Abstract
To quickly realize facial identity recognition in sheep, this paper proposes a lightweight detection algorithm based on SSD with a self-constructed dataset. Firstly, the algorithm replaces the VGG16 backbone of SSD with the lightweight neural network SqueezeNet, creating a lightweight hybrid network model. Secondly, an ECA mechanism is introduced at the front end of the pooling layer with a parameter volume of 12 × 1000 into the feature extraction network. Lastly, the smoothL1 loss function is replaced with the BalancedL1 loss function. The optimal model size has been reduced from the original SSD’s 132 MB to 35.8 MB. The average precision is 82.39%, and the mean frame rate is 66.11 frames per second. Compared to the baseline SSD model, the average precision has improved by 2.17%, the model volume has decreased by 96.2 MB, and the detection speed has increased by 7.13 frames per second. Using the same dataset on different target detection models for comparison tests, the average accuracy mean values are improved by 2.17%, 3.63%, and 1.30% compared to the SSD model, Faster R-CNN model, and Retinanet model, respectively, which substantiates a better overall performance compared to the pre-improvement model. This paper proposes an improved model that significantly reduces the model size and its computation while keeping the model performance at a high level, providing a methodological reference for the digitization of livestock farming.
1. Introduction
Sheep identification can achieve health monitoring and realize a high scale and precision of livestock breeding management, which is of great significance to improving livestock production conditions, reducing labor costs, improving the livestock breeding efficiency, and promoting the digital and intelligent development of the livestock industry [1].
The traditional methods of individual livestock identification include manual observation methods and use invasive equipment techniques. Manual observation methods rely too much on the observers’ experience and memory, which is highly subjective, has a low accuracy rate, and requires a huge amount of labor. Invasive equipment techniques mainly use methods such as ear-marked identification and radio frequency identification (RFID) tags, which have the disadvantages of a high cost, damage to the integrity of the sheep, being difficult to replace, and a low identification efficiency. For instance, Sun Yukun et al. [2] found that only 21% of individual buffaloes were still identifiable after 2 years of wearing ear tags. The traditional methods rely on devices rather than the animals themselves, making the individual identification of animals less reliable.
Currently, an increasing number of scholars both domestically and internationally are applying machine vision technology to the field of agriculture and animal husbandry. The development of deep learning technology has led to the outstanding performance of neural network-based methods in image recognition tasks. However, with the advancement of deep learning, the model structures are becoming increasingly complex, and the scale of training data continues to grow, leading to escalating demands in terms of hardware and computational power [3]. Therefore, the evolution of deep learning has driven the development of lightweight neural networks. This ensures not only the model accuracy but also a smaller model size, faster speed, and efficient image recognition tasks, even in scenarios with limited hardware resources. Various convolutional neural networks (CNNs) have been developed for facial recognition tasks, including the identification of animals such as pigs, cows, and sheep. However, the research on lightweight models in this context has started relatively late, and there is limited literature on the subject [4,5,6].
In 2019, Yi Shi et al. [7] addressed the challenges associated with the nocturnal activity, small target size, high speed, and complex environments of wild rabbits. They combined infrared thermal imaging technology with YOLOV3 (IR-YOLO). The experimental results indicated that IR-YOLO achieved a detection rate of 75% in complex environments captured using infrared thermal imaging videos. The average detection speed was 51 frames per second, representing a 15% improvement in the detection rate and a 5 frames per second increase in the detection speed compared to the original YOLOV3.
In 2019, Yan Hongwen [8] employed the basic principles of convolutional neural networks to construct three network structures: Alex Net, Mini-Alex Net, and Attention-Alex Net, all applied to the facial recognition of pigs. The accuracy rates achieved were 97.48%, 96.66%, and 98.11%, respectively. The lightweight model, Mini-Alex Net, exhibited faster processing speeds.
In 2020, Feng Mingqiang et al. [9] utilized the ResNet50 neural network model for training and prediction on photos. They developed a pig facial recognition app based on the MUI and Django frameworks. The experimental results indicated that, after optimizing the ResNet50 model, the accuracy rate reached around 92%.
In 2020, Yan Hongwen et al. [10] addressed the issue of multi-target detection for individual pigs by combining Feature Pyramid Attention (FPA) with Tiny-YOLO. They used FPA modules of depth 3 to obtain the model FPA3-Tiny-YOLO. After incorporating the FPA-3 module, Tiny-YOLO’s recall, F1, and mAP increased by 6.73, 4.34, and 7.33 percentage points, respectively.
In 2021, Hu Zhiwei et al. [11] aimed to address the challenges posed by factors such as pig adhesion and pigpen obstruction in the multi-object instance detection of individual pigs in complex environments. They introduced a Dual Attention Unit (DAU) and incorporated it into the Feature Pyramid Network structure. Simultaneously, they concatenated PAU units to construct different spatial attention modules. As a result, the accuracy reached 92.8%.
In 2022, Wang et al. [12] designed a lightweight pig facial recognition model based on a deep convolutional neural network algorithm. For pig facial classification, they proposed an improved method based on the Triple Margin Loss function. This enhancement resulted in a 28% increase in the average precision, with a mean average precision (mAP) value of 94.04%.
In 2022, Li et al. [13] designed a lightweight neural network for cattle face recognition in an embedded system. They employed batch normalization to normalizing the neural network inputs and used Dropout after the ReLU activation function to enhance the accuracy. As a result, the model size was significantly reduced, achieving an accuracy of 98.37%.
In 2022, Yang Jialin [14] constructed a sheep face detection model based on the Retina Face model. He chose MobileNet as the feature extraction network for the model. He utilized Complete Intersection over the Union (CIOU) as the loss function. After the improvement, the average precision of the sheep face detection model reached 97.12%, with a computational load reduced to 64.7% of the original.
In 2022, Zhou Lixiang [15] introduced the GhostNet network into the Retina Face detection model. She constructed a lightweight sheep face detection model named G-Retina Face. The experimental results indicate that the G-Retina Face model operates at a faster speed and has a reduced size of 107.1 MB. Information on these studies is shown in year order in Table 1.

Table 1.
Year-order information.
In summary, through the collective efforts of researchers worldwide, deep learning technology has been widely applied to facial recognition in animals. The recognition of pig’s and cattle’s faces has been well developed, while sheep face recognition applications are relatively limited, especially in the domain of lightweight neural networks for sheep face recognition [16,17,18]. Furthermore, the availability of sheep face datasets is currently relatively limited, lacking large-scale publicly accessible datasets for reference [19]. To address the challenge of individual sheep identification in complex scenarios and achieve the requirements of a small model size and fast detection speed, this study focuses on sheep facial recognition and constructs a lightweight neural network model. A dataset was created by collecting 5371 clear facial photos from various angles of 114 sheep. The SSD algorithm was used as a foundation to conduct the sheep facial detection and algorithm improvements. Following that, validation was conducted.
2. Materials and Methods
2.1. Sheep Face Dataset Collection
The experiments took place on a livestock farm in Hak Town, Hulunbuir Grassland, Hailar District, Hulunbuir City, Inner Mongolia. The geographical coordinates are approximately 49°13′ N latitude and 120°04′ E longitude, with an average altitude of 620 m. The research area falls under a typical continental climate. From March 2022 to August 2022, between 2:00 and 4:00 p.m., tracking shots were taken of 114 Small-tailed Han sheep on the breeding farm. The sheep had an average age of 2 years and an average weight of 45 kg, with 102 ewes and 12 rams. A Canon 700 D camera (Canon factory in Tokyo, Japan) was used for the photography, with each sheep video lasting approximately 2 to 3 min at a frame rate of 29.97 frames per second. The dataset parameter information is shown in Table 2. The captured sheep videos were sorted into sequential order from 1 to 114, with each number corresponding to the individual’s identity information. This organization facilitated the subsequent creation of the dataset. The collected sheep videos can be seen in Figure 1, with images extracted at a resolution of 1920 × 1080 pixels. The captured videos were processed using a Python program to extract the images, excluding those that were blurry, heavily obscured, or duplicated or had insufficient lighting. In the end, a total of 5371 facial images from 114 categories of Small-tailed Han sheep were obtained, depicting various angles and quantities. Two methods were employed to augment the dataset images, thereby enhancing the robustness of the detection model. The specific operations are as follows: (1) Perform brightness transformations at various levels, increase the brightness of certain images 1.5 times over or decrease it 0.6 times over, and ensure that the object detection model is not affected by lighting diversity; (2) Increase the image contrast 1.4 times over and attenuate it 0.7 times over. Consequently, enhance the expression of the image clarity, grayscale, and texture details. Annotate the original images using the Make Sense software and create a dataset (Make Sense, https://www.makesense.ai/, accessed on 15 January 2024). The ID numbers for the Small-tailed Han sheep are sheep1, sheep2… sheep114, etc. Generate XML-formatted annotation files after labeling: these include the folder name, image name, image path, image size, ID number, and pixel coordinates of the bounding box. Ultimately, the construction of the sheep face dataset annotation is completed. The training set, test set, and validation set are randomly allocated at an 8:1:1 ratio. The annotation results on the sheep’s facial features can be observed in Figure 1. The different colored boxes shown in the diagram represent different sheep.
Table 2.
Dataset parameter information.

Figure 1.
Sheep labeling diagram.
2.2. SSD Models
The SSD (Single Shot MultiBox Detector) algorithm is a one-stage multi-box prediction method [20]. It utilizes convolutional neural networks to extract features and uniformly performs dense sampling, object classification, and bounding box regression at different positions in an image at various scales and aspect ratios. A structural diagram is shown in Figure 2. The input image first goes through the first to seventh convolutional layers. Afterward, it passes through the improved VGG (Visual Geometry Group) network; then, it proceeds through additional convolutional layers, Conv8 to Conv11, added by the SSD model for feature extraction. The original RGB image is resized to a dimension of 300 × 300 × 3 (with 3 channels) using programmatic resizing. After passing through the modified VGG network, the output grid size becomes 19 × 19 × 1024. Subsequently, it goes through four additional convolutional layers in the SSD feature extraction part, and finally, the output grid size becomes 1 × 1 × 256 [21].
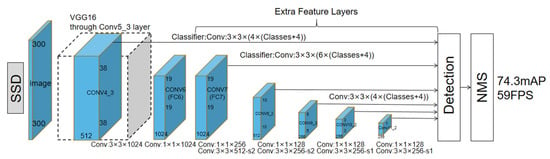
Figure 2.
SSD structure diagram.
2.3. SSD Model Improvement
In this study, SSD is employed as the base network for sheep facial recognition. To address the issues of the large number of parameters and complexity in the SSD algorithm model, this paper proposes an enhanced SSD model: Firstly, the backbone network VGG is replaced with the SqueezeNet network. Secondly, due to the majority of the sheep being white and highly similar, the ECA mechanism is therefore introduced to concentrate the network’s attention on the region of interest on the sheep’s face, further enhancing the capability to extract the target information; finally, the position loss function smoothL1 is replaced with BalancedL1, further reducing the gap between the predictions and actual data and improving the model’s detection accuracy.
2.3.1. Backbone Network Replacement
To meet the practical requirements of a simplified model structure and fast detection speed, in this paper, the backbone network VGG in the original SSD algorithm is replaced with SqueezeNet. SqueezeNet is a lightweight and efficient CNN model proposed by Iandola N. F. et al. [22]. The basic building block of the SqueezeNet network is a modularized convolution known as the Fire module. The Fire module primarily consists of two layers of convolution operations. The first layer is the squeeze layer, which utilizes a 1 × 1 convolutional kernel. The second layer is the expand layer, which combines the usage of 1 × 1 and 3 × 3 convolutional kernels. The basic structure of the Fire module is illustrated in Figure 3. The entire SqueezeNet is constructed by stacking basic Fire modules. The network structure is depicted in Figure 4.

Figure 3.
Fire module.
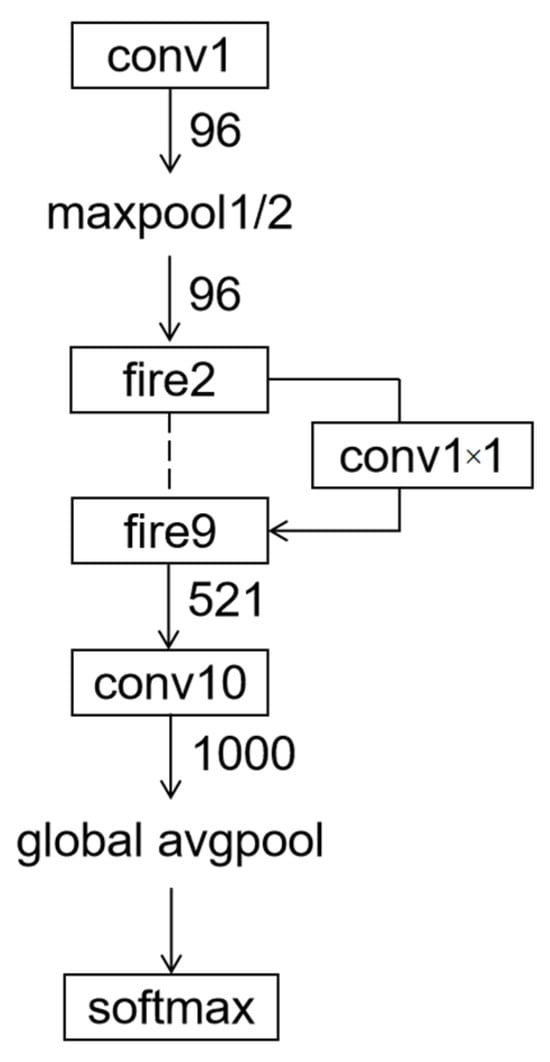
Figure 4.
SqueezeNet module.
In this paper, the SSD backbone network VGG is replaced with three lightweight backbone networks: MobileNetv2, ShuffleNetv1, and SqueezeNet. A comparison of the three lightweight backbone networks is presented in Table 3. SqueezeNet outperforms MobileNetv2 and ShuffleNetv1 in terms of both model size and detection speed. SqueezeNet has a model size that is 20.8 MB smaller than the MobileNetv2 backbone network, with an increase in the detection speed of 0.88 frames/s and an improvement in the mAP by 0.61%. SqueezeNet has a model size that is 52.5 MB smaller than the ShuffleNetv1 backbone network, with an increase in the detection speed of 2.54 frames/s and a decrease in the mAP of 1.32%. Therefore, the introduced SqueezeNet lightweight backbone network in this paper exhibits a superior performance in the application of the model.
Table 3.
Comparison table of three lightweight backbone networks.
2.3.2. Introduction of the Attention Mechanism Module
To address the recognition capability for small objects, this paper incorporates the ECA mechanism at the front end of the feature extraction network avgpool (The number of parameters is 12 × 1000). The ECA mechanism is shown in Figure 5. The idea of ECA is as follows: Initially, input a feature map with dimensions H × W × C. C stands for channel, H for height, and W for width. Compress the spatial features of the feature map, perform global average pooling across the spatial dimensions, and obtain a 1 × 1 × C feature map. Subsequently, conduct channel-wise feature learning on the 1 × 1 × C feature map, learning the correlations between different channels using 1 × 1 convolutions, and output a feature map of size 1 × 1 × C. Then, perform element-wise multiplication between the obtained feature map of size 1 × 1 × C and the input feature map of dimensions H × W × C, resulting in a feature map with channel-wise attention. This design approach enables ECA to maintain the model performance while reducing the model parameter count and computational complexity, further achieving the design of a lightweight network [23].
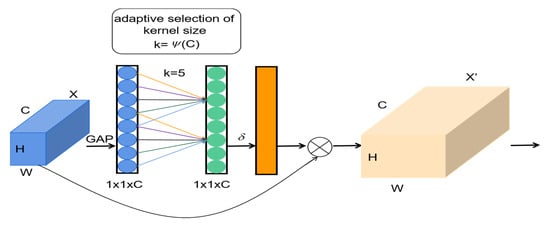
Figure 5.
ECA mechanism module.
2.3.3. BalancedL1 Loss Function
The loss function of SSD includes the position loss function smoothL1 for the bounding boxes and the confidence loss function Softmax. Refer to Equation (1).
In the equation, represents the number of positive samples for prior boxes, is the predicted value for category confidence, is the predicted position value for the bounding box corresponding to the prior box, and is the ground truth position parameter.
To improve the detection accuracy of the model and further reduce the errors between the model predictions and actual values, this paper replaces the position loss function smoothL1 in SSD with the BalancedL1 loss function.
BalancedL1 is inspired by the smoothL1 loss function, where the smoothL1 loss classifies inliers and outliers by setting a turning point and truncates the gradient for outliers using max (p, 1.0). Compared to smoothL1, BalancedL1 significantly enhances the gradient for inliers, allowing these accurate points to play a more crucial role during training [24]. By setting a turning point to distinguish outliers from inliers, for those identified as outliers, the gradient is fixed at 1.
The core idea of BalancedL1 is to boost the crucial regression gradients and balance the included samples, thus achieving more balanced training in terms of classification, overall localization, and precise positioning. The detection box regression loss for BalancedL1 is shown in Equation (2).
The corresponding gradient for BalancedL1 is given in Equation (3).
Based on the above equations, a generalized gradient is designed as shown in Equation (4).
Here, the elevation of the inliers’ gradient is controlled; a smaller gradient enhances inliers without affecting the value of outliers. The parameter adjusts the upper bound of the regression error, aiming to achieve a better balance between different tasks, controlling the balance at both the sample and task levels. By adjusting these two parameters, more balanced training is achieved. The BalancedL1 loss function is given in Equation (5).
The parameters satisfy the following conditions as shown in Equation (6).
Default parameter settings: = 0.5, = 1.5.
2.4. Experimental Platforms
In this paper. The experiments were conducted using a Chinese-made computer with Windows 10 operating system as shown in Table 4.
Table 4.
The parameters of the experimental platform.
2.5. Parameterization and Training
2.5.1. Cosine Annealing Decay Strategy
Analyzing the learning rate trend for the algorithm, it does not exhibit a continuous decrease, as seen in the exponential decay strategy, but rather shows a pattern of “first descending, then ascending” within each epoch. The model introduces a cosine annealing strategy for dynamic learning rate adjustment, which leverages the characteristics of the cosine function in the first half of the cycle, exhibiting a “slow decrease, then fast decrease, followed by a continued slow decrease” pattern. This allows the network to rapidly converge at the beginning of training and gradually converge at the later stages to approach the optimal solution more closely.
The model is configured with the same learning rate and utilizes the Adam optimizer universally, applying both a fixed-step decay strategy and a cosine annealing decay strategy. Through comparison, it is observed that the algorithm model using cosine annealing decay demonstrates faster convergence and achieves a higher detection performance.
2.5.2. Other Parameter Settings
Based on the fluctuation trend in the loss function curve, the training epochs for the network are determined. Considering the limited space on the system disk, the model is configured to save the weights every 5 epochs, and the best weight file is updated accordingly. Based on the performance of the GPU memory and the size of the image files, an appropriate batch size is chosen during the experiments to fully utilize the GPU’s performance.
In order to fully leverage matrix operations, setting Batch_size = 2n, as a larger batch size, provides more accurate gradient estimates but comes with the downside of diminishing returns that are less than linear. A smaller batch size generally leads to a better generalization error but the associated issue is an increase in noise during the training process. Due to the high variance in the gradient estimates, a smaller batch size requires a smaller learning rate to maintain stability. A smaller learning rate leads to longer model training times. We train with different batch sizes within the range allowed by the GPU performance.
The batch size represents the number of images trained in each iteration. The model achieves the highest class average accuracy when trained with 32 images in each iteration. Batch_size = 32 outperforms the model’s detection results when the Batch_size parameter is set to 64, 16, 8, 4, and other values. Among these, Batch_size = 64 is the limit of the GPU’s memory performance used for normal operation in this experimental algorithm model.
With the batch size set to 32, we adjust the number of training epochs. As shown in Figure 6, it can be observed that after 150 epochs, the loss curve essentially stops decreasing, and the accuracy curve of the model also stabilizes. Therefore, in this study, the number of training epochs for the model is set to 300, at which point the model training has converged.
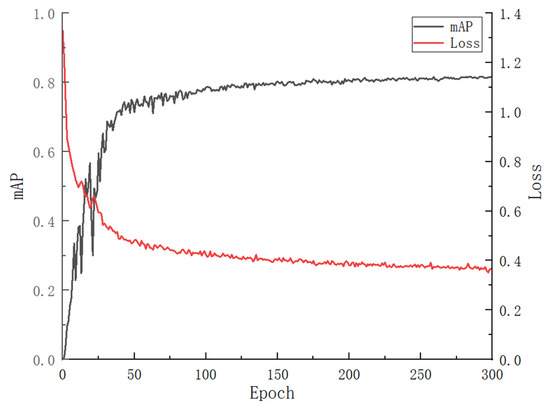
Figure 6.
Model training results at 300 epochs.
2.6. Evaluation Indicators
The main metrics for evaluating the performance of object detection models include the precision (P), recall rate (R), mean average precision (mAP), FPS, and model volume. We set the average intersection over the union (IoU) threshold for the predicted and actual targets to 0.5. If the IoU exceeds this threshold, it is considered a positive sample; otherwise, it is treated as a negative sample.
In the formula, TP (True Positive) = the number of samples correctly identified as positive; FP (False Positive) = the number of samples incorrectly identified as positive; TN (True Negative) = the number of samples correctly identified as negative; and FN (False Negative) = the number of samples incorrectly identified as negative.
Drawing the precision–recall curve based on the training data yields:
AP (average precision) represents the area enclosed by the precision–recall curve and the coordinate axes.
As this study involves the detection of 114 categories of Small-tailed Han sheep, the mean average precision (mAP) for this experiment is:
The model’s parameter count is somewhat related to its computational speed. Evaluating the model’s detection speed is mainly undertaken by comparing the frames per second (FPS), where a higher frame rate indicates a faster model detection speed.
By recording the detection time T for each frame in the code (unit: seconds), the average detection time can be calculated, resulting in:
3. Results
3.1. Comparison of the Test Results after the SSD Improvement
To validate the optimization of sheep face detection using different improvement strategies, using SSD as the base network, the effectiveness of lightweight neural networks (SqueezeNet), the ECA mechanism, and the BalancedL1 loss function are studied. The experimental results are presented in Table 5.
Table 5.
Comparison of experimental results after improvements in SSD.
Replacing the original SSD model’s backbone network VGG with SqueezeNet, the improved network model exhibits a significant reduction in volume, with the detection speed increasing by 4.26 frames/s. However, the average precision mean decreases by 3.62%. These changes demonstrate that the lightweight neural network SqueezeNet effectively reduces the model’s volume at the cost of sacrificing a certain degree of average precision. After incorporating the ECA mechanism into the bottleneck front end of the feature extraction network with a parameter count of 32 × 1024, the average precision mean of the network model increases by 1.91%, the model volume remains basically unchanged, and the detection speed improves by 0.56 frames/s. This demonstrates that the ECA mechanism can effectively enhance the global perception of small-scale features of the sheep faces. Replacing the original network’s smoothL1 loss function with the BalancedL1 loss function, the mean average precision of the network model increases by 1.47%, and the model’s detection speed improves by 3.27 frames/s. This demonstrates that the BalancedL1 loss function, by boosting the gradient of inliers, points to better matching the real target boxes, thereby improving both the detection accuracy and speed.
Considering that attention mechanisms can be easily influenced by the network structure, therefore, based on SSD + Sq as the foundational network, we investigated the strengths and weaknesses of different attention mechanisms. We separately employed CA, SE, CBAM, and ECA modules. Additionally, we incorporated the attention modules into the feature extraction network at both the front end and backend of the average pooling layer with the parameters set at 12 × 1000. It can be observed that the model sizes of the four attention mechanisms remain relatively consistent. The detection speed of the SE1, CBAM2, ECA1, and ECA2 attention mechanism modules showed improvement, with respective increases of 2.79 frames/s, 0.94 frames/s, 3.03 frames/s, and 1.19 frames/s. The detection speed of CA1, CA2, SE2, and CBAM1 decreased, with respective reductions of 8.7 frames/s, 6.46 frames/s, 0.6 frames/s, and 2.36 frames/s. The CA2, SE1, and SE2 attention mechanism modules have an impact on the model’s detection accuracy. The mean average precision of the model decreased by 0.78%, 0.13%, and 0.22%, respectively. This is evidently not suitable for the task of detecting sheep facial features. The CA1, CBAM1, CBAM2, ECA1, and ECA2 attention mechanism modules contributed to a certain improvement in the network’s mean average precision. They, respectively, increased by 2.15%, 0.68%, 0.36%, 2.51%, and 1.9%.Therefore, the introduced ECA1 attention mechanism in this paper demonstrates a superior performance in the application of this model.
3.2. Analysis of the Ablation Experiment Results
The three proposed improvement methods in this study are SqueezeNet, ECA, and BalancedL1. On the self-constructed sheep face dataset, the following ablation experimental methods are designed: (1) Based on the original SSD network before improvements, each of the three enhancement methods is incorporated separately to assess the optimization effect of each improvement method on the original algorithm. (2) Building upon the enhanced SSD algorithm, each of the three improvement methods is individually removed to evaluate the impact of each improvement on the final algorithm, as shown in Table 6. From Table 6, it can be observed that compared to the original SSD algorithm, the ECA mechanism module exhibits the most pronounced improvement in accuracy. Its average precision increased by 1.91%. The model size remained largely unchanged. The detection speed increased by 0.56 frames per second. The introduction of the lightweight neural network SqueezeNet showed the most significant improvement in the detection speed. The detection speed increased by 5.14 frames per second, and the model size decreased by 96.4 MB, but the average precision decreased by 3.01%. Compared to the improved SSD-Sq-ECA1-B algorithm, removing the ECA1 attention mechanism module had the most significant impact on the accuracy, resulting in a decrease of 2.43% in the average precision. The removal of the lightweight neural network SqueezeNet had the most significant impact on the model size. The model size increased by 96.2 MB, and the detection speed decreased by 3.95 frames per second, indicating the most significant impact on speed. The SSD-Sq-ECA1-B algorithm proposed in this paper, compared to the original SSD algorithm, resulted in a 2.17% improvement in the average precision on the sheep face dataset. The model size decreased by 96.2 MB, and the detection speed increased by 7.13 frames per second. The SSD-Sq-ECA1-B algorithm can enhance the detection accuracy while ensuring detection efficiency.
Table 6.
Results of ablation experiment.
3.3. Comparison of Experimental Results of Different Networks
On the self-constructed sheep face dataset, the algorithm model proposed in this paper was compared with three mainstream network models in the same environment, namely SSD, Faster R-CNN, and Retinanet. The results are presented in Table 7. Compared to other models, the algorithm proposed in this paper exhibits significant improvements in both the detection speed and accuracy. The SSD-Sq-ECA1-B algorithm proposed in this paper achieves an average precision of 82.39% and a detection speed of 66.11 frames per second, and the model size has significantly decreased from 132 MB to 35.8 MB. Compared to SSD, Faster R-CNN, and Retinanet, the average precision of this algorithm has improved by 2.17%, 3.63%, and 1.3%, respectively. The detection speed has also increased by 7.13 frames per second, 56.13 frames per second, and 50.68 frames per second, respectively. In summary, the SSD-Sq-ECA1-B algorithm proposed in this paper demonstrates significant advantages in both detection accuracy and efficiency.
Table 7.
Comparison test results with current mainstream methods.
3.4. Comparison with State-of-the-Art Models
To investigate the performance of SSD-Sq-ECA1-B proposed in this study, we compared it with the prior research’s sheep face recognition model. The prior research employed the models YOLOv3 and YOLOv4. The comparison results are presented in Table 6. The comparison results are shown in Table 8. As can be seen in Table 6, SSD-Sq-ECA1-B achieved the best model size and FPS performance. The model size was smaller by 85.85% and 41.79%, respectively. The FPS performance was higher by 72.77% and 86.84%, respectively. This is more mobile friendly. The comparison results show that SSD-v3-EC2-B has significant advantages in terms of the model volume and detection speed.
Table 8.
Comparison of the research results on other sheep face recognition models.
4. Discussion
This study constructed a lightweight sheep face recognition model, SSD-Sq-ECA1-B, for the identification of sheep faces. The SSD-Sq-ECA1-B model exhibits significant advantages in detection speed. The experimental results on the self-constructed sheep face dataset indicate that the SSD-Sq-ECA1-B model achieves an mAP of 82.39%, with a substantial reduction in size from 132 MB to 35.8 MB. Additionally, the detection speed reaches 66.11 frames per second. This provides a method for deploying the SSD-Sq-ECA1-B model on mobile devices for video stream processing.
Due to the limited variety in the captured sheep breeds, which solely consist of the Small-tailed Han sheep from a specific region, future experiments will continue to expand the scale of the sheep face dataset by incorporating facial images from various breeds, thereby enhancing the diversity of the dataset.
From a long-term perspective, in order to facilitate the operations of herders, there is an urgent need to develop an embedded device at the current stage. Therefore, it is essential to minimize the model size as much as possible to facilitate the deployment of embedded devices. Our future research direction is to provide herders with an accurate and efficient recognition device.
5. Conclusions
This study proposes a lightweight sheep face detection algorithm, SSD-Sq-ECA1-B, based on the improved SSD. It offers a new approach to individual sheep identification. As a result, it enhances both the speed and accuracy of detection. The experimental results indicate that the proposed method in this paper can effectively detect the facial identity information of sheep, achieving an average precision of 82.39%. Compared to models such as SSD, Faster R-CNN, and Retinanet, the average precision has been improved by 2.17%, 3.63%, and 1.3%, respectively. The detection speed has also increased by 7.13 frames per second, 56.13 frames per second, and 50.68 frames per second, respectively. This algorithm not only enhances the detection accuracy but also significantly reduces the model size and improves the detection efficiency when applied to sheep face identification. It can serve as a reference for subsequent sheep face identity recognition tasks.
Author Contributions
Conceptualization, Q.S. and M.H.; methodology, Q.S. and M.H.; software, Q.S. and X.Z.; validation, Q.S.; formal analysis, M.H. and C.X.; investigation, Q.S. and M.Z.; resources, C.X.; data curation, Q.S. and X.Z.; writing—original draft preparation, Q.S. and M.H.; writing—review and editing, Q.S. and M.H.; visualization, Q.S. and M.Z.; supervision, M.H. and C.X.; project administration, C.X.; funding, M.H. and C.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the basic research operating expenses of colleges and universities directly in the Inner Mongolia Autonomous Region (grant no. BR221032).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Written informed consent has been obtained from the patient(s) to publish this paper.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Andrew, W.; Gao, J.; Mullan, S.; Campbell, N.; Dowsey, A.W.; Burghardt, T. Visual identification of individual Holstein-Friesian cattle via deep metric learning. Comput. Electron. Agric. 2021, 185, 106133. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Y.; Huo, P.; Huo, Z.; Zhang, Y. A review of the latest research results on individual cow recognition. J. China Agric. Univ. 2019, 24, 62–70. [Google Scholar]
- Jiang, H. Research on Natural Grassland Utilization Assessment Method Based on 3S Technology. Master’s Thesis, Shihezi University, Xinjiang, China, 2019. [Google Scholar]
- Benke, K.K.; Sheth, F.; Betteridge, K.; Pettit, C.J.; Aurambout, J.P. Application of geovisual analytics to modelling the movements of ruminants in the rural landscape using satellite tracking data. Int. J. Digit. Earth 2015, 8, 579–593. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, C.; Ma, Y.; Su, H.; Zhang, M. Biometric facial identification using attention module optimized YOLOv4 for sheep. Comput. Electron. Agric. 2022, 203, 107452. [Google Scholar] [CrossRef]
- Zhang, X.; Xuan, C.; Xue, J.; Chen, B.; Ma, Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End. Animals 2023, 13, 1824. [Google Scholar] [CrossRef] [PubMed]
- Yi, S.; Li, X.; Wu, Z.; Zhu, J.; Yuan, X. Nighttime hare monitoring method based on infrared thermal imaging and improved YOLOV3. J. Agric. Eng. 2019, 35, 223–229. [Google Scholar]
- Yan, H. Research on Pig Face Recognition under Unrestricted Conditions Based on Machine Learning. Ph.D. Thesis, Shanxi Agricultural University, Jinzhong, China, 2019; pp. 2–70. [Google Scholar]
- Feng, M.; Cao, D.; Li, J. Research on the design of pig face recognition APP based on ResNet50 model. Comput. Age 2020, 46–50. [Google Scholar] [CrossRef]
- Yan, H.; Liu, Z.; Cui, Q.; Hu, Z. Multi-objective pig detection based on feature pyramid attention and deep convolutional network. J. Agric. Eng. 2020, 36, 193–202. [Google Scholar]
- Hu, Z.; Yang, H.; Lou, T. Detection of group-reared hogs using dual-attention feature pyramid network. J. Agric. Eng. 2021, 37, 166–174. [Google Scholar]
- Wang, Z.; Liu, T. Two-stage method based on triplet margin loss for pig face recognition. Comput. Electron. Agric. 2022, 194, 106737. [Google Scholar] [CrossRef]
- Li, Z.; Lei, X.; Liu, S. A lightweight deep learning model for cattle face recognition. Comput. Electron. Agric. 2022, 195, 106848. [Google Scholar] [CrossRef]
- Yang, J. Research and Implementation of Lightweight Sheep Face Recognition Method Based on Attention Mechanism. Master’s Thesis, Northwest Agriculture and Forestry University of Science and Technology, Xianyang, China, 2022. [Google Scholar]
- Zhou, L. Research on Sheep Face Recognition Method Based on Lightweight Neural Network. Master’s Thesis, Northwest Agriculture and Forestry University of Science and Technology, Xianyang, China, 2022. [Google Scholar]
- Pahl, C.; Hartung, E.; Grothmann, A.; Mahlkow-Nerge, K.; Haeussermann, A. Suitability of feeding and chewing time for estimation of feed intake in dairy cows. Animal 2015, 10, 1507–1512. [Google Scholar] [CrossRef] [PubMed]
- Braun, U.; Tschoner, T.; Hässig, M. Evaluation of eating and rumination behaviour using a noseband pressure sensor in cows during the peripartum period. BMC Vet. Res. 2014, 10, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Gonzales Barron, U.; Corkery, G.; Barry, B.; Butler, F.; McDonnell, K.; Ward, S. Assessment of retinal recognition technology as a biometric method for sheep identification. Comput. Electron. Agric. 2008, 60, 156–166. [Google Scholar] [CrossRef]
- Vanrell, S.R.; Chelotti, J.O.; Galli, J.R.; Utsumi, S.A.; Giovanini, L.L.; Rufiner, H.L.; Milone, D.H. A regularity-based algorithm for identifying grazing and rumination bouts from acoustic signals in grazing cattle. Comput. Electron. Agric. 2018, 151, 392–402. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Tian, Z. Research on Garbage Classification Algorithm Based on Deep Learning. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2021. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and 1MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional netural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; IEEE Press: Piscataway, NJ, USA, 2020; pp. 11531–11539. [Google Scholar]
- Lv, H.; Lei, Y.; Wang, J.; Xing, X.; Yang, J. Transmission line insulator identification based on improved Libra-RCNN. Hunan Electr. Power 2022, 42, 44–49. [Google Scholar]
- Yang, S.; Liu, Y.; Wang, Z.; Han, Y.; Wang, Y.; Lan, X. Improved YOLO V4 model based on fused coordinate information to recognize cow face. J. Agric. Eng. 2021, 37, 129–135. [Google Scholar]
- Song, S.; Liu, T.; Wang, H.; Hasi, B.; Yuan, C.; Gao, F.; Shi, H. Using Pruning-Based YOLOv3 Deep Learning Algorithm for Accurate Detection of Sheep Face. Animals 2022, 12, 1465. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).