Abstract
Competitive Crowdsourcing Software Development (CCSD) is popular among academics and industries because of its cost-effectiveness, reliability, and quality. However, CCSD is in its early stages and does not resolve major issues, including having a low solution submission rate and high project failure risk. Software development wastes stakeholders’ time and effort as they cannot find a suitable solution in a highly dynamic and competitive marketplace. It is, therefore, crucial to automatically predict the success of an upcoming software project before crowdsourcing it. This will save stakeholders’ and co-pilots’ time and effort. To this end, this paper proposes a well-known deep learning model called Bidirectional Encoder Representations from Transformers (BERT) for the success prediction of Crowdsourced Software Projects (CSPs). The proposed model is trained and tested using the history data of CSPs collected from TopCoder using its REST API. The outcomes of hold-out validation indicate a notable enhancement in the proposed approach compared to existing methods, with increases of 13.46%, 8.83%, and 11.13% in precision, recall, and F1 score, respectively.
1. Introduction
Currently, society is facing international megatrends. Rather than a small, isolated group of developers, software development is increasingly carried out inside large companies [1]. Competitive Crowdsourcing Software Development (CCSD) emerged as a sourcing strategy when Linus Torvalds, a student at the University of Helsinki in Finland, appealed to software engineers from international participants for an open-source operating system project in 1991. The first crowdsourced software project was Linux 1.0, published in 1994. Subsequently, in 2006, Robinson and Howe first used the term “crowdsourcing” [2] and described it as “The act of a company or institution taking a function once performed by employees and outsourcing it to an undefined (and generally large) network of people in the form of an open call”. In contemporary times, CCSD has garnered widespread recognition and proven to be a successful methodology in both academic and industrial contexts [3]. This approach facilitates the prompt delivery of economical, dependable, and top-notch solutions [2]. Its increasing popularity is attributed to its capacity for fostering innovation and creativity, making it adept at offering tailored solutions across a spectrum of software development projects.
CCSD platforms, e.g., TopCoder (https://www.topcoder.com, accessed on 15 March 2023) and Kaggle (https://www.kaggle.com, accessed on 15 March 2023) [4] rely heavily on a decentralized pool of individuals, i.e., TopCoder, with 1,735,550 members registered worldwide who participate in competitive tasks published on these platforms. Projects are split into multiple tasks and published on these platforms for the world’s distributed software community to propose innovative solutions in exchange for monetary rewards [5]. However, since this community is largely unseen, scattered, and uncontrollable, the success of CCSD depends on the participant’s willingness to engage in these competitions [6].
CCSD’s success depends heavily on the excitement of the software community as the quality and amount of resources given by the community is determined by it [7,8,9,10]. To get the community to help with tasks, they are given rewards like money or social perks [8]. Lots of researchers [7,11,12] have looked into why crowds help out, studying how motivation and social ideas affect crowdsourcing.
Online employment platforms and crowdsourcing competitions have grown rapidly in popularity [13]. However, research shows a shortage of competitive crowd-workers for software development compared to market needs [14]. Consequently, crowdsourcing websites like TopCoder may provide low-quality and less inventive software products to requesters [15]. TopCoder has a high submission failure review ratio of 35.4% [6], leading to a significant portion of software development tasks being canceled or unsatisfactory. This highlights the risk factors for failure linked to motivating aspects, such as monetary rewards [16,17].
CCSD is in its early stages and faces challenges, i.e., low submission rates and a high risk of project failure [18]. This results in project cancellation, unsatisfactory solutions [15], and wasting stakeholders’ time and effort [19]. The CCSD environment, characterized by unknown factors, a geographically scattered crowd of developers, and limited visibility and control over project progress, contributes to the platform’s limited predictability [16]. This unpredictability results in client dissatisfaction and negatively affects CCSD platforms’ reputation [15,20]. Therefore, it is imperative to predict the success of CSPs.
To predict CSP success automatically, some numerical representations of the text and classification models have been used [4]. Different M/DL-based strategies are successful in solving different issues in the CCSD domain. For example, recommending the appropriate developer for the required software development project [21,22], investigating the developer’s history [23,24], figuring out other contributing success factors of the CCSD projects [14,25], developing simulation methods for failure prediction and task scheduling [26,27], success prediction in the CCSD [4], and quality assessment [28,29]. Authors [30,31] provided significant contributions to this field, specifically in the context of using deep learning for project success prediction. However, only limited research has been conducted on automatic and immediate CSP success prediction using Bidirectional Encoder Representations from Transformers (BERT).
From this perspective, a fine-tuned BERT approach is proposed for CSP classification. BERT is an advanced deep learning model based on transformers, designed for natural language understanding tasks [32]. The proposed model is trained and tested using the history data of CSPs collected from TopCoder using REST API (https://tcapi.docs.apiary.io, accessed on 15 March 2023). The proposed framework is discussed in detail in Section 3. Its performance is compared with that of state-of-the-art approaches in Section 3.6 to determine its effectiveness. It makes the following contributions:
- An automated approach is proposed to predict the success of CSPs.
- The proposed approach minimizes training time by utilizing the BertTokenizer, thereby eliminating the need for feature engineering.
- The proposed approach is accurate, with average accuracy, precision, recall, and F1-score up to 93.75%, 93.76%, 93.75%, and 93.75%, respectively.
The rest of this paper is organized as follows. Section 2 critically examines the existing research about the classification of CSPs. Section 3 explains the key steps, evaluation procedure, results, and limitations of the proposed approach. Lastly, Section 4 concludes the paper and suggests future improvements.
2. Literature Review
The recent decade has witnessed a significant increase in attention to CCSD among researchers. Researchers have looked at the CCSD model and its applications in several fields. However, the issue of CSP completion has only received minor attention despite the significance of solution prediction. The following are some studies on the SOTA. Section 2.2, Section 2.3, Section 2.4 and Section 2.5 discuss the Success Prediction on the CCSD Platform, recommendations for CCSD decisions, success factors for CCSD projects/platforms, simulation methods for failure prediction and task scheduling, and quality assessment in the CCSD platform, respectively.
2.1. Success Prediction on the CCSD Platform
Illahi et al. [4] addressed the inefficiency in software development by proposing a machine learning model to predict project success, stemming from the challenges of low submission rates and high failure rates in competitive markets. Their novel approach, leveraging a modified keyword ranking algorithm, achieved an average precision of 82.64%, recall of 86.16%, and F-measure of 84.36% in predicting project success using CNN classifiers. Implementing their model can potentially save companies significant time and effort in assessing project feasibility, serving as a benchmark for future algorithmic enhancements. Erica Mazzola et al. [33] explored how network positions, like central and structural hole positions, influence success in crowdsourcing challenges using data from 99 designs. They found that occupying these positions affected success in an inverted U-shaped pattern among the 2479 members studied, impacting access to knowledge and information flows. Their research enriches the crowdsourcing literature, offering insights for both crowd members and managers organizing such competitions.
2.2. Recommendations for CCSD Decisions
Providing a suitable pool of developers for upcoming task proposals [21] or suggesting suitable jobs for workers [22,34] was a form of CCSD decision support. A task recommendation framework for crowdsourcing platforms (TopCoder, MTurkmost, CrowdFlower, and Taskcn) is introduced by X. Yin et al. [34]. Their framework matches tasks to suitable developers and improves client satisfaction using a probabilistic matrix factorization model based on performance and search history. However, collecting detailed worker data for quality control and bias correction remains a limitation.
Yongjun et al. [21] employed a crowdsourcing decision support model for software task selection, enhancing efficiency by recommending crowds based on project characteristics. Using a super decision tool, they implemented a hierarchy of goals, criteria, and alternatives. Meanwhile, Xiaojing Yin et al. [22] addressed collaborative software development in heterogeneous crowdsourcing with a task allocation methodology. Their model, which utilized hidden Markov models and generative adversarial networks, outperformed AI players but required additional experimental data for refinement. Junjie et al. [35] introduced PTRec, a context-aware personalized task-recommendation approach for crowd-testing. Leveraging 60 features, their model achieved significant improvements, with a precision of 82%, a recall of 84%, and an 81% average reduction in exploration effort over existing approaches. Yuen et al. [23] introduced TATaRec, a time-aware task recommendation framework that improves scalability by considering temporal variations in worker preferences. Utilizing workers’ social media activities, their approach surpassed previous studies. Wang et al. [24] addressed biases in crowd-testing worker recommendations with “iRec2.0”, integrating context and fairness components. The model, using Baidu’s dataset, demonstrated effectiveness in reducing non-yielding sessions and enhancing bug identification. He et al. [36] developed a sustainability analysis framework for crowdsourcing platforms, exemplified by a LEGO concept, but it lacks explicit environmental metrics.
2.3. Succcess Factors for CCSD Projects/Platforms
Dubey et al. [14] identified key factors, including task type and worker rating, using ML models to address incomplete tasks in crowdsourcing. They concluded that well-structured tasks, considering trustworthiness, rewards, technology, complication, and duration, attract strong developers and enhance success rates. Messinger [25] stressed quality communities, incentives, transparency, and trust as crucial for successful software crowdsourcing, assessing worker quality through past actions and reliability scores like TopCoder. Yang et al. [19] introduced DCW-DS, a problem formulation and decision-support approach, achieving 99% recall accuracy and precision, reducing quitting rates to under 6% with the top three task recommendations. Borst et al. [37] highlighted rewards as crucial for attracting workers, noting that projects on TopCoder without monetary incentives can still succeed due to high worker motivation. Yang and Saremi [38] proposed an inverted U-curve relationship between the optimal number of workers and rising prize amounts, recommending incentive choices based on task and worker motivation.
Kamar and Horvitz [39] identified trust issues in uncertain task outcomes on CCSD platforms. Machado et al. [40] observed the positive effects of collaboration on crowdsourcing success, emphasizing its impact on task outcomes and product quality. Sultan et al. [41] proposed coordination solutions, like automated project manager selection and regular communication, for effective crowdsourcing software development. Mansour et al. [42] found competitive crowdsourcing tendencies favoring postgraduate students, suggesting that e-learning settings should be tailored to competitive/collaborative crowdsourcing for enhanced achievement and reasoning. Xu et al. [43] emphasized the significance of crowdsourcers’ credibility, asserting that financial rewards and trustworthiness indicators are essential for successful crowdsourcing campaigns. As a result of the work in [44], gamification mechanisms were linked to intrinsic and external motivations and self-determination concepts were proposed as a framework for evaluating actions. Xiaoxiao et al. [45] introduced an integrative model for online crowdsourcing platforms, revealing the impact of personal thinking on solvers’ contributions and the correlation between self-efficacy, outcome expectations, and motivations. Denisse et al. [46] proposed a task diversity measurement approach using K-means clustering, finding that tasks with 60–80% similarity are most likely to succeed in software crowdsourcing.
2.4. Simulation Methods for Failure Prediction and Task Scheduling
The CrowdSim model by the University of Michigan [26] predicts crowd-sourced software project failure, involving agents with intermediate experience levels. Abdullah et al. [16] identified 13 key factors for crowdsourcing failures and proposed a software failure prediction paradigm based on limited task progress visibility and control. Using neural networks, Razieh et al. [47] reduced task failure by 4%, improving the efficiency and success rates of CCSD. They also introduced a task scheduling algorithm [27] with a multiobjective genetic framework, significantly reducing project time (33–78%) through neural network-based task failure predictions.
2.5. Quality Assessment in CCSD Platform
Zhenghui et al. [28] introduced a project score metric for crowdsourced software development, with the clustering-based model outperforming the Squale-based model by 29% on TopCoder, highlighting the need for more data. Hyun Joon Jung [29] proposed a matrix factorization algorithm for project routing, surpassing baselines by predicting developer accuracy using SVD and PMF models. Wu et al. [48] presented an evaluation model for software crowdsourcing, employing a weak min–max mechanism to ensure high-quality product delivery and promote participation and learning in software ecosystems.
Although the studies reviewed in Section 2 report similar findings regarding CCSD, it is important to highlight that our proposed approach differs from these studies as it utilizes a BERT model for project success prediction.
3. Methods
3.1. Overview
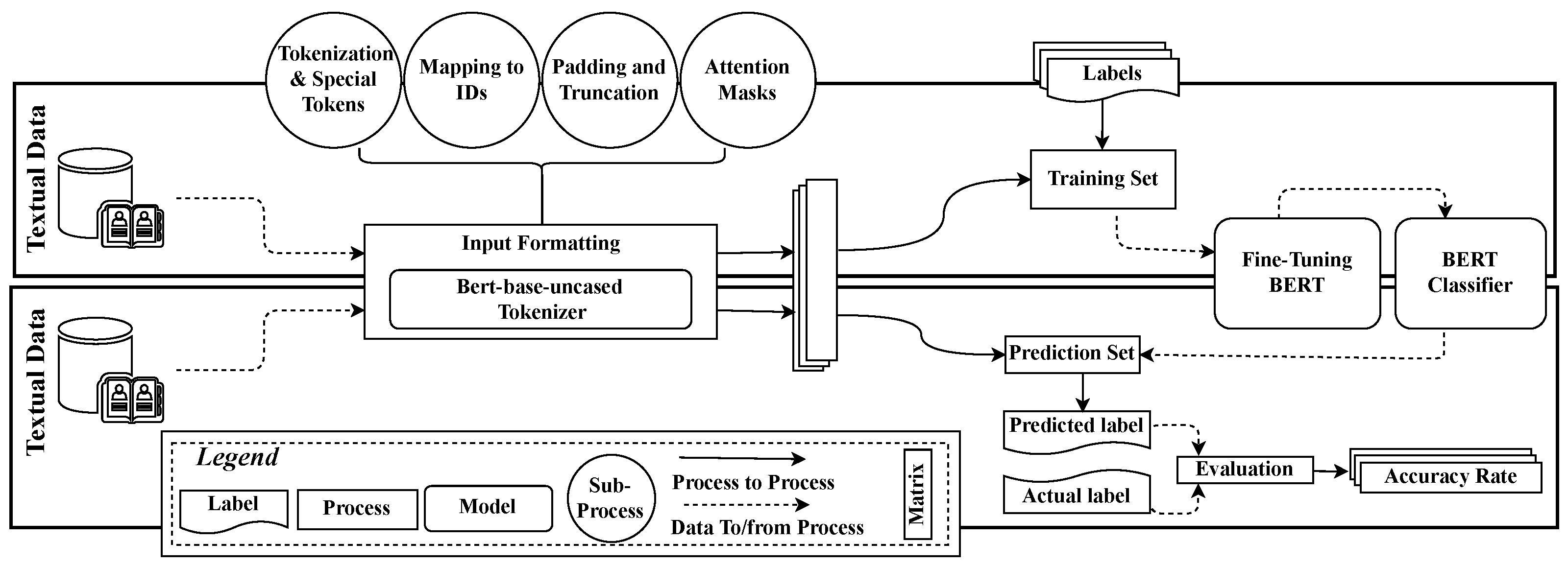
Figure 1 provides an overview of the proposed approach. The method takes the CCSD project as an input and predicts whether it will receive a solution. The output is a binary decision predicting the status (successful (1) or unsuccessful (0)) of the project. We collect the history data of CCSD projects from TopCoder using REST API (https://tcapi.docs.apiary.io, accessed on 15 March 2023). Each project information includes Challenge Name, challenge type, challenge ID, detailed requirements, technology, prize, platforms, and Current Status. The proposed approach works as follows:
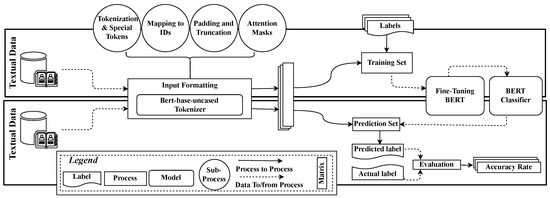
Figure 1.
Overview of the proposed approach.
- First, it performs input formatting for BERT. Proper input formatting is essential for BERT to generate accurate and meaningful contextualized embeddings for classification. The input formatting process involves tokenizing the text input and adding special tokens to mark the beginning and end of the text. It also involves padding and truncating the input to a fixed length and creating attention masks to differentiate between padding and actual input.
- Second, it fine-tunes the BERT classifier for the project’s success prediction task.
- Finally, it predicts the success of an upcoming software project using a fine-tuned BERT classifier.
The following sections provide further details on the proposed approach.
3.2. Illustrating an Example of a CCSD Project
To demonstrate the effectiveness of the proposed approach in predicting success, we consider a sample of TopCoder’s software development project (30049261) as an example to explain its working. The project commenced on 13 March 2015 and concluded on 9 December 2017.
- Project Name: “Google Drive Legal Hold Time Capsule Management Tool Prototype Challenge”.
- Project Type: “UI Prototype Competition”.
- Detailed Requirements: (a snippet from the requirements) “This challenge is to create a working HTML Prototype for the Legal Hold Time Capsule based on the provided requirements document. This is currently envisioned as working within a browser environment. It is not expected that users will access this application beyond a secure environment, and not typically on a mobile device. The clickable prototype should be accessible from traditional browsers, allowing movement among views and basic navigation, dynamically rendered on laptop; desktop screens of various sizes. (There are no device resolution constraints at this time, however, extra points will be awarded for adaptive design for device screen size flexibility). Possible future challenges related to this concept include application development using APIs.”
- Project Id: “30049261”
- Required Technologies: “CSS, HTML, and JavaScript” are the technologies specified for this project’s development.
- Required Platform: “GoogleEC2” is the platform on which the completed project will run (could be more than one).
- Prize: “[1300, 650]” in the detailed information section of a TopCoder project refers to the prize money that will be awarded to the competition winners. In this case, there will be two winners, and the first-place winner will receive a prize of USD 1300, while the second-place winner will receive a prize of USD 650.
- Current Status: “Completed” is a project status that indicates whether the project was successfully completed.
3.3. Problem Definition
A CCSD project p from a set of CCSD projects P can be defined as follows:
In Equation (1), n represents the name of the project, a represents the type of the project, d represents the detailed requirements of the project, i represents the project ID, t represents the required technology, s represents the required platform, and r represents the prize for the development of CCSD project p.
The illustrated example presented in Section 3.2 can be possessed as follows:
where, , , , , , , and are “Google Drive Legal Hold Time Capsule Management Tool Prototype Challenge”, “UI Prototype Competition”, “This challenge is to create a working HTML Prototype for the Legal Hold Time Capsule based on the provided requirements document. The prototype should be accessible from traditional browsers, allowing movement among views and basic navigation, dynamically rendered on laptop and desktop screens of various sizes. It is currently envisioned as working within a browser environment, and it is not expected that users will access this application beyond a secure environment. While there are no device resolution constraints at this time, extra points will be awarded for adaptive design for device screen size flexibility. Possible future challenges related to this concept include application development using APIs”, “30049261”, “CSS, HTML, and JavaScript”, “GoogleEC2”, and “[1300, 650]”, respectively.
Our proposed approach categorizes the CCSD projects into unsuccessful or successful. The class successful indicates that p has been completed, that is, at least one satisfactory solution has been provided. The class unsuccessful represents that p cannot receive a satisfactory solution. Predicting success could be represented by the following function f:
where c represents the classification result (e.g., unsuccessful or 0 or successful or 1) and f represents the categorizing function.
3.4. Input Formatting
Software project success prediction is strongly correlated with representing necessary words to BERT. Recent research [49,50] suggests different types of word representation techniques used in NLP, e.g., Word2Vec [50], GloVe [51], and FastText [52]. However, BERT [32] is a powerful NLP model pre-trained on a large text corpus. Its ability to learn highly contextualized representations of words and phrases makes it effective for various tasks. The input formatting process from Figure 1 presents the process to feed input formatting into BERT for generating word embeddings and performing classification. Bert-base-uncased “BertTokenizer” from the Transformers library is leveraged in this regard. The formatting process of p is as follows:
- (1)
- Tokenization and Adding Special Tokens: BertTokenizer splits the text of the CCSD project into a sequence of subwords, which are then mapped to integer IDs using a pre-defined vocabulary. The tokenizer also adds special tokens, i.e., CLS (classification) and SEP (separator), to mark the beginning and end of the project description, respectively. Its tokenization process can be formulated as follows:where S represents the sequence of subwords of p, is a subword, and n is the total number of subwords per project p.
- (2)
- Token IDs: Every w of S is converted to a numerical ID using a pre-defined vocabulary that can be formulated as:where 101 and 102 are special tokens for CLS and SEP, respectively added by the tokenizer, T represents the sequence of token IDs of p, and is an ID for the corresponding , and n is the total number of token IDs for each p.
- (3)
- Padding and Truncation: In this step of input formatting, token IDs are padded and truncated to 256 tokens. If the total number of IDs for a p is shorter than 256 tokens, it is padded with the special token ‘0’. In the case of more than 256 tokens, the remaining tokens are truncated as follows:where, represents the final IDs after padding and truncation for p.
- (4)
- Attention Masks: Attention masks differentiate between actual tokens and padding tokens in the input sequence. This is crucial since the attention mechanism in the transformer architecture employs these masks to focus on the real tokens and disregard the padding tokens. The attention mask for input sequence can be formulated aswhere the first row of s indicates the actual tokens in the input sequence, and the second row of s indicates the padding tokens.
Using a sequence length of 32, the proposed approach performs input formatting for the illustrated example presented in Section 3.2 as follows:
- (1)
- Input Text: “Google Drive Legal Hold Time Capsule Management Tool Prototype Challenge”.
- (2)
- Tokenization and Adding Special Tokens: [CLS, ‘Google’, ‘Drive’, ‘Legal’, ‘Hold’, ‘Time’, ‘Capsule’, ‘Management’, ‘Tool’, ‘Prototype’, ‘Challenge’, SEP]
- (3)
- Token IDs: [101, 8224, 3140, 3424, 2982, 2051, 13149, 3259, 6999, 9817, 4721, 102]
- (4)
- Padding and Truncation: [101, 8224, 3140, 3424, 2982, 2051, 13149, 3259, 6999, 9817, 4721, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- (5)
- Attention Masks: [101, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
3.5. Training and Prediction
For the training, BERT is fine-tuned on a specific task using labeled data by adding a task-specific layer. However, the input passes through pre-trained BERT layers followed by the task-specific layer. Note that unseen data of CCSD projects are used for the success prediction of CCSD projects. The pre-trained BERT model can be customized for a specific task by fine-tuning its parameters using task-specific data, i.e., the TopCoder dataset. To perform a classification task, we fine-tuned the BERT classifier on our problem and then utilized it to capture the correlation between project features and their success status. BERT is better than other models because of its ability to pre-train large amounts of text data [32], allowing it to learn contextual relationships between words and sentences. The feature-based models, relying on predefined and engineered features, can struggle to capture intricate contextual relationships and nuanced patterns effectively [53]. These models, often depending on handcrafted features, might misclassify instances not fitting well within their predefined feature space [53]. BERT’s pre-training on a large corpus, comprehensive exposure to textual data, architecture design, and fine-tuning techniques enable it to outperform other models on NLP tasks. Moreover, BERT’s attention mechanisms make it suitable for long text sequences [32].
The samples are randomly split into 80–20% train–testing datasets, with 13,516 samples for training and 3378 for testing. The train–test dataset’s token IDs, attention masks, and labels are combined into TensorDatasets to feed into the BERT model. We employ the BERT-based-uncased word-piece model (for English) developed by Google (https://github.com/google-research/bert, accessed on 15 March 2023) and pre-trained on BookCorpus and Wikipedia corpora. The “BertForSequenceClassification” model is used for classification, with recommended hyperparameters by the BERT authors [32]. As the number of encoders and parameters increases, the computational cost of the system escalates. Hence, we opted for the BERT-base model due to its lightweight nature and quick training capabilities with the default setting stated in [32].
The BERT-base model, featuring 12 transformer layers, 12 attention heads, 768 hidden layers, an epsilon value of , a maximum sequence length of 256, trained for 10 epochs, and with a learning rate set at , is employed in the training process using Google Colab. Google Colab offers a single free GPU, either Tesla T4 or Tesla K80, contingent on availability [32]. Noteworthy is our exploration of various hyperparameter combinations, including the number of layers (12/24), BERT heads (12/16), sequence length (64/128), and batch size (16/32/64). However, all other parameters retain their default values. It is essential to highlight that the suggested hyperparameters mentioned earlier yield optimal results. The optimizer updates parameters for each batch during every epoch. The results of each training iteration are assessed by computing loss and accuracy. For instance, the proposed model predicts the CSD project defined in Section 3.2 as successful after training.
3.6. Evaluation
In this section, we define the investigating question, explain the collected dataset, define the process of the proposed approach, and provide the assessment results.
3.6.1. Research Questions
We access the proposed approach by investigating the following research questions:
- RQ1. Is the proposed approach superior to the current state-of-the-art (SOTA)?
- RQ2. What is the effect, if any, of re-sampling on the proposed approach?
- RQ3. When predicting project success, is BERT more effective than other classifiers?
- RQ4. What impact does non-textual data have on the process of fine-tuning BERT?
The first research question looks at how well the BERT model performs compared to the state-of-the-art (SOTA) (ML-SP [4]) approach. Note that the chosen SOTA method for comparison represents the most recent machine/deep learning approach for CCSD success prediction. Although other recent studies [43,54] are available, they provide empirical evaluations of CCSD success prediction. Consequently, these studies cannot be included in comparisons with the proposed approach. The second question explores how re-sampling techniques affect the proposed approach, which is initially biased toward successful projects. Methods like under-sampling and over-sampling are used to address this bias. The third question compares the fine-tuned classifier with traditional M/DL classifiers using BERT embeddings to see if our approach is better at predicting project success. Lastly, the fourth question investigates how numeric data influences BERT’s performance by training the model both with and without numeric data. The goal is to determine the significance of numerical information in the model’s predictions.
3.6.2. Dataset
The historical data of CSPs is collected from TopCoder leveraging the Rest API (https://tcapi.docs.apiary.io, accessed on 15 March 2023). The obtained attributes include the project name, project ID, project type, detailed requirements, technologies, platforms, and prize of projects until July 2018. The extracted data are then saved in a database for further analysis. Notably, the mentioned attributes are selected based on the extensive experiment. The other attributes, i.e., developer name, do not contribute to increasing the performance of the proposed approach. Additionally, neglecting attributes such as project ID, project type, and prize money results in a performance decrease of 0.09% in the proposed approach. In contrast, excluding attributes (i.e., technologies, and platform) decreases the performance of the proposed approach by greater than 2%. However, the attribute (detailed requirements) significantly contributes to the success prediction of crowdsourced projects.
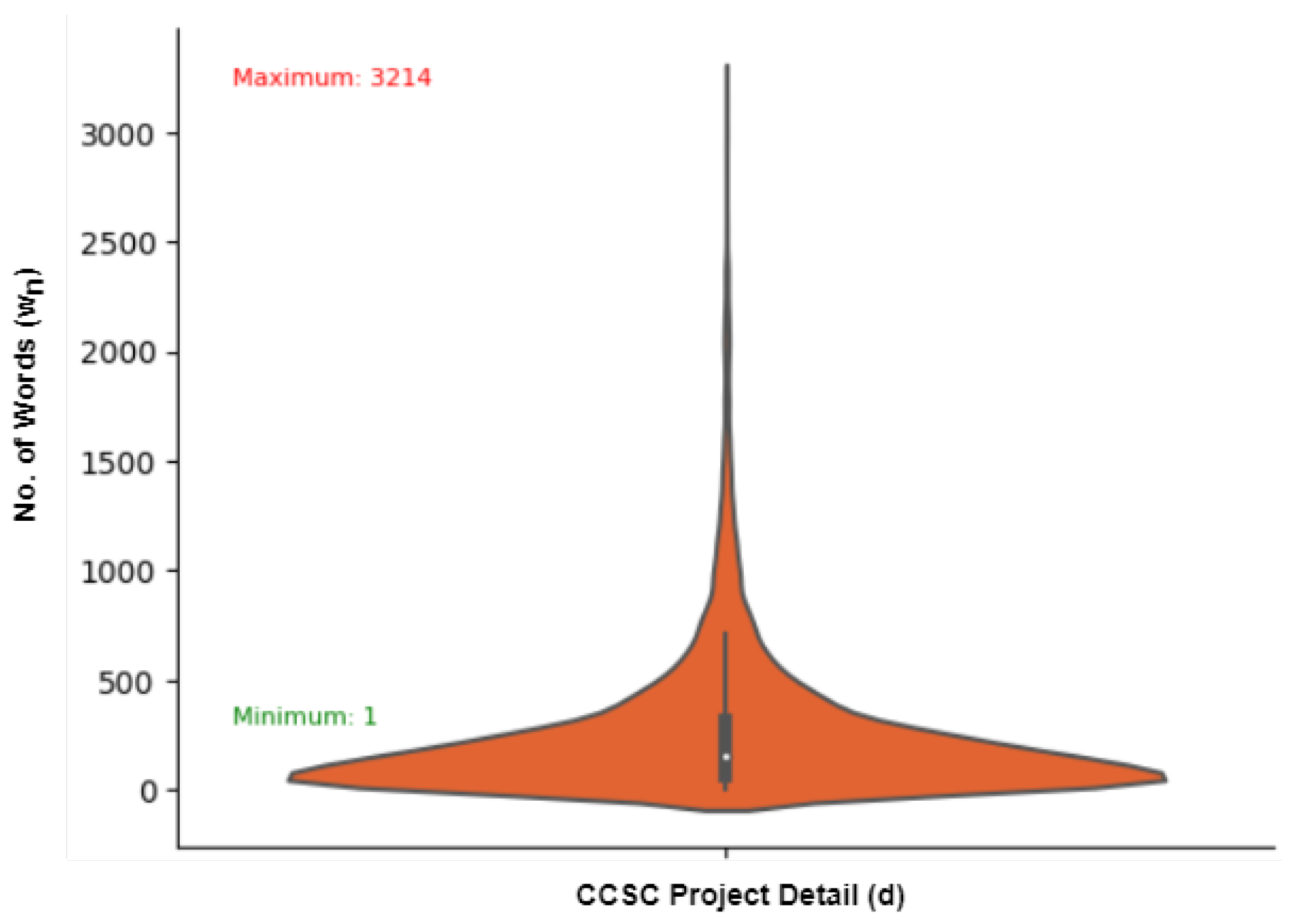
The dataset overview is presented in Table 1. Statistics of Table 1 shows that the dataset contains 16,894 records. Each sample in the dataset has a status of either unsuccessful or successful. Out of 16,894 projects, 14,465 (85.61%) are successful and 2429 (14.39%) are unsuccessful. Moreover, the beanplot (Figure 2) shows the minimum and maximum words () in any project detail (d) from the dataset. The status attribute of a project obtained from the TopCoder specifies whether it is completed or not. However, since the status can have different values, such as completed, canceled-winner, unresponsive, and canceled-failed screening, we convert this multi-class classification into a binary classification. Specifically, we label completed projects with accepted submissions as positive, while completed projects with rejected submissions are labeled as negative. Projects with incomplete submissions, undefined status attributes, empty requirements attributes, or references to other web links are excluded from the analysis.

Table 1.
CCSD dataset statistics.
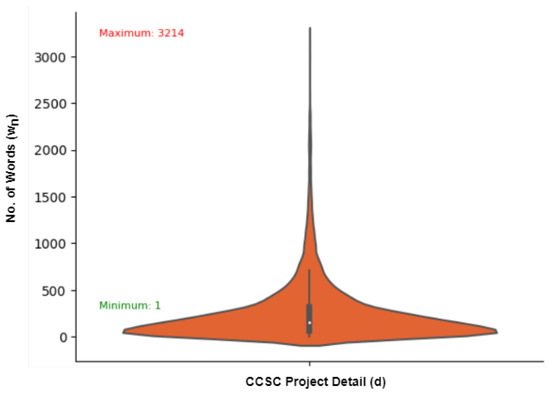
Figure 2.
Distribution of minimum/maximum words CCSD projects.
3.6.3. Process
To evaluate the proposed approach, we follow these steps. Initially, we extracted the projects P from TopCoder. Next, data usually undergo some levels of formatting automatically by the pre-trained BERT tokenizer, such as tokenizing sentences, removing punctuation, converting all characters to lowercase, removing stop words, adding special characters, mapping to token IDs, and padding and truncation to fix length and assigning attention masks. Then, we perform a hold-out validation technique on P by splitting P into 80–20%, where 80% of the projects are taken as a training set and 20% as a testing set. Finally, the BERT (BertForSequenceClassification) model is trained on the training samples, and the performance of the BERT model is evaluated on the testing samples.
For validation of the proposed approach, a step-by-step process is as follows:
- First, we choose the set of training projects.
- Second, the training samples are used to train and test the BERT model.
- Third, Long Short-Term Memory (LSTM), Convolutional Neural Networks (CNN), Gradient Boosting Classifier (GBC), and XGBoost Classifier (XGC) are trained on the training samples and tested on testing samples.
- As a final step, we calculate each classifier’s accuracy, precision, recall, and F1 score to compare their performance.
3.6.4. Evaluation Metrics
To assess the performance of the proposed approach, we employ commonly used metrics for binary classification, including accuracy, precision, recall, and F1 score.
where represents the count of projects correctly classified as successful, represents the count of projects correctly classified as unsuccessful, represents the count of projects incorrectly classified as successful, and represents the count of projects incorrectly classified as unsuccessful.
3.6.5. Results and Discussions
Comparison between the Proposed Approach and SOTA Deep Learning Approaches
To address the first research question, we compare the proposed approach with ML-SP (baseline deep learning approach [4]). The hold-out validation results, presented in Table 2, compare the performance of different classifiers. The results demonstrate that the proposed approach achieves an accuracy of 93.75%, precision of 93.76%, recall of 93.75%, and F1 score of 93.75%. In comparison, the embedding-based LSTM approach attains an accuracy of 86.62%, precision of 86.54%, recall of 99.93%, and F1 score of 92.75%. Likewise, the embedding-based CNN approach achieves an accuracy of 86.56%, precision of 86.53%, recall of 99.86%, and F1 score of 92.72%. Additionally, ML-SP achieves a precision of 82.64%, recall of 86.16%, and F1 score of 84.36% leveraging the CNN classifier.
Table 2.
Comparison against state-of-the-art approach (%).
From Table 2, we draw the following conclusions:
- The BERT model outperforms other models. The proposed approach gives an accuracy of 93.75% and improves the precision, recall, and F1 score upon the baseline deep learning results by 13.46% = (93.76 − 82.64)/82.64) × 100%, 8.83% = (93.75 − 86.16)/86.16) × 100%, and 11.13% = (93.75 − 84.36)/84.36) × 100%, respectively. Moreover, the proposed approach gives an accuracy of 96.8% and improves the precision, recall, and F1 score upon the baseline deep learning results by 17.30% = (96.97 − 82.64)/82.64) × 100%, 12.29% = (96.8 − 86.16)/86.16) × 100%, and 14.80% = (96.81 − 84.36)/84.36) × 100%, respectively. One possible reason is that BERT’s ability to capture complex word relationships makes it a powerful tool in text classification.
- The lowest precision, recall, and F1 scores obtained by the proposed approach surpass the highest precision, recall, and F1 scores achieved by SOTA deep learning methods, as illustrated in Table 2. The improvement is credited to employing the BERT model and its embeddings in training LSTM and CNN classifiers. BERT, a robust language model, creates embeddings that grasp the nuanced meaning of the text. Leveraging LSTM and CNN capabilities, often used in text classification, enables these classifiers to learn complex patterns and connections in input data, extracting pertinent features for classification. Integrating BERT embeddings, with their rich semantic information, further boosts LSTM and CNN performance, resulting in exceptional outcomes for text classification tasks.
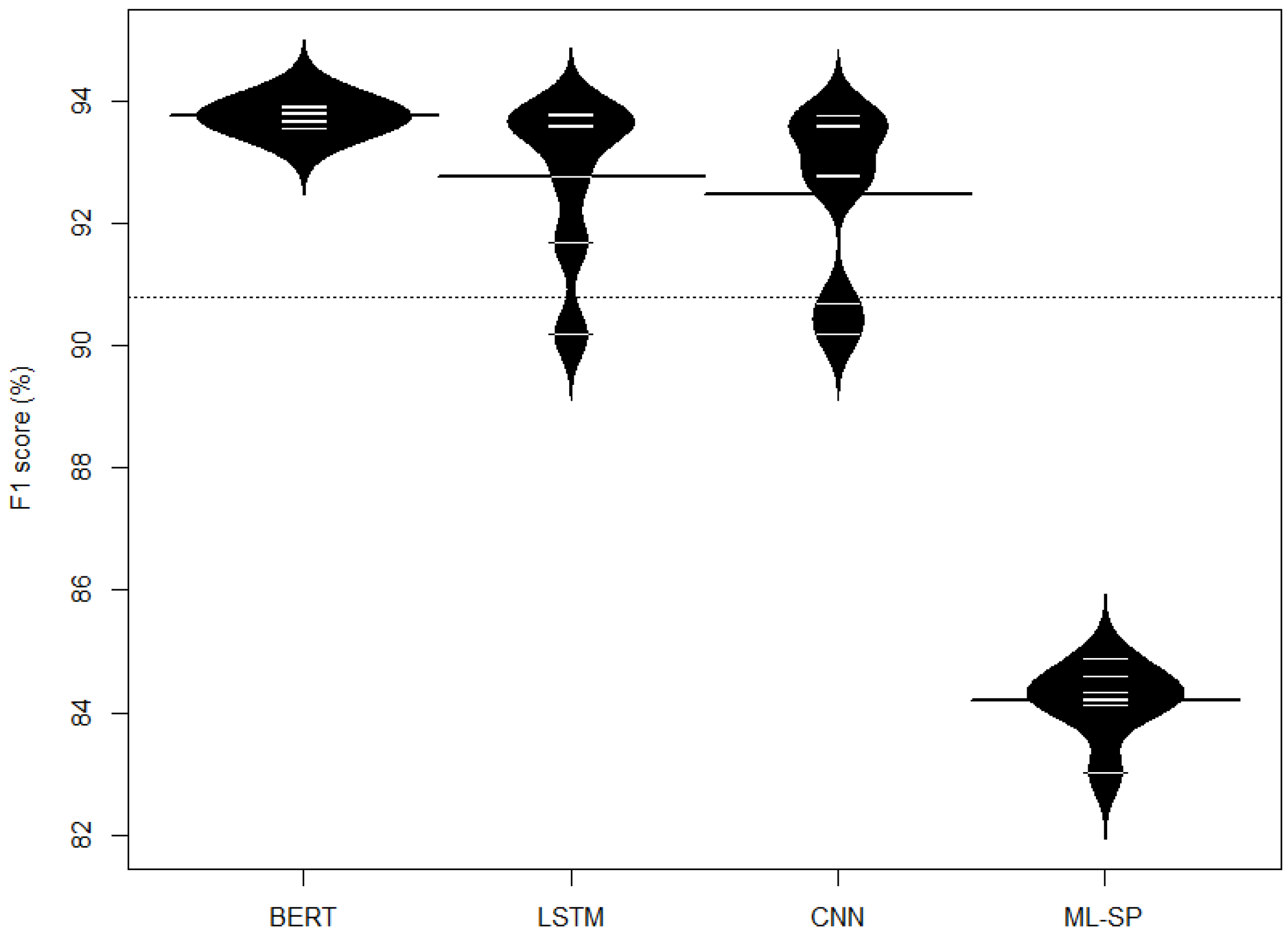
Furthermore, Figure 3 illustrates the distribution of F1 scores in the evaluation of BERT, LSTM, CNN, and ML-SP. A beanplot, employed for this visualization, portrays the distribution of a continuous variable across distinct groups. Each approach is represented by a bean, where the width reflects the data density—with broader beans indicating higher density. Examining Figure 3, it becomes apparent that BERT exhibits a minimum F1 score surpassing the maximum F1 score of ML-SP. Notably, BERT demonstrates greater stability compared to LSTM and CNN.
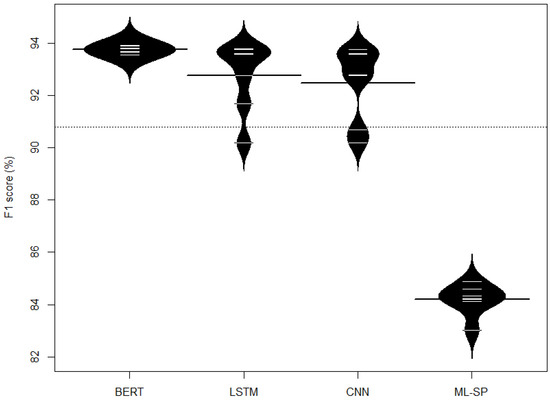
Figure 3.
Distribution of F1 score.
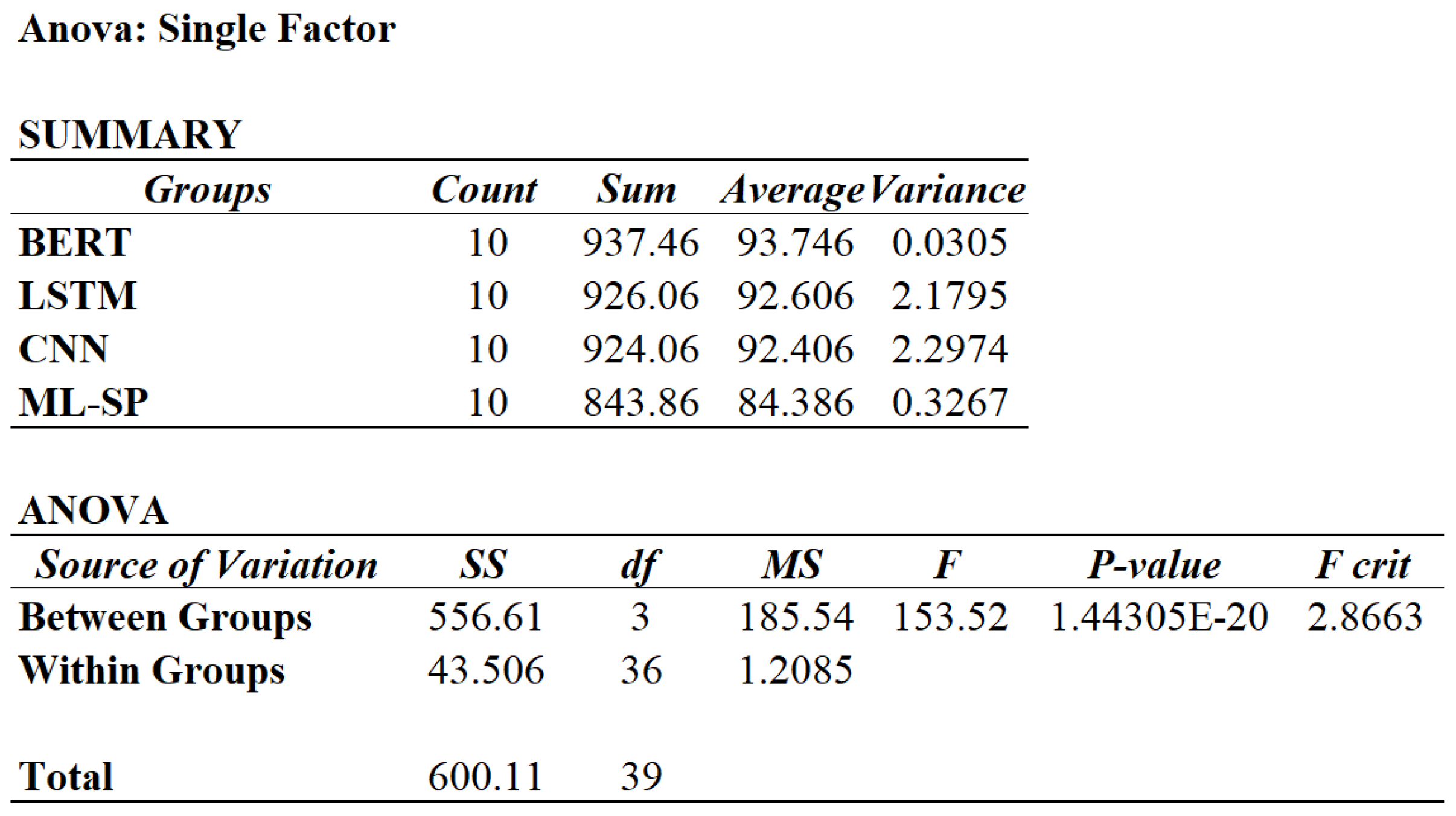
To determine the statistically significant differences in the mean performance (F1 score) among BERT, LSTM, CNN, and ML-SP, a single-factor Analysis of Variance (ANOVA) is conducted. ANOVA is a statistical technique employed to assess whether there exists a significant difference in the means of three or more independent groups or samples. The analysis, executed using default settings in RStudio, is depicted in Figure 4. The results indicate that F (153.52) > (2.87), and p-value (1.44E-20) < ( = 0.05), confirming the significant difference in F1 score among the approaches.
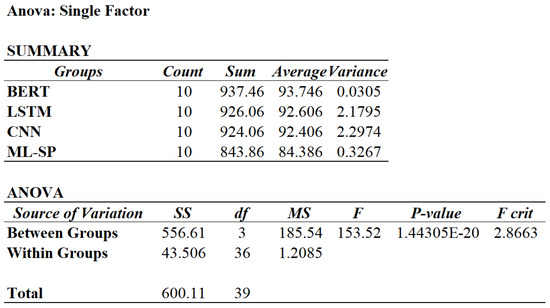
Figure 4.
ANOVA analysis on performance comparison.
We leveraged BERT for CSPs classification because it surpasses other models primarily due to its ability to generate contextualized word embeddings [32], capturing nuanced meanings and relationships in a bidirectional manner. Unlike traditional models, BERT’s pre-training involves exposure to extensive and diverse corpora, enabling it to learn rich linguistic representations [32]. Its adaptability to specific tasks is further enhanced by transfer learning. BERT’s attention mechanism and contextual embeddings allow it to effectively handle long-range dependencies, contributing to its comprehensive understanding of sentence contexts. Its consistent achievement of state-of-the-art results across various benchmarks underscores its superiority in natural language processing tasks. While other models may have limitations in capturing contextual intricacies or handling long-distance dependencies [32], BERT’s advanced features make it a preferred choice for our study.
Importance of Re-Sampling
To address the second research question, we employ two types of re-sampling techniques, namely over-sampling and under-sampling, to address the class imbalance in the dataset. Over-sampling involves generating samples for the minority class using RandomOverSampler, while under-sampling removes excess majority class records from imbalanced datasets using RandomUnderSampler. Evaluation results with and without re-sampling are presented in Table 3 and Figure 5. The first column represents the re-sampling settings, while columns 2–5 display the performance results of accuracy, precision, recall, and F1 score for each re-sampling technique.
Table 3.
Importance of resampling (in %).
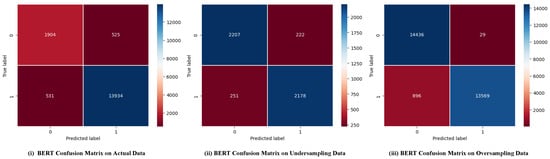
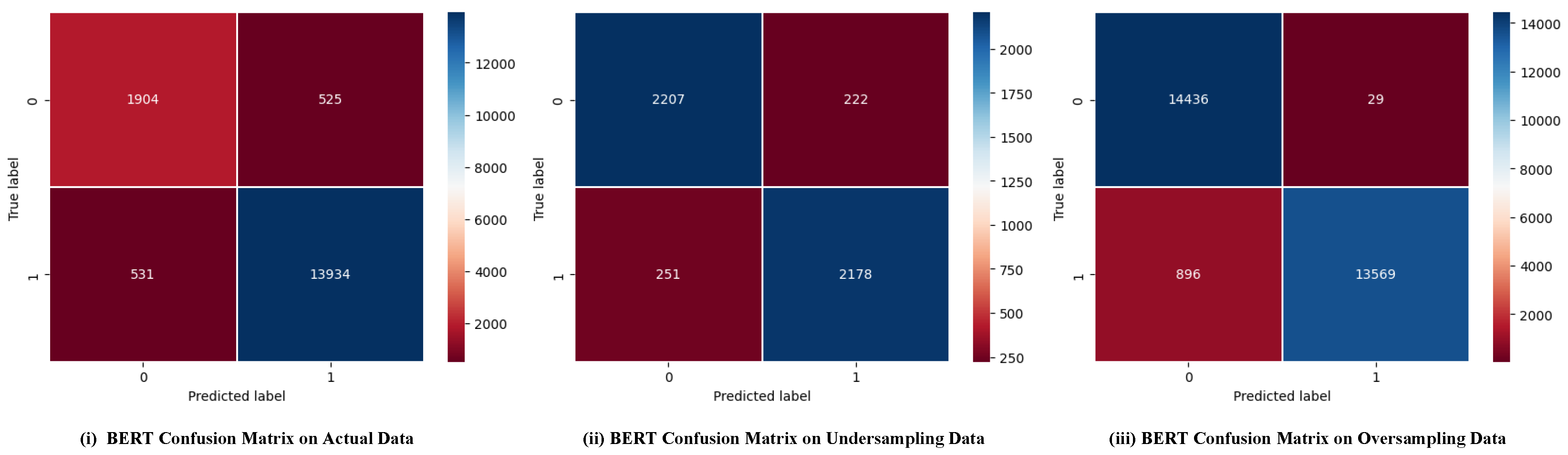
Figure 5.
BERT confusion matrix.
The results indicate that with the over-sampling technique, the accuracy, precision, recall, and F1 score achieve values of 96.8%, 96.97%, 96.8%, and 96.81%, respectively. Similarly, using the under-sampling technique, the accuracy, precision, recall, and F1 score attain values of 90.26%, 90.27%, 90.26%, and 91.28%, respectively.
- The application of the over-sampling technique has shown improvements in accuracy, precision, recall, and F1 score. The increase in accuracy is calculated as 3.26% = (96.80 − 93.75%)/93.75%, precision as 3.42% = (96.97 − 93.76%)/93.76%, recall as 3.26% = (96.80 − 93.75%)/93.75%, and F1 score as 3.27% = (96.81 − 93.75%)/93.75%. This improvement can be attributed to BERT’s exposure to more data, allowing it to learn meaningful patterns more effectively.
- On the other hand, under-sampling reduces the number of samples in the majority class, resulting in a loss of information. Consequently, the majority and minority classes in the fine-tuned BERT exhibit lower performance when under-sampling is applied.
- By examining the confusion matrix (Figure 5), it becomes evident that the true positive and true negative rates are high when over-sampling is used. This indicates that the fine-tuned BERT correctly identifies positive and negative examples. However, when under-sampling is employed, the true positive and true negative rates are relatively low. This suggests that the model may misclassify some examples and require further optimization.
Comparison of BERT with M/DL Algorithms
For the third research question, we use M/DL algorithms (LSTM, CNN, XGBoost, and GradientBoost) with BERT embeddings. We train these algorithms and compare their performance to the BERT classifier.
For the LSTM model, we employ a sequential layer and a LSTM layer with 64 units. Dropout is applied with values up to 0.2 and 12 regularization is used. The final output neuron utilized sigmoid activation. The model is trained and tested on the BERT embedding matrix, employing an 80–20% data splitting ratio. It underwent 10 epochs, had a batch size of 32, and a validation split of 0.1. The CNN model consisted of a sequential layer followed by two conventional layers (with filter sizes of 32 and 64), a MaxPooling1D layer (with a pool size of 2), and a dense layer with 64 units. Dropout with a rate of 0.2 is applied. The dense units employed the Rectified Linear Unit (ReLU) activation function, and the final output neuron utilized sigmoid activation. Like the LSTM model, the CNN model is trained and tested on the BERT embedding matrix with an 80–20% data splitting ratio. It underwent 10 epochs, had a batch size of 32, and a validation split of 0.1. The XGC is trained and validated with 1000 estimators, a learning rate of 0.05, and the following settings: max-depth = 6, min-child-weight = 1, gamma = 0, subsample = 0.8, colsample-bytree = 0.8, objective = ’binary: logistic’, nthread = 4, scale-pos-weight = 1, and seed = 27. The GBC is trained and tested with 300 estimators, a learning rate of 0.05, a max-depth of 5, and a random state of 42. To compare the proposed approach with the machine learning approach, we train and test XGBoost and GradientBoost models using an 80–20% data-splitting ratio.
The evaluation results of BERT, LSTM, CNN, XGC, and GBC classifiers are summarized in Table 4. Each row represents a specific classifier, while columns 2–5 present the performance metrics of accuracy, precision, recall, and F1 score, respectively. The average accuracy, precision, recall, and F1 score of each classifier (BERT, LSTM, CNN, GBC, and XGC) are (93.75% accuracy, 93.76% precision, 93.75% recall, and 93.75% F1 score), (86.62% accuracy, 86.54% precision, 99.93% recall, and 92.75% F1 score), (86.56% accuracy, 86.53% precision, 99.86% recall, and 92.72% F1 score), (86.5% accuracy, 86.54% precision, 99.76% recall, and 92.68% F1 score), and (86.21% accuracy, 87.91% precision, 97.27% recall, and 92.36% F1 score), respectively.
Table 4.
Comparison of different classifiers (%).
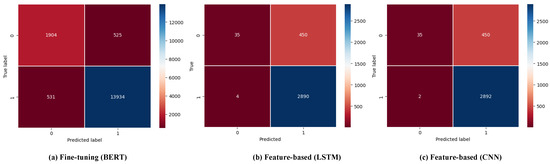
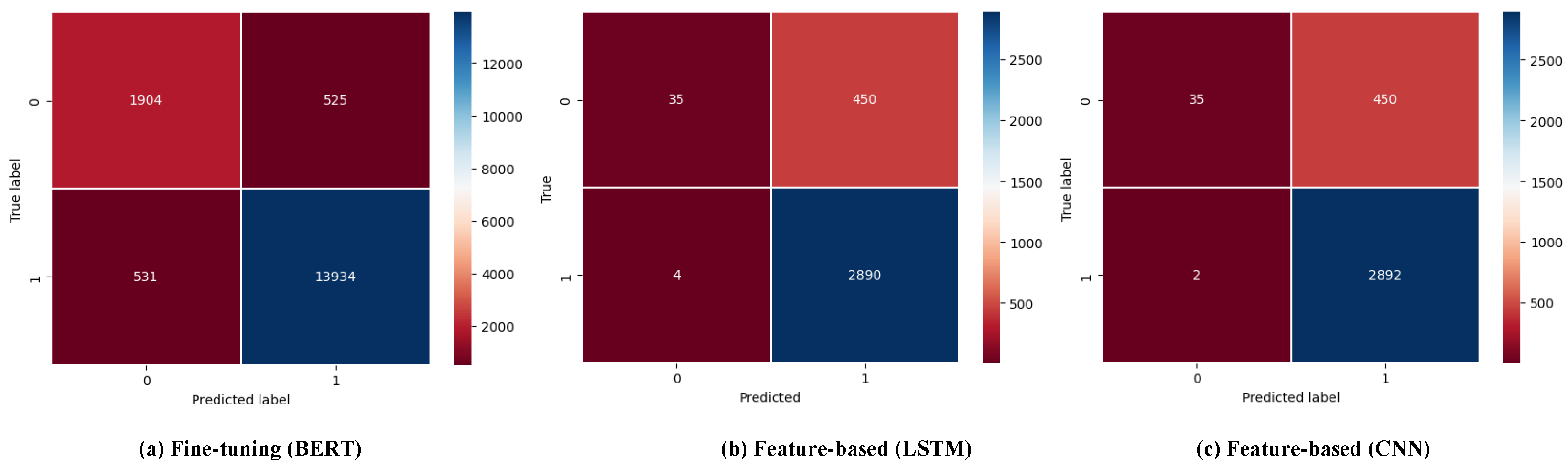
Figure 6.
Confusion matrices of BERT, LSTM, and CNN.
- The BERT outperforms LSTM, CNN, XGC, and GBC. The possible reason for this performance improvement is that it uses pre-training on a large amount of data, which allows it to learn more meaningful and generalized representations of text data. Additionally, BERT uses attention mechanisms to capture long-range dependencies and contextual information, making it more effective in natural language understanding and processing.
- DL models, i.e., BERT, LSTM, and CNN outperform ML models, i.e., XGC and GBC. The possible reason for this improvement is that DL models can learn complex and hierarchical representations of data, leading to improved performance in tasks involving natural language understanding and processing. Additionally, DL models can handle large amounts of data and automatically learn relevant features from the data, eliminating the need for feature engineering.
- Recall of BERT is lower than other models. This is because feature-based M/DL models have a higher false positive rate that can also lead to a higher recall rate, where these models may identify some negative cases as positive. One of the key explanations for this behavior is that feature-based models, which depend on pre-defined and engineered features, may encounter challenges in effectively capturing intricate contextual relationships and nuanced patterns [53]. Often depending on handcrafted features, these models might misclassify instances not fitting well within their predefined feature space [53]. For instance, in sentiment analysis, such models might base sentiment polarity on simple features like word presence and miss contextual nuances where words convey varied sentiments based on their surrounding context. This oversight could lead to mislabeling instances, impacting the model’s recall. On the other hand, BERT, being a contextual language model, considers the entire context of words and sentences due to its bidirectional nature and deep contextual embeddings [32]. It can capture intricate relationships between words and their context, resulting in more accurate classifications and potentially a lower recall than feature-based models. As shown in Figure 6 LSTM and CNN are predicting 92.7%(450) of unsuccessful (485) projects as successful. Whereas, BERT is predicting 21.6%(525) of unsuccessful (2429) projects as successful.
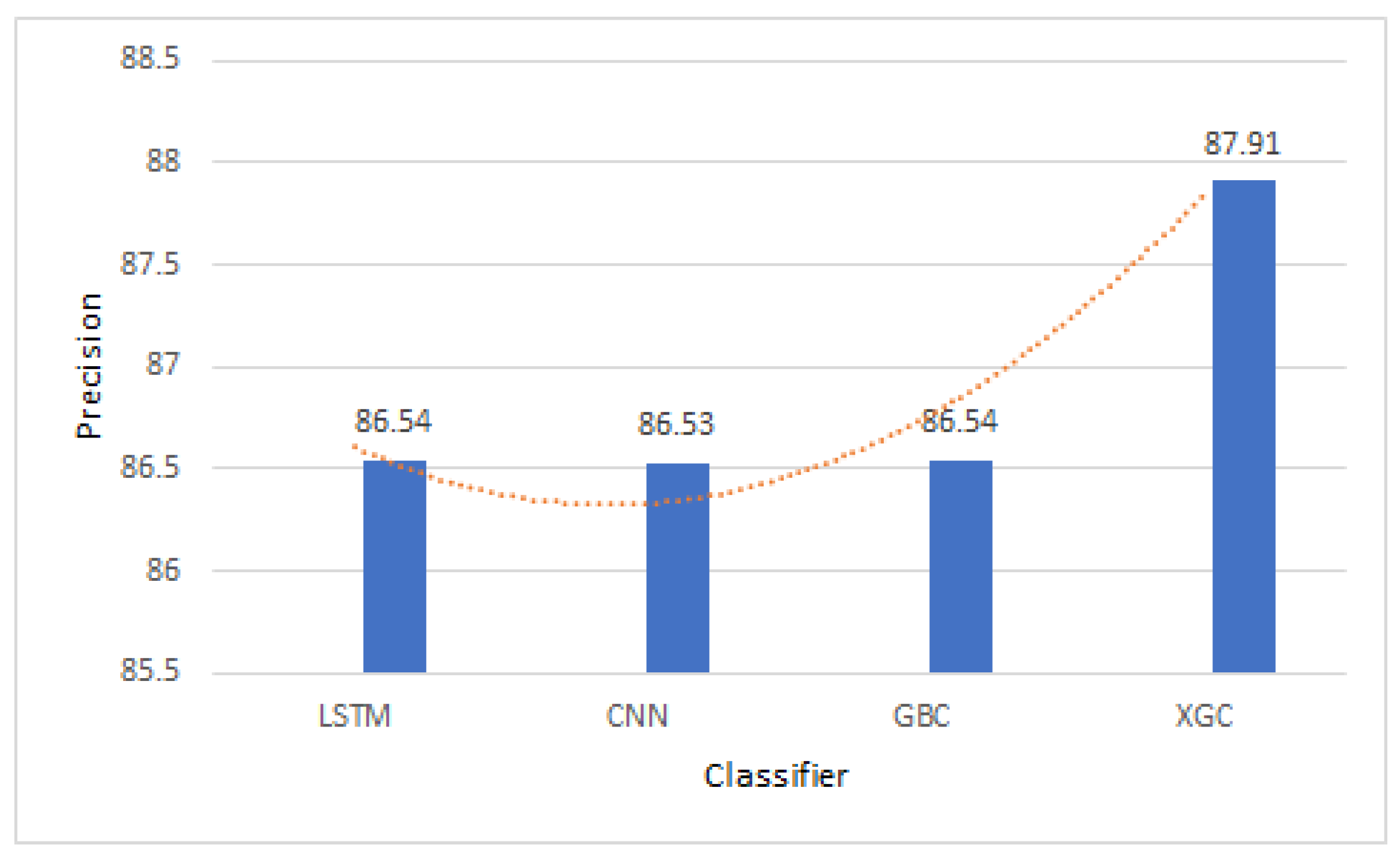
- XGC achieves higher precision than LSTM, CNN, and GBC as shown in Figure 7. This is because it has the ability to handle imbalanced datasets, minimize false positives, and prevent overfitting using regularization techniques. Its gradient-boosting algorithm assigns higher weights to misclassified instances, reducing false positives and improving precision.
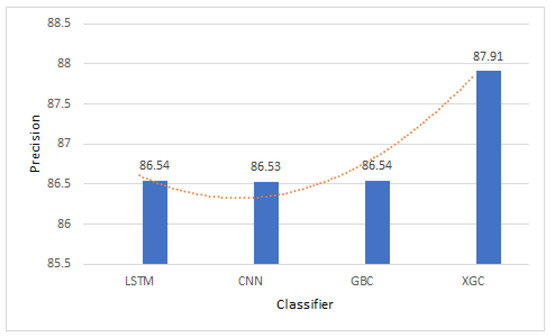 Figure 7. Precision comparison of LSTM, CNN, GBC, and XGC.
Figure 7. Precision comparison of LSTM, CNN, GBC, and XGC.
Impact of Non-Textual Inputs
To answer the fourth research question, we evaluate the outcomes of the proposed approach by turning off non-textual inputs, e.g., project ID and prize. Table 5 illustrates the evaluation outcomes. The first column of the table indicates input settings, while columns 2 to 5 display the accuracy, precision, recall, and F1 score performance metrics. The average precision, recall, and F1 score for the proposed approach with textual and non-textual inputs are 93.75%, 93.76%, 93.75%, and 93.75%, respectively. On the other hand, the average precision, recall, and F1 scores of the proposed approach by turning off non-textual inputs are 93.66%, 93.67%, 93.66%, and 93.67%, respectively.
Table 5.
Impact of non-textual inputs (In%).
From Table 5, we draw the following observations:
- Disabling non-textual features decreases accuracy, precision, recall, and F1 score by 0.10%, 0.10%, 0.10%, and 0.09%, respectively.
- Disabling non-text features in the proposed approach resulted in slightly lower scores across all metrics compared to the default settings. This outcome is attributed to BERT’s ability to learn meaningful patterns and relationships in numerical and textual data, thanks to its pre-training on diverse data types. Unlike traditional machine learning models, BERT’s deep neural network architecture allows it to handle complex relationships. It performs well on a combination of alpha-numeric and textual data. Still, it is unsuitable for handling only numerical data, as it requires a mix of text and non-textual data for optimal performance.
3.6.6. Threats to Validity
We acknowledge potential threats to the proposed approach’s construct validity due to the choice of evaluation metrics. We use accuracy, precision, recall, and F1 score, widely adopted metrics in the research community [18]. However, it is important to consider that the extensive use of these metrics may introduce limitations in terms of construct validity.
We also recognize that classification algorithms are susceptible to validity threats arising from parameter values. To mitigate this, we conduct experiments to identify optimal parameter settings instead of relying on default values. However, it is worth noting that modifications to the selected parameters can potentially impact the results.
Using the BERT model for generating word embeddings from project details introduces a potential threat to constructing validity. While alternative tools are available, BERT was chosen due to its superior performance compared to other models at the time. However, it is important to consider that the lack of comprehensive embedding calculation tools for software engineering text may affect the overall performance of the proposed approach.
Internal validity concerns arise from the implementation of the proposed approach. To address this, we conduct cross-checks to ensure the accuracy of the proposed approach. Nevertheless, there is a possibility that some errors may have been overlooked.
External validity is another area of concern regarding the generalization of the proposed approach. Although our analysis is limited to software development projects on the TopCoder platform, the proposed approach would work on software development projects from other platforms, i.e., Kaggle. However, its performance may vary when applied to projects on other crowdsourcing platforms.
Additionally, the proposed approach may have limited applicability to projects written in languages other than English, posing a potential external validity threat. The training and evaluation of the proposed approach primarily focused on English language projects, which could impact its performance on projects in other languages.
Lastly, the limited number of projects poses an external validity threat. DL algorithms often require fine-tuning parameters and substantial training data to achieve optimal performance. The restricted number of projects may limit the generalizability of our results and the ability to explore the parameter space fully.
4. Conclusions and Future Work
The CCSD paradigm is a popular method for producing creative and cost-efficient solutions in a timely manner, but it faces several obstacles, including a low rate of solution submissions. Consequently, numerous crowdsourcing projects go unresolved, causing developers, CCSD platforms, and companies that depend on crowdsourcing for their software projects to waste time and resources. In this paper, we proposed a fine-tuned BERT model for predicting whether the CSPs will receive a satisfactory outcome or not. The proposed model performs the input formatting of the dataset manually collected from TopCoder by leveraging the BERT-Tokenizer. The formatted data are then fed to fine-tuned BERT architecture for classification. The proposed technique achieved an accuracy of 93.75% for biased and 96.8% for balanced datasets. Moreover, we compared the proposed system’s performance with different classification models. As shown by the results, our method is efficient and robust. In the future, we would like to increase dataset size and also explore other DL architectures.
Author Contributions
Conceptualization, Q.U. and M.A.J.; methodology, Q.U. and T.R.; software, S.A. and H.H.; formal analysis, S.A. and R.B.; data curation, S.A and R.B.; visualization, Q.U. and S.A.; supervision, Q.U. and M.A.J.; writing—original draft, T.R. and S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available upon request from the authors. The data are not publicly available as it is part of an ongoing study.
Acknowledgments
We express our gratitude to Dani Mertens from the Department of Computer Science at Hanyang University, South Korea, for the proofreading of our paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Storey, M.A.; Zagalsky, A.; Figueira Filho, F.; Singer, L.; German, D.M. How social and communication channels shape and challenge a participatory culture in software development. IEEE Trans. Softw. Eng. 2016, 43, 185–204. [Google Scholar] [CrossRef]
- Mao, K.; Capra, L.; Harman, M.; Jia, Y. A survey of the use of crowdsourcing in software engineering. J. Syst. Softw. 2017, 126, 57–84. [Google Scholar] [CrossRef]
- Dwarakanath, A.; Chintala, U.; Shrikanth, N.; Virdi, G.; Kass, A.; Chandran, A.; Sengupta, S.; Paul, S. Crowd build: A methodology for enterprise software development using crowdsourcing. In Proceedings of the 2015 IEEE/ACM 2nd International Workshop on CrowdSourcing in Software Engineering, Florence, Italy, 19 May 2015; pp. 8–14. [Google Scholar]
- Illahi, I.; Liu, H.; Umer, Q.; Niu, N. Machine learning based success prediction for crowdsourcing software projects. J. Syst. Softw. 2021, 178, 110965. [Google Scholar] [CrossRef]
- Tunio, M.Z.; Luo, H.; Cong, W.; Fang, Z.; Gilal, A.R.; Abro, A.; Wenhua, S. Impact of personality on task selection in crowdsourcing software development: A sorting approach. IEEE Access 2017, 5, 18287–18294. [Google Scholar] [CrossRef]
- Fu, Y.; Sun, H.; Ye, L. Competition-aware task routing for contest based crowdsourced software development. In Proceedings of the 2017 6th International Workshop on Software Mining (SoftwareMining), Urbana, IL, USA, 3 November 2017; pp. 32–39. [Google Scholar]
- Brabham, D.C. Moving the crowd at Threadless: Motivations for participation in a crowdsourcing application. Inf. Commun. Soc. 2010, 13, 1122–1145. [Google Scholar] [CrossRef]
- Dwarakanath, A.; Shrikanth, N.; Abhinav, K.; Kass, A. Trustworthiness in enterprise crowdsourcing: A taxonomy & evidence from data. In Proceedings of the 38th International Conference on Software Engineering Companion, Austin, TX, USA, 14–22 May 2016; pp. 41–50. [Google Scholar]
- Boehm, B.W. Software Engineering Economics; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Beecham, S.; Baddoo, N.; Hall, T.; Robinson, H.; Sharp, H. Motivation in Software Engineering: A systematic literature review. Inf. Softw. Technol. 2008, 50, 860–878. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, N.; Peng, Z. Working for one penny: Understanding why people would like to participate in online tasks with low payment. Comput. Hum. Behav. 2011, 27, 1033–1041. [Google Scholar] [CrossRef]
- Kaufmann, N.; Schulze, T.; Veit, D. More Than Fun and Money. Worker Motivation in Crowdsourcing—A Study on Mechanical Turk; University of Mannhein: Mannhein, Germany, 2011. [Google Scholar]
- Martinez, M.G.; Walton, B. The wisdom of crowds: The potential of online communities as a tool for data analysis. Technovation 2014, 34, 203–214. [Google Scholar] [CrossRef]
- Dubey, A.; Abhinav, K.; Taneja, S.; Virdi, G.; Dwarakanath, A.; Kass, A.; Kuriakose, M.S. Dynamics of software development crowdsourcing. In Proceedings of the 2016 IEEE 11th International Conference on Global Software Engineering (ICGSE), Orange County, CA, USA, 2–5 August 2016; pp. 49–58. [Google Scholar]
- Fitzgerald, B.; Stol, K.J. The dos and dont’s of crowdsourcing software development. In Proceedings of the International Conference on Current Trends in Theory and Practice of Informatics, Snezkou, Czech Republic, 24–29 January 2015; pp. 58–64. [Google Scholar]
- Khanfor, A.; Yang, Y.; Vesonder, G.; Ruhe, G.; Messinger, D. Failure prediction in crowdsourced software development. In Proceedings of the 2017 24th Asia-Pacific Software Engineering Conference (APSEC), Nanjing, China, 4–8 December 2017; pp. 495–504. [Google Scholar]
- Afridi, H.G. Empirical investigation of correlation between rewards and crowdsource-based software developers. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C), Buenos Aires, Argentina, 20–28 May 2017; pp. 80–81. [Google Scholar]
- Illahi, I.; Liu, H.; Umer, Q.; Zaidi, S.A.H. An empirical study on competitive crowdsource software development: Motivating and inhibiting factors. IEEE Access 2019, 7, 62042–62057. [Google Scholar] [CrossRef]
- Yang, Y.; Karim, M.R.; Saremi, R.; Ruhe, G. Who should take this task? Dynamic decision support for crowd workers. In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, Ciudad Real, Spain, 8–9 September 2016; pp. 1–10. [Google Scholar]
- Stol, K.J.; Fitzgerald, B. Two’s company, three’s a crowd: A case study of crowdsourcing software development. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 187–198. [Google Scholar]
- Huang, Y.; Nazir, S.; Wu, J.; Hussain Khoso, F.; Ali, F.; Khan, H.U. An efficient decision support system for the selection of appropriate crowd in crowdsourcing. Complexity 2021, 2021, 5518878. [Google Scholar] [CrossRef]
- Yin, X.; Huang, J.; He, W.; Guo, W.; Yu, H.; Cui, L. Group task allocation approach for heterogeneous software crowdsourcing tasks. Peer Peer Netw. Appl. 2021, 14, 1736–1747. [Google Scholar] [CrossRef]
- Yuen, M.C.; King, I.; Leung, K.S. Temporal context-aware task recommendation in crowdsourcing systems. Knowl. Based Syst. 2021, 219, 106770. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Wang, S.; Hu, J.; Wang, Q. Context-and Fairness-Aware In-Process Crowdworker Recommendation. ACM Trans. Softw. Eng. Methodol. TOSEM 2022, 31, 1–31. [Google Scholar] [CrossRef]
- Messinger, D. Elements of Good Crowdsourcing. In Proceedings of the 3rd International Workshop, Austin, TX, USA, 16 May 2016. [Google Scholar]
- Saremi, R.; Yang, Y.; Vesonder, G.; Ruhe, G.; Zhang, H. Crowdsim: A hybrid simulation model for failure prediction in crowdsourced software development. arXiv 2021, arXiv:2103.09856. [Google Scholar]
- Saremi, R.; Yagnik, H.; Togelius, J.; Yang, Y.; Ruhe, G. An evolutionary algorithm for task scheduling in crowdsourced software development. arXiv 2021, arXiv:2107.02202. [Google Scholar]
- Hu, Z.; Wu, W.; Luo, J.; Wang, X.; Li, B. Quality assessment in competition-based software crowdsourcing. Front. Comput. Sci. 2020, 14, 1–14. [Google Scholar] [CrossRef]
- Jung, H.J. Quality assurance in crowdsourcing via matrix factorization based task routing. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; pp. 3–8. [Google Scholar]
- Amelio, A.; Bonifazi, G.; Corradini, E.; Di Saverio, S.; Marchetti, M.; Ursino, D.; Virgili, L. Defining a deep neural network ensemble for identifying fabric colors. Appl. Soft Comput. 2022, 130, 109687. [Google Scholar] [CrossRef]
- Anceschi, E.; Bonifazi, G.; De Donato, M.C.; Corradini, E.; Ursino, D.; Virgili, L. Savemenow. AI: A machine learning based wearable device for fall detection in a workplace. In Enabling Applications in Data Science; Springer: Berlin/Heidelberg, Germany, 2021; pp. 493–514. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mazzola, E.; Piazza, M.; Perrone, G. How do different network positions affect crowd members’ success in crowdsourcing challenges? J. Prod. Innov. Manag. 2023, 40, 276–296. [Google Scholar] [CrossRef]
- Yin, X.; Wang, H.; Wang, W.; Zhu, K. Task recommendation in crowdsourcing systems: A bibliometric analysis. Technol. Soc. 2020, 63, 101337. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Wang, S.; Chen, C.; Wang, D.; Wang, Q. Context-aware personalized crowdtesting task recommendation. IEEE Trans. Softw. Eng. 2021, 48, 3131–3144. [Google Scholar] [CrossRef]
- He, H.R.; Liu, Y.; Gao, J.; Jing, D. Investigating Business Sustainability of Crowdsourcing Platforms. IEEE Access 2022, 10, 74291–74303. [Google Scholar] [CrossRef]
- Borst, I. Understanding Crowdsourcing: Effects of Motivation and Rewards on Participation and Performance in Voluntary online Activities; Number EPS-2010-221-LIS; Erasmus University Rotterdam: Rotterdam, The Netherlands, 2010. [Google Scholar]
- Yang, Y.; Saremi, R. Award vs. worker behaviors in competitive crowdsourcing tasks. In Proceedings of the 2015 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Beijing, China, 22–23 October 2015; pp. 1–10. [Google Scholar]
- Kamar, E.; Horvitz, E. Incentives for truthful reporting in crowdsourcing. AAMAS 2012, 12, 1329–1330. [Google Scholar]
- Machado, L.; Melo, R.; Souza, C.; Prikladnicki, R. Collaborative Behavior and Winning Challenges in Competitive Software Crowdsourcing. Proc. ACM Hum. Comput. Interact. 2021, 5, 1–25. [Google Scholar] [CrossRef]
- Al Haqbani, O.; Alyahya, S. Supporting Coordination among Participants in Crowdsourcing Software Design. In Proceedings of the 2022 IEEE/ACIS 20th International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 22–25 May 2022; pp. 132–139. [Google Scholar]
- Alabdulaziz, M.S.; Hassan, H.F.; Soliman, M.W. The effect of the interaction between crowdsourced style and cognitive style on developing research and scientific thinking skills. EURASIA J. Math. Sci. Technol. Educ. 2022, 18, em2162. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Wu, Y.; Hamari, J. What determines the successfulness of a crowdsourcing campaign: A study on the relationships between indicators of trustworthiness, popularity, and success. J. Bus. Res. 2022, 139, 484–495. [Google Scholar] [CrossRef]
- Feng, Y.; Yi, Z.; Yang, C.; Chen, R.; Feng, Y. How do gamification mechanics drive solvers’ Knowledge contribution? A study of collaborative knowledge crowdsourcing. Technol. Forecast. Soc. Change 2022, 177, 121520. [Google Scholar] [CrossRef]
- Shi, X.; Evans, R.D.; Shan, W. What Motivates Solvers’ Participation in Crowdsourcing Platforms in China? A Motivational–Cognitive Model. IEEE Trans. Eng. Manag. 2022, 1–13. [Google Scholar] [CrossRef]
- Mejorado, D.M.; Saremi, R.; Yang, Y.; Ramirez-Marquez, J.E. Study on patterns and effect of task diversity in software crowdsourcing. In Proceedings of the 14th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Bari, Italy, 5–9 October 2020; pp. 1–10. [Google Scholar]
- Urbaczek, J.; Saremi, R.; Saremi, M.L.; Togelius, J. Scheduling tasks for software crowdsourcing platforms to reduce task failure. arXiv 2020, arXiv:2006.01048. [Google Scholar]
- Wu, W.; Tsai, W.T.; Li, W. An evaluation framework for software crowdsourcing. Front. Comput. Sci. 2013, 7, 694–709. [Google Scholar] [CrossRef]
- Sarzynska-Wawer, J.; Wawer, A.; Pawlak, A.; Szymanowska, J.; Stefaniak, I.; Jarkiewicz, M.; Okruszek, L. Detecting formal thought disorder by deep contextualized word representations. Psychiatry Res. 2021, 304, 114135. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Choi, Y.; Cardie, C.; Riloff, E.; Patwardhan, S. Identifying sources of opinions with conditional random fields and extraction patterns. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 10–12 October 2005; pp. 355–362. [Google Scholar]
- Jo, H.; Bang, Y. Factors influencing continuance intention of participants in crowdsourcing. Humanit. Soc. Sci. Commun. 2023, 10, 824. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).