1. Introduction
Cloud-based solution technologies have seen extraordinary development over the past few years. Cloud computing has become a popular model for providing support for a diverse set of web-based applications and businesses [
1,
2,
3]. For instance, the medical industry leverages cloud computing solutions to securely store and retrieve data. It does this to improve patient care through the use of virtual healthcare applications by monitoring and identifying critical diseases such as cancer and immunological disorders [
4,
5].
The inefficient allocation of resources in cloud-based infrastructure poses a significant impediment. Cloud resource management stands as a forefront domain of study today. Because it does not rely on previous information, the robust module is superior to the stationary module in terms of both its adaptability and its effectiveness. In cloud computing, load balancing is seen as a multidimensional challenge of resource allocation that requires optimal utilization of resources without compromising the quality of service offered to customers [
6,
7,
8,
9,
10]. This requires optimal utilization of resources to fulfill the demands of the problem at hand.
In the complex world of cloud computing, placing virtual machines (VMs) is a crucial task. It involves purposefully assigning virtual computers to physical servers on cloud platforms. The process of determining where virtual machines should be placed is made more difficult by the dynamic nature of workloads and shifting resources. Moreover, load balancing turns into a crucial component that carefully distributes network traffic and computational workloads among several servers to maximize resource efficiency and avoid overloading any one node. The variety of hardware configurations, the unpredictable nature of workloads, and the critical requirement for reliability are a few of the issues that come with these operations [
7]. It can be difficult to forecast and successfully manage resource requirements when dealing with dynamic workloads, which change in response to user demands and application requirements. Decisions about load distribution are made more difficult in heterogeneous cloud environments, which are frequently made up of various hardware and software configurations. Effective load balancing is essential for preserving resource equilibrium, preventing server under- or over utilization, and guaranteeing cost-effectiveness. Moreover, it is necessary for scalability because it enables horizontal scaling, which makes it simple to manage varying workloads. Achieving this equilibrium is essential for maximizing the use of resources, scalability, and fault tolerance, which in turn leads to improved user experience and energy efficiency. By addressing these issues in-depth, the suggested improvements to the simulation model for protected virtual machine deployment aim to establish a standard for attaining peak performance and economy in cloud-based applications.
Load-balancing algorithms typically optimize the selection of prospective target hosts throughout algorithm periods. Load balancing follows host selection. The immediate effect can maximize resource consumption, but it does not ensure task execution performance [
7]. Heuristics methods, such as artificial bee colony (ABC) and ant colony optimization (ACO) [
11] readily acknowledge this reality. The reduction of energy expenditure in VM migration requires promising technologies. Although such methods may yield rapid outcomes in terms of resource utilization, they fail to ensure the utmost efficiency in work completion pace. Algorithm-based approaches acknowledge and compensate for this problem to a great extent by employing well-established techniques like ABC and ACO. Despite this, the situation calls for certain solutions that are both practical and environmentally friendly to guarantee effective energy management during the placement of VM [
12,
13,
14,
15,
16].
To optimize cloud computing load balancing, our proposed study presents the twin fold moth flame algorithm, which takes several constraints into account, and compares the suggested model to other algorithms. The twin fold moth flame (TFM) algorithm as a novel optimization technique for handling the complexity of virtual machine (VM) placement and load balancing in the ever-evolving cloud computing environment, where effective load balancing remains crucial. The TFM algorithm provides a fresh method of optimization and is modeled after the inventive characteristics of flames and moths. TFM uses a two-pronged strategy that combines the accuracy of confluence similar to flame management with the adventurous options reminiscent of moth flight patterns, all based on the notions of biological imitation. Because of this special conjunction, TFM is able to negotiate the complex field of virtual machine placement, taking stability, placement cost, and computation time into account. TFM intends to transform cloud computing effectiveness by adding aspects to load-balancing analysis. This work provides an in-depth evaluation that compares the suggested TFM algorithm with state-of-the-art benchmark methods, assessing its edge in terms of stability, placement cost, and computation time. Our work has made substantial improvements to the field, including the development of an effective load-balancing infrastructure, the TFM algorithm, and the thorough evaluation used to validate its benefits.
The contributions of our work can be summarized in the following:
Algorithm development: The principal contribution of this research is the development of the twin fold moth flame (TFM) algorithm, a novel optimization technique designed to address the challenges related to load balancing and virtual machine (VM) placement in cloud computing environments. This algorithm incorporates special features that are influenced by both flames and moths. It uses a two-pronged approach that combines flame control precision with dynamic exploration similar to moth flight patterns. This creative method is a significant development in cloud computing load-balancing techniques.
A systematic method for load balancing: The TFM algorithm presents a comprehensive method of load balancing by taking into account several factors, such as computation time, placement cost, and stability. In contrast to traditional approaches, TFM integrates these crucial aspects to navigate the complex VM placement terrain, guaranteeing a more complete and efficient load-balancing solution for cloud computing settings.
Biological ingenious optimization: By using biological imitation principles—more specifically, mimicking the traits of flames and moths—this research advances the area by developing an algorithm that successfully negotiates the challenges associated with virtual machine deployment. This novel methodology offers a new viewpoint on optimization techniques by taking inspiration from nature to meet cloud computing difficulties.
Extensive comparative analysis: This research offers a comprehensive analysis that pits the suggested TFM algorithm against the most advanced benchmark techniques. This evaluation takes into account important parameters including calculation time, placement cost, and stability, providing a thorough examination that validates the algorithm’s efficacy and highlights its advantage over current approaches. The thorough analysis performed in this study highlights the useful advantages of the TFM algorithm in optimizing cloud computing settings and advances our knowledge of load-balancing techniques.
This paper presents an advanced simulation approach to address the ongoing problem of optimizing the deployment of virtual machines (VMs) in the ever-changing cloud computing ecosystem. The enhanced methodology described in this paper attempts to address the complicated issues related to virtual machine deployment, redefining standards for efficiency and dependability in cloud-based environments. This study advances the area by proposing a novel simulation methodology that improves and protects virtual machine (VM) deployment in cloud-based systems. This study aims to set new benchmarks for reliability and efficiency in the rapidly evolving field of cloud computing.
The paper is organized as follows in the following sections. The details of cloud computing are covered in detail in
Section 2, with particular attention to load balancing, energy efficiency, and virtual machine (VM) placement. Subsequently,
Section 3 offers a thorough exposition of the design ideas and aims that dictate the suggested virtual machine placement technique, with a focus on load balancing, system dependability, and minimal latency. The paper presents a multifaceted issue formulation in
Section 4 that includes parameters like placement cost, stability, and calculation time for evaluating virtual machines. The twin fold moth flame algorithm and its multifunctional optimization capabilities designed for effective load balancing are the main topics of
Section 5’s in-depth investigation of the suggested model. The focus of
Section 6 is on the investigation of the twin fold moth flame’s three stages. Following this, a comparative analysis is presented to assess the suggested model in relation to current methodologies. In contrast,
Section 7 presents the findings and recommendations for further investigation.
3. A Compact Architectural Description of the Proposed VM Placement Approach
The presented virtual machine placement technique presents a small-scale, yet all-inclusive architectural framework intended to maximize virtual machine (VM) distribution in cloud computing settings. The architecture’s primary goal is to improve availability and performance by giving priority to effective load balancing. The system is carefully engineered to handle the resource consumption issue by dynamically reassigning overworked virtual machines (VMs) to underutilized counterparts, which creates equilibrium in the distribution of the total load. The architectural model leverages knowledge from almost 10 years of intensive research in the field to stress the smooth coordination of virtual machine placement in distributed systems. Sophisticated algorithms and mechanisms are contained in this small design, which also includes real-time monitoring and analysis to help with decision-making on virtual machine transfer. The confidentiality and integrity of the VM placement procedure are guaranteed by the smooth integration of security measures. The suggested architecture is a comprehensive and forward-thinking solution that embodies the changing requirements of cloud computing environments and positions itself as a strong way to deal with the difficulties associated with virtual machine deployment in a constantly changing and developing technological environment.
3.1. Proposed Framework: Task Constraints and Cloud Infrastructure Prototype
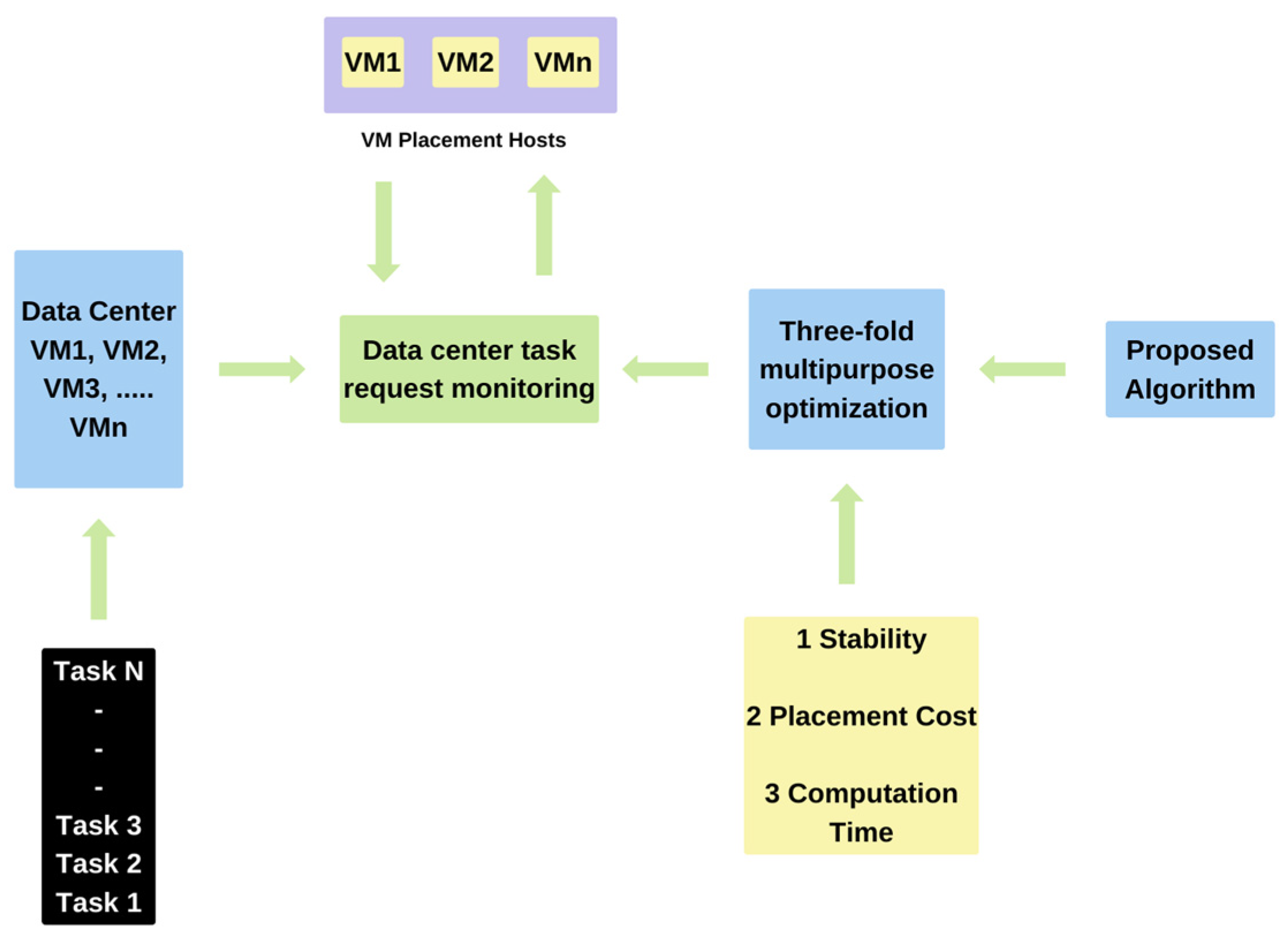
The proposed workflow for securing VM voyages on effective load balancing is explained in
Figure 1.
Table 1 summarizes research on cloud computing VM migration. The table lists the pros and cons of each technique or algorithm. These details highlight the vast range of cloud VM migration improvements offered. VM migration solutions address effectiveness, dependability, cost savings, resource use, and performance. By summarizing each technique and highlighting its pros and downsides, the specifics aim to illuminate VM migration’s considerations and trade-offs. Cloud computing researchers and professionals can utilize this knowledge to understand present tactics, investigate their applications, and develop new VM migration methods.
3.2. Resource Pooling
Each server in a cloud platform resource pool is denoted by Si, where i = 1, 2,…, n. Under the initial state k, Si = VMi1,…, VMik, and the server acknowledges and transmits virtual machines at each endpoint. The i-th virtual machine is VMi. Servers (Si) are equipped with disk storage, computing resources, and networking. Dynamic host selection for VM allocation in cloud environments is difficult. Every kind of management has a specific QoS requirement, expressed as Ti,i = 1, 2, 3, …, n in the server’s request for services. It should be noted that administration requests may have varying arrival, ripening tenure, and other conditions. The cloud platform user assigns Ti,i = 1, 2, 3,…, n to VMs. Task scheduling is determined by VM function execution and VM resource availability. Every task in the interval Ti,i = 1, 2, 3,…, n has three attributes: Ti = {CTU, Stab, CoP}. The three critical parameters for effective load balancing throughout VM placement in this context are computation time utilization (CTU), stability (Stab), and placement cost (CoP). This optimization is addressed using a proposed technique.
5. Virtual Machine Placement Optimization using Solution Embeddings
5.1. Solution Embeddings
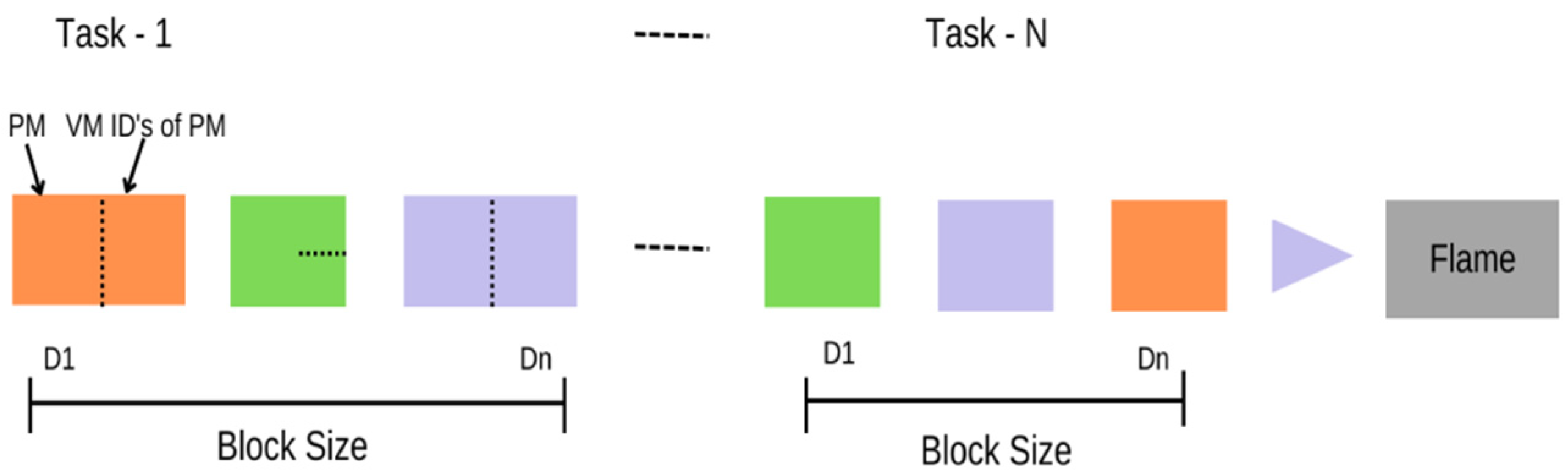
The process of solution embedding is depicted in
Figure 2. The allocation of blocks for comprehensive tasks, denoted as “
Bin;
i = 1, …,
N”, is twice the multiple of the chromosomal length. Each unit comprises two components: the physical machine responsible for task completion and the virtual machine identification assigned by the PM to receive the task (
VMid). The size of the block may vary for each individual job.
As an illustration, let us consider a scenario in which the count of blocks amounts to 44, resulting in a chromosome length of 88. Consequently, the initial 44 chromosomes are occupied by the physical machine, whereas the remaining ones are allocated for the virtual machine.
5.2. The Proposed Model
The moth is lavish and resembles a group of butterflies [
17]. Because the moon is distant, transversal orientation usually aligns the moth and moves linearly. The methods employed in the proposed TFM are shown below:
Stage 1: The general population of the moth Mothm and the Flamew are led off. Here, Mothm is the mth moth of wth flames. The general census of flames is Countflames, and q signifies the conventional iteration census. Moreover, random values ran1 and ran2 are also initialized.
Fitness function determines the function for all moths, according to Equation (1).
Stage 2: When q <= Countflames
- (a)
If ran1 < 0.5
The conventional moth flame optimization technique is used to modify both the moth’s position and flame. The following section elaborates on the actions undertaken:
Equation (4) presents a mathematical formulation of the procedure for transverse alignment for the positioning revamp of the moth with regard to flame. Whereas Equation (5) symbolizes the mathematical representation of the logarithmic spiraling locks of the searching agent.
For the
wth with the renown of the
mth moth,
Rm refers to the shape of the logarithmic spirals, which is quantitatively presented in Equation (6). Furthermore, the number of flames over the length of
t iterations can be calculated using Equation (7).
Thus, Fn and In stand for the total number of flames and repetitions, correspondingly.
- (b)
If ran > 0.5
Using the flame distance and moth Equations (8) and (9), calculate the distance.
Stage 3: Moreover, the moment q > Countflames
- (a)
If ran < 0.5
The conventional MFO method, which is theoretically presented in Equations (7)–(10), updates the position of the moth and the flame.
- (b)
In case ran 2 > 0.5
The proposed approach changes the location of the iteration of the algorithm (moth and flame).
Use Equations (10) and (11) to calculate the separation between the flame
dis and the
moth, correspondingly.
Algorithm 2 displays the pseudocode of the suggested model.
| Algorithm 2: Pseudocode of Generalized Architecture |
| The initialization population pop of the Flamew and the Mothm is calculated. |
| Initialize Countflames, q, ran 1, ran 2. |
| Evaluate fitness input according to Equation (1). |
| for (qmax > q) |
| If the termination requirement is not satisfied: |
| if 1 (q <= Countflames) |
| if 2 (ran 1 < 0.5) |
| Equation (4) implements transverse alignment for flame placement updating with respect to moth. |
| Equation (5) is used to modify the search agent’s logarithmic spiraling location. |
| Equation (7) can be used to compute the number of flames. |
| else 2 |
| Using Equations (8) and (9) to determine the distance between the flame and the moth: |
| end if 2 |
| else if 1 (q > Countflames) |
| if 3 (ran 2 < 0.5) |
| Equation (4) implements the transverse alignment method to update the moth’s flame position. |
| Equation (5) is used to modify the search agent’s logarithmic spiraling location. |
| Equation (7) can be used to compute the number of flames. |
| else 3 |
| Using Equations (10) and (11) to determine the distance between the flame and the moth: |
| end if 3 |
| end if 1 |
| end |
| Terminate |
5.3. Design of Databases
The physical machine’s data for the virtual machine placement load-balancing database comes from
https://www.kaggle.com/datasets/discdiver/clouds/code (accessed on 6 November 2022). The database creates virtual machine data. The variables in
Table 2 are in the PM’s database. VM databases are built using actual machine datasets. The PM’s attributes are also included. The following is a discussion of the database design process for all constraints and limitations:
Let Ti;i (1, 2, 3 ,.., n) represent the PM tasks to be completed. The block sizes for tasks 1–4 are 5, 10, and 12, respectively. The task is given to the PM, which breaks it down and schedules each work in a different virtual machine. Each of the 13 PMs in use here is believed to have 10 virtual machines. There are 130 virtual machines in total to complete the duties.
5.4. Time and Space Complexities of the Proposed Model
Time complexity: The algorithm’s time complexity is determined by the quantity (q) of iterations, as well as the size of the moth and flame populations. The moths and flames are subject to calculations and modifications at each level. The complexity of the equations used to calculate distances and update positions will determine the precise time complexity. The twin fold moth flame algorithm’s overall time complexity can be roughly calculated as O(q), where q is the total number of iterations and assumes that each stage’s calculations can be thought of as constant time operations.
Space complexity: The memory needed to hold the population of moths and flames, as well as any other variables used for computations and updates, determines how much space the program takes up. The size of the issue, including the quantity of moths and flames, will also affect the challenge of space. The space complexity can be approximated as O(N), where N is the total number of moths and flames in the population, and it is assumed that the storage needs for each moth and flame are constant.
6. Observations
6.1. Simulation Methodology
A virtualized placement strategy that was adapted for effective load handling was subjected to extensive testing and MATLAB analysis. An extensive evaluation procedure was applied to the suggested model, including important parameters such as placement cost, stability analysis, and CTU use. The effectiveness of the methodology was evaluated using careful comparisons with prior research findings, offering a strong foundation for evaluating its performance in the field of virtualized placement. MATLAB analysis and testing not only confirmed the validity of the suggested technique but also provided important insights into how well it might optimize load handling, bolstering its potential as a cutting-edge solution in the dynamic field of virtualized settings.
Modifications to virtual machines (VMs) and blocks are part of the assessment. Block characteristics are defined as follows: [20, 25, 30, 35, 40] is the fluctuation range that represents the variability in block characteristics. Meanwhile, for physical machines (PMs), the range of virtual machines (VMs) is [10–50], indicating the variation in virtual machine characteristics linked to each PM. Assignments 1–4 include the replacement of blocks from the available block assortment, implying a dynamic reorganization of components inside the system. This evaluation covers a wide range of adjustments, highlighting the flexibility and diversity inherent in the blocks and virtual machines (VMs), establishing the groundwork for an environment that is both responsive and flexible.
According to the examined database:
Type 1 are [4 4 6 7] 20 total blocks = [T4 T1 T3 T2]
Type 2 includes [5 6 6 8] 25 total blocks = [T4 T3 T1 T2]
Type 3 includes [6 7 7 10] 30 total blocks = [T1 T3 T4 T2]
Type 4 includes [7 8 9 11] 35 total blocks = [T1 T3 T4 T2]
Type 5 includes [5 10 10 15] 40 total blocks = [T1 T2 T3 T4]
6.2. Assessment of CTU Usage
Central processing unit (CPU) utilization, sometimes known as CTU utilization, is the term used to describe the total amount of processing time needed to run a program in cloud computing. Applications that run in the cloud usually require virtual machines (VMs) located in server zones. Once assigned, these virtual machines (VMs) can accomplish a wide range of tasks that correspond with the host’s processing needs. Minimizing CTU utilization is necessary for efficient resource use in cloud environments because it ensures that computing resources are used to their fullest potential. Therefore, reducing CTU consumption is essential to improving overall resource efficiency and making the cloud infrastructure capable of supporting a wide variety of workloads and operations.
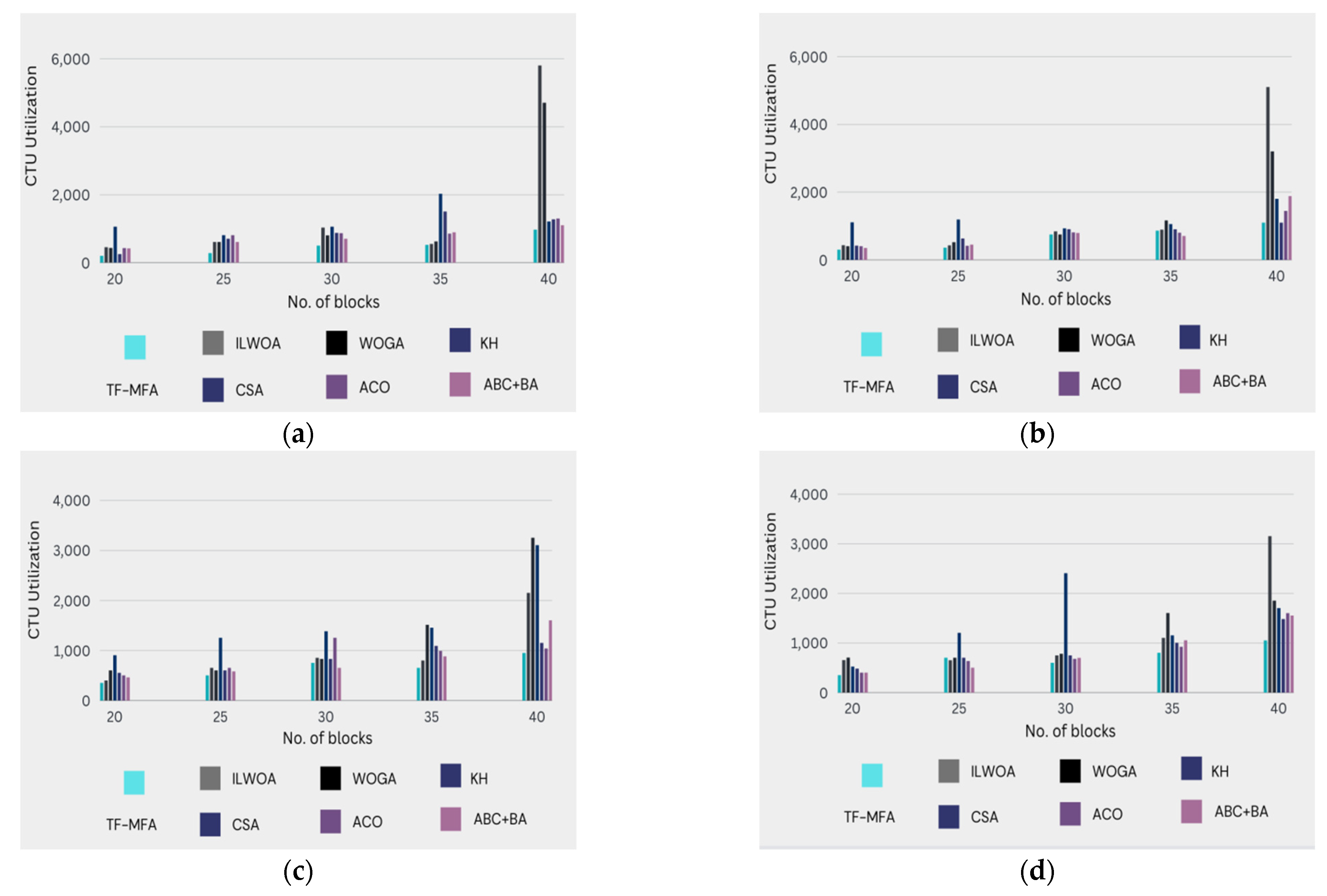
In
Figure 3, a graphical representation of the CTU usage between the proposed work and the previous studies is exhibited. As shown in
Table 3, for 10 VMs: TF-MFA perpetrates a CTU utilization of 886.2, which is much lower than ILWOA (5692.2), WOGA (4712.1), KH (1280.8), CSA (1253.9), ACO (1323.2), and ABC + BA (935.61). This suggests that TF-MFA surpasses the other algorithms in the context of resource utilization for this VM count. For 20 VMs: TF-MFA demonstrates a CTU utilization of 1228.8, which is on descending analogized to ILWOA (5071.9), WOGA (3290.9), KH (1790), CSA (1202.9), ACO (1535.9), and ABC + BA (1679.2). TF-MFA exemplifies better resource utilization efficiency for this VM count, as well. For 30 VMs: TF-MFA attains the lowest CTU utilization value of 963.14 compared with ILWOA (2212.3), WOGA (3215.1), KH (2665.1), CSA (1253.9), ACO (1094.3), and ABC + BA (1597.1). This reveals that TF-MFA provides the most efficient utilization of computational resources for 30 VMs. For 40 VMs and 50 VMs: TF-MFA invariably harbors lower CTU utilization values compared with ILWOA, WOGA, KH, CSA, ACO, and ABC + BA, although the differences vary for each algorithm.
The comprehensive analysis clearly shows that the twin fold moth flame algorithm (TF-MFA) model performs better than other algorithms in terms of central processing unit (CTU) use, exhibiting greater efficiency at different counts of virtual machines. This validation highlights how well the TF-MFA model works to optimize resource allocation and improve overall cloud computing environment virtual machine placement efficiency. The findings support the model’s ability to achieve more efficient use of computing resources and highlight its promise as a cutting-edge and practical approach to handling the difficulties associated with placing virtual machines in a variety of dynamic computing settings.
6.3. Assessment of Stability
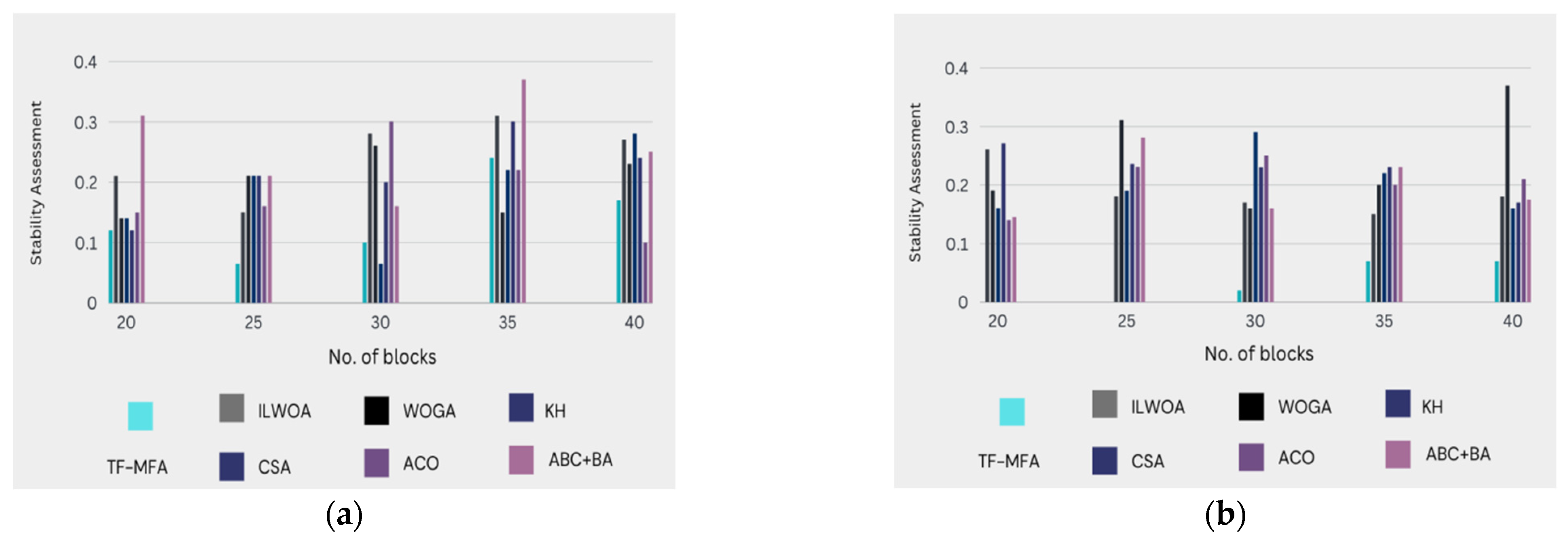
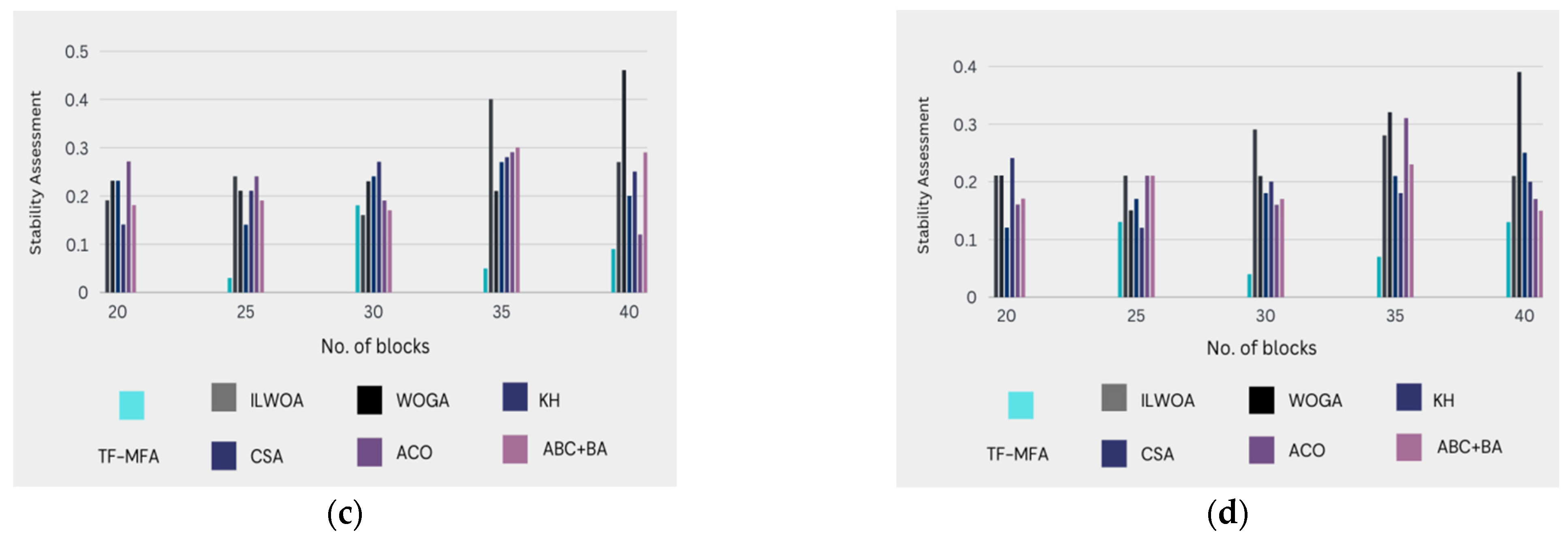
The assessment presented in
Figure 4, which is measured in
Table 4, and the corresponding stability factor values provide a thorough comparison of the advanced technique (TF-MFA) with alternative models, particularly concerning stability influence. This analysis is broken down into a detailed analysis of important stability metrics that show how the TF-MFA model stacks up against other methods. In the context of the proposed evaluation, this thorough assessment is essential for evaluating the TF-MFA model’s stability performance and establishing its effectiveness relative to other models already in use. As such, it provides insightful information in the field of stability optimization.
- ⬩
Graphical analysis: In
Figure 4, it can be observed that the proposed technique (TF-MFA) guarantees immaculate stability in load balancing while posing fewer risks compared to classic models. The graphical representation emphasizes the downsized risk and enhanced stability provided by TF-MFA.
- ⬩
Probability comparison: The suggested methodology illustrates a significantly lower probability of high-risk circumstances compared to prior models. Particularly at 35 counts of clusters in the 30th virtual machine, TF-MFA is 82.32%, 81.71%, 81.45%, 81.13%, 75.18%, and 86.79% superior in terms of reduced probability when analogized to ILWOA, WOGA, KH, CSA, ACO, and ABC + BA, respectively.
- ⬩
Stability factor: The stability factor quantifies the stability achieved by each model. The presented method perpetrates a stability factor of 0.2045 when a physical machine (PM) is assigned 30 virtual machines (VM) for a given role. In comparison, the stability factor values for ILWOA, WOGA, KH, CSA, ACO, and ABC + BA are 0.15561, 0.60420, 0.16100, 0.068853, 0.10240, and 0.16550, respectively, TF-MFA portrays a higher stability factor, signifying improved stability performance.
The overall results of the comparative analysis highlight how much more stable and successful the suggested method, the twin fold moth flame algorithm (TF-MFA), is than other models. Specifically, the TF-MFA model delivers a higher stability factor, reduces the probability of high-risk scenarios, and guarantees outstanding load balancing stability. All these facts lend credence to the claim that the TF-MFA model is a better way to guarantee consistent and fair resource distribution in cloud computing settings. The findings further our knowledge of stability optimization techniques and establish the TF-MFA model as a reliable and practical method for handling the challenges associated with resource allocation in dynamic cloud computing settings.
6.4. Assessment on Placement Cost
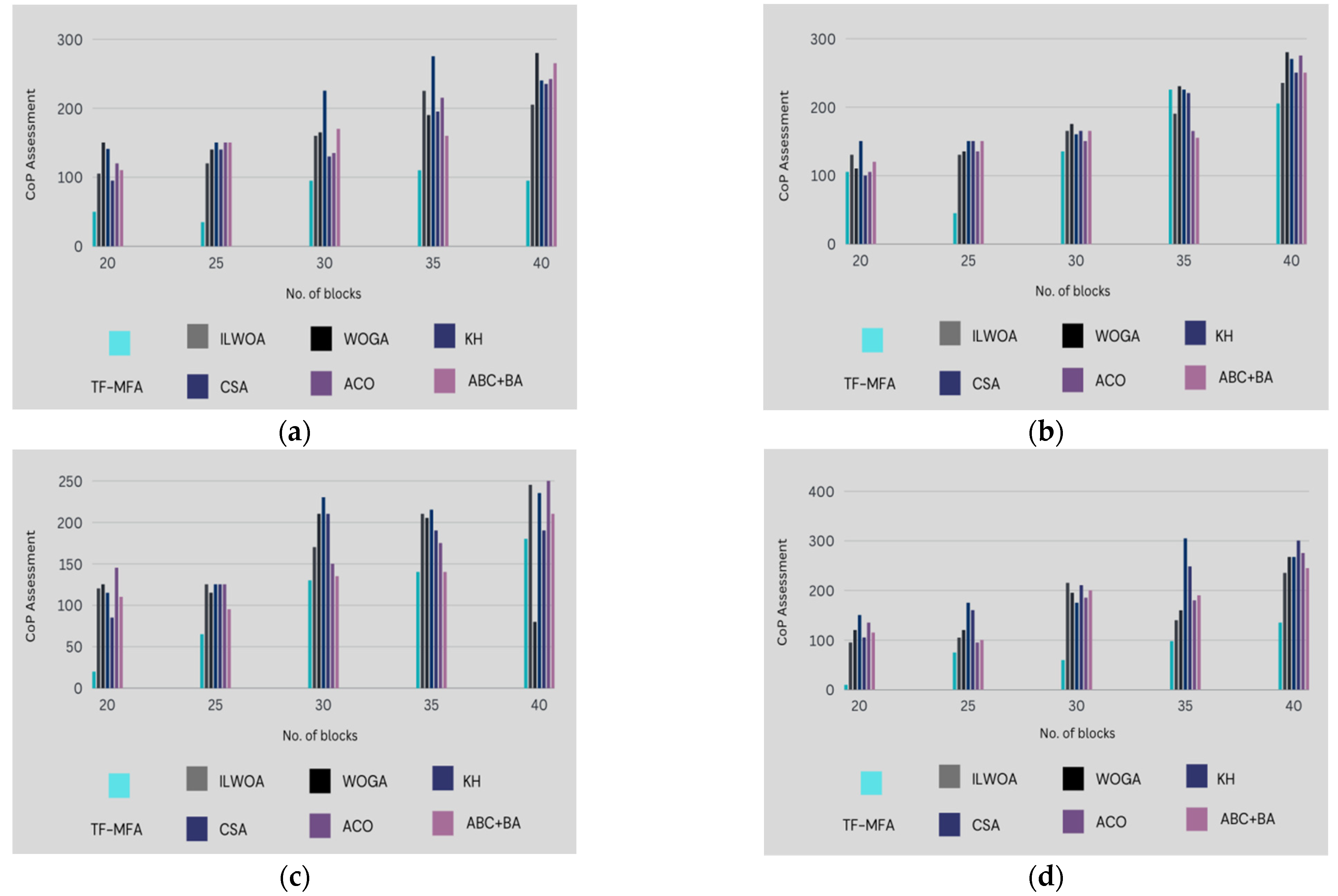
The information shown in
Figure 5 and
Table 5 clarifies the assessment of the twin fold moth flame algorithm (TF-MFA), which is the methodology provided, in addition to other models, regarding placement cost. This breakdown includes a thorough examination of important placement cost parameters, providing information on how the TF-MFA model performs in comparison to other strategies. The thorough evaluation helps determine how cost-effective the TF-MFA model is when compared to other models that are already in use, and it offers insightful information about the financial aspects of virtual machine deployment strategies in cloud computing settings.
- ⬩
Graphical analysis:
Figure 5 displays the placement cost of the presented methodology in comparison to other techniques. It illustrates that the presented work consistently earns the lowest placement cost across different variations in VM and block size, thereby fulfilling the theme of minimizing placement cost.
- ⬩
Percentage comparison: In the case of 40 censuses of blocks and VM = 10, the presented work outperforms prior methods by 64.81%, 61.22%, 59.57%, 60.42%, 65.45%, and 52.5%. This signifies a noteworthy reduction in placement cost compared to alternative procedures.
- ⬩
Total placement overhead:
Table 5 displays a synopsis of the placement overhead for different VM allocations. The presented work reveals a minimal total placement cost, attaining a placement cost of 88.80 when assigning 10 VMs to 1 PM. In comparison, classic approaches show higher placement costs.
- ⬩
Specific comparisons: The presented method also outperforms constant references like ABC + BA, ACO, CSA, KH, WOGA, and ILWOA when allocating 40 VMs to 1 PM. The presented work achieves reductions in placement cost of 33.62%, 44.49%, 47.92%, 47.54%, 37.17%, and 45.53% compared with these reference models, respectively.
Overall, the comparison analysis’s results show that the twin fold moth flame algorithm, or TF-MFA, consistently has the lowest placement cost among the approaches and dramatically lowers installation expenses. This result highlights how economical the TF-MFA technique is for maximizing resource placement and allocation expenses in the context of cloud computing. The results of this study enhance our comprehension of the financial viability of virtual machine placement techniques and establish TF-MFA as a notable and efficient method for attaining optimal resource allocation in dynamic cloud settings while minimizing installation costs.
6.5. Probabilistic Assessment: Proposed Model vs. Traditionally Used Models
Each algorithm undergoes execution 10 times to obtain the figures of the overall integrity that need to be decreased to guarantee an equitable comparison. The quantitative consequence for different counts of VMs allocated to one PM for performing the task scheduling function is displayed in
Table 6. On observing the mean value for 10 counts of VMs, the presented work has the best lowest value of 1786.4, whereas the existing models have higher mean values of ABC + BA = 1996.3, ACO = 2042.5, CSA = 1985.3, KH = 2754.1, WOGA = 2110.5, and ILWOA = 2110.7. When 20 counts of VM are allocated to 1 PM, the best value of the presented model is 3.23%, 8.72%, 10.09%, 27.82%, 6.62%, and 9.61% better than existing ABC + BA, ACO, CSA, KH, WOGA, and ILWOA methods. Furthermore, in the median case scenario, the proposed TF-MFA model is 0.84%, 1.82%, 8.49%, 26.97%, 9.61%, and 7.42% better than existing ABC + BA, ACO, CSA, KH, WOGA, and ILWOA methods for 40 counts of VM. Thus, it is evident from the table that the presented work is much more sufficient for load balancing during VM migration. Additionally, for 40 counts of VM, the offered TF-MFA approach outperforms the current ABC + BA, ACO, CSA, KH, WOGA, and ILWOA approaches by 0.84%, 1.82%, 8.49%, 26.97%, 9.61%, and 7.42% in the median case circumstance. Overall,
Table 6 makes it clear that the amount of work that has been given is far more adequate for managing load throughout virtual machine relocation.
7. Conclusions and Future Directions
The development of a virtual machine placement strategy designed for utilization over wide area network (WAN) links involves the crucial aspect of offline VM selection. The primary objective of offline VM selection is to carefully choose one or more potential virtual machines for placement, ultimately mitigating resource demands on the hosts under consideration. This task is achieved through the implementation of the twin fold moth flame algorithm (TF-MFA) model, which is built upon three key goals: optimizing computing time unit (CTU) utilization, ensuring system stability, and minimizing placement costs. By addressing these goals, the TF-MFA model offers an effective and comprehensive solution for the strategic placement of virtual machines, particularly tailored for scenarios involving WAN links in cloud computing environments. The presented model’s effectiveness was examined by calculating placement costs, computation times, and stability assessment. The most significant result of the presented work was 3.23%, 8.72%, 10.09%, 27.82%, 6.62%, and 9.61% for 20 count data of nodes for the artificial bee colony–bat algorithm, ant colony optimization, crow search algorithm, krill herd, whale optimization genetic algorithm, and improved Lévy-based whale optimization algorithm, as ambiguously portrayed in
Figure 3,
Figure 4 and
Figure 5.
The swift progress of computer science and technology is significantly influencing many aspects of our everyday lives and work settings. Looking ahead, we believe that combining state-of-the-art applied sciences—most notably, artificial intelligence and big data [
30]—will be essential. This evolution is consistent with the ongoing creation of strong and affordable security controls, especially for large-scale networks and software-defined networks (SDN) in particular [
31]. Furthermore, we anticipate creating end-to-end internet of medical things (IoMT) infrastructures using a mixed integer linear programming (MILP) mathematical paradigm [
32]. These expected advancements represent the changing field of computer science and hold the potential to fundamentally alter how we engage with technology and tackle challenging problems across a range of industries, including healthcare and network security.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}