
Research on a Web System Data-Filling Method Based on Optical Character Recognition and Multi-Text Similarity

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Technologies and Research
2.1. OCR Recognition Technology
2.2. Field Matching Technology
2.3. Levenshtein Editing Distance
2.4. Similarity Calculation Method
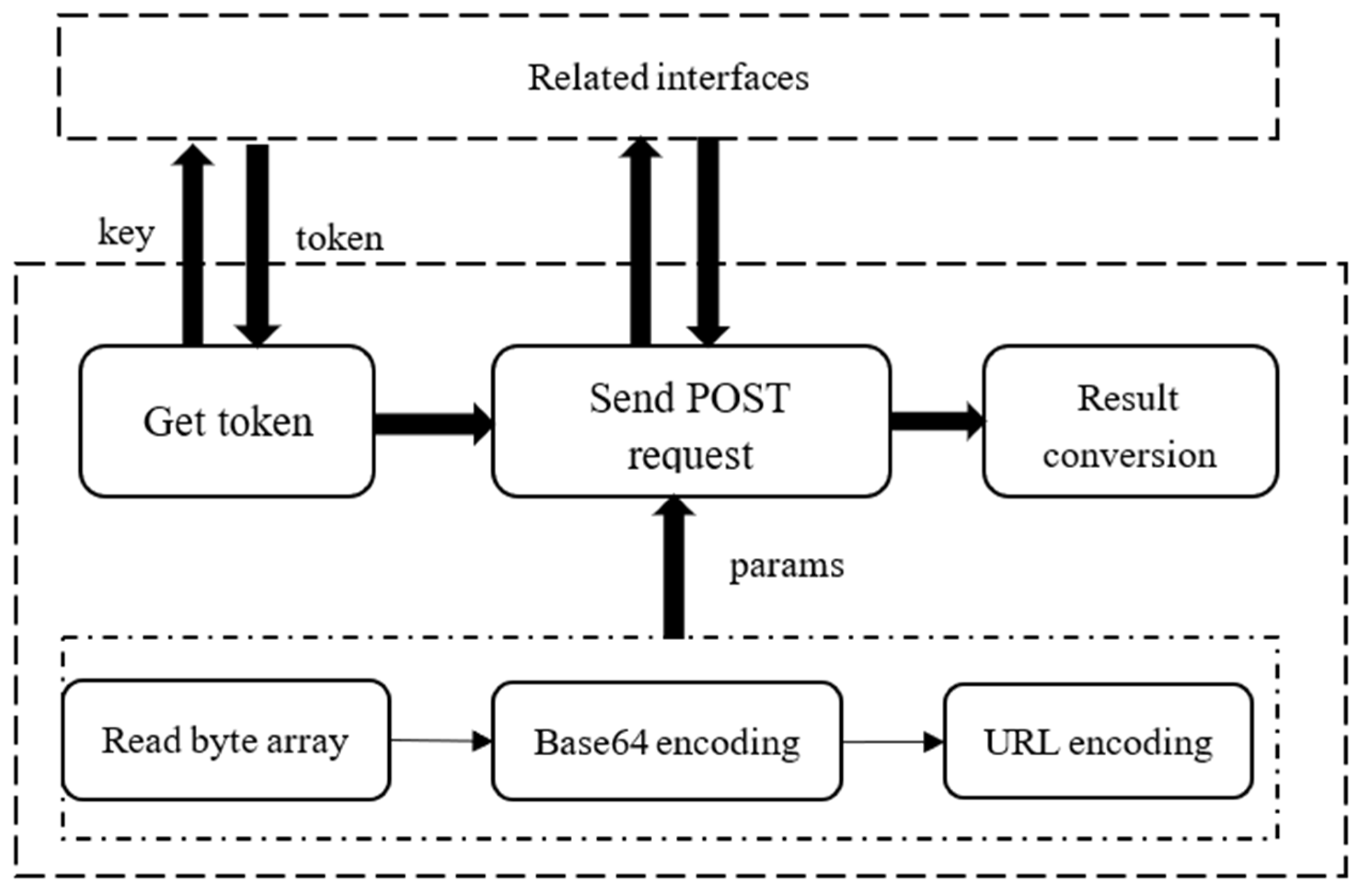
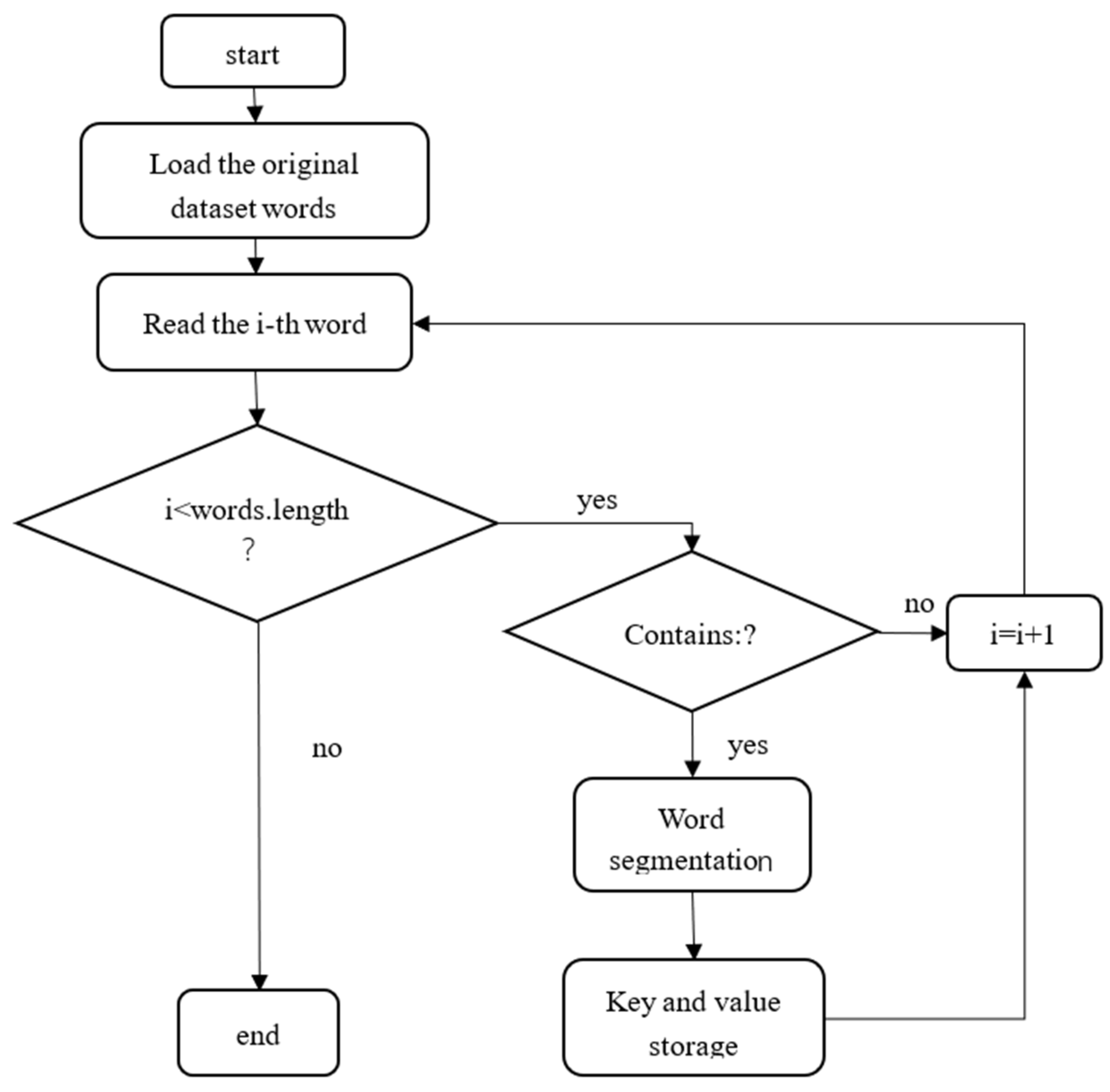
3. Filling Method Based on OCR and Text Similarity
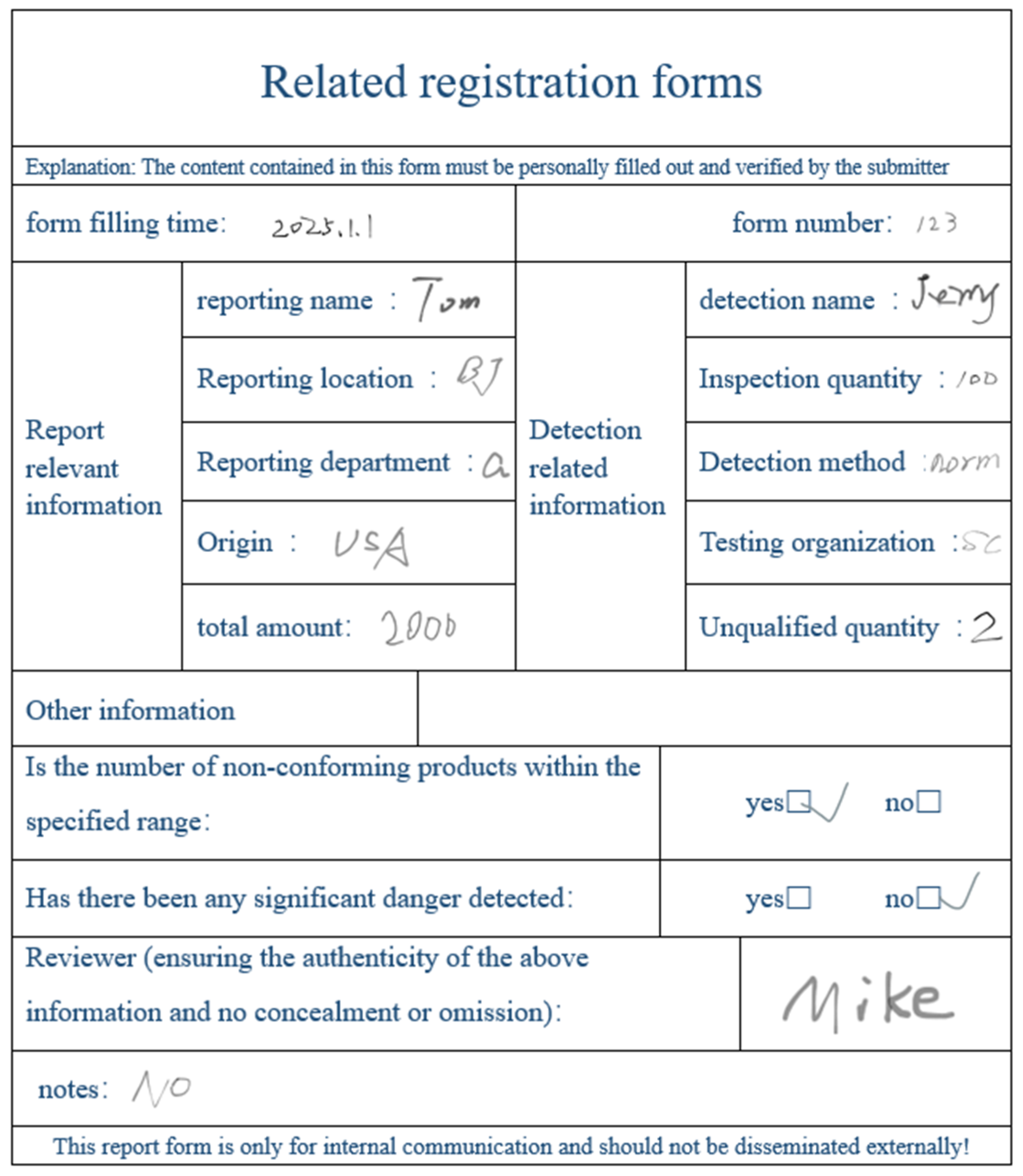
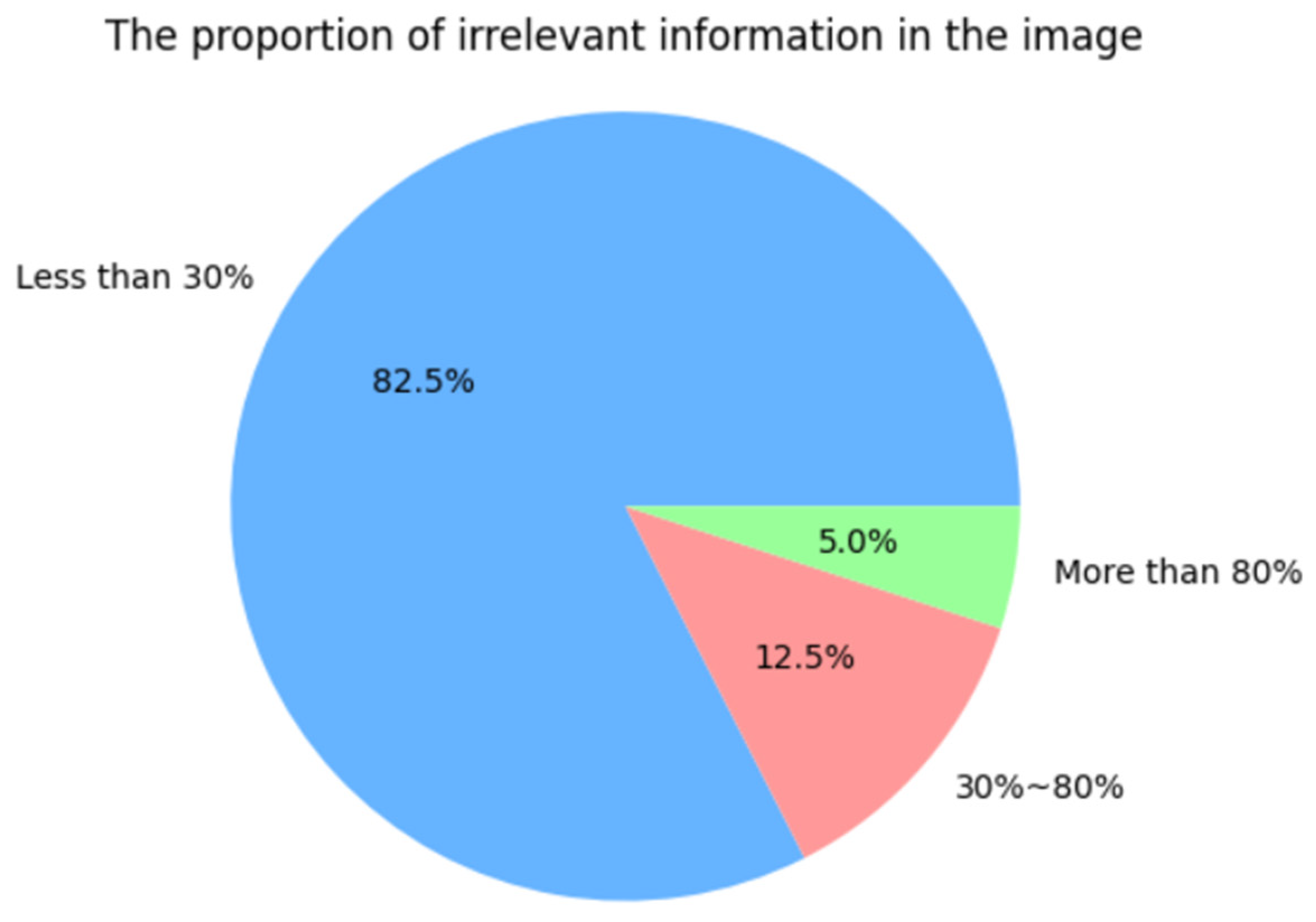
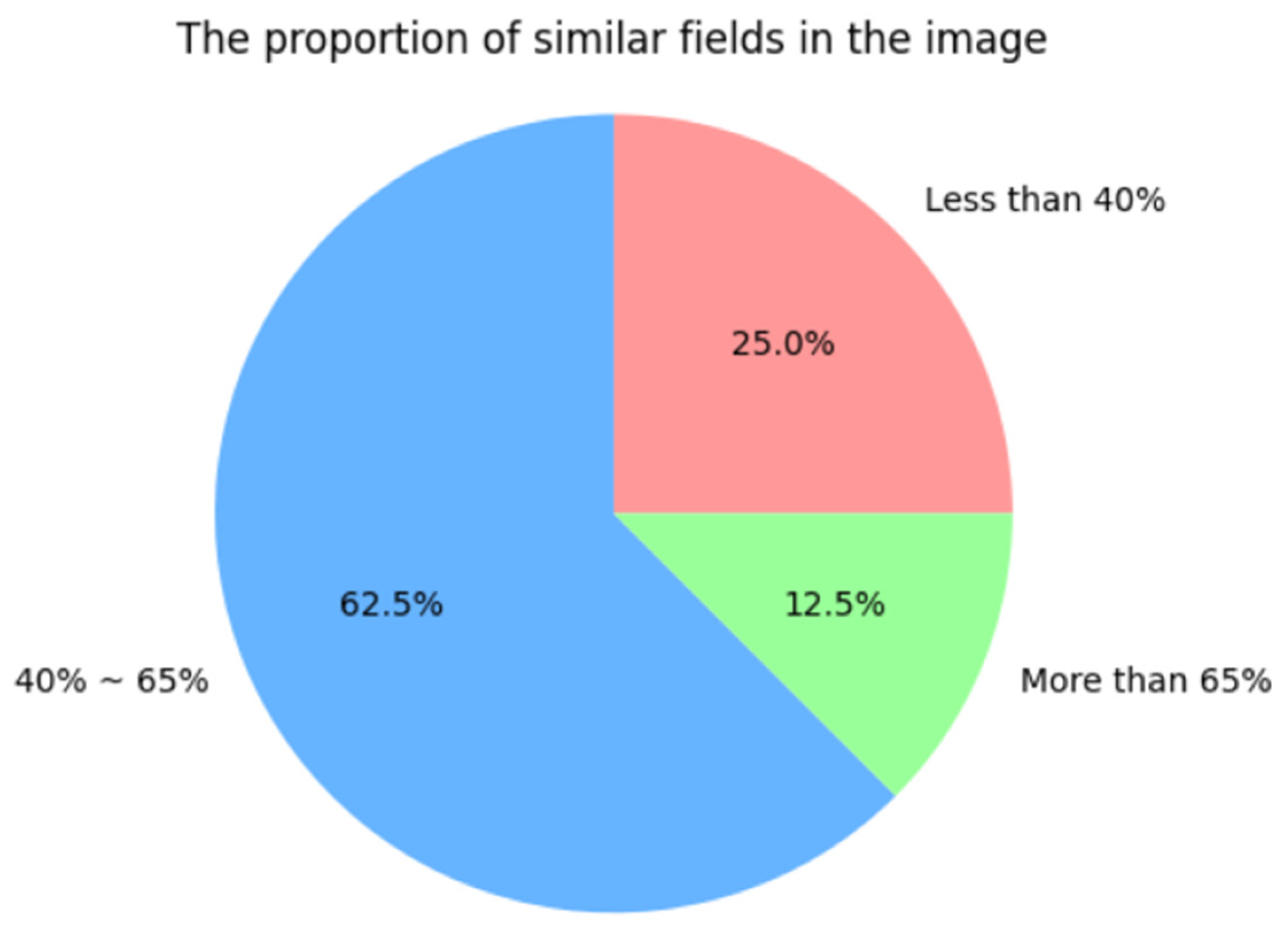
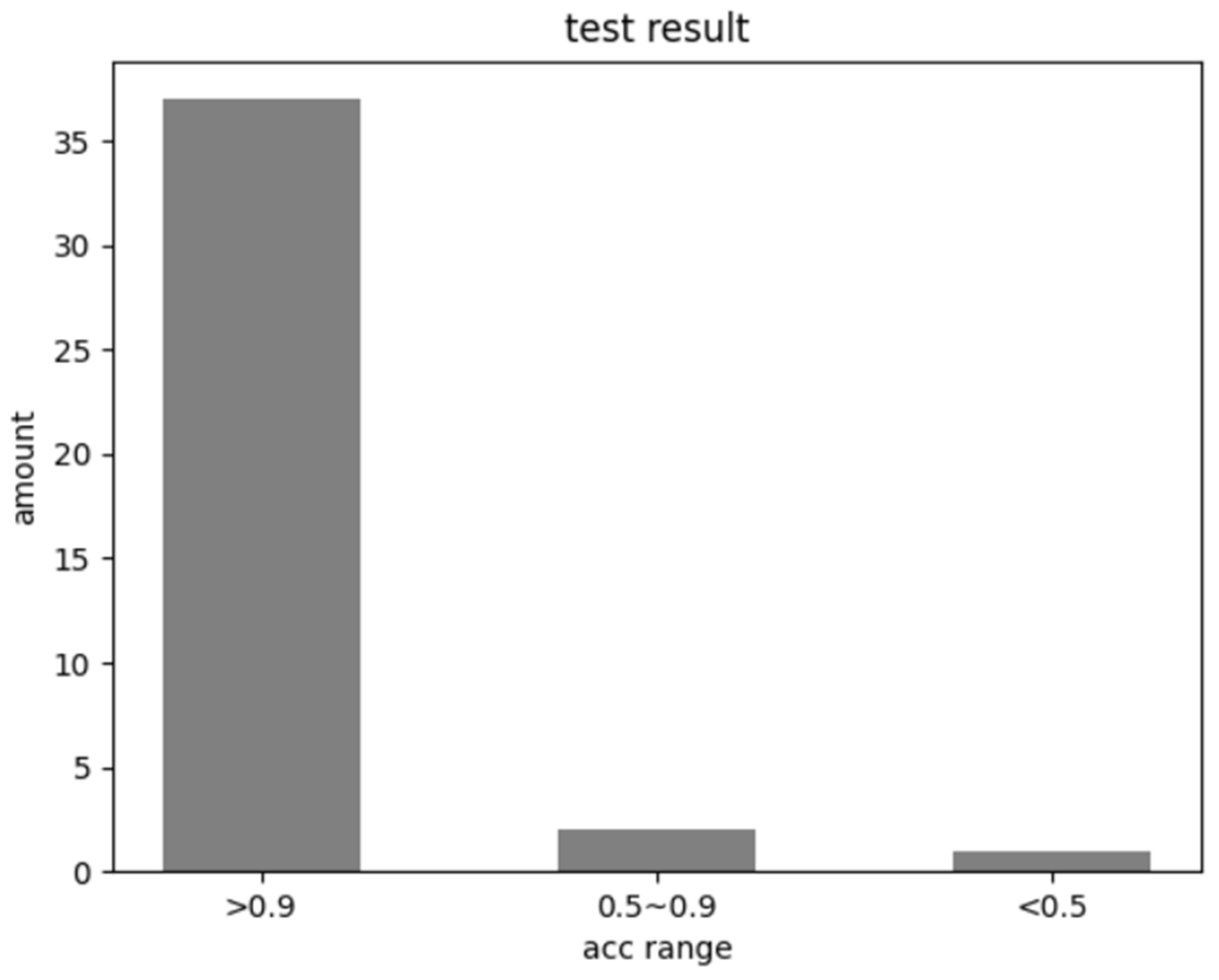
4. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Molina-Ríos, J.; Pedreira-Souto, N. Comparison of development methodologies in web applications. Inf. Softw. Technol. 2020, 119, 106238. [Google Scholar] [CrossRef]
- Xu, Y.; Cao, S. The Implementation of Large Video File Upload System Based on the HTML5 API and Ajax. In Proceedings of the 2015 Joint International Mechanical, Electronic and Information Technology Conference (JIMET-15), Chongqing, China, 18–20 December 2015; pp. 15–19. [Google Scholar]
- Lestari, N.S.; Ramadi, G.D.; Mahardika, A.G. Web-Based Online Study Plan Card Application Design. J. Phys. Conf. Ser. 2021, 1783, 012046. [Google Scholar] [CrossRef]
- Diaz, O.; Otaduy, I.; Puente, G. User-driven automation of web form filling. In Proceedings of the Web Engineering: 13th International Conference, ICWE 2013, Aalborg, Denmark, 8–12 July 2013; pp. 171–185. [Google Scholar]
- Suryadi, A.; Balakrishnan, T.A. Website Based Patient Clinical Data Information Filling and Registration System. Proc. Int. Conf. Nurs. Health Sci. 2023, 4, 197–206. [Google Scholar] [CrossRef]
- Daraee, F.; Mozaffari, S.; Razavi, S.M. Handwritten keyword spotting using deep neural networks and certainty prediction. Comput. Electr. Eng. 2021, 92, 107111. [Google Scholar] [CrossRef]
- Jain, M.; Mathew, M.; Jawahar, C.V. Unconstrained OCR for Urdu Using Deep CNN-RNN Hybrid Networks. In Proceedings of the 2017 4th IAPR Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017; pp. 747–752. [Google Scholar]
- Semkovych, V.; Shymanskyi, V. Combining OCR Methods to Improve Handwritten Text Recognition with Low System Technical Requirements. In Proceedings of the The International Symposium on Computer Science, Digital Economy and Intelligent Systems, Wuhan, China, 11–13 November 2022; pp. 693–702. [Google Scholar]
- Shaw, U.; Mamgai, R.; Malhotra, I. Medical Handwritten Prescription Recognition and Information Retrieval Using Neural Network. In Proceedings of the 2021 6th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 7–9 October 2021; pp. 46–50. [Google Scholar]
- Aluga, D.; Nnyanzi, L.A.; King, N.; Okolie, E.A.; Raby, P. Effect of electronic prescribing compared to paper-based (handwritten) prescribing on primary medication adherence in an outpatient setting: A systematic review. Appl. Clin. Inform. 2021, 12, 845–855. [Google Scholar] [CrossRef]
- Sanuvala, G.; Fatima, S.S. A Study of Automated Evaluation of Student’s Examination Paper Using Machine Learning Techniques. In Proceedings of the 2021 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 19–20 February 2021; pp. 1049–1054. [Google Scholar]
- Thorat, C.; Bhat, A.; Sawant, P.; Bartakke, I.; Shirsath, S. A detailed review on text extraction using optical character recognition. ICT Anal. Appl. 2022, 314, 719–728. [Google Scholar]
- Karthick, K.; Ravindrakumar, K.; Francis, R.; Ilankannan, S. Steps involved in text recognition and recent research in OCR; a study. Int. J. Recent Technol. Eng. 2019, 8, 2277–3878. [Google Scholar]
- Kshetry, R.L. Image preprocessing and modified adaptive thresholding for improving OCR. arXiv 2021, arXiv:2111.14075. [Google Scholar] [CrossRef]
- Mursari, L.R.; Wibowo, A. The effectiveness of image preprocessing on digital handwritten scripts recognition with the implementation of OCR Tesseract. Comput. Eng. Appl. J. 2021, 10, 177–186. [Google Scholar] [CrossRef]
- Ma, T.; Yue, M.; Yuan, C.; Yuan, H. File text recognition and management system based on tesseract-OCR. In Proceedings of the 2021 3rd International Conference on Applied Machine Learning (ICAML), Changsha, China, 23–25 July 2021; pp. 236–239. [Google Scholar]
- Kamisetty, V.N.S.R.; Chidvilas, B.S.; Revathy, S.; Jeyanthi, P.; Anu, V.M.; Gladence, L.M. Digitization of Data from Invoice Using OCR. In Proceedings of the 2022 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; pp. 1–10. [Google Scholar]
- Maliński, K.; Okarma, K. Analysis of Image Preprocessing and Binarization Methods for OCR-Based Detection and Classification of Electronic Integrated Circuit Labeling. Electronics 2023, 12, 2449. [Google Scholar] [CrossRef]
- Nahar, K.M.; Alsmadi, I.; Al Mamlook, R.E.; Nasayreh, A.; Gharaibeh, H.; Almuflih, A.S.; Alasim, F. Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques. Sensors 2023, 23, 9475. [Google Scholar] [CrossRef]
- Yu, W.; Lu, N.; Qi, X.; Gong, P.; Xiao, R. PICK: Processing key information extraction from documents using improved graph learning-convolutional networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4363–4370. [Google Scholar]
- Biró, A.; Cuesta-Vargas, A.I.; Martín-Martín, J.; Szilágyi, L.; Szilágyi, S.M. Synthetized Multilanguage OCR Using CRNN and SVTR Models for Realtime Collaborative Tools. Appl. Sci. 2023, 13, 4419. [Google Scholar] [CrossRef]
- He, Y. Research on Text Detection and Recognition Based on OCR Recognition Technology. In Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; pp. 132–140. [Google Scholar]
- Verma, P.; Foomani, G. Improvement in OCR Technologies in Postal Industry Using CNN-RNN Architecture: Literature Review. Int. J. Mach. Learn. Comput. 2022, 12, 154–163. [Google Scholar]
- Idris, A.A.; Taha, D.B. Handwritten Text Recognition Using CRNN. In Proceedings of the 2022 8th International Conference on Contemporary Information Technology and Mathematics (ICCITM), Mosul, Iraq, 31 August–1 September 2022; pp. 329–334. [Google Scholar]
- Fu, X.; Ch’ng, E.; Aickelin, U.; See, S. CRNN: A joint neural network for redundancy detection. In Proceedings of the 2017 IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017; pp. 1–8. [Google Scholar]
- Nguyen, T.T.H.; Jatowt, A.; Coustaty, M.; Doucet, A. Survey of post-OCR processing approaches. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Kumar, P.; Revathy, S. An Automated Invoice Handling Method Using OCR. In Proceedings of the Data Intelligence and Cognitive Informatics: Proceedings of ICDICI 2020, Tirunelveli, India, 8–9 July 2020; pp. 243–254. [Google Scholar]
- Jiju, A.; Tuscano, S.; Badgujar, C. OCR text extraction. Int. J. Eng. Manag. Res. 2021, 11, 83–86. [Google Scholar] [CrossRef]
- Reid, M.; Zhong, V. LEWIS: Levenshtein editing for unsupervised text style transfer. arXiv 2021, arXiv:2105.08206. [Google Scholar]
- Da, C.; Wang, P.; Yao, C. Levenshtein OCR. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; pp. 322–338. [Google Scholar]
- Rustamovna, A.U. Understanding the levenshtein distance equation for beginners. Am. J. Eng. Technol. 2021, 3, 134–139. [Google Scholar]
- Wang, J.; Xu, W.; Yan, W.; Li, C. Text Similarity Calculation Method Based on Hybrid Model of LDA and TF-IDF. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, Normal, IL, USA, 6–8 December 2019; pp. 1–8. [Google Scholar]
- Zang, R.; Sun, H.; Yang, F.; Feng, G.; Yin, L. Text similarity calculation method based on Levenshtein and TFRSF. Comput. Mod. 2018, 4, 84–89. [Google Scholar]
- Amir, A.; Charalampopoulos, P.; Pissis, S.P.; Radoszewski, J. Dynamic and internal longest common substring. Algorithmica 2020, 82, 3707–3743. [Google Scholar] [CrossRef]
- Irhansyah, T.; Nasution, M.I.P. Development Of Thesis Repository Application In The Faculty Of Science And Technology Use Implementation Of Vue. Js Framework. J. Inf. Syst. Technol. Res. 2023, 2, 66–77. [Google Scholar]
- Zhang, F.; Sun, G.; Zheng, B.; Dong, L. Design and implementation of energy management system based on spring boot framework. Information 2021, 12, 457. [Google Scholar] [CrossRef]
- Jiang, Y.; Dong, H.; El Saddik, A. Baidu Meizu deep learning competition: Arithmetic operation recognition using end-to-end learning OCR technologies. IEEE Access 2018, 6, 60128–60136. [Google Scholar] [CrossRef]
- Fang, H.; Bao, M. Raw material form recognition based on Tesseract-OCR. In Proceedings of the 2021 IEEE Conference on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, 10–11 December 2021; pp. 942–945. [Google Scholar]
- Xu, Y.; Dai, P.; Li, Z.; Wang, H.; Cao, X. The Best Protection is Attack: Fooling Scene Text Recognition With Minimal Pixels. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1580–1595. [Google Scholar] [CrossRef]
- Terra, E.L.; Clarke, C.L. Frequency Estimates for Statistical Word Similarity Measures. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, Canada, 27 May–1 June 2003; pp. 244–251. [Google Scholar]
- Khreisat, L. A machine learning approach for Arabic text classification using N-gram frequency statistics. J. Informetr. 2009, 3, 72–77. [Google Scholar] [CrossRef]
- Shao, M.; Qin, L. Text Similarity Computing Based on LDA Topic Model and Word Co-Occurrence. In Proceedings of the 2014 2nd International Conference on Software Engineering, Knowledge Engineering and Information Engineering (SEKEIE 2014), Singapore, 5–6 August 2014; pp. 199–203. [Google Scholar]
- Li, Z.; Chen, H.; Chen, H. Biomedical text similarity evaluation using attention mechanism and Siamese neural network. IEEE Access 2021, 9, 105002–105011. [Google Scholar] [CrossRef]
- Wen, X.; Jaxa-Rozen, M.; Trutnevyte, E. Accuracy indicators for evaluating retrospective performance of energy system models. Appl. Energy 2022, 325, 119906. [Google Scholar] [CrossRef]
- Ji, M.; Zhang, X. A short text similarity calculation method combining semantic and headword attention mechanism. Sci. Program. 2022, 2022, 8252492. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, H.; Kang, R.; Fan, Y. Research on a Web System Data-Filling Method Based on Optical Character Recognition and Multi-Text Similarity. Appl. Sci. 2024, 14, 1034. https://doi.org/10.3390/app14031034
Su H, Kang R, Fan Y. Research on a Web System Data-Filling Method Based on Optical Character Recognition and Multi-Text Similarity. Applied Sciences. 2024; 14(3):1034. https://doi.org/10.3390/app14031034
Chicago/Turabian StyleSu, Hailu, Ruiqing Kang, and Yunli Fan. 2024. "Research on a Web System Data-Filling Method Based on Optical Character Recognition and Multi-Text Similarity" Applied Sciences 14, no. 3: 1034. https://doi.org/10.3390/app14031034
APA StyleSu, H., Kang, R., & Fan, Y. (2024). Research on a Web System Data-Filling Method Based on Optical Character Recognition and Multi-Text Similarity. Applied Sciences, 14(3), 1034. https://doi.org/10.3390/app14031034