
Supervised Contrastive Learning for 3D Cross-Modal Retrieval


Abstract
:1. Introduction
- The proposed method employs contrastive learning in a supervised 3D cross-modal environment to maximize the difference between the features of different classes. It covers the weakness of center loss, such as dependency on batch size, and enhances inter-class variance while effectively reducing inter-modal variance.
- Through the FPH strategy, the influence of the projection head is decreased to allow better emphasis on the backbone network during the training phase using label prediction.
- The proposed method uses augmented data from each modality, proactively adapting to diverse variations during the evaluation process.
- The newly adopted Softmargin enhances feature learning to extract features with greater similarity within CSupCon.
2. Related Works
2.1. Contrastive Learning
2.2. Cross-Domain and -Modal Feature Learning
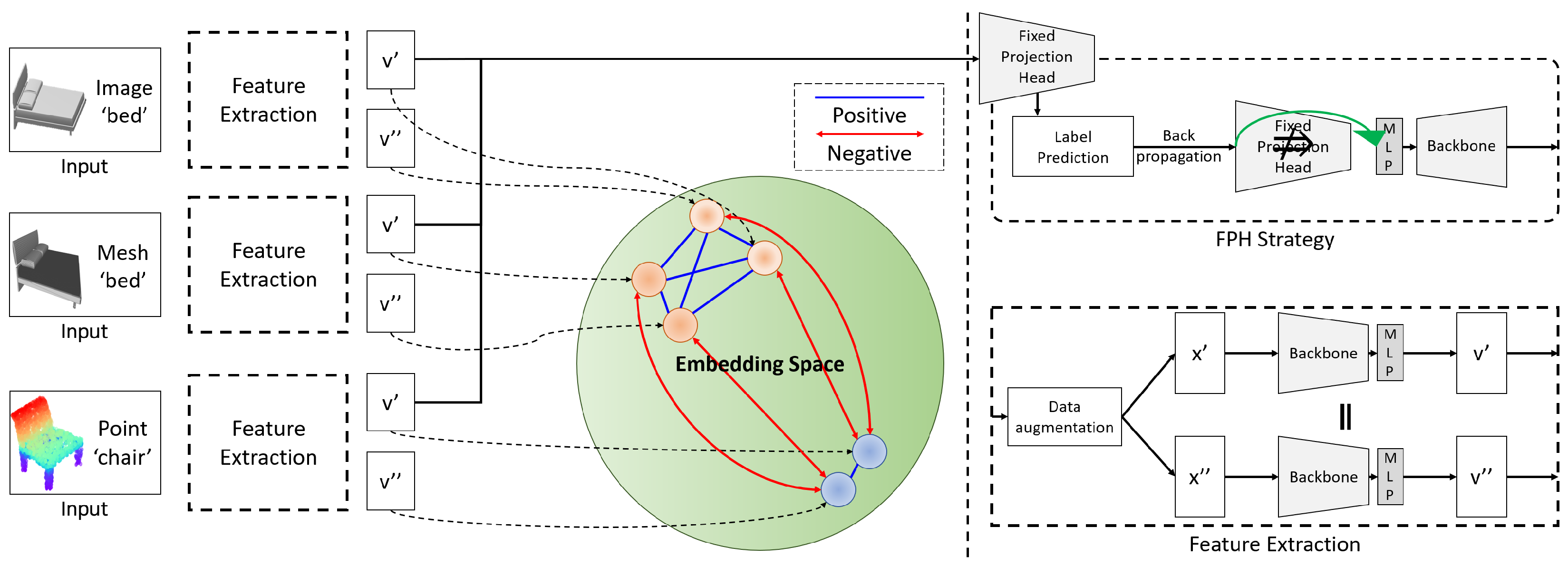
3. Proposed Method
3.1. Preliminaries
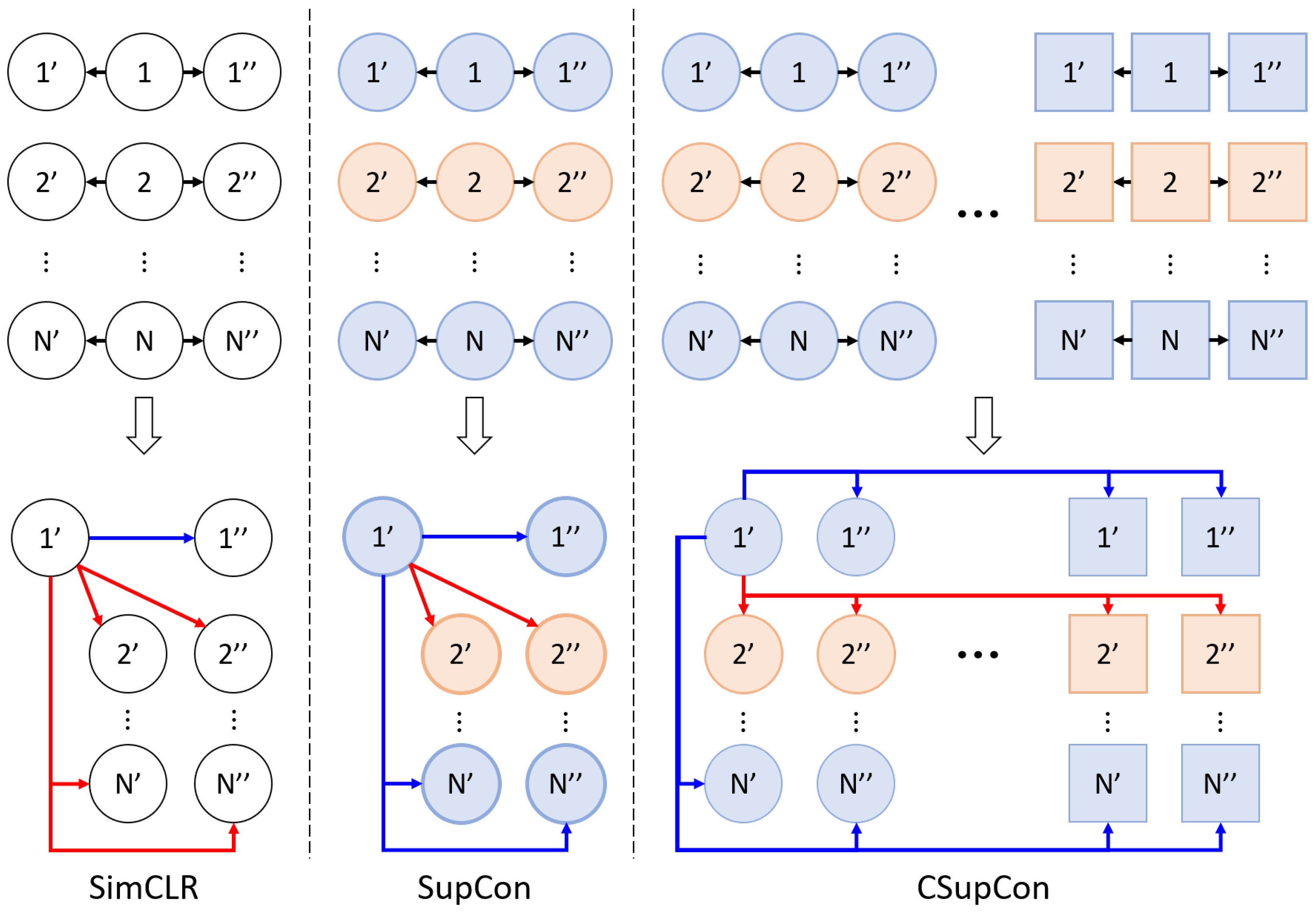
3.2. Cross-Modal Supervised Contrastive Learning
3.3. Label Prediction Using Fixed Projection Head
3.4. Loss Functions
4. Experiments
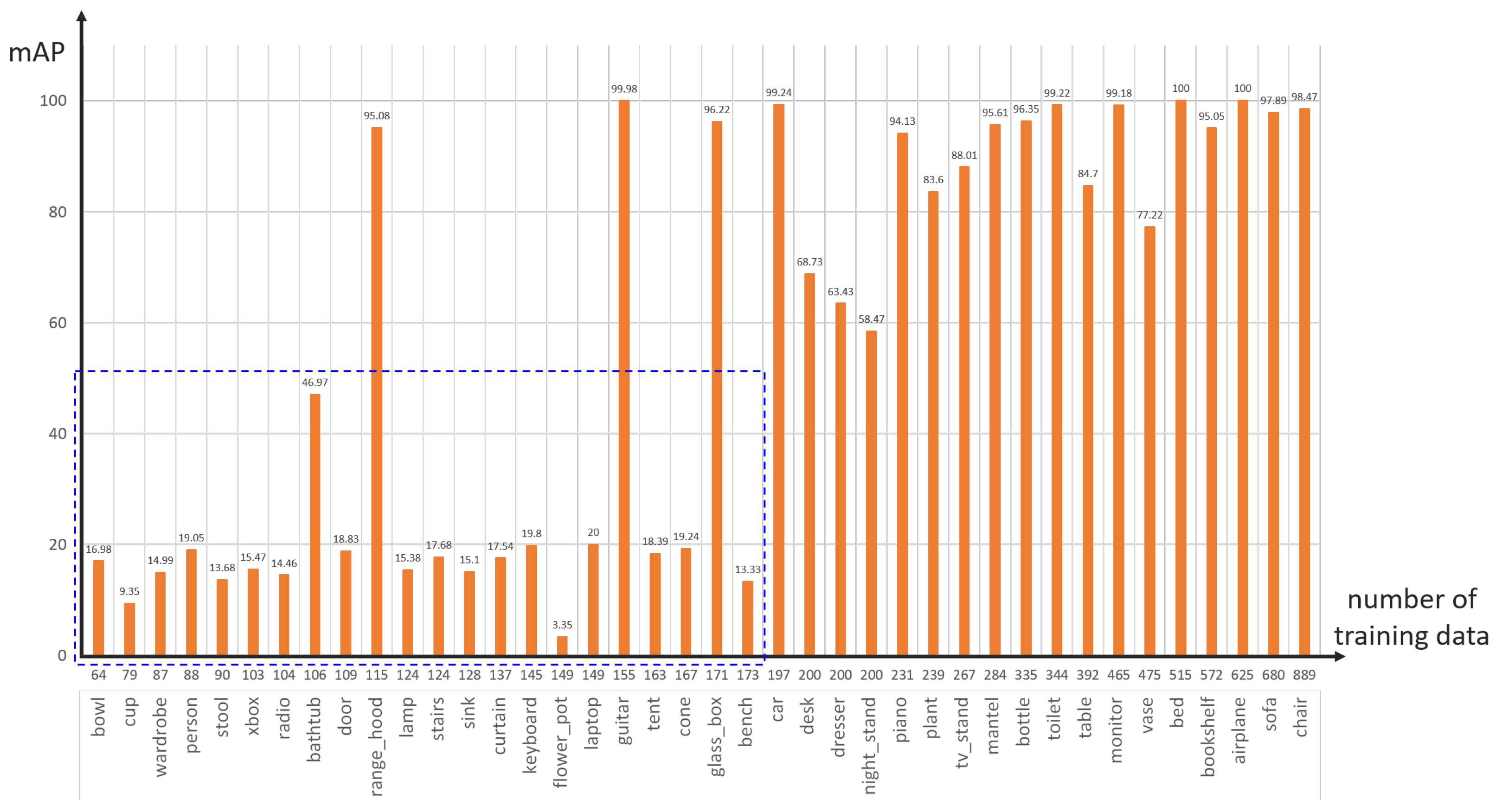
4.1. Datasets
4.2. Experimental Details
4.3. Ablation Study: Impact of Compositions
4.4. Experimental Results for Comparison
- The proposed contrastive learning-based method exhibits better results than the center loss-based methods, as it is less sensitive to external elements. Therefore, the proposed method is suitable for 3D cross-modal retrieval.
- Traditional methods based on center loss do not actively exclude other classes. On the other hand, our proposed method, CSupCon, based on contrastive learning, actively compares with other classes using data augmentation, obtaining better results during evaluation. As shown in Table 5 and Table 6, performance improvements in cross-modal retrieval are observed in four out of six tasks for ModelNet40 and six out of six tasks for ModelNet10. The highest mAPs for cross-modal retrieval tasks are underlined in the tables.
4.5. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, L.; Ni, S.-T.; Wang, Y.; Yu, A.; Lee, J.-A.; Hui, P. Interoperability of the metaverse: A digital ecosystem perspective review. arXiv 2024, arXiv:2403.05205. [Google Scholar]
- Feng, Y.; Zhu, H.; Peng, D.; Peng, X.; Hu, P. RONO: Robust Discriminative Learning with Noisy Labels for 2D-3D Cross-Modal Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 11610–11619. [Google Scholar]
- Jing, L.; Vahdani, E.; Tan, J.; Tian, Y. Cross-Modal Center Loss for 3D Cross-Modal Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3141–3150. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; Shen, H.T. Adversarial Cross-Modal Retrieval. In Proceedings of the 25th ACM International Conference on Multimedia, New York, NY, USA, 23–27 December 2017; pp. 154–162. [Google Scholar]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. HCMSL: Hybrid Cross-Modal Similarity Learning for Cross-Modal Retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 17–20 June 2019; pp. 10386–10395. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.; Azar, M.G.; et al. Bootstrap Your Own Latent—A New Approach to Self-Supervised Learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; pp. 21271–21284. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Afham, M.; Dissanayake, I.; Dissanayake, D.; Dharmasiri, A.; Thilakarathna, K.; Rodrigo, R. CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 9892–9902. [Google Scholar]
- Yuan, X.; Lin, Z.; Kuen, J.; Zhang, J.; Wang, Y.; Maire, M.; Kale, A.; Faieta, B. Multimodal Contrastive Training for Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6991–7000. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised Contrastive Learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; pp. 18661–18673. [Google Scholar]
- Wang, Q.; Breckon, T.P. Cross-domain structure preserving projection for heterogeneous domain adaptation. Pattern Recognit. 2022, 123, 108362. [Google Scholar] [CrossRef]
- Zhu, C.; Wang, Q.; Xie, Y.; Xu, S. Multiview latent space learning with progressively fine-tuned deep features for unsupervised domain adaptation. Inf. Sci. 2024, 662, 120223. [Google Scholar] [CrossRef]
- Cheng, Q.; Tan, Z.; Wen, K.; Chen, C.; Gu, X. Semantic Pre-Alignment and Ranking Learning with Unified Framework for Cross-Modal Retrieval. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 6503–6516. [Google Scholar] [CrossRef]
- Wei, Y.; Zhao, Y.; Lu, C.; Wei, S.; Liu, L.; Zhu, Z.; Yan, S. Cross-Modal Retrieval with CNN Visual Features: A New Baseline. IEEE Trans. Cybern. 2017, 47, 449–460. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Xu, N.; Mao, W.; Zeng, D. An Orthogonal Subspace Decomposition Method for Cross-Modal Retrieval. IEEE Intell. Syst. 2022, 37, 45–53. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D Shapenets: A Deep Representation for Volumetric Shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Feng, Y.; Feng, Y.; You, H.; Zhao, X.; Gao, Y. Meshnet: Mesh neural network for 3D shape representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8279–8286. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Justin, M.S. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Van Der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Retrieval Tasks | Batch Sizes | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 24 | 48 | 96 | 128 | |||||||
| CLF | Ours | CLF | Ours | CLF | Ours | CLF | Ours | |||
| Image | → | Image | 63.56 | 90.07 | 85.64 | 90.08 | 90.23 | 90.43 | 90.30 | 90.37 |
| Image | Mesh | 73.22 | 89.72 | 86.94 | 89.45 | 89.59 | 89.73 | 89.80 | 89.81 | |
| Image | Point | 72.08 | 90.25 | 85.59 | 89.68 | 89.04 | 90.08 | 88.30 | 90.69 | |
| Mesh | Image | 88.44 | 88.35 | 88.91 | 89.13 | 88.51 | 88.95 | 89.10 | 88.15 | |
| Mesh | Mesh | 68.81 | 89.10 | 86.50 | 89.46 | 88.11 | 89.04 | 87.30 | 88.78 | |
| Mesh | Point | 84.60 | 89.13 | 86.67 | 89.12 | 87.37 | 88.84 | 88.20 | 89.01 | |
| Point | Image | 82.44 | 89.47 | 85.44 | 89.19 | 87.04 | 89.86 | 88.70 | 89.92 | |
| Point | Mesh | 67.46 | 89.69 | 84.67 | 89.12 | 87.11 | 89.62 | 88.30 | 89.88 | |
| Point | Point | 83.56 | 90.18 | 86.62 | 89.33 | 87.58 | 90.12 | 88.10 | 90.88 | |
| Average mAP | 76.02 | 89.55 | 86.33 | 89.40 | 88.29 | 89.63 | 88.68 | 89.72 | ||
| Retrieval Tasks | Loss Functions | ||||
|---|---|---|---|---|---|
| Image | Image | 88.28 | 89.95 | 90.37 | |
| Image | Mesh | 87.31 | 89.55 | 89.81 | |
| Image | Point | 86.77 | 90.07 | 90.69 | |
| Mesh | Image | 86.09 | 88.47 | 88.15 | |
| Mesh | → | Mesh | 86.37 | 89.29 | 88.78 |
| Mesh | Point | 85.22 | 89.05 | 89.01 | |
| Point | Image | 83.44 | 89.59 | 89.92 | |
| Point | Mesh | 82.75 | 89.82 | 89.88 | |
| Point | Point | 82.33 | 90.31 | 90.88 | |
| Average mAP | 85.40 | 89.57 | 89.72 | ||
| Retrieval Tasks | FPH Strategy | |||
|---|---|---|---|---|
| w/o FPH | w/ FPH | |||
| Image | Image | 89.32 | 90.37 | |
| Image | Mesh | 89.04 | 89.81 | |
| Image | Point | 88.83 | 90.69 | |
| Mesh | Image | 88.88 | 88.15 | |
| Mesh | → | Mesh | 89.50 | 88.78 |
| Mesh | Point | 88.61 | 89.01 | |
| Point | Image | 89.26 | 89.92 | |
| Point | Mesh | 89.43 | 89.88 | |
| Point | Point | 89.58 | 90.88 | |
| Average mAP | 89.16 | 89.72 | ||
| Retrieval Tasks | Softmargin | |||
|---|---|---|---|---|
| w/o Margin | w/ Margin | |||
| Image | Image | 89.67 | 90.37 | |
| Image | Mesh | 89.20 | 89.81 | |
| Image | Point | 90.12 | 90.69 | |
| Mesh | Image | 87.49 | 88.15 | |
| Mesh | → | Mesh | 88.32 | 88.78 |
| Mesh | Point | 88.59 | 89.01 | |
| Point | Image | 89.41 | 89.92 | |
| Point | Mesh | 89.71 | 89.88 | |
| Point | Point | 90.51 | 90.88 | |
| Average mAP | 89.22 | 89.72 | ||
| Retrieval Tasks | Methods | ||||
|---|---|---|---|---|---|
| CLF | RONO | Ours | |||
| Image | Image | 90.30 | 91.10 | 90.37 | |
| Image | Mesh | 89.80 | 90.10 | 89.81 | |
| Image | Point | 88.30 | 89.10 | 90.69 | |
| Mesh | Image | 89.10 | 89.90 | 88.15 | |
| Mesh | → | Mesh | 87.30 | 90.10 | 88.78 |
| Mesh | Point | 88.20 | 88.30 | 89.01 | |
| Point | Image | 88.70 | 89.10 | 89.92 | |
| Point | Mesh | 88.30 | 89.40 | 89.88 | |
| Point | Point | 88.10 | 89.10 | 90.88 | |
| Average mAP | 88.68 | 89.58 | 89.72 | ||
| Retrieval Tasks | Methods | ||||
|---|---|---|---|---|---|
| CLF | RONO | Ours | |||
| Image | Image | 90.30 | 91.30 | 91.72 | |
| Image | Mesh | 90.70 | 90.60 | 91.47 | |
| Image | Point | 89.50 | 89.80 | 91.64 | |
| Mesh | Image | 88.90 | 89.60 | 90.93 | |
| Mesh | → | Mesh | 91.60 | 91.90 | 91.19 |
| Mesh | Point | 90.00 | 90.40 | 91.20 | |
| Point | Image | 88.70 | 89.50 | 91.35 | |
| Point | Mesh | 89.30 | 90.30 | 91.64 | |
| Point | Point | 88.50 | 89.20 | 92.04 | |
| Average mAP | 89.72 | 90.29 | 91.46 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choo, Y.-S.; Kim, B.; Kim, H.-S.; Park, Y.-S. Supervised Contrastive Learning for 3D Cross-Modal Retrieval. Appl. Sci. 2024, 14, 10322. https://doi.org/10.3390/app142210322
Choo Y-S, Kim B, Kim H-S, Park Y-S. Supervised Contrastive Learning for 3D Cross-Modal Retrieval. Applied Sciences. 2024; 14(22):10322. https://doi.org/10.3390/app142210322
Chicago/Turabian StyleChoo, Yeon-Seung, Boeun Kim, Hyun-Sik Kim, and Yong-Suk Park. 2024. "Supervised Contrastive Learning for 3D Cross-Modal Retrieval" Applied Sciences 14, no. 22: 10322. https://doi.org/10.3390/app142210322
APA StyleChoo, Y.-S., Kim, B., Kim, H.-S., & Park, Y.-S. (2024). Supervised Contrastive Learning for 3D Cross-Modal Retrieval. Applied Sciences, 14(22), 10322. https://doi.org/10.3390/app142210322