
How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation


Abstract
1. Introduction
- It provides a comprehensive timeline of KAN developments, highlighting key applications and tracing the evolution of function bases and activation functions.
- It conducts an in-depth analysis of KAN-based models for classification tasks, including KAN, KAN-Mixer, KANConv_KAN, and KANConv_MLP, comparing their performance against MLP and Small MLP-Mixer, as well as ConvNet_MLP models across multiple datasets (BTSD, CTSD, and GTSRB). This evaluation highlights KAN architectures’ strengths and weaknesses in handling adversarial attacks at various perturbation levels.
- We explore the effectiveness of adversarial defenses such as adversarial training and randomized smoothing training scenarios in strengthening the resilience of KAN models to adversarial attacks.
2. Materials and Methods
2.1. Kolmogorov–Arnold Representation Theorem
Design of KANs
- 1.
- Generalizing the Network Structure: Instead of adhering strictly to the original two-layer structure with 2n + 1 hidden units In Equation (1), they generalize KANs to have arbitrary widths and depths. The main challenge is to find the appropriate functions and . A general KAN network with L layers produces the output, as In Equation (3).
- 2.
- Leveraging Smoothness and Sparsity: Many real-world functions are smooth and possess sparse compositional structures, facilitating more effective Kolmogorov–Arnold representations. This aligns with the physicist’s approach of focusing on typical cases rather than worst-case scenarios, assuming that physical and machine learning tasks inherently possess useful or generalizable structures [56].
2.2. Implementation of KANs
2.3. KAN-Mixer
2.4. Convolutional Kolmogorov–Arnold Networks
3. Adversarial Attacks and Defenses
3.1. Adversarial Attacks
3.1.1. Fast Gradient Sign Method (FGSM)
3.1.2. Projected Gradient Descent (PGD)
3.1.3. Carlini–Wagner (CW) Attack
3.1.4. Basic Iterative Method (BIM)
3.2. Defense Methods
3.2.1. Adversarial Training
3.2.2. Randomized Smoothing
4. Methodology
4.1. Datasets
4.2. Kolmogorov–Arnold Networks and Multilayer Perceptron
4.3. KAN-Mixer and MLP-Mixer
4.4. KAN-Convolution and Convolution Layer
4.5. Evaluation Metrics
5. Results and Discussion
5.1. KAN and MLP Models
5.2. KAN-Mixer vs. MLP-Mixer Models
5.3. KAN-Convolution and Convolution Layer Models
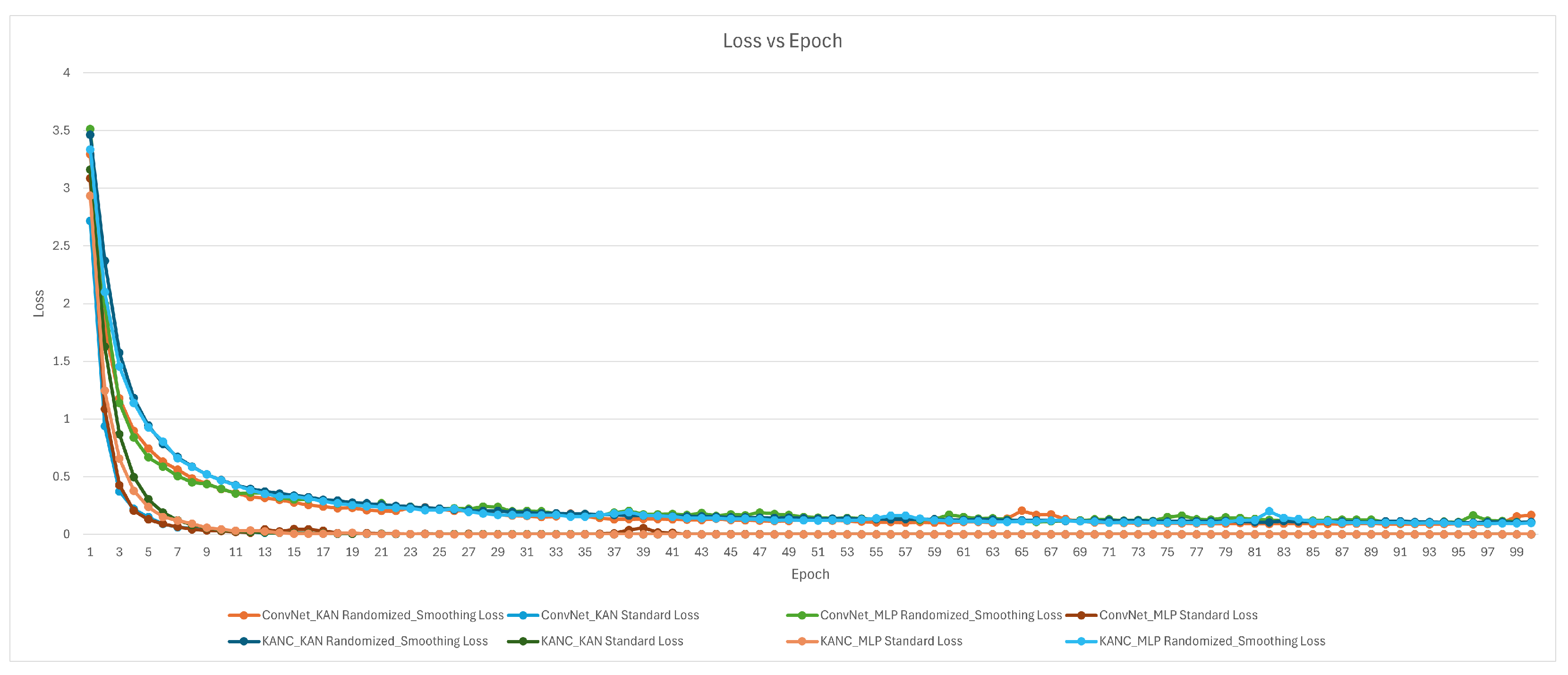
5.4. Visualization Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. KAN: Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2405.08790. [Google Scholar] [CrossRef]
- Arnol’d, V.I. On functions of three variables. Transl. Ser. 2 Am. Math. Soc. 1963, 28, 51–54. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. On the representation of continuous functions of many variables by superposition of continuous functions of one variable and addition. Transl. Ser. 2 Am. Math. Soc. 1963, 28, 55–59. [Google Scholar] [CrossRef]
- Ganesh, A.N. KAN-GPT: The PyTorch Implementation of Generative Pre-Trained Transformers (GPTs) Using Kolmogorov-Arnold Networks (KANs) for Language Modeling. 2024. Release 1.0.0. 9 May 2024. Available online: https://github.com/AdityaNG/kan-gpt/ (accessed on 6 August 2024).
- CG80499. Kan-gpt-2. 2024. Available online: https://github.com/CG80499/KAN-GPT-2 (accessed on 4 August 2024).
- Dash, A. Kansformers. 2024. Available online: https://github.com/akaashdash/kansformers (accessed on 3 August 2024).
- Bogaert, J.; Standaert, F.X. A Question on the Explainability of Large Language Models and the Word-Level Univariate First-Order Plausibility Assumption. arXiv 2024, arXiv:2403.10275. [Google Scholar] [CrossRef]
- Koenig, B.C.; Kim, S.; Deng, S. KAN-ODEs: Kolmogorov-Arnold Network Ordinary Differential Equations for Learning Dynamical Systems and Hidden Physics. Comput. Methods Appl. Mech. Eng. 2024, 432, 117397. [Google Scholar] [CrossRef]
- Peng, Y.; He, M.; Hu, F.; Mao, Z.; Huang, X.; Ding, J. Predictive Modeling of Flexible EHD Pumps using Kolmogorov-Arnold Networks. Biomim. Intell. Robot. 2024, 4, 100184. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Pantidis, P.; Mobasher, M.E. DeepOKAN: Deep Operator Network Based on Kolmogorov Arnold Networks for Mechanics Problems. arXiv 2024, arXiv:2405.19143. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, J.; Bai, J.; Anitescu, C.; Eshaghi, M.S.; Zhuang, X.; Rabczuk, T.; Liu, Y. Kolmogorov Arnold Informed neural network: A physics-informed deep learning framework for solving forward and inverse problems based on Kolmogorov Arnold Networks. arXiv 2024, arXiv:2406.11045. [Google Scholar] [CrossRef]
- Kundu, A.; Sarkar, A.; Sadhu, A. KANQAS: Kolmogorov-Arnold Network for Quantum Architecture Search. arXiv 2024, arXiv:2406.17630. [Google Scholar]
- Genet, R.; Inzirillo, H. TKAN: Temporal Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2405.07344. [Google Scholar] [CrossRef]
- Vaca-Rubio, C.J.; Blanco, L.; Pereira, R.; Caus, M. Kolmogorov-Arnold Networks (KANs) for Time Series Analysis. arXiv 2024, arXiv:2405.08790. [Google Scholar]
- Xu, K.; Chen, L.; Wang, S. Kolmogorov-Arnold Networks for Time Series: Bridging Predictive Power and Interpretability. arXiv 2024, arXiv:2406.02496. [Google Scholar]
- Inzirillo, H.; Genet, R. SigKAN: Signature-Weighted Kolmogorov-Arnold Networks for Time Series. arXiv 2024, arXiv:2406.17890. [Google Scholar] [CrossRef]
- Wang, H. Spectralkan: Spatial-spectral kolmogorov-arnold networks for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 500–515. [Google Scholar]
- Quanwei, T.; Guijun, X.; Wenju, X. MGMI: A novel deep learning model based on short-term thermal load prediction. Appl. Energy 2024, 376, 124209. [Google Scholar] [CrossRef]
- Li, C.; Liu, X.; Li, W.; Wang, C.; Liu, H.; Yuan, Y. U-KAN Makes Strong Backbone for Medical Image Segmentation and Generation. arXiv 2024, arXiv:2406.02918. [Google Scholar]
- Seydi, S.T. Unveiling the Power of Wavelets: A Wavelet-based Kolmogorov-Arnold Network for Hyperspectral Image Classification. arXiv 2024, arXiv:2406.07869. [Google Scholar]
- Azam, B.; Akhtar, N. Suitability of KANs for Computer Vision: A preliminary investigation. arXiv 2024, arXiv:2406.09087. [Google Scholar]
- Bodner, A.D.; Santiago Tepsich, A.; Spolski, J.N.; Pourteau, S. Convolutional Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2406.13155. [Google Scholar]
- Cheon, M. Demonstrating the efficacy of Kolmogorov-Arnold networks in vision tasks. arXiv 2024, arXiv:2406.14916. [Google Scholar]
- Jamali, A.; Roy, S.K.; Hong, D.; Lu, B.; Ghamisi, P. How to Learn More? Exploring Kolmogorov-Arnold Networks for Hyperspectral Image Classification. Remote Sens. 2024, 16, 4015. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, X. GraphKAN: Enhancing Feature Extraction with Graph Kolmogorov Arnold Networks. arXiv 2024, arXiv:2406.13597. [Google Scholar]
- Bresson, R.; Nikolentzos, G.; Panagopoulos, G.; Chatzianastasis, M.; Pang, J.; Vazirgiannis, M. KAGNNs: Kolmogorov-Arnold Networks meet Graph Learning. arXiv 2024, arXiv:2406.18380. [Google Scholar]
- Blealtan; Dash, A. An Efficient Implementation of Kolmogorov-Arnold Network. 2024. Available online: https://github.com/Blealtan/efficient-kan (accessed on 7 August 2024).
- Li, Z. Kolmogorov-Arnold Networks are Radial Basis Function Networks. arXiv 2024, arXiv:2405.06721. [Google Scholar] [CrossRef]
- Sidharth, S.S. Chebyshev Polynomial-Based Kolmogorov-Arnold Networks: An Efficient Architecture for Nonlinear Function Approximation. arXiv 2024, arXiv:2405.07200. [Google Scholar]
- Bozorgasl, Z.; Chen, H. Wav-KAN: Wavelet Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2405.12832. [Google Scholar] [CrossRef]
- Delis, A. FasterKAN = FastKAN + RSWAF Bases Functions and Benchmarking with Other KANs. 2024. Available online: https://github.com/AthanasiosDelis/faster-kan/ (accessed on 17 August 2024).
- Seydi, S.T. Exploring the Potential of Polynomial Basis Functions in Kolmogorov-Arnold Networks: A Comparative Study of Different Groups of Polynomials. arXiv 2024, arXiv:2406.02583. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Z.; Li, J.; Yang, S.; Wang, W.; Hu, X.; Ngai, E.C.H. FourierKAN-GCF: Fourier Kolmogorov-Arnold Network—An Effective and Efficient Feature Transformation for Graph Collaborative Filtering. arXiv 2024, arXiv:2406.01034. [Google Scholar] [CrossRef]
- Qiu, Q.; Zhu, T.; Gong, H.; Chen, L.; Ning, H. ReLU-KAN: New Kolmogorov-Arnold Networks that Only Need Matrix Addition, Dot Multiplication, and ReLU. arXiv 2024, arXiv:2406.02075. [Google Scholar] [CrossRef]
- Aghaei, A.A. fKAN: Fractional Kolmogorov-Arnold Networks with trainable Jacobi basis functions. arXiv 2024, arXiv:2406.07456. [Google Scholar] [CrossRef]
- Ta, H.T. BSRBF-KAN: A combination of b-splines and radial basis functions in kolmogorov-arnold networks. arXiv 2024, arXiv:2406.11173. [Google Scholar]
- Aghaei, A.A. rKAN: Rational Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2406.14495. [Google Scholar] [CrossRef]
- Reinhardt, E.A.F.; Dinesh, P.R.; Gleyzer, S. SineKAN: Kolmogorov-Arnold Networks Using Sinusoidal Activation Functions. arXiv 2024, arXiv:2407.04149. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Wawrzyniak, L.; Macklin, M.; Paliwal, S.G. UKAN: Unbound Kolmogorov-Arnold Network Accompanied with Accelerated Library. arXiv 2024, arXiv:2408.11200. [Google Scholar] [CrossRef]
- Ta, H.T.; Thai, D.Q.; Rahman, A.B.S.; Sidorov, G.; Gelbukh, A. FC-KAN: Function Combinations in Kolmogorov-Arnold Networks. arXiv 2024, arXiv:2409.01763. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing Properties of Neural Networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, A. KANs Can’t Deal with Noise. 2024. Available online: https://github.com/SelfExplainML/PiML-Toolbox/blob/main/docs/Workshop/KANs_Can’t_Deal_with_Noise.ipynb (accessed on 3 August 2024).
- Shen, H.; Zeng, C.; Wang, J.; Wang, Q. Reduced effectiveness of Kolmogorov-Arnold networks on functions with noise. arXiv 2024, arXiv:2407.14882. [Google Scholar]
- Zeng, C.; Wang, J.; Shen, H.; Wang, Q. KAN versus MLP on Irregular or Noisy Functions. arXiv 2024, arXiv:2408.07906. [Google Scholar]
- Chernov, A.V. Gaussian functions combined with Kolmogorov’s theorem as applied to approximation of functions of several variables. Comput. Math. Math. Phys. 2020, 60, 766–782. [Google Scholar] [CrossRef]
- Schmidt-Hieber, J. The Kolmogorov–Arnold representation theorem revisited. Neural Netw. 2021, 137, 119–126. [Google Scholar] [CrossRef]
- Poggio, T.; Banburski, A.; Liao, Q. Theoretical issues in deep networks. Proc. Natl. Acad. Sci. USA 2020, 117, 30039–30045. [Google Scholar] [CrossRef]
- Girosi, F.; Poggio, T. Representation properties of networks: Kolmogorov’s theorem is irrelevant. Neural Comput. 1989, 1, 465–469. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Aziznejad, S.; Gupta, H.; Campos, J.; Unser, M. Deep neural networks with trainable activations and controlled Lipschitz constant. IEEE Trans. Signal Process. 2020, 68, 4688–4699. [Google Scholar] [CrossRef]
- Biswas, K.; Kumar, S.; Banerjee, S.; Pandey, A.K. Smooth Maximum Unit: Smooth Activation Function for Deep Networks using Smoothing Maximum Technique. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14434–14443. [Google Scholar] [CrossRef]
- Biswas, K.; Kumar, S.; Banerjee, S.; Pandey, A.K. TanhSoft—Dynamic Trainable Activation Functions for Faster Learning and Better Performance. IEEE Access 2021, 9, 120613–120623. [Google Scholar] [CrossRef]
- Ibrahum, A.D.M.; Hussain, M.; Zhengyu, S.; Hong, J.E. Investigating Robustness of Trainable Activation Functions for End-to-end Deep Learning Model in Autonomous Vehicles. In Proceedings of the 2024 Fifteenth International Conference on Ubiquitous and Future Networks (ICUFN), Budapest, Hungary, 2–5 July 2024; pp. 466–471. [Google Scholar] [CrossRef]
- Pinkus, A. Approximation theory of the MLP model in neural networks. Acta Numer. 1999, 8, 143–195. [Google Scholar] [CrossRef]
- Lin, H.W.; Tegmark, M.; Rolnick, D. Why does deep and cheap learning work so well? J. Stat. Phys. 2017, 168, 1223–1247. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. International Conference on Learning Representations. 2018. Available online: https://openreview.net/forum?id=rJzIBfZAb (accessed on 16 June 2024).
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), Los Alamitos, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Mathias, M.; Timofte, R.; Benenson, R.; Van Gool, L. Traffic sign recognition—How far are we from the solution? In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–8. [Google Scholar]
- Huang, L. Chinese Traffic Sign Database (CTSRD). Available online: https://nlpr.ia.ac.cn/pal/trafficdata/recognition.html (accessed on 1 August 2024).
- Stallkamp, J.; Schlipsing, M.; Salmen, J.; Igel, C. Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition. Neural Netw. 2012, 32, 323–332. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TT | AT | GTSRB | BTSRB | CTSRD | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KAN | MLP | KAN | MLP | KAN | MLP | |||||||||||||||
| Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | |||
| Standard | N | - | 79.11 | - | 0 | 82.19 | - | 0 | 88.73 | - | 0 | 90.08 | - | 0 | 97.16 | - | 0 | 97.57 | - | 0 |
| FGSM | 0.01 | 27.03 | 53.11 | 14.82 | 35.34 | 48.74 | 14.82 | 45.12 | 44.33 | 13.49 | 60.79 | 30.60 | 13.49 | 34.63 | 62.61 | 10.73 | 49.55 | 48.09 | 10.73 | |
| FGSM | 0.1 | 11.22 | 68.04 | 14.90 | 16.78 | 66.03 | 14.90 | 25.00 | 63.77 | 13.57 | 36.63 | 53.61 | 13.57 | 9.49 | 87.75 | 10.94 | 11.11 | 86.54 | 10.94 | |
| FGSM | 1 | 0.24 | 78.88 | 21.83 | 1.24 | 80.95 | 21.82 | 0.16 | 88.57 | 21.62 | 0.40 | 89.68 | 21.38 | 0.24 | 96.92 | 20.02 | 0.57 | 97.00 | 20.13 | |
| BIM | 0.01 | 77.28 | 2.10 | 0.28 | 80.54 | 1.69 | 0.28 | 87.38 | 1.35 | 0.28 | 89.21 | 0.87 | 0.28 | 96.92 | 0.24 | 0.28 | 96.59 | 1.05 | 0.28 | |
| BIM | 0.1 | 60.30 | 20.18 | 2.55 | 66.00 | 16.43 | 2.55 | 75.00 | 13.93 | 2.53 | 79.01 | 11.11 | 2.53 | 74.70 | 22.63 | 2.40 | 78.51 | 19.14 | 2.40 | |
| BIM | 1 | 5.33 | 73.79 | 15.54 | 8.56 | 73.74 | 15.50 | 18.85 | 69.88 | 14.22 | 23.53 | 66.63 | 14.19 | 5.35 | 91.81 | 11.46 | 6.57 | 91.00 | 11.42 | |
| PGD | 0.01 | 26.05 | 53.99 | 14.82 | 34.12 | 49.91 | 14.82 | 44.37 | 45.08 | 13.49 | 61.03 | 30.40 | 13.49 | 33.98 | 63.26 | 10.73 | 48.34 | 49.31 | 10.73 | |
| PGD | 0.1 | 11.95 | 67.27 | 14.86 | 17.82 | 65.08 | 14.86 | 30.52 | 58.33 | 13.53 | 44.76 | 45.60 | 13.53 | 15.09 | 82.16 | 10.85 | 19.55 | 78.10 | 10.84 | |
| PGD | 1 | 2.16 | 76.95 | 17.87 | 4.89 | 77.30 | 17.85 | 10.32 | 78.41 | 16.79 | 12.06 | 78.10 | 16.89 | 1.70 | 95.46 | 15.19 | 2.51 | 95.05 | 15.20 | |
| CW | - | 26.87 | 52.24 | 11.39 | 34.66 | 47.54 | 9.85 | 44.92 | 43.81 | 9.72 | 60.52 | 29.56 | 8.22 | 36.90 | 60.26 | 7.07 | 52.39 | 45.17 | 5.82 | |
| Adversarial Training | None | - | 79.02 | - | 0 | 82.23 | - | 0 | 88.69 | - | 0 | 90.04 | - | 0 | 97.16 | - | 0 | 97.57 | - | 0 |
| FGSM | 0.01 | 27.53 | 52.57 | 14.82 | 35.50 | 48.63 | 14.82 | 45.36 | 44.05 | 13.49 | 60.87 | 30.56 | 13.49 | 35.69 | 61.56 | 10.73 | 49.80 | 47.85 | 10.73 | |
| FGSM | 0.1 | 11.31 | 67.84 | 14.90 | 16.87 | 65.95 | 14.90 | 25.20 | 63.53 | 13.57 | 36.67 | 53.53 | 13.57 | 9.98 | 87.27 | 10.94 | 11.03 | 86.62 | 10.94 | |
| FGSM | 1 | 0.21 | 78.80 | 21.83 | 1.25 | 80.97 | 21.82 | 0.16 | 88.53 | 21.62 | 0.40 | 89.64 | 21.38 | 0.24 | 96.92 | 20.01 | 0.57 | 97.00 | 20.13 | |
| BIM | 0.01 | 77.13 | 2.10 | 0.28 | 80.52 | 1.72 | 0.28 | 87.38 | 1.31 | 0.28 | 89.21 | 0.83 | 0.28 | 96.92 | 0.24 | 0.28 | 96.59 | 1.05 | 0.28 | |
| BIM | 0.1 | 60.34 | 20.09 | 2.55 | 65.97 | 16.48 | 2.55 | 75.00 | 13.89 | 2.53 | 79.05 | 11.03 | 2.53 | 74.53 | 22.79 | 2.40 | 78.35 | 19.30 | 2.40 | |
| BIM | 1 | 5.32 | 73.70 | 15.54 | 8.55 | 73.78 | 15.50 | 19.01 | 69.68 | 14.22 | 23.57 | 66.55 | 14.19 | 5.35 | 91.81 | 11.46 | 6.57 | 91.00 | 11.42 | |
| PGD | 0.01 | 26.65 | 53.36 | 14.82 | 34.17 | 49.89 | 14.82 | 44.68 | 44.72 | 13.49 | 61.07 | 30.36 | 13.49 | 34.63 | 62.61 | 10.73 | 48.42 | 49.23 | 10.73 | |
| PGD | 0.1 | 12.08 | 67.03 | 14.87 | 17.90 | 65.03 | 14.86 | 30.79 | 58.06 | 13.53 | 44.76 | 45.60 | 13.53 | 15.98 | 81.27 | 10.85 | 19.95 | 77.70 | 10.84 | |
| PGD | 1 | 2.23 | 76.79 | 17.87 | 4.71 | 77.52 | 17.84 | 10.60 | 78.10 | 16.79 | 12.06 | 77.98 | 16.87 | 1.46 | 95.70 | 15.18 | 2.27 | 95.30 | 15.22 | |
| CW | - | 27.40 | 51.62 | 11.30 | 34.70 | 47.52 | 9.85 | 45.24 | 43.45 | 9.72 | 60.48 | 29.56 | 8.22 | 37.47 | 59.69 | 7.03 | 52.80 | 44.77 | 5.82 | |
| Randomized Smoothing | None | - | 77.88 | - | 0 | 80.74 | - | 0 | 88.73 | - | 0 | 89.92 | - | 0 | 97.24 | - | 0 | 97.32 | - | 0 |
| FGSM | 0.01 | 27.97 | 51.25 | 14.90 | 34.76 | 47.41 | 14.90 | 46.11 | 43.33 | 13.57 | 61.15 | 30.24 | 13.57 | 35.69 | 61.80 | 10.94 | 49.72 | 47.93 | 10.94 | |
| FGSM | 0.1 | 11.58 | 66.33 | 14.99 | 16.90 | 64.06 | 14.99 | 26.75 | 62.06 | 13.65 | 37.42 | 52.46 | 13.65 | 9.41 | 87.59 | 11.12 | 11.84 | 85.89 | 11.12 | |
| FGSM | 1 | 0.25 | 77.66 | 21.89 | 1.14 | 79.89 | 21.88 | 0.08 | 88.69 | 21.66 | 0.32 | 89.72 | 21.41 | 0.16 | 97.08 | 20.04 | 0.57 | 97.00 | 20.14 | |
| BIM | 0.01 | 75.53 | 3.70 | 2.70 | 77.43 | 4.27 | 2.70 | 87.46 | 1.83 | 2.72 | 88.57 | 1.31 | 2.71 | 96.68 | 0.49 | 2.73 | 96.76 | 0.89 | 2.73 | |
| BIM | 0.1 | 59.56 | 19.95 | 3.66 | 63.33 | 18.16 | 3.66 | 75.44 | 13.37 | 3.63 | 78.81 | 10.91 | 3.63 | 73.80 | 23.68 | 3.53 | 78.26 | 19.22 | 3.54 | |
| BIM | 1 | 5.61 | 72.30 | 15.58 | 8.57 | 72.19 | 15.55 | 19.25 | 69.56 | 14.27 | 24.09 | 65.64 | 14.25 | 5.51 | 91.73 | 11.62 | 6.81 | 90.35 | 11.58 | |
| PGD | 0.01 | 27.09 | 51.83 | 14.90 | 33.90 | 48.13 | 14.90 | 45.24 | 44.01 | 13.57 | 60.68 | 30.71 | 13.57 | 34.79 | 62.53 | 10.94 | 49.31 | 48.26 | 10.94 | |
| PGD | 0.1 | 12.88 | 65.38 | 14.95 | 18.41 | 62.72 | 14.95 | 31.47 | 57.38 | 13.61 | 45.71 | 44.88 | 13.61 | 15.49 | 81.67 | 11.04 | 20.68 | 77.05 | 11.03 | |
| PGD | 1 | 2.70 | 75.24 | 17.94 | 4.98 | 75.75 | 17.91 | 11.71 | 77.02 | 16.87 | 12.30 | 77.58 | 16.96 | 1.78 | 95.46 | 15.26 | 3.16 | 93.99 | 15.27 | |
| CW | - | 29.54 | 48.88 | 11.95 | 38.92 | 42.41 | 10.86 | 46.55 | 42.38 | 10.61 | 65.16 | 25.08 | 9.12 | 39.90 | 57.58 | 8.30 | 58.96 | 38.44 | 6.89 | |
| TT | AT | GTSRB | BTSRB | CTSRD | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| KAN-Mixer | MLP-Mixer | KAN-Mixer | MLP-Mixer | KAN-Mixer | MLP-Mixer | |||||||||||||||
| Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | |||
| Standard | none | - | 0.715 | 0 | 0 | 0.74 | 0 | 0 | 0.97 | 0 | 0 | 0.985 | 0 | 0 | 0.88 | 0 | 0 | 0.925 | 0 | 0 |
| FGSM | 0.01 | 0.285 | 0.445 | 26.97 | 0.405 | 0.34 | 26.97 | 0.295 | 0.675 | 21.47 | 0.395 | 0.59 | 21.47 | 0.265 | 0.62 | 29.63 | 0.355 | 0.58 | 29.63 | |
| FGSM | 0.1 | 0.045 | 0.67 | 27.13 | 0.035 | 0.705 | 27.13 | 0.07 | 0.9 | 21.87 | 0.005 | 0.98 | 21.87 | 0.115 | 0.765 | 29.81 | 0.11 | 0.815 | 29.81 | |
| FGSM | 1 | 0.005 | 0.71 | 42.56 | 0 | 0.74 | 42.56 | 0.01 | 0.96 | 39.79 | 0 | 0.985 | 39.82 | 0.02 | 0.86 | 43.79 | 0 | 0.925 | 43.81 | |
| BIM | 0.01 | 0.585 | 0.13 | 0.55 | 0.68 | 0.06 | 0.55 | 0.855 | 0.115 | 0.55 | 0.97 | 0.015 | 0.55 | 0.825 | 0.06 | 0.55 | 0.92 | 0.005 | 0.55 | |
| BIM | 0.1 | 0.235 | 0.48 | 4.88 | 0.295 | 0.445 | 5.02 | 0.21 | 0.76 | 4.43 | 0.305 | 0.68 | 4.67 | 0.545 | 0.34 | 5.02 | 0.645 | 0.28 | 5.07 | |
| BIM | 1 | 0 | 0.715 | 27.69 | 0 | 0.74 | 28.01 | 0 | 0.97 | 22.11 | 0 | 0.985 | 22.29 | 0.015 | 0.865 | 30.53 | 0.03 | 0.895 | 30.58 | |
| PGD | 0.01 | 0.095 | 0.625 | 26.97 | 0.315 | 0.43 | 26.97 | 0.135 | 0.835 | 21.47 | 0.255 | 0.73 | 21.47 | 0.2 | 0.68 | 29.63 | 0.285 | 0.64 | 29.63 | |
| PGD | 0.1 | 0 | 0.715 | 27.04 | 0.005 | 0.735 | 27.05 | 0.015 | 0.955 | 21.63 | 0.005 | 0.98 | 21.66 | 0.035 | 0.845 | 29.72 | 0.06 | 0.865 | 29.72 | |
| PGD | 1 | 0 | 0.715 | 33.05 | 0 | 0.74 | 33.32 | 0 | 0.97 | 29.91 | 0 | 0.985 | 30.04 | 0 | 0.88 | 35.31 | 0 | 0.925 | 35.48 | |
| CW | - | 0.28 | 0.435 | 19.46 | 0.395 | 0.345 | 16.87 | 0.27 | 0.7 | 16.95 | 0.385 | 0.6 | 14.64 | 0.3 | 0.58 | 22.39 | 0.32 | 0.605 | 22.39 | |
| Adversarial | none | - | 0.31 | 0 | 0 | 0.36 | 0 | 0 | 0.305 | 0 | 0 | 0.205 | 0 | 0 | 0.315 | 0 | 0 | 0.2 | 0 | 0 |
| FGSM | 0.01 | 0.56 | 0.035 | 26.97 | 0.63 | 0.04 | 26.97 | 0.83 | 0.035 | 21.47 | 0.895 | 0 | 21.47 | 0.5 | 0.03 | 29.63 | 0.47 | 0.02 | 29.63 | |
| FGSM | 0.1 | 0.53 | 0.06 | 27.13 | 0.555 | 0.08 | 27.13 | 0.945 | 0.01 | 21.87 | 0.905 | 0 | 21.87 | 0.49 | 0.07 | 29.81 | 0.475 | 0.035 | 29.81 | |
| FGSM | 1 | 0.02 | 0.3 | 42.33 | 0.05 | 0.33 | 42.45 | 0.15 | 0.28 | 39.57 | 0.11 | 0.19 | 39.58 | 0.09 | 0.3 | 43.48 | 0.045 | 0.19 | 43.82 | |
| BIM | 0.01 | 0.28 | 0.03 | 0.55 | 0.29 | 0.07 | 0.55 | 0.3 | 0.005 | 0.55 | 0.175 | 0.03 | 0.55 | 0.29 | 0.025 | 0.55 | 0.15 | 0.05 | 0.55 | |
| BIM | 0.1 | 0.025 | 0.285 | 5.04 | 0.025 | 0.335 | 4.99 | 0.155 | 0.155 | 4.73 | 0.065 | 0.14 | 4.66 | 0.14 | 0.175 | 5.08 | 0.055 | 0.16 | 5.02 | |
| BIM | 1 | 0 | 0.31 | 27.89 | 0 | 0.36 | 27.82 | 0.05 | 0.255 | 22.31 | 0.055 | 0.15 | 22.25 | 0.015 | 0.3 | 30.48 | 0.005 | 0.195 | 30.40 | |
| PGD | 0.01 | 0.455 | 0.05 | 26.97 | 0.495 | 0.06 | 26.97 | 0.645 | 0.05 | 21.47 | 0.795 | 0 | 21.47 | 0.43 | 0.05 | 29.63 | 0.395 | 0.035 | 29.63 | |
| PGD | 0.1 | 0.085 | 0.26 | 27.05 | 0.18 | 0.24 | 27.05 | 0.165 | 0.175 | 21.67 | 0.225 | 0.085 | 21.67 | 0.135 | 0.22 | 29.72 | 0.085 | 0.155 | 29.72 | |
| PGD | 1 | 0 | 0.31 | 33.20 | 0 | 0.36 | 33.18 | 0 | 0.305 | 30.01 | 0 | 0.205 | 29.94 | 0 | 0.315 | 35.30 | 0.005 | 0.195 | 35.19 | |
| CW | - | 0.275 | 0.035 | 12.49 | 0.315 | 0.045 | 11.04 | 0.27 | 0.035 | 6.01 | 0.205 | 0 | 3.03 | 0.285 | 0.03 | 17.22 | 0.17 | 0.03 | 17.90 | |
| Randomized Smoothing | none | - | 0.805 | 0 | 0 | 0.72 | 0 | 0 | 0.98 | 0 | 0 | 0.95 | 0 | 0 | 0.87 | 0 | 0 | 0.805 | 0 | 0 |
| FGSM | 0.01 | 0.36 | 0.445 | 26.97 | 0.455 | 0.28 | 26.97 | 0.545 | 0.44 | 21.47 | 0.405 | 0.545 | 21.47 | 0.32 | 0.57 | 29.63 | 0.275 | 0.555 | 29.63 | |
| FGSM | 0.1 | 0.075 | 0.73 | 27.13 | 0.255 | 0.47 | 27.13 | 0.16 | 0.82 | 21.87 | 0.225 | 0.725 | 21.87 | 0.175 | 0.695 | 29.81 | 0.17 | 0.65 | 29.81 | |
| FGSM | 1 | 0 | 0.805 | 42.57 | 0 | 0.72 | 42.57 | 0 | 0.98 | 39.78 | 0.01 | 0.94 | 39.80 | 0.02 | 0.85 | 43.81 | 0.03 | 0.775 | 43.80 | |
| BIM | 0.01 | 0.78 | 0.025 | 0.55 | 0.67 | 0.05 | 0.55 | 0.97 | 0.01 | 0.55 | 0.94 | 0.01 | 0.55 | 0.855 | 0.015 | 0.55 | 0.765 | 0.04 | 0.55 | |
| BIM | 0.1 | 0.525 | 0.285 | 5.03 | 0.35 | 0.37 | 5.01 | 0.565 | 0.415 | 4.73 | 0.41 | 0.54 | 4.67 | 0.71 | 0.18 | 5.08 | 0.49 | 0.33 | 5.03 | |
| BIM | 1 | 0 | 0.805 | 28.12 | 0 | 0.72 | 27.97 | 0.02 | 0.96 | 22.44 | 0.005 | 0.945 | 22.29 | 0.045 | 0.825 | 30.91 | 0.015 | 0.79 | 30.54 | |
| PGD | 0.01 | 0.33 | 0.475 | 26.97 | 0.39 | 0.34 | 26.97 | 0.44 | 0.545 | 21.47 | 0.285 | 0.665 | 21.47 | 0.295 | 0.59 | 29.63 | 0.235 | 0.595 | 29.63 | |
| PGD | 0.1 | 0.05 | 0.755 | 27.05 | 0.125 | 0.595 | 27.05 | 0.08 | 0.9 | 21.67 | 0.05 | 0.9 | 21.67 | 0.095 | 0.775 | 29.72 | 0.065 | 0.755 | 29.72 | |
| PGD | 1 | 0 | 0.805 | 33.41 | 0 | 0.72 | 33.24 | 0 | 0.98 | 30.10 | 0 | 0.95 | 29.97 | 0.005 | 0.865 | 35.65 | 0 | 0.805 | 35.33 | |
| CW | - | 0.37 | 0.435 | 17.79 | 0.445 | 0.275 | 14.82 | 0.55 | 0.43 | 10.86 | 0.395 | 0.555 | 14.43 | 0.3 | 0.57 | 22.58 | 0.27 | 0.535 | 22.80 | |
| Training Type | AT | KANC_KAN | ConvNet_MLP | ConvNet_KAN | KANC_MLP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | Acc | SAR | DoC | |||
| Standard | BIM | 0.01 | 81.77 | 2.08 | 0.27 | 88.80 | 2.08 | 0.28 | 84.64 | 1.30 | 0.28 | 83.07 | 1.04 | 0.27 |
| BIM | 0.1 | 73.44 | 11.46 | 2.47 | 71.09 | 19.79 | 2.51 | 73.18 | 12.76 | 2.51 | 72.92 | 11.72 | 2.48 | |
| BIM | 1 | 5.73 | 77.86 | 13.80 | 6.51 | 84.38 | 13.94 | 5.47 | 80.47 | 14.00 | 4.43 | 79.69 | 13.85 | |
| FGSM | 0.01 | 16.93 | 66.67 | 13.35 | 63.54 | 27.86 | 13.35 | 47.66 | 40.89 | 13.35 | 26.82 | 58.07 | 13.35 | |
| FGSM | 0.1 | 11.72 | 71.88 | 13.43 | 13.54 | 77.34 | 13.44 | 14.32 | 71.88 | 13.44 | 11.20 | 73.18 | 13.43 | |
| FGSM | 1 | 0 | 83.59 | 20.36 | 0 | 90.89 | 21.27 | 0 | 85.94 | 21.24 | 0 | 84.11 | 20.46 | |
| PGD | 0.01 | 15.63 | 67.97 | 13.35 | 62.24 | 29.17 | 13.35 | 45.31 | 42.97 | 13.35 | 24.48 | 60.42 | 13.35 | |
| PGD | 0.1 | 8.59 | 75.00 | 13.39 | 23.18 | 67.71 | 13.40 | 20.05 | 66.15 | 13.40 | 9.38 | 74.74 | 13.39 | |
| PGD | 1 | 1.82 | 81.77 | 16.59 | 1.30 | 89.58 | 16.63 | 1.30 | 84.64 | 16.68 | 2.34 | 82.29 | 16.59 | |
| CW | - | 17.71 | 65.89 | 11.23 | 67.19 | 23.70 | 4.63 | 46.61 | 39.32 | 7.20 | 27.60 | 56.51 | 10.04 | |
| None | - | 83.59 | - | - | 90.89 | - | - | 85.94 | - | - | 84.11 | - | - | |
| Randomized Smoothing | BIM | 0.01 | 49.48 | 3.91 | 0.27 | 28.13 | 2.34 | 0.27 | 57.03 | 2.60 | 0.27 | 61.98 | 2.86 | 0.27 |
| BIM | 0.1 | 25.26 | 28.39 | 2.45 | 16.93 | 13.54 | 2.47 | 39.84 | 20.83 | 2.46 | 38.54 | 26.56 | 2.47 | |
| BIM | 1 | 0 | 53.39 | 13.66 | 8.07 | 25.00 | 13.91 | 22.92 | 36.98 | 13.76 | 0.52 | 64.32 | 13.78 | |
| FGSM | 0.01 | 66.93 | 4.43 | 13.35 | 71.61 | 1.30 | 13.35 | 66.15 | 8.07 | 13.35 | 65.10 | 5.99 | 13.35 | |
| FGSM | 0.1 | 53.91 | 10.94 | 13.43 | 48.96 | 5.73 | 13.42 | 31.51 | 30.47 | 13.44 | 33.59 | 31.51 | 13.43 | |
| FGSM | 1 | 1.04 | 53.39 | 20.38 | 13.54 | 17.45 | 19.99 | 0 | 59.64 | 21.08 | 0.52 | 64.58 | 20.54 | |
| PGD | 0.01 | 59.64 | 6.77 | 13.35 | 65.89 | 2.34 | 13.35 | 60.68 | 9.64 | 13.35 | 61.98 | 7.03 | 13.35 | |
| PGD | 0.1 | 24.22 | 30.21 | 13.39 | 34.38 | 10.68 | 13.40 | 35.68 | 26.56 | 13.39 | 29.95 | 34.90 | 13.39 | |
| PGD | 1 | 0 | 53.39 | 16.49 | 1.30 | 29.69 | 16.58 | 13.80 | 46.35 | 16.47 | 0 | 64.84 | 16.52 | |
| CW | - | 49.22 | 4.17 | 4.72 | 29.17 | 1.30 | 4.23 | 53.39 | 6.25 | 4.37 | 60.94 | 3.91 | 4.68 | |
| None | - | 53.39 | - | - | 30.47 | - | - | 59.64 | - | - | 64.84 | - | - | |
| Adversarial Training | BIM | 0.01 | 44.01 | 4.17 | 0.27 | 46.88 | 2.34 | 0.26 | 59.64 | 2.34 | 0.27 | 57.55 | 4.17 | 0.27 |
| BIM | 0.1 | 12.76 | 35.42 | 2.44 | 32.81 | 16.41 | 2.44 | 46.88 | 15.36 | 2.45 | 40.63 | 21.35 | 2.47 | |
| BIM | 1 | 0 | 48.18 | 13.66 | 21.88 | 29.17 | 13.84 | 32.29 | 29.95 | 13.76 | 1.30 | 60.42 | 13.79 | |
| FGSM | 0.01 | 66.41 | 4.17 | 13.35 | 71.61 | 1.30 | 13.35 | 68.75 | 4.95 | 13.35 | 63.80 | 6.77 | 13.35 | |
| FGSM | 0.1 | 53.65 | 10.16 | 13.43 | 47.66 | 11.72 | 13.41 | 38.28 | 26.30 | 13.44 | 34.64 | 27.86 | 13.43 | |
| FGSM | 1 | 3.65 | 48.18 | 20.39 | 23.44 | 25.78 | 18.96 | 0.26 | 61.98 | 21.12 | 0 | 61.72 | 20.51 | |
| PGD | 0.01 | 58.59 | 7.29 | 13.35 | 69.53 | 1.30 | 13.35 | 65.36 | 6.25 | 13.35 | 61.46 | 8.33 | 13.35 | |
| PGD | 0.1 | 19.27 | 32.29 | 13.39 | 40.10 | 15.36 | 13.39 | 45.05 | 18.23 | 13.39 | 30.47 | 31.51 | 13.39 | |
| PGD | 1 | 0 | 48.18 | 16.47 | 7.29 | 43.75 | 16.58 | 15.10 | 47.14 | 16.47 | 0 | 61.72 | 16.53 | |
| CW | - | 44.53 | 3.65 | 4.83 | 48.70 | 0.52 | 3.96 | 57.81 | 4.17 | 4.40 | 56.77 | 4.95 | 4.36 | |
| None | - | 48.18 | - | - | 49.22 | - | - | 61.98 | - | - | 61.72 | - | - | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahum, A.D.M.; Shang, Z.; Hong, J.-E. How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation. Appl. Sci. 2024, 14, 10173. https://doi.org/10.3390/app142210173
Ibrahum ADM, Shang Z, Hong J-E. How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation. Applied Sciences. 2024; 14(22):10173. https://doi.org/10.3390/app142210173
Chicago/Turabian StyleIbrahum, Ahmed Dawod Mohammed, Zhengyu Shang, and Jang-Eui Hong. 2024. "How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation" Applied Sciences 14, no. 22: 10173. https://doi.org/10.3390/app142210173
APA StyleIbrahum, A. D. M., Shang, Z., & Hong, J.-E. (2024). How Resilient Are Kolmogorov–Arnold Networks in Classification Tasks? A Robustness Investigation. Applied Sciences, 14(22), 10173. https://doi.org/10.3390/app142210173