

An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts



Abstract
:1. Introduction
2. Related Work
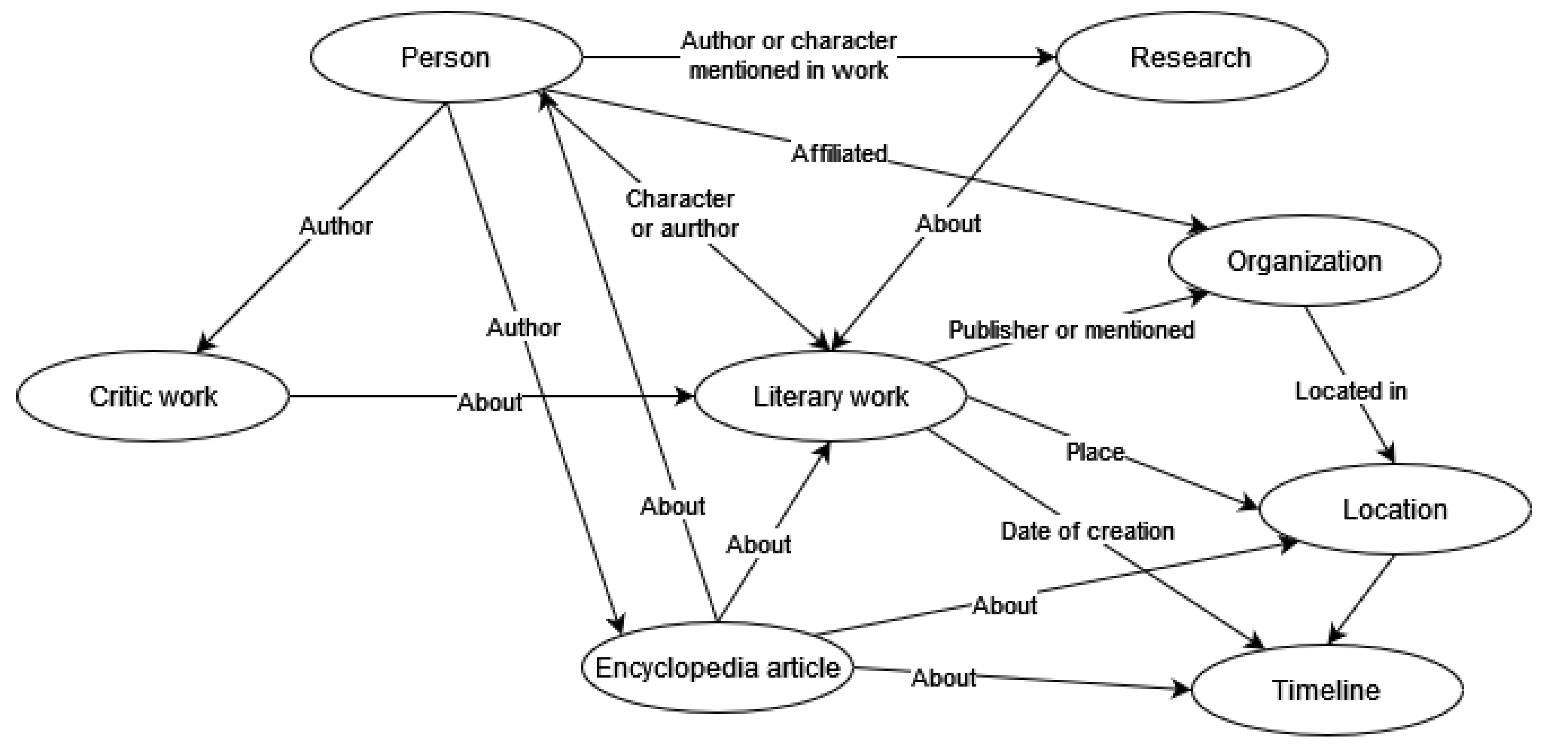
3. Dataset Description
4. Dataset Annotation and Filtering
4.1. Annotating Tool
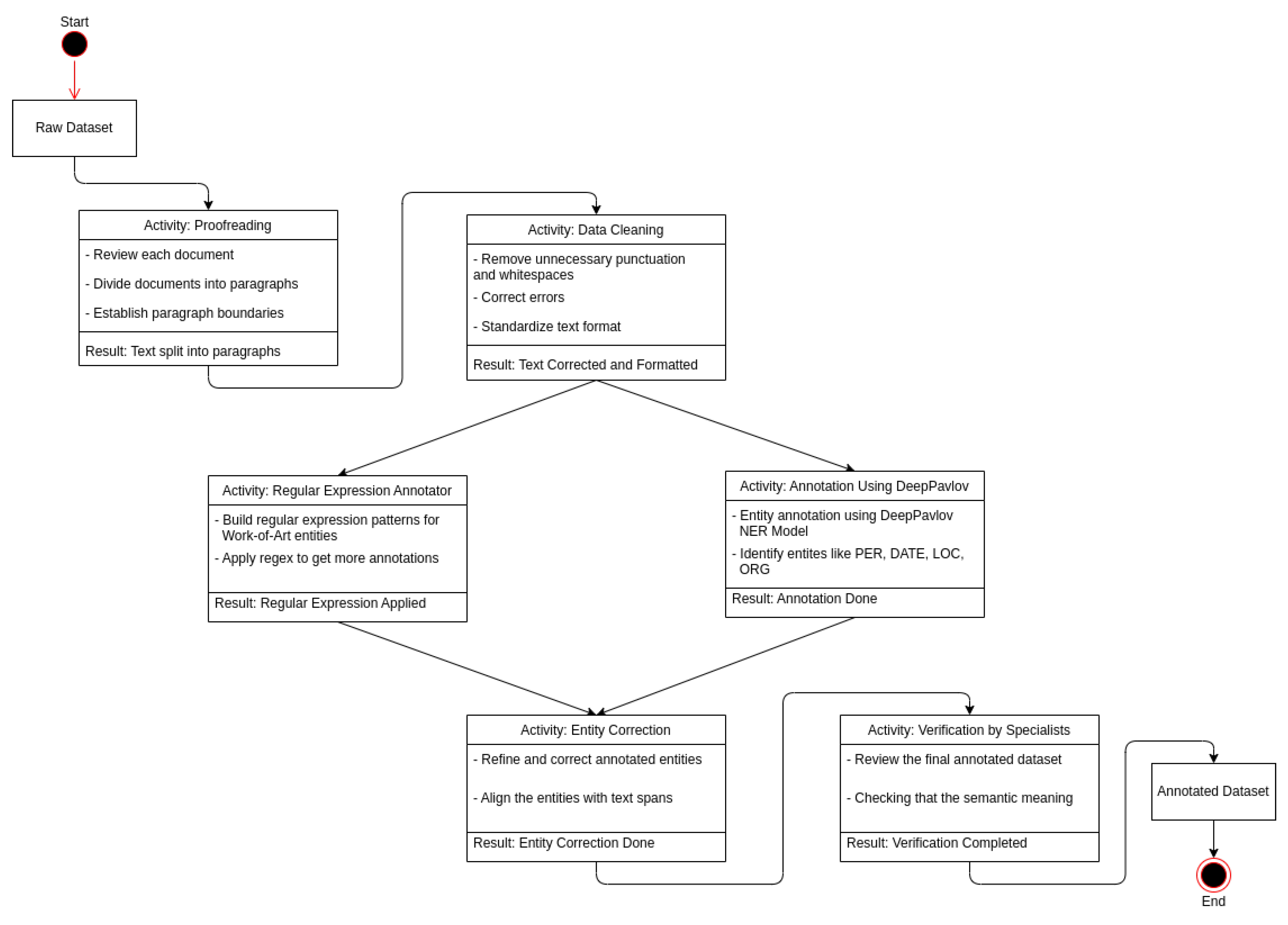
4.2. Annotation Process
- 1.
- Proofreading and Document Structuring: The first step in preparing the dataset is having domain experts examine the raw dataset. Every single text within the dataset undergoes a thorough proofreading and review process to improve its quality and readable content. Text files are also separated into organized paragraphs to make processing steps easier.
- 2.
- Data Cleaning and Formatting: To make sure that the textual data can be analyzed by NER models, a data cleaning and filtering phase was carried out. This involves removing unnecessary punctuation, white spaces, and misspelled characters. The target of this stage is to deliver clear, clean, and organized texts that will enhance performance when training the NER system.
- 3.
- Annotation Using Pre-trained NER Model: Regarding the NER annotation procedure, an advanced Russian pre-trained NER model, such as DeepPavlov [24], is utilized. Named entities in the text can be recognized and annotated using this model. In particular, the annotated entity types are as follows:
- PER (Person): Recognizing people who are referenced in the book, such as historical figures, writers, critics, and commentators.
- DATE (Date): Identifying all the entities that give the text a chronological framework, such as periods and dates.
- LOC (Location): Identifying the regions and locales that are mentioned in the text, such as cities and countries.
- ORG (Organization): Identifying associations and communities mentioned in the text, such as companies and institutions.
- WORK-OF-ART (Work of Art): Recognizing literary works and manuscripts within the text, such as books’ titles and poems’ titles.
- 4.
- Entity Correction and Alignment: After using DeepPavlov to annotate the text, reviewing and editing the annotated entities is a crucial step that should be performed. To make sure they are precisely aligned with the matching text spans, we closely inspected the annotated entities. The entity boundaries are checked for accuracy and contextual relevance, and adjustments are made as necessary.
- 5.
- Regular Expression Annotator for “WORK-OF-ART” Entities: To compensate for the potential poor performance of the DeepPavlov pre-trained NER model, a unique regular expression annotator is constructed for the “WORK-OF-ART” entity. This guarantees the proper recognition and annotation of Pushkin’s literary works inside the text, which might vary greatly and rely on context.
- 6.
- Verification by Domain Specialists: Domain experts carry out a thorough verification procedure on the final annotated dataset. These specialists examine the annotated entities concerning the documents’ context to make sure that the annotations appropriately capture the semantic meaning of the entities and are consistent with the underlying material. This step involves identifying and fixing any inconsistencies or errors.
5. Model Training
- Data Preparation: One of the most important things we had to do during our project was to convert our annotations into different formats to make them compatible with the models and tools that we were using. Initially, we used DeepPavlov to annotate our dataset. Processing from that, we had to convert the annotations to “.ann” format so they could be used in the Brat annotation tools, which allowed the annotation team to collaborate on fixing and adjusting the annotated entities. After that, the annotations were then converted from “.ann” to “.json” format. This transformation was needed to make sure the annotated dataset was perfectly compatible with the SpaCy models for fine-tuning. This procedure made sure that our annotated dataset was correct and complete, as well as prepared for the subsequent stages of model building and training.
- Fine-tuning with Pre-trained Transformer Model: We utilized the powerful structure of SpaCy to train our custom NER model. SpaCy is a great option for our goal as it offers an extensive collection of tools for training NER models. We optimized a BERT-based multilingual transformer model that had already been trained using pre-learned contextual embeddings inside the SpaCy framework. This improved the model’s performance when applied to text in Russian. To handle the linguistic difficulties of the Russian language, it is useful to use a BERT base transformer model that has already been trained. The pre-trained model serves as an excellent starting point, capturing a wide range of linguistic patterns and context, which can be fine-tuned to our specific dataset.
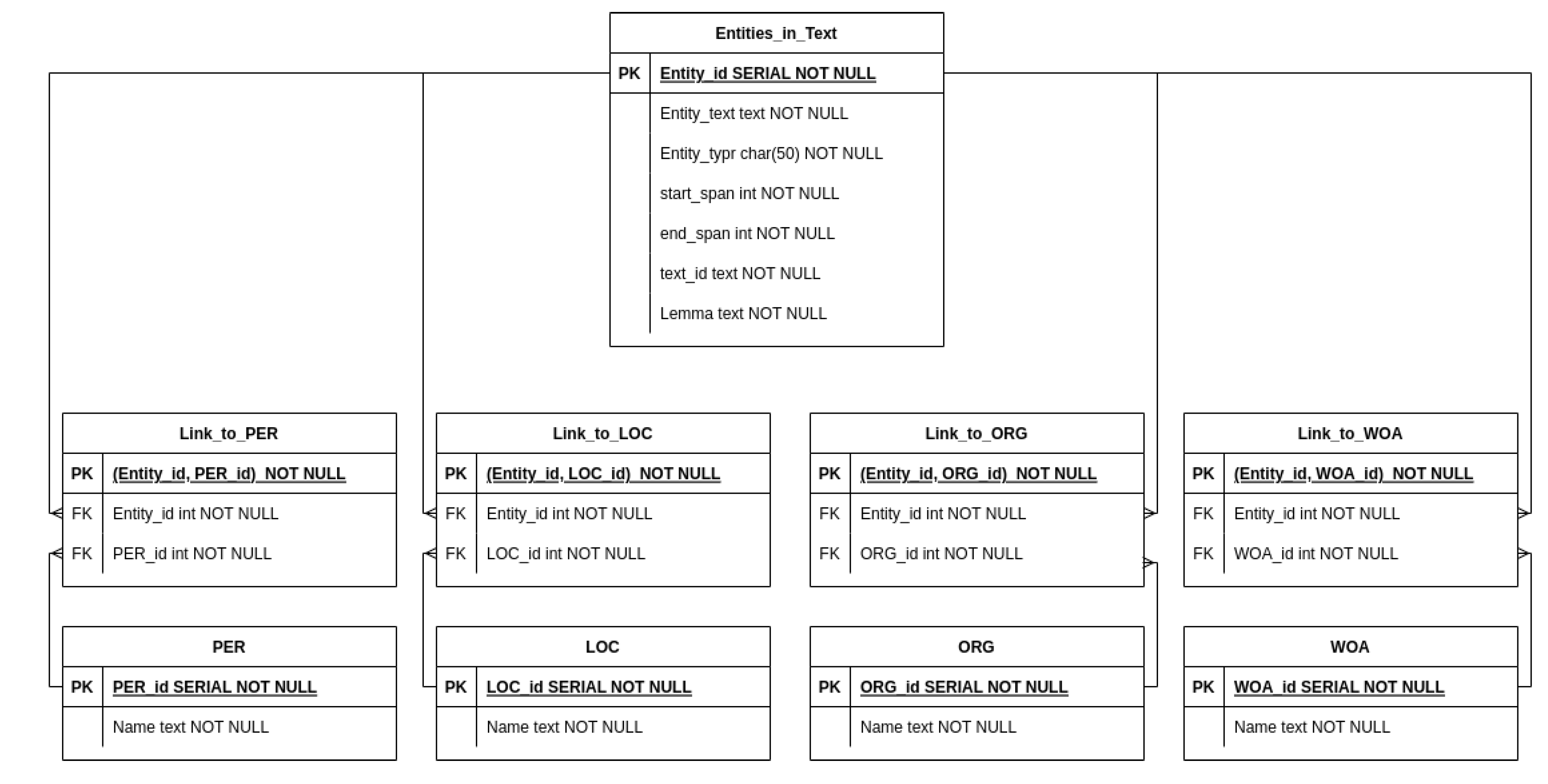
6. Database Creation and Structure
- Main Table: This table contains all the entities extracted from the dataset by utilizing the NER model we trained. Each entity within the table has a unique ID as well as information that describes the entity type, entity span text, and text from which it was extracted.
- Separate Tables for Entity Types: To optimize efficiency and the structure, we created distinct tables for every kind of entity: Persons (PER), Organizations (ORG), Locations (LOC), and Works of Art (WOA). These separate tables ensure an organized and efficient storage solution. Inside each entity type table, we store the unique entities we found in the text under this entity type.
- Link Tables: To achieve connections between the main tables that contain all the extracted entities and the separate tables for each entity type, we built these link tables. These tables act as connectors between entities and their corresponding entity type tables. These link tables help to create a complete and integrated dataset.
- Efficient Storage and Retrieval: This database will allow the user to easily and effectively store the extracted entities while maintaining a well-organized form. The structured database will allow for rapid access for entities and the rapid extraction of information.
- Facilitating Future Enhancements: The database will act as a fundamental structure when we add more data to the dataset—like external URLs—over time. This gives users the freedom to easily add more data and expand the database. It will make the expansion of the stored information easier for future adjustments.
- Enhancing User Experience: Users can do thorough searches in this database to find relevant data linked to a certain entity. Users may quickly access an enormous amount of knowledge on people, places, businesses, and artistic creations listed in the Encyclopedia of A.S. Pushkin by doing database queries. The database facilitates in-depth investigation and study while greatly enhancing the user experience.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mansouri, A.; Affendey, L.; Mamat, A. Named Entity Recognition Approaches. Int. J. Comp. Sci. Netw. Sec. 2008, 8, 339–344. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Gareev, R.; Tkatchenko, M.; Solovyev, V.D.; Simanovsky, A.; Ivanov, V. Introducing Baselines for Russian Named Entity Recognition. In Proceedings of the Conference on Intelligent Text Processing and Computational Linguistics, Samos, Greece, 24–30 March 2013. [Google Scholar]
- Malykh, V.; Ozerin, A. Reproducing Russian NER Baseline Quality without Additional Data. In Proceedings of the CDUD@CLA, Moscow, Russia, 18–22 July 2016. [Google Scholar]
- Lê, T.A.; Arkhipov, M.; Burtsev, M. Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition. In Artificial Intelligence and Natural Language: 6th Conference, AINL 2017, St. Petersburg, Russia, September 20–23, 2017, Revised Selected Papers 6; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 91–103. [Google Scholar]
- Suppa, M.; Jariabka, O. Benchmarking Pre-trained Language Models for Multilingual NER: TraSpaS at the BSNLP2021 Shared Task. In Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing—Association for Computational Linguistics, Kiyv, Ukraine, April 2021; pp. 105–114. [Google Scholar]
- Prelevikj, M.; Žitnik, S. Multilingual Named Entity Recognition and Matching Using BERT and Dedupe for Slavic Languages. In Proceedings of the Workshop on Balto-Slavic Natural Language Processing, Kiyv, Ukraine, April 2021; pp. 80–85. [Google Scholar]
- Arkhipov, M.; Trofimova, M.; Kuratov, Y.; Sorokin, A. Tuning Multilingual Transformers for Language-Specific Named Entity Recognition; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 89–93. [Google Scholar] [CrossRef]
- Mukhin, E. Using Pre-Trained Deeply Contextual Model BERT for Russian Named Entity Recognition; Springer: Berlin/Heidelberg, Germany, 2020; pp. 167–173. [Google Scholar] [CrossRef]
- Luoma, J.; Pyysalo, S. Exploring Cross-sentence Contexts for Named Entity Recognition with BERT. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 1 December 2020; pp. 904–914. [Google Scholar] [CrossRef]
- Kuratov, Y.; Arkhipov, M. Adaptation of Deep Bidirectional Multilingual Transformers for Russian Language. arXiv 2019, arXiv:1905.07213. [Google Scholar]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2177–2190. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, K.; Wang, Z.; Shang, J. Formulating Few-shot Fine-tuning Towards Language Model Pre-training: A Pilot Study on Named Entity Recognition. arXiv 2022, arXiv:2205.11799. [Google Scholar] [CrossRef]
- Chen, S.; Pei, Y.; Ke, Z.; Silamu, W. Low-Resource Named Entity Recognition via the Pre-Training Model. Symmetry 2021, 13, 786. [Google Scholar] [CrossRef]
- Zhang, Y.; Meng, F.; Chen, Y.; Xu, J.; Zhou, J. Target-oriented Fine-tuning for Zero-Resource Named Entity Recognition. arXiv 2021, arXiv:2107.10523. [Google Scholar]
- Grouin, C.; Lavergne, T.; Névéol, A. Optimizing annotation efforts to build reliable annotated corpora for training statistical models. In Proceedings of the LAW VIII—The 8th Linguistic Annotation Workshop, Dublin, Ireland, August 2014; pp. 54–58. [Google Scholar] [CrossRef]
- Tedeschi, S.; Maiorca, V.; Campolungo, N.; Cecconi, F.; Navigli, R. WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. In Proceeding of the Findings of the Association for Computational Linguistics: EMNLP, Punta Cana, Dominican Republic, 11 November 2021. [Google Scholar] [CrossRef]
- Nothman, J.; Murphy, T.; Curran, J.R. Analysing Wikipedia and Gold-Standard Corpora for NER Training. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Athens, Greece, March 2009; pp. 612–620. [Google Scholar]
- Schäfer, H.; Idrissi-Yaghir, A.; Horn, P.; Friedrich, C. Cross-Language Transfer of High-Quality Annotations: Combining Neural Machine Translation with Cross-Linguistic Span Alignment to Apply NER to Clinical Texts in a Low-Resource Language. In Proceedings of the 4th Clinical Natural Language Processing Workshop, Online, 14 July 2022. [Google Scholar] [CrossRef]
- Stenetorp, P.; Pyysalo, S.; Topic, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. brat: A Web-based Tool for NLP-Assisted Text Annotation. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, April 2012. [Google Scholar]
- Arunmozhi; Khan, A.; Kunert, L. Ner-Annotator. Available online: https://github.com/tecoholic/ner-annotator (accessed on 12 May 2023).
- Pierto, C.; Cejuela, J.M. TagTog: The Text Annotation Tool to Train AI. Available online: https://docs.tagtog.com/ (accessed on 20 October 2023).
- Montani, I.; Honnibal, M. Prodigy: An annotation tool for AI, Machine Learning. Available online: https://prodi.gy/ (accessed on 22 October 2023).
- Burtsev, M.; Seliverstov, A.; Airapetyan, R.; Arkhipov, M.; Baymurzina, D.; Bushkov, N.; Gureenkova, O.; Khakhulin, T.; Kuratov, Y.; Kuznetsov, D.; et al. DeepPavlov: Open-Source Library for Dialogue Systems. In Proceedings of the ACL 2018 System Demonstrations, Melbourne, VIC, Australia, 15–20 July 2018. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://zenodo.org/records/10009823 (accessed on 22 October 2023).




{kind=link}
{kind=link}
{kind=link}
| Annotating Tool | Advantages | Disadvantages |
|---|---|---|
| Brat | Open Source: Brat is an open-source tool and free to use for annotation tasks. Web Server Deployment: Bart can be deployed on a web server, which provides a safe and regulated setting for group annotation. Customization: Gives the user freedom to define entity types and annotation policies. | Lacks Machine Learning Integration: Brat cannot integrate machine learning models or perform active learning. Initialization Difficulties: Compared with some other tools, it is harder to set up the configuration files. |
| NER annotator | User-Friendly: An easy-to-use tool developed for non-technical users with a friendly User Interface design. Efficiency: A simple and effective tool for NER annotation tasks. | Limited Features: For intricate or cooperative annotation tasks, NER Annotator might not provide all the functionality you need. Lacks Active Learning: Neither machine learning model integration nor active learning is included in the NER Annotator tool. |
| Tagtog | Collaboration Features: Provides sophisticated tools for collaboration, enabling several annotators to collaborate on a single project. Data Preparation: Reduces the process of preparing data and can aid in the training of machine learning models. | Paid Service: A paid membership may be needed for some services, which makes it less affordable for large-scale projects with tight budgets. Complexity: Advanced features need technical experience to utilize. |
| Prodigy | Active Learning: Utilizes active learning strategies that enable the creation of highly accurate annotation models quickly and with less effort. Scalability: It is suitable for small-scale and large-scale annotation applications. | Cost: Prodigy is a paid tool, which makes it not suitable for some applications. Complexity: For users who are unfamiliar with machine learning integration, utilizing this tool may be difficult. |
| Model | Description |
|---|---|
| Model #1 | Tok2vec model to train on auto-annotated dataset before adjusting the work-of-art entities. |
| Model #2 | Transformer-based model to train on auto-annotated dataset after adjusting the work-of-art entities. |
| Model #3 | Tok2vec model to train on the dataset version checked by specialists. |
| Model #4 | Transformer-based model to train on the dataset version checked by specialists. |
| Model | Comments | Entity | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Model #1 | Tok2vec model before adjusting the work-of-art entities | Ents | 0.6202 | 0.6466 | 0.6331 |
| PER | 0.7804 | 0.8276 | 0.8033 | ||
| LOC | 0.5337 | 0.5471 | 0.5403 | ||
| WOA | 0.1103 | 0.0947 | 0.1019 | ||
| DATE | 0.7280 | 0.9032 | 0.8062 | ||
| ORG | 0.3272 | 0.3333 | 0.3302 | ||
| Model #2 | Transformer-based model after adjusting the work-of-art entities | Ents | 0.7718 | 0.7806 | 0.7761 |
| PER | 0.7994 | 0.8214 | 0.8102 | ||
| LOC | 0.5361 | 0.5597 | 0.5476 | ||
| WOA | 0.8637 | 0.6987 | 0.7725 | ||
| DATE | 0.7306 | 0.8930 | 0.8037 | ||
| ORG | 0.3142 | 0.2868 | 0.2962 | ||
| Model #3 | Tok2vec model trained on the checked dataset | Ents | 0.8742 | 0.8367 | 0.8550 |
| PER | 0.8850 | 0.8674 | 0.8761 | ||
| LOC | 0.6412 | 0.5283 | 0.5793 | ||
| WOA | 0.9030 | 0.9114 | 0.9114 | ||
| DATE | 0.8764 | 0.7880 | 0.8299 | ||
| ORG | 0.7352 | 0.4629 | 0.5681 | ||
| Model #4 | Transformer-based model trained on the checked dataset | Ents | 0.9020 | 0.8885 | 0.8952 |
| PER | 0.9357 | 0.9004 | 0.9177 | ||
| LOC | 0.8478 | 0.7358 | 0.7878 | ||
| WOA | 0.8577 | 0.9083 | 0.8823 | ||
| DATE | 0.9077 | 0.8909 | 0.8992 | ||
| ORG | 0.6949 | 0.7592 | 0.7256 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kassab, K.; Teslya, N. An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts. Appl. Sci. 2024, 14, 585. https://doi.org/10.3390/app14020585
Kassab K, Teslya N. An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts. Applied Sciences. 2024; 14(2):585. https://doi.org/10.3390/app14020585
Chicago/Turabian StyleKassab, Kenan, and Nikolay Teslya. 2024. "An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts" Applied Sciences 14, no. 2: 585. https://doi.org/10.3390/app14020585
APA StyleKassab, K., & Teslya, N. (2024). An Approach to a Linked Corpus Creation for a Literary Heritage Based on the Extraction of Entities from Texts. Applied Sciences, 14(2), 585. https://doi.org/10.3390/app14020585