



Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains

Abstract
:1. Introduction
2. Related Work
3. A Matrix Attention Model Based on the Time and Frequency Domains
3.1. Problem Definition
3.2. The Overall Model Architecture
3.2.1. The Frequency Domain Block
3.2.2. The Time Domain Block
3.2.3. Fusion Block
3.3. The Matrix Attention Mechanism
3.3.1. Independent Matrix Attention Mechanism
3.3.2. Merge Matrix Attention Mechanism
4. Experiments
4.1. Datasets
4.2. Baselines and Setup
4.3. Our Model and Implementation Details
4.4. Comparison of the Results with State-of-the-Art Models
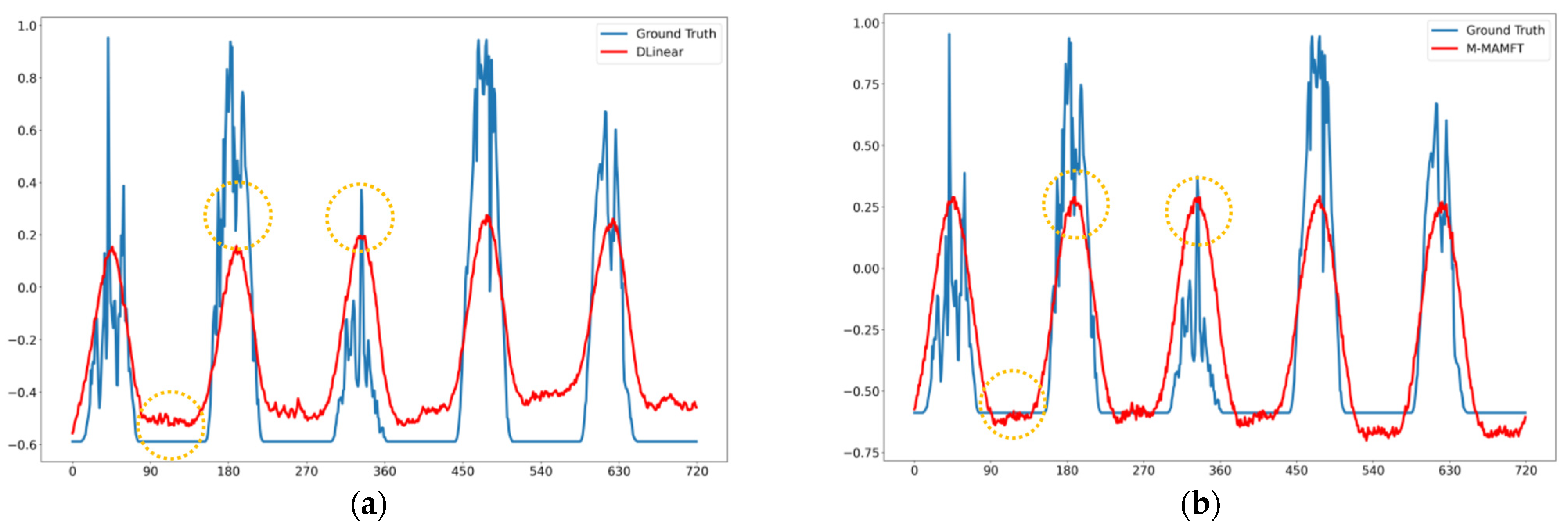
4.5. Visual Analysis
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qi, X.; Mei, G.; Tu, J.; Xi, N.; Francesco, P. A deep learning approach for long-term traffic flow prediction with multifactor fusion using spatiotemporal graph convolutional network. IEEE Trans. Intell. Transp. Syst. 2022, 24, 8687–8700. [Google Scholar] [CrossRef]
- Guo, K.; Yu, X.; Liu, G.; Tang, S. A Long-Term Traffic Flow Prediction Model Based on Variational Mode Decomposition and Auto-Correlation Mechanism. Appl. Sci. 2023, 13, 7139. [Google Scholar] [CrossRef]
- Sen, J.; Mehtab, S. Long-and-Short-Term Memory (LSTM) NetworksArchitectures and Applications in Stock Price Prediction. In Emerging Computing Paradigms: Principles, Advances and Applications; Wiley Online Library: Hoboken, NJ, USA, 2022; pp. 143–160. [Google Scholar]
- Patra, G.R.; Mohanty, M.N. An LSTM-GRU based hybrid framework for secured stock price prediction. J. Stat. Manag. Syst. 2022, 25, 1491–1499. [Google Scholar] [CrossRef]
- Torres, J.F.; Martínez-Álvarez, F.; Troncoso, A. A deep LSTM network for the Spanish electricity consumption forecasting. Neural Comput. Appl. 2022, 34, 10533–10545. [Google Scholar] [CrossRef] [PubMed]
- Moradzadeh, A.; Moayyed, H.; Zare, K.; Mohammadi-Ivatloo, B. Short-term electricity demand forecasting via variational autoencoders and batch training-based bidirectional long short-term memory. Sustain. Energy Technol. Assess. 2022, 52, 102209. [Google Scholar] [CrossRef]
- Hess, P.; Boers, N. Deep learning for improving numerical weather prediction of heavy rainfall. Geosci. Model Dev. 2022, 14, e2021MS002765. [Google Scholar] [CrossRef]
- Djerioui, M.; Brik, Y.; Ladjal, M.; Attallah, B. Heart Disease prediction using MLP and LSTM models. In Proceedings of the 2020 International Con-ference on Electrical Engineering (ICEE), Istanbul, Turkey, 25–27 September 2020; pp. 1–5. [Google Scholar]
- Di, N.; De, M.; Gargano, R.; Granata, F. Tide prediction in the Venice Lagoon using nonlinear autoregressive exogenous (NARX) neural network. Water 2021, 13, 1173. [Google Scholar] [CrossRef]
- Zhou, Q.; Han, R.; Li, T.; Xia, B. Joint prediction of time series data in inventory management. Knowl. Inf. Syst. 2019, 61, 905–929. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond effificient transformer for long sequence time-series forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 11106–11115. [Google Scholar] [CrossRef]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; PMLR 162; pp. 27268–27286. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are transformers effective for time series forecasting? Proc. AAAI Conf. Artif. Intell. 2023, 37, 11121–11128. [Google Scholar] [CrossRef]
- Abonazel, M.R.; Abd-Elftah, A.I. Forecasting Egyptian GDP using ARIMA models. Rep. Econ. Financ. 2019, 5, 35–47. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, P.; Chu, Y.; Li, W.; Wu, Y.; Ni, L.; Bao, Y.; Wang, K. Short-term electrical load forecasting using the Support Vector Regression (SVR) model to calculate the demand response baseline for office buildings. Appl. Energy 2017, 195, 659–670. [Google Scholar] [CrossRef]
- Martínez, F.; Frías, M.P.; Pérez, M.D.; Rivera, A.J. A methodology for applying k-nearest neighbor to time series forecasting. Artif. Intell. Rev. 2019, 52, 2019–2037. [Google Scholar] [CrossRef]
- Nguyen-Huynh, L.; Vo-Van, T. A new fuzzy time series forecasting model based on clustering technique and normal fuzzy function. Knowl. Inf. Syst. 2023, 65, 3489–3509. [Google Scholar] [CrossRef]
- Cho, K.; Van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis. arXiv 2022, arXiv:2210.02186. [Google Scholar]
- Liu, S.; Yu, H.; Liao, C.; Li, J.; Lin, W.; Liu, A.; Dustdar, S. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Zheng, K.; Li, P.; Zhou, S.; Zhang, W.; Li, S.; Zeng, L.; Zhang, Y. A multi-scale electricity consumption prediction algorithm based on time-frequency variational autoencoder. IEEE Access 2021, 9, 90937–90946. [Google Scholar] [CrossRef]
- Shao, X.; Pu, C.; Zhang, Y.; Kim, C.S. Domain fusion CNN-LSTM for short-term power consumption forecasting. IEEE Access 2020, 8, 188352–188362. [Google Scholar] [CrossRef]
- Yang, Z.; Yan, W.-W.; Huang, X.; Mei, L. Adaptive temporal-frequency network for time-series forecasting. IEEE Trans. Knowl. Data Eng. 2020, 34, 1576–1587. [Google Scholar] [CrossRef]
- Long, L.; Liu, Q.; Peng, H.; Yang, Q.; Luo, X.; Wang, J.; Song, X. A time series forecasting approach based on nonlinear spiking neural systems. Int. J. Neural Syst. 2022, 32, 2250020. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; p. 27. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Electricity | Weather | ETTh2 | BCAT |
|---|---|---|---|---|
| Variables | 321 | 21 | 7 | 1 |
| Timesteps | 26,304 | 52,696 | 17,420 | 6600 |
| Frequency | 1 h | 10 min | 1 h | 30 min |
| Dataset | Electricity | Weather | ETTh2 | BCAT |
|---|---|---|---|---|
| Initial learning rate | 0.002 | 0.0001 | 0.0001 | 0.0005 |
| Models | M-MAMFT | I-MAMFT | DLinear | FEDformer | Autoformer | Informer | Pyraformer | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| Electricity | 96 | 0.128 | 0.225 | 0.156 | 0.261 | 0.140 | 0.237 | 0.193 | 0.308 | 0.201 | 0.317 | 0.274 | 0.368 | 0.386 | 0.449 |
| 192 | 0.147 | 0.245 | 0.180 | 0.287 | 0.153 | 0.249 | 0.201 | 0.315 | 0.222 | 0.334 | 0.296 | 0.386 | 0.386 | 0.443 | |
| 336 | 0.162 | 0.261 | 0.206 | 0.307 | 0.169 | 0.267 | 0.214 | 0.329 | 0.231 | 0.338 | 0.300 | 0.394 | 0.378 | 0.443 | |
| 720 | 0.197 | 0.296 | 0.222 | 0.327 | 0.203 | 0.301 | 0.246 | 0.355 | 0.254 | 0.361 | 0.373 | 0.439 | 0.376 | 0.445 | |
| Weather | 96 | 0.151 | 0.209 | 0.147 | 0.212 | 0.176 | 0.237 | 0.217 | 0.296 | 0.266 | 0.336 | 0.300 | 0.384 | 0.896 | 0.556 |
| 192 | 0.202 | 0.259 | 0.194 | 0.259 | 0.220 | 0.282 | 0.276 | 0.336 | 0.307 | 0.367 | 0.598 | 0.544 | 0.622 | 0.624 | |
| 336 | 0.247 | 0.293 | 0.244 | 0.300 | 0.265 | 0.319 | 0.339 | 0.380 | 0.359 | 0.395 | 0.578 | 0.523 | 0.739 | 0.753 | |
| 720 | 0.310 | 0.341 | 0.321 | 0.355 | 0.323 | 0.362 | 0.403 | 0.428 | 0.419 | 0.428 | 1.059 | 0.741 | 1.004 | 0.934 | |
| ETTh2 | 96 | 0.176 | 0.293 | 0.216 | 0.333 | 0.289 | 0.353 | 0.346 | 0.388 | 0.358 | 0.397 | 3.755 | 1.525 | 0.645 | 0.597 |
| 192 | 0.208 | 0.323 | 0.258 | 0.364 | 0.383 | 0.418 | 0.429 | 0.439 | 0.456 | 0.452 | 5.602 | 1.931 | 0.788 | 0.683 | |
| 336 | 0.226 | 0.337 | 0.290 | 0.398 | 0.448 | 0.465 | 0.496 | 0.487 | 0.482 | 0.486 | 4.721 | 1.835 | 0.907 | 0.747 | |
| 720 | 0.266 | 0.379 | 0.393 | 0.465 | 0.605 | 0.551 | 0.463 | 0.474 | 0.515 | 0.511 | 3.647 | 1.625 | 0.963 | 0.783 | |
| BCAT | 96 | 0.290 | 0.362 | 0.290 | 0.362 | 0.297 | 0.373 | 0.297 | 0.394 | 0.290 | 0.377 | 0.310 | 0.366 | 0.301 | 0.373 |
| 192 | 0.313 | 0.379 | 0.313 | 0.379 | 0.324 | 0.389 | 0.314 | 0.402 | 0.342 | 0.420 | 0.367 | 0.384 | 0.327 | 0.388 | |
| 336 | 0.330 | 0.389 | 0.330 | 0.389 | 0.340 | 0.402 | 0.336 | 0.422 | 0.410 | 0.469 | 0.444 | 0.438 | 0.355 | 0.409 | |
| 720 | 0.359 | 0.412 | 0.359 | 0.412 | 0.363 | 0.416 | 0.408 | 0.466 | 0.390 | 0.467 | 0.522 | 0.453 | 0.375 | 0.421 | |
| Models | Metric | ETTh2 | Weather | BCAT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | ||
| M-MAMFT | MSE | 0.176 | 0.208 | 0.227 | 0.266 | 0.151 | 0.202 | 0.247 | 0.310 | 0.290 | 0.313 | 0.330 | 0.378 |
| MAE | 0.293 | 0.323 | 0.337 | 0.379 | 0.209 | 0.259 | 0.296 | 0.341 | 0.362 | 0.379 | 0.389 | 0.417 | |
| only-T | MSE | 0.200 | 0.213 | 0.258 | 0.286 | 0.156 | 0.208 | 0.250 | 0.319 | 0.315 | 0.326 | 0.334 | 0.429 |
| MAE | 0.318 | 0.326 | 0.362 | 0.391 | 0.212 | 0.261 | 0.297 | 0.354 | 0.378 | 0.389 | 0.392 | 0.418 | |
| only-F | MSE | 0.805 | 0.936 | 1.010 | 1.159 | 0.394 | 0.429 | 0.441 | 0.478 | 0.323 | 0.359 | 0.372 | 0.413 |
| MAE | 0.690 | 0.743 | 0.770 | 0.840 | 0.442 | 0.473 | 0.481 | 0.511 | 0.379 | 0.393 | 0.400 | 0.420 | |
| NO-Imag | MSE | 0.179 | 0.209 | 0.249 | 0.309 | 0.151 | 0.204 | 0.252 | 0.313 | 0.302 | 0.340 | 0.360 | 0.401 |
| MAE | 0.296 | 0.329 | 0.359 | 0.422 | 0.210 | 0.260 | 0.304 | 0.353 | 0.374 | 0.414 | 0.424 | 0.423 | |
| NO-Real | MSE | 0.177 | 0.214 | 0.228 | 0.291 | 0.153 | 0.207 | 0.253 | 0.311 | 0.304 | 0.344 | 0.357 | 0.430 |
| MAE | 0.294 | 0.332 | 0.346 | 0.409 | 0.209 | 0.266 | 0.308 | 0.344 | 0.381 | 0.406 | 0.437 | 0.431 | |
| Models | Metric | ETTh2 | Weather | BCAT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | ||
| M-MAMFT | MSE | 0.176 | 0.208 | 0.227 | 0.266 | 0.151 | 0.202 | 0.247 | 0.310 | 0.290 | 0.313 | 0.330 | 0.378 |
| MAE | 0.293 | 0.323 | 0.337 | 0.379 | 0.209 | 0.259 | 0.296 | 0.341 | 0.362 | 0.379 | 0.389 | 0.417 | |
| Auto-Correlation | MSE | 0.193 | 0.246 | 0.268 | 0.319 | 0.153 | 0.203 | 0.251 | 0.313 | 0.298 | 0.335 | 0.375 | 0.400 |
| MAE | 0.314 | 0.352 | 0.378 | 0.424 | 0.209 | 0.261 | 0.300 | 0.342 | 0.364 | 0.383 | 0.426 | 0.420 | |
| Full-Attention | MSE | 0.228 | 0.284 | 0.298 | 0.363 | 0.175 | 0.222 | 0.281 | 0.338 | 0.302 | 0.341 | 0.336 | 0.418 |
| MAE | 0.348 | 0.403 | 0.411 | 0.442 | 0.246 | 0.287 | 0.338 | 0.385 | 0.366 | 0.390 | 0.393 | 0.418 | |
| FEA-f | MSE | 0.330 | 0.359 | 0.383 | 0.462 | 0.160 | 0.217 | 0.260 | 0.339 | 0.299 | 0.332 | 0.339 | 0.406 |
| MAE | 0.438 | 0.464 | 0.449 | 0.510 | 0.245 | 0.301 | 0.330 | 0.408 | 0.371 | 0.386 | 0.404 | 0.429 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, K.; Yu, X. Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains. Appl. Sci. 2024, 14, 2893. https://doi.org/10.3390/app14072893
Guo K, Yu X. Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains. Applied Sciences. 2024; 14(7):2893. https://doi.org/10.3390/app14072893
Chicago/Turabian StyleGuo, Kaixin, and Xin Yu. 2024. "Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains" Applied Sciences 14, no. 7: 2893. https://doi.org/10.3390/app14072893
APA StyleGuo, K., & Yu, X. (2024). Long-Term Forecasting Using MAMTF: A Matrix Attention Model Based on the Time and Frequency Domains. Applied Sciences, 14(7), 2893. https://doi.org/10.3390/app14072893