

UPGCN: User Perception-Guided Graph Convolutional Network for Multimodal Recommendation

Abstract
1. Introduction
- A user perception-guided graph convolutional network for multimodal recommendation is proposed, which combines the multimodal features of items into the GCN model and utilizes the user–item interaction graph and GCN to extract the modal preferences of users better. It obtains a more accurate user representation and effectively fuses the item representation in different modalities.
- A user perception-guided representation enhancement module (UPEM) is developed, which first utilizes the different modal features of the item as inputs, performs graph convolution on the user–item interaction graph to obtain user representations in different modalities, and then utilizes the user representation as a guidance signal to augment the embedding of user ID, thus obtaining a more accurate user representation.
- A multimodal two-step enhanced fusion method is proposed, which extracts useful information from item features with user modality preference and the original item’s multimodal features for enhancing item representation.
- We performed comprehensive experiments on three public datasets to demonstrate the effectiveness of our proposed model.
2. Related Work
2.1. Deep Learning-Based Multimodal Models
2.2. Graph-Based Multimodal Models
2.3. Multimodal Fusion
3. Methods
3.1. Relevant Description
3.1.1. User–Item Interaction Graph
3.1.2. Item–Item Graph
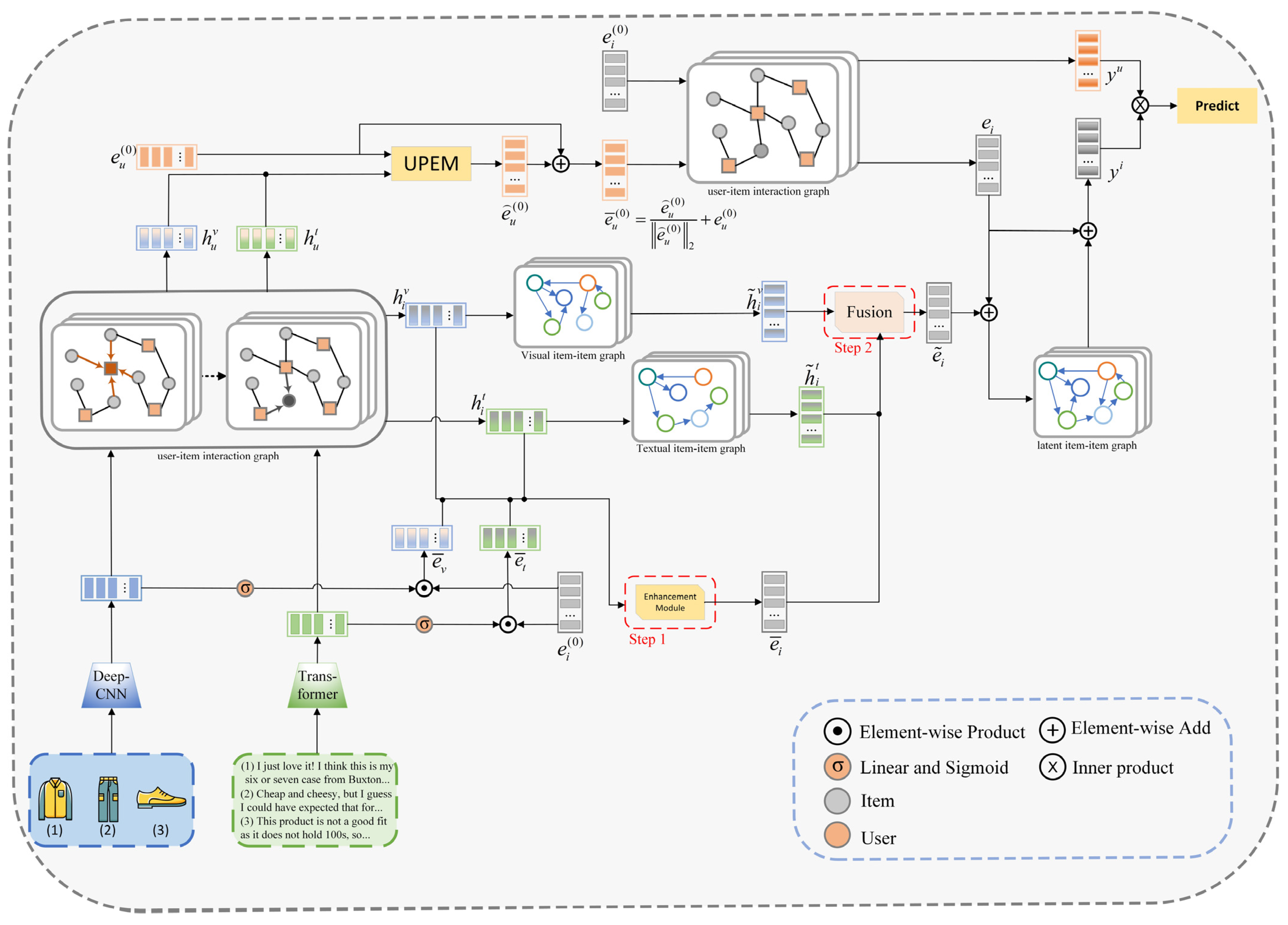
3.2. Overview of the Proposed Model
3.3. User Perception-Guided Representation Enhancement Module
3.4. Multimodal Two-Step Enhanced Fusion Method
3.5. Model Prediction
3.6. Optimization
4. Experiments
4.1. Datasets
4.2. Baselines
- 1.
- General CF Models:
- BPR [1] is a classic collaborative filtering method that optimizes the latent representations of users and items within a matrix factorization (MF) framework through a BPR loss;
- LightGCN [4] is a simplified graph convolution network that omits feature transformation and nonlinear activation layers, focusing on linear propagation and neighbor aggregation.
- 2.
- Multimodal Models:
- VBPR [5] employs the CNN to obtain visual features from product images, subsequently integrating these visual features and ID embeddings of each item as its representation.
- MMGCN [13] constructs the user–item interaction graphs for different modalities based on the features of different modalities and user–item interaction information. It subsequently employs graph convolutional on this graph to obtain user and item representations in different modalities. The user and item representations utilized for the final recommendation are derived from concatenating the user and item representations learned from the above steps across different modalities.
- GRCN [14] has designed a graph refining layer that further refines the interaction graph between user and items by detecting false-positive edges and noisy edges, thereby preventing the propagation and aggregation of noise in the GNN.
- DualGNN [23] initially extracts user representations from the user–item interaction graph across various modalities, subsequently integrates these representations, and constructs an additional user co-occurrence graph.
- LATTICE [24] constructs distinct modality-specific item–item graphs and obtains a latent item–item graph by integrating item–item graphs from all modalities.
- SLMRec [39] is a self-supervised learning framework for multimedia recommendation, which designs three different granularity data augmentation methods to build auxiliary tasks for contrastive learning.
- FREEDOM [25], based on the LATTICE framework, freezes the graph prior to training and employs a degree-sensitive edge pruning method to reduce noise in the interaction graph between users and items.
4.3. Evaluation Metrics
4.4. Parameter Setup
4.5. Performance Comparison with Baselines
4.6. Ablation Studies
4.6.1. Effect of Multimodal Features
- UPGCNw/o-v&t: In this variant, UPGCN eliminates the input of two modalities, thereby transforming into a general recommendation model;
- UPGCNw/o-v: This variant denotes that UPGCN utilizes exclusively the textual modality of the items;
- UPGCNw/o-t: This variant indicates that UPGCN has eliminated the textual modality of the item, thereby utilizing solely its visual modality.
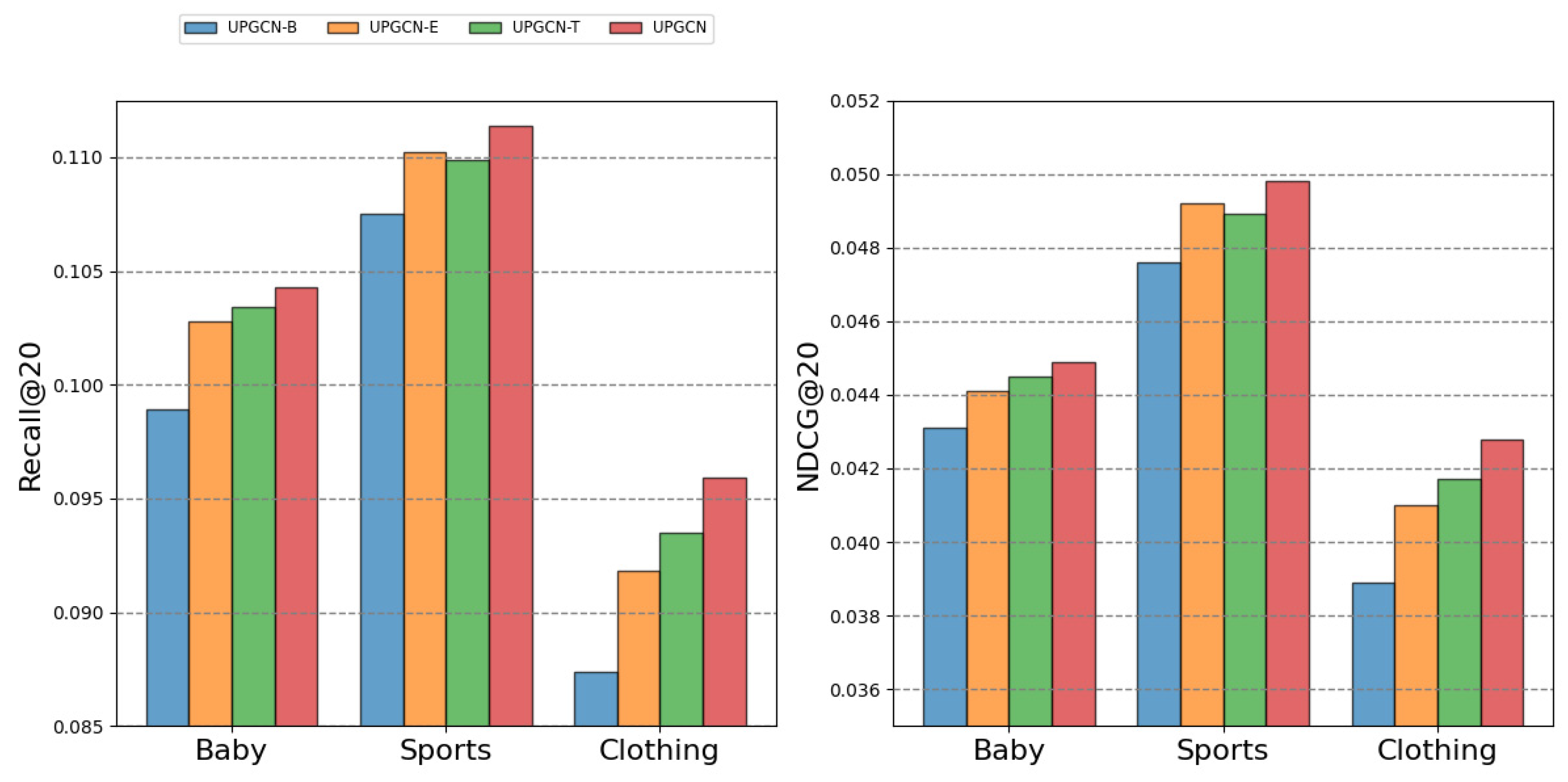
4.6.2. Effect of Modules
- UPGCN-B: This variant removes the UPEM and multimodal enhanced fusion method that we designed;
- UPGCN-E: This variant only uses UPEM to enhance the user representation, and removes the two-step enhanced fusion method;
- UPGCN-T: This variant only uses the multimodal two-step enhanced fusion method to enhance and fuse the item representations in different modalities, removing UPEM.
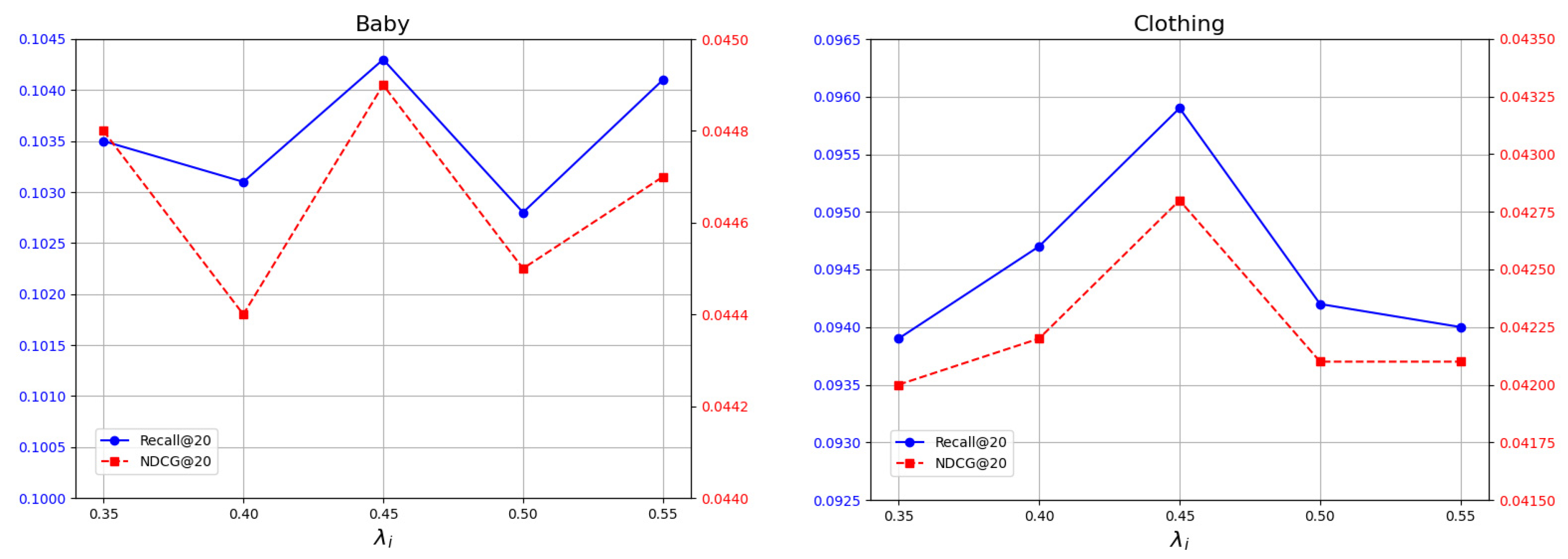
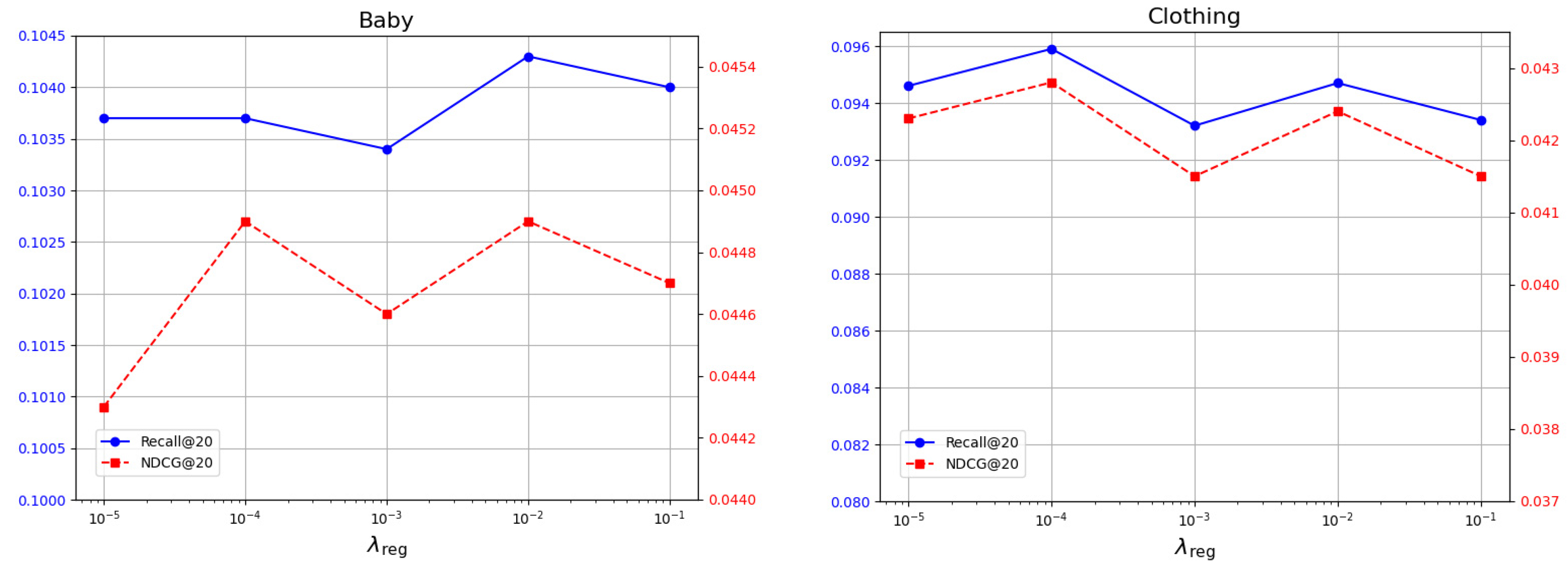
4.7. Hyperparameter Sensitivity Study
4.7.1. Effects of the Fusion Weight
4.7.2. Effects of the Weight for Multimodal BPR Loss
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Steffen, R.; Christoph, F.; Zeno, G.; Lars, S. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Wu, C.; Wu, F.; Qi, T.; Zhang, C.; Huang, Y.; Xu, T. MM-rec: Visiolinguistic model empowered multimodal news recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2560–2564. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 639–648. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Sun, R.; Cao, X.; Zhao, Y.; Wan, J.; Zhou, K.; Zhang, F.; Zheng, K. Multi-modal knowledge graphs for recommender systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, New York, NY, USA, 19–23 October 2020; pp. 1405–1414. [Google Scholar]
- Liu, K.; Xue, F.; Guo, D.; Wu, L.; Li, S.; Hong, R. MEGCF: Multimodal entity graph collaborative filtering for personalized recommendation. ACM Trans. Inform. Syst. 2023, 41, 30. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, X.; He, X.; Nie, L.; Rui, Y.; Chua, T.S. Hierarchical user intent graph network for multimedia recommendation. IEEE Trans. Multimed. 2021, 24, 2701–2712. [Google Scholar] [CrossRef]
- Cai, D.; Qian, S.; Fang, Q.; Hu, J.; Ding, W.; Xu, C. Heterogeneous graph contrastive learning network for personalized micro-video recommendation. IEEE Trans. Multimed. 2022, 25, 2761–2773. [Google Scholar] [CrossRef]
- Mu, Z.; Zhuang, Y.; Tan, J.; Xiao, J.; Tang, S. Learning hybrid behavior patterns for multimedia recommendation. In Proceedings of the 30th ACM International Conference on Multimedia, Seattle, WA, USA, 10–14 October 2022; pp. 376–384. [Google Scholar]
- Yi, Z.; Wang, X.; Ounis, I.; Macdonald, C. Multi-modal graph contrastive learning for micro-video recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1807–1811. [Google Scholar]
- Ye, X.; Cai, G.; Song, Y. Multi-modal Personalized Goods Recommendation based on Graph Enhanced Attention GNN. In Proceedings of the 2022 5th International Conference on Machine Learning and Machine Intelligence, Hangzhou, China, 23–25 September 2022; pp. 146–153. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Hong, R.; Chua, T.S. MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1437–1445. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Chua, T.S. Graph-refined convolutional network for multimedia recommendation with implicit feedback. In Proceedings of the 28th ACM international Conference on Multimedia, Seattle, WA, USA, 12 October 2020; pp. 3541–3549. [Google Scholar]
- Chen, F.; Wang, J.; Wei, Y.; Zheng, H.T.; Shao, J. Breaking isolation: Multimodal graph fusion for multimedia recommendation by edge-wise modulation. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 385–394. [Google Scholar]
- Zhou, H.; Zhou, X.; Zhang, L.; Shen, Z. Enhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation. arXiv 2023, arXiv:2301.12097. [Google Scholar]
- Kim, T.; Lee, Y.C.; Shin, K.; Kim, S.W. MARIO: Modality-aware attention and modality-preserving decoders for multimedia recommendation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 993–1002. [Google Scholar]
- Cui, X.; Qu, X.; Li, D.; Yang, Y.; Li, Y.; Zhang, X. MKGCN: Multi-modal knowledge graph convolutional network for music recommender systems. Electronics 2023, 12, 2688. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, S.; Lei, C.; Wang, G.; Tang, H.; Zhang, J.; Sun, A.; Miao, C. Pre-training graph transformer with multimodal side information for recommendation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 2853–2861. [Google Scholar]
- Zhou, Y.; Guo, J.; Song, B.; Chen, C.; Chang, J.; Yu, F.R. Trust-aware multi-task knowledge graph for recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 8658–8671. [Google Scholar] [CrossRef]
- Liu, F.; Chen, H.; Cheng, Z.; Liu, A.; Nie, L.; Kankanhalli, M. Disentangled multimodal representation learning for recommendation. IEEE Trans. Multim. 2022, 25, 7149–7159. [Google Scholar] [CrossRef]
- Lei, F.; Cao, Z.; Yang, Y.; Ding, Y.; Zhang, C. Learning the user’s deeper preferences for multi-modal recommendation systems. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 138. [Google Scholar] [CrossRef]
- Wang, Q.; Wei, Y.; Yin, J.; Wu, J.; Song, X.; Nie, L. DualGNN: Dual graph neural network for multimedia recommendation. IEEE Trans. Multimed. 2021, 25, 1074–1084. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Liu, Q.; Wu, S.; Wang, S.; Wang, L. Mining latent structures for multimedia recommendation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 3872–3880. [Google Scholar]
- Zhou, X.; Shen, Z. A tale of two graphs: Freezing and denoising graph structures for multimodal recommendation. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 12–16 October 2020; pp. 935–943. [Google Scholar]
- Tao, Z.; Wei, Y.; Wang, X.; He, X.; Huang, X.; Chua, T.S. MGAT: Multimodal graph attention network for recommendation. Inform. Process. Manag. 2020, 57, 102277. [Google Scholar] [CrossRef]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Kang, W.C.; Fang, C.; Wang, Z.; McAuley, J. Visually-aware fashion recommendation and design with generative image models. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 207–216. [Google Scholar]
- Huang, Z.; Xu, X.; Ni, J.; Zhu, H.; Wang, C. Multimodal representation learning for recommendation in Internet of Things. IEEE Internet Things 2019, 6, 10675–10685. [Google Scholar] [CrossRef]
- Chen, X.; Chen, H.; Xu, H.; Zhang, Y.; Cao, Y.; Qin, Z.; Zha, H. Personalized fashion recommendation with visual explanations based on multimodal attention network: Towards visually explainable recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 765–774. [Google Scholar]
- Chen, J.; Zhang, H.; He, X.; Nie, L.; Liu, W.; Chua, T.S. Attentive collaborative filtering: Multimedia recommendation with item-and component-level attention. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 335–344. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Guo, Q.; Qiu, X.; Xue, X.; Zhang, Z. Syntax-guided text generation via graph neural network. Sci. China Inf. Sci. 2021, 64, 152102. [Google Scholar] [CrossRef]
- Liu, Q.; Yao, E.; Liu, C.; Zhou, X.; Li, Y.; Xu, M. M2GCN: Multi-modal graph convolutional network for modeling polypharmacy side effects. Appl. Intell. 2023, 53, 6814–6825. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Liu, Q.; Zhang, M.; Wu, S.; Wang, L. Latent structure mining with contrastive modality fusion for multimedia recommendation. IEEE Trans. Knowl. Data Eng. 2022, 35, 9154–9167. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, H.; Liu, Y.; Zeng, Z.; Miao, C.; Wang, P.; Jiang, F. Bootstrap latent representations for multi-modal recommendation. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 845–854. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Liu, S.; Chen, Z.; Liu, H.; Hu, X. User-video co-attention network for personalized micro-video recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3020–3026. [Google Scholar]
- Tao, Z.; Liu, X.; Xia, Y.; Wang, X.; Yang, L.; Huang, X.; Chua, T.S. Self-supervised learning for multimedia recommendation. IEEE Trans. Multimed. 2022, 25, 5107–5116. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, X.; Yu, W.; Xu, R.; Cao, Z.; Shen, H.T. Combine early and late fusion together: A hybrid fusion framework for image-text matching. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 10–12 January 2021; pp. 1–6. [Google Scholar]
- Chen, J.; Fang, H.R.; Saad, Y. Fast Approximate kNN Graph Construction for High Dimensional Data via Recursive Lanczos Bisection. J. Mach. Learn. Res. 2009, 10, 9. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wu, X.; He, R.; Hu, Y.; Sun, Z. Learning an evolutionary embedding via massive knowledge distillation. Int. J. Comput. Vis. 2020, 128, 2089–2106. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1 | Users | Items | Interactions | Sparsity |
|---|---|---|---|---|
| Baby | 19,445 | 7050 | 160,792 | 99.88% |
| Sports | 35,598 | 18,357 | 296,337 | 99.95% |
| Clothing | 39,387 | 23,033 | 278,677 | 99.97% |
| Dataset | Model | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|---|
| Baby | BPR | 0.0357 | 0.0575 | 0.0192 | 0.0249 |
| LightGCN | 0.0479 | 0.0754 | 0.0257 | 0.0328 | |
| VBPR | 0.0423 | 0.0663 | 0.0223 | 0.0284 | |
| MMGCN | 0.0421 | 0.0660 | 0.0220 | 0.0282 | |
| GRCN | 0.0532 | 0.0824 | 0.0282 | 0.0358 | |
| DualGNN | 0.0513 | 0.0803 | 0.0278 | 0.0352 | |
| SLMRec | 0.0521 | 0.0772 | 0.0289 | 0.0354 | |
| LATTICE | 0.0547 | 0.0850 | 0.0292 | 0.0370 | |
| FREEDOM | 0.0627 | 0.0992 | 0.0330 | 0.0424 | |
| UPGCN | 0.0664 | 0.1043 | 0.0351 | 0.0449 | |
| Improv. (%) | 4.31 | 4.53 | 5.76 | 5.42 | |
| Sports | BPR | 0.0432 | 0.0653 | 0.0241 | 0.0298 |
| LightGCN | 0.0569 | 0.0864 | 0.0311 | 0.0387 | |
| VBPR | 0.0558 | 0.0856 | 0.0307 | 0.0384 | |
| MMGCN | 0.0401 | 0.0636 | 0.0209 | 0.0270 | |
| GRCN | 0.0599 | 0.0919 | 0.0330 | 0.0413 | |
| DualGNN | 0.0588 | 0.0899 | 0.0324 | 0.0404 | |
| SLMRec | 0.0663 | 0.0990 | 0.0335 | 0.0421 | |
| LATTICE | 0.0620 | 0.0953 | 0.0335 | 0.0421 | |
| FREEDOM | 0.0717 | 0.1089 | 0.0385 | 0.0481 | |
| UPGCN | 0.0740 | 0.1114 | 0.0402 | 0.0498 | |
| Improv. (%) | 3.21 | 2.29 | 4.41 | 3.53 | |
| Clothing | BPR | 0.0206 | 0.0303 | 0.0114 | 0.0138 |
| LightGCN | 0.0361 | 0.0544 | 0.0197 | 0.0243 | |
| VBPR | 0.0281 | 0.0415 | 0.0158 | 0.0192 | |
| MMGCN | 0.0227 | 0.0361 | 0.0120 | 0.0154 | |
| GRCN | 0.0421 | 0.0657 | 0.0224 | 0.0284 | |
| DualGNN | 0.0452 | 0.0675 | 0.0242 | 0.0298 | |
| SLMRec | 0.0442 | 0.0659 | 0.0241 | 0.0296 | |
| LATTICE | 0.0492 | 0.0733 | 0.0268 | 0.0330 | |
| FREEDOM | 0.0629 | 0.0941 | 0.0341 | 0.0420 | |
| UPGCN | 0.0644 | 0.0959 | 0.0348 | 0.0428 | |
| Improv. (%) | 2.38 | 1.91 | 2.05 | 1.90 |
| Dataset | Variants | R@10 | R@20 | N@10 | N@20 |
|---|---|---|---|---|---|
| Baby | UPGCNw/o-v&t | 0.0479 | 0.0754 | 0.0257 | 0.0328 |
| UPGCNw/o-t | 0.0527 | 0.0827 | 0.0282 | 0.0359 | |
| UPGCNw/o-v | 0.0616 | 0.0984 | 0.0328 | 0.0422 | |
| UPGCN | 0.0664 | 0.1043 | 0.0351 | 0.0449 | |
| Sports | UPGCNw/o-v&t | 0.0569 | 0.0864 | 0.0311 | 0.0387 |
| UPGCNw/o-t | 0.0610 | 0.0931 | 0.0332 | 0.0415 | |
| UPGCNw/o-v | 0.0716 | 0.1079 | 0.0391 | 0.0484 | |
| UPGCN | 0.0740 | 0.1114 | 0.0402 | 0.0498 | |
| Clothing | UPGCNw/o-v&t | 0.0340 | 0.0526 | 0.0188 | 0.0236 |
| UPGCNw/o-t | 0.0430 | 0.0633 | 0.0229 | 0.0281 | |
| UPGCNw/o-v | 0.0616 | 0.0927 | 0.0336 | 0.0415 | |
| UPGCN | 0.0644 | 0.0959 | 0.0348 | 0.0428 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, B.; Liang, Y. UPGCN: User Perception-Guided Graph Convolutional Network for Multimodal Recommendation. Appl. Sci. 2024, 14, 10187. https://doi.org/10.3390/app142210187
Zhou B, Liang Y. UPGCN: User Perception-Guided Graph Convolutional Network for Multimodal Recommendation. Applied Sciences. 2024; 14(22):10187. https://doi.org/10.3390/app142210187
Chicago/Turabian StyleZhou, Baihu, and Yongquan Liang. 2024. "UPGCN: User Perception-Guided Graph Convolutional Network for Multimodal Recommendation" Applied Sciences 14, no. 22: 10187. https://doi.org/10.3390/app142210187
APA StyleZhou, B., & Liang, Y. (2024). UPGCN: User Perception-Guided Graph Convolutional Network for Multimodal Recommendation. Applied Sciences, 14(22), 10187. https://doi.org/10.3390/app142210187