




Sequential Brain CT Image Captioning Based on the Pre-Trained Classifiers and a Language Model


Abstract
1. Introduction
2. Dataset
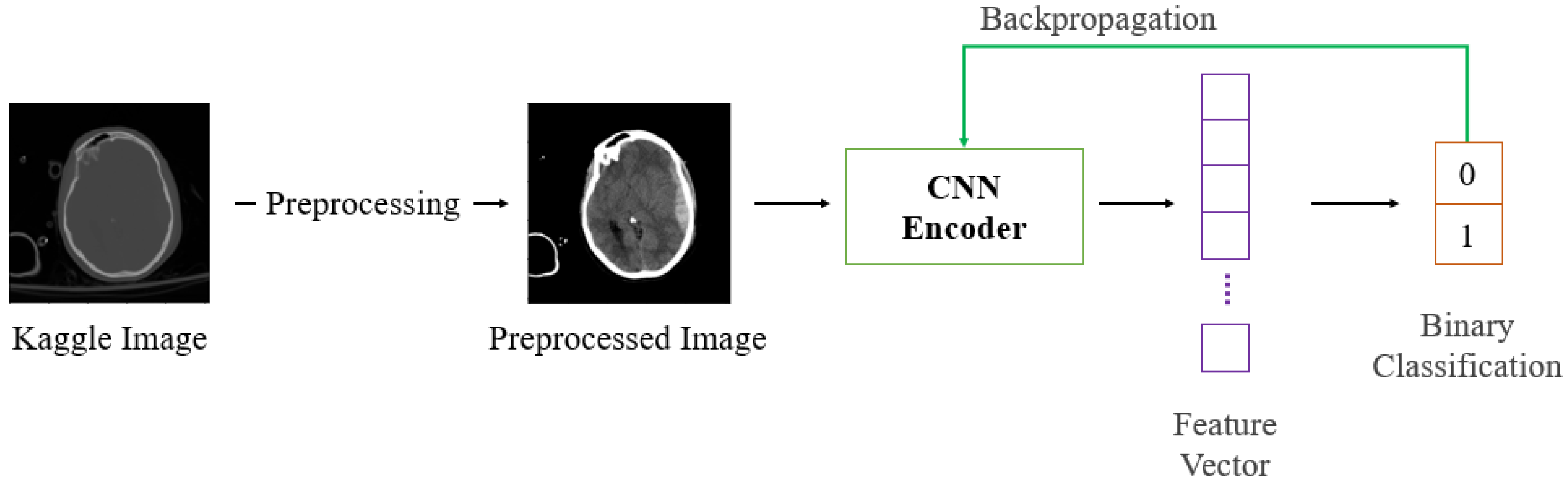
2.1. Fine-Training for Classifier
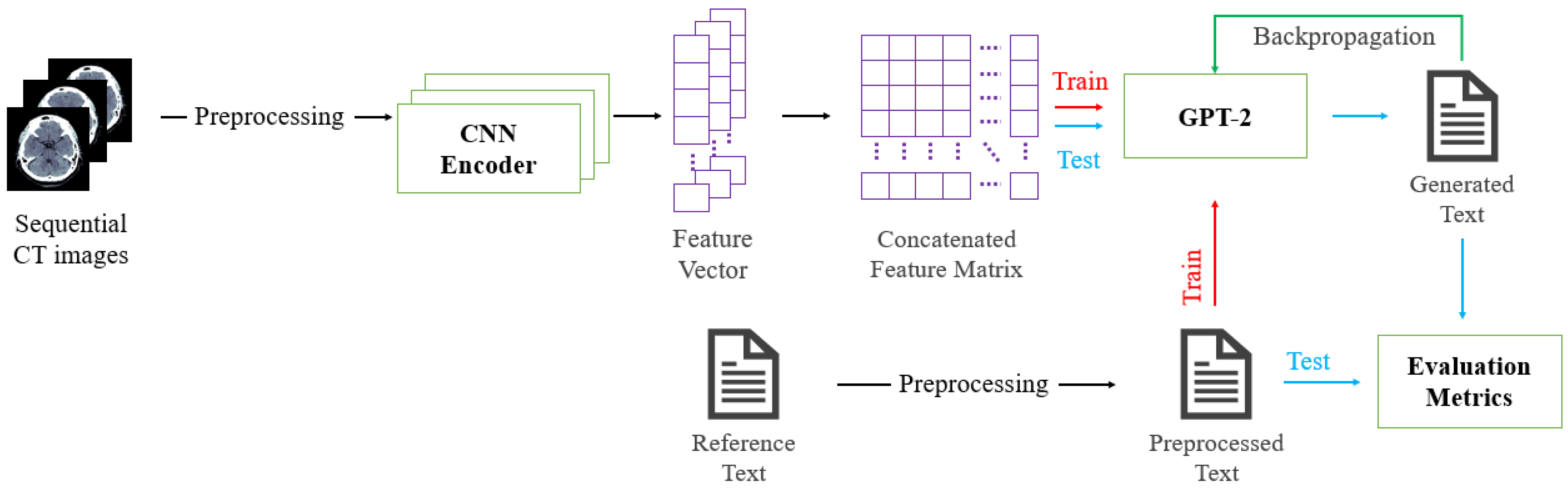
2.2. Image Captioning
3. Methodology
3.1. Pre-Trained CNN Based Classifier
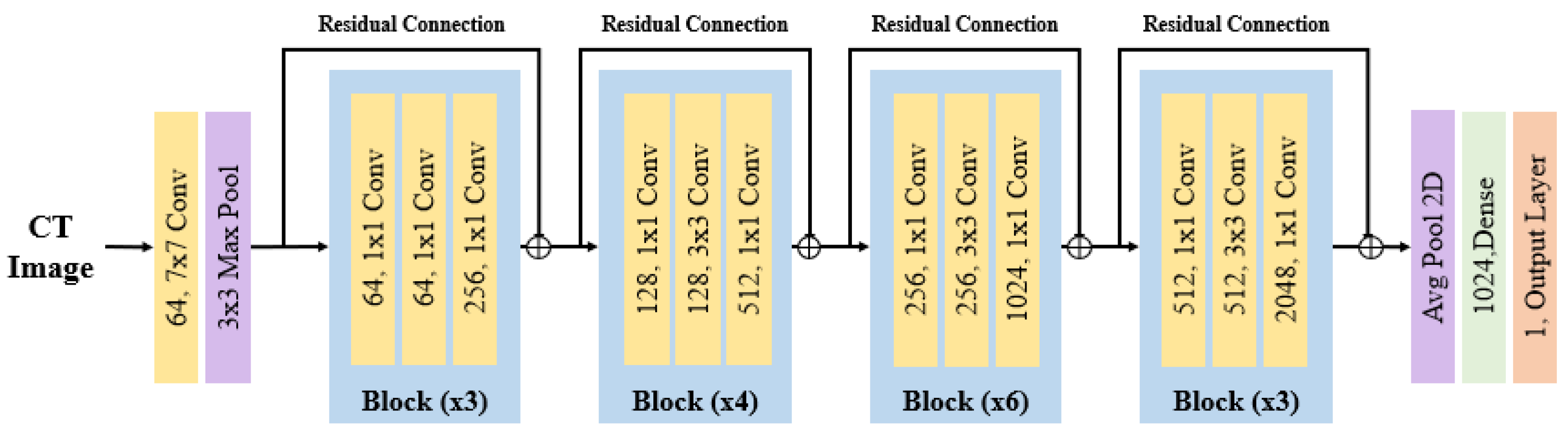
- ResNet-50V2 is a lightweight and efficient model compared to its predecessor, ResNet-50. It utilizes residual connections to improve the learning process by adding skip connections, which add the feature maps extracted from the previous layer to the input of the next layer. This increases the depth of the network, showcasing improved performance during the training process. The architecture of ResNet-50V2, depicted in Figure 4, incorporates pretrained weights that enhance the performance in training with low-resource data, making it adept at feature extraction for untrained data such as medical images. The hyperparameters used in ResNet-50V2 are as follows: the initial layer consists of a 2D convolution layer with a 7 × 7 kernel size and 64 filters, followed by batch normalization and ReLU activation functions. Subsequently, a 3 × 3 max-pooling layer with a stride of 2 is added. The following layers include four residual blocks. The first block has 64 filters and a stride of 2, the second block has 128 filters and a stride of 2, the third block has 256 filters and a stride of 2, and the fourth block has 512 filters with a stride of 1.
- DenseNet-121 is structured with dense blocks and transition layers, utilizing a sequence of convolution layers and skip connections. While ResNet forms a pathway by connecting the immediate layer with an element-wise addition, DenseNet densely connects layers as it goes deeper, employing channel-wise concatenation. The dense block forms dense connections between internal layers, enhancing feature extraction and the ability to reuse information. The transition layer adjusts the size of feature maps, maintaining the efficiency of the model. In addition, through the dense connection structure, features between layers accumulate, enabling the extraction of optimized features for subtle changes or patterns related to ICH. The architecture of DenseNet-121 is depicted in Figure 5, and the hyperparameters used are as follows: the first layer uses a 7 × 7 kernel size with 64 filters, along with batch normalization and ReLU activation functions. Furthermore, the transition layer consists of a 1 × 1 convolution layer and a 2 × 2 average pooling layer.
- VGG-16 consists of 16 layers, comprising 13 convolution layers and 3 fully connected layers. The distinctive feature of VGG-16 is its deep structure and the use of small filter sizes. VGG-16 is a simple yet powerful model primarily employed in computer vision tasks, capable of extracting rich features due to its very deep network architecture. This feature extraction ability enables the detection and extraction of various features of ICH, deriving relevant information. The architecture of VGG-16 is depicted in Figure 6, and the hyperparameters used are as follows: all convolution layers have a 3 × 3 kernel size with ReLU activation functions applied. Max pooling layers reduce the size of feature maps using a 2 × 2 kernel with a stride of 2. The fully connected layer consists of three dense layers with ReLU activation functions.
- VGG-19 is a model with a structure similar to VGG-16, but it has a more complex architecture with additional layers, allowing it to learn more intricate features. It consists of 19 layers, with an additional convolution layer in each of the third, fourth, and fifth blocks compared to VGG-16. The inclusion of these three extra convolution layers in VGG-19 enables it to learn more complex features of ICH and recognize a greater variety of detailed patterns. The architecture of VGG-19 is illustrated in Figure 7, and the hyperparameters used are as follows: it comprises 16 convolution layers with 3 × 3 filter sizes and 3 fully connected layers.
3.2. GPT-2
4. Experiments
4.1. Experimental Setup
4.2. Evaluation Metrics
4.2.1. N-Gram-Based Evaluation Metrics
4.2.2. Embedding-Based Evaluation Metrics
4.2.3. BERT Score
4.3. Experiment Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rindler, R.S.; Allen, J.W.; Barrow, J.W.; Pradilla, G.; Barrow, D.L. Neuroimaging of Intracerebral Hemorrhage. Neurosurgery 2020, 86, E414–E423. [Google Scholar] [CrossRef] [PubMed]
- Ginat, D.T. Analysis of head CT scans flagged by deep learning software for acute intracranial hemorrhage. Neuroradiology 2020, 62, 335–340. [Google Scholar] [CrossRef] [PubMed]
- Ibrahim, A.; Arifianto, M.R.; Al Fauzi, A. Minimally Invasive Neuroendoscopic Surgery for Spontaneous Intracerebral Hemorrhage: A Review of the Rationale and Associated Complications. Complic. Neurosurg. 2023, 130, 103–108. [Google Scholar]
- Ovenden, C.D.; Hewitt, J.; Kovoor, J.; Gupta, A.; Edwards, S.; Abou-Hamden, A.; Kleinig, T. Time to hospital presentation following intracerebral haemorrhage: Proportion of patients presenting within eight hours and factors associated with delayed presentation. J. Stroke Cerebrovasc. Dis. 2022, 31, 106758. [Google Scholar] [CrossRef]
- Mohammed, B.A.; Senan, E.M.; Al-Mekhlafi, Z.G.; Rassem, T.H.; Makbol, N.M.; Alanazi, A.A.; Almurayziq, T.S.; Ghaleb, F.A.; Sallam, A.A. Multi-Method Diagnosis of CT Images for Rapid Detection of Intracranial Hemorrhages Based on Deep and Hybrid Learning. Electronics 2022, 11, 2460. [Google Scholar] [CrossRef]
- Chandrabhatla, A.S.; Kuo, E.A.; Sokolowski, J.D.; Kellogg, R.T.; Park, M.; Mastorakos, P. Artificial Intelligence and Machine Learning in the Diagnosis and Management of Stroke: A Narrative Review of United States Food and Drug Administration-Approved Technologies. J. Clin. Med. 2023, 12, 3755. [Google Scholar] [CrossRef] [PubMed]
- Cordonnier, C.; Demchuk, A.; Ziai, W.; Anderson, C.S. Intracerebral haemorrhage: Current approaches to acute management. Lancet 2018, 392, 1257–1268. [Google Scholar] [CrossRef] [PubMed]
- Bruls, R.; Kwee, R. Workload for radiologists during on-call hours: Dramatic increase in the past 15 years. Insights Imaging 2020, 11, 121. [Google Scholar] [CrossRef]
- Alexander, R.; Waite, S.; Bruno, M.A.; Krupinski, E.A.; Berlin, L.; Macknik, S.; Martinez-Conde, S. Mandating limits on workload, duty, and speed in radiology. Radiology 2022, 304, 274–282. [Google Scholar] [CrossRef]
- Ayesha, H.; Iqbal, S.; Tariq, M.; Abrar, M.; Sanaullah, M.; Abbas, I.; Rehman, A.; Niazi, M.F.K.; Hussain, S. Automatic medical image interpretation: State of the art and future directions. Pattern Recognit. 2021, 114, 107856. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Oussalah, M.; Seppänen, T.; Jennane, R. ACapMed: Automatic Captioning for Medical Imaging. Appl. Sci. 2022, 12, 11092. [Google Scholar] [CrossRef]
- Selivanov, A.; Rogov, O.Y.; Chesakov, D.; Shelmanov, A.; Fedulova, I.; Dylov, D.V. Medical image captioning via generative pretrained transformers. Sci. Rep. 2023, 13, 4171. [Google Scholar] [CrossRef]
- Tsuneda, R.; Asakawa, T.; Aono, M. Kdelab at ImageCLEF 2021: Medical Caption Prediction with Effective Data Pre-processing and Deep Learning. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1365–1374. [Google Scholar]
- Castro, V.; Pino, P.; Parra, D.; Lobel, H. PUC Chile team at Caption Prediction: ResNet visual encoding and caption classification with Parametric ReLU. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1174–1183. [Google Scholar]
- Charalampakos, F.; Karatzas, V.; Kougia, V.; Pavlopoulos, J.; Androutsopoulos, I. AUEB NLP Group at ImageCLEFmed Caption Tasks 2021. In Proceedings of the CLEF (Working Notes), Bucharest, Romania, 21–24 September 2021; pp. 1184–1200. [Google Scholar]
- Alsharid, M.; Cai, Y.; Sharma, H.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Gaze-assisted automatic captioning of fetal ultrasound videos using three-way multi-modal deep neural networks. Med. Image Anal. 2022, 82, 102630. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.-Y.; Oh, B.-D.; Kim, C.; Kim, Y.-S. Convolutional Neural Network and Language Model-Based Sequential CT Image Captioning for Intracerebral Hemorrhage. Appl. Sci. 2023, 13, 9665. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Berkowitz, S.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.-y.; Mark, R.G.; Horng, S. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Sci. Data 2019, 6, 317. [Google Scholar] [CrossRef] [PubMed]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a collection of radiology examinations for distribution and retrieval. J. Am. Med. Inform. Assoc. 2016, 23, 304–310. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13 2014. pp. 740–755. [Google Scholar]
- Ionescu, B.; Müller, H.; Péteri, R.; Abacha, A.B.; Sarrouti, M.; Demner-Fushman, D.; Hasan, S.A.; Kozlovski, S.; Liauchuk, V.; Cid, Y.D.; et al. Overview of the ImageCLEF 2021: Multimedia Retrieval in Medical, Nature, Internet and Social Media Applications. In Proceedings of the Experimental IR Meets Multilinguality, Multimodality, and Interaction: 12th International Conference of the CLEF Association, CLEF 2021, Virtual Event, 21–24 September 2021; Proceedings, 2021. pp. 345–370. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Loper, E.; Bird, S. Nltk: The natural language toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Peterson, L. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Yu, J.; Yang, B.; Wang, J.; Leader, J.; Wilson, D.; Pu, J. 2D CNN versus 3D CNN for false-positive reduction in lung cancer screening. J. Med. Imaging 2020, 7, 051202. [Google Scholar] [CrossRef] [PubMed]
- Kaggle. Kaggle Competitions: RSNA Intracranial Hemorrhage Detection. Available online: https://www.kaggle.com/competitions/rsna-intracranial-hemorrhage-detection (accessed on 5 December 2023).
- Zhou, Q.; Zhu, W.; Li, F.; Yuan, M.; Zheng, L.; Liu, X. Transfer learning of the ResNet-18 and DenseNet-121 model used to diagnose intracranial hemorrhage in CT scanning. Curr. Pharm. Des. 2022, 28, 287–295. [Google Scholar] [CrossRef] [PubMed]
- Mahmoud, A.; Awad, N.A.; Alsubaie, N.; Ansarullah, S.I.; Alqahtani, M.S.; Abbas, M.; Usman, M.; Soufiene, B.O.; Saber, A. Advanced Deep Learning Approaches for Accurate Brain Tumor Classification in Medical Imaging. Symmetry 2023, 15, 571. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.-Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.R.; Zemel, R.; Urtasun, R.; Torralba, A.; Fidler, S. Skip-thought vectors. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Forgues, G.; Pineau, J.; Larchevêque, J.-M.; Tremblay, R. Bootstrapping dialog systems with word embeddings. In Proceedings of the Nips, Modern Machine Learning and Natural Language Processing Workshop, Montreal, QC, Canada, 9–11 December 2014; p. 168. [Google Scholar]
- Rus, V.; Lintean, M. An optimal assessment of natural language student input using word-to-word similarity metrics. In Proceedings of the Intelligent Tutoring Systems: 11th International Conference, ITS 2012, Chania, Crete, Greece, 14–18 June 2012; Proceedings 11 2012. pp. 675–676. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating text generation with BERT. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Tidwell, A.S. Advanced imaging concepts: A pictorial glossary of CT and MRI technology. Clin. Tech. Small Anim. Pract. 1999, 14, 65–111. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dai, Y.; Song, Y.; Liu, W.; Bai, W.; Gao, Y.; Dong, X.; Lv, W. Multi-focus image fusion based on convolution neural network for Parkinson’s Disease image classification. Diagnostics 2021, 11, 2379. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-specific language model pretraining for biomedical natural language processing. ACM Trans. Comput. Healthc. 2021, 3, 1–23. [Google Scholar] [CrossRef]
- Al-Malla, M.A.; Jafar, A.; Ghneim, N. Pre-trained CNNs as Feature-Extraction Modules for Image Captioning: An Experimental Study. ELCVIA Electron. Lett. Comput. Vis. Image Anal. 2022, 21, 1–16. [Google Scholar] [CrossRef]
- Staniūtė, R.; Šešok, D. A systematic literature review on image captioning. Appl. Sci. 2019, 9, 2024. [Google Scholar] [CrossRef]
- Park, H.; Kim, K.; Park, S.; Choi, J. Medical image captioning model to convey more details: Methodological comparison of feature difference generation. IEEE Access 2021, 9, 150560–150568. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers | Precision | Recall | F1-Score | Acc |
|---|---|---|---|---|
| ResNet-50V2 | 0.93 | 0.87 | 0.90 | 0.92 |
| DenseNet-121 | 0.93 | 0.86 | 0.89 | 0.91 |
| VGG-16 | 0.92 | 0.89 | 0.90 | 0.92 |
| VGG-19 | 0.94 | 0.86 | 0.90 | 0.92 |
| Models (With GPT-2) | B1 | B2 | B3 | B4 | B@4 | M | R_L | C | |
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50V2 | B | 0.27 | 0.19 | 0.16 | 0.13 | 0.18 | 0.14 | 0.30 | 0.38 |
| G | 0.25 | 0.19 | 0.15 | 0.13 | 0.18 | 0.13 | 0.30 | 0.36 | |
| DenseNet-121 | B | 0.28 | 0.21 | 0.17 | 0.14 | 0.20 | 0.14 | 0.28 | 0.25 |
| G | 0.28 | 0.21 | 0.17 | 0.14 | 0.20 | 0.14 | 0.29 | 0.27 | |
| VGG-16 | B | 0.20 | 0.14 | 0.12 | 0.10 | 0.14 | 0.10 | 0.21 | 0.18 |
| G | 0.20 | 0.15 | 0.12 | 0.10 | 0.13 | 0.09 | 0.20 | 0.16 | |
| VGG-19 | B | 0.21 | 0.16 | 0.13 | 0.11 | 0.12 | 0.10 | 0.23 | 0.16 |
| G | 0.21 | 0.16 | 0.13 | 0.10 | 0.12 | 0.10 | 0.23 | 0.17 | |
| Models (+GPT-2) | ST | EA | VE | GM | |
|---|---|---|---|---|---|
| ResNet-50V2 | B | 0.51 | 0.69 | 0.44 | 0.63 |
| G | 0.51 | 0.69 | 0.44 | 0.63 | |
| DenseNet-121 | B | 0.54 | 0.71 | 0.46 | 0.63 |
| G | 0.54 | 0.71 | 0.45 | 0.63 | |
| VGG-16 | B | 0.51 | 0.66 | 0.42 | 0.59 |
| G | 0.51 | 0.66 | 0.42 | 0.60 | |
| VGG-19 | B | 0.50 | 0.66 | 0.41 | 0.59 |
| G | 0.51 | 0.67 | 0.44 | 0.59 | |
| PubMedBERT | Precision | Recall | F1-Score |
|---|---|---|---|
| ResNet50V2 + GPT2 | 0.83 | 0.81 | 0.82 |
| DenseNet121 + GPT2 | 0.80 | 0.80 | 0.80 |
| VGG16 + GPT2 | 0.82 | 0.80 | 0.81 |
| VGG19 + GPT2 | 0.81 | 0.80 | 0.80 |
| Ground Truth | ResNet50V2 + GPT2 | DenseNet121 + GPT2 | VGG16 + GPT2 | VGG19 + GPT2 |
|---|---|---|---|---|
| SDH right fronto temporo parietal ICH right temporo parietal brain herniation, otherwise no demonstrable abnormal finding. | SDH left fronto parietal with brain herniation, otherwise no demonstrable abnormal finding. | SDH right fronto temporo parietal and right tentorium small vessel disease with lacunar infarctions, otherwise no demonstrable abnormal finding. | SDH right fronto temporo parietal and falx SDH, otherwise no demonstrable abnormal finding. | SDH in left basal ganglia small vessel disease with lacunar infarctions, otherwise no demonstrable abnormal finding. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kong, J.-W.; Oh, B.-D.; Kim, C.; Kim, Y.-S. Sequential Brain CT Image Captioning Based on the Pre-Trained Classifiers and a Language Model. Appl. Sci. 2024, 14, 1193. https://doi.org/10.3390/app14031193
Kong J-W, Oh B-D, Kim C, Kim Y-S. Sequential Brain CT Image Captioning Based on the Pre-Trained Classifiers and a Language Model. Applied Sciences. 2024; 14(3):1193. https://doi.org/10.3390/app14031193
Chicago/Turabian StyleKong, Jin-Woo, Byoung-Doo Oh, Chulho Kim, and Yu-Seop Kim. 2024. "Sequential Brain CT Image Captioning Based on the Pre-Trained Classifiers and a Language Model" Applied Sciences 14, no. 3: 1193. https://doi.org/10.3390/app14031193
APA StyleKong, J.-W., Oh, B.-D., Kim, C., & Kim, Y.-S. (2024). Sequential Brain CT Image Captioning Based on the Pre-Trained Classifiers and a Language Model. Applied Sciences, 14(3), 1193. https://doi.org/10.3390/app14031193