Abstract
Unsupervised cross-modal hashing is a topic of considerable interest due to its advantages in terms of low storage costs and fast retrieval speed. Despite the impressive achievements of existing solutions, two challenges remain unaddressed: (1) Semantic similarity obtained without supervision is not accurate enough, and (2) the preservation of similarity structures lacks effectiveness due to the neglect of both global and local similarity. This paper introduces a new method, Multi-Grained Similarity Preserving and Updating (MGSPU), to tackle these challenges. To overcome the first challenge, MGSPU employs a newly designed strategy to update the semantic similarity matrix, effectively generating a high-confidence similarity matrix by eliminating noise in the original cross-modal features. For the second challenge, a novel multi-grained similarity preserving method is proposed, aiming to enhance cross-modal hash code learning by learning consistency in multi-grained similarity structures. Comprehensive experiments on two widely used datasets with nine state-of-the-art competitors validate the superior performance of our method in cross-modal hashing.
1. Introduction
As an efficient information retrieval paradigm for big multimedia data [1,2,3], cross-modal retrieval [4,5,6,7,8,9] utilizes one modality as a query to search another modal data. Among the existing techniques [10,11,12,13,14,15,16,17,18], cross-modal hashing [16,17,18,19,20] is popular for its fast retrieval speed and low storage cost. The core of cross-modal hashing is to map high-dimensional data to a low-dimensional common Hamming space, in which multi-modal instances (text, image, audio and video) with similar semantics are closer, and dissimilar instances are far apart. Notwithstanding the strong practical significance, this task is extremely challenging due to the heterogeneity gap between different modalities.
A number of studies are striving to promote the progress of cross-modal hashing. In general, they can be simply divided into two groups: supervised learning methods [21,22,23,24,25] and unsupervised learning methods [26,27,28,29,30]. The supervised learning methods use human-annotated label to guide model learning, which preserves semantic discrimination well to obtain great performance. However, directly obtaining the category information is really difficult in real-world scenarios, while the cost of manual labeling is so huge as to limit the wide application. In contrast, without relying on category annotations, unsupervised learning methods are great at capturing the underlying correlation patterns between different modalities to bridge the heterogeneity gap. Thus, they have gained considerable attention currently.
Motivation. Although existing researches have shown remarkable results on large-scale datasets, unsupervised cross-modal hashing is yet a Herculean task that await further exploration due to the following challenges. The first challenge is how to accurately measure inter-modal and intra-modal similarity without category information. In the early days, several unsupervised learning methods [31,32] used discrete models to calculate binary similarity, namely, defining the similarity between two instances with small distances as “1”, otherwise “−1”. Unfortunately, the naive similarity measurement is far from accurate. To break this limitation, researchers [12,15,33,34] began to use original feature distance to measure the continuous similarity. However, such similarity is still not accurate enough to represent the real relationship between instances due to the noise existing in their original features. The second challenge is how to preserve similarity structure consistency from both local and global view during hash learning process. Undisputedly, using multi-grained similarity relationships across modalities is crucial to narrow cross-modal heterogeneity. However, current methods [35,36,37] either overlook multi-grained similarity learning across various modalities or struggle to capture a consistent distribution of relations within the content details. Additionally, some state-of-the-art methods [38,39,40,41] do not account for the semantic correlation between feature vectors from one modality and the corresponding hash codes from another modality. To conquer these challenges, this paper has made the following two efforts: (1) designing a novel and effective similarity updating strategy to rise the accuracy of underlying similarity measurement, and (2) combining multi-grained similarity information from local and global view to preserve similarity consistency.
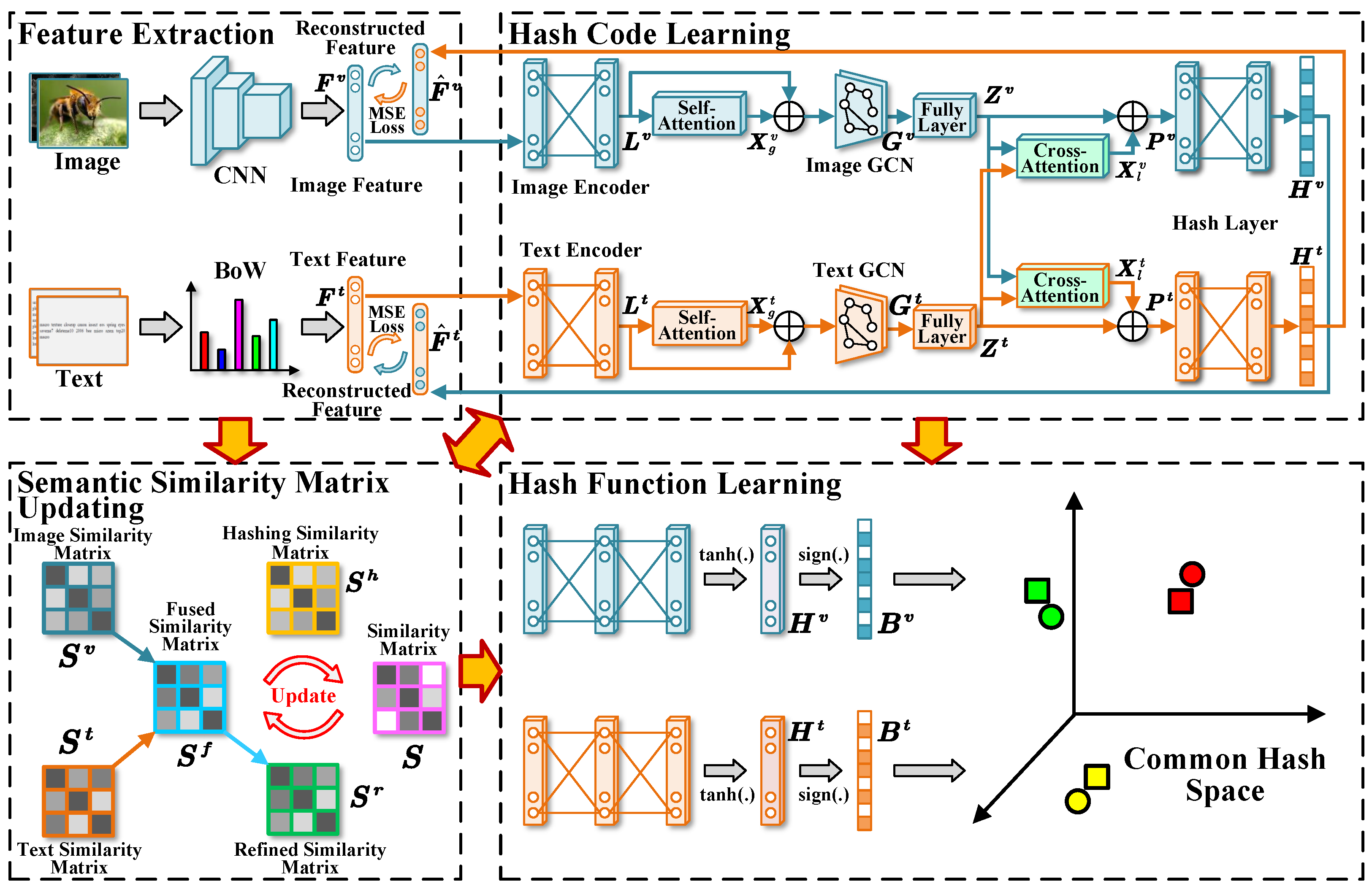
Our Method. We propose a novel cross-modal hashing framework, named Multi-Grained Similarity Preserving and Updating (MGSPU). As shown in Figure 1, this framework consists four module, i.e., feature extraction, semantic similarity matrix updating, hash code learning and hash function learning. To overcome the first challenge, a novel semantic similarity matrix update strategy is developed, which removes noises from the similarity matrix so as to obtain high-confidence supervisory signal. To face the second challenge, we capture the multi-grained similarity structure information from global and local view to preserve similarity consistency better. For global view, we use graph convolutional network (GCN for short) to aggregate the similarity structure information from the neighbors of each instance to enrich the coarse-grained similarity information. For local view, cross-modal attention mechanisms are used to perform cross-modal interaction to enhance similarity learning between instance pairs. Furthermore, we use a similarity consistency reconstruction method to ensure the similarity consistency of hash codes.
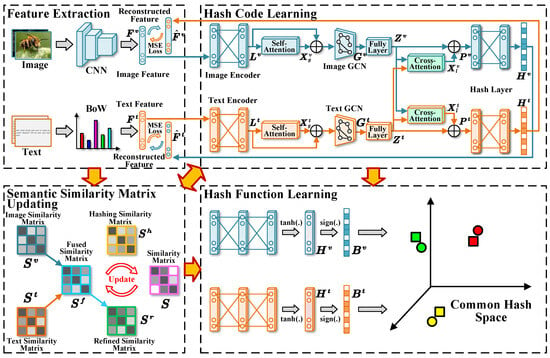
Figure 1.
The framework of MGSPU. It comprises four main modules: feature extraction, semantic similarity matrix updating, hash code learning and hash function learning module.
Contributions. In summary, the contributions of this paper can be summarized as follows:
- We propose an effective unsupervised learning framework, called Multi-Grained Similarity Preserving and Updating, which learns high-quality hash codes by comprehensively improving cross-modal similarity learning.
- We propose a novel semantic similarity matrix updating strategy to effectively remove noises in the original similarity matrix, which produces high-confidence supervisory signal for cross-modal hashing learning.
- We propose a novel multi-grained similarity preserving method to enhance similarity consistency preserving of the cross-modal hash codes.
- We conducted extensive experiments on the widely used datasets MIRFLICKR-25K and NUS-WIDE to validate the superiority of the proposed approach and evaluate the effectiveness of each component.
2. Related Work
According to literatures, cross-modal hashing techniques are generally categorized into two groups: supervised and unsupervised cross-modal hashing. This section reviews the prevailing solutions related to this paper, which are summarized in Table 1 to ease reading.

Table 1.
Related works summary.
2.1. Supervised Cross-Modal Hashing
To obtain common binary representations, supervised cross-modal hashing methods use category information to maintain semantic discrimination. For example, semantic correlation maximization (SCM [42]) learns hash functions by constructing and maintaining semantic similarity matrices. Semantics-preserving hashing (SePH [43]) converts the semantic matrix into a probability distribution and minimizes the Kullback-Leibler divergence so that the learned hash codes are approximately distributed in Hamming space. Thanks to the prosperity of deep learning, researchers began to realize cross-modal retrieval by deep models that explore more discriminative features. Deep cross-modal hashing (DCMH [17]) is a pioneering achievement in this field, which perfectly combines hash function learning with deep feature extraction, and cleverly exploits the labelling information to construct similarity matrices, thus preserving the subtle similarity relationships in cross-modal data. Meanwhile, cross-modal hamming hashing (CMHH [44]) introduces a pairwise focusing loss based on exponential distribution. It penalises instances with similar semantic content but the Hamming distance exceeds a predefined threshold. Semi-supervised adversarial deep hashing (SSAH [45]) is a groundbreaking innovation that shifts the focus to self-supervised methods and integrates adversarial learning into cross-modal hashing, thus making significant progress in the field. Ranking-based deep cross-modal hashing (RDCMH [46]) uses maximum marginal loss to learn uniform Hamming representations. In addition, deep normalized cross-modal hashing with bi-direction relation reasoning (Bi-NCMH [47]) achieved excellent retrieval performance by constructing high-quality similarity matrices to capture similarity relations between instances with multiple labels. Despite the impressive performance of these techniques, their inherent limitations cannot be ignored: they rely heavily on manual annotation to obtain supervision.
2.2. Unsupervised Cross-Modal Hashing
Unsupervised cross-modal hashing methods do not rely on labels so as to apply in real-world scenarios easily. In the existing solutions, constructing a semantic similarity matrix is the key to guide cross-modal relationship learning.Among them, an ingenious method is Deep Joint Semantic Reconstruction Hash (DJSRH [12]), which proposes a joint semantic similarity matrix to simultaneously integrate multi-modal similarity information of cross-modal instances. However, the similarity matrix in DJSRH introduces redundant information from intra-modal fusion items. As an improvement, joint-modal distribution-based similarity hashing (JDSH [36]) involves distribution-based similarity decision and weighting to learn more discriminative hash codes. Deep adaptively-enhanced hashing (DAEH [27]) utilizes distance distributions and similarity ratio information to estimate comparable similarity relationships as complementarity of simple feature distance-based metrics. Although competitive performance is achieved, lack of accurate similarity measurement are these methods since the similarity matrix they rely on are constructed from the original features with noises.
Other unsupervised learning studies make efforts on narrowing the heterogeneity gap by preserving similarity structure consistency. For example, deep graph-neighbor coherence preserving network (DGCPN [48]) explores the relationship information between data and their neighbors to capture neighborhood structure coherence. Aggregation-based graph convolutional hashing (AGCH [26]) employs a GCN to deeply explore the underlying neighborhood structure. Deep relative neighbor relationship preserving hashing (DRNPH [49]) method excavates deep relative neighbor relationships in common Hamming space via binary feature vector based intra- and inter-modal neighbor matrix reconstruction. Impressive progress had been made by these works, however, a common weakness they suffer from is lack of both global and local similarity learning from multi-modal contents.
To address the above shortcomings, we attempt to boost cross-modal hashing learning from two aspects: (1) trying to rise the quality of similarity matrix by reducing noises from original features, and (2) inviting multi-grained similarity learning strategy to capture both global and local similarity relationships. As a results, a novel unsupervised cross-modal hashing technique called multi-grained similarity preserving and updating is developed. The detailed details of this approach will be explored in depth in the next section.
3. Methodology
This section details the proposed MGSPU method across six aspects. Initially, we introduce the notations and problem definition in the Preliminary. Next is an overview of MGSPU, feature extraction, semantic similarity matrix updating, hashing learning (including hash code learning and hashing function learning), and finally a discussion of the optimization algorithm. All abbreviations involved are summarized in Table 2 for easier reading.
Table 2.
Abbreviation summary.
3.1. Preliminary
Notations. For clarity and simplicity, calligraphy uppercase letters, such as , denote sets. Bold uppercase letters, such as , represent matrices. Bold lowercase letters, such as , indicate vectors. In addition, the ij-th element of is represented as , the i-th row of is represented as , the j-th column of is represented as , is the transpose of , represents identity matrix. represents the Frobenius norm of a matrix. represents a sign function, shown as below:
For ease of comprehension, commonly utilized mathematical notations have been compiled in Table 3 to assist in reference.
Table 3.
Notation summary.
Problem Definition. This paper concentrates on cross-modal retrieval between two prevalent modalities, i.e., image v and text t. Let be a cross-modal dataset, and refer to the image and text in the pairwise instance respectively, and represent the dimension of the corresponding features, n denotes the number of instances. Our study aims to learn two hash functions and to map images and texts to a common Hamming space: , , where , C represents the length of the binary code, and are the learnable parameters. In addition, the similarity between two binary codes and is measured by Hamming distance , which is the base for implementing cross-modal hashing retrieval.
3.2. Overview of MGSPU
Figure 1 shows the overview of the MGSPU framework. Specifically, it mainly consists of four modules: (1) feature extraction module, (2) semantic similarity matrix updating module, (3) hash code learning module, and (4) hash function learning module. The feature extraction module maps images and texts into feature subspaces by corresponding encoders: deep CNN for image features and Bag-of-Word (BoW) model for text features. The semantic similarity matrix updating module realizes a novel similarity updating strategy to construct a high-confidence similarity matrix, which effectively enhance the hash code learning and hash function learning. To support hash function learning, the hash code learning module aims at generating real-value hash representations with a novel multi-grained semantic preserving learning strategy. It utilizes a pair of GCNs (each for one modality) to capture global semantic correlation, following by a cross-attention mechanism to enhance cross-modal local feature learning. This technique allows for sufficient semantic correlations preserving of both intra- and inter-modality. The hash function learning module is to learn two hash functions that are implemented by two fully-connected neural networks for image and text, respectively.
In a nutshell, the goal of this method is to optimize the hash function module with other three parts to generate high-quality binary hash codes for cross-modal retrieval task. Thereinafter, we discuss the technical details module by module.
3.3. Feature Extraction
The first step of cross-modal hash code learning is feature extraction from both images and texts. For images, we follow previous works [12,37,48] to extract deep features from CNN model (pre-trained on ImageNet). Specifically, we extract the the 4096-dimensional features from the first fc7 layer (after ReLU) of AlexNet [50] as the original image features for the batch-input images . While for texts we directly adopt the BoW [51] vectors as their original features . It is noted that the proposed MGSPU framework can also be compatible with other deep feature extraction models, such as ResNet [52] for images or LSTM [53] for texts. To better validate the superiority of the proposed technique, we use relatively naive but effective feature extraction models (AlexNet and BoW) when implementing MGSPU. The implementation details are presented in Section 4.3.
3.4. Semantic Similarity Matrix Updating
Unlike supervised hashing learning that do not easily suffer from noises in features due to accurate category annotation, the unsupervised method cannot ensure the high accuracy of latent semantic correlations between instances without category information. To address this issue, we focus on constructing a high-confidence unified similarity matrix as a supervisory signal to filter out noises as much as possible. Accordingly, a novel semantic similarity matrix updating strategy is designed.
3.4.1. Similarity Matrix Construction
To comprehensively consider cross-modal similarity relationships, we first fuse the similarity matrices from image modality and text modality:
where is the fused similarity matrix, and represent the image and text similarity matrices, respectively. is a hyperparameter to balance them. Each element in and is computed by Cosine similarity. Taking image modality as an example:
where and denote the feature of the i-th and j-th image. To rise the accuracy of similarity measurement without supervision, we design a filter-and-augment strategy to refine the similarity matrix, shown as follows:
where denotes the refined similarity matrix, is similarity threshold. the sign function indicates if , ; if , . Meanwhile, inspired by reference [28], we use the non-linear function to compress the remaining values to further expand the distance between similar and non-similar instances. The coefficient 2 of is to control the linear compression, then maps the compressed value to . is an identity matrix to maintain the similarity between instance pairs.
3.4.2. Dual Instruction Fusion Updating
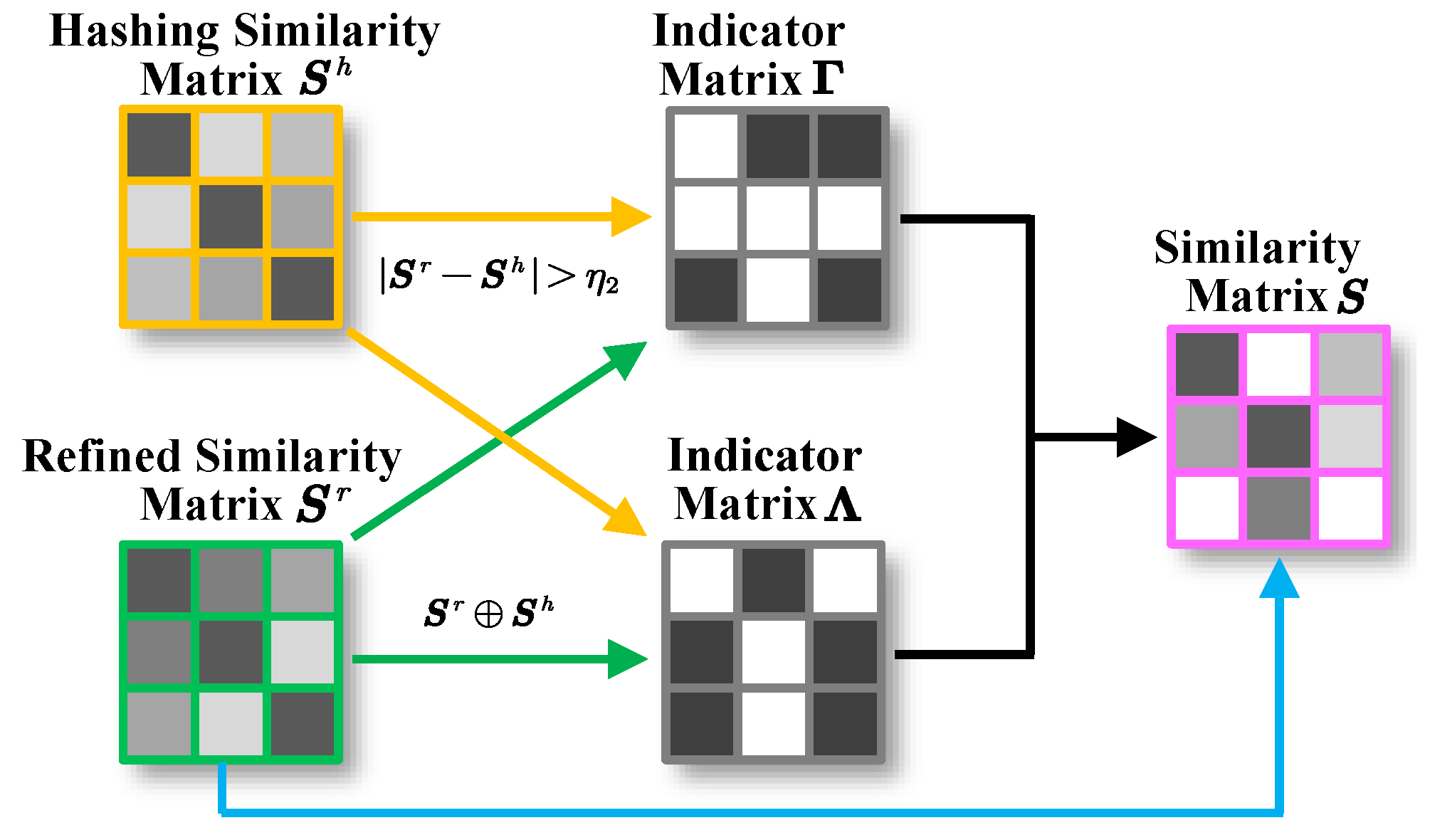
In order to preserve semantic similarity consistency in cross-modal hash codes, a reliable similarity matrix for unsupervised hash function learning is indispensable. During the training process, unfortunately, we found that there is a evident gap between the similarity relationships of cross-modal hash codes and the real relationships of original instances due to the noises existing in the flawed similarity matrix . In other words, the value of is not small enough to correctly guide cross-modal hash function learning. Intuitively, if we rectify these incorrect similarity values, it will effectively embed the correct similarity relationship information into cross-modal hash codes. For this reason, we attempt to construct dual instruction to further denoise the similarity matrix : the one is the difference of similarity value of and , the other is difference of the sign of them. Beyond all doubt, these two instructions actually measure the difference between and from two different perspectives, which could be fused to narrow the gap between and .
From the analysis mentioned, we develop a novel semantic similarity matrix updating strategy, named dual instruction fusion updating, to gradually eliminate the noises. Firstly, we construct the hashing similarity matrix via the real-valued hash code and :
Thereafter, we utilize to update according to the similarity relationship among them. For the convenience of formal description and implementation, we introduce two indicator matrices and at first. The former is defined as , therein ⊕ is XOR operation, which means if , ; otherwise . The latter indicates the numerical difference between and , therein the elements are set to 1 and the others are set to 0. be a threshold to measure the difference between two elements in similar matrices. Accordingly, two cases are considered: (1) Not updating: if and , then the updating do not be conducted since and are similar enough. (2) Updating: according to the value of , we introduce two updating rules: if and , we update by ; if , we update by “0”, which is a way with maximizing entropy to enhance generalization capability. The reason behind this rule is intuitive: if the difference between and is too large, a wise way is not to biased towards either side. To clearly show the update rules, we list a truth table for and in Table 4. Thereby, the updated semantic similarity matrix is generated by the following updating process:
where is a parameter. Finally, we use to guide the cross-modal hash function learning avoiding the interference from similarity noise. Figure 2 illustrates the updating process.
Table 4.
Indicator matrices truth table for dual instruction fusion updating strategy.
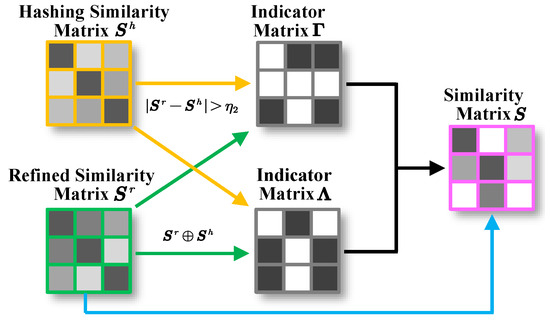
Figure 2.
The process of dual instruction fusion updating. is an indicator matrix that tells us where values need to be updated, when , ; otherwise . , ⊕ is XOR operation. If and , is weighted by and ; if and , then ; the rest of is consistent with 0.
3.5. MGSP for Hash Code Learning
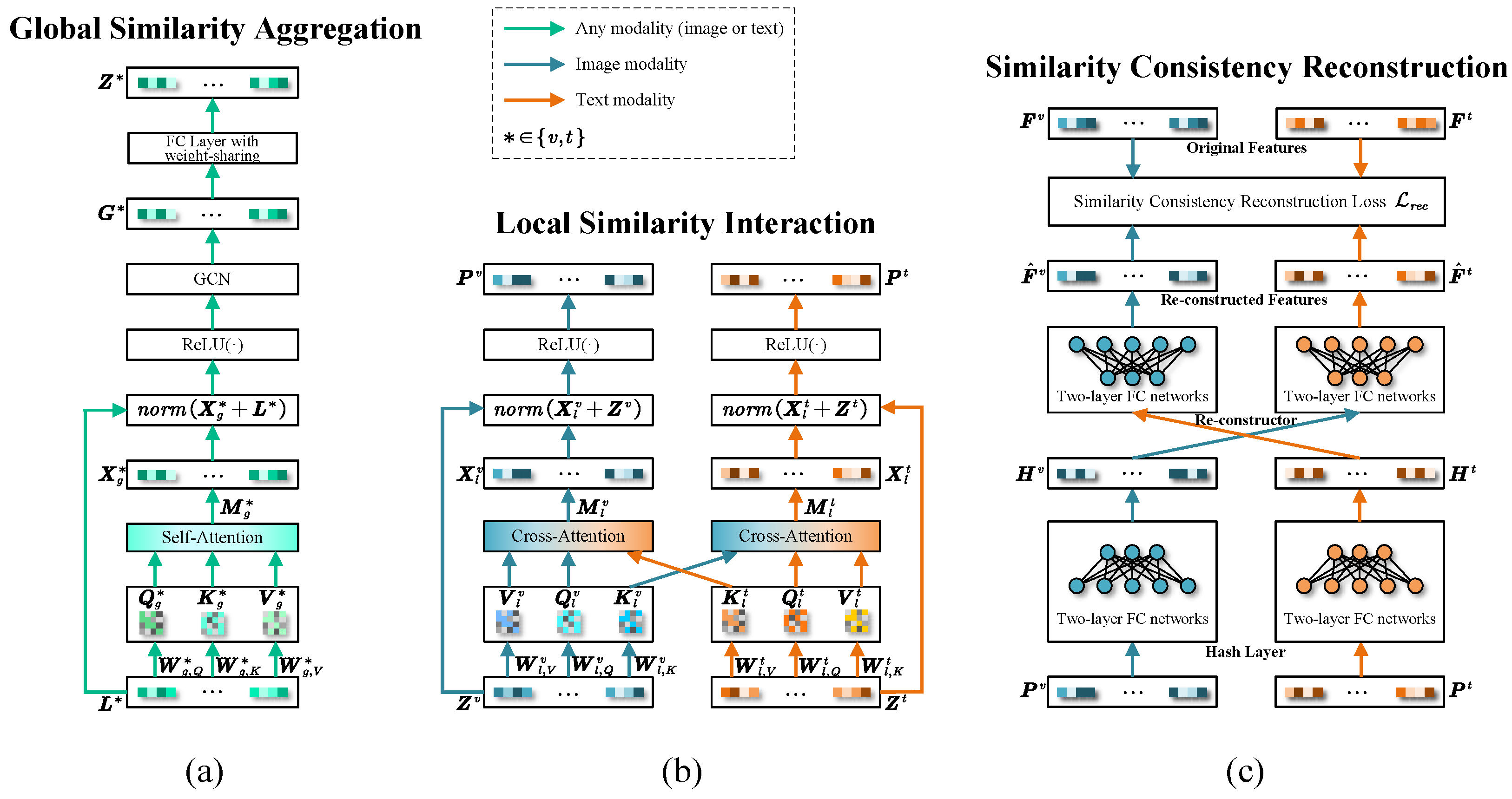
To enhance the cross-modal similarity consistency preserving for hash code learning, a novel technique, called Multi-Grained Similarity Preserving (MGSP) is developed, as shown in Figure 3a. It consists two key sub-modules, i.e., global similarity aggregation (GSA) and local similarity interaction (LSI), which explore multi-grained similarity information: global and local similarity structure information. Furthermore, another sub-module, named Similarity Consistency Reconstruction (SCR) is involved to narrow heterogeneity gap between original features and reconstructed features from hash codes.
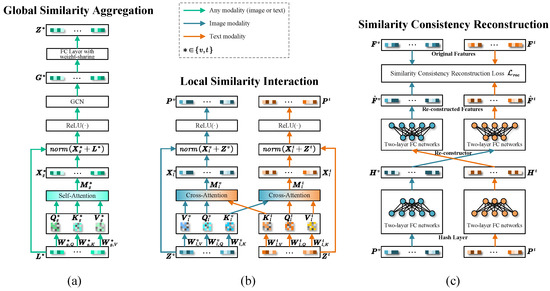
Figure 3.
The details of MGSP. (a–c) illustrate the pipeline of global similarity aggregation, local similarity interaction, and similarity consistency reconstruction, respectively. Best view in color.
3.5.1. Global Similarity Aggregation
The similarity relationship between instances of any modality (image or text) is essential for similarity preserving, which reflects the latent feature distributions of each kind of data. As we known, the intra-modal similarity relationships can be represented as a graph therein each node is an instance and the similarity relationships are represented by edges. In such a graph, each node may be related to others through complex linked structure that can be captured to learn latent global similarity relationships within each modality. To this end, we developed a global similarity aggregation (GSA) sub-module involving the following process: two graphs firstly are constructed, each per modality. Then, we aggregate global similarity information of each node from its neighbors via a graph convolutional network (GCN). Specifically, let , for a batch of samples , we feed them into an encoder to generate the latent representations . To further focus on the crucial features, the key-value self-attention mechanism is used to obtain global similarity aggregation representations . The query , key and value are calculated as:
where are the learnable weight matrices. The attention map is calculated as:
Thus, the global similarity enhanced representations is . To avoid the issue of smaller feature value caused by attention weighting, we add the latent representation with , then normalize it as the input of the GCN:
where the superscript denotes the 0-th layer of convolution, namely the input of GCN, is normalization function, represents a nonlinear activation function, usually the function. The layer-by-layer propagation rule of GCN is formulated as:
where , is an adjacency matrix constructed from the refined similarity matrix via kNN algorithm, k represents the number of neighbors, and represent the input and output of the l-th layer, denotes the learnable parameters of the l-th layer, is function. The final outputs of the GCN are denoted by . Finally, to further mitigate the cross-modal heterogeneity, a two-layer fully-connected network with weigh-sharing is integrated on the top of GCN, and its output are denoted as .
3.5.2. Local Similarity Interaction
Capturing rich similarity structure information among each image-text pair is another desiderata to further enhance cross-modal similarity preserving. This kind of information is mainly reflected in the latent local feature relationships between modalities. To this end, we develop a local similarity interaction (LSI) sub-module to improve similarity consistency preserving within each image-text pair. Specifically, a key-value cross-attention mechanism is used on the top of GSA sub-module to learn fine-grained cross-modal similarity associations. We obtain query and , key and , as well as value and through linear transformation to obtain the visual and textual attention map and :
Thus, the attention-weighted representations are and . Similar to the above self-attention, the local are calculated as follows:
where is still .
3.5.3. Similarity Consistency Reconstruction
The similarity consistency preserving should not only be reflected in cross-modal features, but more importantly, in hash codes. Deep feature reconstruction, namely reducing the heterogeneity between original features and reconstructed features from continuous hash codes, has been verified to be an effective technique. Current literatures indicate that, two different reconstruction strategies, i.e., intra-modal [28] and inter-modal reconstruction [37], are developed for similarity consistency preserving. In this work, we integrate inter-modal reconstruction into our method to narrow cross-modal gap. Specifically, the continuous hash codes and are generated by a couple of two-layer fully-connected networks from and , which then are fed into two re-constructors to output reconstructed features. Accordingly, inspired by [37], a similarity consistency reconstruction loss function is introduced to preserve the similarity structure information into hash codes:
where and denote the reconstructed feature representations.
3.5.4. Hash Code Learning Loss
Furthermore, to preserve similarity consistency of cross-modal hash codes from both intra-modal and inter-modal perspectives, we introduce hash code similarity consistency loss:
Meanwhile, to ensure the accuracy of the similarity matrix, we designed a new loss function as follows:
where is an indicator function, when , , otherwise .
3.6. Hashing Function Learning
Using the semantic similarity matrix and the hash codes , we learn two modality-specific hash functions and to project deep features and to Hamming space. Specifically, to preserving the similarity structure between hash codes and cross-modal features, we introduce similarity loss function as follows:
where and denote the relaxed hash codes generated by the hash functions, and denote the parameters. In addition, in order to numerically align the hash codes generated by the hash function with the hash codes and obtained during the training process, we also introduced loss function :
Finally, the quantization loss transfers semantic information from relaxed hash codes to binary hash codes:
3.7. Optimization
The learning process of MGSPU can be divided into two stages: (1) hash code learning stage, and (2) hash function learning stage. During the hash code learning stage, the optimization of the objective function is performed by minimizing Equations (14)–(16):
During the hash function learning stage, the optimization of the objective function entails minimizing Equations (17)–(19):
The entire algorithm process of MGSPU is outlined in Algorithm 1, which is implemented by Adam adaptive algorithm [54].
| Algorithm 1 Algorithm of MGSPU. |
|
4. Experiments
This section presents experiments and analysis to assess the retrieval performance of the proposed method. We begin by introducing the experimental settings, including datasets, evaluation metrics, baselines, and implementation details. Subsequently, we provide a performance comparison between our method and several baselines, along with an ablation analysis to validate the impact of each component.
4.1. Datasets
We conduct thorough experiments on two prominent multimedia benchmark datasets, namely MIRFLICKR-25K [55] and NUS-WIDE [56], widely employed for cross-modal retrieval evaluation. A concise introduction to these datasets is provided below.
MIRFLICKR-25K. The MIRFLICKR-25K dataset includes 25,000 image-text pairs from the popular photo-sharing platform Flickr. Each image is accompanied by multiple text labels. In our experiment, we specifically selected instances with at least 20 text tags. With AlexNet [50], we converted each image into a depth feature of 4096 dimensions, while the text labels were converted into a BoW [51] vector of 1386 dimensions. In addition, each instance is manually annotated with at least one of 24 unique tags. We experimented with 20,015 examples selected from the dataset.
NUS-WIDE. The NUS-WIDE dataset is a substantial real-world web image collection, featuring more than 269,000 images accompanied by over 5000 user-provided tags and 81 concepts across the entire dataset. Using AlexNet [50], each image instance is represented as a 4096-dimensional deep feature, while the textual content is condensed into a 1000-dimensional BoW [51] vector. For our experiment, we excluded instances lacking labels and focused on those associated with the 10 most frequent categories, resulting in a curated set of 186,577 image-text pairs.
Table 5 presents the statistics of the above two datasets, and some samples of these two datasets are shown in Figure 4.
Table 5.
Details about the datasets used in our experiments.

Figure 4.
Some examples from the MIRFLICKR-25K and NUS-WIDE datasets. (a) MIRFLICKR-25K. (b) NUS-WIDE.
4.2. Evaluation Metrics
In our experiments, we conducted two types of cross-modal retrieval tasks: retrieving texts using image queries (denoted as “I2T”) and retrieving images using text queries (denoted as “T2I”). Next, we utilized two standard hashing performance protocols, Hamming ranking and hash lookup [57], to assess the effectiveness of our method and its competitors. For the Hamming ranking protocol, we utilized mean average precision (mAP) to measure accuracy, while precision-recall curves (P-R curves) were employed for the Hash lookup protocol. For mAP and P-R curves, we considered images and texts to be similar if they shared at least one label; otherwise, they were considered dissimilar. Specifically, given a query , the average precision (AP) of the top-N results is defined as:
where N is the number of relevant instances in the result set, R represents the total amount of data. denotes the precision of the top-r results. If the r-th retrieved result is relevant to the query instances, ; otherwise, . The mAP value is defined as the average AP across all queries :
where M represents the number of queries.
4.3. Baselines and Implementation Details
Baselines. we compare the proposed MGSPU method with nine baselines, including CMFH [31], DBRC [58], UDCMH [35], DJSRH [12], JDSH [36], DSAH [37], AGCH [26], DAEH [27], DRNPH [49], which are briefly described as follows:
- CMFH: This method learns uniform binary feature vectors for different modalities through collective matrix factorization of latent factor models.
- DBRC: This approach proposes a deep binary reconstruction model to preserve inter-modal correlation.
- UDCMH: This method utilizes deep learning and matrix factorization with binary latent factor models for multi-modal data search.
- DJSRH: This approach integrates original neighborhood information from different modalities into a joint-semantics affinity matrix to extract latent intrinsic semantic relations.
- JDSH: This method introduces a distribution-based similarity decision and weighting scheme for generating a more discriminative hash code.
- DSAH: This approach explores similarity information across modalities and incorporates a semantic-alignment loss function to align features’ similarities with those between hash codes.
- AGCH: This method utilizes GCNs to uncover semantic structures, coupled with a fusion module for correlating different modalities.
- DAEH: This approach attempts to train hash functions with discriminative similarity guidance and an adaptively-enhanced optimization strategy.
- DRNPH: This method implements unsupervised deep relative neighbor relationship preserving cross-modal hashing for achieving cross-modal retrieval in a common Hamming space.
Except for CMFH, All other approaches use deep features to generate cross-modal hash codes.
Implementation Details. As discussed above, the learning process is divided into two stages. In hash code learning stage, three hyperparameters are used to weight , respectively. In hash function learning stage, three other hyperparameter are used to adjust the ratio between . On the MIRFLICKR-25K dataset, we set . On NUS-WIDE dataset, we set . In the process of semantic similarity matrix construction, we set on the MIRFLICKR-25K, and set on the NUS-WIDE. In GSA sub-module, kNN algorithm is used to aggregate nodes in a certain neighborhood for each modality. We set and for MIRFLICKR-25K and NUS-WIDE, respectively. The optimization algorithm used is the Adam optimization algorithm [54]. For MIRFLICKR-25K, we set the learning rates for hash code learning and hash function learning to 0.001 and 0.0001, respectively, and for NUS-WIDE, both are set to 0.0001. The batch size is consistently set at 512. The number of iterations is defined as 60 for MIRFLICKR-25K and 100 for NUS-WIDE. It’s worth noting that, under the same experimental setup, we directly utilize mAP@50 results provided in the original papers of the baseline methods.
Experimental Environment. All the experiments are performed on a workstation with Intel(R) Core i9-12900K 3.9 GHz CPU, 128 GB RAM, 1 TB SSD storage, 2TB HDD storage, and 1 NVIDIA GeForce RTX 3090Ti GPU with ubuntu-22.04.1 operating system. All the techniques are implemented by Python 3.9 on PyTorch 2.0.1.
4.4. Performance Evaluation
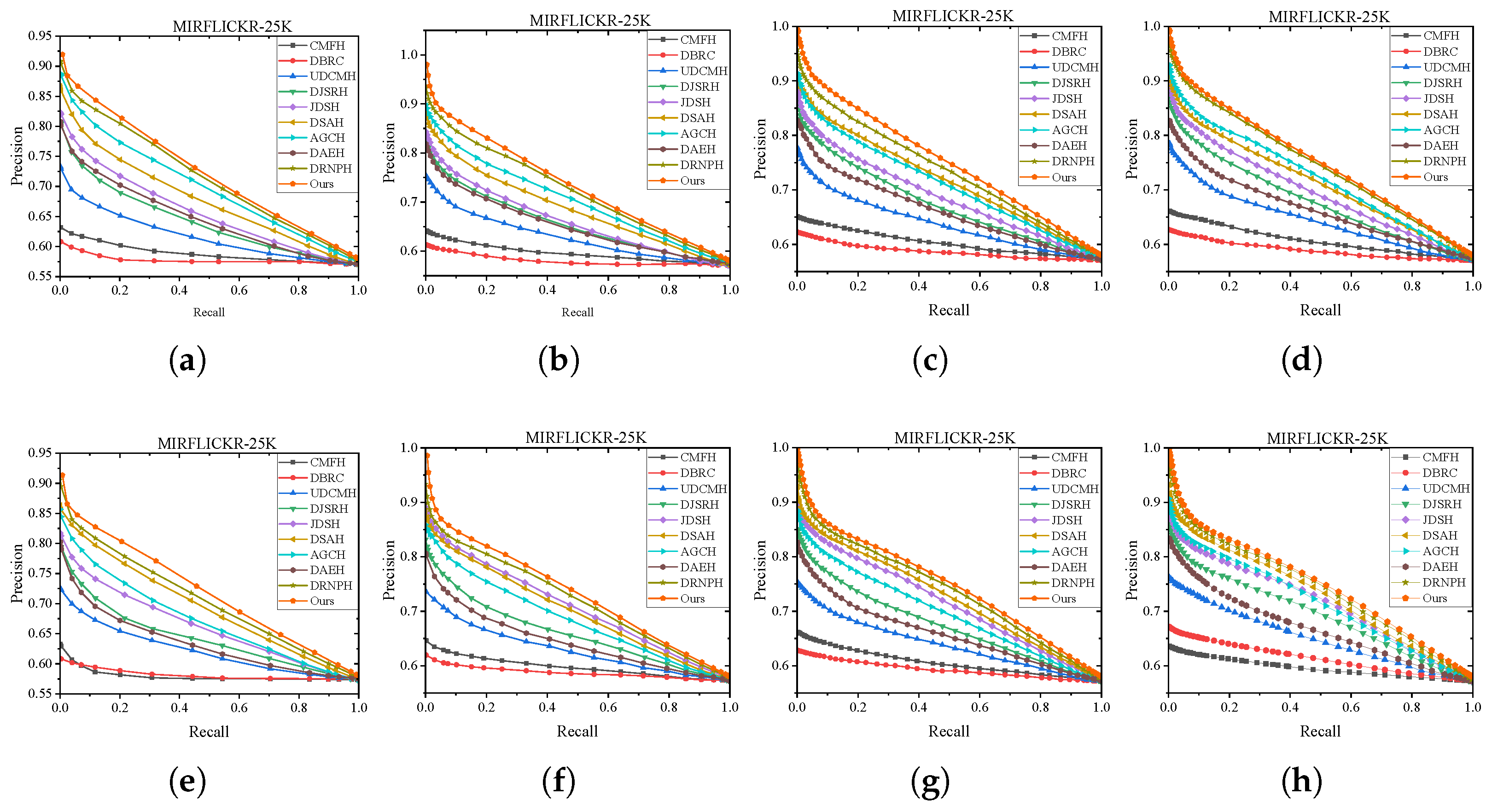
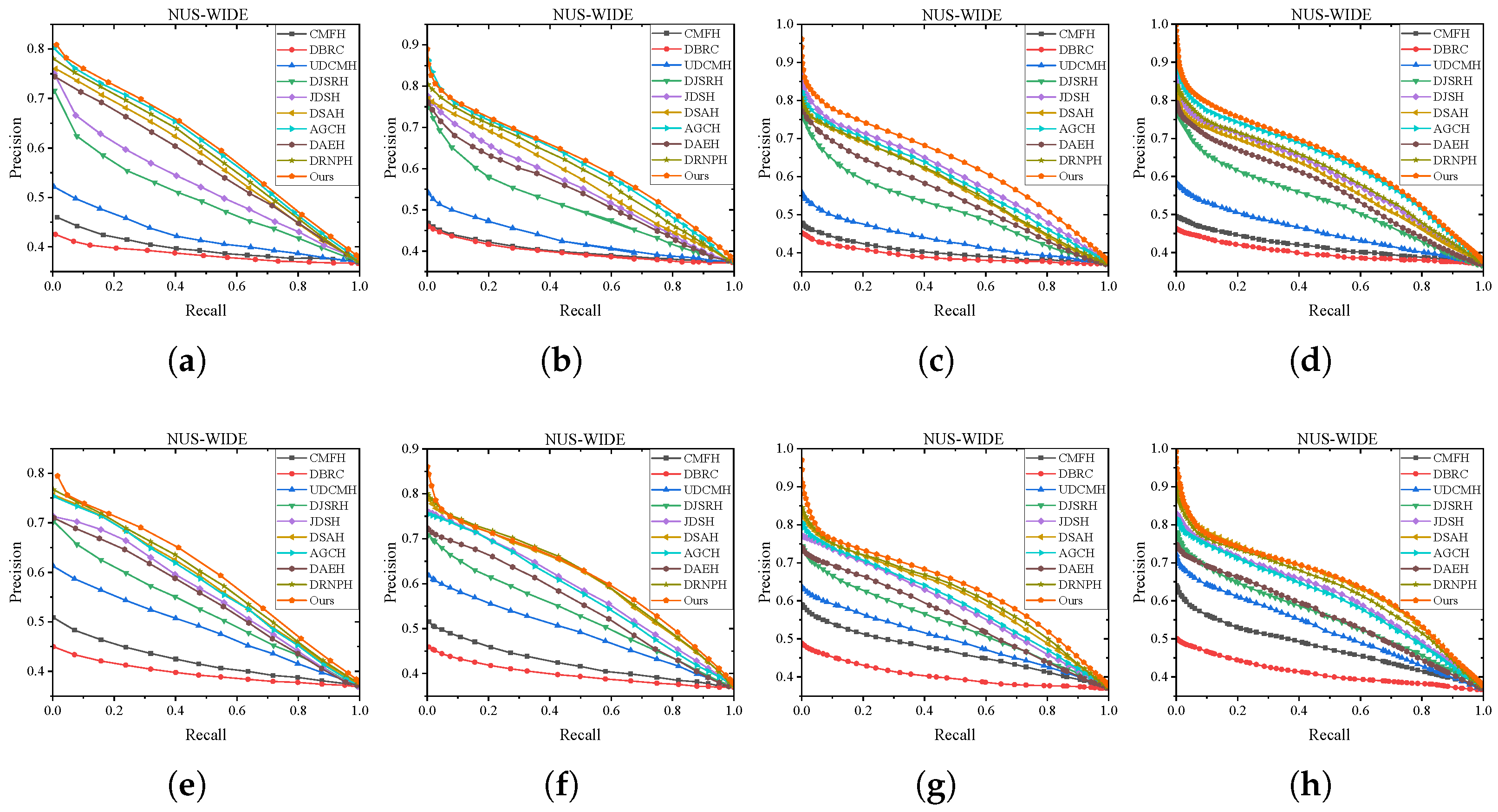
We compare the proposed method with nine baselines on MIRFLICKR-25K and NUS-WIDE datasets. The performance of all these methods are evaluated by Hamming Ranking protocol and hash lookup protocol. Table 6 and Table 7 illustrates the mAP@50 results of our method and the competitors varying hash code lengths (16, 32, 64, 128 bits) on MIRFLICKR-25K and NUS-WIDE. Figure 5 and Figure 6 show the P-R curves on these two datasets in various code length. The detailed analysis and observation are presented as follows.
Table 6.
mAP@50 score of our method and the baselines at various code lengths (bits) on MIRFLICKR-25K.
Table 7.
mAP@50 score of our method and the baselines at various code lengths (bits) on NUS-WIDE.
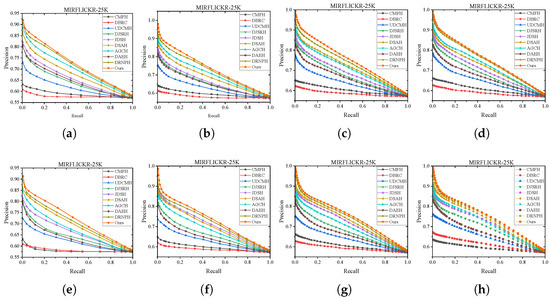
Figure 5.
P-R curves of different models at different lengths on MIRFLICKR-25K dataset. (a) I2T:16bit. (b) I2T:32bit. (c) I2T:64bit. (d) I2T:128bit. (e) T2I:16bit. (f) T2I:32bit. (g) T2I:64bit. (h) T2I:64bit.
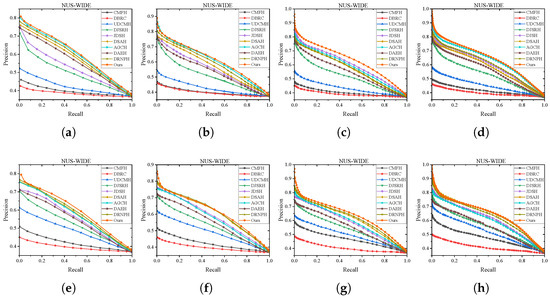
Figure 6.
P-R curves of different models at different lengths on MIRFLICKR-25K dataset. (a) I2T:16bit. (b) I2T:32bit. (c) I2T:64bit. (d) I2T:128bit. (e) T2I:16bit. (f) T2I:32bit. (g) T2I:64bit. (h) T2I:128bit.
Hamming Ranking. It is clearly from the Table 6 and Table 7 that the proposed method performs better than the baselines. Specifically, on MIRFLICKR-25K, we found that our method achieved the highest mAP@50 score for both retrieval tasks (I2T: mAP@50 = 0.898 (16 bits), mAP@50 = 0.915 (32 bits), mAP@50 = 0.927 (64 bits), mAP@50 = 0.936 (128 bits); T2I: mAP@50 = 0.876 (16 bits), mAP@50 = 0.883 (32 bits), mAP@50 = 0.889 (64 bits), mAP@50 = 0.900 (128 bits)). For example, our method beats out the strongest competitor, DRNPH, by a significant margin on both two tasks, especially in shorter hash code length: 0.022 (16 bits), 0.013 (32 bits), 0.013 (64 bits) on I2T task, and 0.016 (16 bits), 0.011 (32 bits) on T2I task. The reason behind these results is obvious: with the engagement of the proposed similarity matrix updating strategy, our method can gradually eliminate the noise of the original features used in the similarity relationship construction so as to improve similarity consistency preserving, which is unfortunately ignored by DRNPH. In all but a few case (32 bits code length on I2T and I2T task, MGSPU was defeated by AGCH and DSAH marginally), our method won the competition again on NUS-WIDE by stand-out performance: mAP@50 = 0.811 (16 bits), 0.826 (32 bits), 0.844 (64 bits), 0.858 (128 bits) on I2T task, and mAP@50 = 0.780 (16 bits), 0.786 (32 bits), 0.806 (64 bits), 0.813 (128 bits) on T2I task. Compared with mainstream solutions, complex similarity correlations can be greatly mined through the semantic similarity matrix update strategy, and the MGSP module further retains the potential similarity structure between data.
Hash Lookup. To comprehensively showcase the comprehensive performance comparison of MGSPU with baselines, we draw P-R curves in Figure 5 and Figure 6 with different code lengths on both two datasets. As expected, in addition to dramatically defeating hand-crafted feature based method CMFH, MGSPU outperforms state-of-the-art competitors DRNPH, DSAH and AGCH on various hash code length. This observation is mainly due to the search performance boosting from the interplay of similarity updating and multi-grained similarity preserving of hash codes.
Discussion. It is no secret that, the main reason of poor performance of early models (such as CMFH and DBRC) is their shallow feature extraction techniques that cannot obtain feature representations with rich semantic information. With the help of powerful deep learning techniques, deep neural networks based methods such as DJSRH, JDSH, AGCH and DAEH achieved good results. Among them, DJSRH is equiped with a reconstruction framework for training, which is more competitive than batch training. AGCH uses GCN to aggregate neighborhood information and enhance feature expression. DAEH leverages teacher networks to enhance weaker hashing networks. However, all of them build similarity matrices based on original features, which inevitably bring noises into semantic relationships so as to introduce biases. Furthermore, these methods either maintain local or global similarities to preserve the semantic relationships. For example, the similarity matrix in DJSRH contains redundant information from intra-modal fusion items, while DAEH ignores the semantic relationships of intra-modal details. Comparing with these solutions, therefore, we argue that stepwise denoising through a similarity matrix update strategy can greatly mine complex similarity correlations, thereby generating high-confidence supervision signals. In addition, the MGSP method can effectively improve the hash code quality due to further preserving the potential similar structures within and between modalities. Both the mAP@50 score on the hash ranking protocol and the area under the P-R curves on the hash lookup procotol strongly support our view.
4.5. Ablation Study
To verify the validity of each design in MGSPU, we conducted ablation experiments on the MIRFLICKR-25K and NUS-WIDE datasets, serveral variations were considered for this purpose:
- MGSPU-1: it removes semantic similarity matrix updating from MGSPU.
- MGSPU-2: it removes the similarity consistency reconstruction from MGSPU.
- MGSPU-3: it modifies similarity consistency reconstruction by replacing inter-modal reconstruction with intra-modal reconstruction.
- MGSPU-4: it removes the GCN module from MGSPU.
From Table 8 and Table 9, the following observations can be obtained: firstly, the comparison of MGSPU-1 with our the full MGSPU method verifies that the proposed dual instruction fusion updating strategy can improve the quality of instance similarity matrix to enhance the retrieval performance. Specifically, the retrieval accuracy of MGSPU-1 for both I2T and T2I task show decrease in some extent: on MIRFLICKR-25K, mAP@50 results of I2T task drop from 0.898 (16 bits), 0.915 (32 bits), 0.927 (64 bits), 0.936 (128 bits) to 0.894 (16 bits), 0.912 (32 bits), 0.924 (64 bits), 0.933 (128 bits), respectively; mAP@50 results of T2I task drop from 0.876 (16 bits), 0.883 (32 bits), 0.889 (64 bits), 0.900 (128 bits) to 0.872 (16 bits), 0.876 (32 bits), 0.883 (64 bits), 0.892 (128 bits), respectively. It indicates that without the semantic similarity matrix updating, complex similarity relationship learning suffers from disturbance by noise. Secondly, we can clearly observe that MGSPU-2 has a remarkably performance degradation compared with the full version of MGSPU. This phenomenon confirms that similarity consistency reconstruction is beneficial to preserve semantic information into hash code. Thirdly, with intra-modal reconstruction, MGSPU-3 performs better than MGSPU-2 especially on long hash codes (e.g., 64 or 128 bits). However, compared with the inter-modal reconstruction used in our method, the performance of MGSPU-3 is slightly weaker, which indicates that the inter-modal reconstruction is more helpful to reduce the heterogeneity between the original feature and the hash code. Lastly, after removing GCN module, MGSPU-4 achieves lower retrieval accuracy than ours. these results show that the structural similarity aggregated from neighborhoods by the GCN module is essential to enrich the similarity relationship information of each instance.
Table 8.
mAP@50 score for ablation study on MIRFLICKR-25K.
Table 9.
mAP@50 score for ablation study on NUS-WIDE.
4.6. Sensitivity to Hyperparameters
This section, we conduct an analysis of the sensitivity of all hyperparameters used in the model: . To explore the comprehensive impact of them, the accuracy of I2T and T2I task is used to visualize the trend of cross-modal hash performance. All these analysis are carried out in 16 bit hash code length on NUS-WIDE dataset.
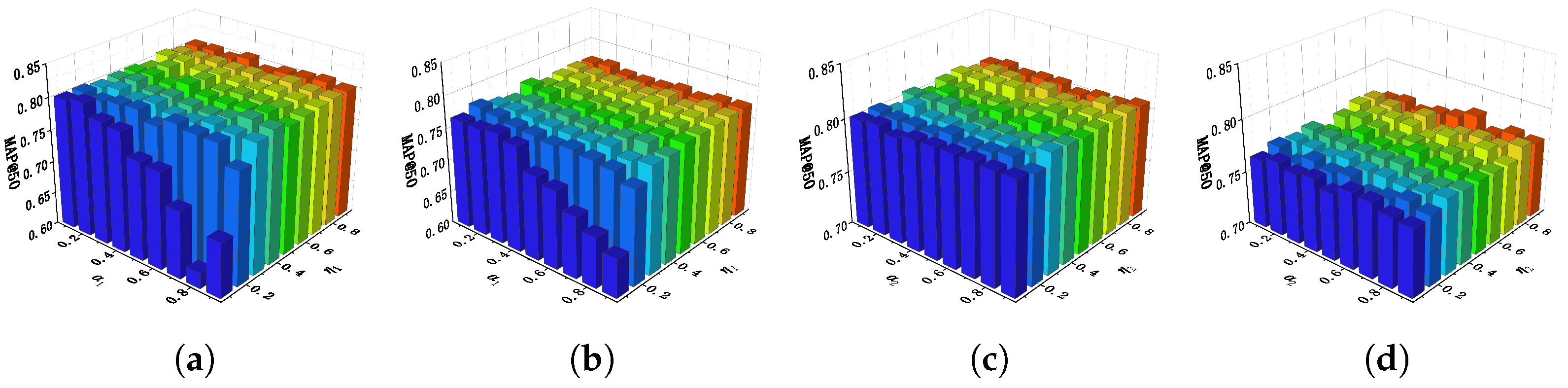
Hyperparameter . In semantic similarity matrix updating module, are used to construct the refined similarity matrix , are used to execute the updating strategy to generate semantic similarity matrix . We observe the performance change of MGSPU by varying and . According to the experimental results in Figure 7, it is clearly that the retrieval accuracy is more susceptible to changes of when the value of is small. We speculate that this phenomenon is caused by the noises that are injected in refined similarity matrix when the value of is small. On the other hand, when we change the and , the fluctuations in model performance are relatively less severe, which still shows that our model performs a bit better if is set to a large value (r.g., ). The reason behind this results is understandable: if a larger threshold is taken, the discrimination of whether and are dissimilar will be more rigorous. Under this circumstance, the semantic similarity matrix updating will be executed more cautiously to preserve robust.
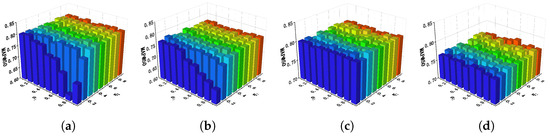
Figure 7.
Sensitivity analysis of , and , on NUS-WIDE dataset. (a) I2T: and . (b) T2I: and . (c) I2T: and . (d) T2I: and .
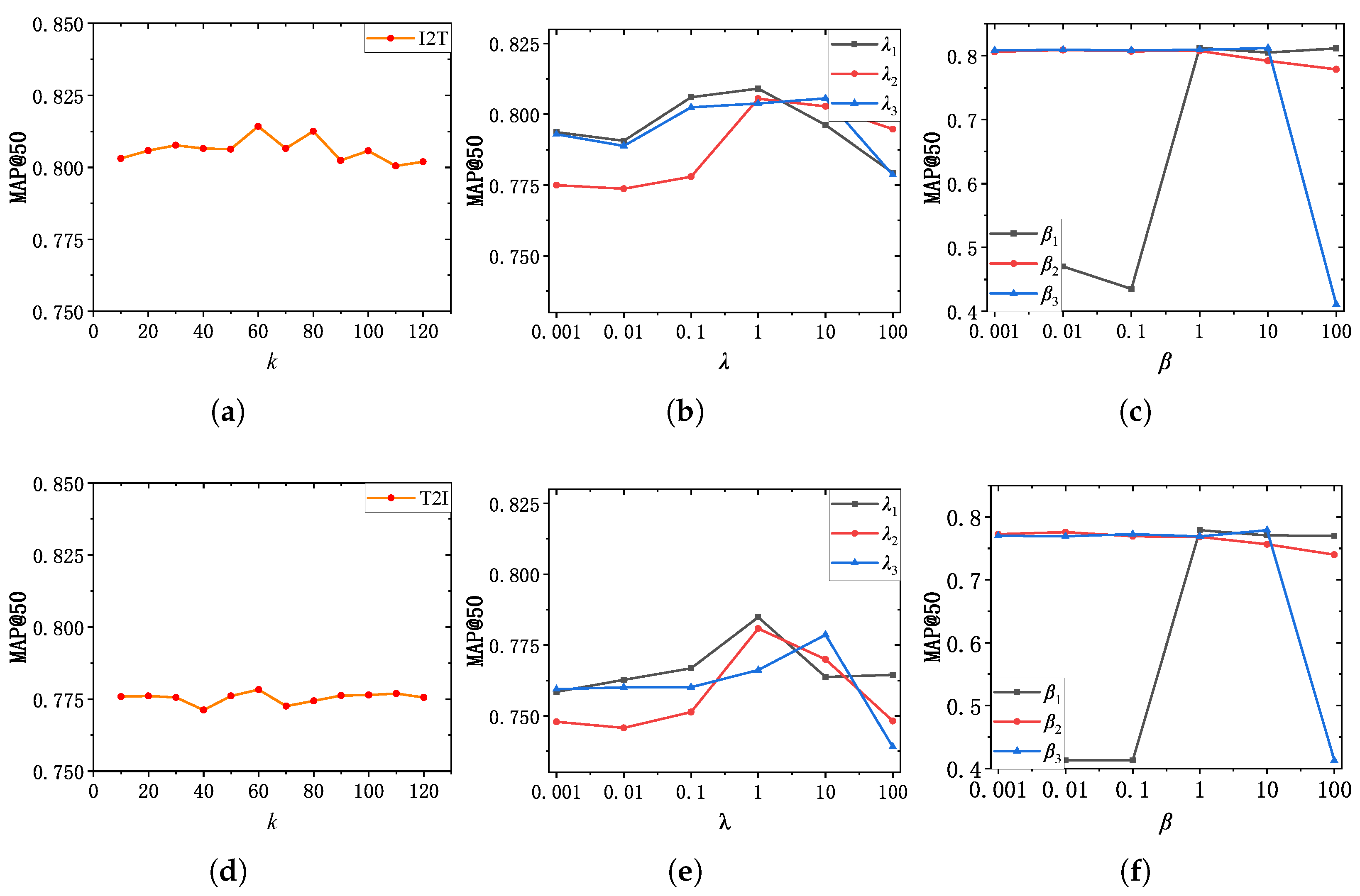
Hyperparameter k. We recorded the performance change by varying the value of k on NUS-WIDE dataset to evaluate the effect by the the number of neighbors in kNN algorithm. As demonstrated in Figure 8, when , the curve changes sharply, while the curve changes more modestly in the rest of the interval. We conjecture that when too many or too few neighbors we selected, noise will be introduced into the intra-modal similarity relationship representation, thereby affecting the latent similarity relationship learning within modality. Particularly, if k is set to 60, MGSPU achieves the highest mAP@50 score for both I2T and T2I task. It indicates that by selecting an appropriate number of neighbors, high-quality intra-modal similarity structure information can be aggregated by GCN to improve intra-modal similarity consistency preserving.
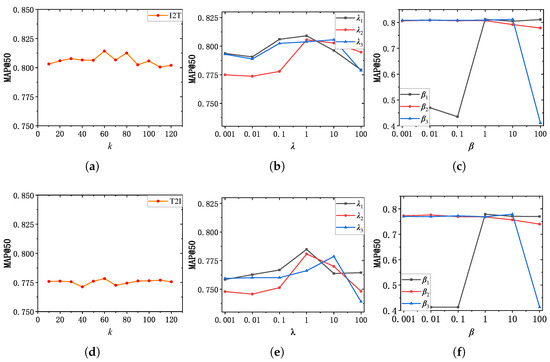
Figure 8.
Sensitivity analysis of k; ; on NUS-WIDE dataset. (a) I2T: k. (b) I2T: . (c) I2T: . (d) T2I: k. (e) T2I: . (f) T2I: .
Hyperparameter. As presented in Equation (20), are used to balance three components, i.e., , and of hash code learning loss function. To analyze the effect by these three losses, we recorded the performance change of our method in Figure 8 by varying from 0.001 to 100 with a 10-fold increase. It is noteworthy that our method obtains the best performance if we set . Among these three losses, we found that the new designed loss has a relatively greater effect on the learning of hash code. We argue that this is mainly due to the indispensability of a reliable similarity matrix for unsupervised hash learning.
Hyperparameter . As depicted in Equation (21), serves as weight factor to balance , , and . The observations in Figure 8 indicates that and contributes more than . We infer that although the duty of is to ensure numerical consistency between the generated hash codes and trained hash codes and , the main goal of cross-modal hash learning is still to eliminate cross-modal heterogeneity, which is only achieved by . Besides, the quantization error is cannot reduced by other losses but . In addition, by setting , our method achieves the best performance.
5. Conclusions
In this paper, we propose a novel unsupervised hashing learning framework, called multi-grained similarity preserving and updating to improve cross-modal hashing performance. To obtain a high-confidence similarity matrix, we develop an update strategy that corrects the similarity values after the original feature fusion using a matrix constructed in Hamming space, and a loss function is designed to guide the similarity update. Also to learn high-quality hash codes, we co-model from multiple granularity to preserve semantic correlations within and between modalities. Specifically, GCNs is used to capture the global similarity relationship within each modality, and a cross-attention mechanism is used to perform interactions between modalities to bridge the heterogeneous gap. In addition, deep feature reconstruction further enhances inter-modal correlations and reduces modal gaps.
In our experiments, we use the hamming ranking protocol and the hash lookup protocol to compare with other benchmark models, and the experimental results on both datasets show that our approach achieves impressive performance. In addition, we set up four different ablation experiments to verify the performance of the designed module, and the results also validate the effectiveness of the designed module.
Although our experimental results achieved excellent results, for text data, we only used a simple bag-of-words model, and the gap between the results of image-retrieval text and text-retrieval image is relatively large. As an exploratory work, we plan to further improve the feature extraction stage in the future to achieve a more accurate alignment of the semantic information of images and text, which will lead to a more balanced cross-modal retrieval.
Author Contributions
R.W. and L.Z. designed the methodology, wrote the original draft, designed and prepared all figures. X.Z. contributed to conceptualization, project administration. X.Z. and L.Z. acquired funding, reviewed and edited the manuscript. R.W. and L.Z. conceived the experiments. R.W., Z.Y. and Y.L. conducted the experiments and acquired experimental results. R.W., L.Z. and Z.Z. analyzed the experimental results. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National Natural Science Foundation of China (62202163, 62072166), the Natural Science Foundation of Hunan Province (2022JJ40190), the Scientific Research Project of Hunan Provincial Department of Education (22A0145), the Key Research and Development Program of Hunan Province (2020NK2033), the Hunan Provincial Department of Education Scientific Research Outstanding Youth Project (21B0200), and the Hunan Provincial Natural Science Foundation Youth Fund Project (2023JJ40333).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
This paper uses the publicly available dataset MIRFLICKR-25K, NUS-WIDE.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–25. [Google Scholar]
- Zhu, L.; Zhang, C.; Song, J.; Liu, L.; Zhang, S.; Li, Y. Multi-graph based hierarchical semantic fusion for cross-modal representation. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhang, B.; Hu, H.; Sha, F. Cross-modal and hierarchical modeling of video and text. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 374–390. [Google Scholar]
- Xie, L.; Shen, J.; Zhu, L. Online cross-modal hashing for web image retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. Number 1. [Google Scholar]
- Tian, Y.; Zhou, L.; Zhang, Y.; Zhang, T.; Fan, W. Deep cross-modal face naming for people news retrieval. IEEE Trans. Knowl. Data Eng. 2019, 33, 1891–1905. [Google Scholar] [CrossRef]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10394–10403. [Google Scholar]
- Wang, K.; Yin, Q.; Wang, W.; Wu, S.; Wang, L. A comprehensive survey on cross-modal retrieval. arXiv 2016, arXiv:1607.06215. [Google Scholar]
- Huang, X.; Peng, Y.; Yuan, M. MHTN: Modal-adversarial hybrid transfer network for cross-modal retrieval. IEEE Trans. Cybern. 2018, 50, 1047–1059. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Yang, Y.; Li, Y.; Liu, L.; Fei, H.; Li, P. Heterogeneous attention network for effective and efficient cross-modal retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Montreal, QC, Canada, 11–15 July 2021; pp. 1146–1156. [Google Scholar]
- Chun, S.; Oh, S.J.; De Rezende, R.S.; Kalantidis, Y.; Larlus, D. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 8415–8424. [Google Scholar]
- Gao, D.; Jin, L.; Chen, B.; Qiu, M.; Li, P.; Wei, Y.; Hu, Y.; Wang, H. Fashionbert: Text and image matching with adaptive loss for cross-modal retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 2251–2260. [Google Scholar]
- Su, S.; Zhong, Z.; Zhang, C. Deep joint-semantics reconstructing hashing for large-scale unsupervised cross-modal retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 3027–3035. [Google Scholar]
- Gu, J.; Cai, J.; Joty, S.R.; Niu, L.; Wang, G. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7181–7189. [Google Scholar]
- Cheng, M.; Jing, L.; Ng, M.K. Robust unsupervised cross-modal hashing for multimedia retrieval. ACM Trans. Inf. Syst. (TOIS) 2020, 38, 1–25. [Google Scholar]
- Yao, H.L.; Zhan, Y.W.; Chen, Z.D.; Luo, X.; Xu, X.S. Teach: Attention-aware deep cross-modal hashing. In Proceedings of the z, Taipei, Taiwan, 21–24 August 2021; pp. 376–384. [Google Scholar]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. Hcmsl: Hybrid cross-modal similarity learning for cross-modal retrieval. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Jiang, Q.Y.; Li, W.J. Deep cross-modal hashing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3232–3240. [Google Scholar]
- Yang, E.; Deng, C.; Liu, W.; Liu, X.; Tao, D.; Gao, X. Pairwise relationship guided deep hashing for cross-modal retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. Number 1. [Google Scholar]
- Ma, L.; Li, H.; Meng, F.; Wu, Q.; Ngan, K.N. Global and local semantics-preserving based deep hashing for cross-modal retrieval. Neurocomputing 2018, 312, 49–62. [Google Scholar] [CrossRef]
- Shen, X.; Zhang, H.; Li, L.; Yang, W.; Liu, L. Semi-supervised cross-modal hashing with multi-view graph representation. Inf. Sci. 2022, 604, 45–60. [Google Scholar]
- Li, C.; Deng, C.; Li, N.; Liu, W.; Gao, X.; Tao, D. Self-supervised adversarial hashing networks for cross-modal retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–20 July 2018; pp. 4242–4251. [Google Scholar]
- Zhang, D.; Wu, X.J.; Yu, J. Label consistent flexible matrix factorization hashing for efficient cross-modal retrieval. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–18. [Google Scholar] [CrossRef]
- Chen, Z.D.; Li, C.X.; Luo, X.; Nie, L.; Zhang, W.; Xu, X.S. SCRATCH: A scalable discrete matrix factorization hashing framework for cross-modal retrieval. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2262–2275. [Google Scholar] [CrossRef]
- Hu, P.; Zhen, L.; Peng, D.; Liu, P. Scalable deep multimodal learning for cross-modal retrieval. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 635–644. [Google Scholar]
- Dong, X.; Liu, L.; Zhu, L.; Nie, L.; Zhang, H. Adversarial graph convolutional network for cross-modal retrieval. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1634–1645. [Google Scholar] [CrossRef]
- Zhang, P.F.; Li, Y.; Huang, Z.; Xu, X.S. Aggregation-based graph convolutional hashing for unsupervised cross-modal retrieval. IEEE Trans. Multimed. 2021, 24, 466–479. [Google Scholar]
- Shi, Y.; Zhao, Y.; Liu, X.; Zheng, F.; Ou, W.; You, X.; Peng, Q. Deep adaptively-enhanced hashing with discriminative similarity guidance for unsupervised cross-modal retrieval. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7255–7268. [Google Scholar]
- Zhu, L.; Wu, X.; Li, J.; Zhang, Z.; Guan, W.; Shen, H.T. Work together: Correlation-identity reconstruction hashing for unsupervised cross-modal retrieval. IEEE Trans. Knowl. Data Eng. 2022, 35, 8838–8851. [Google Scholar] [CrossRef]
- Li, C.; Deng, C.; Wang, L.; Xie, D.; Liu, X. Coupled cyclegan: Unsupervised hashing network for cross-modal retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, January 27–1 February 2019; Volume 33, Number 01. pp. 176–183. [Google Scholar]
- Wang, W.; Shen, Y.; Zhang, H.; Yao, Y.; Liu, L. Set and rebase: Determining the semantic graph connectivity for unsupervised cross-modal hashing. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, YoKohama, Japan, 7–15 January 2021; pp. 853–859. [Google Scholar]
- Ding, G.; Guo, Y.; Zhou, J. Collective matrix factorization hashing for multimodal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2075–2082. [Google Scholar]
- Song, J.; Yang, Y.; Yang, Y.; Huang, Z.; Shen, H.T. Inter-media hashing for large-scale retrieval from heterogeneous data sources. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 785–796. [Google Scholar]
- Tu, R.C.; Mao, X.L.; Lin, Q.; Ji, W.; Qin, W.; Wei, W.; Huang, H. Unsupervised Cross-modal Hashing via Semantic Text Mining. IEEE Trans. Multimed. 2023, 25, 8946–8957. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhu, Y.; Liao, S.; Ye, Q.; Zhang, H. Class concentration with twin variational autoencoders for unsupervised cross-modal hashing. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 349–365. [Google Scholar]
- Wu, G.; Lin, Z.; Han, J.; Liu, L.; Ding, G.; Zhang, B.; Shen, J. Unsupervised Deep Hashing via Binary Latent Factor Models for Large-scale Cross-modal Retrieval. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 1, Number 3. p. 5. [Google Scholar]
- Liu, S.; Qian, S.; Guan, Y.; Zhan, J.; Ying, L. Joint-modal distribution-based similarity hashing for large-scale unsupervised deep cross-modal retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 1379–1388. [Google Scholar]
- Yang, D.; Wu, D.; Zhang, W.; Zhang, H.; Li, B.; Wang, W. Deep semantic-alignment hashing for unsupervised cross-modal retrieval. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 26–29 October 2020; pp. 44–52. [Google Scholar]
- Zhang, Z.; Lin, Z.; Zhao, Z.; Xiao, Z. Cross-modal interaction networks for query-based moment retrieval in videos. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 655–664. [Google Scholar]
- Wang, Z.; Liu, X.; Li, H.; Sheng, L.; Yan, J.; Wang, X.; Shao, J. Camp: Cross-modal adaptive message passing for text-image retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 5764–5773. [Google Scholar]
- Yu, Y.; Xiong, Y.; Huang, W.; Scott, M.R. Deformable siamese attention networks for visual object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 6728–6737. [Google Scholar]
- Gu, W.; Gu, X.; Gu, J.; Li, B.; Xiong, Z.; Wang, W. Adversary guided asymmetric hashing for cross-modal retrieval. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 159–167. [Google Scholar]
- Zhang, D.; Li, W.J. Large-scale supervised multimodal hashing with semantic correlation maximization. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014; Volume 28. Number 1. [Google Scholar]
- Lin, Z.; Ding, G.; Hu, M.; Wang, J. Semantics-preserving hashing for cross-view retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3864–3872. [Google Scholar]
- Cao, Y.; Liu, B.; Long, M.; Wang, J. Cross-modal hamming hashing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 202–218. [Google Scholar]
- Jin, S.; Zhou, S.; Liu, Y.; Chen, C.; Sun, X.; Yao, H.; Hua, X.S. SSAH: Semi-supervised adversarial deep hashing with self-paced hard sample generation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, Number 07. pp. 11157–11164. [Google Scholar]
- Liu, X.; Yu, G.; Domeniconi, C.; Wang, J.; Ren, Y.; Guo, M. Ranking-based deep cross-modal hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, Number 01. pp. 4400–4407. [Google Scholar]
- Sun, C.; Latapie, H.; Liu, G.; Yan, Y. Deep normalized cross-modal hashing with bi-direction relation reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4941–4949. [Google Scholar]
- Yu, J.; Zhou, H.; Zhan, Y.; Tao, D. Deep graph-neighbor coherence preserving network for unsupervised cross-modal hashing. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, Number 5. pp. 4626–4634. [Google Scholar]
- Yang, X.; Wang, Z.; Wu, N.; Li, G.; Feng, C.; Liu, P. Unsupervised Deep Relative Neighbor Relationship Preserving Cross-Modal Hashing. Mathematics 2022, 10, 2644. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ko, Y. A study of term weighting schemes using class information for text classification. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 1029–1030. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, June 26–1 July 2016; pp. 770–778. [Google Scholar]
- Memory, L.S.T. Long short-term memory. Neural Comput. 2010, 9, 1735–1780. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Huiskes, M.J.; Lew, M.S. The mir flickr retrieval evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; pp. 39–43. [Google Scholar]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini Island, Greece, 8–10 July 2009; pp. 1–9. [Google Scholar]
- Liu, W.; Mu, C.; Kumar, S.; Chang, S.F. Discrete graph hashing. Adv. Neural Inf. Process. Syst. 2014, 27, 3419–3427. [Google Scholar]
- Li, X.; Hu, D.; Nie, F. Deep binary reconstruction for cross-modal hashing. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1398–1406. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).