Abstract
Manual assignment of Universal Decimal Classification (UDC) codes is time-consuming and inconsistent as digital library collections expand. This study evaluates 17 large language models (LLMs) as UDC classification recommender systems, including ChatGPT variants (GPT-3.5, GPT-4o, and o1-mini), Claude models (3-Haiku and 3.5-Haiku), Gemini series (1.0-Pro, 1.5-Flash, and 2.0-Flash), and Llama, Gemma, Mixtral, and DeepSeek architectures. Models were evaluated zero-shot on 900 English and Slovenian academic theses manually classified by professional librarians. Classification prompts utilized the RISEN framework, with evaluation using Levenshtein and Jaro–Winkler similarity, and a novel adjusted hierarchical similarity metric capturing UDC’s faceted structure. Proprietary systems consistently outperformed open-weight alternatives by 5–10% across metrics. GPT-4o achieved the highest hierarchical alignment, while open-weight models showed progressive improvements but remained behind commercial systems. Performance was comparable between languages, demonstrating robust multilingual capabilities. The results indicate that LLM-powered recommender systems can enhance library classification workflows. Future research incorporating fine-tuning and retrieval-augmented approaches may enable fully automated, high-precision UDC assignment systems.
1. Introduction
The Universal Decimal Classification (UDC) system has long served as a cornerstone for organizing and retrieving information in libraries, archives, and digital repositories worldwide. By assigning hierarchical numeric codes to subjects, UDC enables precise indexing and effective subject-based searching across diverse domains. However, manual UDC assignment remains labour-intensive and prone to inconsistency, particularly as the volume and interdisciplinarity of digital content continue to grow. In response to this challenge, the emergence of large language models (LLMs) and conversational AI systems offers a promising avenue for automating classification tasks. Leveraging their deep linguistic understanding and ability to generate contextually appropriate outputs, these models may function as UDC code recommenders, reducing manual classification time while maintaining classification quality.
Over the past few years, LLM-based systems such as OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude have demonstrated remarkable capabilities in tasks ranging from text summarization to code generation. Their pre-training on vast textual corpora equips them with nuanced semantic representations, making them well-suited to map document content to standardized classification schemes. Simultaneously, a growing ecosystem of open-weight models, such as those from Meta, Google and DeepSeek, has made advanced language technology more accessible for research and domain-specific adaptation. These developments raise key questions: Can LLM-based systems accurately recommend UDC codes? How do proprietary and open-weight models compare in terms of precision, consistency, and usability for classification support?
Prior work on automated classification has largely focused on machine learning approaches tailored to specific classification systems (e.g., Dewey Decimal Classification (DDC) and Library of Congress Classification (LCC)), often employing feature engineering or supervised classifiers. In recent years, neural-network-based classifiers have shown improved performance but typically require substantial labeled training data and often lack the flexibility to handle out-of-domain documents. In contrast, LLM-based recommenders can, in principle, perform zero- or few-shot classification by leveraging their pretrained knowledge and natural language understanding [1,2]. Yet systematic evaluations of such models for UDC recommendation are scarce, and comparative analyses of proprietary versus open-weight LLMs in this context remain underexplored.
In this study, we evaluate a variety of 17 proprietary and open-weight language models—accessed through various interfaces including conversational platforms and API endpoints—as UDC code recommenders. We assess their performance on a corpus of 900 published and publicly available undergraduate, master’s, and doctoral theses in English and Slovenian, each of which has been manually classified into UDC by professional librarians. Our evaluation metrics combine string-based measures (Levenshtein and Jaro–Winkler similarity) with an adjusted hierarchical similarity metric that captures the structural relationships inherent in the UDC scheme. We also examine practical considerations such as prompt design for use with particular LLMs.
The remainder of this paper is structured as follows. Section 2 provides background on the Universal Decimal Classification System. Section 3 reviews related work in automated library classification systems. Section 4 details our experimental methodology, including dataset description, prompt engineering strategies, and evaluation metrics. Section 5 and Section 6 present and discuss our results respectively, before conclusions are drawn in Section 7.
2. Background
Understanding the structure and characteristics of the UDC system is essential for evaluating automated classification approaches and interpreting our experimental results. This section outlines the key features of the UDC system that are particularly relevant to large language model-based classification, including its hierarchical organization, faceted structure, and multilingual capabilities.
UDC is a comprehensive, faceted classification system designed to organize and categorize knowledge across all fields of information. Developed by Paul Otlet and Henri La Fontaine in 1895, UDC is based on Melvil Dewey’s Decimal Classification but significantly expands upon it with faceted classification, auxiliary tables, and combination capabilities. The system uses a combination of numbers and symbols to create a hierarchical structure that can represent complex subjects and their interrelationships (Table 1 and Table 2).

Table 1.
The top-level classes of the main tables in the UDC.
Table 2.
Hierarchical breakdown of the UDC code 004.738.52.
One of the key strengths of UDC is its flexibility and extensibility. It employs a faceted approach, allowing for the combination of multiple concepts to describe a document’s content precisely. This is achieved through the use of auxiliary signs and special auxiliaries, which enable the expression of various aspects such as time, place, form, and language. For example, the notation “621.39:681.3”, where the colon (:) indicates a relationship between the two concepts, represents “telecommunication in relation to computer science,” demonstrating the system’s ability to express complex interdisciplinary subjects.
UDC offers several advantages for information organization. Its hierarchical structure facilitates both broad and narrow searches, making it equally useful for general browsing and specific information retrieval. The system’s language-independent nature, relying on numbers and symbols, makes it particularly valuable in multilingual or international contexts. Moreover, UDC’s logical structure and combinatorial capabilities make it well suited for computer-based applications and digital library systems. These characteristics make UDC particularly suitable for automated classification approaches, as the hierarchical structure enables similarity measures that can assess partial correctness at different hierarchical levels (Table 3).
Table 3.
Examples of simple and complex UDC expressions with interpretations.
However, UDC is not without its challenges. The system’s complexity can be a double-edged sword; while it allows for precise classification, it also requires significant expertise to apply correctly. This complexity can lead to inconsistencies in classification across different institutions or cataloguers. Additionally, keeping the UDC system up-to-date with rapidly evolving fields of knowledge, particularly in technology and interdisciplinary areas, is an ongoing challenge. Despite these limitations, UDC remains a powerful and widely used tool in libraries and information centers worldwide, valued for its comprehensiveness and adaptability to diverse knowledge domains. These challenges in manual UDC assignment motivate the exploration of automated classification approaches, which this study addresses by evaluating the effectiveness of large language models for UDC recommendation.
3. Related Work
A growing body of research has explored automating library classification assignment through machine learning and ontological approaches. More recently, large language models and conversational AI systems have emerged as promising tools for this task. Early work demonstrated that supervised learning models can assign UDC at the main classes level for scholarly texts, pointing to substantial time savings for librarians [3]. Hybrid and ontology-driven recommenders have further improved precision in domain-specific contexts, particularly in mathematics [4]. Simultaneously, the advent of LLM-powered conversational systems has spurred empirical studies on their effectiveness for traditional cataloguing tasks, revealing both promise and limitations in automated classification [5,6] and subject-heading selection [7,8,9]. However, systematic comparative evaluations of multiple LLM architectures for UDC classification remain limited, despite the system’s widespread use and unique hierarchical structure.
The UDC is one of the most widely adopted international library classification schemes, rooted in the Dewey Decimal Classification system and continually updated to cover new subject areas. Its hierarchical decimal notation enables precise representation of document subjects, supporting faceted navigation and cross-lingual interoperability. Despite its strengths, manual UDC assignment is time-consuming and requires specialized expertise. In [3], a design-science approach was developed using classical machine learning models—trained on 70,000 librarian-classified scholarly texts—to automatically assign UDC to older, digitized documents. Their SVM-based classifier achieved over 90% correct assignment at hierarchical level 3, as corroborated by expert evaluation on 150 randomly selected texts.
Building on classical approaches, recent work has explored deep learning methods. In [10], the authors fine-tuned a BERT transformer within KNIME to build a semi-automatic UDC recommender, reporting high AUC values though noting room for accuracy improvements when full UDC licensing is obtained. In [11], a hybrid model was proposed combining metadata-driven and collaborative filtering techniques tailored to Slovenian digital libraries, further demonstrating that mixed methods can boost recommendation hit rates in real-world cataloging scenarios. Collectively, these studies confirm that machine learning pipelines ranging from classical approaches to deep neural networks can effectively scale UDC assignment across large digital collections.
Furthermore, ontology-driven methods offer semantic grounding that pure statistical models lack. In [4], the authors exploited the OntoMathPRO applied ontology to extract mathematical concepts (methods, problems, and equations) and build code maps for UDC codes in mathematics, enabling fine-grained recommendations with high relevance across closely related subdomains. Such knowledge-based recommenders model the classification decision process more explicitly, positioning them as valuable complements to data-driven classifiers, especially in domains with well-developed ontologies.
The public release of accessible conversational systems like ChatGPT, Gemini, and Claude has catalyzed library-oriented evaluations [12]. In [8], the authors conducted a performance test of these conversational systems on DDC and LCC classification systems, analyzing error typologies and highlighting both potential efficiency gains and critical accuracy concerns in classification number assignment. A study on using ChatGPT for metadata [5] demonstrated that while LLMs may produce inaccurate results for licensed classification systems like DDC, they perform reliably for subject-heading suggestions and keyword generation, provided that prompts are carefully engineered and results systematically vetted. A study using Claude [13] similarly showed that conversational agents can reduce the mental workload of librarians by proposing call numbers and subject terms, albeit with variability across sessions and models. Beyond classification, broader surveys underscore the fast-evolving capabilities of LLM-based conversational systems across sectors, including information retrieval and digital library services [14]. Moreover, retrieval-augmented generation (RAG) LLM deployments [15] illustrate how retrieval augmentation can ground chatbot outputs in authoritative sources [16,17], thus mitigating hallucination risks in compliance-sensitive domains [18,19,20].
User-centered design principles have been applied to recommender interfaces for classification systems [21], revealing that librarian involvement in feature selection and result presentation is key to adoption and trust. While custom LLM pipelines fine-tuned on curated library metadata such as specialized UDC classifiers and ontology-driven recommenders have achieved impressive accuracy in controlled settings [22], most libraries lack the technical infrastructure, licensed training corpora, and in-house expertise required to develop and maintain such models [23]. Instead, many librarians turn to publicly available, off-the-shelf conversational systems like ChatGPT, Gemini, and Claude, which nearly half of surveyed cataloguing professionals report using for classification and subject-heading tasks [24]. This study, therefore, addresses the practical needs of libraries by systematically evaluating the performance of unmodified proprietary LLMs for UDC classification, providing actionable insights for librarians working with readily available tools.
4. Methodology and Implementation
This section presents our methodology for evaluating the performance of large language models in recommending UDC codes for academic documents. We describe our dataset, prompt engineering strategies, experimental design, and evaluation metrics.
4.1. Dataset
The dataset we used is a filtered subset of the OpenScience Metadata Dataset [25], which consists of document full texts and document metadata. The OpenScience Metadata Dataset contains theses and publicly available peer-reviewed academic publications from Slovenian research institutions. Each document’s metadata include bilingual title, abstract, and keywords (English and Slovenian) along with professionally assigned detailed UDC codes. All the documents and metadata within this dataset are publicly available through the Slovenian National Open-Access Infrastructure. The filtered subset consisted of 900 documents, with 100 randomly selected documents from each top-level field of expertise included in the main tables of the UDC. The 900 documents were evenly distributed across the 9 main UDC classes (100 documents each), ensuring balanced representation of all major subject areas.
4.2. Chatbot Recommender Architecture
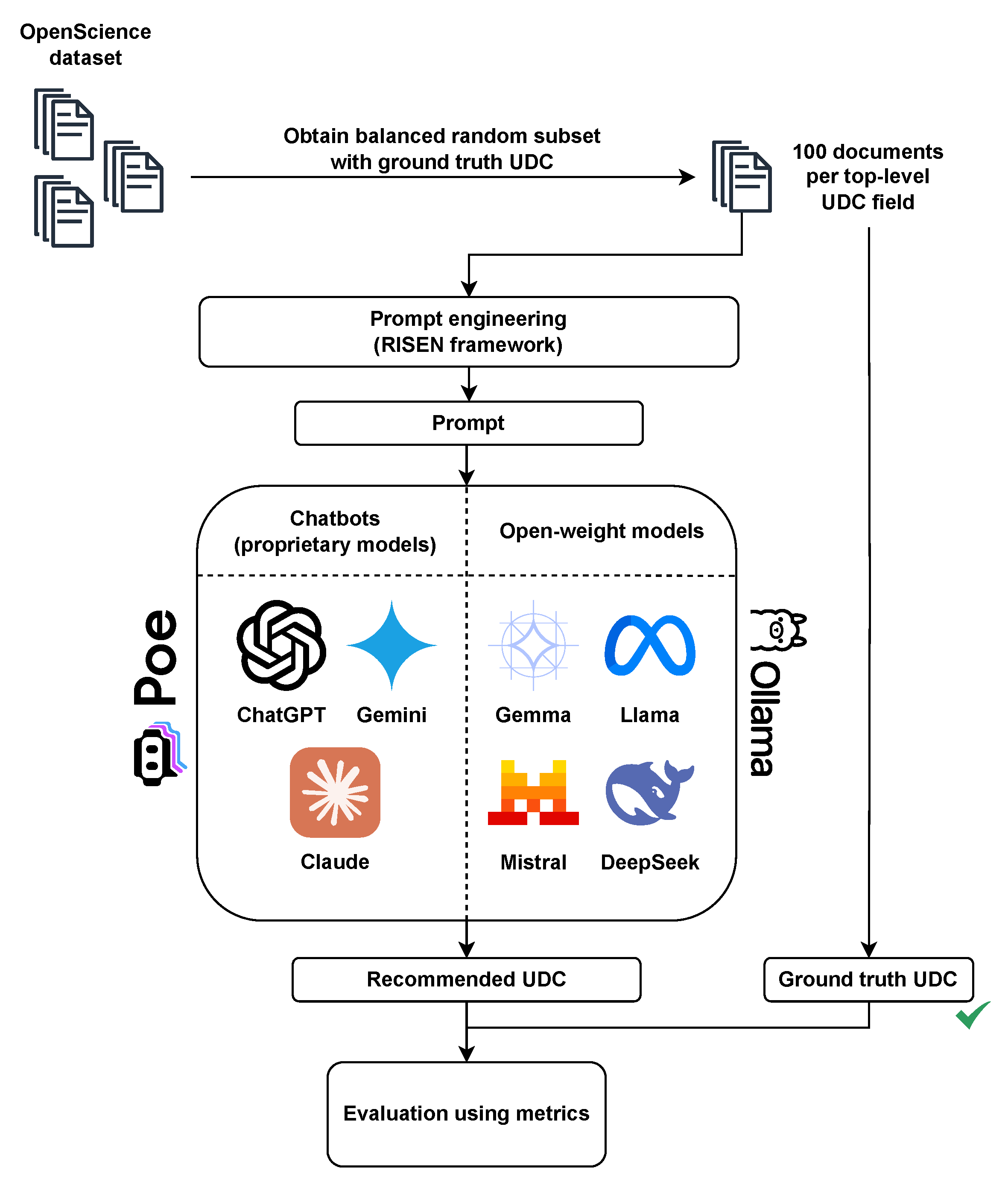
We designed our UDC recommendation in the form of a chatbot application since we decided to investigate how well conversational systems perform as recommenders. The chatbot application supports several different chatbots as well as proprietary and open-weight large language models that are available either through the Poe chatbot platform, or the Ollama framework (Figure 1). The Poe chatbot platform hosts a variety of proprietary and open-weight models that can be paid with credits. This can be a limitation since the quota of free credits is limited per day. However, a paid plan can be used to remove this limitation. The Ollama framework on the other hand is a completely local service which can be used to serve open-weight models; however, its limitation is the hardware capabilities on the local device. It is important to note that chatbot API requests using the Poe chatbot platform send the input text to the chatbot workflow, which is usually not just a generative large language model. Chatbot workflows can be very complex and can include different preprocessing methods, additional classifiers, and even supporting models. We opted to test the chatbot APIs of popular chatbot solutions ChatGPT (models GPT-3.5 Turbo, GPT-4o, and o1-mini), Claude (models Claude-3-Haiku and Claude-3.5-Haiku) and Gemini (models Gemini-1.0-Pro, Gemini-1.5-Flash and Gemini-2.0-Flash).
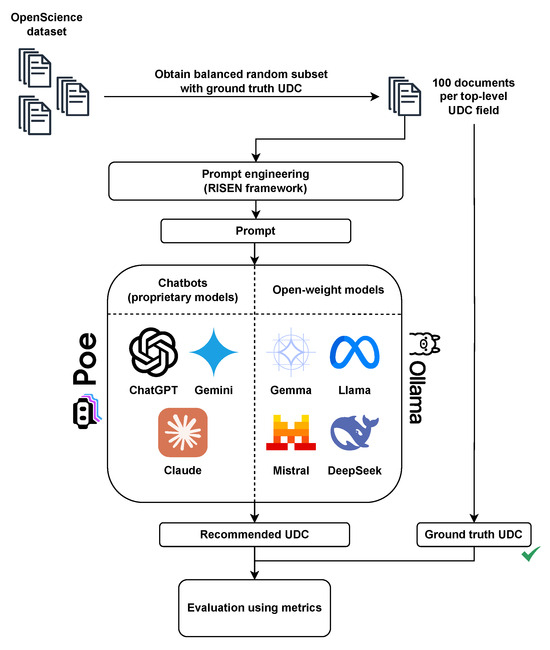
Figure 1.
Our UDC recommendation framework using proprietary and open-weight models.
The Poe chatbot platform also hosts a variety of open-weight LLMs that can be used via APIs which return the generated text response. To further investigate the disparity between performance of proprietary chatbots with complex workflows and chatbots using open-weight LLMs, we tested some well-known LLMs. We used a combination of Poe platform and a local Ollama setup while testing these models. The models included Llama-2-70B, Llama-3-70B, Llama-3.1-7B, Llama-3.2-7B, Llama-3.3-70B, Gemma-7B-Instruct, Gemma-3-4B, Mixtral-8x7B-Chat, and DeepSeek-R1-7B. The details of all LLMs are given in Table 4. The technical details on computing resources, inference time, and costs required during the evaluation are given in Appendix B.
Table 4.
List of tested proprietary (*) and open-weight (†) LLMs.
From the metadata of the documents, we prepared prompts, performed requests to the Poe platform and Ollama APIs using a console application, and saved the resulting responses in JSON files. As context, a prompt included the title, keywords, and the abstract of the document. We used the zero-shot prompting technique since few-shot prompting did not make sense as we did not have predefined examples of suitable UDC codes in terms of documents containing the exact same contexts. The zero-shot prompting approach also closely resembles the manual process of librarians when they classify the documents into the UDC. Consequently, the models received only an instruction to recommend a UDC code, the document’s context in form of a title, keywords, and an abstract, and further limiting instructions as part of our chosen prompting framework. The expected result was either a simple or a complex UDC expression for each document, which was stored into intermediate JSON files. The model outputs were not modified, edited, filtered, or corrected in any way before evaluation. The resulting JSON files that contained the result UDC code, used LLM, and document ID were processed during the analysis where a ground truth UDC value was compared to the result and a similarity metric value was calculated.
4.3. Prompt Engineering
A single-prompt approach assures a constant prompt accross all tested models, which eliminates variablity introduced by alternative phrasings or sampling noise. This ensures that any differences in UDC assignment stem from the models’ capabilities, not from prompt engineering or ensembling effects. During the initial testing phase, we found that prompting different chatbots and LLMs with the same prompt does not always lead to quality results. Because of this, we tailored the prompts using the RISEN prompt engineering framework. The acronym stands for Role, Instructions, Steps, End goal, and Narrowing. By systematically defining each component (Role, Instructions, Steps, End goal, and Narrowing constraints), the chatbots and LLMs had more context on the task at hand. Narrowing the format of the result proved to be the most beneficial, as we struggled to obtain a single UDC code as a response without it. This structured approach helped ensure consistent, parseable outputs across different model architectures. Below are some examples of the prompts we used with the corresponding chatbot or LLM. For chatbots ChatGPT and Claude, the following prompt was used:
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate a single UDC code based on the title, keywords and abstract. Return only one UDC code, without text, explanation or markdown.
Some additional narrowing steps were required for use with Gemini models. Building from the above prompt, the following prompt was used:
… Your task is to generate a single UDC code, based on the title, keywords and abstract. Do not give any explanation in the response. In the response return only the UDC code, do not write any additional words. Do not return the response in markdown. Do not split the UDC code into small parts.
When using LLMs directly (namely DeepSeek, Llama, and Gemma models), some additional narrowing instructions were required to obtain quality responses. Most notably, the limitation for the response length needed to be set. For all tested LLMs, an explicit requirement that the result is given in one line of text seemed to work well. Furthermore, we added limitations on the length of the UDC code and required a result without any other text before or after the resulting UDC code. This proved instrumental in obtaining quality responses from the LLMs. By adding on to the previous prompts, we added even more narrowing instructions:
… The generated UDC code should be in one line. The UDC code should not be longer than 50 characters. The response must not contain anything else before and after the UDC code.
A special addition in the prompt was needed for the DeepSeek-R1-7B model, since this is a reasoning model and it provides thinking steps in the output. We omitted the thinking steps and prompted this model with the following prompt:
Act as librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: “{title}”. The document contains the following keywords: “{keywords}”. The abstract of the document is as follows: “{abstract}”. Your task is to generate only one UDC code, based on the title, keywords and abstract. Do not write any explanation in response. In the response, write only the UDC code, do not write any additional words. Do not write the response with markdown. Do not break the code into small parts. Do not show your thinking.
The different versions of the initial prompt were then used as templates in the process of recommending the UDC codes for each document from the dataset (Appendix A.1). These prompt templates were also translated into Slovenian when used with documents in the Slovenian language (Appendix A.2). The document title, keywords, and abstract were substituted with a corresponding tag within the prompt template and used with the Poe platform API and the Ollama local service to obtain a resulting UDC code.
4.4. Metrics
Evaluating the performance of UDC recommender systems requires metrics that account for both textual similarity and the hierarchical nature of library classification schemes. String similarity measures such as the Levenshtein and Jaro–Winkler similarity are commonly used to assess how closely a predicted string matches the correct one in terms of character-level edits or shared prefixes. While effective for detecting surface-level differences, these metrics may overlook the semantic or structural proximity of UDC codes. To complement them, we develop the adjusted hierarchical similarity metric which extends component-wise string matching by incorporating both positional alignment and a penalty for excessive prediction length. This approach maps more naturally onto the faceted, hierarchical structure of UDC codes. Together, these three metrics form a basis for the robust evaluation of our proposed UDC recommendation approach.
4.4.1. Levenshtein Similarity
The Levenshtein distance, also known as the edit distance, is a string metric for measuring the difference between two sequences. Introduced by Vladimir Levenshtein in 1965, it quantifies the minimum number of single-character edits (insertions, deletions, or substitutions) required to transform one string into another. This metric has found extensive application in various domains, including computational linguistics, DNA sequence analysis, and information retrieval. Formally, the Levenshtein distance between two strings a and b (of length and respectively) is given by , where
Here, i and j are character positions of string a and b, respectively, and is the indicator function equal to 0 when and equal to 1 otherwise. The Levenshtein similarity providing a normalized score between 0 and 1 can be derived from the distance as
In the context of UDC codes, the Levenshtein similarity offers a robust method for comparing classification strings. Unlike the Jaro–Winkler similarity, which emphasizes prefix matching, the Levenshtein similarity treats all positions in the string equally. This property can be advantageous when dealing with UDC’s complex notation system, where significant semantic differences may be encoded by changes in characters at any position within the code. For instance, consider the UDC codes “621.39:004” (telecommunications in relation to computer science) and “621.38:004” (electronics in relation to computer science). Despite their high visual similarity, these codes represent distinct technological domains.
4.4.2. Jaro–Winkler Similarity
The Jaro–Winkler similarity metric, an extension of the Jaro similarity, is a string comparison algorithm that quantifies the similarity between two strings. Originally conceived for record linkage in the context of the U.S. Census, it has found widespread application in duplicate detection and string matching tasks. In the context of UDC codes, this metric offers a potentially valuable tool for comparing and analyzing classification strings. Formally, the Jaro–Winkler similarity for two strings a and b is defined as
where is the Jaro similarity, ℓ is the length of the common prefix (up to four characters), and p is a scaling factor, typically set to 0.1 [26]. The Jaro similarity itself is computed as
Here, m is the number of matching characters, and t represents the number of matching characters that appear in different sequential order in the two strings, divided by two. Characters are considered matching if they are identical and occur within a matching window of positions of each other. In the context of UDC codes, the Jaro–Winkler metric’s emphasis on prefix matching aligns well with the hierarchical structure of UDC notations. For instance, when comparing UDC codes “621.39:681.3” and “621.39:004”, the metric would assign a high similarity score due to the shared prefix “621.39”, reflecting their common root in the classification hierarchy. This property makes the Jaro–Winkler metric particularly suitable for tasks such as identifying related UDC codes, detecting potential classification errors, or suggesting alternative classifications in automated systems. However, the application of Jaro–Winkler to UDC codes requires careful consideration. The metric’s character-by-character comparison may not fully capture the semantic relationships encoded in UDC’s special auxiliaries and faceted structure. For example, the codes “94(44)”18“” (History of France in the 19th century) and “94(45)”18“” (History of Italy in the 19th century) would receive a high similarity score due to their structural similarity, despite representing different geographical entities.
4.4.3. Adjusted Hierarchical Similarity
The adjusted hierarchical similarity metric extends component-wise string similarity (e.g., Jaro–Winkler) by also rewarding correct positional alignment of UDC code components and penalizing any additional components in the prediction. It is designed for comparing two lists of UDC code components, namely, the ground truth and prediction , where and are the number of ground truth and predicted UDC code components, respectively.
The metric uses a component similarity term, an order factor, a component-level matching score and a penalty term. The component similarity term is defined as and is the Jaro–Winkler similarity between the i-th ground truth UDC code component and the j-th predicted UDC code component . The order factor is defined to penalize misaligned positions within the UDC code. It is defined as
where is a hyperparameter controlling the penalty severity due to order differences. The component-level matching score () is then computed for each ground truth component with
The average similarity before penalty is then calculated with
A penalty factor is applied per extra component if there are extra predicted UDC code components (when ):
Finally, the adjusted hierarchical similarity score is given with
In the context of UDC codes, the adjusted hierarchical similarity metric’s combination of component-wise edit similarity, positional weighting, and additional component penalty maps naturally onto UDC’s hierarchical faceted structure. By first decomposing UDC expressions into their component lists using a parser that splits on standard delimiters (colon (:), plus (+), and slash (/)) and considers only main table numbers (ignoring auxiliaries), the metric uses Jaro–Winkler similarity to capture how closely each component matches at the string level. While rewarding components that appear in the correct sequence via an order factor, it gives full credit when the i-th ground-truth component aligns with the i-th prediction. Furthermore, if a prediction introduces additional components, the metric subtracts a penalty proportional to the count of additional components, which discourages over-specific or noisy outputs. In our experiments, and were used as they provided a good balance of penalizing misaligned positions within the UDC code and additional UDC components.
5. Results
The experiment was run on 900 documents classified into the nine main classes, each represented by 100 documents. The recommendations were compared to the ground truth UDC codes provided in the dataset. Similarities between the recommended and ground truth UDC codes were measured with the Levenshtein similarity, Jaro–Winkler similarity, and adjusted hierarchical similarity. The titles, keywords, and abstracts in English and Slovenian were used in the experiment. This was done to compare the performance in different languages, with English being a very well-resourced language and Slovenian being a traditionally resource-constrained language, due to scarcity of text corpora and available large language models. The evaluated models were grouped by their parameter sizes into groups. Large models, which consist of 70B parameters, and smaller models, which consist of 4-7B parameters, were grouped into two distinct groups. For some proprietary models, the size of parameters is unknown, so we grouped those into a separate group. We present the language-specific results for all groups of models in the following subsections.
5.1. Documents in English
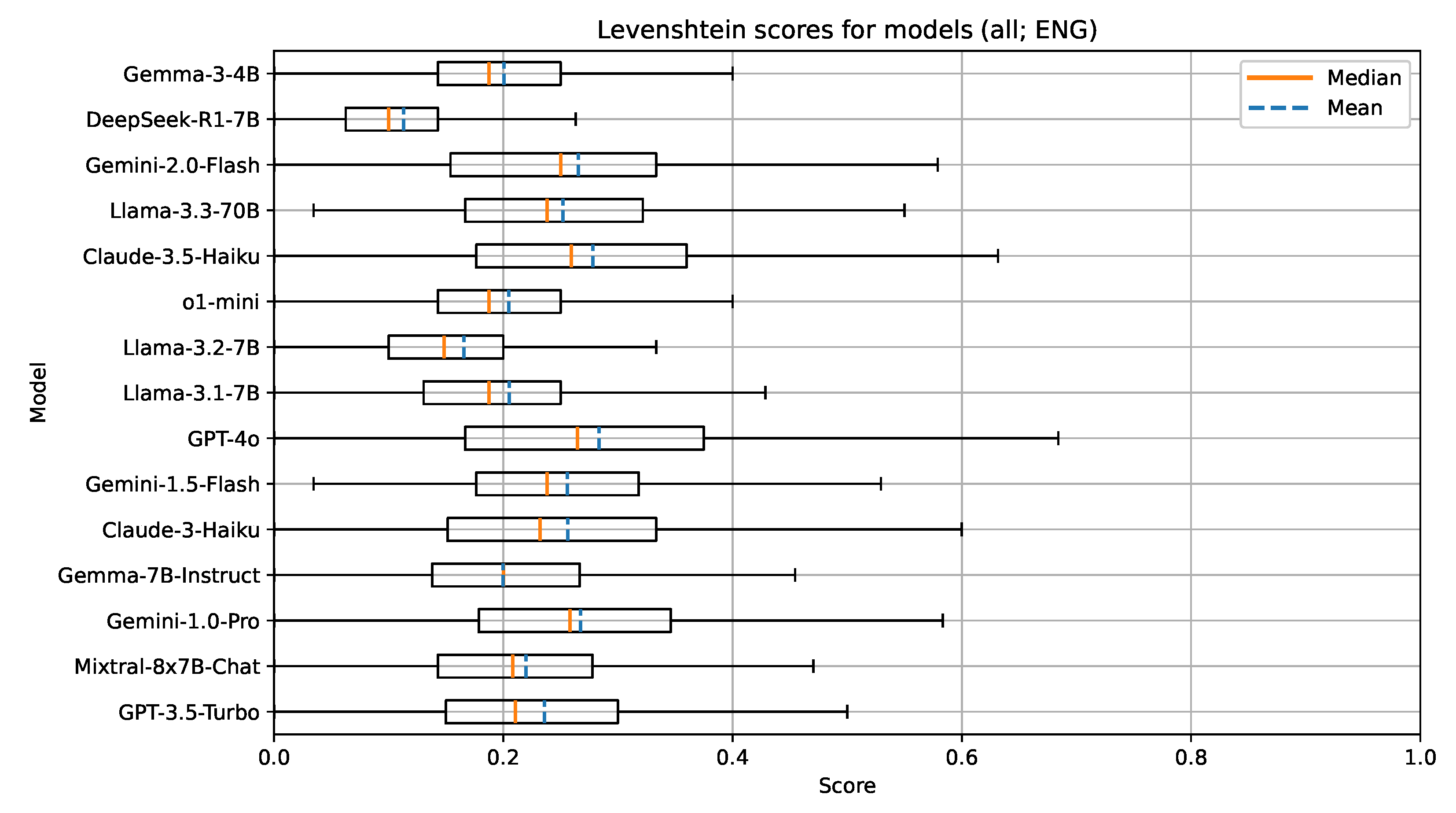
For the document text features in the English language, the selected models seemed to work well (Figure 2, Figure 3 and Figure 4); however, they struggled with the UDC codes that represent very specific fields of expertise. We found that the tested models performed well in recommending UDC codes up to the third hierarchical level of the UDC (e.g., UDC codes like 5, 54, and 545). For further hierarchical levels of the UDC (e.g., UDC codes like 004.738.5), the models sometimes failed to grasp the concept of decimal notation with the period separator (.) and, therefore, returned invalid UDC codes in those cases (e.g., codes like 0047). In the evaluation, invalid UDC codes were not removed or treated in any special way. They were processed like every other valid UDC code. With the used metrics, parts of invalid codes still showed a promising attempt at giving a potentially useful UDC code, due to the hierarchical structure of the UDC.
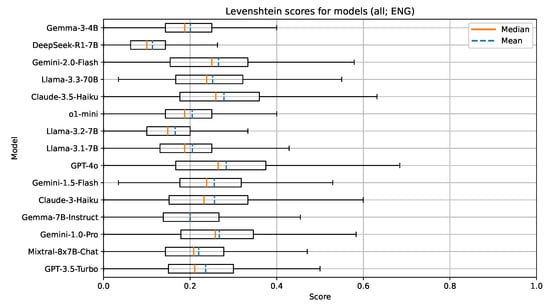
Figure 2.
Boxplot visualization of the Levenshtein similarity for models evaluated on documents in English.
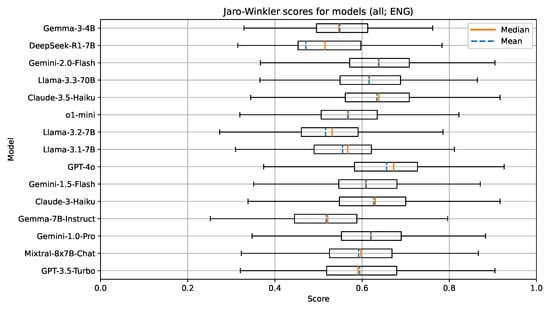
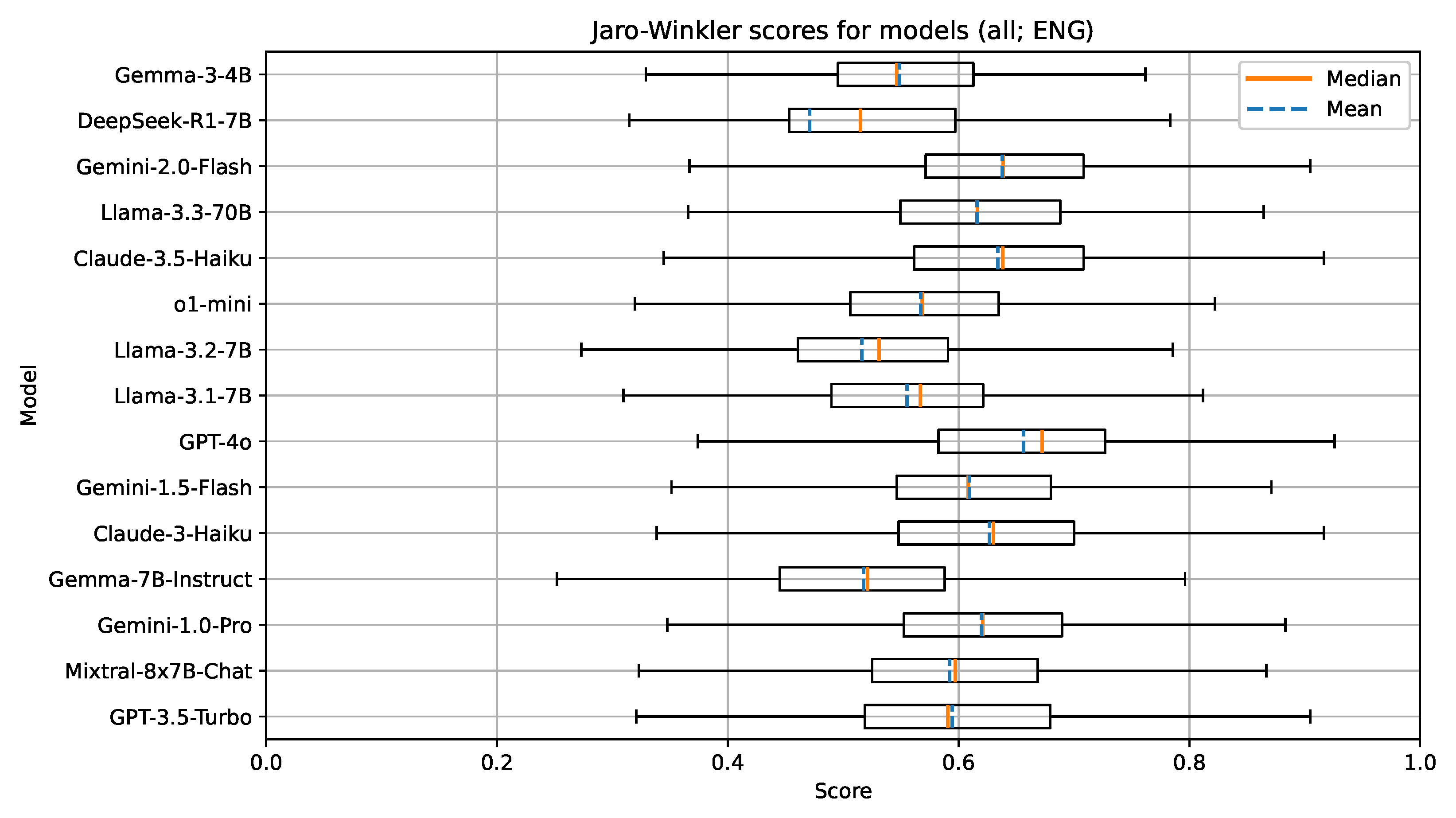
Figure 3.
Boxplot visualization of the Jaro–Winkler similarity for models evaluated on documents in English.
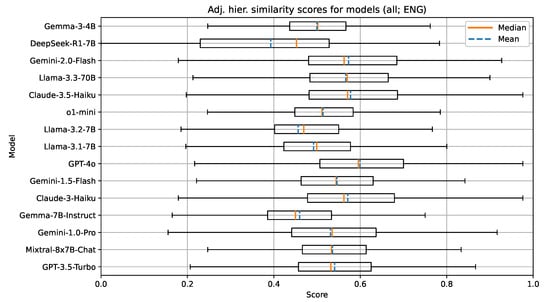
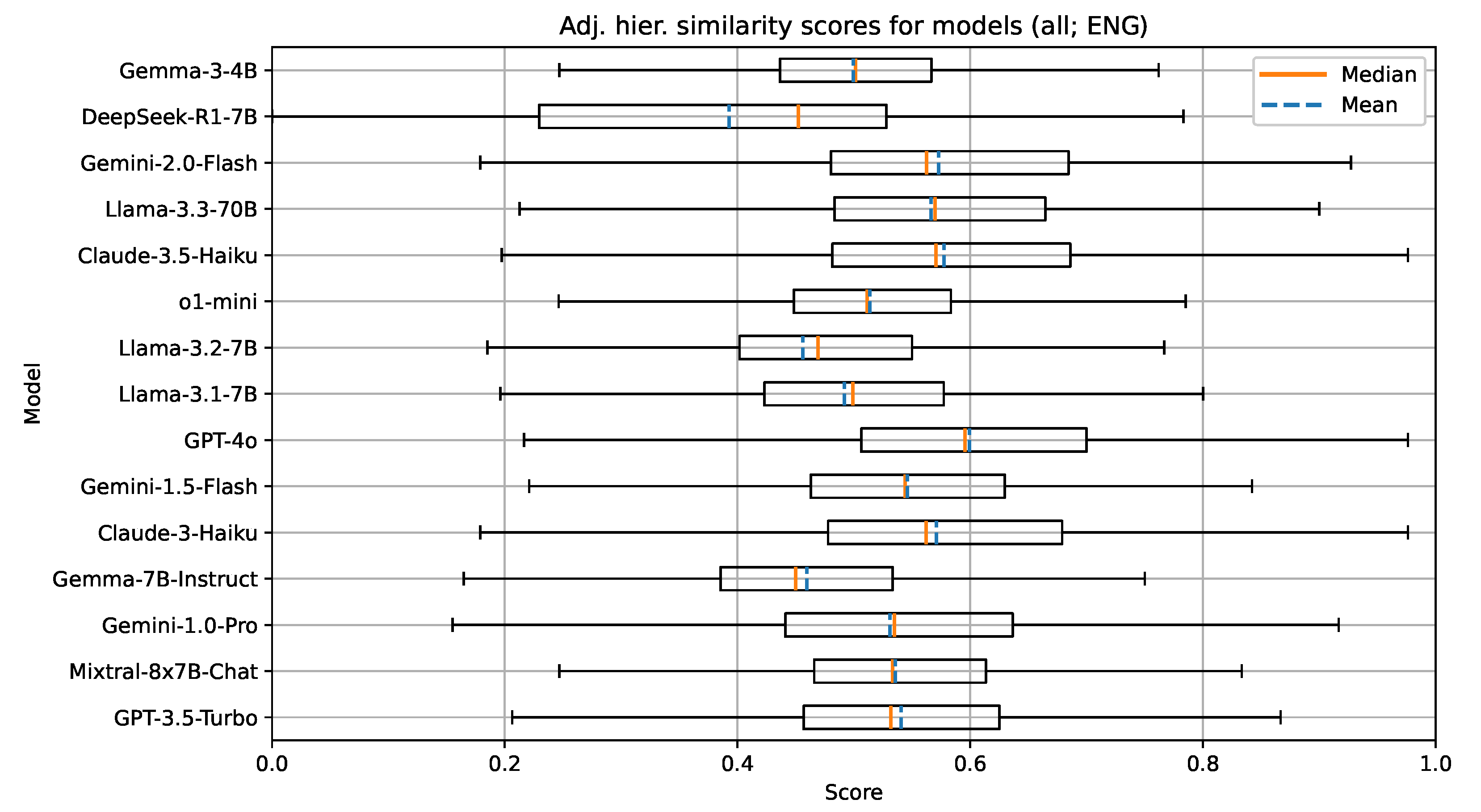
Figure 4.
Boxplot visualization of the adjusted hierarchical similarity for models evaluated on documents in English.
In some cases, the separator was used correctly; however, the numbers behind it were not defined in the UDC catalogue. These specific cases can be classified as hallucinations since the models completely made up UDC classes, which do not exist in practice. Additionally, the most common mistakes made by the models were due to order-switching of disciplines in documents with multidisciplinary content (e.g., models returned UDC code 004:621.3 instead of 621.3:004; computer science in electrical engineering instead of electrical engineering in computer science). This is a common problem even in manual assignment of UDC codes, since the cataloguing process takes place in a domain-specific library. For example, a thesis on online banking could be assigned a code 004:336 (computer science in finance) if it were catalogued by a computer science faculty library, or it could be assigned a code 336:004 (finance in computer science) if it were catalogued by an economics faculty library. This is a consequence of different processes of cataloguing within libraries as they commonly anchor to specific information about the documents such as the author, thesis supervisor, and organization of origin.
Table 5 presents the measured median values and standard deviations of selected metrics for models of size 4-7B parameters. The best performing model on all metrics in this group was Mixtral-8x7B-Chat. All models in this group are open-weight. Surprisingly, the later released models did not perform as well—for example, the newest two models, DeepSeek-R1-7B and Gemma-3-4B, were underperforming, especially on the Levenshtein similarity. This might be due to a change in training data and the parameter size, type, and architecture of the LLM itself (e.g., DeepSeek-R1-7B is a reasoning model with 7B parameters). In general, the lower scores of the Levenshtein similarity stem from its properties and, in our use-case, it can be interpreted as a stricter measure than the other two metrics.
Table 5.
Median values and standard deviations (SD) of selected metrics for models of size 4-7B parameters evaluated on documents in English.
The metric results for the group with larger (70B) parameter size LLMs are given in Table 6. All 70B models were the Llama models of the 2nd and 3rd generation. This is an interesting insight, as it shows the improvements in this particular model family over time. With Llama-2-70B being the oldest and least performant, both Llama-3-70B and Llama-3.3-70B outperformed it on all metrics. The newest model (Llama-3.3-70B) performed the best. In comparison with the 4-7B models, the 70B models perform better on all metrics as expected, due to the increased complexity of the models.
Table 6.
Median values and standard deviations (SD) of selected metrics for models of size 70B parameters evaluated on documents in English.
Table 7 presents the metric scores for the group of models where the parameter sizes were not disclosed publicly. Since these models are proprietary and accessed via an API, it is unknown what the underlying workflow is when the inputs are being processed. All of the LLMs in this group might be just a component within a larger multi-component chatbot process which can affect the end results. The additional components could include intent detection, improved self-prompting, use of additional tools, etc.
Table 7.
Median values and standard deviations (SD) of selected metrics for models with unknown parameter size evaluated on documents in English.
The results show that GPT-4o performed the best, with Claude-3.5-Haiku and Gemini-1.0-Pro and Gemini-2.0-Flash trailing behind. We also included the now obsolete GPT-3.5-Turbo and the o1-mini as benchmarks and references for comparison. OpenAI offers newer reasoning models such as o3 and o4-mini; however, the cost to run these models in an experiment was too high for us to be able to include them. Interestingly, the o1-mini reasoning model underperformed, which was unexpected. We attribute this to the size of the model, since it is a smaller version of the larger o1 model.
From these results, we can also see the same trend as in Table 6—that is, the newer models of similar sizes tend to perform better on the selected metrics. The improved performance on the selected metrics could also be attributed to the use of retrieval-augmented generation techniques which avoid the hard limitations of knowledge up to a certain date. In other words, if an LLM does not have knowledge about the UDC, it will generate a response based on its existing knowledge; meanwhile, a chatbot could use the internet and obtain more context on what the UDC is before generating a response. Of course, we can only speculate that the model sizes are in the same range (e.g., GPT-4o, Gemini-2.0-Flash, and Claude-3.5-Haiku) and what the models’ roles are within more complex chatbot workflows since this information was not specifically disclosed by the publishers of these models.
5.2. Documents in Slovenian
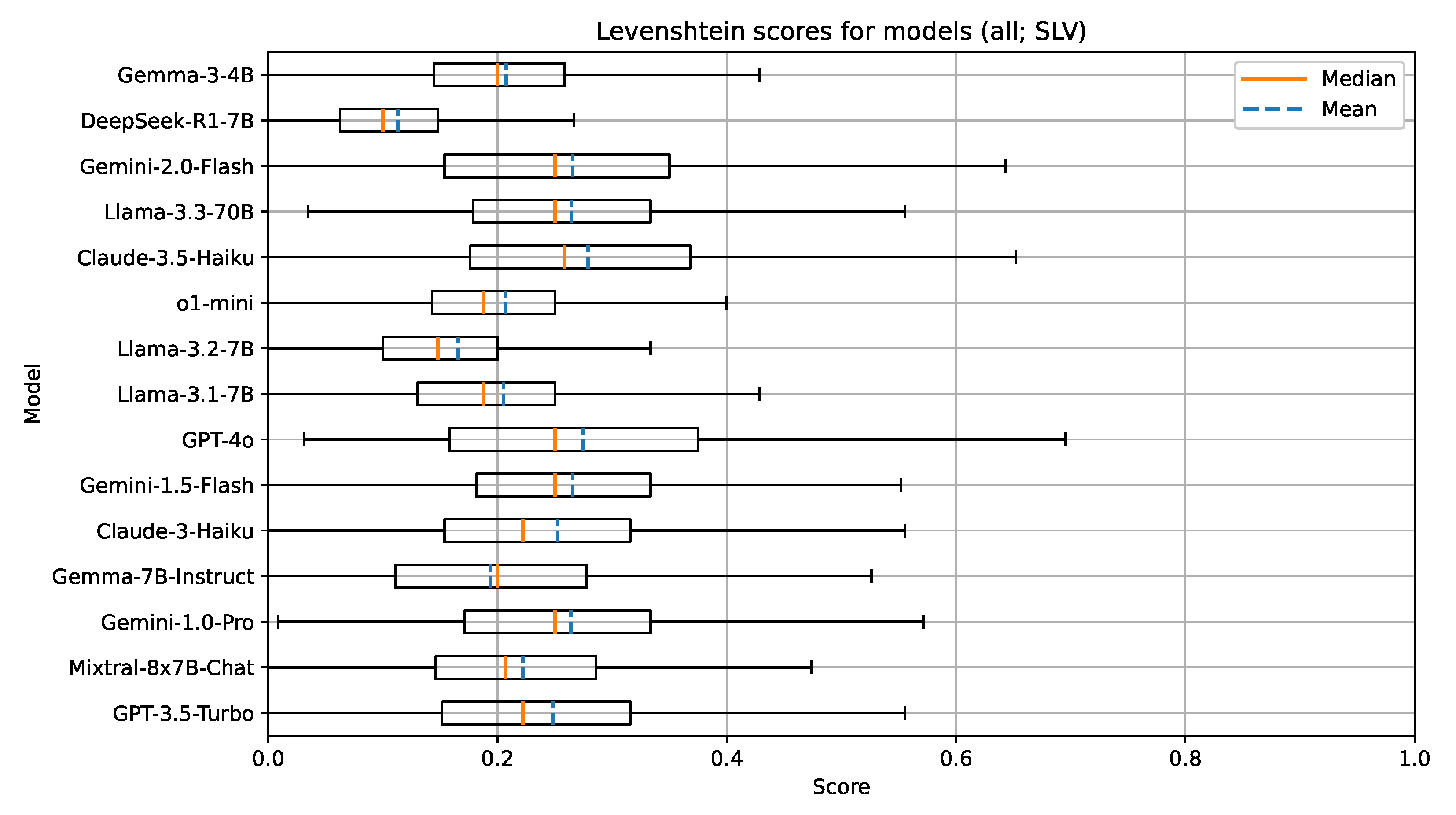
When compared to results for documents in English, similar findings can be observed for the Slovenian language (Table 8, Table 9 and Table 10; Figure 5, Figure 6 and Figure 7). Mixtral-8x7B-Chat again outperforms all other models in the 4-7B parameter size group.
Table 8.
Median values and standard deviations (SD) of selected metrics for models of size 4-7B parameters evaluated on documents in Slovenian.
Table 9.
Median values and standard deviations (SD) of selected metrics for models of size 70B parameters evaluated on documents in Slovenian.
Table 10.
Median values and standard deviations (SD) of selected metrics for models with unknown parameter size evaluated on documents in Slovenian.
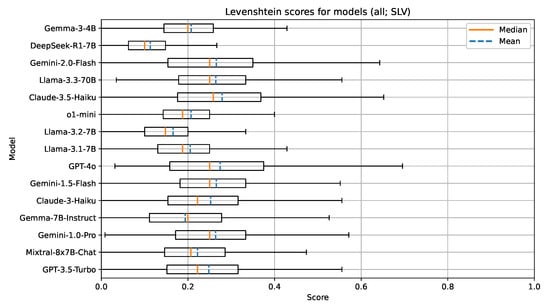
Figure 5.
Boxplot visualization of the Levenshtein similarity for models evaluated on documents in Slovenian.
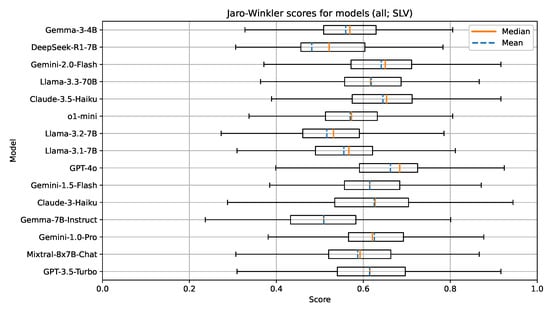
Figure 6.
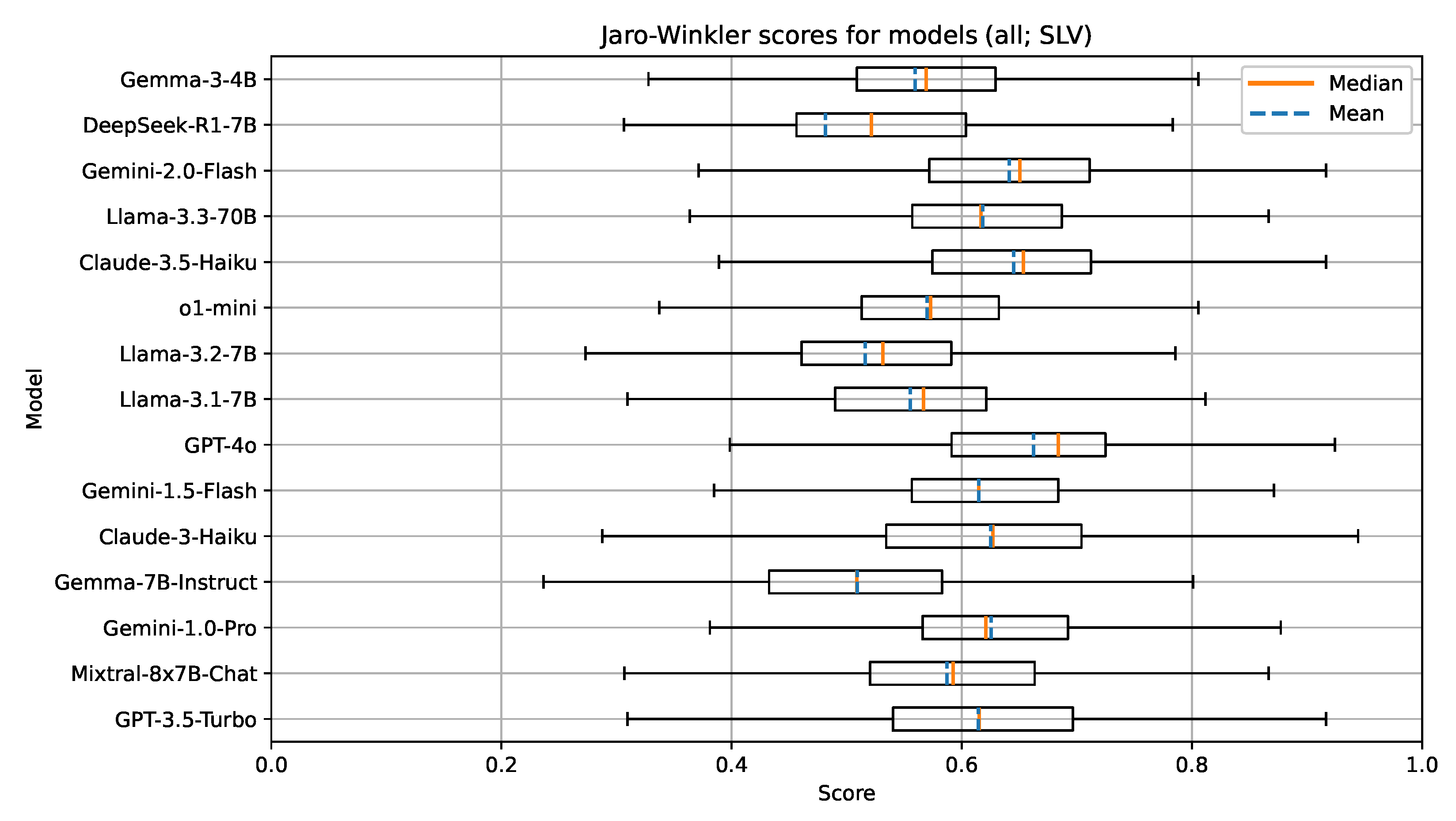
Boxplot visualization of the Jaro–Winkler similarity for models evaluated on documents in Slovenian.
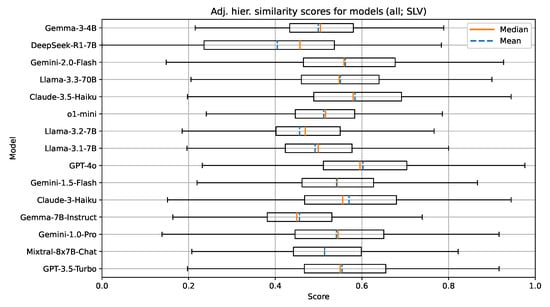
Figure 7.
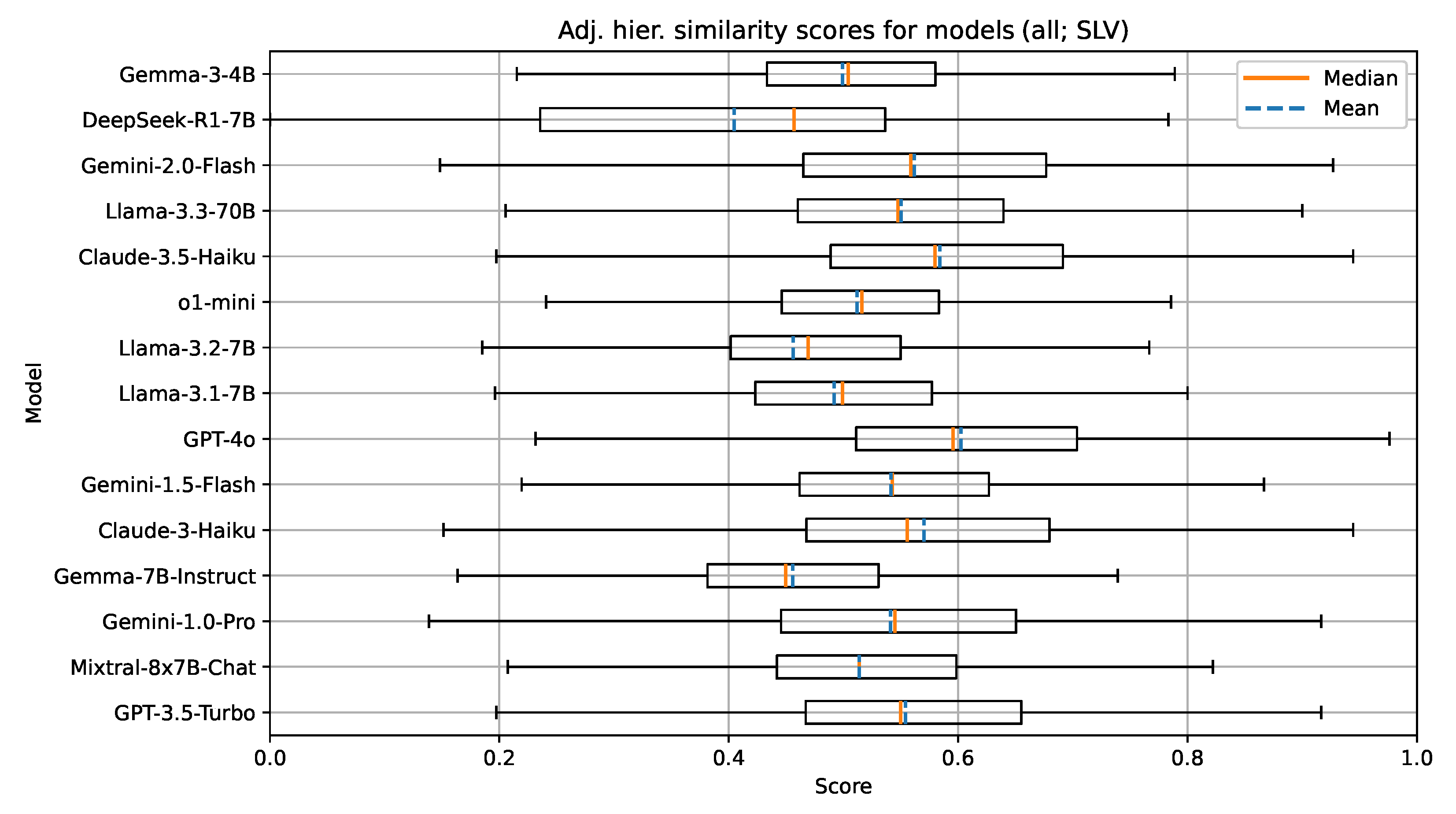
Boxplot visualization of the adjusted hierarchical similarity for models evaluated on documents in Slovenian.
There are also no indications implying that the Slovenian language is less represented with the models in this group. We attribute this to the fact that all of the models in this group are open-weight and have likely been trained on multilingual corpora, which sufficiently represent the Slovenian language. Additionally, efforts by several research groups in Slovenia have been made to improve the availability and accessibility of high quality open-sourced text corpora in the Slovenian language. The understanding of the document context for the task of UDC recommendation in a language like Slovenian, which has limited digital corpora and existing language models, seems to be on par with a well-resourced language such as English.
The group with 70B parameter models consisting of the Llama family models from different generations again shows the effects of model improvements over time. The latest model in the group (Llama-3.3-70B) outperforms both Llama-3-70B and Llama-2-70B on all metrics. Overall, for this group of models, the metric values obtained from testing on the Slovenian language are very similar to those obtained from testing on the English language. These results could imply that the newer Llama family of models has been trained with focus on better multilingual support, including the Slovenian language; however, the best performing models still tend to have higher metric values for the English language.
Finally, in the group with proprietary models and unknown parameter sizes, GPT-4o performs the best on the selected metrics, followed by Claude-3.5-Haiku and the Gemini family of models (Gemini-1.0-Pro, Gemini-1.5-Flash, and Gemini-2.0-Flash). Again, the reasoning model o1-mini underperforms in comparison with other models. Similar to our test on the English documents, we attribute this to the size of this particular model.
Overall, a clear observation can be seen across both tested languages and all tested models. The best performing proprietary models outperform the best performing open-weight models in the range of 5–10% on all metrics. This outlines the current gap between proprietary research groups and research groups publishing open-weight and open-source solutions.
6. Discussion
The DeepSeek model evaluated in this study was not the widely known 671B parameter version, but rather a significantly smaller 7B variant. While this model still demonstrated competent performance, its smaller scale likely limited its capacity for nuanced reasoning and deeper contextual understanding, especially when compared to larger proprietary systems. The limited parameter count restricts the model’s ability to capture complex relationships between classification components, which is crucial for UDC recommendation. Nonetheless, it represents a meaningful step in testing practical alternatives to massive-scale models, especially where resources are constrained.
Similarly, the o1-mini model exhibited weaker results when compared to GPT-4o. This discrepancy can largely be attributed to model size and architecture. GPT-4o likely benefits from extensive fine-tuning, multimodal capabilities, and a larger parameter count, giving it a distinct advantage in both linguistic fluency and classification accuracy. o1-mini’s underperformance reflects the challenges faced by smaller models when tackling structured, multi-level classification tasks. Still, its inclusion is valuable in assessing what performance trade-offs are acceptable for lightweight deployments.
To manage computational resources during experimentation, smaller reasoning-capable models were selected. However, reasoning models are inherently more complex and computationally expensive, and their smaller-scale implementations underperformed in hierarchical classification tasks such as UDC code generation. This result is unsurprising, given that complex reasoning typically emerges only in larger models with sufficient training depth. Nevertheless, these smaller reasoning models provide insight into the baseline capabilities of LLMs when tasked with structured taxonomic reasoning, even if they currently fall short of full automation.
Across the board, open-weight models lagged behind proprietary alternatives on all evaluation metrics. Despite their accessibility and customization potential, current open-weight models still fall short in precision and generalization when compared to systems developed by large private research labs with substantial training data and computational infrastructure. This gap highlights the resource imbalance between community-driven projects and industrial-scale AI development. However, open-source ecosystems continue to evolve rapidly, and their transparency makes them attractive for research, reproducibility, and domain adaptation in settings like digital libraries.
Nonetheless, promising improvements were observed in successive versions of open-weight model families, particularly within the Llama line. This indicates that open-source development is actively closing the performance gap, and newer iterations are already exhibiting better understanding and classification abilities than their predecessors. Llama 3.3 for instance, showed better alignment with UDC’s hierarchical logic and fewer over-predicted code components. If this trend continues, future releases may become viable alternatives to proprietary models in institutional settings.
A consistent trend was observed in relation to model size: Models in the 4–7B range generally performed worse than their 70B counterparts, and both were outperformed by proprietary models whose parameter sizes are undisclosed. This reinforces the importance of scale, both in terms of raw parameters and the depth of training and fine-tuning. Larger models appear more capable of understanding classification hierarchies and responding to subtle textual cues. While they are often computationally prohibitive to run locally, cloud-based deployment or model distillation could bridge this performance-accessibility gap in real-world applications.
Despite these performance gaps, chatbots as UDC recommenders show considerable promise. Even smaller models were capable of generating meaningful and hierarchically plausible classifications, especially when paired with refined prompting strategies or minimal supervision. Their ability to interact with users also introduces novel possibilities for dynamic, assisted classification workflows in digital libraries. This interactive potential makes them suitable not just for fully automatic systems but also as semi-automated tools supporting human cataloguers, improving efficiency while retaining expert oversight.
Looking forward, continued advancements in LLM architectures and reasoning capabilities suggest that fully automated UDC classification by LLM-based agents is within reach. With further gains in both open and proprietary systems, future library infrastructures could deploy such agents to perform high-quality, scalable classification with minimal human intervention, transforming cataloguing workflows in the process. By combining structured prompting, reasoning models, and domain-specific fine-tuning, it is plausible that future LLMs could navigate even complex faceted UDC expressions with near-human accuracy. Such systems would not only streamline metadata generation but could also support multilingual and interdisciplinary cataloguing efforts across diverse library collections.
7. Conclusions
This study demonstrates that state-of-the-art large language models can serve as effective recommender systems for UDC classification across multiple languages. Through comprehensive evaluation of 17 models—including proprietary and open-weight variants—on a balanced corpus of English and Slovenian academic theses, we established that proprietary systems, particularly GPT-4o, consistently outperform open-weight alternatives by approximately 5–10% across lexical and hierarchical similarity metrics. This performance differential reflects underlying differences in model scale, training data diversity, and architectural optimization. However, successive open-weight releases demonstrate rapid convergence toward commercial-grade performance. The implementation of systematic prompt engineering, guided by the RISEN framework, proved essential for generating consistent, single-code UDC classifications in zero-shot configurations. Structured prompting templates and language-specific adaptations ensured that models generated only UDC codes without additional explanatory text, matching standard cataloguing practices. The comparable classification performance across English and Slovenian documents validates the multilingual capabilities of contemporary LLMs, particularly significant for resource-constrained languages in digital library contexts.
Although smaller reasoning-focused models (o1-mini and DeepSeek-R1-7B) exhibited lower absolute performance, their generation of hierarchically coherent recommendations suggests potential utility in human-in-the-loop cataloguing systems that leverage AI assistance while maintaining professional oversight.
Future research should investigate retrieval-augmented fine-tuning approaches, few-shot learning paradigms, and explicit integration of ontological knowledge structures to enhance classification precision, particularly for complex, multi-faceted UDC expressions. Furthermore, our approach is easily applicable to other classification systems like DDC or LCC, since the only adjustments needed would be the formulation of the prompts to the LLMs and a suitable dataset with ground truth DDC and LCC codes. The deployment of LLM-based classification systems within library infrastructures offers the potential for scalable, multilingual, and high-quality UDC assignment, ultimately streamlining cataloguing operations and improving access to structured bibliographic metadata.
Author Contributions
Conceptualization, M.B. and S.M.; methodology, M.B. and S.M.; software, T.L.D. and E.T.; validation, M.B. and S.M.; investigation, M.B., T.L.D., and S.M.; data curation, E.T. and T.L.D.; writing—original draft preparation, M.B. and S.M.; writing—review and editing, M.B., T.L.D., E.T., and S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The OpenScience Slovenia document metadata dataset used in this study is publicly available in the Mendeley Data repository—https://data.mendeley.com/datasets/7wh9xvvmgk/3 (accessed on 10 June 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Prompt Templates
This appendix contains the prompt templates that were used with all evaluated model families in English (Appendix A.1) and Slovenian (Appendix A.2).
Appendix A.1. Prompts in English
Prompt template for ChatGPT and Claude models
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate a single UDC code based on the title, keywords and abstract. Return only one UDC code, without text, explanation or markdown.
Prompt template for Gemini models
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate a single UDC code based on the title, keywords and abstract. Do not give any explanation in the response. In the response return only the UDC code, do not return any additional words. Do not return the response in markdown. Do not split the code into small parts.
Prompt template for Llama and Mixtral models
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate a single UDC code based on the title, keywords and abstract. Do not give any explanation in the response. In the response return only one UDC code. The response must not contain anything else before and after the UDC code.
Prompt template for Gemma models
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate a single UDC code based on the title, keywords and abstract. Do not give any explanation in the response. In the response return only one UDC code. The generated code should be in one line. The UDC code should not be longer than 50 characters. The response must not contain anything else before and after the UDC code.
Prompt template for the DeepSeek-R1 model
Act as a librarian and an expert in UDC classification. You have been asked to assign a UDC code to a document in a library collection. The document is titled: {title}. The document contains the following keywords: {keywords}. The abstract of the document is as follows: {abstract}. Your task is to generate only one UDC code, based on the title, keywords and abstract. Do not write any explanation in response. In the response, write only the UDC code, do not write any additional words. Do not write the response with markdown. Do not break the code into small parts. Do not show your thinking.
Appendix A.2. Prompts in Slovenian
Prompt template for ChatGPT and Claude models
Si knjižničar in strokovnjak za UDK klasifikacijo. Prosili so te, da dodeliš UDK kode dokumentu v knjižnični zbirki. Dokument nosi naslov: {title}. Ključne besede so: {keywords}. Povzetek dokumenta je: {abstract}. Tvoja naloga je generirati UDK kodo, glede na naslov, ključne besede in povzetek dokumenta. V odgovoru vrni samo eno UDK kodo, brez dodatnega besedila ali pojasnila in brez markdown-a.
Prompt template for Gemini models
Si knjižničar in strokovnjak za UDK klasifikacijo. Prosili so te, da dodeliš UDK kode dokumentu v knjižnični zbirki. Dokument nosi naslov: {title}. Ključne besede so: {keywords}. Povzetek dokumenta je: {abstract}. Tvoja naloga je generirati UDK kodo, glede na naslov, ključne besede in povzetek dokumenta. V odgovoru ne vračaj pojasnila. V odgovoru vrni samo eno UDK kodo, brez dodatnega besedila. Odgovora ne vračaj v markdown-u. Ne razčleni UDK kode na manjše dele.
Prompt template for Llama and Mixtral models
Si knjižničar in strokovnjak za UDK klasifikacijo. Prosili so te, da dodeliš UDK kode dokumentu v knjižnični zbirki. Dokument nosi naslov: {title}. Ključne besede so: {keywords}. Povzetek dokumenta je: {abstract}. Tvoja naloga je generirati UDK kodo, glede na naslov, ključne besede in povzetek dokumenta. V odgovoru vrni samo eno UDK kodo. V odgovoru ne sme biti nobenega dodatnega besedila pred in za UDK kodo.
Prompt template for Gemma models
Si knjižničar in strokovnjak za UDK klasifikacijo. Prosili so te, da dodeliš UDK kode dokumentu v knjižnični zbirki. Dokument nosi naslov: {title}. Ključne besede so: {keywords}. Povzetek dokumenta je: {abstract}. Tvoja naloga je generirati UDK kodo, glede na naslov, ključne besede in povzetek dokumenta. V odgovoru ne vračaj pojasnila. V odgovoru vrni samo eno UDK kodo. Generirana UDK koda naj bo v eni vrstici. UDK koda ne sme biti daljša od 50 znakov. V odgovoru ne sme biti nobenega dodatnega besedila pred in za UDK kodo.
Prompt template for DeepSeek-R1 model
Si knjižničar in strokovnjak za UDK klasifikacijo. Prosili so te, da dodeliš UDK kodo dokumentu v knjižnični zbirki. Dokument nosi naslov: {title}. Ključne besede so: {keywords}. Povzetek dokumenta je: {abstract}. Tvoja naloga je generirati UDK kodo, glede na naslov, ključne besede in povzetek. Ne piši pojasnila za kode. Ne piši ničesar pred in za UDK kodo. Ne piši odgovora v obliki markdown. V odgovoru vrni samo eno UDK kodo. V odgovoru ne razčleni UDK kode na manjše dele. Ne vrni podrobnosti svojega razmišljanja.
Appendix B. Inference and Computing Resources
For local LLM inference, we used an Ollama server on a MacBook M3 Pro with these specifications (relevant to LLM processing):
- -
- 12-core CPU (6 performance cores and 6 efficiency cores)
- -
- 18-core GPU
- -
- 16-core Neural Engine
- -
- 150 GB/s memory bandwidth
Using Ollama, we ran inference on smaller open-weight models for a total of 40 h of inference time:
- -
- DeepSeek-R1-7B (25 h)
- -
- Llama-3.1-7B (5 h)
- -
- Llama-3.2-7B (5 h)
- -
- Gemma-3-4B (5 h)
Using Poe, we ran inference on proprietary and open-weight models using 2.5 million credits. Each model had different pricing in terms of credits per request:
- -
- GPT-3.5 Turbo (20 credits/request)
- -
- GPT-4o (262 credits/request)
- -
- o1-mini (420 credits/request)
- -
- Claude-3-Haiku (30 credits/request)
- -
- Claude-3.5-Haiku (95 credits/request)
- -
- Gemini-1.0-Pro (20 credits/request)
- -
- Gemini-1.5-Flash (5 credits/request)
- -
- Gemini-2.0-Flash (19 credits/request)
- -
- Llama-2-70B (10 credits/request)
- -
- Llama-3-70B (75 credits/request)
- -
- Llama-3.3-70B (130 credits/request)
- -
- Gemma-7B-Instruct (15 credits/request)
- -
- Mixtral-8x7B-Chat (20 credits/request)
The total inference time on Poe was 10 days. The inference on Poe took place in February and March 2025. The total price for inference was EUR 57.49 (one monthly subscription of 2.5 million credits/month). The total inference time includes the time used to test and tailor prompts.
References
- Zhao, A.; Huang, D.; Xu, Q.; Lin, M.; Liu, Y.J.; Huang, G. ExpeL: LLM Agents Are Experiential Learners. Proc. AAAI Conf. Artif. Intell. 2024, 38, 19632–19642. [Google Scholar] [CrossRef]
- Gao, J.; Ding, X.; Zou, L.; Cai, B.; Qin, B.; Liu, T. ExpeTrans: LLMs Are Experiential Transfer Learners. arXiv 2025, arXiv:2505.23191. [Google Scholar]
- Kragelj, M.; Borštnar, M. Automatic classification of older electronic texts into the Universal Decimal Classification-UDC. J. Doc. 2020, 77, 755–776. [Google Scholar] [CrossRef]
- Nevzorova, O.A.; Almukhametov, D.A. Towards a Recommender System for the Choice of UDC Code for Mathematical Articles (short paper). In Proceedings of the International Conference on Data Analytics and Management in Data Intensive Domains, Moscow, Russia, 26–29 October 2021. [Google Scholar]
- Bodenhamer, J. The Reliability and Usability of ChatGPT for Library Metadata. In Proceedings of the Brick & Click: An Academic Library Conference, Bellevue, WA, USA, 3 November 2023. [Google Scholar]
- Chow, E.; Kao, T.; Li, X. An Experiment with the Use of ChatGPT for LCSH Subject Assignment on Electronic Theses and Dissertations. Cat. Classif. Q. 2024, 62, 574–588. [Google Scholar] [CrossRef]
- Aboelmaged, M.; Bani-Melhem, S.; Al-Hawari, M.A.; Ahmad, I. Conversational AI Chatbots in library research: An integrative review and future research agenda. J. Librariansh. Inf. Sci. 2024, 57, 09610006231224440. [Google Scholar] [CrossRef]
- Dobreski, B.; Hastings, C. AI Chatbots and Subject Cataloging: A Performance Test. Libr. Resour. Tech. Serv. 2025, 69, 1–22. [Google Scholar]
- D’Souza, J.; Sadruddin, S.; Israel, H.; Begoin, M.; Slawig, D. SemEval-2025 Task 5: LLMs4Subjects—LLM-based Automated Subject Tagging for a National Technical Library’s Open-Access Catalog. arXiv 2025, arXiv:2504.07199. [Google Scholar]
- Roy, A.; Ghosh, S. Automated Subject Identification using the Universal Decimal Classification: The ANN Approach. J. Inf. Knowl. 2023, 60, 69–76. [Google Scholar] [CrossRef]
- Borovič, M.; Ojsteršek, M.; Strnad, D. A Hybrid Approach to Recommending Universal Decimal Classification Codes for Cataloguing in Slovenian Digital Libraries. IEEE Access 2022, 10, 85595–85605. [Google Scholar] [CrossRef]
- Yan, R.; Zhao, X.; Mazumdar, S. Chatbots in libraries: A systematic literature review. Educ. Inf. 2023, 39, 1–19. [Google Scholar] [CrossRef]
- Martins, S. Artificial Intelligence-Assisted Classification of Library Resources: The Case of Claude AI. Libr. Philos. Pract. 2024, 2, 8159. [Google Scholar]
- Dam, S.K.; Hong, C.S.; Qiao, Y.; Zhang, C. A Complete Survey on LLM-based AI Chatbots. arXiv 2024, arXiv:2406.16937. [Google Scholar]
- Choi, Y.; Kim, S.; Bassole, Y.C.F.; Sung, Y. Enhanced Retrieval-Augmented Generation Using Low-Rank Adaptation. Appl. Sci. 2025, 15, 4425. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Satoh, K. ConsRAG: Minimize LLM Hallucinations in the Legal Domain. In Legal Knowledge and Information Systems; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherlands, 2024; Volume 395, pp. 327–332. [Google Scholar] [CrossRef]
- Li, A.; Shrestha, R.; Jegatheeswaran, T.; Chan, H.O.; Hong, C.; Joshi, R. Mitigating Hallucinations in Large Language Models: A Comparative Study of RAG-enhanced vs. Human-Generated Medical Templates. medRxiv 2024. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Online, Red Hook, NY, USA, 6–12 December 2020. [Google Scholar]
- Shuster, K.; Poff, S.; Chen, M.; Kiela, D.; Weston, J. Retrieval Augmentation Reduces Hallucination in Conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.t., Eds.; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 3784–3803. [Google Scholar] [CrossRef]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V.; Arshad, M.A. Emotion-Aware Embedding Fusion in Large Language Models (Flan-T5, Llama 2, DeepSeek-R1, and ChatGPT 4) for Intelligent Response Generation. AI 2025, 6, 56. [Google Scholar] [CrossRef]
- Wakeling, S. The user-centered design of a recommender system for a universal library catalogue. In Proceedings of the Proceedings of the Sixth ACM Conference on Recommender Systems, RecSys ’12, New York, NY, USA, 9–13 September 2012; pp. 337–340. [Google Scholar] [CrossRef]
- Moulaison-Sandy, H.; Coble, Z. Leveraging AI in Cataloging: What Works, and Why? Tech. Serv. Q. 2024, 41, 375–383. [Google Scholar] [CrossRef]
- Gupta, V. Factors influencing librarian adoption of ChatGPT technology for entrepreneurial support: A study protocol. J. Econ. Technol. 2024, 2, 166–173. [Google Scholar] [CrossRef]
- Primary Research Group Inc. Survey of Use of Bard, Bing & ChatGPT for Academic Library Cataloging; Technical Report; Primary Research Group: New York, NY, USA, 2023; 96p. [Google Scholar]
- Borovič, M.; Ferme, M.; Brezovnik, J.; Majninger, S.; Bregant, A.; Hrovat, G.; Ojsteršek, M. The OpenScience Slovenia metadata dataset. Data Brief 2020, 28, 104942. [Google Scholar] [CrossRef] [PubMed]
- Winkler, W. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. Proc. Sect. Surv. Res. Methods 1990. Available online: https://eric.ed.gov/?id=ED325505 (accessed on 10 June 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).