
A Method for Underwater Biological Detection Based on Improved YOLOXs


Abstract
1. Introduction
- (1)
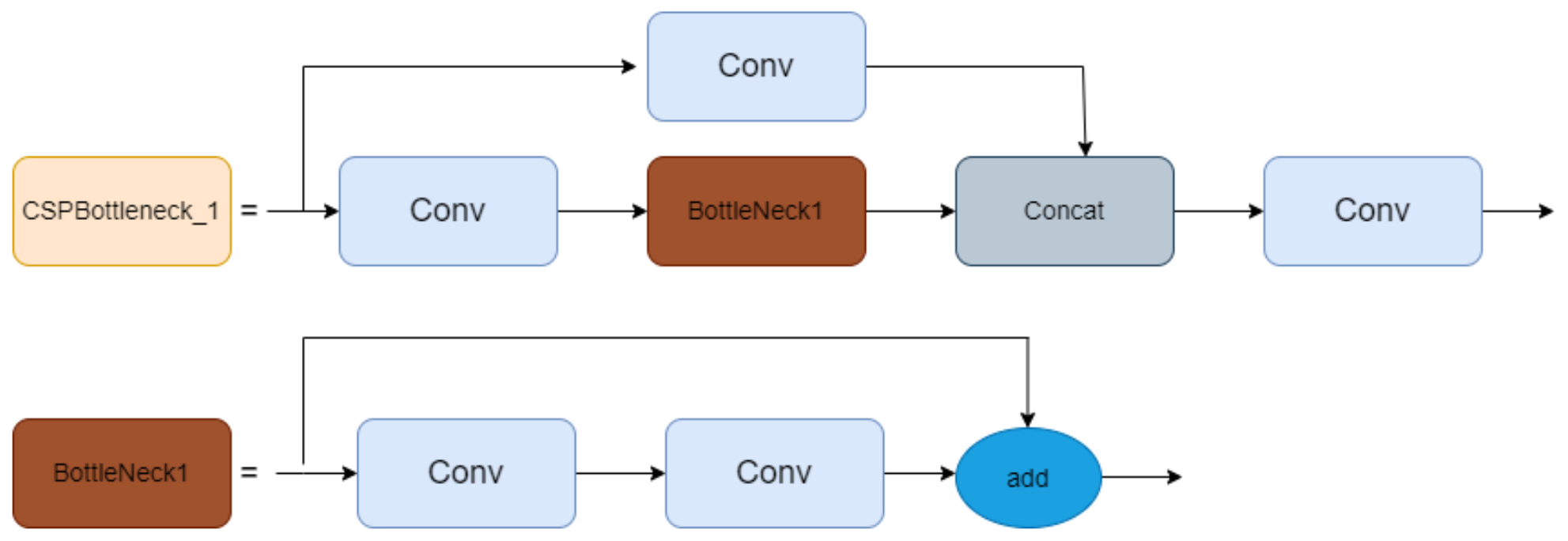
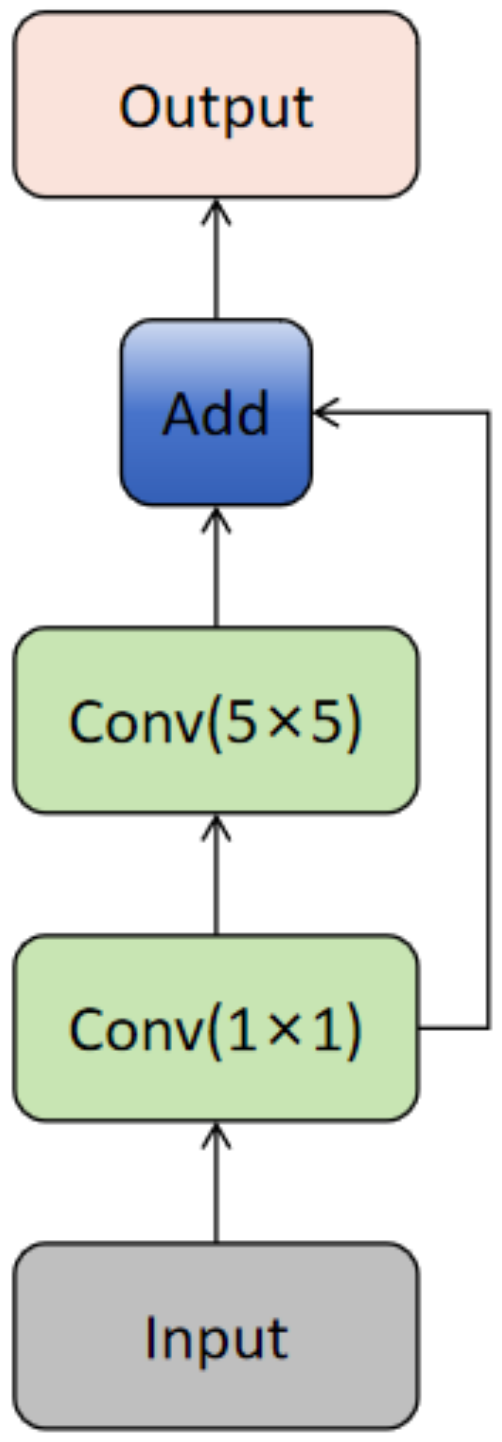
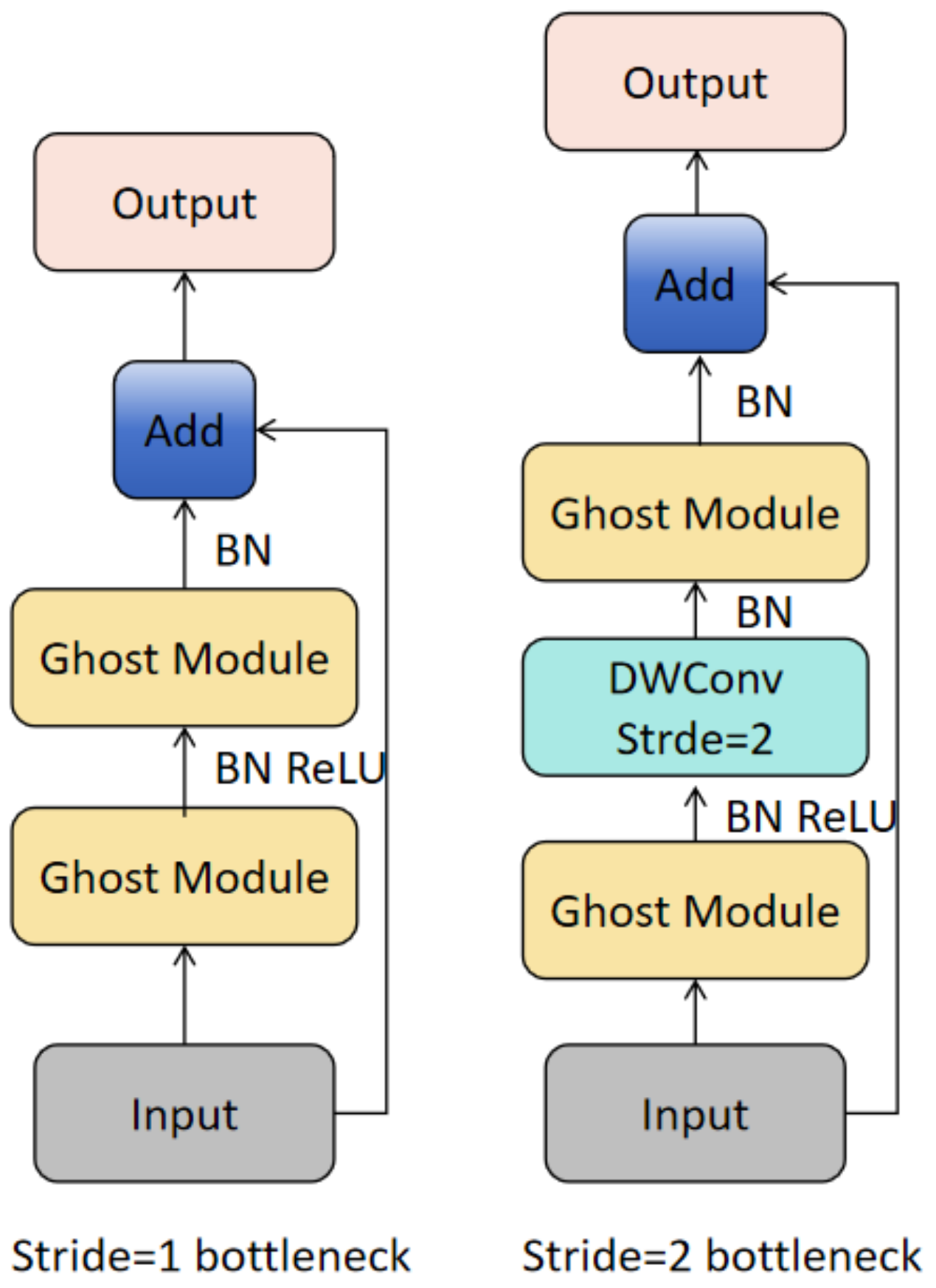
- In the backbone network, standard convolutions are replaced with Ghost convolutions, and Bottleneck1 is replaced with GhostBottleneck. This helps reduce the model’s parameter count and computational load, meeting the real-time requirements of underwater operations.
- (2)
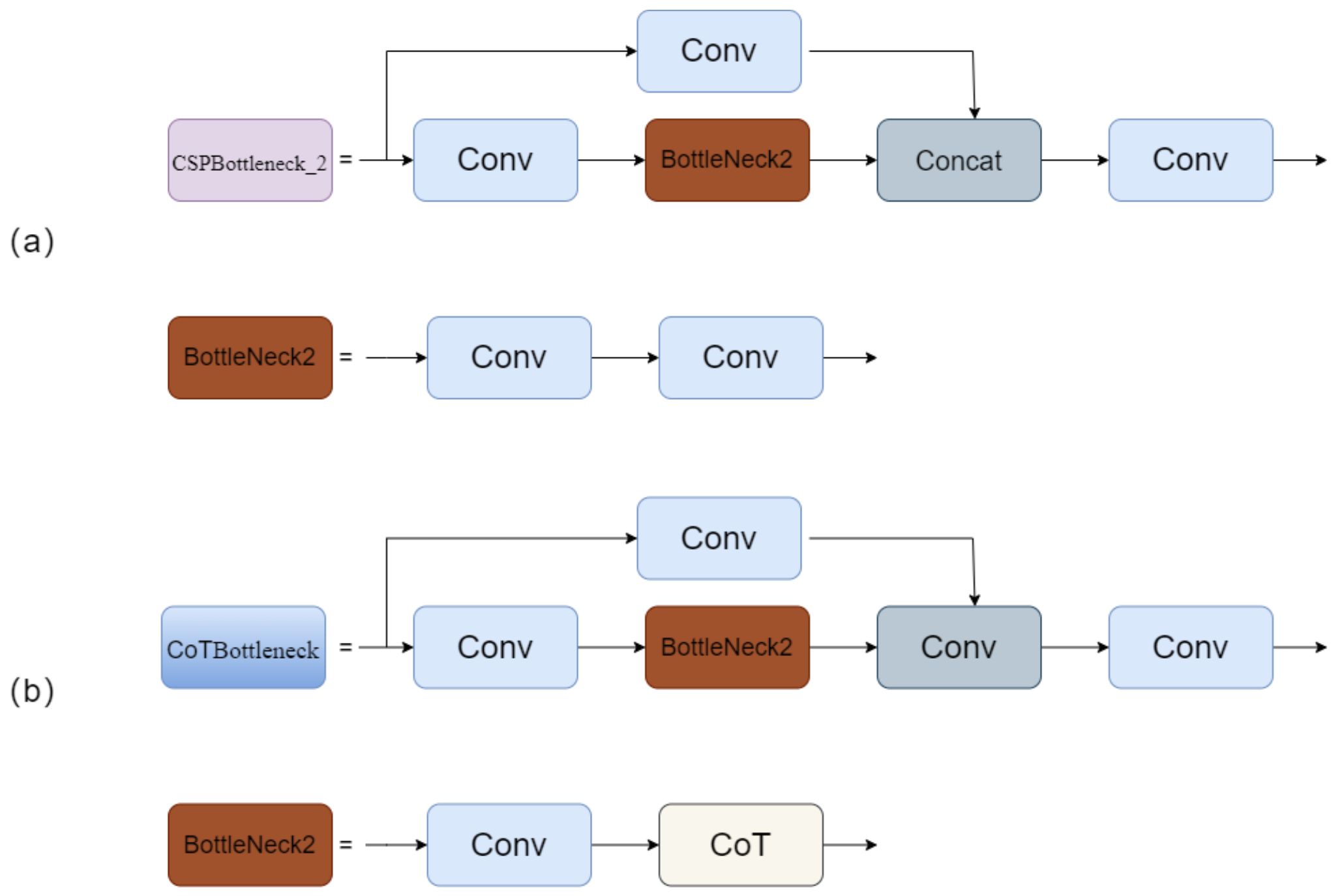
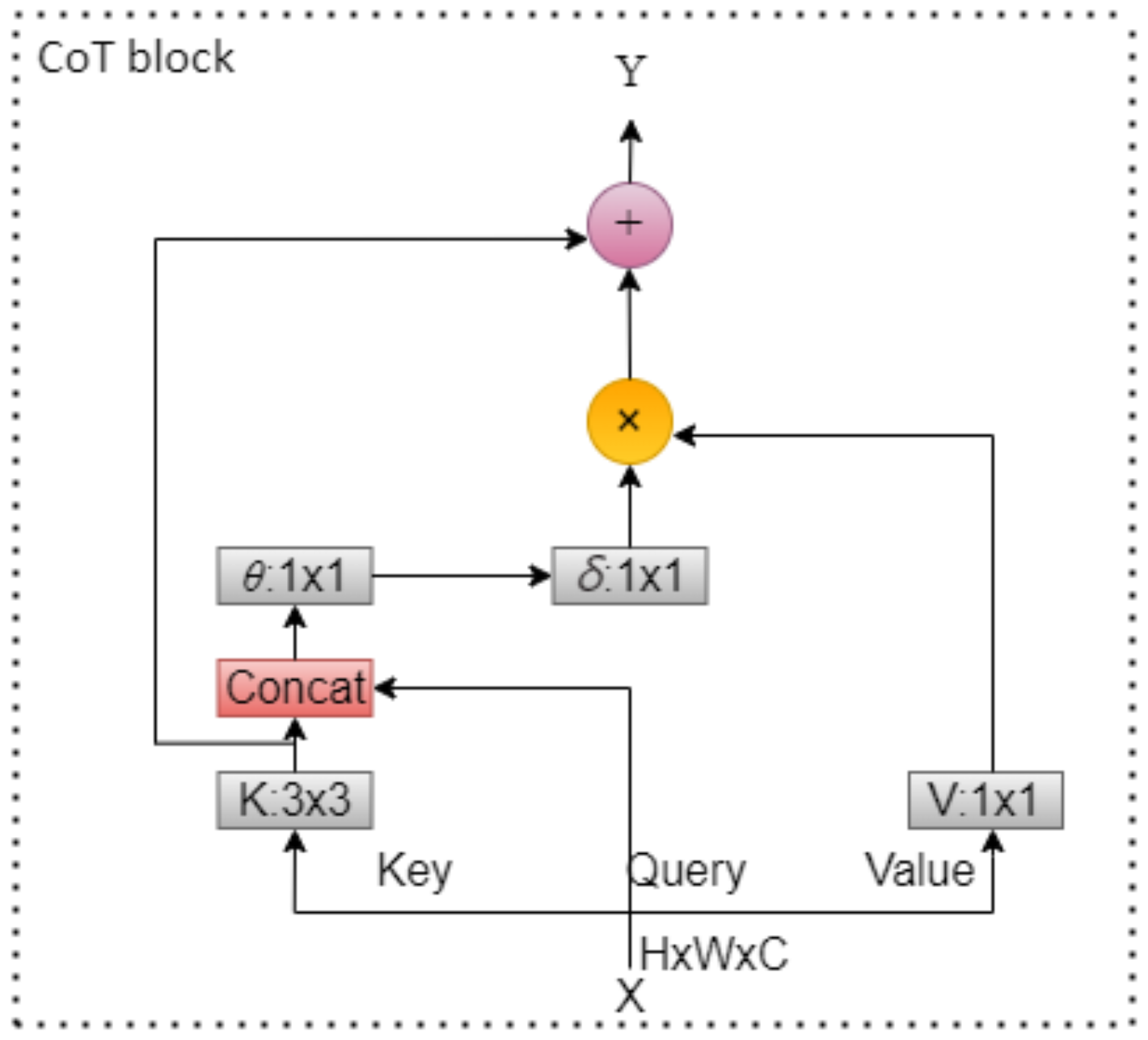
- In the feature fusion network, the Contextual Transformer module is introduced into CSPBottleneck_2, replacing the 3 × 3 standard convolution. This utilizes contextual information among input keys to guide self-attention learning, contributing to improved detection accuracy.
- (3)
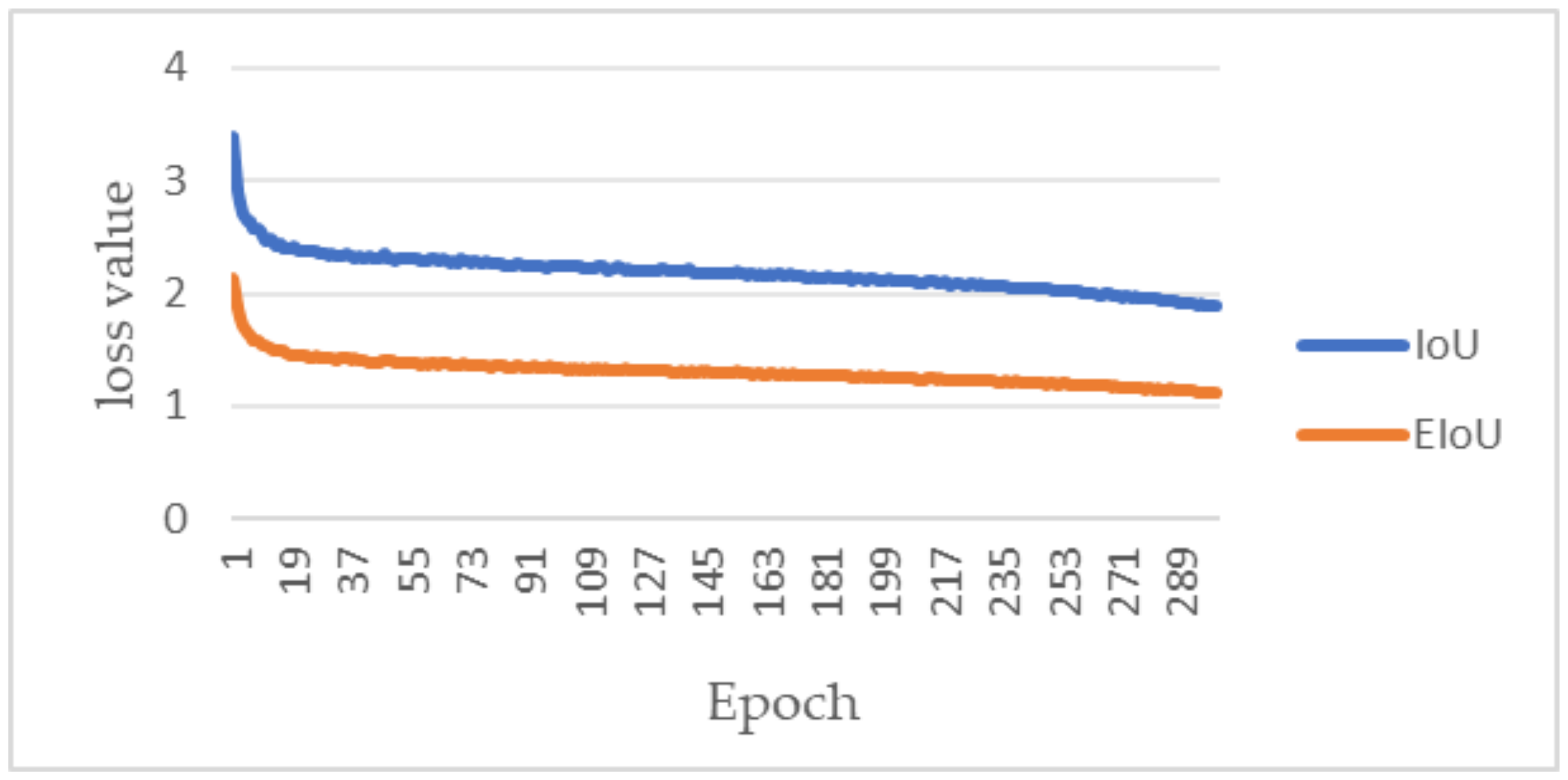
- Focal_EIoU Loss (Focal and Efficient Intersection over Union) is employed instead of IoU (Intersection over Union) Loss to enhance the precision of the predicted bounding boxes and accelerate model convergence.
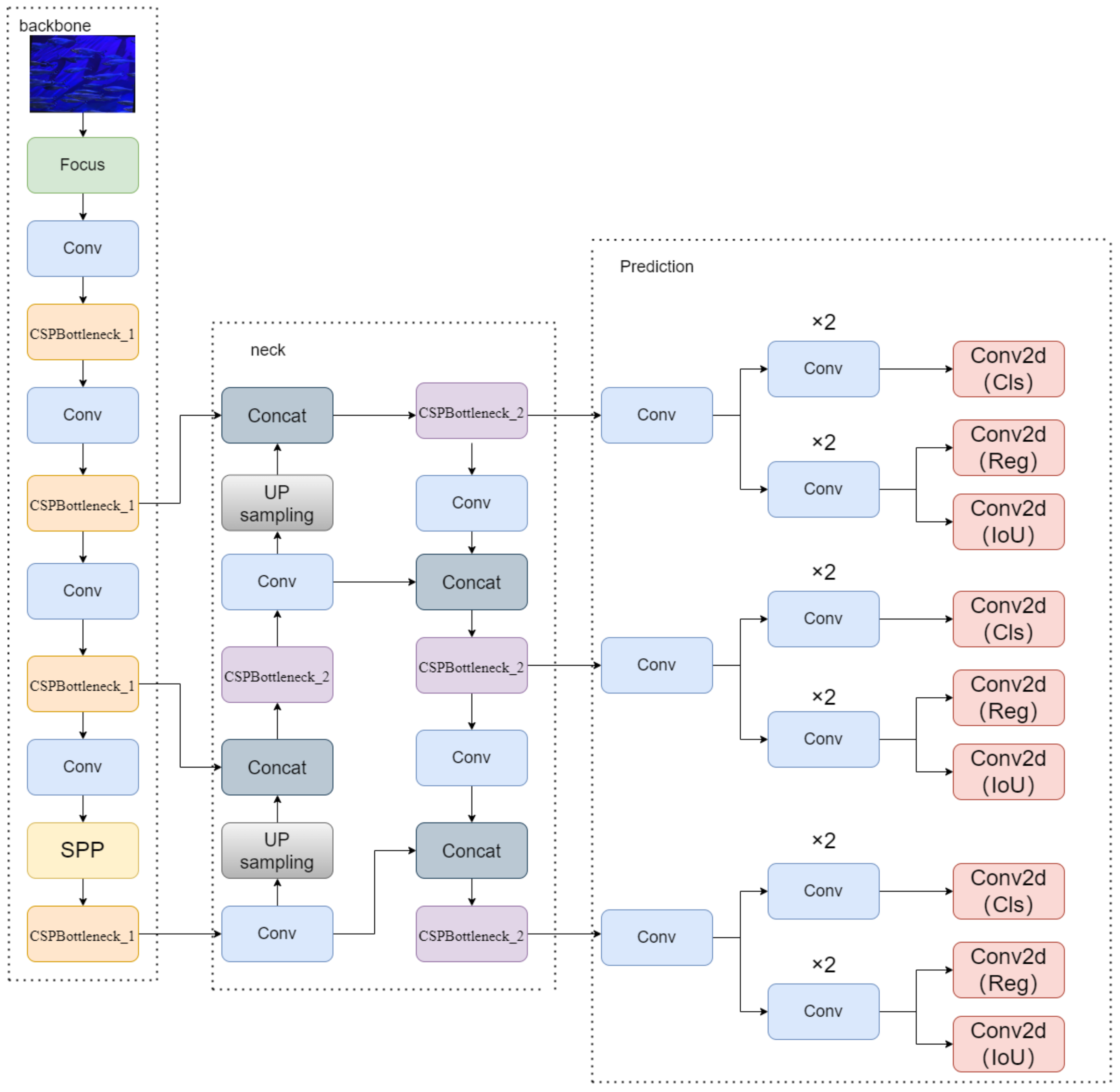
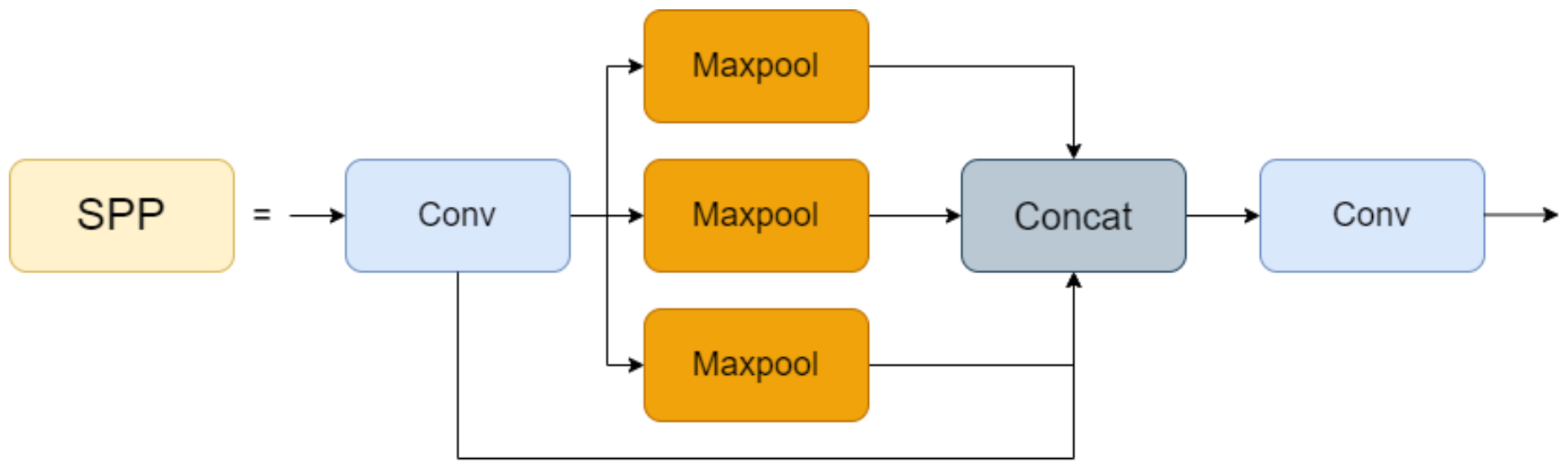
2. YOLOX Network Architecture
3. Methods
3.1. Improvement Strategies for the Backbone Network
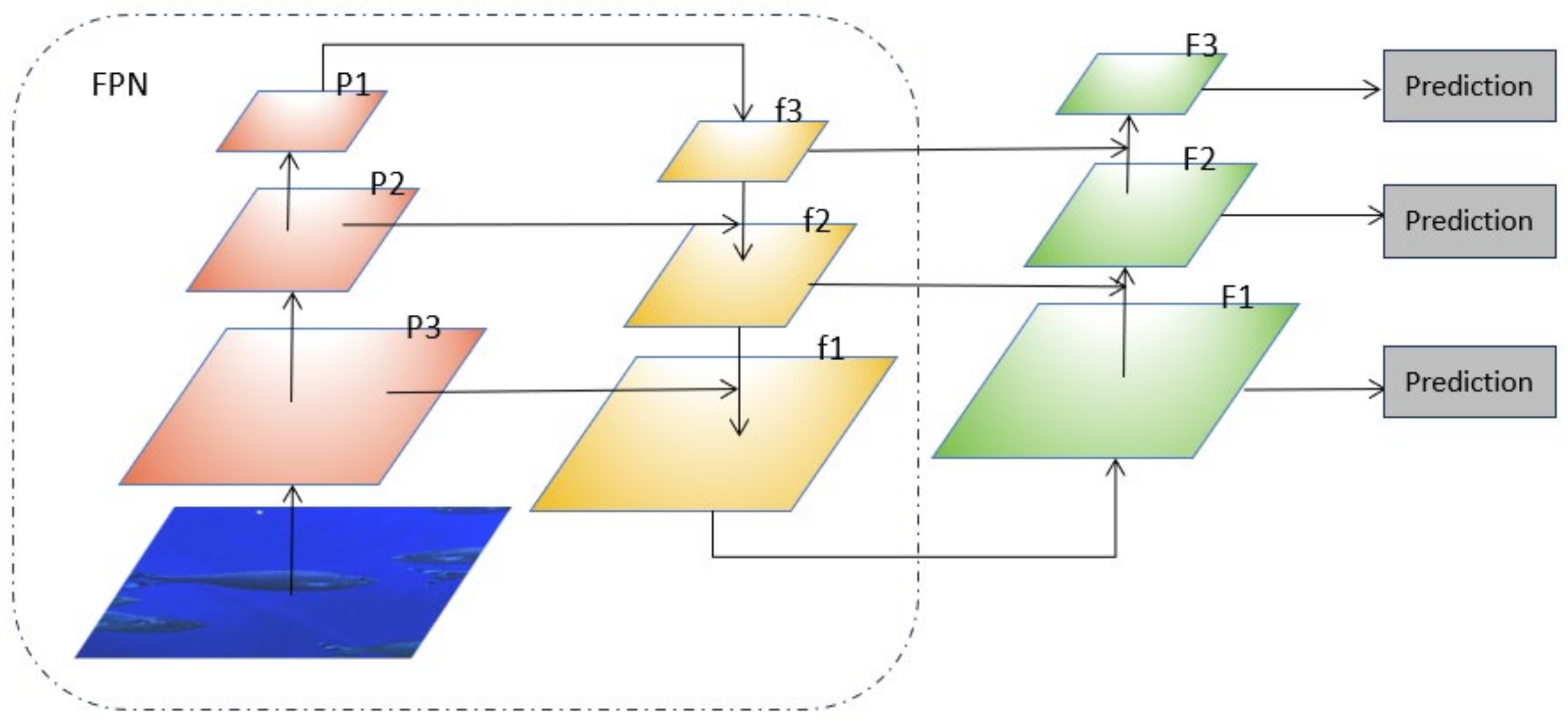
3.2. Feature Fusion Network Improvement Strategy
3.3. Loss Function Improvement
4. Experiments
4.1. Experimental Environment and Settings
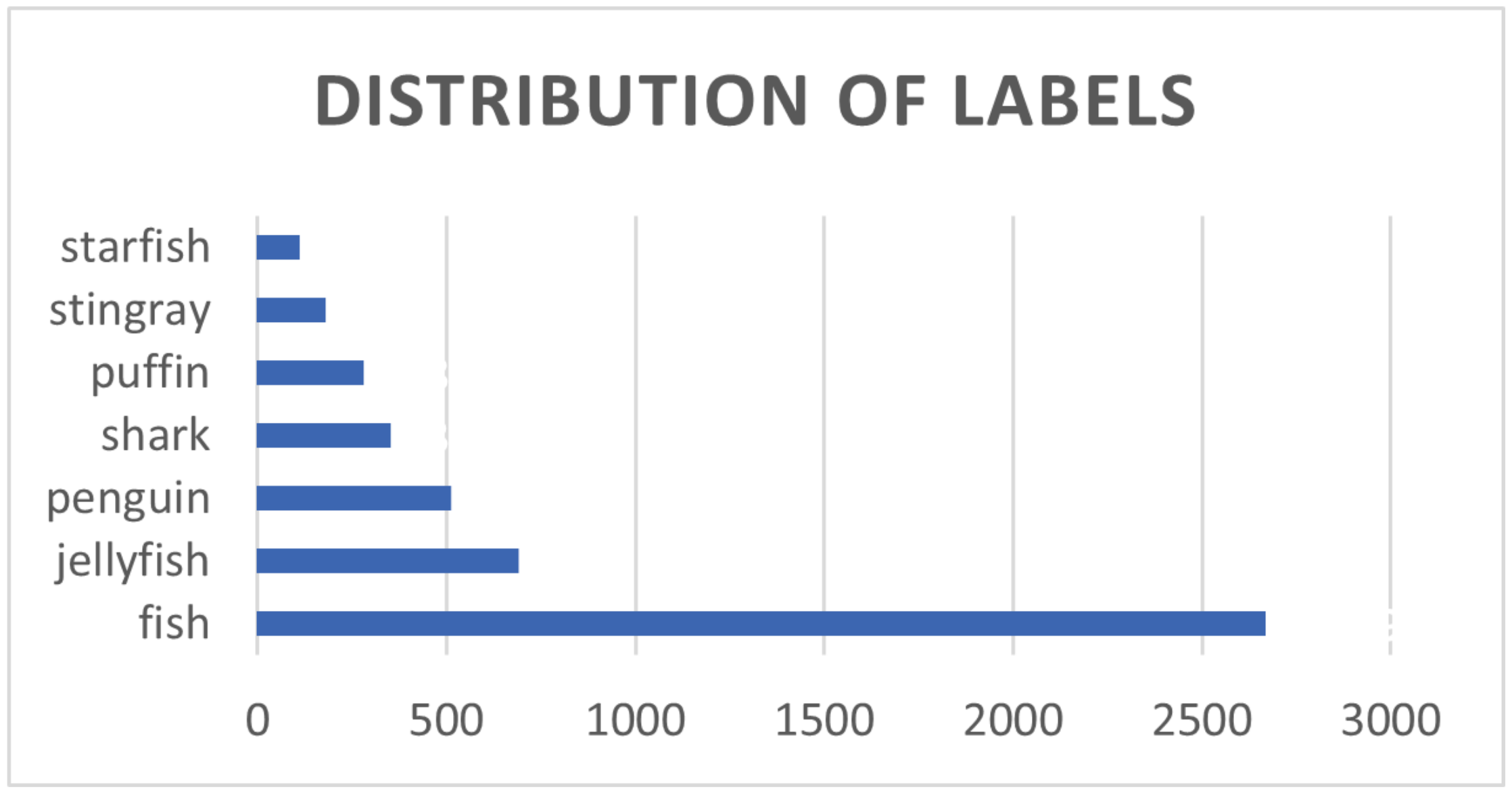
4.2. Introduction to the Experimental Dataset
4.3. Implementation Details
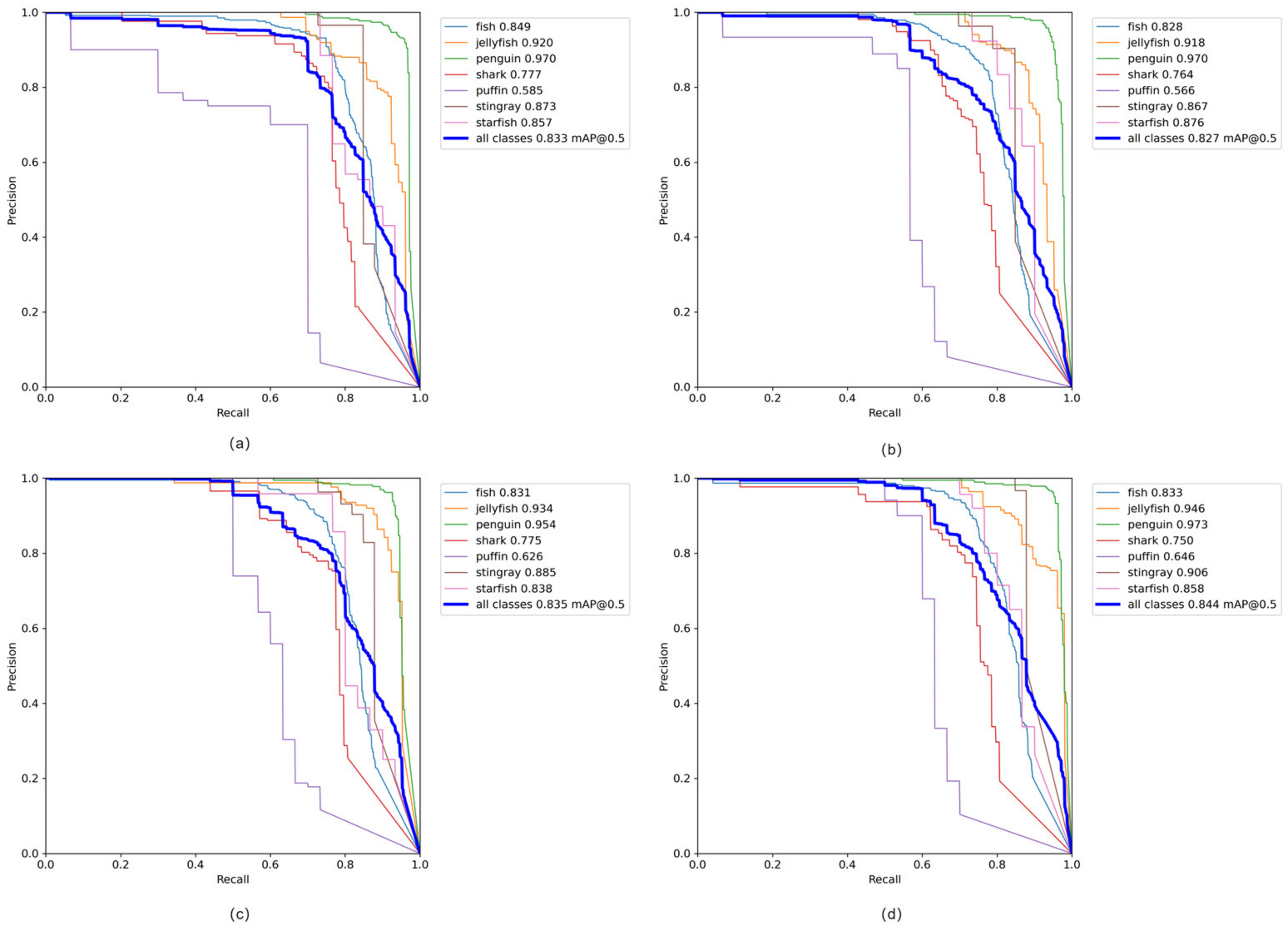
4.4. Ablation Experiments
4.5. Comparative Performance Analysis of Different Loss Functions
4.6. Cross-Sectional Comparative Analysis of Different Detection Models
4.7. Detection Performance Comparison and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, Y.Y. A Preliminary Exploration of the Current Status of China’s Marine Resources in the Perspective of Sustainable Development. Land Nat. Resour. Res. 2020, 2020, 37–38. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Chen, P.H.; Lin, C.J.; Schölkopf, B. A tutorial on v-support vector machines. Appl. Stoch. Models Bus. Ind. 2005, 21, 111–136. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Moniruzzaman, M.; Islam, S.M.S.; Lavery, P.; Bennamoun, M. Faster R-CNN based deep learning for seagrass detection from underwater digital images. In Proceedings of the 2019 Digital Image Computing: Techniques and Applications (DICTA), Perth, Australia, 2–4 December 2019; pp. 1–7. [Google Scholar]
- Jalal, A.; Salman, A.; Mian, A.; Shortis, M.; Shafait, F. Fish detection and species classification in underwater environments using deep learning with temporal information. Ecol. Inform. 2020, 57, 101088. [Google Scholar] [CrossRef]
- Liu, T.; Xu, C.; Liu, H.Z. Improved Underwater Object Detection Based on YOLOv3. In Proceedings of the 25th Annual Conference on New Technologies and Applications in Networking 2021, organized by the Network Application Branch of the China Computer Users Association, Lijiang, China, 29 October–1 November 2021; pp. 159–162. [Google Scholar]
- Huang, T.H.; Gao, X.Y.; Huang, C.D. Research on Underwater Object Detection Algorithm Based on FAttention-YOLOv5. Microelectron. Comput. 2022, 39, 60–68. [Google Scholar]
- Huang, M.; Ye, J.; Zhu, S.; Chen, Y.; Wu, Y.; Wu, D.; Feng, S.; Shu, F. An underwater image color correction algorithm based on underwater scene prior and residual network. In Proceedings of the International Conference on Artificial Intelligence and Security, Qinghai, China, 22–26 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 129–139. [Google Scholar]
- Yin, M.; Du, X.; Liu, W.; Yu, L.; Xing, Y. Multiscale fusion algorithm for underwater image enhancement based on color preser-vation. IEEE Sens. J. 2023, 23, 7728–7740. [Google Scholar] [CrossRef]
- Tao, Y.; Dong, L.; Xu, L.; Chen, G.; Xu, W. An effective and robust underwater image enhancement method based on color correction and artificial multi-exposure fusion. Multimed. Tools Appl. 2023, 84, 1–21. [Google Scholar] [CrossRef]
- Yin, S.; Hu, S.; Wang, Y.; Wang, W.; Li, C.; Yang, Y.-H. Degradation-aware and color-corrected network for underwater image enhancement. Knowl. Based Syst. 2022, 258, 109997. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, J.; Bo, L.; Li, H.; Zhang, H.; Zhong, Z.; Yuan, D. In Retinex based underwater image enhancement using attenuation compensated color balance and gamma correction. In Proceedings of the International Symposium on Artificial Intelligence and Robotics 2021, Fukuoka, Japan, 21–27 August 2021; SPIE: Bellingham, WA, USA, 2021; pp. 321–334. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. In Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Hariharan, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA; 2018; pp. 8759–8768. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2020; pp. 1580–1589. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient iou loss for accurate bounding box regression. arXiv 2021, arXiv:2101.08158. [Google Scholar] [CrossRef]
- Aquarium Combined Dataset > Overview. Available online: https://universe.roboflow.com/brad-dwyer/aquarium-combined (accessed on 1 July 2023).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Module | Params | Strides | Filters | Filter Size |
|---|---|---|---|---|---|
| 0 | Image | 3 | |||
| 1 | Focus | 3520 | 1 | 32 | 3 × 3 |
| 2 | Conv | 18,560 | 2 | 64 | 3 × 3 |
| 3 | CSPBottleneck_1 | 18,816 | 64 | ||
| 4 | Conv | 73,984 | 2 | 128 | 3 × 3 |
| 5 | CSPBottleneck_1 | 156,928 | 128 | ||
| 6 | Conv | 295,424 | 2 | 256 | 3 × 3 |
| 7 | CSPBottleneck_1 | 625,152 | 256 | ||
| 8 | Conv | 1,180,672 | 2 | 512 | 3 × 3 |
| 9 | SPP | 656,896 | 512 | ||
| 10 | CSPBottleneck_1 | 1,182,720 | 512 |
| Layer | Module | Params | Strides | Filters | Filter Size |
|---|---|---|---|---|---|
| 0 | Image | 3 | |||
| 1 | Focus | 3520 | 1 | 32 | 3 × 3 |
| 2 | GhostConv | 10,144 | 2 | 64 | 3 × 3 |
| 3 | CSPGhost | 9656 | 64 | ||
| 4 | GhostConv | 38,720 | 2 | 128 | 3 × 3 |
| 5 | CSPGhost | 43,600 | 128 | ||
| 6 | GhostConv | 151,168 | 2 | 256 | 3 × 3 |
| 7 | CSPGhost | 165,024 | 256 | ||
| 8 | GhostConv | 597,248 | 2 | 512 | 3 × 3 |
| 9 | SPP | 656,896 | 512 | ||
| 10 | CSPGhost | 564,672 | 512 |
| Category | Version Number |
|---|---|
| System | ubuntu20.04 |
| CPU | Intel Xeon Processor (Skylake) |
| Memory | 23 GB |
| GPU | NVIDIA GeForce RTX 3090 |
| Graphics memory | 24 GB |
| Python version | 3.7.0 |
| Deep learning framework | pytorch1.10.1 |
| Environment | CUDA11.4 |
| Parameters | Value |
|---|---|
| Optimizer | Adam |
| Initial learning rate | 10−2 |
| Momentum | 0.9 |
| Number of training rounds | 300 epoch |
| Input size | 640 × 640 |
| Index | Ghost Conv, Ghost Bottleneck | CoT Block | Focal_EIoU Loss | P/% | R/% | mAP@0.5/% | Params/M | FPS |
|---|---|---|---|---|---|---|---|---|
| 1 | 87.1 | 77.8 | 83.3 | 8.05 | 83.3 | |||
| 2 | √ | 90.6 | 74.7 | 82.7 | 6.08 | 77.1 | ||
| 3 | √ | √ | 86.7 | 76.6 | 83.5 | 6.06 | 65 | |
| 4 | √ | √ | √ | 90.8 | 77 | 84.4 | 6.06 | 64.4 |
| Index | Ghost Conv, Ghost Bottleneck | CoT Block | Focal_EIoU Loss | GFLOPs | Model Size/MB |
|---|---|---|---|---|---|
| 1 | 21.6 | 15.5 | |||
| 2 | √ | 15.9 | 11.8 | ||
| 3 | √ | √ | 15.9 | 11.8 | |
| 4 | √ | √ | √ | 15.9 | 11.8 |
| Model | mAP@0.5/% | Params/M | GFLOPs |
|---|---|---|---|
| Faster-RCNN | 80.7 | 41.15 | 20.32 |
| Cascade R-CNN | 79.1 | 68.94 | 22.34 |
| SSD | 70.4 | 24.55 | 34.59 |
| YOLOv3 | 76.4 | 61.56 | 19.40 |
| YOLOv5s | 78.9 | 7.04 | 16.0 |
| yolov7_tiny | 72.9 | 6.02 | 13.1 |
| Ours | 84.4 | 6.06 | 15.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Zhang, P.; You, M.; You, X. A Method for Underwater Biological Detection Based on Improved YOLOXs. Appl. Sci. 2024, 14, 3196. https://doi.org/10.3390/app14083196
Wang H, Zhang P, You M, You X. A Method for Underwater Biological Detection Based on Improved YOLOXs. Applied Sciences. 2024; 14(8):3196. https://doi.org/10.3390/app14083196
Chicago/Turabian StyleWang, Heng, Pu Zhang, Mengnan You, and Xinyuan You. 2024. "A Method for Underwater Biological Detection Based on Improved YOLOXs" Applied Sciences 14, no. 8: 3196. https://doi.org/10.3390/app14083196
APA StyleWang, H., Zhang, P., You, M., & You, X. (2024). A Method for Underwater Biological Detection Based on Improved YOLOXs. Applied Sciences, 14(8), 3196. https://doi.org/10.3390/app14083196