
A Novel Deep Learning Network Model for Extracting Lake Water Bodies from Remote Sensing Images
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Datasets
2.2. R50A3-LWBENet Model Components
2.2.1. ResNet
2.2.2. SE-ResNet
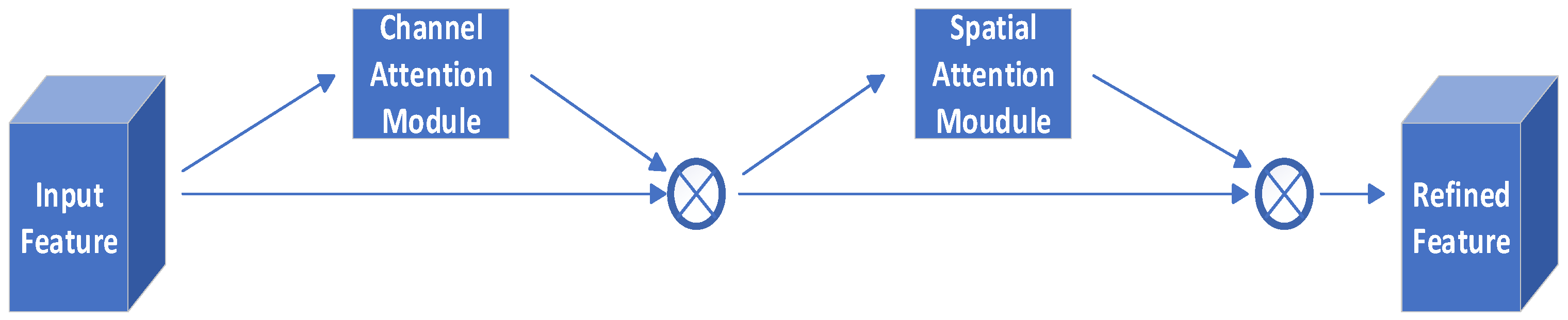
2.2.3. Convolutional Block Attention Module (CBAM)
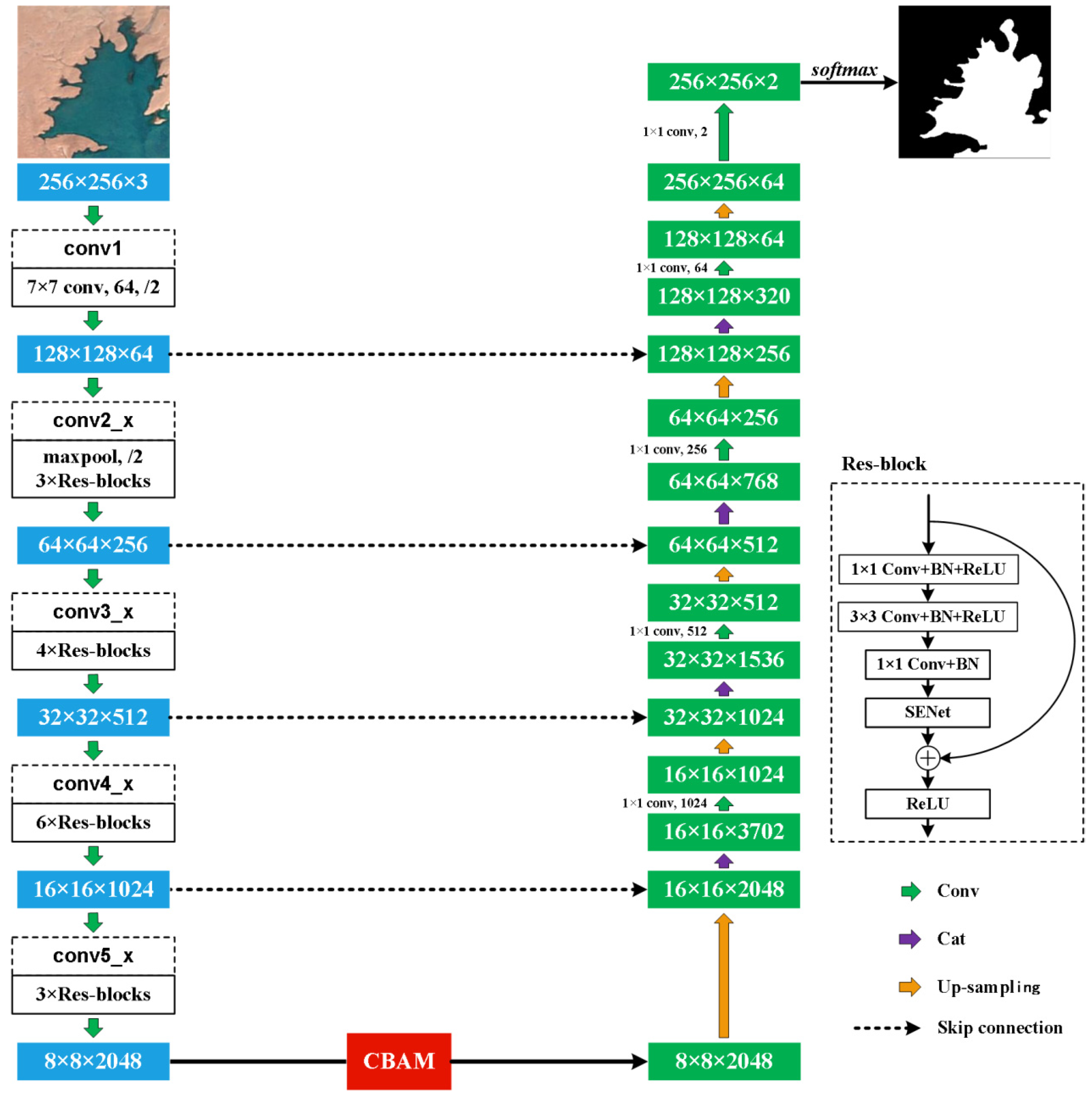
2.3. R50A3-LWBENet Holistic Network Instructure
2.4. Model Performance Evaluation Metrics
2.4.1. Pixel Accuracy (PA)
2.4.2. Mean Pixel Accuracy (MPA)
2.4.3. Mean Intersection over Union (MIoU)
2.5. Cross Entropy Loss Function
3. Results and Discussion
3.1. Experimental Environment Configuration
3.2. ResNet Backbone Selection
3.3. Ablation Study
3.4. Model Performance Comparison
3.4.1. Comparison of Model Visual Observations
- (1)
- Performance comparison for multi-scale features.
- (2)
- Performance comparison for noise interference.
- (3)
- Performance comparison for boundary blurring.
3.4.2. Comparison of Model Performance Evaluation Metrics
3.4.3. Comparison of Model Convergence
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, Q.; Si, W.; Wei, L.; Li, Z.; Xia, Z.; Ye, S.; Xia, Y. Retrieval of Water Quality from UAV-Borne Hyperspectral Imagery: A Comparative Study of Machine Learning Algorithms. Remote Sens. 2021, 13, 3928. [Google Scholar] [CrossRef]
- Liu, C.; Duan, P.; Zhang, F.; Jim, C.; Tan, M.; Chan, N. Feasibility of the Spatiotemporal Fusion Model in Monitoring Ebinur Lake’s Suspended Particulate Matter under The Missing-Data Scenario. Remote Sens. 2021, 13, 3952. [Google Scholar] [CrossRef]
- Faezeh, G.; Taher, R.; Mohammad, Z. Decision Tree Models in Predicting Water Quality Parameters of Dissolved Oxygen and Phosphorus in Lake Water. Sustain. Water Resour. Manag. 2023, 9, 1. [Google Scholar]
- Du, Z.; Qi, J.; Wu, S.; Zhang, F.; Liu, R. A Spatially Weighted Neural Network based Water Quality Assessment Method for Large-Scale Coastal Areas. Environ. Sci. Technol. 2021, 55, 2553–2563. [Google Scholar] [CrossRef] [PubMed]
- Quan, D.; Zhang, S.; Shi, X.; Sun, B.; Song, S.; Guo, Z. Impact of Water Environment Factors on Eutrophication Status of Lake Ulansuhai Based on Monitoring Data in 2013–2018. J. Lake Sci. 2020, 32, 1610–1619. [Google Scholar]
- Song, S.; Li, C.; Shi, X.; Zhao, S.; Tian, W.; Li, Z.; Bai, Y.; Cao, X.; Wang, Q. Under-Ice Metabolism in a Shallow Lake in a Cold and Arid Climate. Freshw. Biol. 2019, 64, 1710–1720. [Google Scholar] [CrossRef]
- Dong, S.; He, H.; Fu, B.; Fan, D.; Wang, T. Remote Sensing Retrieval of Chlorophyll-A Concentration in the Coastal Waters of Hong Kong Based on Landsat-8 OLI and Sentinel-2 MSI Sensors. IOP Conf. Ser. Earth Environ. Sci. 2021, 671, 012033. [Google Scholar] [CrossRef]
- Wang, Y.; Li, S.; Lin, Y.; Wang, M. Lightweight Deep Neural Network Method for Water Body Extraction from High-Resolution Remote Sensing Images with Multisensors. Sensors 2021, 21, 7397. [Google Scholar] [CrossRef]
- Hu, H.; Fu, X.; Li, H.; Wang, F.; Duan, W.; Zhang, L.; Liu, M. Prediction of Lake Chlorophyll Concentration using the BP Neural Network and Sentinel-2 Images Based on Time Features. Water Sci. Technol. 2023, 87, 539–554. [Google Scholar] [CrossRef]
- Jiang, J. Review of Geocomputation of High-Resolution Satellite Remote Sensing Imagery. Acta Geogr. Sin. 2009, 64, 2. [Google Scholar]
- Bi, H.; Wang, S.; Zeng, J.; Zhao, Y.; Wang, H.; Yin, H. Comparison and Analysis of Several Common Water Extraction Methods Based on TM Image. Remote Sens. Inf. 2012, 27, 77–82. [Google Scholar]
- Wang, R.; Liu, B.; Du, Y.; Zhang, H.; Yu, Z. Extraction Method and Accuracy Evaluation of Typical Lake Water Body in Hoh Xil Region Based on GF-6 WFV Data. Bull. Surv. Mapp. 2022, 05, 32–37. [Google Scholar]
- Zhu, Y.; Sun, L.; Zhang, C. Summary of Water Body Extraction Methods Based on ZY-3satellite. IOP Conf. Ser. Earth Environ. Sci. 2017, 100, 012200. [Google Scholar] [CrossRef]
- Paul, A.; Tripathi, D.; Dutta, D. Application and Comparison of Advanced Supervised Classifiers in Extraction of Water Bodies from Remote Sensing Images. Sustain. Water Resour. Manag. 2018, 4, 905–919. [Google Scholar] [CrossRef]
- Zhang, D.; Yang, S.; Wang, Y.; Zheng, W. Refined Water Body Information Extraction of three Gorges Reservoir by using GF-1 Satellite Data. Yangtze River 2019, 50, 233–239. [Google Scholar]
- Evan, S.; Jonathan, L.; Trevor, D. Fully Convolutional Networks for Semantic Segmentation. IEEE Tran. Pattern Anal. Mach. Int. 2017, 39, 640–651. [Google Scholar]
- Olaf, R.; Philipp, F.; Thomas, B. U-Net: Convolutional Networks for Biomedical Image Segmentation. Olaf Ronneberger 2015, 11, 37. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. arXiv 2016. [Google Scholar] [CrossRef]
- Yang, F.; Feng, T.; Xu, G.; Cheng, Y. Applied Method for Water-Body Segmentation Based on Mask R-CNN. J. Appl. Remote Sens. 2020, 14, 014502. [Google Scholar] [CrossRef]
- Guo, H.; He, G.; Jiang, W.; Yin, R.; Yan, L.; Leng, W. A Multi-Scale Water Extraction Convolutional Neural Network (MWEN) Method for GaoFen-1 Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2020, 9, 189. [Google Scholar] [CrossRef]
- Wu, P.; Fu, J.; Yi, X.; Wang, G.; Mo, L.; Maponde, B.T.; Liang, H.; Tao, C.; Ge, W.; Jiang, T.; et al. Research on Water Extraction from High Resolution Remote Sensing Images based on Deep Learning. Front. Remote Sens. 2023, 4, 1283615. [Google Scholar] [CrossRef]
- Wang, X.; Fu, X.; Hu, H.; Li, H. Research on Water Extraction Method from Remote Sensing Images of Lakes in Cold and Arid Regions based on Deep Learning. In Proceedings of the 3rd International Conference on Artificial Intelligence, Automation, and High-Performance Computing, Wuhan, China, 21 July 2023. [Google Scholar]
- Zhang, Y.; Lu, H.; Ma, G.; Zhao, H.; Xie, D.; Geng, S.; Tian, W.; Sian, K.T.C.L.K. MU-Net: Embedding MixFormer into Unet to Extract Water Bodies from Remote Sensing Images. Remote Sens. 2023, 15, 3559. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A Novel Deep Learning Network for Lake Water Body Extraction of Google Remote Sensing Images. J. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Hasanah, A.S.; Pravitasari, A.A.; Abdullah, S.A.; Yulita, I.N.; Asnawi, M.H. A Deep Learning Review of ResNet Architecture for Lung Disease Identification in CXR Image. J. Appl. Sci. 2023, 13, 13111. [Google Scholar] [CrossRef]
- Shaheed, K.; Qureshi, I.; Abbas, F.; Jabbar, S.; Abbas, Q.; Ahmad, H.; Sajid, M.Z. EfficientRMT-Net—An Efficient ResNet-50 and Vision Transformers Approach for Classifying Potato Plant Leaf Diseases. Sensors 2023, 23, 9516. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Chen, J.; Wang, H.; Zheng, S.; Kong, Y. A Deep Learning-based Approach for the Automated Surface Inspection of Copper Clad Laminate Images. Appl. Intell. 2020, 51, 1262–1279. [Google Scholar] [CrossRef]
- Jin, X.; Xie, Y.; Wei, X.; Zhao, B.; Chen, Z.; Tan, X. Delving deep into spatial pooling for squeeze-and-excitation networks. Pattern Recognit. 2022, 121, 108159. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Hu, Y.; Tian, S.; Ge, J. Hybrid Convolutional Network Combining Multiscale 3D Depthwise Separable Convolution and CBAM Residual Dilated Convolution for Hyperspectral Image Classification. Remote Sens. 2023, 15, 4796. [Google Scholar] [CrossRef]
- Xie, W.; Ding, Y.; Rui, X.; Zou, Y.; Zhan, Y. Automatic Extraction Method of Aquaculture Sea Based on Improved SegNet Model. Water 2023, 15, 3610. [Google Scholar] [CrossRef]
- Liu, M.; Hu, H.; Zhang, L.; Zhang, Y.; Li, J. Construction of Air Quality Level Prediction Model Based on STEPDISC-PCA-BP. Appl. Sci. 2023, 13, 8506. [Google Scholar] [CrossRef]
- Liu, M.; Pan, X.; Liu, F.; Zhou, Y.; Jiang, K. Flame Target Detection Based on Stepwise Discrimination and BP Neural Network. Inner Mong. Agric. Univ. (Nat. Sci. Ed.) 2021, 42, 92–96. [Google Scholar]
- Diao, Z.; Jiang, H.; Shi, T. A Unified Uncertainty Network for Tumor Segmentation using Uncertainty Cross Entropy Loss and Prototype Similarity. Knowl. Based Syst. 2022, 246, 108739. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Alom, M.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (R2U-Net) for medical image segmentation. J. Med. Imaging 2019, 6, 6–14. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Platform | Configuration |
|---|---|---|
| Hardware | CPU | Intel(R) Xeon(R) Gold 6240 CPU @ 2.60 GHz |
| Memory | 32 G | |
| GPU | NVIDIA Tesla V100 32 GB | |
| Software | Operating system | Linux Centos 7.6 |
| Programming language | Python 3.6 |
| Backbone | Evaluation Metric | Training Time per Epoch (s) | ||
|---|---|---|---|---|
| PA | MPA | MIoU | ||
| ResNet18 | 98.5 | 98.55 | 96.9 | 28 |
| ResNet34 | 98.6 | 98.65 | 97.1 | 80 |
| ResNet50 | 98.8 | 98.85 | 97.6 | 82 |
| ResNet101 | 98.8 | 98.85 | 97.6 | 95 |
| ResNet152 | 98.8 | 98.85 | 97.6 | 114 |
| SE | CBAM | Evaluation Metric | Training Time per Epoch (s) | ||
|---|---|---|---|---|---|
| PA | MPA | MIoU | |||
| − | − | 97.9 | 97.85 | 95.8 | 77 |
| + | − | 98.1 | 98.2 | 96.2 | 81 |
| − | + | 98.3 | 98.45 | 96.6 | 78 |
| + | + | 98.8 | 98.85 | 97.6 | 82 |
| Model | Evaluation Metric | Training Time per Epoch (s) | ||
|---|---|---|---|---|
| PA | MPA | MIoU | ||
| U-Net | 97.4 | 97.5 | 94.8 | 50 |
| AU-Net | 97.7 | 97.65 | 95.3 | 120 |
| RU-Net | 93.9 | 93.15 | 88 | 300 |
| ARU-Net | 98.3 | 98.4 | 96.5 | 280 |
| SER34AUNet | 98.5 | 98.6 | 97 | 80 |
| MU-Net | 98.6 | 98.7 | 97.2 | 145 |
| R50A3-LWBENet | 98.8 | 98.85 | 97.6 | 82 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Liu, J.; Hu, H. A Novel Deep Learning Network Model for Extracting Lake Water Bodies from Remote Sensing Images. Appl. Sci. 2024, 14, 1344. https://doi.org/10.3390/app14041344
Liu M, Liu J, Hu H. A Novel Deep Learning Network Model for Extracting Lake Water Bodies from Remote Sensing Images. Applied Sciences. 2024; 14(4):1344. https://doi.org/10.3390/app14041344
Chicago/Turabian StyleLiu, Min, Jiangping Liu, and Hua Hu. 2024. "A Novel Deep Learning Network Model for Extracting Lake Water Bodies from Remote Sensing Images" Applied Sciences 14, no. 4: 1344. https://doi.org/10.3390/app14041344