
Multistage Mixed-Attention Unsupervised Keyword Extraction for Summary Generation


Abstract
1. Introduction
2. Related Work
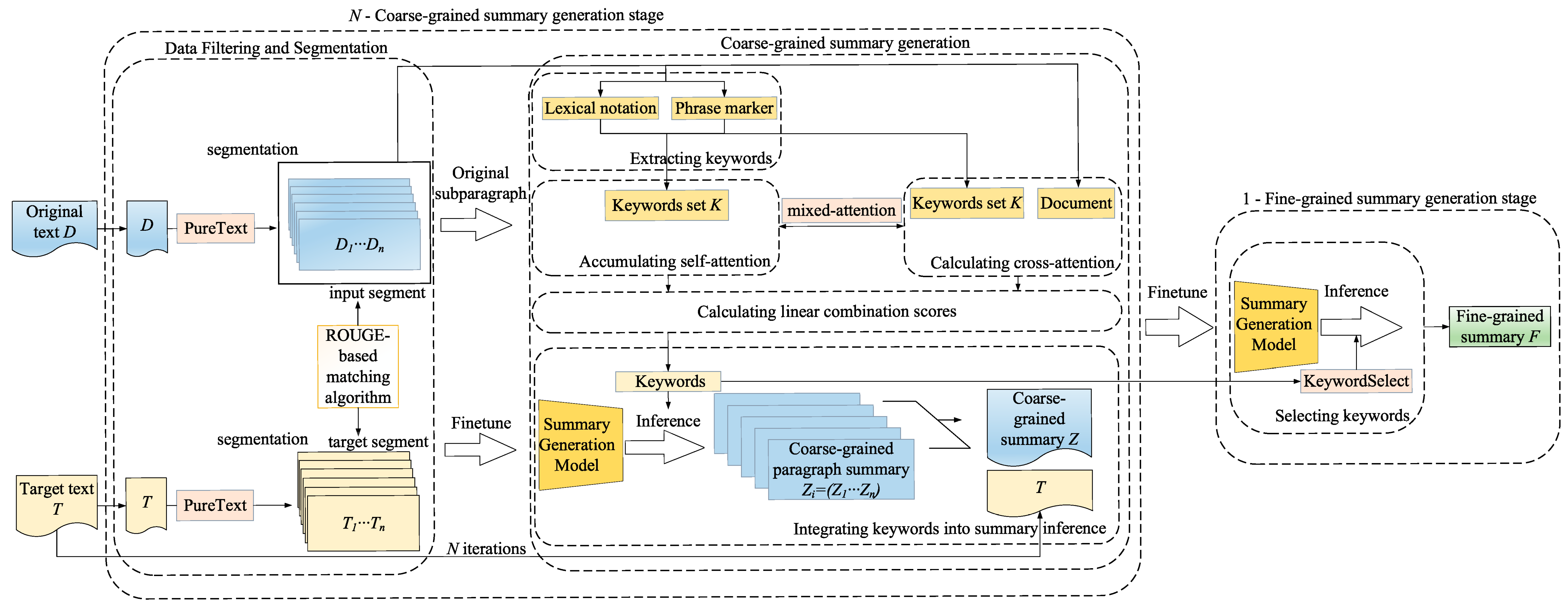
3. MSMAUKE-SummN Model
3.1. N-Coarse-Grained Summary Generation Stage
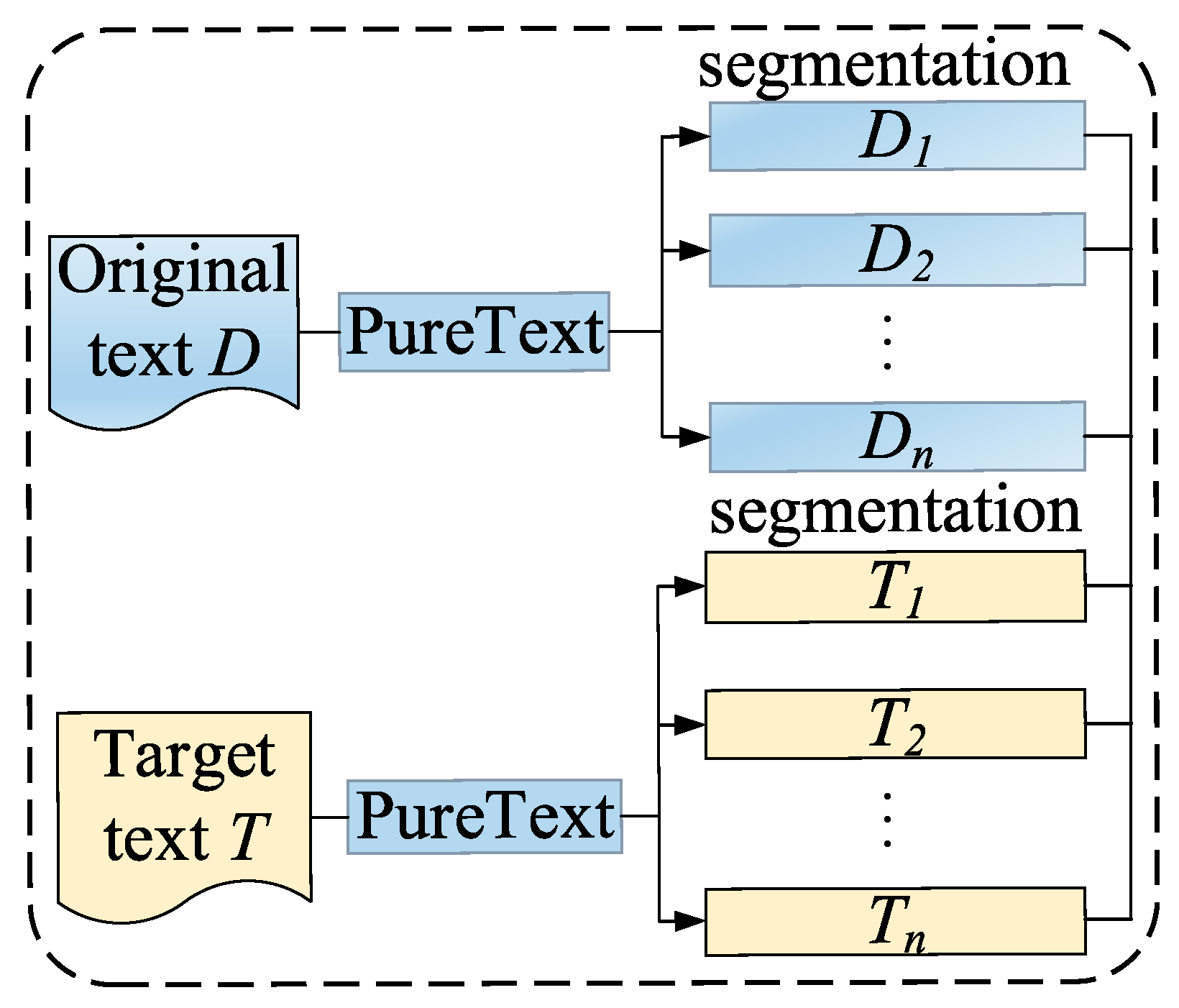
3.1.1. Data Filtering and Segmentation
3.1.2. Coarse-Grained Summary Generation
- (1)
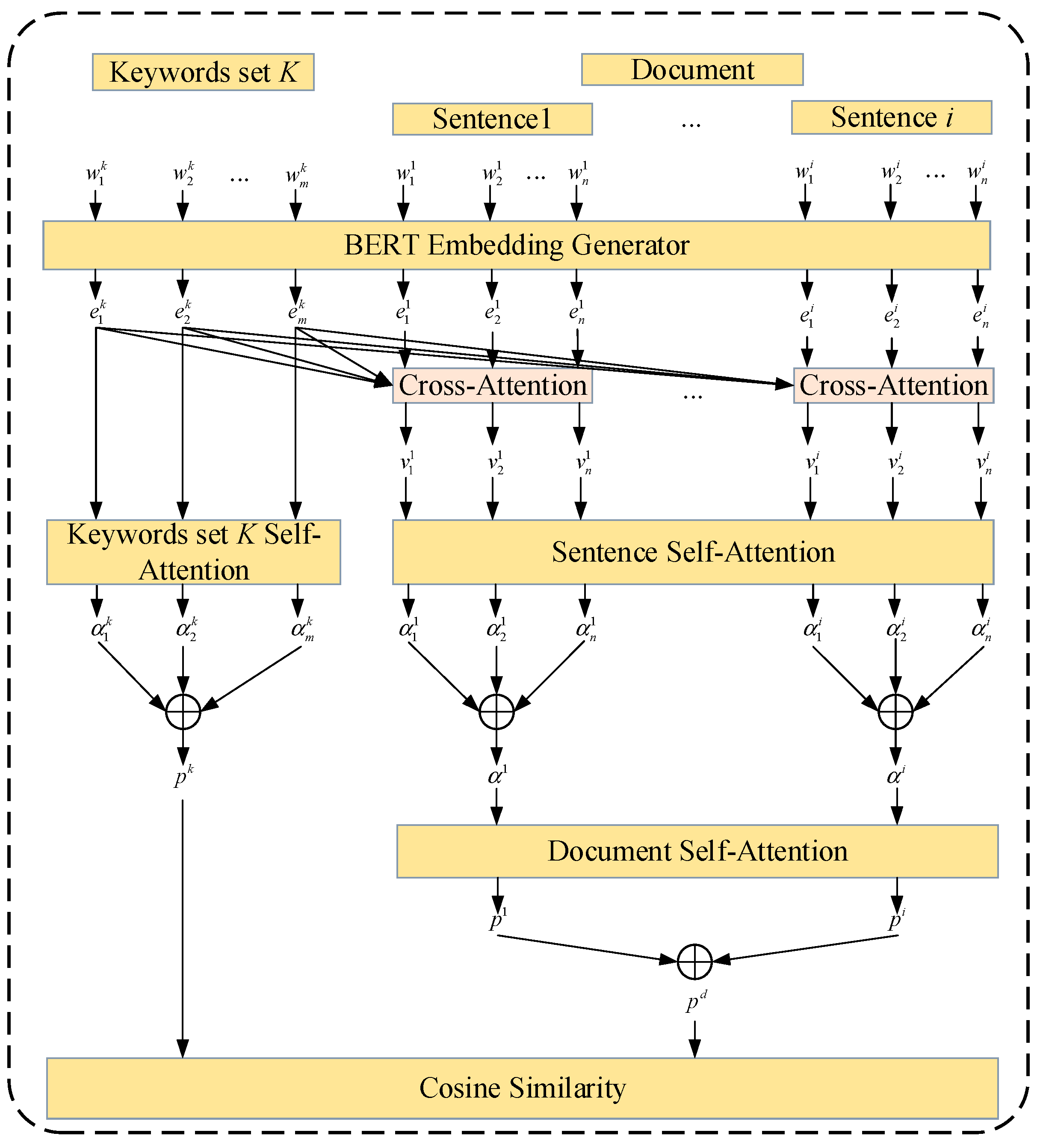
- Keyword Extraction
- (2)
- Self-Attention Accumulation Calculation
- (3)
- Cross-Attention Calculation
- (4)
- Linear Combination Score Calculation
- (5)
- Keyword Incorporation into Summary Inference
3.2. 1-Fine-Grained Summary Generation Stage
| Algorithm 1 MSMAUKE-SummN pseudo-code |
2: Summary Generation Model 3: 4: 5: 6: 7: 8: Summary Generation Model 9: end for 10: 11: return |
4. Experimental Results and Analysis
4.1. Experimental Setup and Dataset
4.2. Evaluation Metrics
4.3. Ablation Experiments
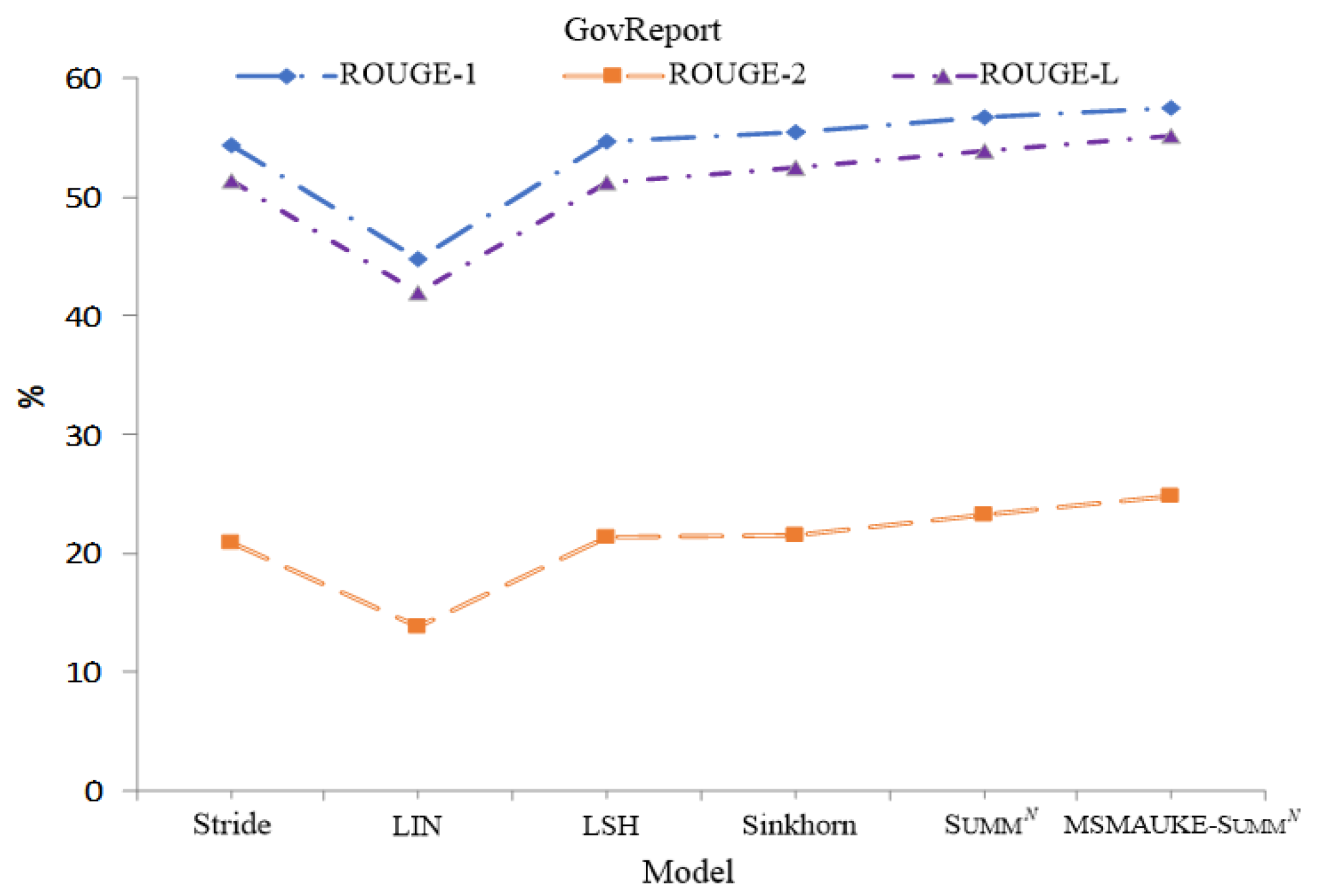
4.4. Comparison Experiments
- HMNet [15]: A hierarchical attention structure and cross-domain pretraining are used by HMNet to extract meeting summaries, and a novel abstract summarization network is constructed to adapt to meeting scenarios. Role vectors are designed to cope with the semantic structure and style of different meeting records, and long meeting records are accommodated through a hierarchical structure.
- TextRank [37]: A graph ranking approach is utilized by TextRank to consider the importance of each node’s information. It recursively calculates the importance weight value of each node in the relationship graph from the global semantic information. It counts and ranks important node information for keyword extraction and text summarization.
- HAT-BART [16]: Layered attention is applied by HAT-BART to Transformer. Visual Hierarchical Encoder–Decoder Attention is designed to overcome the uneven distribution of important information in long texts. Hierarchical Attention Transformer’s (HAT) architecture is used to adapt to longer text inputs.
- DDAMS [38]: Relational maps are used by DDAMS to model different discourse relationships; the interactions between discourses in a meeting are explicitly modeled. A relational graph encoder module is constructed, and graph interaction is used to model the interactions between discourses. The semantic relationships and information structure in the summaries are clarified.
- SummN [17]: The data samples are segmented by SummN. It generates coarse-grained summaries through multiple stages, based on which fine-grained summaries are generated. The framework can handle input text of any length by adjusting the number of stages.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Liu, X.; Zhang, J. Extractive Summarization via ChatGPT for Faithful Summary Generation. In Findings of the Association for Computational Linguistics: EMNLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 3270–3278. [Google Scholar]
- Bao, G.; Ou, Z.; Zhang, Y. GEMINI: Controlling The Sentence-Level Summary Style in Abstractive Text Summarization. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 831–842. [Google Scholar]
- Chen, J.; Yang, D. Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1380–1391. [Google Scholar]
- Yoo, C.; Lee, H. Improving Abstractive Dialogue Summarization Using Keyword Extraction. Appl. Sci. 2023, 13, 9771. [Google Scholar] [CrossRef]
- Chen, T.; Wang, X.; Yue, T. Enhancing Abstractive Summarization with Extracted Knowledge Graphs and Multi-Source Transformers. Appl. Sci. 2023, 13, 7753. [Google Scholar] [CrossRef]
- Xia, W.; Huang, H.; Gengzang, C.; Fan, Y. A review of extractive text summarisation based on unsupervised and supervised learning. Comput. Appl. 2023, 1–17. [Google Scholar]
- Zhang, L.; Chen, Q.; Wang, W.; Deng, C.; Zhang, S.; Li, B.; Wang, W.; Cao, X. MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction. In Findings of the Association for Computational Linguistics: ACL; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 396–409. [Google Scholar]
- Sun, Y.; Qiu, H.; Zheng, Y.; Wang, Z.; Zhang, C. SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-Trained Language Model. IEEE Access 2020, 8, 10896–10906. [Google Scholar] [CrossRef]
- Saxena, A.; Mangal, M.; Jain, G. KeyGames: A Game Theoretic Approach to Automatic Keyphrase Extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 2037–2048. [Google Scholar]
- Leonardo, F.R.R.; Mohit, B.; Markus, D. Generating Summaries with Controllable Readability Levels. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 11669–11687. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Griffin, A.; Alex, F.; Faisal, L.; Eric, L.; Noémie, E. From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting. In Proceedings of the 4th New Frontiers in Summarization Workshop, Singapore, 6–10 December 2023; pp. 68–74. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. International Conference on Learning Representations. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Zhu, C.; Xu, R.; Zeng, M.; Huang, X. A Hierarchical Network for Abstractive Meeting Summarization with Cross-Domain Pretraining. In Findings of the Association for Computational Linguistics: EMNLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 194–203. [Google Scholar]
- Rohde, T.; Wu, X.; Liu, Y. Hierarchical Learning for Generation with Long Source Sequences. arXiv 2021, arXiv:2104.07545. [Google Scholar]
- Zhang, Y.; Ni, A.; Mao, Z.; Wu, C.H.; Zhu, C.; Deb, B.; Awadallah, A.; Radev, D.; Zhang, R. SummN: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 1592–1604. [Google Scholar]
- Fang, J.; Li, B.; You, X.; Lv, X. PLSGA: A staged approach to long text summary generation. Comput. Eng. Appl. 2023, 1–10. [Google Scholar]
- Ren, S.; Zhang, J.; Zhap, Z.; Rao, D. A two-stage text summarization model combining topic and location information. Intell. Comput. Appl. 2023, 13, 158–163. [Google Scholar]
- Mei, A.; Kabir, A.; Bapat, R.; Judge, J.; Sun, T.; Wang, W.Y. Learning to Prioritize: Precision-Driven Sentence Filtering for Long Text Summarization. In Proceedings of the 13th Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022; pp. 313–318. [Google Scholar]
- Sun, S.; Liu, Z.; Xiong, C.; Liu, Z.; Bao, J. Capturing Global Informativeness in Open Domain Keyphrase Extraction. In Proceedings of the Natural Language Processing and Chinese Computing: 10th CCF International Conference, NLPCC 2021, Qingdao, China, 13–17 October 2021. [Google Scholar]
- Song, M.; Jing, L.; Xiao, L. Importance Estimation from Multiple Perspectives for Keyphrase Extraction. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 2726–2736. [Google Scholar]
- Papagiannopoulou, E.; Tsoumakas, G.; Papadopoulos, A. Keyword Extraction Using Unsupervised Learning on the Document’s Adjacency Matrix. In Proceedings of the Fifteenth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15), Mexico City, Mexico, 11 June 2021; pp. 94–105. [Google Scholar]
- Kong, A.; Zhao, S.; Chen, H.; Li, Q.; Qin, Y.; Sun, R.; Bai, X. PromptRank: Unsupervised Keyphrase Extraction Using Prompt. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 10–12 July 2023; Volume 1, pp. 9788–9801. [Google Scholar]
- Joshi, R.; Balachandran, V.; Saldanha, E.; Glenski, M.; Volkova, S.; Tsvetkov, Y. Unsupervised Keyphrase Extraction via Interpretable Neural Networks. In Findings of the Association for Computational Linguistics: EACL; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1107–1119. [Google Scholar]
- Ding, H.; Luo, X. AttentionRank: Unsupervised Keyphrase Extraction using Self and Cross Attentions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 1919–1928. [Google Scholar]
- Kreutz, T.; Daelemans, W. Streaming Language-Specific Twitter Data with Optimal Keywords. In Proceedings of the 12th Web as Corpus Workshop, Marseille, France, 11–16 May 2020; European Language Resources Association: Luxemburg, 2020; pp. 57–64. [Google Scholar]
- Akash, P.S.; Huang, J.; Chang, K.; Li, Y.; Popa, L.; Zhai, C. Domain Representative Keywords Selection: A Probabilistic Approach. In Findings of the Association for Computational Linguistics: ACL; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 679–692. [Google Scholar]
- Venkatesh, E.; Kaushal, M.; Deepak, K.; Maunendra, S.D. DivHSK: Diverse Headline Generation using Self-Attention based Keyword Selection. In Findings of the Association for Computational Linguistics: ACL; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1879–1891. [Google Scholar]
- Sreyan, G.; Utkarsh, T.; Manan, S.; Sonal, K.; Ramaneswaran, S.; Dinesh, M. ACLM: A Selective-Denoising based Generative Data Augmentation Approach for Low-Resource Complex NER. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 104–125. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Peng, H.; Schwartz, R.; Li, D.; Smith, N.A. A Mixture of h − 1 Heads is Better than h Heads. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6566–6577. [Google Scholar]
- Zhang, Y.; Ni, A.; Yu, T.; Zhang, R.; Zhu, C.; Deb, B.; Celikyilmaz, A.; Awadallah, A.H.; Radev, D. An Exploratory Study on Long Dialogue Summarization: What Works and What’s Next. arXiv 2021, arXiv:2109.04609. [Google Scholar]
- Zhong, M.; Yin, D.; Yu, T.; Zaidi, A.; Mutuma, M.; Jha, R.; Awadallah, A.H.; Celikyilmaz, A.; Liu, Y.; Qiu, X.; et al. QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5905–5921. [Google Scholar]
- Chen, M.; Chu, Z.; Wiseman, S.; Gimpel, K. SummScreen: A Dataset for Abstractive Screenplay Summarization. arXiv 2022, arXiv:2104.07091. [Google Scholar]
- Huang, L.; Cao, S.; Parulian, N.; Ji, H.; Wang, L. Efficient Attentions for Long Document Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1419–1436. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Feng, X.; Feng, X.; Qin, B.; Geng, X. Dialogue discourse-aware graph model and data augmentation for meeting summarization. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 3808–3814. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Parameters | Parameter Value |
|---|---|---|
| 1 | Lr | 2 × 10−5 |
| 2 | Coarse-grained beam width | 2 |
| 3 | Fine-grained beam width | 10 |
| 4 | Input_max_token | 1024 |
| Dataset | Type | Domain | Size | Original Text Length | Target Text Length | N + 1 |
|---|---|---|---|---|---|---|
| AMI | Dialogue | Meetings | 137 | 6007.7 | 296.6 | 2 |
| ICSI | Dialogue | Meetings | 59 | 13,317.3 | 488.5 | 3 |
| QMSum | Dialogue | Meetings | 1808 | 9069.8 | 69.6 | 2 |
| SummScreen | Dialogue | TV shows | 26,851 | 6612.5 | 337.4 | 2 |
| GovReport | Document | Reports | 19,466 | 9409.4 | 553.4 | 3 |
| Experiment Number | Sentence Filtering | Mixed-Attention Keyword Extraction | Self-Attention Keyword Selection |
|---|---|---|---|
| 1 | √ | ||
| 2 | √ | ||
| 3 | √ | √ | |
| 4 | √ | √ | |
| 5 | √ | √ | √ |
| Evaluation Metrics | R-1 (%) | R-2 (%) | R-L (%) | |
|---|---|---|---|---|
| Experiment Number | ||||
| 1 | 56.87 | 23.56 | 54.12 | |
| 2 | 57.23 | 24.17 | 54.71 | |
| 3 | 57.35 | 24.33 | 54.85 | |
| 4 | 57.45 | 24.52 | 55.02 | |
| 5 | 57.52 | 24.73 | 55.15 | |
| Dataset | AMI | ICSI | QMSum-All | QMSum-Gold | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | R-1 (%) | R-2 (%) | R-L (%) | R-1 (%) | R-2 (%) | R-L (%) | R-1 (%) | R-2 (%) | R-L (%) | R-1 (%) | R-2 (%) | R-L (%) | |
| HMNET | 52.36 | 18.63 | 24.00 | 45.97 | 10.14 | 18.54 | 32.29 | 8.67 | 28.17 | 36.06 | 11.36 | 31.27 | |
| TextRank | 35.19 | 6.13 | 16.70 | 30.72 | 4.69 | 12.97 | 16.27 | 2.69 | 15.41 | - | - | - | |
| HAT-BART | 52.27 | 20.15 | 50.57 | 43.98 | 10.83 | 41.36 | - | - | - | - | - | - | |
| DDAMS | 53.15 | 22.32 | 25.67 | 40.41 | 11.02 | 19.18 | - | - | - | - | - | - | |
| SummN | 53.44 | 20.30 | 51.39 | 45.57 | 11.49 | 43.32 | 34.03 | 9.28 | 29.48 | 40.20 | 15.32 | 35.62 | |
| MSMAUKE-SummN | 55.19 | 21.46 | 53.35 | 47.54 | 12.85 | 45.25 | 36.29 | 10.8 | 31.22 | 42.2 | 17.09 | 38.09 | |
| Dataset | SummScreen-FD | SummScreen-TMS | |||||
|---|---|---|---|---|---|---|---|
| Model | R-1 (%) | R-2 (%) | R-L (%) | R-1 (%) | R-2 (%) | R-L (%) | |
| Longformer + ATT | 25.9 | 4.2 | 23.8 | 42.9 | 11.9 | 41.6 | |
| NN + BM25 + Neural | 25.3 | 3.9 | 23.1 | 38.8 | 10.2 | 36.9 | |
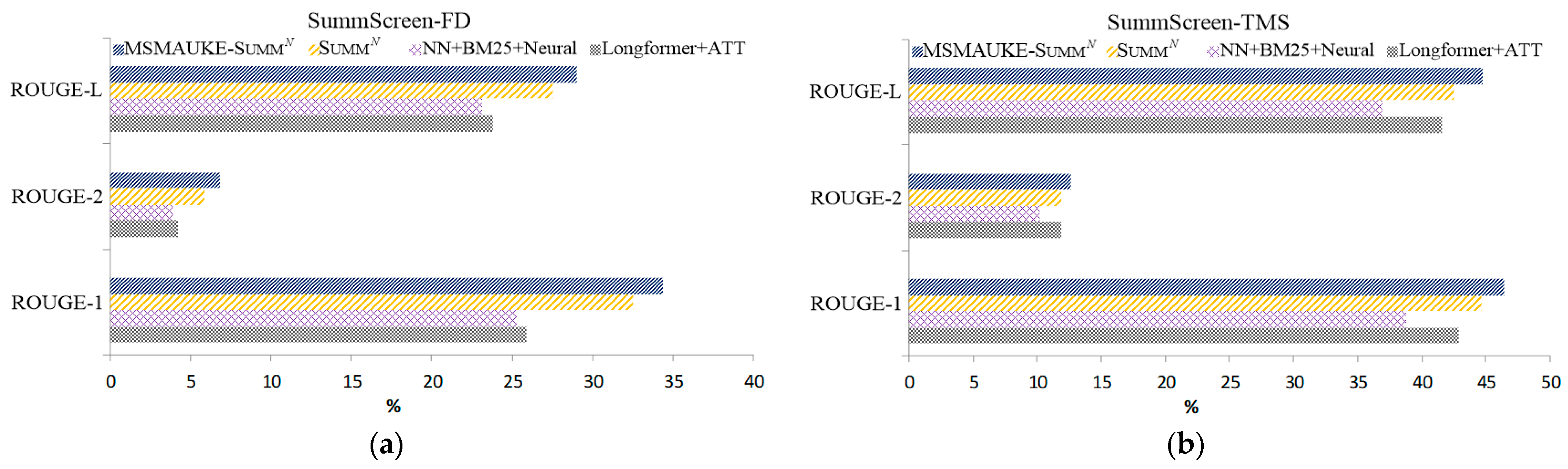
| SummN | 32.48 | 5.85 | 27.55 | 44.64 | 11.87 | 42.53 | |
| MSMAUKE-SummN | 34.34 | 6.86 | 28.98 | 46.38 | 12.64 | 44.74 | |
| Dataset | GovReport | |||
|---|---|---|---|---|
| Model | R-1 (%) | R-2 (%) | R-L (%) | |
| BART Variants | ||||
| Full (1024) | 52.83 | 20.5 | 50.14 | |
| Stride (4096) | 54.29 | 20.8 | 51.35 | |
| LIN. (3072) | 44.84 | 13.87 | 41.94 | |
| LSH (4096) | 54.75 | 21.36 | 51.27 | |
| Sinkhorn (5120) | 55.45 | 21.45 | 52.48 | |
| BART HEPOS | ||||
| LSH (7168) | 55 | 21.13 | 51.67 | |
| Sinkhorn (10,240) | 56.86 | 22.62 | 53.82 | |
| SummN | 56.77 | 23.25 | 53.9 | |
| MSMAUKE-SummN | 57.52 | 24.73 | 55.15 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, D.; Cheng, P.; Zheng, Y. Multistage Mixed-Attention Unsupervised Keyword Extraction for Summary Generation. Appl. Sci. 2024, 14, 2435. https://doi.org/10.3390/app14062435
Wu D, Cheng P, Zheng Y. Multistage Mixed-Attention Unsupervised Keyword Extraction for Summary Generation. Applied Sciences. 2024; 14(6):2435. https://doi.org/10.3390/app14062435
Chicago/Turabian StyleWu, Di, Peng Cheng, and Yuying Zheng. 2024. "Multistage Mixed-Attention Unsupervised Keyword Extraction for Summary Generation" Applied Sciences 14, no. 6: 2435. https://doi.org/10.3390/app14062435
APA StyleWu, D., Cheng, P., & Zheng, Y. (2024). Multistage Mixed-Attention Unsupervised Keyword Extraction for Summary Generation. Applied Sciences, 14(6), 2435. https://doi.org/10.3390/app14062435