Abstract
Since the emergence of ChatGPT, research on large language models (LLMs) has actively progressed across various fields. LLMs, pre-trained on vast text datasets, have exhibited exceptional abilities in understanding natural language and planning tasks. These abilities of LLMs are promising in robotics. In general, traditional supervised learning-based robot intelligence systems have a significant lack of adaptability to dynamically changing environments. However, LLMs help a robot intelligence system to improve its generalization ability in dynamic and complex real-world environments. Indeed, findings from ongoing robotics studies indicate that LLMs can significantly improve robots’ behavior planning and execution capabilities. Additionally, vision-language models (VLMs), trained on extensive visual and linguistic data for the vision question answering (VQA) problem, excel at integrating computer vision with natural language processing. VLMs can comprehend visual contexts and execute actions through natural language. They also provide descriptions of scenes in natural language. Several studies have explored the enhancement of robot intelligence using multimodal data, including object recognition and description by VLMs, along with the execution of language-driven commands integrated with visual information. This review paper thoroughly investigates how foundation models such as LLMs and VLMs have been employed to boost robot intelligence. For clarity, the research areas are categorized into five topics: reward design in reinforcement learning, low-level control, high-level planning, manipulation, and scene understanding. This review also summarizes studies that show how foundation models, such as the Eureka model for automating reward function design in reinforcement learning, RT-2 for integrating visual data, language, and robot actions in vision-language-action models, and AutoRT for generating feasible tasks and executing robot behavior policies via LLMs, have improved robot intelligence.
1. Introduction
To enhance the intelligence of robots in real-world environments that interact with humans, developing robots capable of perceiving, acting, and interacting like humans is a crucial goal. The recent advancements in large language models (LLMs) such as GPT-4o [1] have significantly altered the field of robotic AI research. These LLMs, trained on vast amounts of textual data, have shown excellent performance in enabling robots to communicate with humans more naturally and efficiently. Moreover, beyond the impacts on human–robot interaction (HRI), there is ongoing research aimed at surpassing the limitations of traditional low-level robot control techniques and planning algorithms by utilizing the high-level situational awareness and knowledge-based planning capabilities of LLMs. Notably, the programming capabilities of ChatGPT in the research presented by Microsoft’s ChatGPT for Robotics [2] have introduced a new paradigm for applying LLMs in the robotics field.
The goal of robot intelligence is to enable robots to operate autonomously in complex environments, interact naturally with humans, and make high-level decisions. To promote advancements in robot intelligence, the adoption of foundation models, such as LLMs and vision-language models (VLMs), which boast large parameter scales and pre-training on massive datasets, is accelerating. These foundation models can perform various tasks, such as complex language understanding and generation and visual perception, enabling robots to engage with their environment in a more human-like manner.
While traditional robot intelligence systems are highly effective in structured and predictable environments, they are significantly limited in their ability to adapt to dynamically changing and complex real-world scenarios. In general, the intelligence models used in these robotic systems are based on supervised learning, which requires large amounts of labeled data. This process is inherently resource-intensive. Moreover, these models are designed for a specific environment and require reconfiguration whenever the task or environment changes. This renders the robots challenging to adapt and scale to disparate environments [3]. For practical robot systems, it is essential that they are able to flexibly respond to the ever-changing physical environment. From this perspective, the generalization of affordable tasks, environmental adaptability, and the accuracy of execution, planning, and reasoning capabilities remain significant challenges for traditional robotic intelligence systems [4].
However, LLMs and VLMs help a robot intelligence system to enhance its generalization capability in dynamic and complex real-world environments. LLMs can leverage pre-trained knowledge from extensive datasets to augment their ability to generalize to everyday tasks that are typically expected of robots. Unlike the conventional supervised models, LLMs can utilize zero-shot and few-shot learning to help robots quickly adapt to new environments without additional training [5]. This has the advantage of significantly reducing the need for costly data collection and labeling. In addition, robot systems equipped with LLMs can process complex instructions based on their ability to understand and generate natural language, which can improve human–robot interactions. Furthermore, LLMs can be integrated with multimodal sensors such as LiDAR, depth, voice, tactile, proprioception, and visual information, which enables robots to comprehensively understand and adapt to their environment [6].
LLMs have demonstrated exceptional capabilities in processing and understanding text-based information, significantly enhancing robotic communication abilities. For instance, robots can accurately comprehend and execute natural language commands via LLMs, providing scalability and flexibility beyond traditional word-based robotic command systems. Consequently, robots can respond more adaptably and intelligently in interactions with human users, allowing them to engage in complex problem-solving and decision-making processes beyond simple mechanical tasks.
Additionally, LLMs not only enhance a robot’s communication skills to improve HRI usability but also boost the robot’s planning abilities. Planning involves setting goals and devising a sequence of actions to achieve them, which are essential in determining a robot’s autonomy and efficiency. LLMs interpret natural language from users and complex commands, enabling robots to establish and execute suitable plans in various situations. Moreover, LLMs adapt flexibly to new situations through a zero-shot approach and utilize past data for learning. These capabilities indicate that robots can play a vital role in autonomously navigating changing environments and resolving unexpected issues.
Moreover, VLMs such as CLIP [7], which are trained to solve vision question answering (VQA) tasks, have the ability to process visual and linguistic information simultaneously. This ability allows robots to visually perceive their surroundings and integrate this information into linguistic descriptions, enabling more sophisticated situational awareness. For instance, using VLMs, a robot can recognize objects and provide descriptions, as well as understand and execute user commands based on visual cues. This integrated approach significantly enhances a robot’s autonomy and interaction capabilities.
In practice, building on the capabilities of predecessors RT-1 [8] and RT-2 [9], which enable low-level actuator control using LLMs and VLMs, Google has introduced AutoRT [10]. AutoRT is a system where robots interact with real-world objects to collect motion data. It begins by exploring the surrounding space to identify feasible tasks, then uses a VLM to understand the situation and an LLM to propose possible tasks. By inputting the robot’s operational guidelines and safety constraints into the LLM as prompts, AutoRT assesses the validity of the proposed tasks and the necessity for human intervention. Throughout this process, AutoRT safely selects and executes feasible tasks while collecting relevant data.
Nvidia has also introduced Eureka (Evolution-driven Universal REward Kit for Agent) [11], a system that automatically designs reward functions for reinforcement learning problems using the capabilities of LLMs, which include understanding physical causality in the real world, problem-solving through trial-and-error feedback, and code generation abilities. Eureka can autonomously generate reward functions for a variety of tasks and robots without needing specific templates for each. This allows for the generation of human-level reward functions for diverse robots and tasks without human input. Furthermore, Eureka has demonstrated the ability to solve complex problems that were previously unsolved by expert-designed reward functions.
Given these research outcomes, integrating language models into robotic intelligence presents significant potential to enhance robot capabilities and applications dramatically, thereby redefining their roles in diverse industries and everyday life. Therefore, this survey paper explores recent research trends in LLM- and VLM-based robot intelligence, aiming to provide a comprehensive understanding of future development possibilities by examining the application of language models in various robotic research fields. It also seeks to highlight research cases, identify current limitations, and suggest future research directions.
To chronicle this advancement in robotics research fields, this review paper presents the following contributions:
- This paper summarizes and introduces the foundational elements and tuning methods of LLM architecture.
- It explores and arranges prompt techniques to enhance the problem-solving abilities of LLMs.
- It reviews and encapsulates how LLMs and VLMs have been employed to augment robot intelligence across five topics as shown in Figure 1: (1) reward design for reinforcement learning, (2) low-level control, (3) high-level planning, (4) manipulation, and (5) scene understanding.
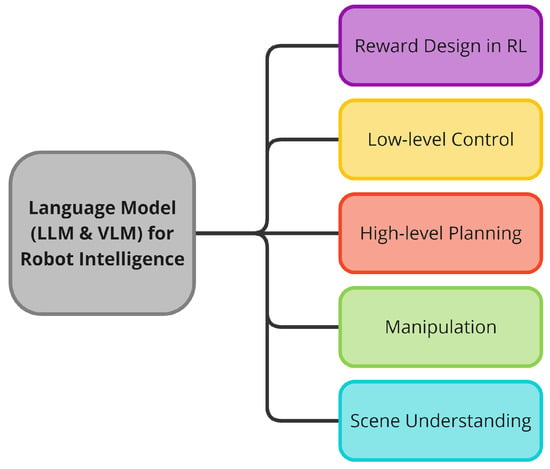 Figure 1. Five categories for robot intelligence with large language models in this study.
Figure 1. Five categories for robot intelligence with large language models in this study.
The reward design in RL category represents a research field in which an LLM develops and enhances reward functions employed in reinforcement learning via code-based descriptions and natural language input. This enables robots to learn optimal policies for specific tasks through reinforcement learning, even in complex environments. The low-level control category includes a research area in which LLMs and VLMs generate command sequences that directly control the robot’s actuators through natural language and visual input. The high-level planning category is a research area where the LLM identifies the present circumstances and objective of the tasks, subsequently developing an explainable plan based on the reasoning required for problem-solving. In this research area, the LLM is also tasked with developing the optimal robot behavior plan, which entails evaluating the feasibility of the established plan. In the manipulation category, the LLM interprets high-level instructions and the VLM (and LLM) analyzes various conditions based on their understanding of the surroundings to assist robot arms in performing the specific tasks. While this category can be broadly included in the high-level planning category, there are numerous studies that are specifically related to manipulation with a robot arm, which is why the manipulation category was separated. The scene understanding category represents a research area that seeks to combine LLMs and VLMs with the objective of assisting robots in comprehending their surrounding environment. This is accomplished by identifying objects based on natural language instructions and visual information, as well as by evaluating the relationships between them. This research area is also closely related to the field of autonomous visual navigation. From a boarder perspective, there is an overlap between the scene understanding category and the perception-related components of the high-level planning category. However, in this review, the scene understanding category was considered a distinct category due to its prevalence as an application of VLM models.
Table 1 lists resources that aid in understanding robot intelligence based on language models. The review [5] examined recent advancements in LLMs with a particular emphasis on four key areas: pre-training, adaptation tuning, utilization, and capacity evaluation. Furthermore, it provided a summary of the resources currently available for the development of LLMs and discussed potential future directions for research in this field. The survey [12] conducted a comprehensive and systematic review of VLMs for visual recognition tasks. It addressed the evolution of the visual recognition paradigm, the principal architectures and datasets, and the fundamental principles of VLMs. Moreover, the paper provided an overview of the pre-training, transfer learning, and knowledge distillation methods employed in the context of VLMs. The review [3] examined the potential for leveraging existing natural language processing and computer vision foundation models in robotics. In addition, it explored the possibility of developing a robot-specific foundation model. The review [13] presented an analysis of recent studies on language-based approaches to robotic manipulation. It comprised an analysis of learning paradigms integrated with foundation models related to manipulation tasks, including semantic information extraction, environment and evaluation, auxiliary tasks, task representation, safety issues, and other pertinent considerations. The survey paper [14] presented an analysis of recent research articles that employed foundation models to address robotics challenges. It investigated the extent to which foundation models enhanced robot performance in perception, decision-making, and control. In addition, it examined the obstacles impeding the implementation of foundation models in robot autonomy and proposed avenues for future advancements. The review paper [15] presented a comprehensive review of the research in the field of vision and language navigation (VLN), encompassing tasks, evaluation metrics, and methodologies related to autonomous navigation.

Table 1.
Useful Review Papers.
2. Review Protocol
This survey covered four databases: Web of Science, ScienceDirect, IEEE Xplore, and arXiv. In fact, many of the articles surveyed had not been peer-reviewed and published at the time of our search because the subject matter was relatively recent. Therefore, a considerable number of articles reviewed in this survey were sourced from the arXiv database.
The selection process of this study primarily relied on two iterations:
- The titles and abstracts of the articles were reviewed to eliminate duplicates and irrelevant articles.
- The full texts of the selected articles from the first iteration were thoroughly examined and categorized.
- Article searching began on 18 September 2023.
Regarding the search queries,
- the publication years were those after 2020,
- the keywords of Robotics and LLM, which were ((“Robotic” OR “Robotics”) AND (“LLM” OR “LM” OR “Large Language Model” OR “Language Model”)), and relevant journal and conference articles written in English were considered.
From these search criteria, recent studies utilizing language models in robotics research were expected to be collected. Our aim is to provide a robust understanding of how language models and their variants have been utilized to enhance robot intelligence in the literature.
All articles that met the above criteria were included in this review. Following an intensive survey of the abstracts of the selected articles, we categorized the research topics into five groups: reward design for reinforcement learning, low-level control, high-level planning, manipulation, and scene understanding. Figure 1 illustrates these five categories. Our categorization was based on a thorough review of the sources in the literature. Subsequently, duplicate articles were removed, and those not meeting the specified eligibility criteria were excluded. The exclusion criteria included: (1) articles in languages other than English and (2) articles discussing general concepts that do not focus on deep reinforcement learning-based manipulation.
3. Related Works
3.1. Language Model
Zhao’s LLM review paper [5] categorizes the evolution of Language Models (LMs) into four phases. The initial stage, the statistical language model (SLM) [16,17,18,19], utilizes methods based on statistical learning techniques and the Markov assumption to construct word prediction models. A notable method from this phase is the n-gram language model, which predicts words based on a fixed context length of n. Although SLMs have enhanced performance in various domains such as information retrieval (IR) [16,20] and natural language processing (NLP) [21,22,23], higher-order language models have encountered limitations due to the curse of dimensionality, which necessitates estimating exponentially increasing transition probabilities.
The subsequent phase of LMs, termed neural language models (NLMs), leveraged neural networks such as multi-layer perceptron (MLP) and recurrent neural networks (RNNs) to model the probability of word sequences [24,25,26]. A key element of this stage is the development of word vectors, also known as word embeddings, which form word prediction models based on vectors that use a distributed representation of words [24,27]. Word2vec, a simplified shallow neural network approach, was introduced to learn these distributed word representations [28,29]. It proved highly effective across various NLP tasks by calculating meaningful similarities between word vectors. NLMs progressed from basic word sequence modeling to sophisticated techniques for representing language through word2vec.
Following the NLM phase, the field advanced to pre-trained language models (PLMs), which encompass models such as ELMO [30] and BERT [31]. PLMs, utilizing large-scale text data, learn text patterns, structures, and meanings to develop pre-trained context-sensitive word representations. They have successfully executed a variety of language understanding and generation tasks using this acquired knowledge. ELMo [30] introduced a pre-training method employing bidirectional LSTM (biLSTM) networks for modeling deep contextualized word representations, optimizing performance through specific fine-tuning of the trained biLSTM network for downstream tasks. ELMo is also characterized as a bidirectional language model for its dual-directional use of language models.
Another PLM model, BERT [31], leverages the transformer architecture [32], exhibiting remarkable effectiveness with self-attention mechanisms and parallel processing. BERT, a pre-trained bidirectional language model, utilizes extensive unlabeled text data. The method of unsupervised learning-based pre-training in BERT comprises two primary tasks: masked language models and next sentence prediction. PLMs that provide pre-trained context-aware word representations are profoundly effective in general-purpose semantic feature extraction, facilitating enhancements in NLP task performance. Owing to these characteristics, numerous subsequent studies employing pre-training and fine-tuning have been introduced, featuring varied structures [33,34] (e.g., BART [33] and GPT-2 [35]) and enhancing pre-training strategies [36,37,38].
Based on subsequent studies, it has been found that increasing the model size or data size of PLMs typically enhances the performance of LM models [39]. This has prompted research into training large-scale PLMs, such as GPT-3 with 175B parameters and PaLM with 540B parameters. The focus of this research, grounded in scaling laws, primarily centers on augmenting model sizes and exploring the capabilities of larger models. These capabilities, known as the emergent abilities of LLMs, have sparked significant interest. For example, GPT-3 can address problems it has not been trained on with minimal examples through in-context learning, a feat GPT-2 finds challenging. Due to these characteristics, the academic community commonly designates these large PLMs as LLMs [40,41,42,43]. Consequently, research in this area is highly active. Notably, since the introduction of OpenAI’s ChatGPT, there has been a surge in the number of arXiv papers on LLMs. Following Microsoft’s announcement [2] about integrating ChatGPT into robotics, a variety of studies have explored the application of LLMs across different areas of robotics research. The available LLM models are presented in chronological order in Table 2. Additionally, Table 3 includes the VLM models.
Table 2.
Chronicle of LLM models.
Table 3.
Chronicle of VLM models.
3.2. LLM Architectures and Tunings
The architecture of LLMs fundamentally utilizes the transformer architecture, with three representative types based on different transformer configurations as shown in Figure 2. Firstly, the prevalent encoder–decoder structure of transformers employs the encoder to process the input sequence and generate a latent representation through multi-head self-attention layers; the decoder then uses cross-attention on this representation to autoregressively produce the target sequence. Notable encoder–decoder PLMs include T5 [47] and BART [33], with Flan-T5 [106] being an encoder–decoder-based LLM. Secondly, the causal decoder employs a unidirectional attention mask to restrict each input token to attend only to past and present tokens, processing input and output tokens similarly through the decoder. This method underpins the development of the GPT series. Lastly, the prefix decoder, resembling the causal decoder’s masking mechanism, allows bidirectional attention on prefix tokens [107] and unidirectional attention on generated tokens. Similar to the encoder–decoder, the prefix decoder bidirectionally encodes the prefix sequence and sequentially predicts output tokens individually. Examples of prefix decoder-based LLMs include GLM-130B [108] and U-PaLM [109]. Additionally, various architectures have been proposed to address efficiency challenges during training or inference with long inputs, due to the quadratic computational complexity of the traditional transformer architecture. For instance, the Mixture-of-Experts (MoE) scaling method [34] sparsely activates a subset of the neural network for each input.
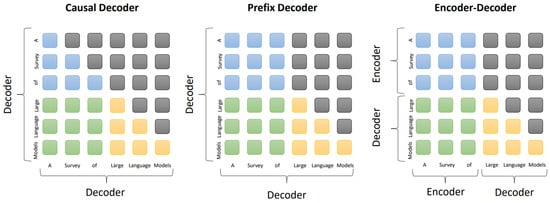
Figure 2.
Attention patterns in three mainstream architectures: Causal Decoder (left), Prefix Decoder (middle), and Encoder–Decoder (right). The blue, green, yellow, and grey rounded rectangles represent attention between prefix tokens, attention between prefix and target tokens, attention between target tokens, and masked attention [5].
In terms of the tuning of LLMs, these models are essentially pre-trained on massive datasets and require fine-tuning for different application domains. However, the considerable model size and number of parameters pose challenges for fine-tuning on standard computers and GPUs. The subsequent sections will discuss methods to address these challenges.
LLM tuning is broadly divided into two categories based on the training objective. Instruction tuning is a form of supervised learning where the training data typically include descriptions of tasks, inputs, and corresponding outputs. This type of tuning is designed (1) to enhance the functional capabilities of LLMs, (2) to specialize them by training with discipline-specific information, and (3) to improve task generalization and consistency through a better understanding of natural language commands. Conversely, alignment tuning (or preference alignment) seeks to align the behavior of LLMs with human values and preferences. Prominent methods include reinforcement learning from human feedback (RLHF) [110], which involves fine-tuning LLMs using human feedback to better reflect human values, and direct preference optimization (DPO) [111], focusing on training with pairs of human preferences that usually include an input prompt and the preferred and non-preferred responses.
For both instruction tuning and alignment tuning, which involve training LLMs with extensively large model parameters, substantial GPU memory and computational resources are required, with high costs typically incurred when utilizing cloud-based resources. Under these conditions, parameter-efficient fine-tuning (PEFT) offers a method designed to efficiently conduct fine-tuning of such LLMs [112].
Among the methods of PEFT, there are four major approaches as shown in Figure 3: adapter tuning, prompt tuning, prefix tuning, and low-rank adaptation (LoRA). Adapter tuning [113,114] involves integrating small neural network modules, known as adapters, into the core components of a transformer model, specifically into the attention and feed-forward layers. These adapters are inserted serially following these layers, allowing fine-tuning of only the adapter modules according to specific task goals, while the parameters of the original language model remain unchanged. Consequently, adapter tuning effectively reduces the number of trainable parameters. Additionally, prompt tuning [115,116] diverges from adapter tuning by adding trainable prompt vectors to the input layer. Prefix tuning [117] entails appending a sequence of prefixes to each transformer layer of the language model, which consists of trainable continuous vectors. During fine-tuning, the model focuses on identifying the optimal prefix vectors, which are retained for use in LLM model inference.
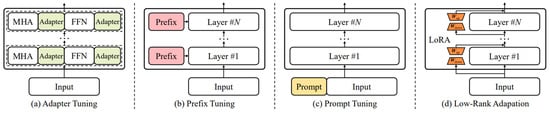
Figure 3.
An overview of four strategies for parameter-efficient fine-tuning: (a) Adapter Tuning, (b) Prefix Tuning, (c) Prompt Tuning, and (d) Low-Rank Adaptation [5].
In practice, a commonly employed method for LLM fine-tuning, LoRA [118], uses a low-rank constraint on transformer layers to approximate the update matrices through training. This method keeps the original LLM parameter matrices fixed and approximates the parameter updates using low-rank decomposition matrices. The primary benefit of LoRA is a substantial reduction in the memory and storage requirements for fine-tuning, such as VRAM. Additionally, quantization methods, which directly minimize the memory size required for parameter representation, are frequently utilized in LLM fine-tuning. Specifically, the practice of merging LoRA with quantization is known as QLoRA [119].
3.3. Prompt Techniques for Increasing LLM Performance
To enhance the performance of LLMs, the most straightforward approach involves training with additional data via fine-tuning techniques, which mirrors supervised learning in conventional machine learning. Another method for improving performance involves the use of in-context learning, which capitalizes on prompts for zero-shot learning, a capability first observed in LLMs with the advent of GPT-3. The adaptation of these prompts for specific tasks is known as prompt engineering. Fundamentally, prompt engineering (or prompting) entails supplying inputs to the model to perform a distinct task, designing the input format to encapsulate the task’s purpose and context, and generating the desired output. The four components of prompt engineering can be analyzed as follows: within the prompt, “Instructions” delineate the specific tasks or directives for the model and “Context” provides external or additional contextual information that can tune the model. Furthermore, “Input data” refers to the type of input or questions seeking answers, and “Output data” defines the output type or format within the prompt, thereby optimizing the LLM’s performance for particular tasks. Various methodologies for creating prompts have been introduced, as described below.
Zero-shot prompting [53] is a technique that allows the model to take on new tasks with no prior examples. The model relies solely on the task description or instructions without additional training. Likewise, few-shot prompting [49] introduces a small number of examples to aid the model in learning new tasks. This approach does not require extensive datasets and can improve the model’s performance through a limited set of examples.
Chain-of-thought (CoT) [41] is a technique that explicitly describes intermediate reasoning steps, enabling the model to perform step-by-step reasoning. This approach allows the model to incrementally solve complex tasks. For instance, when asked, “If someone’s age will be 30 in 5 years, how old are they now?”, the model uses the information “age in 5 years is 30” to perform the intermediate reasoning step of “30 − 5 = 25” to derive the final answer. Self-consistency [120] involves the model generating various independent reasoning paths through few-Shot CoT, ultimately selecting the most consistent answer among the outputs. This method enhances the performance of CoT prompts in both arithmetic and commonsense reasoning tasks. Multimodal CoT [121] is a two-stage framework that integrates text and visual modalities. Initially, intermediate reasoning steps are generated through rationale generation based on multimodal data. Subsequently, the answer inferences are intertwined, and the informative rationales are utilized to derive the final answer.
Generally, CoT relies on human-generated annotations, which may not always provide the optimal solution for problem-solving. To overcome this limitation, active prompt [122] has been proposed. Active prompt enhances model performance by intensively training the model on questions with higher uncertainty levels. It evaluates the uncertainty of answers by posing questions to the model, with or without CoT examples. Questions with high uncertainty are selected for human annotation, and newly annotated examples are used to reason through each question. Program-aided language models (PAL) [123] is a technique that employs the model to understand natural language problems and generate programs as intermediate reasoning steps. Unlike CoT, PAL solves problems stepwise using a program runtime such as Python rather than free-form text.
Tree of thoughts (ToT) [124] is a method whereby the model breaks down a problem into smaller units called thoughts, which it then assesses through a reasoning process to gauge its progress toward a solution. The ability of the model to generate and evaluate these thoughts is integrated with search algorithms such as breadth-first and depth-first search, facilitating systematic thought exploration with lookahead and backtracking capabilities. In contrast to the CoT method, which addresses problems sequentially, ToT concurrently examines multiple pathways to find a solution. Prompt chaining [125] is a strategy where the model divides a task into sub-tasks, uses the outputs of each sub-task as subsequent inputs, and links prompts in input–output pairs. This approach improves the precision and consistency of the outputs at each stage and simplifies the handling of complex tasks by subdividing them into manageable sub-tasks.
Generated knowledge prompting [126] is a technique in which the model incorporates knowledge and information pertinent to the question and provides it alongside the question to generate more accurate answers. This method not only enhances the commonsense reasoning capabilities but also retains the flexibility of existing models. Retrieval augmented generation (RAG) [127] merges external information retrieval with natural language generation. RAG can be fine-tuned for knowledge-intensive downstream tasks and enables straightforward modifications or additions of knowledge within the framework. This facilitates an increase in the model’s factual consistency, enhances the reliability of generated responses, and helps alleviate issues with hallucination. Automatic reasoning and tool-use (ART) [128] is a framework that utilizes external tools to autonomously generate intermediate reasoning steps. It chooses relevant tasks from a library that includes demonstrations and calls on external tools as necessary to integrate their outputs into the reasoning process. The model generalizes from demonstrations using tools to decompose new tasks and learns to use tools effectively. Enhancing ART’s performance is possible by modifying the task library or incorporating new tools. Automatic prompt engineer (APE) [129] is a framework designed for the automatic generation and selection of commands. The model generates command candidates for a problem and selects the most suitable one based on a scoring function, such as execution accuracy or log probability.
Directional stimulus prompting [130] is a technique that directs the model to consider and generate responses in a particular direction. By deploying a tunable policy LM (e.g., T5 [47]), it creates directional stimulus prompts for each input and uses these as cues to steer the model toward producing the desired outcomes [131]. ReAct combines reasoning with action within the model. It enables the model to perform reasoning in generating answers, take actions based on external sources (e.g., documents, articles, and news), and refine reasoning based on observations of these actions. This process facilitates the creation, maintenance, and modification of action plans while incorporating additional information from interactions with external sources. Reflexion [132] augments language-based agents with language feedback. Reflexion involves three models: the actor, the evaluator, and self-reflection. The actor initiates actions within a specific environment to generate task steps, the evaluator assesses these steps, and self-reflection provides linguistic feedback, which the actor uses to formulate new steps and achieve the task’s objective. The introduced prompt techniques are summarized in Table 4.
Table 4.
Prompt Techniques.
4. Language Models for Robotic Intelligence
4.1. Reward Design in Reinforcement Learning
Research in reinforcement learning, closely associated with the field of robotics, has actively incorporated studies using LLM models. Specifically, Nvidia has developed a GPU-based multi-environment reinforcement learning platform. Utilizing its Omniverse 3D virtual environment platform, Nvidia created Isaac Sim, which is dedicated to robot simulation. Isaac Sim published research findings on Isaac Gym (Preview), which achieved significant reductions in reinforcement learning training times through GPU-based multi-environment approaches. Subsequently, Isaac Gym (Preview)’s features were integrated into Isaac Sim and released as Omni Isaac Gym. Later, Nvidia introduced Orbit [133], facilitating the simulation of PhysX 5.1-based cloth, soft-body, fluid, and rigid-body dynamics, along with RGBD, LiDAR, and contact sensor simulation. Orbit also incorporates various robot platforms into the simulation environment. Recently, Orbit was updated to Isaac Lab and integrated into Isaac Sim 4.0. Nvidia has continuously advanced dynamic simulation environment technologies for reinforcement learning using GPU parallel computation. Leveraging this GPU reinforcement learning, they launched Eureka [11], which automates the design of reward functions for reinforcement learning using LLMs. Following this, Nvidia introduced DrEureka [134], an automated platform addressing the Sim2Real problem [135] in reinforcement learning based on Eureka.
Eureka (Evolution-driven Universal REward Kit for Agent) [11], shown in Figure 4, automatically generates reward functions for various tasks using different robots, eliminating the need for specific templates or tailored reward functions for the robot’s form or explanations for reinforcement learning tasks. Eureka consists of three main components: environment-as-context, evolutionary search, and reward reflection. Environment-as-context generates executable reward functions in a zero-shot manner by utilizing virtual environment source (Python) code as context. Evolutionary search iteratively generates reward function candidates and proposes enhanced functions based on previously generated and best-performing ones, while also creating new functions through mutation. Reward reflection offers a text summary of reward function quality based on training statistics recorded during reinforcement learning, which assists in generating subsequent reward functions as feedback for the performance of previous functions. The reward functions generated outperformed expert-generated functions in 83% of benchmark tests. Moreover, Eureka solved the pen spinning problem where a robot hand must spin a pen as much as possible according to predefined rotations, a task previously considered unsolvable through manual reward engineering. Eureka introduces a universal reward function design algorithm based on a code LLM and in-context evolutionary search, facilitating human-level reward generation for various robots and tasks without the need for prompt engineering or human intervention.
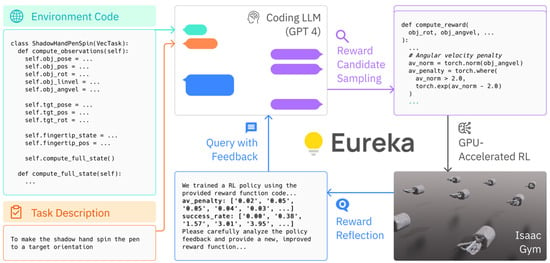
Figure 4.
Eureka leverages LLM to generate reward functions for robotic tasks and surpasses expert-designed functions through iterative improvements [11].
Following Eureka, DrEureka [134], shown in Figure 5, was developed to address the sim-to-real problem by automatically configuring appropriate reward functions and domain randomization for physical environments. DrEureka’s reward-aware physics priors mechanism defines the lower and upper bounds of physical environment parameters based on policies trained through initial reinforcement learning, facilitating reinforcement learning across various physical environment domains. This randomization enables the trained model to excel in actual environments. Consequently, DrEureka achieved benchmark success in real-world quadruped locomotion with walking globe and cube-rotation manipulation using real robots, all without human supervision.
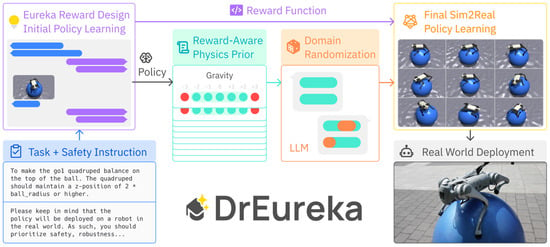
Figure 5.
DrEureka leverages LLM to design reward functions and solves the sim-to-real problem through its Reward-Aware Physics Priors mechanism and domain randomization [134].
Xie [136] introduced Text2Reward, a framework that automatically generated dense reward functions for reinforcement learning using LLMs. Provided with a goal expressed in natural language, Text2Reward produced executable dense reward functions derived from a compact representation of the environment. This framework generated free-form dense reward codes and delivered performance comparable to or surpassing that of policies trained with expert-designed codes across a variety of tasks, including 17 manipulator-related tasks and six novel locomotion behaviors. Additionally, Text2Reward incorporated user feedback to iteratively enhance the generated reward functions, thereby increasing the success rate of the learned policies.
Di Palo [137] explored the use of LLMs and VLMs to improve reinforcement learning agents’ understanding of human intentions. They developed a framework that utilized language as a primary inference tool, investigating how it could address key challenges in reinforcement learning, such as efficient exploration, data reuse in experience, skill scheduling, and observational learning. This framework employed LLMs and VLMs to address these reinforcement learning challenges by (1) efficiently exploring environments with sparse rewards, (2) reusing collected data to sequentially bootstrap the learning of new tasks, (3) scheduling learned skills for novel tasks, and (4) acquiring knowledge from observing expert agents.
Du [138] developed success detectors that identified whether actions or tasks were successfully completed, utilizing the large multimodal language model Flamingo and human reward annotations. The study on success detection spanned three distinct domains: (1) interactive language-conditioned agents in simulated households, (2) real-world robotic manipulation tasks (inserting and removing small, medium, and large gears), and (3) “in-the-wild” human egocentric videos. These success detectors adapted to new language instructions and visual changes using VLMs such as Flamingo, which were trained on a broad range of language and visual data. Furthermore, success detection was reframed as a VQA problem, enabling the tracking of task progress through multiple frames to ascertain whether tasks had been successfully completed. The proposed method proved to be more accurate in detecting success compared to custom reward models in the first two domains, even with new language instructions or visual changes. However, success detection in unseen real-world videos in the third domain posed a more challenging generalization task, underscoring the need for additional research.
Du [139] introduced the ELLM (exploring with LLMs) framework, which provided guidelines for pre-training reinforcement learning using LLMs. ELLM utilized the natural language processing capabilities of LLMs to define goals and furnish reward functions for reinforcement learning agents. This strategy enabled agents to undertake meaningful exploration and learning within their environments. The paper assessed ELLM’s performance in two settings: Crafter, a 2D version of Minecraft, and Housekeep, involving the task of rearranging household objects. Experimental results demonstrated that ELLM surpassed other methods in both settings. In the Crafter setting, ELLM attained high performance through goal-oriented learning, proving especially effective in scenarios with sparse reward signals. In the Housekeep setting, the agent conducted sensible exploration by adhering to goals set by the LLM, achieving a high success rate. While the accuracy of goal setting by the LLM varied with the objects and locations, it generally showed high performance. These experimental findings suggested that ELLM was successful in enhancing reinforcement learning performance across diverse environments, highlighting the vital role of providing reward signals based on human commonsense.
4.2. Low-Level Control
Research is also being conducted on generating commands that directly control a robot’s actuators (i.e., enabling low-level control) through various applications of LLM models. Among these projects, the Google research team developed RT-1 [8], which consists of film-conditioned EfficientNet-B3, TokenLearner, and Transformer. RT-1 is a model that receives images and natural language instructions at a rate of 3Hz and outputs discretized robot actions. RT-1 was trained on a vast demo dataset with over 130k episodes from more than 700 tests collected over 17 months using 13 robots.
A notable feature of RT-1 is its ability to enhance performance by learning from data gathered from heterogeneous robots or simulations. In the study [8], the authors evaluated the performance of a model trained exclusively on data from the EveryDay Robot (EDR) against a model trained using data from both EDR and Kuka IIWA robots. They recorded a 12% improvement in the bin-picking test. Another experiment compared model performance using data from real environments and simulations for items not encountered in actual settings. The findings indicated that incorporating simulation data in RT-1 training enhances performance over using purely real environment data, suggesting that RT-1 can substantially improve model performance by integrating diverse data from robots of varied morphologies or simulations while sustaining existing task capabilities.
RT-2 [9] is defined as a vision-language-action (VLA) model that facilitates fine-grained control of robots through vision and language commands. RT-2 is fine-tuned with robotic trajectory data based on VLM models such as PaLM-E [140], which has 12 billion parameters and is trained on VQA data, alongside PaLI-X [141], which has parameter sizes ranging from 5 billion to 55 billion. The RT-2 system operates as an integrated closed-loop robotic system that combines low-level and high-level control policies. Despite not explicitly learning certain capabilities during pre-training, RT-2 exhibits improved task performance via real-world generalization involving diverse objects, visual scenes, and instructional contexts. The paper [9] quantitatively assesses RT-2’s emergent capabilities in areas such as reasoning, symbol understanding, and human recognition. Furthermore, applying chain-of-thought prompting techniques to RT-2 has proven effective in solving more complex semantic inference tasks, such as using a rock as an improvised hammer or offering an energy drink instead of a carbonated beverage to a thirsty person. In comparison with the earlier study on RT-1, RT-2 demonstrates enhanced performance in both familiar and novel tasks.
AutoRT [10] is a follow-up study based on the research results of RT-1 and RT-2, establishing an orchestration of large-scale robotic agents for data collection in real-world scenarios. AutoRT employed 53 robots to gather 77,000 real robot episodes over seven months through both teleoperation and autonomous robot policies. At the heart of AutoRT is a robust foundation model that generates ‘task proposals’ based on given visual observations. Notably, AutoRT introduces a ‘Robot Constitution’ using constitutional prompting to ensure actions during the task proposal process do not compromise the safety of the robot or nearby individuals. This Robot Constitution, inspired by Asimov’s three laws [142], comprises basic rules, safety rules that identify unsafe or unwanted tasks, and embodiment rules that clarify the robot’s operational boundaries.
AutoRT enhances data collection by initially scanning the surroundings to identify interesting scenes or tasks (exploration). It interprets the given context through a VLM and proposes potential tasks via an LLM (task generation). Subsequently, tasks suggested by the LLM are screened (affordance) to assess their feasibility and the need for human intervention, employing the Robot Constitution. During this procedure, viable tasks are chosen and performed, while pertinent data are gathered (data collection). The collected data are then assessed for (diversity scoring) the visual diversity of the robot trajectories and the linguistic diversity of the language instructions generated by AutoRT (LLM). The aim of this diversity evaluation is to confirm that, unlike simulations, real-world data collection by robots is labor-intensive, making it essential to gather data across a broad spectrum of tasks. Experimental outcomes illustrate that AutoRT achieves higher visual and linguistic diversity compared to RT-1 or BC-Z [143].
Other researchers include Tang [144], who developed an approach that connects natural language user commands with a locomotion controller using foot contact patterns as an interface for low-level commands. This innovative interface translates human commands into the robot’s foot contact patterns, allowing the robot to move at a specified speed with precise timing for each foot’s contact with the ground. To achieve this, the robot used a cyclic sliding window to extract foot contact flags from a pattern template, thus generating the required foot contact patterns. During training, a random pattern generator created foot contact patterns, and during testing, an LLM translated human commands into these patterns. The robot then adjusted its movements based on the foot contact patterns it learned through deep reinforcement learning, closely adhering to the intended foot contact patterns and speed commands. This approach demonstrated a 50% higher success rate in task evaluation (across 30 tasks, including standing still) compared to two baselines (which employed discrete gaits and sinusoidal functions as interfaces), successfully solving 10 more tasks than the baselines.
Mandi [145] introduced a novel method for multi-robot collaboration that utilizes LLMs for both high-level communication and low-level path planning. In this method, the robots employ the LLM to discuss and reason about task strategies. They generate sub-task plans and task space waypoint paths, which a multi-arm motion planner then uses to expedite trajectory planning. Additionally, environmental feedback, such as collision detection, prompts the LLM agent to refine plans and waypoints contextually. This method achieved a high success rate across all tasks in the RoCoBench (including duties such as sweeping the floor), effectively adapting to variations in task semantics. In real-world experiments, specifically the block-sorting task, RoCo demonstrated its ability to communicate and collaborate with other robot agents to successfully complete the tasks.
Wang [146] proposed a novel paradigm for utilizing few-shot prompts in physical environments. This method involved gathering observation and action pairs from existing model-based or learning-based controllers to form the initial text prompts. Data included sensor readings, such as IMU and joint encoders, coupled with target joint positions. These data formed the starting input for LLM inference. As the robot interacted with its environment and collected new observational data, these initial data were updated with outputs from the LLM. In the subsequent prompt engineering phase, observation and action pairs, along with explanatory prompts, were crafted to enable the LLM to function as a feedback policy. The explanatory prompts provided clear descriptions of the robot walking task and control design details, while the observation and action prompts delineated the format and significance of each observation and action. This method allowed the LLM to directly output low-level target joint positions for robot walking. The approach was tested using the ANYmal robot in MuJoCo and Isaac Gym simulators for robot walking, indicating that the LLM could act as a low-level feedback controller for dynamic motion control within sophisticated robot systems.
Liang [147] introduced a new framework named Code as Policies (CaP) that directly constructs robot policies from executable code generated by a code LLM. This framework enabled the interpretation and execution of natural language instructions through an LLM, supporting the creation of high-level policies for robots and accommodating a variety of robotic tasks. Specifically, CaP interpreted natural language instructions through descriptions and formulated an action plan for the robot. Moreover, it utilized VLMs such as ViLD and MDETR to identify objects and ascertain their locations. Based on this information, the framework controlled the robot’s movements to carry out specified tasks. The paper demonstrated the CaP framework across diverse domains, including whiteboard drawing, tabletop manipulation, and mobile robot navigation and manipulation. Experimental results showed that CaP achieved similar or better success rates than existing systems such as CLIPort, displaying notably strong generalization capabilities for new tasks. These findings underscored the flexibility and efficacy of the CaP framework, establishing its effectiveness across various robotic systems.
Mirchandani [148], shown in Figure 6, suggested that pre-trained LLMs could autoregressively complete complex token sequences and function as general sequence modelers through in-context learning without needing additional training. Expanding on this concept, the study evaluated LLMs’ ability to operate as pattern machines in three domains: sequence transformation, sequence completion, and sequence improvement. In sequence transformation, the research demonstrated that LLMs could generalize specific sequence transformations using benchmarks such as ARC (abstraction and reasoning corpus) and PCFG (probabilistic context-free grammar), thereby proving their utility in spatial reasoning tasks for robotics. In sequence completion, the study examined whether LLMs could finish patterns in elementary functions (e.g., sinusoids), illustrating their utility in robotic tasks such as extending a wiping motion from kinesthetic demonstrations or creating drawings on a whiteboard. Finally, in sequence improvement, the research revealed that by utilizing reward-labeled trajectories as context and incorporating online interaction, LLM-based agents could explore small grids and refine simple trajectories using human-in-the-loop methods, such as optimizing a CartPole controller.
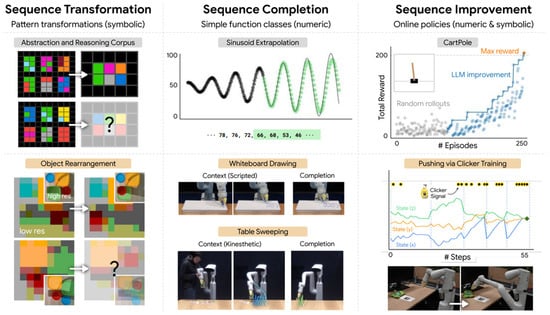
Figure 6.
Pre-trained LLMs can act as general sequence modelers, and their abilities were assessed in sequence transformation, completion, and improvement [148].
4.3. High-Level Planning (Including Decision-Making and Reasoning)
The abstraction and generalization capabilities of LLMs offer effective methodologies for high-level planning tasks in robotic systems. Leveraging these capabilities, various research outcomes have been realized in the fields of planning, decision-making, reasoning, and behavior trees within robotics.
Yoneda [149] introduced Statler, a framework designed to provide LLMs with an explicit world state representation through a continuously maintained ‘memory’. The core of Statler consisted of two components: the world model reader and the world model writer. These components interacted with and sustained the world state. The world model reader interpreted user commands and generated executable code based on the current state representation, while the world model writer updated the system’s state according to execution outcomes. By facilitating access to the world state ‘memory’, Statler improved LLMs’ ability to reason about planning tasks with extended time horizons, overcoming limitations imposed by context length.
Mu [150], shown in Figure 7, introduced EmbodiedGPT, a model specifically designed for Embodied AI, which leverages LLMs. This framework processes visual observations and natural language to establish long-term plans and execute tasks in real-time. EmbodiedGPT utilizes pre-trained vision transformers and the LLaMA language model to encode visual features and map them to the language modality. The generated plan was subsequently converted into specific task commands using general visual tokens, encoded by the vision model. The framework’s functionality comprises (1) encoding current visual features, (2) mapping visual features to the language modality via attention-based interactions between visual tokens and text queries or learnable embedded queries, (3) generating plans with the LLaMA language model and translating them into specific task commands, and (4) querying the encoded visual tokens from the vision model and translating them into low-level control commands through a downstream policy network for task execution. Experimental results, utilizing the MS-COCO dataset, revealed that EmbodiedGPT excels in object recognition and understanding spatial relationships. Notably, implementing a closed-loop design and a “chain-of-thought” training mode significantly enhanced EmbodiedGPT’s performance. These results demonstrate that EmbodiedGPT effectively handles various autonomous tasks, exhibiting superior capability in object recognition, understanding spatial relationships, and generating logical, executable plans.
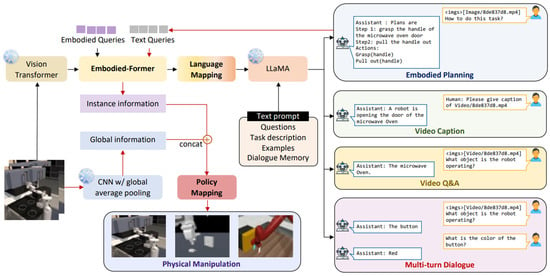
Figure 7.
After encoding visual features, they are mapped using visual tokens and text queries. A plan is then created with the LLaMA model and turned into task commands. The visual tokens are queried and converted into low-level control commands to perform the task [150].
Chen [151] introduced the language-model-based commonsense reasoning (LMCR) framework to assist robots in comprehending incomplete natural language instructions. This framework enabled robots to receive instructions in natural language from humans, observe their surroundings, and employ a commonsense reasoning method to autonomously infer missing information. LMCR utilized a model of commonsense reasoning learned from web-based text materials, allowing robots to understand incomplete instructions and autonomously execute tasks. The framework comprised three main functions: language understanding, commonsense reasoning, and action planning. In language understanding, LMCR translated human natural language instructions into a form interpretable by robots, parsing them into verb frames to convert them into executable structures. During the commonsense reasoning phase, the robot analyzed surrounding objects and employed a language model trained on large-scale unstructured text materials to fill in the missing details from the instructions. This model identified the most suitable verb frame to complete the gaps. Subsequently, based on the completed verb frame, the robot formulated its actions using predefined action plans for each verb to guide the movements of the robot arm and execute the assignment. Experimental results showed that LMCR demonstrated superior generalization performance for novel concepts not presented in the training set and surpassed GCNGrasp, which depends on a predefined graph structure for all concepts and their relationships. This indicated that LMCR was an effective tool, combining the semantic reasoning capabilities of language models with planning that adapted to the robot’s specific environment and context, effectively managing complex and prolonged tasks.
Huang [152] introduced a methodology named grounded decoding (GD), which offers a method for generating LLM-based robot action plans. These plans enable robots to execute long-term tasks across diverse physical environments. The methodology encompasses two primary elements: linking the text generated by the language model to actionable task commands in the physical world via GD and adjusting the tokens generated by the LLM to real-world conditions to formulate feasible commands. This approach synergizes the high-level semantic reasoning of LLMs with plans that are aligned with the robot’s physical environment and capabilities, thus facilitating the execution of complex and long-term tasks. The method addresses several limitations robots face in performing complex, long-term tasks, such as a lack of physical world experience, an inability to process non-verbal cues, and a disregard for necessary robotic constraints such as safety and rewards. The paper details experiments in a simulated tabletop rearrangement, a mini-grid 2D maze, and real-world kitchen mobile manipulation settings to evaluate long-horizon reasoning performance. Comparative experiments with SayCan revealed that while SayCan limits the range of robot actions, GD can represent a wider array of actions. In contrast to CLIPort, which executes high-level language instructions directly, GD achieves enhanced performance through detailed, step-by-step planning.
Huang [153], as shown in Figure 8, proposed the inner monologue method, which allowed LLMs to plan and adjust based on feedback from the environment. This approach enabled robots to formulate plans in dynamic environments, retry upon facing failure, or seek human feedback to refine their strategies. The author clarified that this method emerged from integrating the LLM’s high-level planning capabilities with perceptual feedback and low-level control, thereby facilitating more adaptable and intelligent interactions. Inner monologue integrated various feedback sources into the language model to assist the robot in executing given instructions, including text-based indicators of the robot’s action success or failure, object recognition and descriptions within the scene, the robot’s ability to ask questions to gather additional information, breaking down instructions into multiple steps to establish an execution plan, and enabling the robot to interact with humans to execute and refine the instructions. The inner monologue method was evaluated in both simulated and real-world environments, such as tabletop rearrangement tasks and manipulation tasks in a real kitchen. The results showed that inner monologue was an effective framework, enabling robots to act intelligently in complex interactive settings by effectively integrating environmental feedback to plan and execute tasks.
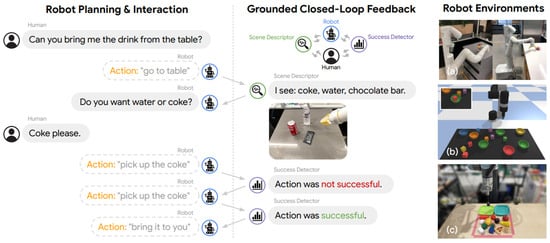
Figure 8.
Inner Monologue integrates various feedback sources into the language model to enable robots to carry out instructions: (a) mobile manipulation and (b,c) tabletop manipulation, in both simulated and real-world environments [153].
Lykov [154] introduced a novel approach to autonomous robot control named LLM-BRAIn, which facilitated the command-based generation of robot behaviors. LLM-BRAIn, a transformer-based LLM, fine-tuned the Stanford Alpaca 7B model to generate robot behavior trees (BTs) from textual descriptions. The developed model was compact enough to operate on a robot’s onboard microcomputer, while adept at constructing complex robot behaviors. It provided structurally and logically correct BTs and demonstrated the ability to handle instructions that were not included in the training set.
Song [155], as shown in Figure 9, proposed LLM-Planner, a system designed for few-shot planning in embodied agents. LLM-Planner processed natural language instructions to generate high-level plans, selected subgoals from these plans, and identified actions via a low-level planner. It continuously updated environmental information as new objects were detected during action implementation and revisited the LLM to adjust the plan if subgoals failed or were delayed based on updated observations. This iterative process was repeated until the subgoal was achieved, after which the system moved to the next goal. Compared to traditional models such as HLSM and FILM, LLM-Planner demonstrated competitive performance with significantly reduced training data and proved its ability to generalize in various tasks (e.g., ALFRED) with minimal examples.
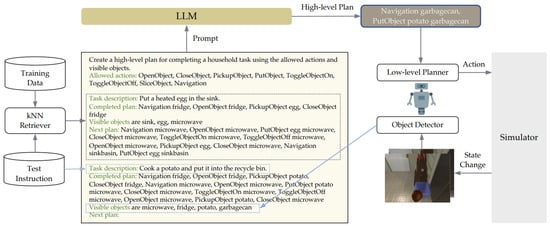
Figure 9.
LLM-Planner is a system that creates high-level plans based on natural language commands, sets subgoals to determine actions, and continuously updates the plan to reflect environmental changes [155].
Singh [156], as shown in Figure 10, introduced ProgPrompt, a programmatic LLM prompt structure designed for generating plans across diverse situated environments, robot capabilities, and tasks. ProgPrompt functioned as a robot task-planning system that leveraged LLMs and included a Python programming structure to facilitate information about the environment and executable actions. It featured a feedback mechanism, using executable program plan examples and assertion statements to mitigate errors, enhancing task success rates. Additionally, ProgPrompt verified the current state through environmental feedback during plan execution and revised the plan accordingly. The results indicated that the integration of programming language features substantially improved task performance in contexts such as VirtualHome and real-world manipulation tasks in terms of success rate, goal conditions recall, and executability.
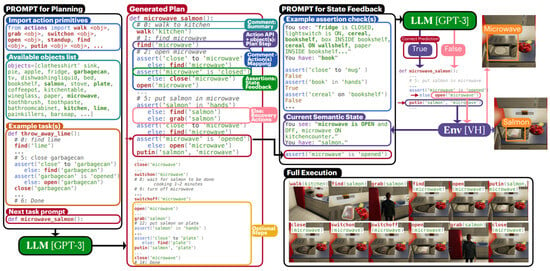
Figure 10.
ProgPrompt is a system that uses Python programming structures to provide environmental information and actions, enhancing the success rate of robot task planning through an error recovery feedback mechanism and environmental state feedback [156].
Rana [157] introduced SayPlan, a scalable method for large-scale task planning using LLMs and based on a 3D Scene Graph (3DSG) representation. SayPlan involved the LLM searching a collapsed 3D scene graph and task instructions to identify all relevant items and then locating the subgraph that contained the necessary items to complete the task. The identified subgraph was subsequently used by the LLM to generate a high-level plan that addressed the navigational aspect of the task. This plan was formatted as a JSON 3D scene graph and subjected to a repetitive replanning process through feedback from the scene graph simulator and a set of API calls for manipulation and operation until an executable plan was determined. SayPlan was tested in two large-scale environments, featuring up to three floors, 36 rooms, and 140 assets and objects, proving its capability to ground large-scale and long-horizon task plans from abstract and natural language instructions, thereby enabling a mobile manipulator robot to execute these tasks.
Zeng [158], as shown in Figure 11, proposed the Socratic model (SM), a modular framework that synergistically utilizes various forms of knowledge and employs multiple pre-trained models to exchange information and leverage new multimodal capabilities. SM operates without fine-tuning by integrating diverse pre-trained models and functions in a zero-shot approach (e.g., using multimodal prompts), which enables it to harness new multimodal capabilities. SM demonstrated state-of-the-art performance in zero-shot image captioning and video-to-text retrieval, and it effectively answered free-form questions about egocentric video. Additionally, it supported interactions with external APIs and databases (e.g., web search) for multimodal assistive dialogue, robot perception, and planning, among other novel applications.
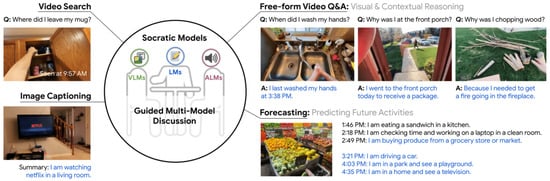
Figure 11.
SM integrates various types of knowledge by using multiple pre-trained models and provides meaningful results even in complex computer vision tasks such as image captioning, context inference, and activity prediction [158].
Lin [159] introduced Text2Motion, a language-based framework designed to handle sequential manipulation tasks that require long-horizon reasoning. Text2Motion interpreted natural language instructions to formulate task plans and generated multiple candidate skill sequences, evaluating the geometric feasibility of each sequence. By employing a greedy search strategy, it selected the optimal skill sequence to verify and execute the final plan. This method enabled Text2Motion to perform complex sequential manipulation tasks with a higher success rate compared to existing language-based planning methods, such as Saycan-gs and Innermono-gs, and provided semantically generalized characteristics among skills with geometric relationships.
Wu [160] investigated personalization in-home cleaning robots that organize and tidy spaces, using an LLM to convert user-provided object placement locations into generalized rules. By using a camera to identify objects and CLIP to categorize them, TidyBot efficiently relocated objects according to these rules. This method attained an impressive accuracy of 91.2% for unseen objects in a benchmark dataset, which encompassed a variety of objects, receptacles, and example placements of both “seen” and “unseen” objects across 96 scenarios. Additionally, it achieved an 85% success rate in removing objects during real-world tests.
4.4. Manipulation by LLMs
In robotics research, the manipulation domain, which includes robotic arms and end effectors, encompasses various areas that benefit from foundation models such as LLMs for language-based interactions and VLMs for object handling. Among the studies integrating manipulation with foundation models, Stone [161] introduced an approach called manipulation of open-world objects (MOO). This approach determined whether a robot could follow instructions involving unseen object categories by linking pre-trained models to robotic policies. MOO utilized pre-trained vision-language models to derive object information from language commands and images, guiding the robot’s actions based on the current image, command, and identified object data. Experimental use of real mobile manipulation robots showed that MOO could adapt to new object types and environments in a zero-shot fashion. Moreover, MOO responded to non-verbal cues such as pointing at specific objects, extending its scope to open-world exploration and manipulation.
Existing VLMs often lack a comprehensive understanding of physical concepts such as material and fragility, which limits their effectiveness in robotic manipulation tasks. To address this issue, Gao [162] introduced PhysObjects, an object-centric dataset featuring 39.6K crowd-sourced annotations and 417K automated annotations of physical concepts. The automated annotations involved assigning specific concept values to predefined object categories or continuous concepts such as material and fragility. Fine-tuning a VLM on PhysObjects enhanced comprehension of physical concepts by capturing human biases related to the visual appearance of objects. Integrating this physically grounded VLM with an LLM-based robotic planner framework improved performance in tasks requiring reasoning about physical concepts.
The traditional pre-training and fine-tuning pipeline often suffers from decreased learning efficiency and challenges in generalizing to unseen objects and tasks due to its reliance on domain-specific action information and domain-general visual information. To address these limitations, Wang [163] proposed a modular approach named ProgramPort, which utilizes the syntactic and semantic structure of language instructions. Wang’s framework incorporated a semantic parser to reconstruct executable programs, composed of functional modules based on vision and action across multiple modalities. Each functional module combined deterministic computation with learnable neural networks. Program execution involved generating parameters for general manipulation primitives used by the robot’s end effector. The entire module network was trainable with an end-to-end imitation learning objective. Experimental results demonstrated that the model effectively separated action and perception, achieving enhanced zero-shot and compositional generalization across various manipulation tasks, specifically 16 tasks related to robot manipulation.
Ha [164] proposed a framework aimed at robot skill acquisition. This framework provided a comprehensive solution by utilizing language guidance, without necessitating expert demonstrations or reward specification/engineering. It consisted of two main components. The first component, scaling up language-guided data generation, employed LLMs to break down tasks into subtasks and generate a hierarchical plan or task tree. This plan was materialized into various robot trajectories using 6-DoF exploration primitives. These trajectories were subsequently verified and retries were performed as needed until success was achieved. This approach enhanced the success rate of data collection and more effectively mitigated the low-level understanding gap in LLMs by incorporating retry processes as part of the robot’s experiences. The second component, distilling down to language-conditioned visuomotor policy, transformed robot experiences into a policy that deduced control sequences from visual observations and natural language task descriptions. By extending diffusion policies, this component handled language-based conditioning for multi-task learning. To assess long-horizon behavior, commonsense reasoning, tool use, and intuitive physics, a new multi-task benchmark comprising 18 tasks related to robot manipulation across five domains (mailbox, transport, drawer, catapult, and bus balance) was developed. This benchmark effectively supported the learning of retry behaviors in the data collection process and enhanced success rates.
Huang [165], as shown in Figure 12, aimed to synthesize dense robot trajectories, including 6-DoF end-effector waypoints, for various manipulation tasks using an open set of instructions and objects. Huang noted that LLMs were skilled at deriving affordances and constraints from free-form language instructions. Further, by harnessing code generation capabilities, Huang developed 3D value maps for the agent’s observation space through interactions with VLMs. These 3D value maps were integrated into a model-based planning framework to generate closed-loop robot trajectories robust to dynamic perturbations in a zero-shot approach. The proposed framework demonstrated efficient learning of the dynamics model for scenes with contact-rich interactions and provided advantages in these complex scenarios.
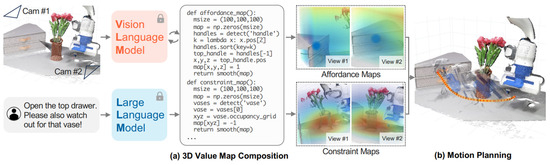
Figure 12.
Based on language instructions and RGB-D data, the LLM interacts with the VLM to generate 3D affordance and constraint maps and design robot trajectories without additional training [165].
Ahn [166] introduced a framework named SayCan, which integrates LLMs with reinforcement learning value functions, enabling robots to follow high-level text instructions. SayCan comprises two primary components: Say, which uses an LLM for task-based decision-making, and Can, which evaluates the feasibility of these decisions via reinforcement learning. Say leverages task-based knowledge from the LLM and reinforcement learning functionality to assess the feasibility of task execution by robots in real-world scenarios. The LLM determines the actions necessary to achieve high-level goals and evaluates the effectiveness of each action in fulfilling the instructions. Learned through reinforcement learning, the affordance function estimates each action’s success probability in the current state, confirming the executability of actions proposed by the LLM. This process allows the LLM to assess the robot’s current state and capabilities, ultimately generating an interpretable action plan. SayCan was evaluated across 101 robot tasks, achieving an 84% plan success rate and a 74% execution success rate in a simulated kitchen environment. In a real kitchen setting, the plan success rate decreased slightly to 81% and the execution success rate fell to 60%, demonstrating that the policy and value functions generalize well to real-world settings.
Huang [167] introduced the Instruct2Act framework, which employs LLMs to sequentially map multi-modality instructions to robot actions. The previous method, CaP, generated robot policy program code directly from in-context examples based on language instructions. However, this approach was constrained by the capabilities of the generated code and encountered difficulties with longer, more complex commands due to the required high precision of code. To overcome these limitations, Instruct2Act introduced a novel strategy that used multi-modality models and LLMs to simultaneously address recognition, task planning, and low-level control modules. Instruct2Act utilized the segment anything model for identifying potential objects in input images for multi-modality recognition and the CLIP model for object classification. As a result, Instruct2Act developed an integrated search system capable of managing various input modalities and instruction types, including both pure language instructions and combined language-visual instructions, facilitating the integration of diverse instruction types into a unified architecture. Moreover, for pointer-language instructions, the framework supported task segmentation based on the user’s clicks.
4.5. Scene Understanding in LLMs and VLMs
To address the VQA problem, robotics research increasingly uses pre-trained VLMs to derive high-level information from visual data. This method is advantageous for scene understanding as it helps determine affordances that describe the relationship between the current state and the next action based on images from cameras. Related studies focus on aspects of scene understanding.
Chen [168] explored methods to integrate commonsense into scene understanding using LLMs and introduced three paradigms for classifying room types within indoor environments based on included objects. The zero-shot approach utilized a pre-trained language model to identify the objects in a room and estimate their types. The feed-forward classifier approach involved inputting sentences that listed a room’s objects into the language model to generate embedding vectors, which were subsequently input into a pre-trained shallow multilayer perceptron to predict each room type. Lastly, the classifier approach embedded images of rooms alongside textual descriptions to identify the best-matching description, thereby determining the room type. These paradigms demonstrated the capacity to generalize to objects not presented in the training set and to make inferences within a space larger than that defined by the trained object labels.
Yang [169] introduced the innovative zero-shot, open-vocabulary, LLM-based 3D visual grounding pipeline called LLM-Grounder. This method breaks down complex natural language queries into semantic components and uses visual grounding tools such as OpenScene or LERF to locate objects within 3D scenes. Subsequently, the LLM evaluates spatial and commonsense relationships among these objects to achieve the final grounding. Remarkably, LLM-Grounder operates without labeled training data and has proven its capacity to adapt to new 3D scenes and diverse text queries, enhancing grounding capabilities for complex language queries and establishing itself as an effective solution.
Chen [170] developed NLMap, an open-vocabulary, queryable scene representation system. Designed to accumulate and incorporate contextual data within a scene representation for natural language queries, this system allows an LLM planner to visualize and query objects, thereby generating contextual plans. Initially, a VLM sets up a scene representation for natural language queries; then, an LLM-based object suggestion module reviews instructions, suggests relevant objects, and queries the scene for object availability and location. Using this information, the LLM planner devises plans uniquely tailored to the scene’s context. NLMap equips robots with the ability to function without a predefined catalog of objects or actions, overcoming the constraints of earlier methods and enabling more adaptable operations in environments with novel or absent objects.
Elhafsi [171] introduced a monitoring framework that employed an LLM with superior contextual understanding and reasoning capabilities to detect edge cases and anomalies within vision-based policies. This framework monitored the robot’s perception stream through an LLM-based module, designed to detect semantic anomalies that might occur during operations. By converting the robot’s visual observations into textual descriptions at regular intervals and integrating these into LLM prompts, it could pinpoint factors leading to policy errors, unsafe behavior, or task confusion. The conversion of visual information into natural language descriptions used various techniques, without restriction to any specific method. This flexibility enabled both fully end-to-end policies and classical autonomy stacks using learned perception to align more closely with human intuition. The findings indicated that semantic anomalies did not always correspond to semantically explainable failures, and end-to-end policies could sometimes behave unpredictably.
Hon [172] introduced a new model family named 3D-LLM, which incorporated 3D world information into LLMs. The 3D-LLM model utilized 3D point clouds and their features as input, enabling it to handle a variety of spatially aware 3D tasks. These tasks included 3D captioning, dense captioning, 3D question answering, task decomposition, 3D grounding, 3D-assisted dialogue, and navigation. The model used a 3D feature extractor to align 3D features from multi-view images with language features, facilitating more precise text generation and question answering based on spatial understanding. To train 3D-LLM, a pre-trained 2D VLM formed the backbone, enhanced by the addition of 3D positional embeddings to better capture 3D spatial information. The model generated location tokens through linguistic descriptions of specific objects and was trained using 3D features as input. Experimental results showed that 3D-LLM excelled in various 3D-related tasks, achieving approximately a 9% higher BLEU-1 score compared to previous models on the ScanQA dataset. It demonstrated superior performance in 3D captioning, task composition, and 3D-assisted dialogue, outperforming 2D VLMs and displaying an improved understanding of object locations, shapes, and interactions.
In the extension of scene understanding using VLMs, the keyword VLN (vision-and-language navigation) is widely used in navigation-related research, where language foundation models are increasingly utilized.
Shah [173], as shown in Figure 13, introduced a robotic navigation system named LM-Nav, which capitalized on the advantages of training with large, unlabeled trajectory datasets while providing a high-level interface for users. LM-Nav utilized three large-scale pre-trained models: ViNG, CLIP, and GPT-3. Initially, the LLM translated natural language instructions into a sequence of textual landmarks. The VLM integrated these textual landmarks with images to identify the relevant images through probabilistic distribution. Subsequently, the VNM utilized these landmarks to plan and execute robot trajectories within the environment. During this process, the robot utilized a graph search algorithm to determine optimal trajectories and to navigate along these paths in the real world. This method demonstrated LM-Nav’s ability to perform long-horizon navigation in complex outdoor environments using natural language instructions.
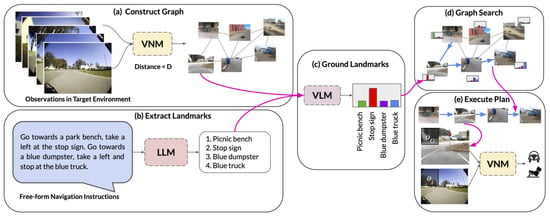
Figure 13.
LM-Nav uses three pre-trained models: (a) VNM builds a topological graph from observations, (b) LLM converts instructions into landmarks, (c) VLM matches landmarks to images, (d) A graph search algorithm then finds the best robot trajectory, and (e) the robot executes the planned path [173].
Zhou [174] introduced NavGPT, an LLM-based navigation agent designed to follow instructions. NavGPT is a vision-language navigation system that employs an LLM to translate visual inputs from a visual foundation model (VFM) into natural language. The LLM then interprets the current state and makes informed decisions to reach the intended goal, based on these converted visuals, navigation history, and potential future routes. NavGPT conducts various functions, including high-level planning, decomposing instructions into sub-goals, identifying landmarks in observed scenes, monitoring navigation progress, and modifying plans as necessary. Although NavGPT’s performance on zero-shot tasks from the R2R dataset has not yet matched that of trained models, it underscored the potential of utilizing multi-modality inputs with LLMs for visual navigation and tapping into the explicit reasoning capabilities of LLMs to enhance learned models.
Huang [175] introduced VLMaps, a spatial map representation that integrates pre-trained vision-language features with a 3D reconstruction of the physical world. VLMaps, when combined with an LLM, translate spatially organized sequences of open-vocabulary navigation goals (e.g., “between the sofa and the TV”) into natural language commands. These commands can be directly localized on a map and generate new obstacle maps in real-time, facilitated by sharing among various robot types. Extensive experiments conducted in both simulated environments (using the Habitat simulator with the Matterport3D dataset and the AI2THOR simulator) and real-world settings (with the HSR mobile robot for indoor navigation) demonstrated that VLMs can navigate based on more complex language instructions than previous methods. The reviewed papers in this study are summarized in Table 5.
Table 5.
Summary of the reviewed papers in this study.
5. Discussion and Future Directions
The review revealed two potentials of foundation models: (1) commonsense reasoning for planning and (2) the ability to generate code.
The first finding from this review study is the potential to enhance robot intelligence through foundation models. Beyond the studies mentioned here, numerous recent studies have shown that pre-trained models such as LLMs and VLMs can enhance various aspects of robot intelligence, such as situational awareness, high-level task planning, and human interaction. LLMs allow communication with humans in natural languages, object utilization based on extensive information, and high-level planning using that information. VLMs can describe tasks in text and understand visual information. Furthermore, the information from VLMs can be supplemented by connecting to knowledge databases via LLMs. These capabilities are crucial for enhancing robot intelligence, broadening the scope of robot applications, and maximizing robot utility.
The second finding is the code generation capability of LLMs, which has the potential to automate the robot development process traditionally performed by humans. Additionally, robots that can autonomously update their own algorithms are no longer just science fiction. Although limitations exist for robots to self-update, frameworks such as Eureka and DrEureka, which automatically enhanced reinforcement learning performance for robot motion control, demonstrate the potential for future advancements. This suggests that LLMs may not only enhance human interactions but could also pave the way for self-improvement without human intervention.
While foundation models offer considerable potential for advancing robotics intelligence, several limitations and future considerations remain. These include (1) the speed of inference required for real-time applications, (2) the computational efficiency necessary for embedded systems, (3) the ability to handle multi-modality information, and (4) the necessity of addressing safety and ethical considerations.
First of all, LLMs and VLMs hold considerable potential for enhancing robot intelligence. Nonetheless, several critical issues remain to be addressed. Foundation models, characterized as large-scale models pre-trained on extensive datasets, face challenges related to real-time requirements and limited computational resources in robotic applications. Moreover, concerns such as personal information protection, privacy, and security from external attacks need resolution to enable cloud-based LLMs for robotics.
Secondly, to enhance the computational efficiency and usability of LMs, there is ongoing research into small language models (SLMs). Despite having fewer parameters, SLMs can achieve performance comparable to LLMs in specific applications. Several SLMs have been introduced, including DistilBERT [224], which is a compact version of Google’s BERT; Phi-3 [61], another SLM; Florence-2 [84], a small VLM model from Microsoft; MobileBERT [225], which is optimized for mobile platforms; and compact open-source versions of OpenAI’s GPT models such as GPT-Neo [226] and GPT-J [227]. Generally, SLMs are streamlined models with fewer parameters compared to LLMs, which can number in the billions. SLMs utilize smaller, domain-specific datasets and require shorter training periods, typically just a few weeks, unlike LLMs, which demand vast datasets for broad learning and multiple months of training. Developing SLMs to excel within specific domains for robotic systems and ensuring real-time performance with minimal computational resources are essential research directions for advancing robot intelligence with SLMs.
The third implication is that LLMs, based on text-centered natural language processing, are limited as single-modality models when applied to real-world robotic systems where information often blends in diverse ways. Research on LLMs is transitioning from single-modality to multimodality models, as evidenced by VLMs and OpenAI Sora [228], with increasing demand for such models. Currently, to address the limitations of LLMs’ single-modality, robotic systems are being developed with multimodality models that integrate vision, such as VLMs. However, relying solely on text and images falls short of the diverse information range required in the real world, including images, sounds, videos, and proprioceptive sensory information (such as the position, orientation, balance, movement degree, and direction of various parts of the robot). Proprioceptive sensory information related to actions and movements is particularly vital for enhancing dynamic human interaction, information processing, and manipulation and planning skills based on dynamic movements. For instance, the integrated VLA model, which facilitates low-level control based on LLMs and VLMs as shown by Google’s RT-2 model, highlights the necessity for models capable of integrating information from a broader range of modalities to enhance robot intelligence.
Finally, the fourth area to consider is how to address safety and ethical issues when LLM is applied to robotic intelligence systems. Studies were conducted to address the issue of discriminatory and unsafe behaviors that may be generated by robot applications powered by LLMs [229]. The outputs of LLMs have the potential to generate content that is biased based on personal characteristics (such as race, nationality, religion, gender, disability, and so forth). In addition, they can also be used to instruct robotic systems to engage in violent or illegal behaviors such as misstatements, sexual predation, etc. Notable examples include discriminatory behaviors such as inadequate recognition of children or individuals with specific skin tones in human detection systems, and the exclusion of individuals with disabilities from task assignments. It is imperative to consider the potential social biases of LLM when integrating with robotic systems. Although this kind of consideration was secondary in traditional robotic systems because of the limitation of their language capability, it is a necessary consideration for LLMs to be able to generate human-like language. To address this issue, previous studies have attempted to resolve it in various ways, such as AutoRT’s constitutional rules [10], DrEureka’s safety instructions [134], and NeMo’s guardrails [230]. The guideline-based output control of LLMs can represent an accessible method to ensure safety.
As an extension of this point, safety issues can be identified when integrating LLMs and VLMs into robotic intelligence systems [231]. Typically, in robotic intelligence systems, LLM models generate high-level action plans in various forms, such as programming codes and behavior trees based on natural language or vector prompts. At this point, a prompt attack has the potential to disrupt the inference of the LLMs, thereby threatening the reliability and safety of the robotic system. Prompt injection is one of the prompt attacks, whereby the inference of LLMs is subtly altered through specific inputs. Jailbreak, another prompt attack, bypasses safety rules and causes LLMs to generate abnormal behaviors to be performed by the robotic system. Consequently, even minor disturbances in the input prompts have the potential to cause the entire robotic system to malfunction. To defend against this critical threat to the reliability and safety of robotic systems, various techniques have been proposed, such as input validation, which filters the model’s input, and context locking, which restricts access based on the history and content of the prompt. Furthermore, strict guardrails that restrict harmful or unsafe outputs from models can be an alternative to improve the reliability of robotic systems. However, it is essential to recognize that the security techniques may potentially lead to a decline in the performance of the robot system. Consequently, the trade-off between performance and safety must be carefully considered.
Since the emergence of ChatGPT and Microsoft’s implementation of robot systems using ChatGPT [2], artificial intelligence components have been applied more widely and intensively in robotics research. Despite existing challenges, it is expected that research involving foundation models to improve robot intelligence will persist across various domains and methods, which will likely enhance the usability and market potential of robot systems influenced by these advancements.
6. Conclusions
In this paper, we have explored the potential impact and applicability of LLMs on robotics research fields by summarizing studies that applied LLMs and VLMs to robots. Fundamentally, LLMs can enhance the capability of robots in natural language processing to interact with humans and to improve the robots’ autonomy in various task scenarios. In particular, the ability of LLMs to understand and generate natural language plays a crucial role in enabling robots to comprehend and execute complex commands. This survey confirmed that the scope of utilizing LLMs in robotics was not limited to simple natural language processing but also extended to broader research areas. This study explored extensive LLM applications in the robotics literature, such as planning, manipulation, and scene understanding, as well as reinforcement learning automation frameworks such as Eureka, and included robot actions in language models such as AutoRT. Moreover, the research direction of current generative AI models is transitioning towards multimodal language models, moving beyond information acquisition and cognition aspects such as text, images, and videos to include actuator actions within large models in the robotics field.
While the surveyed studies indicated that LLMs play a promising role in the future of robotics, certain limitations were also identified. First, the increased computational resources and energy consumption associated with embedding LLMs into robotic systems must be addressed. Second, biases in language models and ethical considerations are significant issues that need to be tackled in robotics. Therefore, continual efforts will be necessary in future research to resolve these challenges.
Overall, LLMs are valuable tools that can significantly advance robotics. This review has revealed that innovative robot applications are possible through the integration of LLMs and VLMs. Moreover, these foundation models are expected to serve as critical elements for future robot research and practical applications in the real world.
Author Contributions
Conceptualization, S.S. and C.K.; methodology, S.S.; formal analysis, H.J., H.L. and S.S.; investigation, H.J., H.L. and S.S.; resources, H.J., H.L., S.S. and C.K.; writing—original draft preparation, H.J., H.L., S.S. and C.K.; writing—review and editing, H.J., H.L., S.S. and C.K.; visualization, H.J. and H.L.; supervision, S.S. and C.K.; project administration, S.S.; funding acquisition, S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Technology Innovation Program (RS-2024-00423702, A Meta-Humanoid with Hypermodal Cognitivity and Role Dexterity: Adroid4X) funded by the Ministry of Trade, Industry, and Energy (MOTIE, Korea) and Regional Innovation Strategy (RIS) through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (MOE) (2023RIS-007).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hello GPT-4o. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 13 August 2024).
- Vemprala, S.H.; Bonatti, R.; Bucker, A.; Kapoor, A. ChatGPT for Robotics: Design Principles and Model Abilities. IEEE Access 2024, 12, 55682–55696. [Google Scholar] [CrossRef]
- Hu, Y.; Xie, Q.; Jain, V.; Francis, J.; Patrikar, J.; Keetha, N.; Kim, S.; Xie, Y.; Zhang, T.; Zhao, S.; et al. Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis. arXiv 2023, arXiv:2312.08782. [Google Scholar]
- Xiao, X.; Liu, J.; Wang, Z.; Zhou, Y.; Qi, Y.; Cheng, Q.; He, B.; Jiang, S. Robot Learning in the Era of Foundation Models: A Survey. arXiv 2023, arXiv:2311.14379. [Google Scholar]
- Mao, Y.; Ge, Y.; Fan, Y.; Xu, W.; Mi, Y.; Hu, Z.; Gao, Y. A Survey on LoRA of Large Language Models. arXiv 2024, arXiv:2407.11046. [Google Scholar]
- Hunt, W.; Ramchurn, S.D.; Soorati, M.D. A Survey of Language-Based Communication in Robotics. arXiv 2024, arXiv:2406.04086. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. Proc. Mach. Learn. Res. 2021, 139, 8748–8763. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J.; et al. RT-1: Robotics Transformer for Real-World Control at Scale. In Proceedings of the Robotics: Science and Systems 2023, Daegu, Republic of Korea, 10–14 July 2023. [Google Scholar] [CrossRef]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Chen, X.; Choromanski, K.; Ding, T.; Driess, D.; Dubey, A.; Finn, C.; et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv 2023, arXiv:2307.15818. [Google Scholar]
- Ahn, M.; Dwibedi, D.; Finn, C.; Arenas, M.G.; Gopalakrishnan, K.; Hausman, K.; Ichter, B.; Irpan, A.; Joshi, N.; Julian, R.; et al. AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents. arXiv 2024, arXiv:2401.12963. [Google Scholar]
- Ma, Y.J.; Liang, W.; Wang, G.; Huang, D.-A.; Bastani, O.; Jayaraman, D.; Zhu, Y.; Fan, L.; Anandkumar, A. Eureka: Human-Level Reward Design via Coding Large Language Models. arXiv 2023, arXiv:2310.12931. [Google Scholar]
- Ma, Y.; Song, Z.; Zhuang, Y.; Hao, J.; King, I. A Survey on Vision-Language-Action Models for Embodied AI. arXiv 2024, arXiv:2405.14093. [Google Scholar]
- Zhou, H.; Yao, X.; Meng, Y.; Sun, S.; Bing, Z.; Huang, K.; Knoll, A. Language-Conditioned Learning for Robotic Manipulation: A Survey. arXiv 2023, arXiv:2312.10807. [Google Scholar]
- Firoozi, R.; Tucker, J.; Tian, S.; Majumdar, A.; Sun, J.; Liu, W.; Zhu, Y.; Song, S.; Kapoor, A.; Hausman, K.; et al. Foundation Models in Robotics: Applications, Challenges, and the Future. arXiv 2023, arXiv:2312.07843. [Google Scholar] [CrossRef]
- Gu, J.; Stefani, E.; Wu, Q.; Thomason, J.; Wang, X.E. Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions. Proc. Annu. Meet. Assoc. Comput. Linguist. 2022, 1, 7606–7623. [Google Scholar] [CrossRef]
- Zhai, C. Statistical Language Models for Information Retrieval; Association for Computational Linguistics: Morristown, NJ, USA, 2007; Volume 94, ISBN 9781598295900. [Google Scholar]
- Gao, J.; Lin, C.Y. Introduction to the Special Issue on Statistical Language Modeling. ACM Trans. Asian Lang. Inf. Process. 2004, 3, 87–93. [Google Scholar] [CrossRef]
- Rosenfeld, R. Two Decdes of Statistical Language Modeling Where Do We Go Form Here? Where Do We Go from Here? Proc. IEEE 2000, 88, 1270–1275. [Google Scholar] [CrossRef]
- Gondala, S.; Verwimp, L.; Pusateri, E.; Tsagkias, M.; Van Gysel, C. Error-Driven Pruning of Language Models for Virtual Assistants. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7413–7417. [Google Scholar] [CrossRef]
- Liu, X.; Croft, W.B. Statistical Language Modeling for Information Retrieval. Annu. Rev. Inf. Sci. Technol. 2005, 39, 1–31. [Google Scholar] [CrossRef]
- Thede, S.M.; Harper, M.P. A Second-Order Hidden Markov Model for Part-of-Speech Tagging. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; Association for Computational Linguistics: Morristown, NJ, USA, 1999; pp. 175–182. [Google Scholar]
- Bahl, L.R.; Brown, P.F.; De Souza, P.V.; Mercer, R.L. A Tree-Based Statistical Language Model for Natural Language Speech Recognition. IEEE Trans. Acoust. 1989, 37, 1001–1008. [Google Scholar] [CrossRef]
- Brants, T.; Popat, A.C.; Xu, P.; Och, F.J.; Dean, J. Large Language Models in Machine Translation. In Proceedings of the EMNLP-CoNLL 2007-Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; Volume 1, pp. 858–867. [Google Scholar]
- Popov, M.; Kulnitskiy, B.; Perezhogin, I.; Mordkovich, V.; Ovsyannikov, D.; Perfilov, S.; Borisova, L.; Blank, V. Catalytic 3D Polymerization of C60. Fuller. Nanotub. Carbon Nanostruct. 2018, 26, 465–470. [Google Scholar] [CrossRef]
- Mikolov, T.; Karafiát, M.; Burget, L.; Jan, C.; Khudanpur, S. Recurrent Neural Network Based Language Model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, INTERSPEECH 2010, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Kombrink, S.; Mikolov, T.; Karafiát, M.; Burget, L. Recurrent Neural Network Based Language Modeling in Meeting Recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 2877–2880. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations Ofwords and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013-Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the NAACL HLT 2018—2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 14 February 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 10 October 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5999–6009. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. Proc. Annu. Meet. Assoc. Comput. Linguist. 2020, 58, 7871–7880. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2022, 23, 1–40. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. Language Models Are Unsupervised Multitask Learners. arXiv 2021, arXiv:2109.08270. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Webson, A.; Raffel, C.; Bach, S.H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Le Scao, T.; Raja, A.; et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Wang, T.; Roberts, A.; Hesslow, D.; Le Scao, T.; Chung, H.W.; Beltagy, I.; Launay, J.; Raffel, C. What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? Proc. Mach. Learn. Res. 2022, 162, 22964–22984. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Shanahan, M. Talking about Large Language Models. Commun. ACM 2024, 67, 68–79. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; de Las Casas, D.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 30016–30030. [Google Scholar]
- Taylor, R.; Kardas, M.; Cucurull, G.; Scialom, T.; Hartshorn, A.; Saravia, E.; Poulton, A.; Kerkez, V.; Stojnic, R. Galactica: A Large Language Model for Science. arXiv 2022, arXiv:2211.09085. [Google Scholar]
- Fausk, H.; Isaksen, D.C. T-Model Structures. Homol. Homotopy Appl. 2007, 9, 399–438. [Google Scholar] [CrossRef]
- Groeneveld, D.; Beltagy, I.; Walsh, P.; Bhagia, A.; Kinney, R.; Tafjord, O.; Jha, A.H.; Ivison, H.; Magnusson, I.; Wang, Y.; et al. OLMo: Accelerating the Science of Language Models. Allen Inst. Artif. Intell. 2024, 62, 15789–15809. [Google Scholar]
- Lozhkov, A.; Li, R.; Allal, L.B.; Cassano, F.; Lamy-Poirier, J.; Tazi, N.; Tang, A.; Pykhtar, D.; Liu, J.; Wei, Y.; et al. StarCoder 2 and The Stack v2: The Next Generation. arXiv 2024, arXiv:2402.19173. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- The Claude 3 Model Family: Opus, Sonnet, Haiku. Available online: https://api.semanticscholar.org/CorpusID:268232499 (accessed on 13 August 2024).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 35, 1877–1901. [Google Scholar]
- Cai, Z.; Cao, M.; Chen, H.; Chen, K.; Chen, K.; Chen, X.; Chen, X.; Chen, Z.; Chen, Z.; Chu, P.; et al. InternLM2 Technical Report. arXiv 2024, arXiv:2403.17297. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Lieber, O.; Lenz, B.; Bata, H.; Cohen, G.; Osin, J.; Dalmedigos, I.; Safahi, E.; Meirom, S.; Belinkov, Y.; Shalev-Shwartz, S.; et al. Jamba: A Hybrid Transformer-Mamba Language Model. arXiv 2024, arXiv:2403.19887. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models Are Zero-Shot Learners. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual, 25–29 April 2022; pp. 1–46. [Google Scholar]
- Pinnaparaju, N.; Adithyan, R.; Phung, D.; Tow, J.; Baicoianu, J.; Datta, A.; Zhuravinskyi, M.; Mahan, D.; Bellagente, M.; Riquelme, C.; et al. Stable Code Technical Report. arXiv 2024, arXiv:2404.01226. [Google Scholar]
- Yoo, K.M.; Han, J.; In, S.; Jeon, H.; Jeong, J.; Kang, J.; Kim, H.; Kim, K.-M.; Kim, M.; Kim, S.; et al. HyperCLOVA X Technical Report. arXiv 2024, arXiv:2404.01954. [Google Scholar]
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar]
- Grok-1.5 Vision Preview. Available online: https://x.ai/blog/grok-1.5v (accessed on 13 August 2024).
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Vallabh Shrimangale Introducing Meta Llama 3: The Most Capable Openly Available LLM to Date. Available online: https://medium.com/@shrimangalevallabh789/introducing-meta-llama-3-the-most-capable-openly-available-llm-to-date-12de163151e1 (accessed on 13 August 2024).
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Abdin, M.; Jacobs, S.A.; Awan, A.A.; Aneja, J.; Awadallah, A.; Awadalla, H.; Bach, N.; Bahree, A.; Bakhtiari, A.; Bao, J.; et al. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv 2024, arXiv:2404.14219. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. OPT: Open Pre-Trained Transformer Language Models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Claude 3.5 Sonnet. Available online: https://www.anthropic.com/news/claude-3-5-sonnet (accessed on 13 August 2024).
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T. Alpaca: A Strong, Replicable Instruction-Following Model. Available online: https://crfm.stanford.edu/2023/03/13/alpaca.html (accessed on 13 August 2024).
- GPT-4o Mini: Advancing Cost-Efficient Intelligence. Available online: https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/ (accessed on 13 August 2024).
- Malartic, Q.; Chowdhury, N.R.; Cojocaru, R.; Farooq, M.; Campesan, G.; Djilali, Y.A.D.; Narayan, S.; Singh, A.; Velikanov, M.; Boussaha, B.E.A.; et al. Falcon2-11B Technical Report. Available online: https://huggingface.co/tiiuae/falcon-11B (accessed on 13 August 2024).
- Li, R.; Allal, L.B.; Zi, Y.; Muennighoff, N.; Kocetkov, D.; Mou, C.; Marone, M.; Akiki, C.; Li, J.; Chim, J.; et al. StarCoder: May the Source Be with You! arXiv 2023, arXiv:2305.06161. [Google Scholar]
- Introducing Llama 3.1: Our Most Capable Models to Date. Available online: https://ai.meta.com/blog/meta-llama-3-1/ (accessed on 13 August 2024).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Mistral AI Mistral Large. Available online: https://mistral.ai/news/mistral-large/?utm_source=www.turingpost.com&utm_medium=referral&utm_campaign=the-ultimate-guide-to-llm-benchmarks-evaluating-language-model-capabilities (accessed on 13 August 2024).
- Yang, A.; Xiao, B.; Wang, B.; Zhang, B.; Bian, C.; Yin, C.; Lv, C.; Pan, D.; Wang, D.; Yan, D.; et al. Baichuan 2: Open Large-Scale Language Models. arXiv 2023, arXiv:2309.10305. [Google Scholar]
- Team, G.; Deepmind, G. Gemma 2: Improving Open Language Models at a Practical Size. arXiv 2024, arXiv:2408.00118. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- An, S.; Bae, K.; Choi, E.; Choi, S.J.; Choi, Y.; Hong, S.; Hong, Y.; Hwang, J.; Jeon, H.; Gerrard, J.J.; et al. EXAONE 3.0 7.8B Instruction Tuned Language Model. arXiv 2024, arXiv:2408.03541. [Google Scholar]
- Guo, D.; Zhu, Q.; Yang, D.; Xie, Z.; Dong, K.; Zhang, W.; Chen, G.; Bi, X.; Wu, Y.; Li, Y.K.; et al. DeepSeek-Coder: When the Large Language Model Meets Programming—The Rise of Code Intelligence. arXiv 2024, arXiv:2401.14196. [Google Scholar]
- Grok-2 Beta Release. Available online: https://x.ai/blog/grok-2 (accessed on 13 August 2024).
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. Lect. Notes Comput. Sci. (Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2020, 12346 LNCS, 213–229. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. Available online: https://github.com/haotian-liu/LLaVA (accessed on 13 August 2024).
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation through Attention. arXiv 2021, arXiv:2012.12877. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. Available online: http://arxiv.org/abs/2304.10592 (accessed on 13 August 2024).
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. arXiv 2021, arXiv:2102.12092. [Google Scholar]
- ChatGPT-4 System Card. Available online: https://cdn.openai.com/papers/gpt-4-system-card.pdf (accessed on 13 August 2024).
- Xiao, B.; Wu, H.; Xu, W.; Dai, X.; Hu, H.; Lu, Y.; Zeng, M.; Liu, C.; Yuan, L. Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. arXiv 2023, arXiv:2311.06242. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. Available online: https://github.com/microsoft/Swin-Transformer (accessed on 13 August 2024).
- Bar-Tal, O.; Chefer, H.; Tov, O.; Herrmann, C.; Paiss, R.; Zada, S.; Ephrat, A.; Hur, J.; Liu, G.; Raj, A.; et al. Lumiere: A Space-Time Diffusion Model for Video Generation. arXiv 2024, arXiv:2401.12945. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 15, 12077–12090. [Google Scholar]
- Adept Fuyu-Heavy: A New Multimodal Model. Available online: https://www.adept.ai/blog/adept-fuyu-heavy (accessed on 13 August 2024).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16X16 Words: Transformers for Image Recognition At Scale. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Gemini Team; Georgiev, P.; Lei, V.I.; Burnell, R.; Bai, L.; Gulati, A.; Tanzer, G.; Vincent, D.; Pan, Z.; Wang, S.; et al. Gemini 1.5: Unlocking Multimodal Understanding across Millions of Tokens of Context. arXiv 2024, arXiv:2403.05530. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. Beit: Bert Pre-Training of Image Transformers. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Dong, X.; Zhang, P.; Zang, Y.; Cao, Y.; Wang, B.; Ouyang, L.; Zhang, S.; Duan, H.; Zhang, W.; Li, Y.; et al. InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD. arXiv 2024, arXiv:2404.06512. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollar, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar]
- Introducing Idefics2: A Powerful 8B Vision-Language Model for the Community. Available online: https://huggingface.co/blog/idefics2 (accessed on 13 August 2018).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. Available online: https://github.com/CompVis/latent-diffusion (accessed on 13 August 2024).
- Laurençon, H.; Tronchon, L.; Cord, M.; Sanh, V. What Matters When Building Vision-Language Models? arXiv 2024, arXiv:2405.02246. [Google Scholar] [CrossRef]
- Nair, S.; Rajeswaran, A.; Kumar, V.; Finn, C.; Gupta, A. R3M: A Universal Visual Representation for Robot Manipulation. arXiv 2022, arXiv:2203.12601. [Google Scholar]
- Chameleon Team. Chameleon: Mixed-Modal Early-Fusion Foundation Models. arXiv 2024, arXiv:2405.09818. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M.; et al. Flamingo: A Visual Language Model for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. BLIP-2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models. Available online: https://github.com/salesforce/LAVIS/tree/main/projects/blip2 (accessed on 13 August 2024).
- Beyer, L.; Steiner, A.; Pinto, A.S.; Kolesnikov, A.; Wang, X.; Salz, D.; Neumann, M.; Alabdulmohsin, I.; Tschannen, M.; Bugliarello, E.; et al. PaliGemma: A Versatile 3B VLM for Transfer. arXiv 2024, arXiv:2407.07726. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. Available online: https://segment-anything.com (accessed on 13 August 2024).
- Ravi, N.; Gabeur, V.; Hu, Y.-T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Raedle, R.; Rolland, C.; Gustafson, L.; et al. SAM 2: Segment Anything in Images and Videos. arXiv 2024, arXiv:2408.00714. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Qwen2-VL: To See the World More Clearly. Available online: https://qwenlm.github.io/blog/qwen2-vl/ (accessed on 1 September 2024).
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling Instruction-Finetuned Language Models. arXiv 2022, arXiv:2210.11416. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified Language Model Pre-Training for Natural Language Understanding and Generation. Adv. Neural Inf. Process. Syst. 2019, 32, 13063–13075. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. GLM-130B: An Open Bilingual Pre-Trained Model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Tay, Y.; Wei, J.; Chung, H.W.; Tran, V.Q.; So, D.R.; Shakeri, S.; Garcia, X.; Zheng, H.S.; Rao, J.; Chowdhery, A.; et al. Transcending Scaling Laws with 0.1% Extra Compute. In Proceedings of the EMNLP 2023—2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 1471–1486. [Google Scholar]
- Kaufmann, T.; Weng, P.; Bengs, V.; Hüllermeier, E. A Survey of Reinforcement Learning from Human Feedback. arXiv 2023, arXiv:2312.14925. [Google Scholar]
- Rafailov, R.; Sharma, A.; Mitchell, E.; Ermon, S.; Manning, C.D.; Finn, C. Direct Preference Optimization: Your Language Model Is Secretly a Reward Model. arXiv 2023, arXiv:2305.18290. [Google Scholar]
- Han, Z.; Gao, C.; Liu, J.; Zhang, J.; Zhang, S.Q. Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey. arXiv 2024, arXiv:2403.14608. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzçbski, S.; Morrone, B.; de Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-Efficient Transfer Learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 4944–4953. [Google Scholar]
- Hu, Z.; Wang, L.; Lan, Y.; Xu, W.; Lim, E.P.; Bing, L.; Xu, X.; Poria, S.; Lee, R.K.W. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. In Proceedings of the EMNLP 2023—2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 5254–5276. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the EMNLP 2021—2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, Punta Cana, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too. AI Open, 2023; in press. [Google Scholar] [CrossRef]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Event, 1–6 August 2021; pp. 4582–4597. [Google Scholar]
- Hu, E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-Rank Adaptation of Large Language Models. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual, 25–29 April 2022; pp. 1–26. [Google Scholar]
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. QLORA: Efficient Finetuning of Quantized LLMs. Adv. Neural Inf. Process. Syst. 2023, 36, 10088–10115. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Zhao, H.; Karypis, G.; Smola, A. Multimodal Chain-of-Thought Reasoning in Language Models. arXiv 2023, arXiv:2302.00923. [Google Scholar]
- Diao, S.; Wang, P.; Lin, Y.; Zhang, T. Active Prompting with Chain-of-Thought for Large Language Models. arXiv 2023, arXiv:2302.12246. [Google Scholar]
- Gao, L.; Madaan, A.; Zhou, S.; Alon, U.; Liu, P.; Yang, Y.; Callan, J.; Neubig, G. PAL: Program-Aided Language Models. Proc. Mach. Learn. Res. 2023, 202, 10764–10799. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.L.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Adv. Neural Inf. Process. Syst. 2023, 36, 11809–11822. [Google Scholar]
- Trautmann, D. Large Language Model Prompt Chaining for Long Legal Document Classification. arXiv 2023, arXiv:2308.04138. [Google Scholar]
- Liu, J.; Liu, A.; Lu, X.; Welleck, S.; West, P.; Le Bras, R.; Choi, Y.; Hajishirzi, H. Generated Knowledge Prompting for Commonsense Reasoning. Proc. Annu. Meet. Assoc. Comput. Linguist. 2022, 1, 3154–3169. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.T.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Paranjape, B.; Lundberg, S.; Singh, S.; Hajishirzi, H.; Zettlemoyer, L.; Ribeiro, M.T. ART: Automatic Multi-Step Reasoning and Tool-Use for Large Language Models. arXiv 2023, arXiv:2303.09014. [Google Scholar]
- Zhou, Y.; Muresanu, A.I.; Han, Z.; Paster, K.; Pitis, S.; Chan, H.; Ba, J. Large Language Models Are Human-Level Prompt Engineers. arXiv 2022, arXiv:2211.01910. [Google Scholar]
- Li, Z.; Peng, B.; He, P.; Galley, M.; Gao, J.; Yan, X. Guiding Large Language Models via Directional Stimulus Prompting. Adv. Neural Inf. Process. Syst. 2023, 36, 62630–62656. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv 2022, arXiv:2210.03629. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language Agents with Verbal Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2023, 36, 8634–8652. [Google Scholar]
- Mittal, M.; Yu, C.; Yu, Q.; Liu, J.; Rudin, N.; Hoeller, D.; Yuan, J.L.; Singh, R.; Guo, Y.; Mazhar, H.; et al. Orbit: A Unified Simulation Framework for Interactive Robot Learning Environments. IEEE Robot. Autom. Lett. 2023, 8, 3740–3747. [Google Scholar] [CrossRef]
- Ma, Y.J.; Liang, W.; Wang, H.-J.; Wang, S.; Zhu, Y.; Fan, L.; Bastani, O.; Jayaraman, D. DrEureka: Language Model Guided Sim-To-Real Transfer. arXiv 2024, arXiv:2406.01967. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence, SSCI 2020, Canberra, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]
- Xie, T.; Zhao, S.; Wu, C.H.; Liu, Y.; Luo, Q.; Zhong, V.; Yang, Y.; Yu, T. Text2Reward: Automated Dense Reward Function Generation for Reinforcement Learning. arXiv 2023, arXiv:2309.11489. [Google Scholar]
- Di Palo, N.; Byravan, A.; Hasenclever, L.; Wulfmeier, M.; Heess, N.; Riedmiller, M. Towards A Unified Agent with Foundation Models. arXiv 2023, arXiv:2307.09668. [Google Scholar]
- Du, Y.; Konyushkova, K.; Denil, M.; Raju, A.; Landon, J.; Hill, F.; De Freitas, N.; Cabi, S. Vision-Language Models As Success Detectors. Proc. Mach. Learn. Res. 2023, 232, 120–136. [Google Scholar]
- Du, Y.; Watkins, O.; Wang, Z.; Colas, C.; Darrell, T.; Abbeel, P.; Gupta, A.; Andreas, J. Guiding Pretraining in Reinforcement Learning with Large Language Models. Proc. Mach. Learn. Res. 2023, 202, 8657–8677. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. PaLM-E: An Embodied Multimodal Language Model. Proc. Mach. Learn. Res. 2023, 202, 8469–8488. [Google Scholar]
- Chen, X.; Djolonga, J.; Padlewski, P.; Mustafa, B.; Changpinyo, S.; Wu, J.; Ruiz, C.R.; Goodman, S.; Wang, X.; Tay, Y.; et al. PaLI-X: On Scaling up a Multilingual Vision and Language Model. arXiv 2023, arXiv:2305.18565. [Google Scholar]
- Asimov, I. Runaround. Astounding Sci. Fict. 1942, 29, 94–103. [Google Scholar]
- Jang, E.; Irpan, A.; Khansari, M.; Kappler, D.; Ebert, F.; Lynch, C.; Levine, S.; Finn, C. BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning. Proc. Mach. Learn. Res. 2021, 164, 991–1002. [Google Scholar]
- Tang, Y.; Yu, W.; Tan, J.; Zen, H.; Faust, A.; Harada, T. SayTap: Language to Quadrupedal Locomotion. Proc. Mach. Learn. Res. 2023, 229, 3556–3570. [Google Scholar]
- Mandi, Z.; Jain, S.; Song, S. RoCo: Dialectic Multi-Robot Collaboration with Large Language Models. arXiv 2023, arXiv:2307.04738. [Google Scholar]
- Wang, Y.-J.; Zhang, B.; Chen, J.; Sreenath, K. Prompt a Robot to Walk with Large Language Models. arXiv 2023, arXiv:2309.09969. [Google Scholar]
- Liang, J.; Huang, W.; Xia, F.; Xu, P.; Hausman, K.; Ichter, B.; Florence, P.; Zeng, A. Code as Policies: Language Model Programs for Embodied Control. In Proceedings of the IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 9493–9500. [Google Scholar]
- Mirchandani, S.; Xia, F.; Florence, P.; Ichter, B.; Driess, D.; Arenas, M.G.; Rao, K.; Sadigh, D.; Zeng, A. Large Language Models as General Pattern Machines. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Yoneda, T.; Fang, J.; Li, P.; Zhang, H.; Jiang, T.; Lin, S.; Picker, B.; Yunis, D.; Mei, H.; Walter, M.R. Statler: State-Maintaining Language Models for Embodied Reasoning. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2023; pp. 1–19. [Google Scholar] [CrossRef]
- Mu, Y.; Zhang, Q.; Hu, M.; Wang, W.; Ding, M.; Jin, J.; Wang, B.; Dai, J.; Qiao, Y.; Luo, P. EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought. Adv. Neural Inf. Process. Syst. 2023, 36, 25081–25094. [Google Scholar]
- Chen, H.; Tan, H.; Kuntz, A.; Bansal, M.; Alterovitz, R. Enabling Robots to Understand Incomplete Natural Language Instructions Using Commonsense Reasoning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1963–1969. [Google Scholar]
- Huang, W.; Xia, F.; Shah, D.; Driess, D.; Zeng, A.; Lu, Y.; Florence, P.; Mordatch, I.; Levine, S.; Hausman, K.; et al. Grounded Decoding: Guiding Text Generation with Grounded Models for Embodied Agents. Adv. Neural Inf. Process. Syst. 2023, 36, 59636–59661. [Google Scholar]
- Huang, W.; Xia, F.; Xiao, T.; Chan, H.; Liang, J.; Florence, P.; Zeng, A.; Tompson, J.; Mordatch, I.; Chebotar, Y.; et al. Inner Monologue: Embodied Reasoning through Planning with Language Models. Proc. Mach. Learn. Res. 2023, 205, 1769–1782. [Google Scholar]
- Lykov, A.; Tsetserukou, D. LLM-BRAIn: AI-Driven Fast Generation of Robot Behaviour Tree Based on Large Language Model. arXiv 2023, arXiv:2305.19352. [Google Scholar]
- Song, C.H.; Sadler, B.M.; Wu, J.; Chao, W.L.; Washington, C.; Su, Y. LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 2986–2997. [Google Scholar]
- Singh, I.; Blukis, V.; Mousavian, A.; Goyal, A.; Xu, D.; Tremblay, J.; Fox, D.; Thomason, J.; Garg, A. ProgPrompt: Generating Situated Robot Task Plans Using Large Language Models. In Proceedings of the IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 11523–11530. [Google Scholar]
- Rana, K.; Haviland, J.; Garg, S.; Abou-Chakra, J.; Reid, I.; Sünderhauf, N. SayPlan: Grounding Large Language Models Using 3D Scene Graphs for Scalable Robot Task Planning. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Zeng, A.; Attarian, M.; Ichter, B.; Choromanski, K.; Wong, A.; Welker, S.; Tombari, F.; Purohit, A.; Ryoo, M.; Sindhwani, V.; et al. Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language. arXiv 2022, arXiv:2204.00598. [Google Scholar]
- Lin, K.; Agia, C.; Migimatsu, T.; Pavone, M.; Bohg, J. Text2Motion: From Natural Language Instructions to Feasible Plans. Auton. Robots 2023, 47, 1345–1365. [Google Scholar] [CrossRef]
- Wu, J.; Antonova, R.; Kan, A.; Lepert, M.; Zeng, A.; Song, S.; Bohg, J.; Rusinkiewicz, S.; Funkhouser, T. TidyBot: Personalized Robot Assistance with Large Language Models. Auton. Robots 2023, 47, 1087–1102. [Google Scholar] [CrossRef]
- Stone, A.; Xiao, T.; Lu, Y.; Gopalakrishnan, K.; Lee, K.H.; Vuong, Q.; Wohlhart, P.; Kirmani, S.; Zitkovich, B.; Xia, F.; et al. Open-World Object Manipulation Using Pre-Trained Vision-Language Models. Proc. Mach. Learn. Res. 2023, 229, 1–18. [Google Scholar]
- Gao, J.; Sarkar, B.; Xia, F.; Xiao, T.; Wu, J.; Ichter, B.; Majumdar, A.; Sadigh, D. Physically Grounded Vision-Language Models for Robotic Manipulation. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Wang, R.; Mao, J.; Hsu, J.; Zhao, H.; Wu, J.; Gao, Y. Programmatically Grounded, Compositionally Generalizable Robotic Manipulation. arXiv 2023, arXiv:2304.13826. [Google Scholar]
- Ha, H.; Florence, P.; Song, S. Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Huang, W.; Wang, C.; Zhang, R.; Li, Y.; Wu, J.; Fei-Fei, L. VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Fu, C.; Gopalakrishnan, K.; Hausman, K.; et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. Proc. Mach. Learn. Res. 2023, 205, 287–318. [Google Scholar]
- Huang, S.; Jiang, Z.; Dong, H.; Qiao, Y.; Gao, P.; Li, H. Instruct2Act: Mapping Multi-Modality Instructions to Robotic Actions with Large Language Model. arXiv 2023, arXiv:2305.11176. [Google Scholar]
- Chen, W.; Hu, S.; Talak, R.; Carlone, L. Leveraging Large (Visual) Language Models for Robot 3D Scene Understanding. arXiv 2022, arXiv:2209.05629. [Google Scholar]
- Yang, J.; Chen, X.; Qian, S.; Madaan, N.; Iyengar, M.; Fouhey, D.F.; Chai, J. LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Chen, B.; Xia, F.; Ichter, B.; Rao, K.; Gopalakrishnan, K.; Ryoo, M.S.; Stone, A.; Kappler, D. Open-Vocabulary Queryable Scene Representations for Real World Planning. In Proceedings of the IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 11509–11522. [Google Scholar]
- Elhafsi, A.; Sinha, R.; Agia, C.; Schmerling, E.; Nesnas, I.A.D.; Pavone, M. Semantic Anomaly Detection with Large Language Models. Auton. Robots 2023, 47, 1035–1055. [Google Scholar] [CrossRef]
- Hong, Y.; Zhen, H.; Chen, P.; Zheng, S.; Du, Y.; Chen, Z.; Gan, C. 3D-LLM: Injecting the 3D World into Large Language Models. Adv. Neural Inf. Process. Syst. 2023, 36, 20482–20494. [Google Scholar]
- Shah, D.; Osinski, B.; Ichter, B.; Levine, S.; Osiński, B.; Ichter, B.; Levine, S. LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action. Proc. Mach. Learn. Res. 2023, 205, 492–504. [Google Scholar]
- Zhou, G.; Hong, Y.; Wu, Q. NavGPT: Explicit Reasoning in Vision-and-Language Navigation with Large Language Models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 7641–7649. [Google Scholar]
- Huang, C.; Mees, O.; Zeng, A.; Burgard, W. Visual Language Maps for Robot Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023; pp. 10608–10615. [Google Scholar]
- Triantafyllidis, E.; Christianos, F.; Li, Z. Intrinsic Language-Guided Exploration for Complex Long-Horizon Robotic Manipulation Tasks. arXiv 2023, arXiv:2309.16347. [Google Scholar]
- Yu, W.; Gileadi, N.; Fu, C.; Kirmani, S.; Lee, K.H.; Arenas, M.G.; Chiang, H.T.L.; Erez, T.; Hasenclever, L.; Humplik, J.; et al. Language to Rewards for Robotic Skill Synthesis. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Perez, J.; Proux, D.; Roux, C.; Niemaz, M. LARG, Language-Based Automatic Reward and Goal Generation. arXiv 2023, arXiv:2306.10985. [Google Scholar]
- Song, J.; Zhou, Z.; Liu, J.; Fang, C.; Shu, Z.; Ma, L. Self-Refined Large Language Model as Automated Reward Function Designer for Deep Reinforcement Learning in Robotics. arXiv 2023, arXiv:2309.06687. [Google Scholar]
- Mahmoudieh, P.; Pathak, D.; Darrell, T. Zero-Shot Reward Specification via Grounded Natural Language. In Proceedings of the Proceedings of Machine Learning Research, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 14743–14752. [Google Scholar]
- Park, J.; Lim, S.; Lee, J.; Park, S.; Chang, M.; Yu, Y.; Choi, S. CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents. IEEE Robot. Autom. Lett. 2024, 9, 1059–1066. [Google Scholar] [CrossRef]
- Wake, N.; Kanehira, A.; Sasabuchi, K.; Takamatsu, J.; Ikeuchi, K. ChatGPT Empowered Long-Step Robot Control in Various Environments: A Case Application. IEEE Access 2023, 11, 95060–95078. [Google Scholar] [CrossRef]
- Palnitkar, A.; Kapu, R.; Lin, X.; Liu, C.; Karapetyan, N.; Aloimonos, Y. ChatSim: Underwater Simulation with Natural Language Prompting. In Proceedings of the Oceans Conference Record (IEEE), Biloxi, MS, USA, 25–28 September 2023. [Google Scholar]
- Yang, R.; Hou, M.; Wang, J.; Zhang, F. OceanChat: Piloting Autonomous Underwater Vehicles in Natural Language. arXiv 2023, arXiv:2309.16052. [Google Scholar]
- Lin, B.Y.; Huang, C.; Liu, Q.; Gu, W.; Sommerer, S.; Ren, X. On Grounded Planning for Embodied Tasks with Language Models. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, AAAI 2023, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 13192–13200. [Google Scholar]
- Dai, Z.; Asgharivaskasi, A.; Duong, T.; Lin, S.; Tzes, M.-E.; Pappas, G.; Atanasov, N. Optimal Scene Graph Planning with Large Language Model Guidance. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Yang, Z.; Raman, S.S.; Shah, A.; Tellex, S. Plug in the Safety Chip: Enforcing Constraints for LLM-Driven Robot Agents. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, Q.; Duan, Y.; Jiang, X.; Cheng, C.; Xu, R. Prompt, Plan, Perform: LLM-Based Humanoid Control via Quantized Imitation Learning. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Liu, Z.; Bahety, A.; Song, S. REFLECT: Summarizing Robot Experiences for FaiLure Explanation and CorrecTion. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Cao, Y.; Lee, C.S.G. Robot Behavior-Tree-Based Task Generation with Large Language Models. CEUR Workshop Proc. 2023, 3433. [Google Scholar]
- Zhen, Y.; Bi, S.; Xing-tong, L.; Wei-qin, P.; Hai-peng, S.; Zi-rui, C.; Yi-shu, F. Robot Task Planning Based on Large Language Model Representing Knowledge with Directed Graph Structures. arXiv 2023, arXiv:2306.05171. [Google Scholar]
- You, H.; Ye, Y.; Zhou, T.; Zhu, Q.; Du, J. Robot-Enabled Construction Assembly with Automated Sequence Planning Based on ChatGPT: RoboGPT. Buildings 2023, 13, 1772. [Google Scholar] [CrossRef]
- Ren, A.Z.; Dixit, A.; Bodrova, A.; Singh, S.; Tu, S.; Brown, N.; Xu, P.; Takayama, L.; Xia, F.; Varley, J.; et al. Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners. Proc. Mach. Learn. Res. 2023, 229. [Google Scholar]
- Chen, Y.; Arkin, J.; Zhang, Y.; Roy, N.; Fan, C. Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems? In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [CrossRef]
- Kannan, S.S.; Venkatesh, V.L.N.; Min, B.-C. SMART-LLM: Smart Multi-Agent Robot Task Planning Using Large Language Models. arXiv 2023, arXiv:2309.10062. [Google Scholar]
- Ding, Y.; Zhang, X.; Paxton, C.; Zhang, S. Task and Motion Planning with Large Language Models for Object Rearrangement. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 2086–2092. [Google Scholar]
- Chen, Y.; Arkin, J.; Dawson, C.; Zhang, Y.; Roy, N.; Fan, C. AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar] [CrossRef]
- Shafiullah, N.M.; Cui, Z.J.; Altanzaya, A.; Pinto, L. Behavior Transformers: Cloning k Modes with One Stone. Adv. Neural Inf. Process. Syst. 2022, 35, 22955–22968. [Google Scholar]
- Zhao, X.; Li, M.; Weber, C.; Hafez, M.B.; Wermter, S. Chat with the Environment: Interactive Multimodal Perception Using Large Language Models. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 3590–3596. [Google Scholar]
- Guo, Y.; Wang, Y.-J.; Zha, L.; Jiang, Z.; Chen, J. DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment. arXiv 2023, arXiv:2307.00329. [Google Scholar]
- Kim, G.; Kim, T.; Kannan, S.S.; Venkatesh, V.L.N.; Kim, D.; Min, B.-C. DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs. arXiv 2023, arXiv:2309.16031. [Google Scholar]
- Dagan, G.; Keller, F.; Lascarides, A. Dynamic Planning with a LLM. arXiv 2023, arXiv:2308.06391. [Google Scholar]
- Wu, Z.; Wang, Z.; Xu, X.; Lu, J.; Yan, H. Embodied Task Planning with Large Language Models. arXiv 2023, arXiv:2307.01848. [Google Scholar]
- Gkanatsios, N.; Jain, A.; Xian, Z.; Zhang, Y.; Atkeson, C.; Fragkiadaki, K. Energy-Based Models Are Zero-Shot Planners for Compositional Scene Rearrangement. In Proceedings of the Robotics: Science and Systems 2023, Daegu, Republic of Korea, 10–14 July 2023. [Google Scholar] [CrossRef]
- Ni, Z.; Deng, X.; Tai, C.; Zhu, X.; Xie, Q.; Huang, W.; Wu, X.; Zeng, L. GRID: Scene-Graph-Based Instruction-Driven Robotic Task Planning. arXiv 2023, arXiv:2309.07726. [Google Scholar]
- Ming, C.; Lin, J.; Fong, P.; Wang, H.; Duan, X.; He, J. HiCRISP: A Hierarchical Closed-Loop Robotic Intelligent Self-Correction Planner. arXiv 2023, arXiv:2309.12089. [Google Scholar]
- Ding, Y.; Zhang, X.; Amiri, S.; Cao, N.; Yang, H.; Kaminski, A.; Esselink, C.; Zhang, S. Integrating Action Knowledge and LLMs for Task Planning and Situation Handling in Open Worlds. Auton. Robots 2023, 47, 981–997. [Google Scholar] [CrossRef]
- Jin, C.; Tan, W.; Yang, J.; Liu, B.; Song, R.; Wang, L.; Fu, J. AlphaBlock: Embodied Finetuning for Vision-Language Reasoning in Robot Manipulation. arXiv 2023, arXiv:2305.18898. [Google Scholar]
- Cui, Y.; Niekum, S.; Gupta, A.; Kumar, V.; Rajeswaran, A. Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation? Proc. Mach. Learn. Res. 2022, 168, 893–905. [Google Scholar]
- Tang, C.; Huang, D.; Ge, W.; Liu, W.; Zhang, H. GraspGPT: Leveraging Semantic Knowledge From a Large Language Model for Task-Oriented Grasping. IEEE Robot. Autom. Lett. 2023, 8, 7551–7558. [Google Scholar] [CrossRef]
- Parakh, M.; Fong, A.; Simeonov, A.; Gupta, A.; Chen, T.; Agrawal, P. Human-Assisted Continual Robot Learning with Foundation Models. arXiv 2023, arXiv:2309.14321. [Google Scholar]
- Bucker, A.; Figueredo, L.; Haddadin, S.; Kapoor, A.; Ma, S.; Vemprala, S.; Bonatti, R. LATTE: LAnguage Trajectory TransformEr. In Proceedings of the IEEE International Conference on Robotics and Automation, 4 August 2023; pp. 7287–7294. [Google Scholar]
- Ren, P.; Zhang, K.; Zheng, H.; Li, Z.; Wen, Y.; Zhu, F.; Ma, M.; Liang, X. RM-PRT: Realistic Robotic Manipulation Simulator and Benchmark with Progressive Reasoning Tasks. arXiv 2023, arXiv:2306.11335. [Google Scholar]
- Xiao, T.; Chan, H.; Sermanet, P.; Wahid, A.; Brohan, A.; Hausman, K.; Levine, S.; Tompson, J. Robotic Skill Acquisition via Instruction Augmentation with Vision-Language Models. Proc. Mach. Learn. Res. 2023, 19, 1–18. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Lin, H.; Xue, X.; Fu, Y. WALL-E: Embodied Robotic WAiter Load Lifting with Large Language Model. arXiv 2023, arXiv:2308.15962. [Google Scholar]
- Shen, W.; Yang, G.; Yu, A.; Wong, J.; Kaelbling, L.P.; Isola, P. Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation. Proc. Mach. Learn. Res. 2023, 229, 1–18. [Google Scholar]
- Sharma, S.; Shivakumar, K.; Huang, H.; Hoque, R.; Imran, A.; Ichter, B.; Goldberg, K. From Occlusion to Insight: Object Search in Semantic Shelves Using Large Language Models. arXiv 2023, arXiv:2302.12915. [Google Scholar]
- Mees, O.; Borja-Diaz, J.; Burgard, W. Grounding Language with Visual Affordances over Unstructured Data. In Proceedings of the IEEE International Conference on Robotics and Automation, 4 October 2023; pp. 11576–11582. [Google Scholar]
- Xu, Y.; Hsu, D. “Tidy Up the Table”: Grounding Common-Sense Objective for Tabletop Object Rearrangement. arXiv 2023, arXiv:2307.11319. [Google Scholar]
- Nanwani, L.; Agarwal, A.; Jain, K.; Prabhakar, R.; Monis, A.; Mathur, A.; Jatavallabhula, K.M.; Abdul Hafez, A.H.; Gandhi, V.; Krishna, K.M. Instance-Level Semantic Maps for Vision Language Navigation. In Proceedings of the 2023 32nd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Busan, Republic of Korea, 28–31 August 2023; pp. 507–512. [Google Scholar] [CrossRef]
- Yu, B.; Kasaei, H.; Cao, M. L3MVN: Leveraging Large Language Models for Visual Target Navigation. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Detroit, MI, USA, 1–5 October 2023; pp. 3554–3560. [Google Scholar]
- Kanazawa, N.; Kawaharazuka, K.; Obinata, Y.; Okada, K.; Inaba, M. Recognition of Heat-Induced Food State Changes by Time-Series Use of Vision-Language Model for Cooking Robot. Lect. Notes Networks Syst. 2024, 795, 547–560. [Google Scholar] [CrossRef]
- Seenivasan, L.; Islam, M.; Kannan, G.; Ren, H. SurgicalGPT: End-to-End Language-Vision GPT for Visual Question Answering in Surgery. In Proceedings of the 26th International Conference, Vancouver, BC, Canada, 8–12 October 2023. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: A Compact Task-Agnostic BERT for Resource-Limited Devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2158–2170. [Google Scholar] [CrossRef]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv 2020, arXiv:2101.00027. [Google Scholar]
- Wang, B.; Komatsuzaki, A. GPT-J 6B. Available online: https://github.com/kingoflolz/mesh-transformer-jax (accessed on 13 August 2024).
- Liu, Y.; Zhang, K.; Li, Y.; Yan, Z.; Gao, C.; Chen, R.; Yuan, Z.; Huang, Y.; Sun, H.; Gao, J.; et al. Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models. arXiv 2024, arXiv:2402.17177. [Google Scholar]
- Azeem, R.; Hundt, A.; Mansouri, M.; Brandão, M. LLM-Driven Robots Risk Enacting Discrimination, Violence, and Unlawful Actions. arXiv 2024, arXiv:2406.08824. [Google Scholar]
- Rebedea, T.; Dinu, R.; Sreedhar, M.; Parisien, C.; Cohen, J. NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails. arXiv 2023, arXiv:2310.10501. [Google Scholar]
- Wu, X.; Chakraborty, S.; Xian, R.; Liang, J.; Guan, T.; Liu, F.; Sadler, B.M.; Manocha, D.; Bedi, A.S. Highlighting the Safety Concerns of Deploying LLMs/VLMs in Robotics. arXiv 2024, arXiv:2402.10340. [Google Scholar]
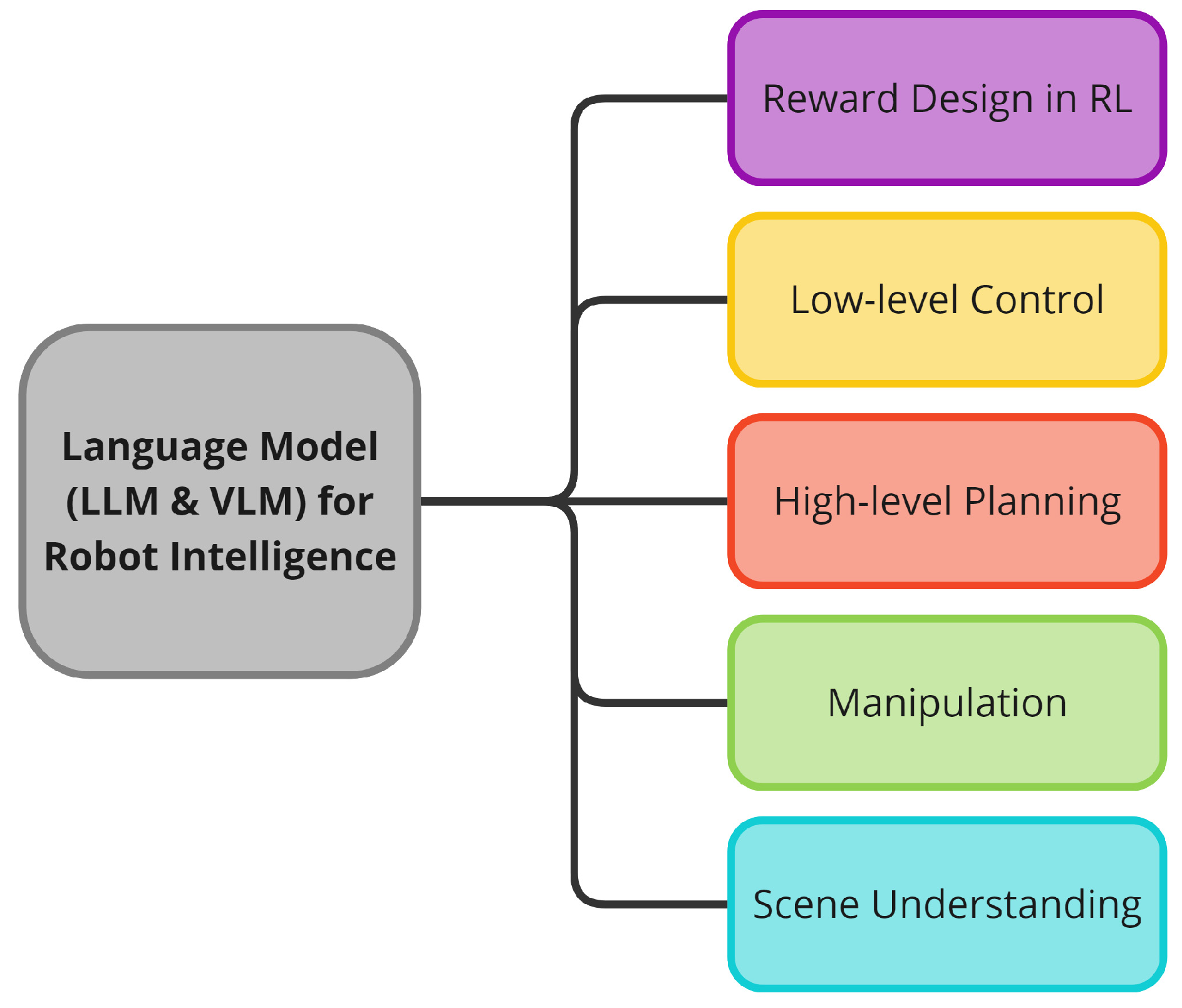
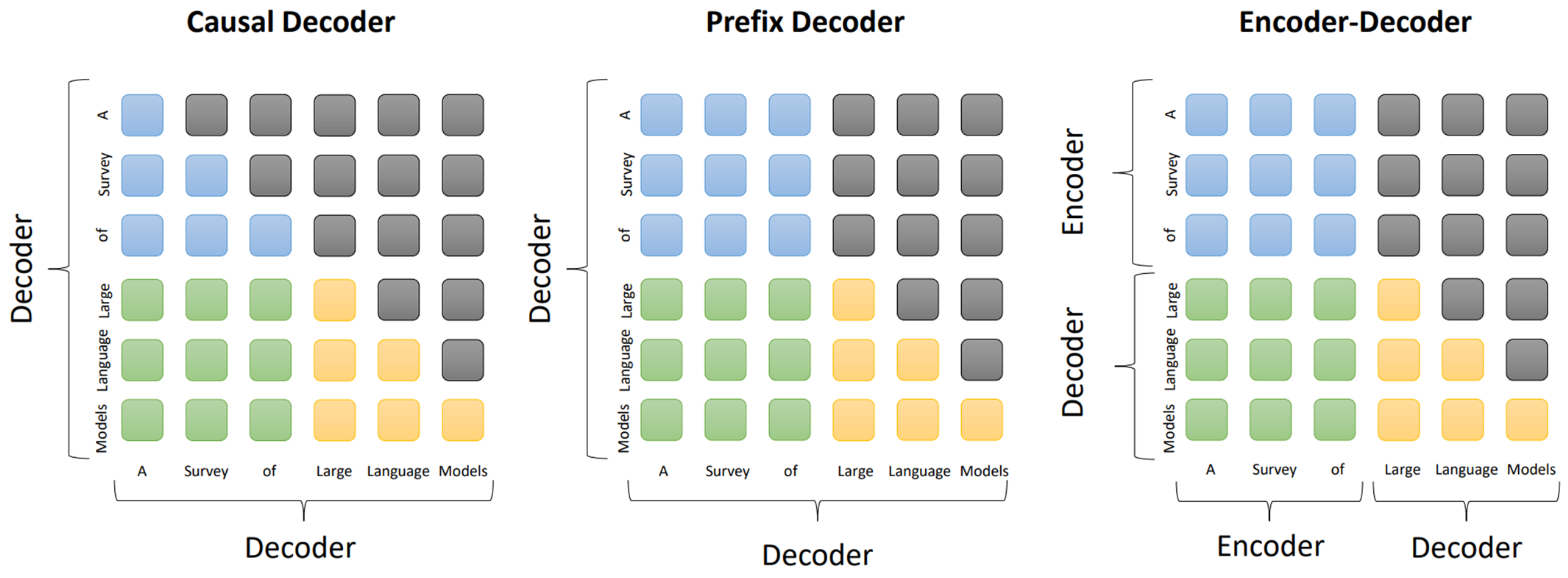
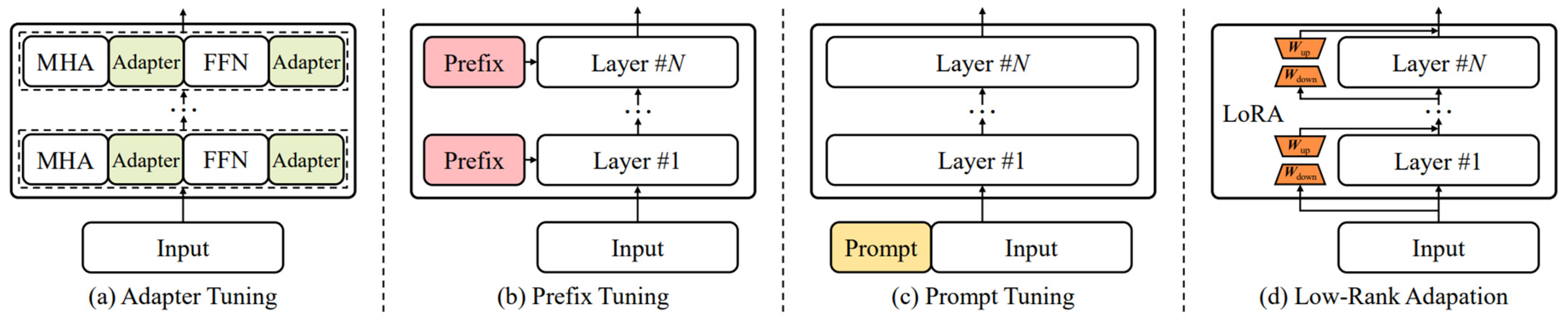
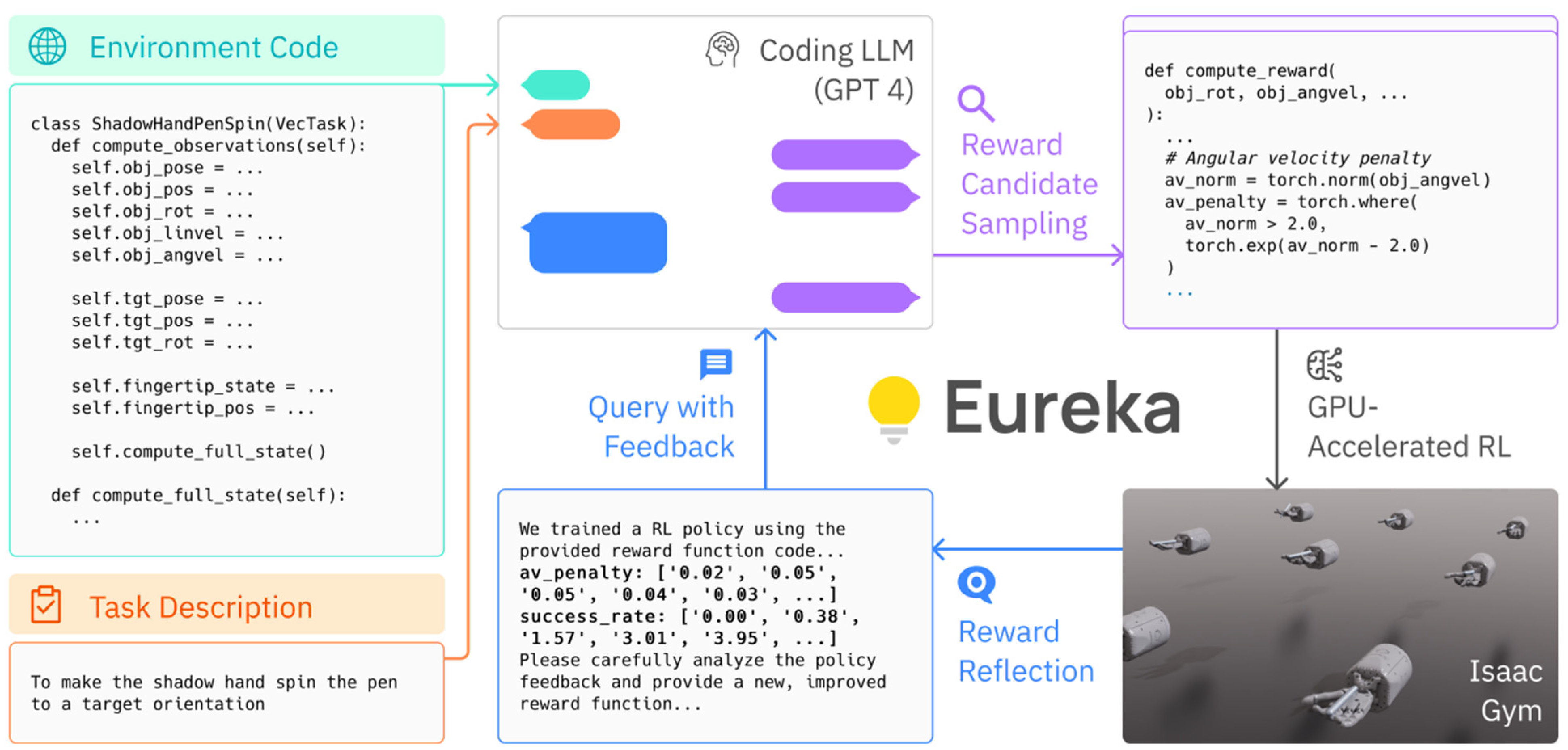
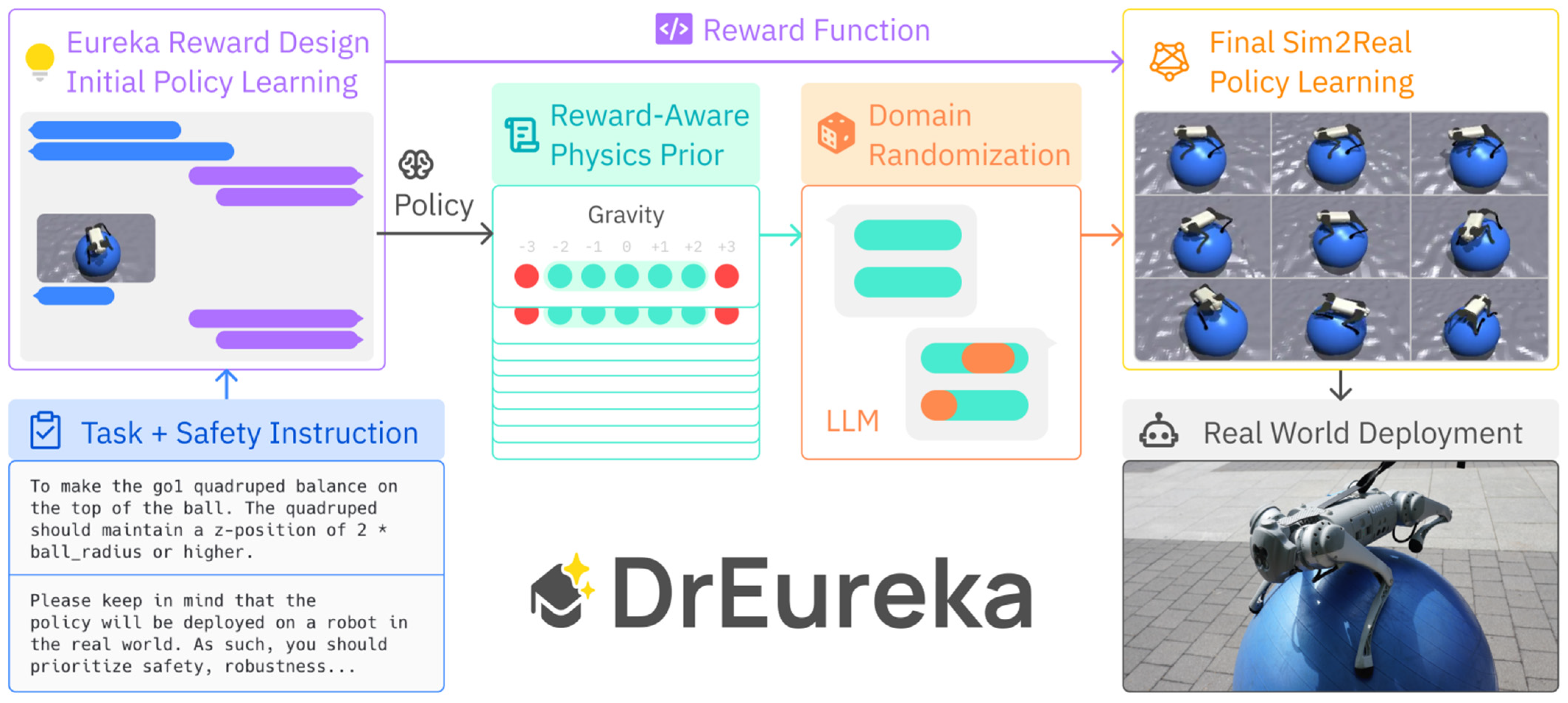
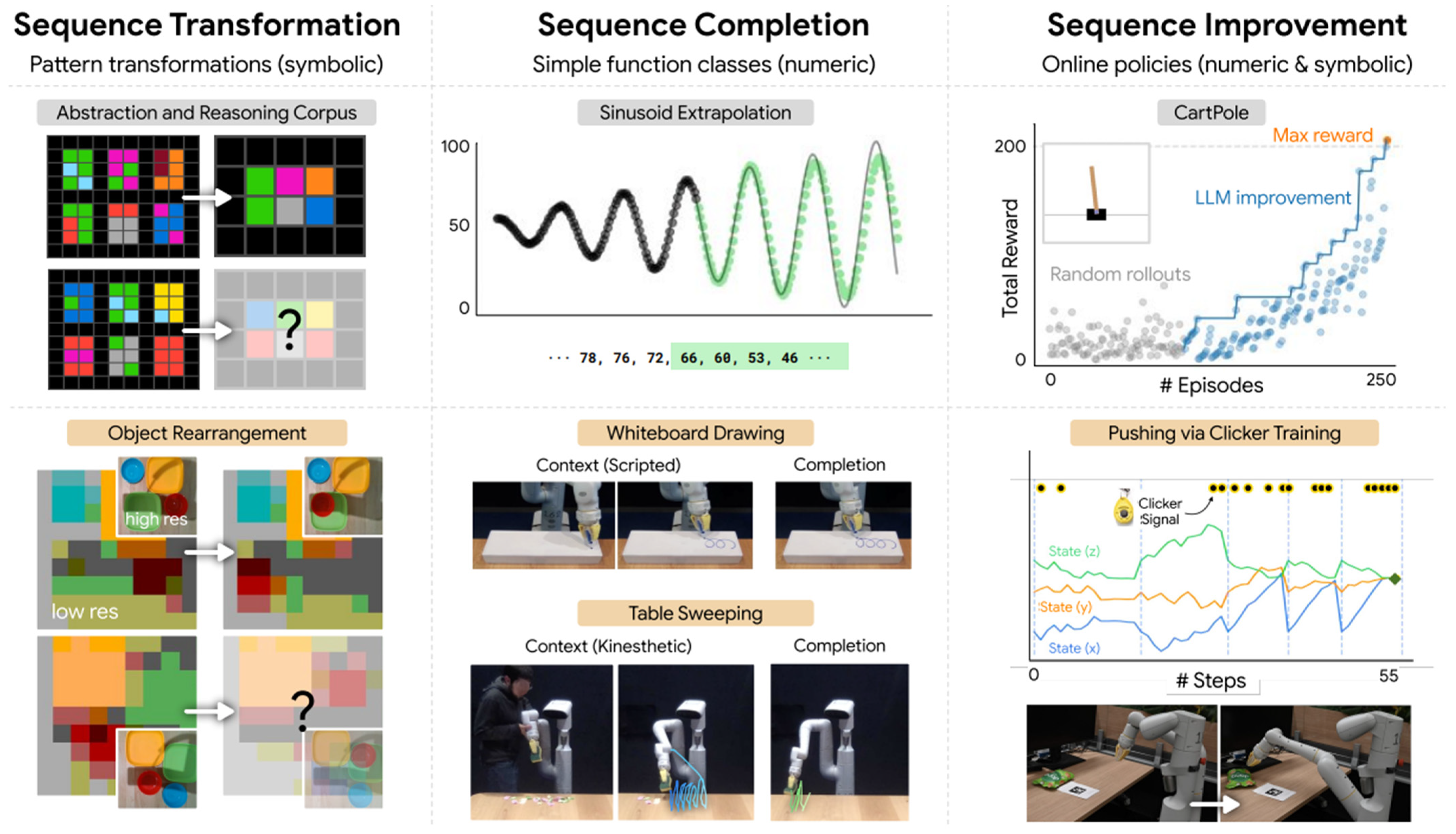
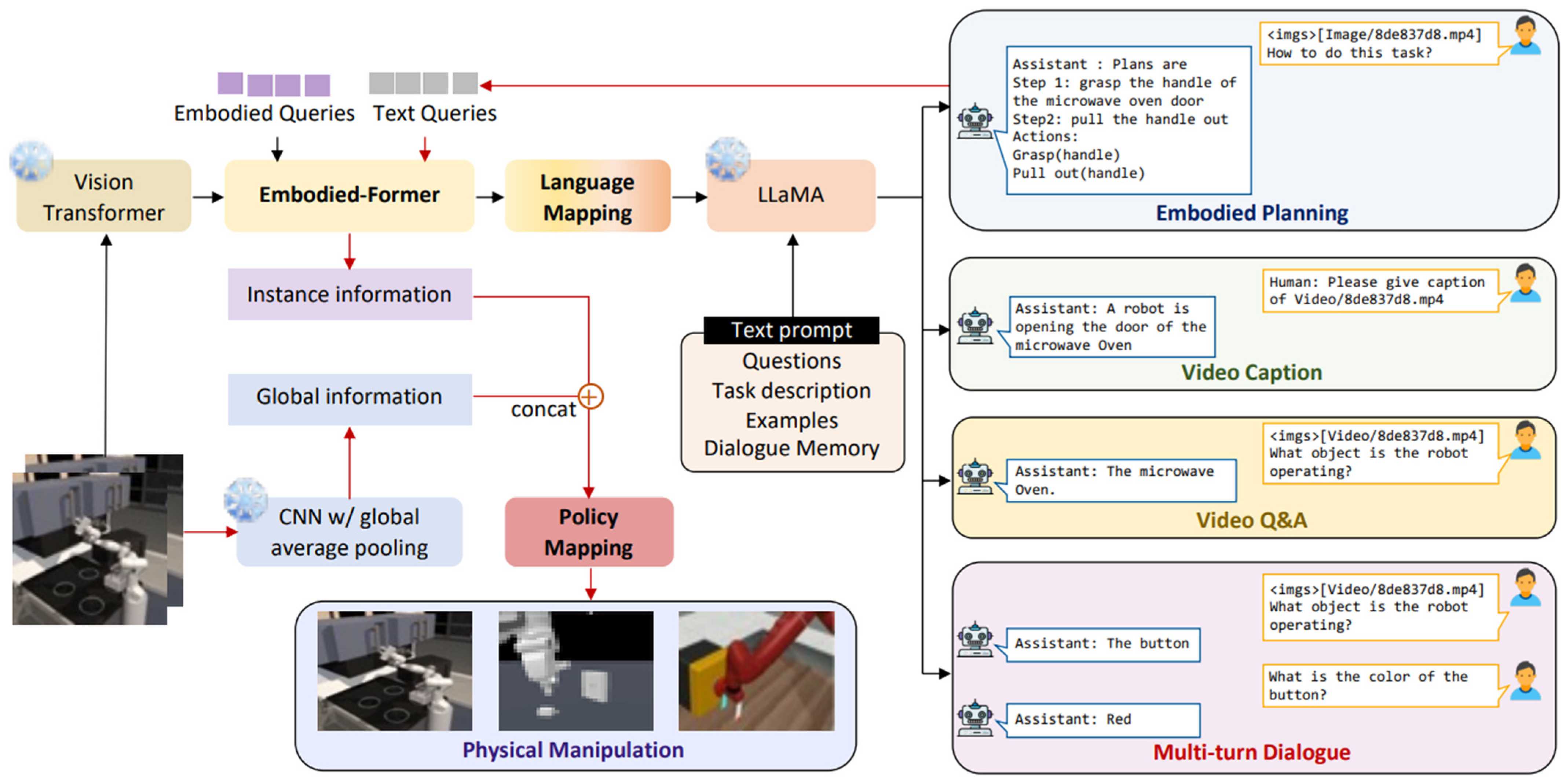
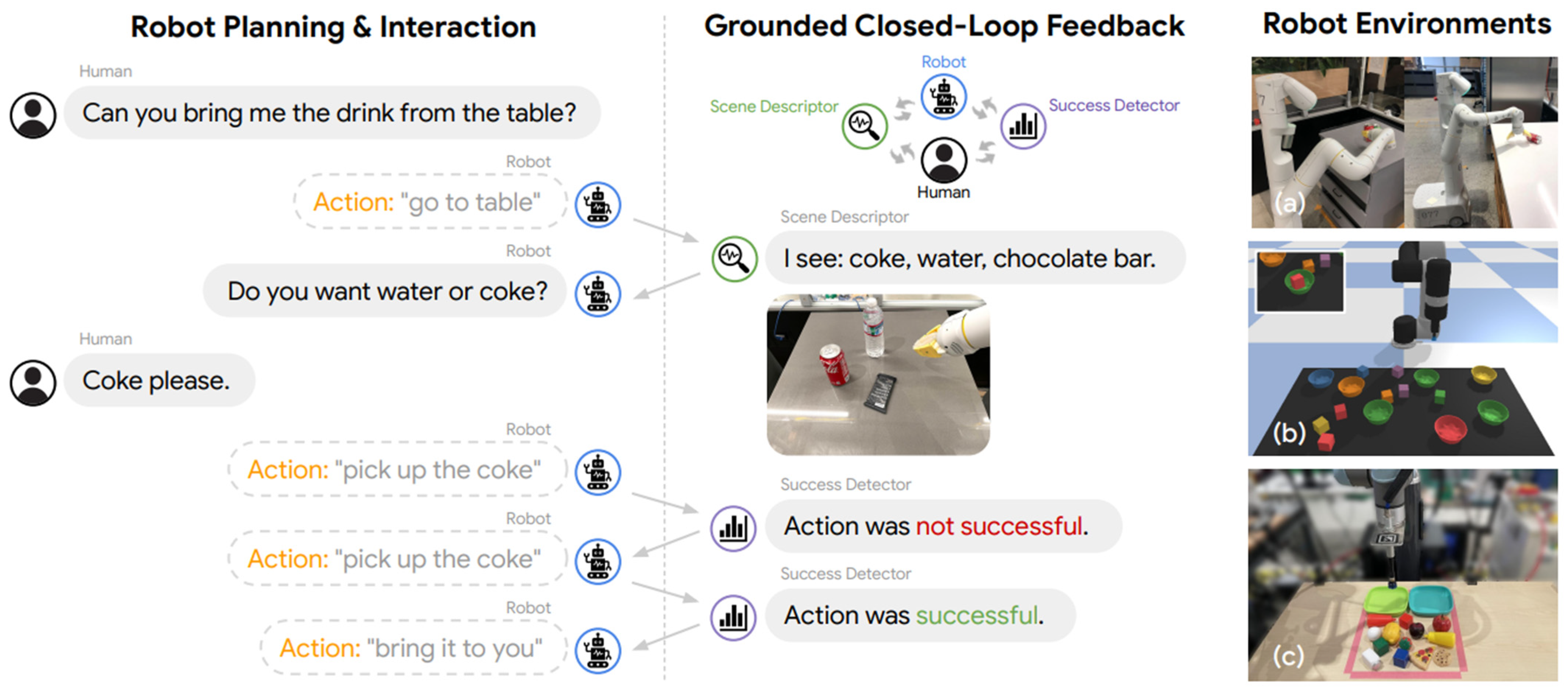
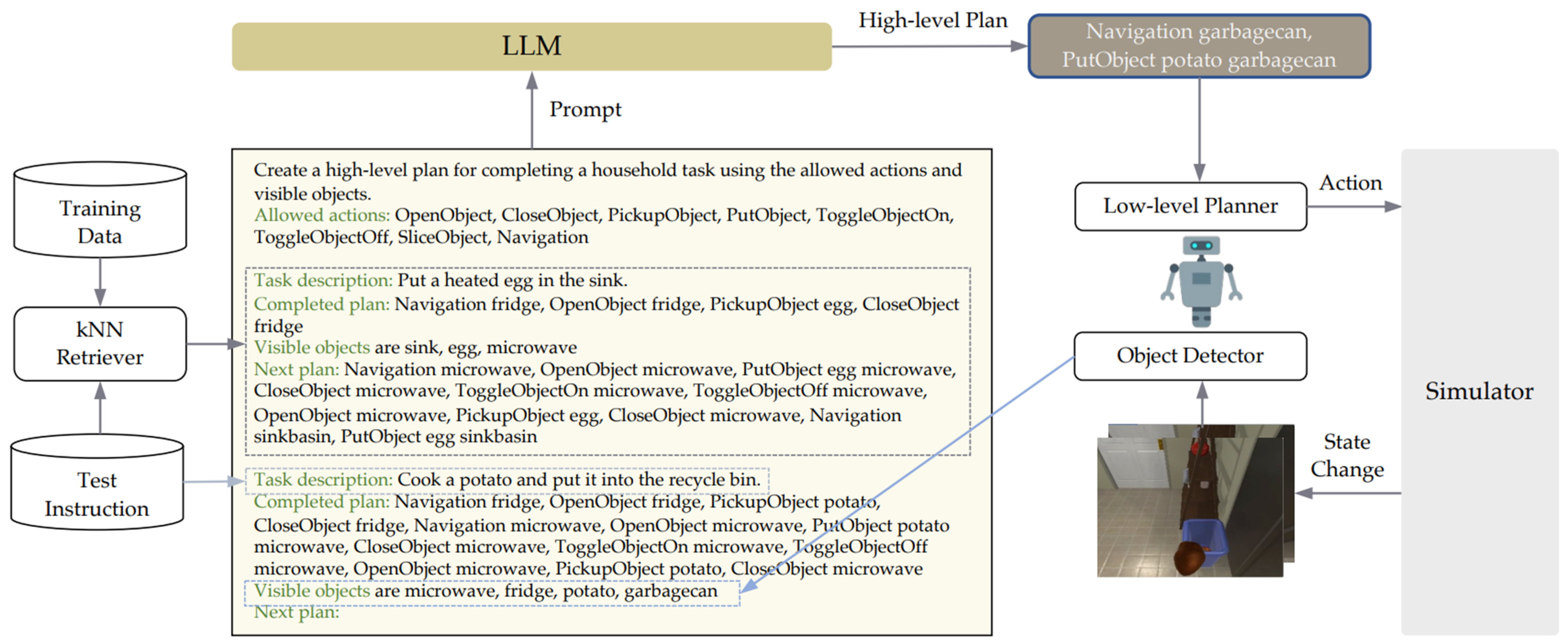
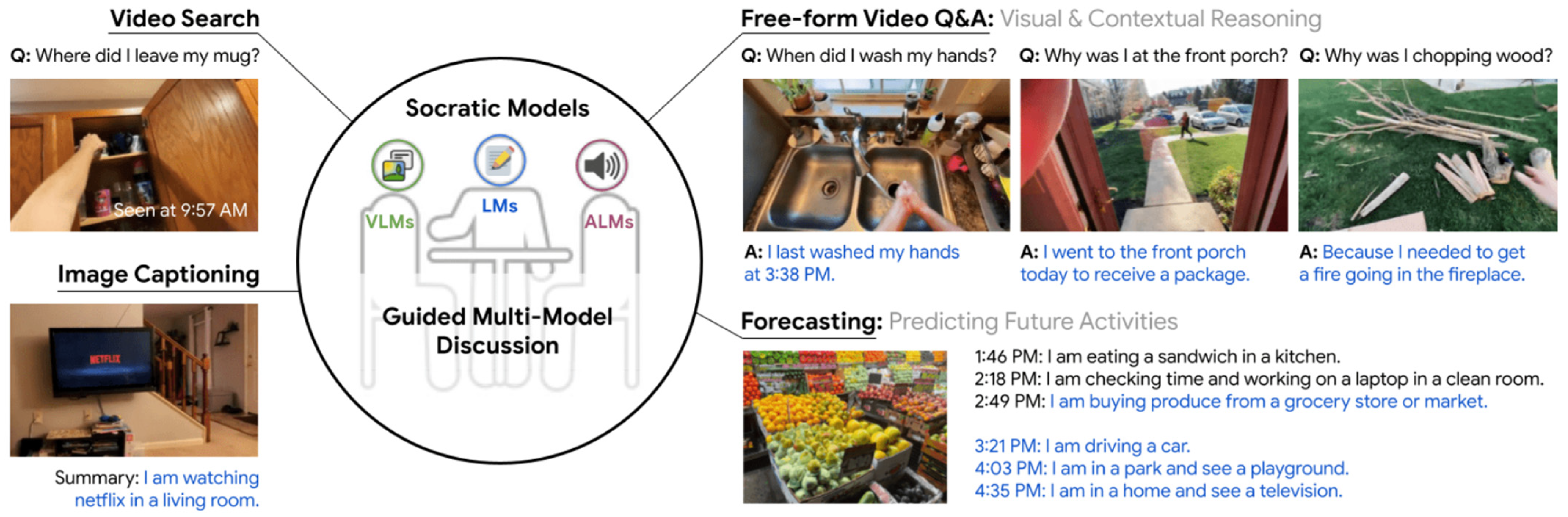
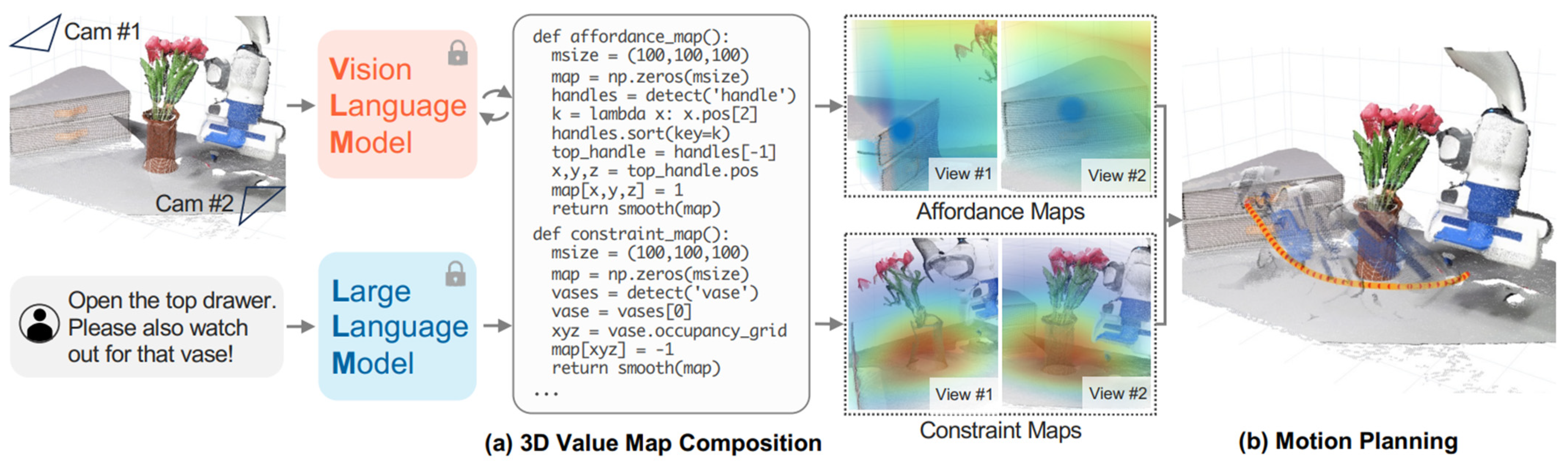
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).