
Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism



Abstract
:1. Introduction
- An innovative end-to-end solution that enhances the flexibility and portability of a model through modular design, capable of effectively handling multiple subtasks within a single end-to-end process, significantly improving the processing efficiency and accuracy.
- By integrating the attention mechanism of GAT with the deep processing capabilities of GCN, there is a significant improvement in processing efficiency for graph-structured data and a deeper understanding of textual content, effectively capturing the complex relationships and rich contextual information within texts.
- By integrating BiLSTM to improve the biaffine attention mechanism, it effectively extracts high-dimensional aspect features, significantly enhancing the capability to process both local and global textual information, and increases the accuracy of the model in capturing long-distance dependencies and recognizing complex emotional expressions.
2. Preliminaries
2.1. Graph Neural Network
2.1.1. GCN
2.1.2. GAT
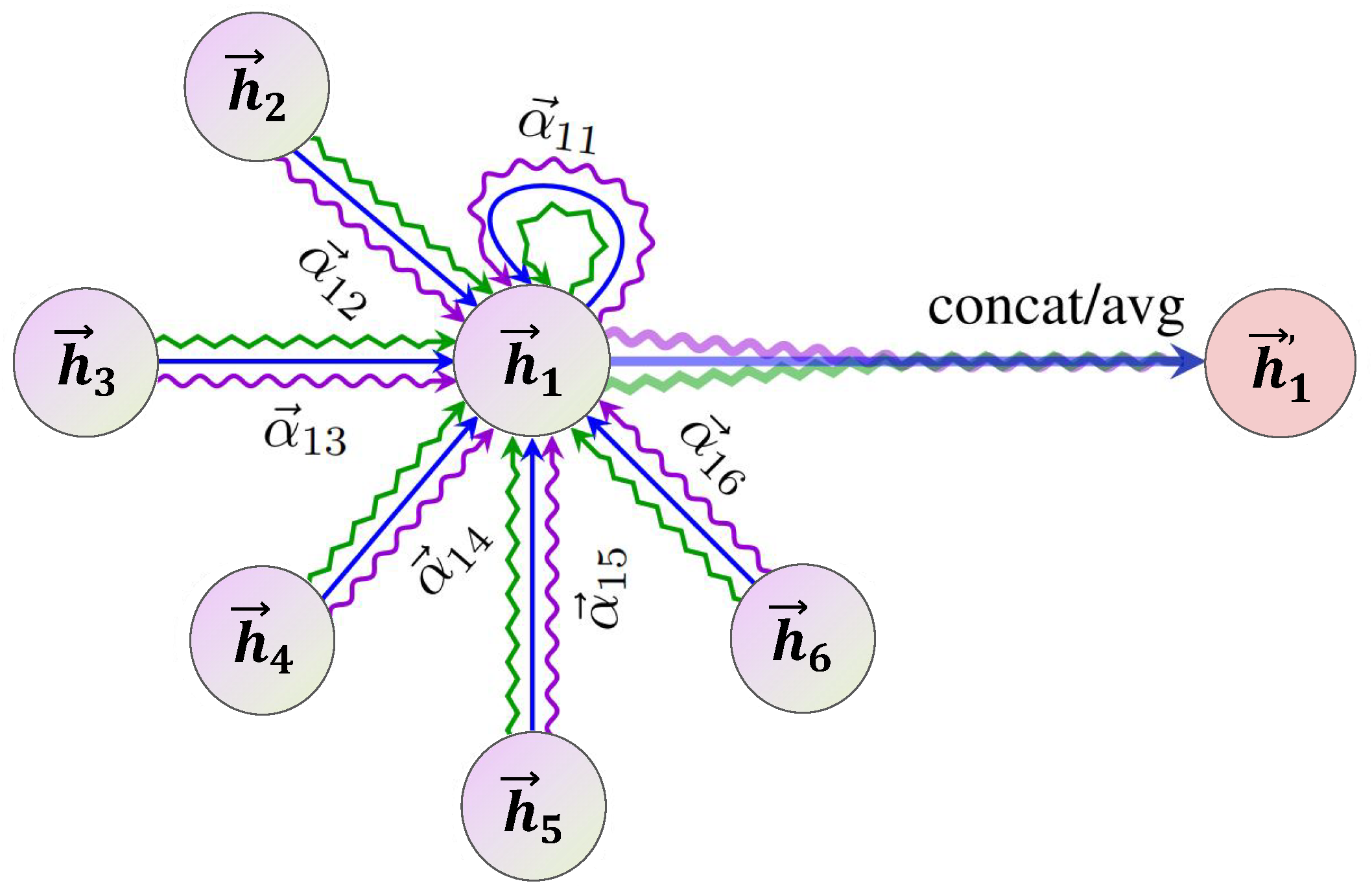
2.2. Biaffine Attention
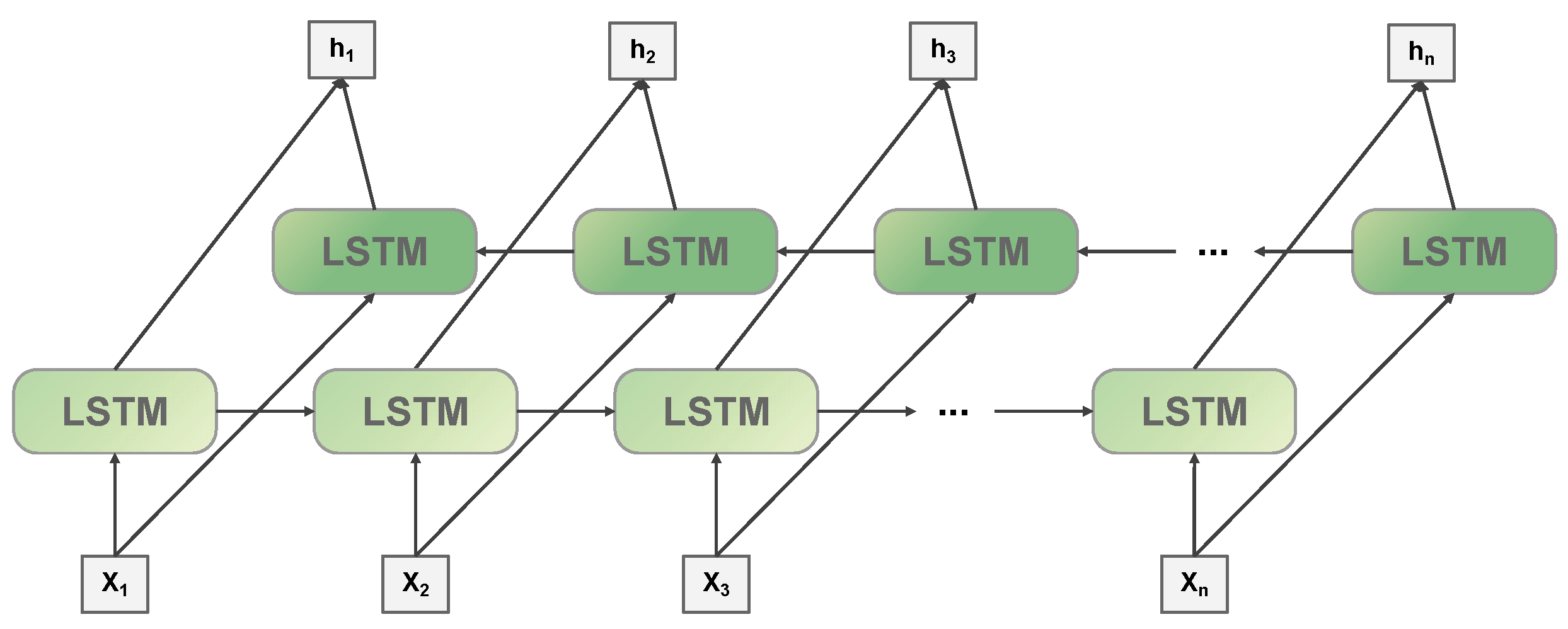
2.3. BiLSTM
3. Proposed Framework
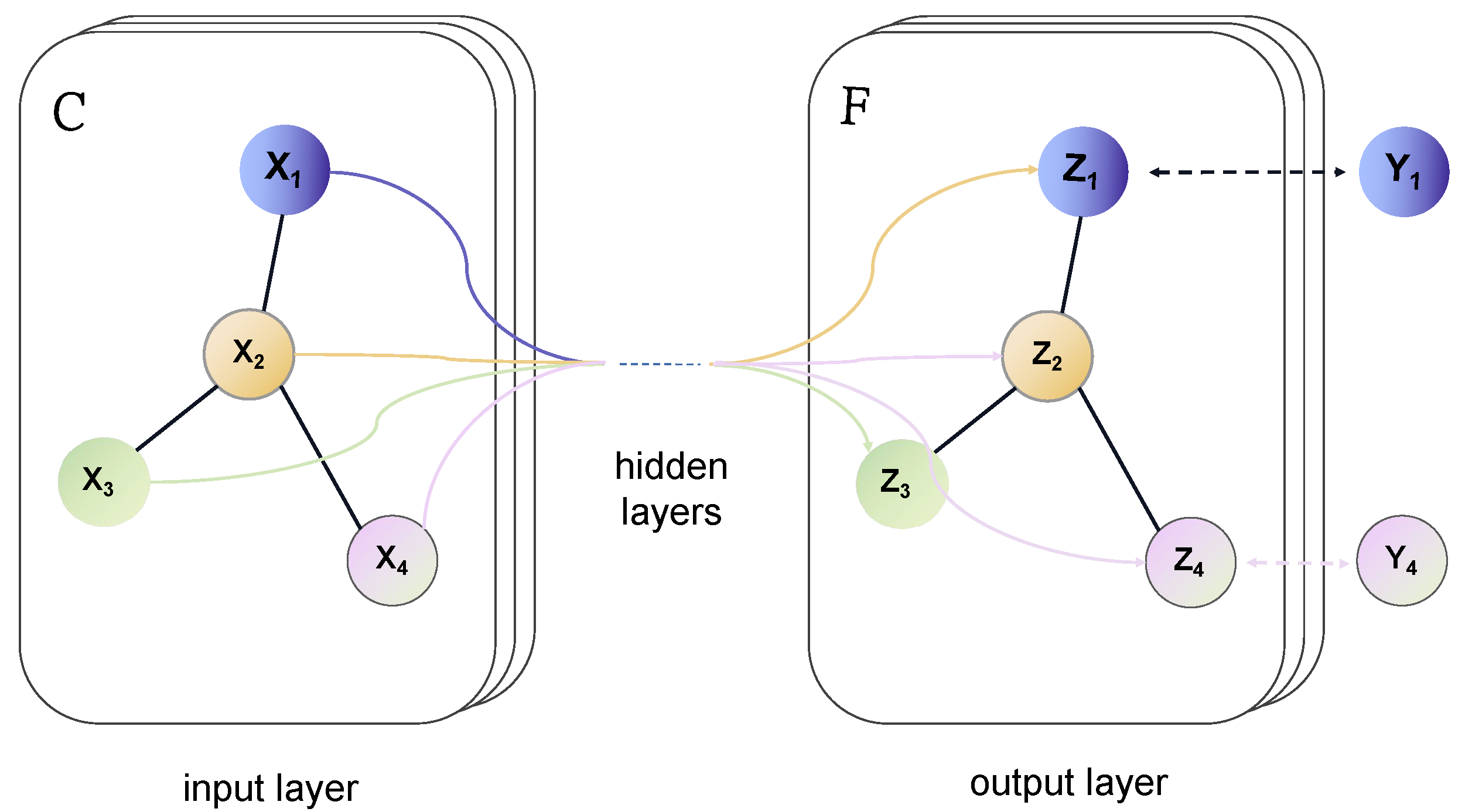
3.1. Task Formulation
3.2. Input and Encoding Layer
3.3. Relation Definition and Table Filling
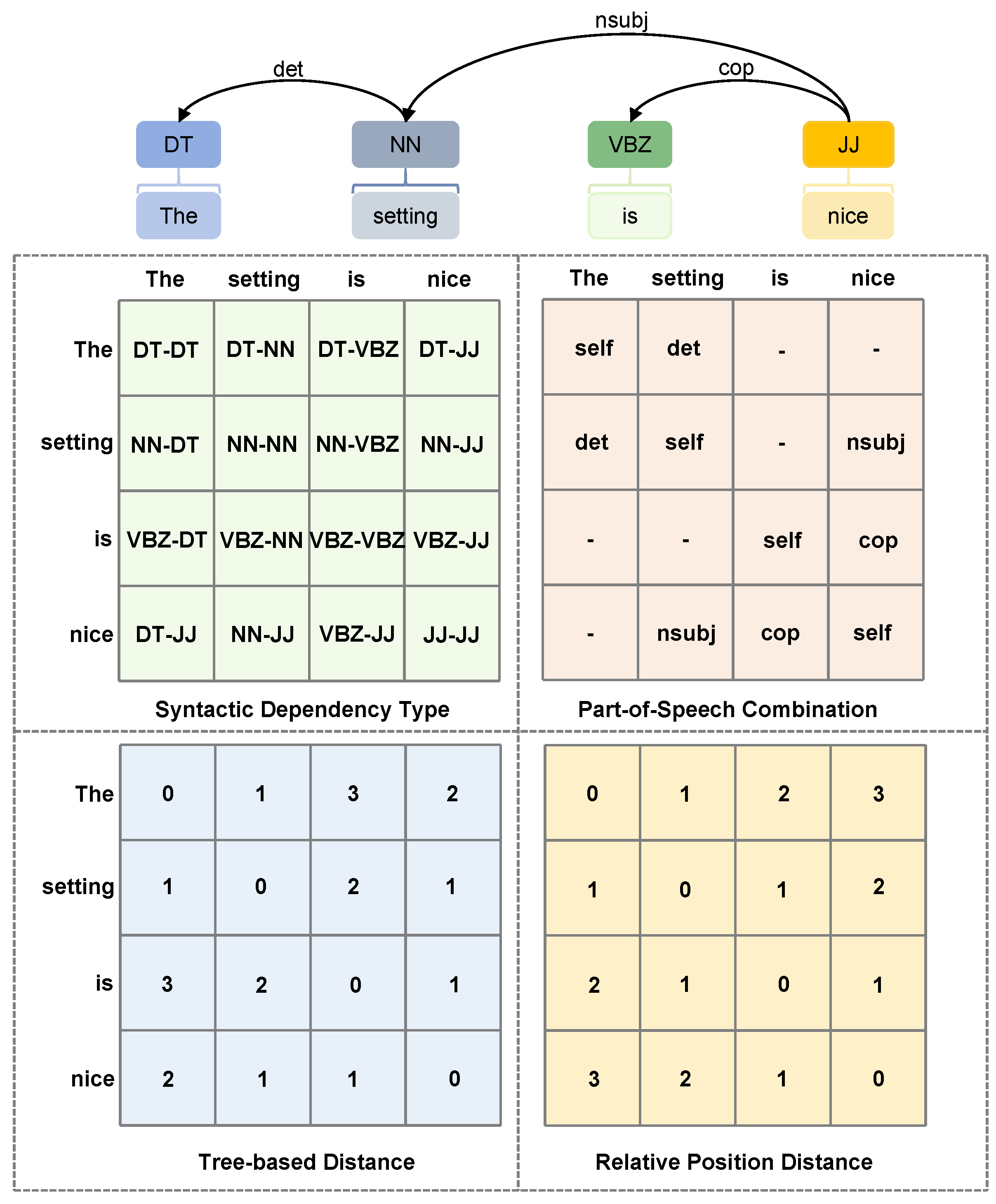
3.4. Linguistic Features
3.5. BiLSTM-Biaffine Attention
3.6. BiLSTM-BGAT-GCN Model
3.7. Refining Strategy and Predict
3.8. Loss Function
4. Experiments and Analysis
4.1. Datasets
4.2. Experimental Parameter Setting
4.3. Baselines
4.4. Main Results
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.F.; Chen, S.N.; Zhang, J.X. Adaptive sliding mode consensus control based on neural network for singular fractional order multi-agent systems. Appl. Math. Comput. 2022, 434, 127442. [Google Scholar] [CrossRef]
- Zhang, J.-X.; Yang, T.; Chai, T. Neural network control of underactuated surface vehicles with prescribed trajectory tracking performance. IEEE Trans. Neural Netw. Learn. Syst. 2022; 1–14. [Google Scholar] [CrossRef]
- Zhang, X.F.; Driss, D.; Liu, D.Y. Applications of fractional operator in image processing and stability of control systems. Fractal Fract. 2023, 7, 359. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, J.X.; Zhang, X.F. Injected infrared and visible image fusion via L1 decomposition model and guided filtering. IEEE Trans. Comput. Imaging 2022, 8, 162–173. [Google Scholar] [CrossRef]
- Zhang, X.F.; Dai, L.W. Image enhancement based on rough set and fractional order differentiator. Fractal Fract. 2020, 6, 214. [Google Scholar] [CrossRef]
- Zhang, X.F.; Liu, R.; Wang, Z.; Ren, J.X.; Gui, L. Adaptive fractional image enhancement algorithm based on rough set and particle swarm optimization. Fractal Fract. 2022, 6, 100. [Google Scholar] [CrossRef]
- Peng, H.; Xu, L.; Bing, L.; Huang, F.; Lu, W.; Si, L. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8600–8607. [Google Scholar] [CrossRef]
- Mao, Y.; Shen, Y.; Yu, C.; Cai, L. A joint training dual-mrc framework for aspect based sentiment analysis. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13543–13551. [Google Scholar] [CrossRef]
- Chen, S.; Wang, Y.; Liu, J.; Wang, Y. Bidirectional machine reading comprehension for aspect sentiment triplet extraction. Proc. AAAI Conf. Artif. Intell. 2021, 35, 12666–12674. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Deng, Y.; Bing, L.; Lam, W. Towards generative aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 1–6 August 2021; Association for Computational Linguistics: New York, NY, USA, 2021; pp. 504–510. [Google Scholar]
- Yan, H.; Dai, J.; Qiu, X.; Zhang, Z. A unified generative framework for aspect-based sentiment analysis. arXiv 2021, arXiv:2106.04300. [Google Scholar]
- Hsu, T.-W.; Chen, C.-C.; Huang, H.-H.; Chen, H.-H. Semantics-preserved data augmentation for aspect-based sentiment analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4417–4422. [Google Scholar]
- Mukherjee, R.; Nayak, T.; Butala, Y.; Bhattacharya, S.; Goyal, P. PASTE: A tagging-free decoding framework using pointer networks for aspect sentiment triplet extraction. arXiv 2021, arXiv:2110.04794. [Google Scholar]
- Fei, H.; Ren, Y.; Zhang, Y.; Ji, D. Nonautoregressive encoder–decoder neural framework for end-to-end aspect-based sentiment triplet extraction. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 5544–5556. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Li, Q.; Song, D.; Wang, B. A multi-task learning framework for opinion triplet extraction. arXiv 2020, arXiv:2010.01512. [Google Scholar]
- Xu, L.; Li, H.; Lu, W.; Bing, L. Position-aware tagging for aspect sentiment triplet extraction. arXiv 2020, arXiv:2010.02609. [Google Scholar]
- Wu, Z.; Ying, C.; Zhao, F.; Fan, Z.; Dai, X.; Xia, R. Grid tagging scheme for aspect-oriented fine-grained opinion extraction. arXiv 2020, arXiv:2010.04640. [Google Scholar]
- Bastings, J.; Titov, I.; Aziz, W.; Marcheggiani, D.; Sima’an, K. Graph convolutional encoders for syntax-aware neural machine translation. arXiv 2017, arXiv:1704.04675. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention guided graph convolutional networks for relation extraction. arXiv 2019, arXiv:1906.07510. [Google Scholar]
- Chen, C.; Teng, Z.; Zhang, Y. Inducing target-specific latent structures for aspect sentiment classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5596–5607. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Binxuan, H.; Carley, K. Syntax-aware aspect level sentiment classification with graph attention networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5469–5477. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational graph attention network for aspect-based sentiment analysis. arXiv 2020, arXiv:2004.12362. [Google Scholar]
- Chen, H.; Zhai, Z.; Feng, F.; Li, R.; Wang, X. Enhanced multi-channel graph convolutional network for aspect sentiment triplet extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 2974–2985. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Manandhar, S. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2014; pp. 27–35. [Google Scholar]
- Papageorgiou, H.; Androutsopoulos, I.; Galanis, D.; Pontiki, M.; Manandhar, S. SemEval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Sementic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the ProWorkshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Type | Feature | |
|---|---|---|
| Pipeline | Peng-two-stage [7] | Build a triplet by breaking down the task into two stages. |
| MRC | Dual-MRC [8] | Build two machine reading comprehension tasks to jointly solve subtasks. |
| BMRC [9] | Transforming the ASTE task into a multi round reading comprehension task. | |
| seq2seq | GAS [10] | Develop the task as a text generation problem. |
| Unified generative framework [11] | Transforming multiple subproblems of sentiment analysis into a unified generative problem. | |
| Semantics-preserved data augmentation [12] | Improving model performance by expanding the dataset and increasing data diversity. | |
| end-to-end | PASTE [13] | Propose a location-based approach to unify the representation of opinion triplets. |
| onautoregressive encoder–decoder [14] | Propose a high-order aggregation mechanism to fully interact with overlapping triplets. | |
| OTE-MTL [15] | Propose a multi-task learning framework to jointly extract aspect words and viewpoint words. | |
| JET-BERT [16] | Using position aware tagging scheme to jointly extract triples. | |
| GTS [17] | Propose a grid tagging scheme to solve the ASTE task through only a unified grid tagging task. | |
| Sequence | Relationship | Meaning |
|---|---|---|
| 1 | Beginning of aspect term | |
| 2 | Inside of aspect term | |
| 3 | A | Aspect term |
| 4 | Beginning of opinion term | |
| 5 | Inside of opinion term | |
| 6 | O | Opinion term |
| 7 | Sentiment polarity is positive | |
| 8 | Sentiment polarity is neutral | |
| 9 | Sentiment polarity is negative | |
| 10 | Not included in the above relationships |
| Dataset | 14res | 14lap | 15res | 16res | |||||
|---|---|---|---|---|---|---|---|---|---|
| #S | #T | #S | #T | #S | #T | #S | #T | ||
| train | 1259 | 2356 | 899 | 1452 | 603 | 1038 | 863 | 1421 | |
| dev | 315 | 580 | 225 | 383 | 151 | 239 | 216 | 348 | |
| test | 493 | 1008 | 332 | 547 | 325 | 493 | 328 | 525 | |
| train | 1266 | 2338 | 906 | 1460 | 605 | 1013 | 857 | 1394 | |
| dev | 310 | 577 | 219 | 346 | 148 | 249 | 210 | 339 | |
| test | 492 | 994 | 328 | 543 | 322 | 485 | 326 | 514 | |
| Model | 14res | 14lap | 15res | 16res | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Peng-two-stage + IOG | 58.89 | 60.41 | 59.64 | 48.62 | 45.52 | 47.02 | 51.70 | 46.04 | 48.71 | 59.25 | 58.09 | 58.67 | |
| GTS-CNN | 70.79 | 61.71 | 65.94 | 55.93 | 47.52 | 51.38 | 60.09 | 53.57 | 56.64 | 62.63 | 66.98 | 64.73 | |
| GTS-BiLSTM | 67.28 | 61.91 | 64.49 | 59.42 | 45.13 | 51.30 | 63.26 | 50.71 | 56.29 | 66.07 | 65.05 | 65.56 | |
| Dual-MRC | 71.55 | 69.14 | 70.32 | 57.39 | 53.88 | 55.58 | 63.78 | 51.87 | 57.21 | 68.60 | 66.24 | 67.40 | |
| IMN + IOG | 59.57 | 63.88 | 61.65 | 49.21 | 46.23 | 47.68 | 55.24 | 52.33 | 53.75 | - | - | - | |
| EMC-GCN | 71.15 | 72.29 | 71.71 | 56.55 | 57.06 | 56.80 | 59.21 | 58.01 | 58.61 | 67.98 | 69.41 | 68.69 | |
| BiLSTM-BGAT-GCN | 73.70 | 73.02 | 73.36 | 62.26 | 54.38 | 58.05 | 52.98 | 65.57 | 58.61 | 66.85 | 71.60 | 69.14 | |
| CMLA | 39.18 | 47.13 | 42.79 | 30.09 | 36.92 | 33.16 | 34.56 | 39.84 | 37.01 | 41.34 | 42.10 | 41.72 | |
| RINANTE | 31.42 | 39.38 | 34.95 | 21.71 | 18.66 | 20.07 | 29.88 | 30.06 | 29.97 | 25.68 | 22.30 | 23.87 | |
| Li-unified-R | 41.04 | 67.35 | 51.00 | 40.56 | 44.28 | 42.34 | 44.72 | 51.39 | 47.82 | 37.33 | 54.51 | 44.31 | |
| Peng-two-stage | 43.24 | 63.66 | 51.46 | 37.38 | 50.38 | 42.87 | 48.07 | 57.51 | 52.32 | 46.96 | 64.24 | 54.21 | |
| OTE-MTL | 62.00 | 55.97 | 58.71 | 49.53 | 39.22 | 43.42 | 56.37 | 40.94 | 47.13 | 62.88 | 52.10 | 56.96 | |
| JET-BERT | 70.56 | 55.94 | 62.40 | 55.39 | 47.33 | 51.04 | 64.45 | 51.96 | 57.53 | 70.42 | 58.37 | 63.83 | |
| BMRC | 75.61 | 61.77 | 67.99 | 70.55 | 48.98 | 57.82 | 68.51 | 53.40 | 60.02 | 71.20 | 61.08 | 65.75 | |
| EMC-GCN | 67.40 | 72.33 | 69.77 | 57.00 | 54.90 | 55.60 | 64.01 | 61.24 | 62.59 | 63.93 | 68.42 | 66.10 | |
| BiLSTM-BGAT-GCN | 73.00 | 70.15 | 71.55 | 61.36 | 60.31 | 60.83 | 55.52 | 62.53 | 58.81 | 61.29 | 71.91 | 66.18 | |
| Model | 14res | 14lap | 15res | 16res | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
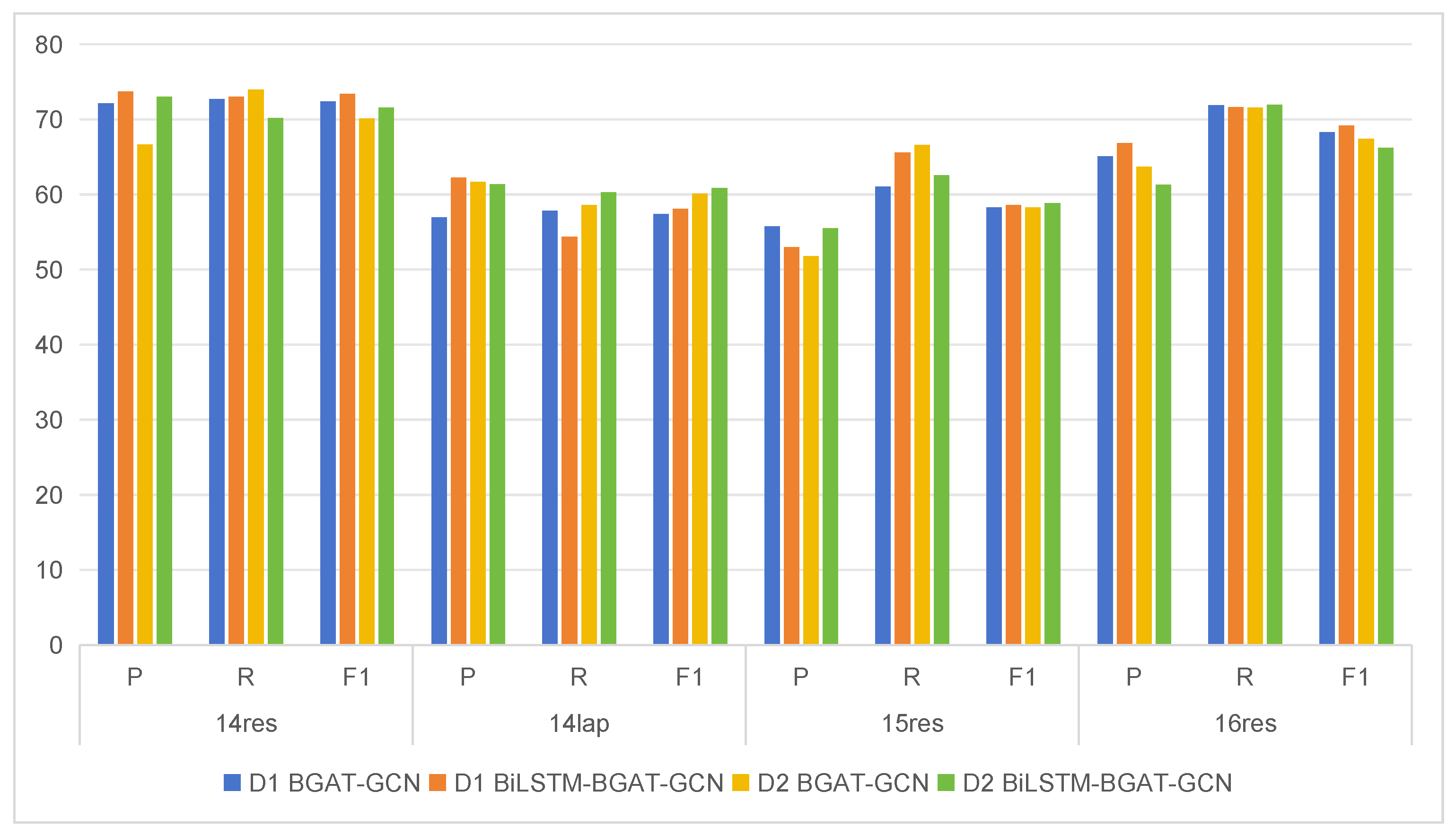
| BGAT-GCN | 72.11 | 72.70 | 72.40 | 56.96 | 57.80 | 57.38 | 55.74 | 61.06 | 58.28 | 65.05 | 71.89 | 68.30 | |
| BiLSTM-BGAT-GCN | 73.70 | 73.02 | 73.36 | 62.26 | 54.38 | 58.05 | 52.98 | 65.57 | 58.61 | 66.85 | 71.60 | 69.14 | |
| BGAT-GCN | 66.64 | 73.96 | 70.11 | 61.67 | 58.60 | 60.10 | 51.76 | 66.60 | 58.25 | 63.71 | 71.54 | 67.40 | |
| BiLSTM-BGAT-GCN | 73.00 | 70.15 | 71.55 | 61.36 | 60.31 | 60.83 | 55.52 | 62.53 | 58.81 | 61.29 | 71.91 | 66.18 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piao, Y.; Zhang, J.-X. Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism. Appl. Sci. 2024, 14, 3524. https://doi.org/10.3390/app14083524
Piao Y, Zhang J-X. Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism. Applied Sciences. 2024; 14(8):3524. https://doi.org/10.3390/app14083524
Chicago/Turabian StylePiao, Yinghao, and Jin-Xi Zhang. 2024. "Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism" Applied Sciences 14, no. 8: 3524. https://doi.org/10.3390/app14083524
APA StylePiao, Y., & Zhang, J.-X. (2024). Text Triplet Extraction Algorithm with Fused Graph Neural Networks and Improved Biaffine Attention Mechanism. Applied Sciences, 14(8), 3524. https://doi.org/10.3390/app14083524