
Automated Text Annotation Using a Semi-Supervised Approach with Meta Vectorizer and Machine Learning Algorithms for Hate Speech Detection

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
- Machine learning modeling uses the meta-vectorizer and meta-classifier methods to determine the best model;
- Carrying out experiments with self-learning scenarios using thresholds of 0.6, 0.7, and 0.8 in the proposed model and labeled datasets with the proportion of 5%, 10%, and 20%, and with a training data to test data ratio of 80%;
- Experimental evaluation of the machine learning methods proposed in this study and their comparisons based on the abovementioned scenarios.
2. Materials and Methods
2.1. Datasets
- Inclusive representation of hate speech, non-hate speech, and very negative hate speech;
- The credibility of the video content from official broadcasting institutions/channels;
- Fair representation of public opinion in YouTube comments due to the absence of the message length restrictions, censorship, and the possibility of user interactions.
- Comments are free and unstructured and contain emoticons, punctuation, and special characters reflecting user sentiments;
- Varied comments, including direct responses to video contents, replies to other comments, and revealing the user’s side;
- Ambiguous elements, such as satire, polysemy, slang words, stop-words, and metaphors.
Population and Sampling
- Hate speech was observed in YouTube video comments about the 2019 Indonesian presidential debate and Covid-19, aligning with the research objectives;
- Publicly available data from YouTube comments could be downloaded free of charge.
2.2. Pre-Processing
- Cleaning the text—removing unnecessary or irrelevant characters, such as punctuation marks or special characters [33];
- Tokenization—splitting the text into smaller units, called tokens, such as words or phrases [34];
- Removing stop-words—common words that lack significant meaning [35], such as “the” or “and”, were eliminated to reduce the text size and improve the performance of the NLP model;
- Stemming and lemmatization—leveraging the Sastrawi library, stemming for the Indonesian language (Bahasa) was performed to reduce words to their base form [36], known as the stem or lemma;
- Part-of-speech tagging—identifying parts of speech, such as nouns or verbs, aids certain NLP tasks [37];
- Normalization—formatting the text consistently, converting all words to lowercase. This streamlines processing for the NLP model [38].
2.3. Meta-Vectorization Based on Text Feature Extraction
2.3.1. Term Frequency-Inverse Document Frequency (TF-IDF)
2.3.2. Word Embedding (Word2Vec)
2.4. Meta-Classification Using Machine Learning Algorithms
2.4.1. Support Vector Machine
2.4.2. Decision Tree (DT)
2.4.3. K-Nearest Neighbors (KNN)
2.4.4. Naive Bayes (NB)
3. Results
3.1. Experimental Scenario Setup
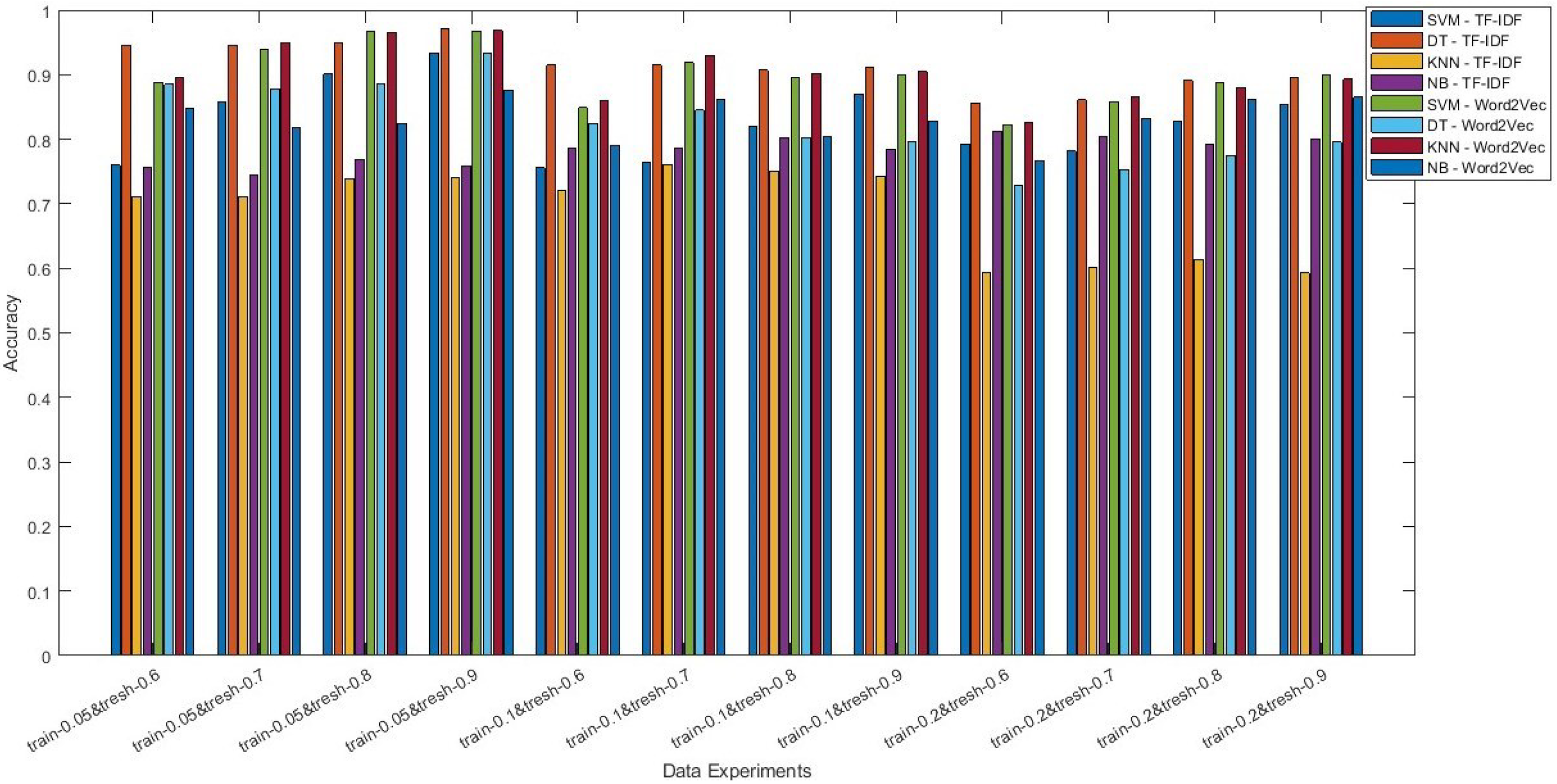
3.2. Experimental Results of the Machine Learning Based Approach
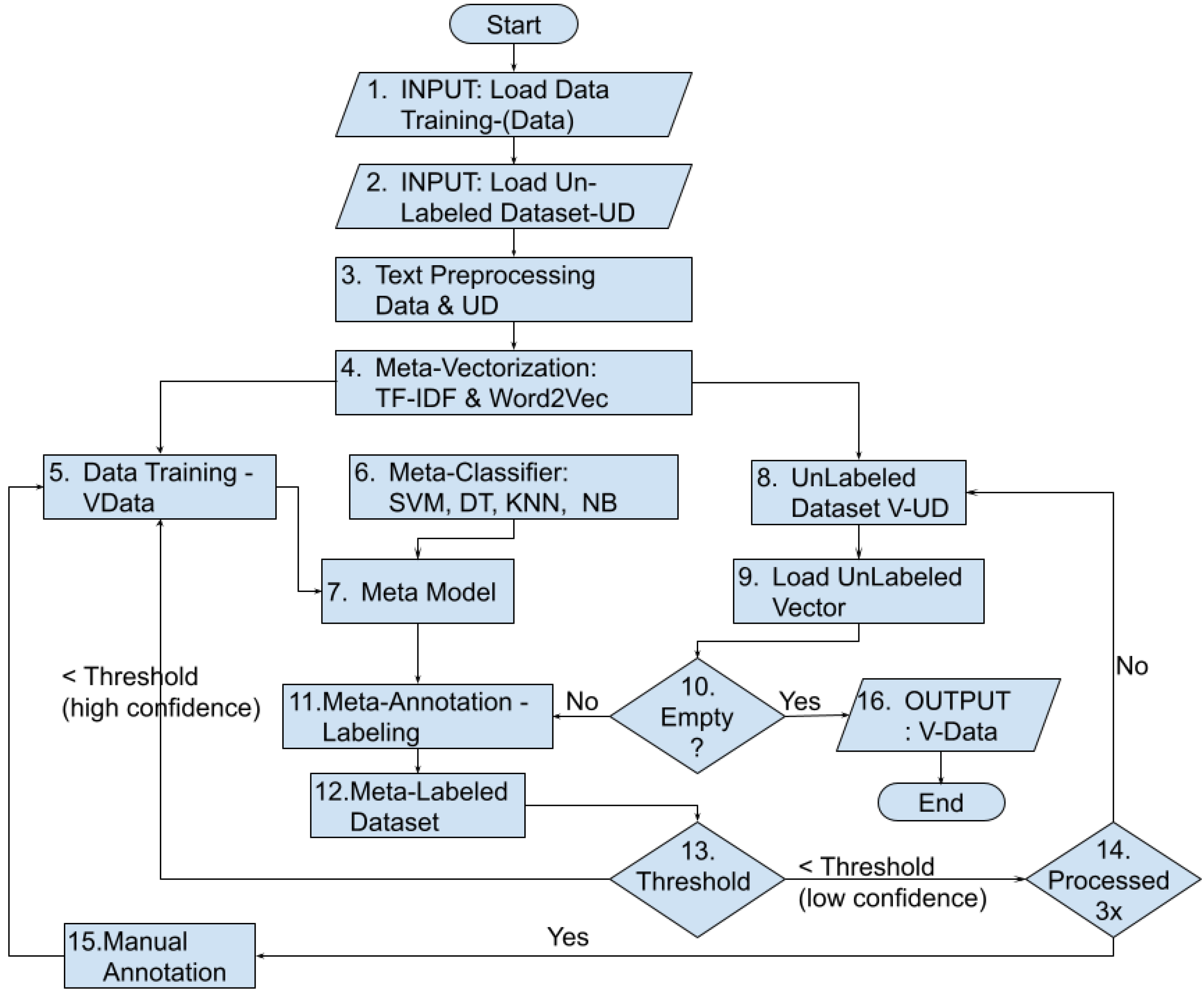
| Listing 1. Text auto-annotation based on the semi-supervised and self-learning approach. |
STEPS :
|
3.3. Discussion
3.3.1. Comparative Analysis with Previous Studies
3.3.2. Accuracy Trends and Method Performance
3.3.3. Discussion on Biases and Mitigation Strategies
3.3.4. Limitations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Labeled Data | Unlabeled Data | Threshold | SVM TF-IDF | DT TF-IDF | KNN TF-IDF | NB TF-IDF | SVM Word2Vec | DT Word2Vec | KNN Word2Vec | NB Word2Vec |
|---|---|---|---|---|---|---|---|---|---|---|---|
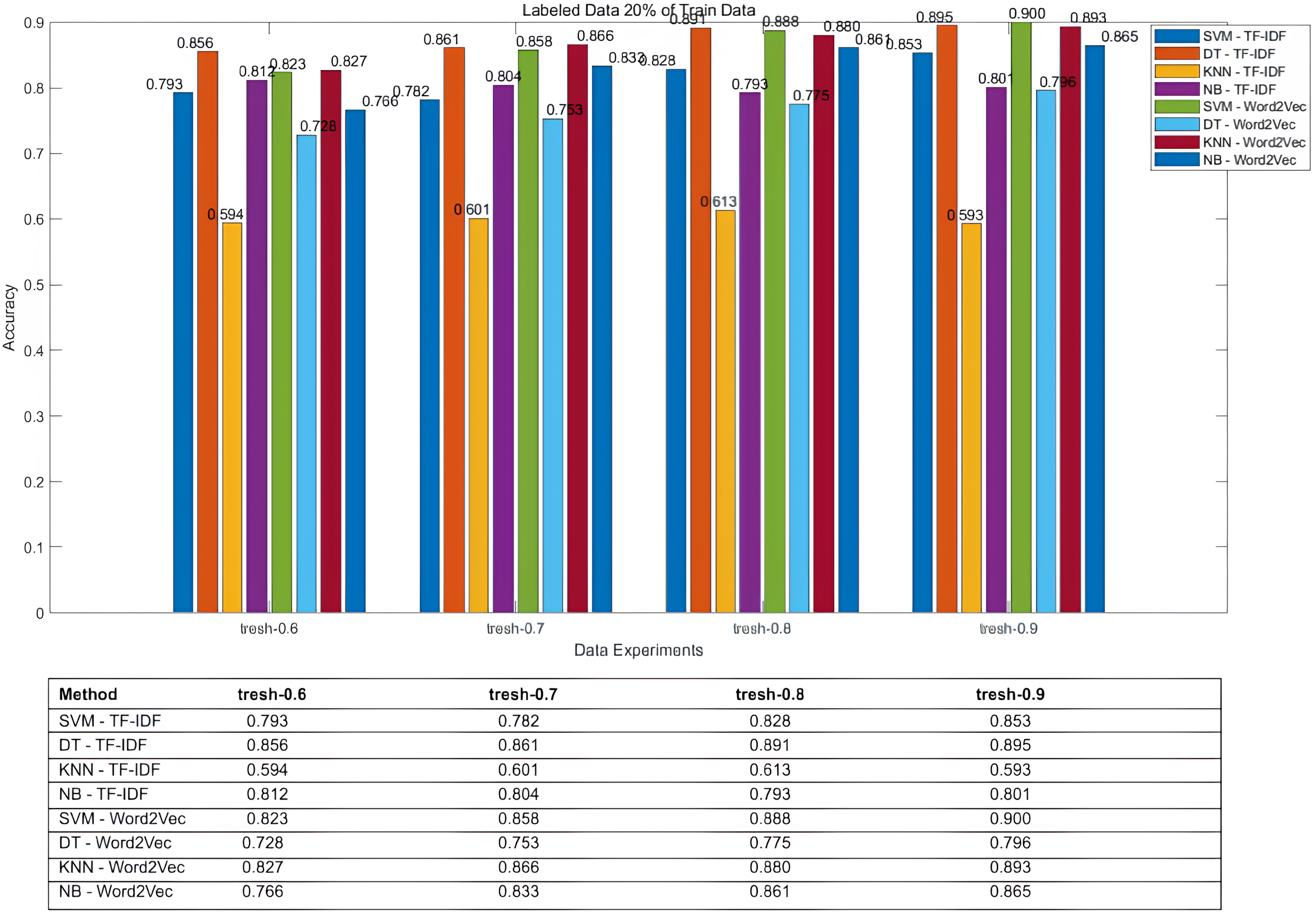
| 1 | 0.2 | 0.8 | 0.6 | 0.793 | 0.856 | 0.594 | 0.812 | 0.823 | 0.728 | 0.827 | 0.766 |
| 2 | 0.2 | 0.8 | 0.7 | 0.782 | 0.861 | 0.601 | 0.804 | 0.858 | 0.753 | 0.866 | 0.833 |
| 3 | 0.2 | 0.8 | 0.8 | 0.828 | 0.891 | 0.613 | 0.793 | 0.888 | 0.775 | 0.88 | 0.861 |
| 4 | 0.2 | 0.8 | 0.9 | 0.853 | 0.895 | 0.593 | 0.801 | 0.9 | 0.796 | 0.893 | 0.865 |
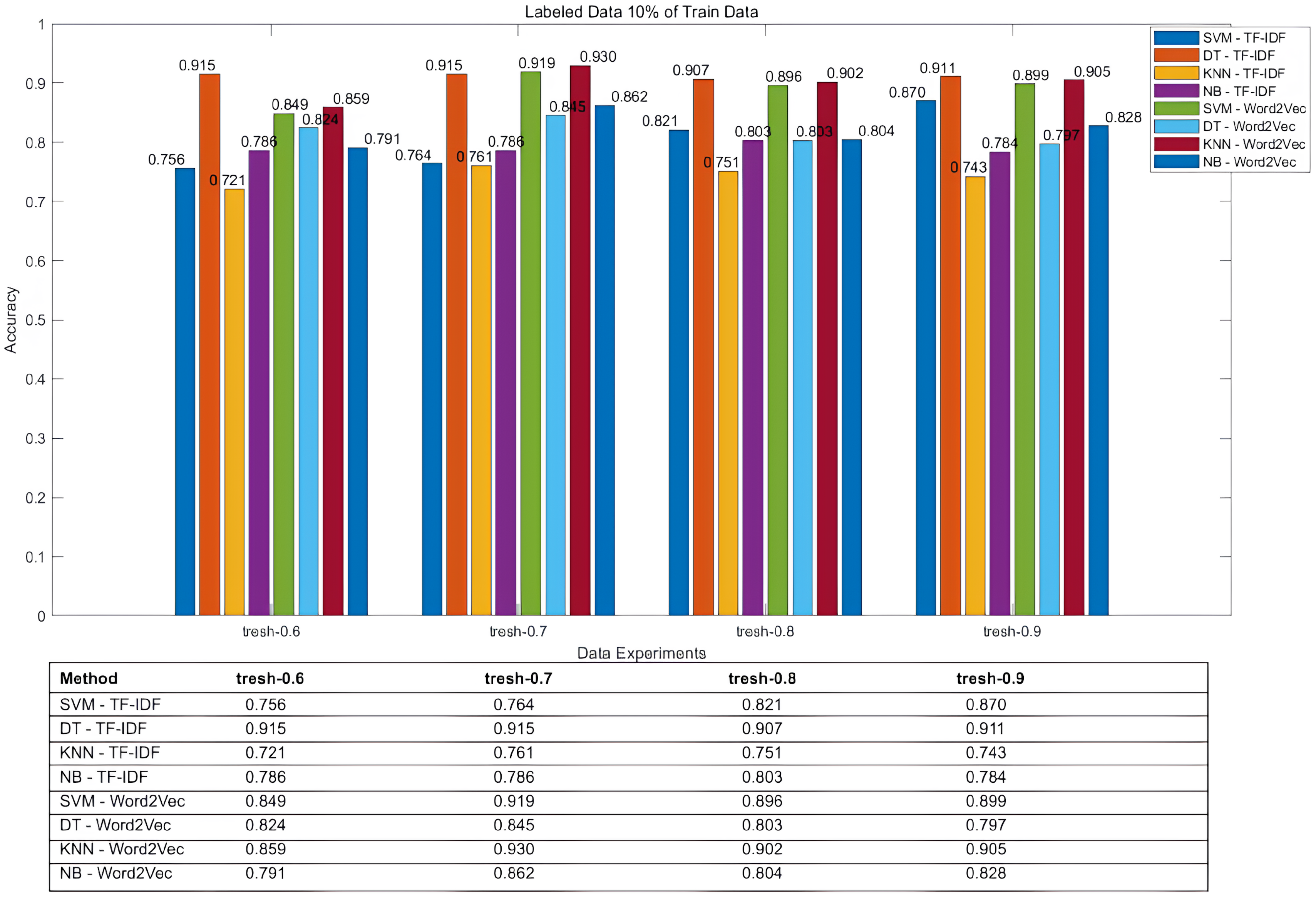
| 5 | 0.1 | 0.9 | 0.6 | 0.756 | 0.915 | 0.721 | 0.786 | 0.849 | 0.824 | 0.859 | 0.791 |
| 6 | 0.1 | 0.9 | 0.7 | 0.764 | 0.915 | 0.761 | 0.786 | 0.919 | 0.845 | 0.93 | 0.862 |
| 7 | 0.1 | 0.9 | 0.8 | 0.821 | 0.907 | 0.751 | 0.803 | 0.896 | 0.803 | 0.902 | 0.804 |
| 8 | 0.1 | 0.9 | 0.9 | 0.87 | 0.911 | 0.743 | 0.784 | 0.899 | 0.797 | 0.905 | 0.828 |
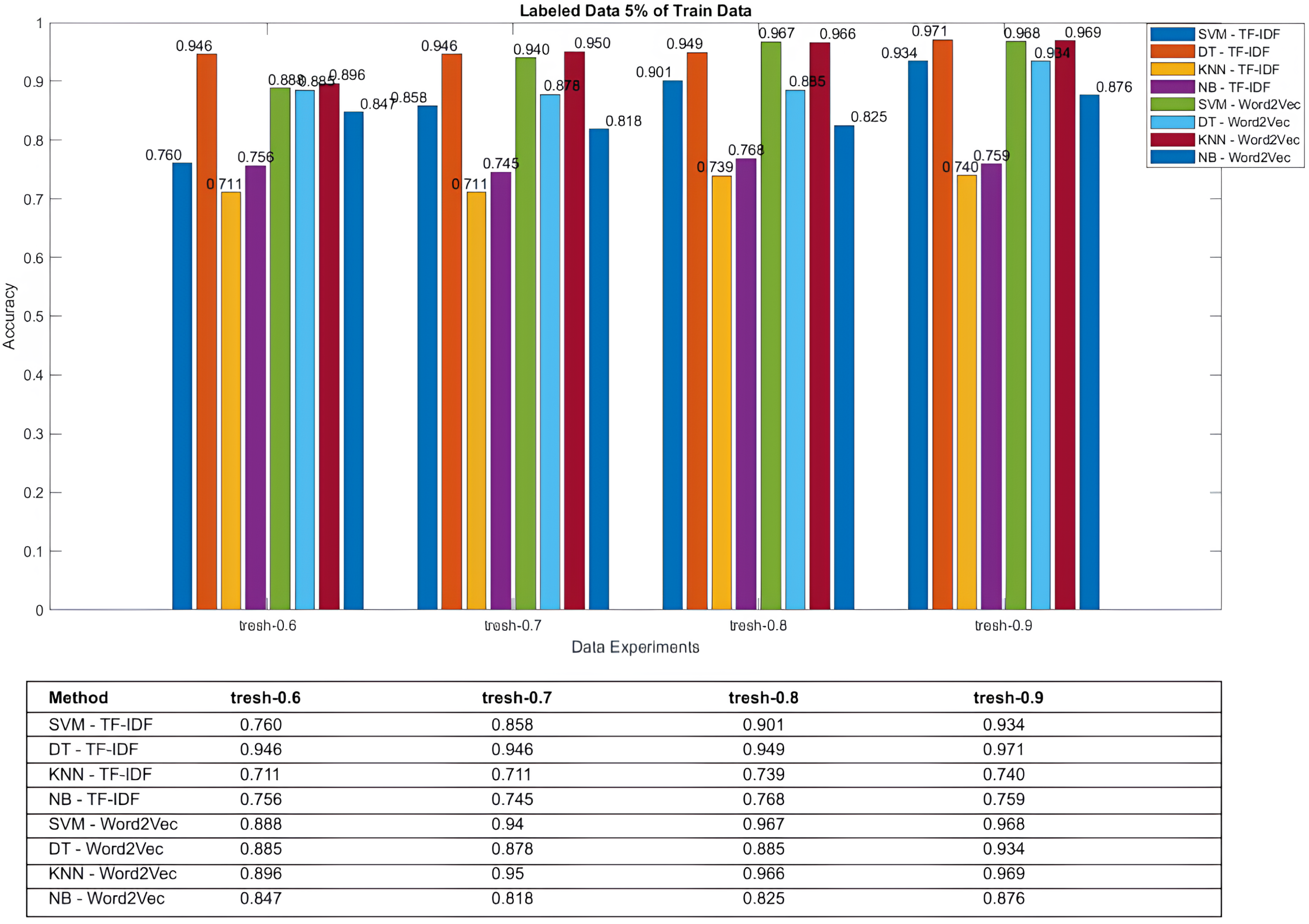
| 9 | 0.05 | 0.95 | 0.6 | 0.76 | 0.946 | 0.711 | 0.756 | 0.888 | 0.885 | 0.896 | 0.847 |
| 10 | 0.05 | 0.95 | 0.7 | 0.858 | 0.946 | 0.711 | 0.745 | 0.94 | 0.878 | 0.95 | 0.818 |
| 11 | 0.05 | 0.95 | 0.8 | 0.901 | 0.949 | 0.739 | 0.768 | 0.967 | 0.885 | 0.966 | 0.825 |
| 12 | 0.05 | 0.95 | 0.9 | 0.934 | 0.971 | 0.74 | 0.759 | 0.968 | 0.934 | 0.969 | 0.876 |
Appendix C
| Compared Scenarios | SVM TF-IDF (%) | DT TF-IDF (%) | KNN TF-IDF (%) | NB TF-IDF (%) | SVM Word2Vec (%) | DT Word2Vec (%) | KNN Word2Vec (%) | NB Word2Vec (%) |
|---|---|---|---|---|---|---|---|---|
| 1–2 | −1.10 | 0.50 | 0.70 | −0.80 | 3.50 | 2.50 | 3.90 | 6.70 |
| 2–3 | 4.60 | 3.00 | 1.20 | −1.10 | 3.00 | 2.20 | 1.40 | 2.80 |
| 3–4 | 2.50 | 0.40 | −2.00 | 0.80 | 1.20 | 2.10 | 1.30 | 0.40 |
| 5–6 | 0.80 | 0.00 | 4.00 | 0.00 | 7.00 | 2.10 | 7.10 | 7.10 |
| 6–7 | 5.70 | −0.80 | −1.00 | 1.70 | −2.30 | −4.20 | −2.80 | −5.80 |
| 7–8 | 4.90 | 0.40 | −0.80 | −1.90 | 0.30 | −0.60 | 0.30 | 2.40 |
| 9–10 | 9.80 | 0.00 | 0.00 | −1.10 | 5.20 | −0.70 | 5.40 | −2.90 |
| 10–11 | 4.30 | 0.30 | 2.80 | 2.30 | 2.70 | 0.70 | 1.60 | 0.70 |
| 11–12 | 3.30 | 2.20 | 0.10 | −0.90 | 0.10 | 4.90 | 0.30 | 5.10 |
References
- Alrehili, A. Automatic Hate Speech Detection on Social Media: A Brief Survey. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Al-Makhadmeh, Z.; Tolba, A. Automatic hate speech detection using killer natural language processing optimizing ensemble deep learning approach. Computing 2019, 102, 501–522. [Google Scholar] [CrossRef]
- Rajman, M.; Besançon, R. Text Mining: Natural Language techniques and Text Mining applications. In Data Mining and Reverse Engineering; Springer: New York, NY, USA, 1998; pp. 50–64. [Google Scholar] [CrossRef]
- Fortuna, P.; Nunes, S. A Survey on Automatic Detection of Hate Speech in Text. ACM Comput. Surv. 2018, 51, 1–30. [Google Scholar] [CrossRef]
- Cahyana, N.H.; Saifullah, S.; Fauziah, Y.; Aribowo, A.S.; Drezewski, R. Semi-supervised Text Annotation for Hate Speech Detection using K-Nearest Neighbors and Term Frequency-Inverse Document Frequency. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 147–151. [Google Scholar] [CrossRef]
- Aman, S.; Szpakowicz, S. Identifying Expressions of Emotion in Text. In Text, Speech and Dialogue. TSD 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 196–205. [Google Scholar] [CrossRef]
- Krouska, A.; Troussas, C.; Virvou, M. The effect of preprocessing techniques on Twitter sentiment analysis. In Proceedings of the 2016 7th International Conference on Information, Intelligence, Systems & Applications (IISA), Chalkidiki, Greece, 13–15 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar] [CrossRef]
- Savigny, J.; Purwarianti, A. Emotion classification on youtube comments using word embedding. In Proceedings of the 2017 International Conference on Advanced Informatics, Concepts, Theory, and Applications (ICAICTA), Denpasar, Indonesia, 16–18 August 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Ningtyas, A.M.; Herwanto, G.B. The Influence of Negation Handling on Sentiment Analysis in Bahasa Indonesia. In Proceedings of the 2018 5th International Conference on Data and Software Engineering (ICoDSE), Mataram, Indonesia, 7–8 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Mariel, W.C.F.; Mariyah, S.; Pramana, S. Sentiment analysis: A comparison of deep learning neural network algorithm with SVM and naïve Bayes for Indonesian text. J. Phys. Conf. Ser. 2018, 971, 012049. [Google Scholar] [CrossRef]
- Mao, R.; Liu, Q.; He, K.; Li, W.; Cambria, E. The Biases of Pre-Trained Language Models: An Empirical Study on Prompt-Based Sentiment Analysis and Emotion Detection. IEEE Trans. Affect. Comput. 2022, 14, 1743–1753. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Gelbukh, A.; Hussain, A. Extending persian sentiment lexicon with idiomatic expressions for sentiment analysis. Soc. Netw. Anal. Min. 2021, 12, 9. [Google Scholar] [CrossRef]
- Imran, A.S.; Yang, R.; Kastrati, Z.; Daudpota, S.M.; Shaikh, S. The impact of synthetic text generation for sentiment analysis using GAN based models. Egypt. Inform. J. 2022, 23, 547–557. [Google Scholar] [CrossRef]
- Balli, C.; Guzel, M.S.; Bostanci, E.; Mishra, A. Sentimental Analysis of Twitter Users from Turkish Content with Natural Language Processing. Comput. Intell. Neurosci. 2022, 2022, 2455160. [Google Scholar] [CrossRef]
- Jain, D.K.; Boyapati, P.; Venkatesh, J.; Prakash, M. An Intelligent Cognitive-Inspired Computing with Big Data Analytics Framework for Sentiment Analysis and Classification. Inf. Process. Manag. 2022, 59, 102758. [Google Scholar] [CrossRef]
- Kabakus, A.T. A novel COVID-19 sentiment analysis in Turkish based on the combination of convolutional neural network and bidirectional long-short term memory on Twitter. Concurr. Comput. Pract. Exp. 2022, 34, e6883. [Google Scholar] [CrossRef] [PubMed]
- Al-Laith, A.; Shahbaz, M.; Alaskar, H.F.; Rehmat, A. AraSenCorpus: A Semi-Supervised Approach for Sentiment Annotation of a Large Arabic Text Corpus. Appl. Sci. 2021, 11, 2434. [Google Scholar] [CrossRef]
- Saifullah, S.; Dreżewski, R.; Dwiyanto, F.A.; Aribowo, A.S.; Fauziah, Y. Sentiment Analysis Using Machine Learning Approach Based on Feature Extraction for Anxiety Detection. In Proceedings of the Computational Science—ICCS 2023: 23rd International Conference, Prague, Czech Republic, 3–5 July 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 365–372. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Lok, P.Y.; Rahim, H.A. A semi-supervised approach in detecting sentiment and emotion based on digital payment reviews. J. Supercomput. 2020, 77, 3795–3810. [Google Scholar] [CrossRef]
- Ibrohim, M.O.; Budi, I. Multi-label Hate Speech and Abusive Language Detection in Indonesian Twitter. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar] [CrossRef]
- Khanday, A.M.U.D.; Rabani, S.T.; Khan, Q.R.; Malik, S.H. Detecting twitter hate speech in COVID-19 era using machine learning and ensemble learning techniques. Int. J. Inf. Manag. Data Insights 2022, 2, 100120. [Google Scholar] [CrossRef]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting Hate Speech on Twitter Using a Convolution-GRU Based Deep Neural Network. In The Semantic Web; Springer International Publishing: New York, NY, USA, 2018; pp. 745–760. [Google Scholar] [CrossRef]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 512–515. [Google Scholar] [CrossRef]
- Cahyani, D.E.; Patasik, I. Performance comparison of TF-IDF and Word2Vec models for emotion text classification. Bull. Electr. Eng. Inform. 2021, 10, 2780–2788. [Google Scholar] [CrossRef]
- Abduljabbar, D.A.; Omar, N. Exam questions classification based on Bloom’s taxonomy cognitive level using classifiers combination. J. Theor. Appl. Inf. Technol. 2015, 78, 447–455. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Kumar, C.S.P.; Babu, L.D.D. Novel Text Preprocessing Framework for Sentiment Analysis. In Smart Intelligent Computing and Applications; Springer: Singapore, 2018; pp. 309–317. [Google Scholar] [CrossRef]
- Ramachandran, D.; Parvathi, R. Analysis of Twitter Specific Preprocessing Technique for Tweets. Procedia Comput. Sci. 2019, 165, 245–251. [Google Scholar] [CrossRef]
- Mohammed, M.; Omar, N. Question classification based on Bloom’s taxonomy cognitive domain using modified TF-IDF and word2vec. PLoS ONE 2020, 15, e0230442. [Google Scholar] [CrossRef] [PubMed]
- Babanejad, N.; Agrawal, A.; An, A.; Papagelis, M. A Comprehensive Analysis of Preprocessing for Word Representation Learning in Affective Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020. [Google Scholar] [CrossRef]
- Albalawi, R.; Yeap, T.H.; Benyoucef, M. Using Topic Modeling Methods for Short-Text Data: A Comparative Analysis. Front. Artif. Intell. 2020, 3, 42. [Google Scholar] [CrossRef] [PubMed]
- Arora, M.; Kansal, V. Character level embedding with deep convolutional neural network for text normalization of unstructured data for Twitter sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 12. [Google Scholar] [CrossRef]
- Elgibreen, H.; Faisal, M.; Sulaiman, M.A.; Abdou, S.; Mekhtiche, M.A.; Moussa, A.M.; Alohali, Y.A.; Abdul, W.; Muhammad, G.; Rashwan, M.; et al. An Incremental Approach to Corpus Design and Construction: Application to a Large Contemporary Saudi Corpus. IEEE Access 2021, 9, 88405–88428. [Google Scholar] [CrossRef]
- Rai, A.; Borah, S. Study of Various Methods for Tokenization. In Applications of Internet of Things; Springer: Singapore, 2020; pp. 193–200. [Google Scholar] [CrossRef]
- Manalu, S.R. Stop words in review summarization using TextRank. In Proceedings of the 2017 14th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 27–30 June 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Zeroual, I.; Lakhouaja, A. Arabic information retrieval: Stemming or lemmatization? In Proceedings of the 2017 Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 17–19 April 2017; IEEE: Piscataway, NJ, USA, 2017. [CrossRef]
- AlKhwiter, W.; Al-Twairesh, N. Part-of-speech tagging for Arabic tweets using CRF and Bi-LSTM. Comput. Speech Lang. 2021, 65, 101138. [Google Scholar] [CrossRef]
- Sharma, A.; Kumar, S. Ontology-based semantic retrieval of documents using Word2vec model. Data Knowl. Eng. 2023, 144, 102110. [Google Scholar] [CrossRef]
- Liang, H.; Sun, X.; Sun, Y.; Gao, Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 211. [Google Scholar] [CrossRef] [PubMed]
- Garouani, M.; Ahmad, A.; Bouneffa, M.; Hamlich, M.; Bourguin, G.; Lewandowski, A. Using meta-learning for automated algorithms selection and configuration: An experimental framework for industrial big data. J. Big Data 2022, 9, 57. [Google Scholar] [CrossRef]
- Kamyab, M.; Liu, G.; Adjeisah, M. Attention-Based CNN and Bi-LSTM Model Based on TF-IDF and GloVe Word Embedding for Sentiment Analysis. Appl. Sci. 2021, 11, 11255. [Google Scholar] [CrossRef]
- Saifullah, S.; Fauziyah, Y.; Aribowo, A.S. Comparison of machine learning for sentiment analysis in detecting anxiety based on social media data. J. Inform. 2021, 15, 45. [Google Scholar] [CrossRef]
- Fauziah, Y.; Saifullah, S.; Aribowo, A.S. Design Text Mining for Anxiety Detection using Machine Learning based-on Social Media Data during COVID-19 pandemic. In Proceedings of the LPPM UPN “Veteran” Yogyakarta Conference Series 2020—Engineering and Science Series, Yogyakarta, Indonesia, 27 October 2020; pp. 253–261. [Google Scholar] [CrossRef]
- Capelle, M.; Hogenboom, F.; Hogenboom, A.; Frasincar, F. Semantic news recommendation using wordnet and bing similarities. In Proceedings of the 28th Annual ACM Symposium on Applied Computing—SAC’13, Coimbra, Portugal, 18–22 March 2013; ACM Press: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Sivakumar, S.; Videla, L.S.; Kumar, T.R.; Nagaraj, J.; Itnal, S.; Haritha, D. Review on Word2Vec Word Embedding Neural Net. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Landgraf, A.J.; Bellay, J. word2vec Skip-Gram with Negative Sampling is a Weighted Logistic PCA. arXiv 2017, arXiv:1705.09755. [Google Scholar] [CrossRef]
- Alkomah, F.; Ma, X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information 2022, 13, 273. [Google Scholar] [CrossRef]
- Saifullah, S.; Drezewski, R. Non-Destructive Egg Fertility Detection in Incubation Using SVM Classifier Based on GLCM Parameters. Procedia Comput. Sci. 2022, 207, 3248–3257. [Google Scholar] [CrossRef]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-Nearest Neighbor, Genetic, Support Vector Machine, Decision Tree, and Long Short Term Memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Kuchipudi, R.; Uddin, M.; Murthy, T.; Mirrudoddi, T.K.; Ahmed, M.; P, R.B. Android Malware Detection using Ensemble Learning. In Proceedings of the 2023 International Conference on Sustainable Computing and Smart Systems (ICSCSS), Coimbatore, India, 14–16 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 297–302. [Google Scholar] [CrossRef]
- Degirmenci, A.; Karal, O. Efficient density and cluster based incremental outlier detection in data streams. Inf. Sci. 2022, 607, 901–920. [Google Scholar] [CrossRef]
- Kesarwani, A.; Chauhan, S.S.; Nair, A.R. Fake News Detection on Social Media using K-Nearest Neighbor Classifier. In Proceedings of the 2020 International Conference on Advances in Computing and Communication Engineering (ICACCE), Las Vegas, NV, USA, 22–24 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Xu, S. Bayesian Naïve Bayes classifiers to text classification. J. Inf. Sci. 2018, 44, 48–59. [Google Scholar] [CrossRef]
- Mwaro, P.N.; Ogada, D.K.; Cheruiyot, P.W. Applicability of Naïve Bayes Model for Automatic Resume Classification. Int. J. Comput. Appl. Technol. Res. 2020, 9, 257–264. [Google Scholar] [CrossRef]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction site accident analysis using text mining and natural language processing techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Saifullah, S.; Cahyana, N.H.; Fauziah, Y.; Aribowo, A.S.; Dwiyanto, F.A.; Drezewski, R. Text Annotation Automation for Hate Speech Detection using SVM-classifier based on Feature Extraction. In Proceedings of the International Conference on Advanced Research in Engineering and Technology, Thai Nguyen, Vietnam, 1–2 December 2022. [Google Scholar]
- Kocoń, J.; Figas, A.; Gruza, M.; Puchalska, D.; Kajdanowicz, T.; Kazienko, P. Offensive, aggressive, and hate speech analysis: From data-centric to human-centered approach. Inf. Process. Manag. 2021, 58, 102643. [Google Scholar] [CrossRef]
- Maniruzzaman, M.; Rahman, M.J.; Ahammed, B.; Abedin, M.M. Classification and prediction of diabetes disease using machine learning paradigm. Health Inf. Sci. Syst. 2020, 8, 7. [Google Scholar] [CrossRef]
- Machova, K.; Mach, M.; Vasilko, M. Comparison of Machine Learning and Sentiment Analysis in Detection of Suspicious Online Reviewers on Different Type of Data. Sensors 2021, 22, 155. [Google Scholar] [CrossRef]





| No | Training Data (%) | Unlabeled Data (%) | Threshold |
|---|---|---|---|
| 1 | 20 | 80 | 0.6 |
| 2 | 20 | 80 | 0.7 |
| 3 | 20 | 80 | 0.8 |
| 4 | 20 | 80 | 0.9 |
| 5 | 10 | 90 | 0.6 |
| 6 | 10 | 90 | 0.7 |
| 7 | 10 | 90 | 0.8 |
| 8 | 10 | 90 | 0.9 |
| 9 | 5 | 95 | 0.6 |
| 10 | 5 | 95 | 0.7 |
| 11 | 5 | 95 | 0.8 |
| 12 | 5 | 95 | 0.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saifullah, S.; Dreżewski, R.; Dwiyanto, F.A.; Aribowo, A.S.; Fauziah, Y.; Cahyana, N.H. Automated Text Annotation Using a Semi-Supervised Approach with Meta Vectorizer and Machine Learning Algorithms for Hate Speech Detection. Appl. Sci. 2024, 14, 1078. https://doi.org/10.3390/app14031078
Saifullah S, Dreżewski R, Dwiyanto FA, Aribowo AS, Fauziah Y, Cahyana NH. Automated Text Annotation Using a Semi-Supervised Approach with Meta Vectorizer and Machine Learning Algorithms for Hate Speech Detection. Applied Sciences. 2024; 14(3):1078. https://doi.org/10.3390/app14031078
Chicago/Turabian StyleSaifullah, Shoffan, Rafał Dreżewski, Felix Andika Dwiyanto, Agus Sasmito Aribowo, Yuli Fauziah, and Nur Heri Cahyana. 2024. "Automated Text Annotation Using a Semi-Supervised Approach with Meta Vectorizer and Machine Learning Algorithms for Hate Speech Detection" Applied Sciences 14, no. 3: 1078. https://doi.org/10.3390/app14031078
APA StyleSaifullah, S., Dreżewski, R., Dwiyanto, F. A., Aribowo, A. S., Fauziah, Y., & Cahyana, N. H. (2024). Automated Text Annotation Using a Semi-Supervised Approach with Meta Vectorizer and Machine Learning Algorithms for Hate Speech Detection. Applied Sciences, 14(3), 1078. https://doi.org/10.3390/app14031078