Abstract
Convolutional neural networks (CNNs) serve as powerful tools in computer vision tasks with extensive applications in daily life. However, they are susceptible to adversarial attacks. Still, attacks can be positive for at least two reasons. Firstly, revealing CNNs vulnerabilities prompts efforts to enhance their robustness. Secondly, adversarial images can also be employed to preserve privacy-sensitive information from CNN-based threat models aiming to extract such data from images. For such applications, the construction of high-resolution adversarial images is mandatory in practice. This paper firstly quantifies the speed, adversity, and visual quality challenges involved in the effective construction of high-resolution adversarial images, secondly provides the operational design of a new strategy, called here the noise blowing-up strategy, working for any attack, any scenario, any CNN, any clean image, thirdly validates the strategy via an extensive series of experiments. We performed experiments with 100 high-resolution clean images, exposing them to seven different attacks against 10 CNNs. Our method achieved an overall average success rate of 75% in the targeted scenario and 64% in the untargeted scenario. We revisited the failed cases: a slight modification of our method led to success rates larger than 98.9%. As of today, the noise blowing-up strategy is the first generic approach that successfully solves all three speed, adversity, and visual quality challenges, and therefore effectively constructs high-resolution adversarial images with high-quality requirements.
1. Introduction
The ability of convolutional neural networks (CNNs) [1] to automatically learn from data has made them a powerful tool in a wide range of applications touching on various aspects of our daily lives, such as image classification [2,3], object detection [4], facial recognition [5], autonomous vehicles [6], medical image analysis [7,8], natural language processing (NLP) [9,10], augmented reality (AR) [11], quality control in manufacturing [12] and satellite image analysis [13,14].
Even so, CNNs are vulnerable to attacks. In the context of image classification, which is considered in the present paper, carefully designed adversarial noise added to the original image can lead to adversarial images being misclassified by CNNs. These issues can lead to serious safety problems in real-life applications. On the flip side, such vulnerabilities can be also leveraged to obscure security and privacy-sensitive information from CNN-based threat models seeking to extract such data from images [15,16,17].
In a nutshell, adversarial attacks are categorized based on two components: the level of knowledge the attacker has about the CNN; the scenario followed by the attack. Regarding the first component, in a white-box attack [3,18,19,20,21] (also known as gradient-based attack), the attacker has full access to the architecture and to the parameters of the CNN. In contrast, in a black box attack [22,23,24,25,26,27], the attacker does not know the CNN’s parameters or architecture; its knowledge is limited to the CNN’s evaluation for any input image, including the label category in which it classifies the image, and the corresponding label value. As a consequence of the knowledge bias, white-box attacks usually generate adversarial images faster than black-box attacks. Regarding the second component, in the target scenario, the goal of the attack is to manipulate the clean input image to create an adversarial image that the CNN classifies into a predefined target category. In the untargeted scenario, the goal of the attack is to create an adversarial image that the CNN classifies into any category other than the category of the clean image. An additional objective in these scenarios is to require that the modifications put on the original clean image to create the adversarial image remain imperceptible to a human eye.
1.1. Standart Adversarial Attacks
To perform image recognition, CNNs start their assessment of any image by first resizing it to its own input size. In particular, high-resolution images are scaled down, say to or for most CNNs trained on CIFAR-10, respectively on ImageNet [28]. Until recently (and still now), to the best of our knowledge, attacks are performed on these resized images. Consequently, the resulting adversarial images’ size coincides with the CNN input’s size, regardless of the size of the original images. Figure 1 describes this standard approach, in which attacks take place in the low-resolution domain, denoted as the domain in this paper.
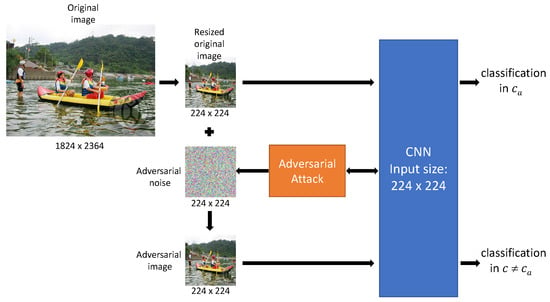
Figure 1.
Standard attacks’ process, where is the CNN’s leading category of the clean resized image, and is the CNN’s leading category of the adversarial image.
As previously highlighted, the susceptibility of CNNs to adversarial attacks can be utilized to obfuscate privacy-sensitive information from CNN-empowered malicious software. To use adversarial images for such security purposes, their sizes must match the sizes of the original clean images considered. In practice, these sizes are usually far larger than . However, generating high-resolution adversarial images, namely adversarial images in the domain as we call it in this paper, poses certain difficulties.
1.2. Challenges and Related Works
Creating adversarial images of the same size as their clean counterparts, as illustrated in Figure 2, is a novel and highly challenging task in termes of speed, adversity, and imperceptibility.
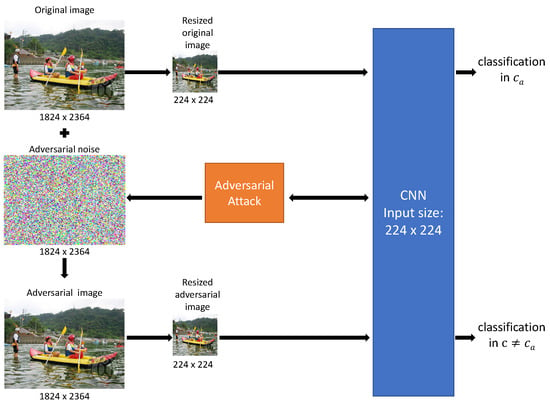
Figure 2.
Direct attack process generating an adversarial image with the same size as the original clean image.
Firstly, the complexity of the problem grows quadratically with the size of the images. This issue impacts the speed of attacks performed directly in the domain. In [29], an evolutionary algorithm-based black-box attack, that successfully handled images of sizes , was tested on a high-resolution image of size via the direct approach illustrated in Figure 2. Despite 40 h of computational efforts, it failed to create a high-resolution adversarial image by this direct method. This indicates that a direct attack in the domain, as described above, is unlikely to succeed. An alternative approach is definitively needed to speed up the attack process in the domain.
Additionally, the adversarial noise in the high-resolution adversarial image should prevail even when the adversarial image is resized to the input size of the CNN. Finally, the difference between the high-resolution original clean image and the high-resolution adversarial image must be imperceptible to a human eye.
A first solution to the speed and adversity challenges is presented in [29,30] as an effective strategy that smoothly transforms an adversarial image — regardless of how it is generated—from the domain to the domain. However, the imperceptibility issue was not resolved.
1.3. Our Contribution
In this article, we introduce a novel strategy, extending our conference paper [31] (and enhancing [29,30]). This strategy stands as the first effective method for generating high visual quality adversarial images in the high-resolution domain in the following sense: The strategy works for any attack, any scenario, any CNN, and any clean high-resolution image. Compared to related works, our refined strategy increases substantially the visual quality of the high-resolution adversarial images, as well as the speed and efficiency in creating them. In summary, the approach amounts to a “blowing-up” to the high-resolution domain of the adversarial noise—only of the adversarial noise, and not of the full adversarial image—created in the low-resolution domain. Adding this high-resolution noise to the original high-resolution clean image leads to an indistinguishable high-resolution adversarial image.
This noise blowing-up strategy is validated in terms of speed, adversity, and visual quality by an extensive set of experiments. It encompasses seven attacks (four white-box and three black-box) against 10 state-of-the-art CNNs trained on ImageNet; the attacks are performed both for the untargeted and the target scenario, with 100 high-resolution clean images. In particular, the visual quality of high-resolution adversarial images generated with our method is thoroughly studied; the outcomes are compared with adversarial images resulting from [29,30].
1.4. Organisation of the Paper
Our paper is organised as follows. Section 2 recalls briefly what are the target and untarget scenarios in , what their versions in , fixes some notations, and lists a series of indicators ( norms and FID) used to assess the human perception of distinct images. Section 3 formalises the noise blowing-up strategy, provides the scheme of the attack that lifts to any attack against a CNN that works in the domain, and that takes advantage of lifting the adversarial noise only. It recalls some complementary indicators used to assess the impact of the obtained tentative adversarial images (Loss function , “safety buffer” ), and again fixes some notations. The experimental study is performed in the subsequent Sections. Section 4 describes the ingredients of the experiments: the resizing functions, the 10 CNNs, the 100 clean high-resolution images, the target categories considered in the target scenario, and the 7 attacks. Section 5 provides the results of the experiments performed under these conditions: success rate, visual quality, and imperceptibility of the difference between adversarial and clean images, timing, and overhead of the noise blowing-up strategy. The cases, where the standard implementation of the strategy failed to succeed, are revisited in Section 6 thanks to the “safety buffer” . Finally, Section 7 provides a comparison of the noise blowing-up method with the generic lifting method [29,30] on three challenging high-resolution images, one CNN, and one attack for the target scenario. Section 8 summarizes our findings, and indicates directions for future research. An Appendix completes the paper with additional data and evidence.
All algorithms and experiments were implemented using Python 3.9 [32] with NumPy 1.23.5 [33], TensorFlow 2.14.0 [34], Keras 3 [35], and Scikit 0.22 [36] libraries. Computations were performed on nodes with Nvidia Tesla V100 GPGPUs of the IRIS HPC Cluster at the University of Luxembourg.
2. CNNs and Attack Scenarios
CNNs performing image classification are trained on some large dataset to sort images into predefined categories . The categories, and their number ℓ, are associated with and are common to all CNNs trained on . One denotes the set of images of size (where is the height, and is the width of the image) natively adapted to such CNNs.
Once trained, a CNN can be exposed to images (typically) in the same domain as those on which it was trained. Given an input image , the trained CNN produces a classification output vector
where for , and . Each -label value measures the plausibility that the image belongs to the category .
Consequently, the CNN classifies the image as belonging to the category if . If there is no ambiguity on the dominating category (as occurs for most images used in practice; we also make this assumption in this paper), one denotes the pair specifying the dominating category and the corresponding label value. The higher the -label value , the higher the confidence that represents an object of the category from CNN’s “viewpoint”. For the sake of simplicity and consistency with the remaining of this paper, we shall write . In other words, ’s classification of is
2.1. Assessment of the Human Perception of Distinct Images
Given two images and of the same size (belonging or not to the domain), there are different ways to assess numerically the human perception of the difference between them, as well as the actual “weight” of this difference. In the present study, this assessment is performed mainly by computing the (normalized) values of for , or ∞ and the Fréchet Inception Distance (FID).
Introduced in [37], FID originally served as a metric to evaluate the performance of GANs by assessing the similarity of generated images. FID is one of the recent tools for assessing the visual quality of adversarial images and it aligns closely with human judgment (see [38,39,40]). On the other hand, [41,42] provide an assessment of -norms as a measure of perceptual distance between images.
In a nutshell, for an image of size , the integer
denotes the value of the pixel positioned in the ith-row, jth-column, of the image for the channel (R = Red, G = Green, B = Blue). Then,
- ,
- ,
- ,
where , and . These quantities satisfy the inequalities:
The closer their values are to 0, the closer are the images to each other.
To effectively capture the degree of disturbance, and therefore to provide a reliable measure of the level of disruption, FID quantifies the separation between clean and disturbed images based on extracting features from images that are provided by the Inception-v3 network [43]. Activations from one of the intermediate layers of the Inception v3 model are used as feature representations for each image. FID assesses the similarity between two probability distributions in a metric space, via the formula:
- FID(, )
where, and denote feature-wise mean vectors for the images and , respectively, reflecting average features observed across the images. and represent covariance matrices for the feature vectors (covariance matrices offer insights into how features in the vectors co-vary with each other). The quantity captures the squared difference in mean vectors (highlighting disparities in these average features), and the trace quantity assesses dissimilarities between the covariance matrices. In the end, FID quantifies how similar the distribution of feature vectors in the is to that in the . The lower the FID value, the more similar the images and .
2.2. Attack Scenarios in the Domain
Let be a trained CNN, be a category among the ℓ possible categories, and a clean image in the domain, classified by as belonging to . Let be its -label value. Based on these initial conditions, we describe two attack scenarios (the target scenario and the untarget scenario) aiming at creating an adversarial image accordingly.
Whatever the scenario, one requires that remains so close to , that a human would not notice any difference between and . This is done in practice by fixing the value of the parameter , which controls (or restricts) the global maximum amplitude allowed for the modifications of each pixel value of to construct an adversarial image . Note that, for a given attack scenario, the value set to usually depends on the concrete performed attack, more specifically on the distance used in the attack to assess the human perception between an original and an adversarial image.
The target scenario performed on requires first to select a category . The attack then aims at constructing an image that is either a good enough adversarial image or a -strong adversarial image.
A good enough adversarial image is an adversarial image that classifies as belonging to the target category , without any requirement on the -label value beyond being strictly dominant among all label values. A -strong adversarial image is an adversarial image that not only classifies as belonging to the target category , but for which its -label value for some threshold value fixed a priori.
In the untarget scenario performed on , the attack aims at constructing an image that classifies in any category .
One writes to denote the specific attack atk performed to deceive in the domain according to the selected scenario, and an adversarial image obtained by running successfully this attack on the clean image . Note that one usually considers only the first adversarial image obtained by a successful run of an attack, so that is uniquely defined.
Finally, one writes the classification of the adversarial image obtained. Note that in the case of the target scenario.
2.3. Attack Scenarios Expressed in the Domain
In the context of high-resolution (HR) images, let us denote by the set of images that are larger than those of . In other words, an image of size (where h designates the height, and w the width of the image considered) belongs to if and . One assumes given a fixed degradation function
that transforms any image into a “degraded” image . Then there is a well-defined composition of maps as shown in the following scheme:
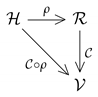
Given , one obtains that way the classification of the reduced image as .
We assume that the dominating category of the reduced image is without ambiguity, and denote by the outcome of ’s classification of .
Thanks to the degradation function , one can express in the domain any attack scenario that makes sense in the domain. This is in particular the case for the target scenario and for the untarget scenario.
Indeed, an adversarial HR image against for the target scenario performed by an attack on is an image , that satisfies two conditions (note that the notation , with t as index, encapsulates and summarizes the fact that the adversarial image is obtained for the specific target scenario considered). On the one hand, a human should not be able to notice any visual difference between the original and the adversarial HR images. On the other hand, should classify the degraded image in the category for a sufficiently convincing -label value. The image is then a good enough adversarial image or a -strong adversarial image if its reduced version is.
Similarly, and mutatis mutandis for the untarget scenario, one denotes by the HR adversarial images obtained by an attack for the untarget scenario performed on , and by its degraded version.
The generic attack scenario on in the HR domain can be visualized in the following scheme:
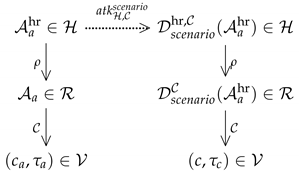
Depending on the scenario considered, one has:
- For the target scenario: , , and with dominant among all categories, and, furthermore, if one additionally requires the adversarial image to be -strong adversarial.
- For the untarget scenario: , , and with c such that .
Whatever the scenario, one also requires that a human is unable to notice any difference between the clean image and the adversarial image in .
3. The Noise Blowing-Up Strategy
The method presented here (and introduced in [31]) attempts to circumvent the speed, adversity, and visual quality challenges mentioned in the Introduction, which are encountered when one intends to create HR adversarial images. While speed and adversity were successfully addressed in [29,30] via a strategy similar to some extent to the present one, the visual quality challenge remained partly unsolved. The refinement provided by our noise blowing-up strategy, which lifts to the domain for any attack working in the domain, addresses this visual quality issue without harming the speed and adversity features. It furthermore simplifies and generalises the attack scheme described in [29,30].
In a nutshell, the noise blowing-up strategy applied to an attack atk on a CNN following a given scenario, essentially proceeds as follows.
One considers a clean image , degraded from a clean image thanks to a degrading function . Then one performs an attack on in the domain, that leads to an image , adversarial against the CNN for the considered scenario. Although getting such adversarial images in the domain is crucial for obvious reasons, our strategy does not depend on how they are obtained and applies to all possible attacks working efficiently in the domain. This feature contributes substantially to the flexibility of our method.
Then one computes the adversarial noise in as the difference between the adversarial image and the clean image in . Thanks to a convenient enlarging function , one blows up this adversarial noise from to . Then, one adds this blown-up noise to , creating that way a high-resolution image, called here the HR tentative adversarial image.
One checks whether this HR tentative adversarial image fulfills the criteria stated in the last paragraph of Section 2.3, namely becomes adversarial once degraded by the function . Should this occur, it means that blowing up the adversarial noise in has led to a noise in that turns out to be also adversarial. If the blown-up noise is not sufficiently adversarial, one raises the expectations at the level accordingly.
The concrete design of the noise blowing-up strategy, which aims at creating an efficient attack in the domain once given an efficient attack in the domain for some scenario, is given step-by-step in Section 3.1. A series of indicators is given in Section 3.2. The assessment of these indicators depends on the choice of the degrading and enlarging functions used to go from to , and vice versa. These choices are specified in Section 4.
3.1. Constructing Images Adversarial in out of Those Adversarial in
Given a CNN , the starting point is a large-size clean image .
In Step 1, one constructs its degraded image .
In Step 2, one runs on to get its classification in a category . More precisely, one gets .
In Step 3, with notations consistent with those used in Section 2.3, one assumes given an attack on in the domain, that leads to an image
adversarial against CNN for the considered scenario. As already stated, how such an adversarial image is obtained does not matter. For reasons linked to Step 5 and to Step 8, one denotes the outcome of the classification by of this adversarial image in . The index “” indicates that these assessments and measures take place before the noise blowing-up process per se (Steps 4, 5, 6 essentially).
Step 4 consists in getting the adversarial noise as the difference
of images living in , one being the adversarial image of the clean other.
To perform Step 5, one needs a fixed enlarging function
that transforms any image of into an image in . Anticipating on Step 8, it is worthwhile noting that, although the reduction function and the enlarging function have opposite purposes, these functions are not necessarily inverse one from the other. In other words, and may differ from the identity maps and respectively (usually they do).
One applies the enlarging function to the low-resolution adversarial noise , what leads to the blown-up noise
In Step 6, one creates the HR tentative adversarial image by adding this blown-up noise to the original high-resolution image as follows:
In Step 7, the application of the reduction function on this HD tentative adversarial image creates an image in the domain.
Finally, in Step 8, one runs on to get its classification . The index “” indicates that these assessments and measures take place after the noise blowing-up process per se (Steps 4, 5, 6 essentially).
The attack succeeds if the conditions stated at the end of Section 2.3 are satisfied according to the considered scenario.
Remarks.—(1) For reasons explained in Step 5, there is no reason that even when classifies both images and in the same category (this condition is expected in the target scenario, provided this common category satisfies ). These label values are very likely to differ. This has two consequences: the first is to make mandatory the verification process performed in Step 8, let alone to make sure that the adversarial image is conveniently classified by according to the considered scenario; the second is that, for the target scenario, one should set the value of in a way such to ensure that the image is indeed adversarial (see Section 3.2). (2) In the context of the untarget scenario, one should make sure that . In the context of the target scenario, one should also aim at getting (provided one succeeds in creating an adversarial image for which ). These requirements are likely to influence the value set to as well (see Section 3.2).
Scheme (11) summarizes these steps. It shows how to create, from a target attack efficient against in the domain, the attack in the domain obtained by the noise blowing-up strategy:
3.2. Indicators
Although both and stem from , belong to the same set of low-resolution images, these images nevertheless differ in general, since . Therefore, as already stated, this fact implies that the verification process performed in Step 8 is mandatory.
For the target scenario, one aims at . Since and are likely to differ, One measures the difference with the real-valued loss function defined for as
In particular, for the target scenario, our attack is effective if one can set accurately the value of to match the inequality for the threshold value , or to make sure that is a good enough adversarial image in the domain while controlling the distance variations between and the adversarial .
For the untarget scenario, one aims at . To hope to achieve , one requires . However, this requirement alone may not be sufficient to obtain . Indeed, depending on the attack, the adversarial image (in the domain) may be very sensitive to the level of trust that (also in the domain) belongs to the category . In other words, even if the attack performed in step 3 of the noise blowing-up strategy succeeded, steps 5 to 9 may not succeed under some circumstances, and it may occur that the image resulting from these steps is classified back to .
Although less pregnant for the target scenario, a similar sensitivity phenomenon may nevertheless occur, leading to (hence to , since in this scenario), and therefore to an unsuccess of the noise blowing-up strategy.
For these reasons, it may be safer to ensure a “margin of security” measured as follows. One defines the Delta function for as:
where is the second best category, namely the category c for which the label value is the highest after the label value of . Enlarging the distance of the label values between the best and second best category before launching the next steps of the noise blowing-up strategy may lead to higher success rates of the strategy (see Section 6).
Remark.—Note that the present approach, at the difference of the approach, initially introduced in [29,30], does not require frequent resizing up and down via the adversarial images. In particular, if one knows how the loss function behaves (in the worst case, or in average) for a given targeted attack, then one can adjust a priori the value of accordingly, and be satisfied with one such resizing up and down. Mutatis mutandis for the untarget attack and the Delta function.
To assess the visual variations and the noise between the images (see Section 2.1), we shall compute the , , and FID values for the following pairs of images:
- and in the domain. One writes () and the corresponding values.
- and in the domain. One writes () and the corresponding values.
- and in the domain. One writes () and the corresponding values.
- , in the domain. One writes the corresponding values.
- and in the domain. One writes the corresponding values.
In particular, when adversarial images are involved, the comparison of some of these values between what occurs in the domain, and what occurs in the domain gives an insight into the weight of the noise at each level, and of the noise propagation once blown-up. Additionally, we shall as well assess the ratio:
This ratio normalizes the weight of the noise with respect to the effect of the anyhow occurring composition . Said otherwise, it evaluates the impact created by the noise normalized by the impact created anyhow by the resizing functions.
4. Ingredients of the Experimental Study
This section specifies the key ingredients used in the experimental study performed in Section 5: degrading and enlarging functions, CNNs, HR clean images, attacks and scenarios. We also take advantage of the outcomes of [29,30,31] for the choice of some parameters used in the experimental study.
4.1. The Selection of and of
The assessment of the indicators of Section 3.2, and therefore the performances and adequacy of the resized tentative adversarial images obtained between and , clearly depend on the reducing and enlarging functions and selected in Scheme (11).
The combination call (performed in Step 1 for the first call of , in Step 5 for the unique call of , and in Step 7 for the second call of ) to the degrading and enlarging functions are “aside” of the actual attacks performed in the domain. However, both the adversity and the visual quality of the HR adversarial images are highly sensitive to the selected combination.
Moreover, as pointed out in [29], enlarging functions usually have difficulties with high-frequency features. This phenomenon leads to an increased blurriness in the resulting image. Therefore, the visual quality of (and the speed to construct, see [29]) the high-resolution adversarial images obtained by our noise blowing-up strategy benefits from a scarce usage of the enlarging function. Consequently, the scheme minimizes the number of times (and consequently ) are used.
We considered four non-adaptive methods that convert an image from one scale to another. Indeed, the Nearest Neighbor [44], the Bilinear method [45], the Bicubic method [46] and the Lanczos method [47,48] are among the most common interpolation algorithms, and are available in python libraries. Note that the Nearest Neighbor method is the default degradation function on Keras function [35]. Tests performed in [29,30] lead to reducing the resizing functions to the Lanczsos and the Nearest methods.
We performed a case study with the 8 possible different combinations obtained with the Lanczsos and the Nearest methods (see Appendix B for the full details). Its outcomes lead us to recommend the combination (see also Section 4.3).
4.2. The CNNs
The experimental study is performed on 10 diverse and commonly used CNNs trained on ImageNet (see [27] for the reasons for these choices). These CNNs are specified in Table 1.

Table 1.
The 10 CNNs trained on ImageNet, their number of parameters (in millions), and their Top-1 and Top-5 accuracy.
4.3. The HR Clean Images
The experiments are performed on 100 HR clean images. More specifically, Table 2 gives the 10 ancestor categories , and the 10 corresponding target categories used in the -target scenario whenever applicable (see Section 4.4). These categories (ancestor or target) are the same as those of [27,49], which were picked at random among the 1000 categories of ImageNet.
Table 2.
For , the second column lists the ancestor category and its ordinal among the categories of ImageNet. Mutatis mutandis in the third column with the target category and ordinal .
For each ancestor category, we picked at random 10 clean ancestor images from the ImageNet validation scheme in the corresponding category, provided that their size satisfies and . This requirement ensures that these images belong to the domain. These images are pictured in Figure A1 in Appendix A, while Table A1 gives their original sizes. Note that, out of the 100 HR clean images in Figure A1, 92 coincide with those used in [27,49] (which were picked at random in this article). We replaced the 8 remaining images used in [27,49] whose sizes did not fulfill the requirement. As a consequence, the images and in the category , in the category , in the category , and in the category differ from those of [27,49].
Although the images are picked from the ImageNet validation set in the categories , CNNs may not systematically classify all of them in the “correct” category in the process of Steps 1 and 2 of Scheme (11). Indeed, Table A2 and Table A3 in Appendix A show that this phenomenon occurs for all CNNs, whether one uses “Lanczos” (L) or “Nearest” (N). Table 3 summarizes these outcomes, where designates the set of “correctly” classified clean images .
Table 3.
For each CNN (1st row), number of clean HR images classified by in the “correct” category either with the degrading function “Lanczos” (2nd row), or with “Nearest” (3rd row).
Table 3 shows that the sets and usually differ. Table A2 and Table A3 proves that this holds as well for although both sets have the same number of elements.
In any case, the “wrongly” classified clean images are from now on disregarded since they introduce a native bias. Experiments are therefore performed only for the “correctly” classified HR clean images belonging to .
4.4. The Attacks
We considered seven well-known attacks against the 10 CNNs given in Table 1. Table 4 lists these attacks, and specifies (with an “x”) whether we use them in the experiments for the targeted scenario, for the untargeted scenario, or for both (see Table 5 for a justification of these choices), and their white-box or black-box nature. To be more precise, if an attack admits a dual nature, namely black box and white-box (potentially semi-white-box), we consider the attack only in its more demanding black-box nature. This leads us to consider three black-box attacks (EA, AdvGAN, SimBA) and four white-box attacks (FGSM, BIM, PGD Inf, PGD L2).
Table 4.
List of attacks considered, their white-box or black-box nature, and the scenarios for which they are run in the present study.
Table 5.
Number of successfully generated adversarial images in the domain.
Let us now briefly describe these attacks while specifying the parameters to be used in the experiments. Note that, except (for the time being) for the EA attack, all attacks were applied with the Adversarial Robustness Toolbox (ART) [50], which is a Python library that includes several attack methods.
–EA attack [25,27] is an evolutionary algorithm-based black-box attack. It begins by creating a population of ancestor image copies and iteratively modifies their pixels over generations. The attack’s objective is defined by a fitness function that uses an individual’s probability obtained from the targeted CNN. The population size is set to 40, and the pixel mutation magnitude per generation is . The attack is executed in both targeted and untargeted scenarios. For the targeted scenario, the adversarial image’s minimum -label value is set to . The maximum number of generations is set to N = 10,000.
–Adversarial GAN attack (AdvGAN) [51] is a type of attack that operates in either a semi-whitebox or black-box setting. It uses a generative adversarial network (GAN) to create adversarial images by employing three key components: a generator, a discriminator, and the targeted neural network. During the attack, the generator is trained to produce perturbations that can convert original images into adversarial images, while the discriminator ensures that the generated adversarial image appears identical to the original image. The attack is executed in the black-box setting.
–Simple Black-box Attack (SimBA) [52] is a versatile algorithm that can be used for both black-box and white-box attacks. It works by randomly selecting a vector from a predefined orthonormal basis and adding or subtracting it from the target image. SimBA is a simple and effective method that can be used for both targeted and untargeted attacks. For our experiments, we utilized SimBA in the black-box setting with the overshoot parameter epsilon set to 0.2, batch size set to 1, and the maximum number of generations set to 10,000 for both targeted and untargeted attacks.
–Fast Gradient Sign Method (FGSM) [53] is a white-box attack that works by using the gradient of the loss function J(X,y) with respect to the input X to determine the direction in which the original input should be modified. FGSM is a one-step algorithm that can be executed quickly. In its untargeted version, the adversarial image is
while in its targeted version it is
where is the perturbation size which is calculated with norm and is the gradient function. We set and .
–Basic Iterative Method (BIM) [54] is a white-box attack that is an iterative version of FGSM. BIM is a computationally expensive attack, as it requires calculating the gradient at each iteration. In BIM, the adversarial image is initialized with the original image X and gradually updated over a given number of steps N as follows:
in its untargeted version and
in its targeted version, where is the step size at each iteration and is the maximum perturbation magnitude of . We use the , , and .
–Projected Gradient Descent Infinite (PGD Inf) [55] is a white-box attack that is similar to the BIM attack, but with some key differences. In PGD Inf, the initial adversarial image is not set to the original image X, but rather to a random point within an -ball around X. The distance between X and is measured using the . For our experiments, we set the norm parameter to ∞, which indicates the use of the norm. We also set the step size parameter to 0.1, the batch size to 32, and the maximum perturbation magnitude to 8/255.
–Projected Gradient Descent (PGD ) [55] is a white-box attack and it is similar to PGD Inf, with the difference that is replaced with . We set , , , and .
5. Experimental Results of the Noise Blowing-Up Method
The experiments, following the process implemented in Scheme (11), essentially proceed in two phases for each CNN listed in Table 1, and for each attack and each scenario specified in Table 4.
Phase 1, whose results are given in Section 5.1, mainly deals with running on degraded images in the domain. It corresponds to Step 3 of Scheme (11). The results of these experiments are interpreted in Section 5.2.
Remark.—It is worthwhile noting that Step 3, which is, of course, mandatory in the whole process, should be considered an independent feature of the noise blowing-up strategy. Indeed, although its results are necessary for the experiments performed in the subsequent steps, the success or failure of Phase 1 measures the success or failure of the considered attack (EA, AdvGAN, BIM, etc.) for the considered scenario (target or untarget) in its usual environment (the low-resolution domain). In other words, the outcomes of Phase 1 do not assess in any way the success or failure of the noise blowing-up strategy. This very aspect is addressed in the experiments performed in Phase 2.
Phase 2, whose results are given in Section 5.3, indeed encapsulates the essence of running via the blowing-up of the adversarial noise from to . It corresponds to Steps 4 to 8 of Scheme (11). The results of these experiments are interpreted in Section 5.4.
5.1. Phase 1: Running
Table 5 summarizes the outcome of running the attacks on the 100 clean ancestor images , obtained by degrading, with “Lanczos” function, the HR clean images represented in Figure A1, against the 10 CNNs , either for the untarget scenario, or for the target scenario.
Table 5 gives the number of successfully generated adversarial images in the domain created by seven attacks against 10 CNNs, for either the targeted (targ) or the untargeted (untarg) scenario. In the last three rows, the maximum, minimum, and average dominant label values achieved by each successful targeted/untargeted attack are reported across all CNNs.
5.2. Interpretation of the Results of Phase 1
Except for SimBA and FGSM for the target scenario, one sees that all attacks are performing well for both scenarios. Given SimBA and FGSM’s poor performance in generating adversarial images for the target scenario (see Remark at the beginning of this Section), we decided to exclude them from the subsequent noise blowing-up strategy for the target scenario.
The analysis of the average dominant label values reveals as expected that white-box attacks usually create very strong adversarial images. This is the case for BIM, PGD Inf, and PGD L2 in both the targeted and untargeted scenarios. A contrario but also as expected, black-box attacks (EA, AdvGan for both scenarios, and SimBA for the untarget scenario) achieved lower label values for the target scenario and significantly lower label value of the dominant category for the untarget scenario. This specific issue (or, better said, its consequences as reported in Section 5.3 and Section 5.4) is addressed in Section 6.
5.3. Phase 2: Running
For the relevant adversarial images kept from Table 5, one proceeds with the remaining steps of Scheme (11) with the extraction of the adversarial noise in the domain, its blowing-up to the domain, its addition to the clean HR corresponding image, and the classification by the CNN of the resulting tentative adversarial image.
The speed of the noise blowing-up method is directly impacted by the size of the clean high-resolution image (as pointed out in [31]). Therefore, representative HR clean images of large size and small sizes are required to assess the additional computational cost (both in absolute and relative terms) involved by the noise blowing-up method. To ensure a fair comparison across various attacks and CNNs, we selected for each scenario (targeted or untargeted) HR clean images where all attacks successfully generated HR adversarial images against 10 CNNs. This led to the images referred to in Table 6 (the Table indicates their respective sizes ).
Table 6.
Images employed for the assessment of the speed/overhead of the noise blowing-up method for each considered scenario and attack.
The performance of the noise blowing-up method is summarized in Table 7 Please revise all mentions according to requested style and ensure all tables are mentioned in numerical order. for adversarial images generated by , and in Table 8 for those generated by for each CNN and attack (except and for reasons given in Section 5.2). The adversarial images in used for these experiments are those referred to in Table 5.
Table 7.
Performance of the Noise blowing-up strategy on adversarial images generated with attacks for the targeted scenario (with ) against 10 CNNs. The symbol ↑ (resp. ↓) indicates the higher (resp. the lower) the value the better.
Table 8.
Performance of the Noise blowing-up technique on adversarial images generated with untargeted attacks against 10 CNNs. The symbol ↑ (resp. ↓) indicates the higher (resp. the lower) the value the better.
For each relevant attack and CNN, the measures of a series of outcomes are given in Table 7 and Table 8.
Regarding targeted attacks (the five attacks EA, AdvGAN, BIM, PGD Inf, and PGD L2 are considered) as summarized in Table 7, the row (and ) gives the number of adversarial images for which the noise blowing-up strategy succeeded. The row SR gives the resulting success rate in % (For example, with EA and , SR ). The row reports the number of adversarial images for which the noise blowing-up strategy failed. The row reports the number of images, among those that failed, that are classified back to . The row gives the mean value of the loss function (see Section 3.2) for the adversarial images that succeeded, namely those referred to in the row . Relevant sums or average values are given in the last column.
Regarding untargeted attacks (the seven attacks are considered) as summarized in Table 8, the row gives the number of adversarial images for which the noise blowing-up strategy succeeded, and the row SR gives the resulting success rate. The row reports the number of images, among those that succeeded, that are classified in the same category as the adversarial image obtained in Phase 1. The row reports the number of images for which the strategy failed. Relevant sums or average values are given in the last column.
To assess the visual imperceptibility of adversarial images compared to clean images, we utilize -norms and FID values (see Section 3.2). The average (Avg) and standard deviation (StDev) values of the -norms and FID values, across all CNNs for each attack, are provided for both targeted and untargeted scenarios in Table 9 and Table 10, respectively (see Table A6 and Table A7 for detailed report of FID values). Table 9 considers only the successful adversarial images provided in Table 7, namely those identified by , provided their number is statistically relevant (what leads to the exclusion of AdvGAN images). Table 10 considers only the successful adversarial images obtained in Table 8, namely those identified by (all considered attacks lead to a number of adversarial images that is statistically relevant). This is indicated by the pair “ of adversarial images used”. Table 9 and Table 10 also provide an assessment of the visual impact of the resizing functions and on the considered clean images for which adversarial images are obtained by .
Table 9.
Visual quality as assessed by -distances and FID values for the target scenario.
Table 10.
Visual quality as assessed by -distances and FID values for the untargeted scenario.
Under these conditions, Table 11 for the target scenario (respectively Table 12 for the untarget scenario) provides the execution times in seconds (averaged over the 10 CNNs for each attack and scenario) for each step of the noise blowing-up method, as described in Scheme (11), for the generation of HR adversarial images from large and small HR clean images (respectively large and small HR clean images).
Table 11.
In the target scenario, for each considered attack , execution time (in seconds, averaged over the 10 CNNs) of each step of Scheme (11) for the generation of HR adversarial images for the HR clean images and . The Overhead column provides the cumulative time of all steps except Step 3. The ‰ column displays the relative per mille additional time of the Overhead as compared to the time required by performed in Step 3.
Table 12.
In the untargeted scenario, for each considered attack , execution time (in seconds, averaged over the 10 CNNs) of each step of Scheme (11) for the generation of HR adversarial images for the HR clean images and . The Overhead column provides the cumulative time of all steps except Step 3. The ‰ column displays the relative per mille additional time of the Overhead as compared to the time required by performed in Step 3.
The Overhead column provides the time of the noise blowing-up method per se, namely computed as the cumulative time of all steps of Scheme (11) except Step 3. The ‰ column displays the relative per mille additional time of the overhead of the noise blowing-up method as compared to the underlying attack performed in Step 3.
5.4. Interpretation of the Results of Phase 2
In the targeted scenario, the noise blowing-up strategy achieved an overall average success rate (overall attacks and CNNs) of (see Table 7).
Notably, the strategy performed close to perfection with PGD Inf, achieving an average success rate of (and minimal loss of ). The strategy performed also very well with PGD L2, EA, and BIM, with average success rates of , , and , respectively. In contrast, the strategy performed poorly with AdvGAN, achieving a success rate oscillating between (for 8 CNNs) and , leading to an average success rate of .
The reason for the success of the noise blowing-up strategy for PGD Inf, PGD L2, EA and BIM, and its failure for AdvGAN is essentially due to the behavior, for these attacks, of the average label values of the dominant categories obtained in Table 5, hence is due to a phenomenon occurring before the noise blowing-up process per se.
Indeed, these values are very high for the white-box attacks PGD Inf (), PGD L2 (), and BIM (), and are quite high for EA (). However, this value is very low for AdvGAN ().
The adversarial noises, obtained after Phase 1 (in the domain) by all attacks except AdvGAN, are particularly robust, and “survive” the Phase 2 treatment: The noise blowing-up process did not significantly reduce their adversarial properties legacy, and the derived adversarial images, obtained after the noise blowing-up process, remained in the target category.
The situation differs for AdvGAN: After Phase 1, the target category is only modestly dominating other categories, and one (or more) other categories achieve only slightly weaker label values than the dominating target category. Consequently, the adversarial noise becomes highly susceptible to even minor perturbations, with the effect that these perturbations can easily cause transitions between categories.
In the untargeted scenario, the noise blowing-up strategy achieved an overall average success rate (overall attacks and CNNs) of (see Table 8).
The strategy performed perfectly or close to perfection with all white-box attacks, namely PGD Inf (average success rate of ), BIM (), PGD L2 () and FGSM (). A contrario, the strategy performed weakly or even poorly for all black-box attacks, namely SimBA (), AdvGAN (), and EA ().
The reason for these differences in the successes of the strategy according to the considered attacks is the same as seen before in the target scenario: the behavior of the average label values of the dominating category obtained in Table 5 (hence, in this case too, before the noise blowing-up process).
Indeed, these values are very high or fairly high for PGD Inf (), BIM (), PGD L2 (), and FGSM (). However, they are much lower for EA (), SimBA (), and AdvGAN ().
The adversarial noises, obtained after Phase 1 by all white-box attacks, are particularly robust, and those obtained by all black-box attacks are less resilient. In this latter case, the adversarial noise leveraged to create the tentative adversarial image by the noise blowing-up process is much more sensitive to minor perturbations, with similar consequences as those already encountered in the target scenario.
Visual quality of the adversarial images: The values of in Table 9 (resp. Table 10) show that the attacks performed for the target scenario manipulate on average of the pixels of the downsized (hence in ) clean image (resp. for the untarget scenario).
Nevertheless, the values of in both tables (hence in the larger domain, after the noise blowing-up process) are lower, with an overall average of for the targeted scenario (resp. for the untargeted scenario). This trend is consistent across all values (), with generally higher than the corresponding values for all attacks (the values are closely aligned, though, for ).
Additionally, values, comparing clean and adversarial images obtained by the noise blowing-up method, ranging between (achieved by BIM) and in the targeted scenario (with average , see Table 9), and between (achieved by EA) and in the untargeted scenario (with average , see Table 10), are significantly low (it is not uncommon to have values in the range 300–500). In other words, the adversarial images maintain a visual quality and proximity to their clean counterparts.
It is important to highlight that the simple operation of scaling down and up the clean images results in even larger values than for for all attacks and scenarios (see Table 9 and Table 10; note that the values for are too small to assess the phenomenon described above). When one compares to , the same phenomenon occurs for three out of 4 targeted attacks (EA is the exception), and for five out of 7 untargeted attacks (FGSM and PGD Inf being the exceptions).
Said otherwise, the interpolation techniques usually cause more visual damage than the attacks themselves, at least as measured by these indicators.
Figure 3 provides images representative of this general behavior. Evidence is furthermore supported numerically by the , () and the , values deduced from these images.

Figure 3.
Examples of images for which the interpolation techniques cause more visual damage than the attacks themselves. Clean HR images in the 1st column; corresponding non-adversarial HR resized images in the 2nd column, with values of , and underneath (in that order); adversarial HR images in the 3rd column ( EA, , target scenario) and in the 4th column ( BIM, , untarget scenario), with , , and underneath (in that order). To enhance visibility, consider zooming in for a clearer view.
More precisely, the 1st column of Figure 3 displays the HR clean images , , and . The 2nd column displays the non-adversarial images, as well as the corresponding and values (in that order).
HR adversarial images are displayed in the 3rd and 4th columns: For EA performed on MobileNet for the targeted scenario in the 3rd column, and for BIM on ResNet50 for the untargeted scenario in the 4th column. The corresponding numerical values of () and of (in that order) are provided as well.
Speed of the noise blowing-up method: The outcomes of Table 11 and Table 12 for the overhead of the noise blowing-up method (all steps except Step 3) and its relative cost as compared to the actual attack (performed in Step 3) are twofold.
Firstly, the performance of the noise blowing-up strategy depends on the size of the image: It is substantially faster (between times and times on average) for smaller than for larger HR clean images.
Secondly, and this is probably the most important outcome of both, the noise blowing-up method demonstrates exceptional speed both in absolute and in relative terms, and consequently an exceptionally minimal overhead, even for large-size HR clean images.
Indeed, the overhead ranges between s and s on average over 10 CNNs ( s achieved in the untargeted scenario for PGD Inf and ; seconds achieved in the targeted scenario for EA and ). This is to compare to the extreme timing values of the attacks performed in Step 3, ranging between and s all in all (and ranging between and s for the cases related to the and s referred to).
Looking at the relative weight of the overhead as compared to is even more saying: It ranges between ‰and ‰, hence is almost negligible.
6. Revisiting the Failed Cases with
The summary of Section 5.4 is essentially threefold. Firstly, the noise blowing-up strategy performs very well and with a negligible timing overhead in the target scenario for all five relevant attacks except AdvGAN, and in the untargeted scenario for all four white-box attacks but not for the three black-box attacks. Secondly, the poor performances of the strategy for AdvGAN (target scenario and untargeted scenario), EA (untargeted scenario), and SimBA (untargeted scenario) are essentially due to too low requirements put on these attacks during Phase 1 (Step 3 of Scheme (11), hence ahead of the noise blowing-up process). Thirdly, although between and of the pixels are modified on average, the adversarial images remain visually very close to their corresponding clean images, and actually and surprisingly the attacks themselves tend to reduce the differences introduced by the interpolation functions.
We revisit these failed cases and make use of the Delta function introduced in Section 3.2 for this purpose. Indeed, we identified the origin of the encountered issues as essentially due to the too low distance between the label values of the dominating category and its closest competitors, hence due to a very small value of for the considered images and CNNs.
Given and (Step 1), and (Step 2), we study in this Subsection how setting the increase of the values of as a requirement in Step 3 of Scheme (11) impacts the success rate of the noise blowing-up strategy for the failed cases. Note that putting additional requirements on may lead to lesser adversarial images at the end of Phase 1 as increases.
We limit this study to EA (untargeted scenario) and AdvGAN (untargeted and target scenario). We regrettably exclude SimBA since we do not have access to its code.
6.1. Revisiting the Failed Cases in Both Scenarios
The untargeted scenario revisited for EA and AdvGAN. The new consideration of the failed cases proceeds by taking a hybrid approach in Step 3, leading to two successive sub-steps Step 3(a) and Step 3(b).
Step 3(a) consists in running until it succeeds in creating a first adversarial image in classified outside the ancestor category . The obtained category is therefore the most promising category outside .
In Step 3(b), we change the version of the attack and run on the adversarial image obtained at the end of Step 3(a) for the target scenario , with a (more demanding) stop condition defined by a threshold value on set at will.
Remarks: (1) To summarize this hybrid approach, Step 3(a) identifies the most promising category outside (and does so by “pushing down” the label value until another category shows up), and Step 3(b) “pushes further” the attack in the direction of until the label value of this dominant category is sufficiently ahead of all other competitors. (2) Although this hybrid approach mixes the untargeted and the target versions of the attack (be it EA or AdvGAN), it fits the untargeted attack scenario nevertheless. Indeed, the category is not chosen a priori as would be the case in the target scenario but is obtained alongside the attack, and is an outcome of .
The target scenario revisited for AdvGAN. We address the failed cases by requiring in Step 3 of Scheme (11), that is classified in and that is large enough.
6.2. Outcome of Revisiting the Failed Cases
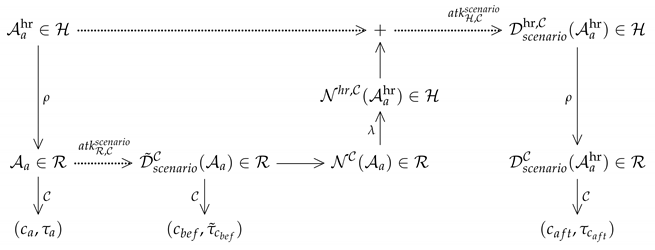
One constructs the graph of the evolution of the success rate (, in %) of the noise blowing-up strategy performed for the considered attack for the untargeted scenario according to step-wise increasing values (x-axis) set to .
Figure 4 for EA (untargeted scenario), Figure 5 for AdvGAN (untargeted scenario) and Figure 6 for AdvGAN (targeted scenario) picture this evolution for an example, namely —MobileNet (a), on average over the 10 CNNs (b), and per CNN for all considered images (c).
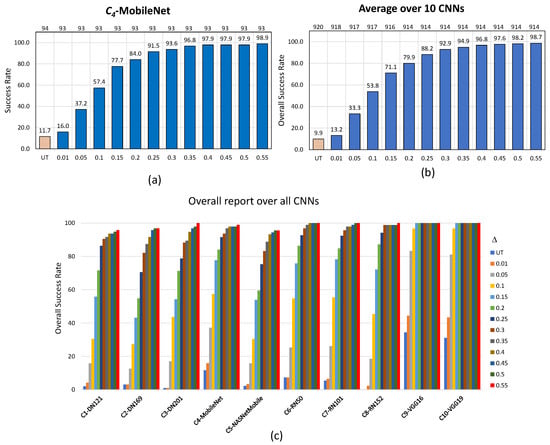
Figure 4.
Performance of the noise blowing-up method for EA in the untargeted scenario with the increased strength of adversarial images: (a) specifically for , (b) averaged across 10 CNNs, and (c) overall report for all CNNs. In (a,b), values are displayed at the bottom, and the resulting number of used images is at the top.
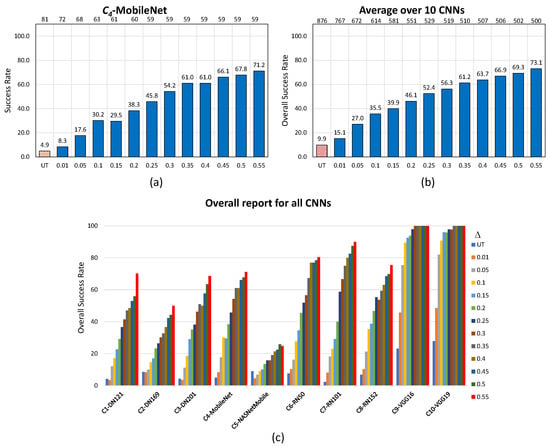
Figure 5.
Performance of the noise blowing-up method for AdvGAN in the untargeted scenario with the increased strength of adversarial images: (a) specifically for , (b) averaged across 10 CNNs, and (c) overall report for all CNNs. In (a,b), values are displayed at the bottom, and the resulting number of used images is at the top.
Figure 6.
Performance of the noise blowing-up method for AdvGAN in the target scenario with the increased strength of adversarial images: (a) specifically for , (b) averaged across 10 CNNs, and (c) overall report for all CNNs. In (a,b), values are displayed at the bottom, and the resulting number of used images is at the top.
UT (resp. T) in (a) and (b) of Figure 4 and Figure 5 (resp. of Figure 6) recalls the “original” success rate achieved by the noise blowing-up method in creating adversarial images without putting extra conditions on (see Table 8, resp. Table 7). The values at the top of the Figures are the number of images obtained after Phase 1, as increases.
In the untargeted scenario for EA, the approach adopted for the revisited failed cases turns out to be overwhelmingly successful, and this in a uniform way over the 10 CNNs. The overall number of considered images drops only by , namely from 920 to 914 (in the example of , this drop is of one image only), while the success rate drastically increases from an original to . In the example of , the success rate increases from to ; a success rate of is even achieved for six out of 10 CNNs, even for moderate values of .
In the untargeted scenario for AdvGAN, the approach is also successful, but to a lesser extent, and with variations among the CNNs. The overall number of considered images drops by , namely from 876 to 500 images (in the example of , this drop amounts to 22 images, hence almost less images), while the success rate increases from an original to (in the example of , the success rate increases from to ). Apart from and , where the success rate of the revisited method achieves at most and , all CNNs are reasonably well deceived by the method; the success rate achieves even for two of them, and this for moderate values of .
In the targeted scenario, for AdvGAN, the approach also proves useful, but to a lesser extent as above, and with larger variations among the CNNs. The overall number of considered images drops by , namely from 758 to 594 images (from 88 to 72 images, hence almost less images for ), while the success rate increases from an original to (in the example of , the success rate increases from to ). It is worthwhile noting that the method works to perfection with a success rate reaching for two CNNs ( and ), even with a moderate value.
Table 13 summarizes the outcomes of the numerical experiments when is set to the demanding value . As a consequence, it is advisable to set (for Phase 1, Step 3) to for , to for , and to for to be on the safe side (these values exceed the maxima referred to in Table 13).
Table 13.
Minimum, maximum, and mean of the label values of adversarial images in the domain (Phase 1, Step 3) when is set to 0.55 per CNN.
Finally, experiments show that the visual quality of the HR adversarial images obtained by the revised method remains outstanding. We illustrate this statement in Figure 7 on an example, where is set to (the highest and most demanding value considered in the present study), and the CNN is . In Figure 7, (a) represents the HR clean image classified by as belonging to the “acorn” category with corresponding label value , (b) the adversarial image created by the strategy applied to the EA attack in the untargeted scenario (classified as “snail” with label value ), (c) the adversarial image created by the strategy with AdvGAN in the untargeted scenario (classified as “dung beetle” with label value ), and (d) the adversarial image created by the strategy with AdvGAN in the targeted scenario (classified as “rhinoceros beetle” with label value ). The images speak for themselves as far as visual quality is concerned.

Figure 7.
Sample of HR adversarial images generated by the noise blowing-up strategy for the EA and AdvGAN attacks in the untargeted scenario, and the AdvGAN attack in the targeted scenario against MobileNet, with set to 0.55 in the domain. Classification (dominant category and label value) of are displayed at the bottom. (a) Clean image acorn: 0.90. (b) snail: 0.61. (c) dung_beetle: 0.55. (d) rhinoceros_beetle: 0.43.
7. Comparison of the Lifting Method and of the Noise Blowing-Up Method
This section provides a comparison between the outcomes of our adversarial noise blowing-up strategy and those of the lifting method introduced in [29,30].
We shall see on three highly challenging examples, that the noise blowing-up strategy leads to a substantial visual quality gain as compared with the lifting method of [29,30] (both strategies achieve comparable and negligible timing overheads as compared to the actual underlying attacks performed). Indeed, the visual quality gain is particularly flagrant when one zooms on some areas that remained visually problematic with the method used in [29,30].
7.1. The Three HR Images, the CNN, the Attack, the Scenario
We make here a case study with three HR images (two of which have been considered in [31]), with VGG-16 trained on ImageNet, for the EA-based black-box targeted attack given in Section 4.4.
The three HR pictures are represented in Table 14. They are the comics Spiderman picture ( retrieved from the Internet and under Creative Commons License), an artistic picture graciously provided by the French artist Speedy Graphito ( pictured in [56]) and Hippopotamus image () taken from Figure A1. An advantage of adding artistic images is that, while a human may have difficulties in classifying them in any category, CNNs do it.
Table 14.
Three clean HR images , their original size, the classification of VGG-16 as of their reduced versions (with “Lanczos”), and the target category.
7.2. Implementation and Outcomes
Regarding implementation issues, we use (Lanczos, Lanczos) for both the lifting method of [29,30] and the noise blowing-up method presented here, whenever needed.
In terms of the steps described in Section 3.1, note that both strategies coincide up to Step 3 included, and start to differ from Step 4 on. In particular, the attack process (Step 3) in the domain is the same for both strategies. In the present case, one shall apply the EA-based targeted attack in the domain, with the aim to create a -strong adversarial image. In other words, (with notations consistent with Section 3). This process succeeded for the three examples.
Figure 8, Figure 9 and Figure 10 provide a visual comparison (both globally and on some zoomed area) of a series of images in the domain for , respectively: (a) the clean image , (b) the non-adversarial resized image , (c) the adversarial image in obtained by the lifting method of [29,30], (d) the adversarial image in obtained by the noise blowing-up method. The non-adversarial image referred to in (b) remains classified by in the category, and the adversarial images referred to in (c) and (d) are classified in the category mentioned in Table 14, with -label values indicated in the Figures.

Figure 8.
Visual comparison in the domain of (a) the clean image , (b) its non-adversarial resized version, the adversarial image obtained with for VGG-16, (c) by the lifting method of [29,30], and (d) by the noise blowing-up method. Both non-adversarial images are classified as “comic books”, (a) with label value and (b) with label value . Both HR adversarial images are classified as “altar”, (c) with label value , and (d) with label value .
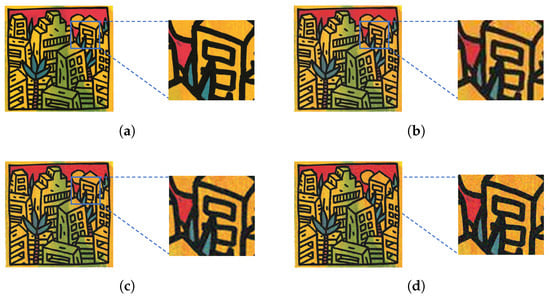
Figure 9.
Visual comparison in the domain of (a) the clean image , (b) its non-adversarial resized version, the adversarial image obtained with for VGG-16, (c) by the lifting method of [29,30], and (d) by the noise blowing-up method. Both non-adversarial images are classified as “Coffee Mug”, (a) with label value and (b) with label value . Both HR adversarial images are classified as “Hamper”, (c) with label value , and (d) with label value .

Figure 10.
Visual comparison in the domain of (a) the clean image , (b) its non-adversarial resized version, the adversarial image obtained with for VGG-16, (c) by the lifting method of [29,30], and (d) by the noise blowing-up method. Both non-adversarial images are classified as “hippopotamus”, (a) with label value and (b) with label value . Both HR adversarial images are classified as “trifle”, (c) with label value , and (d) with label value .
With notations consistent with Table 9 and Table 10, and with the exponent , and indicating respectively that the adversarial images are obtained via the lifting method, and by the noise blowing-up method respectively, Table 15 gives a numerical assessment of the visual quality of the different HR images (b), (c), (d) compared to the clean ones (a) of Figure 8, Figure 9 and Figure 10, as measured by distances and FID values.
Figure 8, Figure 9 and Figure 10 show that, at some distance, both the non-adversarial resized image (b) and the HR adversarial images (c) and (d) seem to have a good visual quality as compared to the HR clean image (a). However, the zoomed areas show that details from the HR clean images become blurry in the HR adversarial images obtained by the lifting method (c) and in the non-adversarial resized images (b). Moreover, a human eye is not able to distinguish the blurriness that occurs in (b) from the one that shows up in (c): The loss of visual quality looks the same in both cases. However, a loss of visual quality does not occur (at least to the same extent) in the HR adversarial images obtained by the noise blowing-up method (d). These observations are also sustained numerically by Table 15: and , as well as and are close one to the other, while and achieve much smaller values than their above counterparts. In particular, we see and measure in these examples, that the noise blowing-up method largely compensates for the negative visual impact of the resizing interpolation functions.
In other words, the adversarial images displayed by the noise blowing-up method in (d) are visually very close to the original clean images (a), while the adversarial images displayed by the lifting method in (c) are visually very close to the non-adversarial resized images in (b).
These experiments strongly speak in favor of our noise blowing-up method, despite the fact that interpolation scaling-up methods result in a loss of high-frequency features in the domain (as seen in (b) and (c)). More precisely, our noise blowing-up method essentially avoids (and even corrects, as shows the behavior of by and FID values) this later issue, while the lifting method does not.
8. Conclusions
In this extensive study, we exposed in detail the noise blowing-up strategy to create high-quality high-resolution images adversarial against convolutional neural networks, and indistinguishable from the original clean images.
This strategy is designed to apply to any attack (black-box or white-box), to any scenario (targeted or untargeted scenario), to any CNN, and to any clean image.
We performed an extensive experimental study on 10 state-of-the-art and diverse CNNs, with 100 high-resolution clean images, three black-box (EA, AdvGAN, SimBA), and four white-box (FGSM, BIM, PGD Inf, PGD L2) attacks, applied in the target and the untarget scenario whenever possible.
This led to the construction of adversarial images for the target scenario and adversarial images for the untarget scenario. Therefore, the noise blowing-up method achieved an overall average success rate of in the target scenario, and of in the untarget scenario; the strategy performing perfectly or close to perfection (with a success rate of or close to it) for many attacks.
We then focused on the failed cases. We showed that a minor additional requirement in one step of the strategy led to a substantial success rate increase (e.g., from circa to in the untarget scenario for the EA attack).
All along, we showed that the additional time required to perform our noise blowing-up strategy is negligible as compared to the actual cost of the underlying attack on which the strategy applies.
Finally, we compared our noise blowing-up method to another generic method, namely the lifting method. We showed that the visual quality and indistinguishability of the adversarial images obtained by our noise blowing-up strategy substantially outperform those of the adversarial images obtained by the lifting method. We also showed that applying our noise blowing-up strategy substantially corrects some visual blurriness artifacts caused natively by interpolation resizing functions.
Clearly, the noise blowing-up strategy, which essentially amounts to the addition to the clean high-resolution image of one layer of “substantial” adversarial noise, blown-up from to , is subject to a series of refinements and variants. For instance, one may instead consider adding to the clean image several “thin” layers of “moderate” blown-up adversarial noise. This would present at least two advantages. Firstly, one can parallelize this process. Secondly, depending on how adding different layers of adversarial noise impacts the overall -value, one could consider relaxing the expectations on the value for each run of the attack in the domain, and still meet and preset thresholds by adding up wisely the successive layers of noise. Both advantages may lead to a substantial speed-up of the process, and potentially to an increased visual quality. One could also consider applying the strategy to the flat scenario, where all ℓ label values are almost equidistributed, henceforth the CNN considers that all categories are almost equally likely (even this variant admits variants, e.g., where one specifies a number of dominating categories for which the attack would create an appropriate flatness).
Another promising direction comes from the observation that in the present method as well as in the method introduced in [29,30], the considered attacks explore a priori the whole image space. In future work, we intend to explore the possibility of restricting the size of the zones to explore. Provided the kept zones are meaningful (in a sense to be defined), one could that way design an additional generic method which, combined with the one presented in this paper, could lead, at a lower computational cost, to high-resolution adversarial images of very good quality, especially if one pays attention to high-frequency areas.
Author Contributions
Conceptualization, F.L., A.O.T. and E.M.; methodology, F.L. and A.O.T.; software, A.O.T., E.M., E.A. and T.G.; validation, F.L., A.O.T. and E.M.; formal analysis, F.L., A.O.T. and E.M.; investigation, F.L., A.O.T. and E.M.; data curation, A.O.T., E.M., E.A. and T.G.; writing—original draft preparation, F.L., A.O.T. and E.M.; writing—review and editing, F.L., A.O.T. and E.M.; visualization, A.O.T. and E.M.; supervision, F.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Acknowledgments
The authors express their gratitude to Speedy Graphito and to Bernard Utudjian for the provision of two artistic images used in the feasibility study and for their interest in this work.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Clean Images

Figure A1.
Representation of the 100 ancestor clean images used in the experiments. pictured in the qth row and pth column () is randomly chosen from the ImageNet validation set of the ancestor category specified on the left of the qth row.
Figure A1.
Representation of the 100 ancestor clean images used in the experiments. pictured in the qth row and pth column () is randomly chosen from the ImageNet validation set of the ancestor category specified on the left of the qth row.

Table A1.
Size (with ) of the 100 clean ancestor images .
Table A1.
Size (with ) of the 100 clean ancestor images .
| Ancestor Images and Their Original Size | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| abacus | 1 | 2448 × 3264 | 960 × 1280 | 262 × 275 | 598 × 300 | 377 × 500 | 501 × 344 | 375 × 500 | 448 × 500 | 500 × 500 | 2448 × 3264 | |
| acorn | 2 | 374 × 500 | 500 × 469 | 375 × 500 | 500 × 375 | 500 × 500 | 500 × 500 | 375 × 500 | 374 × 500 | 461 × 500 | 333 × 500 | |
| baseball | 3 | 398 × 543 | 240 × 239 | 2336 × 3504 | 333 × 500 | 262 × 350 | 310 × 310 | 404 × 500 | 344 × 500 | 375 × 500 | 285 × 380 | |
| broom | 4 | 500 × 333 | 286 × 490 | 360 × 480 | 298 × 298 | 413 × 550 | 366 × 500 | 400 × 400 | 348 × 500 | 346 × 500 | 640 × 480 | |
| brown bear | 5 | 700 × 467 | 903 × 1365 | 333 × 500 | 500 × 333 | 497 × 750 | 336 × 500 | 480 × 599 | 375 × 500 | 334 × 500 | 419 × 640 | |
| canoe | 6 | 500 × 332 | 450 × 600 | 500 × 375 | 375 × 500 | 406 × 613 | 600 × 400 | 1067 × 1600 | 333 × 500 | 1536 × 2048 | 375 × 500 | |
| hippopotamus | 7 | 375 × 500 | 1200 × 1600 | 333 × 500 | 450 × 291 | 525 × 525 | 375 × 500 | 500 × 457 | 424 × 475 | 500 × 449 | 339 × 500 | |
| llama | 8 | 500 × 333 | 618 × 468 | 500 × 447 | 253 × 380 | 500 × 333 | 333 × 500 | 375 × 1024 | 375 × 500 | 290 × 345 | 375 × 500 | |
| maraca | 9 | 375 × 500 | 375 × 500 | 470 × 627 | 1328 × 1989 | 250 × 510 | 375 × 500 | 768 × 104 | 375 × 500 | 375 × 500 | 500 × 375 | |
| mountain bike | 10 | 375 × 500 | 500 × 375 | 375 × 500 | 333 × 500 | 500 × 375 | 300 × 402 | 375 × 500 | 446 × 500 | 375 × 500 | 500 × 333 | |
Table A2.
In Step 1 and 2 of Scheme (11), the Lanczos degrading interpolation function is employed for resizing images to match the input size of CNNs before they are fed into the CNNs. For , the ancestor category -label values given by the 10 CNNs of the image pictured in Figure A1. A label value in red indicates that the category is not the dominant one.
Table A2.
In Step 1 and 2 of Scheme (11), the Lanczos degrading interpolation function is employed for resizing images to match the input size of CNNs before they are fed into the CNNs. For , the ancestor category -label values given by the 10 CNNs of the image pictured in Figure A1. A label value in red indicates that the category is not the dominant one.
| CNNs | p | Abacus | Acorn | Baseball | Broom | Brown Bear | Canoe | Hippopotamus | Llama | Maraca | Mountain Bike |
|---|---|---|---|---|---|---|---|---|---|---|---|
DenseNet-121 | 1 | 1.000 | 0.994 | 0.997 | 0.982 | 0.996 | 0.987 | 0.999 | 0.998 | 0.481 | 0.941 |
| 2 | 1.000 | 0.997 | 0.993 | 0.999 | 0.575 | 0.921 | 0.999 | 0.974 | 0.987 | 0.992 | |
| 3 | 0.999 | 0.954 | 1.000 | 0.999 | 0.999 | 0.675 | 0.993 | 0.996 | 1.000 | 0.814 | |
| 4 | 0.998 | 0.998 | 1.000 | 1.000 | 0.998 | 0.552 | 0.684 | 0.966 | 0.742 | 0.255 | |
| 5 | 1.000 | 0.999 | 1.000 | 0.999 | 0.993 | 0.827 | 1.000 | 0.999 | 0.153 | 0.637 | |
| 6 | 1.000 | 0.998 | 0.946 | 0.997 | 1.000 | 0.975 | 0.991 | 0.961 | 0.684 | 0.995 | |
| 7 | 0.999 | 0.999 | 0.997 | 0.945 | 0.949 | 0.524 | 0.973 | 0.987 | 0.960 | 0.835 | |
| 8 | 1.000 | 0.999 | 0.985 | 0.940 | 0.999 | 0.893 | 1.000 | 0.999 | 0.997 | 0.968 | |
| 9 | 1.000 | 0.996 | 0.967 | 1.000 | 0.998 | 0.710 | 1.000 | 1.000 | 0.991 | 0.969 | |
| 10 | 0.997 | 1.000 | 0.999 | 0.997 | 0.992 | 0.790 | 1.000 | 0.935 | 0.929 | 0.907 | |
DenseNet-169 | 1 | 1.000 | 0.998 | 0.999 | 0.973 | 0.999 | 0.995 | 0.995 | 0.999 | 0.991 | 0.799 |
| 2 | 0.999 | 1.000 | 0.998 | 0.991 | 0.343 | 0.683 | 0.999 | 0.999 | 0.991 | 0.862 | |
| 3 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.929 | 1.000 | 0.997 | 1.000 | 0.922 | |
| 4 | 0.990 | 0.999 | 1.000 | 1.000 | 1.000 | 0.479 | 0.927 | 0.960 | 0.665 | 0.885 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.999 | 0.998 | 0.941 | 1.000 | 0.993 | 0.681 | 0.969 | |
| 6 | 1.000 | 1.000 | 0.999 | 0.999 | 1.000 | 0.997 | 0.997 | 0.991 | 0.829 | 0.952 | |
| 7 | 1.000 | 1.000 | 0.999 | 1.000 | 0.990 | 0.796 | 0.990 | 0.999 | 0.727 | 0.856 | |
| 8 | 1.000 | 1.000 | 0.998 | 0.985 | 1.000 | 0.944 | 0.998 | 1.000 | 1.000 | 0.942 | |
| 9 | 1.000 | 1.000 | 0.886 | 1.000 | 1.000 | 0.949 | 1.000 | 1.000 | 0.908 | 0.941 | |
| 10 | 0.948 | 1.000 | 0.998 | 0.999 | 0.999 | 0.897 | 0.999 | 0.999 | 0.720 | 0.502 | |
DenseNet-201 | 1 | 1.000 | 0.999 | 0.994 | 1.000 | 0.994 | 0.990 | 0.999 | 0.999 | 0.565 | 0.986 |
| 2 | 1.000 | 1.000 | 0.985 | 1.000 | 0.928 | 0.949 | 0.999 | 0.978 | 0.999 | 0.995 | |
| 3 | 0.983 | 0.957 | 0.999 | 1.000 | 0.999 | 0.719 | 1.000 | 0.995 | 1.000 | 0.829 | |
| 4 | 0.937 | 0.987 | 1.000 | 1.000 | 0.999 | 0.846 | 0.919 | 1.000 | 0.732 | 0.752 | |
| 5 | 1.000 | 1.000 | 0.999 | 0.995 | 0.995 | 0.786 | 1.000 | 0.993 | 0.316 | 0.936 | |
| 6 | 1.000 | 1.000 | 0.996 | 1.000 | 1.000 | 0.990 | 1.000 | 0.790 | 0.733 | 0.994 | |
| 7 | 1.000 | 1.000 | 1.000 | 0.998 | 0.997 | 0.817 | 0.997 | 0.984 | 0.959 | 0.682 | |
| 8 | 1.000 | 1.000 | 0.965 | 0.999 | 0.966 | 0.925 | 0.992 | 1.000 | 0.998 | 0.992 | |
| 9 | 1.000 | 0.998 | 0.818 | 1.000 | 0.980 | 0.980 | 1.000 | 0.999 | 0.971 | 0.964 | |
| 10 | 1.000 | 1.000 | 0.995 | 0.998 | 0.979 | 0.976 | 0.964 | 0.990 | 0.604 | 0.966 | |
MobileNet | 1 | 0.944 | 0.216 | 0.609 | 0.646 | 0.966 | 0.287 | 0.876 | 0.621 | 0.324 | 0.736 |
| 2 | 0.867 | 0.984 | 0.966 | 0.957 | 0.506 | 0.751 | 0.613 | 0.838 | 0.972 | 0.937 | |
| 3 | 0.967 | 0.905 | 0.937 | 0.982 | 0.969 | 0.778 | 0.970 | 0.933 | 0.999 | 0.939 | |
| 4 | 0.984 | 0.978 | 0.966 | 0.940 | 0.961 | 0.621 | 0.758 | 0.968 | 0.472 | 0.576 | |
| 5 | 0.915 | 0.984 | 0.917 | 0.829 | 0.971 | 0.836 | 0.9311 | 0.873 | 0.383 | 0.708 | |
| 6 | 0.989 | 0.950 | 0.942 | 0.932 | 0.970 | 0.854 | 0.971 | 0.808 | 0.573 | 0.863 | |
| 7 | 0.970 | 0.962 | 0.929 | 0.903 | 0.895 | 0.524 | 0.683 | 0.989 | 0.740 | 0.671 | |
| 8 | 0.970 | 0.985 | 0.834 | 0.906 | 0.942 | 0.732 | 0.723 | 0.986 | 0.788 | 0.930 | |
| 9 | 0.998 | 0.965 | 0.755 | 0.986 | 0.940 | 0.767 | 0.873 | 0.967 | 0.921 | 0.855 | |
| 10 | 0.923 | 1.000 | 0.804 | 0.934 | 0.772 | 0.877 | 0.975 | 0.766 | 0.844 | 0.850 | |
NASNet Mobile | 1 | 0.948 | 0.930 | 0.888 | 0.880 | 0.887 | 0.904 | 0.911 | 0.945 | 0.699 | 0.867 |
| 2 | 0.972 | 0.917 | 0.882 | 0.901 | 0.426 | 0.897 | 0.941 | 0.954 | 0.976 | 0.915 | |
| 3 | 0.896 | 0.938 | 0.887 | 0.976 | 0.943 | 0.707 | 0.929 | 0.747 | 0.876 | 0.945 | |
| 4 | 0.859 | 0.940 | 0.893 | 0.961 | 0.920 | 0.549 | 0.517 | 0.889 | 0.991 | 0.310 | |
| 5 | 0.949 | 0.950 | 0.879 | 0.956 | 0.896 | 0.577 | 0.914 | 0.977 | 0.720 | 0.792 | |
| 6 | 0.975 | 0.945 | 0.953 | 0.970 | 0.921 | 0.698 | 0.903 | 0.926 | 0.307 | 0.859 | |
| 7 | 0.985 | 0.902 | 0.868 | 0.953 | 0.837 | 0.809 | 0.865 | 0.955 | 0.984 | 0.519 | |
| 8 | 0.969 | 0.955 | 0.879 | 0.922 | 0.881 | 0.870 | 0.800 | 0.969 | 0.498 | 0.912 | |
| 9 | 0.971 | 0.874 | 0.574 | 0.934 | 0.935 | 0.691 | 0.924 | 0.942 | 0.902 | 0.938 | |
| 10 | 0.847 | 0.979 | 0.842 | 0.945 | 0.811 | 0.782 | 0.946 | 0.917 | 0.410 | 0.605 | |
ResNet-50 | 1 | 0.999 | 0.998 | 0.996 | 0.883 | 0.996 | 0.997 | 0.999 | 1.000 | 0.597 | 0.959 |
| 2 | 0.980 | 0.999 | 0.999 | 0.999 | 0.529 | 0.990 | 1.000 | 0.998 | 0.997 | 0.984 | |
| 3 | 0.999 | 0.989 | 0.999 | 0.999 | 0.999 | 0.801 | 1.000 | 1.000 | 1.000 | 0.990 | |
| 4 | 0.999 | 0.999 | 0.999 | 0.999 | 0.998 | 0.831 | 0.970 | 0.994 | 0.350 | 0.444 | |
| 5 | 0.999 | 0.999 | 0.999 | 0.994 | 0.986 | 0.950 | 0.997 | 0.278 | 0.543 | 0.871 | |
| 6 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.985 | 1.000 | 0.920 | 0.725 | 0.685 | |
| 7 | 0.999 | 0.999 | 0.999 | 0.998 | 0.991 | 0.584 | 1.000 | 1.000 | 0.987 | 0.803 | |
| 8 | 1.000 | 0.999 | 0.926 | 0.990 | 0.997 | 0.981 | 0.970 | 1.000 | 0.999 | 0.963 | |
| 9 | 1.000 | 0.999 | 0.808 | 0.999 | 0.999 | 0.911 | 1.000 | 1.000 | 0.998 | 0.991 | |
| 10 | 0.999 | 0.999 | 0.999 | 0.999 | 0.982 | 0.987 | 0.996 | 0.984 | 0.775 | 0.939 | |
ResNet-101 | 1 | 1.000 | 1.000 | 0.997 | 0.999 | 1.000 | 0.999 | 0.999 | 1.000 | 0.665 | 0.973 |
| 2 | 1.000 | 1.000 | 0.972 | 1.000 | 0.836 | 0.984 | 1.000 | 0.868 | 0.995 | 0.992 | |
| 3 | 1.000 | 0.898 | 1.000 | 1.000 | 1.000 | 0.940 | 1.000 | 1.000 | 1.000 | 0.778 | |
| 4 | 0.744 | 1.000 | 1.000 | 1.000 | 0.997 | 0.556 | 0.941 | 0.999 | 0.447 | 0.835 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.999 | 0.968 | 0.939 | 0.999 | 0.894 | 0.325 | 0.694 | |
| 6 | 1.000 | 1.000 | 0.996 | 1.000 | 1.000 | 0.983 | 1.000 | 0.837 | 0.719 | 0.996 | |
| 7 | 1.000 | 1.000 | 1.000 | 0.997 | 0.990 | 0.920 | 1.000 | 1.000 | 0.305 | 0.330 | |
| 8 | 1.000 | 1.000 | 0.999 | 0.997 | 0.978 | 0.993 | 0.943 | 1.000 | 0.997 | 0.988 | |
| 9 | 1.000 | 1.000 | 0.959 | 1.000 | 0.997 | 0.903 | 1.000 | 1.000 | 0.969 | 0.983 | |
| 10 | 1.000 | 1.000 | 1.000 | 1.000 | 0.998 | 0.965 | 0.999 | 0.995 | 0.927 | 0.961 | |
ResNet-152 | 1 | 1.000 | 1.000 | 1.000 | 0.998 | 0.999 | 0.994 | 1.000 | 0.999 | 0.597 | 0.992 |
| 2 | 0.578 | 1.000 | 0.999 | 1.000 | 0.356 | 0.979 | 1.000 | 0.999 | 0.997 | 0.998 | |
| 3 | 1.000 | 0.974 | 1.000 | 1.000 | 1.000 | 0.676 | 1.000 | 1.000 | 1.000 | 0.919 | |
| 4 | 0.996 | 1.000 | 1.000 | 1.000 | 1.000 | 0.610 | 0.961 | 0.985 | 0.597 | 0.896 | |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.909 | 1.000 | 0.919 | 0.161 | 0.928 | |
| 6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.992 | 0.999 | 0.869 | 0.951 | 0.964 | |
| 7 | 0.997 | 1.000 | 1.000 | 1.000 | 0.960 | 0.500 | 1.000 | 1.000 | 0.962 | 0.721 | |
| 8 | 1.000 | 1.000 | 0.999 | 1.000 | 0.995 | 0.986 | 1.000 | 1.000 | 0.998 | 0.967 | |
| 9 | 1.000 | 1.000 | 0.918 | 1.000 | 0.993 | 0.941 | 1.000 | 0.999 | 0.749 | 0.999 | |
| 10 | 1.000 | 1.000 | 1.000 | 1.000 | 0.992 | 0.910 | 1.000 | 0.998 | 0.897 | 0.886 | |
VGG-16 | 1 | 0.996 | 0.430 | 1.000 | 0.973 | 0.996 | 0.991 | 0.999 | 0.855 | 0.586 | 0.832 |
| 2 | 0.540 | 0.976 | 1.000 | 0.913 | 0.925 | 0.896 | 0.999 | 0.964 | 0.693 | 0.963 | |
| 3 | 0.998 | 0.531 | 1.000 | 0.997 | 1.000 | 0.910 | 1.000 | 1.000 | 1.000 | 0.949 | |
| 4 | 0.987 | 0.997 | 1.000 | 0.983 | 0.998 | 0.802 | 0.212 | 0.998 | 0.389 | 0.485 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.959 | 0.999 | 0.819 | 0.999 | 0.854 | 0.226 | 0.652 | |
| 6 | 1.000 | 1.000 | 0.869 | 0.992 | 1.000 | 0.890 | 1.000 | 0.833 | 0.450 | 0.877 | |
| 7 | 0.987 | 0.996 | 0.999 | 1.000 | 0.968 | 0.605 | 0.944 | 1.000 | 0.371 | 0.617 | |
| 8 | 0.917 | 0.995 | 1.000 | 0.858 | 0.999 | 0.931 | 0.997 | 1.000 | 0.954 | 0.941 | |
| 9 | 1.000 | 0.989 | 0.861 | 0.989 | 0.899 | 0.301 | 1.000 | 1.000 | 0.901 | 0.922 | |
| 10 | 0.977 | 1.000 | 1.000 | 0.994 | 0.992 | 0.974 | 1.000 | 0.998 | 0.840 | 0.564 | |
VGG-19 | 1 | 1.000 | 0.959 | 1.000 | 0.669 | 1.000 | 0.740 | 1.000 | 0.989 | 0.466 | 0.879 |
| 2 | 0.993 | 0.996 | 0.999 | 0.947 | 0.939 | 0.756 | 0.999 | 0.970 | 0.785 | 0.818 | |
| 3 | 1.000 | 0.740 | 1.000 | 0.998 | 0.998 | 0.935 | 1.000 | 1.000 | 1.000 | 0.861 | |
| 4 | 0.996 | 0.952 | 1.000 | 0.890 | 0.997 | 0.684 | 0.468 | 0.992 | 0.828 | 0.291 | |
| 5 | 1.000 | 0.999 | 1.000 | 0.743 | 0.999 | 0.499 | 0.999 | 0.252 | 0.587 | 0.794 | |
| 6 | 1.000 | 1.000 | 0.999 | 0.993 | 1.000 | 0.735 | 0.999 | 0.952 | 0.693 | 0.846 | |
| 7 | 0.999 | 0.998 | 0.999 | 0.999 | 0.903 | 0.656 | 0.988 | 1.000 | 0.370 | 0.494 | |
| 8 | 1.000 | 0.999 | 1.000 | 0.987 | 0.998 | 0.744 | 0.994 | 1.000 | 0.996 | 0.795 | |
| 9 | 1.000 | 1.000 | 0.610 | 0.999 | 0.974 | 0.550 | 1.000 | 1.000 | 0.552 | 0.818 | |
| 10 | 0.998 | 1.000 | 1.000 | 0.999 | 0.995 | 0.791 | 1.000 | 0.994 | 0.758 | 0.761 |
Table A3.
In Step 1 and 2 of Scheme (11), the Nearest degrading interpolation function is employed for resizing images to match the input size of CNNs before they are fed into the CNNs. For , the ancestor category -label values given by the 10 CNNs of the image pictured in Figure A1. A label value in red indicates that the category is not the dominant one.
Table A3.
In Step 1 and 2 of Scheme (11), the Nearest degrading interpolation function is employed for resizing images to match the input size of CNNs before they are fed into the CNNs. For , the ancestor category -label values given by the 10 CNNs of the image pictured in Figure A1. A label value in red indicates that the category is not the dominant one.
| CNNs | p | Abacus | Acorn | Baseball | Broom | Brown Bear | Canoe | Hippopotamus | Llama | Maraca | Mountain Bike |
|---|---|---|---|---|---|---|---|---|---|---|---|
DenseNet-121 | 1 | 1.000 | 0.981 | 0.997 | 0.999 | 0.995 | 0.992 | 0.999 | 0.997 | 0.607 | 0.942 |
| 2 | 1.000 | 0.997 | 0.989 | 1.000 | 0.670 | 0.909 | 0.998 | 0.987 | 0.883 | 0.987 | |
| 3 | 0.998 | 0.845 | 1.000 | 1.000 | 0.996 | 0.836 | 0.987 | 0.997 | 1.000 | 0.891 | |
| 4 | 0.996 | 0.997 | 1.000 | 1.000 | 0.997 | 0.620 | 0.239 | 0.984 | 0.312 | 0.619 | |
| 5 | 1.000 | 0.999 | 1.000 | 0.998 | 0.955 | 0.811 | 1.000 | 1.000 | 0.145 | 0.986 | |
| 6 | 1.000 | 1.000 | 0.957 | 0.998 | 1.000 | 0.990 | 0.997 | 0.916 | 0.692 | 0.999 | |
| 7 | 0.998 | 0.999 | 0.999 | 0.973 | 0.937 | 0.525 | 0.985 | 0.974 | 0.902 | 0.940 | |
| 8 | 1.000 | 0.999 | 0.993 | 0.993 | 0.995 | 0.913 | 1.000 | 1.000 | 0.999 | 0.962 | |
| 9 | 1.000 | 0.998 | 0.981 | 1.000 | 0.997 | 0.820 | 0.999 | 1.000 | 0.999 | 0.992 | |
| 10 | 1.000 | 0.996 | 1.000 | 0.999 | 0.995 | 0.923 | 0.999 | 0.886 | 0.572 | 0.870 | |
DenseNet-169 | 1 | 0.999 | 0.978 | 1.000 | 0.999 | 0.999 | 0.997 | 0.997 | 0.999 | 0.952 | 0.873 |
| 2 | 1.000 | 0.999 | 0.998 | 0.992 | 0.535 | 0.764 | 0.998 | 0.999 | 0.995 | 0.861 | |
| 3 | 1.000 | 0.998 | 1.000 | 1.000 | 0.999 | 0.880 | 1.000 | 0.994 | 1.000 | 0.977 | |
| 4 | 0.990 | 0.996 | 1.000 | 1.000 | 1.000 | 0.549 | 0.553 | 0.981 | 0.583 | 0.973 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.994 | 1.000 | 0.915 | 1.000 | 0.994 | 0.530 | 0.997 | |
| 6 | 1.000 | 1.000 | 0.998 | 1.000 | 1.000 | 0.997 | 0.995 | 0.975 | 0.091 | 0.991 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 0.954 | 0.827 | 0.996 | 1.000 | 0.964 | 0.945 | |
| 8 | 1.000 | 1.000 | 0.998 | 0.998 | 0.999 | 0.951 | 0.999 | 1.000 | 1.000 | 0.975 | |
| 9 | 1.000 | 1.000 | 0.943 | 1.000 | 0.999 | 0.905 | 1.000 | 1.000 | 0.993 | 0.964 | |
| 10 | 0.970 | 1.000 | 0.999 | 1.000 | 0.997 | 0.952 | 0.999 | 0.998 | 0.608 | 0.507 | |
DenseNet-201 | 1 | 0.999 | 0.975 | 0.998 | 1.000 | 0.990 | 0.990 | 0.998 | 0.996 | 0.584 | 0.986 |
| 2 | 1.000 | 1.000 | 0.984 | 1.000 | 0.844 | 0.957 | 0.996 | 0.996 | 0.993 | 0.997 | |
| 3 | 0.987 | 0.950 | 1.000 | 1.000 | 0.998 | 0.669 | 0.999 | 0.994 | 1.000 | 0.886 | |
| 4 | 0.886 | 0.994 | 1.000 | 1.000 | 0.998 | 0.822 | 0.870 | 1.000 | 0.541 | 0.947 | |
| 5 | 1.000 | 1.000 | 0.999 | 0.983 | 0.980 | 0.586 | 1.000 | 0.998 | 0.141 | 0.980 | |
| 6 | 1.000 | 1.000 | 0.995 | 1.000 | 1.000 | 0.994 | 0.999 | 0.724 | 0.693 | 0.996 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 0.998 | 0.865 | 0.997 | 0.970 | 0.973 | 0.917 | |
| 8 | 1.000 | 1.000 | 0.993 | 1.000 | 0.874 | 0.978 | 0.990 | 0.999 | 0.997 | 0.993 | |
| 9 | 1.000 | 0.999 | 0.877 | 1.000 | 0.984 | 0.995 | 1.000 | 0.999 | 0.987 | 0.988 | |
| 10 | 1.000 | 1.000 | 0.998 | 0.999 | 0.978 | 0.984 | 0.987 | 0.963 | 0.365 | 0.983 | |
MobileNet | 1 | 0.945 | 0.589 | 0.770 | 0.829 | 0.966 | 0.560 | 0.933 | 0.480 | 0.556 | 0.854 |
| 2 | 0.903 | 0.948 | 0.981 | 0.955 | 0.669 | 0.903 | 0.707 | 0.725 | 0.932 | 0.967 | |
| 3 | 0.922 | 0.850 | 0.935 | 0.971 | 0.985 | 0.830 | 0.958 | 0.938 | 0.999 | 0.985 | |
| 4 | 0.934 | 0.971 | 0.977 | 0.972 | 0.924 | 0.820 | 0.711 | 0.975 | 0.586 | 0.851 | |
| 5 | 0.896 | 0.981 | 0.905 | 0.653 | 0.982 | 0.787 | 0.953 | 0.846 | 0.498 | 0.910 | |
| 6 | 0.990 | 0.976 | 0.881 | 0.973 | 0.913 | 0.818 | 0.989 | 0.774 | 0.355 | 0.935 | |
| 7 | 0.982 | 0.979 | 0.838 | 0.923 | 0.791 | 0.750 | 0.748 | 0.978 | 0.884 | 0.379 | |
| 8 | 0.964 | 0.919 | 0.860 | 0.798 | 0.941 | 0.823 | 0.806 | 0.995 | 0.962 | 0.928 | |
| 9 | 0.997 | 0.851 | 0.730 | 0.996 | 0.943 | 0.692 | 0.970 | 0.988 | 0.848 | 0.758 | |
| 10 | 0.968 | 0.994 | 0.835 | 0.780 | 0.886 | 0.948 | 0.992 | 0.568 | 0.416 | 0.883 | |
NASNet Mobile | 1 | 0.940 | 0.945 | 0.885 | 0.948 | 0.892 | 0.925 | 0.914 | 0.945 | 0.288 | 0.869 |
| 2 | 0.947 | 0.946 | 0.905 | 0.892 | 0.454 | 0.932 | 0.829 | 0.951 | 0.957 | 0.902 | |
| 3 | 0.903 | 0.884 | 0.889 | 0.978 | 0.948 | 0.702 | 0.926 | 0.754 | 0.911 | 0.923 | |
| 4 | 0.844 | 0.929 | 0.895 | 0.961 | 0.910 | 0.513 | 0.656 | 0.928 | 0.993 | 0.667 | |
| 5 | 0.943 | 0.930 | 0.886 | 0.914 | 0.936 | 0.586 | 0.921 | 0.976 | 0.734 | 0.972 | |
| 6 | 0.973 | 0.945 | 0.949 | 0.972 | 0.925 | 0.792 | 0.846 | 0.936 | 0.085 | 0.854 | |
| 7 | 0.983 | 0.897 | 0.842 | 0.944 | 0.872 | 0.869 | 0.893 | 0.941 | 0.885 | 0.781 | |
| 8 | 0.962 | 0.950 | 0.870 | 0.908 | 0.887 | 0.864 | 0.824 | 0.965 | 0.930 | 0.904 | |
| 9 | 0.975 | 0.904 | 0.691 | 0.949 | 0.925 | 0.783 | 0.925 | 0.949 | 0.965 | 0.957 | |
| 10 | 0.861 | 0.957 | 0.851 | 0.955 | 0.809 | 0.860 | 0.941 | 0.929 | 0.397 | 0.495 | |
ResNet-50 | 1 | 1.000 | 0.795 | 0.998 | 0.841 | 0.999 | 0.998 | 0.999 | 0.999 | 0.801 | 0.986 |
| 2 | 0.411 | 1.000 | 1.000 | 1.000 | 0.931 | 0.991 | 1.000 | 0.998 | 0.850 | 0.995 | |
| 3 | 1.000 | 0.901 | 1.000 | 1.000 | 1.000 | 0.778 | 1.000 | 1.000 | 1.000 | 0.993 | |
| 4 | 1.000 | 0.993 | 1.000 | 1.000 | 0.999 | 0.897 | 0.881 | 0.999 | 0.424 | 0.929 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.969 | 0.996 | 0.945 | 1.000 | 0.381 | 0.253 | 0.995 | |
| 6 | 0.999 | 1.000 | 1.000 | 0.999 | 0.999 | 0.995 | 1.000 | 0.771 | 0.211 | 0.941 | |
| 7 | 1.000 | 1.000 | 1.000 | 0.988 | 0.992 | 0.743 | 1.000 | 1.000 | 0.969 | 0.892 | |
| 8 | 1.000 | 0.998 | 0.998 | 0.999 | 0.997 | 0.993 | 0.962 | 1.000 | 0.999 | 0.987 | |
| 9 | 1.000 | 1.000 | 0.695 | 1.000 | 0.999 | 0.971 | 1.000 | 1.000 | 0.998 | 0.999 | |
| 10 | 1.000 | 0.999 | 1.000 | 0.999 | 0.959 | 0.994 | 0.970 | 0.723 | 0.385 | 0.965 | |
ResNet-101 | 1 | 1.000 | 0.982 | 0.999 | 0.995 | 0.999 | 0.999 | 1.000 | 1.000 | 0.984 | 0.969 |
| 2 | 1.000 | 1.000 | 0.973 | 1.000 | 0.941 | 0.986 | 1.000 | 0.988 | 0.975 | 0.997 | |
| 3 | 1.000 | 0.929 | 1.000 | 1.000 | 1.000 | 0.882 | 1.000 | 1.000 | 1.000 | 0.895 | |
| 4 | 0.778 | 0.999 | 1.000 | 1.000 | 0.993 | 0.525 | 0.680 | 0.999 | 0.894 | 0.970 | |
| 5 | 1.000 | 1.000 | 1.000 | 0.991 | 0.945 | 0.835 | 1.000 | 0.940 | 0.557 | 0.990 | |
| 6 | 1.000 | 1.000 | 0.994 | 0.998 | 0.999 | 0.996 | 1.000 | 0.722 | 0.599 | 0.998 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 0.911 | 0.961 | 1.000 | 1.000 | 0.772 | 0.756 | |
| 8 | 1.000 | 1.000 | 1.000 | 0.996 | 0.910 | 0.994 | 0.976 | 1.000 | 0.995 | 0.990 | |
| 9 | 1.000 | 1.000 | 0.979 | 1.000 | 0.997 | 0.848 | 1.000 | 1.000 | 0.959 | 0.980 | |
| 10 | 1.000 | 0.993 | 1.000 | 1.000 | 0.927 | 0.975 | 0.996 | 0.917 | 0.537 | 0.984 | |
ResNet-152 | 1 | 1.000 | 0.998 | 1.000 | 0.996 | 0.992 | 0.987 | 0.999 | 0.999 | 0.954 | 0.991 |
| 2 | 0.713 | 1.000 | 0.997 | 1.000 | 0.513 | 0.983 | 1.000 | 1.000 | 0.956 | 0.998 | |
| 3 | 1.000 | 0.665 | 1.000 | 1.000 | 1.000 | 0.794 | 0.999 | 1.000 | 1.000 | 0.969 | |
| 4 | 0.998 | 0.997 | 1.000 | 1.000 | 1.000 | 0.626 | 0.872 | 0.972 | 0.885 | 0.960 | |
| 5 | 1.000 | 1.000 | 1.000 | 1.000 | 0.999 | 0.841 | 1.000 | 0.927 | 0.219 | 0.993 | |
| 6 | 1.000 | 1.000 | 1.000 | 0.994 | 1.000 | 0.997 | 0.999 | 0.805 | 0.436 | 0.986 | |
| 7 | 1.000 | 1.000 | 1.000 | 1.000 | 0.996 | 0.557 | 0.995 | 1.000 | 0.959 | 0.860 | |
| 8 | 1.000 | 1.000 | 1.000 | 1.000 | 0.951 | 0.965 | 0.999 | 1.000 | 1.000 | 0.991 | |
| 9 | 1.000 | 1.000 | 0.857 | 1.000 | 0.978 | 0.979 | 0.992 | 1.000 | 0.949 | 0.999 | |
| 10 | 1.000 | 1.000 | 1.000 | 1.000 | 0.861 | 0.871 | 1.000 | 0.872 | 0.818 | 0.961 | |
VGG-16 | 1 | 0.999 | 0.392 | 1.000 | 0.725 | 0.997 | 0.990 | 0.999 | 0.940 | 0.592 | 0.862 |
| 2 | 0.952 | 0.997 | 1.000 | 0.918 | 0.922 | 0.918 | 1.000 | 0.968 | 0.683 | 0.979 | |
| 3 | 0.998 | 0.688 | 1.000 | 1.000 | 1.000 | 0.896 | 1.000 | 1.000 | 1.000 | 0.952 | |
| 4 | 0.996 | 0.999 | 1.000 | 0.993 | 0.998 | 0.764 | 0.214 | 0.999 | 0.703 | 0.740 | |
| 5 | 1.000 | 0.999 | 1.000 | 0.913 | 0.997 | 0.678 | 1.000 | 0.918 | 0.175 | 0.936 | |
| 6 | 1.000 | 1.000 | 0.674 | 0.972 | 0.999 | 0.883 | 1.000 | 0.828 | 0.470 | 0.952 | |
| 7 | 0.999 | 0.998 | 0.999 | 0.999 | 0.947 | 0.595 | 0.935 | 1.000 | 0.358 | 0.640 | |
| 8 | 0.987 | 0.995 | 1.000 | 0.844 | 0.999 | 0.952 | 0.999 | 1.000 | 0.979 | 0.973 | |
| 9 | 1.000 | 0.999 | 0.896 | 0.992 | 0.915 | 0.382 | 1.000 | 1.000 | 0.918 | 0.895 | |
| 10 | 0.998 | 1.000 | 1.000 | 0.998 | 0.964 | 0.981 | 1.000 | 0.998 | 0.745 | 0.614 | |
VGG-19 | 1 | 1.000 | 0.959 | 1.000 | 0.503 | 1.000 | 0.547 | 1.000 | 0.977 | 0.507 | 0.909 |
| 2 | 0.990 | 0.998 | 0.999 | 0.957 | 0.984 | 0.812 | 1.000 | 0.983 | 0.514 | 0.903 | |
| 3 | 1.000 | 0.767 | 1.000 | 0.996 | 1.000 | 0.946 | 1.000 | 1.000 | 1.000 | 0.912 | |
| 4 | 0.995 | 0.980 | 1.000 | 0.994 | 0.996 | 0.663 | 0.241 | 0.995 | 0.821 | 0.270 | |
| 5 | 1.000 | 0.999 | 1.000 | 0.617 | 0.997 | 0.716 | 1.000 | 0.463 | 0.436 | 0.934 | |
| 6 | 1.000 | 1.000 | 0.998 | 0.975 | 0.999 | 0.779 | 0.999 | 0.932 | 0.713 | 0.957 | |
| 7 | 1.000 | 0.999 | 1.000 | 0.999 | 0.881 | 0.586 | 0.995 | 1.000 | 0.336 | 0.422 | |
| 8 | 1.000 | 1.000 | 1.000 | 0.956 | 0.997 | 0.846 | 0.997 | 1.000 | 0.994 | 0.930 | |
| 9 | 1.000 | 1.000 | 0.575 | 0.991 | 0.988 | 0.441 | 1.000 | 1.000 | 0.660 | 0.752 | |
| 10 | 0.999 | 1.000 | 1.000 | 1.000 | 0.993 | 0.859 | 0.999 | 0.966 | 0.731 | 0.862 |
Appendix B. Choice of (ρ, λ, ρ) Based on a Case Study
Our previous papers [29,30] showed the sensitivity of tentative adversarial images to the choice of the degrading and enlarging functions. In the present Appendix B, we, therefore, want to find out which degrading and enlarging functions and , and which combination , used in Scheme (11), provide the best outcome in terms of image quality and of adversity. For this purpose, we perform a case study.
Based on the results of [29,30], the study is limited to the consideration of the “Lanczos” (L) and “Nearest” (N) functions, either for the degrading function or for the enlarging function . This leads to 8 combinations for , namely (with obvious notations) L-L-L, L-L-N, L-N-L, N-L-L, L-N-N, N-L-N, N-N-L and N-N-N.
For each such combination , the study is performed on the 100 clean images represented in Figure A1, with the EA-based targeted attack against the CNN VGG-16, according to the pairs specified in Table 2.
However, although the images are picked from the ImageNet validation set in the categories , VGG-16 does not systematically classify all of them in the “correct” category in the process of Steps 1 and 2 of Scheme (11). Indeed, Table A2 and Table A3 in Appendix A show that VGG-16 classifies “correctly” only 93 clean images , and classifies “wrongly” 7 when the degrading function used in Step 1 is L or is N. Let us observe that although the number of “correctly” classified and of “wrongly” classified images are the same independently on the function used, the actual such images are not necessarily the same. The rest of the experiments are therefore performed on the set of “correctly” classified clean images.
With this setting, the targeted attack aims at creating -strong adversarial images in the domain (hence meaning that it aims at creating images for which ).
As explained in Section 4.4, the attack succeeds when a -strong adversarial image in the domain is obtained within 10,000 generations. In the present case study, we also keep track of the unsuccessful such attacks. More precisely, for the images considered, we also report the cases where either the best tentative adversarial image in the domain, obtained after 10,000 generations, is classified in but with a label value , or is classified in a category , or is classified back to .
Note en passant that, although unsuccessful for the -target scenario, the attack in the domain is successful at creating good enough adversarial images in the first case considered in the previous paragraph, respectively for the untarget scenario in the second case.
In the present study, Scheme (11) continues with Steps 4 to 8 only for the adversarial images that correspond to the first or the second component of the quadruplet in , namely those obtained in Step 3 that are classified in . Note that we compute the average of the for these images.
At the end of Step 8, we collect the following data: the number of HR tentative adversarial images classified in (hence adversarial for the target scenario), classified in (hence adversarial for the untarget scenario), classified back in (not adversarial at all). For the images that remain in or , we report their -label values , the value of the loss function, and the values of the two distances where (written as and to simplify the notations) as specified in Section 3.2.
The outcomes of these experiments are summarized in Table A4 and Table A5 for all combinations. Comprehensive reports on these experiments can be accessed via the following link: https://github.com/aliotopal/Noise_blowing_up (accessed on 14 April 2024).
Table A4.
The average, maximum, and minimum dominant category label values before and after the application of the noise blowing-up technique (, ), along with norms (where ) and loss for each combination of (). In this summary, the calculations include good-enough adversarial images.
Table A4.
The average, maximum, and minimum dominant category label values before and after the application of the noise blowing-up technique (, ), along with norms (where ) and loss for each combination of (). In this summary, the calculations include good-enough adversarial images.
| Step 1–3 | Step 4–8 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLL | Avg | 0.548 | 0.504 | 0.955 | 0.94 | 0.99 | 0.03 | 0.02 | 0.02 | 1.77 | 9.9 | 4.5 | 5.3 | 46.6 | 46.2 | 125 | 0.043 |
| Min | 0.294 | 0.273 | 0.910 | 0.88 | 0.90 | 0.01 | 0.01 | 0.00 | 0.25 | 4.7 | 7.0 | 5.4 | 21 | 22 | 18 | 0.007 | |
| Max | 0.554 | 0.543 | 0.974 | 0.97 | 1.00 | 0.04 | 0.04 | 0.11 | 13.5 | 1.6 | 9.7 | 2.0 | 77 | 74 | 200 | 0.116 | |
| LLN | Avg | 0.548 | 0.456 | 0.955 | 0.95 | 0.85 | 0.03 | 0.02 | 0.03 | 0.98 | 9.9 | 4.5 | 7.9 | 46.6 | 46.2 | 196 | 0.499 |
| Min | 0.294 | 0.073 | 0.910 | 0.88 | 0.35 | 0.01 | 0.01 | 0.00 | 0.23 | 4.7 | 7.0 | 7.8 | 21 | 22 | 113 | 0.256 | |
| Max | 0.554 | 0.999 | 0.974 | 0.97 | 0.97 | 0.04 | 0.04 | 0.12 | 3.86 | 1.6 | 9.7 | 2.3 | 77 | 74 | 255 | 0.554 | |
| LNL | Avg | 0.548 | 0.290 | 0.955 | 0.95 | 0.85 | 0.03 | 0.03 | 0.03 | 1.06 | 9.9 | 4.9 | 7.9 | 46.6 | 46.6 | 196 | 0.349 |
| Min | 0.294 | 0.080 | 0.910 | 0.89 | 0.35 | 0.01 | 0.01 | 0.00 | 0.25 | 4.7 | 7.7 | 7.8 | 21 | 21 | 113 | 0.100 | |
| Max | 0.554 | 0.862 | 0.974 | 0.97 | 0.97 | 0.04 | 0.04 | 0.12 | 4.22 | 1.6 | 1.0 | 2.3 | 77 | 77 | 255 | 0.551 | |
| NLL | Avg | 0.548 | 0.423 | 0.956 | 0.95 | 0.99 | 0.03 | 0.02 | 0.03 | 1.25 | 1.0 | 4.6 | 7.3 | 46.8 | 46.7 | 196 | 0.478 |
| Min | 0.350 | 0.053 | 0.928 | 0.92 | 0.90 | 0.01 | 0.01 | 0.00 | 0.29 | 5.5 | 7.0 | 6.9 | 25 | 25 | 56 | 0.129 | |
| Max | 0.553 | 0.997 | 0.974 | 0.97 | 1.00 | 0.04 | 0.04 | 0.13 | 4.61 | 1.5 | 9.5 | 2.7 | 74 | 69 | 320 | 0.553 | |
| LNN | Avg | 0.548 | 0.536 | 0.955 | 0.95 | 0.85 | 0.03 | 0.03 | 0.03 | 1.06 | 9.9 | 4.9 | 7.9 | 46.6 | 46.6 | 196 | 0.526 |
| Min | 0.294 | 0.076 | 0.910 | 0.89 | 0.35 | 0.01 | 0.01 | 0.00 | 0.25 | 4.7 | 7.7 | 7.8 | 21 | 21 | 113 | 0.294 | |
| Max | 0.554 | 0.999 | 0.974 | 0.97 | 0.97 | 0.04 | 0.04 | 0.12 | 4.22 | 1.6 | 1.0 | 2.3 | 77 | 77 | 255 | 0.554 | |
| NLN | Avg | 0.548 | 0.416 | 0.956 | 0.95 | 0.99 | 0.03 | 0.02 | 0.03 | 1.25 | 1.0 | 4.6 | 7.3 | 46.8 | 46.7 | 196 | 0.138 |
| Min | 0.350 | 0.155 | 0.928 | 0.92 | 0.90 | 0.01 | 0.01 | 0.00 | 0.29 | 5.5 | 7.0 | 6.9 | 25 | 25 | 56 | 0.0002 | |
| Max | 0.553 | 0.550 | 0.974 | 0.97 | 1.00 | 0.04 | 0.04 | 0.13 | 4.61 | 1.5 | 9.5 | 2.7 | 74 | 69 | 320 | 0.395 | |
| NNL | Avg | 0.548 | 0.531 | 0.956 | 0.95 | 0.69 | 0.03 | 0.03 | 0.03 | 1.03 | 1.0 | 5.0 | 9.5 | 46.8 | 46.8 | 224 | 0.532 |
| Min | 0.350 | 0.057 | 0.928 | 0.92 | 0.25 | 0.01 | 0.01 | 0.00 | 0.30 | 5.5 | 7.6 | 9.0 | 25 | 25 | 127 | 0.350 | |
| Max | 0.553 | 0.999 | 0.974 | 0.97 | 0.92 | 0.04 | 0.04 | 0.14 | 3.80 | 1.5 | 1.0 | 2.9 | 74 | 74 | 255 | 0.553 | |
| NNN | Avg | 0.548 | 0.402 | 0.955 | 0.95 | 0.69 | 0.03 | 0.03 | 0.03 | 1.01 | 9.9 | 4.9 | 9.5 | 46.6 | 46.6 | 225 | 0.262 |
| Min | 0.350 | 0.098 | 0.928 | 0.92 | 0.25 | 0.01 | 0.01 | 0.00 | 0.30 | 5.5 | 7.6 | 9.0 | 25 | 25 | 127 | 9.5 | |
| Max | 0.556 | 0.979 | 0.974 | 0.97 | 0.92 | 0.04 | 0.04 | 0.14 | 3.80 | 1.5 | 1.0 | 2.9 | 74 | 74 | 255 | 0.552 | |
Table A5 summarizes the main findings from the comparison study for different interpolation techniques. The table includes information on the interpolation methods utilized, Lanczos (L) and Nearest (N), which are shown in Column 1. The remaining columns present the following data: Column 2: the number of adversarial images used for testing noise blowing-up technique, Column 3: the number of images classified in the target category, Column 4: the number of images that remained adversarial in the untargeted category, Column 5: the number of images classified in the ancestor category after employing the noise blowing-up technique, and Column 6: the resulting average loss in target category dominance.
Table A4 indicates that there are no significant differences observed when using different combinations of (, , ) in relation to norms (where . However, Table A5 demonstrates that the combination of L-L-L produces optimal results in terms of both the loss function () and the number of adversarial images remaining in the target category () when utilizing the noise blowing-up technique for generating high-resolution adversarial images. Therefore, in our experiments (see Scheme (11)), we employ the L-L-L combination for (, , ).
Table A5.
The table presents the results of a case study conducted on 92 adversarial images obtained with for VGG-16 and (with notations consistent with Section 3). The technique involves manipulating the adversarial images by extracting noise and applying different combinations (, , ) in Steps 1, 5, and 7 (see Section 3.1).
Table A5.
The table presents the results of a case study conducted on 92 adversarial images obtained with for VGG-16 and (with notations consistent with Section 3). The technique involves manipulating the adversarial images by extracting noise and applying different combinations (, , ) in Steps 1, 5, and 7 (see Section 3.1).
| Number of | Number of | Average Loss | |||
|---|---|---|---|---|---|
| L-L-L | 92 | 92 | 0 | 0 | 0.0439 |
| L-L-N | 92 | 10 | 25 | 57 | 0.5019 |
| L-N-L | 92 | 59 | 11 | 22 | 0.3501 |
| N-L-L | 92 | 16 | 21 | 55 | 0.4802 |
| L-N-N | 92 | 6 | 23 | 63 | 0.5295 |
| N-L-N | 92 | 89 | 0 | 3 | 0.1384 |
| N-N-L | 92 | 1 | 21 | 70 | 0.5345 |
| N-N-N | 92 | 62 | 10 | 20 | 0.2615 |
Appendix C. Enhancing the Noise Blowing-Up Method: Exploring its Performance with Varied Strength Levels of Adversarial Images
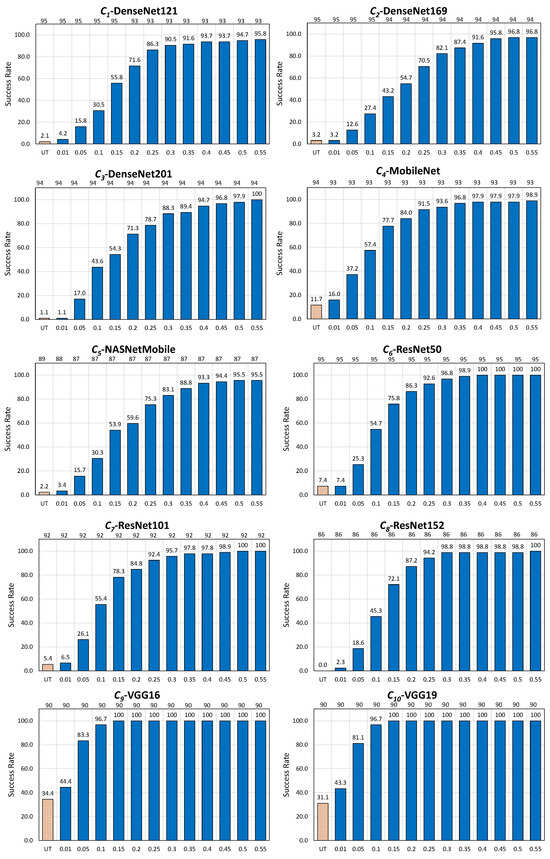
Figure A2.
Evaluating the performance of the noise blowing-up method for EA in untargeted scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
Figure A2.
Evaluating the performance of the noise blowing-up method for EA in untargeted scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
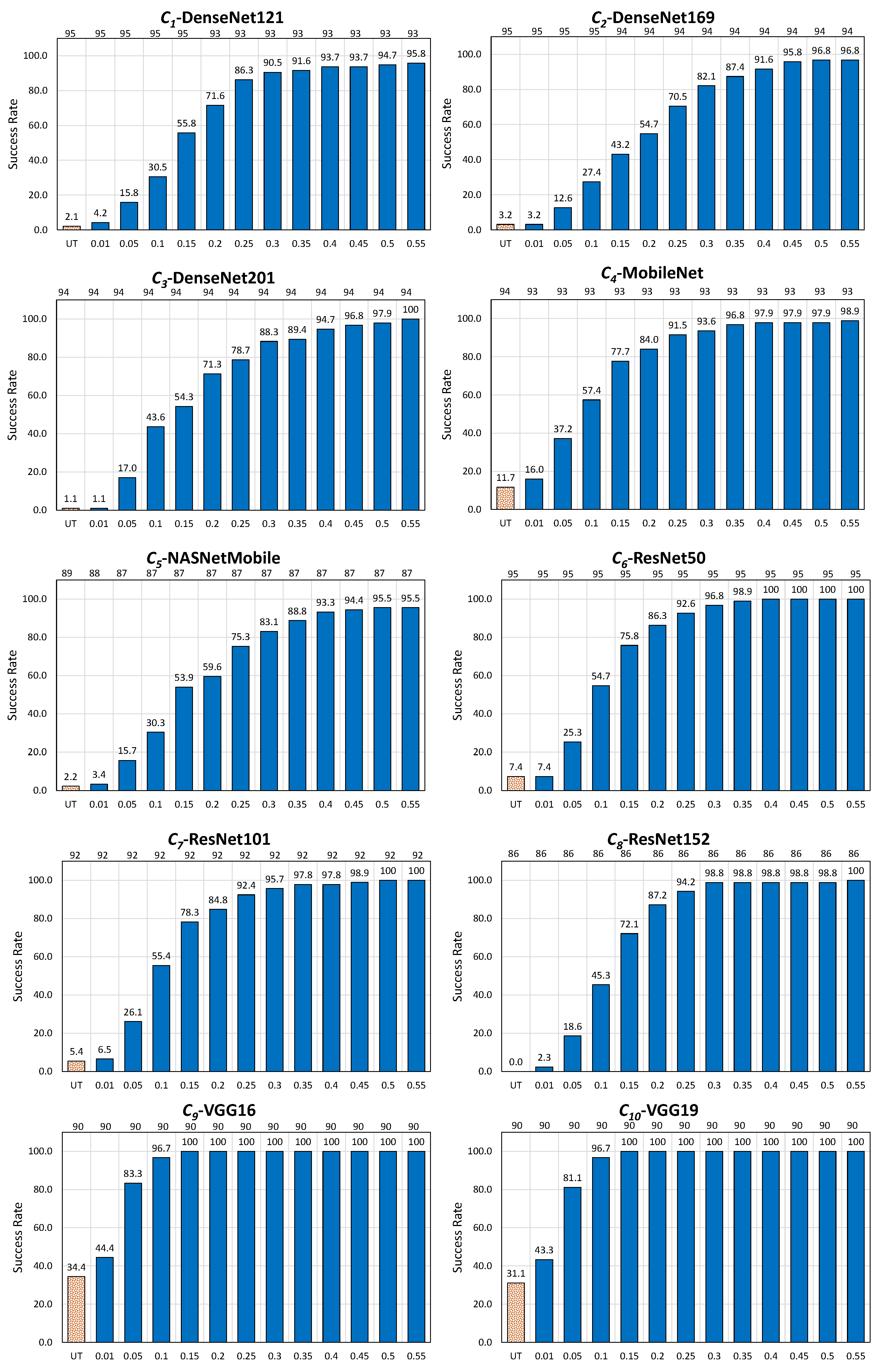
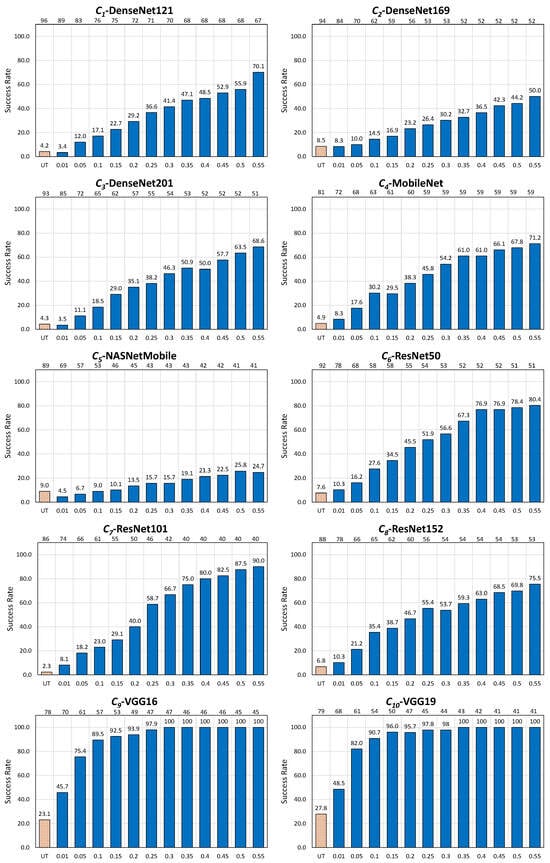
Figure A3.
Evaluating the performance of the noise blowing-up method for AdvGAN in untargeted scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
Figure A3.
Evaluating the performance of the noise blowing-up method for AdvGAN in untargeted scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
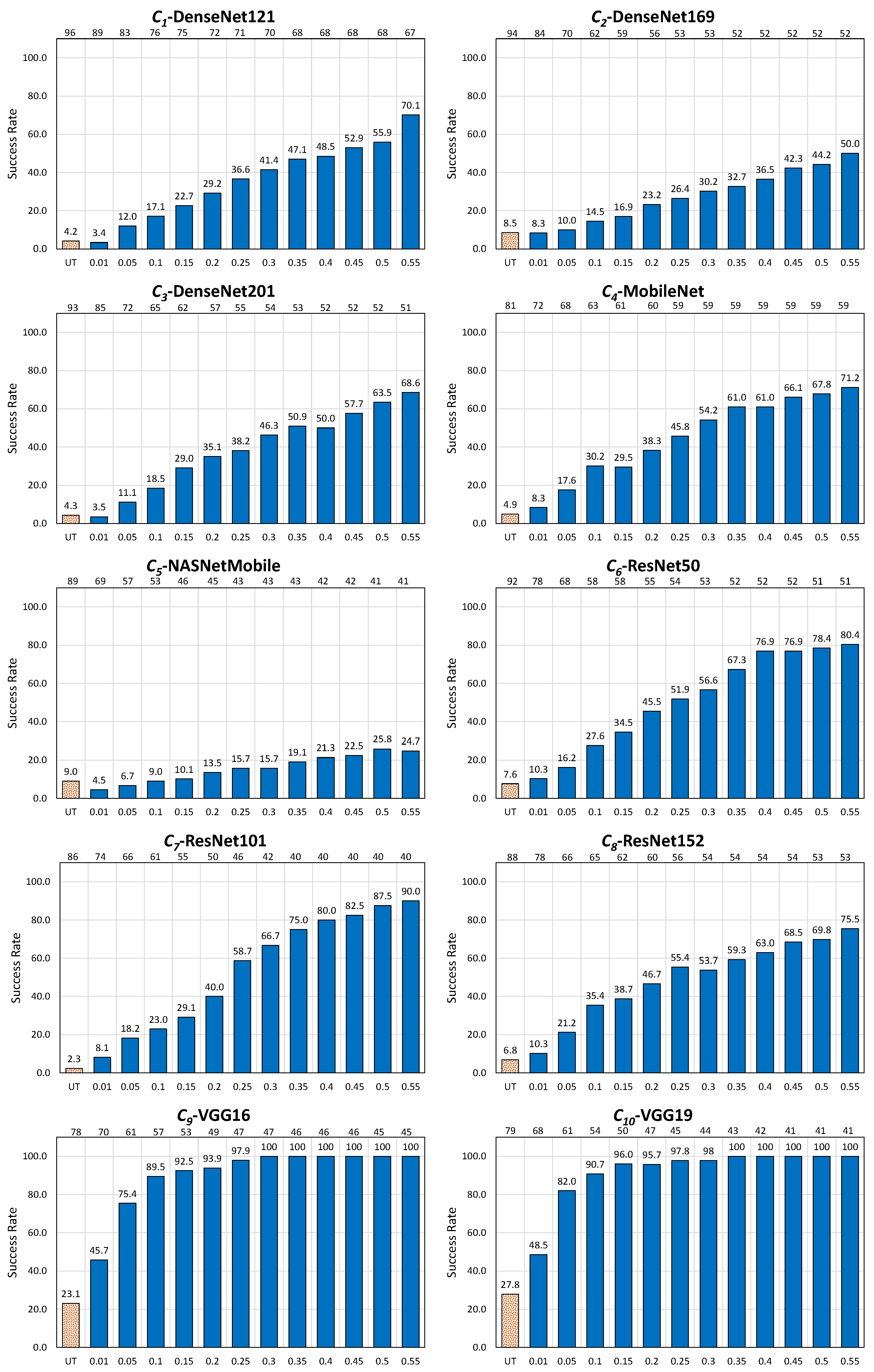
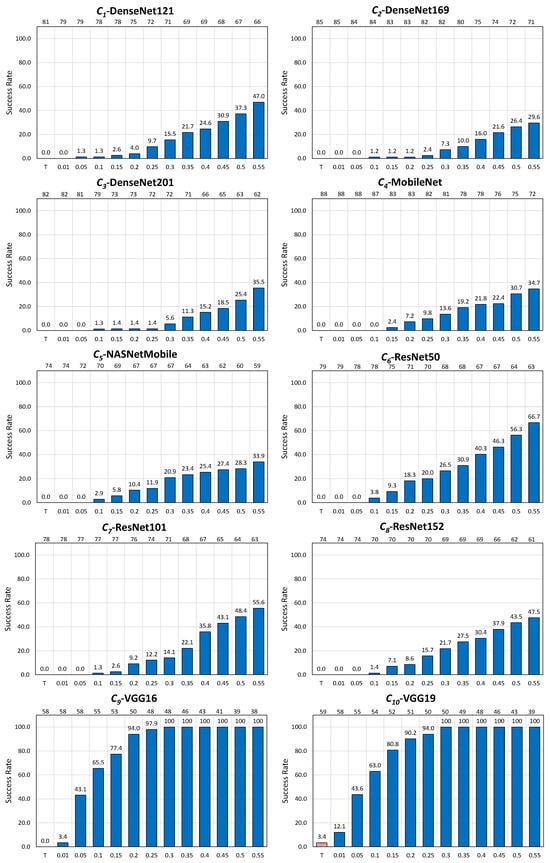
Figure A4.
Evaluating the performance of the noise blowing-up method for AdvGAN in target scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
Figure A4.
Evaluating the performance of the noise blowing-up method for AdvGAN in target scenarios with the increased strength of adversarial images per each CNN. The charts display values at the bottom, along with the corresponding number of images used for the tests at the top.
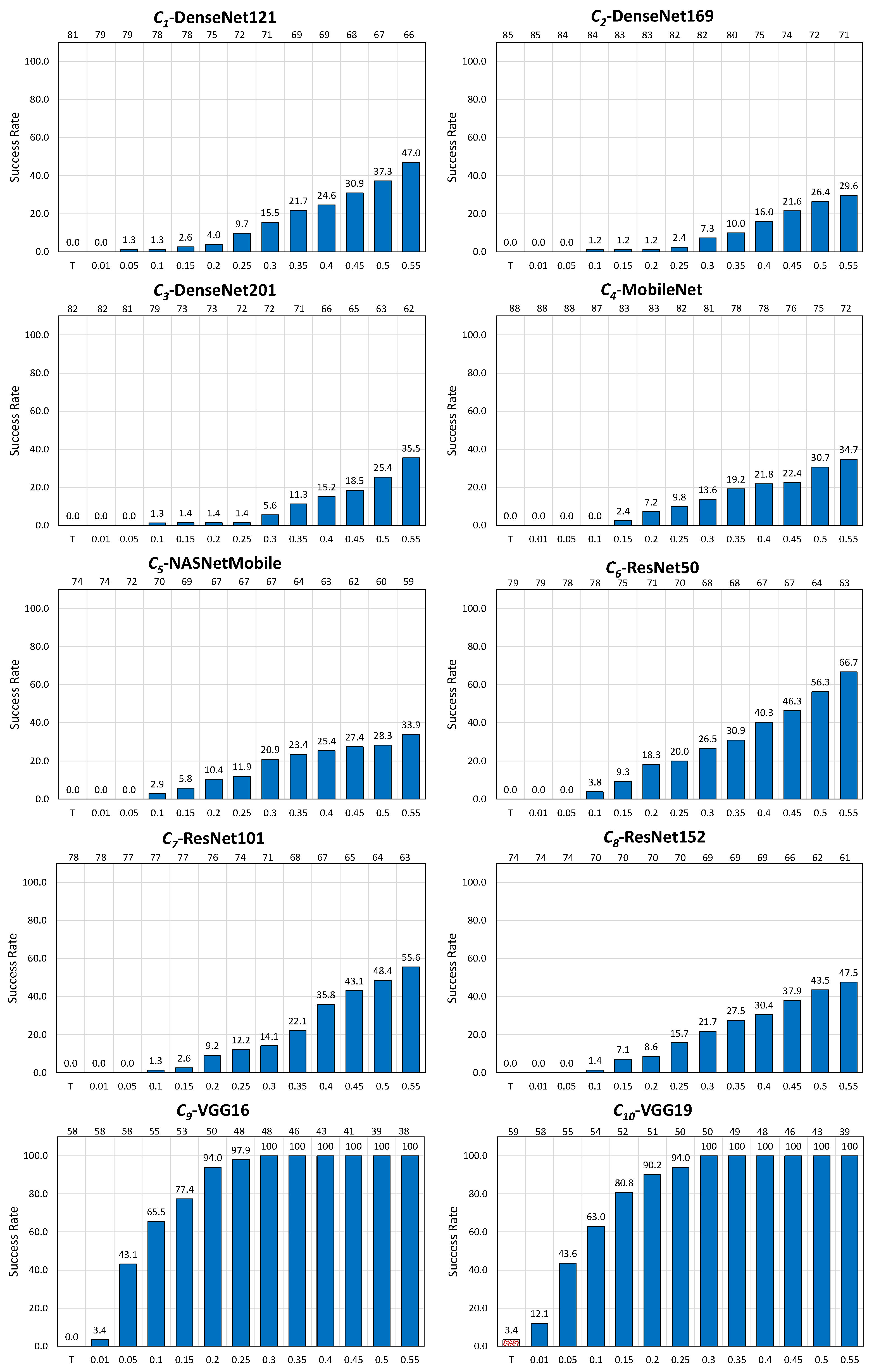
Appendix D. Overall FID Results
In Table A6 and Table A7, we present the average FID values (lower is better) for successfully generated high-resolution adversarial images, presented per attack and CNN. Specifically, Table A6 shows FID values for the images generated by targeted attacks (EA, BIM, PGD Inf, PGD L2), while Table A7 displays FID values of the images generated by untargeted attacks (EA, AdvGAN, SimBA, FGSM, BIM, PGD Inf, PGD L2).
Table A6.
values assessing the human imperceptibility of the crafted adversarial images for the target scenario.
Table A6.
values assessing the human imperceptibility of the crafted adversarial images for the target scenario.
| Targeted | EA | BIM | PGD Inf | PGD L2 |
|---|---|---|---|---|
| 12.586 | 4.605 | 11.873 | 5.439 | |
| 12.043 | 4.654 | 12.146 | 6.527 | |
| 14.038 | 4.944 | 13.574 | 6.917 | |
| 13.873 | 3.438 | 9.345 | 5.037 | |
| 17.848 | 3.065 | 6.437 | 5.006 | |
| 14.572 | 3.671 | 6.617 | 5.434 | |
| 16.277 | 3.867 | 7.494 | 5.970 | |
| 15.926 | 4.133 | 7.801 | 6.137 | |
| 27.902 | 9.705 | 29.225 | 15.025 | |
| 31.200 | 10.933 | 32.713 | 15.681 | |
| Avg | 17.627 | 5.302 | 13.723 | 7.717 |
Table A7.
values assessing the human imperceptibility of the crafted adversarial images for the untargeted scenario.
Table A7.
values assessing the human imperceptibility of the crafted adversarial images for the untargeted scenario.
| Untargeted | EA | AdvGAN | SimBA | FGSM | BIM | PGD Inf | PGD L2 |
|---|---|---|---|---|---|---|---|
| 3.677 | 17.974 | 3.857 | 41.697 | 4.435 | 23.385 | 6.64 | |
| 2.110 | 14.886 | 2.624 | 42.452 | 4.212 | 16.749 | 6.283 | |
| 3.568 | 14.915 | 13.548 | 44.555 | 4.436 | 21.838 | 7.141 | |
| 2.614 | 15.823 | 5.117 | 37.838 | 4.006 | 11.463 | 5.240 | |
| 2.142 | 10.517 | 13.879 | 42.274 | 3.244 | 7.250 | 4.996 | |
| 2.222 | 11.638 | 12.871 | 47.503 | 4.862 | 13.424 | 7.522 | |
| 3.575 | 20.894 | 7.233 | 48.869 | 5.138 | 14.150 | 7.407 | |
| NA | 14.588 | 7.956 | 45.522 | 4.834 | 13.513 | 7.453 | |
| 6.313 | 15.235 | 9.191 | 71.849 | 10.231 | 56.493 | 16.181 | |
| 3.754 | 14.172 | 8.221 | 72.283 | 11.515 | 61.131 | 19.001 | |
| Avg | 3.754 | 15.064 | 8.450 | 49.484 | 5.691 | 23.940 | 8.786 |
References
- Taye, M.M. Theoretical Understanding of Convolutional Neural Network: Concepts, Architectures, Applications, Future Directions. Computation 2023, 11, 52. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. Evolving deep convolutional neural networks for image classification. IEEE Trans. Evol. Comput. 2019, 24, 394–407. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object classification using CNN-based fusion of vision and LIDAR in autonomous vehicle environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Coşkun, M.; Uçar, A.; Yildirim, Ö.; Demir, Y. Face recognition based on convolutional neural network. In Proceedings of the 2017 International Conference on Modern Electrical and Energy Systems (MEES), Kremenchuk, Ukraine, 15–17 November 2017; pp. 376–379. [Google Scholar]
- Yang, S.; Wang, W.; Liu, C.; Deng, W. Scene understanding in deep learning-based end-to-end controllers for autonomous vehicles. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 53–63. [Google Scholar] [CrossRef]
- Ghosh, A.; Jana, N.D.; Das, S.; Mallipeddi, R. Two-Phase Evolutionary Convolutional Neural Network Architecture Search for Medical Image Classification. IEEE Access 2023, 11, 115280–115305. [Google Scholar] [CrossRef]
- Abdou, M.A. Literature review: Efficient deep neural networks techniques for medical image analysis. Neural Comput. Appl. 2022, 34, 5791–5812. [Google Scholar] [CrossRef]
- Chugh, A.; Sharma, V.K.; Kumar, S.; Nayyar, A.; Qureshi, B.; Bhatia, M.K.; Jain, C. Spider monkey crow optimization algorithm with deep learning for sentiment classification and information retrieval. IEEE Access 2021, 9, 24249–24262. [Google Scholar] [CrossRef]
- Fahfouh, A.; Riffi, J.; Mahraz, M.A.; Yahyaouy, A.; Tairi, H. PV-DAE: A hybrid model for deceptive opinion spam based on neural network architectures. Expert Syst. Appl. 2020, 157, 113517. [Google Scholar] [CrossRef]
- Cao, J.; Lam, K.Y.; Lee, L.H.; Liu, X.; Hui, P.; Su, X. Mobile augmented reality: User interfaces, frameworks, and intelligence. ACM Comput. Surv. 2023, 55, 1–36. [Google Scholar] [CrossRef]
- Coskun, H.; Yiğit, T.; Üncü, İ.S. Integration of digital quality control for intelligent manufacturing of industrial ceramic tiles. Ceram. Int. 2022, 48, 34210–34233. [Google Scholar] [CrossRef]
- Khan, M.J.; Singh, P.P. Advanced road extraction using CNN-based U-Net model and satellite imagery. E-Prime Electr. Eng. Electron. Energy 2023, 5, 100244. [Google Scholar] [CrossRef]
- Saralioglu, E.; Gungor, O. Semantic segmentation of land cover from high resolution multispectral satellite images by spectral-spatial convolutional neural network. Geocarto Int. 2022, 37, 657–677. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Liu, J.; Miao, J.; Argyriou, A.; Wang, L.; Xu, Z. 360-attack: Distortion-aware perturbations from perspective-views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15035–15044. [Google Scholar]
- Meng, W.; Xing, X.; Sheth, A.; Weinsberg, U.; Lee, W. Your online interests: Pwned! a pollution attack against targeted advertising. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 129–140. [Google Scholar]
- Hardt, M.; Nath, S. Privacy-aware personalization for mobile advertising. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 662–673. [Google Scholar]
- Biggio, B.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion attacks against machine learning at test time. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 387–402. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Wang, Y.; Liu, J.; Chang, X.; Misic, J.V.; Misic, V.B. IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks. arXiv 2021, arXiv:2102.02128. [Google Scholar] [CrossRef]
- Mohammadian, H.; Ghorbani, A.A.; Lashkari, A.H. A gradient-based approach for adversarial attack on deep learning-based network intrusion detection systems. Appl. Soft Comput. 2023, 137, 110173. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–7 April 2017; pp. 506–519. [Google Scholar]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square attack: A query-efficient black-box adversarial attack via random search. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 484–501. [Google Scholar]
- Chitic, R.; Bernard, N.; Leprévost, F. A proof of concept to deceive humans and machines at image classification with evolutionary algorithms. In Proceedings of the Intelligent Information and Database Systems, 12th Asian Conference, ACIIDS 2020, Phuket, Thailand, 23–26 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 467–480. [Google Scholar]
- Chitic, R.; Leprévost, F.; Bernard, N. Evolutionary algorithms deceive humans and machines at image classification: An extended proof of concept on two scenarios. J. Inf. Telecommun. 2020, 5, 121–143. [Google Scholar] [CrossRef]
- Al-Ahmadi, S.; Al-Eyead, S. GAN-based Approach to Crafting Adversarial Malware Examples against a Heterogeneous Ensemble Classifier. In Proceedings of the 19th International Conference on Security and Cryptography—Volume 1: SECRYPT, INSTICC, Lisbon, Portugal, 11–13 July 2022; SciTePress: Setúbal, Portugal, 2022; pp. 451–460. [Google Scholar] [CrossRef]
- Topal, A.O.; Chitic, R.; Leprévost, F. One evolutionary algorithm deceives humans and ten convolutional neural networks trained on ImageNet at image recognition. Appl. Soft Comput. 2023, 143, 110397. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. The ImageNet Image Database. 2009. Available online: http://image-net.org (accessed on 14 April 2024).
- Leprévost, F.; Topal, A.O.; Avdusinovic, E.; Chitic, R. A Strategy Creating High-Resolution Adversarial Images against Convolutional Neural Networks and a Feasibility Study on 10 CNNs. J. Inf. Telecommun. 2022, 7, 89–119. [Google Scholar] [CrossRef]
- Leprévost, F.; Topal, A.O.; Avdusinovic, E.; Chitic, R. Strategy and Feasibility Study for the Construction of High Resolution Images Adversarial against Convolutional Neural Networks. In Proceedings of the Intelligent Information and Database Systems, 13th Asian Conference, ACIIDS 2022, Ho-Chi-Minh-City, Vietnam, 28–30 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 467–480. [Google Scholar]
- Leprévost, F.; Topal, A.O.; Mancellari, E. Creating High-Resolution Adversarial Images Against Convolutional Neural Networks with the Noise Blowing-Up Method. In Intelligent Information and Database Systems; Nguyen, N.T., Boonsang, S., Fujita, H., Hnatkowska, B., Hong, T.P., Pasupa, K., Selamat, A., Eds.; Springer: Singapore, 2023; pp. 121–134. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Oliphant, T.E. Guide to NumPy; Trelgol, 2006; Available online: https://web.mit.edu/dvp/Public/numpybook.pdf (accessed on 14 April 2024).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org (accessed on 14 April 2024).
- Keras. 2015. Available online: https://keras.io (accessed on 14 April 2024).
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T.; The Scikit-Image Contributors. scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef] [PubMed]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Luo, C.; Lin, Q.; Xie, W.; Wu, B.; Xie, J.; Shen, L. Frequency-driven imperceptible adversarial attack on semantic similarity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15315–15324. [Google Scholar]
- Chen, F.; Wang, J.; Liu, H.; Kong, W.; Zhao, Z.; Ma, L.; Liao, H.; Zhang, D. Frequency constraint-based adversarial attack on deep neural networks for medical image classification. Comput. Biol. Med. 2023, 164, 107248. [Google Scholar] [CrossRef]
- Liu, J.; Lu, B.; Xiong, M.; Zhang, T.; Xiong, H. Adversarial Attack with Raindrops. arXiv 2023, arXiv:2302.14267. [Google Scholar]
- Zhao, Z.; Liu, Z.; Larson, M. Towards large yet imperceptible adversarial image perturbations with perceptual color distance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1039–1048. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Patel, V.; Mistree, K. A review on different image interpolation techniques for image enhancement. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 129–133. [Google Scholar]
- Agrafiotis, D. Chapter 9—Video Error Concealment. In Academic Press Library in signal Processing; Theodoridis, S., Chellappa, R., Eds.; Elsevier: Amsterdam, The Netherlands, 2014; Volume 5, pp. 295–321. [Google Scholar] [CrossRef]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Duchon, C.E. Lanczos filtering in one and two dimensions. J. Appl. Meteorol. Climatol. 1979, 18, 1016–1022. [Google Scholar] [CrossRef]
- Parsania, P.S.; Virparia, P.V. A comparative analysis of image interpolation algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2016, 5, 29–34. [Google Scholar] [CrossRef]
- Chitic, R.; Topal, A.O.; Leprévost, F. ShuffleDetect: Detecting Adversarial Images against Convolutional Neural Networks. Appl. Sci. 2023, 13, 4068. [Google Scholar] [CrossRef]
- Nicolae, M.I.; Sinn, M.; Tran, M.N.; Buesser, B.; Rawat, A.; Wistuba, M.; Zantedeschi, V.; Baracaldo, N.; Chen, B.; Ludwig, H.; et al. Adversarial Robustness Toolbox v1.2.0. arXiv 2018, arXiv:1807.01069. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. arXiv 2019, arXiv:1801.02610. [Google Scholar]
- Guo, C.; Gardner, J.; You, Y.; Wilson, A.G.; Weinberger, K. Simple black-box adversarial attacks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2484–2493. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1810.00069. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. [Google Scholar]
- SpeedyGraphito. Mes 400 Coups; Panoramart: France, 2020. [Google Scholar]
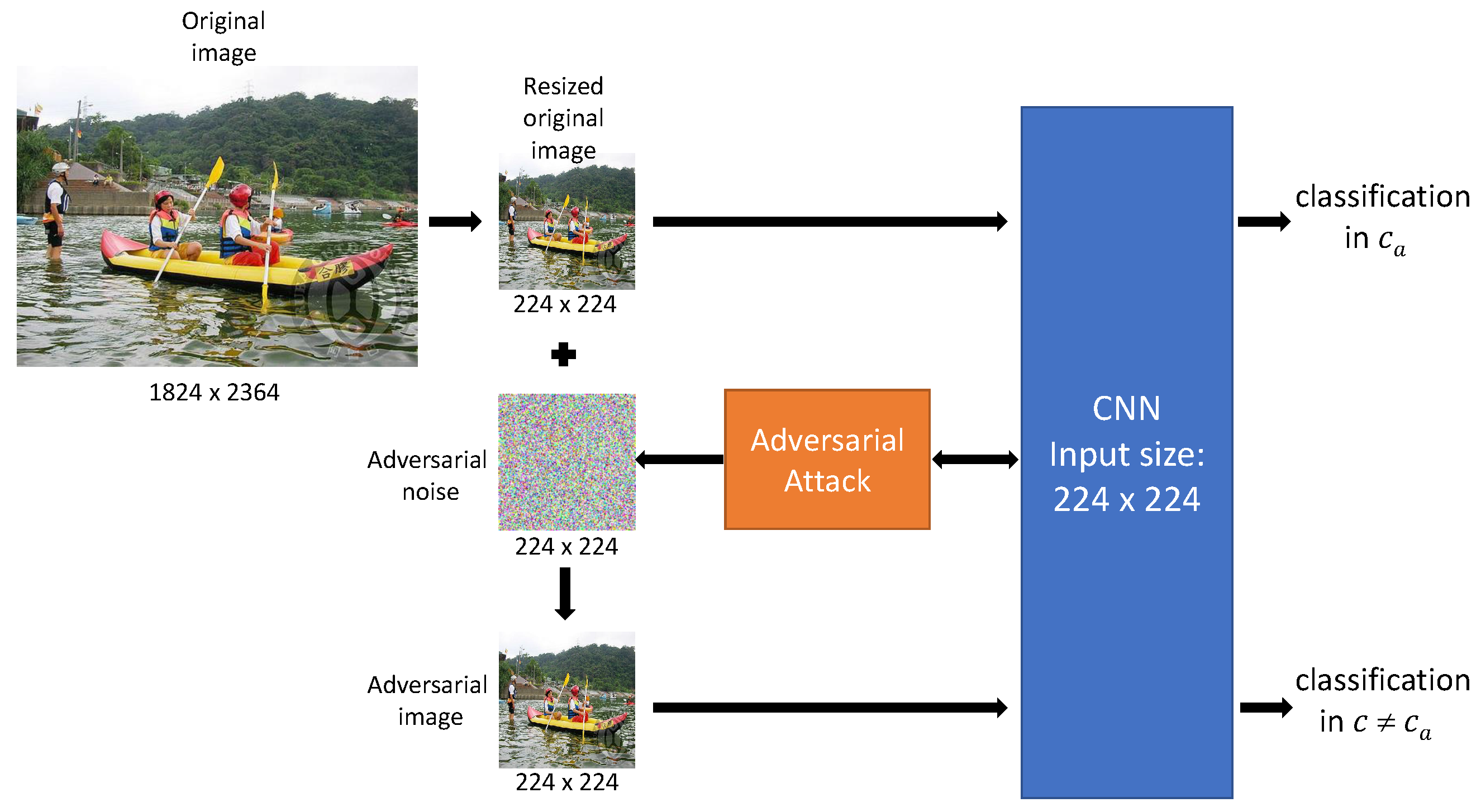
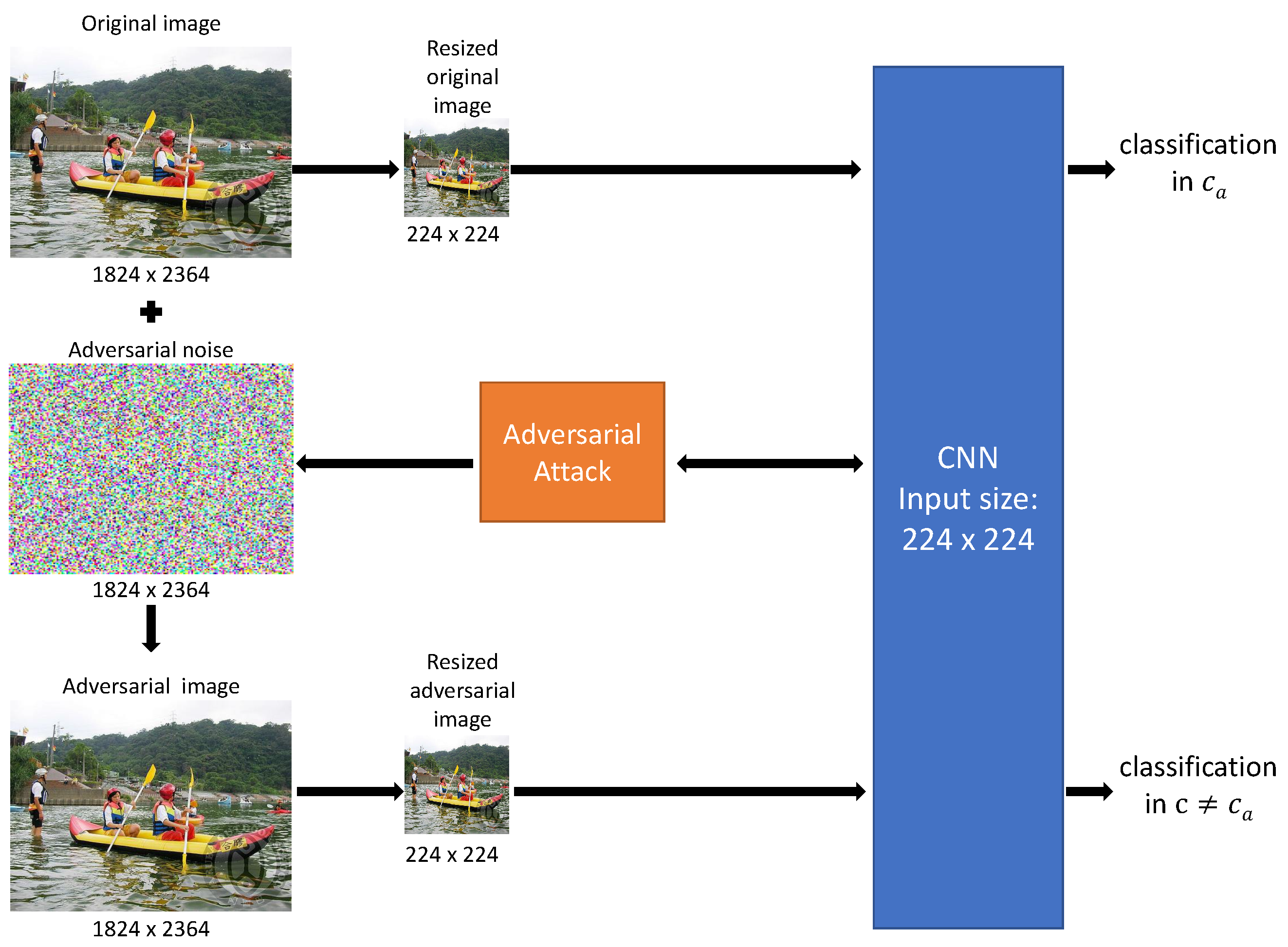

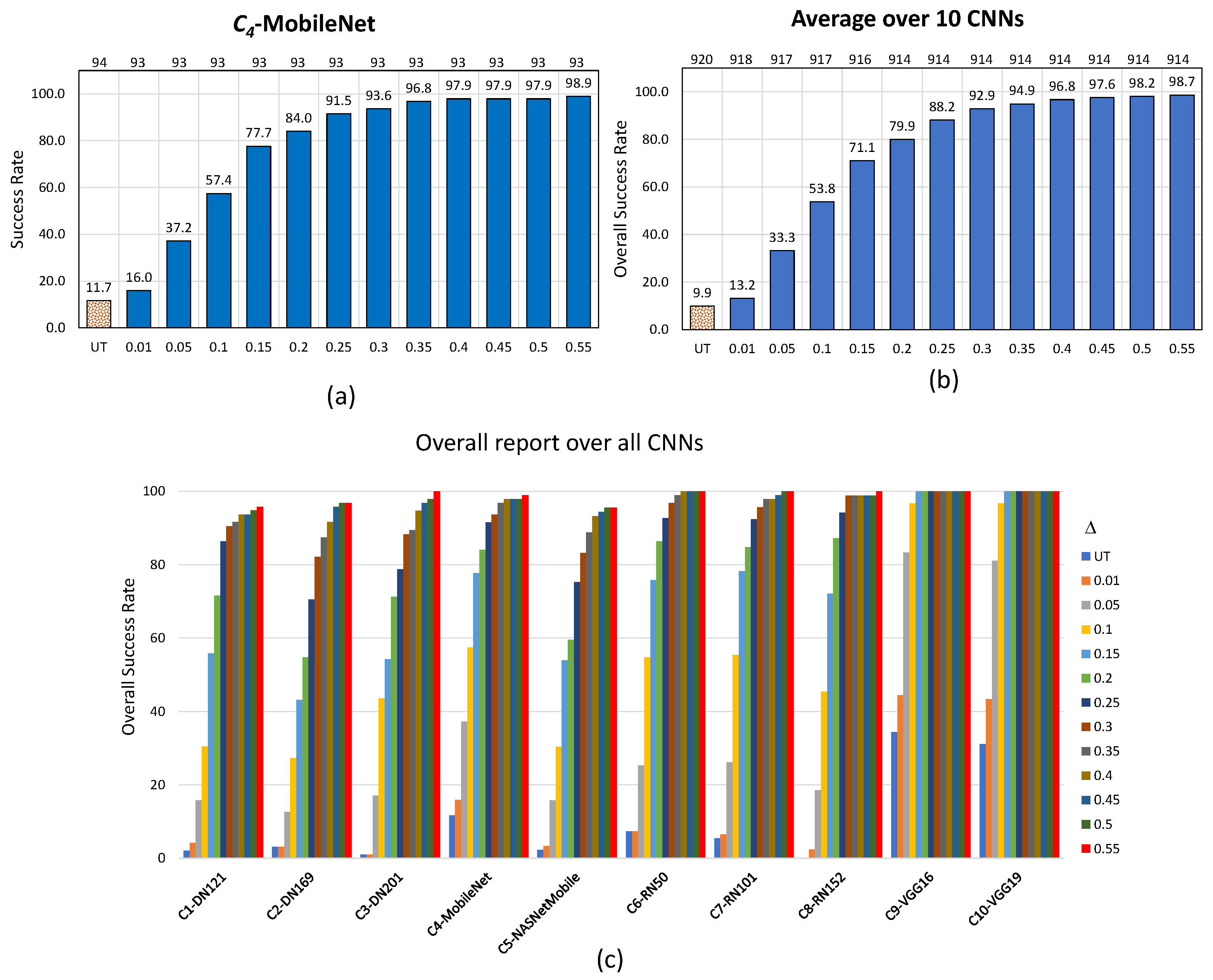
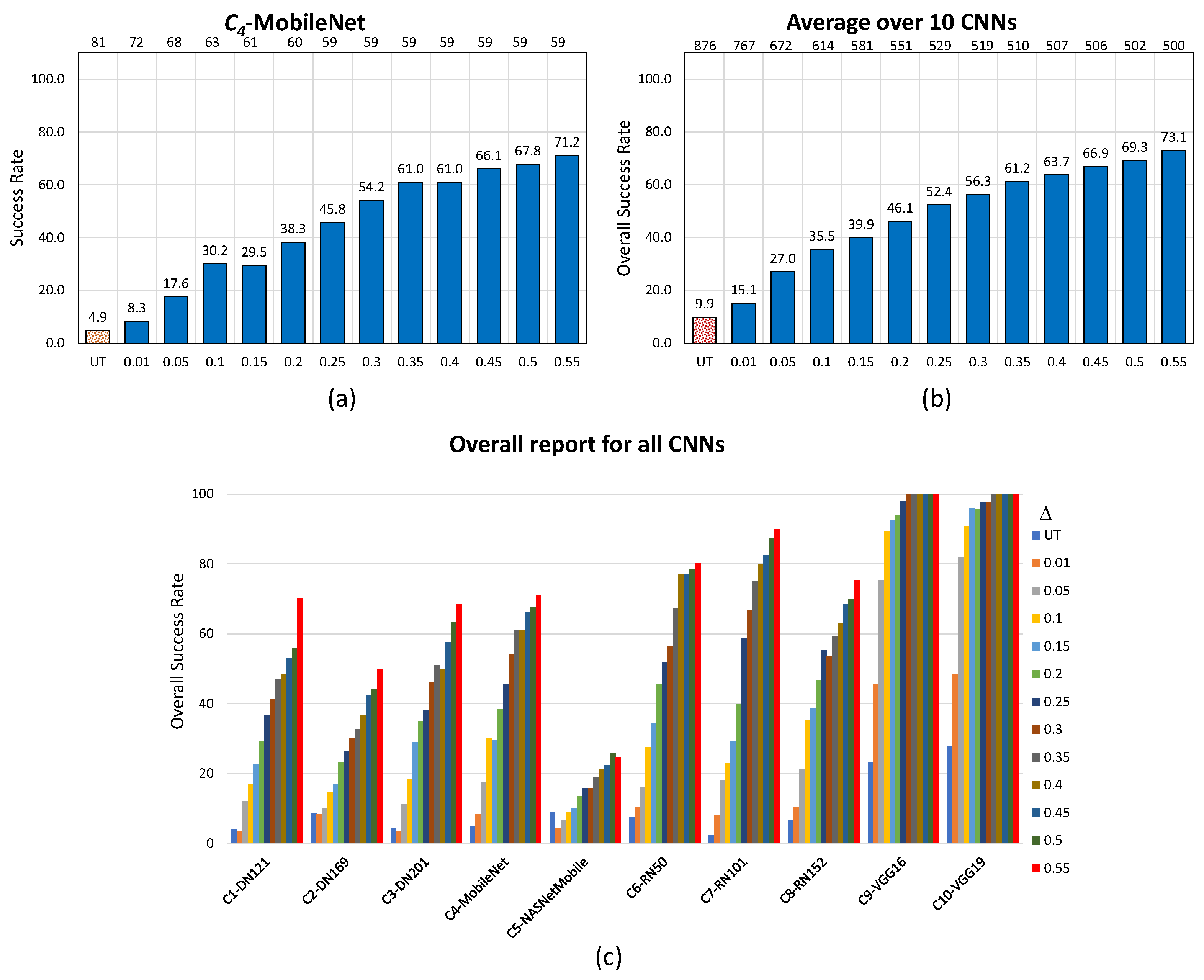
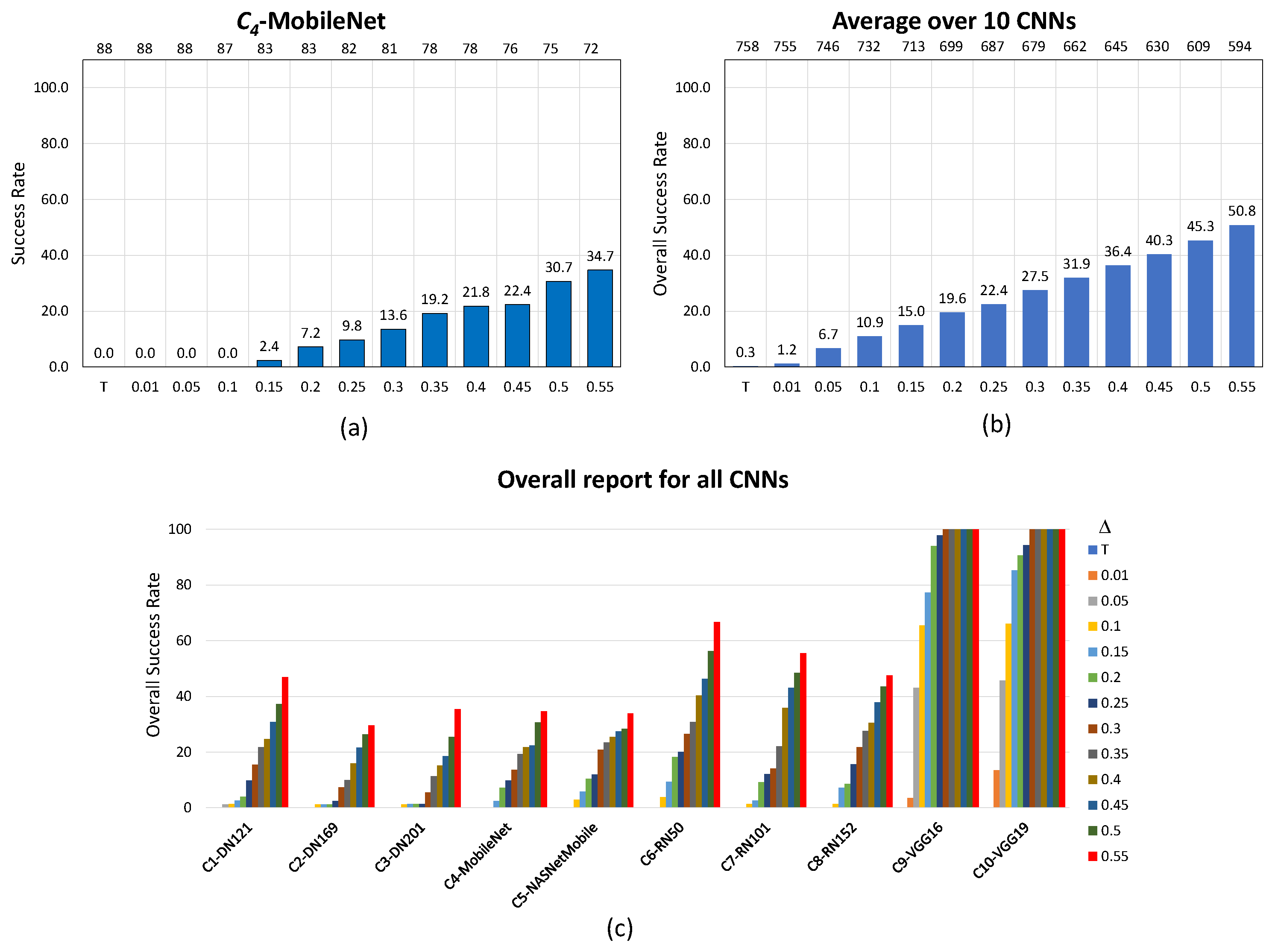

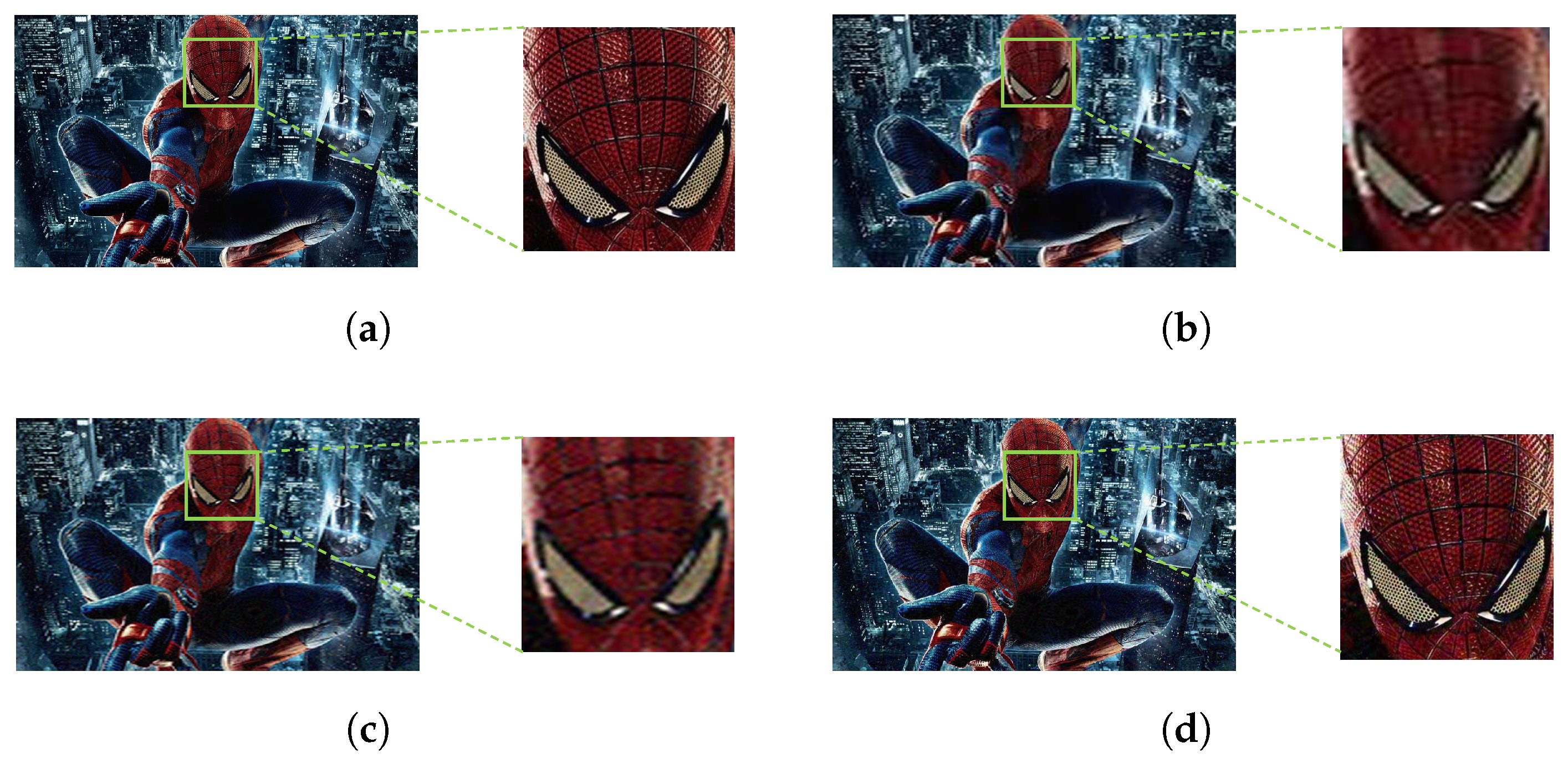
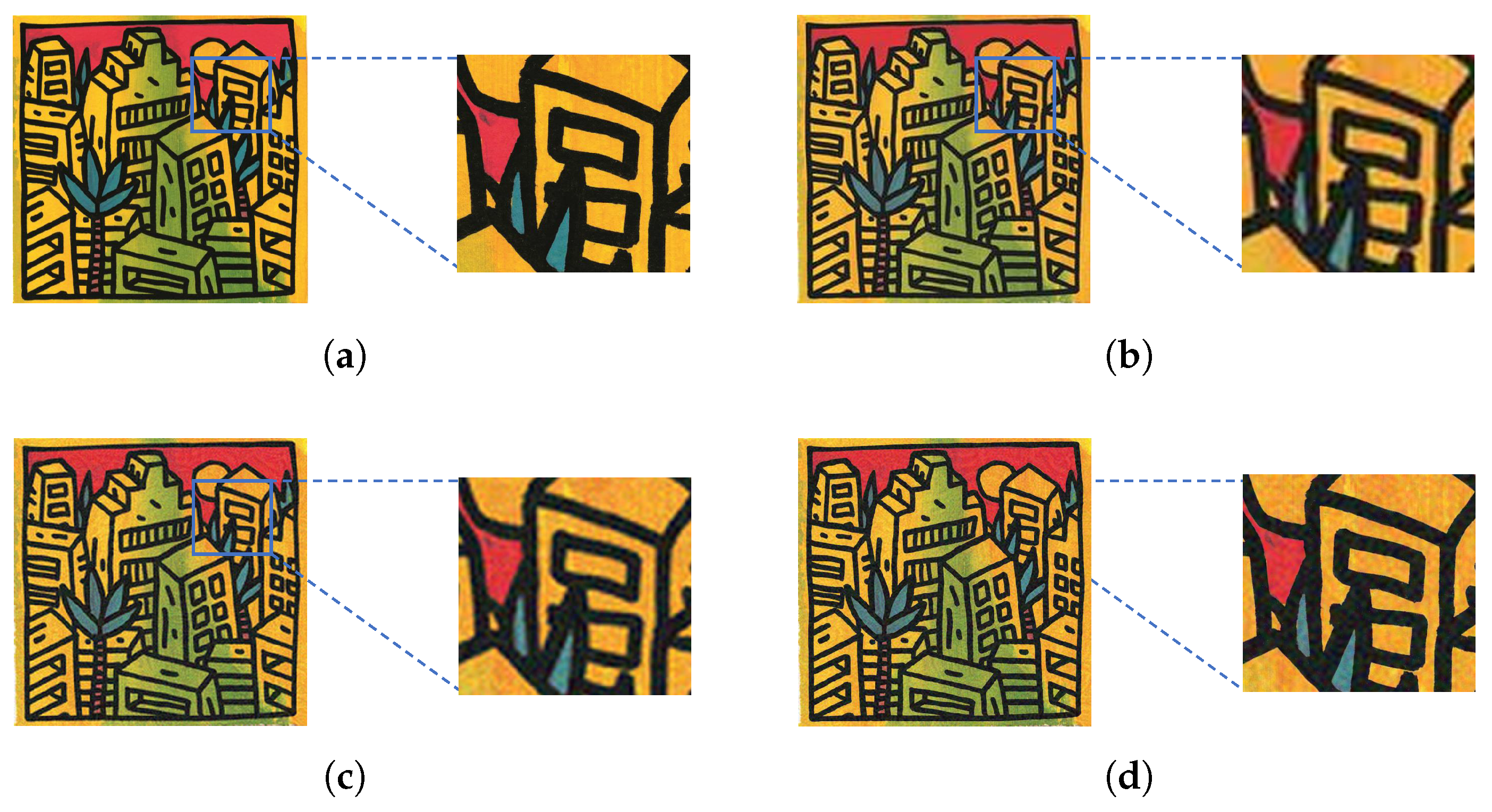




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).