
Online Unmanned Ground Vehicle Path Planning Based on Multi-Attribute Intelligent Reinforcement Learning for Mine Search and Rescue

Abstract
:1. Introduction
- A method for constructing an environmental model and an information feature mining method based on EGM are proposed to address the lack of environmental information in mining SAR.
- An agent-centered path-planning model based on the RL theory is proposed for the online path-planning problem. The optimization reward function designed for multiple scenarios effectively solves the conflict problem between paths, obstacles, and traps.
- A heuristic decision-making strategy based on the gray system theory is proposed for our SAR problem, which helps the model accelerate convergence towards the target and improve the robustness of the intelligent agent decision-making process.
2. Constraints in Search Area Path Planning
2.1. Probability of Detection (POD)
2.2. Relative Distance (RD)
2.3. Characteristic Distance (CD)
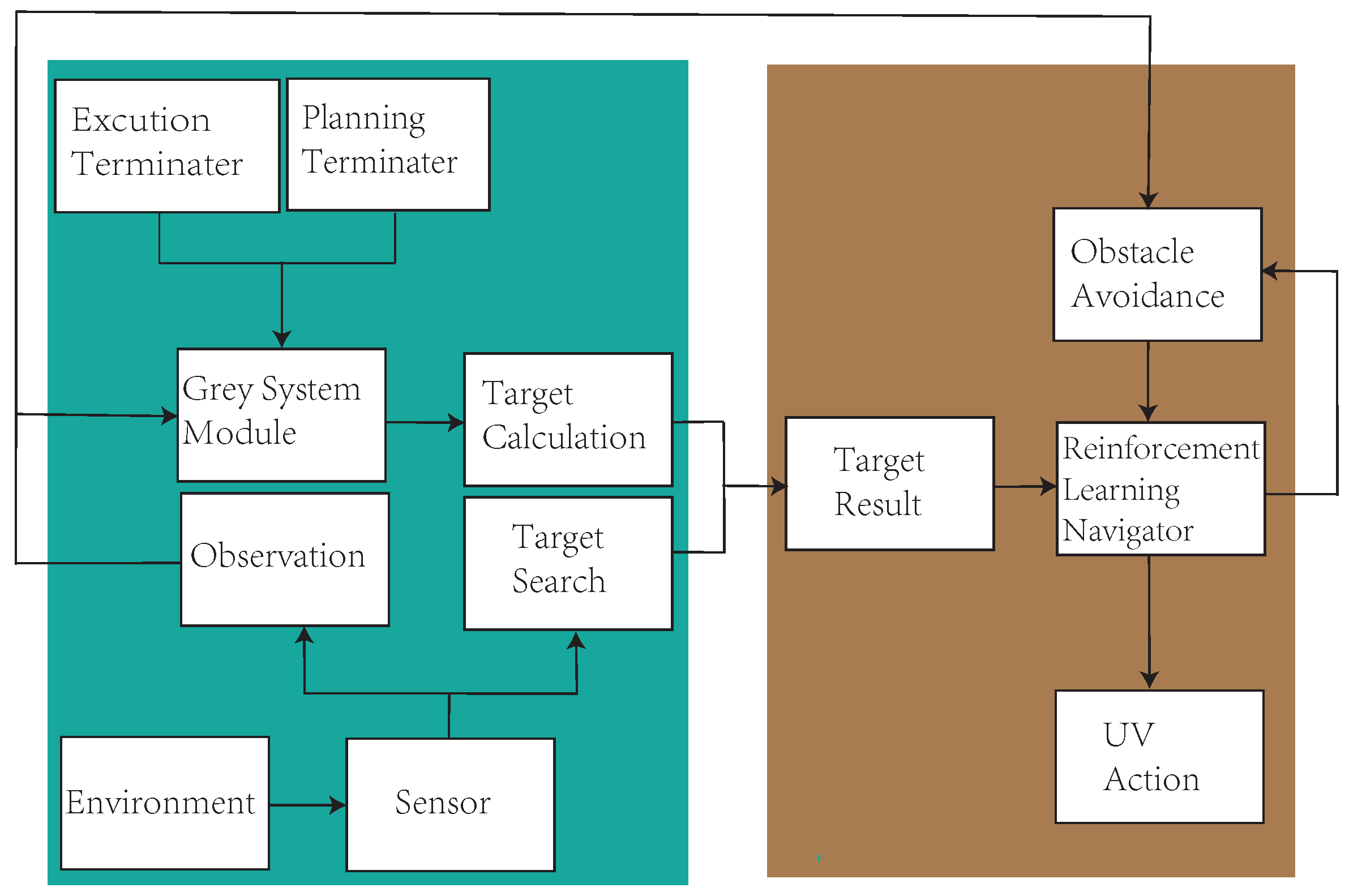
3. SAR Environment Modeling
3.1. Environment Model
- Its position;
- Its operational status, either inactive or active;
- Its field of view (FOV), the grid world size with the cell size, and the set of all possible positions.
3.2. Optimization Problem
4. Search Area Path-Planning Model for Mine SAR
4.1. Local Path-Planning Reward Function
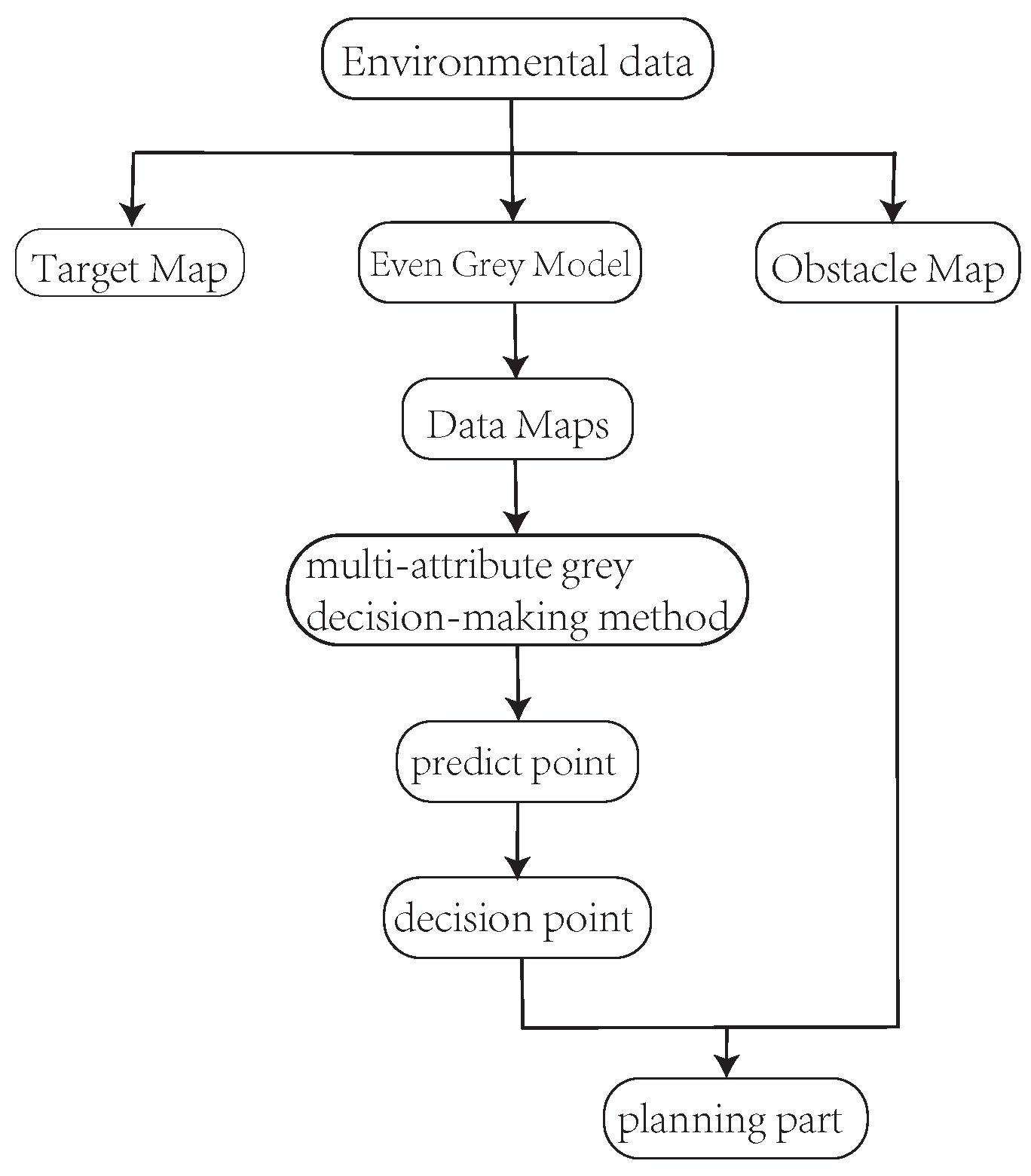
4.2. Environmental Data Prediction Process
4.3. The Multi-Attribute Gray Decision Process
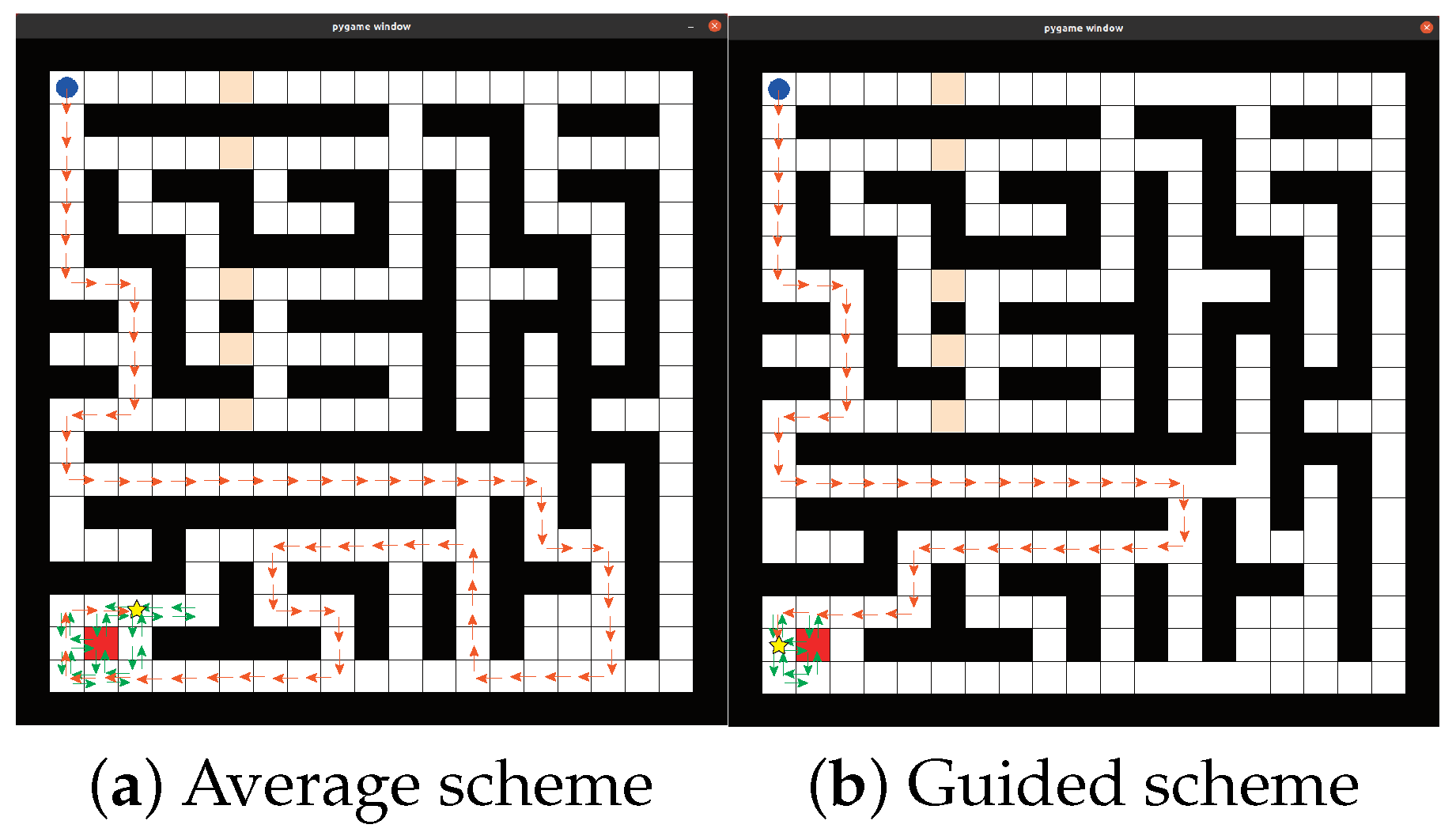
5. Experimental Verification and Result Analysis
5.1. Simulating Scenarios and Experimental Setup
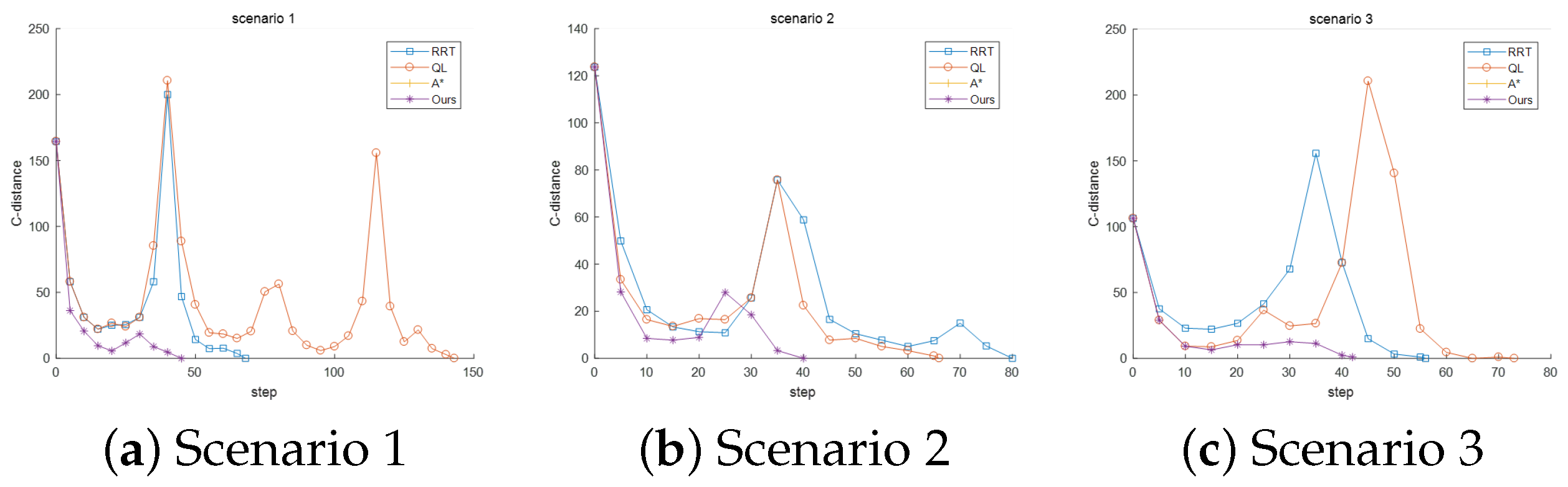
5.2. Simulation and Comparison Experiment
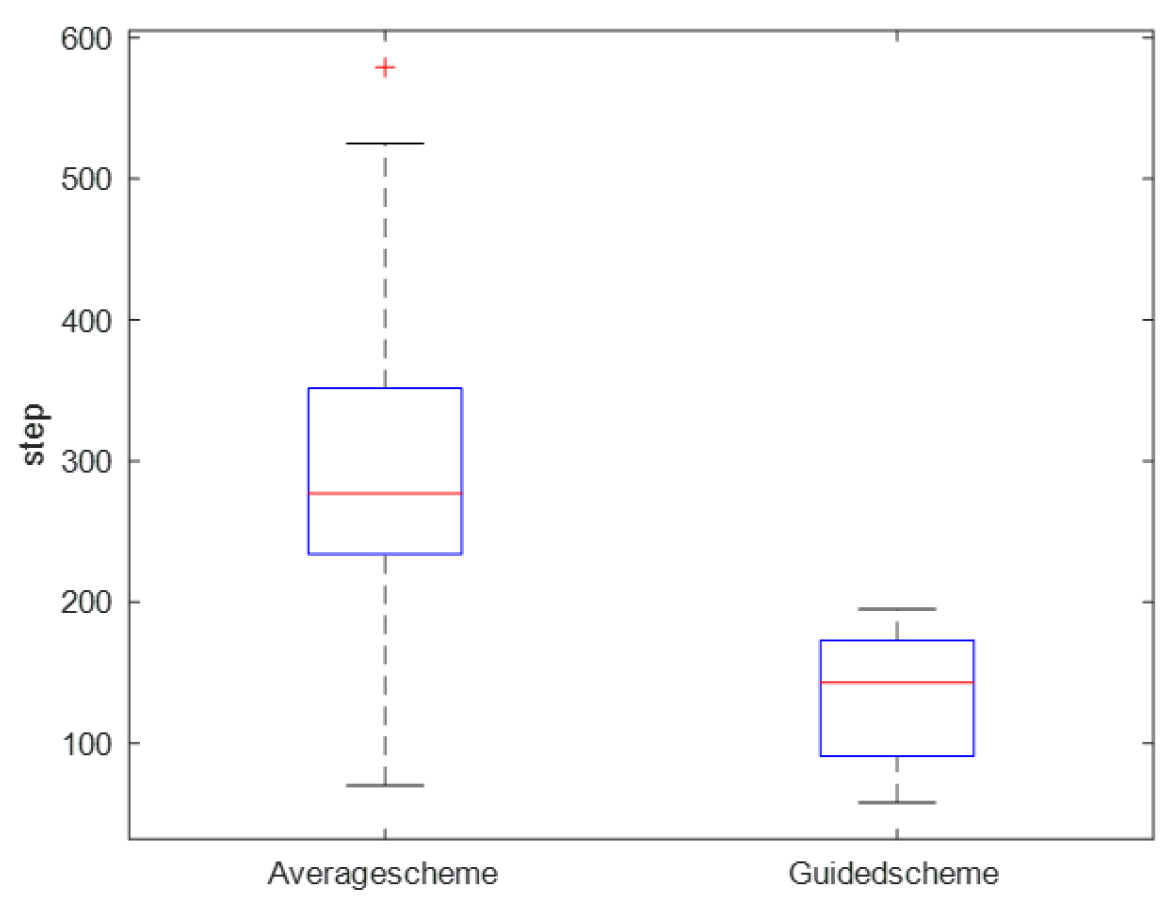
5.3. Policy Evaluation
5.4. Reward Function Evaluation
6. Conclusions and Future Work
- The interaction of UGVs with Cyber–Physical systems could enhance UGV’s adaptability to dynamic environments and validate the effectiveness and feasibility of path-planning algorithms through the use of 3D virtual reality models [39].
- The strategic application of human–machine interaction technology is not just a possibility, but a promising avenue that is poised to play a pivotal role in the rapid advancement of UGV intelligence [40].
- Swarm Intelligence technology can expand UGVs’ application scope and significantly improve its efficiency in completing tasks [41].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hester, G.; Smith, C.; Day, P.; Waldock, A. The Next Generation of Unmanned Ground Vehicles. Meas. Control 2012, 45, 117–121. [Google Scholar] [CrossRef]
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Voronoi-Based Multi-Robot Autonomous Exploration in Unknown Environments via Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 14413–14423. [Google Scholar] [CrossRef]
- Niroui, F.; Zhang, K.; Kashino, Z.; Nejat, G. Deep Reinforcement Learning Robot for Search and Rescue Applications: Exploration in Unknown Cluttered Environments. IEEE Robot. Autom. Lett. 2019, 4, 610–617. [Google Scholar] [CrossRef]
- Ai, B.; Li, B.; Gao, S.; Xu, J.; Shang, H. An Intelligent Decision Algorithm for the Generation of Maritime Search and Rescue Emergency Response Plans. IEEE Access 2019, 7, 155835–155850. [Google Scholar] [CrossRef]
- Tao, X.; Lang, N.; Li, H.; Xu, D. Path Planning in Uncertain Environment with Moving Obstacles Using Warm Start Cross Entropy. IEEE/ASME Trans. Mechatron. 2022, 27, 800–810. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, X.; Li, R.; Dong, P. Path Planning of Maritime Autonomous Surface Ships in Unknown Environment with Reinforcement Learning. In Communications in Computer and Information Science, Proceedings of the Cognitive Systems and Signal Processing, ICCSIP, Beijing, China, 29 November–1 December 2018; Sun, F., Liu, H., Hu, D., Eds.; Springer: Singapore, 2018; Volume 1006. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, C.; Liu, Y.; Chen, X. Decision-Making for the Autonomous Navigation of Maritime Autonomous Surface Ships Based on Scene Division and Deep Reinforcement Learning. Sensors 2019, 19, 4055. [Google Scholar] [CrossRef]
- Tatsch, C.; Bredu, J.A.; Covell, D.; Tulu, I.B.; Gu, Y. Rhino: An Autonomous Robot for Mapping Underground Mine Environments. In Proceedings of the 2023 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Seattle, WA, USA, 28–30 June 2023; pp. 1166–1173. [Google Scholar] [CrossRef]
- Cao, Y.; Zhao, R.; Wang, Y.; Xiang, B.; Sartorettii, G. Deep Reinforcement Learning-Based Large-Scale Robot Exploration. IEEE Robot. Autom. Lett. 2024, 9, 4631–4638. [Google Scholar] [CrossRef]
- Vlahov, B.; Gibson, J.; Fan, D.D.; Spieler, P.; Agha-mohammadi, A.-A.; Theodorou, E.A. Low Frequency Sampling in Model Predictive Path Integral Control. IEEE Robot. Autom. Lett. 2024, 9, 4543–4550. [Google Scholar] [CrossRef]
- Luo, Y.; Zhuang, Z.; Pan, N.; Feng, C.; Shen, S.; Gao, F.; Cheng, H.; Zhou, B. Star-Searcher: A Complete and Efficient Aerial System for Autonomous Target Search in Complex Unknown Environments. IEEE Robot. Autom. Lett. 2024, 9, 4329–4336. [Google Scholar] [CrossRef]
- Cheng, C.X.; Sha, Q.X.; He, B.; Li, G.L. Path planning and obstacle avoidance for AUV: A review. Ocean. Eng. 2021, 235, 109355. [Google Scholar] [CrossRef]
- Peake, A.; McCalmon, J.; Zhang, Y.; Raiford, B.; Alqahtani, S. Wilderness Search and Rescue Missions using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Abu Dhabi, United Arab Emirates, 4–6 November 2020; pp. 102–107. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, J.; Sun, N. A Review of Collaborative Air-Ground Robots Research. J. Intell. Robot. Syst. 2022, 106, 60. [Google Scholar] [CrossRef]
- Palacin, J.; Palleja, T.; Valganon, I.; Pernia, R.; Roca, J. Measuring Coverage Performances of a Floor Cleaning Mobile Robot Using a Vision System. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 4236–4241. [Google Scholar] [CrossRef]
- Ai, B.; Jia, M.X.; Xu, H.W.; Xu, J.L.; Wen, Z.; Li, B.S.; Zhang, D. Coverage path planning for maritime search and rescue using reinforcement learning. Ocean. Eng. 2021, 241, 110098. [Google Scholar] [CrossRef]
- Sun, Y.; Fang, Z. Research on Projection Gray Target Model Based on FANP-QFD for Weapon System of Systems Capability Evaluation. IEEE Syst. J. 2021, 15, 4126–4136. [Google Scholar] [CrossRef]
- Ross, S.; Pineau, J.; Paquet, S.; Chaib-Draa, B. Online planning algorithms for POMDPs. IEEE Robot. Autom. Lett. 2008, 32, 663–704. [Google Scholar] [CrossRef]
- Sartoretti, G.; Kerr, J.; Shi, Y.; Wagner, G.; Kumar, T.K.S.; Koenig, S.; Choset, H. PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning. IEEE Robot. Autom. Lett. 2019, 4, 2378–2385. [Google Scholar] [CrossRef]
- Wang, C.; Cheng, J.; Wang, J.; Li, X.; Meng, M.Q.-H. Efficient Object Search With Belief Road Map Using Mobile Robot. IEEE Syst. J. 2018, 15, 3081–3088. [Google Scholar] [CrossRef]
- Agha-mohammadi, A.-A.; Agarwal, S.; Kim, S.-K.; Chakravorty, S.; Amato, N.M. SLAP: Simultaneous Localization and Planning Under Uncertainty via Dynamic Replanning in Belief Space. IEEE Trans. Robot. 2018, 34, 1195–1214. [Google Scholar] [CrossRef]
- Hubmann, C.; Schulz, J.; Xu, G.; Althoff, D.; Stiller, C. A Belief State Planner for Interactive Merge Maneuvers in Congested Traffic. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; Volume 1, pp. 1617–1624. [Google Scholar] [CrossRef]
- Hubmann, C.; Becker, M.; Althoff, D.; Lenz, D.; Stiller, C. Decision making for autonomous driving considering interaction and uncertain prediction of surrounding vehicles. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; Volume 1, pp. 1671–1678. [Google Scholar] [CrossRef]
- Bai, A.; Wu, F.; Chen, X. Posterior sampling for Monte Carlo planning under uncertainty. Appl. Intell. 2018, 48, 4998–5018. [Google Scholar] [CrossRef]
- Liu, P.; Chen, J.; Liu, H. An improved Monte Carlo POMDPs online planning algorithm combined with RAVE heuristic. In Proceedings of the 2015 6th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 September 2015; Volume 1, pp. 511–515. [Google Scholar] [CrossRef]
- Xiao, Y.; Katt, S.; ten Pas, A.; Chen, S.; Amato, C. Online Planning for Target Object Search in Clutter under Partial Observability. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; Volume 1, pp. 8241–8247. [Google Scholar] [CrossRef]
- Bayerlein, H.; Theile, M.; Caccamo, M.; Gesbert, D. Multi-UAV Path Planning for Wireless Data Harvesting With Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 2, 1171–1187. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Badyal, S.; Wheeler, T.; Gil, S.; Bertsekas, D. Reinforcement Learning for POMDP: Partitioned Rollout and Policy Iteration with Application to Autonomous Sequential Repair Problems. IEEE Open J. Commun. Soc. 2020, 5, 3967–3974. [Google Scholar] [CrossRef]
- Yan, P.; Jia, T.; Bai, C.; Fravolini, M.L. Searching and Tracking an Unknown Number of Targets: A Learning-Based Method Enhanced with Maps Merging. Sensors 2021, 21, 1076. [Google Scholar] [CrossRef]
- Amato, C.; Konidaris, G.; Cruz, G.; Maynor, C.A.; How, J.P.; Kaelbling, L.P. Planning for decentralized control of multiple robots under uncertainty. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; Volume 1, pp. 1241–1248. [Google Scholar] [CrossRef]
- MacDonald, R.A.; Smith, S.L. Active sensing for motion planning in uncertain environments via mutual information policies. Int. J. Robot. Res. 2019, 38, 146–161. [Google Scholar] [CrossRef]
- He, Y.; Chong, K.P. Sensor scheduling for target tracking in sensor networks. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No.04CH37601), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 743–748. [Google Scholar] [CrossRef]
- Gerrig, R.J.; Zimbardo, P.G. Psychology and Life; People’s Posts and Telecommunications Press: Beijing, China, 2011; ch. 5, ses. 3; pp. 114–117. [Google Scholar]
- Duchoň, F.; Babinec, A.; Kajan, M.; Beňo, P.; Florek, M.; Fico, T.; Jurišica, L. Path Planning with Modified a Star Algorithm for a Mobile Robot. Procedia Eng. 2014, 96, 59–69. [Google Scholar] [CrossRef]
- Rodriguez, S.; Tang, X.Y.; Lien, J.M.; Amato, N.M. An obstacle-based rapidly-exploring random tree. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; Volume 1, pp. 895–900. [Google Scholar] [CrossRef]
- Konar, A.; Chakraborty, I.G.; Singh, S.J.; Jain, L.C.; Nagar, A.K. A Deterministic Improved Q-Learning for Path Planning of a Mobile Robot. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 1141–1153. [Google Scholar] [CrossRef]
- Liu, S.F. The Three Axioms of Buffer Operator and Their Application. J. Grey Syst. 1991, I, 178–185. [Google Scholar]
- Wei, Y.; Kong, X.H.; Hu, D.H. A kind of universal constructor method for buffer operators. Grey Syst. Theory Appl. 2011, 3, 39–48. [Google Scholar]
- Cecil, J. A conceptual framework for supporting UAV based cyber physical weather monitoring activities. In Proceedings of the 2018 Annual IEEE International Systems Conference (SysCon), Vancouver, BC, Canada, 23–26 April 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zhu, S.; Xiong, G.; Chen, H. Unmanned Ground Vehicle Control System Design Based on Hybrid Architecture. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 948–951. [Google Scholar] [CrossRef]
- AlShabi, M.; Ballous, K.A.; Nassif, A.B.; Bettayeb, M.; Obaideen, K.; Gadsden, S.A. Path planning for a UGV using Salp Swarm Algorithm. In Proceedings of the SPIE 13052, Autonomous Systems: Sensors, Processing, and Security for Ground, Air, Sea, and Space Vehicles and Infrastructure 2024, 130520L, National Harbor, MD, USA, 7 June 2024. [Google Scholar] [CrossRef]
- Romeo, L.; Petitti, A.; Colella, R.; Valecce, G.; Boccadoro, P.; Milella, A.; Grieco, L.A. Automated Deployment of IoT Networks in Outdoor Scenarios using an Unmanned Ground Vehicle. In Proceedings of the 2020 IEEE International Conference on Industrial Technology (ICIT), Buenos Aires, Argentina, 26–28 February 2020; pp. 369–374. [Google Scholar] [CrossRef]
- Chang, B.R.; Tsai, H.-F.; Lyu, J.-L.; Huang, C.-F. IoT-connected Group Deployment of Unmanned Vehicles with Sensing Units: IUAGV System. Sens. Mater. 2021, 33, 1485–1499. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Algorithms | Step | Coverage (%) | Repeated Coverage (%) |
|---|---|---|---|---|
| Scenario 1 | A* | - | 9.81 | - |
| RRT | 68 | 31.31 | 1.40 | |
| QL | 143 | 57.94 | 9.35 | |
| Ours | 45 | 21.50 | 0 | |
| Scenario 2 | A* | - | 5.96 | - |
| RRT | 80 | 37.16 | 0 | |
| QL | 66 | 30.73 | 0 | |
| Ours | 40 | 15.60 | 3.21 | |
| Scenario 3 | A* | - | 9.95 | - |
| RRT | 56 | 27.01 | 0 | |
| QL | 73 | 32.23 | 2.37 | |
| Ours | 42 | 20.38 | 0 |
| Solution | Parameter | Value |
|---|---|---|
| Improved Solution | learning rate | 0.8 |
| reward decay | 0.9 | |
| greedy | 0.9 | |
| 5 | ||
| 0 | ||
| −1 | ||
| Unimproved Solution | learning rate | 0.4 |
| reward decay | 0.8 | |
| greedy | 0.9 | |
| 1 | ||
| 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Zeng, Q. Online Unmanned Ground Vehicle Path Planning Based on Multi-Attribute Intelligent Reinforcement Learning for Mine Search and Rescue. Appl. Sci. 2024, 14, 9127. https://doi.org/10.3390/app14199127
Zhang S, Zeng Q. Online Unmanned Ground Vehicle Path Planning Based on Multi-Attribute Intelligent Reinforcement Learning for Mine Search and Rescue. Applied Sciences. 2024; 14(19):9127. https://doi.org/10.3390/app14199127
Chicago/Turabian StyleZhang, Shanfan, and Qingshuang Zeng. 2024. "Online Unmanned Ground Vehicle Path Planning Based on Multi-Attribute Intelligent Reinforcement Learning for Mine Search and Rescue" Applied Sciences 14, no. 19: 9127. https://doi.org/10.3390/app14199127