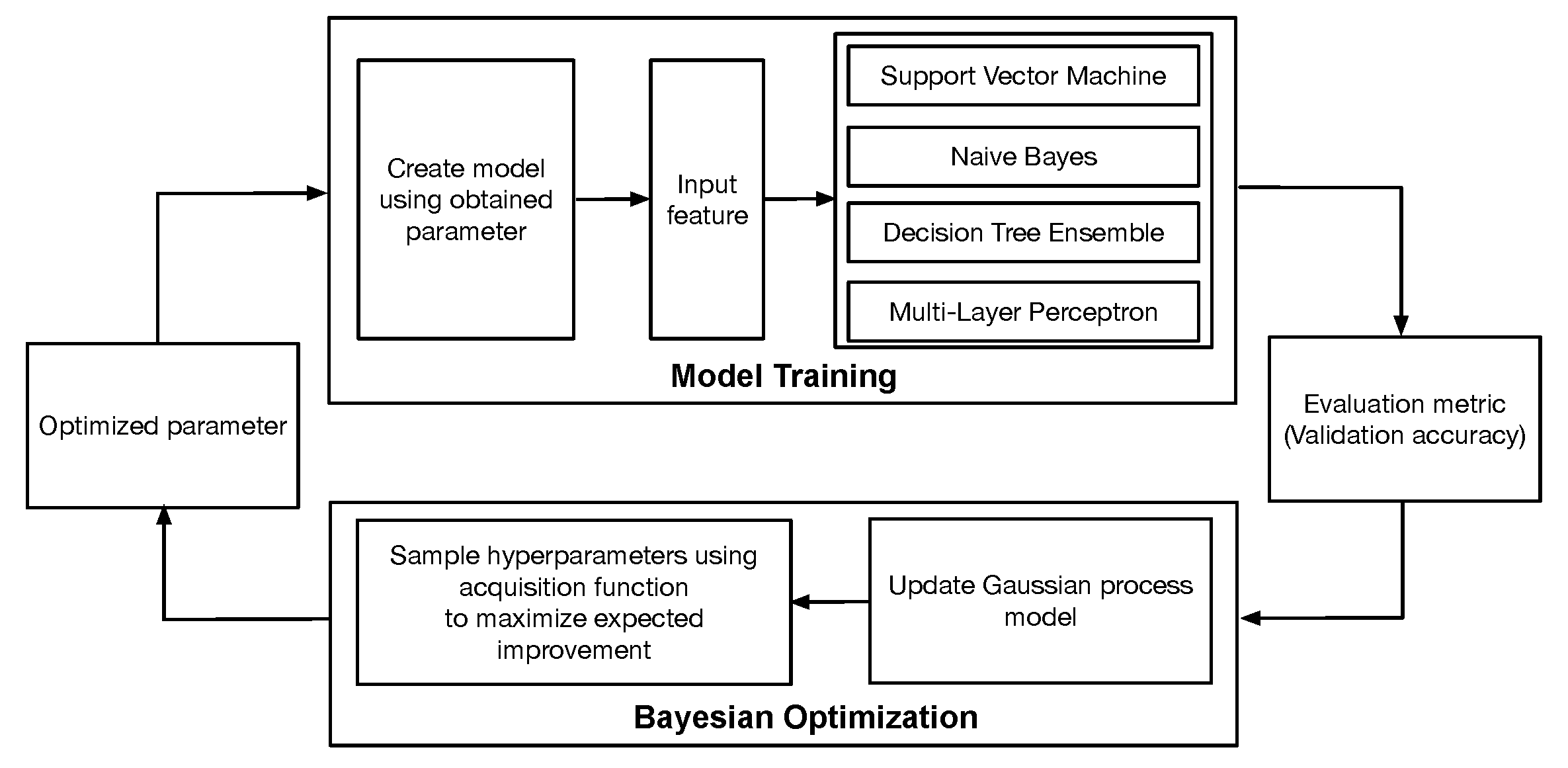
4.1. Comparison between Different Machine Learning Models
The strictly limited amount of samples
may incur serious generalization problems such as overfitting or data selection bias for different ML models. To quantify the uncertainty of limited data, we evaluate the average and standard deviation of classification accuracies of multiple trained models for each ML technique. We train multiple SVM, NB, DTE, and MLP models based on the randomly shuffled dataset with different 10 random seeds.
Table 5 summarizes the average and standard deviation of classification accuracies of 10 trained models of each SVM, NB, DTE, and MLP. The standard deviation of classification accuracy is not significant for each model. Due to the effective dropout layer, the MLP model shows a standard deviation range similar to the other ML models. This result proves that the Bayesian optimization algorithm and the cross-validation efficiently generalize each ML model by reducing the overfitting or data selection bias problems.
Now, we compare the performance of the representative SVM, NB, DTE, and MLP models trained using the same training dataset.
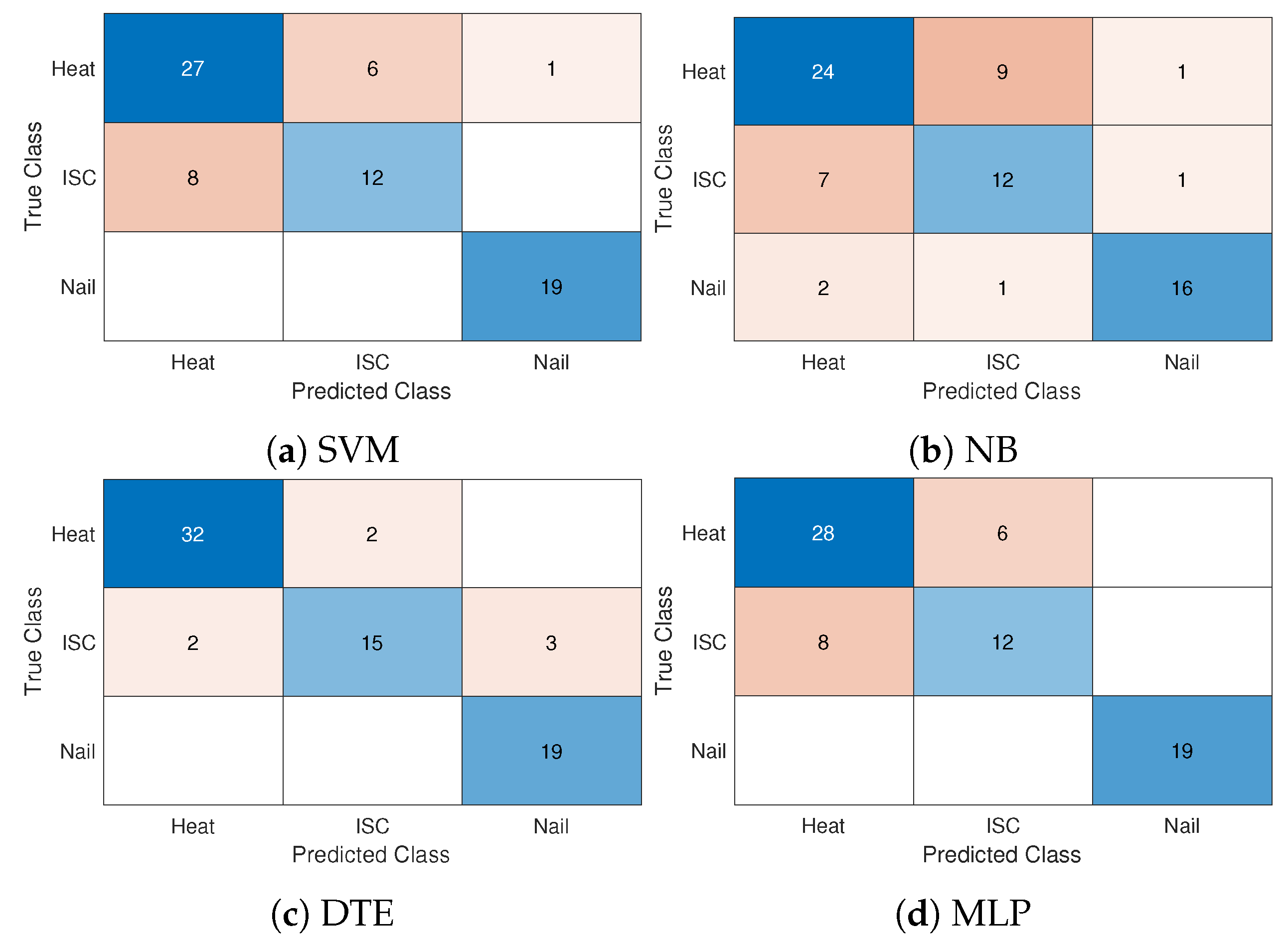
Figure 3 shows the confusion matrices of SVM, NB, DTE, and MLP models to predict three causes, including Heat, ISC, and Nail. A confusion matrix presents how well a classification model performs for the testing dataset [
29]. Overall, the classification accuracies of SVM, NB, DTE, and MLP are
,
,
, and
, respectively. DTE predicts the abuse method of the thermal runaway well compared to other models of SVM, NB, and MLP due to the strength of the model aggregation of multiple decision trees. SVM and MLP show a comparable prediction accuracy of around
, while NB has a higher classification error than other models. We note that the accuracy of DTE is comparable to the average one while other models of SVM, NB, and MLP slightly perform better than the corresponding ones of
Table 5.
We conduct the mid-p McNemar test of DTE since it allows us to evaluate the statistical significance of whether one classification model performs better than another [
30]. The mid-p values of DTE compared to SVM, NB, and MLP are
and
, respectively. All tests have a mid-p value of nearly zero, which indicates that DTE guarantees better prediction than other models.
Both Heat and ISC classes are generally hard to distinguish for different classification models, as shown in
Figure 3. Although the ISC abuse may occur at a considerably lower temperature than the one of Heat, there are no measured features that explicitly provide the detailed heat and mass changes during the thermal runaway experiments using FTRC. Furthermore, the real-time measurements are also hard to obtain in practice. The classification accuracies of DTE are around
and
for Heat and ISC classes, respectively, greater than SVM, NB, and MLP. SVM, NB, and MLP models show considerably low classification accuracy for the ISC class around
. While SVM, DTE, and MLP perfectly predict nail abuse, the classification accuracy of NB is only around
for the Nail class. The NB model has classification errors between all abuse methods of the thermal runaway.
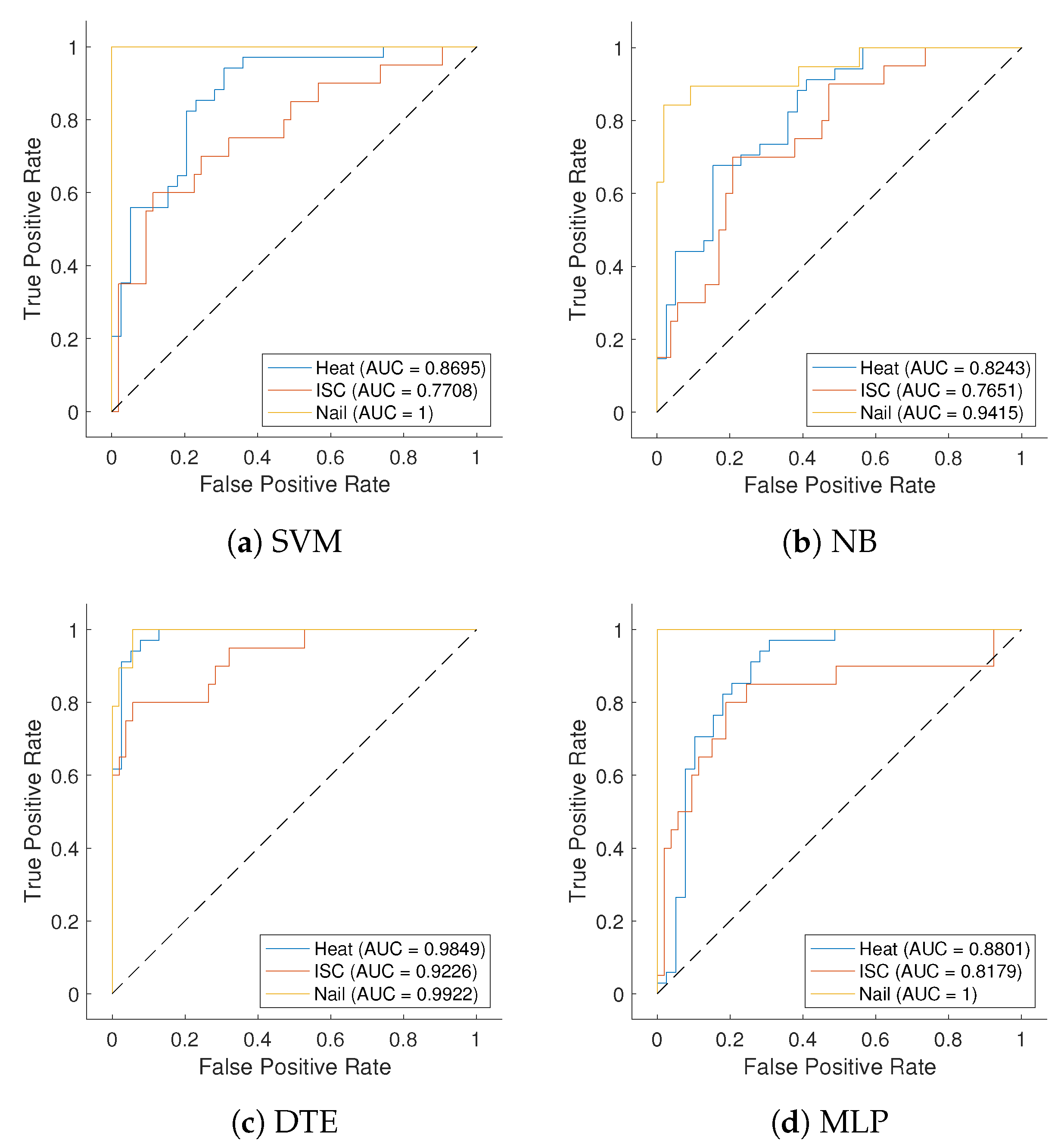
Figure 4 presents the ROC curves using SVM, NB, DTE, and MLP models for different ISC, Heat, and Nail abuses. It shows the true positive ratio (TPR) over the false positive ratio (FPR) of each abuse throughout threshold intervals of
. In each figure, as the curve approaches the upper left corner and the diagonal line, the classifier improves and worsens, respectively. Note that the upper left corner is the optimal operating point (i.e., TPR = 100%, FPR = 0%) of the classifier. The DTE curve moves toward the upper left corner, especially for Heat and Nail, because of the low FPR of DTE. DTE significantly outperforms other classifiers for all causes.
To provide a more detailed analysis,
Figure 4 also summarizes the AUCs of all models for different abuse methods. The DTE model consistently provides higher AUCs than those using other models for the Heat and Nail classes. For the ISC abuse, the AUC value of DTE remains above
, while other models, including SVM, NB, and MLP, show relatively low AUC values below
. Hence, the comparison between different models proves the strengths of the ensemble aggregation methods of diverse decision trees to capture the complex relationship between various features and abuse methods.
Next, we discuss the performance sensitivity of ML models for various batteries of cell formats and manufacturers.
Table 6 summarizes the classification accuracies of trained ML models for various cell formats, including 18650 and 21700, and manufacturers including KULR, LG, Molicel, Saft, Samsung, Sanyo, Sony, and Soteria. DTE still performs better than any other models for 18650 and 21700 cells. The prediction accuracy of the 21700 cell is worse than that of the 18650 cell for all models. The main reason is the imbalanced data between different cell formats of the open failure dataset [
18]. The dataset ratio between 18650 and 21700 cell formats is 0.77:0.23.
Similarly, DTE shows better accuracy than other models, even for all different manufacturers. We note that the prediction accuracy of Saft, Samsung, Sanyo, and Sony does not heavily affect the overall performance since the number of testing samples for these products is around 3–4. In
Table 6, KULR and Soteria batteries show relatively low accuracy for all models. Even though 21,700 cells from both KULR and LG are used for abuse tests, the prediction accuracies are considerably different. While the DTE model perfectly classifies the abuse classes for all 18,650 and 21,700 cells of LG, both cell formats of KULR return a significantly low prediction performance. The description of the KULR battery does not provide any distinct factors compared to other batteries from different manufacturers. On the other hand, one of the specific Soteria 18,650 cells has lower prediction accuracy when it includes the standard current collectors and a Dreamweaver gold separator, which is different from other battery products. Thus, we might need more experimental data and additional features to better predict the abuse classes of KULR and Soteria battery failure.
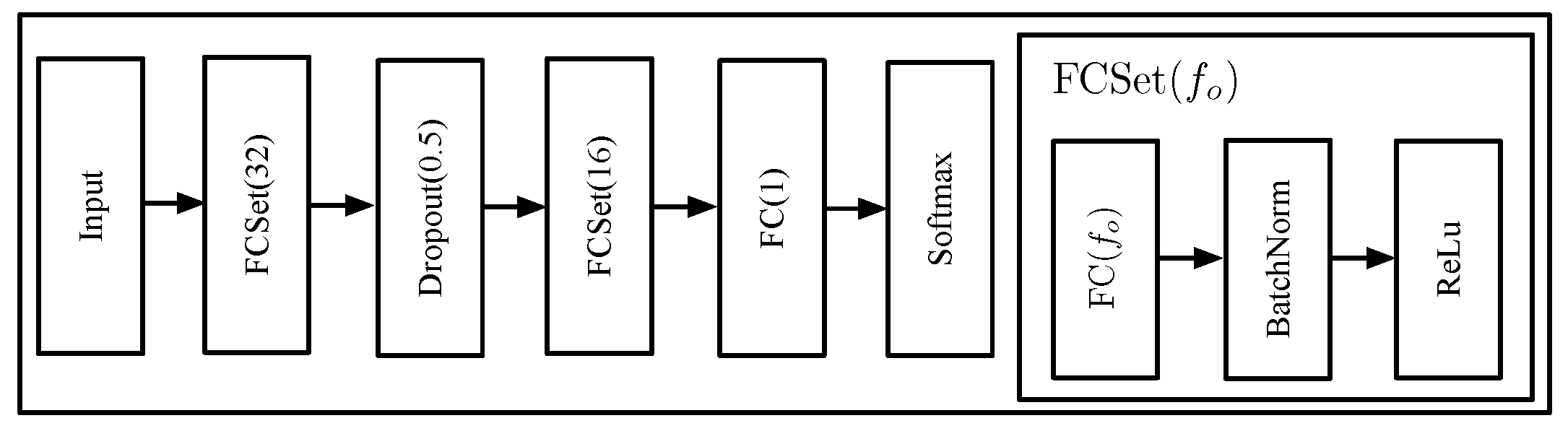
4.2. Sensitivity and Feature Analysis of DTE
Since the DTE model considerably outperforms other models, we analyze more details of DTE, including the sensitivity of dataset size and feature importance. Even though the relationship between the dataset size and model heavily depends on the specific problems, ML models generally improve their performance with dataset size. However, the experimental battery failure data are costly to obtain in practice, especially for the thermal runaway of the battery. Thus, we conduct a sensitivity analysis to quantify the relationship between dataset size and model performance.
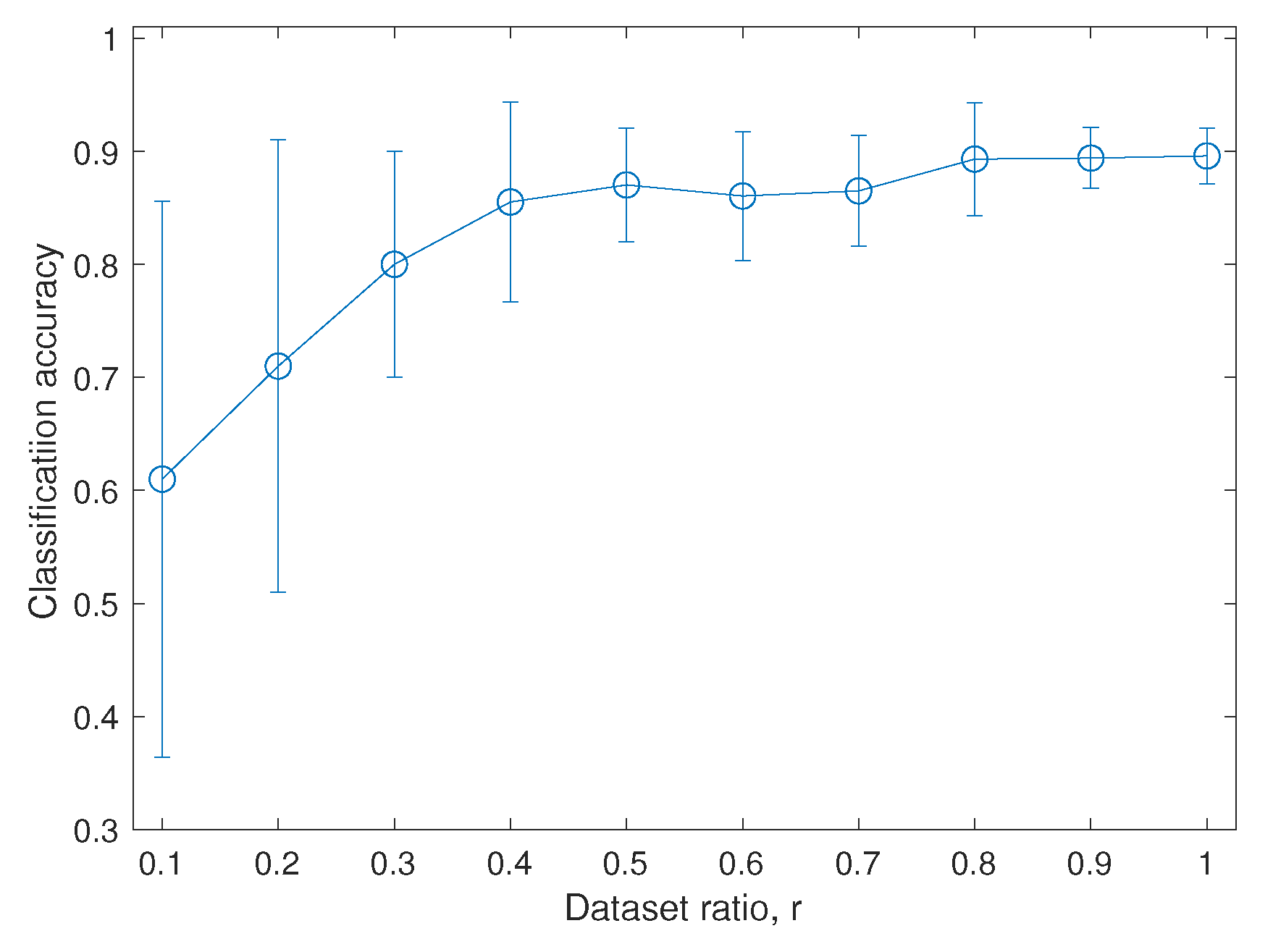
Figure 5 presents the classification accuracy of DTE as a function of different ratios
of the dataset size with respect to the total number of available samples
. The error bar shows the standard deviation around the average accuracy. We observe a nearly logarithmic relationship of the average accuracy with the dataset size. The uncertainty shown as the error bar dramatically increases for the small dataset
and stabilizes for the modest dataset
. We could achieve a comparable average accuracy of DTE for the dataset
even though the uncertainty is still high for the dataset
.
Figure 6 compares the feature rank obtained by feature independence analysis using chi-square tests with the feature importance score of DTE. We first evaluate the independence of each feature variable to the abuse classes by using chi-square tests.
Figure 6a shows the feature scores, defined as the negative logarithm of the
p-values. The seven most important features of the feature independence analysis are
HeatLossRate,
NegEnP,
CellEn,
CellCap,
BodyEnP,
CorrLossEn, and
ConfPos. The ratio of these seven scores over the total score sum is around
in
Figure 6a. We further analyze the feature importance score of DTE, which is defined as the total changes in the risk due to splits on each feature divided by the number of branch nodes of the decision tree, as shown in
Figure 6b [
31]. Note that the minimum importance score is 0. The weighted average is then applied to the feature importance score of the overall weak learners of the ensemble.
HeatLossRate is the most crucial feature, followed by
PreCellM and
NegEnP. The ratio of the score sum of the three most important features of
HeatLossRate,
PreCellM, and
NegEnP over the total score sum is
. We observe that
HeatLossRate and
NegEnP are still critical factors even for the trained DTE model.
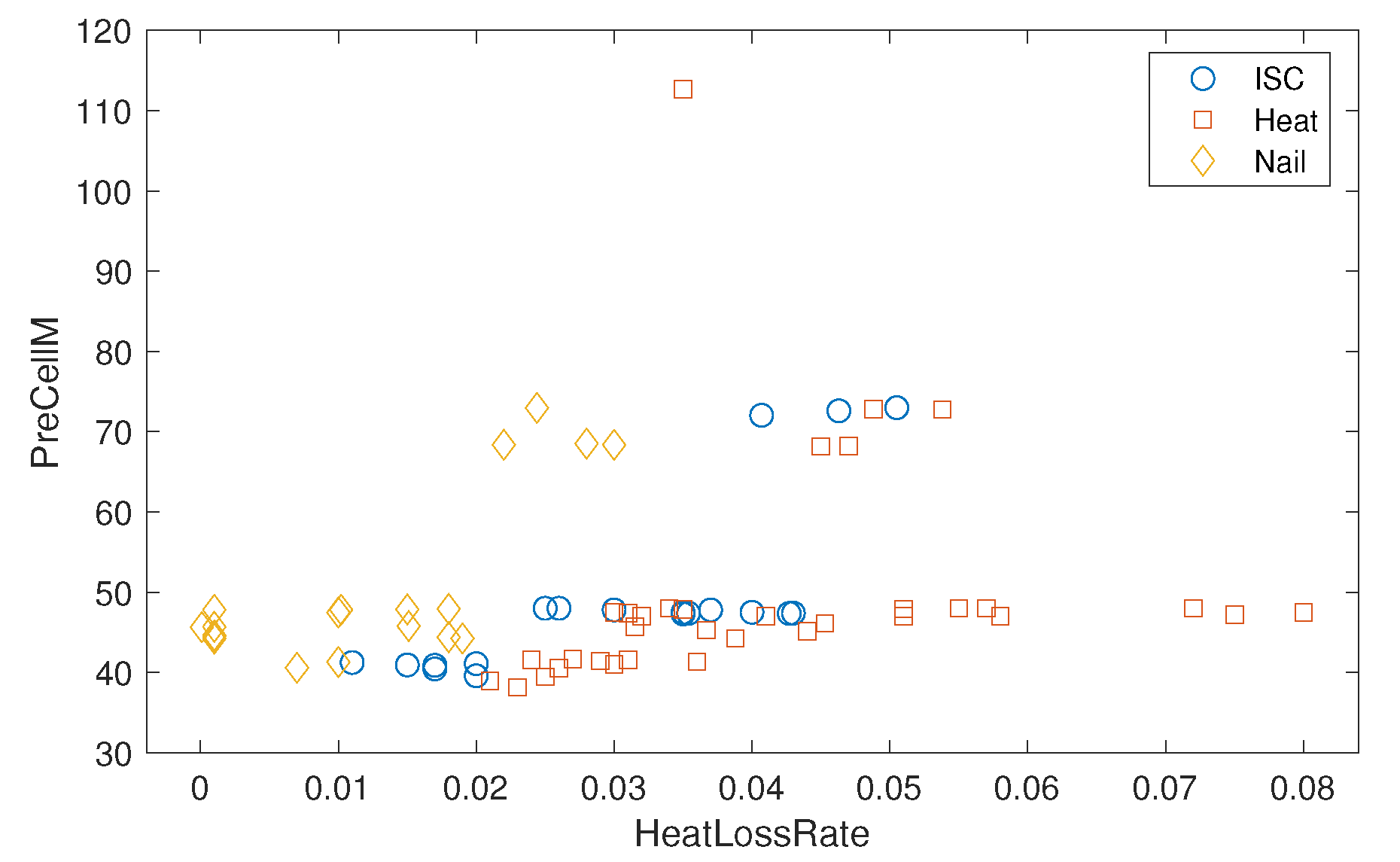
Figure 7 presents three abuse classes, Heat, ISC, and Nail, against the two most critical features of DTE, namely,
HeatLossRate and
PreCellM, obtained from
Figure 6b. The Nail class is relatively easy to separate from other classes of Heat and ISC. The Nail class has the lowest
HeatLossRate, while the boundary with other classes increases as the
PreCellM value increases. On the other hand, the Heat class shows the highest variation in
HeatLossRate, particularly for
PreCellM . The classification boundaries between Heat and ISC classes are apparent when
HeatLossRate is in the range between
and
for
PreCellM. Thus, this explains the dominant classification errors between Heat and ISC classes of different models, as shown in the confusion matrix of
Figure 3.
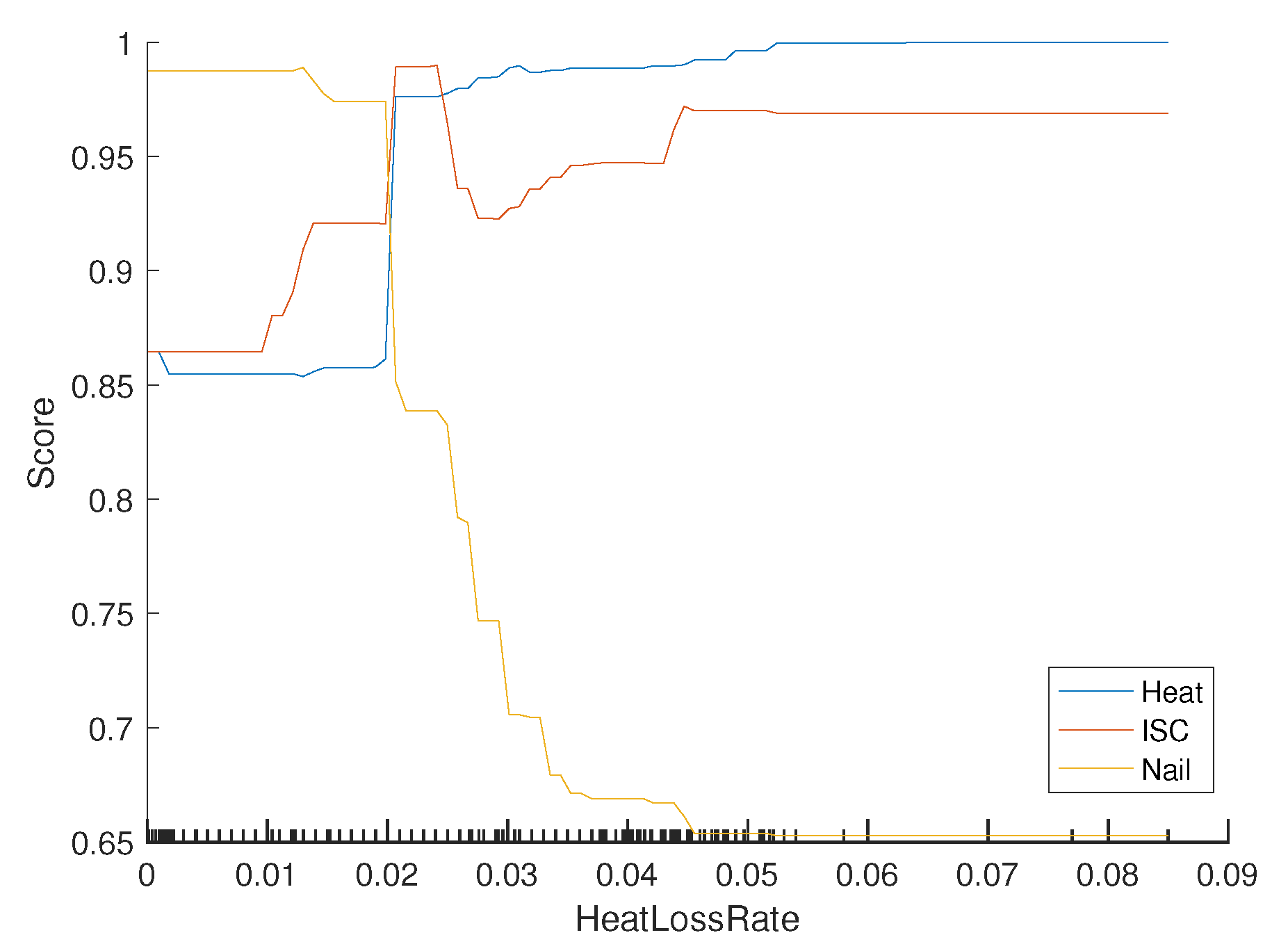
Partial dependence represents the relationships between feature variables and predicted scores (posterior probabilities) of all abuse methods obtained by the trained DTE model [
31].
Figure 8 shows the estimated partial dependence of DTE for all abuse classes against the most critical features,
HeatLossRate. According to DTE, the probability of the Heat class significantly changes around
HeatLossRate , then stays almost flat. The probability of Nail is greater than
for
HeatLossRate, while it drops fast to almost
for
HeatLossRate. The probabilities of both Heat and ISC classes are similar, being greater than
for
.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}