
Experimental Evaluation of Possible Feature Combinations for the Detection of Fraudulent Online Shops


Abstract
:1. Introduction
2. Materials and Methods
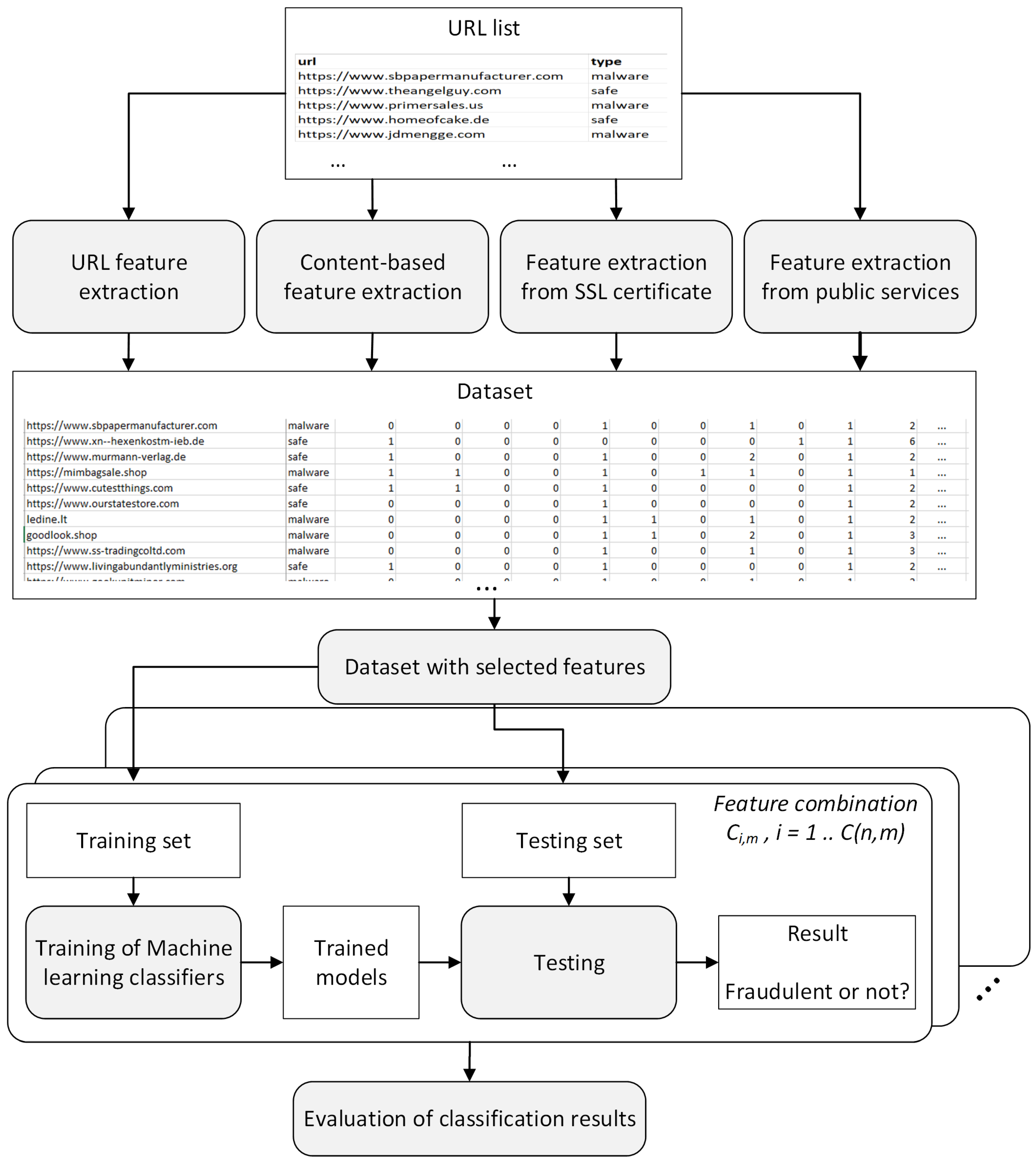
2.1. Methodology
- True Positive (TP). The number of cases where an online shop is correctly classified as fraudulent.
- False Positive (FP). The number of cases where an online shop is incorrectly classified as fraudulent.
- True Negative (TN). The number of cases where an online shop is correctly identified as legitimate.
- False Negative (FN). The number of cases where an online shop is incorrectly classified as legitimate.
2.2. Primary Dataset Preparation
- The majority of the publicly available datasets contain all kinds of phishing websites, characterized by different features, some of them completely not relevant to online shops.
- The existing datasets dedicated to online shops do not contain all the proposed features, which require one to extract additional data from the website content and third-party services.
2.3. Experimental Setup
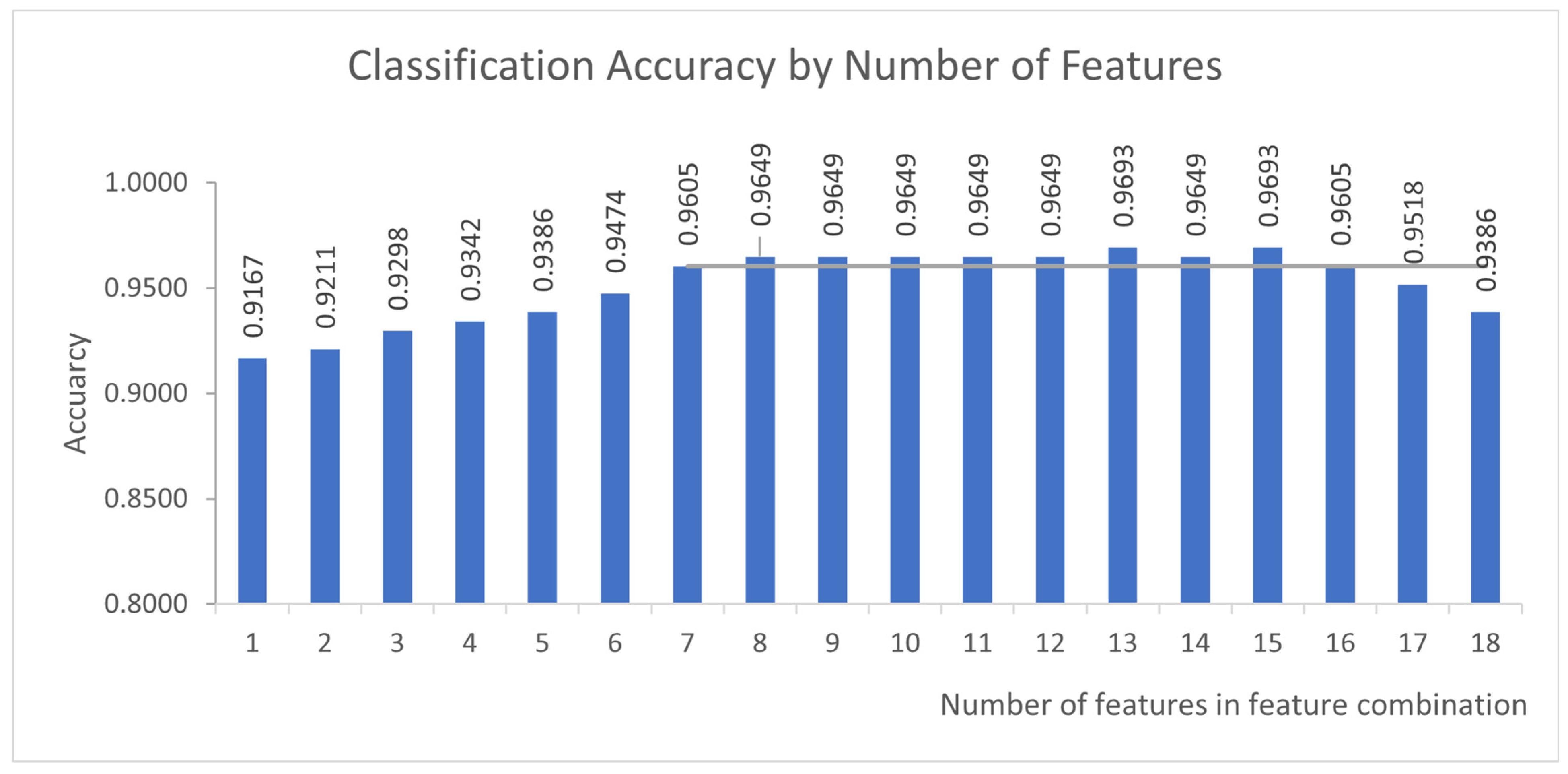
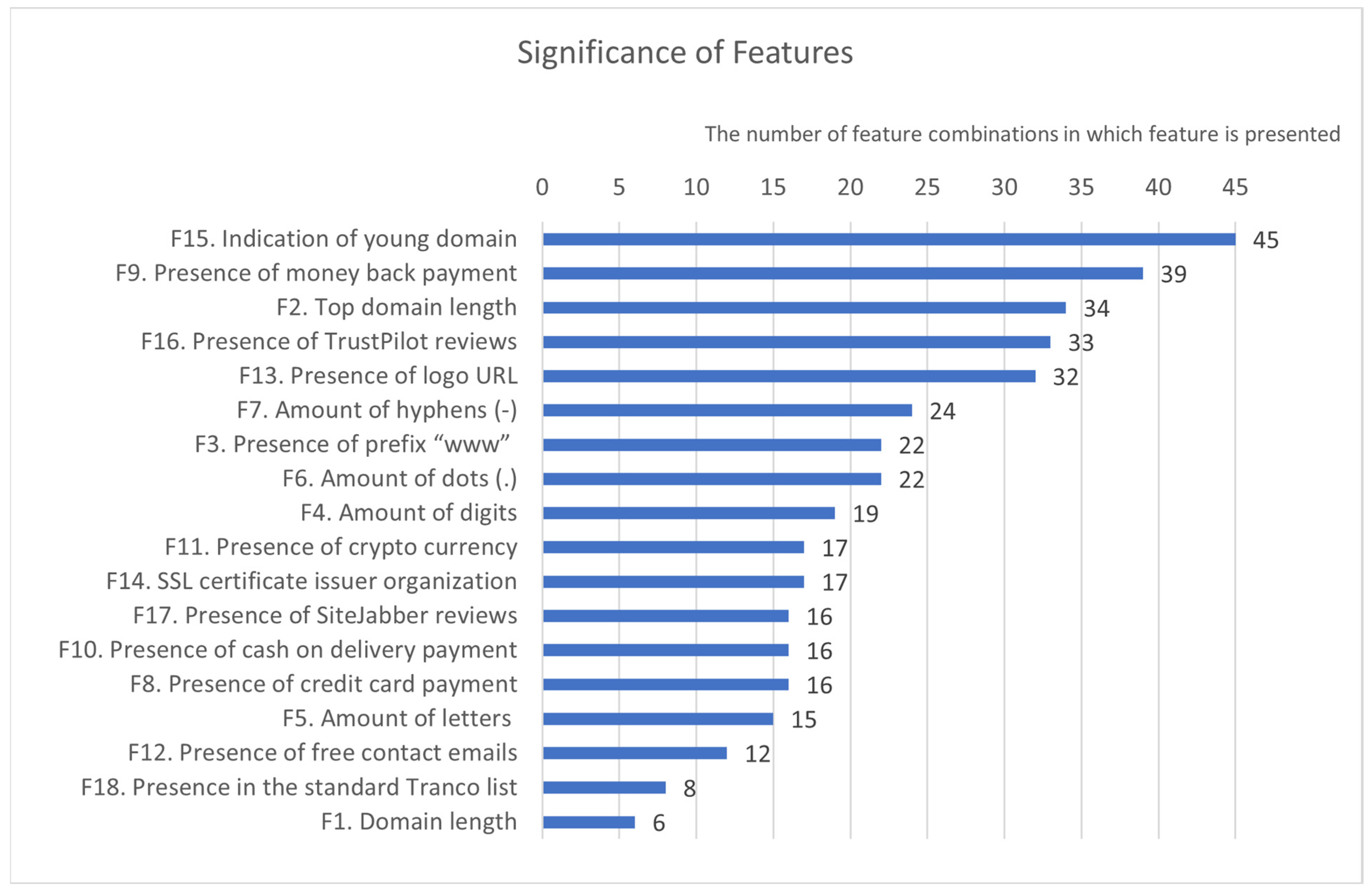
3. Results
4. Discussion
4.1. Context and Major Findings
4.2. Comparison to Similar Studies
4.3. Importance of the Features
4.4. Comparison of Classifiers
4.5. Practical Applicability of the Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hilal, W.; Gadsden, S.A.; Yawney, J. Financial Fraud: A Review of Anomaly Detection Techniques and Recent Advances. Expert Syst. Appl. 2022, 193, 116429. [Google Scholar] [CrossRef]
- Al-Hashedi, K.G.; Magalingam, P. Financial Fraud Detection Applying Data Mining Techniques: A Comprehensive Review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Tang, L.; Mahmoud, Q.H. A Survey of Machine Learning-Based Solutions for Phishing Website Detection. Make 2021, 3, 672–694. [Google Scholar] [CrossRef]
- Zieni, R.; Massari, L.; Calzarossa, M.C. Phishing or Not Phishing? A Survey on the Detection of Phishing Websites. IEEE Access 2023, 11, 18499–18519. [Google Scholar] [CrossRef]
- Coppola, D. Global Number of Digital Buyers 2014–2021. Available online: https://www.statista.com/statistics/251666/number-of-digital-buyers-worldwide/ (accessed on 30 April 2023).
- Coppola, D. Share of Online Shopping Scam Victims Who Lost Money Worldwide 2015–2022. Available online: https://www.statista.com/statistics/1273302/consumers-who-lost-money-due-to-online-shopping-scams/ (accessed on 30 April 2023).
- Chevalier, S. Median Monetary Loss per Online Purchase Scam Worldwide 2015–2022. Available online: https://www.statista.com/statistics/1273330/median-money-lost-to-online-purchase-scams/ (accessed on 30 April 2023).
- PhishTank. Available online: https://www.phishtank.com (accessed on 30 April 2023).
- Alexa. Available online: https://www.alexa.com (accessed on 5 April 2023).
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 30 April 2023).
- OpenPhish. Available online: https://openphish.com/ (accessed on 30 April 2023).
- Common Crawl Index Server. Available online: https://commoncrawl.org/ (accessed on 30 April 2023).
- URL Dataset (ISCX-URL2016). Available online: https://www.unb.ca/cic/datasets/url-2016.html (accessed on 30 April 2023).
- Ishikawa, T.; Liu, Y.-L.; Shepard, D.L.; Shin, K. Machine Learning for Tree Structures in Fake Site Detection. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Virtual Event Ireland, 25 August 2020; ACM: New York, NY, USA; pp. 1–10. [Google Scholar]
- Al-Sarem, M.; Saeed, F.; Al-Mekhlafi, Z.G.; Mohammed, B.A.; Al-Hadhrami, T.; Alshammari, M.T.; Alreshidi, A.; Alshammari, T.S. An Optimized Stacking Ensemble Model for Phishing Websites Detection. Electronics 2021, 10, 1285. [Google Scholar] [CrossRef]
- Tanaka, S.; Matsunaka, T.; Yamada, A.; Kubota, A. Phishing Site Detection Using Similarity of Website Structure. In Proceedings of the IEEE Conference on Dependable and Secure Computing (DSC), Aizuwakamatsu, Fukushima, Japan, 30 January 2021; pp. 1–8. [Google Scholar]
- Khoo, E.; Zainal, A.; Ariffin, N.; Kassim, M.N.; Maarof, M.A.; Bakhtiari, M. Fraudulent E-Commerce Website Detection Model Using HTML, Text and Image Features. In Proceedings of the 11th International Conference on Soft Computing and Pattern Recognition (SoCPaR 2019), Hyderabad, India, 13–15 December 2019; Abraham, A., Jabbar, M.A., Tiwari, S., Jesus, I.M.S., Eds.; Advances in Intelligent Systems and Computing. Springer International Publishing: Cham, Switzerland, 2021; Volume 1182, pp. 177–186, ISBN 978-3-030-49344-8. [Google Scholar]
- Chen, J.-L.; Ma, Y.-W.; Huang, K.-L. Intelligent Visual Similarity-Based Phishing Websites Detection. Symmetry 2020, 12, 1681. [Google Scholar] [CrossRef]
- Chiew, K.L.; Chang, E.H.; Sze, S.N.; Tiong, W.K. Utilisation of Website Logo for Phishing Detection. Comput. Secur. 2015, 54, 16–26. [Google Scholar] [CrossRef]
- Mostard, W.; Zijlema, B.; Wiering, M. Combining Visual and Contextual Information for Fraudulent Online Store Classification. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14 October 2019; pp. 84–90. [Google Scholar]
- Rendall, K.; Nisioti, A.; Mylonas, A. Towards a Multi-Layered Phishing Detection. Sensors 2020, 20, 4540. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.K.; Gupta, B.B. Phishing Detection: Analysis of Visual Similarity Based Approaches. Secur. Commun. Netw. 2017, 2017, 5421046. [Google Scholar] [CrossRef]
- Aljofey, A.; Jiang, Q.; Qu, Q.; Huang, M.; Niyigena, J.-P. An Effective Phishing Detection Model Based on Character Level Convolutional Neural Network from URL. Electronics 2020, 9, 1514. [Google Scholar] [CrossRef]
- Butnaru, A.; Mylonas, A.; Pitropakis, N. Towards Lightweight URL-Based Phishing Detection. Future Internet 2021, 13, 154. [Google Scholar] [CrossRef]
- Kumar, J.; Santhanavijayan, A.; Janet, B.; Rajendran, B.; Bindhumadhava, B.S. Phishing Website Classification and Detection Using Machine Learning. In Proceedings of the International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 22–24 January 2020; pp. 1–6. [Google Scholar]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine Learning Based Phishing Detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]
- Yang, R.; Zheng, K.; Wu, B.; Wu, C.; Wang, X. Phishing Website Detection Based on Deep Convolutional Neural Network and Random Forest Ensemble Learning. Sensors 2021, 21, 8281. [Google Scholar] [CrossRef] [PubMed]
- ScamAdviser. Available online: https://www.scamadviser.com/ (accessed on 12 May 2023).
- URLVoid. Website Reputation Checker. Available online: https://www.urlvoid.com/ (accessed on 12 May 2023).
- VirusTotal. Available online: https://www.virustotal.com (accessed on 12 May 2023).
- Trustpilot. Available online: https://www.trustpilot.com (accessed on 12 May 2023).
- Shin, K.; Ishikawa, T.; Liu, Y.-L.; Shepard, D.L. Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake E-Commerce Sites. Make 2021, 3, 95–122. [Google Scholar] [CrossRef]
- WHOIS. Available online: https://who.is/ (accessed on 5 December 2023).
- Le Pochat, V.; Van Goethem, T.; Tajalizadehkhoob, S.; Korczynski, M.; Joosen, W. Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Sitejabber. Available online: https://www.sitejabber.com/ (accessed on 11 July 2023).
- Janaviciute, A.; Liutkevicius, A. Fraudulent and Legitimate Online Shops Dataset. Mendeley Data, 2023, V1. [CrossRef]
- Beltzung, L.; Lindley, A.; Dinica, O.; Hermann, N.; LindJner, R. Real-Time Detection of Fake-Shops through Machine Learning. In Proceedings of the IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10 December 2020; pp. 2254–2263. [Google Scholar]
- Sánchez-Paniagua, M.; Fidalgo, E.; Alegre, E.; Jáñez-Martino, F. Fraudulent E-Commerce Websites Detection Through Machine Learning. In Hybrid Artificial Intelligent Systems; Sanjurjo González, H., Pastor López, I., García Bringas, P., Quintián, H., Corchado, E., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12886, pp. 267–279. ISBN 978-3-030-86270-1. [Google Scholar]
- Metz, C.E. Basic Principles of ROC Analysis. Semin. Nucl. Med. 1978, 8, 283–298. [Google Scholar] [CrossRef] [PubMed]
- Watchlist Internet. Available online: https://www.watchlist-internet.at (accessed on 11 January 2024).
- Artists Against 419. Fake Sites List. Available online: https://db.aa419.org (accessed on 15 January 2024).
- Global E-Commerce Websites List. Available online: https://www.kaggle.com/datasets/wiredwith/websites-list (accessed on 15 January 2024).
- Online Shopping with Trusted Shops. Available online: https://www.trustedshops.eu/ (accessed on 15 January 2024).
- The Ecommerce Europe Trustmark. Available online: https://ecommercetrustmark.eu/ (accessed on 15 January 2024).
- EHI Geprüfter Online-Shop. Available online: https://ehi-siegel.de/ (accessed on 15 January 2024).
- Retail Excellence Ireland. Available online: https://www.retailexcellence.ie/ (accessed on 15 January 2024).
- Similarweb. Available online: https://www.similarweb.com/ (accessed on 15 January 2024).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Stancin, I.; Jovic, A. An Overview and Comparison of Free Python Libraries for Data Mining and Big Data Analysis. In Proceedings of the 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 977–982. [Google Scholar]
- XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/latest/index.html (accessed on 15 January 2024).
- Anaconda. Available online: https://www.anaconda.com/ (accessed on 12 May 2023).
- Spyder. The Scientific Python Development Environment. Available online: https://www.spyder-ide.org/ (accessed on 12 May 2023).




{kind=link}
{kind=link}
{kind=link}
| Features | Description | Possible Values |
|---|---|---|
| F1—Domain length | Number of symbols in the host domain name. | Number, [7 … 38] * |
| F2—Top domain length | Number of symbols in the top domain name. | Number, [2 … 13] * |
| F3—Presence of prefix “www” | Presence of the prefix ‘www’ in the active URL of the online shop. | {0, 1} |
| F4—Number of digits | Number of digits in the URL. | Number, [0 … 4] * |
| F5—Number of letters | Number of letters in the URL. | Number, [11 … 39] * |
| F6—Number of dots (.) | Number of dots in the URL. | Number, [1 … 3] * |
| F7—Number of hyphens (-) | Number of hyphens in the URL. | Number, [0 … 4] * |
| F8—Presence of credit card payment | Presence of payment methods, which offer the consumer the option to pay using credit cards. | {0, 1} |
| F9—Presence of money back payment | Presence of payment methods, which offer the consumer the option of getting their money back. | {0, 1} |
| F10—Presence of cash on delivery payment | Presence of payment methods, which allow the consumer to pay for goods once they are received. | {0, 1} |
| F11—Presence of crypto currency | Presence of the ability to use cryptocurrencies for payments. | {0, 1} |
| F12—Presence of free contact emails | Indication of whether public e-mail services are used for contact e-mail. | {0, 1, 2, 3} 0—email address not found 1—free email address 2—domain email address 3—other email address |
| F13—Presence of logo URL | Indication of whether the website uses its own favicon, which is associated with the online shop logo and is shown in the browser’s address bar. | {0, 1} |
| F14—SSL certificate issuer organization | The ID of the organization of the SSL certificate issuer: 1—Cloudflare, Inc., 2—Let’s Encrypt, 3—Sectigo Limited, 4—cPanel, Inc., 5—GoDaddy.com, Inc., 6—Amazon, 7—DigiCert, Inc., 8—GlobalSign nv-sa, 9—Google Trust Services LLC, 10—ZeroSSL, 11—other organization. | [1 … 11] |
| F15—Indication of young domain | Shows whether the domain is young, registered 400 days ago or later. Due to data protection, not all domain owners provide a date of registration; such domains are identified using a special value ‘hidden’. The domain registration date comes from the WHOIS database. | {0, 1, 2} 0—‘old’ domain name 1—‘young’ domain name 2—‘hidden’ |
| F16—Presence of TrustPilot reviews | Indicates whether the website has at least one review on the TrustPilot platform. | {0, 1} |
| F17—Presence of SiteJabber reviews | Indicates whether the website has at least one review on the SiteJabber platform. | {0, 1} |
| F18—Presence in the standard Tranco list | Indicates whether the domain of the website is included in the standard Tranco list based on the average number of visits. | {0, 1} |
| Classifier | Parameters |
|---|---|
| DecisionTreeClassifier | (criterion = ‘gini’, splitter = ‘best’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = None, random_state = None, max_leaf_nodes = None, min_impurity_decrease = 0.0, class_weight = None, ccp_alpha = 0.0) |
| RandomForestClassifier | (n_estimators = 100, criterion = ‘gini’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = ‘sqrt’, max_leaf_nodes = None, min_impurity_decrease = 0.0, bootstrap = True, oob_score = False, n_jobs = None, random_state = None, verbose = 0, warm_start = False, class_weight = None, ccp_alpha = 0.0, max_samples = None) |
| SGDClassifier | (loss = ‘hinge’, penalty = ‘l2’, alpha = 0.0001, l1_ratio = 0.15, fit_intercept = True, max_iter = 1000, tol = 0.001, shuffle = True, verbose = 0, epsilon = 0.1, n_jobs = None, random_state = None, learning_rate = ‘optimal’, eta0 = 0.0, power_t = 0.5, early_stopping = False, validation_fraction = 0.1, n_iter_no_change = 5, class_weight = None, warm_start = False, average = False) |
| LogisticRegression | (penalty = ‘l2’, dual = False, tol = 0.0001, C = 1.0, fit_intercept = True, intercept_scaling = 1, class_weight = None, random_state = None, solver = ‘liblinear’, max_iter = 2000, multi_class = ‘ovr’, verbose = 0, warm_start = False, n_jobs = 1, l1_ratio = None) |
| GaussianNB | (priors = None, var_smoothing = 1 × 10−9) |
| MLPClassifier | (hidden_layer_sizes = (100,), activation = ‘relu’, solver = ’sgd’, alpha = 0.0001, batch_size = ‘auto’, learning_rate = ‘constant’, learning_rate_init = 0.001, power_t = 0.5, max_iter = 2000, shuffle = True, random_state = None, tol = 0.0001, verbose = False, warm_start = False, momentum = 0.9, nesterovs_momentum = True, early_stopping = False, validation_fraction = 0.1, beta_1 = 0.9, beta_2 = 0.999, epsilon = 1 × 10−8, n_iter_no_change = 10, max_fun = 15,000) |
| XGBoost | (base_score = 0.5, booster = ‘gbtree’, device = ‘cpu‘, colsample_bylevel = 1, colsample_bynode = 1, colsample_bytree = 1, gamma = 0, interaction_constraints = ‘‘, learning_rate = 0.1, max_delta_step = 0, max_depth = 6, min_child_weight = 1, monotone_constraints = ‘()’, n_estimators = 10, num_parallel_tree = 1, objective = ‘binary:logistic’, random_state = 0, reg_alpha = 0, reg_lambda = 1, scale_pos_weight = 1, subsample = 1, sampling_method = ’uniform’, tree_method = ‘auto‘, scale_pos_weight = 1, grow_policy = ‘depthwise’, max_leaves = 0, max_bin = 256, validate_parameters = 1, verbosity = 1, use_rmm = False) |
| Number of Features | Features * Used in Feature Combinations | Accuracy of Classifiers ** | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | F11 | F12 | F13 | F14 | F15 | F16 | F17 | F18 | DT | RF | SGD | LR | GNB | MP | XGB | |
| 1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | X | - | - | - | 0.9167 | 0.9167 | 0.8596 | 0.8596 | 0.8596 | 0.8596 | 0.9079 |
| 2 | - | - | - | - | - | - | - | - | - | - | - | - | X | - | X | - | - | - | 0.9211 | 0.9211 | 0.8640 | 0.8640 | 0.6184 | 0.8640 | 0.9167 |
| - | - | - | - | - | - | - | - | - | - | - | - | - | X | X | - | - | - | 0.9211 | 0.9211 | 0.8596 | 0.8509 | 0.8509 | 0.8816 | 0.8947 | |
| 3 | - | - | - | X | - | - | - | - | - | - | - | - | - | X | X | - | - | - | 0.9211 | 0.9298 | 0.5307 | 0.8553 | 0.8596 | 0.8816 | 0.8947 |
| - | - | - | - | - | - | X | - | X | - | - | - | - | - | X | - | - | - | 0.9298 | 0.9298 | 0.8596 | 0.8596 | 0.8596 | 0.8596 | 0.9254 | |
| 4 | - | - | - | X | - | - | X | - | X | - | - | - | - | - | X | - | - | - | 0.9342 | 0.9342 | 0.8596 | 0.8596 | 0.8640 | 0.8772 | 0.9298 |
| - | - | - | - | - | - | X | - | X | - | - | - | X | - | X | - | - | - | 0.9342 | 0.9254 | 0.6140 | 0.8509 | 0.6667 | 0.8772 | 0.9211 | |
| - | - | - | - | - | - | X | - | X | - | - | - | - | - | X | - | X | - | 0.9298 | 0.9342 | 0.8596 | 0.8596 | 0.5658 | 0.8728 | 0.9254 | |
| - | - | - | X | - | - | X | - | - | - | - | - | - | X | X | - | - | - | 0.9211 | 0.9342 | 0.7851 | 0.8553 | 0.8421 | 0.8816 | 0.8991 | |
| 5 | - | - | - | X | - | - | X | - | X | - | X | - | - | - | X | - | - | - | 0.9386 | 0.9342 | 0.8596 | 0.8596 | 0.8596 | 0.8728 | 0.9298 |
| - | X | - | - | - | - | X | - | X | - | - | - | - | - | X | X | - | - | 0.9342 | 0.9386 | 0.7895 | 0.8860 | 0.8333 | 0.9079 | 0.9386 | |
| - | X | X | - | - | - | - | - | X | - | - | - | - | - | X | X | - | - | 0.9342 | 0.9386 | 0.8640 | 0.8904 | 0.8596 | 0.8991 | 0.9298 | |
| - | X | - | - | X | - | - | - | X | - | - | - | - | - | X | X | - | - | 0.9167 | 0.9342 | 0.8553 | 0.8860 | 0.8684 | 0.9167 | 0.9386 | |
| - | - | - | - | X | X | - | - | - | - | - | X | X | - | X | - | - | - | 0.8816 | 0.9035 | 0.8421 | 0.8333 | 0.8816 | 0.8070 | 0.9386 | |
| 6 | - | X | - | - | X | X | - | - | X | - | - | - | - | - | X | X | - | - | 0.9298 | 0.9474 | 0.5088 | 0.8728 | 0.8640 | 0.8991 | 0.9342 |
| - | X | X | - | - | - | X | - | X | - | - | - | - | - | X | X | - | - | 0.9430 | 0.9474 | 0.8333 | 0.8904 | 0.8640 | 0.9079 | 0.9342 | |
| - | X | - | - | X | X | - | - | X | - | - | - | X | - | X | - | - | - | 0.9342 | 0.9474 | 0.7939 | 0.8377 | 0.8991 | 0.8904 | 0.9211 | |
| - | X | - | - | - | - | X | - | X | - | - | - | X | - | X | X | - | - | 0.9342 | 0.9474 | 0.8465 | 0.8860 | 0.8991 | 0.8947 | 0.9342 | |
| - | X | X | - | - | - | - | - | X | - | - | - | X | - | X | X | - | - | 0.9386 | 0.9474 | 0.7412 | 0.8860 | 0.9123 | 0.8947 | 0.9342 | |
| - | X | - | - | - | - | - | X | X | - | - | X | - | X | X | - | - | 0.9342 | 0.9474 | 0.8640 | 0.8816 | 0.8816 | 0.9123 | 0.9342 | ||
| 7 | - | X | - | - | - | X | - | - | X | - | - | - | X | X | X | X | - | - | 0.9254 | 0.9605 | 0.8684 | 0.8728 | 0.9079 | 0.8860 | 0.9254 |
| - | X | - | - | - | X | X | - | X | - | - | - | X | - | X | X | - | - | 0.9342 | 0.9605 | 0.9035 | 0.8772 | 0.9167 | 0.8947 | 0.9386 | |
| 8 | - | X | X | - | - | - | X | - | X | - | - | - | X | X | X | X | - | - | 0.9254 | 0.9649 | 0.8816 | 0.8728 | 0.9079 | 0.8860 | 0.9211 |
| 9 | - | X | X | X | - | - | X | - | X | - | X | - | X | - | X | X | - | - | 0.9298 | 0.9649 | 0.8947 | 0.8772 | 0.9211 | 0.8947 | 0.9386 |
| - | X | - | - | - | X | X | - | X | - | - | - | X | X | X | X | X | - | 0.9211 | 0.9649 | 0.8904 | 0.8772 | 0.8553 | 0.8904 | 0.9342 | |
| - | X | X | X | - | - | X | - | X | X | - | - | X | - | X | X | - | - | 0.9254 | 0.9649 | 0.8640 | 0.8904 | 0.8947 | 0.9079 | 0.9342 | |
| 10 | X | X | - | - | - | X | - | X | X | - | - | X | X | - | X | X | X | - | 0.9079 | 0.9649 | 0.8026 | 0.8904 | 0.8816 | 0.8904 | 0.9298 |
| 11 | - | X | X | - | X | X | - | - | X | X | - | X | X | - | X | X | X | - | 0.9254 | 0.9649 | 0.8947 | 0.9035 | 0.8684 | 0.8991 | 0.9298 |
| - | X | X | X | - | X | X | - | X | X | X | - | X | - | X | X | - | - | 0.9342 | 0.9649 | 0.9298 | 0.8904 | 0.9035 | 0.9079 | 0.9386 | |
| 12 | - | X | X | - | X | X | X | X | X | - | X | - | X | X | X | X | - | - | 0.9167 | 0.9649 | 0.5175 | 0.8947 | 0.8991 | 0.8728 | 0.9211 |
| - | X | X | - | X | X | - | X | X | - | X | - | X | X | X | X | X | - | 0.9123 | 0.9649 | 0.8684 | 0.9035 | 0.8553 | 0.8772 | 0.9254 | |
| - | X | X | X | - | - | X | X | X | - | X | - | X | X | X | X | X | - | 0.9386 | 0.9649 | 0.9123 | 0.8904 | 0.8684 | 0.8772 | 0.9211 | |
| X | X | - | X | - | X | - | X | X | X | - | X | X | - | X | X | X | - | 0.9167 | 0.9649 | 0.8816 | 0.8947 | 0.8772 | 0.8991 | 0.9211 | |
| - | X | X | X | X | X | - | X | X | - | X | - | X | X | X | X | - | - | 0.9211 | 0.9649 | 0.8860 | 0.9035 | 0.9079 | 0.8772 | 0.9254 | |
| - | X | - | - | X | X | - | X | X | X | X | X | X | - | X | X | X | - | 0.9254 | 0.9649 | 0.8816 | 0.8991 | 0.8596 | 0.8991 | 0.9342 | |
| - | X | X | X | - | - | X | X | X | X | X | - | X | X | X | X | - | - | 0.9386 | 0.9649 | 0.8553 | 0.8816 | 0.8947 | 0.8860 | 0.9254 | |
| 13 | - | X | X | - | X | X | - | X | X | X | X | - | X | X | X | X | X | - | 0.9211 | 0.9693 | 0.8596 | 0.8991 | 0.8596 | 0.8728 | 0.9167 |
| 14 | X | X | X | X | - | X | - | X | X | X | - | X | X | - | X | X | X | X | 0.9167 | 0.9649 | 0.8904 | 0.8991 | 0.8377 | 0.9079 | 0.9211 |
| - | X | X | X | - | X | X | X | X | X | X | - | X | X | X | X | - | X | 0.9386 | 0.9649 | 0.8991 | 0.9079 | 0.8684 | 0.8816 | 0.9254 | |
| 15 | - | X | X | X | X | X | - | - | X | X | X | X | X | X | X | X | X | X | 0.9167 | 0.9693 | 0.8947 | 0.8947 | 0.8333 | 0.9035 | 0.9123 |
| 16 | - | X | X | X | X | X | X | X | X | X | X | X | X | - | X | X | X | X | 0.9211 | 0.9605 | 0.8947 | 0.8991 | 0.8333 | 0.9079 | 0.9298 |
| X | X | X | X | X | - | X | X | X | X | X | X | X | - | X | X | X | X | 0.9167 | 0.9605 | 0.8947 | 0.9035 | 0.8289 | 0.8947 | 0.9342 | |
| 17 | - | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | 0.9123 | 0.9518 | 0.8465 | 0.8947 | 0.8421 | 0.8947 | 0.9167 |
| X | X | X | X | - | X | X | X | X | X | X | X | X | X | X | X | X | X | 0.9211 | 0.9518 | 0.8991 | 0.8947 | 0.8333 | 0.9035 | 0.9211 | |
| 18 | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | 0.8991 | 0.9386 | 0.9035 | 0.9167 | 0.8289 | 0.8947 | 0.9211 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Janavičiūtė, A.; Liutkevičius, A.; Dabužinskas, G.; Morkevičius, N. Experimental Evaluation of Possible Feature Combinations for the Detection of Fraudulent Online Shops. Appl. Sci. 2024, 14, 919. https://doi.org/10.3390/app14020919
Janavičiūtė A, Liutkevičius A, Dabužinskas G, Morkevičius N. Experimental Evaluation of Possible Feature Combinations for the Detection of Fraudulent Online Shops. Applied Sciences. 2024; 14(2):919. https://doi.org/10.3390/app14020919
Chicago/Turabian StyleJanavičiūtė, Audronė, Agnius Liutkevičius, Gedas Dabužinskas, and Nerijus Morkevičius. 2024. "Experimental Evaluation of Possible Feature Combinations for the Detection of Fraudulent Online Shops" Applied Sciences 14, no. 2: 919. https://doi.org/10.3390/app14020919
APA StyleJanavičiūtė, A., Liutkevičius, A., Dabužinskas, G., & Morkevičius, N. (2024). Experimental Evaluation of Possible Feature Combinations for the Detection of Fraudulent Online Shops. Applied Sciences, 14(2), 919. https://doi.org/10.3390/app14020919