
Exploring Deep Neural Networks in Simulating Human Vision through Five Optical Illusions


Abstract
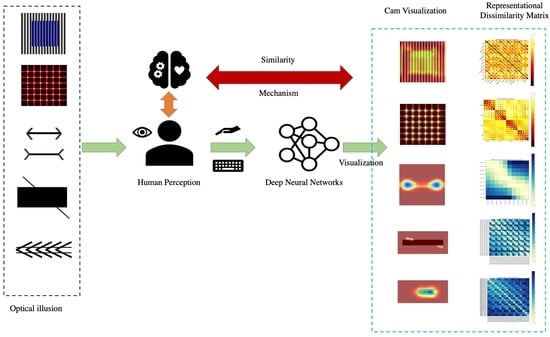
1. Introduction
2. Materials and Methods
2.1. Participant Characteristics
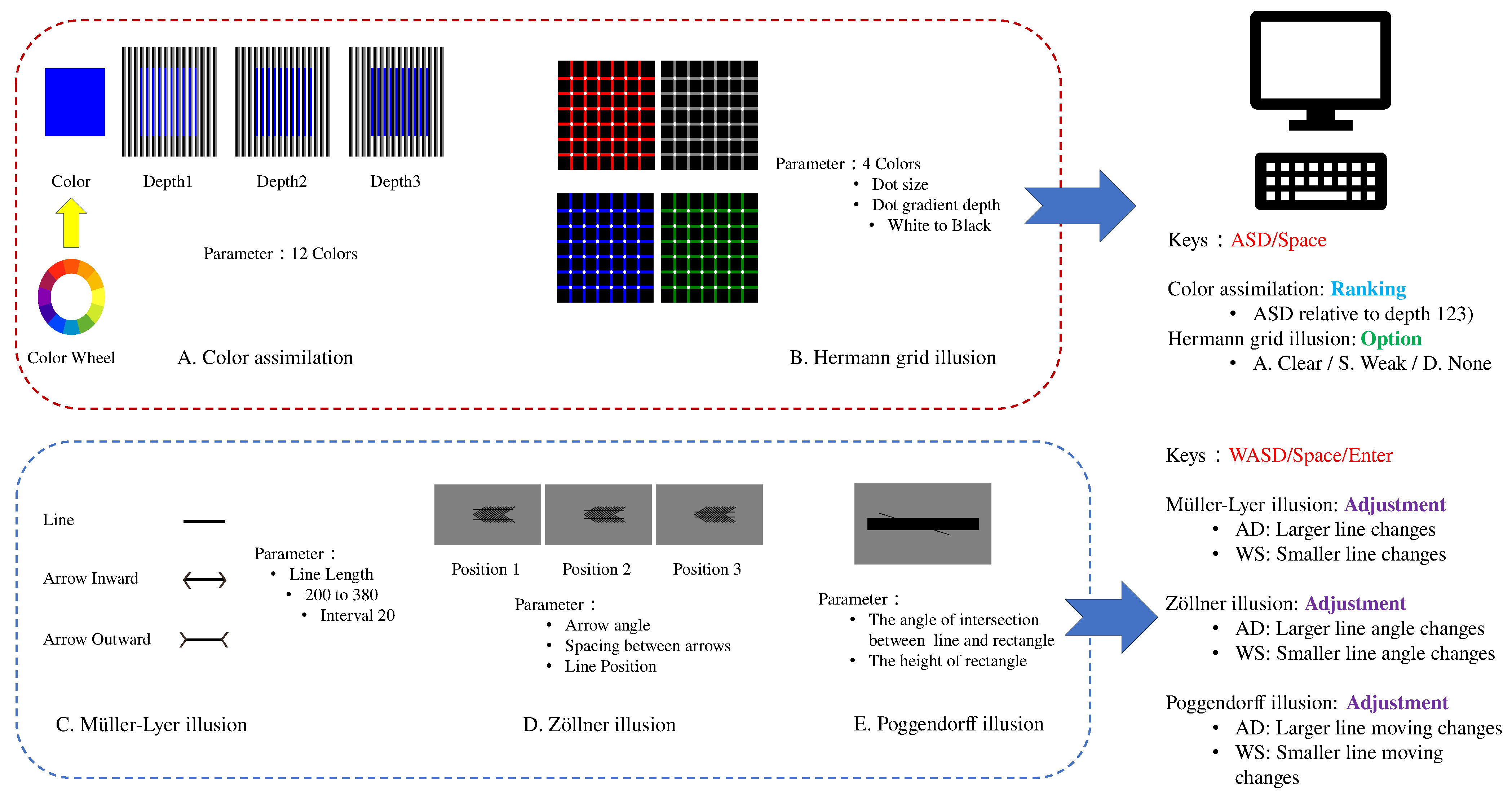
2.2. Optical Illusions
2.2.1. Stimuli and Procedures
- Color assimilation: Each round displayed a group of colored squares and corresponding three depths with black, gray, and white striped backgrounds, with WASD displayed as labels on the screen (Figure 2A). Subjects were asked to observe the squares labeled ASD (corresponding to depths 1 to 3) and the original color on the right, and rank them from the highest to the lowest similarity. The pressed space to enter the next group.
- Hermann grid illusion: 100 stimuli images were randomly displayed (Figure 2B), with ASD corresponding to “Clear”, “Weak”, “None”. The subjects chose based on their perception of flickering dots. They pressed the chosen option to proceed to the next round.
- Müller-Lyer illusion: Lines 200 to 380 pixels (20 increments) were randomly displayed at the top of the screen. Below them, lines with inward or outward arrows of random lengths were shown (Figure 2C). Subjects observed the lines and adjusted the length of the arrowed lines using WASD; AD for larger adjustments (±10 pixels) and WS for smaller adjustments (±1 pixels). They pressed space to proceed.
- Zöllner illusion: 35 stimuli were randomly displayed in the middle of the screen (Figure 2D). In each round, a line parallel to (and at the same angle as) the line above the rectangle was shown below it, randomly positioned along the bottom of the rectangle. Subjects adjusted the lower line’s position until it visually aligned with the upper line. AD is for larger adjustments, WS is for smaller. They pressed space to proceed.
- Poggendorff illusion: 54 stimuli randomly appeared at the top of the screen, with two parallel, horizontal lines below them (Figure 2E). Subjects adjusted the angle of the lower lines based on the perceived angle of the line in the upper stimulus. They pressed ENTER to switch the control between lines. AD is for larger adjustments (±0.1°), WS is for smaller (±0.02°). Adjustments were optional; they pressed space to proceed.
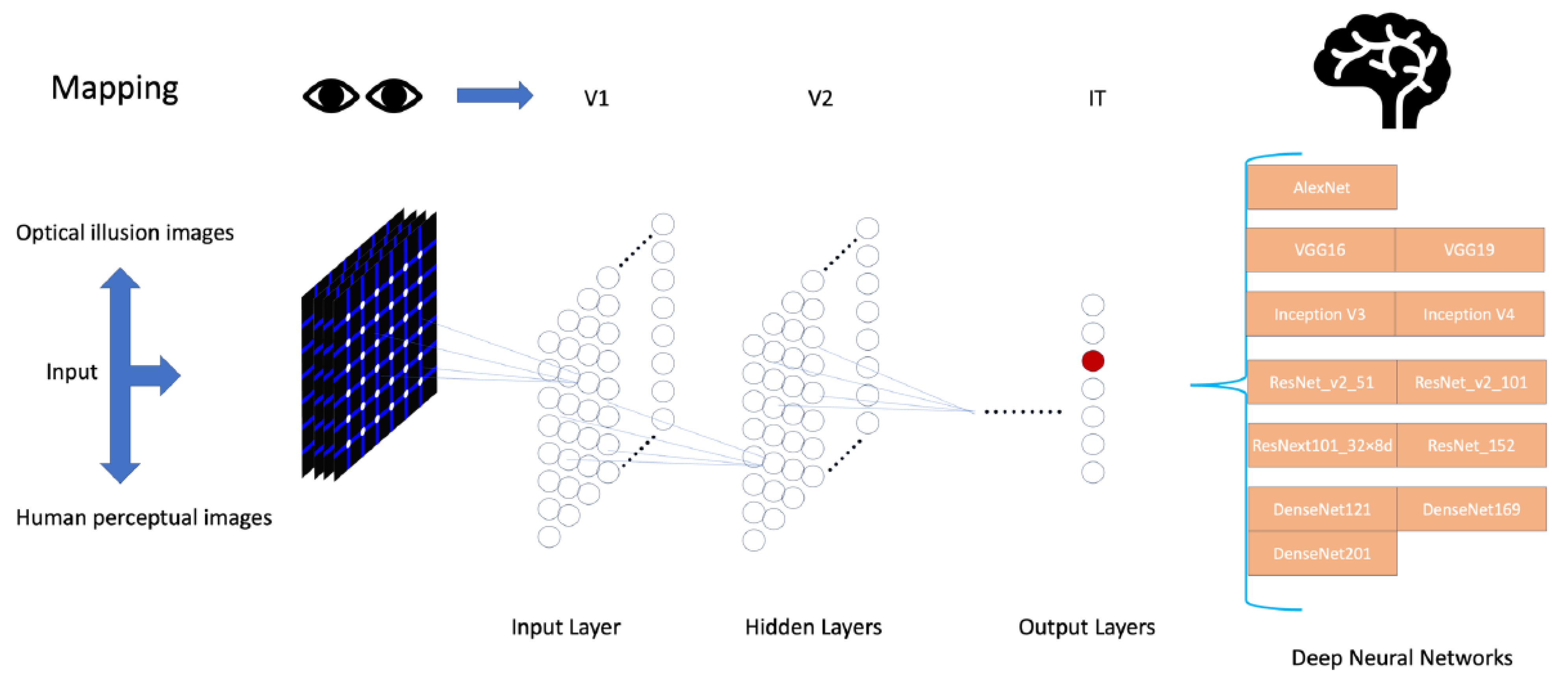
2.2.2. Brain-like Deep Neural Networks
- x is the input vector.
- is the output of the ith hidden layer.
- and are the weight and bias of the ith layer, respectively.
- is the activation function, such as ReLU or Sigmoid.
- y is the output vector.
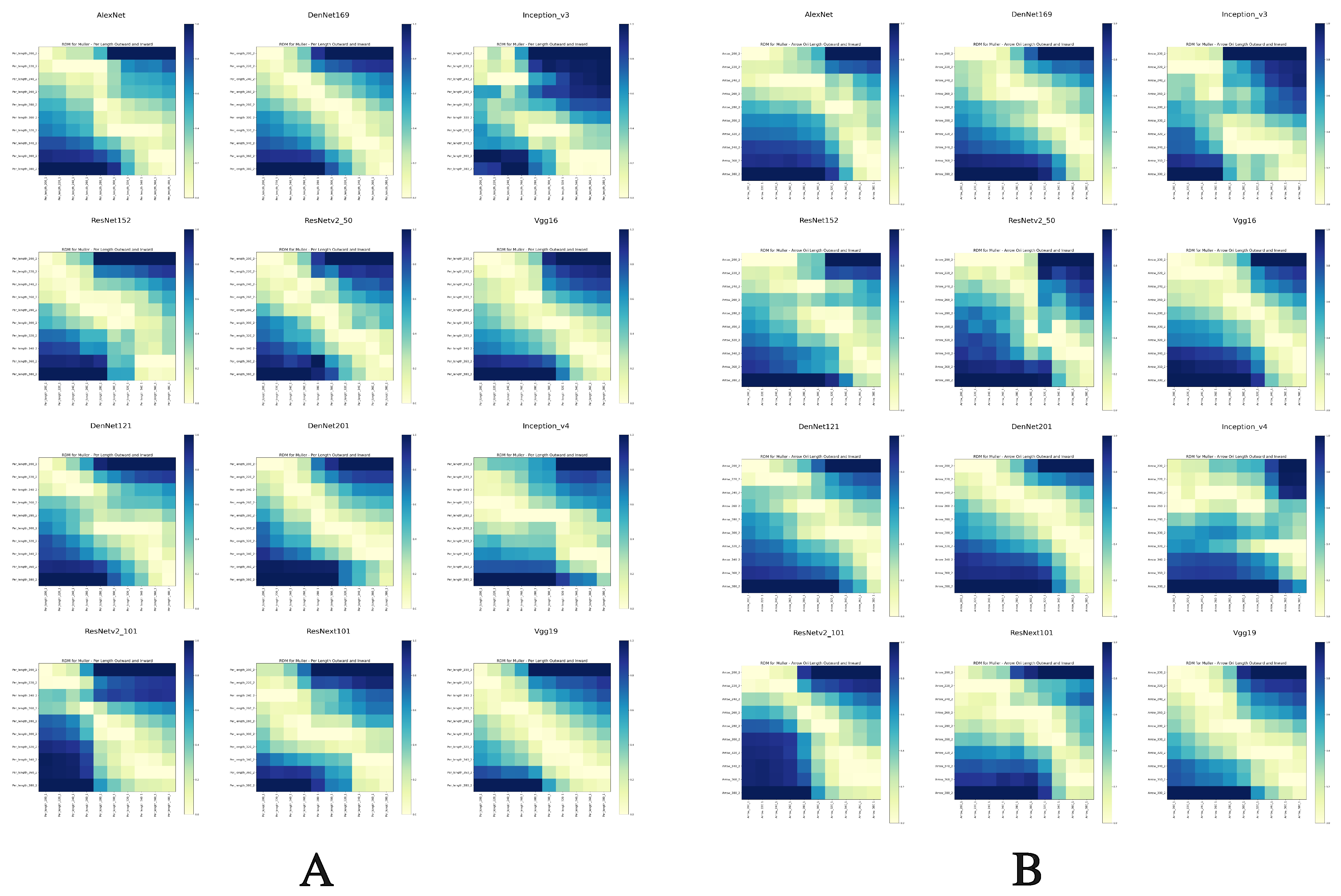
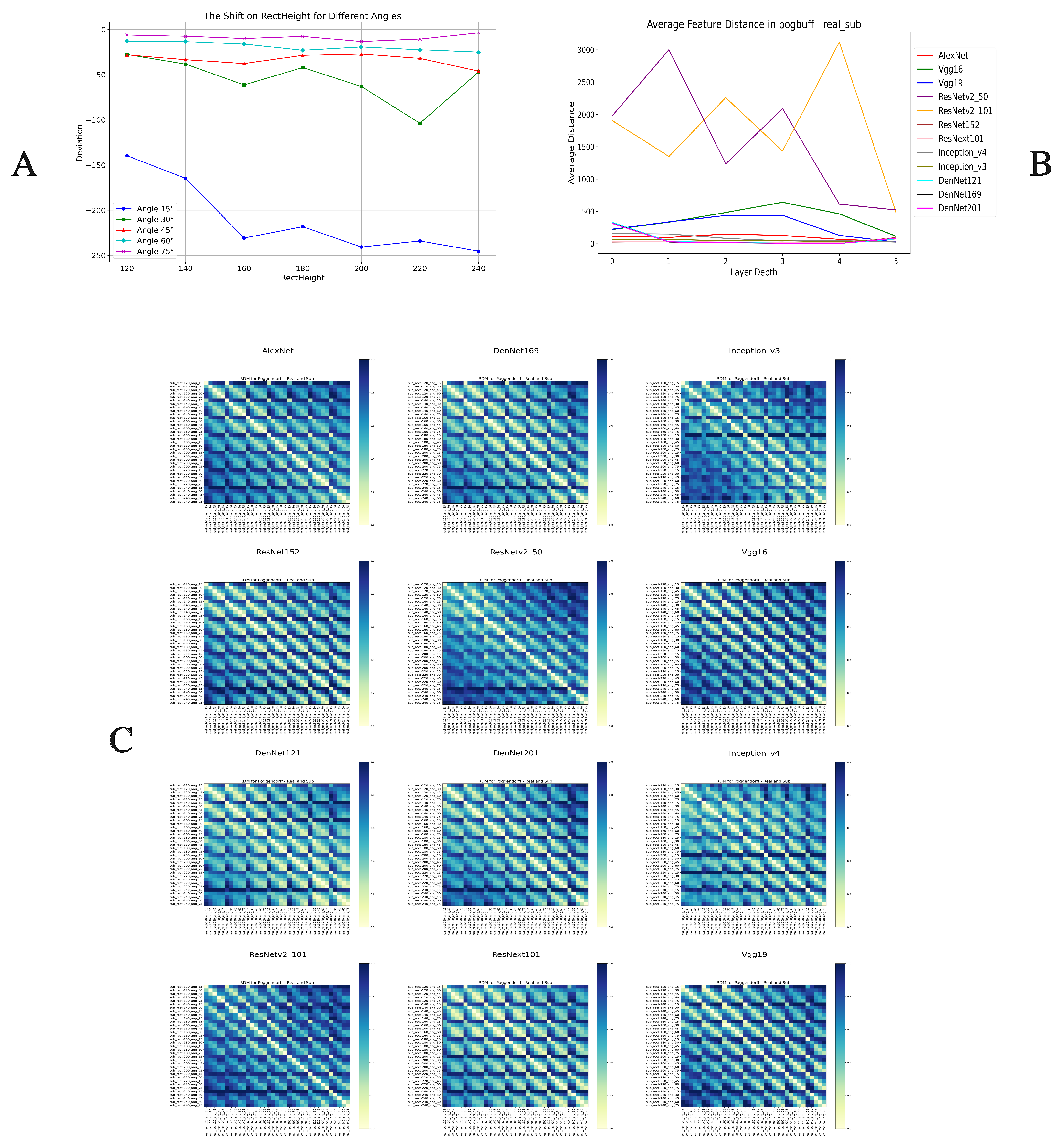
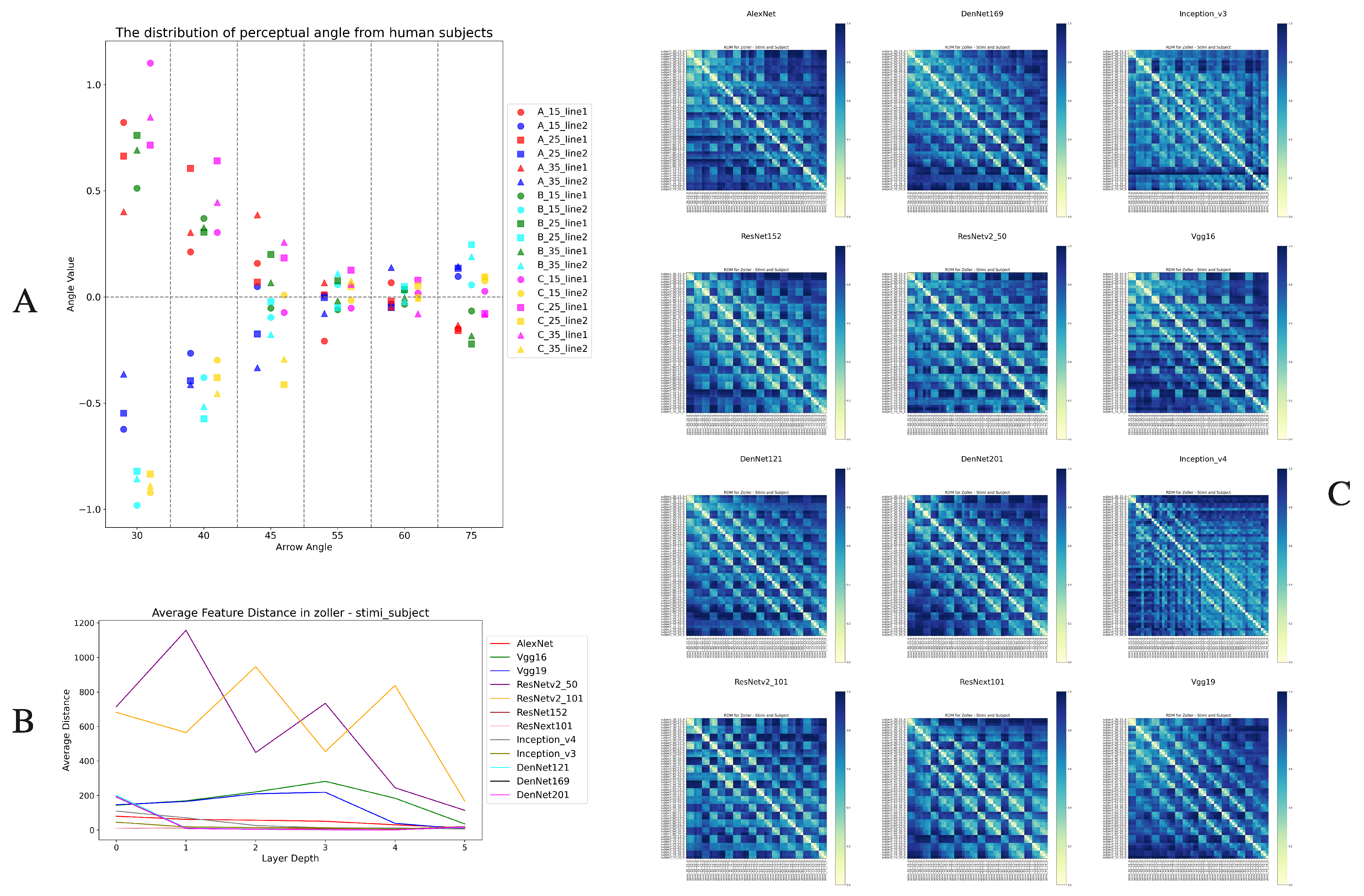
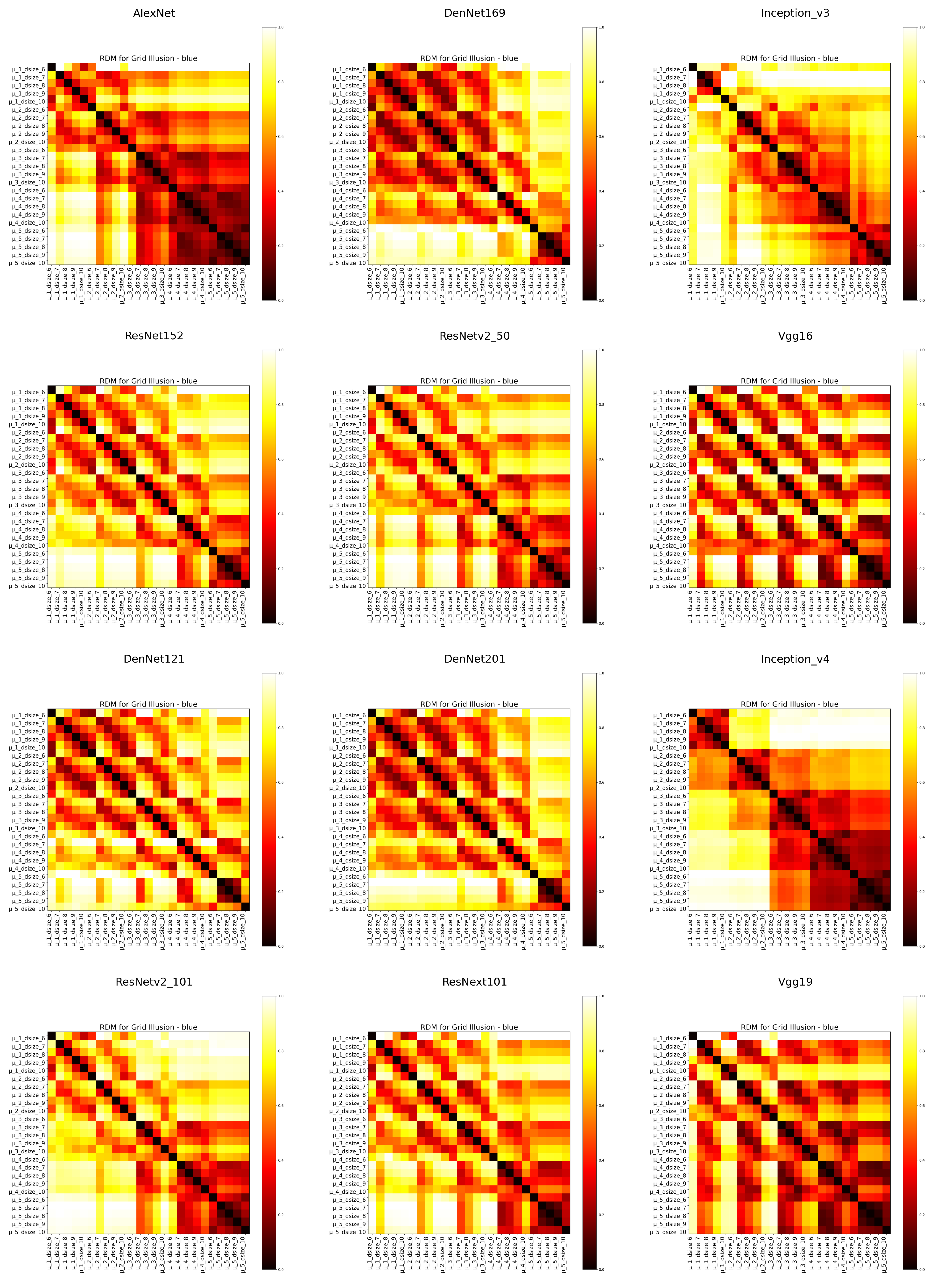
2.2.3. Representational Dissimilarity Matrices
- Color assimilation: A 48 × 48 RDM composed of 12 colors.
- Hermann grid illusion: A 25 × 25 RDM for each color, corresponding to different parameter combinations.
- Müller-Lyer illusion: A 10 × 10 RDM, based on the direction of arrows in perception data.
- Zöllner illusion: A 54 × 54 RDM, based on stimulus images and adjusted perceptual images.
- Poggendorff illusion: A 35 × 35 RDM, also based on stimulus images and adjusted perceptual images.
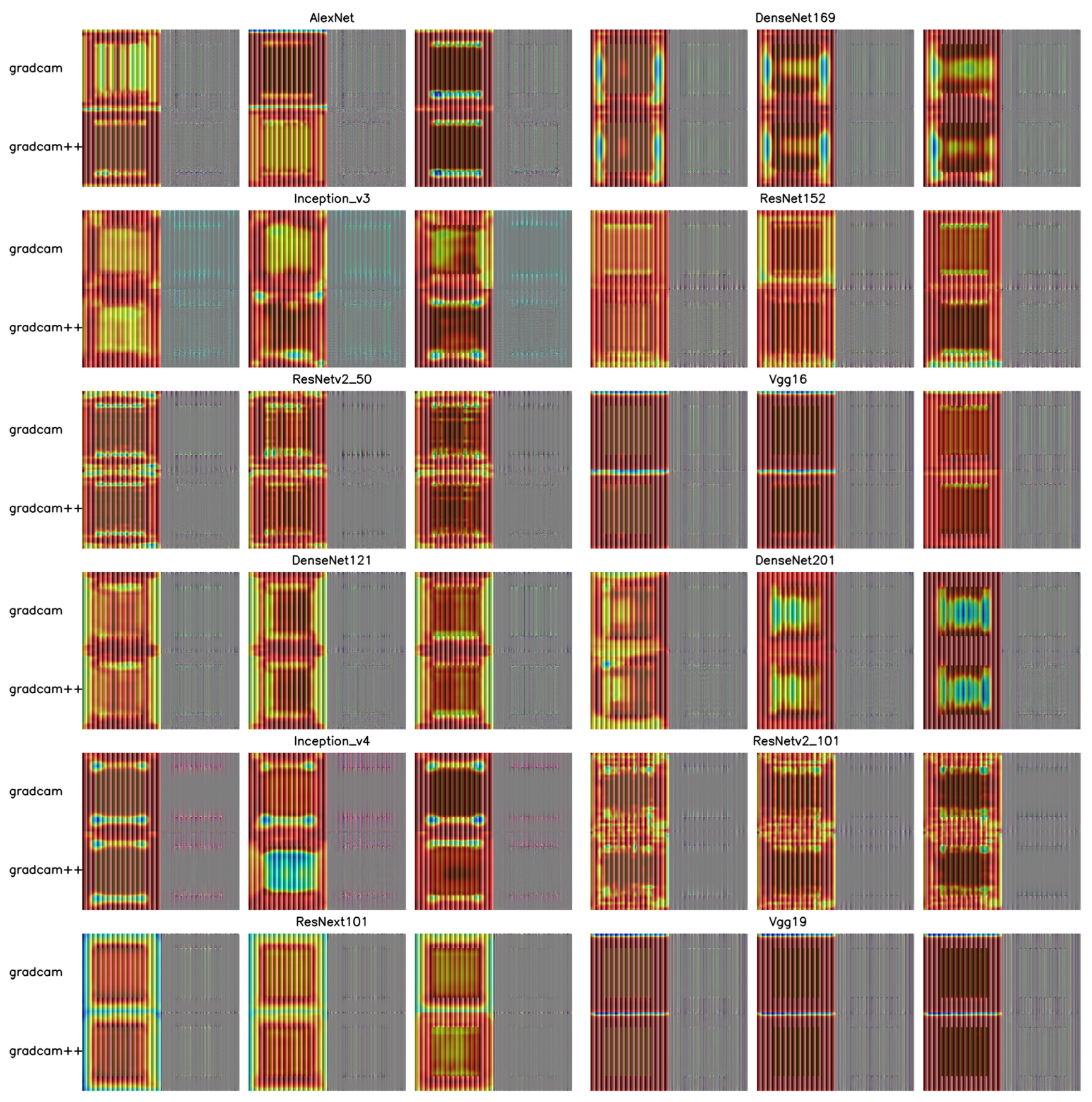
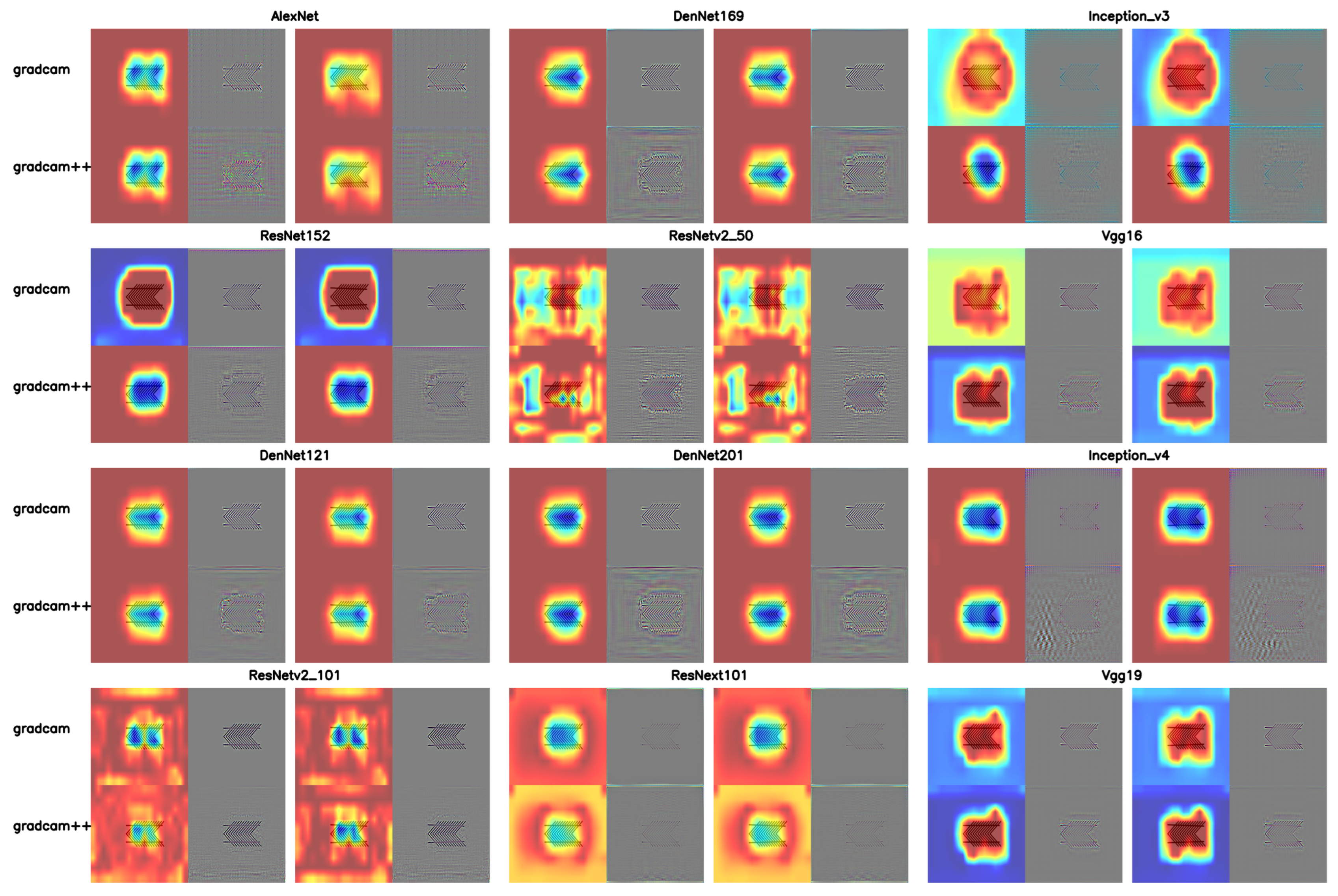
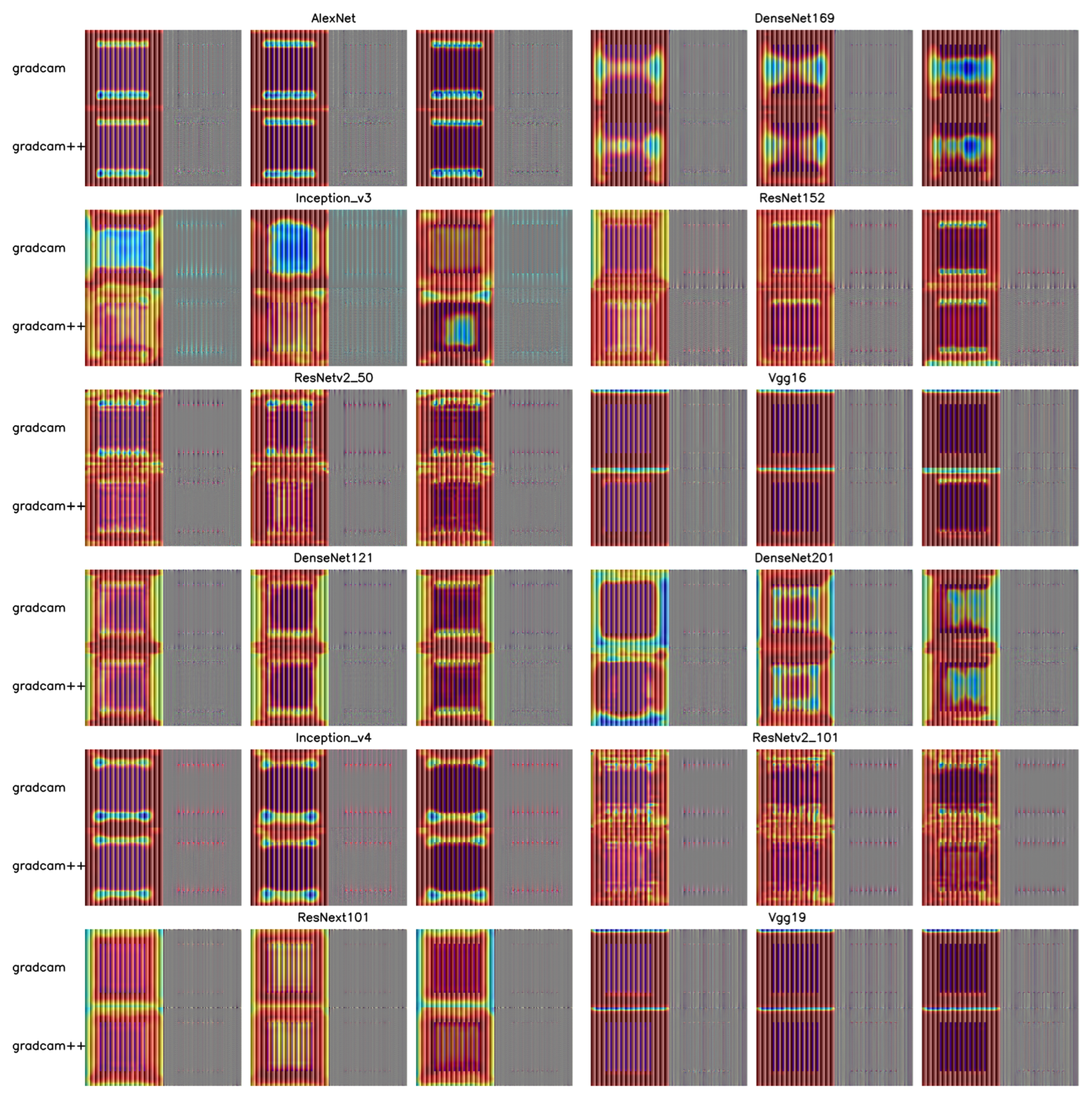
2.2.4. Cam Visualization
- is the importance weight of category c for feature map .
- is the kth feature map of a specific convolutional layer.
- The ReLU function is used to retain features that positively influence category c and remove features that have a negative influence.
2.2.5. Proposed Visualization
- x represents the input visual stimulus.
- and denote the feature vectors derived from DNNs and human perceptual data, respectively, for the input x.
- calculates the representational dissimilarity matrix for the given pairs of feature vectors, representing the multidimensional quantitative dissimilarities.
- signifies the activation maps for category c when processing input x through a DNN.
- generates the CAM heatmap based on the activation maps, highlighting regions of interest for the specific category.
- ⊗ represents an operation that overlays or integrates the dissimilarity information from RDMs onto the spatial heatmap generated by CAM, thus combining multidimensional dissimilarity with spatial attention cues.
3. Results
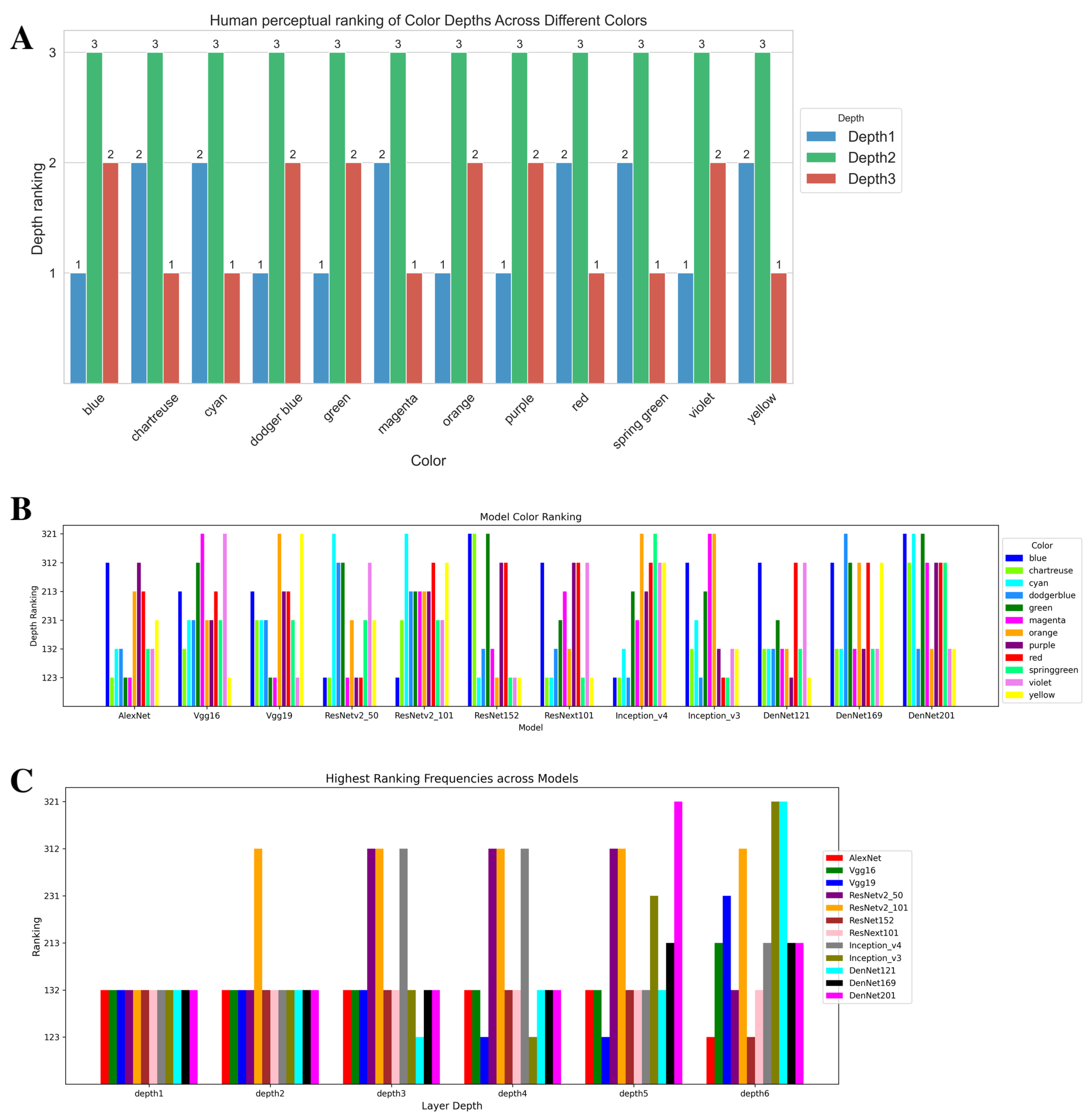
3.1. Color Assimilation
3.2. Hermann Grid Illusion
3.3. Müller-Lyer Illusion
3.4. Poggendorff Illusion
3.5. Zöllner Illusion
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A




References
- Eagleman, D.M. Visual illusions and neurobiology. Nat. Rev. Neurosci. 2001, 2, 920–926. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, V.S.; Hubbard, E.M. Synaesthesia—A window into perception, thought and language. J. Conscious. Stud. 2001, 8, 3–34. [Google Scholar]
- Gregory, R.L. Knowledge in perception and illusion. Philos. Trans. R. Soc. London. Ser. Biol. Sci. 1997, 352, 1121–1127. [Google Scholar] [CrossRef] [PubMed]
- Lotto, R.B.; Purves, D. The empirical basis of color perception. Conscious. Cogn. 2002, 11, 609–629. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Watanabe, E.; Kitaoka, A.; Sakamoto, K.; Yasugi, M.; Tanaka, K. Illusory motion reproduced by deep neural networks trained for prediction. Front. Psychol. 2018, 9, 345. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Yoshida, S.; Li, Z. Decoding Illusion Perception: A Comparative Analysis of Deep Neural Networks in the Müller-Lyer Illusion. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 1898–1903. [Google Scholar] [CrossRef]
- Sun, E.D.; Dekel, R. ImageNet-trained deep neural networks exhibit illusion-like response to the Scintillating grid. J. Vis. 2021, 21, 15. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Yoshida, S.; Li, Z. Brain-like illusion produced by Skye’s Oblique Grating in deep neural networks. PLoS ONE 2024, 19, e0299083. [Google Scholar] [CrossRef] [PubMed]
- Yamins, D.L.; DiCarlo, J.J. Using goal-driven deep learning models to understand sensory cortex. Nat. Neurosci. 2016, 19, 356–365. [Google Scholar] [CrossRef] [PubMed]
- Cadieu, C.F.; Hong, H.; Yamins, D.L.; Pinto, N.; Ardila, D.; Solomon, E.A.; Majaj, N.J.; DiCarlo, J.J. Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Comput. Biol. 2014, 10, e1003963. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How does the brain solve visual object recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed]
- Yamins, D.L.; Hong, H.; Cadieu, C.F.; Solomon, E.A.; Seibert, D.; DiCarlo, J.J. Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl. Acad. Sci. USA 2014, 111, 8619–8624. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12 June 2015; pp. 427–436. [Google Scholar] [CrossRef]
- Ward, E.J. Exploring perceptual illusions in deep neural networks. BioRxiv 2019, 19, 687905. [Google Scholar]
- Schrimpf, M.; Kubilius, J.; Hong, H.; Majaj, N.J.; Rajalingham, R.; Issa, E.B.; Kar, K.; Bashivan, P.; Prescott-Roy, J.; Geiger, F.; et al. Brain-score: Which artificial neural network for object recognition is most brain-like? BioRxiv 2018. BioRxiv:407007. [Google Scholar] [CrossRef]
- Schrimpf, M.; Kubilius, J.; Lee, M.J.; Murty, N.A.R.; Ajemian, R.; DiCarlo, J.J. Integrative benchmarking to advance neurally mechanistic models of human intelligence. Neuron 2020, 108, 413–423. [Google Scholar] [CrossRef] [PubMed]
- Nonaka, S.; Majima, K.; Aoki, S.C.; Kamitani, Y. Brain hierarchy score: Which deep neural networks are hierarchically brain-like? IScience 2021, 24, 103013. [Google Scholar] [CrossRef] [PubMed]
- Kriegeskorte, N.; Kievit, R.A. Representational geometry: Integrating cognition, computation, and the brain. Trends Cogn. Sci. 2013, 17, 401–412. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Brainard, D.H.; Vision, S. The psychophysics toolbox. Spat. Vis. 1997, 10, 433–436. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017; pp. 1492–1500. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Wightman, R. PyTorch Image Models. 2019. Available online: https://github.com/rwightman/pytorch-image-models (accessed on 5 April 2024).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Pinna, B.; Brelstaff, G.; Spillmann, L. Surface color from boundaries: A new ‘watercolor’ illusion. Vis. Res. 2001, 41, 2669–2676. [Google Scholar] [CrossRef] [PubMed]
- Berry, J.W. Ecology, perceptual development and the Müller-Lyer illusion. Br. J. Psychol. 1968, 59, 205–210. [Google Scholar] [CrossRef] [PubMed]
- Day, R.; Dickinson, R. The components of the Poggendorff illusion. Br. J. Psychol. 1976, 67, 537–552. [Google Scholar] [CrossRef] [PubMed]
- Oyama, T. Determinants of the Zöllner illusion. Psychol. Res. 1975, 37, 261–280. [Google Scholar] [CrossRef] [PubMed]
- Gomez-Villa, A.; Martín, A.; Vazquez-Corral, J.; Bertalmío, M.; Malo, J. Color illusions also deceive CNNs for low-level vision tasks: Analysis and implications. Vis. Res. 2020, 176, 156–174. [Google Scholar] [CrossRef] [PubMed]
- Engilberge, M.; Collins, E.; Süsstrunk, S. Color representation in deep neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 20 September 2017; pp. 2786–2790. [Google Scholar] [CrossRef]
- Flachot, A.; Gegenfurtner, K.R. Color for object recognition: Hue and chroma sensitivity in the deep features of convolutional neural networks. Vis. Res. 2021, 182, 89–100. [Google Scholar] [CrossRef] [PubMed]
- Kriegeskorte, N. Deep neural networks: A new framework for modeling biological vision and brain information processing. Annu. Rev. Vis. Sci. 2015, 1, 417–446. [Google Scholar] [CrossRef] [PubMed]
- Schiller, P.H.; Carvey, C.E. The Hermann grid illusion revisited. Perception 2005, 34, 1375–1397. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Zhang, M.; Chen, Q. The Poggendorff illusion driven by real and illusory contour: Behavioral and neural mechanisms. Neuropsychologia 2016, 85, 24–34. [Google Scholar] [CrossRef] [PubMed]
- Plewan, T.; Weidner, R.; Eickhoff, S.B.; Fink, G.R. Ventral and dorsal stream interactions during the perception of the Müller-Lyer illusion: Evidence derived from fMRI and dynamic causal modeling. J. Cogn. Neurosci. 2012, 24, 2015–2029. [Google Scholar] [CrossRef] [PubMed]
- Grill-Spector, K.; Malach, R. The human visual cortex. Annu. Rev. Neurosci. 2004, 27, 649–677. [Google Scholar] [CrossRef] [PubMed]
- Todorović, D. Polarity-dependent orientation illusions: Review, model, and simulations. Vis. Res. 2021, 189, 54–80. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Illusion | Independent Variable | Perception | Total |
|---|---|---|---|
| Color Assimilation | Color(12)/Depth(3) | Ranking | 36 |
| Hermann-grid illusion | Color(4)/Dot_size(5)/Gradient_depth(5) | Option | 100 |
| Müller-Lyer illusion | Line_length(10) | Adjustment | 20 |
| Zöllner illusion | Angle(5)/Rectangle_width(7) | Adjustment | 35 |
| Poggendorff illusion | Angle(6)/Arrow_space(3)/Position(3) | Adjustment | 54 |
| Models | Pre-Trained Dataset | Package | Parameters (Millions) |
|---|---|---|---|
| AlexNet | IMAGENET1K | Torchvision | 61.10 |
| VGG16 | IMAGENET1K | Torchvision | 138.36 |
| VGG19 | IMAGENET1K | Torchvision | 143.67 |
| ResNetv2_50 | IMAGENET1K | Timm | 25.55 |
| ResNetv2_101 | IMAGENET1K | Timm | 44.54 |
| ResNet152 | IMAGENET1K | Torchvision | 60.19 |
| ResNext101 | IMAGENET1K | Torchvision | 88.79 |
| Inception_v3 | IMAGENET1K | Timm | 23.83 |
| Inception_v4 | IMAGENET1K | Timm | 42.68 |
| DenNet121 | IMAGENET1K | Torchvision | 7.98 |
| DenNet169 | IMAGENET1K | Torchvision | 14.15 |
| DenNet201 | IMAGENET1K | Torchvision | 20.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Yoshida, S. Exploring Deep Neural Networks in Simulating Human Vision through Five Optical Illusions. Appl. Sci. 2024, 14, 3429. https://doi.org/10.3390/app14083429
Zhang H, Yoshida S. Exploring Deep Neural Networks in Simulating Human Vision through Five Optical Illusions. Applied Sciences. 2024; 14(8):3429. https://doi.org/10.3390/app14083429
Chicago/Turabian StyleZhang, Hongtao, and Shinichi Yoshida. 2024. "Exploring Deep Neural Networks in Simulating Human Vision through Five Optical Illusions" Applied Sciences 14, no. 8: 3429. https://doi.org/10.3390/app14083429
APA StyleZhang, H., & Yoshida, S. (2024). Exploring Deep Neural Networks in Simulating Human Vision through Five Optical Illusions. Applied Sciences, 14(8), 3429. https://doi.org/10.3390/app14083429