Abstract
Heterogeneous network embedding aims to project multiple types of nodes into a low-dimensional space, and has become increasingly ubiquitous. However, several challenges have not been addressed so far. First, existing heterogeneous network embedding techniques typically rely on meta-paths to deal with the complex heterogeneous network. Using these meta-paths requires prior knowledge from domain experts for optimal meta-path selection. Second, few existing models can effectively consider both heterogeneous structural information and heterogeneous node attribute information. Third, existing models preserve the structure information by considering the first- and/or the second-order proximities, which cannot capture long-range structural information. To address these limitations, we propose a novel attributed heterogeneous network embedding model referred to as Node-to-Attribute Generation Network Embedding (NAGNE). NAGNE comprises two major components, the attributed random walk which samples node sequences in attributed heterogeneous network, and the node-to-attribute generation which learns the mapping that translates each node sequence itself from the node sequence to the node attribute sequence. Extensive experiments on three heterogeneous network datasets demonstrate that NAGNE outperforms state-of-the-art baselines in various data mining tasks.
1. Introduction
Network embedding, or network representation learning, has attracted a great deal of attention in recent years [1]. Most of the existing network embedding methods focus on homogeneous networks [2,3,4]. However, real-world networks typically consist of multiple types of nodes and edges, commonly known as heterogeneous information networks (HIN) [5]. Some prevalent instances of such networks include the Facebook entity network, academic networks and movie networks. Using the movie network IMDB as an illustration, it contains three types of nodes, movie, actor and director, with different types of relationships between them.
Over the past decade, a significant amount of research has been conducted to explore mining in heterogeneous networks. Most of these studies’ concepts are based on the idea of meta-paths. A meta-path describes a composite relationship between the involved node types, representing an ordered sequence of node types and edge types defined in the network schema. For example, the relationship between two movies can be revealed by the meta-paths Movie–Actor–Movie (MAM), describing the co-actor relationship, and Movie–Director–Movie (MDM), which signifies that they share the same director. Therefore, a meta-path can be perceived as high-order proximity between two nodes, with different meta-paths conveying semantic meanings. To integrate meta-paths in network embedding, existing techniques usually perform meta-path-guided random walks to sample node pairs for learning node embeddings. For instance, ESim [6] accepts meta-paths as guidance to learn node embeddings for similarity searches. Metapath2Vec [7] proposes meta-path-guided random walks to handle the heterogeneity in HIN. HAN [8] generates node embeddings by aggregating features from meta-path-based neighbors in a hierarchical manner.
Although existing heterogeneous network embeddings have achieved state-of-the-art results in many tasks, such as node classification and link prediction, they still suffer from at least one of the following limitations: (1) It is quite challenging to find an optimal combination of meta-paths. (2) The models do not leverage node attribute information; as the attribute and the topological structure are highly non-linear, capturing this non-linearity makes it difficult to discover the underlying patterns. (3) The existing methods preserve the structured information such as the first- and second-order proximities, but they cannot capture long-range structures.
In light of these limitations, we propose a novel attributed heterogeneous network embedding model that translates node sequences to node attributes, named the Node-to-Attribute Generation Network Embedding (NAGNE) model. To address the limitations of meta-paths mentioned above, we introduce an attributed random walk method based on the node attributes. More precisely, we first apply a type-specific mapping function for each type of node by mapping node attributes into attribute types. Then, we conduct random walks on the network based on the attribute type. When performing random walks, the next node is generated by probabilistically considering the following two steps: (1) selecting a target attribute type based on the current node and (2) sampling the target node from the selected attribute type. To capture long-range structure and non-linearity between node attributes and node topological structures, we cast the network embedding problem as a machine translation problem and determine the mapping from node identity sequences to node attribute type sequences. Specifically, given a mass of sampled node sequences using the attributed random walk, we employ attention mechanisms to encode each node identity sequence into a compressed vector as mentioned in Transformer [9], and then we decode this vector to generate the corresponding node attribute type sequence. By mapping the node sequences to node attribute type sequences, the node attribute information and structural information are seamlessly merged into the latent vectors of hidden layers, which can effectively serve as the embedding of nodes. Since the node structure is preserved in the sequence context vector learned via attention mechanisms, it avoids the rigid assumption of the scope of neighborhood and can flexibly determine the appropriate scope of neighborhood information.
The contributions of this paper can be summarized as follows:
- We propose an attributed random walk method on a heterogeneous network, which can integrate node attributes into the generated node sequence and does not require a predefined meta-path.
- We propose a heterogeneous network neural network model, i.e., NAGNE, for network embedding on a heterogeneous network. NAGNE is able to capture both structural and attribute heterogeneity, and can flexibly determine the appropriate scope of neighborhood information.
- We conduct extensive experiments on several public datasets, and the results show that our model significantly outperforms state-of-the-art network embedding models in various tasks.
2. Related Work
2.1. Graph Neural Network
The goal of graph neural networks (GNNs) is to extend deep neural networks to accommodate arbitrary graph-structured data, which has recently gained substantial attention. GraphSAGE [4] uses a neural network-based aggregator over a fixed-size node neighborhood. GAT [3] incorporates a self-attention mechanism into the aggregation function to measure the impacts of different neighbors and combine them to obtain node embeddings. GGNN [10], on the other hand, treats the aggregated neighborhood information as input to the gated recurrent unit (GRU) of the current timestep, enhancing the aggregator function with a GRU. To address spatiotemporal graphs, GaAN [11] merges the GRU with a gated multi-head attention mechanism. However, all the aforementioned GNNs apply only to homogeneous graphs and cannot be naturally adapted to heterogeneous networks.
2.2. Heterogeneous Network Embedding
Heterogeneous network embedding aims to map nodes in a heterogeneous network into a low-dimensional vector space. This approach has recently attracted increasing research interest due to its focus on preserving meta-path-based structural information. Metapath2vec [7] generates meta-path-based random walks and applies the Skip-Gram [12] model to address heterogeneity in HIN. ASPEM [13] captures multiple aspects of semantic information in HINs. HERec [14] introduces a type constraint strategy to transform a heterogeneous network into a homogeneous graph, then uses DeepWalk [1] to learn node embeddings. HAN [8] employs node-level and semantic-level attention to discern the importance of nodes and meta-paths, capturing the complex structures and rich semantics within a heterogeneous network. HetGNN [15] proposes a model that preserves both first- and second-order proximities. HGT [16] designs node-type- and edge-type-dependent parameters to characterize the heterogeneous attention for each edge. NSHE [17] proposes a novel network schema sampling method to address the bias among different types of nodes.
RHINE [18] introduces two criteria for consistently distinguishing heterogeneous relations into affiliation and interaction relationships. HGNN-AC [19] leverages topological relationships to tackle missing attributes in heterogeneous graphs. HGSL [20] addresses structure learning and GNN parameter learning for classification tasks by considering feature similarity and complex heterogeneous interactions jointly. PT-HGNN [21] employs node- and schema-level pretraining tasks to preserve heterogeneous semantic and structural properties contrastively, suggesting the use of relation-based personalized PageRank for efficient pretraining of large-scale heterogeneous graphs. HeCo [22] employs a cross-view contrastive mechanism to concurrently capture local and high-order structures, extracting positive and negative embeddings from two views. HGCN [23] devises a hierarchical aggregation architecture that evaluates meta-paths within a set limit, identifying and utilizing the most beneficial ones for each target object, thus reducing computational costs. Megnn [24] utilizes heterogeneous convolution to integrate various bipartite subgraphs associated with edge types into a unified, trainable graph structure. SeHGNN [25] precomputes the neighbor aggregation using a light-weight mean aggregator, which reduces complexity by removing overused neighbor attention and avoiding repeated neighbor aggregation in every training epoch. HGMAE [26] is a novel heterogeneous graph masked autoencoder model that develops meta-path masking and adaptive attribute masking to enable effective and stable learning on heterogeneous graphs.
In order to enhance the comparison of NAGNE with previous methods, we select several typical heterogeneous network embedding methods. The comparison is conducted from three aspects: whether they can handle structural heterogeneity, whether they can handle attribute heterogeneity, and whether they require predefined meta-paths. The results are shown in Table 1.

Table 1.
The comparison of different methods.
3. Preliminary
In this section, we give formal definitions of some important terminologies frequently used in this paper.
Definition 1
(Attributed Heterogeneous Network [27,28]). An attributed heterogeneous network is denoted as , and is associated with a node type mapping function and an edge type mapping function . and denote the sets of predefined node types and edge types, with , where is the node set; is the edge set, where indicates an edge exists between nodes and ; is the node attribute set; is the node attribute matrices of node type ; is the node set of ; and is the node attribute dimension for node type . The weighted adjacency matrix of is denoted by . If , ; otherwise, . We use to denote the neighborhood of node .
Definition 2
(Attributed Heterogeneous Network Embedding). Given an attributed heterogeneous network , attributed heterogeneous network embedding aims to design a model to learn the d-dimensional embeddings that are able to capture the rich structural and node attribute information involved in .
Definition 3
(Node Attribute Mapping). Given an attributed heterogeneous network , node attribute mapping aims to map each node attribute to a set of attribute types, where .
Definition 4
(Node-to-Attribute Generation). Let be a sequence of nodes sampled from a network, and be the corresponding node neighborhood sequence and node attribute type sequence respectively. Given a set of node neighborhood sequences and a set of the corresponding attribute type sequences , node-to-attribute generation learns a mapping function for each and .
4. Methodology
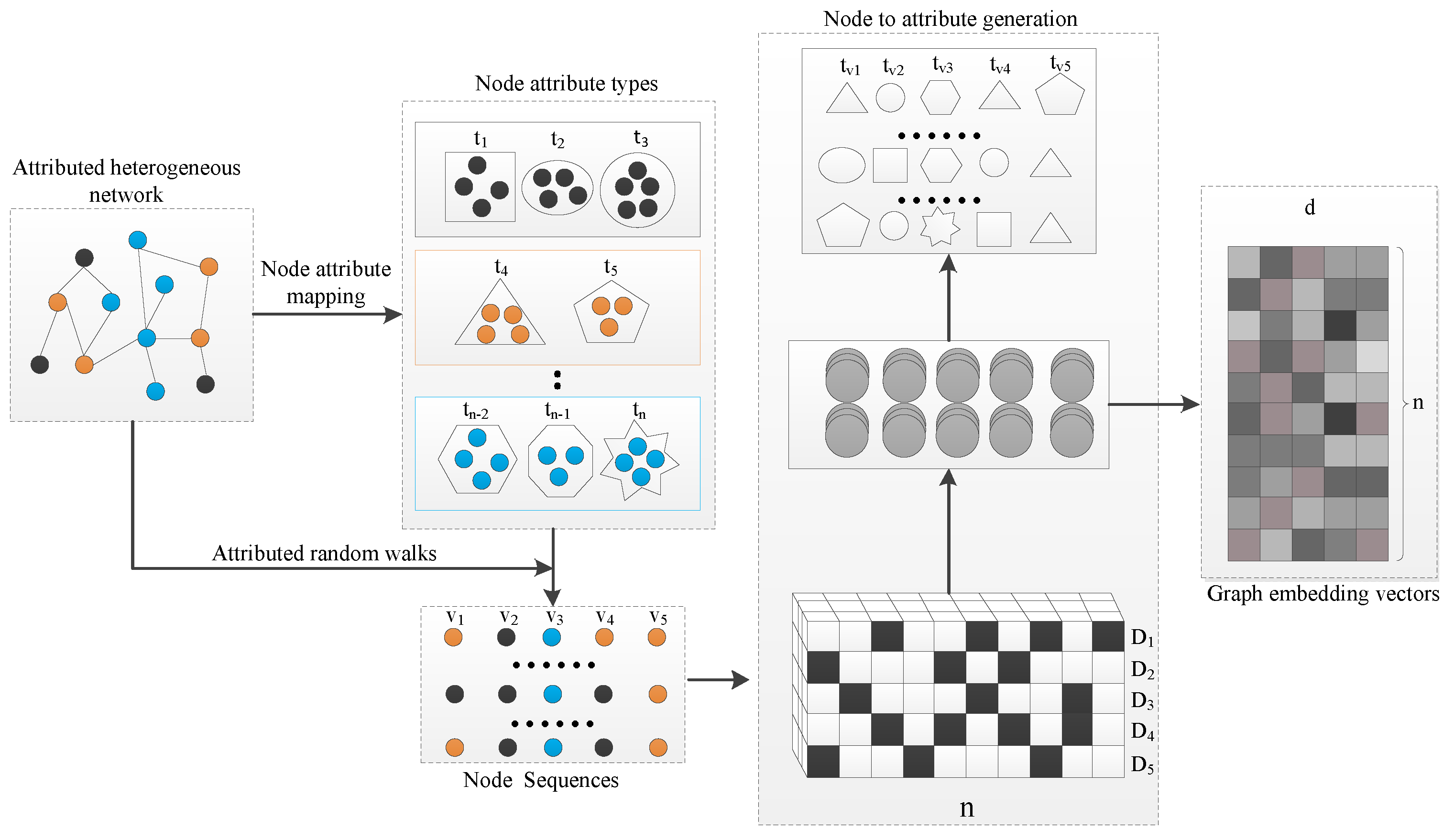
In this section, we propose a novel network embedding model for attributed heterogeneous networks. Figure 1 illustrates the framework of the proposed NAGNE. The model is constructed by three major components: node attribute mapping, attributed random walks and node-to-attribute generation.
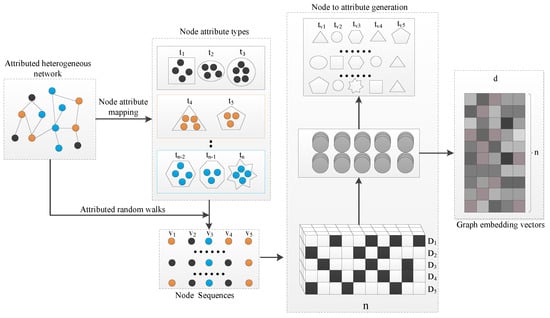
Figure 1.
The overall architecture of NAGNE.
4.1. Node Attribute Mapping
Due to the fact that different types of nodes may lie in different attribute spaces, we apply a type-specific mapping function for each type of node by mapping node attributes into attribute types. Given the node attribute matrices for node type , for one node attribute vector , we have
Thus, for each node type , we have a function that maps the nodes of type to a set of attribute types based on the attribute matrix , where . The node attribute mapping aims to map the nodes with similar attributes into the same attribute types. Note that the function is a modeling choice, which could be learned automatically or defined manually by the user. In this paper, we map the nodes to their attribute types by using the Non-negative Matrix Factorization (NMF) [29] algorithm. Given the node attribute matrices for node type , the attribute similarity matrix is calculated based on the node attributes. Each element is the attribute cosine similarity of nodes and . NMF aims to find non-negative matrix factors and such that
where and ; is the number of attribute types of , which is usually chosen to be smaller than ; and is the attribute type indicator matrix, where each element presents the tendency that the i-th node belongs to the j-th attribute type. Then, we partition into disjoint sets based on the values of .
4.2. Attributed Random Walks
Random walks [1] have received much attention in homogeneous networks. However, as nodes in heterogeneous networks are associated with a dominant number of paths, random walks in heterogeneous networks are biased to highly visible types of nodes. Subsequently, the learned node embeddings are also biased to these types in the sense that they mostly preserve the node proximity in these types. In addition, random walks ignore the attributes of nodes and cannot integrate attributes into the node embeddings. Thus, we propose an attributed random walk method in a heterogeneous network. In our attributed random walks, there are two steps to select the next node in a random walk. Consider an attributed random walk that just resides at node , and the next node is selected via the following steps:
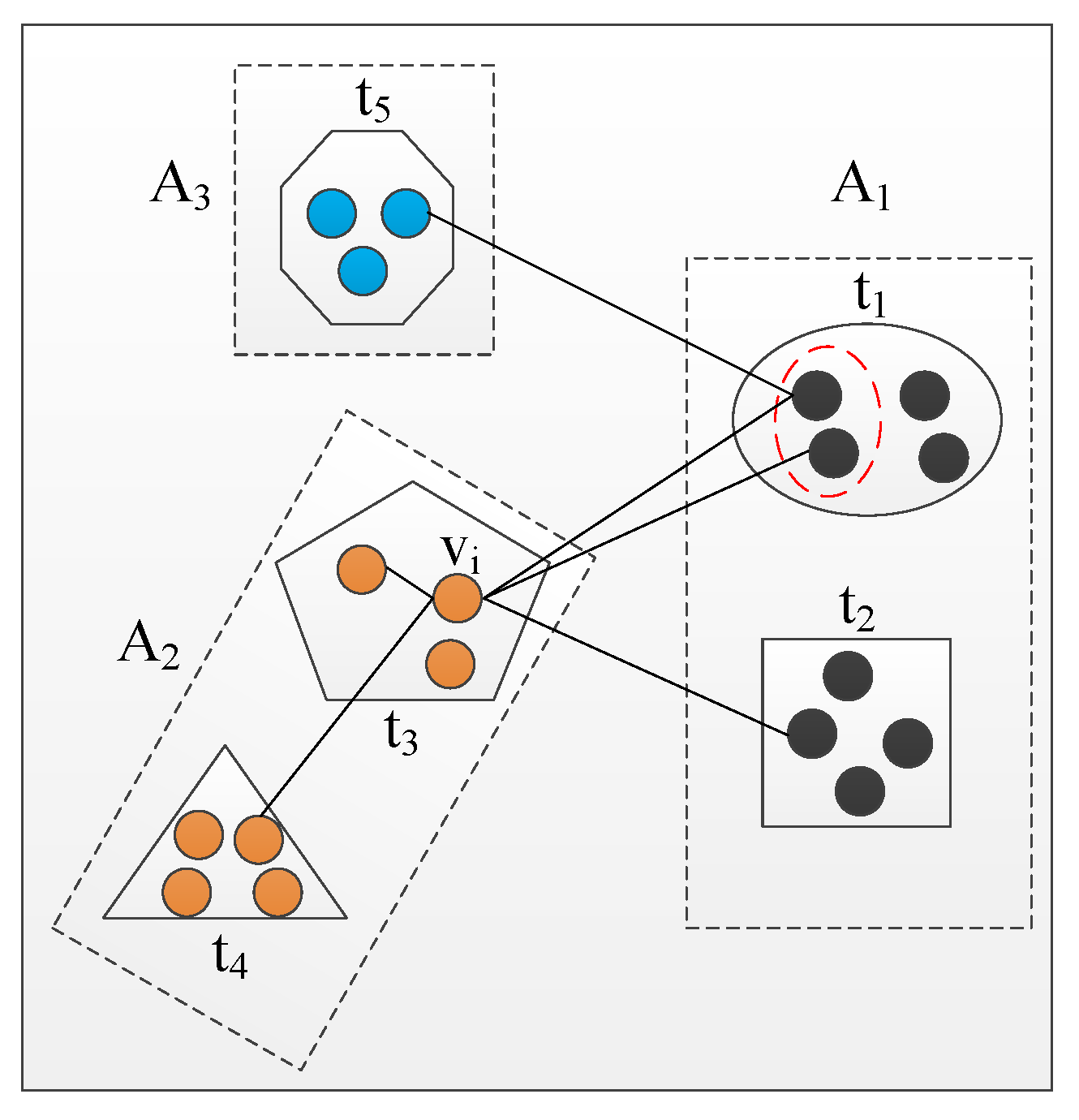
- Selecting a target attribute type t. Sampling one attribute type t from those that have nodes connected to via heterogeneous edges. The candidate set of attribute types for selecting is denoted as . According to the node type of , can be divided into two parts, and , which are denoted aswhere is the node type of . contains the attribute types of the node which has the same node type as , and otherwise. For example, in Figure 2, , and .
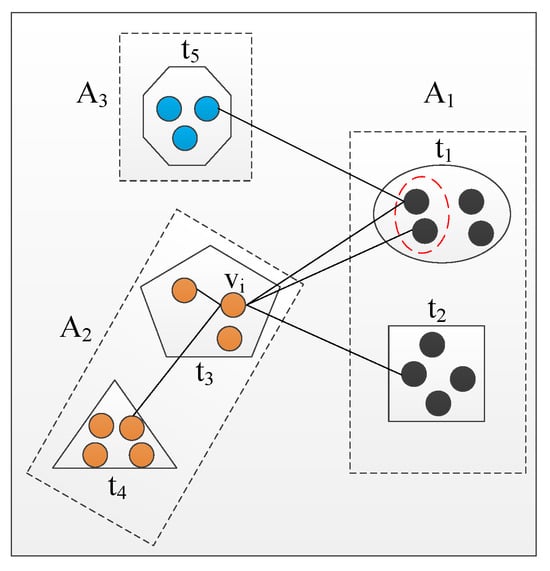 Figure 2. An example of selecting where to jump.To overcome the problem that the node distribution from the random walk sequences are skewed towards these highly visible node types, we first sample one set from with the following probability:where is an initial probability, which is determined in advance. s is the number of nodes consecutively visited in the same node type of the current node . By sampling the attribute type t from with a probability , and otherwise, we adopt an exponential decay function to penalize the case that the walk stays in one node type for too long. After that, we uniformly sample one attribute type t from .
Figure 2. An example of selecting where to jump.To overcome the problem that the node distribution from the random walk sequences are skewed towards these highly visible node types, we first sample one set from with the following probability:where is an initial probability, which is determined in advance. s is the number of nodes consecutively visited in the same node type of the current node . By sampling the attribute type t from with a probability , and otherwise, we adopt an exponential decay function to penalize the case that the walk stays in one node type for too long. After that, we uniformly sample one attribute type t from . - Sampling the target node . Sampling one node from the nodes with the selected attribute type t. The corresponding candidate set of nodes is denoted as . After selecting a target attribute type t, we can uniformly sample one node as from with the following probability:where is the un-normalized transition probability between nodes and ; in unweighted networks, , Z is the normalizing constant. However, intuitively, the nodes in that have edges with have more similarities with it, which should make them easier to sample. Figure 2 shows an example of the sampling. In Figure 2, if is the selected attribute type, the two nodes in the red dotted circle should be easier to sample than the others in as they have edges with . We use to denote the node sets that have edges with , and otherwise. Then, we define the un-normalized transition probability in networks as the following:Parameter q controls the search procedure in the walk. As we hope the nodes in are more likely to be sampled, we set . Note that by generating the next node based on the attribute type, the attributed random walk samples nodes not only from those connected to , but also from the nodes have similar attributes with , which allows the random walk to explore both the structural and attribute information of the network. The pseudocode is shown in Algorithm 1.
| Algorithm 1 Attributed Random Walks |
Require: graph , initial stay probability controlling parameters and s, random walks parameter q, number of random walks per node r, maximum walk length
|
4.3. Node-to-Attribute Generation
4.3.1. Node Sequence Encoder
Let be a sequence of nodes sampled from a network using attributed random walks; the corresponding nodes neighborhood sequence and node attribute type sequence are and , respectively. For each type of node, we apply a type-specific linear transformation to project the neighborhood of different types of nodes into the same latent factor space. For a node in node sequence , we have
where is the projected latent vector of node , and is the parametric weight matrix for node type . Then, the sequence of node neighborhood is projected as
where is an matrix. To capture the global topology information over sequences, NAGNE uses an encoder to encode the sequence of the node neighborhood vector , as mentioned in Transformer. The encoder is composed of a stack of L identical layers. Each layer has four sub-layers. The output of each layer is obtained from the output of the previous via four sub-layers as follows:
where denotes the hidden units of the layer and, particularly, is the node sequence neighborhood projecting ; , F and , respectively, denote the sub-layers of residual connection plus layer normalization, feed-forward network and multi-head attention; and ∘ denotes the composition operator between two functions. and F map a vector to another vector and we refer to reader to Transformer for detailed definitions. Multi-head attention allows the model to jointly attend to information from different representation sub-spaces, which is defined as follows:
where is a linear projection function, and
where , , are transformation matrices for head i, and
The softmax function applied to the scaled dot-product attention scores normalizes them into a probability distribution over the input tokens. It is mathematically defined as
Here, is a vector containing attention scores before normalization, is the j-th element of , and K is the total number of elements in the vector. By exponentiating and normalizing each score, the softmax function ensures that the output is a valid probability distribution, with all elements between 0 and 1 and summing up to 1.
After applying the attention mechanism at each layer, the node’s neighborhood sequence is effectively compressed into the representation through a stack of L identical layers, which each potentially leverage the aforementioned attention computation.
4.3.2. Node Attribute Generation
The representation seamlessly fuses the attribute information and the structural information. Similar to the encoder, the decoder is also composed of a stack of L identical layers. The output of each layer is obtained from the output of the previous layer as follows:
where is the hidden units of the layer in the decoding phase and, particularly, denotes the embedding of the corresponding node attribute type sequence . Note that the encoding phase differs from the decoding phase in an additional multi-head attention mechanism over the hidden unit sequence derived from the encoding phase. After obtaining , we need to map each vector in to a -dimension vector through a fully connected layer, and then a softmax layer transforms into the probabilities :
Then, we use a cross-entropy loss to measure the correctness of the translation:
where is a binary function that outputs 1 if equals k; otherwise, it outputs 0. denotes the k- element of . Then, we use Momentum to optimize the parameters in the model.
5. Experiment
5.1. Experimental Setup
5.1.1. Datasets
- DBLP [18]: A frequently used bibliographic network in heterogeneous network studies. We extract a subset of DBLP containing nodes from three domains, including 2000 authors (A), 9556 papers (P) and 20 conferences (C).
- IMDB [30]: A movie rating website with nodes also in three domains. We composed a heterogeneous network with 4353 actors (A), 3676 movies (M) and 1678 directors (D). Movies were categorized into action, comedy and drama classes asabels based on their genres.
- ACM [30]: This network contains papers from prestigious conferencesike KDD, SIGMOD, SIGCOMM, MobiCOMM and VLDB. Our subset of the ACM includes 3025 papers, 5835 authors and 56 subjects. Paper features are represented through a bag-of-words model of keywords.
- Aminer [31]: Bibliographic graphs. The papers in Aminer areabeled with 17 research fields, e.g., Artificial Intelligence, which are used for node classification. Our subset of the Aminer includes 302402 papers and 520456 authors.
5.1.2. Baselines
- DeepWalk [1]: A homogeneous network embedding model that integrates random walks and the skip-gram to learn network embeddings.
- Metapath2Vec [7]: A heterogeneous network embedding method adopting meta-path-based random walks and a heterogeneous skip-gram model.
- HIN2Vec [32]: A neural network-based approach that learns embeddings through multiple predictive training tasks.
- MAGNN [33]: This model uses node content transformation along with intra- and inter-metapath aggregations to generate node embeddings.
- HAN [8]: This approach utilizes neural networks for heterogeneous networks, generating embeddings by aggregating features from meta-path-based neighbors hierarchically.
- GTN [34]: GTN transforms heterogeneous networks into new graphs using meta-paths and applies convolution to these meta-path-derived graphs to learn node embeddings.
- HGNN-AC [19]: This model transforms a heterogeneous graph into multiple meta-path-defined graphs, learning node representations through convolution and completing attributes for nodes lacking them via weighted aggregation.
- HGSL [20]: HGSL concurrently learns the structure of a heterogeneous graph and the parameters of GNNs for classification tasks.
- Megnn [24]: Megnn merges different bipartite sub-graphs tied to edge types into a novel trainable graph structure using heterogeneous convolution.
5.2. Multi-Label Classification
In node classification, we predict the labels of unlabeled nodes, as performed in previous studies. We designate 80% of labeled nodes as training data to train an SVM classifier, and the remainder for testing. The performances in Micro-F1 and Macro-F1 are displayed in Table 2. Our model, NAGNE, sans prior knowledge, consistently outperforms other baselines across various datasets, affirming its proficiency in multi-label classification tasks.
Table 2.
Performance evaluation of multi-label classification.
5.3. Node Clustering
By applying the K-Means algorithm to the derived node embeddings, we cluster nodes into classes, evaluating the clustering outcomes via normalized mutual information (NMI) [35], with results in Table 3. NAGNE again surpasses others in most cases, corroborating its effectiveness.
Table 3.
Normalized mutual information (NMI) on the node clustering task.
5.4. Visualization
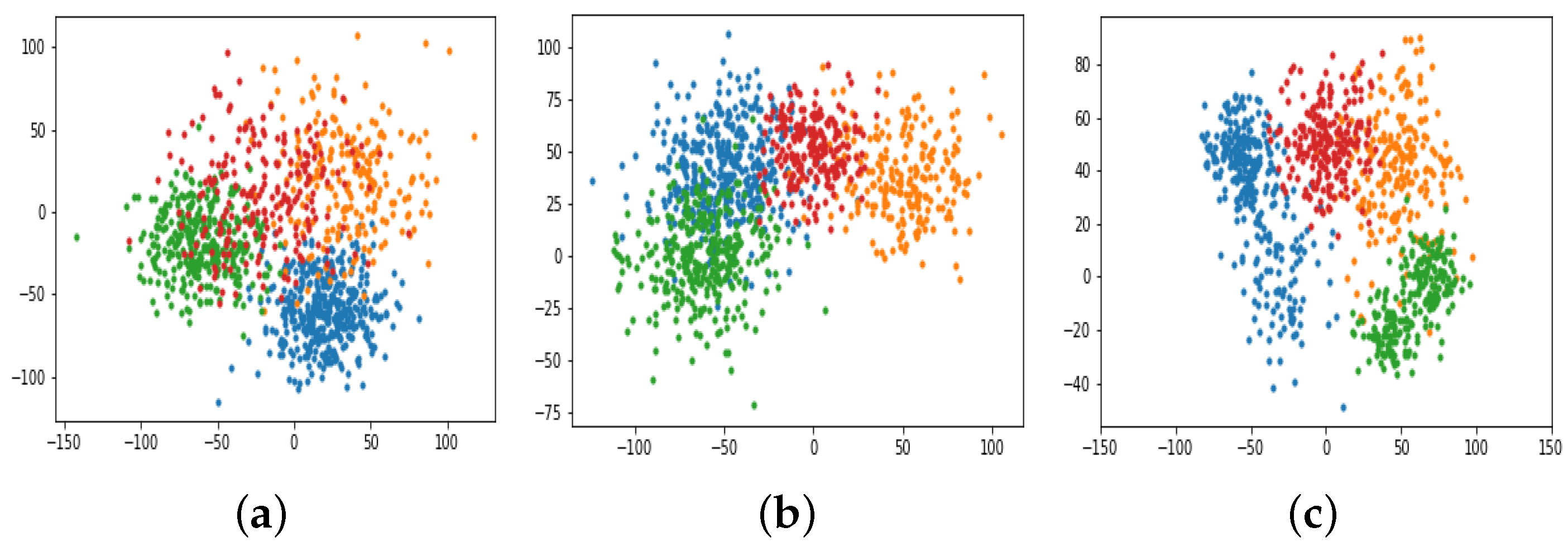
We use the t-SNE [36] algorithm to project the learned node embeddings of author nodes in DBLP into a 2-dimensional space. We select the visualization results of DeepWalk and Metapath2Vec as the representative baselines for homogeneous and heterogeneous embedding methods. The result is shown in Figure 3. As we can see, our model clearly clusters the author nodes into different research areas, which demonstrates that our model learns superior node embeddings by distinguishing the heterogeneous relations in heterogeneous networks.
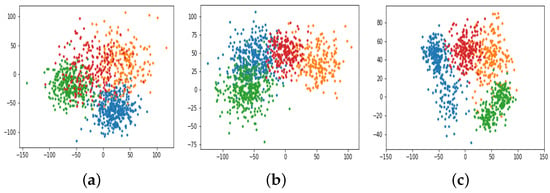
Figure 3.
Visualization of node embeddings: (a) DeepWalk. (b) Metapath2Vec. (c) NAGNE.
6. Conclusions
This paper has delved into attributed heterogeneous network embedding. We introduced an innovative attributed random walk strategy that addresses the limitations of meta-path reliance. Subsequently, we formulated the embedding task as akin to machine translation and presented NAGNE to capture both structural and attribute heterogeneity. Through a node-to-attribute generation model, NAGNE flexibly ascertains the neighborhood information’s appropriate breadth. Experimental validations reinforce the model’s superiority over state-of-the-art alternatives.
Author Contributions
Funding acquisition, Y.D.; project administration, Y.D.; supervision, H.X., Y.L. and Z.Z. (Zhaoyu Zhai); writing—original draft, Z.Z. (Zheding Zhang); writing—review and editing, Y.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by “the Fundamental Research Funds for the Central Universities” No. ZJ22195006 and the National Natural Science Foundation of China under grant no. 62072247.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: DBLP: https://dblp.uni-trier.de/, IMDB: https://www.kaggle.com/carolzhangdc/imdb-5000-movie-dataset, ACM: https://dl.acm.org/ and Aminer: https://www.aminer.cn/data/ (accessed on 11 December 2023).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Chang, S.; Han, W.; Tang, J.; Qi, G.J.; Aggarwal, C.C.; Huang, T.S. Heterogeneous Network Embedding via Deep Architectures. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 10–13 August 2015; KDD ‘15. pp. 119–128. [Google Scholar] [CrossRef]
- Shang, J.; Qu, M.; Liu, J.; Kaplan, L.M.; Peng, J. Meta-Path Guided Embedding for Similarity Search in Large-Scale Heterogeneous Information Networks. arXiv 2016, arXiv:1610.09769. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D.Y. Gaan: Gated attention networks for learning on large and spatiotemporal graphs. arXiv 2018, arXiv:1803.07294. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Shi, Y.; Gui, H.; Zhu, Q.; Kaplan, L.; Han, J. Aspem: Embedding learning by aspects in heterogeneous information networks. In Proceedings of the 2018 SIAM International Conference on Data Mining, San Diego, CA, USA, 3–5 May 2018; pp. 144–152. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous graph transformer. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2704–2710. [Google Scholar]
- Zhao, J.; Wang, X.; Shi, C.; Liu, Z.; Ye, Y. Network Schema Preserved Heterogeneous Information Network Embedding. In Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI), Virtual, 7–15 January 2020. [Google Scholar]
- Lu, Y.; Shi, C.; Hu, L.; Liu, Z. Relation structure-aware heterogeneous information network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 4456–4463. [Google Scholar]
- Jin, D.; Huo, C.; Liang, C.; Yang, L. Heterogeneous Graph Neural Network via Attribute Completion. In Proceedings of the WWW ’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Zhao, J.; Wang, X.; Shi, C.; Hu, B.; Song, G.; Ye, Y. Heterogeneous Graph Structure Learning for Graph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Jiang, X.; Jia, T.; Fang, Y.; Shi, C.; Lin, Z.; Wang, H. Pre-training on Large-Scale Heterogeneous Graph. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021. [Google Scholar]
- Wang, X.; Liu, N.; Han, H.; Shi, C. Self-supervised heterogeneous graph neural network with co-contrastive learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14–18 August 2021; pp. 1726–1736. [Google Scholar]
- Yang, Y.; Guan, Z.; Li, J.; Zhao, W.; Cui, J.; Wang, Q. Interpretable and efficient heterogeneous graph convolutional network. IEEE Trans. Knowl. Data Eng. 2021, 35, 1637–1650. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, C.; Hu, W.; Zheng, Z.; Zhou, X.; Chen, S. Megnn: Meta-path extracted graph neural network for heterogeneous graph representation learning. Knowl.-Based Syst. 2022, 235, 107611. [Google Scholar] [CrossRef]
- Yang, X.; Yan, M.; Pan, S.; Ye, X.; Fan, D. Simple and efficient heterogeneous graph neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 10816–10824. [Google Scholar]
- Tian, Y.; Dong, K.; Zhang, C.; Zhang, C.; Chawla, N.V. Heterogeneous graph masked autoencoders. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 9997–10005. [Google Scholar]
- Cen, Y.; Zou, X.; Zhang, J.; Yang, H.; Zhou, J.; Tang, J. Representation Learning for Attributed Multiplex Heterogeneous Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1358–1368. [Google Scholar] [CrossRef]
- Liu, M.; Liu, J.; Chen, Y.; Wang, M.; Chen, H.; Zheng, Q. AHNG: Representation learning on attributed heterogeneous network. Inf. Fusion 2019, 50, 221–230. [Google Scholar] [CrossRef]
- Wang, F.; Li, T.; Wang, X.; Zhu, S.; Ding, C. Community discovery using nonnegative matrix factorization. Data Min. Knowl. Discov. 2011, 22, 493–521. [Google Scholar] [CrossRef]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; Yang, S. Community preserving network embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Wan, H.; Zhang, Y.; Zhang, J.; Tang, J. AMiner: Search and Mining of Academic Social Networks. Data Intell. 2019, 1, 58–76. [Google Scholar] [CrossRef]
- Fu, T.y.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph transformer networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 11983–11993. [Google Scholar]
- Shi, C.; Kong, X.; Huang, Y.; Philip, S.Y.; Wu, B. Hetesim: A general framework for relevance measure in heterogeneous networks. IEEE Trans. Knowl. Data Eng. 2014, 26, 2479–2492. [Google Scholar] [CrossRef]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).