

Advanced Deep Learning Model for Predicting the Academic Performances of Students in Educational Institutions




Abstract
1. Introduction
2. Related Works
3. Background
3.1. Artificial Immune Recognition System v2.0
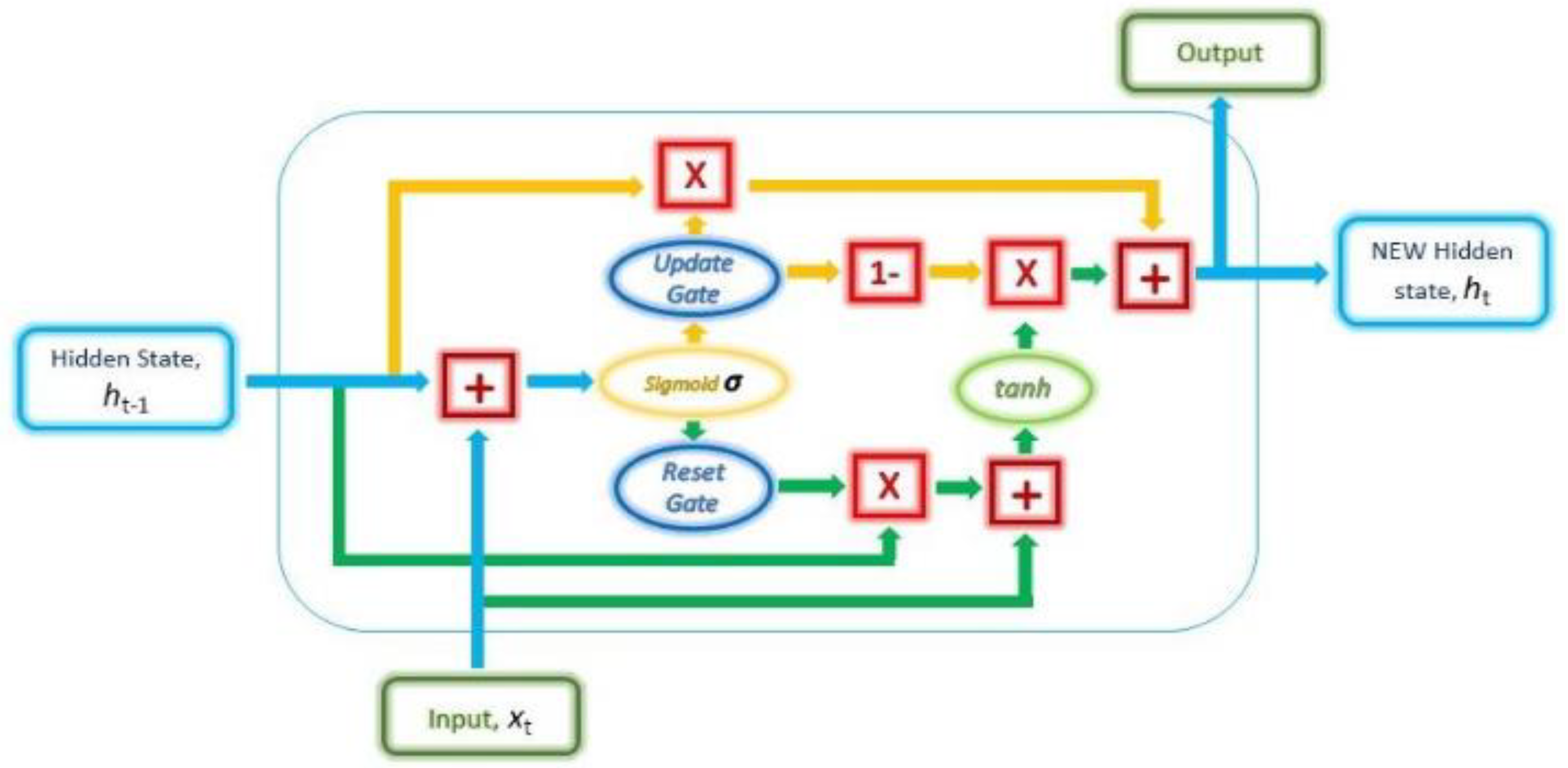
3.2. Recurrent Neural Netwrk (RNN)
3.3. AdaBoost Classification Techniques
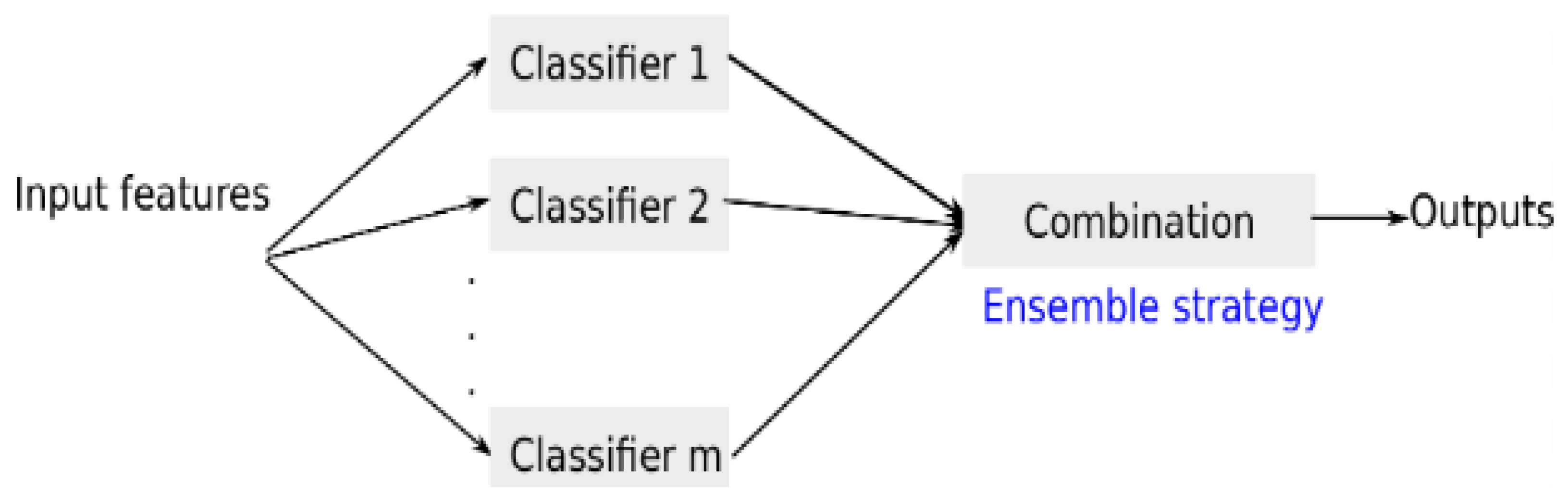
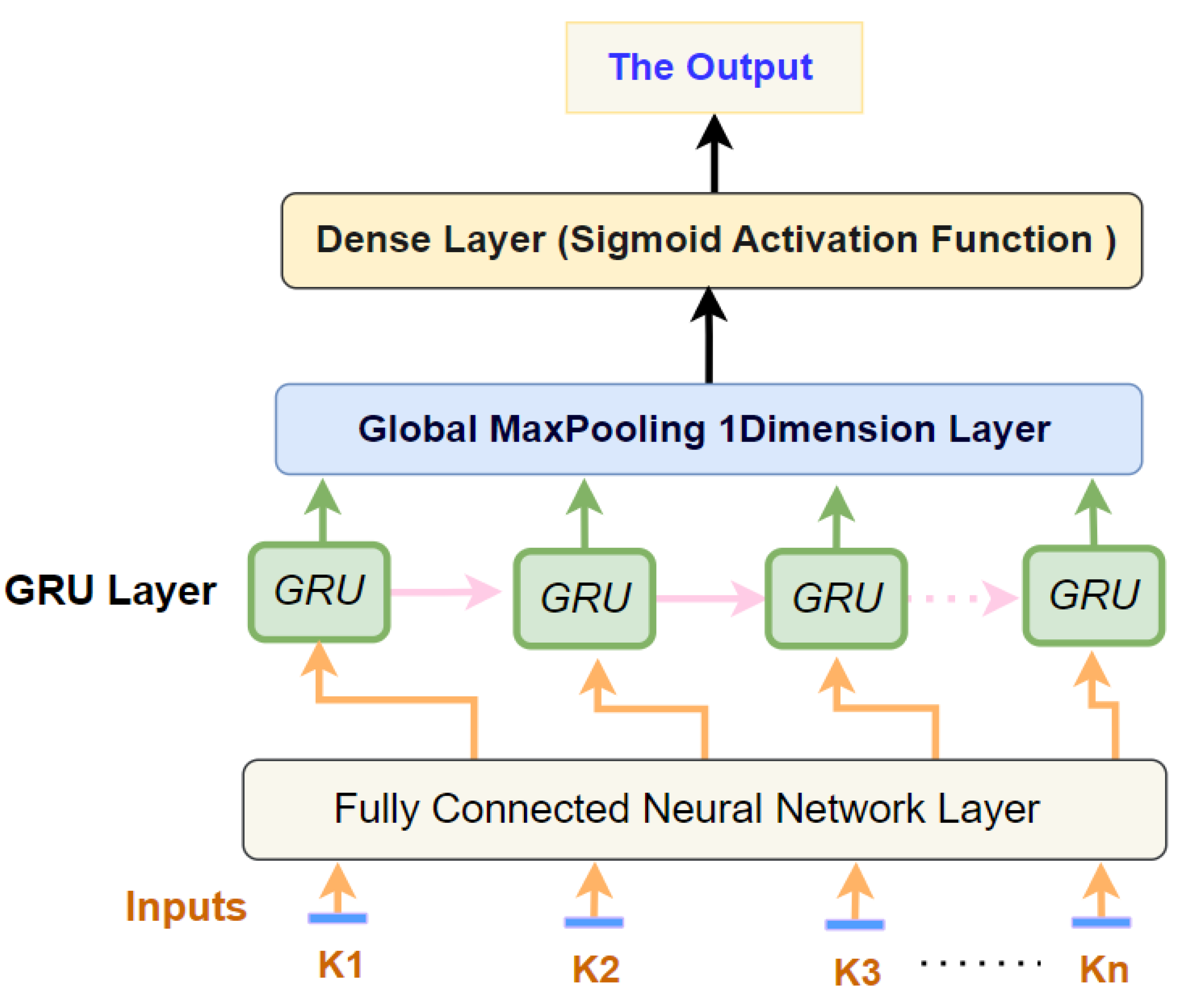
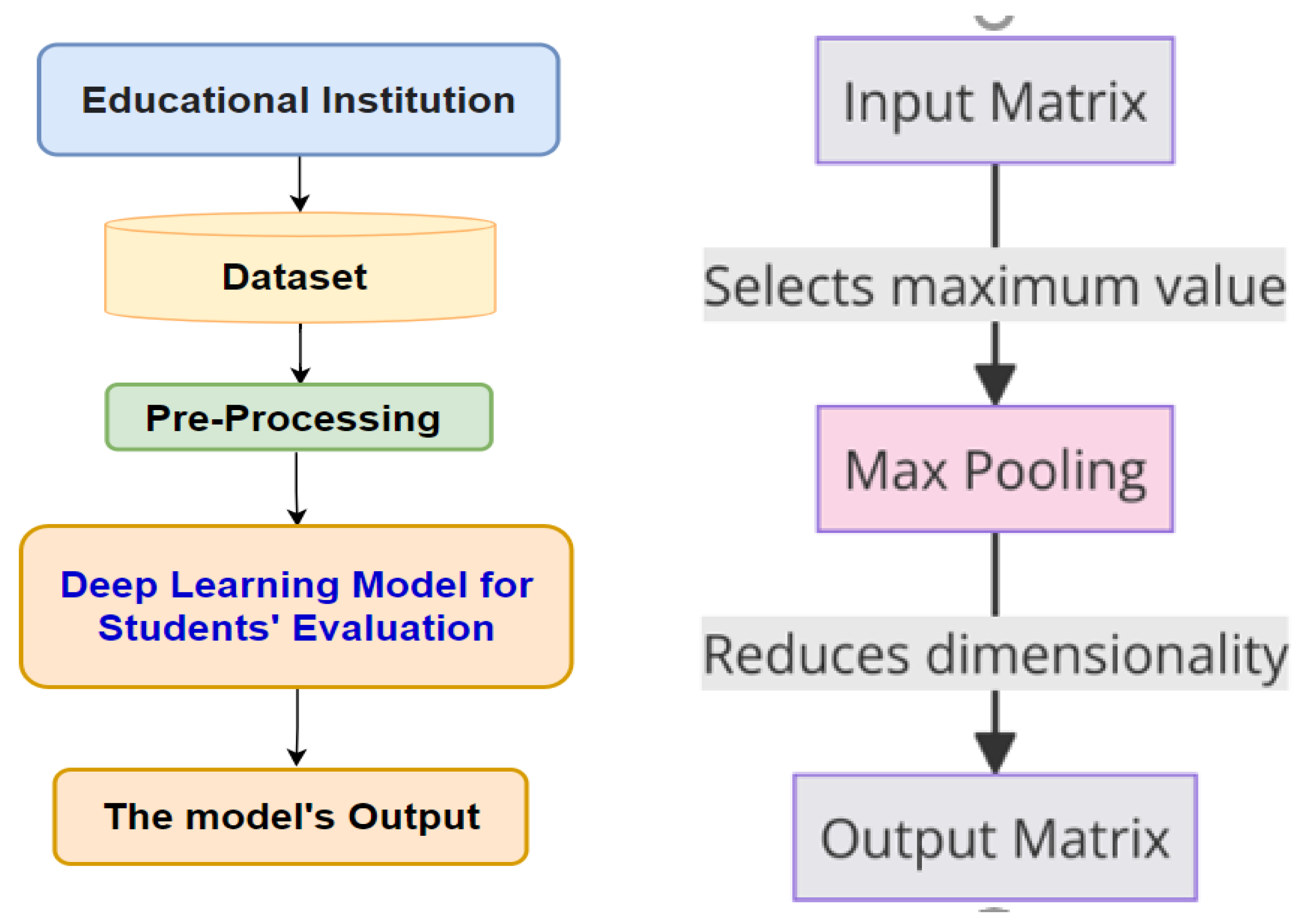
4. The Architecture of the Proposed Deep Learning Model for the Prediction of Students’ Performance in Educational Institutions
4.1. Max Pooling
4.2. Dense Layer
4.3. ADAM Optimization Algorithim
5. Experiments
5.1. Datasets
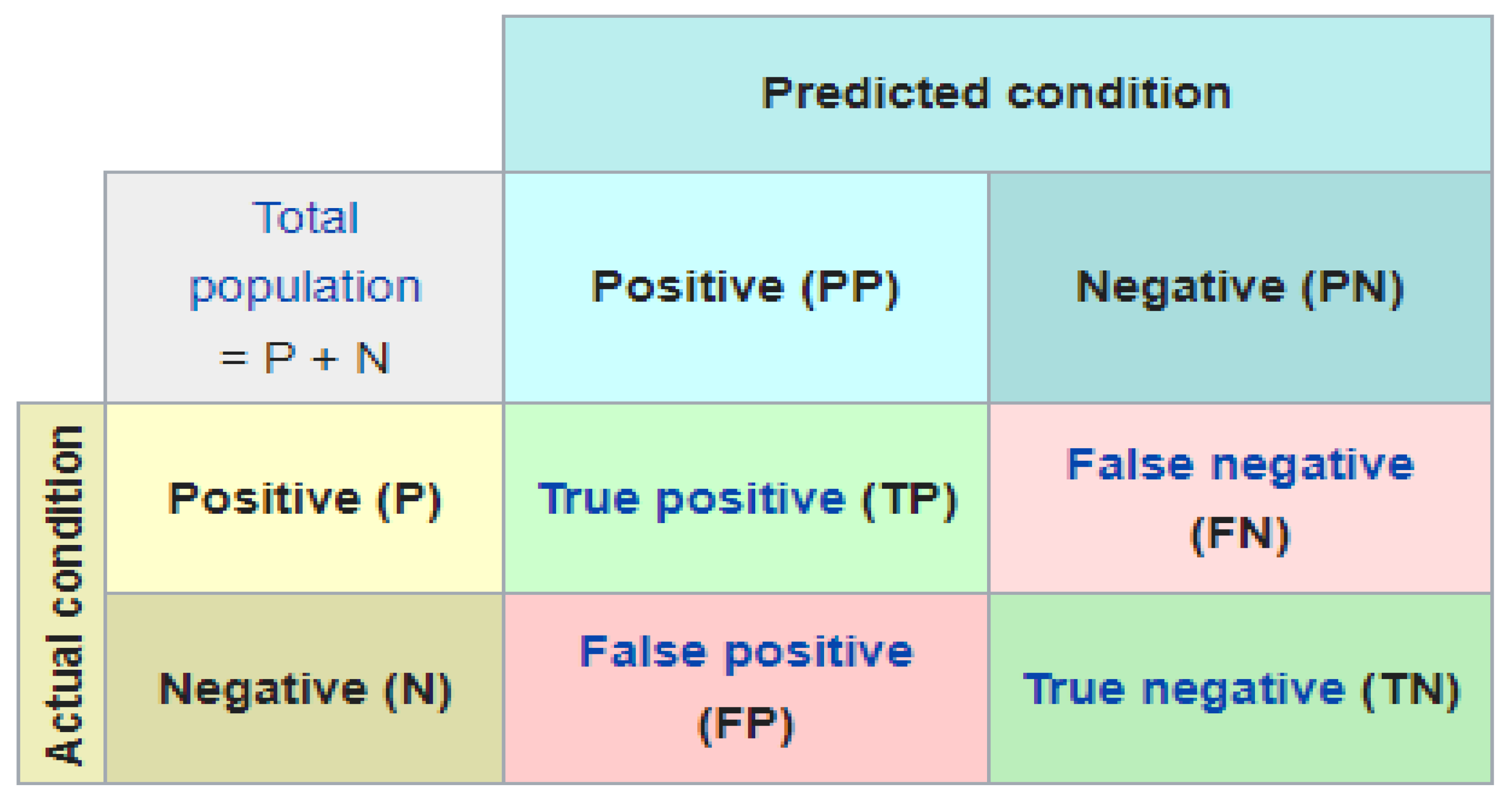
5.2. Evaluation Metrics
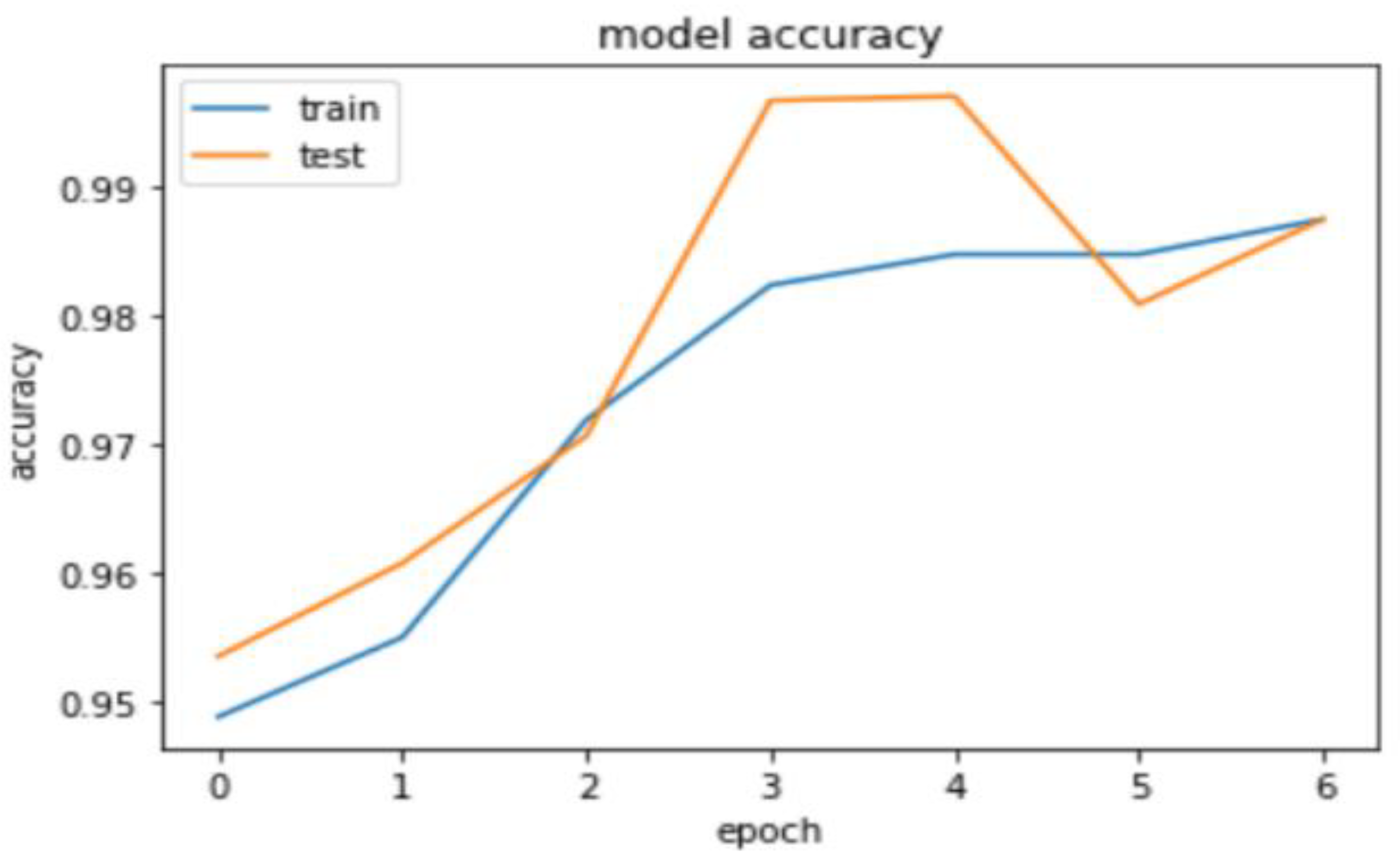
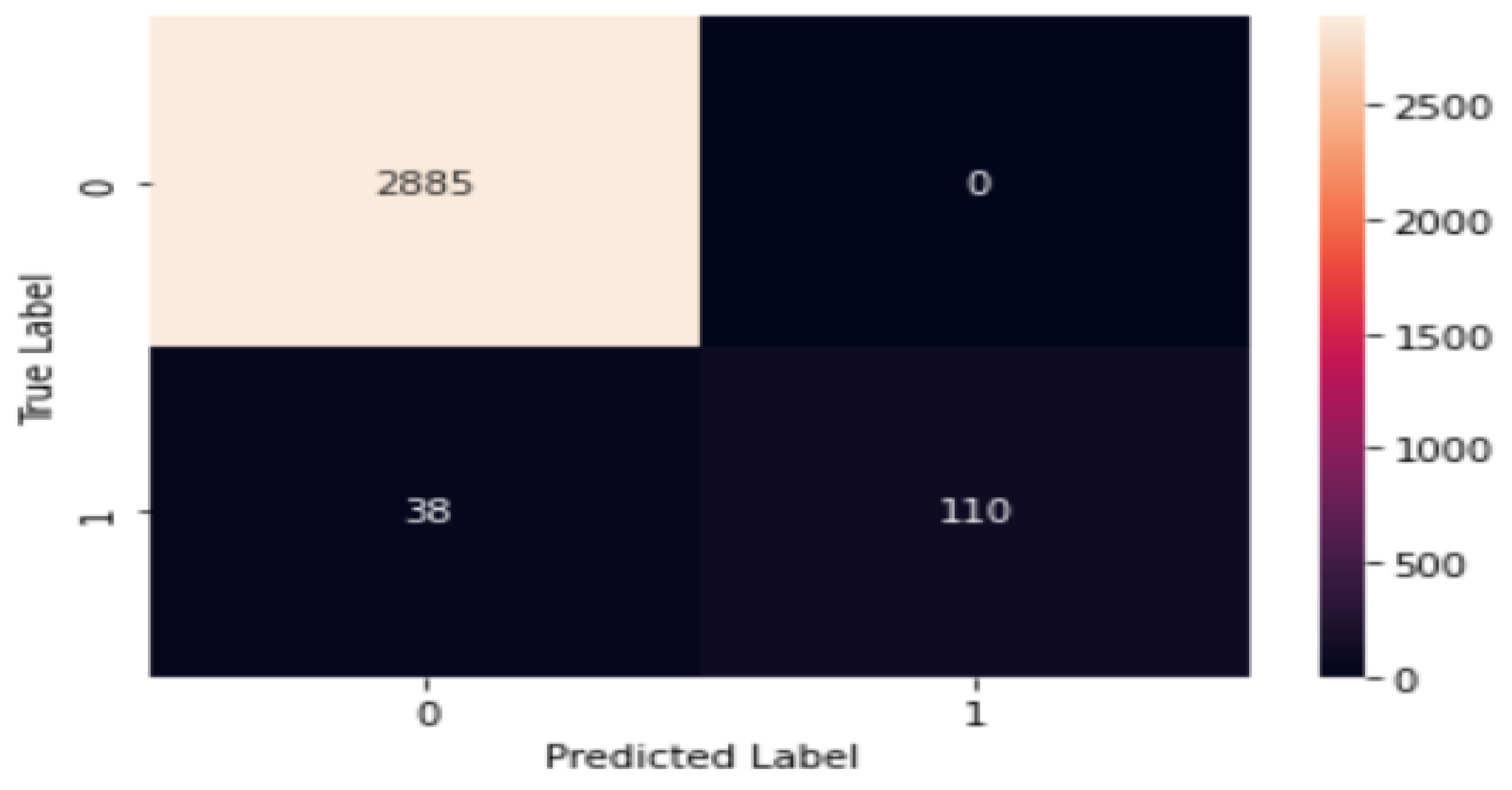
5.3. Results and the Proposed Model Hyperparameters
- The complexity of educational data, characterized by large datasets with missing entries, necessitated meticulous preprocessing to maintain data integrity.
- The risk of overfitting was significant due to the model’s complexity. Strategies like dropout and early stopping were implemented to mitigate this risk.
- Optimizing the model involved intricate parameter tuning to identify the ideal learning rates and layer configurations amidst a vast parameter space.
- The training process demanded substantial computational resources to manage the extensive dataset and intricate model architecture efficiently.
- Ensuring the model’s generalization capability across different educational institutions required thorough testing and validation to confirm its efficacy on unseen data.
5.4. Key Findings
- A new deep learning model utilizing a GRU to classify academically underperforming students was introduced.
- Specific neural network features including dense layers, max-pooling layers, and ADAM optimization were incorporated.
- Training was conducted on a dataset of 15,165 student records from various academic institutions.
- A remarkable accuracy of 99.70% was achieved, surpassing other educational recommendation systems.
- Benchmarked against RNN models, AdaBoost, and Artificial Immune Recognition System v2, the proposed model showcased a superior performance.
- The model’s potential in educational settings was emphasized for the identification of students needing additional academic support early.
- The efficiency and computational advantages of the GRU model in handling large datasets were highlighted.
- The practical application of deep learning was demonstrated in enhancing educational outcomes through data-driven insights.
- The strategic use of this model by educational institutions for timely intervention and support was advocated for.
- Avenues for future research in predictive analytics within education to further improve student success rates were opened.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agrawal, R.S.; Pandya, M.H. Survey of papers for Data Mining with Neural Networksto Predict the Student’s Academic Achievements. Int. J. Comput. Sci. Trends Technol. (IJCST) 2015, 3, 15. [Google Scholar]
- Beikzadeh, M.R.; Delavari, N. A New Analysis Model for Data Mining Processes in Higher Educational Systems. In Proceedings of the 6th Information Technology Based Higher Education and Training, Istanbul, Turkey, 7–9 July 2005. [Google Scholar]
- Steiner, C.; Kickmeier-Rust, M.; Albert, D. Learning Analytics and Educational Data Mining: An Overview of Recent Techniques. Learn. Anal. Serious Games 2014, 6, 6–15. [Google Scholar]
- Khan, S.; Alqahtani, S. Big Data Application and its Impact on Education. Int. J. Emerg. Technol. Learn. (iJET) 2020, 15, 36–46. [Google Scholar] [CrossRef]
- Ouatik, F.; Erritali, M.; Ouatik, F.; Jourhmane, M. Predicting Student Success Using Big Data and Machine Learning Algorithms. Int. J. Emerg. Technol. Learn. (iJET) 2022, 17, 236. [Google Scholar] [CrossRef]
- Chen, C.P.; Zhang, C.Y. Data-intensive applications, challenges, techniques, and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Huan, S.; Yang, C. Learners’ Autonomous Learning Behavior in Distance Reading Based on Big Data. Int. J. Emerg. Technol. Learn. (Online) 2022, 17, 273. [Google Scholar] [CrossRef]
- Alsharaiah, M.A.; Baniata, L.H.; Aladwan, O.; AbuaAlghanam, O.; Abushareha, A.A.; Abuaalhaj, M.; Sharayah, Q.; Baniata, M. Soft Voting Machine Learning Classification Model to Predict and Expose Liver Disorder for Human Patients. J. Theor. Appl. Inf. Technol. 2022, 100, 4554–4564. [Google Scholar]
- Alsharaiah, M.A.; Baniata, L.H.; Adwan, O.; Abu-Shareha, A.A.; Abuaalhaj, M.; Kharma, Q.; Hussein, A.; Abualghanam, O.; Alassaf, N.; Baniata, M. Attention-based Long Short Term Memory Model for DNA Damage Prediction in Mammalian Cells. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 91–99. [Google Scholar] [CrossRef]
- Alsharaiah, M.A.; Baniata, L.H.; Al Adwan, O.; Abuaalghanam, O.; Abu-Shareha, A.A.; Alzboon, L.; Mustafa, N.; Baniata, M. Neural Network Prediction Model to Explore Complex Nonlinear Behavior in Dynamic Biological Network. Int. J. Interact. Mob. Technol. 2022, 16, 32–51. [Google Scholar] [CrossRef]
- Krish, K. Data-Driven Architecture for Big Data. In Data Warehousing in the Age of Big Data; MK of Big Data-MK Series on Business Intelligence; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Kastranis, A. Artificial Intelligence for People and Business; O’ Reily Media Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Siemens, G.; Baker, R.S. Learning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012. [Google Scholar]
- Aher, S.B. Data Mining in Educational System using WEKA. In Proceedings of the International Conference on Emerging Technology Trends (ICETT), Nagercoil, India, 23–24 March 2011. [Google Scholar]
- Aher, S.B.; Lobo, L.M.R.J. Mining Association Rule in Classified Data for Course Recommender System in E-Learning. Int. J. Comput. Appl. 2012, 39, 1–7. [Google Scholar]
- Felix, I.M.; Ambrosio, A.P.; Neves, P.S.; Siqueira, J.; Brancher, J.D. Moodle Predicta: A Data Mining Tool for Student Follow Up. In Proceedings of the International Conference on Computer Supported Education, Porto, Portugal, 21–23 April 2017. [Google Scholar]
- International Educational Data Mining Society. Available online: www.educationaldatamining.org (accessed on 25 January 2024).
- Gijbels, D.; Van de Watering, G.; Dochy, F.; Van den Bossche, P. The relationship between students’ approaches to learning and the assessment of learning outcomes. Eur. J. Psychol. Educ. 2005, 20, 327–341. [Google Scholar] [CrossRef]
- Onyema, E.M.; Elhaj, M.A.E.; Bashir, S.G.; Abdullahi, I.; Hauwa, A.A.; Hayatu, A.S.; Edeh, M.O.; Abdullahi, I. Evaluation of the Performance of K-Nearest Neighbor Algorithm in Determining Student Learning Style. Int. J. Innov. Sci. Eng. Technol. 2020, 7, 2348–7968. [Google Scholar]
- Anjali, J. A Review of Machine Learning in Education. J. Emerg. Technol. Innov. Res. (JETIR) 2019, 6, 384–386. Available online: http://www.jetir.org/papers/JETIR1905658.pdf (accessed on 25 January 2024).
- Hussain, S.; Dahan, N.A.; Ba-Alwib, F.M.; Najoua, R. Educational Data Mining and Analysis of Students’ Academic Performance Using WEKA. Indones. J. Electr. Eng. Comput. Sci. 2018, 9, 447–459. [Google Scholar] [CrossRef]
- López, M. Classification via clustering for predicting final marks based on student participation in forums. In Proceedings of the 5th International Conference on Educational Data Mining, Chania, Greece, 19–21 June 2012. [Google Scholar]
- Klašnja-Milićević, A. E-Learning personalization based on hybrid recommen recommendation strategy and learning style identification. Comput. Educ. 2011, 56, 885–899. [Google Scholar] [CrossRef]
- Ayesha, S. Data Mining Model for Higher Education System. Eur. J. Sci. Res. 2010, 43, 24–29. [Google Scholar]
- Alfiani, A.P.; Wulandari, F.A. Mapping Student’s Performance Based on the Data Mining Approach (A Case Study). Agric. Agric. Sci. Procedia 2015, 3, 173–177. [Google Scholar]
- Bovo, A. Clustering moodles data as a tool for profiling students. In Proceedings of the International Conference on E-Learning and E-Technologies in Education (ICEEE), Lodz, Poland, 23–25 September 2013; pp. 121–126. [Google Scholar]
- Antonenko, P.D.; Toy, S.; Niederhauser, D.S. Using cluster analysis for data mining in educational technology research. Educ. Technol. Res. Dev. 2012, 60, 383–398. [Google Scholar] [CrossRef]
- Méndez Suárez, M.; Crespo Tejero, N. Impact of absenteeism on academic performance under compulsory attendance policies in first to fifth year university students. Rev. Complut. Educ. 2021, 32, 627–637. [Google Scholar] [CrossRef]
- Chavez, H.; Chavez-Arias, B.; Contreras-Rosas, S.; Alvarez-Rodríguez, J.M.; Raymundo, C. Artificial neural network model to predict student performa. Front. Educ. 2023, 8. [Google Scholar] [CrossRef]
- Xiong, S.Y.; Gasim, E.F.M.; Xin Ying, C.; Wah, K.K.; Ha, L.M. A Proposed Hybrid CNN-RNN Architecture for Student Performance Prediction. Int. J. Intell. Syst. Appl. Eng. 2022, 10, 347–355. [Google Scholar]
- Peng, Y.; Lu, B. Hybrid learning clonal selection algorithm. Inf. Sci. 2015, 296, 128–146. [Google Scholar] [CrossRef]
- Saidi, M.; Chikh, A.; Settouti, N. Automatic Identification of Diabetes Diseases using an Artificial Immune Recognition System2 (AIRS2) with a Fuzzy K-Nearest Neighbor. In Proceedings of the Conférence Internationale sur l’Informatique et ses Applications, Saida, Algeria, 13–15 December 2011. [Google Scholar]
- Bendangnuksung, P.P. Students’ Performance Prediction Using Deep Neural Network. Int. J. Appl. Eng. Res. 2018, 13, 1171–1176. [Google Scholar]
- Dey, R.; Salem, F.M. Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Ravanelli, M.; Brakel, P.; Omologo, M.; Bengio, Y. Light Gated Recurrent Units for Speech Recognition. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 92–102. [Google Scholar] [CrossRef]
- Pomerat, J.; Segev, A.; Datta, R. On Neural Network Activation Functions and Optimizers in Relation to Polynomial Regression. In Proceedings of the IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Zhang, Z. Improved Adam Optimizer for Deep Neural Networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018. [Google Scholar]
- K. Document. Available online: https://keras.io/search.html?query=maxpooling (accessed on 20 December 2023).
- Dense Layer. Keras. Available online: https://keras.io/api/layers/core_layers/dense/ (accessed on 15 January 2024).
- Sadiq, H.; Zahraa, F.M.; Yass, K.S. Prediction Model on Student Performance based on Internal Assessment using Deep Learning. Int. J. Emerg. Technol. Learn. 2019, 14, 4–22. [Google Scholar]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2018, 17, 168–192. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Explanation | Values |
|---|---|---|
| Exam | Three-Year Degree Six-Semester Examinations | {‘BA’, ‘BSC’} Two tests are listed in the account, i.e., BA and BSc |
| IN_Sem1 | Major/Honours Topics Of Bachelor and Master Programs | {‘ENGM’, ’PHYM’, etc.} ENGM- Major/Honours in English PHYM- Major/Honours in Physics |
| IN_Sem2 | Internal Evaluation Grades Acquired in the BA/BSc 1st Semester Examination | Maximum marks: 20 Marks achieved by the students in the range of 1 to 20. Mean: 15.66257 Standard deviation, SD: 2.593816 |
| IN_Sem3 | Internal Evaluation Grades Obtained in the BA/BSc 3rd Semester Examination | Maximum marks: 40 Marks achieved by the students in the range of 1 to 40. Mean: 31.95765 Standard deviation, SD: 5.101312 |
| IN_Sem4 | Internal Evaluation Grades Obtained in the BA/BSc 4th Semester Examination | Maximum marks: 40 Marks achieved by the students in the range of 1 to 40. Mean: 30.80859 Standard deviation: 5.43647 |
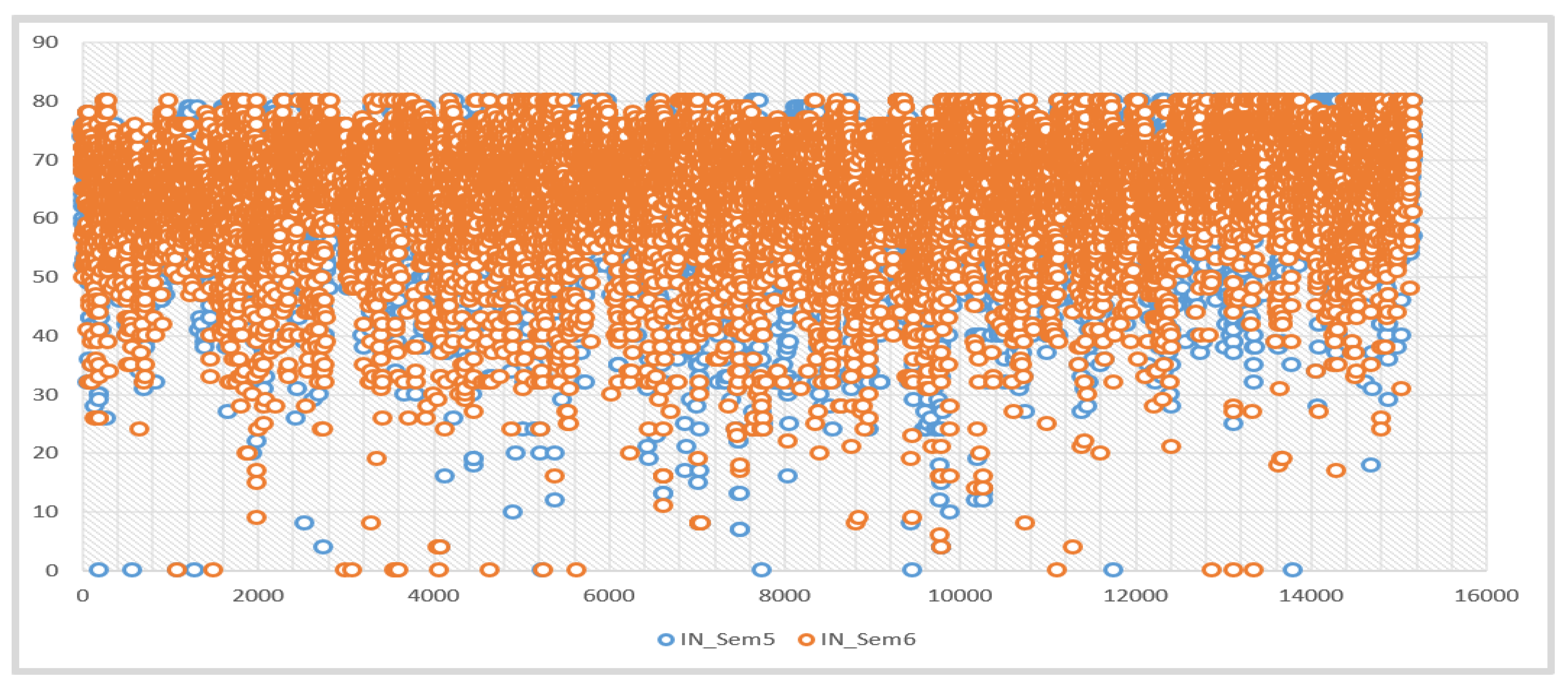
| IN_Sem5 | Internal Evaluation Grades Obtained in the BA/BSc 5th Semester Examination | Maximum marks: 80 Marks achieved by the students in the range of 1 to 80. Mean: 64.71536 Standard deviation: 10.18944 |
| IN_Sem6 | Internal Evaluation Grades Obtained in the BA/BSc 6th Semester Examination | Maximum marks: 80 Marks achieved by the students in the range of 1 to 80. Mean: 64.79921 Standard deviation: 10.3252 |
| InPc | Overall Percentage Secured by the Candidate in all Six Semesters in the Internal Assessments | Mean: 80.44676 Standard deviation: 11.01706 |
| Result | Overall result of the Applicant Established in all Six Semesters: Theory and Interior Assessment | {‘Pass’, ‘Fail’} If a student secures 40% or over, they are termed as ‘Pass’; else, ‘Fail’ |
| No. of Parameters | Output Shape | Layer (Type) |
|---|---|---|
| 0 | (None, 10, 1) | Input_1 (inputLayer) |
| 200 | (None, 10, 100) | Word_dense (Dense) |
| 274,944 | (None, 10, 256) | Gru (GRU) |
| 0 | (None, 256) | Global_max_pooling (Global MaxpoolingID) |
| 514 | (None, 2) | Dense |
| Total Parameters: 275,658 | ||
| Trainable Parameters: 275,658 | ||
| Non-Trainable Parameters: 275,658 | ||
| Classifier | Precision | Recall | F-Score | Accuracy |
|---|---|---|---|---|
| RNN model | 0.96 | 0.99 | 0.98 | 95.34 |
| ARD V.2 | 0.926 | 0.932 | 0.939 | 93.18 |
| AdaBoost | 0.934 | 0.946 | 0.939 | 94.57 |
| The proposed model | 0.986 | 0.963 | 0.974 | 99.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baniata, L.H.; Kang, S.; Alsharaiah, M.A.; Baniata, M.H. Advanced Deep Learning Model for Predicting the Academic Performances of Students in Educational Institutions. Appl. Sci. 2024, 14, 1963. https://doi.org/10.3390/app14051963
Baniata LH, Kang S, Alsharaiah MA, Baniata MH. Advanced Deep Learning Model for Predicting the Academic Performances of Students in Educational Institutions. Applied Sciences. 2024; 14(5):1963. https://doi.org/10.3390/app14051963
Chicago/Turabian StyleBaniata, Laith H., Sangwoo Kang, Mohammad A. Alsharaiah, and Mohammad H. Baniata. 2024. "Advanced Deep Learning Model for Predicting the Academic Performances of Students in Educational Institutions" Applied Sciences 14, no. 5: 1963. https://doi.org/10.3390/app14051963
APA StyleBaniata, L. H., Kang, S., Alsharaiah, M. A., & Baniata, M. H. (2024). Advanced Deep Learning Model for Predicting the Academic Performances of Students in Educational Institutions. Applied Sciences, 14(5), 1963. https://doi.org/10.3390/app14051963