Abstract
The introduction of artificial intelligence (AI) has triggered changes in modern dance education. This study investigates the application of diffusion-based modeling and virtual digital humans in dance instruction. Utilizing AI and digital technologies, the proposed system innovatively merges music-driven dance generation with virtual human-based teaching. It achieves this by extracting rhythmic and emotional information from music through audio analysis to generate corresponding dance sequences. The virtual human, functioning as a digital tutor, demonstrates dance movements in real time, enabling students to accurately learn and execute dance postures and rhythms. Analysis of the teaching outcomes, including effectiveness, naturalness, and fluidity, indicates that learning through the digital human results in enhanced user engagement and improved learning outcomes. Additionally, the diversity of dance movements is increased. This system enhances students’ motivation and learning efficacy, offering a novel approach to innovating dance education.
1. Introduction
In the digital age, technological advancements are transforming various fields at an unprecedented pace, with dance education also experiencing significant changes. As a widely practiced art form, dance is increasingly attracting attention. Traditional dance instruction primarily relies on face-to-face interaction and hands-on demonstrations. However, this conventional approach faces limitations, including restricted teaching resources, challenges in personalizing student learning progress, and inadequate real-time feedback [1]. Consequently, integrating digital technologies with dance education to offer learners a more intuitive and engaging learning experience has emerged as a valuable research topic.
This system represents an innovative integration of music-driven dance generation with virtual digital human teaching. It employs audio analysis to extract the rhythm, beat, and emotional content of music, generating corresponding dance sequences that align with these musical elements. Digital technology is utilized to simulate real-world dance teaching scenarios, thereby offering students a more vivid, intuitive, and interactive learning experience. The core innovation of this system lies in the synthesis of music-driven dance generation and virtual digital human technologies. The audio analysis component accurately captures the rhythm, beat, and emotional nuances of the music, ensuring that the generated dance movements are harmoniously synchronized with the musical elements. The virtual digital human serves as a personal tutor, providing real-time demonstrations of dance movements, offering expert guidance, and facilitating the enhancement of students’ dance skills. This approach enables students to engage in dance practice anytime and anywhere, transcending traditional constraints of time and space, and delivering a personalized and efficient learning experience.
However, with the rapid development of modern artificial intelligence technology, network security issues have become increasingly prominent. The widespread application of artificial intelligence and virtual digital humans in dance teaching systems has raised urgent concerns about preventing potential network attacks, data breaches, and identity theft. While large-scale collection and analysis of user behavior data and learning preferences enable the system to provide personalized teaching plans, this process also introduces risks of privacy leaks. For instance, on a dance learning platform, users’ audio and video data, motion analysis results, and other sensitive information could become potential targets for attackers. Therefore, the design and implementation of robust network security mechanisms are crucial when building such intelligent systems. This involves multi-level security measures, including data encryption, access control, and user identity authentication [2]. Ensuring the effectiveness of these mechanisms is essential not only for safeguarding against network threats but also for protecting user privacy and data security while delivering a high-quality teaching experience.
The research significance of this system lies in its comprehensive integration of music’s structure, style, and rhythmic characteristics, effectively mapping the relationship between music and dance. Furthermore, it introduces new methodologies in education, significantly improving both the appeal and efficacy of dance instruction.
2. Related Work
In the context of research on music-driven digital human dance movement teaching systems, research work in related fields can be categorized as follows:
- (1)
- Artificial intelligence in education
In recent years, the application of artificial intelligence (AI) technology in education has been steadily increasing. Klein et al. developed a student classroom behavior recognition system (WITS) utilizing convolutional neural networks (CNNs) and created a comprehensive student behavior dataset. Their system achieved an accuracy rate of 89.8% following extensive training [3]. Chunbo Hou explored the role of intelligent transformation in music education, examined its necessity, and proposed directions for developing an intelligent music teaching system [4]. The focus of educational AI research is to enhance the learning environment by analyzing and understanding students’ learning activities.
- (2)
- Virtual digital human technology
Virtual digital human technology has demonstrated significant potential across various domains. Chang Hong suggested that in the innovative development and effective preservation of intangible cultural heritage, the creation of a story system centered around virtual digital human characters represents a promising new direction [5]. In the entertainment sector, Wu discussed the extensive use of virtual digital humans in films and games. By creating virtual idols through realistic digital human representations, this technology enhances user immersion and engagement [6].
- (3)
- Music-driven dance generation
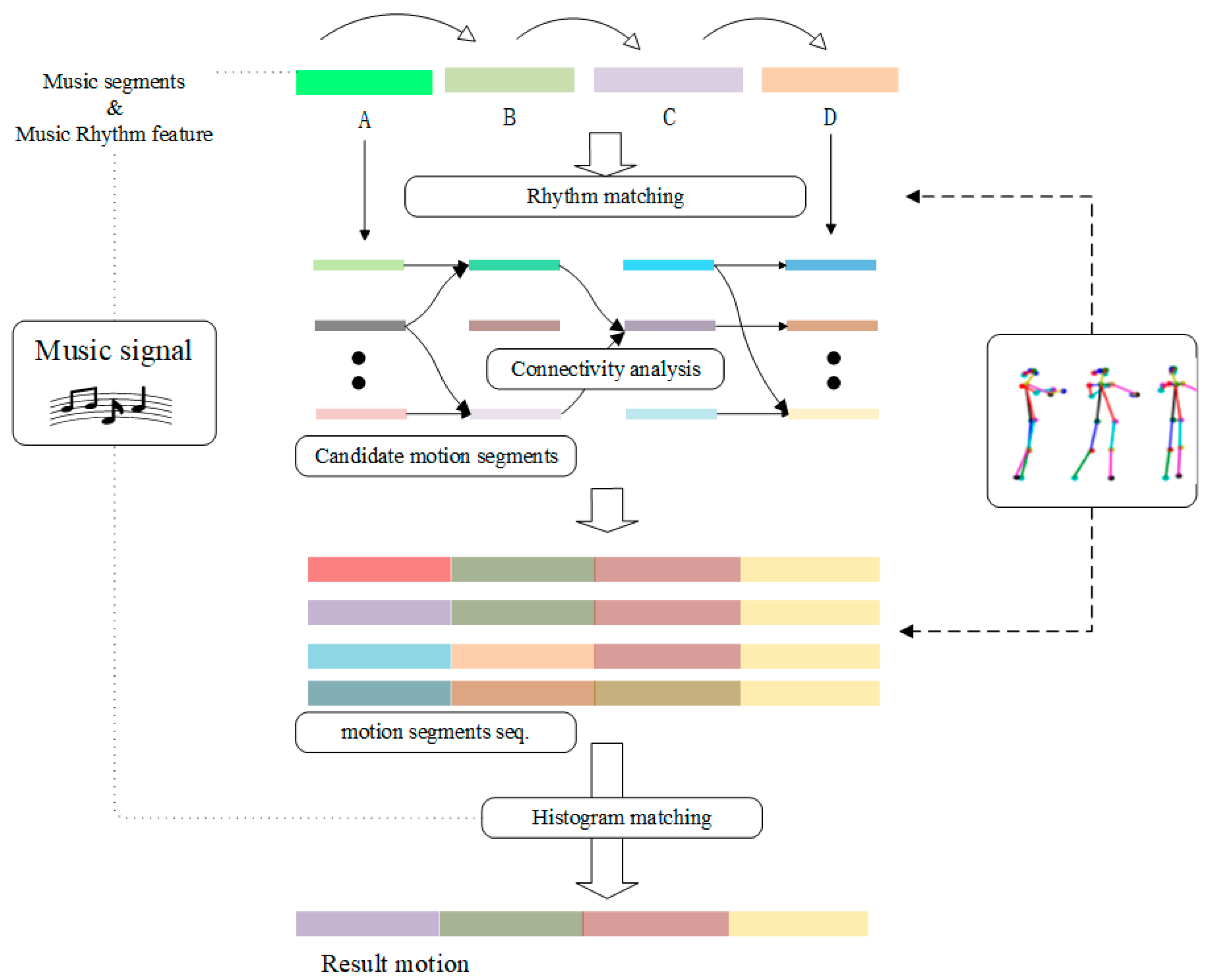
Research on music-driven dance has evolved through three distinct stages. In the early stage, approaches focused on path matching, where choreography was developed based on the analysis of musical similarities. The middle stage introduced classical machine learning and deep learning techniques for music-based choreography. In the later stage, the field advanced with the application of generative artificial intelligence, incorporating multimodal and diffusion modeling methods, marking the onset of a new era in music-driven dance research. The concept of computer choreography was first proposed by Lansdown in 1978, who generated dance poses based on movement probability. However, this approach lacked musical constraints, resulting in suboptimal outcomes [7]. In 2005, Hsieh incorporated Newton’s laws to aid computer choreography, which enabled the generation of several movements but with limited diversity [8]. In 2006, Shiratori advanced the field by utilizing musical movement features to achieve synchronized dance movement synthesis. He extracted intensity features and beat changes from both movement and audio data, analyzed their relationship for dance movement synthesis, and compared and matched features between music and stored dance sequences to complete the choreography. An overview of the movement synthesis algorithm is illustrated in Figure 1 [9].
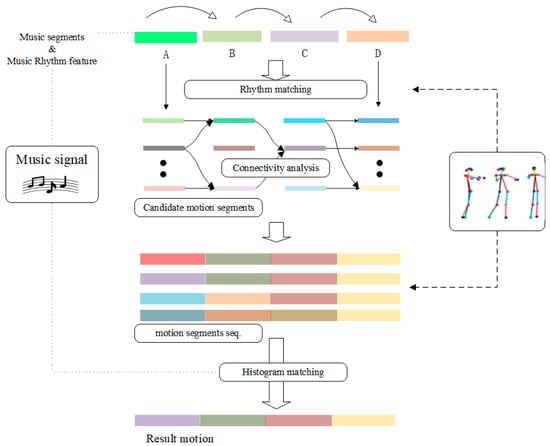
Figure 1.
Motion Synthesis Algorithm Diagram.
In 2016, Luka and Louise developed a Recurrent Neural Network (RNN) choreography system using deep learning techniques that could generate new dance sequences with some semantic coherence. However, their system did not account for musical factors [10]. Duan et al. approached music-driven dance by symbolizing dance movements and reformulating the music-to-dance translation as an utterance retrieval problem. They introduced a semi-supervised learning method for music-driven dance, but the reduction of rhythmic information in the encoder input adversely affected the quality of the generated dance [11]. In 2022, Tevet et al. incorporated the diffusion model into human animation generation, achieving text-driven animation creation [12]. Building on this, Tseng et al. applied the diffusion model to music-driven dance, enabling the generation of dance movements from real audio inputs. Nonetheless, their approach requires further refinement in music feature encoding and dance generation [13].
Based on the research foundation of the above literature, this system will further explore and integrate the diffusion model and music-driven dance generation technology to realize a high degree of fusion between music and dance through AIGC technology, and to promote the application of virtual digital man in dance teaching.
3. Theoretical Framework of Digital Human Dance Teaching System
3.1. Technical Route
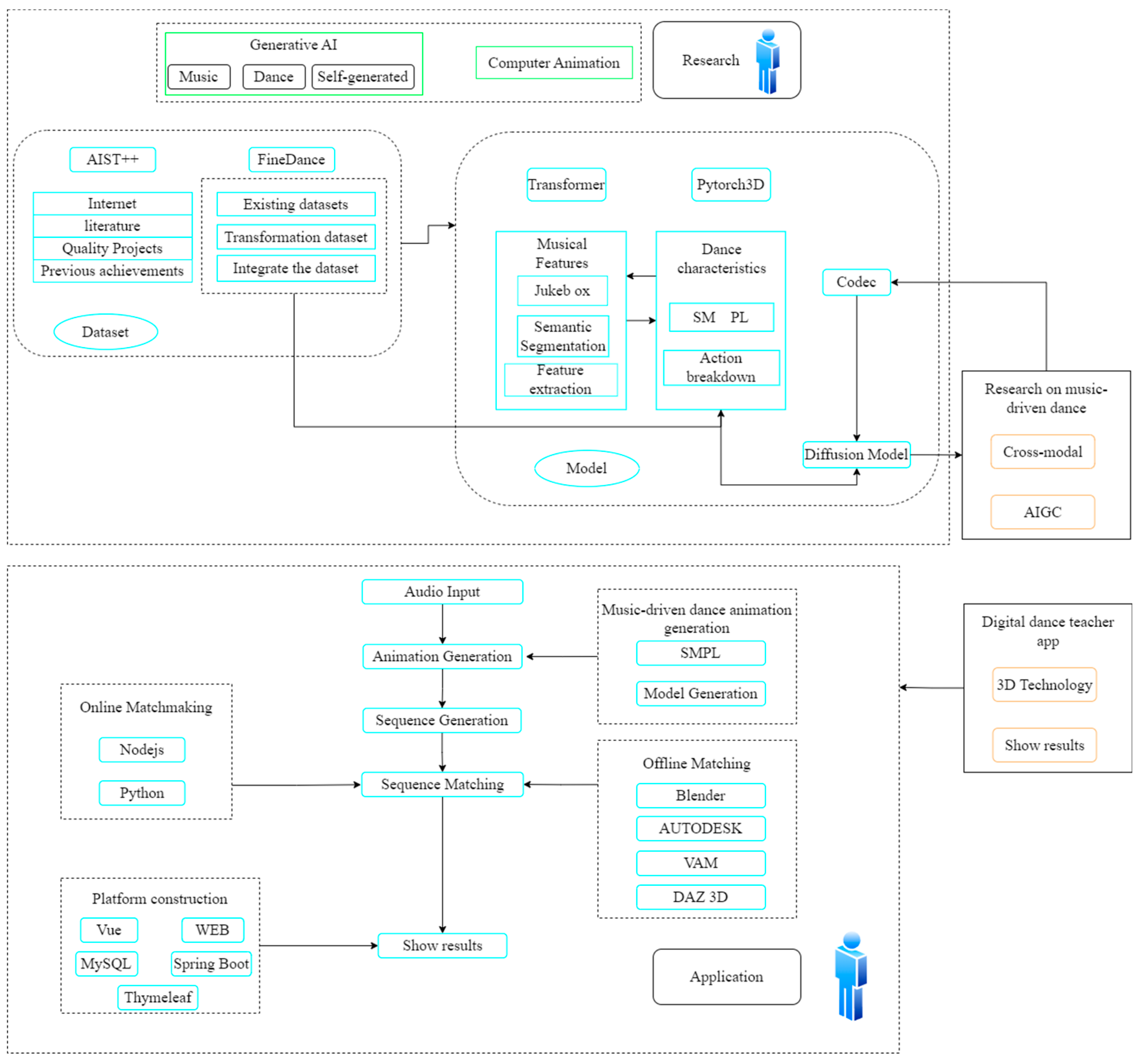
The proposed technical approach for this system is illustrated in Figure 2. To develop the Diffusion Model-based digital human dance teaching system, the project is divided into two main components: research and application. The research component focuses on music-driven dance and follows a deep learning workflow. This includes constructing a dataset, performing feature extraction, and sequence matching. The diffusion model and codec are employed to train the model and develop an effective generative model for dance sequences. The application component involves converting the generated dance sequences into animations. This includes the creation of both online and offline versions of the digital human display program. The online version facilitates real-time dance movement display, while the offline version utilizes WEB technology for video rendering and platform display. This dual approach ensures the effective application of the system and enables the realization of a Diffusion Model-based digital human dance movement teaching system.
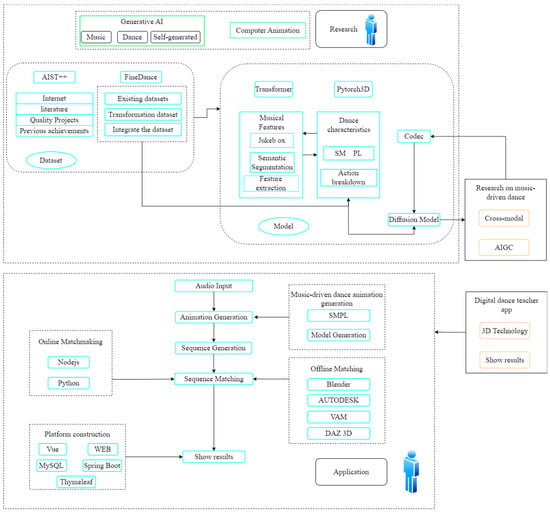
Figure 2.
System Technology Roadmap.
3.2. Dataset
In this system, model training is critically dependent on the dataset. Significant improvements have been made to music and dance datasets through the efforts of previous researchers. The dataset is designed as a benchmark for motion generation and prediction tasks. It may also benefit other tasks, such as 2D/3D human pose estimation. To the best of our knowledge, AIST++ is the largest 3D human dance dataset, containing 1408 sequences, 30 subjects, and 10 dance genres, encompassing both basic and advanced choreography [14]. In contrast, FineDance is the largest dataset for music-dance pairing, encompassing a wide variety of dance genres [15]. These datasets are currently the most suitable for research on music-driven dance. As shown in Table 1. The evaluation metrics of the dataset are shown in bold in Table 1. Pos and Ros means 3D position and Rotation information respectively. Fbx (FilmBox) is one of the main 3D exchange formats as used by many 3D tools. “avg Sec per Seq” means the average seconds per sequence.

Table 1.
Comparison table for each music and dance dataset.
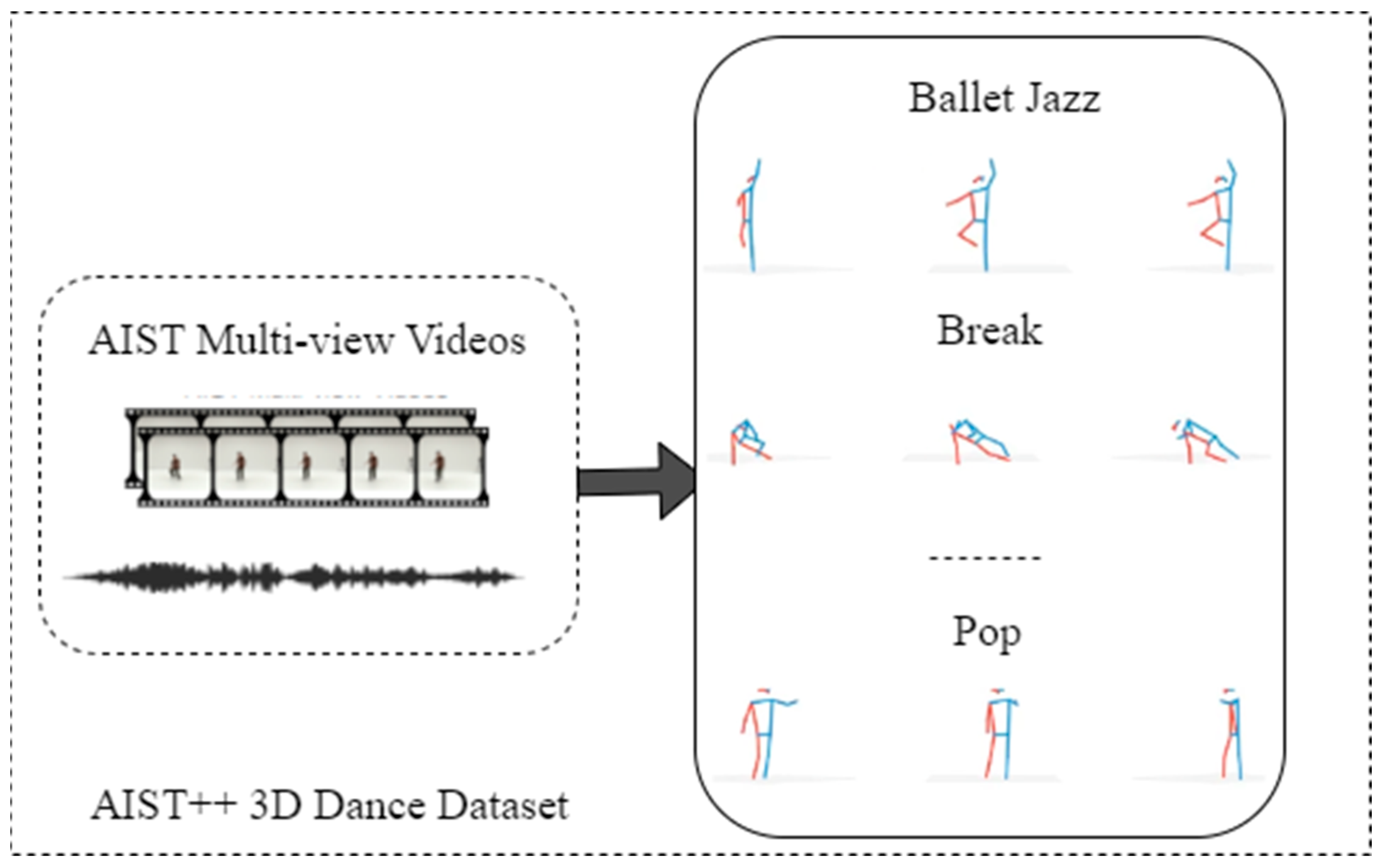
The AIST++ dance movement dataset is derived from the AIST Dance Video DB and includes 1408 3D human dance movement sequences, represented as joint rotations and root trajectories. The dataset encompasses a diverse range of dance movements distributed across 10 dance genres and hundreds of choreographies. Movement durations vary from 7.4 to 48.0 s. Each dance sequence is paired with its corresponding music, making AIST++ a foundational dataset for this research. The AIST++ dataset is shown in Figure 3.
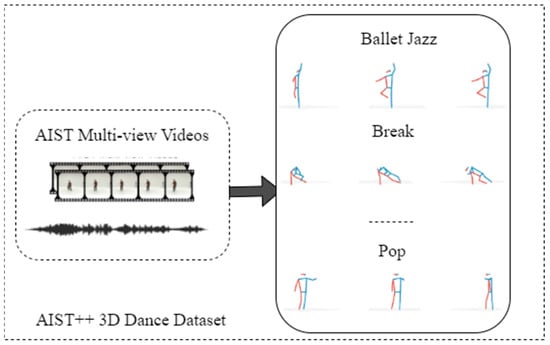
Figure 3.
Schematic of the AIST++ dataset.
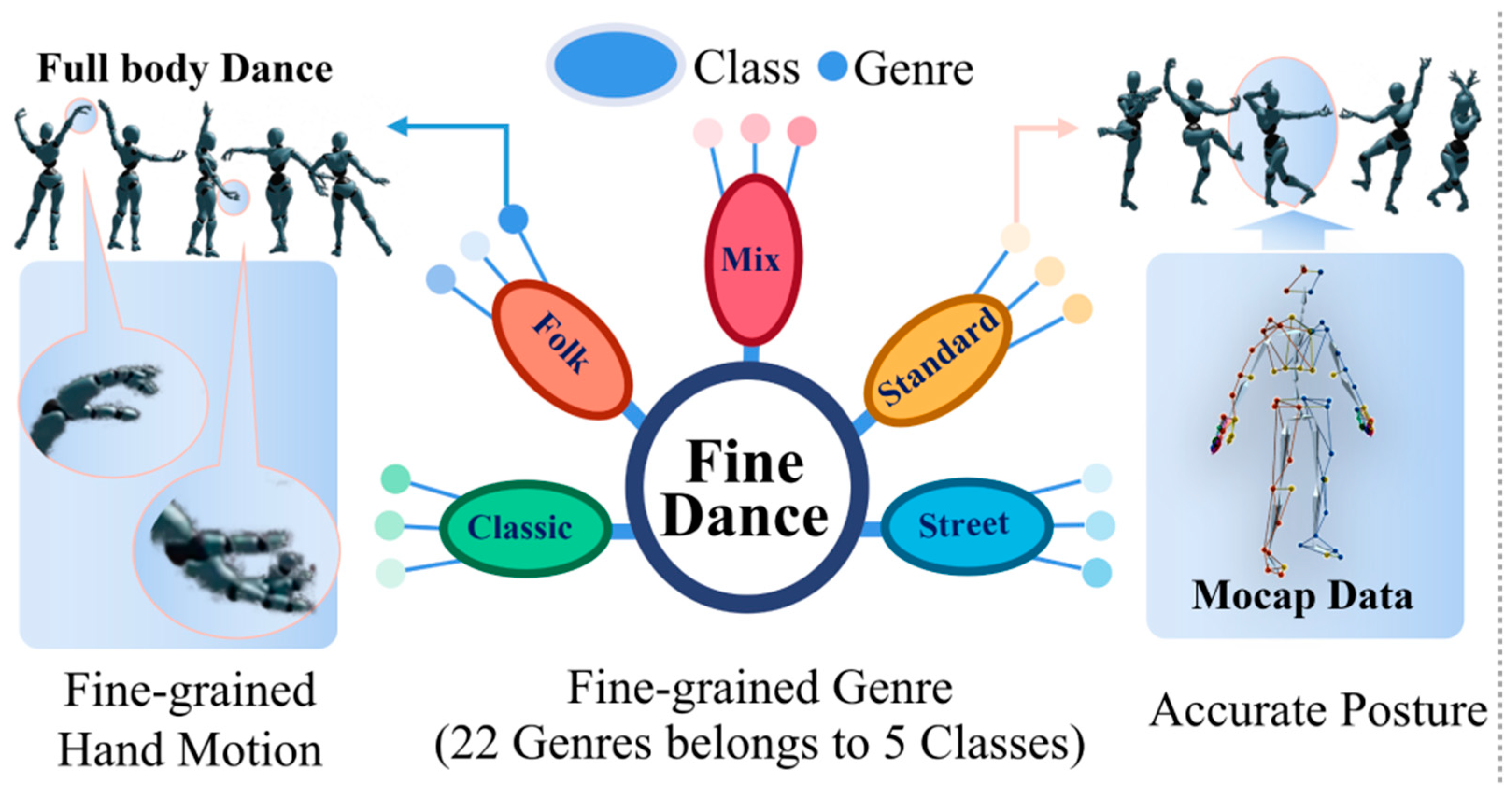
The FineDance dataset comprises 14.6 h of music and dance pairing data, featuring detailed hand movements, a comprehensive categorization of 22 dance types, and precise pose information. In this system, FineDance is integrated with the AIST++ dataset, and the final data format for the dance sequences is SMPL. An illustration of the FineDance dataset is shown in Figure 4.
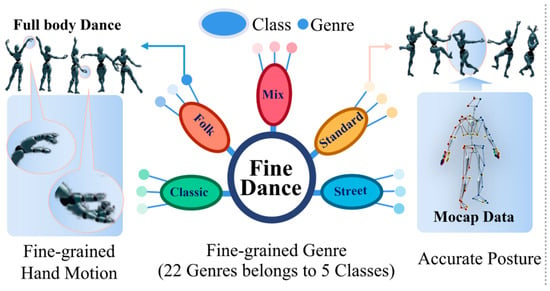
Figure 4.
Schematic of the FineDance dataset.
Data Extraction and Processing
- (1)
- Data extraction: The AIST++ dataset is initially downloaded as BVH or FBX files, which contain skeletal motion capture data. After downloading, these files are converted into JSON format to facilitate the easy extraction and manipulation of joint positions, rotation angles, and frame data.
- (2)
- Data segmentation: Each dance sequence in AIST++ is divided into smaller segments based on dance phases or specific moves. For example, a single dance move can be divided into “beginning”, “middle”, and “end” phases or categorized by specific moves such as spins, jumps, or transitions. These segments are precisely aligned in time to ensure smooth transitions between different dance phases. This segmentation approach helps create seamless choreography when the segments are stitched together.
- (3)
- Data augmentation: To increase the variability of the dataset, we employed pose augmentation techniques. These techniques involve making subtle adjustments to joint positions or rotation angles to simulate variations in different performers’ styles or to account for noise in the motion capture data. Missing or noisy data points within the sequence were addressed using interpolation and smoothing methods, ensuring that the dataset used for model training remained clean and continuous.
- (4)
- Feature extraction: Extract key features such as joint angles, velocities, and accelerations from the skeleton data. Extract key features such as joint angles, velocities, and accelerations from the skeleton data. These features are essential for capturing the dynamics of dance movements and are used as input features for training the model.
- (5)
- Combined dataset: The data processed and segmented by AIST++ and FineDance are combined into a unified dataset, which includes synchronized 3D motion capture data and corresponding music. This dataset is well suited for training models that require both motion and music input.
- (6)
- Database construction: A structured database is constructed, with each entry containing a pair of music and its corresponding dance sequence, along with metadata such as dance style, rhythm, and key movements. This database serves as the foundation for the system’s choreography generation and teaching modules.
3.3. Diffusion Model Training
The foundation of this system is the diffusion model, specifically the Denoising Diffusion Probabilistic Model (DDPM). This model is employed by companies such as OpenAI, Google, and Stability AI to achieve advancements in text-to-image generation, thereby advancing the field of Artificial Intelligence Generated Content (AIGC). In this system, the diffusion model is utilized to perform noise prediction for dance sequences. The model operates in a Gaussian space to predict and match dance sequences, fulfilling the requirements for driving the dance generation process. Compared to other AI generation methods, the diffusion model offers significant advantages, including effective sequence prediction and enhanced diversity in the generated dance movements, providing robust technical support for the system.
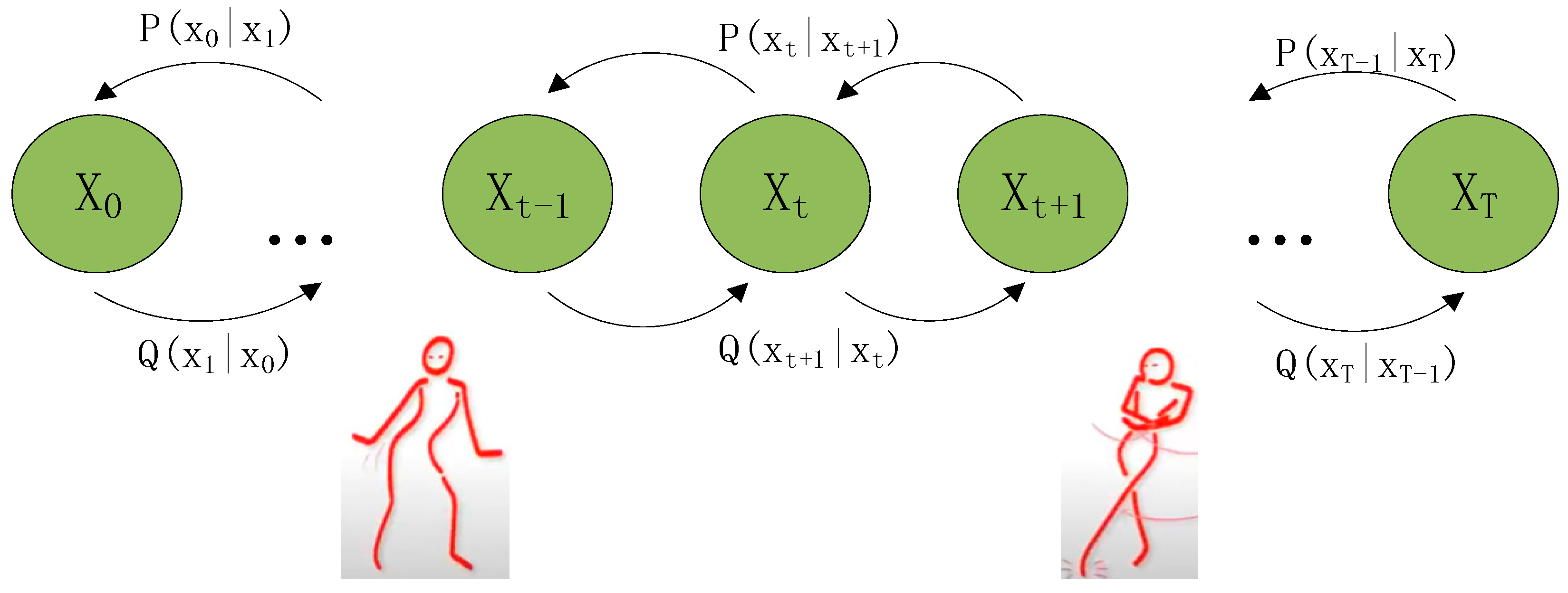
In general, the diffusion model comprises two main processes: the forward diffusion process and the backward sampling process, as illustrated in Figure 5 [16]. The forward diffusion process involves adding Gaussian noise to transform the dance sequence into random noise. The backward sampling process, or denoising process, employs a series of Gaussian distributions parameterized by a neural network. The diffusion model utilizes these trained networks to constitute the final generative model. Specifically, noise is first added to the dance sequence, and then the denoising process is applied to predict and generate the dance sequence.
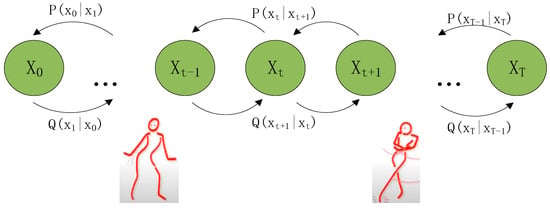
Figure 5.
Diffusion modeling to predict dance sequences.
The diffusion model employed in this system is based on the Denoising Diffusion Probabilistic Model (DDPM). It defines the diffusion process as a Markov process characterized by a forward noise process . The backward process is derived from the data distribution, with the forward noise process described as follows:
where is a constant that follows a monotonically decreasing time and approximates as approaches zero.
Where the musical condition is set for diffusion restriction, and the forward propagation process is inverted by predicting the model parameters , and thus estimating , in time step . We optimize the objective function using the following:
where denotes the mathematical expectation, is the dance sequence, is the time step, and is the musical condition.
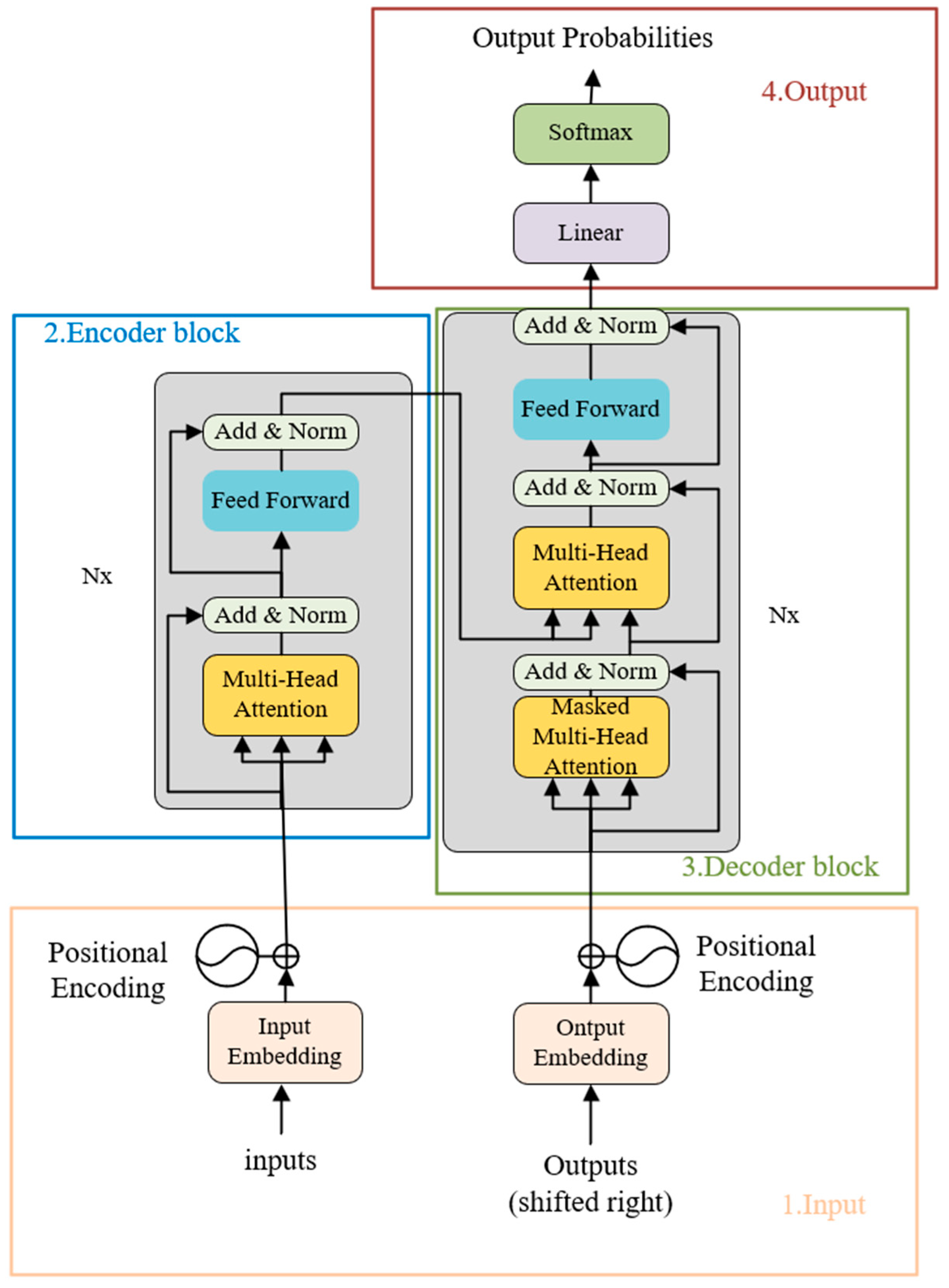
This system utilizes the Transformer architecture for the forward prediction in diffusion models. The Transformer is known for its ability to “vectorize” any text or sentence, thereby capturing and maximizing the precise meaning of the input. It has demonstrated significant success across various domains in AI, including natural language processing, computer vision, and audio processing. In 2021, a paper co-authored by Stanford University referred to models based on the Transformer architecture as “foundational models”, highlighting its role in driving a paradigm shift in AI [17]. In this system, Nx = 6 denotes that the encoder consists of 6 stacked encoder blocks. Each block, as depicted in Figure 6, comprises a Multi-Head Attention mechanism and a Fully Connected Feed-Forward Network.
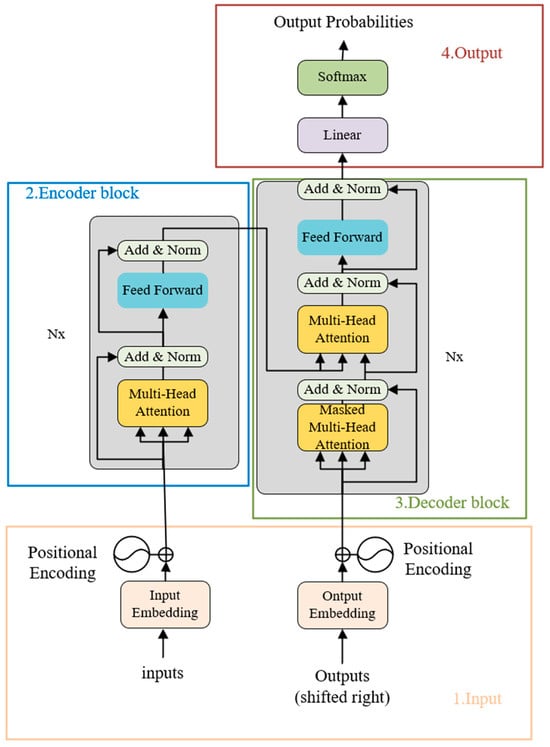
Figure 6.
Transformer model structure.
The attention mechanism is the core of the Transformer, and using it can excellently accomplish the task of dance sequence prediction, the specific process is as follows:
where , , are matrices consisting of query, key, and value vectors, respectively.
3.4. Construction of Music-Driven Generative Dance Models
The core idea of this system is to generate dance movement sequences based on user input of various music types. This involves using diffusion modeling to iteratively refine the initial dance sequences through multiple iterations. The final result is a dance movement demonstration performed by a digital human. The model is illustrated in Figure 7.
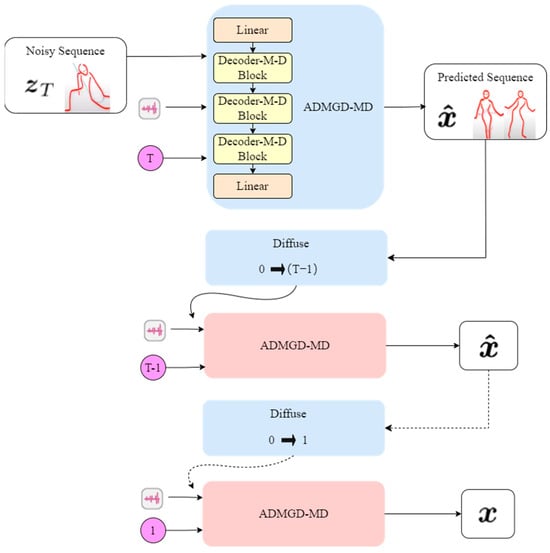
Figure 7.
Music-Driven Dance Generation Modeling Diagram.
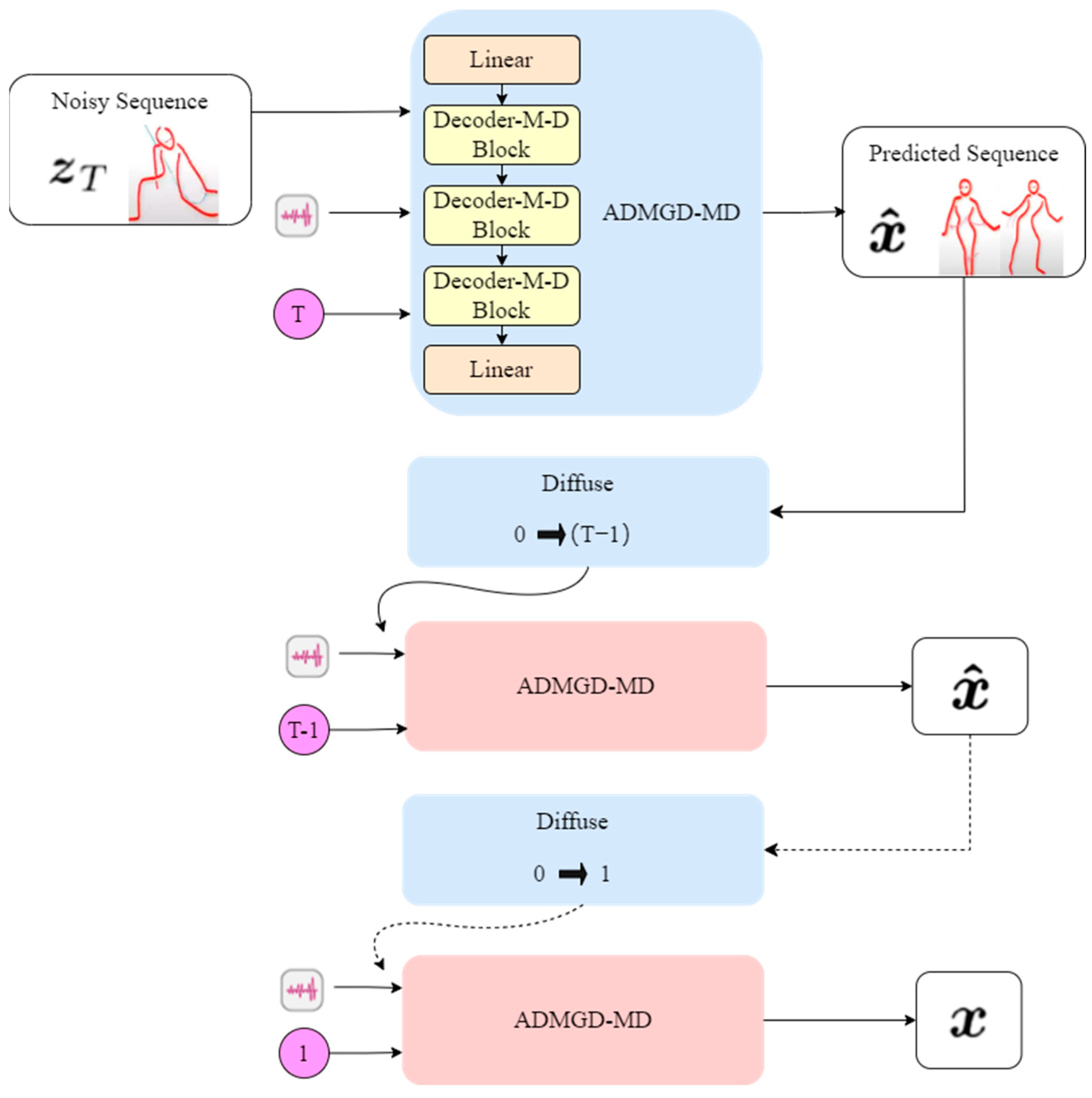
The model network is divided into two main components: the cross-modal matching module and the dance sequence diffusion module. The network simulates the diffusion process by iteratively denoising dance sequences from time step T to time step 0. At each denoising step T, the cross-modal matching module performs a sample prediction of the dance sequences. Subsequently, the diffusion network denoises the dance sequences for the next time step. This process continues iteratively until the final dance sequences are obtained at time step 0.
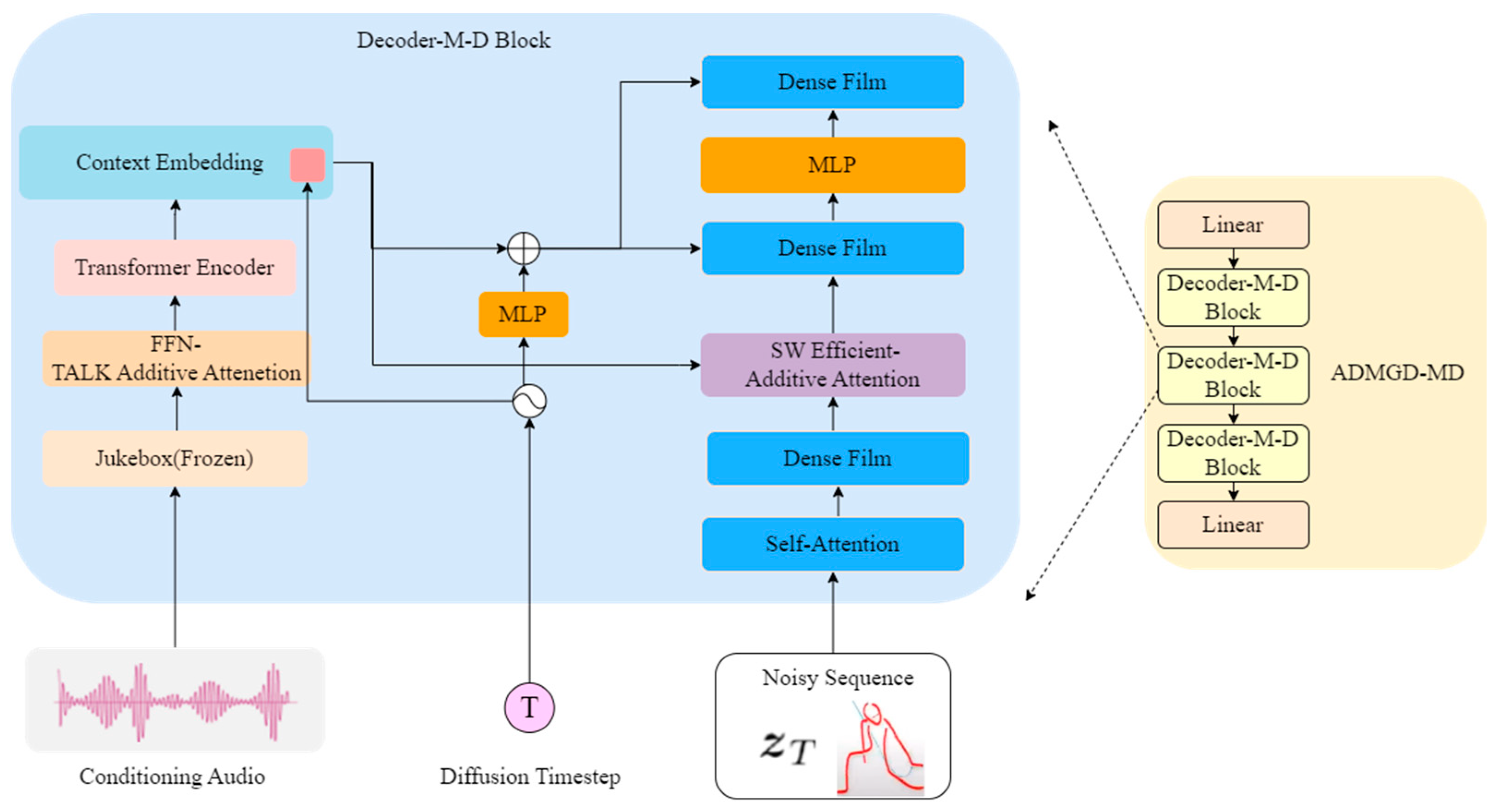
In the network model, the ADMGD-MD module realizes the prediction of noise to dance sequences, learns the parameters in the forward process of the diffusion model, and obtains the dance sequences at the moment of T in the inverse process, so that the diffusion model can complete the prediction of music-driven dance sequences [18]. Therefore, the use of this module to solve the problem of insufficient musical feature encoding capability of the old model is not coordinated with the generation of dance sequences; the specific internal structure is shown in Figure 8 below.
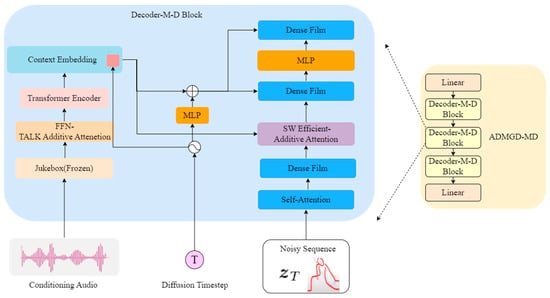
Figure 8.
ADMGD-MD Module Structure Diagram.
For the evaluation of the model, the system uses the following technical indicators:
In terms of kinematic quality, to assess the kinematic quality of the generated dance sequences, we followed the previous method to calculate the Frechet Inception Distance (FID) distance between the kinematic features of the generated dances and the real dance sequences. The kinematic features (subscript “k”) represent the velocity and acceleration of the movement and reflect the physical characteristics of the dance. Therefore, the FID distance FIDk between kinematic features measures the physical reality of the movement. Geometric features (subscript “g”) are computed based on multiple predefined movement templates; therefore, the FID distance FIDg between geometric features reflects the quality of the overall choreography.
In terms of movement diversity, in order to evaluate the movement diversity of the generated dance sequences, we compute the average Euclidean distance within the kinematic feature space, in agreement with Bailando. DIVk denotes the movement diversity in the kinematic feature space, while DIVg denotes the diversity in the geometric feature space.
For the beat alignment scores, to evaluate the beat consistency between the generated dances and the given music, we followed Bailando and used BAS to evaluate our method.
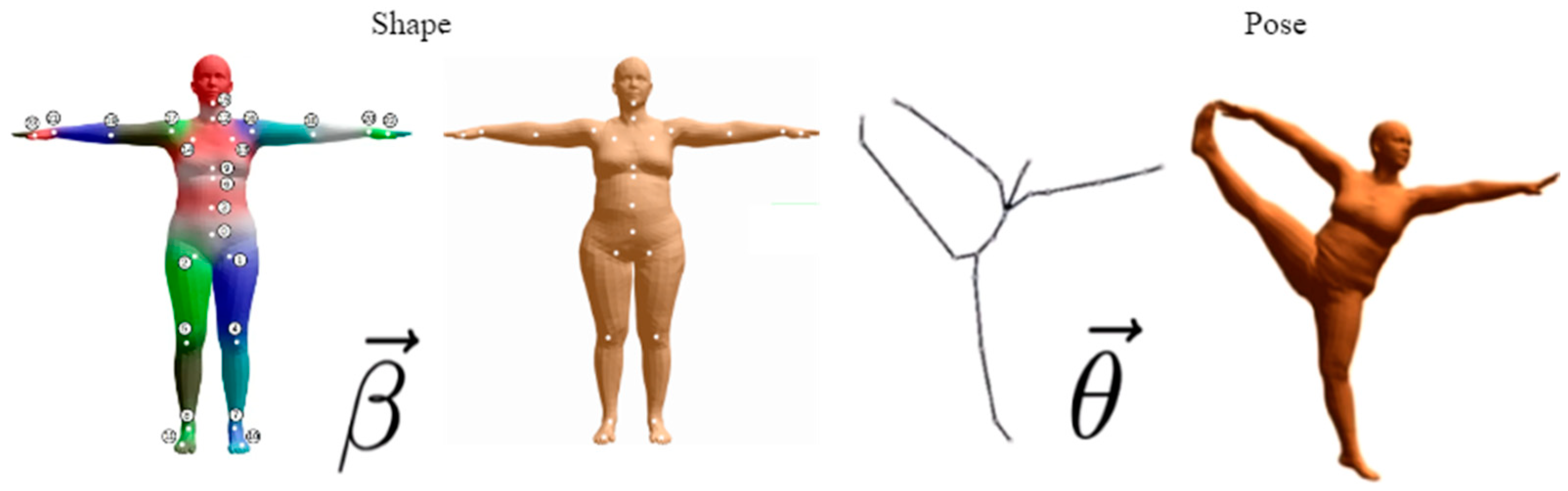
The dance sequences in this system follow the skinned multiplayer linear model data format, which is abbreviated as SMPL [19]. SMPL better solves the historical problem of skin collapse and wrinkles that can occur in linear hybrid skinning algorithms, and is suitable for the field of animation, which can be deformed naturally with pose changes and accompanied by natural movements of soft tissues. Therefore, it can better fit the shape of the human body and the deformation under different poses, and the shape and pose of the human body model can be parametrically represented, as shown in Figure 9 below.
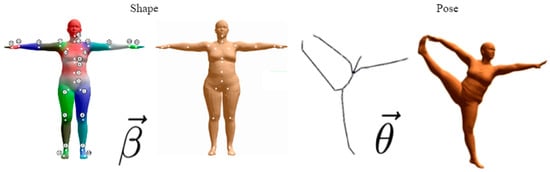
Figure 9.
SMPL model diagram.
4. Implementation of Digital Human Dance Movement Teaching System
4.1. System Functional Modules
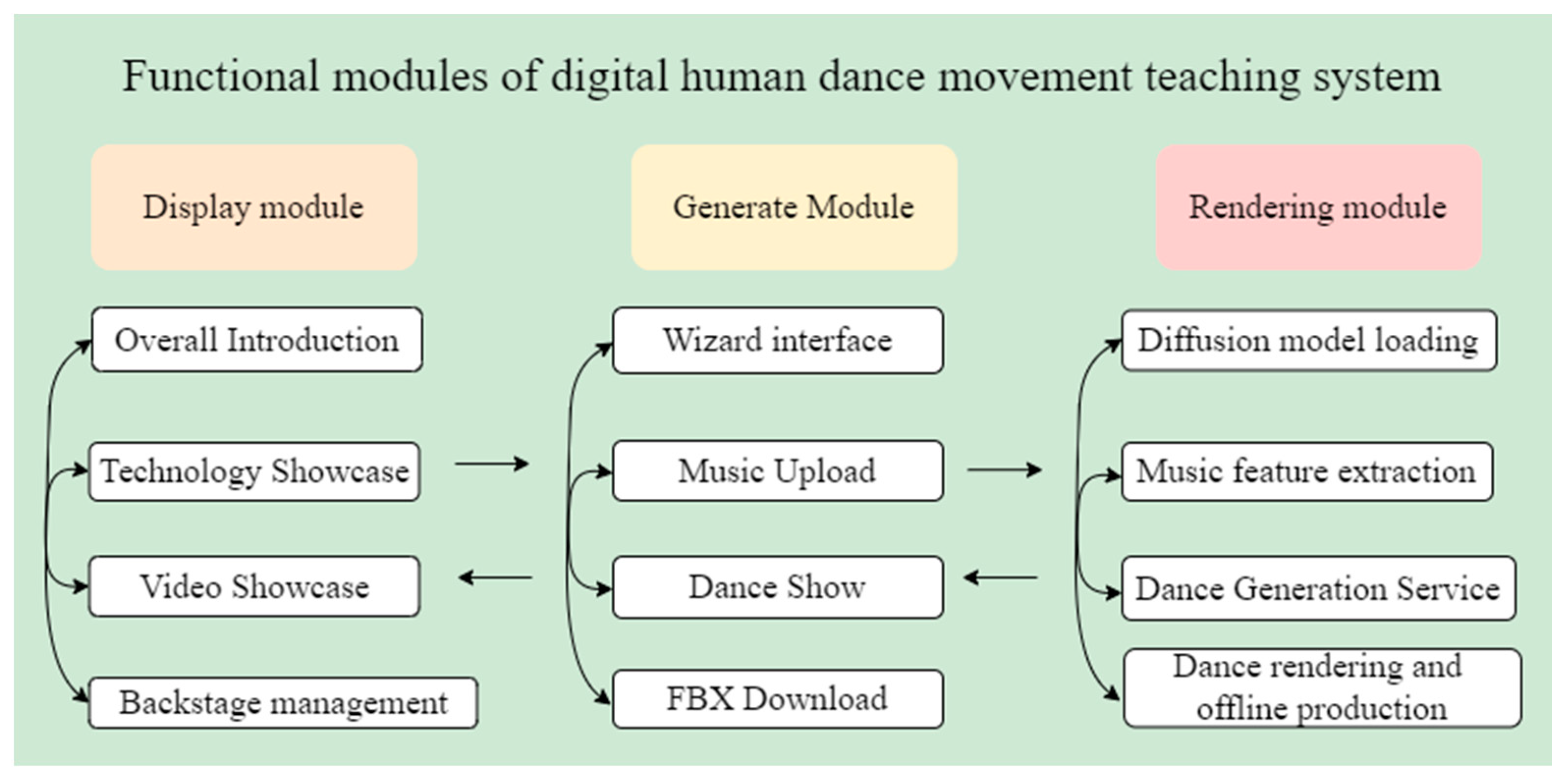
As illustrated in Figure 10, the realization of this system depends on three primary functional modules: the music-driven dance animation technology and video display module, the music-driven dance animation generation module, and the digital human dance rendering module. Each module performs its specific function, and together, the three modules support each other to create a digital human dance movement teaching system based on the diffusion model.
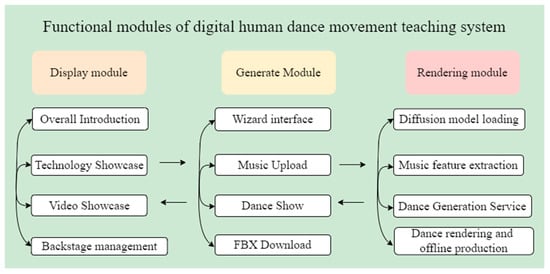
Figure 10.
Functional Module Diagram.
The music-driven dance animation technology and video display module are implemented using Java Web technologies. This module provides a front-end interface for the playback of dance animation videos and a back-end portal for system management and control. Users can browse and view the generated dance animations and learn through the detailed decomposition of digital human movements. The module functions as a classic web service, utilizing Thymeleaf (version 3.0.15.RELEASE) as the template engine on the front end and employing Spring Boot (version 2.7.5), MyBatis (version 3.5.11), and MySQL (version 8.0.32) for back-end content management. Additionally, it leverages AliCloud OSS (version 3.10.2) for object storage to handle data storage needs, thereby fulfilling the requirements for displaying digital human dance movements.
The music-driven dance animation generation module is developed using the Vue.js framework for the front-end interface, facilitating user interaction. In this module, users can upload music files and preview the generated dance animation effects after selecting a dance type. To enable the rendering of FBX models, the system incorporates the Three.js framework. The design of this module emphasizes user experience, featuring a user-friendly and intuitive interface, and supports the import of various music formats.
The digital human dance movement rendering module incorporates an artificial intelligence algorithm based on a diffusion model [20]. In this system, the diffusion model is trained to learn the mapping between music and dance movements. When a user uploads a music file, the module analyzes the music data and automatically generates the corresponding dance movement sequence using the trained model. A well-designed loss function and various regularization strategies are employed during model training to enhance its generalization capabilities. After generating the dance movements, the module maps the movement data to a 3D human model. PyTorch3D is used to load the classic SMPL human model, which is driven in real time by the generated action data. Ultimately, as illustrated in Figure 11, the digital human model is output in motion capture data format for visual rendering and playback in the front-end module.

Figure 11.
Digital human model.
4.2. System Effect Display
The Diffusion Model-Based Digital Human Dance Movement Teaching System integrates diffusion modeling technology, dance animation generation, and virtual digital humans to innovate dance teaching content creation. This system leverages diffusion models and other artificial intelligence technologies to develop a high-quality music-driven dance generation model capable of producing dance sequences. These sequences can then be associated with either online or offline virtual digital humans through virtual reality technologies, addressing the needs of dance education programs with both high feasibility and cost-effectiveness. The process of music-driven dance movement generation is illustrated in Figure 12.

Figure 12.
Dance Movement Sequence Diagram.
Users can choose the music they are interested in and the corresponding dance type, and the system will generate music-driven dance movements to be demonstrated and taught by their favorite virtual digitizers, which will ultimately help them learn and master the dance. Among them, students can interact with the virtual teaching digitizers to learn different types of dance techniques and movements, observe and imitate dance performances, and enhance their body coordination and dance performance ability. Figure 13 and Figure 14 show two different styles of digital human dance teaching courses, respectively.

Figure 13.
Digital Human National-Style Dance Teaching.

Figure 14.
Teaching Modern Dance Moves to Digital Human.
4.3. Results Analysis of Digital Human Dance Teaching System
To ensure the practicality and effectiveness of the research model, we first conducted a series of performance tests, focusing on evaluating the model’s ability to generate music-driven dance movements and examining the degree of matching between the generated dance sequences and the music’s rhythm and intensity characteristics. After successful performance evaluation, we further explored the model’s performance in real-world application scenarios. We applied the proposed innovative method to dance teaching and tested the auxiliary advantages of this technological solution in helping users learn dance through interactive experiences.
4.3.1. Music-Driven Generation of Dance Performance Tests
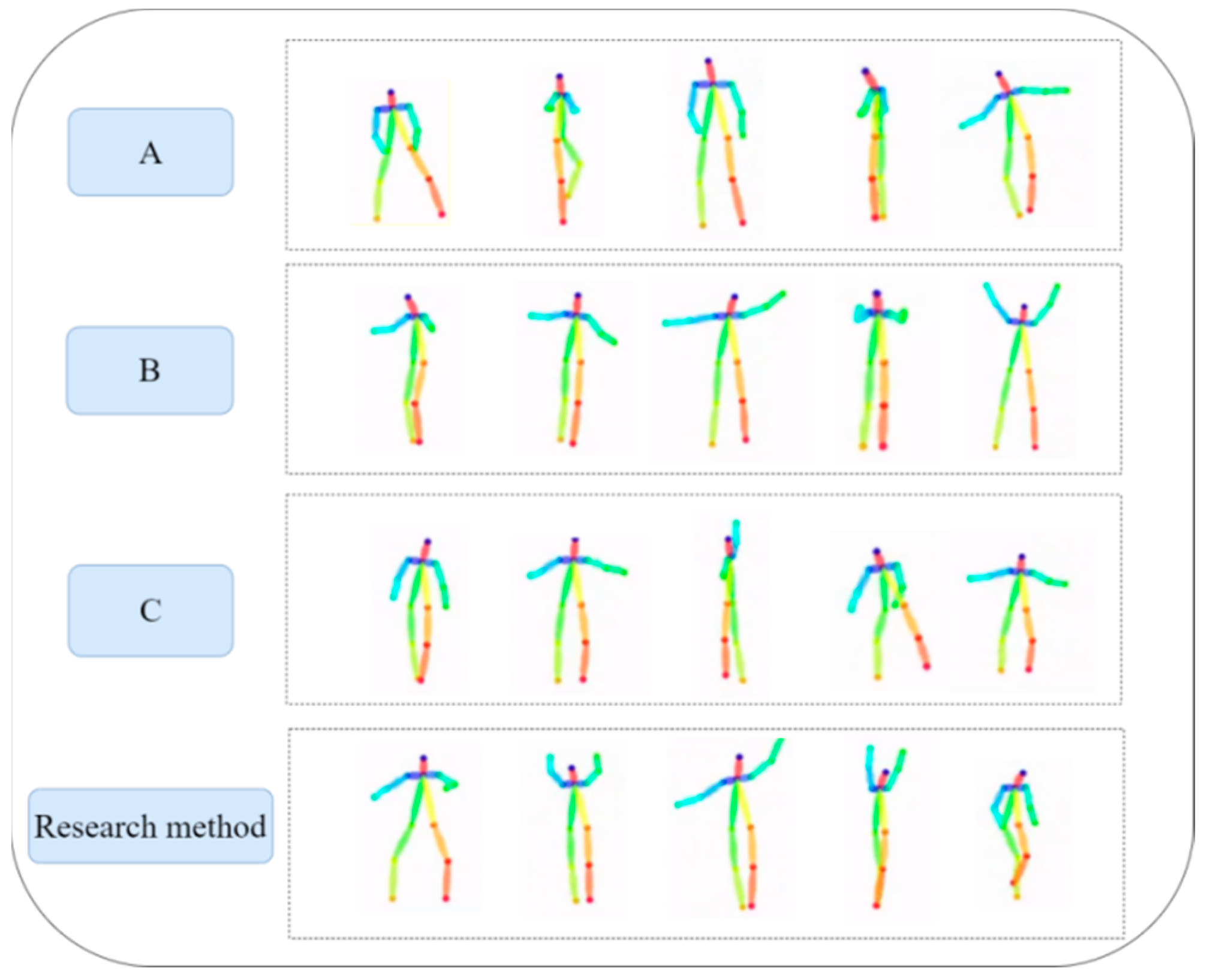
We input a piece of random music into all four models. The results are illustrated in Figure 15. We conducted comparative experiments with three existing dance movement teaching systems: A (ChoreoMaster), B (TM2D), and C (AIxDance). Analysis of Figure 15 reveals that the dance movements generated by our system are notably more diverse and optimized in terms of naturalness and fluency. They better align with the natural movement characteristics of human arm joints. Additionally, the dance movements produced by this system exhibit a high degree of harmony with the music, resulting in improved synchronization of rhythm, intensity, and melody. This enhances the interaction between the music and the dance movements, thereby reflecting the aesthetic quality of the dance.
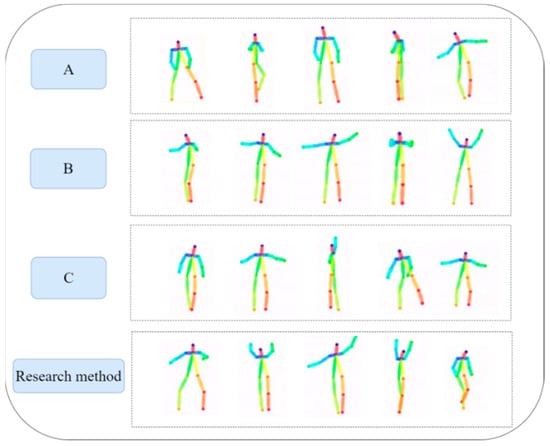
Figure 15.
Comparison of dance sequences generated by different methods.
In Figure 16, we used the same music to generate three different types of dance sequences: Breaking, Locking, and Pop. Breaking dance clips typically feature fast ground movements (such as spins and windmills) and complex actions that showcase strength and agility. Locking is known for its precise and intricate movements, as well as the locking and unlocking of the body. Common movements include quick arm swings, leg bounces, and exaggerated facial expressions. Pop is characterized by rapid and precise muscle contractions and relaxations. Typical movements include chest fluctuations, arm bounces, and sudden stops of the feet. As can be seen from the figure, each dance sequence displays the characteristics of its respective dance style.

Figure 16.
Different types of dance sequences.
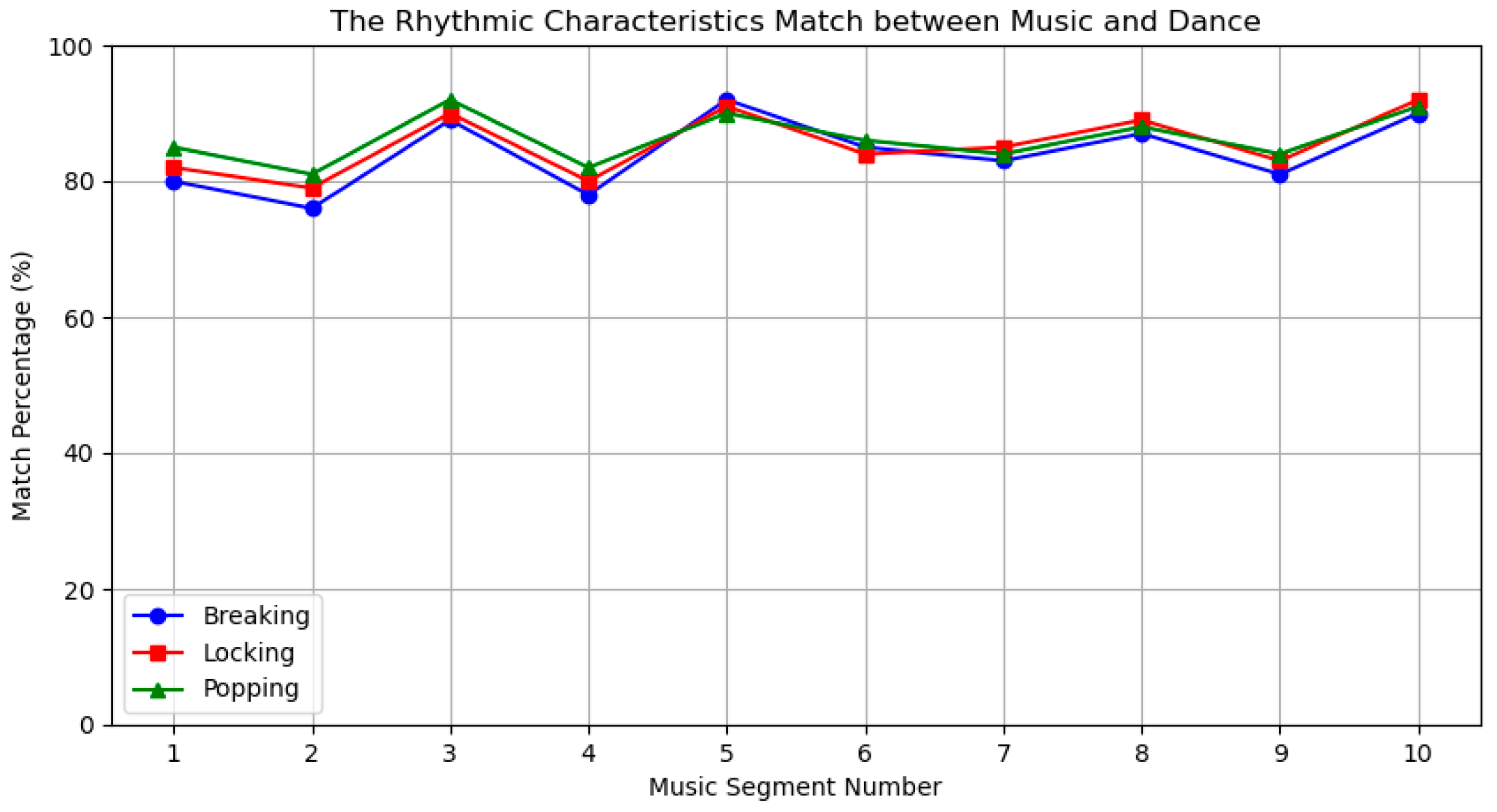
To verify the matching of rhythm and intensity features between music and dance, we compared their respective rhythm and intensity characteristics, as shown in Figure 17. We divided the music into 10 different segments, performed rhythm analysis on each segment, and calculated the matching percentage. Although the rhythm fluctuation curves do not completely overlap, the trends and fluctuation amplitudes of the curves are very similar, indicating a high degree of matching in rhythm features.
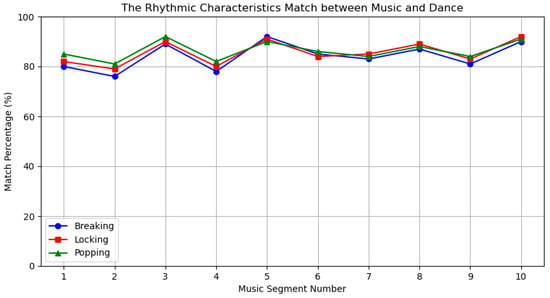
Figure 17.
Rhythm characteristics.
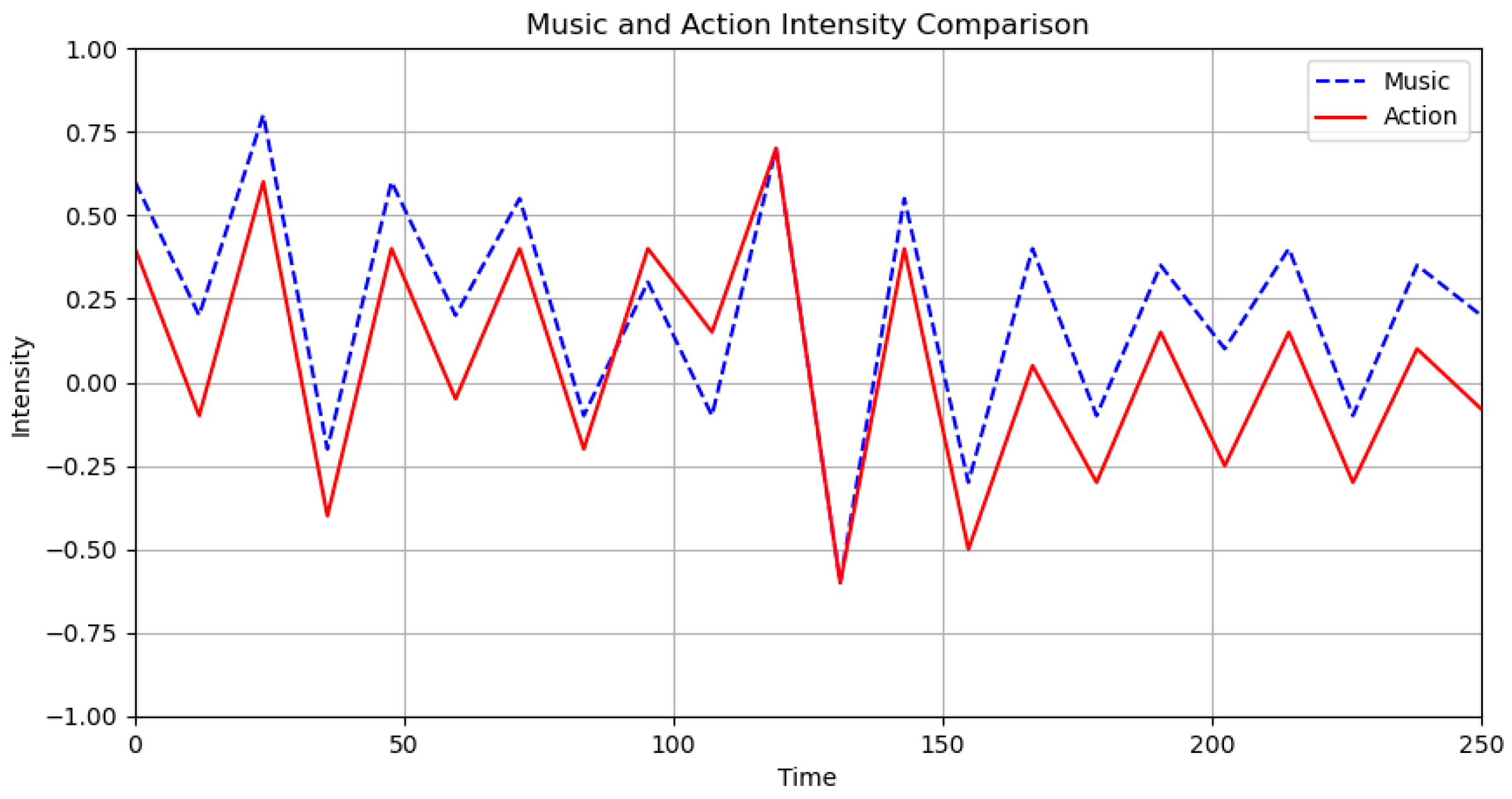
The matching degree of music and dance intensity features is shown in Figure 18. Within the [100, 150] interval, the intensity feature curves fit closely and completely overlap, indicating a high degree of matching between the intensity features of music and dance.
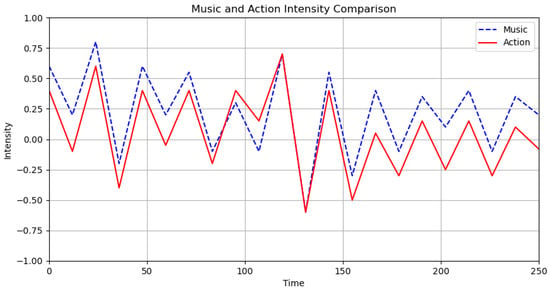
Figure 18.
Intensity characteristics.
4.3.2. Evaluation of Digital Human Dance Teaching System
To assess the applicability and advantages of this system for dance movement teaching, we conducted a comparative experiment with three existing dance movement teaching systems: A (ChoreoMaster), B (TM2D), and C (AIxDance). We recruited 20 students with no prior dance experience to learn four different dance sequences generated from the same music. Professional dance instructors were then invited to evaluate the effectiveness of the learning outcomes.
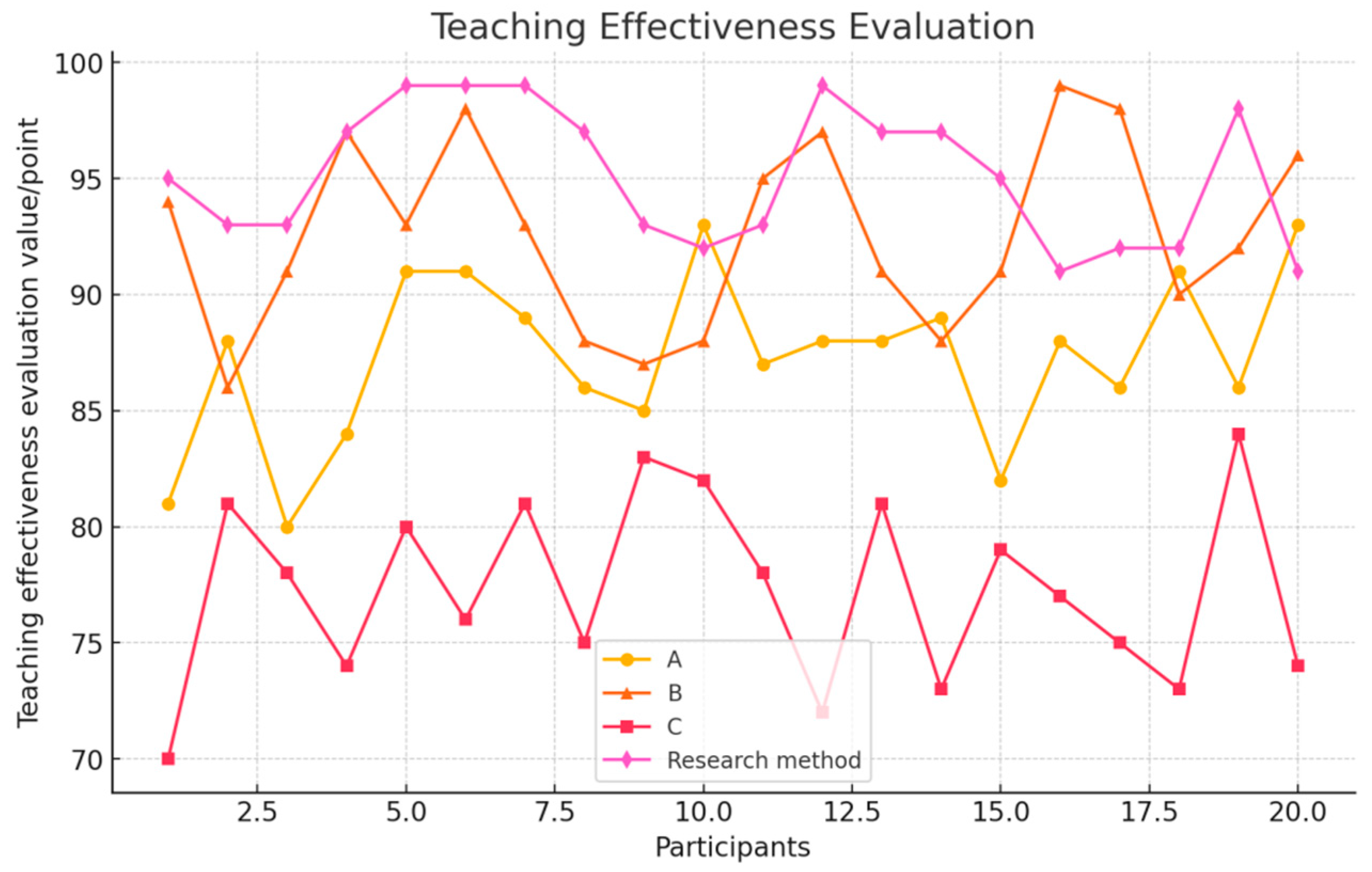
The assessment results are depicted in Figure 19. Significant differences were observed in the teaching effectiveness among the four different dance teaching methods. The system proposed in this study achieved the highest evaluation score, with a maximum of 98 points. Notably, volunteers No. 5 and No. 19 excelled, scoring 80, 91, and 93 points respectively with the dance movements generated by the other three methods. This indicates a substantial advantage of the proposed method. The average teaching effectiveness score for the proposed system was 95.23, underscoring its efficacy in teaching dance. This result demonstrates that beginners can successfully utilize the dance teaching system developed in this study, achieving commendable results.
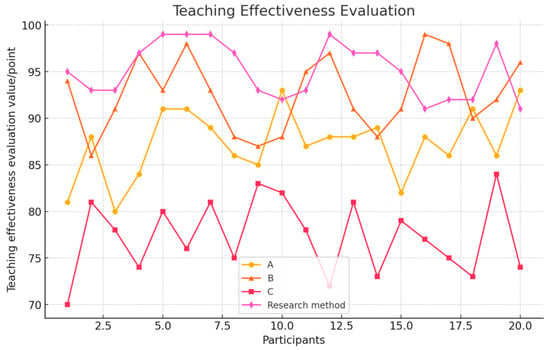
Figure 19.
Comparison of the teaching effects of four types of dance.
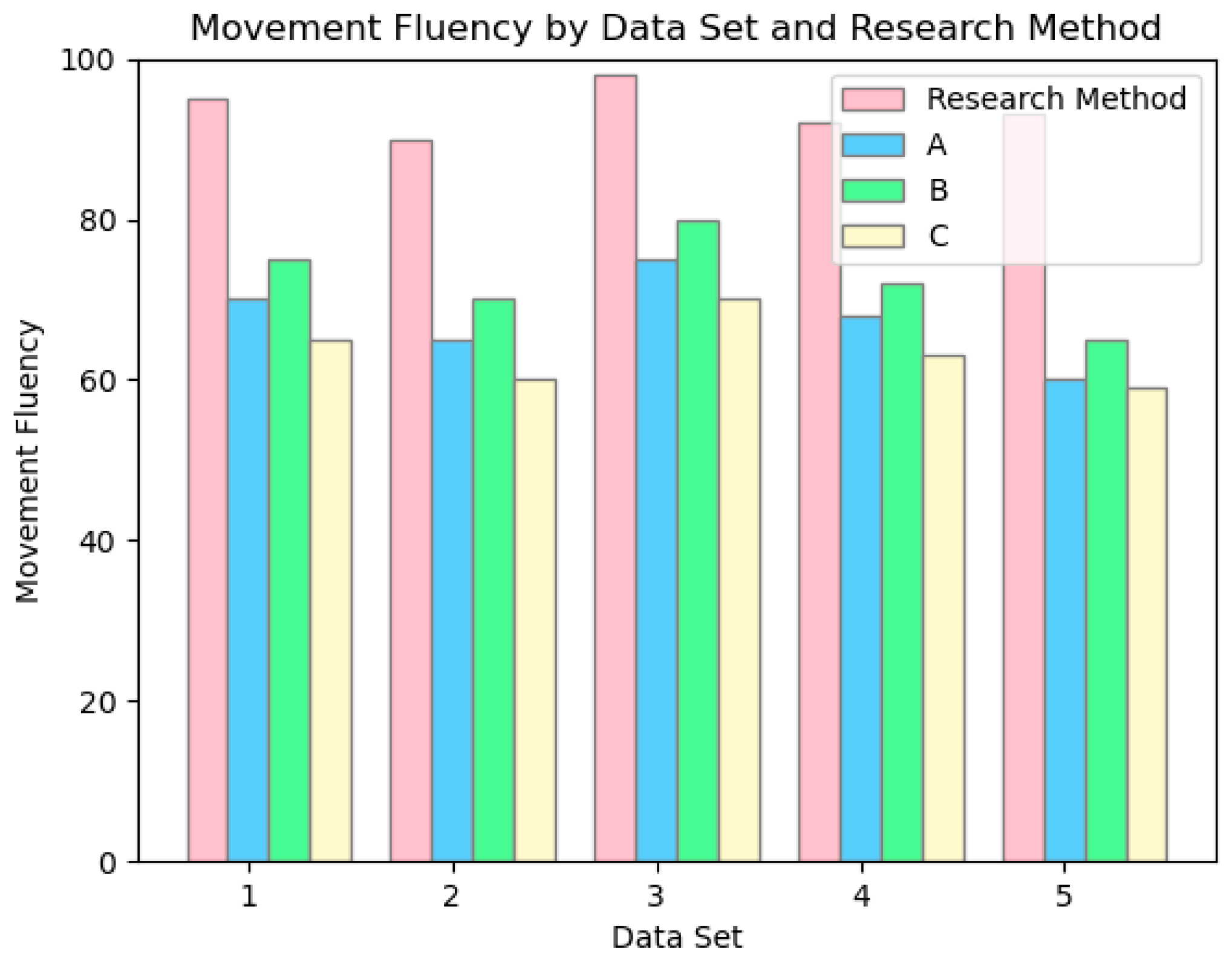
As illustrated in Figure 20 we categorized the dataset into five music styles: Break, Pop, Locking, Hip-hop, and Ballet Jazz. The fluency of the generated dance movements was evaluated by a professional dance instructor, with scores ranging from 0 to 100. The results indicate that our system exhibits a significant advantage in fluency. The fluency scores for all five dance styles remain consistently high, with an average score of 93.6. In contrast, Methods A, B, and C demonstrate potential issues with movement coordination.
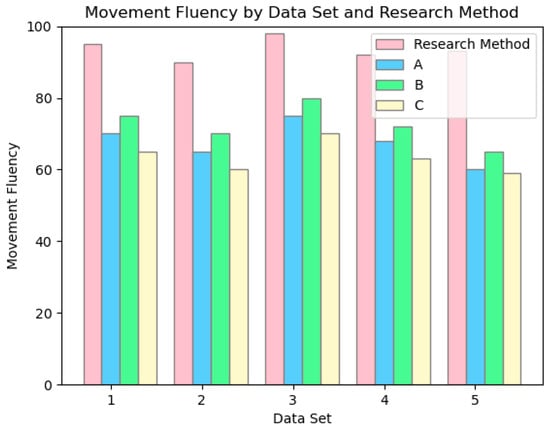
Figure 20.
Comparison of fluency of dance images generated by four methods.
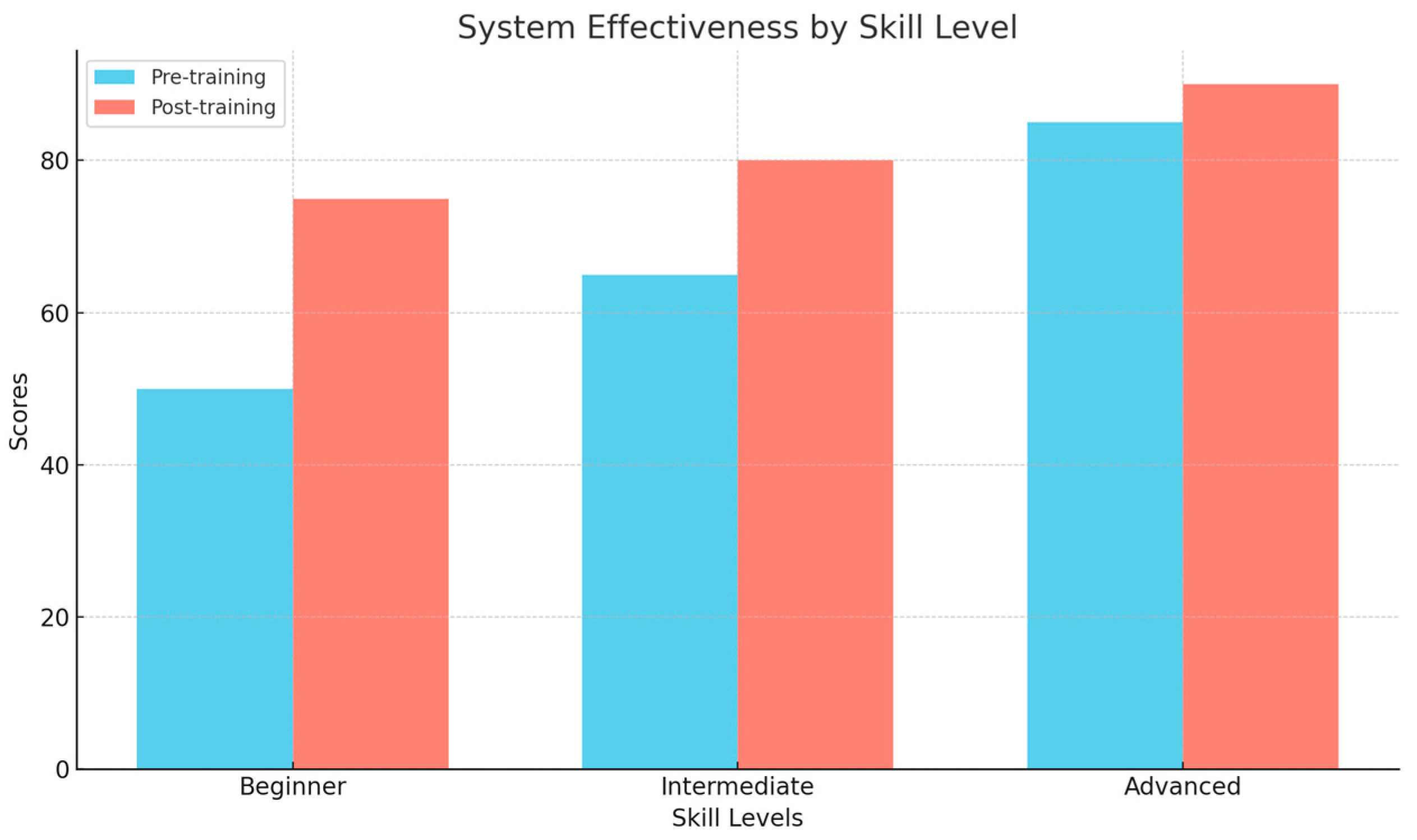
In order to better validate the applicability of the research method, we selected 20 beginners, intermediate, and advanced dancers to use the system for learning and recorded their performance changes before and after training. We collected dancers’ performance scores through evaluations by dance teachers and compared the score differences before and after learning. As shown in Figure 21, dancers of all skill levels improved their performance after using the system, especially beginners.
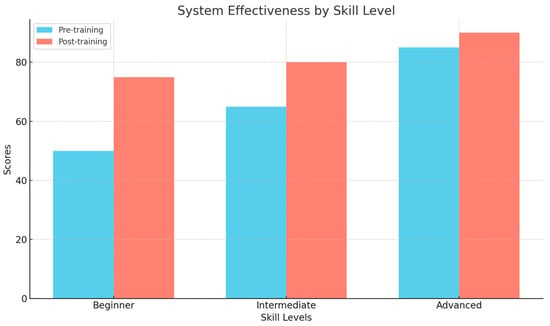
Figure 21.
Comparison of effects at different skill levels.
As shown in Figure 21, dancers of all skill levels (including beginners, intermediate, and advanced) saw score improvements after learning with the system. This indicates that the system is effective for dancers at all levels. Among them, beginners experienced the most significant improvement, with their scores increasing from around 45 points to nearly 70 points, demonstrating the system’s substantial benefit for beginners. Intermediate dancers also saw an increase in scores, though the magnitude was smaller, rising from around 65 points to about 80 points. This may suggest that intermediate dancers already have a solid foundation, and the system helps them further enhance their skills. Advanced dancers experienced smaller improvements, but the increase was still noticeable, with scores rising from around 80 points to about 85 points, indicating that even advanced dancers can benefit from the system.
5. Conclusions
The integration of digital media, virtual digital humans, and other emerging technologies into dance education has introduced new possibilities and development opportunities for traditional teaching methods [21]. Dance, a discipline that combines physical education with artistic expression, places significant demands on students’ physical coordination, sense of rhythm, and expressiveness.
The system demonstrates innovation in several key areas. Traditional models typically employ simple convolutional or Transformer networks for music feature encoding. By incorporating frequency domain processing and attention mechanisms, this system significantly enhances the accuracy and effectiveness of music feature encoding. Additionally, the dance sequence encoding enhancement module improves the quality and consistency of the generated dance movements, addressing common issues such as incoherence and unnatural defects prevalent in traditional models. The innovations of the system are as follows:
- (1)
- Music-driven dance generation based on diffusion model implementation
The system employs diffusion modeling in conjunction with other artificial intelligence techniques to develop a network model for music-driven dance generation. A music feature encoding module is introduced to address the limitations of previous models, thereby enhancing the alignment between music features and dance movements.
- (2)
- Improved Dance Sequence Encoding
Following the development of an initial music-driven dance generation model, a dance sequence feature encoding module is introduced to address the shortcomings of previous models in dance sequence coding quality. This enhancement improves the coherence and naturalness of the generated dance movements.
- (3)
- Teaching Dance + Digital Human
Compared to traditional dance teaching videos, the Digital Human Dance Movement Teaching System significantly enhances the precision and detail of movement simulation. Additionally, the system’s intelligent algorithm can adapt dance movements to various styles and learning needs, thereby improving the system’s applicability and scalability.
The Diffusion Model-based digital human dance movement teaching system presented in this paper demonstrates significant advantages in naturalness, fluency, and overall teaching effectiveness. It shows substantial potential for advancing dance education and virtual digital human applications, offering new opportunities and advancements in educational technology. However, the system currently relies on static snapshots and animated video displays. Future research should focus on further optimizing the model to enhance the accuracy and diversity of dance movement generation and explore its applicability across a broader range of scenarios.
Author Contributions
L.Z.: Responsible for writing the original draft of the manuscript, including the development and articulation of the core ideas and content, and drafted the manuscript; Contributed to the design of the study; assisted in the development of the system; conducted experiments; and revised the manuscript critically for important intellectual content. J.Z.: Managed the validation of the diffusion modeling-based system, ensuring the accuracy and reliability of the results and methods. J.H.: Contributed to the review and editing of the manuscript, providing critical revisions and feedback to enhance the clarity and quality of the final submission. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Metauniverse and artificial intelligence research and development fund, China (No: YYK202301).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, S. Exploration of digital transformation of dance education and teaching. Netw. Inf. Cent. Beijing Danc. Acad. 2023, 4, 11–13. [Google Scholar]
- Pleshakova, E.; Osipov, A.; Gataullin, S.; Gataullin, T.; Vasilakos, A. Next gen cybersecurity paradigm towards artificial general intelligence: Russian market challenges and future global technological trends. J. Comput. Virol. Hacking Tech. 2024, 7, 23. [Google Scholar] [CrossRef]
- Klein, R.; Celik, T. The Wits Intelligent Teaching System: Detecting student engagement during lectures using convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Hou, C. Artificial Intelligence Technology Drives Intelligent Transformation of Music Education. Appl. Math. Nonlinear Sci. 2024, 9, 21–23. [Google Scholar] [CrossRef]
- Hong, C. Application of virtual digital people in the inheritance and development of intangible cultural heritage. People’s Forum 2024, 6, 103–105. [Google Scholar]
- Wu, J.; Gan, W.; Chen, Z.; Wan, S.; Lin, H. Ai-generated content (aigc): A survey. arXiv 2023, arXiv:2304.06632. [Google Scholar]
- Lansdown, J. The computer in choreography. Computer 1978, 11, 19–30. [Google Scholar] [CrossRef]
- Hsieh, H.F.; Shannon, S.E. Three approaches to qualitative content analysis. Qual Health Res. 2005, 15, 1277–1288. [Google Scholar] [CrossRef] [PubMed]
- Shiratori, T.; Nakazawa, A.; Ikeuchi, K. Synthesizing Dance Performance using Musical and Motion Features. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3654–3659. [Google Scholar]
- Crnkovic-Friis, L.; Crnkovic-Friis, L. Generative choreography using deep learning. arXiv 2016, arXiv:1605.06921. [Google Scholar]
- Duan, Y.; Shi, T.; Zou, Z.; Qin, J.; Zhao, Y.; Yuan, Y.; Fan, C. Semi-supervised learning for in-game expert-level music-to-dance translation. arXiv 2020, arXiv:2009.12763. [Google Scholar]
- Tevet, G.; Raab, S.; Gordon, B.; Shafir, Y.; Cohen-or, D.; Bermano, A. Human motion diffusion model. arXiv 2022, arXiv:2209.14916. [Google Scholar]
- Tseng, J.; Castellon, R.; Liu, K. Edge: Editable dance generation from music. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 448–458. [Google Scholar]
- Li, R.; Yang, S.; Ross, D.A.; Kanazawa, A. AI Choreographer: Music Conditioned 3D Dance Generation with AIST++. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13381–13392. [Google Scholar]
- Li, R.; Zhao, J.; Zhang, Y.; Su, M.; Ren, Z.; Zhang, H.; Tang, Y.; Li, X. FineDance: A Fine-grained Choreography Dataset for 3D Full Body Dance Generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 10200–10209. [Google Scholar]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef] [PubMed]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. ACM Comput. Surv. 2023, 55, 16–21. [Google Scholar] [CrossRef]
- Sun, Y.; Dong, L.; Huang, S.; Ma, S.; Xia, Y.; Xue, J.; Wang, J.; Wei, F. Retentive network: A successor to transformer for large language models. arXiv 2023, arXiv:2307.08621. [Google Scholar]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A skinned multi-person linear model. ACM Trans. Graph. 2015, 34, 851–866. [Google Scholar] [CrossRef]
- Copet, J.; Kreuk, F.; Gat, I.; Remez, T.; Kant, D.; Synnaeve, G.; Adi, Y.; Défossez, A. Simple and Controllable Music Generation. arXiv 2023, arXiv:2306.05284. [Google Scholar]
- Chen, K.; Tan, Z.; Lei, J.; Zhang, S.H.; Guo, Y.C.; Zhang, W.; Hu, S.M. ChoreoMaster: Choreography-oriented music-driven dance synthesis. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).