervised Data Augmentation for Consistency Training. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6256–6268. [Google Scholar]
- Ahmed, H.; Traore, I.; Mamun, M.; Saad, S. Text augmentation using a graph-based approach and clonal selection algorithm. Mach. Learn. Appl. 2023, 11, 100452. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, R.; Luo, Z.; Hu, C.; Mao, Y. Adversarial word dilution as text data augmentation in low-resource regime. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; AAAI Press: Washington, DC, USA, 2023. AAAI’23/IAAI’23/EAAI’23. [Google Scholar] [CrossRef]
- Feng, Z.; Zhou, H.; Zhu, Z.; Mao, K. Tailored text augmentation for sentiment analysis. Expert Syst. Appl. 2022, 205, 117605. [Google Scholar] [CrossRef]
- Liesting, T.; Frasincar, F.; Truşcă, M.M. Data Augmentation in a Hybrid Approach for Aspect-Based Sentiment Analysis. In Proceedings of the 36th Annual ACM Symposium on Applied Computing, New York, NY, USA, 22–26 March 2021; SAC ’21. pp. 828–835. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Duong, H.T.; Nguyen-Thi, T.A. A review: Preprocessing techniques and data augmentation for sentiment analysis. Comput. Soc. Netw. 2021, 8, 1. [Google Scholar] [CrossRef]
- Fredriksen, V.; Jahren, B.; Gambäck, B. Utilizing Large Twitter Corpora to Create Sentiment Lexica. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; Calzolari, N., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Hasida, K., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., et al., Eds.; European Language Resources Association (ELRA): Miyazaki, Japan, 2018. [Google Scholar]
- Padmakumar, V.; He, H. Unsupervised Extractive Summarization using Pointwise Mutual Information. arXiv 2021. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. SemEval-2015 Task 12: Aspect Based Sentiment Analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, Colorado, 4–5 June 2015; pp. 486–495. [Google Scholar] [CrossRef]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. SemEval-2016 Task 5: Aspect Based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar] [CrossRef]
- Guo, B.; Han, S.; Huang, H. Selective Text Augmentation with Word Roles for Low-Resource Text Classification. arXiv 2022. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Fixing Weight Decay Regularization in Adam. arXiv 2017. [Google Scholar] [CrossRef]
- Ganguly, D. Learning variable-length representation of words. Pattern Recognit. 2020, 103, 107306. [Google Scholar] [CrossRef]
- Tang, C.; Ma, K.; Cui, B.; Ji, K.; Abraham, A. Long text feature extraction network with data augmentation. Appl. Intell. 2022, 52, 17652–17667. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).