1. Introduction
Artificial neural networks are fundamental in processing information for decision-making across diverse domains like business, computing, and healthcare, drawing inspiration from the human brain’s structure and functions [
1,
2,
3,
4]. While effective in simple tasks such as classification, regression, or clustering, artificial neural networks face limitations with complex datasets [
2,
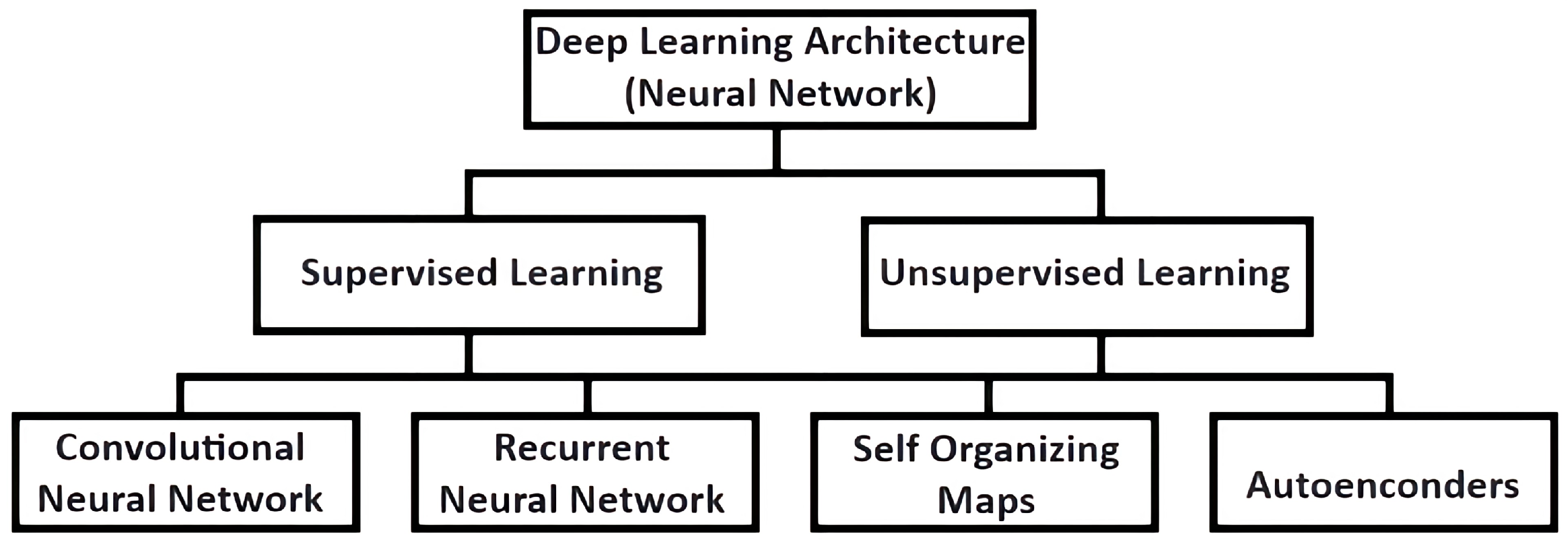
3]. Addressing these challenges, artificial neural networks have evolved into deep neural networks or deep learning, characterized by multiple neuron layers that enhance the ability to learn and represent intricate patterns [
2,
4]. Deep neural networks are equipped to solve more sophisticated problems than artificial neural networks, handling higher complexity data more effectively [
2,
4,
5,
6,
7].
Data analysis hinges on various critical factors, such as the problem’s nature, computational resources, dataset complexity, the model’s type (classification, regression, or clustering), and performance evaluation metrics. These elements necessitate thorough consideration by designers [
2,
3,
4,
6,
7], underscoring the significance of the designer’s experience in these decisions [
8].
In image-based data analysis, particularly for clinical pathologies, processing hinges on factors like small and imbalanced datasets [
9,
10], computational requirements [
11], and image quality [
12,
13]. The prevalent issue of class imbalance, often due to limited medical data [
14], can introduce statistical biases leading to result misinterpretations [
10]. This imbalance allows larger classes to disproportionately influence model predictions [
15], affecting model performance as highlighted in various studies [
16,
17]. Therefore, choosing appropriate metrics is crucial to accurately reflect model performance, especially in AI-driven models [
17].
Studies such as that of [
16] underscore the importance of metrics as confidence indicators in algorithms and methodologies. However, ref. [
17] critiques the misuse of performance metrics in classification models, while [
9] addresses the complexities in comparing AI models due to numerous balancing criteria.
In [
14], an interesting study is conducted regarding the scarcity of chest X-ray images, employing deep neural network-based models through transfer learning. Despite the use of metrics associated with the confusion matrix, they do not guarantee performance-related outcomes. Other studies have presented their results obtained with models developed from imbalanced data associated with clinical pathology images, showing promising results in terms of accuracy and other performance indicators, and they even specify the metrics used. In [
18], feature extraction from images for lung cancer classification is explored, using accuracy, precision, recall, specificity, and F1 Score to assess model performance.
In [
19], research focuses on developing classifiers using unprocessed images via transfer learning, with performance assessed through confusion matrix metrics against models from processed data, highlighting the underexplored area of image preprocessing necessity. Similarly, ref. [
20] examines lung nodule detection through transfer learning, utilizing confusion matrix-derived metrics. In [
21], a comprehensive review of lung cancer imaging is performed, detailing various evaluation metrics and pointing out the challenge of selecting the most appropriate one. In [
22], a systematic review of AI techniques in detecting and classifying COVID-19 medical images is presented, emphasizing the lack of studies on AI technique evaluation in classification tasks. Additionally, ref. [
23] explores an automated system using an artificial neural network for identifying key diabetic retinopathy features. Systematic reviews by [
24,
25] discuss the application of deep learning, particularly convolutional neural networks, in COVID-19 detection from radiographic images and deep-learning techniques in image analysis.
In all these studies and approaches, the versatility and applicability of artificial and deep neural networks in various tasks related to clinical pathology image processing are primarily emphasized. However, it is concerning that in most of the reviewed articles, insufficient attention is given to the proper use of evaluation metrics, particularly addressing issues stemming from data scarcity that can lead to imbalances in the processed datasets. In many works, results are summarized globally in terms of accuracy, while other metrics, such as sensitivity, specificity, and precision, derived from the confusion matrix and allowing for individual class prediction assessment, are often overlooked. This leads to a lack of comprehensive understanding of discrimination among different involved classes and the local influence each of them might have on the model’s performance.
It is relevant to highlight that in several of the previously mentioned works, which deal with sets of images related to clinical pathologies, reports are made on model predictions using only two defined classes from the dataset, even though, in many cases, the problem involves more than two classes. This lack of clarity regarding the effect of all classes during model training can also negatively impact the accuracy of the diagnoses issued. It is crucial to appropriately address model evaluation in class-imbalanced scenarios and consider the local influence of classes on model performance to achieve more reliable results in the detection and diagnosis of clinical pathologies.
To support and further enrich the foundation of this research, it is essential to delve deeper into information extracted from previous studies. An outstanding example can be found in the analysis conducted by [
26], where an exploration of chest X-ray images related to various lung pathologies is carried out. This study points out that pulmonary pneumonia can have viral or bacterial origins [
26]. This assertion is corroborated by consulting the public repository [
27], which effectively categorizes pneumonia images into the corresponding virus and bacteria categories.
On the other hand, another repository has been reviewed, such as the one presented in [
28], which has been used in the research by [
9]. These repositories contain images from nine categories of common signs of lung diseases, and the results obtained with the proposed methods are promising. However, it is important to note that they do not make clear distinctions between the different classes that cause pneumonia and their impact on the trained models. Additionally, ref. [
29] points out the possibility of confusing pneumonia with other conditions, such as bronchitis or cardiomegaly, among other diseases. The study focuses on the [
27] repository and does not differentiate between the classes causing pneumonia.
In summary, in situations involving multiple classes, it is necessary to incorporate all of them into the model training and validation process, giving significant importance to the analysis of specific metrics for each category. It can be understood from [
10] that, in most cases, individualized evaluation for each class is highlighted as the most informative and comparative strategy, which can lead to superior results in model training. This aspect is crucial in this research because, even though pneumonia is clearly distinguished into two classes, the cited works group it into a single class as “pneumonia” and do not provide information on how these classes have influenced the training process locally, nor do they report the influence of classes on the results in the test sets used to validate their models.
Finally, in all these studies reporting good results, there is no clear analysis of the impact of classes on the model’s performance or the effect of sample imbalance by classes in the treated clinical image datasets. In this context, this work aims to demonstrate how sample imbalance in a dataset can significantly affect the informativeness of metrics when making global-level predictions. To achieve this, the following objectives are proposed:
Develop effective image classification models for lung pathology using artificial and deep neural networks, implementing available algorithms in R packages.
Evaluate the effectiveness of the image classification models for lung pathology developed with artificial and deep neural networks using confusion matrix metrics provided by R packages.
Identify models that achieve the highest overall accuracy rates and record specific metrics for each class.
Compare global metrics with local metrics to demonstrate how sample imbalance in a lung pathology-related dataset can have a significant impact on the interpretation of global-level metrics.
The a priori selection of metrics provided by the confusion matrix is based on its ability to inform not only about the overall predictions generated by a classification model but also about point predictions or predictions by class [
15,
30]. Several studies have already used the confusion matrix to measure the effectiveness of classification models [
15,
31], although few of them employ this method to compare the effectiveness of different classification models [
15].
The confusion matrix is not only used to measure the efficacy of models in the analysis of clinical pathologies but has also been extensively examined in numerous studies that make direct use of its metrics or combinations thereof. Authors such as [
10,
16,
17,
32,
33] highlight various aspects of performance evaluation, focusing on this metric among others. They share a common view on its applications and the limitations it presents in contexts with imbalanced clinical data.
Among the metrics used, overall accuracy serves to indicate the proportion of correct predictions in relation to the total number of cases. However, its effectiveness can be compromised in situations where a specific class dominates. Sensitivity and specificity, derived from the confusion matrix, are established as standards in medical evaluations to determine the model’s ability to identify positive and negative cases, respectively, although specificity may be insufficient in contexts with class imbalance. The AUC (Area Under the Curve) provides a comprehensive assessment of the model’s performance across various decision thresholds but may not fully address deficiencies in the classification of minority classes in unbalanced environments. Additionally, the F1 Score is considered, which attempts to balance precision and sensitivity, although it may not always effectively reflect efficacy across all classes in unbalanced datasets. The IoU metric compares the overlap of model predictions with actual annotations, being susceptible to biases towards more frequent classes, which can result in high IoU for these classes and low for less common ones. Regarding MAP, this metric assesses detection accuracy at different thresholds and can be negatively affected in unbalanced contexts if the model favors the detection of the majority class, especially when all classes contribute equally to the calculation of MAP. Metrics such as MSE (Mean Squared Error) and MAE (Mean Absolute Error), common in regression models, are also analyzed, which may not fully capture the impact of inaccurate predictions on minority samples in the presence of class imbalance.
To maintain consistency and avoid ambiguities with different authors, in this study, efficiency is defined as a model’s ability to achieve high accuracy rates. In turn, the accuracy rate is defined as the number of samples predicted correctly out of the total number of samples. This measure is commonly referred to as precision and is part of the various metrics provided by the confusion matrix [
30]. It can be measured either globally, considering all the samples predicted correctly, or locally when examining a particular class [
15]. The definitions provided will later be used to understand the qualitative evaluation based on the metrics from the confusion matrix obtained from the quantitative results when testing the dataset associated with lung pathology images after the models have been trained.
The structure of the remainder of this work is organized as follows.
Section 2 presents the materials and methods.
Section 3 focuses on the results and their analysis.
Section 4 is dedicated to a discussion of the results in contrast to other findings. Finally,
Section 5 covers the conclusions and future work.
3. Results and Analysis
In this section, the results obtained from processing the set of images associated with lung pathologies using the different classification models generated, as indicated in
Section 2.8, are presented. This was done using the R packages discussed in
Section 2.4. All models were evaluated according to the metrics outlined in
Section 2.5. The experiments conducted aim to demonstrate how sample imbalance in a dataset can significantly affect the informativeness of metrics when making predictions at a global level.
3.1. Results and Analysis for One Layer
In this preliminary exploration using various R packages, the challenge lies in determining the optimal number of neurons in the hidden layer and other aspects of network topology to achieve high accuracy rates in both training and testing. The objective is to achieve high accuracy values both in training and testing or at least to approximate those found in related works involving image datasets associated with lung pathologies discussed in this study. Notably, not every combination of neurons can achieve this, but due to the lack of clear guidelines, empirical rules are utilized, suggesting that the number of neurons in the hidden layers should fall within the range defined by the neuron counts of the input and output layers. Experimentation plays a crucial role in determining the best configuration.
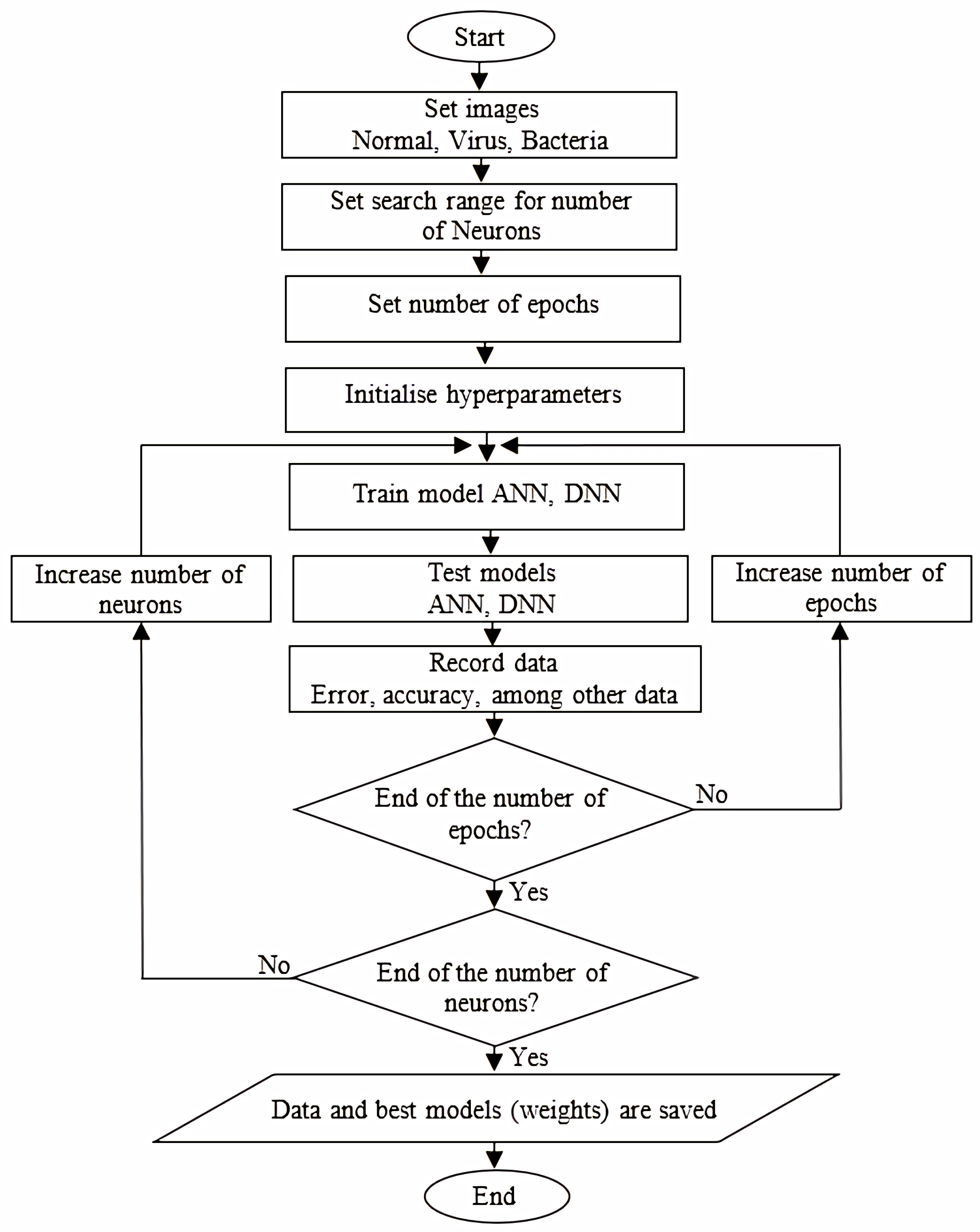
To address this issue, an exploratory experiment was conducted aiming to find the optimal number of neurons in the hidden layer, varying this parameter from 10 to 500 neurons. The increments were made in intervals of 10 neurons up to the first 100 neurons and increments of 50 neurons thereafter. Each increase in the number of neurons was accompanied by training epochs ranging from 1 to 100. For a clearer understanding of the experiment,
Figure 9 can be referred to, which depicts the flowchart. With each increase in neurons and epochs, information was gathered to analyze the generated models. Additionally, experiments were conducted with both balanced and unbalanced data, seeking optimal cases for each package from among 1900 possibilities.
Table 1 presents a summary of the outstanding results, focusing on the overall accuracy achieved in the training set as the primary evaluation criterion. These results are detailed in Column 6. Additional training details are observed in Columns 2, 3, 4, and 5, such as the search range established to determine the number of neurons in the hidden layer, the type of dataset used (whether balanced or imbalanced), the specific number of neurons set to achieve the best result, and the training epochs, respectively.
It should be noted that when analyzing different packages, the overall accuracy in the training set is consistently higher when the dataset is unbalanced. Contrast Columns 1, 3, and 6 of
Table 1 to verify this. As mentioned in
Section 2.5, the overall accuracy during training reflects how well patterns from the training data have been captured by the model, although it may not provide information on the model’s performance on new data.
Analyzing the models’ performance on new data, one can observe the overall accuracy in the test set in Column 7, indicating that it is also consistently higher when the dataset is unbalanced. In this initial experiment, it is evident that the best-performing model was generated using the Keras package with convolutional layers, achieving an 80% overall accuracy on new data. While this value is respectable, it does not truly inform about the model’s performance concerning the individual classes present. In other words, an 80% overall accuracy on new (test) data suggests that out of every 100 samples analyzed by the model, 80 were correctly predicted. However, the following crucial question arises: does this hold true for all samples? According to the results obtained in this initial experiment, it becomes apparent that this is not the case.
To demonstrate this, the total number of processed labels during testing, as well as the number of actual and predicted labels for samples of normal (N) pathologies, viruses (V), and bacteria (B), are recorded from Column 8 to Column 15. Based on the provided information, the Keras package is analyzed in its implementation version for convolutional layers (see keras_cnn in Row 11 of
Table 1), where an 80% overall accuracy in testing has been achieved. However, this model predicted 380 samples with normal labels when there were actually 373. It also predicted 90 and 167 samples with virus and bacteria labels, respectively, when there are actually 118 and 146 of each. These results do not align adequately with the observed overall accuracy of 80% in the tests, as there would be an expectation to see 298, 94, and 116 respective samples for the labels involved.
While the initial analysis focuses on the highest-performing model, the assessment of alternative models reveals that the overall accuracy achieved in tests does not provide a comprehensive representation of predictive performance by class. Referencing the Deepnet package, which achieves an overall accuracy of 65% in evaluations (see Deepnet in Row 2 of
Table 1), a predisposition towards identifying features associated with normal pathology samples is detected, resulting in 451 predictions for this category, despite there being only 373 actual samples. Furthermore, this model shows an inability to identify bacterial pathology samples, failing to predict any of the 146 samples belonging to this classification. This discrepancy between observed results and the indicated overall accuracy of 65% suggests that evaluation metrics do not adequately reflect specific predictive performance by category, with distributions of 242, 76, and 94 samples for the respective labels being expected.
Exploring more alternative models is feasible; however, the inclination towards ineffective predictions indicated by the overall accuracy will continue to be misleading. This stems from its fundamental inability to elaborate on the predictions made by the model for each class, a limitation consistently observed across all implementations with
R packages. Additionally, a discrepancy has been noted in the results presented in
Table 1, marked by figures that exceed the actual quantities of predicted labels. This phenomenon suggests the existence of underlying causes presented below:
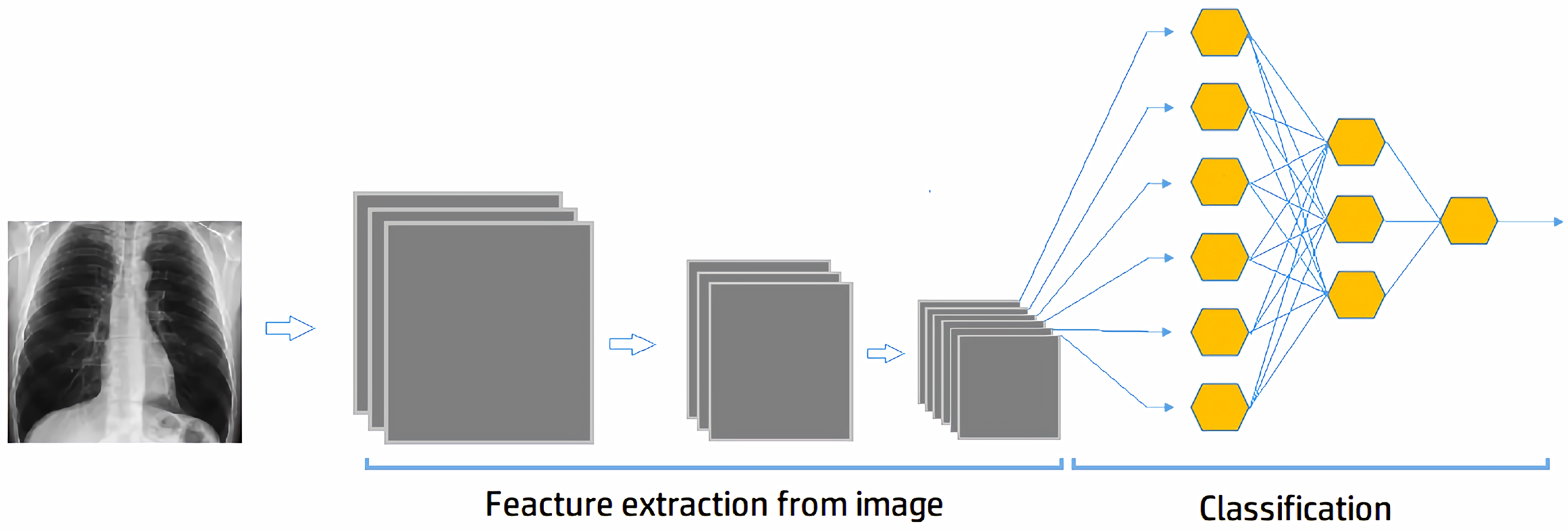
The number of dimensions handled per image. Despite preprocessing that reduces the image set to 900 features, it is high for certain neural networks, limiting their ability to map patterns effectively. However, improved mapping is observed for neural networks developed with the Keras package, especially when working with convolutional layers. In this case, pattern extraction is more efficient because convolutional layers do not specialize in individual pixels but rather in their spatial distribution, as discussed in
Section 2.3.
The topology. The experiments in this first part involve only a single layer. This can be addressed by increasing the number of layers, which will be tested in subsequent phases.
The selection of hyperparameters. The neural networks handled by the various packages used in this work allow for the selection of multiple hyperparameters. To keep the experiments less complicated, tests were conducted with the default hyperparameter settings, and adjustments were made only in cases where contrasting results were not achieved or when the tests consumed a significant amount of time (see
Section 2.4).
The established epochs for training. The pattern of inefficient predictions observed in all models developed with the R packages may be a result of the limited training, which barely reaches 100 epochs in this initial experiment. During each epoch, the different neural networks need to process and extract information from the images to update their weights; however, 100 epochs may not be sufficient for this task. To address this limitation, subsequent experiments will involve training the best-performing models with more epochs to achieve more robust results.
The number of neurons per layer. Not only the number of layers or topology, as it is often called, can affect the effectiveness of a neural network, but also the number of neurons per layer. However, the optimal models for a single layer have already been presented in
Table 1, where the number of neurons can be observed in Column 4.
The dataset used. In the introduction, it has been noted that the dataset can significantly impact the model’s performance, including class balance. In this initial experiment, these variables have been controlled. Although the dataset was initially unbalanced, during preprocessing, the quantities of images per class were equalized. The summary in
Table 1, particularly in Columns 3, 6, and 7, enables a comparison to understand the data balance’s influence.
Based on the preliminary discussion and the data from
Table 1, a second experiment is conducted using the best models, selected based on the highest values of overall accuracy in both the training and testing sets (see Columns 6 and 7 of
Table 1). This entails considering only the models trained with unbalanced datasets (see Column 3 of
Table 1). However, not all selected models allowed for the second experiment, so their results are not displayed in
Table 2.
Table 2 summarizes the data obtained after 1000 training epochs and testing for these models. The model selected from
Table 1 and the overall accuracy achieved after completing the 1000 training epochs are shown in Columns 1 and 6, respectively. An increase in overall training accuracy is observed in all models. Regarding overall test accuracy, the Keras_30, Keras_150, and Keras_cnn_40 models show improvements, Kera_cnn_450 remains unchanged, and Neuralnet_100 experiences a 2-point decline. However, upon analyzing the record from Columns 8 to 16, an improvement in some classes is reflected, although it is noted that overall accuracy in testing does not truly reflect the model’s performance in relation to the individual classes present.
This is confirmed in
Table 3, where metrics per class obtained from the testing data after completing the 1000 training epochs are presented. These metrics are derived from the confusion matrix introduced in
Section 2.5 using the Caret package in R. In
Table 3, from Columns 8 to 15, sensitivity, specificity, and precision metrics are shown for each class normal (N), virus (V), and bacteria (B), respectively.
The analysis of these metrics reveals a bias in the models’ prediction towards the normal class, demonstrated by higher sensitivity and precision for this class, while specificity is more conservative.
A deeper analysis of the overall accuracy in tests reveals its limitation in reflecting the performance of class-specific predictions for each model, as demonstrated by cross-referencing data from
Table 1 and
Table 2, which are detailed in
Table 4. This table includes, in its first two Columns, the evaluated models and their respective training epochs, while the third column displays the overall accuracy in tests for each model. Columns 4, 7, and 10 detail the actual quantities of labels per class, and Columns 5, 8, and 11 present the class label estimates derived from the overall test accuracy. Considering the keras_30 model (see Row 1 of
Table 4), with an overall accuracy of 71%, one would expect approximately 264, 83, and 103 samples for the classes of normal (N), virus (V), and bacteria (B) samples, respectively. However, Columns 6 and 9 reveal that this model predicted 450 and 187 samples for the N and V classes, respectively, and made no predictions for the B class, as shown in Column 12. The percentages contrasting overall test accuracy against class-specific accuracy are examined in Columns 13 to 18, providing a detailed perspective on the observed discrepancies.
An additional example highlighting the limited capability of overall test accuracy to reflect class-specific performance is observed in the keras_cnn_40 model (see Row 7 of
Table 4). Upon analyzing this model, which achieves an overall accuracy of 81% in tests,
Table 4 provides estimates of 302, 95, and 118 samples for the examined classes based on their respective quantities. However, the actual predictions per class are 359, 67, and 92. Therefore, it would be inaccurate to claim that this model achieves an 81% accuracy in class prediction, as the actual class-specific prediction percentages are 96.25%, 56.78%, and 63.01%, thus demonstrating the limitations of using a global metric as an indicator of detailed class performance.
This analysis concludes by highlighting a significant discrepancy between the overall accuracy in tests and the class-specific accuracy within models. It is emphasized that a high level of overall accuracy does not necessarily ensure equitable performance across all classes. Models exhibit considerable variability in predicting labels for specific classes, suggesting that overall accuracy might mask significant shortcomings in class-specific accuracy. Additionally, phenomena such as overfitting and targeted improvements in the prediction of particular classes are not necessarily reflected in the overall accuracy. This underscores the importance of conducting a detailed evaluation of class-specific performance to gain a comprehensive understanding of a model’s effectiveness, particularly in situations where maintaining a balance among classes is crucial.
3.2. Results and Analysis for Two Layers
In this exploratory experiment, an additional layer is introduced to create a two-layer structure within the topology. Unlike the previous experiments detailed in
Section 3.1, Deepnet is excluded here due to its inability to produce results comparable to other packages. This limitation stems from its incapacity to handle the 900 features (dimensions) remaining after image preprocessing. Consequently, the evaluation is narrowed down to the Neuralnet, RSNNS, and Keras packages. The aim is to achieve high accuracy values in both training and testing, which requires determining the optimal combination of the number of neurons per layer, ranging from 50 to 300 in increments of 50 neurons. A total of 100 training epochs are maintained for each combination of neurons in the layers, and then the collected information is analyzed.
In contrast to the first experiment, the search is restricted to 36 cases per
R package for both balanced and unbalanced data.
Table 5 provides a summary of the best results found over 100 training epochs, including an additional column for the neurons in the second layer for each model. A slight improvement in overall accuracy is observed in the training set for some models, but it remains consistently higher when the data are unbalanced.
Regarding the accuracy in the test set, it does not reveal a significant improvement compared to the previous scenario, except for some models. For this reason, the best models undergo an additional 1000 epochs of training. A summary of the information obtained, including the metrics of interest, is presented in
Table 6.
Again, the overall accuracy in training after 1000 epochs corresponds to models implemented with unbalanced data, with those implemented using the Keras package, including its two models with convolutional layers being better (see Column 7, Rows 2, 4, and 5 of
Table 6). As for the test accuracy, the best model achieves 79%, which is keras_cnn_100_150 implemented with convolutional layers.
For this overall accuracy value in tests or any other reported in
Table 6, it is feasible to apply an analysis similar to the one conducted in
Section 3.1. This analysis demonstrates the limited informative capacity of this global metric to reflect class-specific sample predictions. For instance, based on the expectation generated by a 79% accuracy in tests, one would anticipate 294, 93, and 115 samples, respectively, for each assessed class. However, as detailed class accuracy in Row 4, Columns 15, 16, and 17 of
Table 6 indicates, the actual predictions reach 96%, 52%, and 58%, corresponding to 358, 61, and 84 predicted samples, respectively, for the involved classes. This discrepancy from the estimates provided by the global accuracy underscores, once again, that global metrics do not provide a faithful overview of class-specific predictions of a trained model.
The analysis of overall accuracy versus class-specific accuracy in models such as keras_250_300 and keras_cnn_100_150 reveals a significant contrast, with high success rates in training that do not directly translate into effective generalization during testing, where accuracy notably decreases. This phenomenon is accentuated when examining class-specific accuracy, where despite high percentages being achieved in class N, classes V and B display considerably lower accuracies, highlighting inequalities in the model’s predictive capability. Furthermore, the comparison between models trained with balanced and unbalanced data indicates that although data balancing may not optimize overall accuracy, it promotes a fairer distribution in the detection of all classes, improving equity in classification. Sensitivity and specificity by class complement this picture, showing that a high ability to identify true negatives does not necessarily ensure equitable detection of all positive classes, underscoring the need for strategies that promote balanced and effective performance in class-specific classification of the developed models.
3.3. Results and Analysis of Layers Three and Four
In these experiments, a comprehensive exploration of the Neuralnet, RSNNS, and Keras packages is conducted to identify the most effective model in terms of 3 and 4-layer topologies, focusing exclusively on the unbalanced dataset. In accordance with the methodology of prior experiments, the aim is to achieve the optimal neuron configuration in each layer to attain high accuracy in both training and testing phases by adjusting this parameter across a range from 50 to 300, with increments of 50 neurons. These experiments examine 216 and 1296 possible cases for 3 and 4 layers, respectively.
After completing 100 training epochs for each combination of neurons in the 3 and 4-layer topologies, meticulous data collection was carried out for subsequent analysis. The best models were selected at the end of the 100 epochs and subjected to additional training of 1000 and 3000 epochs. A summary of the metrics obtained is shown in
Table 7 and
Table 8, along with the results of the 2-layer topology for comprehensive comparison. It is important to mention that the Neuralnet and RSNNS packages only completed 100 and 200 training epochs, respectively, so they are labeled as only_100 and only_200 in the epoch column in the tables because they did not show significant improvements with an additional 1000 epochs.
A comprehensive evaluation of models trained with 1000 and 3000 epochs reveals crucial insights into the balance between fitting to training data and generalizing to unseen data sets. Primarily, it is observed that increasing the number of epochs improves accuracy during training; however, this improvement is not proportionally reflected in the accuracy of tests, indicating a tendency towards overfitting in extensively trained models. Specifically, sensitivity by class tends to increase slightly with more training epochs for class N, although classes V and B continue to experience relatively low sensitivities, highlighting persistent challenges in impartial classification across all categories.
Furthermore, the high specificity in all models, regardless of the number of epochs, suggests a robust competence in correctly identifying true negatives. However, accuracy by class does not show significant improvements with the increase in epochs, underlining that effective detection of true negatives does not directly translate into an enhanced ability to accurately classify all classes.
Crucially, the model architecture, especially the inclusion of convolutional layers and a balanced distribution of neurons in the keras_cnn models, stands out as a determinant factor in effective generalization. This finding highlights the importance of optimal model architecture and suggests that appropriate neuronal configuration strategies are essential for enhancing the overall performance of the model.
The analysis also underscores that a greater number of training epochs does not necessarily guarantee an improvement in the capacity for generalization, highlighting the challenge of overfitting, especially in models trained for 3000 epochs. This emphasizes the need to adopt a nuanced approach in model design and in the implementation of effective strategies to combat overfitting.
Finally, the importance of meticulously balancing the fit to training data with the ability to effectively generalize to new data is highlighted. Optimizing the model architecture, including the strategic selection of convolutional layers and neuronal configuration, along with a careful approach to training duration, emerges as crucial for achieving optimal performance. This synthesis of findings emphasizes the relevance of a detailed and holistic evaluation of model performance, which goes beyond overall accuracy to include sensitivity, specificity, and accuracy by class, thus ensuring robust and equitable classification systems.
3.4. Additional Results and Analysis
In
Section 3.2 and
Section 3.3, a comprehensive analysis of the Neuralnet, RSNNS, and Keras packages was conducted to determine the most effective model for 2, 3, and 4-layer topologies, with a specific focus on imbalanced datasets. The optimal combination of neurons in each layer was sought, varying this parameter between 50 and 300. Neuron combinations in the range of 10 to 40 were excluded from these experiments, although some results in
Table 1 for the Keras and Neuralnet packages showed models with 30, 40, and even 10 neurons (see rows 6, 10, and 14 in
Table 1). For this reason, additional experiments were conducted within this range to determine if superior models to those previously discussed could be obtained. These experiments were carried out using the Neuralnet, Keras, and RSNNS packages. Despite RSNNS initially not producing models with few neurons, it was included in the analysis. The results of these additional experiments are detailed in
Table 9, from which the following conclusions are drawn.
The analysis of the data suggests a disparity between training accuracy and test accuracy, yet it shows a strong inclination to corroborate previous findings. This is highlighted by the wide variability in training accuracy, ranging from 56% to 96%, as opposed to the narrower test accuracy range of 54% to 82%. This pattern underscores a tendency towards overfitting in certain configurations, where excessive optimization on training data undermines the model’s effectiveness with new samples.
The detailed examination of the overall accuracy in tests once again confirms the limitation of this global metric in accurately projecting class-specific prediction estimates. This is demonstrated by observing the accuracy per class, highlighting the challenges that models face in achieving a uniform classification across all categories. In
Table 3 and
Table 6,
Table 7,
Table 8 and
Table 9, it is observed that a high overall test accuracy does not necessarily translate into high test accuracy across all classes.
Table 10 provides a contrast between the overall test accuracy and the test accuracy per class for the most outstanding models that employ keras with convolutional layers (keras_cnn). The data in Columns 1, 2, and 3 allow for the verification of information corresponding to the table, row, and column. It is reported that the overall test accuracy for these selected models ranges from 79% to 82%.
However, a detailed inspection of accuracy per class (N, V, and B) reveals more pronounced variations. Class N proves to be robust across all models, which could indicate adequate representation or clearer distinction of its characteristics within the dataset. In contrast, classes V and B exhibit lower and more erratic performance, with class V achieving accuracies ranging from 51% to 59%, and class B from 58% to 70%, suggesting potential challenges related to data representativeness or the keras_cnn model’s ability to capture the specific features of these classes. Despite the prior knowledge of the number of samples per class, these results reflect the existing imbalance in the training data. The consistency of high accuracy for class N, as opposed to the variability for classes V and B, points to a potential model bias toward class N. Given the stability of the overall accuracy, it could be inferred that class N is predominant in the datasets, which could lead to misguided conclusions about the model’s overall effectiveness.
Class sensitivity highlights significant differences, consistently demonstrating superior effectiveness in identifying positive cases, especially for class N, in models that incorporate convolutional layers (keras_cnn). On the other hand, specificity remains high across all models, showcasing an efficient ability to correctly recognize true negatives.
Regarding neuron configuration, models based on artificial neural network algorithms typically exhibit lower accuracy with fewer neurons. However, the four-layer Neuralnet model achieves a slight edge in precision over its counterparts. For deep-learning models subjected to 1000 epochs of training, the resulting accuracy remains consistent, unaffected by the number of neurons deployed.
Concluding with the number of training epochs, it is observed that models trained for 1000 epochs generally exhibit a better balance between accuracy in training and testing than those trained for only 100 or 200 epochs.
4. Discussion
The presented research comprehensively addresses the impact of sample imbalance and the configuration of neural network-based models on the reporting capability of metrics used in the classification of pulmonary pathologies. In this regard, experiments were conducted to evaluate classification models under various neuronal configurations and data balance conditions. The central premise was to examine how these variables affect the global accuracy and class-specific performance of the models in detecting pulmonary pathologies from images.
In the initial exploration for a single layer, selecting the optimal number of neurons emerged as a critical challenge to achieve high accuracy in training and testing. The findings highlight the complexity of adjusting the network topology to optimize performance, suggesting there is no single rule for neuron configuration that guarantees success. Interestingly, results indicate that models with unbalanced datasets tend to show higher accuracy in training, though this phenomenon does not necessarily translate into improved generalization capability on new data.
When analyzing performance on test datasets, it was revealed that global accuracy does not adequately reflect the model’s performance with respect to individual classes. Particularly in high-performing models, such as those implemented with the Keras package and its variants with convolutional layers, significant discrepancies were observed in class-specific accuracy. This underscores the importance of looking beyond global metrics to understand the model’s behavior in classifying different types of pathologies.
The inclusion of additional layers in subsequent experiments provided an opportunity to investigate the influence of more complex topologies on model effectiveness. While marginal improvements in accuracy were observed with the addition of layers, the persistence of data imbalance as a critical factor in evaluating global and class-specific accuracy remained. Models trained with 1000 or more epochs showed improvements in training accuracy, highlighting the need for a holistic approach to training and evaluating the models’ generalization capabilities.
The discussion on the informative capacity of global metrics highlights an inherent limitation in capturing the true performance of models in classifying different categories. This aspect is critical, especially in medical applications where accuracy in detecting specific pathologies is paramount.
With the proposed data preprocessing techniques, the implemented models are close to the results reported in many previous studies for the same dataset. Assuming the results presented in [
26] are associated with test sets, they report an accuracy of 85% with a sensitivity of 84.1%. While these results are very close to this study, they do not address the problems demonstrated in this study. Nor do they detail the effect of classes individually. The work of [
26] rather merges the virus and bacteria classes, which can be counterproductive as it may hide potential biases in the final results [
51].
It is crucial to prevent the spread of errors among classes. Thus, a class-specific analysis, as conducted in this study, is recommended, demonstrating that individual classes impact model performance. Indeed, the sensitivity value indicates that the model correctly identifies the positive class, typically pneumonia cases, 84.1% of the time, suggesting that 84.1% may correspond to a viral or bacterial pathology. However, this value is not truly representative of either class because the original dataset is imbalanced, with a significantly larger number of samples in the normal class, leading to bias if the training is not carefully managed. Notably, in many instances, sensitivity may appear high, as in the work of [
26] where classes are merged, but taking the best model implemented with the Keras package using convolutional layers, a much lower combined sensitivity of approximately 70% is observed than shown in this work. This calculated measure of combined sensitivity is not standard but draws attention to the results presented in many studies when classes are merged, and the impact of the involved classes is not detailed, especially if they are imbalanced.
This research is also compared to the analysis conducted by [
14], which examines lung images affected by tuberculosis and pneumonia, as well as those of healthy individuals, focusing on the equitable use of 306 samples per category, data augmentation techniques, and the application of deep neural networks through transfer learning. Although the [
14] study reports high AUC scores of 90%, 93%, and 99% for the respective categories, a potential bias is identified from grouping all pneumonia cases into a single class without considering their distinct viral or bacterial causes. This approach could limit the accuracy of the training by overlooking specific patterns during feature extraction, as suggested by [
26]. In contrast, the current study favors metrics derived from the confusion matrix, which offers greater sensitivity to class imbalance. Furthermore, it is highlighted that models trained with balanced data show significantly lower performance compared to those obtained with imbalanced data, suggesting that the impressive AUC values reported by [
14] might not adequately reflect effective discrimination between classes.
In the study [
9], significant progress is highlighted in the field of medical image retrieval, particularly focusing on the identification of pulmonary pathologies through common image signs found in computed tomographies. The research underscores how the inclusion of contextual and semantic analysis, along with visual characteristics, significantly contributes to improved precision in finding relevant images. This is demonstrated by an increase in the MAP from 60% to 70% and an improvement in the AUC from 0.48 to 0.58. The findings emphasize the drawback of relying solely on visual characteristics. Delving deeper into the details of this study, it is evident that grouping distinctive features of the examined pathologies can decrease the precision of training by overlooking specific patterns during the feature extraction process.
The comparison between preprocessing methodologies implemented in previous studies and the research presented illustrates significant variations in approaches and technical procedures, especially in the context of analyzing X-ray images for the detection of pulmonary diseases. The referenced studies, including [
9,
14,
26], establish a methodological basis for the preprocessing of medical images, while the research under discussion introduces detailed techniques aimed at overcoming specific challenges, such as the dimensional variability of the images and class balance.
Regarding selection and resizing, the adoption of selection criteria based on specific dimensions (>1000 pixels) is emphasized to prevent deformations during resizing, a step not mentioned in previous studies. This method ensures the preservation of relevant information through standardized cropping to 1000 × 1000 pixels and further reduction to 30 × 30 pixels, therefore optimizing the uniformity and quality of the images for subsequent analysis.
Regarding the application of statistical analysis and class balance, the research incorporates statistical analysis to guide image selection, in contrast to the more generalized methodologies of previous studies. This analysis enables informed selection, enhancing the representativeness of the dataset. The formation of balanced and imbalanced sets directly addresses the impact of class balance on the effectiveness of the classification model, an aspect not always explicitly dealt with in the compared studies.
The review of studies highlights significant deficiencies in considering the differential impact of classes and specific patterns during the feature extraction phases, underscoring the lack of detailed analysis on the influence of classes and common image signs. This omission points to a critical need for more detailed classificatory evaluations to ensure precise and balanced interpretations in the classification of pulmonary diseases. The importance of a holistic approach that prioritizes the optimization of architectures and the calibration of the training period for improved generalization becomes evident. Furthermore, the need for adaptive and meticulous preprocessing of medical images to address challenges such as dimensional variability and class imbalance is emphasized. The current research underlines the relevance of customizing preprocessing techniques and conducting a model performance analysis that includes sensitivity, specificity, and class precision. This directs towards the development of more robust and equitable classification models, urging future research to establish clear guidelines for hyperparameter tuning and neural network architectures, therefore facilitating significant advances in the application of deep-learning technologies for medical diagnosis.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}