
The Task of Post-Editing Machine Translation for the Low-Resource Language

Abstract
:1. Introduction
1.1. Review of Research Studies
1.2. Overview of Post-Editing Types in Machine Translation
- High post-editing: No differences from human translation; the result is an accurate, error-free translation.
- Full post-editing: Emphasizes translation quality, aiming to eliminate errors.
- Light post-editing: Involves editing the machine translation output to make its meaning clear, accurate, and unambiguous, but it may still contain grammar, spelling, and sequence problems. The original style and tone are not emphasized.
- Weak post-editing: Focuses on understanding over language quality and allows for linguistic and stylistic issues [24].
1.3. Description of Machine Translation Challenges for the Kazakh Language and Problem Statement
- Morphological complexity. Kazakh is an agglutinative language, which means that words can have multiple forms due to prefixes and suffixes. This complexity poses challenges for machine translation, as it is necessary to correctly interpret and translate each morpheme. Translation between Kazakh and languages with different morphological structures, such as English, can lead to a lack or excess of information in the target text [25].
- Low-resource language: The Kazakh language is considered low-resource because there are currently much fewer training data available for Kazakh compared to languages such as English or Russian. This complexity makes the training of highly effective machine translation models more difficult. Additionally, the absence of specialized corpora for specific domains or professions further limits the translation quality in these areas [26].
- Transition to Latin script: It is also worth noting that the plans to transition the Kazakh language from Cyrillic to Latin script add an additional layer of complexity. Machine translation systems need to be adapted to both writing systems, further complicating the translation process.
- Cultural and idiomatic differences: Idioms, proverbs, and other culturally specific expressions in the Kazakh language might lack direct equivalents in other languages, requiring careful adaptation during translation [27].
- Syntactic differences: Syntactic differences, such as word order and sentence structure, in the Kazakh language can vary from other language groups like Germanic, Slavic, and others. This creates additional challenges for machine translation, as translation models need to account for these differences to generate grammatically correct and comprehensible sentences [28].
- Data collection, processing, and structuring; for this, it is necessary to collect and structure large bodies of bilingual texts, as well as develop tools for automatic preprocessing and text annotation;
- Development of a post-editing approach for English–Kazakh and Russian–Kazakh machine translation based on machine learning;
- Quality assessment, conducting an objective assessment of the quality of translation using modern methods and tools.
2. Materials and Methods
2.1. Post-Editing of Machine Translation for English–Kazakh and Russian–Kazakh Translation
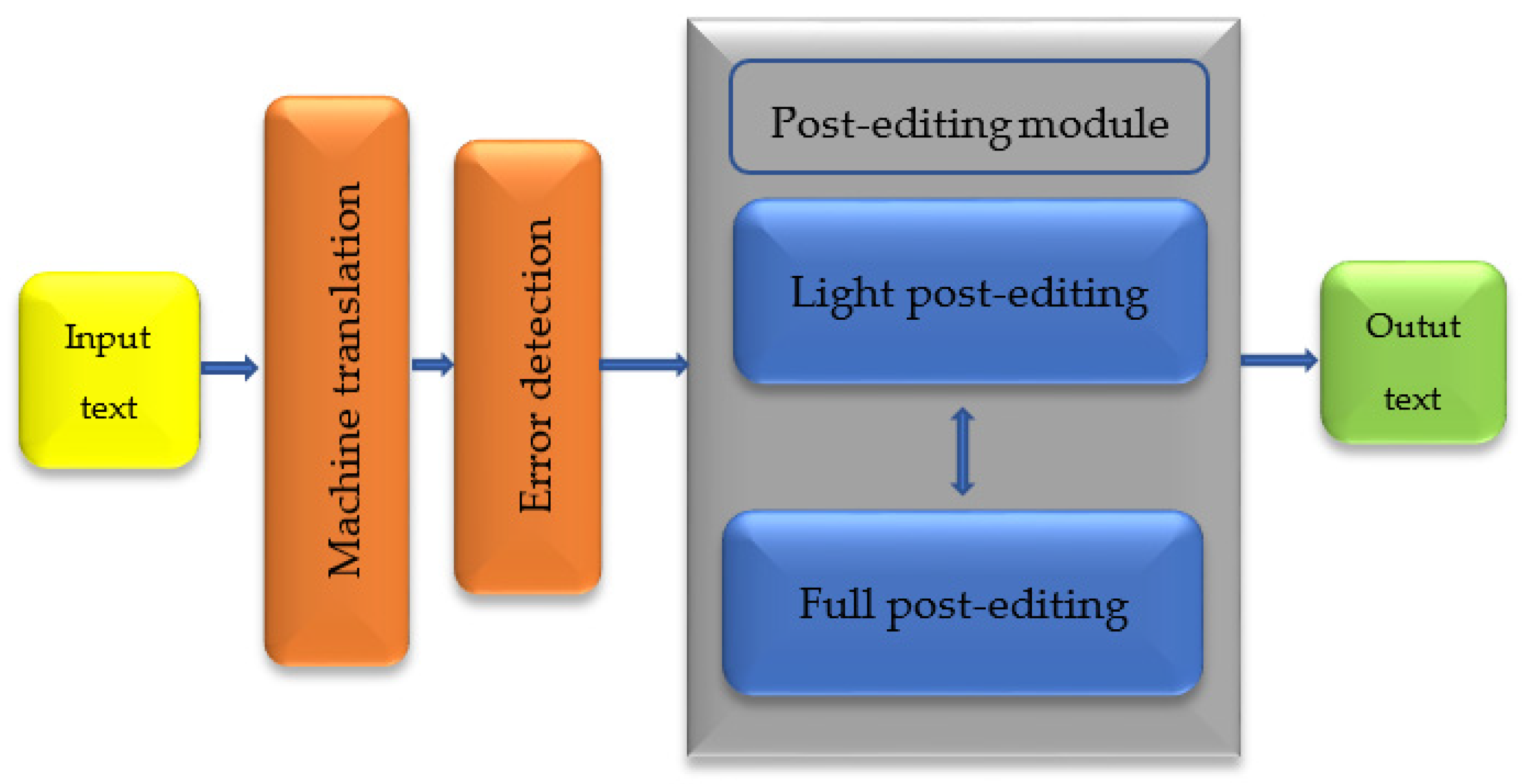
- Preparation of the source text. To do this, the initial input is scanned to check the correctness of the format and identify possible problems; after that, the source language is determined, and then the input text is divided into sentences or phrases.
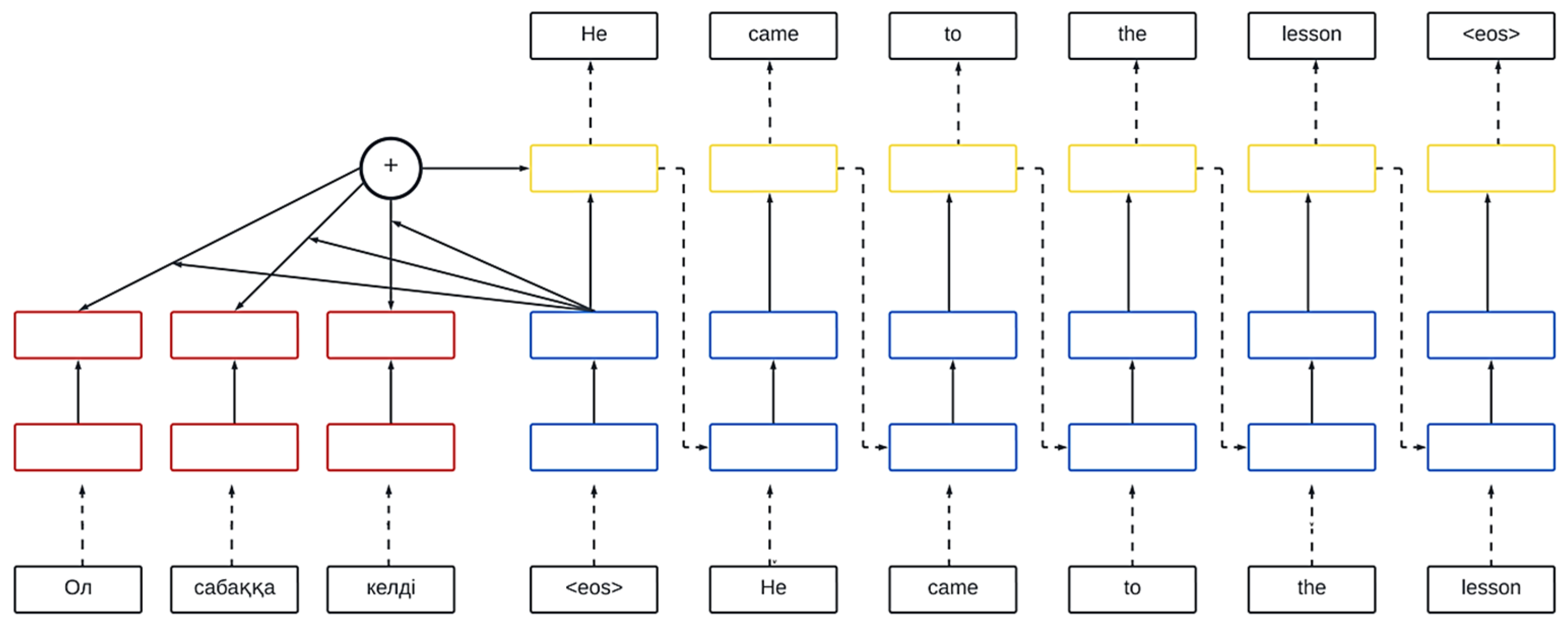
- Second item: The process of machine translation consists of tokenization, that is, splitting sentences into separate words or tokens, morphological analysis, the determination of morphological features of the language, a neural model, which is used by a trained MT model (for example, based on the transformer architecture) for the initial translation, and detokenization, that is, the conversion of tokenized text back into a readable format.
- The post-editing stage: the initial review of the MT output data is carried out for the presence of obvious errors. After that, if the main goal is a general understanding, the text undergoes light editing, that is, only obvious errors are corrected. And, if the goal is a high-quality translation, the text undergoes complete editing and all kinds of errors, stylistic, grammatical, lexical, and semantic, are edited. The choice between light and full post-editing usually depends on the purpose of the translation, the project budget, and quality requirements.
- Adaptive reverse cycle: corrections made during post-editing are returned back to the MP system to improve future translations. This stage is optional and depends on the availability of adaptive capabilities of the MT system.
- Output data and verification: quality control is carried out, or rather, automatic checks for the presence of untranslated segments, inconsistencies, or problems with the format. The final review, the last stage, is performed to make sure that the translation meets the required quality standards. At the very end, the result is provided in the form of a ready translation and is output in the required format or medium. Figure 2 shows the general architecture of post-editing for the low-resource language.
2.2. Development of the Light Post-Editing Level
- Correcting only the most obvious typos and lexical and grammatical errors;
- Rectifying machine errors;
- Removing unnecessary or redundant translation options generated by the machine.
- Aligning sentences {mt} obtained from machine translation with high-quality sentences in the target language {pe};
- Conducting sentence tokenization;
- Splitting into training and validation sets, as well as building a vocabulary;
- Processed data are fed into a recurrent neural network;
- The trained model is used to translate the test corpus, and the results are compared using the BLEU metric {mt}-{pe} and {mt}-{ape}, where ape represents the text corpus obtained after the post-editing stage.
- Elimination of glaring grammatical, orthographic, and punctuation errors;
- Correction of machine-translated phrases or words that clearly do not match the original text;
- Preservation of the basic formatting and structure of the original text without additional effort on high-quality formatting;
- In the case of extremely complex or ambiguous translations, it may decide to skip or make minimal changes to maintain the text’s clarity.
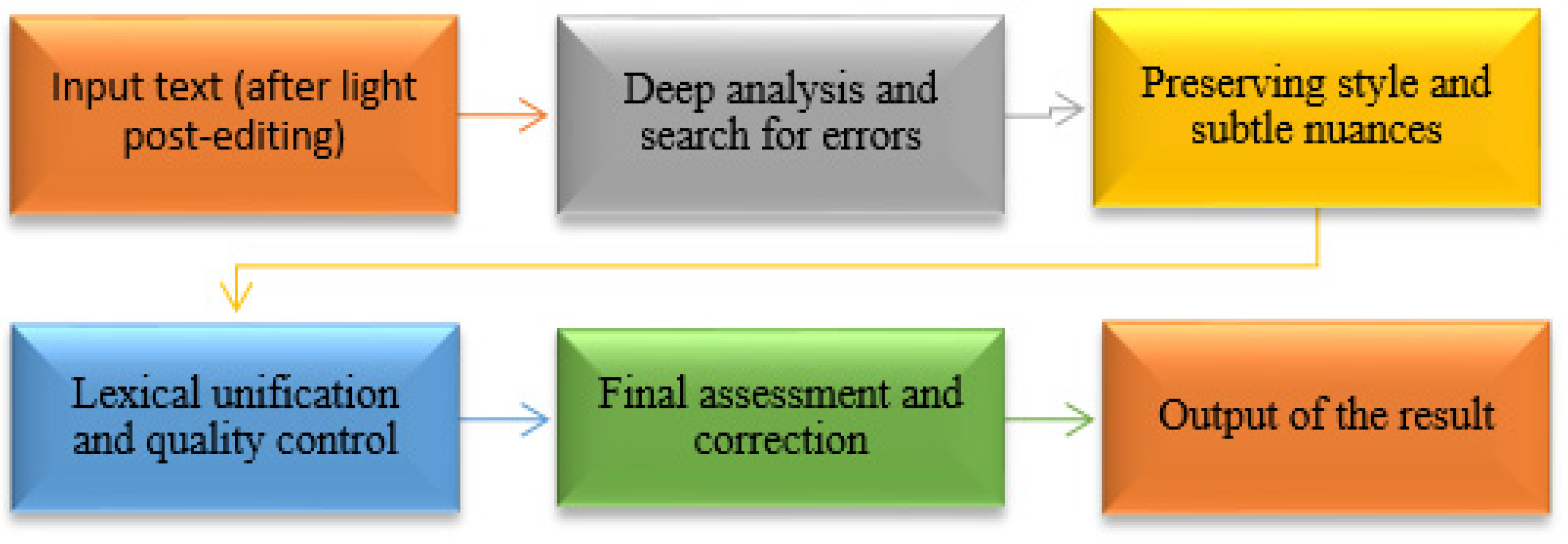
2.3. Development of the Full Post-Editing Level
- Conducts comprehensive deep editing of machine translation, taking into account the syntactic and semantic properties of the output Kazakh language;
- Ensures the preservation of the structure of the original text and the properties of the Kazakh language for simple and complex sentences;
- Ensures uniform translation of terms and phrases and evaluates the logical integrity and meaning of the text to ensure that the translation accurately conveys the ideas and information of the original text;
- Conducts a final check of the translation to ensure that the text fully meets the requirements.
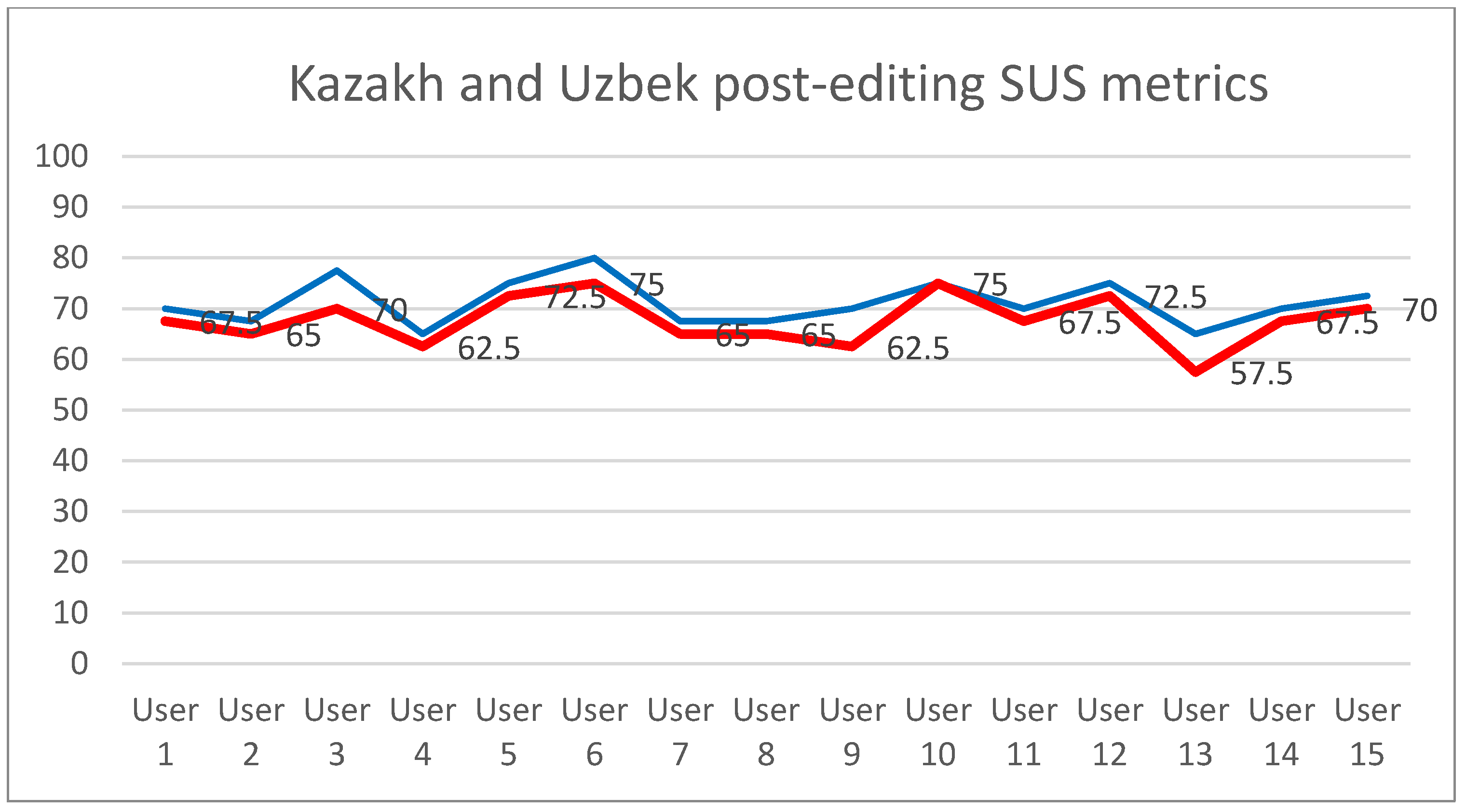
3. Results
- Client-interface module;
- Post-edit module;
- NL resource module.
- Input windows for processing and editing functions linked to the post-edit module.
- Output result windows.
- Processing level: this level involves linguistic and statistical processing of input data, removing stop words, correcting the input text, normalization, stemming, identifying incorrect words, resolving abbreviations, and proper noun resolution;
- Structural level: this level addresses grammatical errors in the text, determining the correct syntactic structure of simple and complex sentences in the Kazakh language;
- Edit level: at this level, semantic analysis of the text is performed, resolving word ambiguity, possible substitutions, and text editing.
Dataset
- A parallel Treebank corpus for Kazakh, Russian, and English languages;
- Dictionaries;
- Sets of rules and data for the Kazakh language.
- Abbreviation dictionary;
- Synonym dictionary;
- Proper noun dictionary [35].
- General grammatical features:
- General phonetic features:
- Cultural influence:
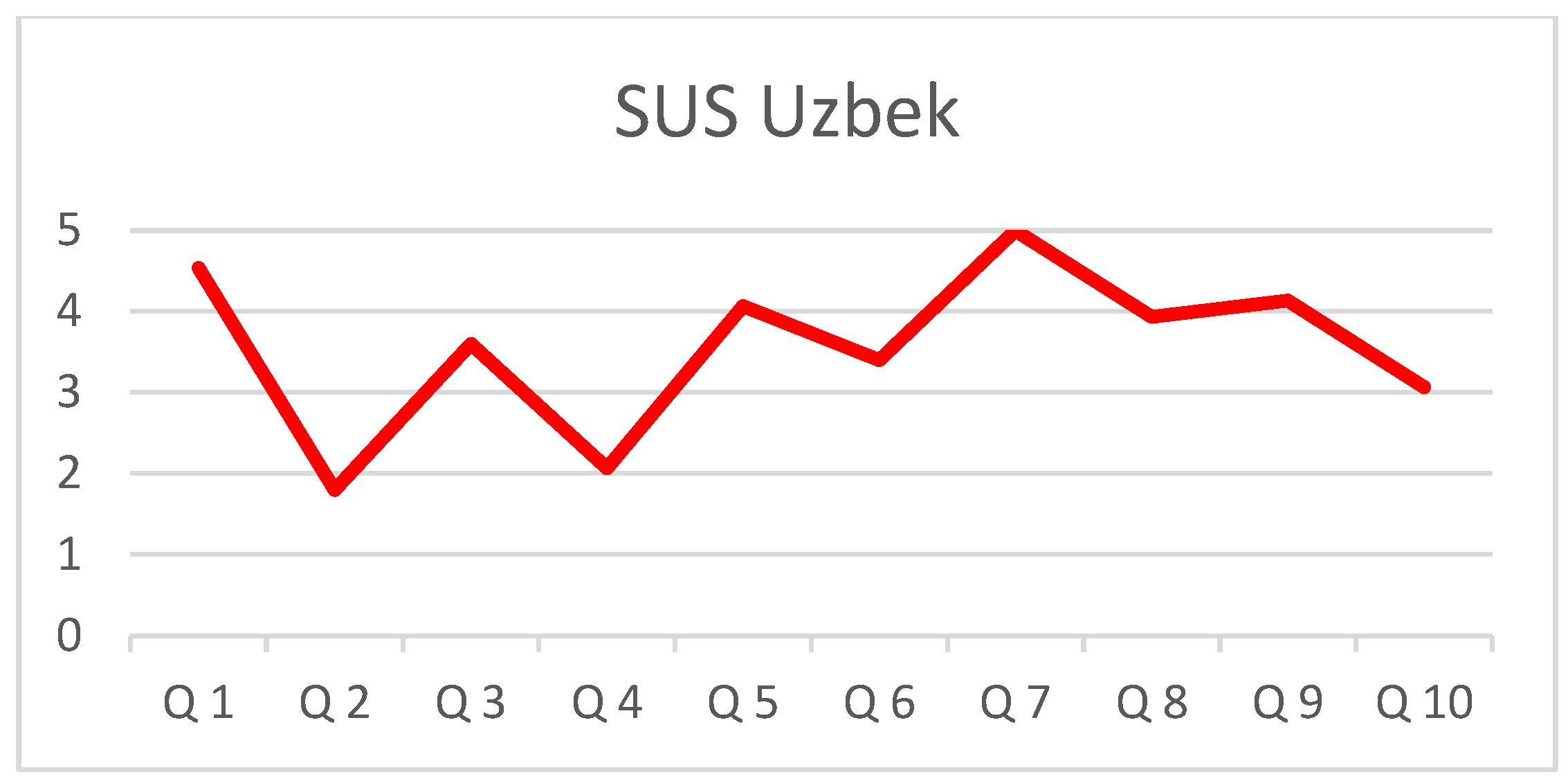
- 1—Completely disagree
- 2—I do not agree
- 3—Neutral
- 4—Agree
- 5—Completely agree
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohamed, S.A.; Elsayed, A.A.; Hassan, Y.F.; Abdou, M.A. Neural machine translation: Past, present, and future. Neural Comput. Appl. 2021, 33, 15919–15931. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 4, 1–9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Bissembayeva, L. Spiritual unity of the Kazakh and Kyrgyz peoples under colonialism (second half of the 19th century–beginning of the 20th century). In Proceedings of the International Scientific-Practical Conference “Academician Council Nurpeys and the History of the Revival of Kazakh Statehood” Held in the Framework of “Nurpeys Studies” on the Occasion of the 85th Anniversary of the Birth of Nurpeys Kenesy Nurpeysuly, Astana, Kazakhstan; 2020; pp. 153–158. (In Kazakh). [Google Scholar]
- Makazhanov, A.; Myrzakhmetov, B.; Assylbekov, Z. Manual vs Automatic Bitext Extraction. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; pp. 3834–3838. [Google Scholar]
- Vieira, L.N.; Alonso, E.; Bywood, L. Introduction: Post-editing in practice—Process, product and networks. J. Spec. Transl. 2019, 31, 2–13. [Google Scholar]
- Shterionov, D.; do Carmo, F.; Moorkens, J.; Hossari, M.; Wagner, J.; Paquin, E.; Schmidtke, D.; Groves, D.; Way, A. A roadmap to neural automatic post-editing: An empirical approach. Mach. Transl. 2020, 34, 67–96. [Google Scholar] [CrossRef] [PubMed]
- Negri, M.; Turchi, M.; Bertoldi, N.; Federico, M. Online Neural Automatic Post-editing for Neural Machine Translation. In Proceedings of the Fifth Italian Conference on Computational Linguistics, Torino, Italy, 10–12 December 2018; pp. 525–536. [Google Scholar]
- ISO 18587:2017; Translation Services—Post-Editing of Machine Translation Output—Requirements. ISO: Geneva, Switzerland, 2017. Available online: https://www.iso.org/obp/ui/en/#iso:std:iso:18587:ed-1:v1:en (accessed on 1 December 2023).
- Koponen, M.; Salmi, L.; Nikulin, M. A product and process analysis of post-editor corrections on neural, statistical and rule-based machine translation output. Mach. Transl. 2019, 33, 61–90. [Google Scholar] [CrossRef]
- Koehn, P. Statistical Machine Translation. Draft of Chapter 13: Neural Machine Translation. arXiv 2017, arXiv:1709.07809. [Google Scholar]
- Zhumanov, Z.M.; Tukeyev, U.A. Development of machine translation software logical model (translation from Kazakh into English language). In Proceedings of the Third Congress of the World Mathematical Society of Turkic Countries, Almaty, Kazakhstan, 6 July 2009; Volume 1, pp. 356–363. [Google Scholar]
- Tukeyev, U.; Zhumanov, Z.; Rakhimova, D. Features of development for natural language processing. In ICT—From Theory to Practice; Milosz, M., Ed.; Polish Information Processing Society: Warszawa, Poland, 2010; pp. 149–174. [Google Scholar]
- Tukeyev, U.; Rakhimova, D. Augmented attribute grammar in meaning of natural languages sentences. In Proceedings of the 6th International Conference on Soft Computing and Intelligent Systems, and the 13th International Symposium on Advanced Intelligent Systems, SCIS-ISIS2012, Kobe, Japan, 20–24 November 2012; pp. 1080–1085. [Google Scholar]
- Farrús Cabeceran, M.; Costa-Jussà, M.R.; Mariño Acebal, J.B.; Rodríguez Fonollosa, J.A. Linguistic-based evaluation criteria to identify statistical machine translation errors. In Proceedings of the 14th Annual Conference of the European Association for Machine Translation, Saint-Raphaël, France, 27–28 May 2010; pp. 167–173. [Google Scholar]
- Matthias, E.; Stephan, V.; Alex, W. Communicating Unknown Words in Machine Translation. In Proceedings of the International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Sinha, R.M.K. Dealing with unknowns in machine translation. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, e-Systems and e-Man for Cybernetics in Cyberspace, Tucson, AZ, USA, 7–10 October 2001; pp. 940–944. [Google Scholar]
- Turganbayeva, A.; Tukeyev, U. The Solution of the Problem of Unknown Words Under Neural Machine Translation of the Kazakh Language. In Proceedings of the Intelligent Information and Database Systems 12th Asian Conference, Phuket, Thailand, 23–26 March 2020; pp. 319–328. [Google Scholar]
- Zhang, J.; Zhai, F.; Zong, C. Handling unknown words in statistical machine translation from a new perspective. In Proceedings of the First CCF Conference Natural Language Processing and Chinese Computing, Beijing, China, 31 October–5 November 2012; pp. 176–187. [Google Scholar]
- Marton, Y.; Callison-Burch, C.; Resnik, P. Improved statistical machine translation using monolingually-derived paraphrases. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language, Singapore, 6–7 August 2009; pp. 381–390. [Google Scholar]
- Zhang, J.; Zhai, F.; Zong, C. A substitution-translation-restoration framework for handling unknown words in statistical machine translation. J. Comput. Sci. Technol. 2013, 28, 907–918. [Google Scholar] [CrossRef]
- Lyu, C.; Xu, J.; Wang, L. New Trends in Machine Translation using Large Language Models: Case Examples with ChatGPT. arXiv 2023, arXiv:2305.01181. [Google Scholar]
- Gulcehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the unknown words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 140–149. [Google Scholar]
- Li, X.; Zhang, J.; Zong, C. Towards zero unknown word in neural machine translation. In Proceedings of the International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2852–2858. [Google Scholar]
- Turganbayeva, A.; Rakhimova, D.; Karyukin, V.; Karibayeva, A.; Turarbek, A. Semantic Connections in the Complex Sentences for Post-Editing Machine Translation in the Kazakh Language. Information 2022, 13, 411. [Google Scholar] [CrossRef]
- Makhambetov, O.; Makazhanov, A.; Sabyrgaliyev, I.; Yessenbayev, Z. Data-driven morphological analysis and disambiguation for Kazakh. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Cairo, Egypt, 14–20 April 2015; pp. 151–163. [Google Scholar]
- Tukeyev, U.; Karibayeva, A. Inferring the complete set of Kazakh endings as a language resource. In Proceedings of the ICCCI 2020, Communications in Computer and Information Science, Da Nang, Vietnam, 30 November–3 December 2020; Springer: Cham, Switzerland, 2020; Volume 1287. [Google Scholar]
- Tukeyev, U.; Karibayeva, A.; Zhumanov, Z. Morphological Segmentation Method for Turkic Language Neural Machine Translation. Cogent Eng. 2020, 7, 1856500. [Google Scholar] [CrossRef]
- Rubino, R.; Marie, B.; Dabre, R. Extremely low-resource neural machine translation for Asian languages. Mach. Transl. 2020, 34, 347–382. [Google Scholar] [CrossRef]
- Rakhimova, D.; Turarbek, A.; Karyukin, V.; Karibayeva, A.; Turganbayeva, A. The development of the Light post-editing module for English-Kazakh translation. In Proceedings of the ACM International Conference Proceeding Series: Proceedings of the 7th International Conference on Engineering & MIS, Almaty Kazakhstan, 11–13 October 2021. [Google Scholar]
- Lee, W.; Park, J.; Go, B.-H.; Lee, J.-H. Transformer-based Automatic Post-Editing with a Context-Aware Encoding Approach for Multi-Source Inputs. arXiv 2019, arXiv:1908.05679. [Google Scholar]
- Chatterjee, R.; Gebremelak, G.; Negri, M.; Turchi, M. Online Automatic Post-editing for MT in a Multi-Domain Translation Environment. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 525–535. [Google Scholar]
- Vu, T.; Haffari, G. Automatic Post-Editing of Machine Translation: A Neural Programmer-Interpreter Approach. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3048–3053. [Google Scholar]
- Pal, S.; Naskar, S.; Vela, M.; Genabith, J. A Neural Network based Approach to Automatic Post-Editing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 281–286. [Google Scholar]
- Rakhimova, D.; Sagat, K.; Zhakypbaeva, K.; Zhunussova, A. Development and Study of a Post-Editing Model for Russian-Kazakh and English-Kazakh Translation Based on Machine Learning. In Proceedings of the Advances in Computational Collective Intelligence. ICCCI 2021. Communications in Computer and Information Science, Rhodos, Greece, 29 September–1 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Github. Available online: https://github.com/danielvarga/hunalign (accessed on 15 August 2022).
- Lee, W.; Jung, B.; Shin, J.; Lee, J.-H. Adaptation of Back-translation to Automatic Post-Editing for Synthetic Data Generation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Kyiv, Ukraine, 19–23 April 2021; pp. 3685–3691. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Nguyen, V.; Senellart, J.; Rush, A.M. OpenNMT: Neural machine translation toolkit. In Proceedings of the AMTA 2018—13th Conference of the Association for Machine Translation in the Americas, Boston, MA, USA, 17–21 March 2018; Volume 1, pp. 177–184. [Google Scholar]
- Gong, Y.; Yan, D. A toolset to integrate OpenNMT into production workflow. In Proceedings of the 20th Annual Conference of the European Association for Machine Translation, EAMT 2017, Prague, Czech Republic, 29–31 May 2017; p. 25. [Google Scholar]
- BLUE Metrics. Available online: https://en.wikipedia.org/wiki/BLEU (accessed on 21 October 2023).
- WER Metrics. Available online: https://medium.com/nlplanet/two-minutes-nlp-intro-to-word-error-rate-wer-for-speech-to-text-fc17a98003ea (accessed on 19 September 2023).
- TER Metrics. Available online: https://kantanmtblog.com/2015/07/28/what-is-translation-error-rate-ter/ (accessed on 5 October 2023).
- System Usability Scale—What Is It? Available online: https://thestory.is/en/journal/system-usability-scale-what-is-it/ (accessed on 20 December 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Post-Editing | High Post-Editing | Full Post-Editing | Light Post-Editing | Weak Post-Editing |
|---|---|---|---|---|
| Description | Accurate, error-free translation without linguistic and stylistic errors | High-quality translation with respect to structure and style | Understanding and meaning of the original text | Conditional understanding of the original and linguistic errors |
| Main objective | Provide a clear and accurate translation without errors | Provide a high-quality translation | Improve the understanding of the text without paying attention to grammar and structure | Understand the basic understanding of the original, but make mistakes in grammar and structure |
| Errors allowed | Punctuation and grammar errors. The translation may contain errors in punctuation and structure | Minor errors may be present | Grammatical and spelling mistakes, but they are acceptable | Linguistic and stylistic errors |
| Time and effort | Minimal time and effort. Does not require correction. | Considerable time and effort | Moderate time and effort | Considerable time and effort |
| Examples of tasks | Translation of instructions and technical documents. Technical translation. Translation of diagrams | Translation of literary works. Academic translation | Translation of scientific texts. Product and technical descriptions | Understanding the general content of the text. Quick correction of basic errors |
| Text with Errors in Proper Names | Test for Editing Proper Names | Translation from English |
|---|---|---|
| Қазахстан аумағында Алтаи тауы орналасқан. | Қазақстан аумағында Алтай тауы орналасқан. | Altai Mountain is located on the territory of Kazakhstan. |
| Алматe қаласы-көне қалалардың бірі. | Алматы қаласы-көне қалалардың бірі. | Almaty is one of the oldest cities. |
| Казахстан Республикасының мүгедектігі бар адамдарды әлеуметтiк қорғау туралы заңнамасын бұзу | Қазақстан Республикасының мүгедектігі бар адамдарды әлеуметтiк қорғау туралы заңнамасын бұзу | Violation of the legislation of the Republic of Kazakhstan on social protection of people with disabilities |
| Translation from English | Text before Editing | Text after Editing Abbreviations |
|---|---|---|
| Changing the DNS server requires only entering the selected IP addresses into the appropriate fields of the router or other content configuration page | DNS серверін өзгерту тек таңдалған IP-мекен-жайларды маршрутизатордың сәйкес өрістеріне немесе басқа контентті конфигурациялау бетіне енгізуді талап етеді | DNS (Domain Name System—Домендік атаулар жүйесі-система доменных имен) серверін өзгерту тек таңдалған IP-мекен-жайларды маршрутизатордың сәйкес өрістеріне немесе басқа контентті конфигурациялау бетіне енгізуді талап етеді. |
| WHO reports that since 1950, the suicide rate among men between the ages of 15 and 24 has increased to 268%. | WHO 1950 жылдан бастап 15 пен 24 жас аралығындағы ерлер арасындағы суицид деңгейі 268%-ға дейін өскенін хабарлады. | ДДСҰ (Дүниежүзілік денсаулық сақтау ұйымы) 1950 жылдан бастап 15 пен 24 жас аралығындағы ерлер арасындағы суицид деңгейі 268%-ға дейін өскенін хабарлады. |
| Note from ILLI! See Article 920 for the procedure for the implementation of this Codex. | ЗҚАИ-ның ескертпесі! Осы Кодекстің қолданысқа енгізілу тәртібін 920-баптан қараңыз. | ЗҚАИ (Заңнама және құқықтық ақпарат институты)-ның ескертпесі! Осы Кодекстің қолданысқа енгізілу тәртібін 920-баптан қараңыз. |
| Corpus | Architecture | BLEU | WER | TER |
|---|---|---|---|---|
| English–Kazakh translation | BRNN | 0.37 | 0.49 | 0.57 |
| Russian–Kazakh translation | BRNN | 0.25 | 0.56 | 0.25 |
| Post-editing of Kazakh text | Transformer | 0.49 | 0.45 | 0.47 |
| Corpus | Architecture | BLEU | WER | TER |
|---|---|---|---|---|
| English–Uzbek translation | BRNN | 0.26 | 0.54 | 0.59 |
| Post-editing of Uzbek text | Transformer | 0.35 | 0.47 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakhimova, D.; Karibayeva, A.; Turarbek, A. The Task of Post-Editing Machine Translation for the Low-Resource Language. Appl. Sci. 2024, 14, 486. https://doi.org/10.3390/app14020486
Rakhimova D, Karibayeva A, Turarbek A. The Task of Post-Editing Machine Translation for the Low-Resource Language. Applied Sciences. 2024; 14(2):486. https://doi.org/10.3390/app14020486
Chicago/Turabian StyleRakhimova, Diana, Aidana Karibayeva, and Assem Turarbek. 2024. "The Task of Post-Editing Machine Translation for the Low-Resource Language" Applied Sciences 14, no. 2: 486. https://doi.org/10.3390/app14020486
APA StyleRakhimova, D., Karibayeva, A., & Turarbek, A. (2024). The Task of Post-Editing Machine Translation for the Low-Resource Language. Applied Sciences, 14(2), 486. https://doi.org/10.3390/app14020486