Abstract
Multi-Label Classification refers to the classification task where a data sample is associated with multiple labels simultaneously, which is widely used in text classification, image classification, and other fields. Different from the traditional single-label classification, each instance in Multi-Label Classification corresponds to multiple labels, and there is a correlation between these labels, which contains a wealth of information. Therefore, the ability to effectively mine and utilize the complex correlations between labels has become a key factor in Multi-Label Classification methods. In recent years, research on label correlations has shown a significant growth trend internationally, reflecting its importance. Given that, this paper presents a survey on the label correlations in Multi-Label Classification to provide valuable references and insights for future researchers. The paper introduces multi-label datasets across various fields, elucidates and categorizes the concept of label correlations, emphasizes their utilization in Multi-Label Classification and associated subproblems, and provides a prospect for future work on label correlations.
1. Introduction
With the rapid growth of internet data, the content contained in data objects is becoming increasingly rich, and the label information is correspondingly becoming more complex. To better understand and analyze data, researchers have conducted studies related to classification tasks. The goal of classification tasks is to train models using training samples of known categories and use the obtained model to predict the categories of unknown samples [1]. Traditional classification methods typically deal with single-label classification problems, where each sample is associated with only one label. However, in practical applications, classification tasks often involve complex data objects, where samples may be assigned multiple labels simultaneously [2]. Based on the number of labels, such data is referred to as multi-label data. Compared to single-label data, multi-label data can more accurately capture the ambiguity of objects in the real world. Methods for classifying multi-label data, known as Multi-Label Classification (MLC) methods, have become a prominent research focus [3].
A straightforward approach to addressing the MLC problem is to treat labels independently, transforming the multi-label problem into a set of binary classification tasks [4], where the presence of each label in a sample is predicted separately. However, this method overlooks the fact that, in real-world multi-label data, labels are not independent of one another but instead exhibit certain relationships [5]. For instance, some labels might frequently co-occur, while others may be mutually exclusive. This interdependence among labels is referred to as label correlations. Label correlations are a crucial characteristic of MLC. Effective utilization of label correlations can significantly enhance the MLC process and help learn more effective and robust classifiers [6]. If there is a strong dependency between two labels, and , instances associated with label are likely also to possess label . Therefore, when a classifier predicts that an instance has a certain label, it can also estimate the likelihood of the instance having other strongly correlated labels. Multi-label Data has become increasingly common in modern applications, with major challenges including high-dimensional feature spaces and a large, sparse label space. High-dimensional data often contains complex label correlations and feature redundancy, which further complicates classification, while the sparsity of the label space leads to label imbalance in MLC. Additionally, noisy data in some datasets can severely affect model performance. To address complex label correlations and redundant features resulting from high-dimensional data, Fan et al. [7] proposed a multi-label feature selection method, Learning Correlated and Independent Feature Selection (LCIFS), which simultaneously explores label correlations and regulates feature redundancy. To tackle incomplete label sets, Zhou et al. [8] introduced an updated Correlation-Enhanced Feature Learning (uCeFL) approach for MLC. To address label noise, Qin et al. [9] proposed a novel multi-label feature selection method called AGLE. This method leverages adaptive graph learning and label information enhancement to mitigate label noise and has been validated across multiple datasets. In this context, leveraging label correlations can effectively reduce classifier complexity, minimize the number of incorrectly predicted labels, mitigate the impact of noisy labels, and improve classification performance. Additionally, in some large-scale datasets, the sparsity of positive samples for certain labels poses a class imbalance challenge, which can lead to a decline in prediction performance for rare labels during training and generalization. Particularly in Extreme Multi-Label Text Classification (XMTC) tasks, which aim to assign relevant labels to unseen texts from a large-scale label set, challenges arise from the massive number of labels and the inherent complexity of the task. These challenges often include imbalanced label distribution, difficulties in feature extraction, and substantial computational resource consumption. Therefore, effectively exploring and utilizing label correlations has become a crucial research question. The comprehensive exploration and effective utilization of label correlations have been proven to be a key approach for improving the performance and generalization ability of MLC [10], and have become a significant research focus in this field.
The application of label correlations is extensive, and their potential value should not be underestimated. With the development of deep learning technologies, Graph Convolutional Networks (GCNs) have been proven to be an effective approach for studying label correlations in Multi-Label Image Classification (MLIC) [11]. Graph-based methods have also found wide application in the field of MLC, as they can model label correlations [12]. Modeling label correlations can not only significantly improve MLC performance but also contribute to various domains such as recommender systems [13], information retrieval [14,15], and social networks [16]. For instance, in recommender systems where the interest information of new users is sparse, label correlations can be used to expand user interests, thereby enhancing the diversity of recommendation results. When retrieving resources using tags, similar tags can be displayed to discover more diverse retrieval results. In social networks, label correlations can be used to analyze user relationships, improving the quality of user recommendations and social connections. By analyzing users’ tagging behaviors, the system can recommend users who have similar tags in interests or activities, thus fostering more meaningful social relationships.
Currently, numerous researchers have proposed various strategies to learn and utilize label correlations. However, there is still a lack of review articles systematically summarizing the research progress on label correlations. In view of this, this paper focuses on label correlations in MLC, providing a comprehensive and systematic review of related work. The literature was primarily retrieved using academic search tools such as Google Scholar, Web of Science, and ScienceDirect, with keywords such as “Multi-Label Classification” and “Label Correlation”. A total of 88 articles, published in the last decade and highly relevant to the application of label correlations in multi-label tasks, were selected for analysis. The contributions of this paper include investigating and analyzing Multi-Label Learning (MLL) methods that incorporate label correlations, presenting different types of label correlations, methods for mining label correlations, and summarizing the applications of label correlations in MLC and its subproblems. The aim is to provide useful references and inspiration for future researchers.
2. Overview of Label Correlation
In the real world, multi-label data is prevalent and widely applied across various domains. As the number of labels in data continues to increase, the relationships between labels have become increasingly complex. Given the ubiquity and practical significance of multi-label data, the issue of label correlations has garnered increasing attention from the academic community. This chapter will first introduce the basic concepts of multi-label data and then categorize the related label correlations.
2.1. Multi-Label Data
According to the processing of data features, multi-label data can be divided into two categories. First, one category comprises data that has undergone preprocessing and feature engineering. The features of such datasets are already prepared, making them ready for direct input into machine learning algorithms for training and application. Second, the other category consists of raw, unprocessed data, such as text, images, audio, or video in various formats. These datasets typically require feature extraction and are suitable for deep learning models that can automatically learn data features.
Table 1 presents several multi-label datasets from various application domains. The Label Cardinality (LC) denotes the average number of labels associated with each instance, as indicated in Equation (1). Here, denotes the label vector corresponding to instance , and represents the number of instances in the dataset

Table 1.
MLC datasets in different domains.
In the following, these two types of datasets are introduced, which more or less imply the key feature of label correlations.
The CAL500 [17] dataset is a music dataset consisting of 500 songs. It includes a total of 174 music-related labels, with each song annotated with multiple labels. The Yeast [18] dataset represents individual yeast genes, comprising a total of 2,417 yeast genes. Each gene is associated with a group of labels representing gene functions, annotated with one or more of the 14 gene functions. The Medical [19] dataset comprises 978 medical case reports, each labeled with one or more of the 45 disease codes, and is primarily used for text classification tasks. The Delicious [20] dataset contains 16,105 web pages of text data along with their labels. The Tmc2007 [21] dataset belongs to the aviation flight safety report dataset, containing 28,596 aviation safety text reports and 22 labels representing flight problem types. The PubMed dataset [22], maintained by the U.S. National Library of Medicine (NLM), contains a vast collection of biomedical literature, covering medical information networks, life science journals, and online books. In addition to providing literature retrieval services, PubMed classifies and indexes documents using MeSH (Medical Subject Headings), a vocabulary of over 26,000 medical terms organized in a hierarchical structure.
Another type of dataset suitable for deep learning multi-label tasks includes Pascal VOC2007 [23] and MS COCO2014 [24]. The Pascal VOC dataset is primarily used for object detection, image classification, and semantic segmentation tasks. It contains a total of 9963 images, with 5011 images in the training and validation sets and 4952 images in the test set, covering 20 label categories. In addition, MS COCO is a large-scale computer vision dataset used for tasks such as object recognition, object detection, and image segmentation. It includes over 123,000 annotated images across 80 different object categories, with an average of 2.9 label categories per image. This dataset encompasses a wide range of everyday objects, such as people, animals, vehicles, and food.
In summary, we list multi-label datasets primarily to demonstrate the scope and diversity of MLC problems across various domains. Through these datasets, researchers can better understand the complexity of multi-label problems in real-world scenarios and how to design and evaluate MLC algorithms accordingly. Effectively leveraging label correlations to address issues such as high-dimensional features and label imbalance in multi-label data can not only improve model performance but also facilitate more efficient application to downstream tasks.
2.2. Introduction to Label Correlation
Label correlations refers to the relationship between labels in MLC. In MLC, one of the keys to improving classification performance is the effective utilization of the complex correlations among output labels [25,26,27]. The quality of model performance often depends on the effective utilization of label correlations. Labels typically exhibit complex relationships, including rich semantic information, hierarchical structures, various intricate associations, and ambiguities. Efficiently leveraging label correlations can assist the model in better learning feature representations, thereby improving feature representation, enhancing prediction accuracy, reducing feature dimensionality and noise impact, boosting model generalization ability and training efficiency, and optimizing model complexity. In practical applications, the specific impact of label correlations on model performance can be empirically validated through experiments, and adjustments and optimizations can be made based on actual requirements. Most current methods, in the process of exploring label correlations, usually abstract the complex relationships between labels further and reduce them to a “co-occurrence” relationship. When two label objects frequently appear together, they are considered to have a strong positive association. Previous methods mostly use co-occurrence information between labels [28,29] to model the degree of correlation between different labels. If a model algorithm can effectively learn the potentially valuable information present among various labels, it will be easier to distinguish between such “co-occurring” labels. For instance, Wang et al. [30] proposed a novel multi-label analysis method (CXR×MLAGCPL) for analyzing chest X-ray (CXR) images, which effectively learns the valuable information among various pathologies and aids in distinguishing co-occurring pathologies. Zhu et al. [31] noted that although graph-based methods perform well in MLC tasks, they only calculate the co-occurrence probabilities between label pairs and overlook higher-order label associations. To address this issue, they proposed a MLC method called DGCL, which aims to leverage both second-order and higher-order label associations to generate label-specific features. Additionally, this method updates the two types of label semantic relationships through a contrastive learning objective.
However, in real-world scenarios, labels are not just simply co-occurring in the same entity or data; they may also exhibit mutually exclusive relationships. This mutually exclusive relationship means that certain labels are logically or practically unlikely to appear together in the same entity or scenario. Therefore, according to the nature of the interrelationships between labels, label co-occurrence relationships can be classified as positive label correlations, while mutually exclusive relationships can be classified as negative label correlations.
Furthermore, some research works classify label correlations based on their applicable scope, i.e., the granularity of sharing. Specifically, when label correlations apply to the entire data sample set, they are referred to as global label correlations; when they apply only to local data subsets, they are referred to as local label correlations. As shown in Figure 1, the following section will classify label correlations based on the two dimensions of the nature of label correlations and the granularity of sharing, and introduce each type of label correlations.
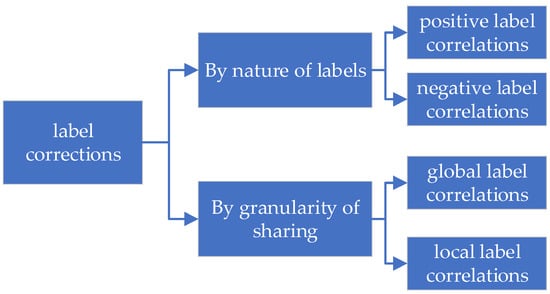
Figure 1.
Classification of label correlations.
2.2.1. Classification of Label Correlation Based on the Nature of Interrelationships
In multi-label data, labels are not independent; there are correlations between them. Utilizing label correlations effectively is a key means of improving MLC methods [32]. Based on the nature of label relationships, label correlations can be divided into positive and negative correlations.
- (1)
- Positive Label Correlation
Previous methods of utilizing label correlations have typically focused on the positive promotion between labels. Specifically, when an object is assigned a particular label, it often tends to simultaneously have other labels associated with that label. As shown in Figure 2a, an image labeled as “ship” is more likely to also be labeled as “ocean”. Such mutually reinforcing label relationships are referred to as positive label correlations. When dealing with multi-label datasets, positive label correlations often manifest as label co-occurrence, where multiple related labels appear simultaneously in the same data instance.

Figure 2.
Examples of positive and negative label correlations. (a) Examples of positive label correlations; (b) Examples of negative label correlations.
- (2)
- Negative Label Correlation
In practical applications, the presence of one label for an instance may indicate a lower likelihood of it having another label, or the absence of a label may increase the probability of the instance having a different label. This phenomenon is referred to as label negative correlation, and labels exhibiting strong negative correlations are known as mutually exclusive labels. For example, in the emotional labels of music, a sad song may evoke feelings of sadness and sorrow but is unlikely to bring joy to the listener. This example reflects the positive correlation between the labels “sadness” and “sorrow” as well as the mutually exclusive relationship between the labels “sadness” and “joy”. Similarly, as shown in Figure 2b, the label “bicycle” is highly unlikely to appear in the same scene as the labels “ocean” and “dining table”. Experiments have demonstrated that incorporating negative label correlations in multiple datasets positively impacts improving MLC performance [33].
2.2.2. Classification Based on Granularity of Sharing
In MLL, the granularity of sharing for label correlations defines the extent or scope to which label correlations are shared across the entire multi-label dataset. The granularity of sharing describes whether label correlations are shared among all samples or only among a subset of samples. Based on the granularity of sharing, label correlations can be classified into global label correlations and local label correlations.
- (1)
- Global Label Correlation
Global label correlations refers to label correlations that apply to the entire dataset. Traditional MLC methods that incorporate label correlations typically impose these correlations on all data samples [20,21,22,23,24], assuming that the mined label correlations are universally applicable. However, in various real-world scenarios, this global assumption often has limitations. Its overly broad applicability can lead to unnecessary erroneous predictions. These mispredictions usually manifest as predictions of irrelevant labels, thereby compromising the model’s performance.
- (2)
- Local Label Correlation
In real-world tasks, there are cases where certain label correlations only apply to local subsets of data, rather than to the entire dataset. For example, in a news dataset, from technology-related articles, we may observe a high correlation between the labels “Apple” and “Tim Cook”, while in lifestyle news, the “Apple” is highly correlated with “Fruit”. This example illustrates that in different contextual environments, such as technology and lifestyle domains, “Apple” exhibits different label relationships, indicating that label relationships derived from specific domains and contexts are not generalizable and should not be shared by all data.
Addressing this issue, Huang and Zhou et al. [34] first introduced the concept of local label correlations in 2012, suggesting that there are label correlations that are only applicable to local subsets of data in practical tasks, rather than to the entire dataset. Subsequent work has studied local label correlations [32,35,36] and experimentally demonstrated that considering local label correlations positively impacts model performance.
3. Label Correlation Mining Methods
Currently, methods for mining label correlations can be roughly divided into three categories: label graph-based methods, label sequences-based methods, and joint distribution methods. The three categories of methods are described specifically in the following.
3.1. Label Graph-Based Methods
Using graph structures to model relationships between labels is an effective method [37,38]. When constructing label graph structures, each label is considered as a vertex in the graph, and the relationships between labels are represented by edges. To quantify the strength of these relationships, the edges in the graph are typically assigned corresponding weights based on label co-occurrence frequency, conditional probability, and other related information, reflecting the correlations between labels. Furthermore, for a more accurate exploration of label correlations, it is necessary to consider the complex relationships between labels. This includes analyzing label co-occurrence or exclusion relationships present in specific datasets or scenarios [28,39], which can reveal the latent interdependence or exclusionary characteristics between labels. Additionally, labels may also be organized in a hierarchical tree structure, forming hierarchical relationships [40]. This hierarchical relationship aids in describing the logical and semantic connections between labels. Graph structures, as a flexible and powerful modeling tool, can effectively model not only single types of label relationships but also integrate various types of label relationships.
In the early stages of research, researchers primarily focused on exploring the hierarchical relationships between labels and used tree structures or more complex directed acyclic graphs to reveal these relationships. In the process of constructing hierarchical structures for labels, researchers often relied on external prior knowledge, such as various knowledge graphs and common-sense semantic networks, to provide clues about the hierarchical relationships between labels. For example, commonly used lexical semantic networks like WordNet [41] and ConceptNet [42] provide rich hierarchical relationship information for MLC tasks. Marszalek et al. [43] extracted synonym sets corresponding to category labels from WordNet and then utilized WordNet’s hypernym-hyponym relationships and part-whole relationships to provide two types of semantic hierarchical relationships, thus constructing a comprehensive label semantic hierarchy graph that considers multiple relationships. Based on this label hierarchy graph, they designed a semantic hierarchy classifier for visual object detection, successfully integrating the relevance of image labels in visual recognition tasks.
Later, Deng et al. [44] proposed a new representation structure based on WordNet, called HEX graph, which simultaneously characterizes three types of relationships between labels: exclusion, co-occurrence, and hierarchy. As shown in Figure 3, the labels “Dog” and “Cat” indicate a mutually exclusive relationship, meaning that these two categories cannot simultaneously apply to the same object instance. The overlapping area between the labels “Husky” and “Puppy” represents a co-occurrence relationship, indicating that a single “Puppy” can be classified as both a “Husky” and a “Dog”. Additionally, the label “Dog”, as a parent class of “Husky” and “Puppy”, illustrates a hierarchical relationship, where one label encompasses another. This work was the first to jointly model label hierarchy and label exclusion relationships. Ding et al. [37] further extended the HEX graph to allow for the introduction of soft or probabilistic relationships between labels. Additionally, Hu et al. [45] also extracted structured label relationships by parsing relationships in WordNet, including positive and negative label correlations, and then generated a label relationship graph to enhance the inference process of neural networks.
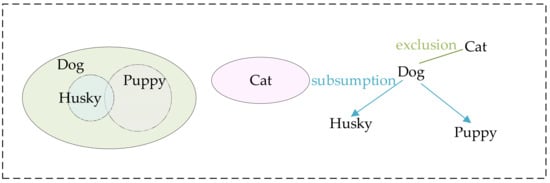
Figure 3.
The HEX structure diagram illustrates three distinct types of relationships among different labels [44].
The commonality among the aforementioned works is the use of WordNet as an external knowledge source for label relationships, leveraging this prior knowledge to construct a hierarchical structure graph of labels and guide learning tasks. When label hierarchy structures exist naturally or can be obtained externally, integrating this knowledge to guide traditional supervised learning is beneficial. In practical applications, such as text classification [46] and gene function prediction [47], introducing label hierarchies can help to improve prediction accuracy. These methods typically assume a hierarchical structure for labels and use hierarchical clustering [48] or Bayesian networks [49] to construct label hierarchy graphs. Silvestri et al. [22] proposed the Hierarchical Deep Neural Network (HDNN), which is specifically well-suited for XMTC tasks and for large-scale datasets with hierarchical label structures, such as the PubMed dataset. The researchers argue that when the label hierarchy is known, embedding it directly into the network topology not only improves classification performance but also enhances the interpretability of results, especially in terms of revealing hierarchical relationships.
However, in many application scenarios, it is difficult to form a standardized hierarchical structure between labels, or a hierarchical structure may not even exist. Additionally, when it comes to domain knowledge, external knowledge sources may not provide comprehensive label relationships, and manually constructing a label hierarchy graph requires expert knowledge and is time-consuming. Given the limited generality of label hierarchy graphs, recent works have shifted towards using ordinary graph structures to model more commonly occurring label co-occurrence relationships.
In many fields, MLC tasks often lack a predefined label graph structure, which necessitates constructing a label correlation matrix in a data-driven way to build a label graph. Using this graph, some approaches use Graph Convolutional Networks (GCN) to encode label correlations. Zhang et al. [50] proposed constructing a label graph based on label co-occurrence data and utilized DeepWalk to learn low-dimensional representations of label nodes, effectively addressing label sparsity in large-scale MLC. Chen et al. [28] introduced the ML-GCN framework, which captures global label correlations by leveraging insights from co-occurrence data. This approach uses GCN to map label word embeddings to a set of interdependent target classifiers, which are directly applied to image features for classification. Similarly, Liu et al. [25] utilized GCN’s mapping function to learn interdependent object classifiers, aiming to model higher-order label relationships and enhance performance in text-based MLC models. To improve the accuracy of chest X-ray image classification, Wang et al. [30] employed a data-driven approach to create two types of association matrices: a local adaptive graph and a global co-occurrence graph. These matrices are used to capture local correlations between categories and global co-occurrence relationships between categories, respectively.
However, estimating label correlations by co-occurring labels in training data may lead to overfitting. Furthermore, when certain labels have few positive instances in the training data, the co-occurrence information of labels is not reliable. To address this, Wang et al. [29] proposed the KSSNet method, which overlays a prior knowledge-based label graph onto a statistical-based label graph to construct the final label graph, instead of solely relying on label co-occurrence information as in ML-GCN. Additionally, unlike traditional graph-enhanced CNN approaches that utilize label system information only in the final recognition stage, the KSSNet method introduces shallow, medium, and deep lateral connections between CNN and GCN, injecting label system information into the backbone CNN for label perception in feature learning.
In contrast to schemes introducing prior knowledge, Li et al. [51] addressed the drawback of manually designing label graphs in ML-GCN by proposing an adaptive label graph module to learn global label correlations in an end-to-end manner. Ye et al. [52] proposed using heterogeneous graph Transformers to construct and learn label heterogeneous graphs, which combine label hierarchical structures with statistical relationships of label co-occurrence. Zhao et al. [53] proposed a Transformer-based model called TLC-XML, designed to address the XMTC task by leveraging label correlations within the label space. This model consists of three modules: First, it constructs a label association graph using the semantic and co-occurrence information of labels, grouping highly related labels together; Second, it applies a cluster association learning algorithm that utilizes Graph Convolutional Networks (GCN) to extract associations between different clusters; Finally, it employs a label interaction learning algorithm to integrate the original label predictions with information from neighboring labels.
In contrast to the aforementioned methods, Sun et al. [54] proposed the MLSF method, which models positive label correlations through meta-label learning. This method views meta-labels as collections of multiple labels, where member labels exhibit strong dependencies among themselves, while the dependencies with non-member labels are weaker. To identify the hidden meta-labels in the label space, the approach combines information from both the label space and the instance space when constructing the association matrix for the label graph, treating the association matrix as the edge matrix of the label graph. Subsequently, the label grouping problem is transformed into a graph cut problem, utilizing spectral clustering techniques to partition the label graph into K subgraphs, grouping highly correlated labels into a single subgraph, or meta-label. To leverage the correlations preserved within the meta-labels, classifier chains are constructed for each meta-label. However, the limitation of the MLSF method lies in the fact that when certain labels are missing from the training data, the meta-label learning phase may fail to capture comprehensive and accurate label relationships.
Overall, early research often leveraged external knowledge sources to construct hierarchical relationships among labels to exploit label correlations. However, the drawback of this approach is that when dealing with domain-specific multi-label datasets, existing external knowledge sources find it difficult to provide prior knowledge of label correlations for all labels within the dataset. Additionally, due to the varying semantic connotations of labels across different domains, the defined label relationships also exhibit significant differences. Therefore, directly adopting generic external knowledge sources in domain-specific datasets may lead to the introduction of incorrect label relationships. Although methods utilizing dataset statistics, such as label co-occurrence information, have been widely applied due to their generality and simplicity, these methods often yield biased label correlations in real-world scenarios with imbalanced label data, failing to reflect the true label correlations within the dataset. To overcome this limitation, supplementing statistical information with external prior knowledge has emerged as a viable approach. This method helps enhance the accuracy and reliability of label relationships.
3.2. Label Sequences-Based Methods
This approach views MLL as a label sequence prediction problem, incorporating label dependencies when constructing the label sequence. The key challenge is how to determine the optimal label sequence.
Read et al. [55] first introduced the Classifier Chains (CC) method in 2011. This approach stacks multiple binary classifiers in a chain structure and incorporates the outputs of all preceding classifiers in the chain as additional information into the feature space of the current classifier, leveraging these new features for training. This chain structure enhances MLL by capturing the implicit dependencies among labels. However, the performance of the CC method is highly sensitive to the order of labels in the chain, and during the prediction phase, error propagation may occur, introducing noise and reducing classification accuracy. To mitigate this drawback, the paper also proposed an ensemble version of the CC method, ECC [55]. The ECC method randomly generates multiple label sequences, calls the CC algorithm multiple times to train multiple classifier chains, and takes the ensemble result of all classifier chains when predicting new samples. Although the ECC method can eliminate the adverse effects of label order, it has a higher time complexity because the multiple binary classifiers on multiple classifier chains in ECC cannot be trained in parallel.
To address the issue of label ordering, Read et al. [56] proposed the MCC method, which uses a Monte Carlo approach to determine label sequences. Cheng et al. [57] extended the CC method by introducing the Probabilistic Classifier Chains (PCC) model, aimed at mitigating the error propagation problem while accounting for the conditional probabilities of different label combinations. Sun and Kudo [58] optimized the classifier chain order from the perspective of maximizing conditional likelihood. Liu and Tsang [59] used dynamic programming techniques to search for the globally optimal label order for CC. Since searching all different label orders to find the global optimum is very time-consuming, they further proposed a Greedy Classifier Chain algorithm to find a locally optimal label order to accelerate the search speed. It is important to emphasize that in MLC, the size of the label set increases exponentially with the number of labels, especially in MLC problems with a large number of labels.
For large-scale datasets, traditional multi-label algorithms such as Binary Relevance and classifier chain-based methods incur extremely high computational costs. Therefore, when dealing with MLC problems involving a large number of labels, more efficient algorithms and optimization strategies with lower computational costs are required. To address this issue, Yang et al. [60] proposed a neural network-based solution for MLC, framing the task as a sequence generation problem. They introduced a sequence generation model (SGM) with a novel decoder architecture (as shown in Figure 4). The text sequence is input into a bidirectional LSTM, which encodes it into hidden states. The bidirectional LSTM reads the text sequence from both directions, and then generates the context vector through the attention mechanism at time step . The decoder utilizes this context vector, the hidden state from the previous time step, and the embedding vector to generate the hidden state for the current time step, ultimately outputting the probability distribution through the masked Softmax layer. In this model, the decoder employs LSTM [61] to sequentially generate labels, predicting the next label based on the previously predicted one. As a result, the SGM model leverages the LSTM structure to manage the sequential dependencies among labels while accounting for label correlations. When dealing with a large number of labels, accurately predicting all true labels becomes complex and challenging. However, by incorporating the LSTM structure and the concept of sequence generation, the SGM model effectively alleviates this challenge to some extent.
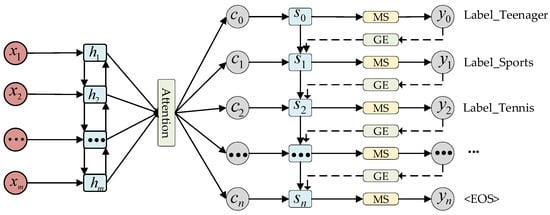
Figure 4.
SGM model framework. denotes the text sequence, denotes the hidden state, denotes the context vector, denotes the predicted hidden state, denotes the probability distribution, MS denotes the masked Softmax layer, and GE denotes the global embedding [60].
3.3. Joint Distribution Modeling Methods
Current MLC methods typically consider learning label correlations directly from true labels. For instance, second-order and high-order strategy methods respectively consider correlations between pairs of labels and among multiple labels. Wang et al. [27] argue that current second-order and high-order strategy methods fail to utilize the complete label correlations. They suggest that multi-label joint distribution modeling, which considers various types of label correlations, is a more thorough approach.
To address this, Wang et al. [27] proposed a method based on an adversarial learning framework, aiming to enhance the similarity between the predicted label distribution and the true label distribution, thereby effectively utilizing label correlations. This framework consists of a multi-label classifier and a label discriminator. The multi-label classifier identifies multiple labels associated with an instance from the feature space, while the discriminator assesses the probability that each input label vector comes from the true label set. Through adversarial learning between the classifier and the discriminator, the joint label distribution of the predicted labels converges to the inherent joint label distribution of the true labels, ultimately improving the performance of MLL.
Additionally, Bai et al. [62] proposed a method based on a multivariate probabilistic variational autoencoder, which encodes instances and labels into latent space and uses a decoder to transform latent variables back into label space. During the decoding process, the covariance matrix is learned to model the joint distribution of the output labels using a multivariate probabilistic approach, thereby utilizing this covariance matrix to uncover correlations between labels.
4. Applications of Label Correlation in MLC Methods
Based on different types of label correlations, MLC methods can also be divided into those utilizing positive correlations, negative correlations, global correlations, and local correlations. In MLC methods, existing methods can be categorized into global relation methods, local relation methods, and global-local relation methods, depending on the granularity of label correlations considered. By distinguishing the granularity of shared global and local label correlations, a finer-grained understanding of the relationships between labels can be achieved, enhancing the adaptability of models in different scenarios.
Based on whether label correlations are considered, MLC methods can be divided into two main categories: those that do not consider label correlations and those based on label correlations. Traditional label correlation-based methods focus on leveraging positive label correlations globally to enhance classification performance. However, this global assumption overlooks the significance of local label correlations and negative correlations. In fact, label correlations are not always positive; sometimes, there can be negative correlations, where the presence of certain labels decreases the likelihood of other labels occurring. Additionally, label correlations often exhibit locality, implying that the correlations between labels may vary across different subsets of data or in specific contexts.
The following sections will introduce global methods considering positive label correlations, local methods considering positive label correlations, global-local methods considering positive label correlations, and global/local methods introducing negative label correlations from the perspective of label correlations types. The specific method classifications are shown in Table 2, where ‘/’ indicates the absence of methods corresponding to that category.
Table 2.
MLC methods of using different types of label correlations.
4.1. Global MLC Methods Considering Only Positive Label Correlation
Methods based on label correlations can be categorized into second-order and higher-order strategies, depending on the level of label correlations considered. Second-order strategies primarily focus on the correlations between pairs of labels. For instance, the Calibrated Label Ranking (CLR) [64] method transforms the MLC task into a pairwise ranking problem, aiming to ensure that the correct labels are ranked higher than the incorrect ones for each instance. The CLR method considers pairwise combinations of labels, which provides good generalization ability. However, in practical applications, the relationships between labels can be quite complex, making it insufficient to rely solely on pairwise relationships to accurately describe label correlations in real-world scenarios.
Higher-order strategy methods aim to investigate the relationships among all labels or their subsets. For instance, the Classifier Chains (CC) method reformulates the MLC task into a series of binary classification problems by sequentially linking single-label classifiers. In this approach, each classifier’s input includes the outputs of all previous classifiers, thereby considering the influence of all preceding labels on the current label. The Label Powerset (LP) algorithm [63] leverages higher-order correlations by focusing on subsets of labels, treating each unique label combination in the training data as a separate class, effectively converting the task into a single-label MLC problem. However, a key limitation of LP is its ability to only predict label sets that are present in the training data. As the number of labels increases, the potential combinations of labels grow exponentially, which can lead to sparse samples for each new class and result in class imbalance. To tackle this challenge, Tsoumakas et al. [77] introduced the Random k-labelsets (RAkEL) algorithm, which integrates randomly chosen k label sets, ensemble learning, and the LP method to enhance its performance. Although these high-order strategy methods are more comprehensive, they significantly increase computational complexity, making them difficult to use for large-scale learning problems.
4.2. Local MLC Methods Considering Only Positive Label Correlation
Traditional global MLC methods typically learn and utilize positive label correlations from a global perspective, assuming they are applicable to all sample instances. This approach can have some negative impacts, such as imposing incorrect constraints on certain instances, leading the model to assign many irrelevant or even erroneous labels to instances. To mitigate these negative effects, it is necessary to explore label correlations locally.
These methods locally learn label correlations within each data subset, following the basic assumption that dataset instances can be divided into different groups, with instances within each group sharing a subset of label correlations. Therefore, it is necessary to partition the dataset into different groups.
How can a dataset be divided into different groups? The ML-LOC method [34] groups the dataset using the k-means clustering algorithm [78] by measuring the similarity between instances in the label space, assuming that instances with similar label vectors typically share the same label correlations. The GD-LDL-SCL method [36] follows a similar premise, focusing on measuring the similarity between instances in the label space, which is generally smaller than the feature space, thus effectively reducing the time required for clustering. In contrast, the GCC method [65] posits that similar instances not only share label correlations but also tend to have similar labels; therefore, it treats the label space as an additional feature in the original feature space and performs clustering in the combined feature space. In contrast, the LPLC [33] and LF-LPLC [76] methods identify the k-nearest neighbors of instances in the feature space using Euclidean distances and learn the local correlations of labels within these neighbors.
After grouping data based on different assumptions, existing local relation methods employ various strategies to utilize the local label correlations within different groups. For instance, the ML-LOC [34] method constructs a LOC code vector for each instance. In this code vector, the larger the value of an element in the corresponding position, the more the subset of label correlations shared by instances in that group helps the instance. In other words, each instance’s LOC code reflects the influence of various label correlations subsets on the instance. The LOC code is then used as an additional feature to the original features, and a classifier is trained based on the extended features, thereby encoding the local impact of label correlations. Inspired by ML-LOC, Jia et al. [36] designed local correlation vectors based on different local samples after clustering, which were used as additional features for each instance, introducing local label correlations in label distribution learning. The GCC method proposed by Huang et al. [65] learns directed label dependency graphs in each cluster after clustering the dataset. The dependency probabilities between two labels are modeled by label co-occurrence, and then a specific classifier chain is constructed based on the instances in each group and the corresponding label dependency graph.
In summary, compared to global methods, local methods effectively mitigate the potential negative impacts of global methods by focusing on finer-grained label correlations. Experimental results on multiple datasets indicate that local methods achieve better performance than global methods in certain situations, further demonstrating the significant potential and advantages of local methods in addressing specific problems. The exploration of local label correlations also provides new ideas and approaches for addressing label correlations issues.
4.3. Global-Local MLC Methods Considering Only Positive Label Correlation
Previous research has primarily focused on utilizing global or local label correlations separately, while current studies on MLC aim to integrate both global and local correlations. To establish a unified learning framework that simultaneously addresses global and local label correlations, researchers have proposed various strategies and methods to achieve this goal.
Zhu et al. [66] proposed the GLOCAL method to investigate label correlations. This method is based on the assumption that “the stronger the positive correlation between labels, the closer the corresponding classifier outputs will be, and vice versa”. It employs manifold regularization by introducing global and local manifold regularizers to leverage both global and local label correlations in addressing both complete and missing labels. Faraji et al. [35] introduced the MLFS-GLOCAL method, which selects discriminative features among multiple labels by utilizing both global and local label correlations. The LCFM multi-label classification method proposed by Yu et al. [71] accurately extracts label correlations by learning global and local label-specific features, effectively tackling the issue of missing labels. Yan et al. [67] proposed the GLkEL method, which employs a higher-order label correlation assessment strategy based on approximate joint mutual information, selecting the most relevant k-label sets from the label space to evaluate global correlations. Additionally, this method clusters the training data into different groups, assesses local label correlations within each group, and linearly combines global and local correlations.
Liu et al. [69] calculated pairwise label similarities across the entire label space to create a global label correlation matrix. They then assigned a local label correlation matrix to each instance subset based on the cosine similarities of label vectors within clusters. Finally, they integrated global and local label correlation regularization terms into the objective function. Weng et al. [70] introduced the LFGLC method, which determines global label correlations from label co-occurrence frequencies between pairs and learns local label correlations from the neighborhoods of individual instances.
Overall, considering both global and local label correlations has demonstrated significant practical utility and advantages in real-world applications. However, this approach inevitably increases the complexity of the methods, requiring a balance between implementation efficiency and performance.
4.4. Global MLC Methods Considering Only Negative Label Correlation
Chen et al. [73] were the first to explore the application of negative label correlation in MLIC. Their extensive experiments on real-world visual classification tasks demonstrated that incorporating negative label correlation significantly enhances classification performance. Subsequently, many researchers have begun to investigate the potential for further integrating negative label correlation in the field of MLC. Chen et al. proposed the LELR [73] method, which constructs a weighted graph to describe the mutual exclusivity between labels, where the edge set represents the mutual exclusivity between pairs of nodes. The weight matrix associated with graph G is set according to the following rule: if labels and do not appear together in any training image, then is set to 1; otherwise, it is set to 0. Then, the graph shift method is used to find dense subgraphs in graph G, where each set of nodes in a dense subgraph is considered as a mutually exclusive label group. The LELR method employs a linear representation approach with a sparse-induced regularizer for MLIC. Given a multi-label query image and learned mutually exclusive label groups, the LELR method assigns each group’s labels mutually exclusively to the query image. This dense subgraph search method automatically learns mutually exclusive label sets from the training data. However, this method does not account for the more frequently occurring positive label correlations, which somewhat limits its classification performance.
4.5. Global or Local MLC Methods Considering Both Positive and Negative Label Correlation
To enhance classification performance, recent studies have started investigating how to address both positive and negative label correlations within a unified framework. This approach seeks to leverage the intricate relationships between labels more effectively. For instance, the LPLC [33] and LF-LPLC [76] methods integrate negative label correlations into MLC by incorporating them into local pairwise label correlations. The LPLC method identifies the most positively and negatively correlated labels for each true label from the nearest neighbor sets, determined by maximum a posteriori probability. Similarly, the LF-LPLC method employs nearest neighbor techniques to introduce pairwise label negative correlations and incorporates label-specific features, demonstrating robust generalization in MLC tasks. Wang et al. [39] proposed a method that utilizes a Bayesian network to directly model label correlations, where each node represents a label and captures the probabilistic dependencies among them through conditional probabilities. Wu et al. [75] introduced a cost-sensitive MLC model called CPNL, which considers both positive and negative correlations between pairs of labels. Nan et al. [32] enhanced the RakEL method [77] by integrating local label negative correlations and introduced a novel multi-label ensemble classification approach. This approach utilizes KNN techniques to refine the original label membership information and employs matrix similarity measures to identify local pairwise label negative correlations. Additionally, a calibration mechanism is applied during the classification process to modify the ensemble model’s output in accordance with label correlations.
The aforementioned methods primarily focus on exploring negative correlations between pairwise labels, while other methods introduce negative label correlations by investigating the mutual exclusion relationships among multiple labels. To identify the mutual exclusion relationships among multiple labels, Papagiannopoulou et al. [74] utilize the Apriori [79] algorithm to find all maximal sets of mutually exclusive labels, starting from pairwise mutually exclusive labels and progressively identifying triplets, quadruplets, and so forth.
In general, the approach that incorporates both positive and negative label correlations can more comprehensively consider the complex relationships between labels. These methods that comprehensively consider positive and negative label correlations have certain advantages when dealing with datasets with complex label structures, and they are of significant importance for thoroughly analyzing label relationships to enhance model performance.
5. Applications of Label Correlation to MLC Subproblems
As research in the field of MLL progresses, many MLC problems under various settings have attracted the attention of researchers. Collecting data with comprehensive annotation information is often challenging, significantly increasing the complexity and workload of manual annotation. Given the scarcity of annotated data and the complexity of the annotation process, researchers have started to focus on solving MLC problems under limited supervision conditions. Examples include MLC with missing labels, semi-supervised MLC, and Partial Multi-Label Learning (PML). The missing labels problem posits that only a portion of the true labels is available, leaving some true labels unannotated. In contrast, partial multi-label problems assume that each instance is linked to a candidate label set that may contain incorrect labels. These scenarios aim to develop a multi-label classifier capable of learning from such ambiguous data and assigning relevant labels to test instances. Semi-supervised MLC integrates fully labeled and unlabeled data to train a multi-label classifier.
As the volume of data rapidly increases, multi-label data obtained from various real-world applications often features a vast feature space that contains numerous irrelevant and redundant features. This high-dimensional characteristic can negatively impact classification tasks. In MLL, the labels for each category may be determined by specific subsets of features. Consequently, some researchers have begun to design multi-label feature selection algorithms aimed at identifying features that are rich in information and representative, thereby achieving dimensionality reduction and enhancing the performance of classifiers.
In these MLC subproblems, label correlations also play an important role. Label correlations reflect the intrinsic connections between different labels and can be utilized to optimize various aspects of MLC tasks. For example, existing studies have successfully utilized label correlations to reconstruct missing labels, aiding in solving the MLML problem [66,80,81]. Additionally, Silvestri et al. [22] proposed a method called Hierarchical Label Set Expansion (HLSE) to address some missing label levels within the MeSH label hierarchy. This method utilizes the hierarchical relationships between labels by adding missing ancestor labels to the label set of each sample, thereby expanding the label set for each document. The aim is to maintain consistency in the hierarchical structure of the training dataset, thereby enhancing the standardization and effectiveness of the training process. Su et al. [72] introduced a model named Imbalanced and Missing Multi-label Data Learning with Global and Local Structure (IMLGL), which is designed to address both missing labels and class imbalance issues in MLL simultaneously.
Multi-label feature selection is also crucial in addressing the high-dimensional challenges associated with MLL. Research indicates that label correlation can aid the label-specific feature selection process [54,70,76,82], thereby significantly enhancing the accuracy and efficiency of feature selection. Previous studies often treated the label space as static; however, in practical applications, labels are frequently dynamic. To address this, Liu et al. [83] proposed the LLSL method, which develops a feature transformation mechanism to integrate specific features for each dynamic label.
In the field of Semi-Supervised MLC (SS-MLC), a few studies have developed graph-based learning methods by constructing label relationship graphs [84]. Additionally, in MLIC tasks, Stoimchev et al. [85] proposed a semi-supervised remote sensing image classification method that combines deep learning with predictive clustering trees, effectively leveraging unlabeled data to enhance classification performance.
The PML problem aims to address the challenge of training data that contains both true and noisy labels. In this context, all samples are associated with a set of candidate labels, but only some of these labels are accurate. Research has begun to focus on how label correlation can improve classification performance on ambiguous data [68]. To resolve the ambiguity of candidate labels, Zou et al. [86] proposed a method called Learning Shared and Non-redundant Label-specific Features (LSNRLS). Meanwhile, Zhong et al. [87] introduced a disambiguation method for PML (PML-ND), which aims to enhance label accuracy by utilizing negative labels and noise information. Table 3 illustrates the application of label correlations in various MLC subproblems.
Table 3.
Applications of label correlations to other MLC subproblems.
6. Analysis and Discussion
The paper explores the application of label correlations in MLC, with a focus on analyzing both positive and negative correlations between labels and their impact on classification performance. It examines the applicability of both global and local label correlations, the granularity of shared correlations, and methods for integrating label correlations within MLC models. Additionally, it highlights the beneficial effects of incorporating label correlations on classification performance. Moreover, it is crucial to flexibly adjust the application strategies of label correlations according to the characteristics of different tasks and datasets. Furthermore, when balancing global and local label correlations within models, it is essential to consider both computational complexity and classification performance.
Despite significant progress in the application of label correlations in MLC, several limitations remain. Firstly, many methods rely on external knowledge sources (such as WordNet or ConceptNet), which may not be applicable to domain-specific datasets, leading to the introduction of incorrect label relationships. Additionally, large-scale datasets often face challenges related to high-dimensional feature data and noise. Secondly, when addressing label imbalance, the computation of label correlations can be biased and may not accurately reflect the true situation. Furthermore, current methods encounter high computational complexity when dealing with a large number of labels, with classifier chain methods being particularly sensitive to label order, which can lead to error propagation issues. Finally, existing research into label correlations remains limited in depth and breadth, often considering only simple co-occurrence or hierarchical relationships, and lacking in-depth exploration of complex label interactions. Therefore, while MLC theoretically holds broad application potential, current algorithms still exhibit notable limitations in handling complex label relationships and large-scale data.
7. Future Work Prospects
In the field of MLL, label correlation is a crucial concept, referring to the potential value of one label’s information for the learning of other related labels. This correlation is an indispensable knowledge source in MLC, and many classification algorithms benefit from its effective utilization. However, despite the excellent performance of existing methods in practical applications, several core issues remain that require further investigation.
Firstly, with the rapid expansion of dataset sizes and the increase in the number of labels, existing methods often face issues of excessively high computational complexity when dealing with large-scale, multi-label datasets. Future research could explore more efficient algorithms, such as those based on Graph Convolutional Networks (GCNs), to capture higher-order correlations between labels. Such methods can effectively represent complex dependencies among labels through graph structures, thereby reducing computational costs and improving classification performance. Additionally, Self-Attention Mechanisms could be utilized to dynamically adjust the weights of label correlations, making the model more flexible in handling large-scale data.
Secondly, high-order interactions among labels represent an important research direction. In image annotation tasks, label combinations often include multiple related objects and scenes, such as “beach”, “umbrella”, and “swimming ring”. These high-order relationships are crucial for enhancing classification performance. Future research could explore how to leverage multimodal learning to integrate image and text information, further capturing contextual information between labels. For instance, using cross-modal contrastive learning to jointly learn label representations for both images and text could improve the model’s ability to capture complex label relationships.
Additionally, the issue of class imbalance remains a significant challenge in MLC. In real-world datasets, the distribution of labels is often highly uneven, with minority class labels frequently being overlooked. Future research could explore the use of generative models, such as Generative Adversarial Networks (GANs), to generate samples for rare labels or employ data augmentation strategies to balance label distributions. Simultaneously, during model optimization, weighted loss functions could be designed to allocate more appropriate weights to minority class labels, thereby improving the model’s classification performance under imbalanced data conditions.
Finally, the application of label correlation varies significantly across different industries and domains. For instance, in medical image analysis, modeling the co-occurrence of diseases through label correlation can help the model more accurately identify conditions; in text classification, the co-occurrence of multiple topic labels often reflects underlying semantic associations. Future research should consider the specific needs of different fields to design more adaptable label correlation mining methods, thereby enhancing the practicality and performance of MLC.
8. Conclusions
In exploring the broad prospect of MLL, the importance of label correlations as one of its core features is self-evident. Nonetheless, the current academic realm suffers from a dearth of systematic reviews on label correlations, lacking a comprehensive and profound framework to articulate its evolutionary journey and recent advancements. Given that, this paper endeavors to bridge this gap by presenting a comprehensive and systematic summation of label correlations within MLC.
We meticulously classify label correlations starting from two key dimensions, aiming to reveal their inherent complexity. Next, this paper innovatively conducts a comprehensive review of methods and discusses various techniques for mining label correlations in detail for the first time. These methods not only enrich the toolbox for MLC but also provide valuable practical references for subsequent research.
Building on this classification, we further categorize existing MLC methods based on the different types of label correlations used. This step not only deepens the understanding of the connections and differences among various approaches but also provides researchers with clear guidance in selecting the appropriate method.
In addition, this paper also organizes the application examples of label correlations in each subproblem of MLL and shows its strong potential and wide application in practical problem-solving. These examples not only validate the importance of label correlations research, but also point out possible directions for future research.
Finally, we look forward to the future research direction of label correlations research and analyze the main challenges currently faced. By proposing a series of forward-looking thoughts and questions, this paper aims to provide researchers with new perspectives and inspiration, and promote the continuous development of the field of MLC.
Author Contributions
Conceptualization, S.H. and B.L.; Writing—original draft preparation, S.H., W.H. and B.L.; Writing—review and editing, S.H., W.H., Q.F. and X.X.; Supervision, Q.F., X.Z. and H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the Research Program of National University of Defense Technology under Grant No. ZK23-58, and in part by the National Natural Science Foundation of China under Grant No. 62402510.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zheng, X.; Li, P.; Chu, Z.; Hu, X. A survey on multi-label data stream classification. IEEE Access 2019, 8, 1249–1275. [Google Scholar] [CrossRef]
- Han, M.; Wu, H.; Chen, Z.; Li, M.; Zhang, X. A survey of multi-label classification based on supervised and semi-supervised learning. Int. J. Mach. Learn. Cybern. 2023, 14, 697–724. [Google Scholar] [CrossRef]
- Siahroudi, S.K.; Kudenko, D. An effective single-model learning for multi-label data. Expert Syst. Appl. 2023, 232, 120887. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Li, Y.-K.; Liu, X.-Y.; Geng, X. Binary relevance for multi-label learning: An overview. Front. Comput. Sci. 2018, 12, 191–202. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhang, K. Multi-label learning by exploiting label dependency. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 999–1008. [Google Scholar]
- Bao, J.; Wang, Y.; Cheng, Y. Asymmetry label correlation for multi-label learning. Appl. Intell. 2022, 52, 6093–6105. [Google Scholar] [CrossRef]
- Fan, Y.; Liu, J.; Tang, J.; Liu, p.; Lin, Y.; Du, Y. Learning correlation information for multi-label feature selection. Pattern Recognit. 2024, 145, 109899. [Google Scholar] [CrossRef]
- Zhou, Z.; Zheng, X.; Yu, Y.; Dong, X.; Li, S. Updating Correlation-Enhanced Feature Learning for Multi-Label Classification. Mathematics 2024, 12, 2131. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, H.; Mi, Y.; Luo, C.; Horng, S.-J.; Li, T. Multi-label Feature selection with adaptive graph learning and label information enhancement. Knowl.-Based Syst. 2024, 285, 111363. [Google Scholar] [CrossRef]
- Wang, L.; Chen, S.; Zhou, H. Boosting up segment-level video classification performance with label correlation and reweighting. In Proceedings of the 3rd Workshop YouTube-8M Large-Scale Video Understanding, Seoul, Republic of Korea, 28 October 2019. [Google Scholar]
- Kuang, W.; Li, Z. Multi-label image classification with multi-layered multi-perspective dynamic semantic representation. Mach. Learn. 2024, 113, 3443–3461. [Google Scholar] [CrossRef]
- Singh, I.P.; Ghorbel, E.; Oyedotun, O.; Aouada, D. Multi-label image classification using adaptive graph convolutional networks: From a single domain to multiple domains. Comput. Vis. Image Underst. 2024, 247, 104062. [Google Scholar] [CrossRef]
- Shi, W.; Liu, X.; Yu, Q. Correlation-aware multi-label active learning for web service tag recommendation. In Proceedings of the 2017 IEEE International Conference on Web Services, Honolulu, HI, USA, 25–30 June 2017; pp. 229–236. [Google Scholar]
- Li, H.; Zhang, C.; Jia, X.; Gao, Y. Adaptive label correlation based asymmetric discrete hashing for cross-modal retrieval. IEEE Trans. Knowl. Data Eng. 2021, 35, 1185–1199. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, L.; Chen, Q.; Deng, Y.; Siebert, J.; Han, Y.; Li, Z.; Kong, D.; Cao, Z. Contrastive label correlation enhanced unified hashing encoder for cross-modal retrieval. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 2158–2168. [Google Scholar]
- Huang, J.; Li, G.; Wang, S.; Huang, Q. Categorizing social multimedia by neighborhood decision using local pairwise label correlation. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 913–920. [Google Scholar]
- Turnbull, D.; Barrington, L.; Torres, D.; Lanckriet, G. Semantic annotation and retrieval of music and sound effects. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 467–476. [Google Scholar] [CrossRef]
- Elisseeff, A.; Weston, J. A kernel method for multi-labelled classification. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, Vancouver, BC, Canada, 3–8 December 2001; pp. 681–687. [Google Scholar]
- Pestian, J.; Brew, C.; Matykiewicz, P.; Hovermale, D.J.; Johnson, N.; Cohen, K.B.; Duch, W. A shared task involving multi-label classification of clinical free text. In Biological, Translational, and Clinical Language Processing; BioNLP@ACL: Prague, Czech Republic, 29 June 2007; pp. 97–104. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Effective and efficient multilabel classification in domains with large number of labels. In Proceedings of the 2008 Workshop on Mining Multidimensional Data, Antwerp, Belgium, 15–19 September 2008; Volume 21, pp. 53–59. [Google Scholar]
- Srivastava, A.N.; Zane-Ulman, B. Discovering recurring anomalies in text reports regarding complex space systems. In Proceedings of the 2005 IEEE Aerospace Conference, Big Sky, MT, USA, 5–12 March 2005; pp. 3853–3862. [Google Scholar]
- Silvestri, S.; Gargiulo, F.; Ciampi, M. Integrating PubMed Label Hierarchy Knowledge into a Complex Hierarchical Deep Neural Network. Appl. Sci. 2023, 13, 13117. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.-L. Microsoft COCO: Common objects in context. In Proceedings of the 13th European Conference of Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Liu, B.; Liu, X.; Ren, H.; Qian, J.; Wang, Y. Text multi-label learning method based on label-aware attention and semantic dependency. Multimed. Tools Appl. 2022, 81, 7219–7237. [Google Scholar] [CrossRef]
- Si, C.; Jia, Y.; Wang, R.; Zhan, M.; Feng, Y.; Qu, C. Multi-label classification with high-rank and high-order label correlations. IEEE Trans. Knowl. Data Eng. 2023, 36, 4076–4088. [Google Scholar] [CrossRef]
- Wang, S.; Peng, G.; Zheng, Z. Capturing joint label distribution for multi-label classification through adversarial learning. IEEE Trans. Knowl. Data Eng. 2019, 32, 2310–2321. [Google Scholar] [CrossRef]
- Chen, Z.-M.; Wei, X.-S.; Wang, P.; Guo, Y. Multi-label image recognition with graph convolutional networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5177–5186. [Google Scholar]
- Wang, Y.; He, D.; Li, F.; Long, X.; Zhou, Z.; Ma, J.; Wen, S. Multi-label classification with label graph superimposing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12265–12272. [Google Scholar] [CrossRef]
- Wang, G.; Wang, P.; Wei, B. Multi-label local awareness and global co-occurrence priori learning improve chest X-ray classification. Multimed. Syst. 2024, 30, 132. [Google Scholar] [CrossRef]
- Zhu, X.; Zhu, T.; Li, J.; Wang, J. Dual-channel graph contrastive learning for multi-label classification with label-specific features and label correlations. Neural Comput. Appl. 2024, 36, 14483–14502. [Google Scholar] [CrossRef]
- Nan, G.; Li, Q.; Dou, R.; Liu, J. Local positive and negative correlation-based k-labelsets for multi-label classification. Neurocomputing 2018, 318, 90–101. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Wang, S.; Xue, Z.; Huang, Q. Multi-label classification by exploiting local positive and negative pairwise label correlation. Neurocomputing 2017, 257, 164–174. [Google Scholar] [CrossRef]
- Huang, S.-J.; Zhou, Z.-H. Multi-label learning by exploiting label correlations locally. Proc. AAAI Conf. Artif. Intell. 2012, 26, 949–955. [Google Scholar] [CrossRef]
- Faraji, M.; Seyedi, S.A.; Tab, F.A.; Mahmoodi, R. Multi-label feature selection with global and local label correlation. Expert Syst. Appl. 2024, 246, 123198. [Google Scholar] [CrossRef]
- Jia, X.; Li, Z.; Zheng, X.; Li, W.; Huang, S. Label distribution learning with label correlations on local samples. IEEE Trans. Knowl. Data Eng. 2019, 33, 1619–1631. [Google Scholar] [CrossRef]
- Ding, N.; Deng, J.; Murphy, K.P.; Neven, H. Probabilistic label relation graphs with ising models. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1161–1169. [Google Scholar]
- Shi, M.; Tang, Y.; Zhu, X.; Liu, J. Multi-label graph convolutional network representation learning. IEEE Trans. Big Data 2020, 8, 1169–1181. [Google Scholar] [CrossRef]
- Wang, S.; Wang, J.; Wang, Z.; Ji, Q. Enhancing multi-label classification by modeling dependencies among labels. Pattern Recognit. 2014, 47, 3405–3413. [Google Scholar] [CrossRef]
- Gibaja, E.; Ventura, S. Multi-label learning: A review of the state of the art and ongoing research. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014, 4, 411–444. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; p. 31. [Google Scholar]
- Marszalek, M.; Schmid, C. Semantic hierarchies for visual object recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Deng, J.; Ding, N.; Jia, Y.; Frome, A.; Murphy, K.; Bengio, S.; Li, Y.; Neven, H.; Adam, H. Large-scale object classification using label relation graphs. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 48–64. [Google Scholar]
- Hu, H.; Zhou, G.-T.; Deng, Z.; Liao, Z.; Mori, G. Learning structured inference neural networks with label relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2960–2968. [Google Scholar]
- Han, M.; Wu, H.; Chen, Z.; Li, M.; Zhang, X. A Survey of Multi-Label Classification under Supervised and Semi-Supervised Learning. Comput. Sci. 2022, 49, 12–25. [Google Scholar]
- Barutcuoglu, Z.; Schapire, R.E.; Troyanskaya, O.G. Hierarchical multi-label prediction of gene function. Bioinformatics 2006, 22, 830–836. [Google Scholar] [CrossRef] [PubMed]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Koski, T.J.; Noble, J. A review of Bayesian networks and structure learning. Math. Appl. 2012, 40, 51–103. [Google Scholar]
- Zhang, W.; Yan, J.; Wang, X.; Zha, H. Deep extreme multi-label learning. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 100–107. [Google Scholar]
- Li, Q.; Peng, X.; Qiao, Y.; Peng, Q. Learning label correlations for multi-label image recognition with graph networks. Pattern Recognit. Lett. 2020, 138, 378–384. [Google Scholar] [CrossRef]
- Ye, C.; Zhang, L.; He, Y.; Zhou, D.; Wu, J. Beyond text: Incorporating metadata and label structure for multi-label document classification using heterogeneous graphs. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3162–3171. [Google Scholar]
- Zhao, F.; Ai, Q.; Li, X.; Wang, W.; Gao, Q.; Liu, Y. TLC-XML: Transformer with Label Correlation for Extreme Multi-label Text Classification. Neural Process. Lett. 2024, 56, 25. [Google Scholar] [CrossRef]
- Sun, L.; Kudo, M.; Kimura, K. Multi-label classification with meta-label-specific features. In Proceedings of the 2016 23rd International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 1612–1617. [Google Scholar]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Read, J.; Martino, L.; Luengo, D. Efficient monte carlo methods for multi-dimensional learning with classifier chains. Pattern Recognit. 2014, 47, 1535–1546. [Google Scholar] [CrossRef]
- Cheng, W.; Hüllermeier, E.; Dembczynski, K.J. Bayes optimal multilabel classification via probabilistic classifier chains. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 279–286. [Google Scholar]
- Sun, L.; Kudo, M. Optimization of classifier chains via conditional likelihood maximization. Pattern Recognit. 2018, 74, 503–517. [Google Scholar] [CrossRef]
- Liu, W.; Tsang, I. On the optimality of classifier chain for multi-label classification. Adv. Neural Inf. Process. Syst. 2015, 28, 712–720. [Google Scholar]
- Yang, P.; Sun, X.; Li, W.; Ma, S.; Wu, W.; Wang, H. SGM: Sequence generation model for multi-label classification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3915–3926. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.; Kong, S.; Gomes, C. Disentangled variational autoencoder based multi-label classification with covariance-aware multivariate probit model. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 4313–4321. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Hüllermeier, E.; Loza Mencía, E.; Brinker, k. Multilabel classification via calibrated label ranking. Mach. Learn. 2008, 73, 133–153. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Wang, S.; Zhang, W.; Huang, Q. Group sensitive classifier chains for multi-label classification. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo, Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Zhu, Y.; Kwok, J.T.; Zhou, Z.-H. Multi-label learning with global and local label correlation. IEEE Trans. Knowl. Data Eng. 2017, 30, 1081–1094. [Google Scholar] [CrossRef]
- Yan, Y.; Li, S.; Zhang, X.; Wang, A.; Li, Z.; Zhang, J. k-Labelsets for Multimedia Classification with Global and Local Label Correlation. In Proceedings of the MultiMedia Modeling: 24th International Conference, MMM 2018, Bangkok, Thailand, 5–7 February 2018; pp. 177–188. [Google Scholar]
- Sun, L.; Feng, S.; Liu, J.; Lyu, G.; Lang, C. Global-local label correlation for partial multi-label learning. IEEE Trans. Multimed. 2021, 24, 581–593. [Google Scholar] [CrossRef]
- Liu, Y.; Cao, F. A relative labeling importance estimation algorithm based on global-local label correlations for multi-label learning. Appl. Intell. 2023, 53, 4940–4958. [Google Scholar] [CrossRef]
- Weng, W.; Wei, B.; Ke, W.; Fan, Y.; Wang, J.; Li, Y. Learning label-specific features with global and local label correlation for multi-label classification. Appl. Intell. 2023, 53, 3017–3033. [Google Scholar] [CrossRef]
- Yu, Y.; Zhou, Z.; Zheng, X.; Gou, J.; Ou, W.; Yuan, F. Enhancing Label Correlations in multi-label classification through global-local label specific feature learning to Fill Missing labels. Comput. Electr. Eng. 2024, 113, 109037. [Google Scholar] [CrossRef]
- Su, X.; Xu, Y. Imbalanced and missing multi-label data learning with global and local structure. Inf. Sci. 2024, 677, 120910. [Google Scholar] [CrossRef]
- Chen, X.; Yuan, X.-T.; Chen, Q.; Yan, S.; Chua, T.-S. Multi-label visual classification with label exclusive context. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 834–841. [Google Scholar]
- Papagiannopoulou, C.; Tsoumakas, G.; Tsamardinos, I. Discovering and exploiting deterministic label relationships in multi-label learning. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 915–924. [Google Scholar]
- Wu, G.; Tian, Y.; Liu, D. Cost-sensitive multi-label learning with positive and negative label pairwise correlations. Neural Netw. 2018, 108, 411–423. [Google Scholar] [CrossRef] [PubMed]
- Weng, W.; Lin, Y.; Wu, S.; Li, Y.; Kang, Y. Multi-label learning based on label-specific features and local pairwise label correlation. Neurocomputing 2018, 273, 385–394. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Random k-labelsets for multilabel classification. IEEE Trans. Knowl. Data Eng. 2010, 23, 1079–1089. [Google Scholar] [CrossRef]
- Hamerly, G.; Elkan, C. Learning the k in k-means. Adv. Neural Inf. Process. Syst. 2003, 16, 281–288. [Google Scholar]
- Agrawal, R. Fast Algorithms for Mining Association Rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Bi, W.; Kwok, J. Multilabel classification with label correlations and missing labels. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; p. 28. [Google Scholar]
- Cheng, Z.; Zeng, Z. Joint label-specific features and label correlation for multi-label learning with missing label. Appl. Intell. 2020, 50, 4029–4049. [Google Scholar] [CrossRef]
- Che, X.; Chen, D.; Mi, J. A novel approach for learning label correlation with application to feature selection of multi-label data. Inf. Sci. 2020, 512, 795–812. [Google Scholar] [CrossRef]
- Liu, J.; Wei, W.; Lin, Y.; Yang, L.; Zhang, H. Learning implicit labeling-importance and label correlation for multi-label feature selection with streaming labels. Pattern Recognit. 2024, 147, 110081. [Google Scholar] [CrossRef]
- Chen, G.; Song, Y.; Wang, F.; Zhang, C. Semi-supervised multi-label learning by solving a sylvester equation. In Proceedings of the 2008 SIAM International Conference on Data Mining, Atlanta, GA, USA, 24–26 April 2008; pp. 410–419. [Google Scholar]
- Stoimchev, M.; Levatić, J.; Kocev, D.; Džeroski, S. Semi-Supervised Multi-Label Classification of Land Use/Land Cover in Remote Sensing Images with Predictive Clustering Trees and Ensembles. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4706416. [Google Scholar] [CrossRef]
- Zou, Y.; Hu, X.; Li, P.; Ge, Y. Learning shared and non-redundant label-specific features for partial multi-label classification. Inf. Sci. 2024, 656, 119917. [Google Scholar] [CrossRef]
- Zhong, J.; Shang, R.; Zhao, F.; Zhang, W.; Xu, S. Negative Label and Noise Information Guided Disambiguation for Partial Multi-Label Learning. IEEE 2024, 1–16. [Google Scholar] [CrossRef]
- Liu, H.; Chen, G.; Li, P.; Zhao, P.; Wu, X. Multi-label text classification via joint learning from label embedding and label correlation. Neurocomputing 2021, 460, 385–398. [Google Scholar] [CrossRef]

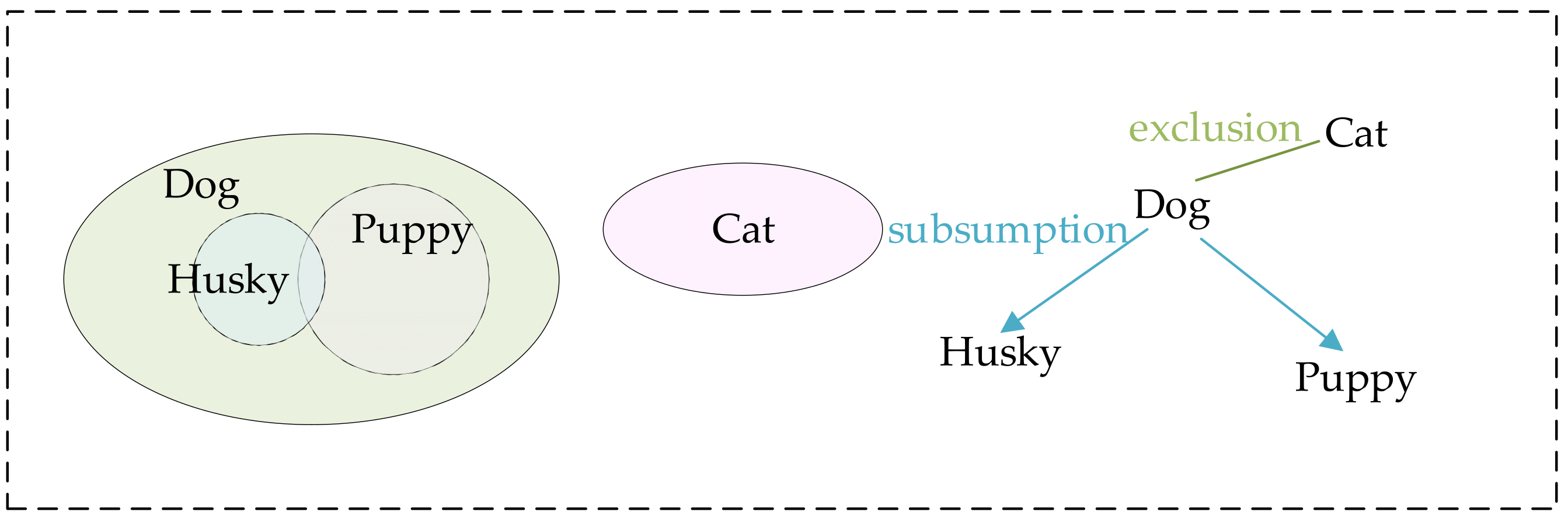
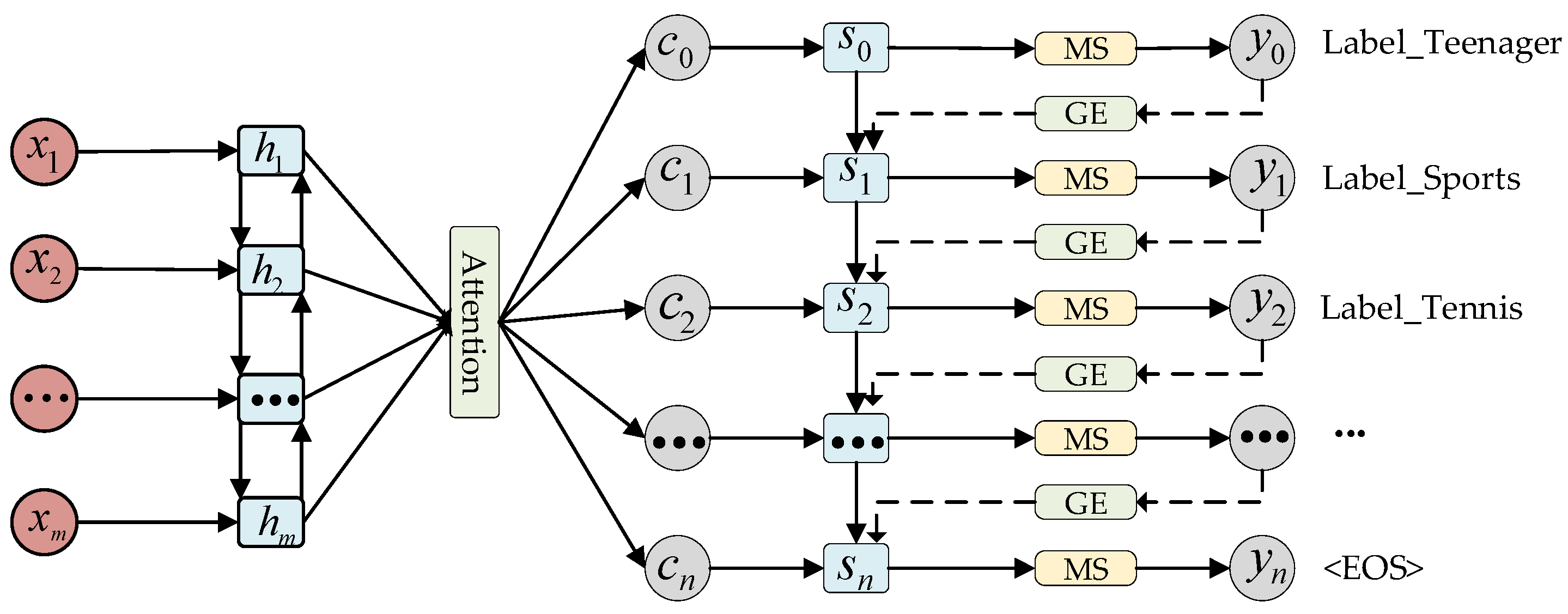
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).