Abstract
Complex tasks in the real world involve different modal models, such as visual question answering (VQA). However, traditional multimodal learning requires a large amount of aligned data, such as image text pairs, and constructing a large amount of training data is a challenge for multimodal learning. Therefore, we propose VL-Few, which is a simple and effective method to solve the multimodal few-shot problem. VL-Few (1) proposes the modal alignment, which aligns visual features into language space through a lightweight model network and improves the multimodal understanding ability of the model; (2) adopts few-shot meta learning in the multimodal problem, which constructs a few-shot meta task pool to improve the generalization ability of the model; (3) proposes semantic alignment to enhance the semantic understanding ability of the model for the task, context, and demonstration; (4) proposes task alignment that constructs training data into the target task form and improves the task understanding ability of the model; (5) proposes generation alignment, which adopts the token-level training and multitask fusion loss to improve the generation ability of the model. Our experimental results show the effectiveness of VL-Few for multimodal few-shot problems.
1. Introduction
With the development of language models [1,2,3,4,5,6], vision models [7], and multimodal models [8,9,10,11,12,13,14], there are many applications that bring people more efficiency and convenience in their lives based on this state-of-the-art technology, such as smartphone assistants [15], chatbots [16], smart healthcare [17], smart transportation [18], smart shopping guides [19], autonomous driving [20], and so on. The success of applying this technology requires large different modal data for training like text, image, voice, video, table, graph, machine recording, and so on to train the models. However, how to make the language models understand other different modal data is a different matter. In the visual question answering (VQA) [21,22,23,24,25,26,27,28,29,30,31,32] task, the main modes of the data are vision and language because vision represents the eyesight and language represents the thinking of the brain, which are the key functions people use to interact with the environment and complete tasks. Making language models understand data from other modalities such as images, videos, speech, point clouds, etc., is a promising ability that will help language models understand real-world knowledge, complete more complex and realistic tasks, assist humans in completing tasks, and improve productivity.
The core of multimodal learning ability is modal alignment. For example, aligning visual features into language space enables language models to understand images or videos. The traditional method is to train a multimodal model from scratch, but this approach requires preparing a large amount of high-quality multimodal alignment data in advance. For example, CLIP [10] constructs a large number of image text pairs, but it cannot understand the modalities that have not been learned, thereby resulting in limited scalability. Inheriting the modal processing ability learned by the pretrained model to complete multimodal tasks is a promising research direction.
This problem is more serious in the few-shot scenario because of scarce training data. So, to alleviate the low-resource problem and improve the generalization ability of the model, meta learning [33,34,35,36,37,38] and few-shot learning [39,40,41,42,43,44,45,46,47,48,49,50,51,52] can be considered. Meta learning can construct a task pool to improve the generalization ability of the model. Few-shot learning can reduce the dependence on the data size of the model.
Therefore, to solve the multimodal few-shot problem, we propose VL-Few, a multimodal few-shot meta learning framework as shown in Figure 1. VL-Few uses a small amount of data, combines meta learning to build a task pool, and constructs a small number of training inputs with small samples. Through multimodal feature mappers, the language model can understand visual features and reduce the number of parameters for model training, thus reducing the dependence of the model on data volume and ultimately completing the VQA task. There are some differences between other research studies and ours. For model architecture, other methods require retraining of the vision model (Frozen) or only consider mapping vision image features and language question features into the same (CLIPCap [53]) or fewer (MML [54]) tokens through mappers to help the model understand vision image features. However, our method realizes that the prominent problem with understanding multimodal data is that the features are not in the same feature space, and the failure to align multimodal features effectively results in the model being unable to understand other modal data. Therefore, we consider both vision image features and the interaction features between vision images and language questions. We ultimately fuse them with other auxiliary features through a fully connected layer to form the final input feature. In addition, our experiment used less data to achieve better performance. The experiment shows that our method can improve the efficiency of extracting and fusing modal features, as well as enhance the vision understanding ability of the model language model. Our method uses less data, with only 4 or 20 pieces of data in the training set. In addition, the model has fewer parameters and only about 8.2 M trainable parameters, thus providing higher accuracy.
Figure 1.
VL-Few VQA model architecture. We construct the whole model structure network to align the vision feature into language space.
The main contributions can be summarized as follows:
- We propose multimodal alignment, which uses multimodal feature mappers to align the vision feature into a language feature space that can make the language model understand images;
- We adopt few-shot meta learning in the multimodal problem in which the meta task pool helps the model learn the generalization ability, and few-shot learning uses few data to train the model;
- We propose semantic alignment, which includes task instruction, data context, and demonstration context that provide the input semantic information for learning the understanding ability of the task, context, and demonstration;
- We propose task alignment, which constructs the task training data form like VQA, including the images, questions, and answers, by question generation and caption augmentation;
- We adopt token-level training in the multimodal few-shot meta problem to make the model pay attention to the answer token and adopt the multitask fusion task to help the model learn the multiple-task processing abilities.
The following sections are shown as follows. Section 2 describes the related work about multimodal learning and multimodal few-shot learning. Section 3 introduces our main methods of VL-Few. Section 4 presents the training dataset, pre-training models, and training strategies in the experiments. Section 5 makes the conclusion and some future work.
2. Related Work
There are some research studies on multimodal learning to perform the VQA task. CLIPCap [53] proposes to use CLIP-ViT [10] to extract image features, interact with images and captions through a trainable mapper network, obtain image features containing text, use them as input prefixes, input them together with the question into GPT-2 [3], and finally generate an answer to the image viewing question. This method can enable language models to understand images by training only a small number of model parameters. However, it requires a large amount of data for training, thus making it difficult to apply to small sample scenarios. BLIP-2 [23] proposes a Q-former (querying transformer) structure to map image features into language feature space. Specifically, this method extracts image features through the frozen image encoder CLIP-ViT [10], and it inputs both image features and learned queries into the Q-former. The Q-former fuses image features into learned queries, outputs learned queries, and obtains new image features through a fully connected layer. The new image features are used as prefix text and input together with the question into the language model. Finally, the language model generates the answers based on the image and question. This method obtains image features through a learnable sequence, which is then fused with the questions to obtain image features related to the problem, thus ultimately resulting in a good representation of the image features. However, this method requires a large number of data for pretraining, which is a total of 129 M, thus making it difficult to apply it to small sample scenarios. NExT-GPT [55] proposes to extract features from the data of different modalities through corresponding encoders and then map the features to the language space through the projections. The core task is understood through a language model, and the language features are mapped to different modality spaces through instruction following. Finally, the target modality data are generated through the diffusion model of the different modalities. This framework proposes a unified approach to convert data from different modalities into data from other modalities. However, this method requires a large amount of aligned data during the training phase, which poses challenges for small sample scenarios.
There are some research studies regarding multimodal few-shot learning to perform the VQA task. Frozen [56] proposes a multimodal few-shot method that freezes the language model, trains only the visual encoder, and directly inputs image features into the language model. Frozen not only reduces the number of training parameters by updating the visual encoder parameters but also enables image features to be understood by language models. In addition, Frozen provides demonstrations of the task that help the model understand the task form and the input and output for the task. However, this method requires a large amount of data to train the visual encoder, thus making it difficult to apply to small sample scenarios. MML [54] proposes the meta mapper to map the image features to language feature space. Specifically, MML extracts image features through a visual encoder and inputs them together with a visual prefix into the meta mapper. The meta mapper maps image features to visual prefixes through the network structure. Subsequently, the visual prefix is inputted into the language model along with the sentence to help the model understand the images and generate the answer. This method freezes the visual and language models and only trains the meta mapper network, which reduces the number of trainable parameters and has good scalability. However, this method still requires a certain amount of data for training.
The above research studies need a lot of data for training, even large-scale data for pretraining. However, our method only needs a few samples, like 20 or even 4, for training to perform the VQA task.
3. VL-Few
In this section, we will present our VL-Few method as follows. Section 3.1 talks about instruction prompts, and Section 3.2 introduces how to align the modal understanding ability. Section 3.3 researches few-shot meta learning in the multimodal problem. Section 3.4 talks about how to align semantic understanding ability. Section 3.5 introduces how to align task understanding ability, and Section 3.6 presents about how to align the generation ability.
3.1. Problem Definition
For multimodal learning, VQA is an answer to a question based on an image. We have a VQA dataset D as shown in Equation (1), where V is a set of Ith images, Q is a set of Ith questions, and A is a set of Ith answers.
For each VQA data value, there are several tokens corresponding to the image , question , and answer as shown in Equations (2)–(4), where there are ith image tokens v in the Ith image V, jth question tokens q in the Ith question Q, and kth answer tokens a in the Ith answer token A.
We propose the VL-Few, which could help a language model understand the vision information and answer the question based on the image, as shown in Equation (5):
For meta learning, we first sample N categories and then randomly sample K examples as the support set which is called N-way K-shot meta learning. Fewer N and more K make the task easier. Correspondingly, we randomly sample M examples as the query set. We construct a meta task pool by creating such a task T times in a set.
To perform meta learning, we first randomly sample N categories from the name list of the training set as shown in Equations (6) and (7), where name_list is all the classification of the training set, and we randomly sample n times to construct the meta category list.
To construct the support set, we randomly sample K examples based on the N categories in the training set as shown in Equations (8) and (9), where means the kth in the support set based on the category, and it can be written as .
Similarly, to construct the query set, we randomly sample M examples based on the N categories in the training set as shown in Equations (10) and (11), where means the mth in the query set based on the category, and it can be written as .
To construct a meta task, we combine the support set and the query set based on each category as shown in Equations (12) and (13):
Above all, we construct a task for the meta task pool using meta learning; then, we just repeat this method to obtain T tasks for the final meta task pool as shown in Equations (14) and (15):
For few-shot learning, we just use a few examples to train the model and want the performance to be similar to the model trained using more data. In our setting, few-shot learning means the training set size T × N × K is small. The details of the few-shot learning setting can be found in Section 3.3.
To make the model understand images, we propose a double mapper architecture, which comprises the vision-mapper that can map the image to the language feature space and the vision-language-mapper that can map the image with the question to the language feature space as shown in Equations (16) and (19), respectively, where is the ath token of the vision feature , and is the bth token of the vision–language feature . So, the input is changed to .
To help the model understand the task, we provide the instruction as a task instruction as shown in Equation (20), where is the oth task instruction of .
To give the model more information about the context, we construct some context prompts to provide the information on the input as shown in Equations (21)–(24), where is the pth token of the image (vision) prompt , is the qth token of the image–question prompt , is the rth token of the question prompt , and is the sth token of the answer prompt .
To demonstrate the model, we make a demonstration E of the task for the model using in-context learning as shown in Equations (25)–(27), where is the ath token of the , is the bth token of the , is the fth token of the , is the gth token of the , and is the eth token of the example E.
The multimodal fusion mapper can fuse all parts as shown in (28) and (29). Based on the Equations (1)–(29), we construct the input X as shown in Equation (30), where is the mth token of the input X.
The ground truth Y can be represented as shown in Equation (32), where is the kth token of the ground truth Y.
To represent the data, we adopt the decoder to represent the data in the language feature space using token-level training as shown in Equations (34)–(36), where is the token embedding matrix, is the position embedding matrix, is the embedding of the input, is the feature of the input, and the token-level training just inputs tokens one by one to align to the output, which sets the n from one to the length of the input.
We reweight three losses to train the model. First, we use the language modeling (LM) loss to make the model learn the generation ability as shown in Equation (37), where is based on the previous section of the input.
Second, we adopt the SEMantic (SEM) matching loss [57], which compares the semantic similarity of the predictive sentences and the answers and brings it closer to one as shown in Equations (38) and (39), where the similarity function is the COSine (COS) value, y means the predictions y, and means the targets .
Third, we use the Cross Entropy (CE) loss to calculate the prediction error during training as shown in Equation (40). The n is the index of the category from 1 to N. The is a normalization term used to ensure that the weights of different samples are taken into account when calculating the average. The denominator of this term is the weight for all samples multiplied by an indicator function. If is not equal to ignore_index then it is 1; otherwise, it is 0. This ensures that the weights of different samples are taken into account when calculating the average. The is the weight of category , which is used for weighting between different categories. This allows for the emphasis or reduction of or in certain categories of contributions in the training. The measures the error between the output probability distribution of the model and the actual label. The is a means that specifies a target value like a padding token that is ignored and does not contribute to the input gradient.
3.2. Modal Alignment
Training a model, even if not a large model but a pretrained model, requires a large computation power and time. For multimodal tasks like VQA, some works retrain the vision encoder to make the vision feature understood by the language decoder. However, this method requires much data, computation power, and time to achieve training, which is an obstacle for low source learners.
Modal alignment aligns data from different modalities into the model space, thereby enabling the model to understand data from different modalities. Firstly, we use the vision encoder, which is the CLIP-ViT with 87 M frozen parameters to extract the vision image features, and we use the language encoder, which is the GPT-2 with 123.65M frozen parameters to extract the language question features of the model. We input the vision feature into the vision mapper, which is a linear layer with 0.59M parameters, and the vision image feature into the vision representation alignment tokens, which can represent the images. Then, we extract visual features by using the vision encoder that has frozen parameters, which is a CLIP ViT with 87 M frozen parameters, and the language encoder, which is a GPT-2 with 123.65M frozen parameters, to extract the language question features. We adopt the vision language mapper, which is a transformer layer with 7.09M parameters, to map the vision image features and language question features into the vision language representation alignment tokens to represent the vision image features based on the language questions to understand the images based on the questions. Subsequently, we adopt the multimodal fusion mapper, which is a linear layer with 0.59M parameters, to fuse all input parts, including task prompt tokens, into one whole input. Finally, we input all of them into the language decoder to generate the answers based on the images and the questions.
3.3. Multimodal Few-Shot Meta Training
The few-shot training dataset was not large enough to train a model, even a light architecture, because of the not large amount of data. Some methods like data augmentation could increase the number of data, but these just provide a little more information and cannot improve the model to understand the task.
The language models need lots of data to construct the task to help the model learn the ability such as answering the question based on the image, which is called VQA, and bounding boxes in image processing for object detection and tracking. Using a few examples to train a model to learn a new domain data or even a new task is difficult because the model can only learn from the data to learn the data knowledge and task knowledge. So, how to train a model using less data to reach a better performance is important and promising.
Single modal tasks are difficult to solve regarding complex real-world problems, so for multimodal tasks, such as VQA, enabling models to understand data from different modalities is a promising solution. Compared to other methods that require the retraining of multimodal models or a large amount of training data, our method has designed an algorithm framework that only requires a small amount of training data to train three mappers, which constitute a transformer layer with 7.09M parameters and a linear layer with 0.59M parameters. This allows us to directly reuse multiple single modal pretrained models to complete multimodal tasks. Based on our previous research on VL-Meta [58], we constructed a task pool using meta learning to improve diversity and generalization, as well as help the model understand the task. Specifically, we constructed a task that samples N categories, and each category samples K data as the training set, samples N categories, and each category samples M data as the evaluation set. We constructed T tasks for the multimodal few-shot meta task pool for training and evaluating our model. These parameters could determine the training pool size T × N × K, validation pool size T × N × M, and the total data pool size T × N × .
In our experiment setting, we set the few-shot meta task pool size to based on the few-shot problem. The training set was only T × N × × 2 × or T × N × × 2 × , and the evaluation set was T × N × × 2 × .
3.4. Semantic Alignment
The model finds it difficult to distinguish the different modality inputs and cannot utilize existing knowledge to apply this information where the multiple modal data are input at once. Therefore, to enable the input to be understood by the model for different modal data parts, we used semantic alignment for different modal information.
3.4.1. Task Instruction
Models usually obtain the outputs by processing the inputs, which only include the data but not any description of the task. It can only use the input information or knowledge but can hardly learn what the task means and what needs to be done.
We added the description of the task into the inputs, which could let the model learn what the task is and how to do it. That is a kind of description we call task instruction or task prompting, which gives the model an instruction about the task to indicate how the model does the task.
We designed a task instruction that describes the task content and objectives, which can help the model understand the task information and complete the task, as shown in Listing 1.
| Listing 1. VQA task instruction. |
 |
3.4.2. Data Context
Inputting all different modal data into the model is a common practice for performing multimodal tasks like VQA. However, the multimodal inputs include some different modal data, which are difficult for the model to identify. We adopted some different kinds of descriptions of the different modal data like image prompt, image–question prompt, question prompt, and answer prompt. We used the data prompts to provide the data types and separate the different modal data, which could help the model distinguish the multimodal data. To provide the model with more information, the content of the answer prompt can change depending on the different datasets to fit their characteristics, especially the answer token length.
We designed a data context, which is the description of data in the context, also known as data meta information, which is equivalent to the data of the data. The data context includes the vision prompt, vision language prompt, question prompt, and answer prompt as shown in Listing 2.
| Listing 2. VQA image question and answer prompt. |
 |
3.4.3. Demonstration Context
Training, validating, and testing a model on a multimodal task like VQA requires pairs of images, questions, and answers. However, a large model or even a pretrained model learns an ability that if we give more information about the task or data, the performance could be improved. It could invoke the learned knowledge within the model to assist in completing the task. Based on this, we adopted the demonstration context to provide the model with an example of the task, like a pair of images, questions, and answers, in the VQA task to make the model understand what the task looks like and how the complete task should be.
The demonstration context is a complete task example. This task example can provide the model with specific task forms, inputs, and outputs. Specifically, we randomly constructed a demonstration context for each input so that the demonstration context for each input would be different, thereby avoiding overfitting the model to that part and improving the generalization ability of the model. We used the vision encoder to extract the vision image features. We used the language encoder to extract language question features and language answer features and used the language embedding module to extract the language question embeddings. The specific form of the demonstration context is shown in Listing 3.
| Listing 3. VQA demonstration context. |
 |
3.5. Task Alignment
There may be a distance between the dataset and the task due to the inconsistency between the task form and the dataset. Therefore, we used task alignment to construct the dataset to task form.
3.5.1. Caption Alignment
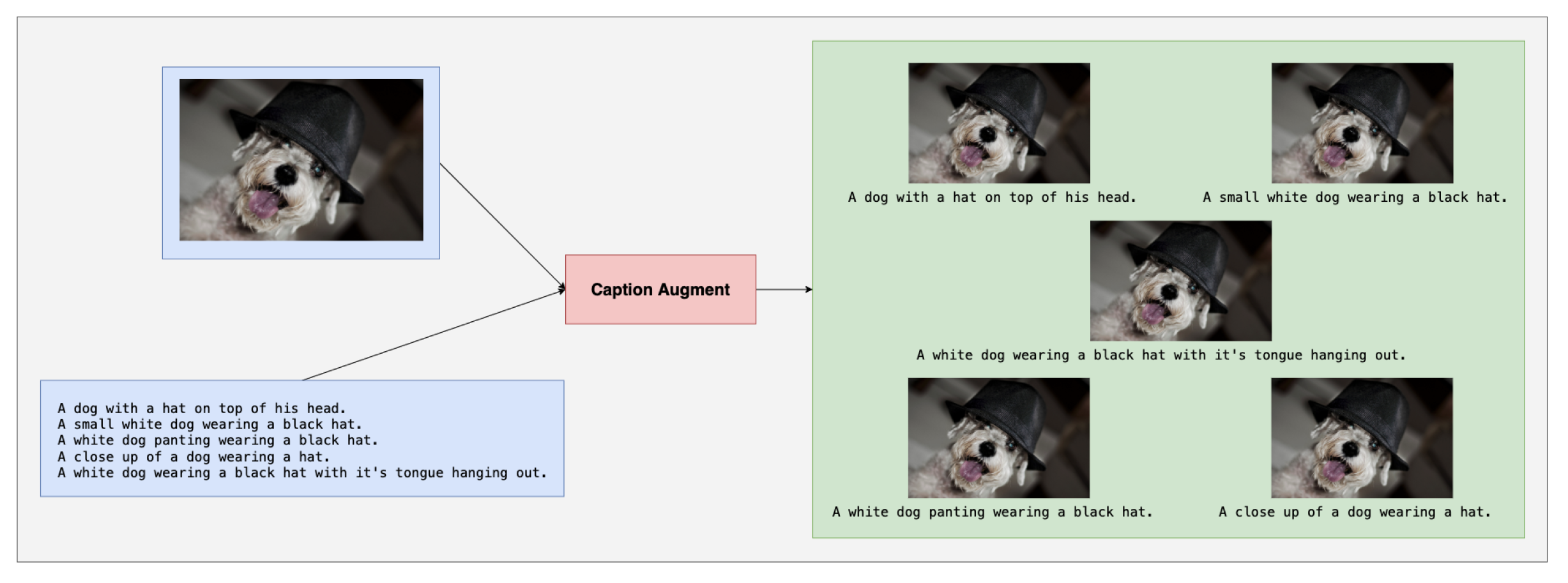
To improve the model performance for few-shot learning, we found each image corresponding to five images in the training dataset, which could make more training data. Furthermore, we analyzed the captions of images and found that the captions usually described the image from different perspectives, which could provide more information about each image. So, we constructed the training data with multiple captions to help the model understand each image from different viewpoints. That could also reduce the cost of the task because, in an application scenario like the medical imaging field, it is rare for researchers to obtain a medical image of magnetic resonance imaging (MRI) about a rare disease due to cost and rarity. So, only labeling the text based on the image could reduce the cost to obtain more data, which is a useful method to solve the few-shot problem to achieve the data augment. As shown in Figure 2, there are five captions of each image in the training data. We constructed five pairs of image captions to increase the training dataset size.
Figure 2.
Caption alignment process. We constructed 5 pairs of image captions using one image and its corresponding captions.
The training set we constructed is from COCO2017, which is an image caption task. Other studies have not considered the complex visual information contained in an image and have not understood it from different perspectives. For this situation, we considered that one image can correspond to data from multiple captions. Therefore, we constructed our training set based on the dataset COCO2017, thus constructing multiple captions of an image into multiple image caption data.
3.5.2. Question Alignment
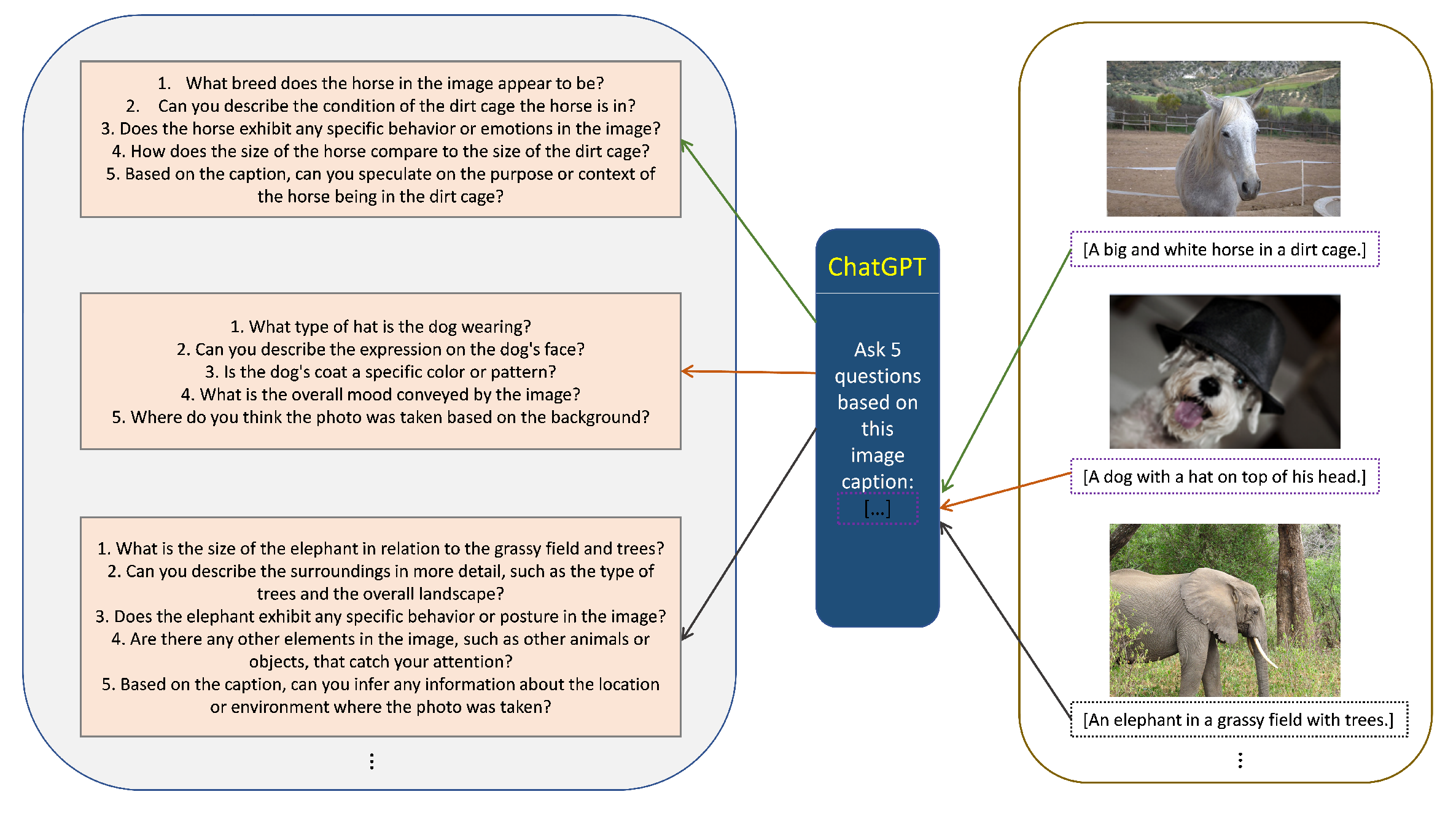
In the VQA task, one image corresponds to one question and one answer. However, the dataset we constructed through the caption alignment method only has the images and captions, without any questions. However, because the training data COCO2017 have no question of the images, it cannot learn the complete task form, which will make the model not do well in the actual task. To construct a VQA task, we used the question generation method, which uses the captions as the answer and generates the questions based on the answers by using ChatGPT [16]. That could help the model understand how to respond to the answers based on images and questions tasks. As shown in Figure 3, we used the caption corresponding to the image to generate multiple questions through ChatGPT.
Figure 3.
Question generation process. The text in the purple box is the caption corresponding to the image in the dataset. We constructed the question for each pair of image captions.
This method can synthesize data into the form required for our task and help the model understand the image based on the question from multiple aspects, thereby improving the understanding of vision abilities.
3.6. Generation Alignment
Input and output are the learning and generation capabilities of a model, respectively. Starting from the training stage and objective function, we used a generation alignment to improve the generation capability of the model.
3.6.1. Token-Level Training
During training, the model and updating the parameters, and the language modeling (LM) predicts the last token based on the previous input tokens. But when generating the output, the model generates the response token by token, which is not the same as the training method. So, based on our previous research using VL-Meta [58], we adopted token-level training to align the training to generating as follows. The sentence here contains a token . According to token-level training, the content we input is , , , , and . This method aligns the training process of the model with the generation process, improves the generation ability of the model, enables the model to learn more detailed text content, and has the function of data augmentation as shown in Listing 4.
| Listing 4. Token-level training example. |
 |
3.6.2. Multitask Fusion Loss
The training objective is a core part of training the model. However, only one training objective could do the specific task, which has a low generalization ability. For this reason, we adopted multitask fusion loss to make the model learn more than one objective at the same time to perform the multimodal task. We adopted LM loss to learn the generation ability to output the answers, adopted SEM loss to learn the semantic similarity ability to close the output to the answer, and adopted CE loss to learn the understanding ability to generate better responses.
3.7. Pseudocode
To make our VL-Few easier to understand, we introduce it using pseudocode as in Algorithm 1.
| Algorithm 1 VL-Few pseudocode. |
|
4. Multimodal Evaluation
4.1. Training Dataset
There were two datasets in our experiments, which are COCO2017 [59] for training and Visual Genome [60] for testing.
4.1.1. COCO2017
The dataset COCO2017 [59] is an upgraded version based on COCO2014 [61]. The total amount of the two datasets is the same, but the partition ratio is different as shown in Listing 5.
| Listing 5. COCO2017 dataset example. |
 |
It includes images of 91 object types and 2.5 million labeled instances from 328 thousand images, which involve complex daily scenes, including common objects in the natural environment. It aims to understand visual scenes involving many tasks like recognizing what objects are present, localizing the objects, and providing a semantic description of the scene. Each image includes the object classifications that could construct the N-way K-shot meta task pool based on the N object categories present in the images. But, this dataset is mainly for the image caption task, which means it has no questions for images. So, we proposed to construct the VQA task by generating questions for the image captions.
4.1.2. Visual Genome
The model was trained on a dataset; however, it can also be used in an out-of-domain dataset. To test the generalization ability of the model, we adopted an out-of-the-training dataset domain named Visual Genome [60], which is a guided VQA dataset. It consists of 101174 images from MSCOCO [61] with 1.7 million question–answer pairs and an average of 17 questions per image as shown in Listing 6.
| Listing 6. Visual Genome dataset example. |
 |
We used this dataset as the test set to evaluate the generalization ability.
4.2. Crossdomain Evaluation
The evaluation of the same domain of the training data is a general method used to validate model performance. However, it cannot show the ability of the model on a different domain dataset to show the generalization and how well it is in a new domain. We adopted the crossdomain evaluation, which validates the model on a different dataset from the training data to verify the generalization of the model.
4.3. Implementation Details
We proposed the VL-Few model structure as shown in Figure 1. Specifically, we adopted CLIP-ViT with 87.46M frozen parameters as the vision encoder to obtain the vision features from images and employed GPT-2 with 123.65M frozen parameters as the language encoder to obtain the language question features from questions. Then, vision mapper, which is a linear layer with 0.59M parameters, mapped the vision features to the vision representation alignment tokens. The vision-language mapper, which is a transformer layer with 7.09M parameters, mapped the vision and language features to the vision-language representation alignment tokens. These two different tokens contain their input semantics and could represent the original data. Then, we input all the parts into the multimodal fusion mapper, which is a trainable linear layer with 0.59M parameters, to fuse all the inputs. Finally, we input them into the language decoder, which is also the frozen GPT-2, to obtain the answers. The few-shot meta task pool size was 2, which means we only sampled two tasks for training. The lengths of the vision mapper prompt and vision-language mapper were 10. The learning rate was .
4.4. Evaluation Metric
To compare with other research, we adopted the accuracy as our evaluation metric, as shown in (42).
Our evaluation metric is accuracy, which is a common metric used to evaluate the performance of the model.
4.5. Results and Discussion
The core problem is that the language model cannot see the vision information. For research on the multimodal few-shot problem, we compared three related methods by using the crossdomain dataset Real-Fast VQA based on 2-way 1-shot or 5-shots to evaluate the performance of our method, as shown in Table 1. Note that there are few research studies on this problem; thus, the compared results are not many. With or without means whether or not to use the meta learning method. The evaluation metric is accuracy (%), which can evaluate the understanding of visual information of the model and complete VQA tasks based on this. Frozen [56] freezes the language decoder and trains the vision encoder, which is also the baseline of this problem. MML [54] is a method that uses a mapper to convert the vision feature into language feature space, which trains by using the meta learning to construct a new training dataset. Our method VL-Few proposes to use the learnable vision prompt and vision-language prompt to carry out the vision information to make the model learn images, which could help the model understand the images that are the different modal data. Our training set sizes were T × N × × 2 × or T × N × × 2 × , which are small samples for training. VL-Few reached the best accuracy in the 1-shot and 5-shots, which shows the feasibility and effectiveness of our method. More samples could provide more data and task knowledge, which could improve the model performance. Meta could further improve the accuracy of the model. We observed that our VL-Few reached the best accuracy in the 1-shot and 5-shots, even without multimodal few-shot meta training. This shows that our method could improve the modal understanding ability of the model by using multimodal alignment, and multimodal few-shot meta training could further improve the performance of the model. Specifically, the modal alignment method aligns the vision feature into the language space by mapping the vision feature into the language feature space, which improves the modal understanding, and multimodal few-shot meta training reduces the data dependence of the model by constructing the training set and training input, which improves its generalization ability.

Table 1.
VL-Few comparison on 2-way crossdomain Real-Fast VQA task in accuracy. The × means the methods without meta learning and the ✓ means it with the meta learning. The bold font accuracies are the best with meta in their results. The underlined font accuracies are the best without meta in their results.
4.6. Ablation Study
To evaluate the contributions of the meta learning and the out-of-domain dataset, we designed an ablation experiment as shown in Table 2. Our method VL-Few had four experiment settings on whether or not to use the meta learning method and whether or not to use the crossdomain dataset, which could evaluate the contributions for each setting based on 2-way 1-shot and 5-shots. Whether or not to use the crossdomain means the test set is from MSCOCO2017 or Guided VQA. The first two experiments show that the crossdomain learned the ability to generalize.
Table 2.
Ablation experiment of comparison of meta and crossdomain of VL-Few on 2-way Real-Fast VQA task in accuracy. The × means the methods without meta learning and the ✓ means it with the meta learning. The bold font is the best accuracy in the results.
Only using the meta task pool method cannot improve the model performance; we analyzed that, although there were many meta tasks in the pool, we sampled just a few tasks to train the model. This method did not receive significant benefits due to the lack of scale effect.
4.7. Qualitative Analysis
To evaluate the contributions of each part and module of VL-Few, we designed another ablation experiment as shown in Table 3. We compared each method in our experiment based on 2-way 1-shot and 5-shots.
Table 3.
Ablation experiment of comparison of VL-Few on 2-way Real-Fast VQA task in accuracy. The bold font is the best accuracy in the results.
The task instruction includes the task description that could provide the context for the input of the model. The data context provides differentiation ability for input sequences, which can help the model distinguish different modalities and parts, thereby helping the model understand the input sequence. The demonstration context provides task examples to enable the model to mimic the form of tasks and output expected content. These two results show that semantic alignment can improve the semantic understanding of the model.
The question generation can provide some general questions for datasets that are without questions, which can help the model improve its understanding of images and improve its testing performance. The caption augmentation can construct more data using different captions for one image, which can help alleviate the small sample problem. These two results show that task alignment can help improve the task understanding ability of the model.
The token-level training can make the model pay attention to each answer token, thus giving more opportunities to the model to learn from the training set. The multitask fusion loss makes the model achieve different objects, which helps the model learn different abilities from different perspectives of the dataset to enhance the overall abilities. These two results show that generation alignment helps the generation ability of the model.
5. Conclusions
The few-shot problem is hard to solve because of limited training data, which becomes even more difficult in multimodal scenarios. Constructing multimodal data requires manual alignment, and increasing the amount of data also requires time and cost. Our research provides an effective solution: V-Few. This method achieves the modeling of multimodal tasks with limited data. The main contributions of this article are as follows. A new learnable framework has been proposed, which includes the vision mapper, vision-language mapper, and fusion module. This mechanism could reduce the trainable parameters number and make the language model understand images. The task instruction improves the task content and objectives understanding ability of the model. The data context enhances the interpretability of data and provides modal differentiation prompts, thereby improving the data understanding ability of the model. The demonstration context improves the specific forms of task understanding ability of the model. The question generation method provides the general questions for the training data, which improves the transfer ability in the target task form of the model. The answer augmentation method provides multiple answers per image, which helps the model understand the content of each image and improves the data and task understanding ability of the model. Token-level training enables the model to focus on each token of the answer, thereby improving the answer generation ability of the model. Multitask fusion loss can learn and solve multiple tasks simultaneously, which can improve the overall performance of the model. Our method can effectively alleviate the multimodal few-shot problem, and the good experimental results demonstrate the effectiveness of the model.
Our method VL-Few could help the blind understand real-world vision information to help them perceive the environment. It can help the blind understand real-world vision information, thereby enabling them to navigate and interact with their surroundings with heightened awareness. This technology bridges the gap between the sighted and the visually impaired, thereby fostering independence and inclusivity. We have considered designing the VL-Few algorithm as glasses that perceive the surrounding environment, and visually impaired individuals can perceive the surrounding environment through voice interaction by wearing glasses equipped with our algorithm. When visually impaired people want to drink water, then they need to know the position of the cup. Our method can take photos of the surrounding environment, recognize it as text with the previously recorded question, and input it into the algorithm together. The algorithm generates answers and converts the text into speech through voice broadcasting to help visually impaired people understand the position of the cup. At present, the accuracy of this method is still difficult to achieve in a practical application. We could try to improve the ability of the model by using more data or designing more efficient algorithms.
More data means more knowledge, which can help the model learn tasks and achieve performance improvement. We consider using more data and involving more efficient algorithms to improve the task capability of the model. In the future, we can further explore some directions, such as using more meta task pool samples to analyze the impact of different sizes on model performance. In addition, we can generate more specific questions to explore the impact of fine-grained questions on model performance, fine-tuning the encoder and decoder to explore the impact of task data on the model, and using large language models to provide stronger language ability.
Author Contributions
Conceptualization, H.M.; methodology, H.M.; software, H.M.; validation, H.M. and B.F.; formal analysis, H.M.; investigation, H.M. and B.F.; resources, B.K.N.; data curation, H.M. and B.F.; writing—original draft preparation, H.M.; writing—review and editing, H.M., B.F., B.K.N. and C.-T.L.; visualization, H.M. and B.F.; supervision, B.K.N. and C.-T.L.; project administration, B.K.N.; funding acquisition, B.K.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Macao Polytechnic University via grant number RP/ESCA-02/2021.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. These data can be found here: https://cocodataset.org/#download (accessed on 24 June 2021), https://storage.googleapis.com/dm-few-shot-learning-benchmarks/guided_vqa.tar.gz (accessed on 3 November 2021).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. Glm-130b: An open bilingual pre-trained model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X.V.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Koromilas, P.; Giannakopoulos, T. Deep multimodal emotion recognition on human speech: A review. Appl. Sci. 2021, 11, 7962. [Google Scholar] [CrossRef]
- Wang, J.; Mao, H.; Li, H. FMFN: Fine-grained multimodal fusion networks for fake news detection. Appl. Sci. 2022, 12, 1093. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual. 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Sun, Z.; Shen, S.; Cao, S.; Liu, H.; Li, C.; Shen, Y.; Gan, C.; Gui, L.Y.; Wang, Y.X.; Yang, Y.; et al. Aligning large multimodal models with factually augmented rlhf. arXiv 2023, arXiv:2309.14525. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen technical report. arXiv 2023, arXiv:2309.16609. [Google Scholar]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Hong, D.; Cho, C.H. Factors affecting innovation resistance of smartphone AI voice assistants. Int. J. Hum.-Interact. 2023, 39, 2557–2572. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Rani, S.; Chauhan, M.; Kataria, A.; Khang, A. IoT equipped intelligent distributed framework for smart healthcare systems. In Towards the Integration of IoT, Cloud and Big Data: Services, Applications and Standards; Springer: Singapore, 2023; pp. 97–114. [Google Scholar]
- Oladimeji, D.; Gupta, K.; Kose, N.A.; Gundogan, K.; Ge, L.; Liang, F. Smart transportation: An overview of technologies and applications. Sensors 2023, 23, 3880. [Google Scholar] [CrossRef] [PubMed]
- Kümpel, M.; Dech, J.; Hawkin, A.; Beetz, M. Robotic Shopping Assistance for Everyone: Dynamic Query Generation on a Semantic Digital Twin as a Basis for Autonomous Shopping Assistance. In Proceedings of the International Conference on Autonomous Agents and Multiagent Systems, London, UK, 29 May–2 June 2023; pp. 2523–2525. [Google Scholar]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.D.; et al. A survey on multimodal large language models for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–10 January 2024; pp. 958–979. [Google Scholar]
- Chen, X.; Wang, X.; Changpinyo, S.; Piergiovanni, A.; Padlewski, P.; Salz, D.; Goodman, S.; Grycner, A.; Mustafa, B.; Beyer, L.; et al. Pali: A jointly-scaled multilingual language-image model. arXiv 2022, arXiv:2209.06794. [Google Scholar]
- Wang, W.; Bao, H.; Dong, L.; Bjorck, J.; Peng, Z.; Liu, Q.; Aggarwal, K.; Mohammed, O.K.; Singhal, S.; Som, S.; et al. Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv 2022, arXiv:2208.10442. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv 2023, arXiv:2301.12597. [Google Scholar]
- Zhang, X.; Zeng, Y.; Zhang, J.; Li, H. Toward Building General Foundation Models for Language, Vision, and Vision-Language Understanding Tasks. arXiv 2023, arXiv:2301.05065. [Google Scholar]
- Chen, S.; He, X.; Guo, L.; Zhu, X.; Wang, W.; Tang, J.; Liu, J. Valor: Vision-audio-language omni-perception pretraining model and dataset. arXiv 2023, arXiv:2304.08345. [Google Scholar]
- Wang, P.; Wang, S.; Lin, J.; Bai, S.; Zhou, X.; Zhou, J.; Wang, X.; Zhou, C. ONE-PEACE: Exploring One General Representation Model Toward Unlimited Modalities. arXiv 2023, arXiv:2305.11172. [Google Scholar]
- Liu, S.; Fan, L.; Johns, E.; Yu, Z.; Xiao, C.; Anandkumar, A. Prismer: A vision-language model with an ensemble of experts. arXiv 2023, arXiv:2303.02506. [Google Scholar]
- Hu, Y.; Stretcu, O.; Lu, C.T.; Viswanathan, K.; Hata, K.; Luo, E.; Krishna, R.; Fuxman, A. Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models. arXiv 2023, arXiv:2312.03052. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T.; et al. Palm-e: An embodied multimodal language model. arXiv 2023, arXiv:2303.03378. [Google Scholar]
- Yu, Z.; Ouyang, X.; Shao, Z.; Wang, M.; Yu, J. Prophet: Prompting Large Language Models with Complementary Answer Heuristics for Knowledge-based Visual Question Answering. arXiv 2023, arXiv:2303.01903. [Google Scholar]
- Lu, J.; Gan, R.; Zhang, D.; Wu, X.; Wu, Z.; Sun, R.; Zhang, J.; Zhang, P.; Song, Y. Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects. arXiv 2023, arXiv:2312.05278. [Google Scholar]
- Park, S.; Whang, T.; Yoon, Y.; Lim, H. Multi-view attention network for visual dialog. Appl. Sci. 2021, 11, 3009. [Google Scholar] [CrossRef]
- Talagala, T.S.; Hyndman, R.J.; Athanasopoulos, G. Meta-learning how to forecast time series. J. Forecast. 2023, 42, 1476–1501. [Google Scholar] [CrossRef]
- Zhang, Y.; Gong, K.; Zhang, K.; Li, H.; Qiao, Y.; Ouyang, W.; Yue, X. Meta-transformer: A unified framework for multimodal learning. arXiv 2023, arXiv:2307.10802. [Google Scholar]
- Shakeel, M.; Itoyama, K.; Nishida, K.; Nakadai, K. Metric-based multimodal meta-learning for human movement identification via footstep recognition. In Proceedings of the IEEE/SICE International Symposium on System Integration (SII), Atlanta, GA, USA, 17–20 January 2023; pp. 1–8. [Google Scholar]
- Jaafar, N.; Lachiri, Z. Multimodal fusion methods with deep neural networks and meta-information for aggression detection in surveillance. Expert Syst. Appl. 2023, 211, 118523. [Google Scholar] [CrossRef]
- Rao, S.; Huang, J. Leveraging enhanced task embeddings for generalization in multimodal meta-learning. Neural Comput. Appl. 2023, 35, 10765–10778. [Google Scholar] [CrossRef]
- Ma, H.; Yang, K. MetaSTNet: Multimodal Meta-learning for Cellular Traffic Conformal Prediction. IEEE Trans. Netw. Sci. Eng. 2023, 1–14. [Google Scholar] [CrossRef]
- Lin, Z.; Yu, S.; Kuang, Z.; Pathak, D.; Ramanan, D. Multimodality helps unimodality: Cross-modal few-shot learning with multimodal models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19325–19337. [Google Scholar]
- Moor, M.; Huang, Q.; Wu, S.; Yasunaga, M.; Dalmia, Y.; Leskovec, J.; Zakka, C.; Reis, E.P.; Rajpurkar, P. Med-flamingo: A multimodal medical few-shot learner. In Proceedings of the Machine Learning for Health (ML4H)—PMLR, New Orleans, LA, USA, 10 December 2023; pp. 353–367. [Google Scholar]
- Yang, X.; Feng, S.; Wang, D.; Zhang, Y.; Poria, S. Few-shot Multimodal Sentiment Analysis based on Multimodal Probabilistic Fusion Prompts. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 6045–6053. [Google Scholar]
- Wanyan, Y.; Yang, X.; Chen, C.; Xu, C. Active Exploration of Multimodal Complementarity for Few-Shot Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6492–6502. [Google Scholar]
- Khiabani, P.J.; Zubiaga, A. Few-shot learning for cross-target stance detection by aggregating multimodal embeddings. IEEE Trans. Comput. Soc. Syst. 2023, 1–10. [Google Scholar] [CrossRef]
- D’Alessandro, M.; Alonso, A.; Calabrés, E.; Galar, M. Multimodal Parameter-Efficient Few-Shot Class Incremental Learning. arXiv 2023, arXiv:2303.04751. [Google Scholar]
- Khoshboresh-Masouleh, M.; Shah-Hosseini, R. Multimodal few-shot target detection based on uncertainty analysis in time-series images. Drones 2023, 7, 66. [Google Scholar] [CrossRef]
- Wang, P.; Guo, Y.; Wang, Y. Few-shot multi-modal registration with mono-modal knowledge transfer. Biomed. Signal Process. Control 2023, 85, 104958. [Google Scholar] [CrossRef]
- Cai, J.; Wu, L.; Wu, D.; Li, J.; Wu, X. Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning. Information 2023, 14, 148. [Google Scholar] [CrossRef]
- Ye, G. Transductive few-shot image recognition with ranking-based multi-modal knowledge transfer. In Proceedings of the International Conference on Cyber Security, Artificial Intelligence, and Digital Economy (CSAIDE 2023), Nanjing, China, 3–5 March 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12718, pp. 471–476. [Google Scholar]
- Ouali, Y.; Bulat, A.; Matinez, B.; Tzimiropoulos, G. Black box few-shot adaptation for vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 15534–15546. [Google Scholar]
- Chadha, A.; Jain, V. Few-shot Multimodal Multitask Multilingual Learning. arXiv 2023, arXiv:2303.12489. [Google Scholar]
- Jiang, G.; Xu, M.; Xin, S.; Liang, W.; Peng, Y.; Zhang, C.; Zhu, Y. MEWL: Few-shot multimodal word learning with referential uncertainty. arXiv 2023, arXiv:2306.00503. [Google Scholar]
- Yang, M.; Chen, J.; Velipasalar, S. Cross-Modality Feature Fusion Network for Few-Shot 3D Point Cloud Classification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 653–662. [Google Scholar]
- Mokady, R.; Hertz, A.; Bermano, A.H. ClipCap: CLIP Prefix for Image Captioning. arXiv 2021, arXiv:2111.09734. [Google Scholar]
- Najdenkoska, I.; Zhen, X.; Worring, M. Meta Learning to Bridge Vision and Language Models for Multimodal Few-Shot Learning. arXiv 2023, arXiv:2302.14794. [Google Scholar]
- Wu, S.; Fei, H.; Qu, L.; Ji, W.; Chua, T.S. Next-gpt: Any-to-any multimodal llm. arXiv 2023, arXiv:2309.05519. [Google Scholar]
- Tsimpoukelli, M.; Menick, J.L.; Cabi, S.; Eslami, S.; Vinyals, O.; Hill, F. Multimodal few-shot learning with frozen language models. Adv. Neural Inf. Process. Syst. 2021, 34, 200–212. [Google Scholar]
- Kervadec, C.; Antipov, G.; Baccouche, M.; Wolf, C. Estimating semantic structure for the VQA answer space. arXiv 2021, arXiv:2006.05726. [Google Scholar]
- Ma, H.; Fan, B.; Ng, B.K.; Lam, C.T. VL-Meta: Vision-Language Models for Multimodal Meta-Learning. Mathematics 2024, 12, 286. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).